
Abstract
With the rapid development of service computing technology, more and more companies and organizations are encapsulating and publishing their operational data or resources to the Internet in the form of Web services, resulting in an exponential increase in the number of Web services. To automatically generate or recommend a group of Web services according to the user's natural language requirements description, to build a Mashup application to meet the user's requirement is a hot topic in service computing. Some researchers enhance the quality of Web service recommendation by using auxiliary information into the recommendation system. However, they mainly focus on adding external information (e.g., pre-training of external corpora) to enhance semantic features, while some internal statistical features of the corpus such as word distribution on labels and frequency are not fully exploited. Compared to other exterior knowledge, statistical features are naturally compatible with Web service recommendation tasks. To fully exploit the statistical features, this paper proposes a Web service recommendation method based on adaptive gate network and xDeepFM model. In this method, firstly, the description document of Web services is taken as the basic corpus, the semantic and statistical information in the corpus are mined by utilizing the adaptive gate network, and the statistical features are encoded by a variational encoder. Secondly, the similarity between Web services is derived from the semantic features, at the same time the popularity and co-occurrence of Web services are calculated. Thirdly, the xDeepFM model is used to mine the explicit and implicit higher-order interactions in the sparse matrix which consists of the above information to recommend Web services for Mashup application. Finally, a multiple sets of experiments based on the dataset crawled from the ProgrammableWeb have been conducted to evaluate the proposed method and the experimental result shows that the proposed method has better performance in the \(AUC\) and \(Logloss\) compared with the state-of-art baseline methods.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
With the booming development of the Internet and its related technologies, the deep integration of information technology and service industry, represented by big data [1], has promoted far-reaching changes in the software industry, while accelerating the cross-field integration and innovative development of service computing technology [2]. As the most prospective technology based on service-oriented computing (SOC) [3], Web services are widely used in applications based on service-oriented architecture (SOA) by providing services through a typical Web services protocol to ensure that application services from different platforms can interoperate. Therefore, a growing amount of modern organizations and companies are encapsulating their business, data or resources into online services and publishing them on the Internet, which leads to a significant increase in the number of Web services [5]. Web services composition enables developers to create applications tailored to their needs and quickly build Mashup applications [6]. As it overcomes the problem of information island [4], it provides an efficient and fast solution for the integration of applications in the distributed heterogeneous environment, thus becoming the most critical aspect in facilitating the efficiency of service development.
The emergence of a large number of online services brings information overload. Therefore, recommendation systems are attracting more and more attention from researchers as an effective solution to the information overload problem. Traditional recommendation methods mainly include content-based, collaborative filtering and hybrid recommendation methods [6]. Among this, content-based recommendation is based on the item’s content, which is simple and effective, but the content features are limited and only one kind of recommendation result can be returned. Collaborative filtering, on the other hand, makes recommendations based on the interaction between users and items, but it is limited by cold starts, data sparsity, and insufficient feature depth interaction capabilities. Hybrid recommendation methods [8] are expected to better improve the quality of recommendations, which usually combine the collaborative filtering recommendations and content-based recommendations to overcome the problems inherent in using a single approach.
In the process of recommendation, exploring different kinds of auxiliary information can promote the quality and performance of the recommendation system, and enable it to provide more relevant recommendation results based on the existing Web services description documents [9]. Nevertheless, how to effectively introduce complex and different kinds of auxiliary information into recommendation systems is an important issue faced by researchers [22]. Several researchers use deep recommendation models and techniques such as factorization machine (FM) [10], to extract wide range of relevant features from heterogeneous and multi-source information to enrich the deep feature representation of users and items. However, the above research works often tend to focus on describing the description documents of Web services when adding auxiliary information, while ignoring the original features such as word distribution and frequency, which are intrinsic, static, and easy to retrieve [25][26]. One of the most representative algorithms that utilizes statistical information is term frequency-inverse document frequency (TF-IDF) [25], which is a direct information retrieval technique for document modeling. However, due to the limitation of bag-of-words, TF-IDF is unable to capture fine-grained semantics using word location information, which makes TF-IDF less advantageous than other deep learning models.
