
Abstract
Flexible Query Answering Systems (FQAS) is a multidisciplinary research field at the crossroad of Information retrieval, databases, data mining, multimedia and geographic information systems, knowledge based systems, social networks, Natural Language Processing (NLP) and semantic web technologies, whose aim is to improve human ability to retrieve relevant information from databases, libraries, heterogeneous archives, the Web and the Web 2.0. The present paper has the objective to outline the perspectives and challenges offered by the heterogeneous panorama of current techniques.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

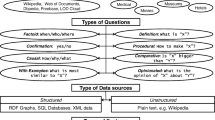

Keywords
1 Introduction
Query Answering Systems (QASs) have the main objective of satisfying the needs of end users to retrieve information contents they are interested in, including structured data typically managed in databases, unstructured and semi-structured texts in natural language such as Web documents typically managed by information retrieval systems and search engines, documents containing spatial and/or temporal information, multimedia documents containing audio, image and videos files, structured RDF data in the Semantic Web, social posts within social networks and, last but not least, natural language processing and knowledge based answers [1, 27,28,29,30]. In such a varied context, formulating queries that can be flexibly interpreted by the systems is an essential objective in order to satisfy users’ needs.
The International Conference on Flexible Query Answering Systems (FQAS), firstly organized in 1994 in Roskilde, Denmark, has been the premier conference concerned with this up-to-date issue of improving user systems interaction when searching for information, by investigating the proposals of flexible querying facilities and intuitive access to information. This was before the first question-answering (Q/A) evaluations track started in 1999 as part of the Text Retrieval Conference (TREC) [2].
Traditionally, FQAS has been a multidisciplinary conference gathering research contributors at the crossroad of different disciplines, such as Information retrieval, databases, data mining, multimedia information systems, geographic information systems, knowledge based systems, social network querying and mining, Question Answering (Q/A), Natural Language Processing (NLP) and semantic web technologies, in order to aid retrieval from information repositories such as databases, libraries, heterogeneous archives, the Web and the Web 2.0.
Traditional flexible querying has been strongly related to human-computer interaction (HCI) defined by the Association for Computing Machinery (ACM) as “…a discipline that is concerned with the design, evaluation and implementation of interactive computing systems for human use and with the study of major phenomena surrounding them”. It is easy to see that this has human and machine aspects. From the machine point of view, issues exemplified by computer graphics or development environments are relevant, while from the human point of view, issues related to communication, argumentation, graphic design, natural language, cognitive and psychological analyses, to just mention a few, are important.
More recently, it has become more and more obvious that virtually all problems related to flexible querying, as well as many other related areas, are plagued by uncertainty, imprecision, vagueness, incompleteness, etc. which should be reflected in analyses, designs and implementations.
It has become obvious that the traditional widely employed logical, probabilistic and statistical tools and techniques that have been used for decades cannot cope with those problems with the omnipresent broadly perceived imperfect information. Luckily enough, progression in view of both more sophisticated logics and probabilistic and statistical tools and techniques, including fuzzy logic, rough sets theory and their extensions exemplified by intuitionistic fuzzy sets theory, possibilistic analyses, fuzzy rough/rough fuzzy sets theory, etc. have made it possible to deal with many more aspects of the imperfection of information, notably uncertainty, imprecision, vagueness, incompleteness etc. A high potential of these new fields has been recognized by the flexible querying community, and reflected in the list of topics considered, of the FQAS Conferences since the very beginning.
Within elective frameworks to make human interaction flexible using such diverse techniques, model-based approaches are defined with the main shared characteristics to be representation based and human interpretable in the first place, i.e., “explainable by design” ex-ante to their use. Furthermore, they are also ex-post explainable in the second place, i.e., the criteria that yield results can be understandable to humans since they accurately describe model behaviour in the entire feature space [3].
These methods are increasingly competing with data-driven approaches based on Machine Learning, mainly Deep learning (DL) and Embedding technologies, which indeed exhibited high accuracy in many contexts, such as IR, NLP, speech to text, etc.
