
Abstract
Cardiac imaging is of paramount importance in the diagnosis and management of patients with heart disease. Multiple modalities are encompassed within cardiac imaging, including echocardiography, magnetic resonance imaging (MRI), computed tomography (CT), and nuclear medicine. All of the modalities are primed to utilize artificial intelligence to increase accuracy, efficiency, and discover novel relationships between disease and outcomes. Artificial intelligence in cardiac imaging can improve multiple sections in the imaging process: acquisition, optimization, measurements, interpretation, and decision support. Important strides forward have already been made in each of the modalities; some have shown the ability to automatically diagnose disease, others to improve efficiency of clinical workflow, and still others to predict morbidity. Reproducibility and challenges with deployment remain barriers to widespread use of artificial intelligence in cardiac imaging, but the road ahead shows promise.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
1 Introduction
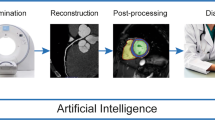
The utility of “big data” and artificial intelligence (AI) in healthcare is growing. As efforts to translate theoretical results into clinical practice have become more successful, there will be an exponential growth in the development of AI applications. Cardiac imaging is ripe for the use of artificial intelligence, as it is a frontline tool for diagnosis, generates large amounts of granular data, and can be used alone or with other clinical data for personalized disease management. Moreover, the multiple steps involved in cardiac imaging, such as image acquisition, image optimization, measurements, interpretation, and reporting, provide immense opportunities for improvement in any part of the chain (Fig. 1). AI has the potential to positively affect clinical outcomes, reduce variability, and increase accessibility to broader populations. In this chapter, we review the basic terminology of AI, explore some current AI applications in cardiac imaging, and discuss future challenges and opportunities in the field.

Process of cardiac imaging chain (in echocardiography) and target areas for artificial intelligence
AI is defined as a computer system that can complete tasks that typically require human intelligence (e.g., visual recognition, speech processing, and decision-making) by using data as input [1]. Vast amounts of health data exist within the medical record and diagnostic testing to serve as input for algorithms designed to aid in diagnosis or management [2]. In the past, there were significant limitations in processing complex health data, but recent advances in collating, labeling, and machine learning techniques have helped popularize AI in healthcare [2]. Lastly, technological developments and increased user access to AI technologies have contributed to improved incorporation into clinical workflows. Thus, three important aspects to successfully implement AI applications in cardiac imaging are input data (source, amount, and variety), algorithm design, and validation and implementation strategy (testing, bias, and deployment).
2 Data Management
The Gartner Report defined successful use of “Big Data” using the concept of the “3Vs”: volume, variety, and velocity [3]. More recently, the addition of fourth and fifth “Vs” has been suggested—veracity and value. Volume refers to the need for large amounts of data, while variety refers to the type and source of data [3]. Velocity is the ability to generate and process datasets, while veracity focuses on the reliability and quality of said datasets [3, 4]. Value is less about the data and more about whether the endpoint results in actionable insights that have downstream impact [5]. Healthcare data can be obtained from electronic health records, patient-generated data (e.g., wearable devices, social media), laboratory results, imaging and diagnostic testing, genomic data, and outcomes, to name a few [6]. There has been growing interest in formally organizing the enormous volume of data, in the form of biobanks or public datasets in order to derive meaningful results [7, 8]. The benefits of applying AI to big data include the ability to rapidly digest large amounts of data and identify novel patterns that would otherwise be missed; humans would not be able to process the same amount or variety of data.
Big data has traditionally been touted as a necessity for successful implementation of AI in healthcare, but recent paradigm shifts suggest that smaller datasets can be effective as well. One way to use a smaller dataset effectively is to extract granular pieces of data. This is particularly beneficial in cardiac imaging, where each data point could focus at the pixel level (color, shapes, brightness, motion, borders) or report level (phrases and descriptive terms) [9]. These derived data points are referred to as “features.” The features distilled from the dataset directly impact the success of an AI algorithm; the features and associated labelling should be accurate, diverse, and of high quality. Inaccurate features and the classification of input data adversely affect the ability of the algorithm to understand relevant real-world data.
3 Algorithm Design
Machine learning (ML) is a subset of AI that is characterized by the ability of an algorithm to improve task performance by “learning” from new data by identifying patterns without specific programming. Machine learning is categorized into two types: supervised and unsupervised. A supervised learning strategy trains the computational model to identify patterns by associating predetermined outcomes with input data [10]. In addition, Supervised models can be honed by selecting and weighting certain features over others to arrive at the desired outcome. Regression analysis, support vector machines, and random forests are all supervised learning methods [11, 12]. Neural networks are a more complex form of supervised learning, often referred to as deep learning, and are meant to recreate human thought processes. Convolutional neural networks (CNNs) are multi-layered neural networks that use prior experiences to improve on outcomes [9, 13]. Unsupervised learning models are comparatively free-form; the model is left to discover patterns in the data that may have never been identified before [14]. In this strategy, data is “clustered” into various categories based on similarities that the model has identified, and additional statistical evaluation is required to identify the actual similar characteristic or feature. Hierarchical, k-means, and model-based clustering are examples of cluster analysis types. A combination of supervised and unsupervised learning strategies was used. In this approach, an unsupervised model provides novel features that can be plugged into a supervised model to be weighted and used to predict an outcome [15].
