
Abstract
A Sturmian sequence is an infinite nonperiodic string over two letters with minimal subword complexity. In two papers, the first written by Morse and Hedlund in 1940 and the second by Coven and Hedlund in 1973, a surprising correspondence was established between Sturmian sequences on one side and rotations by an irrational number on the unit circle on the other. In 1991 Arnoux and Rauzy observed that an induction process (invented by Rauzy in the late 1970s), related with the classical continued fraction algorithm, can be used to give a very elegant proof of this correspondence. This process, known as the Rauzy induction, extends naturally to interval exchange transformations (this is the setting in which it was first formalized). It has been conjectured since the early 1990s that these correspondences carry over to rotations on higher dimensional tori, generalized continued fraction algorithms, and so-called S-adic sequences generated by substitutions. The idea of working towards such a generalization is known as Rauzy’s program. Recently Berthé, Steiner, and Thuswaldner made some progress on Rauzy’s program and were indeed able to set up the conjectured generalization of the above correspondences. Using a generalization of Rauzy’s induction process in which generalized continued fraction algorithms show up, they proved that under certain natural conditions an S-adic sequence gives rise to a dynamical system which is measurably conjugate to a rotation on a higher dimensional torus. Moreover, they established a metric theory which shows that counterexamples like the one constructed in 2000 by Cassaigne, Ferenczi, and Zamboni are rare. It is the aim of the present chapter to survey all these ideas and results.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

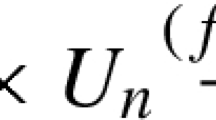
3.1 Introduction
A Sturmian sequence is an infinite string over two letters with low subword complexity. In particular, it has exactly n + 1 different subwords of a given length \(n\in \mathbb {N}\). Sturmian sequences have been studied extensively in the literature from various points of view and we refer to Lothaire [101, Chapter 2] or Pytheas Fogg [82, Chapter 6] for detailed accounts. The history of the research surveyed in the present chapter starts with two papers written by Morse and Hedlund [107] as well as Coven and Hedlund [67] in 1940 and 1973, respectively. In these papers the authors established a surprising correspondence between Sturmian sequences and rotations by an irrational number α on the torus \(\mathbb {T}=\mathbb {R}/\mathbb {Z}\). In their proof “balance properties” of Sturmian sequences play a prominent role. Several decades later, Arnoux and Rauzy [22] observed that an induction process in which the classical continued fraction algorithm appears can be used to give another very elegant proof of this correspondence (see also Rauzy’s earlier papers [112, 113] on this induction process). Their proof also shows how arithmetic and Diophantine properties of an irrational number α are encoded in the corresponding Sturmian sequence.
It has been conjectured since the early 1990s that these correspondences between rotations on \(\mathbb {T}\), continued fractions, and Sturmian sequences carry over to rotations on higher dimensional tori, generalized continued fraction algorithms, and so-called S-adic sequences generated by substitutions. The idea of working towards such a generalization is known as Rauzy’s program and starting with Rauzy [114] a number of examples which hint at such a generalization was devised. A natural class of S-adic sequences to study in this context are so-called Arnoux-Rauzy sequences which go back to Arnoux and Rauzy [22]. These are sequences over three letters that behave analogously to Sturmian sequences in many regards. However, in 2000 Cassaigne et al. [63] could construct Arnoux-Rauzy sequences with strong “imbalance”, a property which cannot occur for a Sturmian sequence. Cassaigne et al. [62] even constructed Arnoux-Rauzy sequences that give rise to weakly-mixing dynamical systems which are far from rotations in their dynamical behavior. All this shows the limitations of Rauzy’s program and indicates that the situation in the general setting is more complicated than it is in the classical case.
Nevertheless, recently Berthé et al. [52] made some progress on Rauzy’s program and were indeed able to set up the conjectured generalization of the above correspondences. Using a generalization of Rauzy’s induction process in which generalized continued fraction algorithms show up, they proved that under certain natural conditions an S-adic sequence gives rise to a dynamical system which is measurably conjugate to a rotation on a higher dimensional torus. Moreover, they established a metric theory which shows that exceptional cases like the ones constructed in [62] and [63] are rare. A prominent role in this generalization is played by tilings induced by generalizations of the classical Rauzy fractal introduced by Rauzy [114].
Another idea which can be linked to the above results goes back to Artin [26], who observed that the classical continued fraction algorithm and its natural extension can be viewed as a Poincaré section of the geodesic flow on the space of two-dimensional lattices \(\mathrm {SL}_{2}(\mathbb {Z})\setminus \mathrm {SL}_{2}(\mathbb {R})\). Arnoux and Fisher [14] revisited Artin’s idea and showed that the correspondence between continued fractions, rotations, and Sturmian sequences can be interpreted in a very nice way in terms of an extension of this geodesic flow to pointed lattices which is called the scenery flow. Currently, Arnoux et al. [12] are setting up a generalization of this connection between continued fraction algorithms and geodesic flows. In particular, they code the Weyl Chamber Flow, a diagonal \(\mathbb {R}^{d-1}\)-action on the space of d-dimensional lattices \(\mathrm {SL}_{d}(\mathbb {Z})\setminus \mathrm {SL}_{d}(\mathbb {R})\), arithmetically and geometrically by generalized continued fraction algorithms. In this coding, which provides a new view of the relation between S-adic sequences and rotations on higher dimensional tori, non-stationary Markov partitions defined in terms of generalized Rauzy fractals are of great importance.
It is the aim of the present chapter to survey all these ideas and results. In Sect. 3.2 we deal with the case of Sturmian sequences and Sect. 3.3 discusses the problems with the extension of the theory to the more general situation. From Sect. 3.4 onwards we set up the general theory of S-adic sequences and their relation to generalized continued fraction algorithms and rotations on higher dimensional tori.
3.2 The Classical Case
We start our journey by giving some elements of the interaction between Sturmian sequences, the classical continued fraction algorithm, and irrational rotations on the circle. After that we discuss natural extensions of continued fractions and show how all these objects turn up in the study of the geodesic flow acting on the space \(\mathrm {SL}_2(\mathbb {Z})\backslash \mathrm {SL}_2(\mathbb {R})\) of lattices and its extension to pointed lattices. We will prove most of the results that we state and although our exposition is self-contained we recommend the reader to have a look at the survey [82, Chapter 6] in order to find more background information on the subject of this section.
3.2.1 Sturmian Sequences and Their Basic Properties
For a finite set {1, 2, …, d} denote by {1, 2, …, d}∗ the set of all finite wordsv 0…v n−1 whose lettersv i, 0 ≤ i < n, are contained in {1, 2, …, d}. Moreover, let \(\{1,2,\ldots , d\}^{\mathbb {N}}\) be the space of (right-infinite) sequencesw = w 0w 1… whose letters w i, \(i\in \mathbb {N}\), are elements of {1, 2, …, d}. The shift \(\varSigma :\{1,2,\ldots , d\}^{\mathbb {N}}\to \{1,2,\ldots , d\}^{\mathbb {N}}\) on this space of sequences is defined by Σ(w 0w 1…) = w 1w 2… Let \(w=w_{0}w_{1}\ldots \in \{1,2,\ldots , d\}^{\mathbb {N}}\) be a sequence. A factor (or subword) of w is a word v 0…v n−1 ∈{1, 2, …, d}∗ for which there is k ≥ 0 such that w k…w k+n−1 = v 0…v n−1. In this case we say that v occurs in w at position k. The complexity function \(p_w:\mathbb {N}\to \mathbb {N}\) of w assigns to each integer n the number of words v 0…v n−1 ∈{1, 2, …, d}∗ that are factors of w. If w is ultimately periodic in the sense that there exist k > 0 and N ≥ 0 with w n = w n+k for each n ≥ N then p w is a bounded function. On the other hand, a result by Coven and Hedlund [67] which is not hard to prove states that a sequence \(w\in \{1,2,\ldots , d\}^{\mathbb {N}}\) that admits the inequality p w(n) ≤ n for a single choice of n is ultimately periodic (see also [82, Proposition 1.1.1]). It is the class of not ultimately periodic sequences with smallest complexity function that we are interested in.
Definition 3.2.1 (Sturmian Sequence)
A sequence \(w\in \{1,2\}^{\mathbb {N}}\) is called a Sturmian sequence if its complexity function satisfies p w(n) = n + 1 for all \(n\in \mathbb {N}\).
It is a priori not clear that Sturmian sequences exist at all. However, we will see in Theorem 3.2.11 below that they can be characterized as so-called natural codings of irrational rotations which are easy to construct (and will be defined in Sect. 3.2.4).
A detailed account on the early history of Sturmian sequences, which goes back to Bernoulli [39], is given in [101, Notes to Chapter 2]. The name “Sturmian sequence” was coined in 1940 by Morse and Hedlund [107]. Sturmian sequences have been studied extensively. For an overview on fundamental properties of Sturmian sequences we refer in particular to Lothaire [101, Chapter 2], Pytheas Fogg [82, Chapter 6], or Allouche and Shallit [6, Chapters 9 and 10]. Belov et al. [38] discuss some aspects of Sturmian sequences which are related to the present survey.
We start with the discussion of basic properties of Sturmian sequences. The fact that p w(n) = n + 1 holds for a Sturmian sequence entails that for each n there is only one factor v 0…v n−1 of w with the property that both words v 0…v n−11 and v 0…v n−12 are factors of w. Such a word v 0…v n−1 is called right special factor of w. Left special factors are defined analogously.
Our first lemma deals with recurrence of Sturmian sequences. Recall that a sequence \(w\in \{1,2\}^{\mathbb {N}}\) is called recurrent if each factor of w occurs infinitely often, i.e., at infinitely many positions, in w.
Lemma 3.2.2 (Cf. e.g. [82, Proposition 6.1.2])
A Sturmian sequence is recurrent.
Proof
Suppose that this is wrong and let w be a nonrecurrent Sturmian sequence. Then there exists a factor v of length n, say, that occurs only finitely many times in w. Then there exists \(k\in \mathbb {N}\) such that w′ = Σ kw does not contain v as a factor. However, as p w(n) = n + 1 this implies that \(p_{w'}(n)\le n\) and, hence, w ′ is ultimately periodic. However, then also w is ultimately periodic, a contradiction. □
Next we discuss balance. To give a formal definition we introduce some notation. For a word v ∈{1, 2}∗ we denote by |v| its length, i.e., the number of letters of v. Moreover, for i ∈{1, 2}, we write |v|i for the number of occurrences of the letter i in v.
Definition 3.2.3 (Balanced Sequence)
A sequence \(w\in \{1,2\}^{\mathbb {N}}\) is called balanced if each pair of factors (v, v′) of w with |v| = |v′| satisfies ||v|1 −|v′|1| ≤ 1.
As was observed already in [107], there is a tight relation between Sturmian sequences and balance.
Proposition 3.2.4
Let \(w\in \{1,2\}^{\mathbb {N}}\) be given. Then w is a Sturmian sequence if and only if w is not ultimately periodic and balanced.
The proof of this result is combinatorial. It is based on the observation that for a sequence w which is not balanced there is a word v ∈{1, 2}∗ such that 1v1 and 2v2 are factors of w. Since the details are a bit tricky we do not give them here and refer the reader to [107] or [82, Chapter 6, p. 147ff ].
The fact that Sturmian sequences are balanced will now be exploited in order to prove that they can be coded using the Sturmian substitutions
The domain of these substitutions can naturally be extended from {1, 2} to {1, 2}∗ and \(\{1,2\}^{\mathbb {N}}\) by concatenation. The next statement essentially says that balance is maintained by “desubstitution”.
Lemma 3.2.5 (See e.g. [14, Lemma 4.2])
If a sequence \(w\in \{1,2\}^{\mathbb {N}}\)is not balanced, then for each a ∈{1, 2} the sequence σ 1(aw) is not balanced.
Proof
If w is not balanced it is easy to see that there are words u and v with |u| = |v| and |u|1 = |v|1 such that 1u1 and 2v2 are factors of w. Since 1u1 occurs in w there is b ∈{1, 2} such that b1u1 occurs in aw (we need a in case 1u1 is the initial word of w). As σ 1(b) always ends with 1 and σ 1(2) begins with 2, the words 11σ 1(u)1 and 21σ 1(v)2 have the same length and both occur in σ 1(aw). As the number of 1s in these two words clearly differs by 2 the lemma follows. □
Let \(w=w_0w_1\ldots \in \{1,2\}^{\mathbb {N}}\) be given. If w is a Sturmian sequence, it contains exactly three of the four factors 11, 12, 21, 22. Since it clearly contains 12 and 21 as factors, it either doesn’t contain 22, in which case we say that w is of type 1, or it doesn’t contain 11, in which case we say it is of type 2. Using recurrence one can easily see that for each Sturmian sequence \(w\in \{1,2\}^{\mathbb {N}}\) at least one of the sequences 1w and 2w is Sturmian as well. A Sturmian sequence \(w\in \{1,2\}^{\mathbb {N}}\) is called special if 1w as well as 2w are both Sturmian sequences. With these notions we get the following “desubstitution” of Sturmian sequences (see also [22, Section 1] where an analog of this was proved along somewhat different lines).
Lemma 3.2.6 (See e.g. [14, Proposition 4.3])
Let u be a Sturmian sequence of type 1.
-
(i)
If u is not special then either u = σ 1(v) with v Sturmian, or u = Σσ 1(v) with v Sturmian starting with 2 (but not both).
-
(ii)
If u is special then u = σ 1(v 1) = Σσ 1(v 2) where Σv 1 = Σv 2is a special Sturmian sequence.
If u is of type 2 the same statement with the symbols 1 and 2 interchanged holds.
Proof
Since u is of type 1 it is immediate that it can be written as u = σ 1(v) for some \(v\in \{1,2\}^{\mathbb {N}}\).
To prove (i) suppose that u is not special. Then either 1u or 2u is Sturmian, but not both.
If 1u is Sturmian, 1u = σ 1(v′) with v ′ starting with 1 and, hence, by Lemma 3.2.5 and Proposition 3.2.4, v = Σv ′ is Sturmian, and u = σ 1(v). If u starts with 2 then u ≠ Σσ 1(v′) for v ′ starting with 2. If u starts with 1 then also v starts with 1. If we replace the first letter of v by 2 this yields a sequence w satisfying u = Σσ 1(w). However, if w is also Sturmian Σv = Σw is special and, hence, one easily checks that u is special, a contradiction and we are done.
If 2u is Sturmian then 12u has to be Sturmian (since 22 is forbidden) and thus 12u = σ 1(1v) with v Sturmian and beginning with 2. Thus u = Σσ 1(v). As before, we can write u = σ 1(w) where w is the word obtained from v by replacing the first letter by 1. This leads again to the contradiction of u being special.
To show (ii) assume u is special. Then, as u has to start with 1 the sequences 12u = σ 1(12v) and 21u = σ 1(21v) are Sturmian (11u cannot be Sturmian for imbalance reasons, see [82, Proposition 6.1.23]). By Lemma 3.2.5 and Proposition 3.2.4 the sequences 1v and 2v are Sturmian, so v is special and u = σ 1(1v) = Σσ 1(2v).
The proof of the type 2 case is analogous. □
From the proof of Lemma 3.2.6 we see that for a special sequence u of type 1 there exists a special sequence v such that 21u = σ 1(21v) and 12u = σ 1(12v) are Sturmian sequences. If u is special of type 2 we get the existence of a special sequence v with 21u = σ 2(21v) and 12u = σ 2(12v) Sturmian by analogous reasoning. If u is a special Sturmian sequence then the two Sturmian sequences 12u and 21u are called limit sequences or fixed sequences. By the above arguments they can be desubstituted to sequences that are limit sequences as well. This process can be iterated: let w be a limit sequence. Then there is a sequence (w (n))n≥0 of limit sequences with
This can be rewritten as
As w is Sturmian, the sequence \((i_n)\in \{1,2\}^{\mathbb {N}}\) has to change its value infinitely often because otherwise w would be ultimately constant. Now observe that a sequence w (n) starting with a letter a results in a sequence w (0) also starting with a. Moreover, since the sequence (i n) changes its value infinitely often we see that the first letter of w (n) determines a prefix of w whose length tends to infinity with n. Thus, equipping \(\{1,2\}^{\mathbb {N}}\) with the product topology of the discrete topology yields
where a is the first letter of w (note that we slightly abuse notation here: to be exact the argument of \(\sigma _{i_n}\) should be \(aa\ldots \in \mathcal {A}^{\mathbb {N}}\) since the limit is not defined for finite words). We could also group the blocks of the sequence (i n). So if it starts with a block of a 0 times the symbol 1 followed by a block of a 1 times the symbol 2 and so on we can rewrite (3.3) as
A sequence w that can be represented by iteratively composing substitutions as in (3.2) is called an S-adic sequence.
Note that for arbitrary Sturmian sequences a similar coding as in (3.2) is possible, however, in the general case shifts have to be inserted between the composed substitutions on the appropriate places according to Lemma 3.2.6. Inserting these shifts does not change the collection of factors (called language) of the sequence. Thus each Sturmian sequence w is associated with a sequence \((\sigma _{i_m})\) which determines its language. We call this sequence the coding sequence of w. Summing up we proved the following proposition.
Proposition 3.2.7 (See [22, Section 1])
Let σ 1, σ 2be the Sturmian substitutions. Then for each Sturmian sequence w there exists a coding sequence \({\boldsymbol {\sigma }}=(\sigma _{i_n})\), where (i n) takes each symbol in {1, 2} an infinite number of times, such that w has the same language as
Here a ∈{1, 2} can be chosen arbitrarily.
Since it will turn out that (3.3) and (3.4) are nonabelian versions of the classical continued fraction algorithm we will now review the basics of this well-known concept.
3.2.2 The Classical Continued Fraction Algorithm
The “S-adic” representations of a Sturmian sequence given in (3.3) and (3.4) are related to continued fraction expansions of irrational numbers. For this reason we provide a brief discussion of the classical continued fraction algorithm (see e.g. [76, Chapter 3] for an introduction to continued fractions of a dynamical flavor or [41] for a discussion of continued fractions in a context related to the present paper).
We start with the well-known additive Euclidean algorithm. Given a pair of two nonnegative real numbers (a, b) ≠ (0, 0) we define the mapping \(F:\mathbb {R}_{\ge 0}^2\setminus \{\mathbf {0}\}\to \mathbb {R}^2_{\ge 0} \setminus \{\mathbf {0}\}\) by
If we iterate this mapping starting with \((a,b)\in \mathbb {R}^2_{>0}\) we see that we reach a pair of the form (0, c) or (c, 0) with c > 0 if and only if the ratio a∕b is rational. If \(a/b\not \in \mathbb {Q}\) the iterations of F on (a, b) produce an infinite sequence of pairs of strictly positive numbers. Setting
we see that \(F(a,b)^t=M_1^{-1}(a,b)^t\) if a > b and \(F(a,b)^t=M_2^{-1}(a,b)^t\) if a ≤ b. Thus iterating F on a pair (a, b) with \(a/b\not \in \mathbb {Q}\) produces an infinite sequence \((M_{i_n})_{n\in \mathbb {N}}\in \{M_1,M_2\}^{\mathbb {N}}\) defined by
This sequence \((M_{i_n})\) is called the additive continued fraction expansion of (a, b). In (3.14) we will see that, up to a scalar factor, (a, b) is determined by the sequence (i n).
Since the sequence \((M_{i_n})\) is invariant under the multiplication of (a, b) by a scalar, we may use projective coordinates. This motivates the following definition. Let \(\mathbb {P}\) be the projective line and \(X=\{[a:b] \in \mathbb {P}\,:\, a\ge 0,\, b\ge 0\}\). Define M : X →{M 1, M 2} by M([a : b]) = M 1 if a > b and M([a : b]) = M 2 if a ≤ b. Then the mapping
is called the linear additive continued fraction mapping.
Since (a, b) ≠ (0, 0) we can define a projective version of (3.7). Indeed, we can write [a : b] = [1, b∕a] if a > b and [a : b] = [a∕b, 1] if a ≤ b and the mapping F can be written as (c ∈ [0, 1])
Since the coordinate 1 contains no information in (3.8) and c ∈ [0, 1], this defines a mapping f : [0, 1] → [0, 1] by
The mapping f is called projective additive continued fraction mapping or Farey map. It is visualized in Fig. 3.1.

