
Abstract
RoleSim and SimRank are popular graph-theoretic similarity measures with many applications in, e.g., web search, collaborative filtering, and sociometry. While RoleSim addresses the automorphic (role) equivalence of pairwise similarity which SimRank lacks, it ignores the neighboring similarity information out of the automorphically equivalent set. Consequently, two pairs of nodes, which are not automorphically equivalent by nature, cannot be well distinguished by RoleSim if the averages of their neighboring similarities over the automorphically equivalent set are the same.
To alleviate this problem: 1) We propose a novel similarity model, namely RoleSim*, which accurately evaluates pairwise role similarities in a more comprehensive manner. RoleSim* not only guarantees the automorphic equivalence that SimRank lacks, but also takes into account the neighboring similarity information outside the automorphically equivalent sets that are overlooked by RoleSim. 2) We prove the existence and uniqueness of the RoleSim* solution, and show its three axiomatic properties (i.e., symmetry, boundedness, and non-increasing monotonicity). 3) We provide a concise bound for iteratively computing RoleSim* formula, and estimate the number of iterations required to attain a desired accuracy. 4) We induce a distance metric based on RoleSim* similarity, and show that the RoleSim* metric fulfills the triangular inequality, which implies the sum-transitivity of its similarity scores. Our experimental results on real and synthetic datasets demonstrate that RoleSim* achieves higher accuracy than its competitors while retaining comparable computational complexity bounds of RoleSim.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


1 Introduction
RoleSim is a role-based similarity measure that quantifies the closeness between two objects based on graph topology, with a proliferation of real-life applications [9, 10, 23] in, e.g., link prediction (social network), co-citation analysis (bibliometrics), motif discovery (bioinformatics), and collaborative filtering (information retrieval). It recursively follows a SimRank-like reasoning that “two nodes are assessed as role similar if they interact with automorphically equivalent sets of in-neighbors”. Intuitively, automorphically equivalent nodes in a graph are objects having similar roles that can be exchanged with minimum effect on the graph structure. Similar to the well-known measure SimRank [7], the recursive nature of RoleSim allows to capture the multi-hop neighboring structures that are automorphically equivalent in a network. Unlike SimRank that measures the similarity of two nodes from the paths connecting them, RoleSim quantifies their similarities through the paths connecting their different roles. As a result, two nodes that are disconnected each other will not be considered as dissimilar by RoleSim if they have similar roles. For evaluating similarity score s(a, b) between nodes a and b, as opposed to SimRank whose similarity s(a, b) takes the average similarity of all the neighboring pairs of (a, b), RoleSim computes s(a, b) by averaging only the similarities over the maximum bipartite matching of all the neighboring pairs of (a, b). This subtle difference enables RoleSim to guarantee the automorphic equivalence, which SimRank lacks, in final scoring results. Therefore, RoleSim has been demonstrated as an effective similarity measure in many real applications. We summarize two of these applications below.
Application 1 (Similarity Search on the Web). Discovering web pages similar to a query page is an important task in information retrieval. In a Web graph, each node represents a web page, and an edge denotes a hyperlink from one page to another. RoleSim can be applied to measure the similarity of two web pages, based on the intuition that “two web pages are role-similar if they are pointed to by the automorphically equivalent sets of their in-neighboring pages”. This similarity measure produces more reliable similarity results than the SimRank model [10].
Application 2 (Social Network De-anonymisation). Social network de-anonymisation is a method to validate the strength of anonymisation algorithms that protect a user’s privacy. RoleSim has been applied to de-anonymise node mappings based on the similarity information between a crawled network and an anonymised one. Based on the observation that “correct mappings tend to have higher similarity scores”, RoleSim iteratively evaluates pairwise node similarities between two networks, and captures the reasoning that “a pair of nodes between two networks is more likely to be a correct mapping if their neighbors are correct mappings”. RoleSim has demonstrated superior performance as compared with other existing de-anonymization algorithms [23].
Despite its popularity in real-world applications, RoleSim has a major limitation: with the aim to achieve automorphic equivalence, its similarity score s(a, b) only considers the limited information of the average similarity scores over the automorphically equivalent set (i.e., the maximum bipartite matching) of a’s and b’s in-neighboring pairs, but neglects the rest of the pairwise in-neighboring similarity information that is out of the automorphically equivalent set. Consequently, RoleSim does not always produce comprehensive similarity results because two pairs of nodes, which are not automorphically equivalent by nature, should be distinguished from each other even though the average values of their in-neighboring similarities over the set of the maximum bipartite matching are the same, as illustrated in Example 1.