4 Validation and Implementation
The successful validation and deployment of a machine learning model requires sufficient “training” and “testing” of data. To train the model, a subset of the total data is utilized for “training.” The model uses this subset of data to identify patterns and determine the features that are more or less important in predicting the determined outcome. “Testing” data is a separate subset (or new data) to assess the model’s ability to accurately predict the correct outcome despite never having seen the test data. This process is referred to as validation (Fig. 2). The ability of the model to handle variations in new data determines its generalizability and success in clinical practice. When a model is trained on insufficient data, there is a risk of “overfitting,” where the model can only work on data that is extremely close to the original dataset. This has the additional risk of introducing bias to a model if the data have certain homogenous characteristics that do not reflect real-world distribution. As AI technologies have been developed for imaging in clinical practice, their implementation depends on the ability to define important features in the imaging data, applying the correct type of machine learning, and designing deployable applications.

Machine learning process of training, validation, and testing
5 Implementation in Cardiac Imaging
AI has been steadily gaining traction in all forms of cardiac imaging, including echocardiography, magnetic resonance imaging (MRI), computed tomography (CT), and nuclear medicine. Unlike the early focus of AI on radiology applications with static image datasets, cardiac imaging poses additional challenges owing to the video-based or non-static format of the data. Moreover, there are multiple areas for potential improvement, including operator skill impacting image quality, variability in measurements, and differences in interpretation. The introduction of novel AI technologies that can tackle some of these challenges, while also decreasing costs and improving efficiency, could have a profound impact on patient care and outcomes. Machine learning applications in cardiac imaging are therefore primarily focused on the following four categories: image acquisition and quality, automated measurements, diagnostic support, and outcome prediction [9, 16, 17]. In this section, we review some of the current technologies that have been developed for various cardiac imaging modalities.
5.1 Echocardiography
Echocardiography is the most common imaging modality in cardiology and remains a frontline diagnostic and management tool. However, it is heavily dependent on operator skill for image acquisition, quality, and measurements, leading to considerable concerns about intra- and inter-observer variability in data collection and clinical interpretation [18, 19]. AI technologies are continually being developed to reduce variability and improve interpretation [20,21,22,23,24,25,26].
Narang et al. [27] used a deep-learning-based algorithm to aid novices in acquiring echocardiographic images. In this study, healthcare providers with no prior ultrasound experience performed ultrasound with or without deep learning guidance. With the deep learning algorithm, providers were able to obtain 10 standard transthoracic echocardiographic views that provided some diagnostic assessment for ventricular size and function [27]. EchoNet, a deep learning model, by Ghorbani et al. used CNNs to accurately identify cardiac structures and evaluate left ventricular function [28]. Zhang et al. trained CNNs on 14,035 echocardiograms to automatically identify 23 imaging planes, segment the images, measure cardiac structure and function, and detect disease [29]. This study demonstrated forward progress in the area of automated measurements by using the model to calculate left ventricular volumes, mass, and ejection fraction. The automated measurements for ejection fraction and longitudinal strain deviated from manual measurements by approximately 6 and 1.6% [29]. Currently, 3D echocardiography is generally considered to have better accuracy than 2D evaluation, but is limited in clinical practice due to a high standard of operator expertise [30]. However, Narang et al. used a machine learning-based algorithm to automate the measurement of dynamic left ventricular and left atrial volumes that showed it was both accurate compared to manual 3D measurements and MRI, as well as efficient by shortening the time required to analyze the datasets [22]. Knackstedt et al. [20] and Salte et al. [31] have already shown the successful clinical workflow implementation of full automated assessment of global longitudinal strain.
Studies have also begun to focus on the use of machine learning models to aid in diagnostic support and interpretation. Zhang et al. used the aforementioned dataset of >14,000 echocardiograms to effectively detect hypertrophic cardiomyopathy, pulmonary hypertension, and cardiac amyloidosis using two echocardiographic planes, with a C statistic (area under the receiving operating characteristic curve) of greater than 0.85 for all three diseases [29]. A few studies have evaluated the ability to accurately assess the severity of valve dysfunction; Moghadddasi et al. [32] and Playford et al. [33] used machine learning models to grade mitral and aortic valve dysfunction, respectively. Moghaddasi et al. developed a model that had greater than 99% overall sensitivity and specificity in predicting whether a mitral valve was normal and graded the severity of regurgitation [32]. The algorithm designed by Playford et al. used data from the entire echocardiogram, as opposed to only the left ventricular outflow tract, to more accurately predict severe aortic stenosis [33].
