
Abstract
The change in climate threatens the abundance of usable water across the globe. Most of the river basins are unable to cope up with the impact of climate change. Hence, assessing the future scenario has become the need of today. General Circulation Model (GCM) provides information at a course grid resolution. Downscaling can help in getting the information at a local scale level from GCM data, which helps the researchers to work on a regional level. Statistical downscaling method is preferred over dynamic downscaling method due to its less complex calculations. Statistical downscaling model (SDSM) is widely used in prediction of future climate scenarios. Here Brahmani–Baitarani river basin is selected as a case study for the downscaling of precipitation in the monthly time scale. SDSM version 4.2 is used as the model and precipitation is taken as the predictand. Predictors are chosen from the NCEP global variables like air temperature, geopotential height, specific humidity, zonal and meridional wind velocities, precipitable water and surface pressure data. The outcome of the study shows an increasing trend in the rainy season of the year. The mean rainfall increases significantly in 2040s than other epoches.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
27.1 Introduction
Climate change has adverse impact on the surface of earth starting from forest ecosystem to flood plain of rivers. Surface hydrology, forestry, floods, soil erosion, land use changes, ground water, environment, living beings and their ecosystems; all are affected by the climate change. Its adverse effect on water resources threatens the abundance of usable water availability. Water is the basis of lifeline on earth. Population explosion associated with various anthropogenic activities like per capita use, industrialization and others require more water in coming decades. Increase in demand of water with population explosion but possible decrease in availability of usable water creates a critical situation for the water resources planners (Chiew et al. 2010).
Study by researchers indicates that “the central India has been found to be the most vulnerable to climate change. Parts of north western, north eastern and southern India appear to be resilient to cope with droughts while the rest of the country is non resilient” (Sharma et al. 2017). Therefore, a proper assessment of past and prediction of probable future precipitation and the resulting run off over time is necessary for hydrologist (Anandhi et al. 2008).
General circulation models (GCMs) are considered as the most effective tools to simulate climatic conditions on earth. They provide information at a coarse grid resolution (usually 1°–2°). But data at a finer grid are required to work on a smaller study area like a smaller catchment. To manage the gap between the lower resolution and higher resolution, downscaling is used. It tries to link between the GCM information and information needed by the hydrologists (Walsh 2011).
Downscaling methods can be broadly classified into two groups; dynamical and statistical. Statistical downscaling method is preferred to dynamic downscaling method because of less computational work. Again it is classified into three subgroups; regression methods, weather generators and weather typing schemes. All the methods deal with the basic concept that regional climates (predictand) are the function of the large scale atmospheric state (predictor). This relationship between predictor and predict and can be deterministic or probabilistic function.
SDSM (statistical downscaling model) is the most commonly used model for this purpose. SDSM combine uses a conceptual water balance model and a mass-balance water quality model to investigate climate change impact assessment (Wilby and Harris 2006). Many authors have compared SDSM with other statistical downscaling models. Harpham and Wilby (2005) concluded that SDSM yields better daily precipitation quantiles and intersite correlation when compared with artificial neural networks (ANNs). Khan et al (2006) also concluded that SDSM is very efficient in reproducing various statistical parameters of data set in the downscaled results with a confidence level of 95%. Rath et al. concluded that future trends in precipitation for annual and seasonal period from the SDSM indicates a decrease in precipitation pattern for the time period 2020s and 2080s while an increase in 2050s for both A2 and B2 scenarios (Rath et al. 2016).
The present work focuses on the application of SDSM to the Brahmani–Baitari river basin in India to simulate the future scenarios of the precipitation and other parameters.
27.2 Study Area
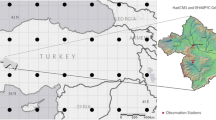
Brahmani and Baitarani river basin is situated in the central-east India between latitude 20° 28′ to 23° 35′ N and longitude 83° 52′ to 87° 30′ E. The basin extends over the states of Odisha, Jharkhand and Chhattisgarh draining an area of 51, 822 Sq.km which is 1.7% of total geographical area of the country. Major part of its catchment area is situated in the state of Odisha. Both the rivers are seasonal in nature. They are rejuvenated at the onset of monsoon as they are fed by rain. At the time of summer, their discharge is significantly decreased. Though 90% of the basin receives an average annual rainfall of between 1400 and 1600 mm, some places like Dhenkanal and Jashpur district are drought prone areas. Two hydro-observation stations Jenapur and Gomlai are taken for this study. Jenapur station has a drainage area of 33,955 km2 and Gomlai has a drainage area of 21,950 km2. Figure 27.1 shows the two stations in the considered river basin.