Recently, some researchers have proposed the adaptive gate network (AGN) model [12]. This model is able to train in a corpus to obtain statistical information. It uses a novel adaptive gate network to add corpus-level statistical features (e.g., word frequency, word distribution on labels) to low-confidence semantic features to enrich the semantic features and thus improve the performance of model. Since the above statistical features are derived from the Web services description documents, which are naturally compatible with the recommendation task. So it can effectively enrich the knowledge of recommendation system and promote the performance of the recommendation accordingly. xDeepFM model, on the other hand, is capable of jointly learning both explicit and implicit higher-order interaction features. It completes the high-order explicit interaction between Web service features through compressed interaction network (CIN). In addition, xDeepFM uses DNNs to learn the implicit higher-order interactions between features. Thus, xDeepFM can fully exploit the explicit and implicit higher-order features in the Web service description documents. Inspired by the above researches, this paper proposes a Web services recommendation method based on AGN and xDeepFM [13], denoted as AGN-xDeepFM. In this method, firstly, it applies AGN to extract the semantic features of the Web service description document carrying statistical information. Then, it calculates the similarity, popularity and co-occurrence between Web services, and using them as the input of the xDeepFM model. Finally, xDeepFM mines the above information and recommends the most appropriate Web services for building Mashup application. To sum up, the main contributions of this paper are outlined as below:
-
To our best knowledge, this is the first attempt by using deep learning technology to fully mine the statistical information of word frequency and labels distribution at corpus level to achieve efficient Web service recommendation.
-
A new Web service recommendation method AGN-xDeepFM is proposed in this paper. It rises the accuracy of similarity calculation by adding the statistical information of word frequency and labels distribution to the semantic features in the description documents of Web services through the AGN model, and uses the xDeepFM model to fuse multi-dimensional features such as similarity, popularity and co-occurrence to recommend Web services.
-
The experiments are conducted on real datasets of ProgrammableWeb platform and the experimental results show that the AGN-xDeepFM outperforms other popular Web service recommendation methods based on deep neural network and effectively improves the performance and quality of Web service recommendation.
The remainder of this paper is organized as follows. In Section II, the research work related to Web service recommendation is introduced in detail. Section III provides a detailed description of the AGN-xDeepFM proposed in this paper. Section IV analyzes and discusses the experimental results and variable parameters. Section V summarizes the work in the paper and presents the future work.
2 Related Work
Web services with various functionality are constantly emerging on the Internet, developers can create more complex, composable Web service applications, such as Mashup, by aggregating various Web services from diverse platforms through the typical Web protocols [14]. Effective Web service recommendation method can facilitate Web service discovery, composition and application. There are many research findings on Web service recommendation based on collaborative filtering algorithm, but the recommendation quality and effect are not satisfying due to the limitation of data sparsity and cold start. To overcome these problems, some researchers improve the performance of Web service recommendation by adding auxiliary information to the recommendation system [15].
Currently, many researchers study on the application of deep neural networks in Web service recommendation, such as CNN proposed by Conneau [16], which operates directly at the character level and can perform convolutional and pooling operations using smaller convolutional kernels. Shi et al. [17] proposes a recommendation system for mining Web services’ functional description documents using LSTM. Wang et al. [18] presents a QoS prediction algorithm which utilizes LSTM to predict future reliability. Based on the Text-GCN model proposed by Yao et al. [23], the WSC-GCN model is designed by Ye et al. [24] to model and predict the network structure of word hiding in documents. These works show that using DNNs can achieve better results in Web service recommendation. Ye et al. [19] devises a Wide&Bi-LSTM method for Web service functionality description document modeling that fully exploits the content semantic information of Web service functionality description documents in both breadth and depth to achieve automatic Web services classification. Kang et al. [20] propose the NAFM method, which uses neural and attentional factorization machine for Web service recommendation. All the mentioned works achieve good results, which indicate that the proper using of external auxiliary information can effectively improve the performance of the recommendation model.
In recommendation systems, the interaction features of services and users are often discrete and sparse, so some researchers use logistic regression (LR) [21] to model these discrete, high-dimensional features. However, the LR ignores the relationship between different features, so some researchers propose the factorization machines (FM) [10] model, which alleviates the problems caused by sparse matrices by interacting with feature vectors. To explore the interactional features of services and users, many scholars apply deep neural networks to integrate the information between different features and utilize the DeepFM model [13], which mines the input sparse matrix by deep neural networks to integrate low-order feature interactions and high-order feature interactions, and consequently improves the efficiency and accuracy of the recommender system.