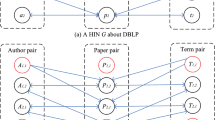
Limitation of RoleSim (RS) on a tiny web graph, where node-pairs (1, 2) and (1, 3) have the same RoleSim score (0.426) since RS aggregates only the in-neighboring pairs that are automorphically equivalent (colored in green) whose sums are the same \((0.488+0.360=0.848)\), while ignoring the remaining pairs. (Color figure online)
Example 1 (Limitation of RoleSim)
Consider the web graph G in Fig. 1, where each node denotes a web page, and each edge depicts a hyperlink from one page to another. Using RoleSim, we evaluate pairs of similarities between nodes, as partially illustrated in the ‘RS’ column of the right table. It is discerned that node-pairs (1, 2) and (1, 3) have the same RoleSim similarity values, which is not reasonable. Because node 2 and node 3 are not strictly automorphically equivalent by nature, their similarities with respect to the same query node 1, i.e., s(1, 2) and s(1, 3), should not be the same.
We notice that the main reason why s(1, 2) and s(1, 3) are assessed to be the same by the RoleSim model is that its similarity s(a, b) considers only the average similarity scores over the maximum bipartite matching, denoted as \(M_{a,b}\), of (a, b)’s in-neighboring pairs \(I_a \times I_b\), where \(I_a\) denotes the in-neighbor set of node a, and \(\times \) is the Cartesian product of two sets. Thus, the similarity information in the remaining in-neighboring pairs of (a, b), i.e., \(I_a \times I_b-M_{a,b}\), are totally ignored. For example, if unfolding the in-neighboring pairs of (1, 2) and (1, 3) respectively, we see that, in the gray cells, \(M_{1,2}=\{(4,6),(5,7)\}\) (resp. \(M_{1,3}=\{(4,9),(5,10)\}\)) is the maximum bipartite matching of (1, 2)’s (resp. (1, 3)’s) in-neighboring pairs \(I_1 \times I_2\) (resp. \(I_1 \times I_3\)). The sum of the similarity values over \(M_{1,2}\) is \(0.488+0.360=0.848\), which is the same as that over \(M_{1,3}\). Thus, RoleSim cannot distinguish s(1, 2) from s(1, 3). \(\square \)
Example 1 illustrates that, to effectively evaluate s(a, b), relying only on the in-neighboring-pairs similarities in the maximum bipartite matching \(M_{a,b}\) (e.g., RoleSim) is not enough. Although RoleSim has the advantage of finding the most influential pairs \(M_{a,b}\) among all the in-neighboring pairs \(I_a \times I_b\) for achieving automorphic equivalence, it completely ignores the similarity information outside \(M_{a,b}\). For instance in Example 1, there are opportunities to take good advantage of the similarity values in the regions \(I_1 \times I_2-M_{1,2}\) and \(I_1\times I_3-M_{1,3}\) which would be helpful to distinguish s(1, 2) from s(1, 3) further when the average similarities over \(M_{1,2}\) and \(M_{1,3}\) are the same.
Contributions. Motivated by this, our main contributions are as follows:
1) We first propose a novel similarity model, RoleSim*, which accurately evaluates pairwise role similarities in a more comprehensive fashion. Compared with the existing well-known similarity models (e.g., SimRank and RoleSim), RoleSim* not only guarantees the automorphic equivalence that SimRank lacks, but also takes into consideration the pairwise similarities outside the automorphically equivalent sets that are overlooked by RoleSim. (Sect. 3.1)
2) We prove the existence and uniqueness of the RoleSim* solution, and show three key axiomatic properties of RoleSim*, i.e., symmetry, boundedness, and non-increasing monotonicity of its iterative similarity scores. (Sect. 3.2)
3) We derive an iterative formula for computing RoleSim* similarities, and a concise upper bound is obtained, which can estimate the total number of iterations required for attaining a desired accuracy. (Sects. 3.3 and 3.4)
4) We induce a distance metric based on our RoleSim* measure, and rigorously show that the RoleSim* distance metric fulfills the triangular inequality which other measures (e.g., cosine distance) lack. This implies the sum-transitivity of the RoleSim* measure. (Sect. 3.5)
5) We conduct an experimental study to validate the effectiveness of our RoleSim* model. Our empirical results show that RoleSim* achieves higher accuracy than the existing competitors (e.g., RoleSim and SimRank) while entailing comparable computational complexity bounds of RoleSim. (Sect. 4)
2 Related Work
Graph-based similarity models have been popular since SimRank measure was proposed by Jeh and Windom [7]. SimRank is a node-pair similarity measure, which follows the recursive idea that “two nodes are considered as similar if they are pointed to by similar nodes”. Since then, there have been surges of studies focusing on optimization problems to accelerate SimRank computation as the naive SimRank computing method entails quadratic time in the number of nodes. According to assumptions on data updates, recent results can be divided into static algorithms [1, 4, 5, 11, 15, 20, 24, 27, 29, 32, 37], and dynamic algorithms on evolving graphs [8, 12, 18, 22, 25, 31, 35]. According to types of queries, these results are classified into single-source SimRank [8, 11, 18, 24, 35], single-pair SimRank [6, 14], all-pairs SimRank [1, 19, 29, 30], and partial-pairs SimRank [20, 34].