Schematic diagram of Brahmani–Baitarani river basin
27.3 Data
The observed large-scale predictors have been derived from the NCEP reanalysis data sets that contain 41 years of daily observed predictor data normalized over the period 1961–1990. These data have been interpolated into the grid size of 2.5 latitude *3.75 longitude before the normalization is implemented. The HadCM3 (Hadley center for climate and prediction and research, UK) model output both for A2 and B2 scenarios are directly downloaded from website http://climate-scenarios.canada.ca. The long-term meteorological data from the period 1981–2016 are obtained from the central water commission (CWC) India on daily basis at the Gomlai and Jenapur in the state of Odisha. A total 36 years of data are taken as baseline period, out of which 25 years are used for calibration and 11 years are needed for validation of the model.
27.4 Methodology
27.4.1 SDSM
Among the handful models that are available for downscaling, the SDSM is very popularly used. Statistical downscaling model (SDSM) is a statistical weather generator based on linear multiple regression. It is used to predict the climate parameters such as the precipitation or temperature in long time duration. It uses large-scale atmospheric variables to condition the local scale weather generators. It also uses stochastic techniques in variance of daily time series. In fact it is the combination of transfer function and stochastic weather generator methods.
27.4.2 Multiple Linear Regressions
Multiple linear regressions are used to explain the relationship between one continuous dependent variable (predictand) with one or more than one independent variables (GCM outputs). For a given data set, a linear regression model assumes a linear relationship between the variables. The equation used for the multiple linear regressions is written as:
where, y is the dependent predictant variable with respect to x, x1, x2, x3…. xn the independent predictor variables, a, b1, b2…bn the intercepts or parameters of the equation. Figure 27.2 shows the flowchart of climate scenario generation in SDSM.

(Source SDSM user manual)
Climate scenario generation in SDSM
27.5 Results and Discussion
Any error in the observed data may result the model to fail in the prediction of future climate scenario. Hence, before the simulations, the observed data are subjected to quality control in order to check for any missing data codes or gross data errors. For selecting a set of predictors, it is necessary to access the effect of predictors on the precipitation at that particular station. A correlation matrix is generated among the large scale global predictors and user specified predictand. Predictors are selected based on the highest correlation value. Partial r, p values and scatter plots are also considered in screening of the predictors. Predictor variables selected for each station after the screening test are given in Table 27.1.
For calibration of the model, 25 years of precipitation data (collected from CWC), between 1980 and 2005, are considered. A multiple linear regression is established between the NCEP variables and precipitation at that particular station. The intercepts of the regression equation are calculated by the forced entry method. Synthetic daily weather series is created by weather generation using the observed predictors. When a calibrated model is selected, SDSM automatically relates all necessary predictors to regression model weights. In the present study, monthly time scale is taken for analysis and no conditional factors are added. An ensemble size of 20 is used for the analysis. Results of model calibration for Gomlai station are shown in Fig. 27.3.

Calibration of model
Remaining 11 years data (2006–2016) are used for validation of the model. The statistical plot between observed and simulated value is plotted to compare the model output. Figure 27.4 shows the plot for validation of the model.