Recently, Li et al. [12] proposes the adaptive gate network approach in 2021, which uses a valve component to selectively add statistical information to semantic information for improving the performance of recommendation models. Lian et al. [13] designs a method called eXtreme deep factorization machine (xDeepFM) in 2018, which learns explicit and implicit higher-order feature interactions and lower-order feature interactions. Inspired by these works, this paper proposes a Web service recommendation method that fuses AGN and xDeepFM. In this method, firstly, it selectively integrates the statistical and semantic information of corpus-level Web service description documents to obtain more accurate similarity between Web services. Then, it uses xDeepFM to learn high-order and low-order feature interactions to fully explore the multi-dimensional information of Web service, such as similarity, popularity, co-occurrence, so as to obtain better Web service prediction and recommendation results. Finally, the experiments results show that the proposed method effectively improves the quality of Web service recommendation.
3 AGN-xDeepFM Method
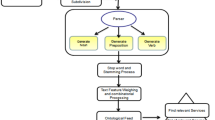
The framework of AGN-xDeepFM method is shown in Fig. 1, which includes data processing, similarity calculation based on AGN model, Web service prediction based on xDeepFM, and Web service recommendation.

The Framework of the Proposed Method
-
Pre-processing. To eliminate the information which is unfavorable to the Web service recommendation, the pre-processing is performed.
-
Similarity calculation based on AGN model. The AGN model is applied to explore the semantic and statistical features of the available APIs, and the similarity is calculated between Mashups and Mashups, APIs and APIs.
-
Web service prediction based on xDeepFM. The xDeepFM is used to mine complex feature composition relationships and predict the probability of Web APIs that is called by Mashups. Meanwhile, Web service prediction is achieved in the modeling of xDeepFM by inputting the similarity between Mashups, the similarity between APIs, and the popularity and co-occurrence of APIs.
-
Web service recommendation. As for users’ Mashup requirement, the matched APIs are identified by using AGN model and the called probability is predicted by utilizing xDeepFM model. The predicted scores are ranked, the high-quality APIs are recommended for Mashup creation.
3.1 Data Preprocessing
Web service description document is composed of elements such as words, phrases, sentences, paragraphs, and as the length of the elements increases, the information contained in the documents becomes richer, but the number of feature compositions will also increase. It is necessary to eliminate meaningless information from the document corpus. This allows the model to perform semantic mining in a Web service corpus which contains Mashups and Web APIs with higher information density. The data preprocessing mainly includes the below steps:
-
Load the experimental data: use pandas to load experimental data set and remove the data with incomplete information and messy code.
-
Tokenization: apply NLTK (Natural Language Toolkit) in python to divide the Web service description documents into series of phrases or words according to space characters, i.e., divide Web service description document into the list of characters, and distinguish the punctuation marks from words.
-
Remove stop words and stemming: exploit the deactivation word list in NLTK to percolate words and punctuation that are not useful for semantic mining. At the same time, the suffixes from words are removed such as “ing”, “ly”, “s”, in a rule-based way. For instance, “betrayal” will be extracted as “betray” and “incentive” will be extracted as “incent”. This process will effectively improve the accuracy of the subsequent similarity calculations.
-
One-hot encoding: utilize the prefix array to build the dictionary space, the words in the dictionary space and Web service description documents are converted into one-hot vectors, which are used as the input data of AGN-xDeepFM model.
3.2 Similarity Calculation Based on AGN Model
The input of AGN model is consist of the description documents of Mashup and API. AGN is able to fuse content semantics and statistical information of Mashup and API.

The AGN Model.
AGN Model. The structural composition of the AGN model which comprises three main components, i.e., V-Net component, S-Net component (Bert base) and Valve component, is illustrated in detail in Fig. 2.
Global Information. TCoL is obtained directly from the corpus of Web service description document. These features are raw, but by identifying the relevance of words, extensive information can be mined and utilized for feature selection and information retrieval. That is to say, the importance of a word \(\omega \) will increase if the distribution of that word is higher or lower in a particular category.