These approaches have polarized the landscape of papers presented in recent editions of ACM SIGIR, ECIR, ACM CIKM just to cite the most renowned international venues on the topics of IR, databases and knowledge based systems.
This dynamic is also reflected in the types of contributions submitted to FQAS in recent years. In fact, in the case of FQAS being a traditional venue for model-based approaches, the change of paradigm from model-based to data-driven, is also reflected in the lower number of contributions submitted to the FQAS conference in the last years and in a growing number of contributions proposing data driven approaches.
In an attempt to promote and stimulate the interest for the research on Flexible QAS and possibly to pave the way to renewed editions of future FQAS Conferences, in the following section we trace some challenges for future perspectives and views of the research on Flexible QA and QAS.
2 Challenges for Research on Flexible Query Answering Systems
During the last editions of the FQAS Conference, an increasing number of contributions applying data driven approaches is starting to appear, mainly exploiting Deep Learning (DL) and Embedding techniques. Such approaches investigate the applicability of deep learning and their comparison with representation based models for query answering tasks. In the following we discuss some possible perspectives of the research on FQAS that spring from the panorama of the techniques in use.
2.1 Coping with an Insufficient Effectiveness of Data Driven Models by Model Based Approaches to FQAS
There are domain contexts in which the performance of deep learning approaches need to be re-assessed since these can hardly be applied in the case of scarcity of training data and in highly specialized contexts.
As an example, [4] reports that the state-of-the-art data driven approaches can only achieve about 28% accuracy on the largest open question answering dataset in the legal domain (JEC-QA), collected from the National Judicial Examination of China [5], while skilled humans and unskilled humans can reach 81% and 64% accuracy, respectively. This huge gap between humans and machines on this domain indicates that FQAS is a current challenge in specialized domains.
Another issue of ML approaches is the fact that it can be unfair to rely on black box approaches when the training was done using data affected by some systematic bias [6], like for instance when using word embedding created from training texts expressing discrimination and unfairness towards women, disabled, black people, or when recognizing objects in images based on properties of the background [7, 8].
A current challenge is defining flexible query answering methods for mining possible bias affecting training collections: before training a DL approach for a given task it can be useful to evaluate the data suitability by querying the training collection for identifying biased opinions and detecting unbalanced polarity relatively to facts, people, genre, etc., cf. also a recent growing interest in countering disinformation/fake-news spreading.
Besides, fairness, reliability and interpretability are also important properties of QASs since to capture users’ trust, the connection between the query and the retrieved documents should be understandable. This is a requirement in many contexts of high risk such as the medical and legal domains and more generally in safety-critical tasks, in which both retrieving relevant documents and answering questions require the ability of logical reasoning that must be understood by humans to obtain fidelity and trust [9].
Here comes the problem of defining what an explanation should be provided by a QAS, that we can regard as a decision making activity, whose objective is to retrieve a pertinent answer by evaluating a request expressing criteria for contents’ selection.
There are two fundamental types of explanations: the first one is an ex-ante explanation relative to the system’s general logic, and functionality. On the other hand, the second one is an ex-post explanation that unveils the specific answer taken by the system, which means explaining the rationale and individual circumstances of a specific answer.
We argue that this second type of explanation is what matters in a FQAS context in order to explain “why” a given document/item/piece of information has been retrieved as an answer to a query. To this end, since model-based FQASs are ex-ante explainable by their very nature, ex-post explanations of their answers to a query can be easily derived by knowing their logic.
Conversely, data driven DL query answering approaches, being mostly opaque mechanisms, need to be translated into, or approximated by, model-based FQASs mechanisms to generate ex-post explanations of their results.
In this respect we envisage a synergic role of DL and model-based FQAS approaches, where the first type of systems is used to yield answers to the queries so as to exploit their high accuracy for many tasks, while their translated/approximated version by a model-based FQAS is used to derive explanations of the answers.
