
Abstract
A recent line of research has developed around logics of belief based on evidence [4, 6]. The approach of [6] understands belief as based on information confirmed by a reliable source. We propose a finer analysis of how belief can be based on information, where the confirmation comes from multiple possibly conflicting sources and is of a probabilistic nature. We use Belnap-Dunn logic and its probabilistic extensions to account for potentially contradictory information on which belief is grounded. We combine it with an extension of Łukasiewicz logic, or a bilattice logic, within a two-layer modal logical framework to account for belief.
The research of Marta Bílková was supported by the grant GA17-04630S of the Czech Science Foundation. The research of Sabine Frittella and Sajad Nazari was funded by the grant ANR JCJC 2019, project PRELAP (ANR-19-CE48-0006). The research of Ondrej Majer was supported by the grant GA16-15621S.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
To form beliefs about the world, we collect and process data of different origins to provide us with reliable information concerning particular issues. Information derived from data typically is of a probabilistic nature, and, as obtained from multiple sources of different origins, it inevitably is incomplete and often conflicting concerning the issues we wish to resolve. In this context, we propose logics to formalize how an agent can build beliefs based on information (uncertain, incomplete, and sometimes inconsistent) provided from the available collected data, and how to reason with and about such beliefs.
Incompleteness of information alone is ever-present when reasoning about data. Applications, such as relational databases, often use many-valued logics to properly account for indefiniteness. Namely, Kleene’s three-valued logic [23] became the design choice of SQL and similar systems (the use of Kleene’s logic in this context was first proposed by [8], and argued optimal in [9].) In [5], Belnap introduced a four-valued logic with intended database applications (see e.g. [18]), which extends Kleene’s logic, but also allows to model reasoning with non-trivial inconsistencies. Further developed by Dunn [13], Belnap-Dunn four-valued logic \(\textsf {BD}\), also referred to as First Degree Entailment, became a prominent logical framework which encompasses reasoning with both incomplete and inconsistent information. This logic evaluates formulas to Belnap-Dunn square – a lattice built over an extended set of truth values \(\{t,f,b,n\}\) (true, false, both, neither), where b and n correspond to inconsistent and incomplete information respectively (Fig. 1, middle). One of the underlying ideas of this logic is that not only truth, but also amount of information that formulas carry (reflected by the four semantical values) matters. This idea was generalized by introducing the algebraic notion of bilattices by Ginsberg [17] in the context of AI, and studied further in [22, 26]. Bilattices contain two lattice orders simultaneously: a truth order, and a knowledge (or an information) order. Belnap-Dunn square, the smallest interlaced bilattice, can be seen as the product bilattice of the two-element lattice (Fig. 1, left) where the truth-values are pairs of classical values which can be naturally interpreted as representing two independent dimensions of information – positive and negative oneFootnote 1. We can understand them as providing positive and negative support for statements independently. It was used to provide the logic with the double-valuation frame semantics by Dunn [13].
The problem of dealing with inconsistency concerns probabilistic information as well. There are essentially two ways out. One way is to get rid of inconsistencies, the other way is to develop systems with inference rules which can work with inconsistent premises. While on the logic side there are systems providing both kinds of solutions, for example belief revision or paraconsistent logics, the majority of solutions on the probability side go for the first solution – getting rid of inconsistency (cf. the Dempster–Shafer theory of belief functions [11]) – and the attempts of the second kind emerged only relatively recently. Zhou [28] extends the theory of belief functions to the setting of distributive lattices, in particular bilattices and de Morgan lattices, and provides a complete logic to reason about belief functions based on BD. Michael Dunn [14] defines a probablistic framework over four-valued logic and studies properties of the resulting probabilistic entailment. The idea of an independent account for positive and negative information, underlying the double-valuation semantics of BD, naturally generalizes to probabilistic extensions of Belnap-Dunn four-valued logic proposed in [24], which we will use in this paper. It generalizes Belnap–Dunn logic in a similar way as classical probability theory generalizes propositional logic, and is referred to as theory of non-standard probabilities.
When it comes to management of uncertainty, probability and other measures of uncertainty can be understood as graded notions, as one tries to quantify the plausibility of unverified events typically over the interval [0,1]. Graded notions are one of the subjects traditionally studied by methods of fuzzy logics. As probability is not truth-functional, it does not admit a straightforward treatment by logical methods. However, one may deal with probability as a modal operator in logical systems (cf. [21]), for example in the systems of modal fuzzy logic [19]. There are two main approaches to probabilistic modalities over classical logic: two-layered and intensional. The two-layered logical formalism introduced in [15, 20] separates the non-modal lower language of events from the modal upper language of probabilities. The system divides into three parts: lower level of classical propositional reasoning, reasoning about probabilities consisting of the axioms that characterize probability measures in finite spaces, and the upper level of reasoning about (Boolean combinations of) linear inequalities. Hájek [19] proposed to replace the quantitative reasoning in form of linear inequalities with many-valued reasoning, namely Łukasiewicz logic, in such formalism on the upper level to obtain a fuzzy probability logic for formal reasoning under uncertainty. The graded modality “probably”, which can be used to model belief of an agent understood as a kind of subjective probability, is interpreted as a finitely-additive probability on a Boolean algebra of events with values in the real unit interval. Consequently, a class of modal logics for dealing with virtually any uncertainty measure has been covered by the formalism in [7]. In this paper, we aim at extending the framework to encompass reasoning with inconsistent probability information.
We look at an agent who considers a set of issues, has access to (multiple) sources providing positive and negative information on the issues in form of non-standard probabilities, and builds beliefs based on information aggregated from these sources. From plethora of possible scenarios we single out two case studies that we use to illustrate the different concepts at stake.
Example 1 (Aggregating heterogeneous data)
A company launching a new car model needs to decide its selling price and its advertising strategy. Hence, its data analysts must study the reports on the sells of the previous products launched by the company and the success or failure of the advertisement campaigns. This study relies on factual information such as “during the year 2015, the company sold n items of product Y”, but also on statement based on statistical analyses such as “the advertisement broadcasted in June 2016 increased the sells of product Y among the 20–30 years old of 30%”. The second statement is based on aggregated information about the buyers that might be partial and partly false. Plus, the company has access to statistical studies about the population on increase or decrease in expenses for cars.
Example 2
(How to lead an investigation). An investigator needs to know if one of the suspects was present at the crime scene. She collects information from various sources: CCTV camera recordings, ATM logs, witnesses’ statements, etc. No information of this kind is absolutely precise, and typically different sources of information contradict each other. Sources provide information of a probabilistic nature: camera recordings are imprecise due to light conditions, witnesses are not absolutely sure what they have seen. Moreover, the pieces of evidence confirming investigator’s hypothesis that the suspect was present at the place of crime (that is, the positive information) are different from, and somewhat independent of, those rejecting it (that is, the negative information): there is a CCTV camera closed to the crime scene vs. ATM in a supermarket in a different city. For example, a lack of evidence supporting the suspect was present at the crime scene does not yield a proof she was not there. In the end, the investigator has to aggregate the available information and form beliefs about what likely happened.
In many scenarios we can adapt aggregation strategies that have been introduced on classical probabilities: a company that has access to a huge amount of heterogeneous data from various sources and uses software capable of analyzing these data. In this case it makes sense to consider aggregation methods that require a substantial computational power. A natural strategy here is to evaluate sources with respect to their reliability and aggregate them by taking their weighted average. Another kind of agent is an investigator of a criminal case who builds her opinion on the guilt of a suspect based on different pieces of evidence. We assume that all the sources are equally reliable and the investigator is very cautious and does not want to draw conclusions hastily. Hence, she relies on statements as little as all her sources agree on them, and the aggregation she uses returns the minimum of the positive and the minimum of the negative probabilities provided by the sources. If on the other hand the investigator considers all the sources being perfectly reliable, she accepts every piece of evidence and builds her belief using the aggregation maximazing both probabilities.
In what follows, we will propose two-layer modal logics of belief of a single agent, belief that is grounded on probabilistic information provided (positive and negative information independently) by multiple sources. The underlying logic of facts or events is chosen to be BD, the upper logic varies between BD and logics derived from Łukasiewicz logic and based on product or bilattice algebras, to systematically account for positive and negative information independently (and thus incompleteness and conflict) on both levels.