Deep learning models are also utilized in fetal echocardiography and pediatric echocardiography. Arnaout et al. [34] used 107,832 fetal echocardiogram images to create a CNN to automatically identify standard fetal cardiac planes, automate segmentation to allow for biometric measurements, and differentiate between normal hearts and those with congenital heart disease. Le et al. [35] similarly studied a machine learning model using random forests to detect congenital heart disease using retrospective data. Others have studied how to automate image acquisition in fetal echocardiography, as well as interpreting Doppler signals [36,37,38] utilizing big data and artificial intelligence in pediatric echocardiography is relatively new, with a few studies in the abstract phase applying deep learning models to automate view identification, [39] and assessment of ejection fraction [40].
5.2 Cardiac Magnetic Resonance Imaging
Cardiac magnetic resonance imaging (CMR) has made significant strides in the application of deep learning to clinical practice. The use of AI in CMR has led to improvements in some areas that had previously been significant barriers to the widespread use of CMR. The extensive time required for image acquisition and post-processing, artifacts affecting image quality related to cardiac motion, and patient factors have been the focus of various studies aimed at streamlining the CMR imaging chain.
Leiner et al. and Frick et al. have both published on the automation of image acquisition planes, image optimization, and artifact detection [41, 42]. More recent work by Kustner et al. used deep learning methods to allow for reconstruction of low resolution CMR data to clinically comparable image quality as high resolution images in less than 1 min [43]. Similarly, Steeden et al. [44] used CNNs to recreate high resolution images from a low-resolution three-dimensional dataset in patients with congenital heart disease. Tissue characterization in CMR imaging often requires gadolinium contrast. However, Zhang et al. developed a CNN model to optimize existing imaging sequences, resulting in images with superior quality and comparable tissue burden quantification without the use of gadolinium [45].
Segmentation of image contours has historically been a manual task; however, this process is time-consuming and suffers from significant intra- and inter-observer variability. Multiple efforts have been successful at automatically segmenting right and left ventricles [46,47,48,49,50]. Owing to the relative scarcity of CMR data in patients, Winther et al. [50] used four separate sources to train a vendor-neutral CNN, which is an enormous advantage that allows for broader implementation. Bidhendi et al. [51] similarly demonstrated the success of a CNN in pediatric patients with congenital heart disease, which performed better than the baseline platform.
Radiomics, a relatively new area of study in cardiac imaging, is a method to extract features from large amounts of medical imaging data that can identify previously unseen patterns and characteristics. Texture analysis (TA) uses machine-learning strategies to evaluate subtle variations in image intensities at the pixel level. Multiple studies have already demonstrated the use of machine learning to accurately identify clinically relevant variations in imaging texture that are not obvious to the naked eye [52,53,54]. Mancio et al. [54] employed TA to quantify tissue changes within the myocardium of patients with hypertrophic cardiomyopathy to help risk-stratify patients with a lower probability of having scar tissue. Neisius et al. [52] discovered features using TA that could identify differences between CMRs in patients with hypertension and hypertrophic cardiomyopathy, which is a common challenge in typical clinical practice.
CMR studies have also shown promise for predictive modelling and decision support. Bello et al. used CNN modeling to segment labeled CMR images to develop 3D models that identified features to predict survival in patients with pulmonary hypertension [55]. Diller et al. used a U-net algorithm to evaluate CMR video clips to automatically trace endocardial borders in two views to directly predict prognosis in patients with tetralogy of Fallot [56]. Kotu et al. used a combination of multiple machine learning algorithms to stratify patients into high and low risk of arrhythmia after myocardial infarction [57].
5.3 CT
Cardiac computed tomography (CCT) is an important imaging modality in cardiology owing to its efficiency and image quality, particularly for small structures within the heart. However, radiation dose is a constant area of concern. Machine learning algorithms utilizing CCT have focused on improving image quality while reducing contrast. Santini et al. used a supervised learning model to “transform” non-contrast CCT scans into an image quality comparable to contrast CCT scans [55]. Geng et al. [58] also focused on improving image quality by using an unsupervised method to reduce “noise” in non-contrast CCTs.