Indeed, it is a current issue to provide DL FQAS with the desirable characteristics of ex-post explainability, which are also considered essential aspects of the European Union’s way to Artificial Intelligence [10, 11], in line with the European General Data Protection Regulation (GDPR) that restricted the use of black box machine learning and automated decision-making concerning individuals [12]. Specifically, GDPR promotes transparency of automated systems, by requiring that systems provide meaningful information about the used logic, and a justification of outcomes in order to enable understanding and, possibly, to contest their results [9]. As an example, microblogging platforms such as Twitter have been used by many systems to report information about natural disasters since real-time posts are useful in identifying critical events and planning aids [31, 32]. Such systems need to be interpretable so that decision-makers can use them in real operational contexts. Nevertheless, they use NLP and DL methods to classify tweets, and explaining the rationale of the classification of short, noisy tweets is still questionable and has not been explored enough yet.
Methods for “transforming” DL approaches trained for a given QA task, for example by exploiting classified query logs, into transparent models are then a current challenge.
To qualitatively explain the criteria justifying the answer to a query, the “transformations” can approximate the network’s behaviour [13].
Besides that, making a model behind DL-based FQAS explicit can be useful to assess if transfer learning of the models for new query intents can be applied without the need of re-training the network. This predictive ability has great practical impact since re-training a FQAS model for each new class of queries may be inefficient and costly.
There may be several kinds of explanations depending on several contextual factors such as:
-
The knowledge of the user who formulated the question; for example, data scientists, domain experts, and decision makers need different explanations taking into account their knowledge, history and profiles.
-
The query intent, i.e., if it is informational, navigational, or transactional [15]; for example, the results of a spatial query searching for restaurants may be explained with different geographic granularity depending on the fact that the query was formulated by a user in a specific location, who wants the best suitability possible in order to reach the restaurant, in this case the explanation can be “it is the closest restaurant to your current location”. For a travel agency that needs to identify areas with many restaurants in a given city, the explanation can be “it is the densest area of restaurants in the city”.
-
The kind of information: for example, in the healthcare domain there are basically three main applications of FQASs: medical imaging interpretation in which explanations can be visual by showing similar cases, FQAS in huge collections of health documents in natural language, and FQAS for medical diagnosis in classic databases.
-
Finally, also the level of the risks of the decision regarding fundamental rights, health, privacy demands different explanations.
Depending on the context, the “explanation” should be evaluated by considering its interpretability, describing the criteria used by the system in a way that is understandable to humans, its completeness and fidelity, assessing to which extent the model is able to imitate the black-box predictor by describing the functions of the system in an accurate way [13], and its accuracy, assessing to which extent the model can correctly predict unseen instances [14]. Nevertheless, accurate and complete explanations, for example by mathematical formalization of all the operations performed by the system, are hardly human interpretable for non-experts. Thus matching these evaluation criteria at the same time may lead to design persuasive systems rather than transparent systems. A persuasive system may be unethical if it oversimplifies the description of a complex system by hiding its undesirable characteristics in an attempt to attract trust of the user [13].
In this context, explanations of opaque FQAS mechanisms for example based on decision trees and fuzzy rules providing a description of the functions executed in each neuron of a DL configuration, or based on neuron clustering and summarizing their functions, have the advantage of offering hierarchical explanations, where each level reflects a distinct degree of complexity and interpretability: a high level qualitative explanation using linguistic terms is human interpretable; a lower level quantitative explanation based on fuzzy sets, allows to “precisiate” the semantics of linguistic terms. This way both interpretable and transparent QA systems can be designed.
2.2 Coping with Big Data
Other research challenges relate to the increasing use of big data. On the one hand, novel technologies and applications like social media, sensors and Internet of Things generate tremendous amounts of data. On the other hand, technologies for managing textual documents evolved a lot, bringing along a demand for a seamless integration of textual data in database and information management systems.
Data management of big data is generally recognized to be subject to challenges related to, among others, volume, variety, velocity and veracity [33]. NoSQL and more recently NewSQL database systems have been proposed as solutions for managing data that cannot be (easily) transformed to fixed tabular structured data formats. Such systems have the common characteristics to rely on a horizontal scaling, with distributed (cloud) data storage and these are meant to (co)operate as components of a polyglot database system architecture also containing conventional database systems. Hence, one system is longer fitting everything, bringing along new system and data integration challenges.