The product bilattice \(2\odot 2 \) (left), which is isomorphic to Dunn-Belnap square \(\mathbf {4}\) (middle), and its continuous probabilistic extension (right). Negation flips the values along the horizontal line.
2 Preliminaries
We will first introduce algebraic structures involved as algebras of truth-values in the resulting two-layer logics of belief presented in Sect. 3, where we also motivate their choice (namely bilattices of Examples 3, 4, and 6, and the product algebra of Example 5). Then we briefly describe the Belnap-Dunn logic, and explain the approach to probability based on Belnap-Dunn logic.
2.1 Some Bilattices and MV Algebras
A bilattice is an algebra \(\mathbf {B} = (B, \wedge , \vee , \sqcap , \sqcup , \lnot )\) such that the reducts \((B, \wedge , \vee )\) and \((B, \sqcap , \sqcup )\) are both lattices and the negation \(\lnot \) is a unary operation satisfying that for every \(a,b\in B\),
with \(\le _t\) (resp. \(\le _k\)) the order on \((B, \wedge , \vee )\) (resp. \((B, \sqcap , \sqcup )\)) called the truth (resp. knowledge or information) order. A bilattice is interlaced if each one of the four operations \(\wedge \), \(\vee \), \(\sqcap \), \(\sqcup \) is monotone w.r.t. both orders \(\le _t\) and \(\le _k\). Bilattices, as well as interlaced bilattices, form a variety.
Given an arbitrary lattice \(\mathbf {L}=(L,\wedge _L,\vee _L)\), we can construct the product bilattice \(\mathbf {L} \odot \mathbf {L}=(L \times L , \wedge , \vee , \sqcap , \sqcup , \lnot )\) as follows: for all \((a_1, a_2), (b_1,b_2) \in L \times L\),

\(\mathbf {L} \odot \mathbf {L}\) is always an interlaced bilattice, and any interlaced bilattice can be represented as a product billatice: a bilattice \(\mathbf {B}\) is interlaced if and only if there is a lattice \(\mathbf {L}\) such that \(\mathbf {B} \cong \mathbf {L} \odot \mathbf {L}\) [2].
Example 3
The smallest interlaced bilattice is the product bilattice of the two-element lattice \(\mathbf {2}\odot \mathbf {2}\) (Fig. 1 left). It is isomorphic to Dunn-Belnap square \(\mathbf {4}\) used as a matrix of truth values for Belnap-Dunn logic (Fig. 1 middle), with \(\{t,b\}\) being the designated values.
Example 4
A probabilistic extension of Dunn-Belnap square (Fig. 1 right) can be seen as based on the product bilattice \(\mathbf {L}_{[0,1]} \odot \mathbf {L}_{[0,1]}\), where \(\mathbf {L}_{[0,1]}= ([0,1], \min , \max ).\)
A residuated lattice is an algebra \(\mathbb {L}=(L, \wedge _L, \vee _L, \cdot , \setminus , / )\), where the reduct \((L, \wedge _L, \vee _L)\) is a lattice, \((L, \cdot )\) is a semi-group (i.e. the operation \(\cdot \) is associative) and the residuation properties hold: for all \(a,b,c \in L\):

Example 5
-
1.
 , the standard algebra of Łukasiewicz logic, is a residuated lattice, an MV algebraFootnote 2, and it generates the variety of MV algebras. (As
, the standard algebra of Łukasiewicz logic, is a residuated lattice, an MV algebraFootnote 2, and it generates the variety of MV algebras. (As  is commutative, the two implications coincide.) For all \(a,b\in [0,1]\), we define a negation
is commutative, the two implications coincide.) For all \(a,b\in [0,1]\), we define a negation  , and the standard operations
, and the standard operations 
-
2.
 arises turning the standard algebra upside down, and is isomorphic to the original one. Here, we have
arises turning the standard algebra upside down, and is isomorphic to the original one. Here, we have  ,
, 
-
3.
Finally, we will consider the product MV algebra
 with operations defined pointwise, \({\sim }(a_1,a_2) := a\rightarrow (0,1) = ({\sim }a_1,{\sim }a_2)\), and:
with operations defined pointwise, \({\sim }(a_1,a_2) := a\rightarrow (0,1) = ({\sim }a_1,{\sim }a_2)\), and: 
As both the projections are surjective homomorphisms of MV algebras, this algebra also generates the variety of MV algebras.
 , the standard algebra of Łukasiewicz logic, is a residuated lattice, an MV algebra
, the standard algebra of Łukasiewicz logic, is a residuated lattice, an MV algebra is commutative, the two implications coincide.) For all
is commutative, the two implications coincide.) For all  , and the standard operations
, and the standard operations 
 arises turning the standard algebra upside down, and is isomorphic to the original one. Here, we have
arises turning the standard algebra upside down, and is isomorphic to the original one. Here, we have  ,
, 
 with operations defined pointwise,
with operations defined pointwise, 
Given a residuated lattice \(\mathbf {L}=(L, \wedge _L, \vee _L, \cdot , \setminus , / )\) the product residuated bilattice [22] \(\mathbf {L} \odot \mathbf {L} =(L \times L, \wedge , \vee , \sqcap , \sqcup , \supset , \subset , \lnot )\) is defined as follows: the reduct \((L \times L, \wedge , \vee , \sqcap , \sqcup )\) is the product bilattice \((L, \wedge _L, \vee _L) \odot (L, \wedge _L, \vee _L)\) and, for all \((a_1, a_2), (b_1,b_2) \in L \times L\),
One can then define the following operations: for all \(a,b \in L \times L\),
For any product residuated bilattice, the structure \((L \times L, \wedge , \vee , *, \rightarrow , \leftarrow , \lnot )\) is a residuated bilattice endowed with an involutive negation. If \(\cdot \) is commutative (associative), so is \(*\).
Example 6
The product residuated bilattice arising from the standard MV algebra is the structure  where:
where:

and (1, 1) acts as the unit of the \(*\): \((1,1)*a = a *(1,1) = a\).Footnote 3 We define

