
Abstract
The ensemble data assimilation system is beneficial to express flow-dependent model errors. Furthermore, the effectiveness of this system depends on the accuracy of the flow-dependent background error covariance. However, the background error covariance is often underestimated due to limited ensemble size, sampling errors and model errors, which causes a filter divergence problem—the analysis state diverges from the nature stage ignoring the observation influence. As one of the remedies to solve this problem, the stochastic representations address the model-related uncertainties by perturbing the model tendency or parameters using a random forcing to replenish the insufficient model errors. In this study, we implemented a stochastic perturbation hybrid tendencies (SPHT) scheme, which perturbs both physical tendency and dynamical tendency using the random forcing, and assessed its impact on the spread of ensemble forecast and ensemble mean error.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


1 Introduction
Ensemble data assimilation (EnsDA) finds the best initial conditions of the numerical weather prediction (NWP) model using model forecasts and their error covariance as well as observations Evensen (1994). In particular, it describes the flow-dependent forecast error covariance through an ensemble of the model forecasts. Therefore, it contains uncertainties in both the initial conditions and the model. Model uncertainty representations can be distinguished from actual model errors: the former samples model perturbations from some distribution while the latter presents only one realization per model and forecast Leutbecher et al. (2017). In this study, we focus on the model uncertainty in the EnsDA system using the stochastic representations that simulate the errors of model tendencies from random components.
In EnsDA, the model uncertainty is used in the ensemble background error covariance (BEC) through the 6-h forecasts. However, it is found to be underdispersive due to the limited ensemble size, sampling error, and imperfect model parametrization, resulting in over-confidence in ensemble forecasts Buizza et al. (2005). This problem is usually covered by covariance inflation, e.g., multiplicative inflation Anderson and Anderson (1999), additive inflation Mitchell and Houtekamer (2000), combined multiplicative and additive inflation Whitaker and Hamill (2012), relaxation to the prior Zhang et al. (2004), multischeme ensembles Meng and Zhang (2007), and so on.
In general, the ensemble BEC, composed of an ensemble spread \(\left( \sigma (x)\right) \), i.e., the standard deviation to the ensemble mean \((\bar{x})\), should reflect the ensemble mean error \(\left( e(\bar{x})\right) \) because the ensemble spread distribution determines the analysis status (see Fig. 1). Here, the model error is expressed by the distance between the ensemble mean and the observation while the ensemble spread is represented by the pre-described ensemble distribution. The optimal ensemble spread is expected to have a spread similar to the ensemble mean (Fig. 1a), i.e.,
then, the analysis includes reliable information from the model and observations. The underdispersive ensemble members show a smaller ensemble spread compared to the model error, i.e.,
where the analysis ignores the observation and trusts the model more due to small ensemble BEC (Fig. 1b). The overdispersive ensemble members show the larger ensemble spread compared to the model error, i.e.,
In this case, the analysis ignores the model errors and relies more on the observation due to the larger ensemble BEC (Fig. 1c).


Schematic diagram of the ensemble spread, \(\sigma (x)\), and the ensemble mean error, \(e(\bar{x})\): a optimal ensemble spread, b underdispersive ensemble spread, and c overdispersive ensemble spread
To remedy the general problem of the underdispersive model error, various stochastic schemes can be used, e.g., Buizza et al. (1999), Shutts (2005), Palmer et al. (2009). It is based on the fact that the NWP models represent the physical process with simplifications and approximations due to incomplete knowledge and computational costs. The European Centre for Medium-Range Weather Forecasts (ECMWF) developed the original version of the Stochastically Perturbed Parametrization Tendencies (SPPT) scheme—called the Buizza-Miller-Palmer (BMP) scheme Buizza et al. (1999)—for the first time and introduced the stochastic representation of model uncertainty that perturbs the total parametrized physics tendencies using the random forcing. After major revisions on random patterns and distribution of perturbations in 2009 Palmer et al. (2009), the BMP scheme has evolved into the SPPT scheme. Since then, the SPPT scheme has been employed by many operational NWP centers, e.g., Environment Canada (EC), Japan Meteorological Agency (JMA), the United States National Centers for Environmental Prediction (NCEP), and the United Kingdom Met Office (UKMO), for their global prediction systems Charron et al. (2010), Leutbecher et al. (2017). It has also been implemented in regional prediction systems, e.g., the Application of Research to Operations at Mesoscale convection-permitting model (AROME) of Meteo-France Bouttier et al. (2012) and the Weather Research and Forecasting (WRF) model Romine et al. (2014), Berner et al. (2015).