The Farey map
The additive continued fraction algorithm can be “accelerated” in the following way. Assume that a, b > 0 are given. If a > b we do not just subtract b from a. We subtract it m times where m is chosen in a way that 0 ≤ a − mb < b. If a ≤ b we proceed analogously. This results in the multiplicative Euclidean algorithm \(G:\mathbb {R}_{>0}^2\to \mathbb {R}^2_{\ge 0} \setminus \{\mathbf {0}\}\) with
As in (3.6), iterating G on a pair \((a,b)\in \mathbb {R}_{>0}^2\) yields a sequence of matrices \(M_{1}^{a_0},M_{2}^{a_1},M_{1}^{a_2},\ldots \) with positive integers a 0, a 1, … satisfying (we assume a > b here; otherwise the sequence would start with a power of M 2)
However, contrary to (3.6) this sequence stops if the iteration runs into a vector one of whose coordinates is 0 because G is not defined for such vectors. Indeed, as can easily be verified, we run into such a vector if and only if \(a/b \in \mathbb {Q}\).
Again we move to the projective line and set \(X=\{[a:b] \in \mathbb {P}\,:\, a> 0,\, b> 0\}\). Define \(M:X\to \{M_1^m, M_2^m \,:\, m \ge 1\}\) by \(M([a:b]) = M_1^m\) if a > b and 0 ≤ a − mb < b and \(M([a:b]) = M_2^m\) if a ≤ b and 0 ≤ b − ma < b. Then the mapping
is called the linear multiplicative continued fraction mapping.
Similar to the additive case assume that a, b > 0 and choose the representatives [a : b] = [1, b∕a] if a > b and [a : b] = [a∕b, 1] if a ≤ b. The mapping G can then be written as (c ∈ (0, 1])

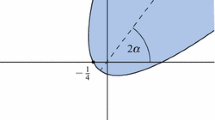
As the coordinate 1 contains no information in (3.11) this defines a mapping g : (0, 1] → [0, 1) by
The mapping g is called projective multiplicative continued fraction mapping or Gauss map . It is visualized in Fig. 3.2.