Automated measurements and segmentation have also been evaluated for CCT. Zreik et al. evaluated 55 patients as part of a training set to perform automatic segmentation of the left ventricle, which resulted in high sensitivity and specificit [59] coronary artery disease (CAD) is a primary disease state that utilizes CCT as a diagnostic tool. Given that CAD is a leading cause of mortality globally, [60] early diagnosis by CCT has shown benefits to aid in treatment and prevention [61] and can avoid unnecessary invasive testing [62, 63]. Coronary artery calcium (CAC) is used as a predictive score for adverse cardiac events [61] and multiple studies have tackled the ability to automatically estimate the value. Using a CNN architecture to generate a CAC score, Wolterink et al. [64] achieved able to reach 72%. In light of the focus on contrast reduction, Lessmann et al. [65] used non-contrast CT scans and the aforementioned model by Wolterink et al. to detect calcium and identify false positives by using paired CNNs. There was a high detection rate of CAC, but the model was less successful in identifying calcium in the mitral and aortic valves [65]. However, the potential to utilize non-contrast CTs to predict CACS is very promising.
Diagnostic interpretation is another important focus of the application of AI to CCT. Van Hamersvelt et al. [66] evaluated the use of texture analysis (TA) of the myocardium to automatically identify significant coronary artery stenosis in favor of a typical approach in which a model is trained to identify features determined by a human expert. Using a combination of methods, including supervised and unsupervised techniques, a deep learning model showed an improved prediction of coronary stenosis [66].
Finally, CCT is one of the few cardiac imaging modalities that has used a broad registry to predict adverse cardiovascular events. Both Motwani et al. [67] and Van Rosendael [68] utilized the CONFIRM (Coronary CT Angiography EvaluatioN For Clinical Outcomes: An inteRnational Multicenter) registry [69, 70] to apply artificial intelligence to estimate the survival and prognosis of patients with cardiovascular disease. The Framingham risk score is widely accepted as a method for the risk stratification of patients; it uses a combination of patient demographics, laboratory values, and CAC. Motwani et al. [67] incorporated CCT data and clinical markers to train an AI-based algorithm that performed better than the Framingham score. Motwani et al. trained their model by ranking the importance of expert-determined features and placing more weight on some findings than on others. Van Rosendael employed a similar strategy with imaging as the only input, and found comparable success [68].
6 Nuclear Medicine
Nuclear medicine in cardiac imaging typically encompasses myocardial perfusion imaging (MPI) by SPECT (single-photon emission computed tomography (SPECT) and positron emission tomography (PET). SPECT is more commonly used in clinical practice, although PET requires less radiation. SPECT is unique to other imaging modalities because many of the measurements are already automated, including quantitative perfusion assessment, ventricular volumes, myocardial mass, ejection fraction, myocardial thickening, and dyssynchrony. In fact, there is already a large registry, REFINE SPECT, with >20,000 patients from multiple centers collecting imaging and clinical data to serve as a dataset for AI applications [71]. Therefore, AI applications for SPECT are geared towards automating diagnosis, prognostication, and management [72].
Betancur et al. [73] used the REFINE SPECT registry to train and develop a deep learning algorithm to detect coronary artery stenosis in <1 s The model was trained on catherization-based coronary angiography to identify coronary artery stenosis and then given the automated SPECT images as an input and performed better than the conventional method (AUC 0.8 vs. 0.78) [73] Nakajima et al. [74] used a supervised learning model based on expert labels from a multi-center dataset to design a neural network that performed better than human experts (AUC 0.97). Multiple studies have combined imaging variables and clinical factors to serve as inputs for machine learning models and have yielded better diagnostic accuracy than visual assessment alone [75, 76]. Haro Alonso et al. [77] compared a support vector machine (SVM) to traditional regression models to accurately predict cardiac death in patients. The study used SPECT data to train the model and found that the SVM performed better than the regression model (AUC 83 vs. 0.77).
7 Challenges and Pitfalls
The deployment of machine learning models in the real world remains one of the biggest challenges facing the incorporation of AI into clinical practice. Initial concerns about the inexplicability, or “black box” nature, of results from AI-derived data has plagued the adoption of AI in the healthcare field despite ongoing focus on designing models that are more transparent [78]. “Explainable AI” could include neural networks with built-in layers to assess decision-making and quality, allowing users to gain insight into the features that the model has selected [79]. Another approach asks the model to provide confidence intervals for its own predictions, allowing the user to provide clearer feedback focused on predictions that have wide intervals [80].
Another major challenge is the lack of infrastructure in most healthcare institutions, impacting the initiation of projects, inconsistent data labeling, difficulty navigating privacy laws and data sharing, and lack of technical support. This often limits research to single-center studies, often with retrospective data. While the model may perform well, it is unlikely to generalize widely and effectively impact clinical practice effectively [81] large datasets are necessary to adequately train deep learning models. This is especially difficult to overcome in patients with rare diseases or relatively small patient populations (congenital heart disease). In addition, the risk of utilizing narrow patient groups has been shown to result in a significant bias that could have a negative impact on the healthcare system; [82] it is of paramount importance to have adequately diverse datasets. Given the heavy involvement of vendors in cardiac imaging, it can also be challenging to incorporate vendor-neutral models, although there have been a few [83]. In the same vein, it is difficult to prove the benefit of AI-based care without extensive testing with human experts. Lastly, most clinicians do not have the opportunity to learn or experiment with AI concepts or how they can be incorporated into clinical practice. This can adversely affect the uptake of new technologies and the progress of stymie.