Definition 1: Given a word \(\omega \) in Web service description and a Web service description document with \(c\) categories, the term-count-of-label (TCoL) vector for the word \(\omega \) is:
where \({\complement }_{i}\) is the number of words \(\omega \) in category i. Now, given a sentence \({{s=\{\omega }_{i}\}}_{i=1}^{m}\) in Web service description, then the TCoL of the sentence is:
V-Net. V-Net stands for variational encoding network. In V-Net, statistical information which is initially incompatible with the semantic features of the Web service description document will be converted to a valid representation. In this paper, variational autoencoder (VAE) is used to encode TCoL, which can restrict the latent space to a representation encoded by a multivariate gaussian distribution, thus obtaining a high-quality statistical feature matrix. Before fusing TCoL with the semantic features of Web service description document, it is necessary to generate TCoL from all sentences in the Web service description document, and obtain \(A={{\{C}_{(i)}^{s}\}}_{i=1}^{M}\). It is a composition of \(\mathrm{M}\) discrete TCoL variables \(C\) with id \(i\). Assume that the TCoL vector of all Web service description document is obtained by the process \({p}_{\theta }(C|a)\). In the process, there is a latent variable \(a\) of TCoL vector involved that is obtained by sampling from a prior distribution \({p}_{\theta }(a)\). Then, variational approximation \({q}_{\varphi }(a|C)\) is used to jointly learn the TCoL vector’s variational parameters \(\varphi \) and \(\theta \) as a way to solve the intractable problem of computing the posterior \({p}_{\theta }(a|C)\) of TCoL vector. Therefore, the model is optimized by maximizing the marginal likelihood which consists of the sum of the marginal likelihoods of individuals \(C\).
Next, the likelihood term \(L\left(\theta ,\varphi ;C\right)\) of TCoL vector can be derived to obtain a variational lower bound on the marginal likelihood, i.e.,
The variational framework is applied to the autoencoder by using the re-parameterization, and two encoders are exploited to respectively generate two sets \(\alpha \) and \(\beta \) as the mean value and standard deviation of the prior distribution. Since the approximate prior used in this paper as a multivariate gaussian distribution, the variational posterior is represented by the diagonal covariance:
Thus, by training the unsupervised VAE model, the probabilistic encoder obtains the latent variable \({C}^{a}\), which is the global representation of the TCoL of the Web service description document. The training of V-Net is independent of the other components, \({C}^{a}\) is generated at the beginning of the model and fused with the semantic information of the Web service description document through the Valve component.
S-Net. S-Net stands for semantic representation projection network, which can extract the semantic features from Web service description document and project them into an information space for evaluation. The input of S-Net is a fixed-length Web service description sentence \(s\). Then the specific function of the component is described as follows:
Firstly, a pre-trained Bert base model is used for Web service feature map extraction:
\(M\) denotes the Web service feature map extracted by the Bert model.
Next, the semantic features of the Web service description document are mapped into the information space through a dense layer:
\({F}^{M}\) denotes the semantic features of the Web service description document in the information space, which facilitates Valve components to perform information merging. Finally, input \({F}^{M}\) into the sigmoid-activated function to obtain \(F{\prime}^M = \sigma \left( {F^M } \right)\), where \(\sigma \) represents the sigmoid equation used to evaluate the confidence of the semantic features of the Web service description document.
Valve Components. Valve component can merge the semantic information and statistic information of Mashup and Web APIs. Since the TCoL representation \({C}^{a}\) of the trained Web service description document is obtained offline. To utilize the statistical features of the Web service document effectively, this paper uses a dense layer to project \({C}^{a}\) into the information space which is shared with the semantic features of the Web service description documents:
The Valve component fuses \({F}^{M}\) and \({F}^{C}\) and outputs a statistically-informed content semantic feature \({F}^{U}\) via an \(AdaGate\) function:
where \(ReLU\) is the activation function. The values in \({{F}^{^{\prime}}}^{M}\) are expressed as probabilities, and the purpose of the Valve function is to use the statistical features of Web service to strengthen the entries with low confidence (\(\alpha \to 0.5\)), in order to match the elements in \({F}^{C}\). Means that for each \(m\in {{F}^{^{\prime}}}^{M}\):
where \(\varepsilon \) is a hyper-parameter that adjusts the confidence threshold. Therefore, using the \(Valve(m,\varepsilon )\) function as a filter is able to integrate the necessary statistical information of the Web service description document into the semantic features of it at the element level.
Similarity Calculation. After obtaining \({F}^{U}\) that combines the statistical features with semantic features, a cosine similarity function is used to calculate the similarity of the feature vector for each Web service description document \({f\in F}^{U}\) with all the other feature vectors for Web services description documents:
where \(f\) denotes the feature vector of the current Web service description document and \(t\) denotes all the other feature vectors for Web services description documents. \(Similarity\left(f,t\right)\in [\mathrm{0,1}]\), its value more closes to 1 means the higher the similarity of the two Web services, and vice-versa.