From [22], we know that the (isomorphic copies of) product residuated bilattices obtained from MV algebras form a variety, and its axiomatization can be obtained by translating the one of MV algebras (in the language of residuated lattices)Footnote 4.
2.2 Belnap-Dunn Logic
Belnap-Dunn four-valued logic \(\textsf {BD}\), in the propositional language \(\mathcal {L}_\textsf {BD}\) built from a (countable) set \(\mathtt {Prop}\) of propositional variables using connectives \(\{\wedge , \vee , \lnot \}\), evaluates formulas to Belnap-Dunn square – the (de Morgan) lattice \(\mathbf {4}\) built over an extended set of truth values \(\{t,f,b,n\}\) (Fig. 1, middle).
The consequence relation of logic \(\textsf {BD}\) is given, based on the logical matrix \((\mathbf {4},F)\) with \(F = \{t,b\}\) being the designated values, as
A frame semantics can also be given for \(\textsf {BD}\), in two ways. Belnap-Dunn four-valued model is a tuple \(\langle W,\mathbf {4}, e\rangle \) where W is a set of states and e is a valuation of atomic formulas \(e: \mathtt {Prop}\times W \rightarrow \mathbf {4}\). The valuation is extended to formulas of \(\mathcal {L}_\textsf {BD}\) using the algebraic operations on \(\mathbf {4}\) in the expected way.
Following Dunn’s approach [13], we adopt a double valuation model \(M = \langle W, \Vdash ^+, \Vdash ^- \rangle \), giving the positive and negative support of atomic formulas in the states, extending in the following way:

It can be seen as locally evaluating formulas in the product bilattice \(2\odot 2\) (Fig. 1 left), and thus in \(\mathbf {4}\) (Fig. 1, middle), connecting it with the four-valued frame semantics above. BD is completely axiomatized using the following axioms and rules:

It is known to be (strongly) complete w.r.t. the algebraic and the double valuation (or 4-valued) frame semantics. BD is also known to be locally finite.Footnote 5
We will use BD in the two-layer formalism mainly to capture the underlying information states on which sources of probabilistic information are based.
2.3 Non-standard Probabilities
The idea of independence of positive and negative information naturally generalizes to probabilistic extensions of BD logic as follows. A probabilistic Belnap-Dunn (\(\textsf {BD}\)) model [24] is a double valuation BD model extended with a classical probability measure on the power set of states P(W) generated by a mass function on the set of states W.Footnote 6 The positive and negative probabilities of a formula are defined as (classical) measures of its positive and negative extensions:
The probabilities satisfy the following axioms (see [24, Lemma 1]):

