
Abstract
The groundwater level is required to keep within the permissible limit for sustainable groundwater development in any area. In the present study, an Artificial Neural Network (ANN) model has been developed for groundwater development with respect to state variables of a groundwater system, i.e., a maximum depth to water table for agricultural purposes. The zonal cropping areas are considered as inputs to the ANN model. The methodology has been illustrated in the Yamuna-Hindon Inter basin, India. The ANN model is performed for two different training algorithms like (i) Levenberg–Marquardt (LM) and (ii) Bayesian regularization (BR) and their performance was compared with the backpropagation (BP) algorithm. The prediction accuracy of both algorithms was tested using performance indices viz. mean square error (MSE), root mean square error (RMSE), and correlation coefficient (R2). The performance of both the ANN training algorithms in predicting maximum depth to water table over the study area was found to be almost similarly good. However, the performance of the LM algorithm was found slightly superior to that of the BR algorithm as well as the BP algorithm.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
- Artificial Neural Network (ANN)
- Feedforward Multilayer Neural Network (FNN)
- Levenberg–Marquardt algorithm (LM)
- Bayesian regularization algorithm (BR)
- Groundwater modeling
10.1 Introduction
Groundwater is a very precisely available and dependable natural resource all over the world among various users to meet several needs (Firouzkouhi 2011). This resource should be utilized judiciously to maintain sustainability. But the lowering trend of groundwater level and aquifer depletion due to indiscriminate groundwater development and also increasing trend of groundwater/subsurface pollution are threatening the sustainability of water resources. Unsustainable groundwater usage leads to several socio/technical consequences, and these issues are increasing day by day throughout the world, especially in developing countries. In the present scenario, it is the first priority or utmost concern of a planner/manager, or user to maintain the yield from aquifers in a sustainable manner for long period (Sophocleous 2005; Todd and Mays 2005; Gorelick and Zheng 2015). Therefore, appropriate sustainable management/planning of surface water and groundwater usage conjunctively is the most important concern. Planning of groundwater development is carried out at two stages viz. (i) feasibility—ensuring acceptability/appropriateness of the groundwater development without affecting the social/technical restrictions and (ii) optimality—choose the best among all feasible alternatives. Feasibility means to check the desired level of various groundwater state variables like groundwater table depth, stream–aquifer inter-flow, seawater intrusion, etc. within a certain specified limit by considering relevant socio/technical issues. The next stage toward the planning is to pick up the most rewarding (kashyap and Chandra 1982) or least penalizing (Emch and Yeh 1998) optimal pattern from the array of the evolved feasible pattern.
The groundwater management problems have been addressed by forming an optimization problem. The optimization problem mainly comprises an array of decision variables, one or more than one objective function as per manager requirement, and an array of relevant constraints. The constraints and objective functions are explicit or implicit functions of the decision variables and state variables (Deininger 1970; Maddock 1972). The numerous significant constraints of groundwater management are limitations on the state variables such as maximum/minimum groundwater table depth (Ghosh and Kashyap 2012a, b), stream–aquifer interactions (Young and Bredehoeft 1972; Pulido-Velazquez et al. 2007), and seawater intrusion (Werner and Simmons 2009). The state variables are generally computed by physically based simulation models (Bredehoeft and Young 1970; Kashyap and Chandra 1982; Kumar 2013). Therefore, said models are numerical solutions of the selected governing differential equations using the finite difference/element method. And it becomes computationally quite expensive in planning programs due to the sequential calling of simulation models. The computational cost of planning problems has been reduced considerably in case of some planning practices like the kernel function-based approach (Maddock 1972; Ghosh and Kashyap 2012a, b), embedded technique (Gorelick and Remson 1982), and the physically based modeling techniques are also very much data-intensive. Thus, the use of a physically based model is being restricted due to the scarcity of required data which is a common problem in several parts of developing countries. Therefore, the computationally expensive and data-intensive physically based simulation models can be replaced by approximate/black-box models (Lefkoff and Gorelick 1990; Bhattacharya and Datta 2005, ASCE 2000, Mohanty et al. 2013) using relatively less computational time and data. The current study invokes artificial neural network (ANN) models as a simulation model. The ANN models are being used to simulate the aquifer response by considering several sets of inputs like pumping patterns, weather parameters, and aquifer characteristics/conditions (Morshed and Kaluarachchi 1998; and Safavi et al. 2010). The outputs from the ANN models are aquifer parameters (Rizzo and Dougherty 1994), and water table/piezometric heads (Coulibaly et al. 2001; Daliakopoulos et al. 2005; Uddameri 2007; Trichakis et al. 2011). The input–output data sets for training and testing of the ANN models are generated from simulation models (Singh and Datta 2006; Safavi et al. 2010) or from field data (Coppola et al. 2005; Feng et al. 2008).