8 Future Directions
Despite the challenges mentioned in the previous section, the advances that have already been made in the areas of cardiac imaging and AI are impressive. For each imaging modality, studies have demonstrated improved image acquisition, quality, diagnostic accuracy, measurement automation, and outcome prediction. The results are promising and have the potential for far-reaching impacts on improving workflows and patient care. Future endeavors should focus on multicenter collaboration to create broadly representative datasets to encourage generalizable and reproducible results. Additional efforts should be placed on the effective deployment of algorithms and a way to compare algorithms that attempt to solve the same diagnostic question. As AI applications become more pervasive in healthcare, the combination of imaging data and radiomics and the other “-omics” (genomics, proteomics, and metabolomics) will strengthen the ability of machine learning predictions to provide individualized care to patients.
References
Russell S, Norvig P (2003) Artificial intelligence: a modern approach, 2nd edn. Prentice Hall, Upper Saddle River, New Jersey
Darcy AM, Louie AK, Roberts LW (2016) Machine learning and the profession of medicine. JAMA 315(6):551–552
Beyer MLD (2012) The importance of “big data”: a definition
McAfee A, Brynjolfsson E (2012) Big data: the management revolution. Harv Bus Rev 90(10):60–66, 68, 128
George G, Haas MR, Pentland A (2014) Big data and management. In: Vol 57: academy of management Briarcliff manor, NY, pp 321–326
De Mauro A, Greco M, Grimaldi M (2016) A formal definition of big data based on its essential features. Library Rev
Coffey S, Lewandowski AJ, Garratt S et al (2017) Protocol and quality assurance for carotid imaging in 100,000 participants of UK Biobank: development and assessment. Eur J Prev Cardiol 24(17):1799–1806
Petersen SE, Matthews PM, Bamberg F et al (2013) Imaging in population science: cardiovascular magnetic resonance in 100,000 participants of UK Biobank - rationale, challenges and approaches. J Cardiovasc Magn Reson 15:46
Lee JG, Jun S, Cho YW et al (2017) deep learning in medical imaging: general overview. Korean J Radiol 18(4):570–584
Mayr A, Binder H, Gefeller O, Schmid M (2014) The evolution of boosting algorithms. From machine learning to statistical modelling. Methods Inf Med 53(6):419–427
Chykeyuk KCD, Noble JA (2011) Feature extraction and wall motion classification of 2D stress echocardiography with relevance vector machines. In: Paper presented at: international symposium on biomedical imaging
Domingos JS, Stebbing RV, Lesson P, Noble JA (2014) Stuctured random forests for myocardium delineation in 3D echocardiography, Springer International Publishing
Krittanawong C, Tunhasiriwet A, Zhang H, Wang Z, Aydar M, Kitai T (2017) Deep learning with unsupervised feature in echocardiographic imaging. J Am Coll Cardiol 69(16):2100–2101
Aye CYL, Lewandowski AJ, Lamata P et al (2017) Disproportionate cardiac hypertrophy during early postnatal development in infants born preterm. Pediatr Res 82(1):36–46
Arsanjani R, Xu Y, Hayes SW et al (2013) Comparison of fully automated computer analysis and visual scoring for detection of coronary artery disease from myocardial perfusion SPECT in a large population. J Nucl Med 54(2):221–228
Stebbing RV, Namburete AI, Upton R, Leeson P, Noble JA (2015) Data-driven shape parameterization for segmentation of the right ventricle from 3D+t echocardiography. Med Image Anal 21(1):29–39
Fatima MPM (2017) Survey of machine learning algorithms for disease diagnosis. J Intel Learn Syst Appl 9:1–16
Davis A, Billick K, Horton K et al (2020) Artificial intelligence and echocardiography: a primer for cardiac sonographers. J Am Soc Echocardiogr 33(9):1061–1066
Nagata Y, Kado Y, Onoue T et al (2018) Impact of image quality on reliability of the measurements of left ventricular systolic function and global longitudinal strain in 2D echocardiography. Echo Res Pract 5(1):27–39
Knackstedt C, Bekkers SC, Schummers G et al (2015) Fully automated versus standard tracking of left ventricular ejection fraction and longitudinal strain: the FAST-EFs multicenter study. J Am Coll Cardiol 66(13):1456–1466