3.3 Web Services Recommendation based on xDeepFM
xDeepFM Model. The input of the xDeepFM model is a discrete multi-dimensional information matrix which is composed of information such as one-hot codes, similarity scores of Web services, co-occurrence and popularity of Web service. This model will learn from the input matrix and predict the score or probability that the target Mashup will invoke Web API.
xDeepFM is composed of three components, i.e., CIN, DNN, and Linear part, which first reduces the discrete information in the input discrete multi-dimensional information matrix containing Web service features into a dense, low-dimensional, real-value vector by embedding layer, and then inputs it into CIN, DNN respectively. The CIN crosses the feature vectors by using vector-wise fashion. The embedding matrix is represented in CIN as \({X}^{0}\in {\mathbb{R}}^{m\times D}\). The row \(i\) of \({X}^{0}\) denotes the embedding vector of Web service features corresponding to the \(i\) field, there are totally \(m\) real-value vector with \(D\)-dimension. Each layer of CIN will produce an intermediate results, and the output matrix of the \(k\) layer is denoted as \({X}^{k}\in {\mathbb{R}}^{{H}_{k}\times D}\), \({H}_{0}=m\) and \({H}_{k}\) denotes the number of feature vectors in the \(k\) layer, where the intermediate results are calculated as follows:
where \(\Upsilon_{i,j}^{k + 1,h}\) denotes a scalar value that is a parameter on the position of row \(\mathrm{i}\) and column \(\mathrm{j}\). \({X}_{i,*}^{k}\) denotes the feature vector in the \(\mathrm{i}\)-th row of the output matrix at the \(k\)
layer in the CIN, and \({X}_{h,*}^{k+1}\) denotes the feature vector in the \(\mathrm{h}\)-th row in \({X}^{k+1}\).
After obtaining the output of each layer, all intermediate results in each layer of CIN will be pooled to transform \({X}^{k}\) into a vector \({v}^{k}=[{v}_{1}^{k},{v}_{2}^{k},\dots ,{v}_{{H}_{k}}^{k}]\) with the length \({\mathrm{H}}_{\mathrm{k}}\), and stitched together to obtain \({v}^{+}=[{v}^{1},{v}^{2},\dots ,{v}^{k}]\) and the output is the multidimensional discrete features \(c=\frac{1}{1+exp({({v}^{k+})}^{T}{W}^{^\circ })}\) of the Web service after feature vector crossover. Among this, the \({\mathrm{W}}^{^\circ }\) is a parameter vector with the length \(\sum_{k=1}^{{H}_{k}}\). DNN learns the implicit higher-order feature interaction, which is complementary to CIN and further enhances the effectiveness of the model for service recommendation. Linear takes the original Web service features without embedding as input, denoted as \(y=\sigma ({W}_{linear}^{T}a)\), where \(a\) is the original Web service multidimensional discrete information matrix and \(\sigma \) is the activation function.
The above components are combined to obtain the final output \(\widehat{y}\) of the xDeepFM model, where \(\widehat{y}\in \left(\mathrm{0,1}\right)\). If \(\widehat{y}\ge 0.5\), then the Web API is recommended to the Mashup, and if \(\widehat{y}<0.5\), then the Web API is not recommended to the Mashup:
where \({W}_{linear}^{T}\), \({W}_{dnn}^{T}\), and \({W}_{cin}^{T}\) respectively correspond to the trainable parameters of the linear component, DNN component, and CIN component, \(b\) is a global bias item. Consequently, xDeepFM module effectively improves the effectiveness of Web service recommendations through above processing.
The Popularity and Co-occurrence of Web Service. The popularity of Web service represents the QoS information and users’ preference, and its calculation formula is as follows:
where \(Inv\left({a}_{i}\right)\) indicates the number of the Web API “\({a}_{i}\)” invoked by all Mashups, and \(MinInv\left(\cdot \right)\) indicates the smallest number of the Web API invoked by Mashup in the history record, and \(MaxInv\left(Category\left({a}_{i}\right)\right)\) indicates the maximum number of the Web API invoked in the history record, and \(Category\left({a}_{i}\right)\) indicates the Web APIs that belong to the same category as the Web API “\({a}_{i}\)”.