The Gauss map \(x\mapsto \{ \frac 1x\}\)
By direct calculation (see e.g. [76, Chapter 3]) it follows from the definition that for each irrational x ∈ (0, 1) the Gauss map g can be iterated infinitely often. This iteration process determines a sequence (a n) of positive integers defined by \(a_n=\big \lfloor \frac {1}{g^n(x)} \big \rfloor \) which admits to develop x in its (multiplicative) continued fraction expansion

(which will be denoted by x = [a 0, a 1, …]). By definition this is the same sequence (a n) as the one we obtain in the exponents of the matrices in (3.9) when setting (a, b) = (1, x). One can show that this sequence is ultimately periodic if and only if x is a quadratic irrational. If x is rational one can associate a finite sequence with x in this way.
Continued fractions play an eminent role in Diophantine approximation. It is therefore of special interest that they will appear in our theory of Sturmian sequences naturally without being presupposed.
3.2.3 Dynamical Properties of Sturmian Sequences
We want to have a look at the “abelianized” version of (3.3) and (3.4) in order to get a link between Sturmian sequences and the classical continued fraction algorithm. For a word v ∈{1, 2}∗ define the abelianizationl(v) = (|v|1, |v|2)t, and for i ∈{1, 2} associate to the Sturmian substitution σ i from (3.1) the incidence matrixM i = (|σ i(k)|j)1≤j,k≤2. Then M 1 and M 2 are the matrices defined in (3.5) which were used to define the linear version of the classical additive continued fraction algorithm in (3.7). Indeed, since lσ i(v) = M il(v) we see that the vectors (here e 1, e 2 are the standard basis vectors)
form an abelianized version of the expression in the limit of (3.3). Since (i n) changes its value infinitely often, \(M_{i_n}M_{i_{n+1}}\) is a positive matrix for infinitely many n (in particular, \(M_{i_n}M_{i_{n+1}}=M_1M_2\) for infinitely many n; we therefore call the whole sequence \((M_{i_n})\) a primitive sequence of matrices). This property entails that the positive cone \(\mathbb {R}^2_{\ge 0}\) is shrunk to a line by these matrices, more precisely, there exists a vector \(\mathbf {u}\in \mathbb {R}^2_{>0}\) such that
(see [84, pp. 91–95], [125, Chapter 26], or Proposition 3.5.5 below). This says that the additive continued fraction algorithm defined by (3.6) is weakly convergent (as is well known, this algorithm is even strongly convergent which is related to the balance property of Sturmian sequences). We call u, which is uniquely defined up to scalar factors by the sequence \((M_{i_n})\), a generalized right eigenvector of \((M_{i_n})\). We also see from (3.14) that the vector (a, b)t in (3.6) is defined by the sequence \((M_{i_n})\) up to a scalar factor.
We go back to the (nonabelian) S-adic setting. Assume that a Sturmian sequence w = w 0w 1… has a coding sequence \((\sigma _{i_n})\) whose associated sequence of incidence matrices \((M_{i_n})\) satisfies (3.14). We will now prove that in this case w has uniform letter frequencies, i.e., the limit
exists uniformly in k for each i ∈{1, 2}. We get even more, namely, the following lemma holds. In its proof and in all the remaining part of this section we use the abbreviations
Lemma 3.2.8
Let w = w 0w 1… be a Sturmian sequence with coding sequence \((\sigma _{i_n})\)whose associated sequence of incidence matrices \((M_{i_n})\)has a generalized right eigenvectoru. Then w has uniform letter frequencies and \((f_1(w),f_2(w))^t=\frac {\mathbf {u}}{\Vert \mathbf {u}\Vert _1}\).
Proof
Let u∕∥u∥1 = (u 1, u 2)t. By Proposition 3.2.7 for all \(k,\ell ,n\in \mathbb {N}\) we can write
for some p, v, s ∈{1, 2}∗, where the lengths of p, s are bounded by the number \(\max \{|\sigma _{i_{[0,n)}}(1)|,|\sigma _{i_{[0,n)}}(2)|\}\).
Now, for each a ∈{1, 2} we have the inequality
By the convergence of the positive cone to u in (3.14) we know that \(|\sigma _{i_{[0,n)}}(b)|{ }_a/|\sigma _{i_{[0,n)}}(b)|\) is close to u a for all a, b ∈{1, 2} if n is large. Thus for each ε > 0 there is \(N\in \mathbb {N}\) such that whenever ℓ ≥ N we can choose n in a way that |p|, |s|≤ εℓ and \(\big ||\sigma _{i_{[0,n)}}(b)|{ }_a-|\sigma _{i_{[0,n)}}(b)|u_a \big | < \varepsilon |\sigma _{i_{[0,n)}}(b)|\) for all letters a and b. This proves that the right hand side of (3.15) is bounded by 3ε and thus limℓ→∞|w k…w k+ℓ−1|a∕ℓ = u a uniformly in k. □
For a proof of Lemma 3.2.8 along similar lines in a more general setting we refer to Lemma 3.5.10 (see also Berthé and Delecroix [44, Theorem 5.7]; a proof using balance, which also gives irrationality of the frequencies, is contained in [82, Proposition 6.1.10]).
In the same way as for letters, we can define uniform frequencies for factors of an infinite sequence \(w\in \{1,2\}^{\mathbb {N}}\). Let w be a Sturmian sequence with coding sequence \((\sigma _{i_n})\). The sequence is the shifted image of another Sturmian sequence under an arbitrary large block \(\sigma _{i_{[0,n)}}\) of substitutions. This enables one to show that for the words \(\sigma _{i_{[0,n)}}(a)\) there exist uniform frequencies in w. Since (i n) changes its value infinitely often, the length of the words \(\sigma _{i_{[0,n)}}(a)\) tends to infinity for each letter a if n →∞. Using this fact one can prove the following result along similar lines as Lemma 3.2.8 (for details we refer to the proof of Lemma 3.5.10 below; see also [44, Theorem 5.7]).
Lemma 3.2.9
Let \(w=w_0w_1\ldots \in \{1,2\}^{\mathbb {N}}\)be a Sturmian sequence with coding sequence \((\sigma _{i_n})\)whose associated sequence of incidence matrices \((M_{i_n})\)has a generalized right eigenvectoru. Let v ∈{1, 2}∗be given, and let |w kw k+1…w k+ℓ−1|vbe the number of occurrences of the factor v in the factor w kw k+1…w k+ℓ−1of w. Then |w kw k+1…w k+ℓ−1|v∕ℓ tends to a limit f v(w) for ℓ →∞ uniformly in k.
We can associate a dynamical system with a Sturmian sequence w in a very natural way. Let \(X_w = \overline {\{\varSigma ^k w \;:\; k\in \mathbb {N}\}}\) be the closure of the shift orbit of w. Alternatively, X w can be viewed as the set of all sequences u whose languageL(u) (i.e., its set of factors) satisfies L(u) ⊆ L(w). Thus if \({\boldsymbol {\sigma }}=(\sigma _{i_n})\) is the coding sequence of w, Proposition 3.2.7 implies that X w contains all Sturmian sequences with coding sequence σ. Since X w is shift invariant the shift Σ acts on X w and the dynamical system (X w, Σ) is well defined. We call (X w, Σ) a Sturmian system. From what we know about Sturmian sequences we can derive a number of properties for these dynamical systems. The notions of minimality and unique ergodicity of a dynamical system used in the following lemma are defined precisely in Definitions 3.5.2 and 3.5.7, respectively.
Proposition 3.2.10
A Sturmian system (X w, Σ) has the following properties.
-
(i)
The system (X w, Σ) is minimal.
-
(ii)
The set X wis the set of all Sturmian sequences having the same language.
-
(iii)
The set X wis the set of all Sturmian sequences having the same coding sequenceσ.
-
(iv)
The system (X w, Σ) is uniquely ergodic.
-
(v)
We have \(X_w=X_{w'}\)for any w′∈ X w.
Proof
Let \((\sigma _{i_n})\) be the coding sequence of w with \((M_{i_n})\) being the associated sequence of matrices.
We start with (i). By Proposition 3.2.7 we may assume w.l.o.g. that \(w = \lim _{n\to \infty } \sigma _{i_{[0,n)}}(1)\). Let v ∈ X w be given. To prove minimality it suffices to show that L(v) = L(w). Since L(v) ⊆ L(w) is true by definition we need to prove the reverse inclusion. Let u ∈ L(w). By the definition of w and the primitivity of the sequence \((M_{i_n})\) there is \(m\in \mathbb {N}\) such that u occurs in \(\sigma _{i_{[0,m)}}(1)\). However, there is a Sturmian word w (m) satisfying \(w=\sigma _{i_{[0,m)}}(w^{(m)})\). Since w (m) is balanced by Proposition 3.2.4, the letter 1 occurs in w (m) with bounded gaps. This implies that \(\sigma _{i_{[0,m)}}(1)\) and, hence, u occurs in w with bounded gaps. Thus u occurs in each element of the orbit closure X w of w, hence, also in v. Thus L(v) = L(w) is established.
Since L(v) = L(w) holds for each v ∈ X w according to the previous paragraph we have p v(n) = p w(n) = n + 1 for all \(n\in \mathbb {N}\), hence, v is Sturmian with the same language as w. This proves (ii).
To prove (iii) we follow the proof of [82, Lemma 6.3.12]. Assume w.l.o.g. that the elements of X w are of type 1 and let u, u′∈ X w. Then according to Lemma 3.2.6 there exist Sturmian words v, v ′ such that u = σ 1(v) or u = Σσ 1(v) as well as u′ = σ 1(v′) or u′ = Σσ 1(v′). We first prove that v, v ′ belong to the same Sturmian system. By (ii) we have to show that L(v) = L(v′). Suppose that x ∈ L(v). Since x occurs infinitely often in v by recurrence, there is y ∈ L(v) starting with the letter 2 such that x is a subword of y. The word σ 1(y) occurs in u and by (ii) it occurs also in u ′ and because σ 1(y) begins with 2 and ends with 1 it can be desubstituted in only one way by σ 1, namely to y. This proves that y and, hence, also x occurs in v ′. Thus L(v) ⊆ L(v′). The other inclusion follows by interchanging the roles of v and v ′. Iterating this argument yields that u and u ′ have the same coding sequence. Thus all elements of X w have the same coding sequence. As Sturmian sequences with the same coding sequence have the same language by Proposition 3.2.7, X w contains all Sturmian sequences having the same coding sequence as w.
Item (iv) follows immediately by combining Lemma 3.2.9 with [82, Proposition 5.1.21] (see also Proposition 3.5.9 below) which states that the existence of uniform word frequencies implies unique ergodicity. Alternatively, one can use Boshernitzan [56].
Finally, (v) follows from (ii). □
We emphasize on the fact that for minimality and unique ergodicity of (X w, Σ) the recurrence of w as well as the primitivity of the sequence \((M_{i_n})\) is of importance. This will be the same in the general case (see Sect. 3.5 below). In view of assertion (iii) of the previous lemma we will write X σ instead of X w, where σ is the coding sequence of w.
3.2.4 Sturmian Sequences Code Rotations
It was observed already by Morse and Hedlund [107] and Coven and Hedlund [67] that each Sturmian sequence is a natural coding of a rotation by some irrational number α. We now sketch a proof of this fact which goes back to Rauzy and in which the multiplicative continued fraction expansion of α pops up when we represent such a coding in an S-adic fashion. For proofs of this kind we refer to [13, 14, 46, 47]; a different, combinatorial proof along the lines of the original proof by Morse, Coven, and Hedlund is presented in [101, Theorem 2.1.13] and [6, Section 10.5].
Before we give the main result of this section we provide some definitions. Let \(\mathbb {T}\) be the 1-torus, i.e., the unit interval [0, 1] with its end points glued together. A rotation or translation on \(\mathbb {T}\) by a real number α is a mapping \(R_\alpha : \mathbb {T}\to \mathbb {T}\) with x↦x + α (mod 1). If \(\alpha \not \in \mathbb {Q}\) this gives a minimal dynamical system. Moreover, observe that R α can be regarded as a two interval exchange of the intervals I 1 = [0, 1 − α) and I 2 = [1 − α, 1) or of the intervals \(I^{\prime }_1=(0,1-\alpha ]\) and \(I^{\prime }_2=(1-\alpha ,1]\), see Fig. 3.3. We say that a sequence \(w=w_0w_1\ldots \in \{1,2\}^{\mathbb {N}}\) is a natural coding of R α if there is \(x\in \mathbb {T}\) such that \(R_\alpha ^k(x) \in I_{w_k}\) for each \(k\in \mathbb {N}\) or \(R_\alpha ^k(x) \in I^{\prime }_{w_k}\) for each \(k\in \mathbb {N}\).