Volpato V, Mor-Avi V, Narang A et al (2019) Automated, machine learning-based, 3D echocardiographic quantification of left ventricular mass. Echocardiography 36(2):312–319
Narang A, Mor-Avi V, Prado A et al (2019) Machine learning based automated dynamic quantification of left heart chamber volumes. Eur Heart J Cardiovasc Imaging 20(5):541–549
Tamborini G, Piazzese C, Lang RM et al (2017) Feasibility and accuracy of automated software for transthoracic three-dimensional left ventricular volume and function analysis: comparisons with two-dimensional echocardiography, three-dimensional transthoracic manual method, and cardiac magnetic resonance imaging. J Am Soc Echocardiogr 30(11):1049–1058
Tsang W, Salgo IS, Medvedofsky D et al (2016) Transthoracic 3D echocardiographic left heart chamber quantification using an automated adaptive analytics algorithm. JACC Cardiovasc Imaging 9(7):769–782
Asch FM, Poilvert N, Abraham T et al (2019) Automated echocardiographic quantification of left ventricular ejection fraction without volume measurements using a machine learning algorithm mimicking a human expert. Circ Cardiovasc Imaging 12(9):e009303
Muraru D, Spadotto V, Cecchetto A et al (2016) New speckle-tracking algorithm for right ventricular volume analysis from three-dimensional echocardiographic data sets: validation with cardiac magnetic resonance and comparison with the previous analysis tool. Eur Heart J Cardiovasc Imaging 17(11):1279–1289
Narang ABR, Hong H, Thomas Y, Surette S, Cadieu C (2020) Acquisition of diagnostic echocardiographic images by novices using a deep learning based image guided algorithm. J Am College Cardiol 75:1564
Ghorbani A, Ouyang D, Abid A et al (2020) Deep learning interpretation of echocardiograms. NPJ Digit Med 3:10
Zhang J, Gajjala S, Agrawal P et al (2018) Fully automated echocardiogram interpretation in clinical practice. Circulation 138(16):1623–1635
Lang RM, Badano LP, Mor-Avi V et al (2015) Recommendations for cardiac chamber quantification by echocardiography in adults: an update from the American Society of Echocardiography and the European Association of Cardiovascular Imaging. J Am Soc Echocardiogr 28(1):1–39 e14
Salte IM, Oestvik A, Smistad E, Melichova D, Nguyen TM, Brunvand H (2020) Deep Learning/artificial intelligence of automatic measurement of global longitudinal strain by echocardiography. Eur Heart J Cardiovasc Imaging 21
Moghaddasi H, Nourian S (2016) Automatic assessment of mitral regurgitation severity based on extensive textural features on 2D echocardiography videos. Comput Biol Med 73:47–55
Playford D, Bordin E, Mohamad R, Stewart S, Strange G (2020) Enhanced diagnosis of severe aortic stenosis using artificial intelligence: a proof-of-concept study of 530,871 echocardiograms. JACC Cardiovasc Imaging 13(4):1087–1090
Arnaout R, Curran L, Zhao Y, Levine JC, Chinn E, Moon-Grady AJ (2021) An ensemble of neural networks provides expert-level prenatal detection of complex congenital heart disease. Nat Med 27(5):882–891
Le TKTV, Nguyen-Vo T-H (2020) Application of machine learning in screening of congenital heart disease using fetal echocardiography. J Am Coll Cardiol 75:648
Sulas E, Ortu E, Raffo L, Urru M, Tumbarello R, Pani D (2018) Automatic recognition of complete atrioventricular activity in fetal pulsed-wave doppler signals. Annu Int Conf IEEE Eng Med Biol Soc 2018:917–920
Dong J, Liu S, Liao Y et al (2020) A generic quality control framework for fetal ultrasound cardiac four-chamber planes. IEEE J Biomed Health Inform 24(4):931–942
Baumgartner CF, Kamnitsas K, Matthew J et al (2017) SonoNet: real-time detection and localisation of fetal standard scan planes in freehand ultrasound. IEEE Trans Med Imaging 36(11):2204–2215
Gearhart A, Goto S, Powell A, Deo R (2021) An automated view identification model for pediatric echocardiography using artificial intelligence. In: Abstract oral presentation presented at american heart association scientific sessions
He B, Ouyang D, Lopez L, Zou J, Reddy C (2021) Video-based deep learning model for automated assessment of ejection fraction in pediatric patients. American Heart Association Scientific Sessions
Frick M, Paetsch I, den Harder C et al (2011) Fully automatic geometry planning for cardiac MR imaging and reproducibility of functional cardiac parameters. J Magn Reson Imaging 34(2):457–467