These axioms are weaker than classical Kolmogorovian ones. In particular, axiom A3 can be derived from Kolmogorovian axioms of additivity and normalization, but additivity is strictly stronger and cannot be derived from A1-A3Footnote 7. As \(p(\lnot \varphi ) \ne 1- p(\varphi )\) in general, this account of probability admits positive probability of classical contradictions and thus allows for a non-trivial treatment of classically inconsistent information. When defined as above, the positive and negative probabilities are mutually definable via negation as \(p^-(\varphi ) = p^+(\lnot \varphi )\). It has been shown in [24, Theorem 4] that any non-standard probability assignment (i.e., positive and negative probability satisfying the four axioms) arises from a classical probability measure on a BD double-valuation model as described above.
We can diagrammatically represent non-standard probabilities on a continuous extension of Belnap-Dunn square (Fig. 1, right), which we can see as a product bilattice \(\mathbf {L}_{[0,1]} \odot \mathbf {L}_{[0,1]}\). For example, the point (0, 0) corresponds to no information being provided (neither \(\varphi \) nor \(\lnot \varphi \) is supported by any state with positive measure in the underlying model), while (1, 1) is the point of maximally conflicting information (both \(\varphi \) and \(\lnot \varphi \) are “certain” - supported by every state with positive measure). The left-hand triangle (1, 0), (0, 0), (0, 1) corresponds to the cases of incomplete information, the right-hand triangle (1, 0), (1, 1), (0, 1) corresponds to the cases of conflicting information. The vertical dashed line corresponds to the “classical” probabilities when positive and negative support sum up to 1. The horizontal line represents situations where we have as much information supporting \(\varphi \) as contradicting it.
Example 7 (Consulting a panel)
The company assembles a panel to which they ask whether a word describes the car well or not. That is, they ask how much they agree with the statements: “the car has property \(\phi \) (e.g. being a family car)?” and “the car does not have property \(\phi \)?” If humans were classical agents, every person would answer with a probability p that belongs to the vertical line of the probabilistic extension of the Belnap-Dunn square. However, experience has shown that often people don’t reason classically [1]. When a person answers \((p^+(\phi ), p^-(\phi ) )\), if \(p^+(\phi )+ p^-(\phi ) > 1\), then she is conflicted about whether the property \(\phi \) describes the car, if \(p^+(\phi )+ p^-(\phi ) < 1\), then there might be some uncertainty on how to judge whether the car has property \(\phi \).
2.4 Aggregating Probabilities
We model an agent that considers a set of topics listed by the atomic variables in \(\mathtt {Prop}\), has access to sources giving information within the framework of non-standard probabilities (which we will call simply probabilities) and builds beliefs based on these sources using a so-called aggregation strategy. We focus on cases where the agent has no prior beliefs about the topics at stake. Depending on the context, the aggregation strategy should satisfy different properties.
A source s is a probability assignment over the set of formulas \(s : \ \mathcal {L}_\textsf {BD}\rightarrow [0,1]\times [0,1]\). In particular, we will later identify a source with a mass function on the BD states of a double-valuation model. An aggregation strategy \(\mathtt {Agg}\) is a function that takes in input a set of sources \(\mathcal {S}= \{ s_i \}_{i \in I}\) and returns a map \(\mathtt {Agg}_\mathcal {S}: \ \mathcal {L}_\textsf {BD}\rightarrow [0,1]\times [0,1]\). For every \(\varphi \in \mathcal {L}_\textsf {BD}\), we denote \(\mathtt {Agg}_\mathcal {S}(\varphi )^+\) (resp. \(\mathtt {Agg}_\mathcal {S}(\varphi )^-\)) the positive (resp. negative) support assigned to \(\varphi \).
\(\mathtt {Agg}\) is monotone if \(\varphi \vdash \psi \) implies \(\mathtt {Agg}_\mathcal {S}(\varphi ) \le \mathtt {Agg}_\mathcal {S}(\psi )\) for all \(\varphi ,\psi \in \mathcal {L}_\textsf {BD}\) and for every \(\mathcal {S}\). \(\mathtt {Agg}\) is \(\lnot \)-compatible if \(\mathtt {Agg}_\mathcal {S}(\varphi )^- = \mathtt {Agg}_\mathcal {S}(\lnot \varphi )^+\) for every \(\varphi \in \mathcal {L}_\textsf {BD}\) and for every \(\mathcal {S}\). \(\mathtt {Agg}\) preserves probabilities if \(\mathtt {Agg}_\mathcal {S}\) is a probability for every \(\mathcal {S}\).
Many aggregation strategies have been introduced on classical probabilities. Some of them, such as the (weighted) average, straightforwardly generalize to non-standard probabilities. In the following, we present aggregation strategies for our two case studies.
Weighted Average. In Example 1, a company has access to a huge amount of heterogeneous data from various sources and to software to analyse these data. A natural proposal is to grade every source \(s_i\) with respect to its reliability \(w_i\) and to take the weighted average of the probabilities. The aggregation is then the map \(\mathrm {WA}\ : \ \mathcal {L}_\textsf {BD}\rightarrow [0,1]\times [0,1]\) such that, for every \(\varphi \in \mathcal {L}_\textsf {BD}\),
One can easily prove that \(\mathrm {WA}\) preserves probabilities, it is monotone, and \(\lnot \)-compatible. This aggregation strategy is however not feasible when modelling human reasoning.
A Very Cautious Investigator. In Example 2, an investigator builds her opinion on the suspect based on different sources. We assume all the sources are equally reliable and the investigator does not want to draw conclusions hastily. Hence, she relies only on statements all her sources agree on. The aggregation is then the map \(\mathrm {Min}\ : \ \mathcal {L}_\textsf {BD}\rightarrow [0,1]\times [0,1]\) such that
Reasoning with Trusted Sources. Staying in Example 2, we now assume all the sources are perfectly reliable. Hence, the investigator builds her belief on every statement supported by at least one source. The aggregation is then the map \(\mathrm {Max}\ : \ \mathcal {L}_\textsf {BD}\rightarrow [0,1]\times [0,1]\) such that
Here, one has high chances of reaching contradiction. In a scientific analyses, if one gets experiments or information that is contradictory, there are two options. Either the information is incorrect or there is a mistake in the interpretation of the data. Here, if the sources are 100% reliable, reaching a contradiction state will simply indicate to our investigator that there is a flaw in her analysis of the problem and she needs to change perspective to resolve the conflict.
The two latter aggregation strategies are monotone and \(\lnot \)-compatible, and they in general do not preserve probabilities.
3 Two-Layer Logics
To make a clear distinction between the level of events or facts, information on which the agent bases her beliefs, and the level of reasoning about her beliefs, we use a two-layer logical framework. The formalism originated with [15, 19], and was further developed in [3, 7] into an abstract algebraic framework with a general theory of syntax, semantics and completeness (we will employ this framework to derive completeness of the logics we define).
Syntax \((\mathcal {L}_e, \mathcal {M}, \mathcal {L}_u)\) of a two layer logic \(\mathcal {L}\) consists of a lower language \(\mathcal {L}_e\) of events or facts (we denote formulas of \(\mathcal {L}_e\) by \(\varphi ,\psi ,\ldots \)), an upper language \(\mathcal {L}_u\) (we denote formulas of \(\mathcal {L}_u\) by \(\alpha ,\beta ,\ldots \)), and a set of unary modalities \(\mathcal {M}\) which can only be applied to a non-modal formula of \(\mathcal {L}_e\), forming a modal atomic formula of \(\mathcal {L}_u\) (in particular, no nesting of modalities can occur).
Semantics of a two layer logic \(\mathcal {L}\) is, in the abstract approach of [7], based on frames of the form \(F = (W, E, U, \langle \mu ^{\heartsuit }\rangle _{\heartsuit \in \mathcal {M}}),\) where W is a set of states, E is a local algebra of evaluation of the lower language \(\mathcal {L}_e\) within the statesFootnote 8, U is an upper-level algebra interpreting the modal formulas, and for each modality its semantics is given by a map \(\mu ^{\heartsuit }: \prod _{s\in W} E \rightarrow U\), returning a value in the upper-level algebra for a tuple of values from the lower algebra (assigned to an argument formula within the states). We write algebras, but often we need to use matrices to evaluate formulas, i.e. algebras with a set of designated values. Such a frame is called E-based and U-measured. A model is a frame equipped with valuations of \(\mathcal {L}_e\) in E (the values of atomic modal formulas are then computed by \(\mu \), and values of modal formulas are computed in U in an expected way). A non-modal formula \(\varphi \) is valid in a model iff it is assigned a designated value in E by all the states, a modal formula \(\alpha \) is valid in a model iff its value is designated in U. A consequence relation is defined via preserving validity in every model. It is of the sorted form \(\varPsi ,\varGamma \vDash \xi \) where \(\varPsi \subseteq \mathcal {L}_e, \varGamma \subseteq \mathcal {L}_u,\xi \in \mathcal {L}_e\cup \mathcal {L}_u\).
The resulting logic as an axiomatic system \(L = (L_e, M, L_u)\) consists of an axiomatics of the lower logic \(L_e\), modal rules (i.e. rules with non-modal premises and modal conclusion) and modal axioms (modal rules with zero premises) M, and an axiomatics of the upper logic \(L_u\). Proofs can be defined in the expected way. We can see that \(\varPsi ,\varGamma \vdash \varphi \) iff \(\varPsi \vdash _{L_e} \varphi \), and \(\varPsi ,\varGamma \vdash \alpha \) iff \(\varPsi _{MR},\varGamma \vdash _{L_u} \alpha \), where \(\varPsi _{MR}\) consists of conclusions of modal rules whose premises are derivable from \(\varPsi \) in \(L_e\) (for more detail see [3, Proposition 3]).
3.1 Logic of Probabilistic Belief
In scenarios like that of Example 1, it is reasonable to represent agents beliefs as probabilities. In such two-layer logics, the bottom layer is that of events or facts, represented by BD-information states. A source provides probabilistic information given as a mass function on the states, multiple sources are to be aggregated with an aggregation strategy preserving probabilities. The modality is that of probabilistic belief. For the upper-layer – the logic of thus formed beliefs – we propose two logics derived from Łukasiewicz logic. The main reason to choose Łukasiewicz logic as a starting point is that it can express the probability axioms, and contains a well-behaved (continuous) implication. We however also aim at a formalism that allows us to separate the positive and negative dimensions of information or support also on the level of beliefs (just like BD does on the lower level). This motivates the use of product or bilattice algebras (those of Examples 5 and 6) on the upper level.
I. An extension of Łukasiewicz logic with bilattice negation. Consider the product of the standard algebra of Łukasiewicz logic  with the algebra
with the algebra  , as introduced in Example 5(3.), with only (1, 0) as the designated value. The logic of this product algebra (understood as the set of theorems - formulas always evaluated at (1, 0) - or as a consequence relation preserving the value (1, 0)) is Łukasiewicz logic
, as introduced in Example 5(3.), with only (1, 0) as the designated value. The logic of this product algebra (understood as the set of theorems - formulas always evaluated at (1, 0) - or as a consequence relation preserving the value (1, 0)) is Łukasiewicz logic  . It can be axiomatized in the (complete) language \(\{\rightarrow , \sim \}\) by axioms of weakening, suffixing, commutativity of disjunction, and contraposition, and the rule of Modus Ponens (see the axioms below). To be able to operate the pairs of values as a positive and negative support of formulas, we extend the signature of the algebra with the bilattice negation \(\lnot (a_1,a_2)=(a_2,a_1)\), and extend the language to \(\{\rightarrow , \sim , \lnot \}\) (notice in particular, that \(\oplus \) and \(\ominus \) can be defined as in Example 5). We obtain the following axioms and rules, and denote the resulting consequence relation
. It can be axiomatized in the (complete) language \(\{\rightarrow , \sim \}\) by axioms of weakening, suffixing, commutativity of disjunction, and contraposition, and the rule of Modus Ponens (see the axioms below). To be able to operate the pairs of values as a positive and negative support of formulas, we extend the signature of the algebra with the bilattice negation \(\lnot (a_1,a_2)=(a_2,a_1)\), and extend the language to \(\{\rightarrow , \sim , \lnot \}\) (notice in particular, that \(\oplus \) and \(\ominus \) can be defined as in Example 5). We obtain the following axioms and rules, and denote the resulting consequence relation  :
:
The \(\lnot \) negations can be pushed to the atomic formulas, and we can thus consider formulas up to provable equivalence in a negation normal form (nnf), i.e. formulas built using \(\{\rightarrow , \sim \}\) from literals of the form \(p, \lnot p\). It is easy to see, because we have \(\lnot {\sim }\alpha \leftrightarrow {\sim }\lnot \alpha \) and \(\lnot (\alpha \rightarrow \beta )\leftrightarrow {\sim }{\sim }\lnot (\alpha \rightarrow \beta )\leftrightarrow {\sim }({\sim }\lnot \alpha \rightarrow {\sim }\lnot \beta )\) provable. A procedure can be defined which turns each \(\alpha \) into \(\alpha ^\lnot \) in nnf, so that we can prove, by induction, that \(({\sim }\alpha )^\lnot \leftrightarrow {\sim }\alpha ^\lnot \) and \( (\alpha \rightarrow \beta )^\lnot \leftrightarrow {\sim }({\sim }\alpha ^\lnot \rightarrow {\sim }\beta ^\lnot )\). We denote \(\boxdot \varGamma := {\sim }\lnot \varGamma \cup \varGamma \).
Lemma 1
For any finite set of formulas \(\varGamma ,\alpha \) in a nnf,