Afterward, the Stochastic Kinetic Energy Backscatter (SKEB) scheme was introduced to represent the model uncertainties for scale interactions what is absent in a truncated numerical model by randomly perturbing the stream function and potential temperature tendencies Shutts (2005). The SKEB has also been used for global ensembles in many operational center, e.g., ECMWF, EC, and UKMO Charron et al. (2010), Tennant et al. (2011), Sanchez et al. (2016) as well as regional ensembles (e.g., WRF) Berner et al. (2011), Berner et al. (2015). Recently, a stochastic convective backscatter scheme has been introduced Shutts (2015).
Alternately, the Stochastically Perturbed Dynamical Tendencies (SPDT) scheme, which perturbs the total dynamical tendencies using the random forcing, was introduced: the scheme proved to be effective in global ensemble forecasting Koo and Hong (2014), e.g., in the Global/Regional Integrated Model system (GRIMs) Hong et al. (2013). By combining the SPDT and SPPT schemes, Lim et al. Lim et al. (2020) devised the stochastic perturbation hybrid tendencies (SPHT) scheme to improve the underestimated BEC in the EnsDA system of the Korean Integrated Model (KIM) Hong et al. (2018)—a global model developed at the Korea Institute of Atmospheric Prediction System (KIAPS).
In this study, we introduce the SPHT scheme in the EnsDA system as a covariance inflation method in order to solve the underestimated ensemble BEC by taking into account that model variables are integrated by changes in physical and dynamic tendencies every time. The methodology is described in Sect. 2, and the experimental designs and results are in Sects. 3 and 4, respectively. Section 5 provides the summary and suggests the direction to further development.
2 Methodology
2.1 Local Ensemble Transform Kalman Filter (LETKF)
We employ the EnsDA system of KIAPS, which is a four-dimensional local ensemble transform Kalman filter (4D-LETKF). The analysis is obtained by assimilating the available observations within a local region Hunt et al. (2007), Shin et al. (2016), Shin et al. (2018). This LETKF also provides ensemble perturbations to the hybrid four-dimensional ensemble-variational (H4DEV) system, another data assimilation system operated by KIAPS. In this study, we use the LETKF results just to distinguish the changes of ensemble BEC.
The control variables are zonal wind, meridional wind, potential temperature, mixing ratio, and surface pressure. The KIM Package for Observation Processing (KPOP) provides quality-controlled real observations to the data assimilation system Kang et al. (2018), including the sonde, surface, aircraft, Global Positioning System-Radio Occultation (GPS-RO), Infrared Atmospheric Sounding Interferometer (IASI), Advanced Microwave Sounding Unit-A (AMSU-A), Cross-track Infrared Sounder (CrIS), Microwave Humidity Sounder (MHS), Advanced Technology Microwave Sounder (ATMS), Atmospheric Motion Vectors (AMVs), and tropical cyclone initialization.
In resolving the filter divergence problems in LETKF, three approaches used to be applied in terms of ensemble size, localization, and inflation method, which are specified below for this study:
-
1.
Ensemble size: Increasing the ensemble size is commonly limited due to computational costs. At the early stage of developing LETKF, we used an ensemble size of 30 members, which is now increased to 50 members and is used in this study.
-
2.
Localization: We implemented both horizontal and vertical localizations. The horizontal localization is expressed by a Gaussian-like piecewise fifth-order rational function Gaspari and Cohn (1999), Miyoshi (2011) varying from 660 to 1800 km depending on vertical levels Kleist and Ide (2015). The vertical localization varies depending on the observational types (e.g., conventional versus satellite data). For conventional data, it is defined by a Gaussian-like rational function, represented by \(2\sqrt{10/3}\) \(\cdot \) \(\sigma _v\) where \(\sigma _{v}\) is chosen to be \(0.2 \ln {p}\) for wind and surface pressure and \(0.1 \ln {p}\) for mass variables. For the satellite radiance data, the vertical weighting function is defined by the gradient of transmittance of the measured radiance Thépaut (2003).