Two iterations of the irrational rotation R α on \( \mathbb {T}\) which is subdivided into the two intervals I 1 and I 2
Theorem 3.2.11
A sequence \(w\in \{1,2\}^{\mathbb {N}}\)is Sturmian if and only if there exists \(\alpha \in \mathbb {R}\setminus \mathbb {Q}\)such that w is a natural coding of the rotation R α.
The sufficiency part of the theorem is easy. Indeed, it just follows from the observation that
whose proof is an easy exercise (see [46, Lemma 2.7]).
The proof of the necessity part of Theorem 3.2.11 needs more work and we will see that the classical continued fraction algorithm pops up along the way without being presupposed. We need the following key lemma.
Lemma 3.2.12
For α ∈ (0, 1) irrational let u be the coding of the point 1 − α∕(α + 1) under the irrational rotation R α∕(α+1). Then there is a sequence \((\sigma _{i_n})\)of substitutions such that
The sequence \((i_n)\in \{1,2\}^{\mathbb {N}}\)is of the form \(1^{a_0}2^{a_1}1^{a_2}2^{a_3}\ldots \)where the sequence [a 0, a 1, a 2, a 3, …] is the continued fraction expansion of α. For α > 1 a similar result with switched symbols holds.
Proof
We assume α < 1 (α > 1 can be treated in a similar way). For computational reasons consider the rotation R by α on the interval J = [−1, α) with the partition P 1 = [−1, 0) and P 2 = [0, α). The natural coding u of 1 − α∕(α + 1) by R α∕(α+1) is the natural coding of 0 by R. Let R ′ be the first return map of R to the interval \(J'=\Big [\alpha \big \lfloor \frac 1\alpha \big \rfloor -1 , \alpha \Big )\). Let v be a coding of the orbit of 0 for R ′. As can be seen from Fig. 3.4, after each occurrence of 2 in u we leave the interval J ′ and there follows a block of 1s of length \(\left \lfloor \frac 1\alpha \right \rfloor \) before we enter the interval J ′ again. Thus v emerges from u by removing such a block of 1s after each letter 2 occurring in u. By the definition of σ 1 this just means that \(u=\sigma _1^{\lfloor 1/\alpha \rfloor }(v)\). We can now renormalize the interval J ′ by dividing it by − α and, as illustrated in Fig. 3.4, then R ′ is conjugate to a rotation (called R ′ again) by \(\left \{\frac 1\alpha \right \}\) on the interval \(\Big (-1,\big \{\frac 1\alpha \big \}\Big ]\), where v is the natural coding of the partition \(P^{\prime }_2=(-1,0]\) and \(P^{\prime }_1=\Big (0,\big \{\frac 1\alpha \big \}\Big ]\). Note that the Gauss map \(\alpha \mapsto \left \{\frac 1\alpha \right \}\) from (3.12) comes up here without being presupposed. Since we are in the same setting as before (just with the letters 1 and 2 interchanged), we can iterate this process and thereby obtain a sequence (u (n))n≥0 of natural codings such that
for some sequence \((\sigma _{i_n})\) with \((i_n)\in \{1,2\}^{\mathbb {N}}\) having infinitely many changes between the letters 1 and 2. Arguing in the same way as in Sect. 3.2.1 we gain that
where a = 2 is the first letter of u. The assertion on the continued fraction expansion follows from the above proof as well. Just note that the interval we use has length α + 1 so that the rotation by α on this interval is conjugate to R α∕(α+1). □

The rotation R ′ induced by R
Proof (Conclusion of the Proof of Theorem 3.2.11)
The sufficiency assertion has been treated in (3.16). The necessity part of the theorem can now be obtained as follows. Let w be a Sturmian sequence. Consider its coding sequence \((\sigma _{i_n})\) and write \((i_n)\in \{1,2\}^{\mathbb {N}}\) as \(1^{a_0}2^{a_1}1^{a_2}2^{a_3}\ldots \) Then \(u=\lim _{n\to \infty }\sigma _{i_0}\circ \dots \circ \sigma _{i_n}(2)\) is a natural coding of R α∕(1+α) where α = [a 0, a 1, a 2, …]. By Proposition 3.2.7 the sequence w has the same language as u and (3.16) together with an approximation argument implies that w is a natural coding of R α∕(1+α) (it is easy to verify that there are limit cases where we really need the intervals \(I_1^{\prime }\), \(I_2^{\prime }\) to define the natural coding for w). □
The fact that Sturmian sequences have irrational uniform letter frequencies is an immediate consequence of Theorem 3.2.11. Moreover, we have the following corollary of Theorem 3.2.11 for Sturmian systems.
Corollary 3.2.13
A Sturmian system (X σ, Σ, μ) is measurably conjugate to an irrational rotation \((\mathbb {T},R_\alpha ,\lambda )\). Here μ is the unique Σ-invariant measure on X σand λ is the Haar measure on \(\mathbb {T}\).
Proof
Let \(\varphi : X_{\boldsymbol {\sigma }} \to \mathbb {T}\) be defined by φ(w 0w 1…) = x if \(R_\alpha ^k(x) \in I_{w_k}\) for each \(k\in \mathbb {N}\) or \(R_\alpha ^k(x) \in I^{\prime }_{w_k}\) for each \(k\in \mathbb {N}\). Using Theorem 3.2.11 and the minimality of R α it is easy to check that this is well defined. Surjectivity of φ follows immediately from Theorem 3.2.11. To investigate injectivity let u = u 0u 1… and v = v 0v 1… be distinct elements of X σ with φ(u) = φ(v). By the minimality of R α this is only possible if the orbit of φ(u) passes through 0 and u is naturally coded by I 1, I 2 while v is naturally coded by \(I_1^{\prime }\), \(I_2^{\prime }\) (or vice versa).Footnote 1 Since the set of such elements u and v is countable, φ is bijective everywhere save for a countable set. Moreover, φ is easily seen to be continuous and φ ∘ Σ = R α ∘ φ holds by the definition of φ. This implies the result. □
We illustrate the concepts of this section by a classical example.
Example 3.2.14 (A Variant of the Fibonacci Sequence)
Let σ be given by
This is a reordering of the square of the well-known Fibonacci substitution (which is defined by 1↦12, 2↦1; see for instance in [82, Section 1.2.1]). Consider the coding sequence σ = (σ). In this case the associated limit sequences are “purely substitutive”. One of the two limit sequences is
Since only one substitution plays a role here, the associated “S-adic” system (X σ, Σ) is called a substitutive system. Let \(\varphi =\frac {1+\sqrt {5}}{2}\). By the Perron-Frobenius theorem the generalized right eigenvector u of the sequence of incidence matrices M of σ is the eigenvector (φ, 1)t corresponding to the dominant eigenvalue φ 2 of the incidence matrix of σ. Let L be the eigenline defined by this eigenvector. Being a Sturmian sequence, w is balanced by Proposition 3.2.4 and has uniform letter frequencies \((f_1(w),f_2(w))^t=\frac {1}{1+\varphi }(\varphi ,1)^t\) by Lemma 3.2.8. This is reflected by the fact that the “broken line”
associated with the sequence w stays at bounded distance from the eigenline L (see Fig. 3.5).

The broken line and its projection to the Rauzy fractal
Because w =limn→∞σ n(2) =limn→∞(σ 1 ∘ σ 2)n(2), it has coding sequence σ 1, σ 2, σ 1, σ 2, … Since the “run lengths” of σ i in this sequence are always equal to 1 we set α = [1, 1, 1, …] = φ −1 and, hence, α∕(α + 1) = φ −2. Thus from Theorem 3.2.11 and its proof we see that w is a natural coding of the rotation by φ −2 of the point 1 − α∕(α + 1) = φ −1 ∈ [0, 1) with respect to the partition I 1 = [0, φ −1), I 2 = [φ −1, 1) (or the according partition \(I_1^{\prime },I_2^{\prime }\)) of [0, 1). This gives us an easy way to construct w (and the broken line B). Indeed, start at the origin, write out 2 and go up to the lattice point (0, 1)t. After that, inductively proceed as follows: whenever the current lattice point is above L, write out 1 and go right to the next lattice point by adding the vector (1, 0)t and whenever the current lattice point is below L, write out 2 and go up to the next lattice point by adding the vector (0, 1)t.Footnote 2
Let  be the projection along L to the line L
⊥ orthogonal to L. If we project all points on the broken line and take the closure of the image, due to the irrationality of u we obtain the interval
be the projection along L to the line L
⊥ orthogonal to L. If we project all points on the broken line and take the closure of the image, due to the irrationality of u we obtain the interval

on L ⊥ (the subscript u indicates that \(\mathcal {R}_{\mathbf {u}}\) lives in the space L ⊥ = u ⊥ orthogonal to u which is an arbitrary choice; other choices will play a roll in subsequent sections). We color the part of the interval for which we write out 1 at the associated lattice point light grey, the other part dark grey. This subdivides the interval \(\mathcal {R}_{\mathbf {u}}\) into two subintervals \(\mathcal {R}_{\mathbf {u}}(1)\) and \(\mathcal {R}_{\mathbf {u}}(2)\), where