Volume.
QA being an essential component of any data management system also faces new challenges when applied in a big data context. Querying large data volumes that are subject to horizontal scaling [34] requires efficient distributed querying facilities and indexing mechanisms. QA processing should efficiently cope with “sharding” [35], distributed bitmap indexing and other horizontal scaling techniques. Querying heterogeneous data sources often involves (transparent) query decomposition and data integration techniques being applied to query answers.
Variety.
Due to the lack of fixed database schemes QA in NoSQL in general only supports limited querying facilities (usually not supporting join operations). In NoSQL systems data availability is usually a higher priority than data consistency and reflecting the so-called eventual consistency in QA results is challenging. NewSQL [36] tries to solve this problem with advanced distributed transaction processing, bringing along new query answering challenges as NewSQL currently only works under specific conditions (i.e., simple predictable transactions that are not requiring full database scans). Sensor data and multimedia data require advanced content-based querying and indexing techniques, which implies interpreting, processing and retrieving data not relying on metadata, but on the content itself. Information retrieval in textual document collections has to cope with data semantics and context. This should lead to better interconnections between texts and novel query answering facilities.
Velocity.
NoSQL systems are designed giving priority to fast data insertion. This implies that no time is wasted on data transformations (to a fixed database schema format), nor on data integrity checks and transaction processing. A disadvantage is that query processing in general becomes more complex and time consuming. However, modern Internet of Things and social media applications might also be demanding with respect to query execution times. Hence, the demand for faster query execution techniques in distributed, heterogeneous data environments.
Veracity.
Large distributed heterogeneous data collections can only guarantee data consistency under limited circumstances. Moreover, trust in data is an important issue as bad data propagates to bad data analyses and querying results [37, 38]. A lot of research is spent on quality driven QA [39, 40] and on data quality frameworks being able to assess and handle data quality in order to better inform users on the quality of data processing results [41, 42]. Informing the users on the quality of QA or information retrieval results and improving data quality where possible and relevant is considered to be an important research challenge.
Last, but not least there are also the legal aspects of data management. General Data Protection Regulation (GDPR) [43] requirements demand for techniques like anonymization and pseudonymisation in order to guarantee the privacy of users and can be quite challenging to develop in case of textual data or multimedia data [44].
2.3 Emerging FQAS Topics
For a human being the most convenient way of communication is using natural language. Thus, the flexibility of man-machine interaction, notably in the context of query answering, may be achieved via the use of natural language. This has been a point of departure for the related domain of Question answering (Q/A), which aims at answering requests in natural language on data sources and, therefore, combines methods from NLP, IR and database processing. This is one of the traditional areas of interest within classical artificial intelligence [27, 29].
In the global world, a large number of Q/A systems have been developed for various languages. Some Q/A systems, specifically in English and Latin languages, have better performances than systems using Arabic, Semitic and Sino Tibetan languages in general. This may depend on the characteristics of the language and the different level of maturity of the research. Cross-lingual text classification and retrieval methods working on different language-dependent feature spaces and exploiting class-class correlations can be a direction to explore to design more effective Q/A systems in different languages [16].
As far as the types of systems are concerned, there is a current increasing trend of asking queries within community based systems: this reflects the increasing popularity of social networks and online communities in the acquisition of knowledge. Nevertheless, in evaluating queries in community based systems, a major issue is to assess the quality and veracity of the answers by estimating the trust of the information sources. Model-based FQA applying multi criteria decision making and aggregation operators can be a potential promising approach.
As stated in [17], the most crucial and ambitious goal of Semantic Web research for user’s information needs is Q/A over Knowledge Graphs (KGQA). Users express their information needs by a question using their own terminology and retrieve a concise answer generated by querying an RDF knowledge base. This relieves them from the need to know both a formal language like SPARQL and the domain terminology of the knowledge base they are querying. This goal poses the problem of filling the lexical gap: different users with the same information needs may use different words to query a knowledge graph; on the other hand, answers to the same query with the same semantics may differ from a lexical point of view.