-
3.
Inflation method: We used two inflation methods in this study. The additive inflation adds the perturbations randomly sampled from the bias-corrected lagged forecast differences to each ensemble member after the analysis step Whitaker et al. (2008). The relaxation to prior spread (RTPS) relaxes the ensemble standard deviation of analysis back to the background Whitaker and Hamill (2012). However, the LETKF still requires additional inflation method to make a sufficient ensemble BEC: we will cover it through the stochastic representation method in this study.
2.2 Numerical Weather Prediction (NWP) Model
We employ the KIM, a global NWP model developed at KIAPS Hong et al. (2018), which has recently been operationally implemented in the Korea Meteorological Administration (KMA). It is a non-hydrostatic model on a cubed sphere with state-of-the-art physics parametrization packages—including radiation, gravity wave drag, vertical mixing, convection, cloud physics, and so on.
Since our concern is a BEC in the data assimilation process, we only deal with the 6-h forecast (prior) results. The ensemble size is 50 members and the horizontal resolution for the ensemble forecast is 50 km. The initial conditions of the ensemble forecast have been generated by the lagged forecast difference samples, which are used to generate the static BEC in H4DEV Kwon et al. (2018).
2.3 Stochastic Perturbation Hybrid Tendencies (SPHT) Scheme
In this study, we introduce a stochastic perturbation hybrid tendencies (SPHT) scheme that perturbs the dynamic tendency \(\left( \frac{\partial {\mathbf {x}}}{\partial {t}}\right) _{dyn}\) and the physical tendency \(\left( \frac{\partial {\mathbf {x}}}{\partial {t}}\right) _{phy}\) of the model variables \({\mathbf {x}}\) at each time step n using the multiplicative random forcing (r):
where \(\mu \in \{0,1\}\) represents the vertical tapering function (\(e^{\eta -1}\)) in the generalized vertical coordinate \(\eta \). The model variable \({\mathbf {x}}\) consists of temperature and humidity mixing ratio only. Note that in the KIM, physics and dynamics are coupled by time-splitting method; thus, this approach differs from the method of perturbing total model tendency by simply adding up perturbations of two tendencies, i.e.,
Here, r is a 2-dimensional value following the Gaussian distributed zero-mean perturbation considering spatial and temporal correlation. Occasionally, \(\mu \) is applied to perturbations for the upper model levels to avoid the instability issue. The amplitude is determined by the standard-deviation \((\sigma )\), and the length and time scales are based on the decorrelation lengths (L) and times (t), respectively.
The SPPT assumes that the model errors from the parametrized physical tendency are proportional to the total physical tendency Buizza et al. (1999), Palmer et al. (2009) while the SPDT assumes that the model errors from the dynamic tendency concern with the computational representations of the underlying partial differential equations Koo and Hong (2014). Since both methods deal with the model tendency, we devised a hybrid stochastic scheme (i.e., SPHT) by combining the two perturbation tendencies based on Eq. (4). The SPHT scheme is applied to the ensemble forecasting in LETKF to obtain an ensemble BEC.
3 Experimental Designs
To identify how the SPHT scheme increases the ensemble spread, we designed two experiments: CTRL (representing the control run) is without the SPHT scheme and STOC (representing the stochastic run) uses the SPHT scheme to perturb the model variables (e.g., temperature and specific humidity). To avoid instability due to excessive inflation, we suppressed perturbation of wind variables. To test the effectiveness of the inflation method, the warm cycle is started from 1200 UTC 22 June 2018 and ended on 1200 UTC 7 July 2018.