There are many studies on semantic problems of pairwise similarity measures. Various SimRank-like measures have come into play, including C-Rank [26], SimFusion [33], P-Rank [36], RoleSim [9], MatchSim [17], ASCOS [2], SimRank* [32], CoSimRank [21], SemSim [27]. Among them, RoleSim has stood out as a promising role-based similarity model, due to its elegant intuition that “if two nodes are automorphically equivalent, they should share the same role and their role similarity should be maximal”. To speed up the RoleSim computation, an approximate heuristic, named Iceberg RoleSim, was devised to prune small similarity values below a threshold.
Unlike SimRank that takes the average similarity of all the neighboring pairs of (a, b), RoleSim computes s(a, b) by averaging only the similarities over the maximum bipartite matching \(M_{a,b}\). However, all the similarity information not included in the matching \(M_{a,b}\) is completely ignored by RoleSim. In contrast, our RoleSim* model can effectively capture these information while guaranteeing automorphic equivalence.
There have also been a host of studies on variations of RoleSim [3, 13, 17, 23]. Lin et al. [17] introduced MatchSim whose similarity is defined to be the average similarity of (a, b)’s maximum matched neighbors. It differs from RoleSim in that MatchSim initialises \(s_0(a,b)=1 \) if \(a=b\), and 0 otherwise, whereas RoleSim initialises all \(s_0(*,*) = 1 \). As a result, MatchSim scores do not guarantee automorphic equivalence. Li et al. [13] proposed CentSim, a centrality based role similarity measure, which compares the centrality values of two nodes to evaluate their similarity. This measure employs several types of centralities including PageRank, Degree and Closeness for each node, and considers the weighted average of them for evaluating CentSim scores. Recently, Shao et al. [23] introduced RoleSim++, an extension of RoleSim, which considers both incoming and outgoing neighbors in a digraph for social network de-anonymisation. It employs a novel matching algorithm, called NeighborMatch, to find matching for inner and outer neighbors, respectively. Furthermore, a threshold based version, \(\alpha \)-RoleSim++, is proposed to eliminate tiny scores for speedup further. Most recently, Chen et al. [3] suggest a scalable model, StructSim, with an efficient BinCount matching algorithm and present a hierarchical scheme, which achieves a more efficient role similarity computation.
3 RoleSim*
3.1 RoleSim* Formulation
The central intuition underpinning RoleSim* follows a recursive concept that “two distinct nodes are assessed to be similar if they
-
1.
mainly interact with the automorphically equivalent sets of in-neighbors, and
-
2.
are in-linked by similar nodes that are out of automorphically equivalent sets.
The starting point for this recursion is to assign each pair of nodes a similarity score 1, meaning that initially no pairs of nodes are thought of to be more (or less) similar than others.
Notations. Before illustrating the mathematical definition to reify the RoleSim* intuition, we introduce the following notations.
Let \(G=(V,E)\) be a directed graph with a set of nodes V and a set of edges E. Let \(I_a\) be all in-neighbors of node a, and \(|I_a|\) the cardinality of the set \(I_a\). For a pair of nodes (a, b) in G, we denote by \(I_a \times I_b=\{(x,y) \ | \ \forall x \in I_a \text { and } \forall y \in I_b\}\) all in-neighboring pairs of (a, b), and s(a, b) the RoleSim* similarity score between nodes a and b. Using \(I_a \times I_b\) and s(a, b), we define a weighted complete bipartite graph, denoted by \(K_{|I_a|, |I_b|}= (I_a \cup I_b, I_a \times I_b)\), with each edge \((x,y) \in I_a \times I_b\) carrying the weight s(a, b). We denoted by \(M_{a,b} \ (\subseteq I_a \times I_b)\) the maximum weighted matching in bipartite graph \(K_{|I_a|, |I_b|}\).
Example 2
Recall digraph G in Fig. 1. For nodes 1 and 2, their in-neighbors sets are \(I_1=\{4, 5\}\) and \(I_2=\{6, 7, 8\}\), respectively. The set of all in-neighboring pairs of (1, 2) is \(I_1 \times I_2=\{\mathbf {(4,6)},(4,7),(4,8),(5,6),\mathbf {(5,7)},(5,8)\}\). The maximum matching of bipartite graph \((I_1 \cup I_2, I_1 \times I_2)\) is \(M_{1,2}=\{(4,6),(5,7)\}\) (bold). \(\square \)
Other notations frequently used throughout this paper are listed in Table 1.