Leiner T, Rueckert D, Suinesiaputra A et al (2019) Machine learning in cardiovascular magnetic resonance: basic concepts and applications. J Cardiovasc Magn Reson 21(1):61
Kustner T, Munoz C, Psenicny A et al (2021) Deep-learning based super-resolution for 3D isotropic coronary MR angiography in less than a minute. Magn Reson Med 86(5):2837–2852
Steeden JA, Quail M, Gotschy A et al (2020) Rapid whole-heart CMR with single volume super-resolution. J Cardiovasc Magn Reson 22(1):56
Zhang Q, Burrage MK, Lukaschuk E et al (2021) Toward replacing late gadolinium enhancement with artificial intelligence virtual native enhancement for gadolinium-free cardiovascular magnetic resonance tissue characterization in hypertrophic cardiomyopathy. Circulation 144(8):589–599
Duan J, Bello G, Schlemper J et al (2019) Automatic 3D bi-ventricular segmentation of cardiac images by a shape-refined multi-task deep learning approach. IEEE Trans Med Imaging 38(9):2151–2164
Avendi MR, Kheradvar A, Jafarkhani H (2016) A combined deep-learning and deformable-model approach to fully automatic segmentation of the left ventricle in cardiac MRI. Med Image Anal 30:108–119
Ruijsink B, Puyol-Anton E, Oksuz I et al (2020) Fully automated, quality-controlled cardiac analysis from CMR: validation and large-scale application to characterize cardiac function. JACC Cardiovasc Imaging 13(3):684–695
Sudlow C, Gallacher J, Allen N et al (2015) UK biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med 12(3):e1001779
Winther HB, Hundt C, Schmidt B et al (2018) nu-net: deep learning for generalized biventricular mass and function parameters using multicenter cardiac MRI data. JACC Cardiovasc Imaging 11(7):1036–1038
Karimi-Bidhendi S, Arafati A, Cheng AL, Wu Y, Kheradvar A, Jafarkhani H (2020) Fullyautomated deeplearning segmentation of pediatric cardiovascular magnetic resonance of patients with complex congenital heart diseases. J Cardiovasc Magn Reson 22(1):80
Neisius U, El-Rewaidy H, Nakamori S, Rodriguez J, Manning WJ, Nezafat R (2019) Radiomic analysis of myocardial native T1 imaging discriminates between hypertensive heart disease and hypertrophic cardiomyopathy. JACC Cardiovasc Imaging 12(10):1946–1954
Wang J, Yang F, Liu W et al (2020) Radiomic analysis of native T1 mapping images discriminates between MYH7 and MYBPC3-related hypertrophic cardiomyopathy. J Magn Reson Imaging 52(6):1714–1721
Mancio J, Pashakhanloo F, El-Rewaidy H et al (2021) Machine learning phenotyping of scarred myocardium from cine in hypertrophic cardiomyopathy. Eur Heart J Cardiovasc Imaging
Bello GA, Dawes TJW, Duan J et al (2019) Deep learning cardiac motion analysis for human survival prediction. Nat Mach Intel 1:95–104
Diller GP, Orwat S, Vahle J et al (2020) Prediction of prognosis in patients with tetralogy of Fallot based on deep learning imaging analysis. Heart 106(13):1007–1014
Kotu LP, Engan K, Borhani R et al (2015) Cardiac magnetic resonance image-based classification of the risk of arrhythmias in post-myocardial infarction patients. Artif Intell Med 64(3):205–215
Geng M, Deng Y, Zhao Q et al (2018) Unsupervised/semi-supervised deep learning for low-dose CT enhancement
Zreik M, Leiner T, de Vos BD, van Hamersvelt RW, Viergever MA, Isgum I (2016) Automatic segmentation of the left ventricle in cardiac CT tomography using convolutional neural networks. In: Paper presented at international symposium biomedical imaging
Mozaffarian D, Benjamin EJ, Go AS (2016) Heart disease and stroke statistics—2016 update. Lippincott Williams and Wilkins Hagerstown
Denissen SJ, van der Aalst CM, Vonder M, Oudkerk M, de Koning HJ (2019) Impact of a cardiovascular disease risk screening result on preventive behaviour in asymptomatic participants of the ROBINSCA trial. Eur J Prev Cardiol 26(12):1313–1322
Moss AJ, Williams MC, Newby DE, Nicol ED (2017) The updated NICE guidelines: cardiac CT as the first-line test for coronary artery disease. Curr Cardiovasc Imaging Rep 10(5):15
Saraste A, Barbato E, Capodanno D et al (2019) Imaging in ESC clinical guidelines: chronic coronary syndromes. Eur Heart J Cardiovasc Imaging 20(11):1187–1197
Wolterink JM, Leiner T, de Vos BD, van Hamersvelt RW, Viergever MA, Isgum I (2016) Automatic coronary artery calcium scoring in cardiac CT angiography using paired convolutional neural networks. Med Image Anal 34:123–136