Besides, in distributed knowledge based systems, in which local domain ontologies coexist to represent heterogeneous domains, alignments must be defined to interpret knowledge from a given peer’s point of view. Queries may be expressed by selecting terms from a local ontology, and the retrieved answers extracted from different knowledge based systems have to be translated into terms of the same ontology [24].
In KGQA, several approaches tackled the issues of answering queries asking for facts, list of resources/documents and yes/no answers, since these queries can be mapped into SPARQL queries using SELECT and ASK with distinct levels of complexity.
A novel issue is answering procedural queries, closely related to the one very well known in the area of expert systems, involving “why”, asking for reasons, and “how”, asking for instructions to solve a task. For example, people describe their disease symptoms by queries to search engines and want to know the reason why they experience such illness, and how to solve their problem. One may ask “How to relieve back pain preferably while sleeping” or “how to wrap a gift quickly”. Furthermore, procedural queries may involve geography and time such as in requesting “how to reach a skiing area on the Alps by passing near a picturesque lake where to stop for lunch around midday”, or asking “why severe floods caused huge damages in North West Germany during July 2021” [18].
Current research follows template based and natural language interfaces approaches which aid non-technical users to formulate formal queries using natural language by mapping input questions to either manually or semi-automatically created SPARQL query templates [25]. Other approaches exploit procedural knowledge automatically extracted from textual documents, i.e. by classifying procedural documents, by applying neural networks and language models. Finally, some approaches aid users in carrying out a specific task by responding to the query interactively, step by step, such as in a Chatbot mechanism [19]. A possible alternative approach to answer procedural queries is to retrieve multimedia documents in the form of images, audio files and videos illustrating or exemplifying the requested procedures by leveraging on neural systems’ ability of modeling multimodal information sources [26]. Finally, since procedural queries generally involve vague and imprecise conditions, such as in the above queries “near a lake district”, “around midday” and preferences “while sleeping” model based FQA approaches are a promising solution.
An emerging topic of Question Answering is Visual QA (VQA) in which a system takes as input both an image and a question about the image content, expressed in natural language, and produces a natural language answer as the output [20]; for example to aid visually-impaired users recognize the content of an image. To solve such tasks, VQA attention based approaches have been proposed in which a deep neural network, typically a CNN, is trained to recognize objects in the images so that the attention mechanism chooses from a predefined list of possible answers, the one that responds to the question. Nevertheless, till now, a few approaches proposed to combine Visual QA with word attention models, typically based on RNN [21]. To this end, flexible querying combined with VQA attention models can be a viable alternative to RNN word attention in order to highlight the different importance of the words in the questions on which the system must place its attention.
Finally, an important topic is answering queries which involve geographic entities or concepts and that require evaluating spatial operations. The importance of geographic searches is outlined by a Google survey reporting that four out of five people used search engines to conduct local searches [22]. Currently, geographic questions are still difficult to answer due to several limitations of QA systems that generally lack proper geographic representations of both entities and spatial relationships, whose meaning is generally vague. There are many entities with unsharp, imprecise or varying and context dependent boundaries: for example, in winter and summer time the river’s border may change and the boundary of a forest may be vague. Spatial relationships are costly to evaluate in real time, and their meaning is strongly vague and dependent on both the user’s context and the query intent. For example, the meaning of “near” changes if one is moving on foot or by car, if one is young and healthy or a disabled person, and if one is looking for either a restaurant “near” my hotel, or a small medieval town “near” Milano. Moreover, the uncertainty affecting the geometries of spatial entities makes it difficult to answer factoid queries, such as “how many lakes are there in Finland” or “how long is the coast of Norway?”, “how far is downtown Paris?”. Thus, current challenges are the ability to deal with the variability and context dependent meaning of linguistic terms; the ability to exploit several sources of data with distinct resolution; and, finally, the ability to be robust in handling the vagueness and uncertainty of geographic information and relationships [23].