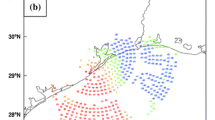
The random forcing in both SPPT and SPDT is described in Fig. 2. The SPPT (Fig. 2a) has horizontal correlation scales of 500 km (mesoscale), decorrelation times of 6 h, and standard deviations of 1.0. On the other hand, the SPDT (Fig. 2b) has horizontal correlation scales of 500 km, decorrelation times of 3 h, and a standard deviation of 0.5. The SPDT especially used a tapering function that decreased exponentially with height (e.g., in the upper level) to prevent instability. It is designed to generate a smaller random forcing to ensure stability because the dynamic tendency variability is sensitive to r.


Random patterns of (a) SPPT and (b) SPDT at model 90-th level, represented as an ensemble mean of the 6-h forecast initiated from 1200 UTC 6 June 2018
4 Results
We have evaluated the SPHT scheme through the root-mean-square difference (RMSD) and ensemble spread. The RMSD represents the model error while the ensemble spread explains the model uncertainty. Here, we assume that the true state is the ECMWF Integrated Forecast System (IFS) analysis, which is well known for high forecast skill. To identify the vertical distribution of ensemble mean spread and ensemble mean error globally, we analyzed the zonal mean during the experiment periods, excluding the spin-up. The STOC, including both SPPT and SPDT, increases the ensemble spread below 700 hPa in the troposphere and above 10 hPa in the stratosphere (Fig. 3).


The difference of zonal mean ensemble spread (STOC − CTRL) for the prior for (a) temperature (in K), (b) specific humidity (in g kg\(^{-1}\)), and (c) zonal wind (in m s\(^{-1}\)), averaged for the period of 1800 UTC 25 June – 1800 UTC 7 July 2018. Black dots indicate 95% statistical significance based on two-tail t-test
Increase in ensemble spread is evident because the model variables are perturbed by the random forcing. Therefore, it is essential to check if the increase in ensemble spread induces reduction in ensemble mean error: if the ensemble mean error increased, the ensemble spread increase is ineffectual. The augmented ensemble spread reduces the ensemble mean RMSD as well, mostly in the tropical troposphere for wind and in the low to mid-troposphere for temperature and specific humidity (Fig. 4).


Same as in Fig. 3 but for the difference of zonal mean RMSD against IFS analysis
We also have assessed the performance of the SPHT scheme, which is applied to the KIM global model, by evaluating the ensemble quality via the globally-averaged RMSD and ensemble spread. The global performance at each prior (the 6-h background) is evaluated with regard to the vertically-averaged RMSD from 1000 hPa to 10 hPa over the globe (see Fig. 5). As shown in Fig. 5, the ensemble spread augmentation obviously brought on the RMSD reduction during the whole experiment period. For temperature, the ensemble mean RMSD decreased by 1% when the ensemble mean spread increased by 3.7%; for specific humidity, the former decreased by 0.65% when the latter increased by 2.0%.


Time series of the globally-averaged ensemble mean spread (dotted line) and the ensemble mean RMSD (solid line) in the prior for STOC (red) and CTRL (black) for (a) temperature (in K), (b) specific humidity (in g kg\(^{-1}\)), and (c) zonal wind (in m s\(^{-1}\))
5 Summary
We implemented the stochastic perturbation hybrid tendencies (SPHT) scheme perturbing both the physical tendency and the dynamic tendency in a global numerical weather prediction model—the Korean Integrated Model (KIM)—which has recently been operational in the Korea Meteorological Administration. The SPHT scheme inflates the insufficient ensemble background error covariance coupled with the local ensemble transform Kalman filter system: it leads to an increase in ensemble spread as well as a decrease in the ensemble mean errors, thus improving the ensemble background error covariance and ensemble prediction.
The stochastic schemes can be used in various fields as the demand for ensemble systems increases. Recently, Ollinaho et al. Ollinaho et al. (2017) developed the stochastically perturbed parametrizations (SPP) scheme to perturb the parameters and variables in physical parametrizations. For example, many physical processes, including turbulent diffusion, sub-grid orography, convection, cloud, large-scale precipitation, and radiation, used to be perturbed to cover the model uncertainty in the European Centre for Medium-Range Weather Forecasts (ECMWF). As demonstrated, we can extend the use of the stochastic perturbation schemes on demand to overcome underestimation of model uncertainty.