10.2 Present Study
The water requirement/demand for agricultural purposes is generally met by groundwater water entirely or in conjunction with surface water in canal command areas. As a result, the water table level declined excessively due to the unplanned withdrawal of groundwater resources. Effective modeling is essential to achieve sustainable agricultural groundwater development to restrict the lowering trend of water table depth. The ANN model has been developed considering crop areas and maximum water table depth as input and output, respectively, and illustrated at Yamuna-Hindon inter basin (Ghosh and Kashyap 2012a). The area falls under the command area of the Eastern Yamuna Canal system that starts from Yamuna river at Tajewala and also has abundant groundwater. In spite of that, the sustained lowering trend of water table level is observed in the several past reported studies (Kashyap and Chandra 1982; Mishra 1987; Rathi 1997; Ghosh 2011; Ghosh and Kashyap 2012a, b). Therefore, the ANN-based technique is utilized to simulate the groundwater levels for agricultural purposes considering the relevant groundwater state variable, i.e., a maximum depth to the water table. The zone-wise cropping pattern is a decision variable to quantify the requirement of groundwater for irrigation. In this study, the array of input–output data sets is used from the preceding studies (Ghosh and kashyap 2012a). Training of the ANN model has been done using two algorithms, i.e., Levenberg–Marquardt (LM) and Bayesian regularization (BR) and ANN architecture as feedforward multilayer neural network (FNN), and the developed ANN model performance with the previous study where training has been done using backpropagation is compared (Ghosh and Kashyap 2012a). The limitation of the backpropagation training algorithm is that it is an inefficient algorithm because of its slow convergence (Wilamowski and YuHao 2010). Therefore, in the present study, ANN models have been developed using Levenberg–Marquardt (LM) and Bayesian regularization (BR) training algorithms and with ANN architecture as a feedforward multilayer neural network (FNN).
10.3 Zonal Cropping Pattern
The study area is divided into two zones of uniform cropping pattern having alike hydrogeological characteristics, namely (I) centralized zone and (II) outer zone with five different major crops, (a) paddy, (b) other kharif, (c) sugarcane, (d) wheat, and (e) other rabi.
10.4 Study Area
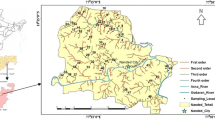
The study area is an agricultural area viz. the Hindon-Yamuna inter basin under the Eastern Yamuna canal system (India), area of 0.6 million hectares, from latitude 29° 18′–30° 25' N and longitude 77° 1′ 30″–77° 40′ 45″ E (Fig. 10.1). The Yamuna and Hindon rivers are in the west and east directions, respectively, of the area. The two rivers meet at the southern end. The Siwalik Mountains are on the north side of the area.

Study area (Ghosh and Kashyap 2012a)
10.5 Data
The major crops in this area are (a) paddy, (b) other kharif, (c) sugarcane, (d) wheat, and (e) other rabi. The area is separated in two zones (0.14 and 0.46 million ha) based on uniform cropping patter (Fig. 10.1). The tens crop-area matrix are as follows: [{(ajl), j = 1, 2, 3, 4, 5}, l = 1, 2]. The generated zonal crop areas of each crop are used from previous studies (Ghosh 2011).