Moreover, we see that moving a step along the broken line amounts to exchanging these two intervals in the projection: points in \(\mathcal {R}_{\mathbf {u}}(1)\) are moved downwards by a fixed vector, while points in \(\mathcal {R}_{\mathbf {u}}(2)\) are moved upwards by a fixed vector.
Thus passing along the broken line each step amounts to exchanging the intervals \(\mathcal {R}_{\mathbf {u}}(1)\) and \(\mathcal {R}_{\mathbf {u}}(2)\) in the projection. If we identify the end points of \(\mathcal {R}_{\mathbf {u}}\) this interval exchange becomes a rotation. This is the rotation which is coded by the Sturmian sequence w. The union \(\mathcal {R}_{\mathbf {u}}=\mathcal {R}_{\mathbf {u}}(1)\cup \mathcal {R}_{\mathbf {u}}(2)\) is called the Rauzy fractal associated with the substitution σ (or with the sequence σ = (σ)). The reason why we speak about fractals here will become apparent in Sect. 3.6.1 when we define the analogs of \(\mathcal {R}_{\mathbf {u}}\) in a more general setting.
Suppose we would be given an arbitrary sequence \(w\in \{1,2\}^{\mathbb {N}}\) with letter frequency vector u whose broken line stays within bounded distance of the line \(L=\mathbb {R}_+\mathbf {u}\). Then we could draw a similar picture as in Fig. 3.5. However, although the projection  would project the vertices of the associated broken line to a bounded set, there is no reason for its closure \(\mathcal {R}_{\mathbf {u}}\) to be an interval. Also, if we use two colors as in the example above, it may well happen that the two sets \(\mathcal {R}_{\mathbf {u}}(1)\) and \(\mathcal {R}_{\mathbf {u}}(2)\) have considerable overlap. This bad behavior prevents us from seeing a rotation in the projections.
would project the vertices of the associated broken line to a bounded set, there is no reason for its closure \(\mathcal {R}_{\mathbf {u}}\) to be an interval. Also, if we use two colors as in the example above, it may well happen that the two sets \(\mathcal {R}_{\mathbf {u}}(1)\) and \(\mathcal {R}_{\mathbf {u}}(2)\) have considerable overlap. This bad behavior prevents us from seeing a rotation in the projections.
Making sure that the closure of the projection of the broken line behaves topologically well and allows a partition whose atoms are essentially different will be our main concern when we establish a theory of S-adic sequences that are codings of rotations on higher dimensional tori in the subsequent sections and, hence, give rise to dynamical systems that are measurably conjugate to torus rotations.
3.2.5 Natural Extensions and the Geodesic Flow on \(\mathrm {SL}_2(\mathbb {Z})\setminus \mathrm {SL}_2(\mathbb {R})\)
In this section we talk about natural extensions of the Gauss map and of the coding map of Sturmian sequences by substitutions. Moreover, we show how to relate these natural extensions to the geodesic flow on the space \(\mathrm {SL}_2(\mathbb {Z})\setminus \mathrm {SL}_2(\mathbb {R})\) of unimodular two-dimensional lattices.
So far we could relate Sturmian sequences to rotations on the circle by using the classical continued fraction algorithm. In our discussion we coded a Sturmian sequence w by a sequence of substitutions \((\sigma _{i_n})\) as
(see (3.4)). In the induction process used in the proof of Theorem 3.2.11 we recoded w by a “desubstitution” process. If we look at the first step of this process we produce the sequence
However, the mapping w↦u cannot be inverted since it is not possible to reconstruct a 0 from u. Similarly, the Gauss map g cannot be inverted since g([a 0, a 1, …]) = [a 1, a 2, …], and a 0 cannot be reconstructed from the image [a 1, a 2, …].
In this section we want to make both of these mappings bijective by constructing a geometric model for their natural extensions (in the sense of Rohlin [116]). To this matter we look again at the induction used in Lemma 3.2.12 which is visualized once more in Fig. 3.6a. In this figure we see why this induction process cannot be reversed: the intervals [R(0), R 2(0)) and [R 2(0), R 3(0)) get lost during the induction process and cannot be reconstructed.

(a) Induction without restacking loses some part of the information. The intervals [R(0), R 2(0)) and [R 2(0), R 3(0)) depicted in light gray are no longer present in the induced rotation. (b) Induction together with restacking the intervals keeps all the information. The light gray intervals [R(0), R 2(0)) and [R 2(0), R 3(0)) are stacked on the longer interval of the induced rotation
A first idea on how to mend this is indicated in Fig. 3.6b: one could “stack” the lost intervals on the larger interval of the induced rotation. This would keep the information of the last induction step. However, acting in this way we can go back at most to the setting from which we started but not farther to the “past”.
To make the induction process bijective, it is more convenient to build rectangular boxes above the intervals as indicated in Fig. 3.7 (this approach is extensively exploited in Arnoux and Fisher [14]; we follow here [82, Section 6.6]). The lengths of the boxes are given by the intervals on which the induction process starts: one box is of length 1, the other one has length α for some \(\alpha \in (0,1)\setminus \mathbb {Q}\). The heights are chosen in a way that the longer rectangle is also the higher one and that the total area of the two rectangles is equal to one. The induction process can now be performed on the rectangles as indicated in Fig. 3.7: let a × d be the size of the left rectangle and b × c the size of the right one. Slice the larger rectangle by vertical cuts into pieces of lengths equal to b until a slice of length less than b remains. Then stack all slices of length b on the smaller rectangle. The result can be seen in the middle of Fig. 3.7. After that renormalize the resulting pair of rectangles (as we did in the induction process on the intervals) by making it “thinner” and “longer” in a way that the length of the larger rectangle is equal to 1 again and the area of the whole region remains 1.

Step 1: restack the boxes. Step 2: renormalize in a way that the larger box has length 1 again
Call the resulting mapping on the rectangles Ψ. A priori, the mapping Ψ is a mapping from a subset of \(\mathbb {R}^4\) to a subset of \(\mathbb {R}^4\). However, since ad + bc = 1 and \(\max \{a,b\}=1\), we can eliminate two coordinates and we are left with a mapping in two variables.
We make this precise in the following definition.
Definition 3.2.15 (Natural Extension of the Gauss Map, see [14])
Let Δ m be the set of pairs (a × d, b × c) of rectangles of total area 1 such that the widest one is the highest one (i.e., a > b ⇔ d > c) and such that the width of the widest one is equal to 1 (i.e., \(\max \{a,b\}=1\)). Let Δ m,0 be the subset of Δ m with a = 1, and Δ m,1 the subset of Δ m with b = 1.
The mapping Ψ is defined on Δ m,1 as
and similarly on Δ m,0. It is called the natural extension of the Gauss map (which is seen in the first coordinate).
Remark 3.2.16
The subscript “m” stands for multiplicative since we work here with the multiplicative version of the classical continued fraction algorithm defined by the Gauss map. An analogous theory exists for the additive algorithm as well, see [14].
The mapping Ψ is bijective as becomes clear from its geometric interpretation. Moreover, it is easy to show that Ψ preserves the Lebesgue measure. By integrating away the second coordinate one can show that the invariant measure of the Gauss map is \(\frac {dx}{\ln 2(1+x)}\) (see e.g. [76, Chapter 3]). We mention that another natural extension of the Gauss map defined on the unit square is provided in [108].
We can also see Sturmian sequences in the rectangular boxes. To this end note first that a pair of boxes a × d and b × c is a fundamental domain of the lattice spanned by the vectors (a, c)t and (−b, d)t. This is illustrated in Fig. 3.8 and has the consequence that the “L-shaped” region formed by this pair of boxes can be used to tile the plane with respect to this lattice as indicated in Fig. 3.9.