where \(\varDelta \) contains instances of \(\lnot \)-axioms.
Proof
The right-left direction is almost trivial:  is a subsystem of
is a subsystem of  , and all the axioms in \(\varDelta \) are provable in
, and all the axioms in \(\varDelta \) are provable in  , and, thanks to the \({\sim }\lnot \)-rule,
, and, thanks to the \({\sim }\lnot \)-rule,  for each \(\gamma \in \varGamma \).
for each \(\gamma \in \varGamma \).
For the other direction, we proceed in a few steps. First, we denote by  provability in
provability in  without the \({\sim }\lnot \)-rule. By routine induction on proofs (and using that \({\sim }\lnot \) distributes from/to implications and negations), we can see that
without the \({\sim }\lnot \)-rule. By routine induction on proofs (and using that \({\sim }\lnot \) distributes from/to implications and negations), we can see that

Then we can list all the instances of \(\lnot \)-axioms in the proof in \(\varDelta \), and obtain:

First, note that we can list in \(\varDelta \) all instances of \(\lnot \)-axioms for all subformulas of \(\varGamma ,\alpha \) as well and still keep the Lemma valid. This will come handy in the following proof. Second, we stress that in the final proof  in
in  , we still use language of
, we still use language of  , where formulas starting with \(\lnot \) are seen from the point of view of
, where formulas starting with \(\lnot \) are seen from the point of view of  as atomic.\(\Box \)
as atomic.\(\Box \)
Lemma 1 provides a translation of provability in  to provability in
to provability in  and allows us to observe that the extension of
and allows us to observe that the extension of  by \(\lnot \) is conservative. Now, using finite completeness of
by \(\lnot \) is conservative. Now, using finite completeness of  , we can see that
, we can see that  is finitely strongly complete w.r.t.
is finitely strongly complete w.r.t.  :
:
Lemma 2
(Finite strong standard completeness of  ). For a finite set of formulas \(\varGamma \),
). For a finite set of formulas \(\varGamma \),

Proof
The left-right direction is soundness, and consists of checking that the axioms are valid and the rules sound. We only do some cases:
First the \({\sim }\lnot \)-rule: assume that e is given and \(e(\alpha )=(1,0)\). Then \(e({\sim }\lnot \alpha ) = {\sim }\lnot (1,0) = {\sim }(0,1) = (1,0)\).
Next, for any e,  ,
,
and, 
Last, for any e,  .
.
For the other direction, let us assume that  . Then for some finite \(\varDelta \) containing instances of \(\lnot \)-axioms (in particular those for subformulas of \(\varGamma ,\alpha \)), we have
. Then for some finite \(\varDelta \) containing instances of \(\lnot \)-axioms (in particular those for subformulas of \(\varGamma ,\alpha \)), we have  Because
Because  is finitely standard complete, there is an evaluation
is finitely standard complete, there is an evaluation  sending all formulas in \(\boxdot \varGamma ,\varDelta \) to 1, while \(e(\alpha )< 1\). Here, \(\mathrm {At}\) contains literals from \(\varGamma ,\alpha \) of the form \(p,\lnot p\), and atoms and formulas of the form \(\lnot \delta \) from \(\boxdot \varGamma ,\varDelta \). We define
sending all formulas in \(\boxdot \varGamma ,\varDelta \) to 1, while \(e(\alpha )< 1\). Here, \(\mathrm {At}\) contains literals from \(\varGamma ,\alpha \) of the form \(p,\lnot p\), and atoms and formulas of the form \(\lnot \delta \) from \(\boxdot \varGamma ,\varDelta \). We define  by \(e'(p) = (e(p), e(\lnot p))\). We can then prove, by routine induction, that for each formula \(e'(\beta ) = (e(\beta ),e(\beta ^\lnot ))\). We use the fact that \(e[\varDelta ]\subseteq \{1\}\), and \(\varDelta \) contains all instances of \(\lnot \)-axioms for all subformulas of \(\varGamma ,\alpha \).
by \(e'(p) = (e(p), e(\lnot p))\). We can then prove, by routine induction, that for each formula \(e'(\beta ) = (e(\beta ),e(\beta ^\lnot ))\). We use the fact that \(e[\varDelta ]\subseteq \{1\}\), and \(\varDelta \) contains all instances of \(\lnot \)-axioms for all subformulas of \(\varGamma ,\alpha \).
We now immediately see that \(e'(\alpha ) < (1,0)\), because \(e(\alpha ) < 1\). To prove that indeed \(e'[\varGamma ]\subseteq \{(1,0)\}\), we use the fact that \(e[\boxdot \varGamma ]\subseteq \{1\}\): as for all \(\gamma \in \varGamma \), \(e({\sim }\lnot \gamma ) = 1\), \(e(\lnot \gamma ) = e(\gamma ^\lnot ) = 0\). For the latter, we again need to use the fact that \(e[\varDelta ]\subseteq \{1\}\), and \(\varDelta \) contains all instances of \(\lnot \)-axioms for all subformulas of \(\varGamma \), as they prove, by means of  , that \(\lnot \gamma \leftrightarrow \gamma ^\lnot \), and e has to respect that. Now we conclude, that for all \(\gamma \in \varGamma \), \(e'(\gamma ) = (e(\gamma ),e(\gamma ^\lnot )) = (1,0)\). \(\Box \)
, that \(\lnot \gamma \leftrightarrow \gamma ^\lnot \), and e has to respect that. Now we conclude, that for all \(\gamma \in \varGamma \), \(e'(\gamma ) = (e(\gamma ),e(\gamma ^\lnot )) = (1,0)\). \(\Box \)
We can now put together the two-layer syntax of the first two-layer logic to be
-
\(\mathcal {L}_e = \{\wedge ,\vee ,\lnot \}\) language of BD,
-
\(\mathcal {M} = \{B\}\) a belief modality,
-
\(\mathcal {L}_u = \{\rightarrow , {\sim }, \lnot \}\) language of
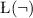 .
.
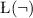 .
.The intended models can be described as follows: the lower layer is a double-valuation model of BD \((W,\Vdash ^+,\Vdash ^-)\) (a set of states W, and the two support relations, which in fact can be seen as arising from an evaluation of formulas of BD locally in the states in the product bilattice \(2\odot 2\), which is isomorphic to \(\mathbf {4}\), as noted in Subsect. 2.2). A source is given by a mass function on the states \(m_i: W \rightarrow [0,1]\), we assume there are n sources, and each source comes with a weight \(w_i\in [0,1]\). For a non-modal formula \(\varphi \in \mathcal {L}_e\), we obtain the value  as a pair of its positive and negative probabilities as follows. First, for each source \(m_i\), we have \((\sum _{v\, \Vdash ^+\varphi } m_i(v), \sum _{v\, \Vdash ^-\varphi } m_i(v)) = (p_i^+(\varphi ),p_i^-(\varphi )).\) Now, applying the weighted average aggregation strategy we obtain
as a pair of its positive and negative probabilities as follows. First, for each source \(m_i\), we have \((\sum _{v\, \Vdash ^+\varphi } m_i(v), \sum _{v\, \Vdash ^-\varphi } m_i(v)) = (p_i^+(\varphi ),p_i^-(\varphi )).\) Now, applying the weighted average aggregation strategy we obtain
The modal part M of the two-layer logic consists of two axioms and a rule reflecting directly the axioms of probabilities listed in Subsect. 2.3:Footnote 9