The cropping areas and corresponding maximum groundwater table depth (D) are calculated using the ground elevations and model computed groundwater table elevations by Eq. (10.1) in previous studies (Ghosh 2011) and these data sets are used in this study.
- D :
-
Maximum groundwater table depth
- G i :
-
The ground elevations
- h * ik :
-
Head under dynamic equilibrium.
There are shown some of the typical samples of data sets of input and output (Table 10.1), whereas inputs are that of zones 1 and 2, crop areas (% of geographical area) of a1, a2, a3, a4, a5, and Dmax is the output that is the maximum depth of the groundwater in meter sample in Table 10.1.
10.6 Artificial Neural Network
Artificial Neural Network (ANN) is an artificial intelligence method motivated by the working of the human brain. The human brain is possibly the most powerful information processing tool. ANN is a dominant huge data-driven, flexible computational tool having the ability to capture the physical behavior of any nonlinear and complex physical process with an acceptable accuracy level. An ANN comprises input, hidden, and output layers. The input layer represents input variables that are connected to the hidden layer and output layer simultaneously. The nodal output values of the hidden layer are computed through specified activation functions and it computes the weights of the variables to search for the effects of predictors upon the target (dependent) variables. In the output layer, the computation process is ended and the results, i.e., output variables are achieved with a minor estimation error.
In this study, regarding the ANN model, ANN architecture as a feedforward neural network (FNN) is used. In the previous studies (Ghosh and kashyap 2012a), a backpropagation training algorithm had been used for ANN model. The limitation of the backpropagation training algorithm is that it converges slowly (Wilamowski and Hao 2010). Therefore, in the present study, ANN models have been developed using Levenberg–Marquardt (LM) and Bayesian regularization (BR) training algorithms.
10.7 Development of ANN Models
Generally, the large input–output data sets for the training and testing of the ANN networks are essential for ANN model development. In this study, 750 sets of uniform cropping patterns and the corresponding maximum depth of the groundwater tables are used to train and test an artificial neural network (Ghosh and Kashyap 2012a). 675 data sets are used for ANN training and the remaining 75 data sets are used for validation. The ANN models have been developed using Levenberg–Marquardt (LM) and Bayesian regularization (BR) training algorithms and with ANN architecture as feedforward multilayer neural network (FNN) using the MATLAB R2014a Neural Network Toolbox. In the training phase, the number of hidden layers and number of neurons at each hidden layer is increased one by one starting from the bare minimum model. The parameters like epoch and maximum fail also change to achieve the desired accuracy of the ANN model. The ANN architecture, i.e., the number of hidden layers and number of neurons at every layer is finalized by the trial-and-error method keeping performance indices of the trained ANN model in an acceptable range. Inputs and outputs of the ANN model have been normalized in the range of (0–1, 0.1–0.9), and to observe the effect of normalization. The adaption learning function is LEARGDM, the performance function is MSE, and the transfer function is LOGSIG. After the successful training of the ANN model, the ANN architecture is fixed and then tested with the remaining data sets. The mean squared error (MSE) and correlation coefficient (R2) are computed for the training and testing phases, respectively (Tables 10.3 and 10.4) and considered as performance evaluation criteria in training and testing phases of the developed ANN model. The efficiency of the ANN model is measured by minimizing the MSE and maximizing the R2 value.
10.8 Results and Discussion
After several trial runs with different combinations of epochs and maximum fails, the optimal ANN architecture is chosen for minimum MSE, i.e., 0.0044, and maximum R2, i.e., 0.940.
An optimal design is completed for one hidden layer (10-10-1) with a feedforward multilayer neural network (FNN), and corresponding R2 and MSE are given in Table 10.3 (normalized range: 0–1) and Table 10.4 (normalized range: 0.1–0.9). The two training algorithms such as Levenberg–Marquardt (LM) and Bayesian regularization (BR) are used for ANN training and their efficiency is computed. The target values and corresponding ANN computed values (Table 10.2) show good match for LM training and testing (Fig. 10.2) and BR training and testing (Fig. 10.3) in the (0–1) normalized range. In Figs. 10.4 and 10.5, it is observed that the target and ANN computed maximum groundwater table depth is also quite a good match using BR training for the (0.1–0.9) normalized range. Therefore, it may be concluded from Tables 10.3 and 10.4 that there is as such no more effect on the ANN model efficiency considering two separate normalized ranges viz. (0–1) and (0.1–0.9). And the application of an ANN has been successfully demonstrated using FNN architecture to compute maximum groundwater table depth for an agricultural area

Target and ANN computed Dmax Levenberg–Marquardt training and testing (0–1)
.