References
Anderson JL, Anderson SL (1999) A Monte Carlo implementation of the nonlinear filtering problem to produce ensemble assimilations and forecasts. Mon Weather Rev 127:2741–2758
Berner J, Ha SY, Hacker JP, Fournier A, Snyder C (2011) Model uncertainty in a mesoscale ensemble prediction system: Stochastic versus multiphysics representations. Mon Weather Rev 139:1972–1995
Berner J, Fossell KR, Ha SY, Hacker JP, Snyder C (2015) Increasing the skill of probabilistic forecasts: understanding performance improvements from model-error representations. Mon Weather Rev 143:1295–1320
Bouttier F, Vié B, Nuissier O, Raynaud L (2012) Impact of stochastic physics in a convection-permitting ensemble. Mon Weather Rev 140:3706–3721
Buizza R, Miller M, Palmer TN (1999) Stochastic representation of model uncertainties in the ECMWF Ensemble Prediction System. J R Meteorol Soc 125:2887–2908
Buizza R, Houtekamer PL, Toth Z, Pellerin G, Wei M, Zhu Y (2005) A comparison of the ECMWF, MSC, and NCEP global ensemble prediction systems. Mon Weather Rev 133:1076–1097
Charron M, Pellerin G, Spacek L, Houtekamer PL, Gagnon N, Mitchell HL, Michelin L (2010) Toward random sampling of model error in the Canadian ensemble prediction system. Mon Weather Rev 138:1877–1901
Evensen G (1994) Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J Geophys Res 99:10143–10162
Gaspari G, Cohn SE (1999) Construction of correlation functions in two and three dimensions. Q J R Meteor Soc 125:723–757
Hong SY, Park H, Cheong HB, Kim JEE, Koo MS, Jang J, Ham S, Hwang SO, Park BK, Chang EC, Li H (2013) The global/regional integrated model system (GRIMs). Asia-Pacific J Atmos Sci 49:219–243
Hong S-Y, Kwon YC, Kim T-H, Kim J-EE, Choi S-J, Kwon I-H, Kim J, Lee E-H, Park R-S, Kim D-I (2018) The Korean Integrated Model (KIM) system for global weather forecasting. Asia-Pac J Atmos Sci 54:267–292
Hunt B, Kostelich E, Szunyogh I (2007) Efficient data assimilation for spatiotemporal chaos: a local ensemble transform Kalman filter. Physica D 230:112–126
Kang J-H, Chun HW, Lee S, Song H-J, Ha J-H, Kwon I-H, Han H-J, Jeong H, Kwon H-N (2018) Development of an observation processing package for data assimilation in KIAPS. Asia-Pac J Atmos Sci 54:303–318
Kleist DT, Ide K (2015) An OSSE-based evaluation of hybrid variational-ensemble data assimilation for the NCEP GFS. Part I: System description and 3D-hybrid results. Mon Weather Rev 143:433–451
Koo M-S, Hong SY (2014) Stochastic representation of dynamic model tendency: formulation and preliminary results. Asia-Pac J Atmos Sci 50:497–506
Kwon I-H, Song H-J, Ha J-H, Chun H-W, Kang J-H, Lee S, Lim S, Jo Y, Han H-J, Jeong H, Kwon H-N, Shin S, Kim T-H (2018) Development of operational hybrid data assimilation system at KIAPS. Asia-Pac J Atmos Sci 54:319–335
Leutbecher M, Lock S-J, Ollinaho P, Lang ST, Balsamo G, Bechtold P, Bonavita M, Christensen HM, Diamantakis M, Dutra E, English S, Fisher M, Forbes RM, Goddard J, Haiden T, Hogan RJ, Juricke S, Lawrence H, MacLeod D, Magnusson L, Malardel S, Massart S, Sandu I, Smolarkiewicz PK, Subramanian A, Vitart F, Wedi N, Weisheimer A (2017) Stochastic representations of model uncertainties at ECMWF: state of the art and future vision. Quart J Roy Meteor Soc 143:2315–2339
Lim S, Koo M-S, Kwon I-H, Park SK (2020) Model error representation using the stochastically perturbed hybrid physical-dynamical tendencies in ensemble data assimilation system. Appl Sci 2020 (in press)
Meng Z, Zhang F (2007) Tests of an ensemble Kalman filter for mesoscale and regional-scale data assimilation. Part II: imperfect model experiments. Mon Weather Rev 135:1403–1423