The resulting logic is  . As \(\textsf {BD}\) is locally finite and strongly complete w.r.t. \(\mathbf {4}\), and
. As \(\textsf {BD}\) is locally finite and strongly complete w.r.t. \(\mathbf {4}\), and  is finitely strongly complete w.r.t.
is finitely strongly complete w.r.t.  , we can apply [7, Theorems 1 and 2] directly to obtain finite strong completeness (soundness of the modal axioms and rules is easy to see). But first, we need to observe that the frames as we have described them can be seen within the framework of [7]:
, we can apply [7, Theorems 1 and 2] directly to obtain finite strong completeness (soundness of the modal axioms and rules is easy to see). But first, we need to observe that the frames as we have described them can be seen within the framework of [7]:
The frames, seen in the format of [7], are  , formulas of \(\mathcal {L}_e\) are evaluated locally in the states of W using \(\mathbf {4}\), as in the four-valued models for BD (which we can see as equivalent to the double-valuation models). The interpretation of modalities \(\mu ^B\) is computed as follows. A source is given by a mass function on the states \(m: W \rightarrow [0,1]\). Each source comes with a weight \(w_i\in [0,1]\). Given \(\mathbf {e}\in \prod _{v\in W}\mathbf {4}\), we obtain, for each source \(m_i\), first the following sums of weights over states: \((\sum _{\mathbf {e}_v\in \{t,b\}} m_i(v), \sum _{\mathbf {e}_v\in \{f,b\}}m_i(v)) = (p_i^+(\mathbf {e}),p_i^-(\mathbf {e}))\). The assignment \(\mu ^B\) now computes the weighted average of those as follows:
, formulas of \(\mathcal {L}_e\) are evaluated locally in the states of W using \(\mathbf {4}\), as in the four-valued models for BD (which we can see as equivalent to the double-valuation models). The interpretation of modalities \(\mu ^B\) is computed as follows. A source is given by a mass function on the states \(m: W \rightarrow [0,1]\). Each source comes with a weight \(w_i\in [0,1]\). Given \(\mathbf {e}\in \prod _{v\in W}\mathbf {4}\), we obtain, for each source \(m_i\), first the following sums of weights over states: \((\sum _{\mathbf {e}_v\in \{t,b\}} m_i(v), \sum _{\mathbf {e}_v\in \{f,b\}}m_i(v)) = (p_i^+(\mathbf {e}),p_i^-(\mathbf {e}))\). The assignment \(\mu ^B\) now computes the weighted average of those as follows:
Thus, for a non-modal formula \(\varphi \in \mathcal {L}_e\), applying \(\mu ^B\) to the tuple of its values in the states (which we denote by \(||\phi ||\)), we obtain the value of \(B\varphi \) as  as a pair of its positive and negative probabilities as follows: First, for each source we haveFootnote 10
as a pair of its positive and negative probabilities as follows: First, for each source we haveFootnote 10
Now, applying the weighted average aggregation we obtain
We can now conclude the completeness as follows:
Corollary 1
 is finitely strongly complete w.r.t. \(\mathbf {4}\) based,
is finitely strongly complete w.r.t. \(\mathbf {4}\) based,  -measured frames validating M.
-measured frames validating M.
In such frames, \(\mu ^B\) interprets B as a probability: For a frame to validate the axioms in M means they are sent to (1, 0), by an evaluation in  induced by \(\mu ^B\) over the lower state valuations (which determines values of modal atomic formulas). An equivalence \(\alpha \leftrightarrow \beta \) is evaluated at (1, 0) iff the values of \(\alpha \) and \(\beta \) are equal. \(B(\varphi )^M = \mu ^B(\varphi ^M) = (p^+(\varphi ),p^-(\varphi ))\). Therefore, the first two axioms say that
induced by \(\mu ^B\) over the lower state valuations (which determines values of modal atomic formulas). An equivalence \(\alpha \leftrightarrow \beta \) is evaluated at (1, 0) iff the values of \(\alpha \) and \(\beta \) are equal. \(B(\varphi )^M = \mu ^B(\varphi ^M) = (p^+(\varphi ),p^-(\varphi ))\). Therefore, the first two axioms say that
Similarly, the fact that the frame validates the rule say that \(p^+\) (\(p^-\)) are monotone (antitone) w.r.t. \(\varphi \vdash _{\textsf {BD}}\psi \). Analogous observation holds for the case the upper logic is the bilattice one.
From [24, Theorem 4], we know that it is the induced probability function of exactly one mass function on the \(\textsf {BD}\) canonical model, which in fact yields completeness w.r.t. the intended frames described above (with a single source).
II. A bilattice Łukasiewicz logic. Alternatively, if we wish to use full expressivity of a bilattice language, we can take in the upper layer \(\mathcal {L}_u =\{\wedge ,\vee ,\sqcap ,\sqcup ,\subset ,\lnot ,0\}\) to be the language of the product residuated bilattice  , defined in the spirit of [22] in Example 6. We evaluate formulas of the upper logic in the matrix
, defined in the spirit of [22] in Example 6. We evaluate formulas of the upper logic in the matrix  with \(F = \{(1,a) \mid a\in [0,1]\}\) as the designated values, so that we send 0 to (0, 0). The constants and connectives \(\top ,\bot ,1,*,\rightarrow ,{\sim },\oplus ,\ominus \) are definable as follows:
with \(F = \{(1,a) \mid a\in [0,1]\}\) as the designated values, so that we send 0 to (0, 0). The constants and connectives \(\top ,\bot ,1,*,\rightarrow ,{\sim },\oplus ,\ominus \) are definable as follows:
For an evaluation e, it holds that \(e(\alpha \rightarrow \beta )\in F\) iff \(e(\alpha \rightarrow \beta )\ge _t (1,1)\) iff \(e(\alpha )\le _te(\beta )\). The upper logic \(L_u\) as a consequence relation is defined to be