RoleSim* Formula. Based on our aforementioned intuition, we formally formulate the RoleSim* model as follows:

In Eq. (1), for every pair of nodes (a, b), the set of their in-neighboring pairs, \(I_a \times I_b\), is split into two subsets: \(I_a \times I_b = M_{a,b} \cup (I_a \times I_b-M_{a,b})\). As a result, the definition of RoleSim* consists of two parts: Part 1 is the average similarity over maximum matching \(M_{a,b}\), indicating the contribution from (a, b) interacting with the automorphically equivalent set, \(M_{a,b}\), of (a, b)’s in-neighbors pairs. Part 2 is the average similarity over \((I_a \times I_b)-M_{a,b}\), corresponding to the contribution from (a, b) being pointed to by the rest of (a, b)’s in-neighbors pairs out of automorphically equivalent set \(M_{a,b}\). The relative weight of Part 1 and 2 is balanced by a user-controlled parameter \(\lambda \in [0,1]\). \(\beta \) is a damping factor between 0 and 1, which is often set to 0.6 or 0.8, implying that similarity propagation made with distant in-neighbors is penalised by an attenuation factor \(\beta \) across edges. When \(I_a\) (or \(I_b\)) \(=\emptyset \), which implies the maximum matching \(M_{a,b}=\emptyset \), we define Part 1 and Part 2 = 0 in order to avoid the denominators of the fraction in Part 1 and 2 being zeros.
Fixed-Point Iteration. To solve RoleSim* similarity s(a, b) in Eq. (1), we adopt the following fixed-point iterative scheme:
where \(s_k(a,b)\) denotes the RoleSim* score between nodes a and b at iteration k. Based on Eqs. (2) and (3), we can iteratively compute all pairs of similarity scores \(s_{k+1}(*,*)\) from those at the last iteration \(s_{k}(*,*)\). The fixed-point scheme in Eqs. (2) and (3) implies an iterative algorithm for RoleSim* computation, which requires \(O(K{|E|}^2)\) time to compute \({|V|}^2\) node-pairs for K iterations.
Threshold-Based RoleSim*. To accelerate RoleSim* computation, we notice that there are a significant number of node pairs whose iterative similarity values \(s_k(*,*)\) are very close to their convergent scores \(s(*,*)\) and thus will not change much in subsequent iterations. Hence, we propose the following threshold-based RoleSim* model, where \(\delta \) is a user-controlled threshold, which is a speed-accuracy trade-off.
3.2 Axiomatic Properties for RoleSim* Iterative Similarity
Based on the definition of iterative similarity \(s_{k}(a,b)\) in Eqs. (2) and (3), we next show three axiomatic properties of RoleSim*, i.e., symmetry, boundedness, and non-increasing monotonicity, based on the following theorem.
Theorem 1
The iterative RoleSim* \(\{s_{k}(a,b)\}\) in Eqs. (2) and (3) have the following key properties: for any node pair (a, b) and each iteration \(k=0,1,\cdots \),
-
1.
(Symmetry) \(s_k(a,b) = s_k(b,a)\)
-
2.
(Boundedness) \(1-\beta \le s_k(a,b) \le 1\)
-
3.
(Monotonicity) \(s_{k+1}(a,b) \le s_k(a,b)\)
Proof
Please refer to [28] for a detailed proof of all theorems and lemmas.
Theorem 1 indicates that, for every iteration \(k=0,1,2,\cdots \), \(\{s_{k}(a,b)\}\) is a bounded symmetric scoring function. Moreover, as \(k \rightarrow \infty \), it can be readily verified that the exact solution s(a, b) also is a bounded symmetric measure, which is similar to SimRank and RoleSim. In comparison, other measures (e.g., Hitting Time and Random Walk with Restart) are asymmetric ones.
3.3 Existence and Uniqueness
It is worth mentioning that, as opposed to SimRank whose iterative similarity is non-decreasing between 0 and 1 w.r.t. k, RoleSim* similarity is non-increasing between \(1-\beta \) and 1. The bounded non-increasing property of RoleSim* guarantees the existence and uniqueness of its exact solution s(a, b), as shown below:
Theorem 2 (Existence and Uniqueness)
There always exists a unique solution s(a, b) (i.e., the exact RoleSim score) to Eqs. (2) and (3) such that the iterative RoleSim similarity \(\{s_{k}(a,b)\}\) converges to it, i.e., \(\lim _{k \rightarrow \infty } s_{k}(a,b) = s(a,b)\).
3.4 Accuracy Estimation
Having proved the existence and uniqueness of the exact RoleSim* solution, we are now ready to investigate the error bound of the difference between the k-th iterative similarity \(s_k(a,b)\) and exact one s(a, b). In virtue of the non-increasing monotonicity of \(\{s_k(a,b)\}\), one can readily show that the exact s(a, b) is the lower bound of all the iterative similarities \(\{s_k(a,b)\}\), i.e., \(s_k(a,b) \ge s(a,b) \ \ (\forall k)\). The following theorem further provides a concise upper bound to measure the closeness between \(s_k(a,b)\) and s(a, b).
Theorem 3 (Iterative Error Bound)
For every iteration number \(k=0,1,2, \cdots \), the difference between \(s_k(a,b)\) and s(a, b) is bounded by
Theorem 3 derives a concise exponential upper bound for the difference between the k-th iterative similarity \(s_k(a,b)\) and exact s(a, b). Combining this bound with the non-increasing monotonicity \(s_k(a,b) \ge s(a,b)\), we can obtain that the k-th iterative error \(s_k(a,b) - s(a,b)\) is between 0 and \(\beta ^{k+1}\). Moreover, Theorem 3 also implies that, given desired accuracy \(\epsilon >0\), the total number of iterations required for computing RoleSim* similarity is \(K = \lceil \log _{\beta } \epsilon \rceil \).