Validation of the model
It is quite clear from Fig. 27.4 that the model operates efficiently for calibration and validation. Hence future scenario is generated using this calibrated model. Scenario A2 experiment results show a very heterogeneous world with continuously increasing global population and regionally oriented economic growth that is more fragmented and slower than in other experiments; while that of B2 scenario experiment represents a world in which the emphasis is on local solutions to economic, social, and environmental sustainability, with continuously increasing population (lower than A2) and intermediate economic development. Both the scenarios are considered for the present study.
Outcome of climate model HadCM3 is used for scenario generation for six decades (2030–2090) in two subgroups as 2030–2060 and 2060–2090. These GCM outputs are normalized to 360 days, 12 months with 30 days of each duration. Results are presented in Tables 27.2 and 27.3.
Graphical representation of the mean monthly precipitation of baseline period (observed period) and forecasted period are shown in Fig. 27.5, (a) Jenapur station, (b) Gomlai station; which provides a comparative analysis of change in precipitation in future time period.


Comparison of monthly mean precipitation in forecasted period with that of baseline period
27.6 Conclusions
As the model is statistical in nature, the accuracy is highly dependent on the selection of predictors and user’s expertise. The predictor selection process is based on the correlation values, for which, sometimes the model underperforms for conditional predictands like precipitation. The performance of model was satisfactory for the two stations considered in this study; however analysis at more number of stations is required to evaluate model performance in complete river basin. Based on the present study on the statistical downscaling of GCM outputs and simulation of rainfall scenarios for Brahmni–Baitarani River basins in Odisha, the quantity of mean monthly precipitation shows an increasing graph with time for all epoches. It can also be noted that the increase is more in the rainy season (June, July, August) with respect to other time of the year, which might be indicating increase in runoff as well leading to flood events. But no conclusion can be drawn regarding increase in discharge without considering other factors like temperature, land-use, land-cover change etc.
References
Anandhi A, Srinivas VV, Nanjundiah RS, Nagesh Kumar D (2008) Downscaling precipitation to river basin in India for IPCC SRES scenarios using support vector machine. Int J Climatol 28:401–420. https://doi.org/10.1002/joc.1529
Chiew FHS, Young WJ, Cai W, Teng J (2010). Current drought and future hydroclimate projections in southeast Australia and implications for water resources management. Stochastic Environ Res Risk Assess, 602–612
Khan MS, Coulibaly P, Dibike Y (2006) Uncertainty analysis of statistical downscaling methods. J Hydrol 319:357–382
Pervez MS, Henebry GM (2014) Projections of the ganges-brahmaputra precipitation-downscaled from GCM predictors. J Hydrol 517:120–134
Prayas R, Patra KC (2016) Assessment of the impact of climate change on the hydrological parameters using statistical downscaling. Thesis submitted to the NIT, Rourkela in partial fulfillment of the requirements for the dual degree of Bachelor and Master of Technology in Civil Engineering
Sharma A, Goyal MK (2017) Assessment of ecosystem resilience to hydroclimatic disturbances in India. Global Change Biol
Walsh J (2011) Statistical downscaling. In: NOAA Climate Services Meeting
Wilby RL, Harris I (2006) “A framework for assessing uncertainties in climate change impacts: low-flow scenarios for the river thames UK. Water Resour Res 42:W02419. https://doi.org/10.1029/2005WR004065
Wilby RL, Dawson CW, Barrow EM (2002) SDSM—a decision support tool for the assessment of regional climate change impacts. Environ Model Softw 17(2):145–157
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Sahoo, L.L., Patra, K.C. (2021). Statistical Downscaling of GCM Output and Simulation of Rainfall Scenarios for Brahmani Basin. In: Jha, R., Singh, V.P., Singh, V., Roy, L.B., Thendiyath, R. (eds) Climate Change Impacts on Water Resources. Water Science and Technology Library, vol 98. Springer, Cham. https://doi.org/10.1007/978-3-030-64202-0_27
Download citation
DOI: https://doi.org/10.1007/978-3-030-64202-0_27
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-64201-3
Online ISBN: 978-3-030-64202-0
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)