The co-occurrence of Web service refers the association relationship of Web service composition, which can be calculated by exploiting Jaccard similarity coefficient:
where \(\left|{a}_{i}\bigcap {a}_{j}\right|\) indicates the total number that Web API “\({a}_{i}\)” and Web API “\({a}_{j}\)” are invoked by the same Mashup, \(\left|{a}_{i}\bigcup {a}_{j}\right|\) indicates the total number of Web API “\({a}_{i}\)” and Web API “\({a}_{j}\)” are invoked by all Mashups.
4 Experimental Result and Analysis
4.1 Dataset and Experimental Setting
To evaluate the proposed method, this paper uses a real dataset of Web services crawled from the ProgrammableWeb platform. The dataset contains about 6000 Mashups and nearly 20,000 Web APIs, which includes detailed Web service description documents and their tag information. The top 30 categories with the highest quantity of Web services in this dataset is shown in Table 1. Moreover, the experimental data is divided into 60% training set, 20% validating set, and 20% testing set.
4.2 Evaluation Metrics
The evaluation metrics include \(AUC\) and \(Logloss\), which are widely used in the recommendation system to evaluate the model performance from different aspects. The \(AUC\) is the area under the \(ROC\) curve:
In \(ROC\) space, the coordinates \((fpr,tpr)\) represent the trade-off between false positive cases and true positive cases, \(\mathrm{fpr}\) stands for false positive rate and \(\mathrm{tpr}\) stands for true positive rate. \(AUC\in (\mathrm{0,1})\), when \(0.5<AUC<1\), the model outperforms the random classifier, and the closer the value of \(AUC\) is to 1 indicates that the model is better for Web service recommendation.
\(Logloss\) measures the accuracy of the classifier by penalizing the incorrect classification. A smaller \(Logloss\) means that the model is more accurate in Web service recommendation, and the \(\mathrm{Logloss}\) reflects the average bias of the sample:
Among this, \(N\) denotes the total sample quantity of mobile applications, \(\widehat{{p}_{i}}\) denotes the predicted tag of the \(i\)-th sample, and \({p}_{i}\) denotes the actual tag of the \(i\)-th sample.
4.3 Baselines
-
AGN-DeepFM: The adaptive gate network is used to compute similarity and the DeepFM is applied to recommend Web services. The DeepFM learns both low-order and high-order feature interactions, reducing the usage of parameters and sharing the embedding of FM and DNN.
-
CNN-xDeepFM: The convolutional neural network is used to compute similarity, and the xDeepFM is exploited to recommend Web services. CNN utilizes multiple kernels of different sizes to extract key information from Web service description document, thus enabling more efficient extraction of important features.
-
CNN-DeepFM: The convolutional neural network is used to compute similarity, and the DeepFM is exploited to recommend Web services.
-
LSTM-xDeepFM: The long short-term memory neural network is used to compute similarity, and the xDeepFM is exploited to recommend Web services. The LSTM can fully apply the historical context information in the Web service description document to enhance the performance of Web service recommendation.
-
LSTM-DeepFM: The long short-term memory neural network is used to compute similarity, and the DeepFM is exploited to recommend Web services.
-
Transformer-xDeepFM: The transformer is used to compute similarity, and the xDeepFM is exploited to recommend Web services. Transformer achieves better accuracy by using only encoder-decoder and attention mechanism.
-
Transformer-DeepFM: The transformer is used to compute similarity, and the DeepFM is exploited to recommend Web services.
4.4 Experimental Results and Analysis
The experimental results are shown in Figs. 3 and 4, where the horizontal axis indicates the training size and the vertical axis indicates the performance metrics. In general, the proposed AGN-xDeepFM method has a better performance than other comparative methods in terms of \(AUC\) and \(Logloss\).

AUC

Logloss
-
AGN-xDeepFM has the best performance compared to the baseline methods. The difference between AGN-xDeepFM and Transformer-xDeepFM is small when the training size is 0.8, and the difference in \(AUC\) is only 0.13% and the difference in \(Logloss\) is only 0.15%. However, the difference in \(AUC\) increases to 1.09% and the difference in \(Logloss\) increases to 1.1% when the training size is equal to 0.9. It shows that the using the original corpus-level statistical information to deep learning for Web service recommendation can effectively raise its performance. And with the increasing of Web service data, the more significant the improvement of AGN-xDeepFM compared with other methods. It is clear that methods that use the xDeepFM have better recommendation quality compared to methods that use the DeepFM when the training size grows from 0.2 to 0.9. This is because the methods using xDeepFM consider both high-order and low-order items, and take into account both explicit and implicit combinations when recommending, thus effectively improving the performance of Web service recommendation.