3.5 “Sum-Transitivity” of RoleSim* Similarity
In this section, we investigate the transitive property of the proposed RoleSim* similarity measure. Intuitively, when a similarity measure \(s(*,*)\) fulfills the transitive property, it means that, for any three nodes a, b, c in the graph, if a is similar to b and b is similar to c, it implies that a is likely to be similar to c. The transitivity feature is useful in many real applications, e.g., for predicting and recommending links in a graph.
To study the transitive property of RoleSim*, let us induce a distance \(d(a,b):=1-s(a,b)\) from the RoleSim* measure. Due to \(s(*,*) \in [1-\beta , 1]\), the distance \(d(*,*)\) is between 0 and \(\beta \). In what follows, we will show that \(d(*,*)\) satisfies the triangular inequality, which is an indication of \(s(*,*)\) transitivity.
We first show the following lemma, which is needed for further proof of RoleSim* triangular inequality.
Lemma 1
Let \(s_k(*,*)\) be the k-th iterative RoleSim* similarity to Eqs. (2) and (3). For any three nodes a, b, c in a graph, if \(s_k(a,b)+s_k(b,c)-s_k(a,c) \le 1\) holds at iteration k, the following inequalities holds:

Leveraging Lemma 1, we are now ready to show the sum-transitivity of the RoleSim* similarity distance, which is the main result in this subsection:
Theorem 4
The RoleSim* similarity s(a, b) defined by Eq. (1) satisfies the following “sum-transitive” property: Let \(d(a,b):=1-s(a,b)\) be the closeness between nodes a and b. Then, for any three nodes a, b, c in a graph, the following triangular inequality holds, i.e.,
4 Experimental Evaluation
4.1 Experimental Settings
Datasets. We use both real and synthetic datasets, as illustrated below:
Datasets | Abbr. | #Node-Pairs | #Nodes | #Edges | Type |
|---|---|---|---|---|---|
Amazon | (AMZ) | 25, 867, 396 | 5, 086 | 8, 970 | Directed |
DBLP | (DBLP) | 5, 626, 384 | 2, 372 | 7, 106 | Undirected |
Synthetic | (SYN) | 4, 000, 000 | 2, 000 | 5, 481 | Undirected |
-
 . A co-purchasing digraph crawled from Customers Who Bought This Item Also Bought feature of AmazonFootnote 1. Each node is a product, and edge \(i \rightarrow j\) means that product j appears in the frequent co-purchasing list of i.
. A co-purchasing digraph crawled from Customers Who Bought This Item Also Bought feature of AmazonFootnote 1. Each node is a product, and edge \(i \rightarrow j\) means that product j appears in the frequent co-purchasing list of i. -
 . A collaboration (undirected) graph taken from DBLP bibliography.Footnote 2 We extract a co-authorship subgraph from six top conferences in computer science (SIGMOD, VLDB, PODS, KDD, SIGIR, ICDE) during 2018–2020. If two authors (nodes) co-authored a paper, there is an edge between them.
. A collaboration (undirected) graph taken from DBLP bibliography.Footnote 2 We extract a co-authorship subgraph from six top conferences in computer science (SIGMOD, VLDB, PODS, KDD, SIGIR, ICDE) during 2018–2020. If two authors (nodes) co-authored a paper, there is an edge between them. -
 . A random scale-free graph with a power-law degree distribution, generated by GenRndPowerLaw function in C++ SNAP Library.Footnote 3
. A random scale-free graph with a power-law degree distribution, generated by GenRndPowerLaw function in C++ SNAP Library.Footnote 3
 . A co-purchasing digraph crawled from Customers Who Bought This Item Also Bought feature of Amazon
. A co-purchasing digraph crawled from Customers Who Bought This Item Also Bought feature of Amazon . A collaboration (undirected) graph taken from DBLP bibliography.
. A collaboration (undirected) graph taken from DBLP bibliography. . A random scale-free graph with a power-law degree distribution, generated by GenRndPowerLaw function in C++ SNAP Library.
. A random scale-free graph with a power-law degree distribution, generated by GenRndPowerLaw function in C++ SNAP Library.All experiments are conducted on a PC with Intel Core i7-10510U 2.30GHz CPU and 16 GB RAM, using Windows 8 Professional 64-bit. Each experiment is repeated 5 times and the average is reported.