Lessmann N, van Ginneken B, Zreik M et al (2018) Automatic calcium scoring in low-dose chest CT using deep neural networks with dilated convolutions. IEEE Trans Med Imaging 37(2):615–625
van Hamersvelt RW, Zreik M, Voskuil M, Viergever MA, Isgum I, Leiner T (2019) Deep learning analysis of left ventricular myocardium in CT angiographic intermediate-degree coronary stenosis improves the diagnostic accuracy for identification of functionally significant stenosis. Eur Radiol 29(5):2350–2359
Motwani M, Dey D, Berman DS et al (2017) Machine learning for prediction of all-cause mortality in patients with suspected coronary artery disease: a 5-year multicentre prospective registry analysis. Eur Heart J 38(7):500–507
van Rosendael AR, Maliakal G, Kolli KK et al (2018) Maximization of the usage of coronary CTA derived plaque information using a machine learning based algorithm to improve risk stratification; insights from the CONFIRM registry. J Cardiovasc Comput Tomogr 12(3):204–209
Min JK, Berman DS, Budoff MJ et al (2011) Rationale and design of the DeFACTO (determination of fractional flow reserve by anatomic computed tomographic angiography) study. J Cardiovasc Comput Tomogr 5(5):301–309
Hadamitzky M, Achenbach S, Al-Mallah M et al (2013) Optimized prognostic score for coronary computed tomographic angiography: results from the CONFIRM registry (COronary CT Angiography EvaluatioN For Clinical Outcomes: an InteRnational Multicenter Registry). J Am Coll Cardiol 62(5):468–476
Slomka PJ, Betancur J, Liang JX et al (2020) Rationale and design of the REgistry of fast myocardial perfusion imaging with NExt generation SPECT (REFINE SPECT). J Nucl Cardiol 27(3):1010–1021
Slomka PJ, Dey D, Sitek A, Motwani M, Berman DS, Germano G (2017) Cardiac imaging: working towards fully-automated machine analysis & interpretation. Expert Rev Med Devices 14(3):197–212
Betancur J, Commandeur F, Motlagh M et al (2018) Deep learning for prediction of obstructive disease from fast myocardial perfusion SPECT: a multicenter study. JACC Cardiovasc Imaging 11(11):1654–1663
Nakajima K, Kudo T, Nakata T et al (2017) Diagnostic accuracy of an artificial neural network compared with statistical quantitation of myocardial perfusion images: a Japanese multicenter study. Eur J Nucl Med Mol Imaging 44(13):2280–2289
Arsanjani R, Dey D, Khachatryan T et al (2015) Prediction of revascularization after myocardial perfusion SPECT by machine learning in a large population. J Nucl Cardiol 22(5):877–884
Arsanjani R, Xu Y, Dey D et al (2013) Improved accuracy of myocardial perfusion SPECT for the detection of coronary artery disease using a support vector machine algorithm. J Nucl Med 54(4):549–555
Haro Alonso D, Wernick MN, Yang Y, Germano G, Berman DS, Slomka P (2019) Prediction of cardiac death after adenosine myocardial perfusion SPECT based on machine learning. J Nucl Cardiol 26(5):1746–1754
Singh A, Sengupta S, Lakshminarayanan V (2020) Explainable deep learning models in medical image analysis. J Imaging 6(6)
Holzinger a BC, Pattichis C, Kell D (2017) What do we need to build explainable AI systems for the medical Domain?
Hazarika S, Biswas A, Shen HW (2018) Uncertainty visualization using copula-based analysis in mixed distribution models. IEEE Trans Vis Comput Graph 24(1):934–943
Keane PA, Topol EJ (2018) With an eye to AI and autonomous diagnosis. NPJ Digit Med 1:40
Puyol-Anton E, Ruijsink B, Mariscal Harana J, Piechnik SK, Neubauer S, Petersen SE (2021) Fairness in cardiac magnetic resonance imaging: assessing sex and racial bias in deep learning-based segmentation
Tao Q, Yan W, Wang Y et al (2019) Deep learning-based method for fully automatic quantification of left ventricle function from cine MR images: a multivendor, multicenter study. Radiology 290(1):81–88
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Reddy, C.D. (2022). Big Data and AI in Cardiac Imaging. In: Sakly, H., Yeom, K., Halabi, S., Said, M., Seekins, J., Tagina, M. (eds) Trends of Artificial Intelligence and Big Data for E-Health. Integrated Science, vol 9. Springer, Cham. https://doi.org/10.1007/978-3-031-11199-0_5
Download citation
DOI: https://doi.org/10.1007/978-3-031-11199-0_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-11198-3
Online ISBN: 978-3-031-11199-0
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)