The intended frames now use  as the upper algebra, otherwise semantics of atomic modal formulas is computed (from multiple sources) as in the previous logic. We also obtain literally the same modal axioms M as above. Only here, apart from a very generic completeness w.r.t. \(\mathbf {4}\) based frames, where the upper algebra is an algebra (in fact the Lindenbaum-Tarski algebra) of the upper logic, we cannot provide a better insight at the moment and leave axiomatization of \(L_u\), and completeness w.r.t
as the upper algebra, otherwise semantics of atomic modal formulas is computed (from multiple sources) as in the previous logic. We also obtain literally the same modal axioms M as above. Only here, apart from a very generic completeness w.r.t. \(\mathbf {4}\) based frames, where the upper algebra is an algebra (in fact the Lindenbaum-Tarski algebra) of the upper logic, we cannot provide a better insight at the moment and leave axiomatization of \(L_u\), and completeness w.r.t  -measured frames to further investigations (cf. footnote 4).
-measured frames to further investigations (cf. footnote 4).
3.2 Logic of Monotone Coherent Belief
The simplest logic we propose to deal with scenarios like the one of Example 2 is of the form \((\textsf {BD}, M, \textsf {BD})\). Both lower and upper languages are the language of BD, \(\mathcal {M}\) consists of a single belief modality B. The intended frames are based on double-valuation semantics of BD as before, only now we evaluate formulas of the upper logic in the bilattice \(\mathbf {L}_{[0,1]}\odot \mathbf {L}_{[0,1]}\) on Fig. 1 (right). A source is given by a mass function on the states \(m_i: W \rightarrow [0,1]\), we again assume there are n sources. For a non-modal formula \(\varphi \), we obtain the value \(||B\varphi ||\in \mathbf {L}_{[0,1]}\odot \mathbf {L}_{[0,1]}\) as follows. First, for each source \(m_i\), we have \((\sum _{v\, \Vdash ^+\varphi } m_i(v), \sum _{v\, \Vdash ^-\varphi } m_i(v)) = (p_i^+(\varphi ),p_i^-(\varphi )).\) Now, applying the \(\mathrm {Min}\) aggregation strategy we obtain
Similarly, we may use the \(\mathrm {Max}\) aggregation strategy when reasoning with trusted sources. As before, we can see the frames inside the framework of [7] to derive completeness: frames are of the form \(F = (W, \mathbf {4}, \mathbf {L}_{[0,1]}\odot \mathbf {L}_{[0,1]}, \mu ^B)\) where \(\mu ^B: \prod _{v\in W} \mathbf {4}\rightarrow \mathbf {L}_{[0,1]}\odot \mathbf {L}_{[0,1]}\) computes the \(\mathrm {Min}\) (\(\mathrm {Max}\)) aggregation of the probabilities given by the individual sources. In general this aggregation strategy does not yield a probability, but it is monotone and \(\lnot \)-compatible. This motivates considering logic \((\textsf {BD}, M, \textsf {BD})\), where the modal part M consists of the following two axioms and a rule