Compared Algorithms. We implemented all the following algorithms in VC++:
Models | Abbr. | Description |
|---|---|---|
RoleSim* | (RS*) | Our proposed RoleSim* model in Section 3.1 |
SimRank | (SR) | A pairwise similarity model proposed by Jeh and Widom [7] |
MatchSim | (MS) | A similarity model relying on the matched neighbors of node pairs [16] |
RoleSim | (RS) | A model that guarantees the automorphically equivalence of nodes [9] |
RoleSim++ | (RS++) | An enhanced RoleSim that considers both in- and out-neighbors [23] |
CentSim | (CS) | A similarity model that compares the centrality values of node pairs [13] |
Parameters. We use the following parameters as default: (a) damping factor \(\beta =0.8\), (b) relative weight \(\lambda =0.7\), (c) total number of iterations \(K=4\).
Semantic Evaluation. We design an unsupervised evaluation setting to quantify the effectiveness of the similarity measures in preserving self-similarity under different conditions. In particular, we study the effect of sampling the immediate neighborhood of a query point on similarity scores in RoleSim* compared with SimRank and RoleSim. Consider a single query node q. In our experiment, we create a node \(q'\) and add it to the graph. We connect \(q'\) to some proportion (\(\eta \)) of the total number of neighbors of q, and hereby refer to \(q'\) as the “sampled clone”. The similarity scores of q to all other points in the graph are computed using SimRank, RoleSim, and RoleSim*. We evaluate how much the relative similarities are preserved when different measures are used. We vary \(\eta \) in \(q'\) with step size 0.25 (and ensuring no orphaned nodes), and additionally consider \(\lambda ={0.0, 0.3, 0.5, 0.7, 1.0}\) for RoleSim*. Our results are aggregated over 20 queries on DBLP and AMZ graphs respectively, where query nodes are chosen as having high degree of neighbors.

Effect of Sampling Ratio \((\eta )\) and Weight \((\lambda )\) on Ranking Quality (DBLP)

Effect of Sampling Ratio \((\eta )\) and Weight \((\lambda )\) on Ranking Quality (AMZ)
4.2 Experimental Results
Semantic Accuracy. We first count the number of queries where the sampled clone \(q^{\prime }\) appears in the top-k (\(k={1,5,10}\)) similar nodes to query q for RoleSim*. Intuitively, this studies how much structural information is gleaned about a query node. Figure 2(a) presents the number of such queries out of 20 on the undirected DBLP graph, considering top-5 similarity scores. Other top-k plots are omitted, but show that with increasing k for a given sampling proportion there are more such queries even at lower \(\lambda \).
Next, we test the impact of sampling \(\eta \) and \(\lambda \) on ranking quality in RoleSim*. We plot the average ranking quality (normalized discounted cumulative gain (nDCG)), considering top-100 similar nodes of the sampled clone and comparing this to the baseline original query. We observe that the trend (with respect to \(\eta \)) seen in Fig. 2(b) and Fig. 3(b) for \(\lambda =1\) resembles that for RoleSim, and the trend for \(\lambda =0.5\) is close to that for SimRank.
Finally, we consider a fixed value of \(\lambda =0.7\) and confirm that the RoleSim* has higher ranking quality compared to SimRank and RoleSim, with respect to the average nDCG. Figure 2(c) with undirected DBLP graph shows that RoleSim* produces a more consistent nDCG even with small \(\eta \). For the directed AMZ graph in Fig. 3(c) too, RoleSim shows significant improvement at lower sampling, and the performance of SimRank is negatively affected throughout, while RoleSim* remains stable.
Qualitative Case Study. Table 2 compares the similarity ranking results from three algorithms (SR, RS and RS*) for retrieving top-10 most similar authors w.r.t. query “Philip S. Yu” on DBLP. From the results, we see that the top rankings of RS* are similar to RS, highlighting its capability to effectively capture automorphic equivalent neighboring information. For instance, “Jure Leskovec” is top-ranked in RS* list. This is reasonable because he and “Philip S. Yu” have similar roles - they are both Professors in Computer Science with close research expertise (e.g., knowledge discovery, recommender systems, commonsense reasoning). However, the rankings of RS* are different from those of RS. For example, “Jure Leskovec” is ranked \({350}^{\text {th}}\) by SR, but \({4}^{\text {th}}\) by RS* and RS. This is because SimRank can only capture connected paths between two authors while ignoring their automorphic equivalent structure. “Jure Leskovec” has rare collaborations with “Philip S. Yu”, both direct and indirect, thus leading to a low SimRank score.
To evaluate RS* further, we choose two different values for \(\lambda \in \{0.6, 0.8\}\) to show how RS* ranking results are perturbed w.r.t. \(\lambda \). From the results, we notice that, when \(\lambda \) is varied from 0.6 to 0.8, nodes with small SR scores (e.g., “Jure Leskovec”) exhibit a stable position in RS* ranking, whereas nodes having higher SR scores (e.g., “Huan Liu”) have a substantial change. This conforms with our intuition because “Huan Liu”’s collaboration with “Philip S. Yu” is closer than “Jure Leskovec”’s, and RS* is able to capture both connectivity and automorphic equivalence of two authors using a balanced weight \(\lambda \).