Target and ANN computed Dmax Bayesian regularization training and testing (0–1)

Target and ANN computed Dmax Levenberg–Marquardt training and testing (0.1–0.9)

Target and ANN computed Dmax Bayesian regularization training and testing (0.1–0.9)
10.9 Conclusion
ANN models have been developed in the case of groundwater development for irrigation considering the relevant groundwater state variable, i.e., Maximum depth of the groundwater table. The cropping pattern is a decision variable to quantify the requirement of groundwater for irrigation. An optimal design is completed for one hidden layer with ANN architecture as a feedforward multilayer neural network (FNN). The two training algorithms viz. LM and BR are used and their performance is assessed.
The application of an ANN has been successfully demonstrated using FNN architecture to predict maximum groundwater table depth in the agricultural area. The prediction accuracy of both the ANN training algorithms has been tested using two performance indices like mean square error (MSE) and efficiency criterion (R2).
LM and BR training achieved the desired accuracy level faster than BP. From Tables 10.3 and 10.4, it is clearly evident that the performance of both the ANN training algorithms to predict groundwater levels in this area is shown to be almost equally good, though the performance of the LM training algorithm shows slightly superior to that of the BR as well as the BP training algorithm. The normalized data set was done from the range 0.1–0.9 to avoid the extreme limits of the transfer function. But still, there is no effect after normalizing the range 0.1–0.9 and the same LM training algorithm was found slightly improved than that of the BR training algorithms. The ANN model with respect to cropping pattern-maximum groundwater depth to the water table is more relevant for groundwater development for canal command area for irrigation than pumping-groundwater level done in the previous study.
References
ASCE (2000) Task committee on applications of artificial neural networks in hydrology. Artificial neural networks in hydrology. I: preliminary concepts. Hydrol Eng 5(2):115–123
Bhattacharya R, Datta B (2005) Optimal management of coastal aquifers using linked simulation optimization approach. Water Resour Manage 19:295–320
Bredehoeft JD, Young RA (1970) The temporal allocation of groundwater-a simulation approach. Water Resour Res 6(1):3–21
Coppola E, Rana A, Poulton M, Szidarovszky F, Uhl V (2005) A neural network model for predicting water table elevations. J. Ground Water 43(2):231–241
Coulibaly P, Anctil Ramon F, Bernard Bobee A (2001) Artificial neural network modeling of water table depth fluctuations. Water Resour Res 37(4):885–896
Daliakopoulos IN, Coulibaly P, Tsanis IK (2005) Groundwater level forecasting using artificial neural network. J Hydrol 309:229–240
Deininger RA (1970) System analysis of water supply systems. Water Resour Bull 6(4):573–580
Emch PG, Yeh WW (1998) Management model for conjunctive use of coastal surface water and ground water. J Water Resour Plan Manag 124(3):129–139
Feng S, Kang S, Huo Z, Li W, Chen S, Mao X (2008) Using neural network to simulate regional ground water affected human activities. J Ground Water 46(1):80–90
Firouzkouhi R (2011) Simulating groundwater resources of Aghili-Gotvand plain by using mathematical model of finite differences. MSD (Doctoral dissertation, Thesis, Shahid Chamran University of Ahwaz, Iran)
Ghosh S (2011) Kernel function and ANN based planning of groundwater development for irrigation. Doctoral thesis, Indian Institute of Technology, Roorkee, India
Ghosh S, Kashyap D (2012a) ANNbased model for planning of groundwater development for agricultural usage. Irrig Drain 61(4):555–564