Mitchell HL, Houtekamer PL (2000) An adaptive ensemble Kalman filter. Mon Weather Rev 128:416–433
Miyoshi T (2011) The Gaussian approach to adaptive covariance inflation and its implementation with the local ensemble transform Kalman filter. Mon Weather Rev 139:1519–1535
Ollinaho P, Lock SJ, Leutbecher M, Bechtold P, Beljaars A, Bozzo A, Forbes RM, Haiden T, Hogan RJ, Sandu I (2017) Towards process-level representation of model uncertainties: stochastically perturbed parametrizations in the ECMWF ensemble. Q J R Meteor Soc 143:408–422
Palmer TN, Buizza R, D-R F, Jung T, Leutbecher M, Shutts GJ, Steinheimer M, Weisheimer A, (2009) Stochastic parametrization and model uncertainty. ECMWF Tech Memo, vol 598, p 42
Romine GS, Schwartz CS, Berner J, Fossell KR, Snyder C, Anderson JL, Weisman ML (2014) Representing forecast error in a convection-permitting ensemble system. Mon Weather Rev 142:4519–4541
Sanchez C, Williams KD, Collins M (2016) Improved stochastic physics schemes for global weather and climate models. Q J R Meteor Soc 142:147–159
Shin S, Kang J-S, Jo Y (2016) The local ensemble transform Kalman filter (LETKF) with a global NWP model on the cubed sphere. Pure Appl Geophys 173:2555–2570
Shin S, Kang J-H, Chun H-W, Lee S, Sung K, Cho K, Jo Y, Kim J-E, Kwon I-H, Lim S, Kang J-S (2018) Real data assimilation using the local ensemble transform Kalman Filter (LETKF) system for a global non-hydrostatic NWP model on the cubed-sphere. Asia-Pacific J Atmos Sci 54:351–360
Shutts G (2005) A kinetic energy backscatter algorithm for use in ensemble prediction systems. Q J R Meteor Soc 131:3079–3102
Shutts G (2015) A stochastic convective backscatter scheme for use in ensemble prediction systems. Q J R Meteor Soc 141:2602–2616
Tennant WJ, Shutts GJ, Arribas A, Thompson SA (2011) Using a stochastic kinetic energy backscatter scheme to improve MOGREPS probabilistic forecast skill. Mon Weather Rev 139:1190–1206
Thépaut JN (2003) Satellite data assimilation in numerical weather prediction: an overview. Meteorological Training Course Lecture Series, ECMWF, Reading https://www.ecmwf.int/node/12657
Whitaker JS, Hamill TM (2012) Evaluating methods to account for system errors in ensemble data assimilation. Mon Weather Rev 140:3078–3089
Whitaker JS, Hamill TM, Wei X, Song Y, Toth Z (2008) Ensemble data assimilation with the NCEP global forecast system. Mon Weather Rev 136:463–482
Zhang F, Snyder C, Sun J (2004) Impacts of initial estimate and observation availability on convective-scale data assimilation with an ensemble Kalman filter. Mon Weather Rev 132:1238–1253
Acknowledgements
This work has been carried out as part of the R&D project on the development of global numerical weather prediction systems of the Korea Institute of Atmospheric Prediction System funded by the Korea Meteorological Administration. S. Lim is partly supported by the Ewha Womans University scholarship of 2018. S. K. Park is supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (2018R1A6A1A08025520).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter
Cite this chapter
Lim, S., Park, S.K. (2022). Stochastic Representations for Model Uncertainty in the Ensemble Data Assimilation System. In: Park, S.K., Xu, L. (eds) Data Assimilation for Atmospheric, Oceanic and Hydrologic Applications (Vol. IV). Springer, Cham. https://doi.org/10.1007/978-3-030-77722-7_6
Download citation
DOI: https://doi.org/10.1007/978-3-030-77722-7_6
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-77721-0
Online ISBN: 978-3-030-77722-7
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)