Elapsed time comparison for different threshold-based RS*
Computational Time. Figure 4(a) compares the computational time of six algorithms (RS*, RS, MS, RS++, CS, SR) on various datasets (AMZ, DBLP, SYN), respectively. We notice that, on each dataset, RS* has comparable computational time to RS and MS. This implies that RS* achieves high accuracy without sacrificing running speed. In addition, RS*, RS, and MS are 2–4 times faster than RS++. This is because RS* need to find two maximum bipartite matchings for both in- and out-neighboring pairs, as opposed to RS* that involves the computation of only one matching. SR is slightly slower than RS*. This is consistent with our analysis as SR simply takes the average of all similarities of the in-neighboring pairs without the need to find the maximum bipartite matching. CS achieves the fastest speed since it simply assesses a node-pair similarity by aggregating their centrality values, thereby leading to low accuracy.
Figures 4(b) and (c) show the effect of iteration number k and threshold \(\delta \) on the running time of RS* on DBLP and AMZ, respectively. For each dataset, we vary \(\delta \) from 0 to 0.05. When \(\delta =0\), it reduces to RS* algorithm. From the results on both datasets, we discern that, for each fixed \(\delta \), the running time of threshold-based RS* increases as k grows. When \(\delta \) becomes larger, the growth rate of RS* time tends to be sublinear. For example, when \(\delta =0.05\) on DBLP, only after \(k=5\) iterations, the increasing time of threshold-based RS* has leveled off. In contrast, when \(\delta =0.01\), the time becomes steady after \(k=8\) iterations. The reason is that a higher setting of threshold \(\delta \) implies a larger number of pairs to be pruned per iteration, thus leading to the growth rate of the running time decreasing in an earlier stage during iterations.
5 Conclusion
We propose RoleSim*, a novel similarity model that guarantees automorphic equivalence and also considers neighboring similarity information beyond automorphically equivalent sets, thereby achieving better performance than both SimRank and RoleSim. We prove the existence and uniqueness of the RoleSim* solution, show that iteratively computing RoleSim* is bounded, and induce a RoleSim* distance obeying sum-transitivity of similarity scores. We also evaluate our model on DBLP, AMZ, and SYN datasets to demonstrate its superior ranking quality and comparable complexity to competitors.
References
Antonellis, I., Garcia-Molina, H., Chang, C.-C.: SimRank++: query rewriting through link analysis of the click graph. In: PVLDB, vol. 1, no. 1 (2008)
Chen, H., Giles, C.L.: ASCOS++: an asymmetric similarity measure for weighted networks to address the problem of SimRank. ACM Trans. Knowl. Discov. Data 10(2), 15:1–15:26 (2015)
Chen, X., Lai, L., Qin, L., Lin, X.: StructSim: querying structural node similarity at billion scale. In: ICDE, pp. 1950–1953 (2020)
Fujiwara, Y., Nakatsuji, M., Shiokawa, H., Onizuka, M.: Efficient search algorithm for SimRank. In: ICDE, pp. 589–600 (2013)
He, G., Feng, H., Li, C., Chen, H.: Parallel SimRank computation on large graphs with iterative aggregation. In: KDD (2010)
He, J., Liu, H., Yu, J.X., Li, P., He, W., Du, X.: Assessing single-pair similarity over graphs by aggregating first-meeting probabilities. Inf. Syst. 42, 107–122 (2014)
Jeh, G., Widom, J.: SimRank: a measure of structural-context similarity. In: KDD, pp. 538–543 (2002)
Jiang, M., Fu, A.W., Wong, R.C., Wang, K.: READS: a random walk approach for efficient and accurate dynamic SimRank. PVLDB 10(9), 937–948 (2017)
Jin, R., Lee, V.E., Hong, H.: Axiomatic ranking of network role similarity. In: Apté, C., Ghosh, J., Smyth, P. (eds.) Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011, pp. 922–930. ACM (2011)
Jin, R., Lee, V.E., Li, L.: Scalable and axiomatic ranking of network role similarity. TKDD 8(1), 3:1–3:37 (2014)
Kusumoto, M., Maehara, T., Kawarabayashi, K.: Scalable similarity search for SimRank. In: SIGMOD, pp. 325–336 (2014)
Li, C., et al.: Fast computation of SimRank for static and dynamic information networks. In: EDBT (2010)
Li, L., Qian, L., Lee, V.E., Leng, M., Chen, M., Chen, X.: Fast and accurate computation of role similarity via vertex centrality. In: Dong, X.L., Yu, X., Li, J., Sun, Y. (eds.) WAIM 2015. LNCS, vol. 9098, pp. 123–134. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-21042-1_10