As \(\textsf {BD}\) is strongly complete w.r.t. both \(\mathbf {4}\) and \(\mathbf {L}_{[0,1]}\odot \mathbf {L}_{[0,1]}\)Footnote 11, we can apply [7, Theorem 1] to conclude that \((\textsf {BD}, M, \textsf {BD})\) is strongly complete w.r.t. \(\mathbf {4}\)-based \(\mathbf {L}_{[0,1]}\odot \mathbf {L}_{[0,1]}\)-measured frames validating M. In such frames, \(\mu ^B\) interprets B as a monotone and \(\lnot \)-compatible assignment (not necessarily a probability). We cannot in general see it as coming from a measure, or a set of measuresFootnote 12, on the lower states (to recover sources), and connect it with the intended semantics.
One could however replace the upper language with the full bilattice language, consider modalities indexed by sources, and express the \(\mathrm {Min}\ (\mathrm {Max})\) aggregations explicitly using \(\sqcap , \sqcup \) connectives.
4 Conclusion and Further Directions
We have proposed two-layer logics of belief based on potentially inconsistent probabilistic information coming from multiple sources. The framework keeps positive and negative aspect of information (support, evidence, belief) separate, though inter-linked, in both layers of the semantics, and thus allows for reasoning with inconsistencies, in contrast to getting rid of them. Doing so, we believe we have laid groundwork to a modular framework to model reasoning with inconsistent probabilistic information.
We see our contribution in the following: to see how Belnap-Dunn’s logic BD (on the lower layer, and behind the non-standard probabilities) can be combined with many-valued reasoning on the upper layer provides a novel example of two-layer logics for reasoning under uncertainty. The only examples considered so far used either classical logic [15], or quantitative reasoning in form of linear inequalities on the upper layer [28]. The logic  , extending Łukasiewicz logic with bi-lattice negation, we introduced in Subsect. 3.1 and proved its finite strong standard completeness, is to our best knowledge new and might be of independent interest. (The same can be said about the bi-lattice Łukasiewicz logic, which however remains to be axiomatized and its completeness studied.)
, extending Łukasiewicz logic with bi-lattice negation, we introduced in Subsect. 3.1 and proved its finite strong standard completeness, is to our best knowledge new and might be of independent interest. (The same can be said about the bi-lattice Łukasiewicz logic, which however remains to be axiomatized and its completeness studied.)
The project is subject to ongoing work. Apart from investigating further the logics proposed in this paper, we are pursuing the following research directions:
In the continuation of [16] that generalises Dempster-Shafer theory [27] to finite lattices, we are currently working on adapting the theory to the BD-based setting, and putting it in context of existing literature on belief functions. This would allow us to consider Dempster-Shafer combination rule as another aggregation strategy.
To cover cases when a source does not give an opinion about each formula of the language, we need to account for sources providing partial probability maps. Also cases where sources provide heterogeneous information need to be included.
An important direction to move further is to capture dynamics of information and belief given by updates on the level of sources, and to generalize the framework to the multi agent setting involving group modalities and dynamics of belief. Specifically, forming group belief, like common and distributed belief, will involve communication and sharing or pooling of sources. It might call for a use of various upper-layer languages, among those we see the ones with additional (nestable) modalities inside the upper logic to account for reflected, higher-order beliefs, in contrast to the beliefs grounded directly in the sources.
Notes
- 1.
This independence assumption has in fact a support in scientific practice – if an experiment confirming a hypothesis fails, does not automatically mean it is rejected.
- 2.
For more on Łukasiewicz logic and MV algebras (in particular finite standard completeness w.r.t.
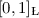 ) see e.g. [12].
) see e.g. [12]. - 3.
Definitions of \(\rightarrow ,*\) match those used in [10] for interval based fuzzy logics, via a transformation given by \((x_1,x_2)\mapsto (x_1,1-x_2)\) (symmetry across the (0, 0.5)(1, 0.5) line).
- 4.
[22] hints at the correspondence between subvarieties of residuated lattices and residuated bilattices being categorial. This would mean that the mentioned variety is in fact generated by the product bilattice of the standard MV algebra. One could then use the translation from [22] to obtain axiomatics of the logic introduced at the end of Subsect. 3.1.
- 5.
- 6.
The probability of a set \(X\subseteq W\) is defined as the sum of masses of its elements.
- 7.
- 8.
For this paper, we always consider the lower algebras be the same for all states. But different algebras can be later used when modelling heterogeneous information.
- 9.
Considering just the right-left implication in the first axiom, we can express belief functions.
- 10.
The value of \(\varphi \) in v being among \(\{t,b\}\) means it is positively supported in v, i.e. \(v\Vdash ^+\varphi \). Similarly \(\{f,b\}\) means negative support.
- 11.
Because it has \((2\odot 2,\{(1,0),(1,1)\})\) as a sub-matrix: the obvious embedding is a strict homomorphism of de Morgan matrices - it preserves and reflects the filters.
- 12.
It is not hard to provide an example of such assignment which cannot be obtained by \(\mathrm {Min}\ (\mathrm {Max})\) aggregation of probabilities.
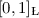 ) see e.g. [
) see e.g. [References
Aerts, D., Sozzo, S., Veloz, T.: New fundamental evidence of non-classical structure in the combination of natural concepts. Philos. Trans. R. Soc. A 374 (2016)
Avron, A.: The structure of interlaced bilattices. Math. Struct. Comput. Sci. 6(3), 287–299 (1996)
Baldi, P., Cintula, P., Noguera, C.: On two-layered modal logics for uncertainty (2020, manuscript)
Baltag, A., Bezhanishvili, N., Özgün, A., Smets, S.: Justified belief and the topology of evidence. In: Väänänen, J., Hirvonen, Å., de Queiroz, R. (eds.) WoLLIC 2016. LNCS, vol. 9803, pp. 83–103. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-52921-8_6
Belnap, N.D.: How a computer should think. New Essays on Belnap-Dunn Logic. SL, vol. 418, pp. 35–53. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-31136-0_4
Bílková, M., Majer, O., Peliš, M.: Epistemic logics for sceptical agents. J. Logic Comput. 26(6), 1815–1841 (2015)
Cintula, P., Noguera, C.: Modal logics of uncertainty with two-layer syntax: a general completeness theorem. In: Kohlenbach, U., Barceló, P., de Queiroz, R. (eds.) WoLLIC 2014. LNCS, vol. 8652, pp. 124–136. Springer, Heidelberg (2014). https://doi.org/10.1007/978-3-662-44145-9_9
Codd, E.F.: Understanding relations (installment #7). FDT - Bull. ACM SIGMOD 7(3), 23–28 (1975)
Console, M., Guagliardo, P., Libkin, L.: Propositional and predicate logics of incomplete information. In: Proceedings of KR 2018, Tempe, Arizona, pp. 592–601. AAAI Press (2018)
Cornelis, C., Deschrijver, G., Kerre, E.E.: Advances and challenges in interval-valued fuzzy logic. Fuzzy Sets Syst. 157, 622–627 (2006)
Dempster, A.P.: A generalization of Bayesian inference. J. Roy. Stat. Soc.: Ser. B (Methodol.) 30(2), 205–232 (1968)
Di Nola, A., Leustean, I.: Łukasiewicz logic and MV-algebras. In: Cintula, P., Hajek, P., Noguera, C. (eds.) Handbook of Mathematical Fuzzy Logic, vol. 2. College Publications (2011)
Dunn, J.M.: Intuitive semantics for first-degree entailments and ‘coupled trees’. Philos. Stud. 29(3), 149–168 (1976)
Dunn, J.M.: Contradictory information: too much of a good thing. J. Philos. Logic 39, 425–452 (2010)
Fagin, R., Halpern, J.Y., Megiddo, N.: A logic for reasoning about probabilities. Inf. Comput. 87, 78–128 (1990)
Frittella, S., Manoorkar, K., Palmigiano, A., Tzimoulis, A., Wijnberg, N.: Toward a Dempster-Shafer theory of concepts. Int. J. Approx. Reason. 125, 14–25 (2020)
Ginsberg, M.: Multivalued logics: a uniform approach to reasoning in AI. Comput. Intell. 4, 256–316 (1988)
Grahne, G., Moallemi, A., Onet, A.: Intuitionistic data exchange. In: 9th Alberto Mendelzon International Workshop on Foundations of Data Management (2015)
Hájek, P.: Metamathematics of Fuzzy Logic, Trends in Logic, vol. 4. Kluwer (1998)
Halpern, J.: Reasoning About Uncertainty. MIT Press, Cambridge (2005)
Hamblin, C.L.: The modal ‘probably’. Mind 68, 234–240 (1959)
Jansana, R., Rivieccio, U.: Residuated bilattices. Soft. Comput. 16(3), 493–504 (2012)
Kleene, S.C.: Introduction to Metamathematics. North-Holland, Amsterdam (1952)
Klein, D., Majer, O., Raffie-Rad, S.: Probabilities with gaps and gluts. http://arxiv.org/abs/2003.07408, submitted
Přenosil, A.: Reasoning with inconsistent information. Ph.D. thesis, Charles University, Prague (2018)
Rivieccio, U.: An algebraic study of bilattice-based logics. Ph.D. thesis, University of Barcelona - University of Genoa (2010)
Shafer, G.: A Mathematical Theory of Evidence. Princeton University Press, Princeton (1976)
Zhou, C.: Belief functions on distributive lattices. Artif. Intell. 201, 1–31 (2013)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Bílková, M., Frittella, S., Majer, O., Nazari, S. (2020). Belief Based on Inconsistent Information. In: Martins, M.A., Sedlár, I. (eds) Dynamic Logic. New Trends and Applications. DaLi 2020. Lecture Notes in Computer Science(), vol 12569. Springer, Cham. https://doi.org/10.1007/978-3-030-65840-3_5
Download citation
DOI: https://doi.org/10.1007/978-3-030-65840-3_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-65839-7
Online ISBN: 978-3-030-65840-3
eBook Packages: Computer ScienceComputer Science (R0)