Ghosh S, Kashyap D (2012b) Kernel function model for planning of agricultural groundwater development. J Water Resour Plan Manage, ASCE (published online). https://doi.org/10.1061/(ASCE)WR.1943-5452.0000178
Gorelick SM, Remson I (1982) Optimal location and management of waste disposal facilities affecting groundwater quality. Water Resour Bull 18:43–51
Gorelick SM, Zheng C (2015) Global change and the groundwater management challenge. Water Resour Res 51(5):3031–3051
Jeff Lefkoff L, Gorelick SM (1990) Simulating physical processes and economic behavior in saline, irrigated agriculture: model development. 26(7):1359–1369
Kashyap D, Chandra S (1982) A distributed conjunctive use model for optimal cropping pattern. In: Proceedings of the Exeter symposium, July, IAHS Publication 135, 377–384
Kumar CP (2013) Numerical modelling of ground water flow using MODFLOW. Ind J Sci 2(4):86–92
Maddock T III (1972) Algebric technological function from a simulation model. Water Resour Res 8(1):129–134
Mishra R (1987) Distributed aquifer response modeling in Yamuna-Hindon Doab. MTech dissertation, Indian Institute of Technology Roorkee, India
Mohanty S, Madan KJ, Kumar A, Panda DK (2013) Comparative evaluation of numerical model and artificial neural network for simulating groundwater flow in Kathajodi-Surua Inter-basin of Odisha. India J Hydrol 495:38–51
Morshed and Kaluarachchi (1998) Application of artificial neural network and genetic algorithm in flow and transport simulations. Adv Water Resour 22(2):145–158
Pulido-Velazquez D, Sahuquillo A, Andreu J (2007) An efficient conceptual model to simulate surface water body–aquifer interaction in conjunctive use management models. Water Resour Res 43:1–15
Rathi S (1997) Numerical modeling of aquifer response in Yamuna-Hindon doab. MTech dissertation, Indian Institute of Technology, Roorkee, India
Rizzo DM, Dougherty DE (1994) Characteristics of aquifer parameters using artificial neural networks: neural kriging. Water Resour Res 30(2):483–497
Safavi HR, Darzi F, Marino MA (2010) Simulation-optimization modelling of conjunctive use of surface and groundwater. Water Resour Manage 24(10):1965–1988
Singh RM, Datta B (2006) Identification of groundwater pollution sources using GA-based linked simulation optimization model. J Hydrol Eng ASCE 11(2):101–109
Sophocleous MA (2005) Groundwater recharge and sustainability in the high plains aquifer in Kansas, USA. Hydrogeol J 13:351–365
Trichakis JC, Nikolos IK, Karatzas GP (2011) Artificial neural network (ANN) based modelling for karstic groundwater level simulation. Water Resour Manage 25(4):1143–1152
Todd DK, Mays LW (2005) Groundwater hydrology. Wiley, Hoboken, N.J
Uddameri V (2007) Using statistical and artificial neural network models to forecast potentiometric levels at a deep well in South Texas. Environ Geol 51:885–895
Werner AD, Simmons CT (2009) Impact of sea-level rise on seawater intrusion in coastal aquifers. Ground Water 47(2):197–204
Wilamowski BM, Yu Hao (2010) Improved computation for Levenberg–Marquardt training. IEEE Trans Neural Netw 21(6):930–937
Young RA, Bredehoeft JD (1972) Digital computer simulation for solving management problems of conjunctive groundwater and surface water systems. Water Resour Res 8(3):533–556
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Malakar, P., Ghosh, S. (2022). ANN Modeling of Groundwater Development for Irrigation. In: Jha, R., Singh, V.P., Singh, V., Roy, L., Thendiyath, R. (eds) Groundwater and Water Quality. Water Science and Technology Library, vol 119. Springer, Cham. https://doi.org/10.1007/978-3-031-09551-1_10
Download citation
DOI: https://doi.org/10.1007/978-3-031-09551-1_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-09550-4
Online ISBN: 978-3-031-09551-1
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)