Context plays an important role in QA, not only with respect to the geographic searches. Admittedly it is not a new topic in QA (cf., e.g., [45, 46]) but there are surely new avenues which should be explored, in particular with the use of a more flexible understanding of the very notion of context. Relevance of a search result may depend on external factors such as location of the user, time a query is posed, the history of other queries posed within the same session etc. It may, however, also non-trivially depend on the internal aspects of the search, i.e. on the content of the data source. In the database querying framework, a good example of an approach providing means for taking into account such an internal context are queries with the skyline operator [47] or, a more general approach related to Chomicki’s preference queries [48]. A newer example of such an approach are contextual bipolar queries [49]. Some new approaches in this vein include [50] where some more flexible understanding of the sophisticated context considered within analytic queries is proposed and [51] where a new idea of searching for a context is proposed.
We believe that the cross fertilization of data-driven approaches with model-based ones can offer more interpretable and explainable solutions to Flexible QA systems. Investigating hybrid Flexible QA models can be a fruitful direction of research to design more transparent systems.
3 Conclusions
This paper is motivated, first of all, by a long time experience of the authors and their active and intensive involvement in research and practical applications in the field of QA and related areas, hence a deep familiarity with the field. This has been amplified by the involvement of the editors in the organization and running of practically all FQAS conferences which have always provided a premiere forum for the presentation of novel developments by the whole research community in the respective areas. Moreover, the FQAS have always provided a venue for the presentation of many new proposals and solutions, often of a visionary type. This has made the FQAS one of those scientific gatherings that have always inspired the community. This paper, on the perspectives and views of the research on FQASs was written with the intention of further stimulating the interest towards the synergic and hybrid application of two paradigms for FQAS, the model-based and the data driven approach. We are aware that the identified challenges and the described topics offer only a partial view of the research on FQASs, filtered by our own expertise. However, we hope that it will help to reflect on the current situation, to outline the limitations and vocations of the single FQAS conference.
References
Hirschman, L., Gaizauskas, R.: Natural language question answering: the view from here. Nat. Lang. Eng. Spec. Issue Quest. Answer. 7(4), 275–300 (2001)
Voorhees, E.M.: The TREC-8 question answering track report. In: Proceedings of TREC-8, pp. 77–82 (1999)
Markus, A.F., Kors, J.A., Rijnbeek, P.R.: The role of explainability in creating trustworthy artificial intelligence for health care: a comprehensive survey of the terminology, design choices, and evaluation strategies. arXiv (2020). arXiv:2007.15911
Zhong, H., Xiao, C., Tu, C., Zhang, T., Liu, Z., Sun, M.: JEC-QA: a legal-domain question answering dataset. In: Proceedings of the AAAI Conference on Artificial Intelligence (2020), vol. 34, no. 05, pp. 9701–9708. https://doi.org/10.1609/aaai.v34i05.6519
Zhong, H., Xiao, C., Tu, C., Zhang, T., Liu, Z., Sun, M.: 1JEC-QA: a legal-domain question answering dataset. https://arxiv.org/pdf/1911.12011.pdf. Accessed 24 May 2021
Buhrmester, V., Münch, D., Arens, M.: Analysis of explainers of black box deep neural networks for computer vision: a survey. arXiv:1911.12116v1 [cs.AI], 27 November 2019
Hirschberg, J., Manning, C.D.: Advances in natural language processing. Science 349(6245), 261–266 (2015)