Li, P., Liu, H., Yu, J.X., He, J., Du, X.: Fast single-pair simrank computation. In: Proceedings of the SIAM International Conference on Data Mining, SDM 2010, Columbus, Ohio, USA, 29 April–1 May, pp. 571–582. SIAM (2010)
Li, Z., Fang, Y., Liu, Q., Cheng, J., Cheng, R., Lui, J.C.S.: Walking in the cloud: parallel SimRank at scale. PVLDB 9(1), 24–35 (2015)
Lin, Y., Sundaram, H., Chi, Y., Tatemura, J., Tseng, B.L.: Detecting splogs via temporal dynamics using self-similarity analysis. TWEB 2(1), 4:1–4:35 (2008)
Lin, Z., Lyu, M.R., King, I.: MatchSim: a novel similarity measure based on maximum neighborhood matching. Knowl. Inf. Syst. 32(1), 141–166 (2012). https://doi.org/10.1007/s10115-011-0427-z
Liu, Y., et al.: ProbeSim: scalable single-source and top-k SimRank computations on dynamic graphs. PVLDB 11(1), 14–26 (2017)
Lizorkin, D., Velikhov, P., Grinev, M.N., Turdakov, D.: Accuracy estimate and optimization techniques for SimRank computation. VLDB J. 19(1), 45–66 (2010). https://doi.org/10.1007/s00778-009-0168-8
Maehara, T., Kusumoto, M., Kawarabayashi, K.: Scalable simrank join algorithm. In: ICDE, pp. 603–614 (2015)
Rothe, S., Schütze, H.: CoSimRank: a flexible & efficient graph-theoretic similarity measure. In: ACL, pp. 1392–1402. The Association for Computer Linguistics (2014)
Shao, Y., Cui, B., Chen, L., Liu, M., Xie, X.: An efficient similarity search framework for SimRank over large dynamic graphs. PVLDB 8(8), 838–849 (2015)
Shao, Y., Liu, J., Shi, S., Zhang, Y., Cui, B.: Fast de-anonymization of social networks with structural information. Data Sci. Eng. 4(1), 76–92 (2019). https://doi.org/10.1007/s41019-019-0086-8
Tian, B., Xiao, X.: SLING: a near-optimal index structure for SimRank. In: SIGMOD, pp. 1859–1874 (2016)
Wang, Y., Lian, X., Chen, L.: Efficient simrank tracking in dynamic graphs. In: ICDE pp. 545–556 (2018)
Yoon, S., Kim, S., Park, S.: C-Rank: a link-based similarity measure for scientific literature databases. Inf. Sci. 326, 25–40 (2016)
Youngmann, B., Milo, T., Somech, A.: Boosting SimRank with semantics. In: EDBT, pp. 37–48 (2019)
Yu, W., Iranmanesh, S., Haldar, A., Ferhatosmanoglu, M.Z.H.: An axiomatic role similarity measure based on graph topology, Technical report (2020). https://warwick.ac.uk/fac/sci/dcs/people/weiren_yu/rolesim_star.pdf
Yu, W., Lin, X., Zhang, W.: Towards efficient SimRank computation on large networks. In: ICDE, pp. 601–612 (2013)
Yu, W., Lin, X., Zhang, W., McCann, J.A.: Fast all-pairs SimRank assessment on large graphs and bipartite domains. IEEE Trans. Knowl. Data Eng. 27(7), 1810–1823 (2015)
Yu, W., Lin, X., Zhang, W., McCann, J.A.: Dynamical SimRank search on time-varying networks. VLDB J. 27(1), 79–104 (2017). https://doi.org/10.1007/s00778-017-0488-z
Yu, W., Lin, X., Zhang, W., Pei, J., McCann, J.A.: SimRank*: effective and scalable pairwise similarity search based on graph topology. VLDB J. 28(3), 401–426 (2019). https://doi.org/10.1007/s00778-018-0536-3
Yu, W., Lin, X., Zhang, W., Zhang, Y., Le, J.: SimFusion+: extending simfusion towards efficient estimation on large and dynamic networks. In: SIGIR, pp. 365–374 (2012)
Yu, W., McCann, J.A.: Efficient partial-pairs SimRank search for large networks. PVLDB 8(5), 569–580 (2015)
Yu, W., Wang, F.: Fast exact CoSimRank search on evolving and static graphs. In: WWW, pp. 599–608 (2018)
Zhao, P., Han, J., Sun, Y.: P-Rank: a comprehensive structural similarity measure over information networks. In: CIKM (2009)
Zhu, R., Zou, Z., Li, J.: SimRank computation on uncertain graphs. In: ICDE, pp. 565–576 (2016)
Acknowledgments
This work was supported by the National Natural Science Foundation of China (61972203), and Natural Science Foundation of Jiangsu Province (BK20190442).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Yu, W., Iranmanesh, S., Haldar, A., Zhang, M., Ferhatosmanoglu, H. (2020). An Axiomatic Role Similarity Measure Based on Graph Topology. In: Qin, L., et al. Software Foundations for Data Interoperability and Large Scale Graph Data Analytics. SFDI LSGDA 2020 2020. Communications in Computer and Information Science, vol 1281. Springer, Cham. https://doi.org/10.1007/978-3-030-61133-0_3
Download citation
DOI: https://doi.org/10.1007/978-3-030-61133-0_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-61132-3
Online ISBN: 978-3-030-61133-0
eBook Packages: Computer ScienceComputer Science (R0)