A pair of boxes is a fundamental domain of a lattice

The vertical line is coded by a Sturmian sequence u, the horizontal line by a Sturmian sequence v. The restacking procedure desubstitutes u and substitutes v. The shaded region is a restacked fundamental domain
Let us mark a point in this tiling. If we start from this point and move upwards and write out 1 whenever we pass through a large rectangle, and 2, whenever we pass through a small one, we get the coding u of a rotation by α on the interval (−1, α) which, by Theorem 3.2.11, is a Sturmian sequence. This is indicated in Fig. 3.9. In the same way we can produce a Sturmian sequence v by moving horizontally.
If we restack each of the fundamental domains, according to the procedure described above, we get a new fundamental domain (indicated by the shaded region in Fig. 3.9). We now code the same vertical line using this restacked region. Doing this we obtain another Sturmian sequence u (1) which, by the definition of the restacking process, satisfies u = σ(u (1)), where σ is the substitution defining the induction process as in the proof of Lemma 3.2.12. On the other hand, looking at the horizontal line we get v (−1) = σ(v) as the new coding. Thus the restacking process corresponds to the mapping
As mentioned at the beginning of this section, we cannot reconstruct u from u (1), however we can reconstruct (u, v) from (u (1), v (−1)) since the type of the Sturmian sequence v (−1) tells us (which power of) which of the two substitutions σ 1, σ 2 from (3.1) we have to use to get back. This makes the coding process bijective as well. We could mark the pair of rectangles discussed above by a point (x, y) and look at the itinerary of this point under the restacking process. This would give an extension \(\tilde \varPsi \) of the mapping Ψ that is defined on the \(\mathbb {T}^2\)-fibers over Δ m (see [14]).
The following remark is of particular importance.
Remark 3.2.17
Regardless of the point in the “L-shaped” region in which we start, the “vertical” Sturmian sequence will always be contained in the same Sturmian system. Thus we can say that the “L-shaped” pairs of rectangles parametrize the Sturmian systems (which are characterized by their coding sequence according to Proposition 3.2.10(iii)), while the (x-coordinates of the) points in a given region parametrize the sequences contained in this system. The same is true for the “vertical” Sturmian sequence w.r.t. the y-coordinates.
We also mention that the vertical line producing the coding u can also be extended downwards. This yields a sequence \(\tilde u \in \mathcal {A}^{\mathbb {Z}}\) as a coding. Such a sequence is an example of a bi-infinite Sturmian sequence (the same can be done in the horizontal direction). Bi-infinite Sturmian sequences are studied for instance in [82, Section 6.2]. It turns out that some of their properties are nicer than in our one-sided case since one no longer has troubles coming from “the beginning” of the sequences.
Artin [26] observed that the continued fraction algorithm can be viewed as a Poincaré section of the geodesic flow on the unit tangent bundle \(\mathrm {SL}_2(\mathbb {Z})\setminus \mathrm {SL}_2(\mathbb {R})\) of the modular surface \(\mathrm {SL}_2(\mathbb {Z})\setminus \mathbb {H}\). In the meantime this correspondence between the continued fraction algorithm and the geodesic flow was studied by many authors (see e.g. Series [121]) and discussed in connection with our setting by Arnoux [10] and later by Arnoux and Fisher [14]. The necessary details on the modular surface and its unit tangent bundle including an explanation why the flow diag(e t, e −t) which will come up below is a geodesic flow on the homogeneous space \(\mathrm {SL}_2(\mathbb {Z})\setminus \mathrm {SL}_2(\mathbb {R})\) can be found for instance in [10] or [76, Chapter 9].
We now explain briefly how the geodesic flow on \(\mathrm {SL}_2(\mathbb {Z})\setminus \mathrm {SL}_2(\mathbb {R})\) enters our model. We have to restack the rectangles as above and then renormalize the lattice again. This can be done also in the following way. First multiply the basis of the lattice from the right by diag(e t, e −t) for t varying from 0 to the threshold value for which the width of the smallest rectangle equals 1. Then restack as above to end up at a pair of rectangles whose larger rectangle has width 1. Altogether, starting from a pair of rectangles drawn on the left hand side of Fig. 3.7 we ended up with a pair drawn on its right side. We just did the renormalization smoothly and we did it before the restacking instead of after it.
What we do can be explained more precisely as follows:
-
Define the set
$$\displaystyle \begin{aligned} \varOmega_{\mathrm{m}} = & \varOmega_{\mathrm{m},0} \cup \varOmega_{\mathrm{m},1} \\ = &\left\{ M=\begin{pmatrix}a & c \\ -b &d \end{pmatrix}\; :\; 0 < a <1 \le c, \; 0 < d < b,\; ad+bc=1 \right\} \cup \\ & \left\{ M=\begin{pmatrix}a & c \\ -b &d \end{pmatrix}\; :\; 0 < c < 1 \le a, \; 0 < b < d, \; ad+bc=1 \right\}. \end{aligned}$$One can show that a.e. lattice has exactly one basis made of row vectors of a matrix in Ω m (see [10]). Thus Ω m is a (measure theoretic) fundamental domain for the action of \(\mathrm {SL}_2(\mathbb {Z})\) on \(\mathrm {SL}_2(\mathbb {R})\).
-
Start with a lattice, associate with it a basis taken from Ω m.
-
Hit this lattice (together with the chosen basis) with the geodesic flow diag(e t, e −t), t ≥ 0.
-
For increasing t this will eventually deform the basis in a way that the width of the smaller rectangle gets equal to 1 (and we would leave Ω m when deforming this basis further). If we restack at this point we end up with a pair of rectangles contained in the Poincaré sectionΔ m: indeed, after restacking the larger rectangle will have width 1.
-
Change the basis of the lattice to the basis corresponding to the new pair of rectangles according to Fig. 3.8. Note that restacking does not change the lattice, so the geodesic flow, which acts on \(\mathrm {SL}_2(\mathbb {Z})\setminus \mathrm {SL}_2(\mathbb {R})\), is not affected by this base change. However, this restacking has the effect that it creates a new basis of the lattice that remains inside Ω m when it gets further deformed by the action of the flow. Thus we can repeat the procedure.
-
Repeating this procedure, the geodesic flow yields a sequence of restackings: any time the width of the smaller rectangle gets equal to 1 by restacking, the according basis gets inside the Poincaré sectionΔ m. This restacking performs one step of the natural extension of the Gauss map.
-
Thus the geodesic flow on \(\mathrm {SL}_2(\mathbb {Z})\setminus \mathrm {SL}_2(\mathbb {R})\) can be regarded as a so-called suspension flow of the natural extension of the Gauss map.
This viewpoint has many advantages and one can prove results on continued fractions using the well-developed theory of the geodesic flow on \(\mathrm {SL}_2(\mathbb {Z})\setminus \mathrm {SL}_2(\mathbb {R})\).
The same procedure can also be performed for pointed pairs of rectangles (which we needed to study Sturmian sequences, see Fig. 3.9). This has the effect that the geodesic flow on \(\mathrm {SL}_2(\mathbb {Z})\setminus \mathrm {SL}_2(\mathbb {R})\) has to be replaced by the so-called scenery flow which also takes care of the distinguished point in the “L-shaped” region. All this is described in detail in [14].
We mention that similar results have been obtained for variants of the classical continued fraction algorithm. For instance, Arnoux and Schmidt [23, 24] proved that the α-continued fraction algorithm, Rosen’s continued fraction algorithm as well as Veech’s continued fraction algorithm can be viewed as Poincaré sections of a geodesic flow. The material presented in this section also forms an easy case of the wide and appealing field of interval exchange transformations and their dynamics (see e.g. Viana [125] for a survey).
3.3 Problems with the Generalization to Higher Dimensions
According to Cassaigne et al. [63] it was conjectured since the beginning of the 1990s that the beautiful correspondence between Sturmian sequences, continued fractions, and irrational rotations on the circle described in Sect. 3.2 can be extended to higher dimensions. The same paper gives strong indications towards the wrongness of this conjecture. Indeed, in [63] Arnoux-Rauzy sequences over a three letter alphabet that are not balanced and that cannot be viewed as natural codings of rotations on the two dimensional torus with finite fundamental domain are constructed. It is the objective of the present section to explain their work and to give an account on further results by Cassaigne et al. [62] concerning weakly mixing Arnoux-Rauzy systems as well as Arnoux-Rauzy systems with nontrivial eigenvalues.
3.3.1 Arnoux-Rauzy Sequences
In an attempt to pave the way for a generalization to higher dimensions of the correspondence between combinatorics, arithmetics, and dynamical systems outlined in Sect. 3.2, Arnoux and Rauzy [22] defined sequences over the alphabet {1, 2, 3} whose properties are inspired by Sturmian sequences.
In the following definition a right special factor of a sequence \(w\in \{1,2,3\}^{\mathbb {N}}\) is a factor v of w for which there are distinct letters a, b ∈{1, 2, 3} such that va and vb both occur in w. A left special factor is defined analogously. The definition of several other objects and notations from Sect. 3.2 carry over from two to three letter alphabets without any change and we will use them without defining them again (we will give exact definitions for the general setting from Sect. 3.4 onwards).
Definition 3.3.1 (Arnoux-Rauzy Sequence, see [22])
A sequence \(w\in \{1,2,3\}^{\mathbb {N}}\) is called Arnoux-Rauzy sequence if p w(n) = 2n + 1 and if w has only one right special factor and only one left special factor for each given length n.
Let w be an Arnoux-Rauzy sequence. Let (Γ n) be a sequence of directed graphs defined in the following way. For each \(n\in \mathbb {N}\) the vertices of Γ n are the factors of length n of w. There is a directed edge from u to v if and only if there are letters a, b ∈{1, 2, 3} and a word x ∈{1, 2, 3}∗ such that u = ax and v = xb. Inspecting these graphs we see that two cases can occur. If the left special factor v of length n is also the right special factor then Γ n is a bouquet of three circles whose common vertex is v, otherwise it is a union of three circles that share the line between the vertices corresponding to the right and left special factor. An investigation of these graphs (as done in [22, Section 2]) shows that Arnoux-Rauzy sequences are “S-adic” and we get the following analog of Proposition 3.2.7.
Proposition 3.3.2 (See [22, Section 2])
Let the Arnoux-Rauzy substitutions σ 1, σ 2, σ 3be defined by
Then for each Arnoux-Rauzy sequence w there exists a sequence \({\boldsymbol {\sigma }}=(\sigma _{i_n})\), where (i n) takes each symbol in {1, 2, 3} an infinite number of times, such that w has the same language as
By this proposition each Arnoux-Rauzy sequence w has a coding sequenceσ of Arnoux-Rauzy substitutions and we may define the dynamical system (X w, Σ) = (X σ, Σ) as the dynamical system associated with w, where X w = X σ is the set of sequences whose language equals the language of w and which just depends on σ. These dynamical systems are called Arnoux-Rauzy systems.
Let w be an Arnoux-Rauzy sequence with coding sequence \({\boldsymbol {\sigma }}=(\sigma _{i_n})\) and let \((M_{i_n})\) be the associated sequence of incidence matrices. Since each symbol in {1, 2, 3} occurs infinitely often in (i n) the associated sequence of incidence matrices \((M_{i_n})\) is easily seen to be primitive in the sense that for each \(m\in \mathbb {N}\) there is n > m such that \(M_{i_{[m,n)}}\) is a positive matrix. Indeed, a block \(M_{i_{[m,n)}}\) is primitive if and only if it contains each of the three matrices M 1, M 2, M 3 at least once.
Lemma 3.3.3
Let w be an Arnoux-Rauzy sequence with coding sequenceσ. Then the dynamical system (X σ, Σ) is minimal and uniquely ergodic.
Proof
Minimality follows if we can show that L(v) = L(w) for each v ∈ X σ. This in turn holds if each factor of w occurs infinitely often in w with bounded gaps, which we will now prove. Let x be a factor of w. As w has the same language as the sequence u in (3.19), by primitivity of \((M_{i_n})\) there is \(m\in \mathbb {N}\) such that x occurs in \(\sigma _{i_{[0,m)}}(1)\). Using primitivity again we see that there exists n > m such that \(M_{i_{[m,n)}}\) is a positive matrix. This entails that the word \(\sigma _{i_{[m,n)}}(b)\) contains 1 for any b ∈{1, 2, 3} and, hence, \(\sigma _{i_{[0,n)}}(b)\) contains \(\sigma _{i_{[0,m)}}(1)\) and, a fortiori, also x for each b ∈{1, 2, 3}. Thus x occurs in w infinitely often with gaps bounded by \(2\max \{|\sigma _{i_{[0,n)}}(b)| \,:\, b\in \{1,2,3\}\}\).
Unique ergodicity of (X σ, Σ) can be derived from a general result of Boshernitzan [56] due to the fact that (X σ, Σ) is minimal and its elements have linear complexity with slope less than 3. □
This proof implies that each Arnoux-Rauzy sequence is uniformly recurrent.
Generalizing an idea of Arnoux [9], in [22] it was shown that each Arnoux-Rauzy sequence w can be viewed as a coding of a 6-interval exchange transformation (by using sequences over an alphabet with only three letters!) and that each Arnoux-Rauzy system can be represented by such a 6-interval exchange. In view of a result by Katok [94] this implies that Arnoux-Rauzy systems cannot be mixing. The incidence matrices of Arnoux-Rauzy substitutions can be used to define a generalized continued fraction algorithm in the sense of Sect. 3.4.2 below. However, this algorithm only works for vectors taken from a set of measure zero, the so-called Rauzy gasket. For more on this interesting set we refer to [25, 29, 30, 69, 99].
Another interesting class of sequences of complexity 2n + 1 over the alphabet {1, 2, 3} has been defined recently in [64] and is currently subject to intensive investigation. Compared to Arnoux-Rauzy sequences it has the advantage that it is defined in terms of only two substitutions and gives rise to a continued fraction algorithm that works on a set of full measure.
3.3.2 Imbalanced Arnoux-Rauzy Sequences
To get the perfect analogy with the Sturmian case it would be desirable to represent a given Arnoux-Rauzy sequence w as a natural coding of a rotation on the two-dimensional torus \(\mathbb {T}^2\). In the seminal paper of Rauzy [114], this was achieved for the sequence \(w=\lim \sigma ^n(1)\), where σ is the famous Tribonacci substitution defined by