Angwin, J., Larson, J., Mattu, S., Kirchner, L.: Machine bias. https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing. Accessed 24 May 2021
Hamon, R., Junklewitz, H., Malgieri, G., De Hert, P., Beslay, L., Sanchez, I.: Impossible explanations? Beyond explainable AI in the GDPR from a COVID-19 use case scenario. In: Proceedings of ACM FAccT 2021 (2021)
European Commission 2020. White Paper: On Artificial Intelligence - A European approach to excellence and trust. European Commission. https://ec.europa.eu/info/sites/default/files/commission-white-paper-artificial-intelligence-feb2020_en.pdf. Accessed 24 May 2021
European Commission High Level Expert Group on Artificial Intelligence 2019. Ethics Guidelines for Trustworthy AI. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai. Accessed 24 May 2021
European Parliament and Council of the European Union 2016. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation)
Gilpin, L.H., Bau, D., Yuan, B.Z., Bajwa, A., Specter, M., Kagal, L.: Explaining explanations: an overview of interpretability of machine learning. In: IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), pp. 80–89 (2018)
Guidotti, R., Monreale, A., Ruggieri, S., Turini, F., Giannotti, F., Pedreschi, D.: A survey of methods for explaining black box models. ACM Comput. Surv. 51(5), 1–42 (2019). Article no. 93
Broder, A.: A taxonomy of web search. In: Proceedings of SIGIR Forum, vol. 36, no. 2, pp. 3–10 (2002)
Moreo, A., Pedrotti, A., Sebastiani, F.: Heterogeneous document embeddings for cross-lingual text classification. In: Proceedings of ACM SAC 2021, IAR track, pp. 685–688 (2021)
Trotman, A., Geva, S., Kamps, J.: Report on the SIGIR 2007 workshop on focused retrieval. SIGIR Forum 41(2), 97–103 (2007)
Höffner, K., Walter, S., Marx, E., Usbeck, R., Lehmann, J., Ngonga Ngomo, A.C.: Survey on challenges of question answering in the semantic web. Semant. Web 8(6), 895–920 (2017)
Maitra, A., Garg, S., Sengupta, S.: Enabling interactive answering of procedural questions. In: Métais, E., Meziane, F., Horacek, H., Cimiano, P. (eds.) NLDB 2020. LNCS, vol. 12089, pp. 73–81. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-51310-8_7
Antol, S., et al.: VQA: visual question answering. In: Proceedings of ICCV 2015 (2015)
Lu, J., Yang, J., Batra, D., Parikh, D.: Hierarchical question-image co-attention for visual question answering. In: Proceedings of the 30th International Conference on Neural Information Processing Systems, pp. 289–297 (2016)
Maia, G., Janowic, K., Zhua, R., Caia, L., Lao, N.: Geographic question answering: challenges, uniqueness, classification, and future directions. arXiv:2105.09392v1 [cs.CL] 19 May 2021. Accessed 24 May 2021
Hosseinzadeh Kassani, S., Schneider, K.A., Deters, R.: Leveraging protection and efficiency of query answering in heterogenous RDF data using blockchain. In: Alhajj, R., Moshirpour, M., Far, B. (eds.) Data Management and Analysis. SBD, vol. 65, pp. 1–15. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-32587-9_1
Affolter, K., Stockinger, K., Bernstein, A.: A comparative survey of recent natural language interfaces for databases. VLDB J. 28, 793–819 (2019)
Kafle, S., de Silva, N., Dou, D.: An overview of utilizing knowledge bases in neural networks for question answering. In: Proceedings of the 20th International Conference on Information Reuse and Integration in Data Science (IRI), pp. 326–333 (2019)
Lehnert, W.: Human and computational question answering. Cogn. Sci. 1(1), 47–73 (1977)
Wolfram Research, Inc., Wolfram|Alpha Notebook Edition, Champaign, IL (2020)
Simmons, R.F.: Natural language question-answering systems. Commun. ACM 13(1), 15–30 (1969)
Ferrucci, D., et al.: Building Watson: an overview of the DeepQA project. AI Mag. 31(3), 59–79 (2010)
Nguyen, D.T., Ali Al Mannai, K., Joty, S., Sajjad, H., Imran, M., Mitra, P.: Robust classification of crisis-related data on social networks using convolutional neural networks. In: Proceedings of the 11th International AAAI Conference on Web and Social Media (ICWSM 2017) (2017)