-
The recommendation performance of the AGN-xDeepFM gradually raises with the increasing of the experimental data. Especially, when the training size increases from 0.2 to 0.5, the recommendation performance of the AGN-xDeepFM raises the most. Among them, \(AUC\) increases by 4.45% and \(Logloss\) decreases by 35.29%. This is because as the experimental data adds, the hidden information of Web services mined by the AGN-xDeepFM is also increased, which effectively improves the performance of Web service recommendation. However, when the training size goes up from 0.8 to 0.9, the performance improvement of it is slower than that before. It is because in the increasing process of the experimental data, the information obtained by the recommendation system tends to be saturated and the information of the Web service contained in the categories with low ranking is less than that before, which is equivalent to the increase of “dirty” data to a certain extent, resulting in the performance degradation of Web service recommendation.
4.5 Hyper-parameter Analysis
-
To prevent the AGN-xDeepFM model from over-fitting, this paper deeply investigates the effect of \(dropout rate\) on the AGN part of the AGN-xDeepFM, as shown in Fig. 5(a) and (b), which demonstrate the change process of \(\mathrm{AUC}\) and \(\mathrm{Logloss}\) when the \(dropout rate\) grows from 0.1 to 0.8 in steps of 0.1. It can be seen that the AGN-xDeepFM has the best performance when the \(dropout rate\) is equal to 0.5, as well as the \(AUC\) value gradually increases and the \(Logloss\) value gradually decreases when the \(dropout rate\) tends to 0.5. This verify that a suitable value of the \(dropout rate\) in the AGN-xDeepFM improves the generalization ability of the model.
-
To explore the effect of sentence length \(s\) in the AGN-xDeepFM, the value range of \(s\) is from 8 to 256. From Fig. 5(c) and (d), it can be seen that \(AUC\) shows an increasing trend and \(\mathrm{Logloss}\) indicates a decreasing trend when \(s<=64\) and forms a stable and optimal performance when \(s>64\). That is to say, constantly increasing the value of \(s\) does not significantly improve the performance of the AGN-xDeepFM, but instead will consume more memory in the experiment. Thus, the length of sentence \(s\) is set to 64.
-
It is noted that the hyperparameter ε in the Valve component defines the confidence interval for triggering information fusion. In the experiment, we use 0.1 as the step size and train with different ε values when growing from 0 to 0.5 to explore the effect of \(\upvarepsilon \). From Fig. 5(e) and (f), we can see that the Valve component can effectively combine the information from different sources. Comparing to models without statistical information (i.e., \(\varepsilon =0\)) or models that completely use statistical information (i.e., \(\varepsilon =0.5\)), adaptively exploiting a part of statistical information can achieve better recommendation performance, and the AGN-xDeepFM has the best performance when ε = 0.2. This phenomenon effectively argues that it is useful to selectively integrate semantic and statistical information, not all statistical information, and some of them may bring noise to the model.

Hyper-parameter Analysis
5 Conclusion
This paper focuses on the problem of how to recommend Web service efficiently and accurately, and proposes a Web service recommendation method AGN-xDeepFM by combining AGN model and xDeepFM model. In this method, it firstly fuses the corpus-level statistical and semantic information of Web service description document, which enriches the feature information of Web service description document. Then, it extracts the multi-dimensional features of Web service and uses xDeepFM to learn the explicit and implicit higher-order feature interactions for Web service recommendation. Finally, the experimental results show that the AGN-xDeepFM method is much better than other baseline methods in recommendation performance. In the future work, we will focus on exploring the using of federal learning models to Web service recommendation to further improve its performance on the premise of ensuring data privacy.