Since σ 3 = σ 1 ∘ σ 2 ∘ σ 3 the sequence w is an example of an Arnoux-Rauzy sequence (with periodic coding sequence). Several years ago Barge, Štimac, and Williams [37] as well as Berthé et al. [48] could generalize this result and proved that each Arnoux-Rauzy sequence w with periodic coding sequence is a natural coding of a rotation on \(\mathbb {T}^2\) (a weaker result in this direction is already contained in [18]). A general theory for nonperiodic sequences was established only recently, see Berthé et al. [52], and we will come back to this in later sections.
We recall that a sequence \(w=w_0w_1\ldots \in \{1,2,3\}^{\mathbb {N}}\) is a natural coding of a rotation R on \(\mathbb {T}^2\) if there exists a fundamental domain Ω of \(\mathbb {T}^2\) in \(\mathbb {R}^2\) together with a partition Ω = Ω 1 ∪ Ω 2 ∪ Ω 3 such that on each Ω i the map R ′ induced on Ω by the rotation R acts as a translation by a vector \({\mathbf {a}}_i\in \mathbb {R}^2\) and for some point x ∈ Ω we have \(R^{\prime k}(x)\in \varOmega _{w_k}\) for each \(k\in \mathbb {N}\) (see also Definition 3.9.2).
An Arnoux-Rauzy sequence is not always a coding of a rotation on \(\mathbb {T}^2\) with bounded fundamental domain. The reason for this is the lack of balance for some particular instances of such sequences. Following Cassaigne et al. [63] we now sketch the construction of an Arnoux-Rauzy sequence that is not balanced.
Let C ≥ 1 be an integer. Generalizing the notion of balance from Sect. 3.2.1 we say that a sequence \(w\in \{1,2,3\}^{\mathbb {N}}\) is C-balanced if each pair of factors (u, v) of w having the same length satisfies ||u|a −|v|a| ≤ C for each a ∈{1, 2, 3}. The following result implies that there is no uniform C that gives C-balance for each Arnoux-Rauzy sequence. Here a substitution is called primitive if its incidence matrix is primitive.
Lemma 3.3.4 (See [63, Proposition 2.2])
For each integer C ≥ 1 there is a finite sequence of Arnoux-Rauzy substitutions \(\sigma _{i_1},\ldots ,\sigma _{i_k}\)such that \(\sigma = \sigma _{i_1}\circ \cdots \circ \sigma _{i_k}\)is primitive and for each Arnoux-Rauzy sequence w the Arnoux-Rauzy sequence σ(w) is not C-balanced.
Proof
We prove by induction that for each n ≥ 2 there exist \(a_n,b_n,c_n\in \mathbb {N}\) and a primitive composition of Arnoux-Rauzy matrices σ (n) such that for each Arnoux-Rauzy sequence w the sequence σ (n)(w) contains two factors u (n) and v (n) of equal length with
for some choice i, j, k with {i, j, k} = {1, 2, 3}. This will prove the result because ||u (n)|j −|v (n)|j| = n shows that σ (n)(w) is not (n − 1)-balanced.
For the induction start take n = 2 and σ (2) = σ 1σ 2 with u (2) = 212 and v (2) = 131.
To perform the induction step assume that the result is true for some n and let u (n), v (n), a n, b n, c n, i, j, k, and σ (n) be as above. Set \(\sigma ^{(n+1)}=\sigma _k^n\circ \sigma _i^n\circ \sigma ^{(n)}\). We now construct u (n+1) and v (n+1). Let u be a nonempty factor of some Arnoux-Rauzy sequence w. Then for each a ∈{1, 2, 3} the word σ a(u)a is a factor of σ a(w) which begins with a. If we define σ (a,+)(u) = σ a(u)a and σ (a,−)(u) as the suffix of σ a(u) of length |σ a(u)|− 1 (i.e., the first letter of σ a(u) is canceled) we see that \(u^{(n+1)}=\sigma _{(k,-)}^n\sigma _{(i,+)}^n(v_n)\) and \(v^{(n+1)}=\sigma _{(k,+)}^n\sigma _{(i,-)}^n(v_n)\) are factors of σ (n+1)(w). Using the definition of σ (a,+) and σ (a,−) one can now check directly that
where
□
This lemma can even be sharpened in the following way.
Lemma 3.3.5 (See [63, Proposition 2.3])
For each integer C ≥ 1 and each composition of Arnoux-Rauzy substitutions σ there exists a primitive composition of Arnoux-Rauzy sequences σ ′such that for each Arnoux-Rauzy sequence w the Arnoux-Rauzy sequence σ ∘ σ′(w) is not C-balanced.
The proof is technical and we do not provide it here. The idea is to use Lemma 3.3.4 in order to choose σ ′ in a way that σ′(w) is not K-balanced for each Arnoux-Rauzy sequence w, where K, which depends on the incidence matrix of σ, is so large that even after the application of σ we cannot reach C-balance.
We are now able to establish the following result.
Theorem 3.3.6 (See [63, Theorem 2.4])
There exists an Arnoux-Rauzy sequence which is not C-balanced for any C ≥ 1.
Proof
By Lemma 3.3.5 one can construct primitive compositions of Arnoux-Rauzy substitutions σ (1), …, σ (C) such that σ (1) ∘⋯ ∘ σ (C)(w) is not C-balanced for any Arnoux-Rauzy sequence w. Thus u =limC→∞σ (1) ∘⋯ ∘ σ (C)(w) is the desired sequence. □
Using this proposition we are able to establish the following result of [63] which strongly indicates that an unconditional generalization of the theory presented in Sect. 3.2 is not possible.
Corollary 3.3.7 (Cf. [63, Corollary 2.6])
There exists an Arnoux-Rauzy sequence which is not a natural coding of a minimal rotation on the 2-torus with bounded fundamental domain.
Proof
By Theorem 3.3.6 there is an Arnoux-Rauzy sequence w which is not C-balanced for any C > 0. Assume that w is a natural coding of a minimal rotation on \(\mathbb {T}^2\) with bounded fundamental domain Ω. Each letter j ∈{1, 2, 3} corresponds to a translation a j on Ω and, hence, to each word u = u 0…u n−1 ∈{1, 2, 3}∗ there corresponds the translation \({\mathbf {a}}_{u}=\sum _{k=0}^{n-1}{\mathbf {a}}_{u_k}\) on Ω. Since Ω is bounded and the rotation is minimal one easily checks that the vectors a 1, a 2, a 3 satisfy \(\mathbb {R}_+{\mathbf {a}}_1 +\mathbb {R}_+{\mathbf {a}}_2 + \mathbb {R}_+{\mathbf {a}}_3 = \mathbb {R}^2\). This implies that there exists a constant γ > 0 such that two words u, v ∈{1, 2, 3}∗ with ||u|i −|v|i| ≥ C for some i ∈{1, 2, 3} satisfy ∥a u −a v∥1 > γC.
Since w is not balanced there is a letter i ∈{1, 2, 3} such that for each C > 0 there exist two factors u, v ∈{1, 2, 3}∗ of w with ||u|i −|v|i| ≥ C. Thus ∥a u −a v∥1 > γC. Since C can be arbitrarily large, this difference can be made arbitrarily large. Thus one of the two vectors a u, a v can be made arbitrarily large. Assume w.l.o.g. that this is a u. Since there is an element x ∈ Ω with x + a u ∈ Ω, the diameter of Ω is bounded from below by the length of a u. This contradicts the boundedness of the fundamental domain Ω. □
Remark 3.3.8
We mention that in [63, Corollary 2.6] it is claimed that Corollary 3.3.7 is true without assuming that the fundamental domain is bounded. However, we were not able to verify this proof.
3.3.3 Weak Mixing and the Existence of Eigenvalues
In Cassaigne et al. [62] the authors give a criterion for weak mixing for some class of Arnoux-Rauzy systems. On the other hand they provide a class of Arnoux-Rauzy systems that admit nontrivial eigenvalues. Before we give the details, we recall the required terminology from ergodic theory (good references here are for instance Einsiedler and Ward [76] or Walters [126]; we also mention Halmos [85] where some concepts are illustrated in an intuitive way).
Let (X, T, μ) be a dynamical system with invariant measure μ. We say that a complex number λ is a measurable eigenvalue of T if there exists f ∈ L 1(μ), f ≠ 0, such that f(Tx) = λf(x) for μ-almost every x. Such an f is called an eigenfunction for λ. For topological dynamical systems the notion of topological eigenvalue is defined analogously by using continuous eigenfunctions instead of functions from L 1(μ).
The transformation T is called weakly mixing if for each A, B ⊂ X of positive measure we have
Weak mixing is equivalent to the fact that 1 is the only measurable eigenvalue of T and the only eigenfunctions are constants (in this case the dynamical system is said to have continuous spectrum ). We note that rotations are never weakly mixing. They have pure discrete spectrum (with will be defined in Definition 3.9.1), meaning that they have “a lot of eigenfunctions” and therefore they have a completely different dynamical behavior. Indeed, from the definition of weak mixing we see that iterated preimages of each set tend to “smear” (or mix) over the whole space, this is of course not the case for the iterated preimages of a rotation.
We now come back to the aim of this section and discuss mixing properties of Arnoux-Rauzy systems. Let
with i n ≠ i n+1 be an Arnoux-Rauzy sequence. We define (n ℓ) to be the sequence of indices n for which i n ≠ i n+2. The sequence u is uniquely defined by the sequences (k n) and (n ℓ) (up to permutation of letters). The following result shows a result on weak mixing Arnoux-Rauzy systems for large partial quotients (k n).
Theorem 3.3.9 (See [62, Theorem 2])
For an Arnoux-Rauzy sequence w with coding sequenceσand associated sequences (k n) and (n ℓ) the system (X σ, Σ, μ) (with μ being the unique invariant measure) is weakly mixing if the sequence \((k_{n_\ell +2})_{\ell \in \mathbb {N}}\)is unbounded and the sums \(\sum _{\ell \ge 1}\frac 1{k_{n_\ell +1}} \)and \( \sum _{\ell \ge 1}\frac 1{k_{n_\ell }} \)converge.
This implies that (X σ, Σ, μ) is not measurably conjugate to a rotation on \(\mathbb {T}^2\).
The proof of this result is quite involved. In fact, to get weak mixing, by definition one has to show that there exists no measurable eigenvalue apart from 1 for the system (X σ, Σ, μ). This is achieved by verifying the following criterion (see [62, Proposition 10]): if 𝜗 is a measurable eigenvalue of (X σ, Σ, μ), then k n+1{h n𝜗}→ 0 for n →∞. Here h n is the length of \(\sigma _{i_1}^{k_1}\circ \cdots \circ \sigma _{i_{n}}^{k_n}(1)\). This criterion is proved using a sequence of nested Rohlin towers which are naturally built using the coding sequence σ. As mentioned above, because an Arnoux-Rauzy system can be represented by a 6-interval exchange, it cannot be mixing in view of Katok [94].
To give this section a good end we mention that [62] also contains results that support the hope that at least something along the lines of Sect. 3.2 can be done in higher dimensions. Indeed, the authors are able to exhibit criteria for the existence of nontrivial continuous eigenvalues (not equal to 1) for Arnoux-Rauzy systems which implies that these systems have a rotation as a continuous factor. The novelty here is the fact that these systems still have unbounded partial quotients (k n). For bounded partial quotients criteria for the existence of continuous and measurable eigenvalues are provided in the more general setting of linear recurrent minimal Cantor systems in Cortez et al. [66].
It will be our concern in the subsequent sections to exhibit S-adic sequences that are even measurable conjugates of rotations on tori of dimension greater than or equal to two.
3.4 The General Setting
So far we have seen some elements of the correspondence between Sturmian sequences, the classical continued fraction algorithm, and rotations on the circle. We have also reviewed some results that highlight the problems and limitations of a generalization of this nice interplay between several branches of mathematics to higher dimensions. Nevertheless, we are able to set up a quite general extension of the results contained in Sect. 3.2. Indeed, in the subsequent sections of this chapter we will relate sequences generated by substitutions on alphabets over d letters to generalized continued fraction algorithms and to rotations on the (d − 1)-dimensional torus. From this point on we will give exact definitions of all objects we use. This may seem redundant as some objects have already been introduced before but as the subject is quite difficult and a variety of concepts and notations is needed along the way we found it better for the reader to do it that way.
3.4.1 S-adic Sequences
We now define so-called S-adic sequences which form analogs of sequences of the form (3.2) and (3.19) for arbitrary “coding sequences” of substitutions over a fixed finite alphabet. To this end we need some notation.
Let \(\mathcal {A}=\{1,2,\ldots ,d\}\) be a finite alphabet whose elements will be called letters or symbols. Define \(\mathcal {A}^*\) to be the free monoid generated by \(\mathcal {A}\) equipped with the operation of concatenation. The elements of \(\mathcal {A}^*\), which are of the form v = v 0v 1…v n−1 with \(n\in \mathbb {N}\) and \(v_{i}\in \mathcal {A}\) for i ∈{0, 1, …, n − 1}, will be referred to as words. The integer n, which is equal to the number of letters in the word v, is called the length of v and will be denoted by |v|. The unique word of length 0 is called the empty word. Let \(\mathcal {A}^{\mathbb {N}}\) be the space of right infinite sequencesw = w 0w 1… with \(w_i\in \mathcal {A}\) for each \(i\in \mathbb {N}\). We equip \(\mathcal {A}^{\mathbb {N}}\) with the product topology of the discrete topology on \(\mathcal {A}\). To a sequence \(w=w_0w_1\ldots \in \mathcal {A}^{\mathbb {N}}\) we associate a function \(p_{w}:\mathbb {N}\to \mathbb {N}\) which is defined by
The function p w is called the complexity function of the sequence w. For more on this function we refer for instance to Cassaigne and Nicolas [65].
A substitutionσ over the alphabet \(\mathcal {A}\) is an endomorphism on \(\mathcal {A}^*\) that in our setting will always assumed to be nonerasing in the sense that the image of each letter is a nonempty word taken from \(\mathcal {A}^*\). Being a morphism, a substitution is completely defined by giving its image for each letter. Thus our previous examples of Sturmian substitutions in (3.1) and of Arnoux-Rauzy substitutions in (3.18) are indeed substitutions. We can extend the domain of a substitution σ to \(\mathcal {A}^{\mathbb {N}}\) in a natural way by defining it symbol-wise, i.e., by setting σ(w 0w 1…) = σ(w 0)σ(w 1)… The mapping σ defined in this way is continuous on \(\mathcal {A}^{\mathbb {N}}\).
With each substitution σ over the alphabet \(\mathcal {A}\) we associate the \(|\mathcal {A}|\times |\mathcal {A}|\)incidence matrixM σ whose columns are the abelianized images of σ(i) for \(i\in \mathcal {A}\). More precisely, letting |v|i be the number of occurrences of a given letter \(i\in \mathcal {A}\) in a word \(v\in \mathcal {A}^*\) this matrix is given by M σ = (m ij) = (|σ(j)|i). The incidence matrix can be seen as the abelianized version of σ. If we define the abelianization mapping \(\mathbf {l}:\mathcal {A}^* \to \mathbb {N}^d\) by l(w) = (|w|1, …, |w|d)t (here x t is the transpose of a vector \(\mathbf {x}\in \mathbb {R}^d\)) we have the commutative diagram