Verma, S., et al.: Natural language processing to the rescue? Extracting “situational awareness” tweets during mass emergency. In: Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media (ICWSM) (2011)
De Mauro, A., Greco, M., Grimaldi, M.: A formal definition of big data based on its essential features. Libr. Rev. 65, 122–135 (2016)
Cattell, R.: Scalable SQL and NoSQL data stores. ACM SIGMOD Rec. 39(4), 12–27 (2010)
Bagui, S., Nguyen, L.T.: Database sharding: to provide fault tolerance and scalability of big data on the cloud. Int. J. Cloud Appl. Comput. 5(2), 36–52 (2015)
Pavlo, A., Aslett, M.: What’s really new with NewSQL? SIGMOD Rec. 42(2), 45–55 (2016)
Lukoianova, T., Rubin, V.L.: Veracity roadmap: is big data objective, truthful and credible? Adv. Classif. Res. Online 24(1), 4–15 (2014)
Berti-Equille, L., Lamine Ba, M.: Veracity of big data: challenges of cross-modal truth discovery. ACM J. Data Inform. Qual. 7(3), art.12 (2016)
Mihaila, G.A., Raschid, L., Vidal, M.E.: Using quality of data metadata for source selection and ranking. In: Proceedings of the Third International Workshop on the Web and Databases, WebDB 2000, Dallas, USA, pp. 93–98 (2000)
Naumann, F.: Quality-Driven Query Answering for Integrated Information Systems. Springer, Berlin (2002). https://doi.org/10.1007/3-540-45921-9
Batini, C., Scannapieco, M.: Data Quality: Concepts, Methodologies and Techniques Data-Centric Systems and Applications). Springer, New York (2006)
Cichy, C., Rass, S.: An overview of data quality frameworks. IEEE Access 7, 24634–24648 (2019)
Voigt P., von dem Bussche A.: The EU General Data Protection Regulation (GDPR): A Practical Guide. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-57959-7
Bolognini, L., Bistolfi, C.: Pseudonymization and impacts of Big (personal/anonymous) Data processing in the transition from the Directive 95/46/EC to the new EU General Data Protection Regulation. Comput. Law Secur. Rev. 33(2), 171–181 (2017)
Martinenghi, D., Torlone, R.: Querying context-aware databases. In: Andreasen, T., Yager, R.R., Bulskov, H., Christiansen, H., Larsen, H.L. (eds.) FQAS 2009. LNCS (LNAI), vol. 5822, pp. 76–87. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-04957-6_7
Bordogna, G., Ghisalberti, G., Psaila, G.: Geographic information retrieval: modeling uncertainty of user’s context. Fuzzy Sets Syst. 196, 105–124 (2012)
Börzsönyi, S., Kossmann, D., Stocker, K.: The skyline operator. In: Proceedings of the 17th International Conference on Data Engineering, pp. 421–430 (2001)
Chomicki, J.: Preference formulas in relational queries. ACM Trans. Database Syst. 28(4), 427–466 (2003)
Zadrożny, S., Kacprzyk, J., Dziedzic, M., De Tré, G.: Contextual bipolar queries. In: Jamshidi, M., Kreinovich, V., Kacprzyk, J. (eds.) Advance Trends in Soft Computing. SFSC, vol. 312, pp. 421–428. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-03674-8_40
Zadrożny, S., Kacprzyk, J.: Fuzzy analytical queries: a new approach to flexible fuzzy queries. In: Proceedings of the 29th IEEE International Conference on Fuzzy Systems, FUZZ-IEEE 2020, pp. 1–8. IEEE, Glasgow (2020)
Zadrożny, S., Kacprzyk, J., Dziedzic, M.: A concept of context-seeking queries. In: Proceedings of the 30th IEEE International Conference on Fuzzy Systems, FUZZ-IEEE 2021, pp. 1–6. IEEE, Luxembourg (2021)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Andreasen, T., De Tré, G., Kacprzyk, J., Larsen, H.L., Bordogna, G., Zadrożny, S. (2021). Perspectives and Views of Flexible Query Answering. In: Andreasen, T., De Tré, G., Kacprzyk, J., Legind Larsen, H., Bordogna, G., Zadrożny, S. (eds) Flexible Query Answering Systems. FQAS 2021. Lecture Notes in Computer Science(), vol 12871. Springer, Cham. https://doi.org/10.1007/978-3-030-86967-0_1
Download citation
DOI: https://doi.org/10.1007/978-3-030-86967-0_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-86966-3
Online ISBN: 978-3-030-86967-0
eBook Packages: Computer ScienceComputer Science (R0)