References
Katal, A., Wazid, M., Goudar, R.H.: Big data: Issues, challenges, tools and good practices, ICCC2013 (2013)
Weerawarana, S., Curbera, F., et al.: Web Services Platform Architecture: SOAP, WSDL, WS-Policy, WS-Addressing, WS-BPEL, WS-Reliable Messaging and More. Prentice Hall PTR (2005)
Deng, S., Wu, H., Hu, D., Leon Zhao, J.: Service selection for composition with QoS correlations. IEEE Trans. Serv. Comput. 9(2), 291–303 (2014)
Kim, G., Trimi, S., Chung, J.: Big-data applications in the government sector. Commun. ACM 57(3), 78–85 (2014)
Milanovic, N., Malek, M.: Current solutions for web service composition. IEEE Internet Comput. 8(6), 51–59 (2004)
Huang, L., Jiang, B., Lv, S., Liu, Y., Li, D.: Survey on deep learning-based recommender systems. Chin. J. Comput. 41(7), 1619–1647 (2018)
Su, X., Khoshgoftaar, T.M.: A survey of collaborative filtering techniques. Adv. Artif. Intell. 29(12), 426–434 (2009)
X. Wang, and Y. Wang, Improving content-based and hybrid music recommendation using deep learning, ACM Multim. 627–636 (2014)
Zeng, Z., et al.: Knowledge transfer via pre-training for recommendation: a review and prospect. Front. Big Data. 4, 602071 (2021)
Rendle, S.: Factorization Machines. In: ICDM2010 (2010)
Guo, H., Tang, R., Ye, Y., Li, Z., He, X.: DeepFM: A factorization-machine based neural network for CTR prediction. In: IJCAI, pp. 1725–1731 (2017)
Li, X., Li, Z., Xie, H., Li, Q.: Merging statistical feature via adaptive gate for improved text classification. In: AAAI2021 (2021)
Lian, J., Zhou, X. et al.: xDeepFM: Combining explicit and implicit feature interactions for recommender systems. In: ACM SIGKDD2018 (2018)
Xia, B., Fan, Y., et al.: Category-aware API clustering and distributed recommendation for automatic mashup creation. IEEE Trans. Serv. Comput. 8(5), 674–687 (2015)
Bobadilla, J., Ortega, F., et al.: Recommender systems survey. Know. Based Syst. 46, 109–132 (2013)
Conneau, A., Schwenk, H., et al.: Very deep convolutional networks for text classification. In: ACL2017, pp. 1107–1116 (2017)
Shi, M., Tang, Y., Liu, J.: Functional and contextual attention-based LSTM for service recommendation in mashup creation. IEEE Trans. Parallel Distrib. Syst. 30(5), 1077–1090 (2019)
Wang, H., Yang, Z., Yu, Q.: Online reliability prediction via long short-term memory for service-oriented systems. In: ICWS2017 (2017)
Ye, H., Cao, B., et al.: Web services classification based on wide & Bi-LSTM model. IEEE Access 7, 43697–43706 (2019)
Kang, G., Liu, J., et al.: NAFM: Neural and attentional factorization machine for web API recommendation. In: ICWS2020 (2020)
Richardson, M., Dominowska, E., Ragno, R.: Predicting clicks: Estimating the click-through rate for new ads. In: WWW2007 (2007)
Yao, L., Mao, C., Luo, Y.: Graph convolutional networks for text classification. In: AAAI2019 (2019)
Ye, H., Cao, B. et al.: A web services classification method based on GCN. In: ISPA2019 (2019)
Aizawa, A.: An information-theoretic perspective of TF-IDF measures. Inf. Process. Manag. 39(1), 45–65 (2003)
Yang, Y., Pedersen, J.O.: A comparative study on feature selection in text categorization. In: ICML1997, pp.412–420 (1997)
Ramos, J.: Using TF-IDF to determine word relevance in document queries. In: ICML2013 (2013)
Acknowledgments
The authors thank the anonymous reviewers for their valuable feedback and comments. The work is supported by the National Natural Science Foundation of China (No. 61873316, 61872139, 61832014, and 61702181), Hunan Provincial Natural Science Foundation of China under grant No. 2021JJ30274, the Educational Commission of Hunan Province of China (No.20B244), and the Scientific Research Project of Huaihua University (No. HHUY2020-18). Buqing Cao and Hongfan Ye are the corresponding author of this paper.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 Springer Nature Switzerland AG
About this paper

Cite this paper
Tao, Z., Cao, B., Ye, H., Kang, G., Peng, Z., Wen, Y. (2023). A Web Service Recommendation Method Based on Adaptive Gate Network and xDeepFM. In: Meng, W., Lu, R., Min, G., Vaidya, J. (eds) Algorithms and Architectures for Parallel Processing. ICA3PP 2022. Lecture Notes in Computer Science, vol 13777. Springer, Cham. https://doi.org/10.1007/978-3-031-22677-9_9
Download citation
DOI: https://doi.org/10.1007/978-3-031-22677-9_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-22676-2
Online ISBN: 978-3-031-22677-9
eBook Packages: Computer ScienceComputer Science (R0)