which says that lσ(w) = M σl(w) holds for each \(w\in \mathcal {A}^*\).
We will be interested in special classes of substitutions. Let σ be a substitution. Then σ is called unimodular if \(|\det M_\sigma |=1\), it is called primitive if M σ is a primitive matrix (i.e., M σ has a power each of whose entries is greater than zero), it is called irreducible if M σ has irreducible characteristic polynomial, and it is called Pisot if the characteristic polynomial of M σ is the minimal polynomial of a Pisot number. We recall that a Pisot number is an algebraic integer β > 1 whose Galois conjugates (apart from β itself) are all smaller than 1 in modulus.
In full generality substitutions are studied for instance in [6, 40, 87] and, in a context related to the present chapter, in [82].
We will now define the analogs of the “coding sequences” used in Sects. 3.2 and 3.3 for a more general setting. We go in the reverse direction: in the mentioned earlier sections the sequence (of letters) was there first and we constructed a sequence of substitutions that generates this sequence. Now we start with a sequence of substitutions in order to define a sequence of letters.
Let \({\boldsymbol {\sigma }}=(\sigma _n)_{n\in \mathbb {N}}\) be a sequence of substitutions over a given finite alphabet \(\mathcal {A}\). For convenience, we will set \(M_n=M_{\sigma _n}\) for the incidence matrix of σ n and write M = (M n) for the sequence of these incidence matrices. Moreover, as we will often need blocks of substitutions as well as blocks of matrices we set
for positive integers m ≤ n (here we set σ [n,n)(a) = a for all \(a\in \mathcal {A}\) and define M [n,n) to be the \(|\mathcal {A}|\times |\mathcal {A}|\) identity matrix).
We associate with σ a sequence of languages, for all \(m\in \mathbb {N}\),
and call \(\mathcal {L}_{\boldsymbol {\sigma }}=\mathcal {L}^{(0)}_{\boldsymbol {\sigma }}\) the language ofσ. Here \(u\in \mathcal {A}^*\) is a factor of \(v\in \mathcal {A}^*\) if \(v\in \mathcal {A}^*u\mathcal {A}^*\), or, more informally, if the word u occurs somewhere as subword in the word v. We will use this notation also for (right infinite) sequences later. Then \(u\in \mathcal {A}^*\) is a factor of \(v\in \mathcal {A}^{\mathbb {N}}\) if \(v\in \mathcal {A}^*u\mathcal {A}^{\mathbb {N}}\). The set of all factors of a sequence v is called the language of v. It is denoted by L(v). We also introduce the notion of prefix and suffix that will be used later. A prefix of a word \(v\in \mathcal {A}^*\) is a word \(u\in \mathcal {A}^*\) with \(v\in u\mathcal {A}^*\) and a suffix of \(v\in \mathcal {A}^*\) is a word \(u\in \mathcal {A}^*\) with \(v\in \mathcal {A}^*u\). A prefix of a sequence \(v\in \mathcal {A}^{\mathbb {N}}\) is a word \(u\in \mathcal {A}^*\) with \(v\in u\mathcal {A}^{\mathbb {N}}\).
After these preparations we can define S-adic sequences for a given sequence of substitutions σ. The terminology “S-adic” goes back to Ferenczi [77]. In our definition we follow Arnoux et al. [20] (see also [52, Section 2.2]).
Definition 3.4.1 (S-adic Sequence)
Let \(\mathcal {A}\) be a given finite alphabet, let σ = (σ n)n≥0 be a sequence of substitutions over \(\mathcal {A}\), and set \(S:=\{\sigma _n\,:\, n\in \mathbb {N}\}\). We call a sequence \(w\in \mathcal {A}^{\mathbb {N}}\) an S-adic sequence (or a limit sequence ) for σ if there exists a sequence (w (n))n≥0 of sequences \(w^{(n)}\in \mathcal {A}^{\mathbb {N}}\) with
In this case we call σ the coding sequence or the directive sequence for w. (Note that (3.22) says that w can be “desubstituted” infinitely often).
Let S be a finite set of substitutions over a given alphabet \(\mathcal {A}\). For this case S-adic sequences have been thoroughly studied in the literature. With Sturmian sequences and Arnoux-Rauzy sequences we already discussed two prominent classes of S-adic sequences. Durand [71, 72] proved that linearly recurrentFootnote 3 sequences are S-adic with finite S. Ferenczi [77] and Leroy [97] showed that a uniformly recurrentFootnote 4 sequence w with an at most linear complexity function p w is S-adic with finite S; see also [98]. The so-called S-adic conjecture (see e.g. [82, Section 12.1.2] or [73, 97]) is also formulated for a finite set of substitutions S. It asks to what extent a converse of this assertion can be true, i.e., which criteria are needed for an S-adic sequence w to have linear complexity function p w. Berthé and Labbé [49] show linearity of the complexity of S-adic sequences associated with the Arnoux-Rauzy-Poincaré multidimensional continued fraction algorithm (their bound \(p_w(n)\le \frac 52n + 1\) is even strong enough to conclude from Boshernitzan [56] that, like Arnoux-Rauzy sequences, these sequences pertain to uniquely ergodic dynamical systems). Arnoux et al. [20] study S-adic sequences in the same context as we will do it. However, they restrict their attention to sets of substitutions S whose elements have a common incidence matrix. If S is a singleton, an S-adic sequence is called substitutive. Substitutive sequences are very well studied (see for instance [82]; moreover in the paragraphs following Definition 3.4.2 we review the literature on substitutive sequences related to our subject). They are strongly related to automatic sequences by Cobham’s Theorem, see e.g. [6, Theorem 6.3.2].
Generalizing Sturmian systems we introduce dynamical systems for S-adic sequences. To this end, for a finite alphabet \(\mathcal {A}\) define the shift on \(\mathcal {A}^{\mathbb {N}}\) as \(\varSigma :\mathcal {A}^{\mathbb {N}}\to \mathcal {A}^{\mathbb {N}}\) by Σ(w 0w 1…) = w 1w 2…
Definition 3.4.2 (S-adic System)
For an S-adic sequence w over a finite alphabet \(\mathcal {A}\) we denote by \(X_w=\overline {\{\varSigma ^kw\,:\, k\in \mathbb {N}\}}\) the orbit closure of w under the action of the shift Σ. If we denote the restriction of Σ to X w by Σ again we call the pair (X w, Σ) the S-adic system (or S-adic shift) generated by w.
Alternatively, the set X w can be defined using languages by setting \(X_w=\{v \in \mathcal {A}^{\mathbb {N}} \,:\, L(v)\subseteq L(w)\}\). The proof of the fact that both definitions of X w agree is an easy exercise. Also the set \(X_{{\boldsymbol {\sigma }}}=\bigcup X_{w}\), where the union is extended over all S-adic sequences with directive sequence σ, and the associated dynamical system (X σ, Σ) are of interest.Footnote 5 A recent survey on S-adic systems is provided in [44].
In all what follows we will assume that all our substitutions and matrices are unimodular.
The case of σ = (σ), the constant sequence formed by a given unimodular substitution σ over some alphabet \(\mathcal {A}\), has been studied extensively. In this case we call (X (σ), Σ) a substitutive system (see Queffelec [110] for a profound study of dynamical properties of these systems). The theory of Sect. 3.2 can be generalized quite well to substitutive systems if σ is a unimodular Pisot substitution. The seed for such a generalization was planted by Rauzy [114]. Constructing the prototype of what is now called Rauzy fractal, he proved that the dynamical system (X σ, Σ) is measurably conjugate to a rotation on \(\mathbb {T}^2\) if σ = (σ) with σ being the Tribonacci substitution introduced in (3.20). It was conjectured since then that each unimodular Pisot substitution σ gives rise to a substitutive system (X (σ), Σ) which is measurably conjugate to a rotation on the torus. This conjecture is still open and known as Pisot (substitution) conjecture .
In the meantime, the Pisot conjecture was studied by many people and interesting partial results have been achieved. We mention Arnoux and Ito [18] as well as Ito and Rao [91] who could prove the Pisot conjecture subject to some combinatorial coincidence conditions. Conditions of this type will also play an important role in the general theory we will develop here, see Sect. 3.8.2. Recently, Barge [32, 33] made considerable progress on this subject using refinements of the notion of proximality (see [27, 35]). For survey papers on the subject we refer e.g. to [4, 51]. For extensions of this theory to the nonunimodular case see [106, 122].
3.4.2 Generalized Continued Fraction Algorithms
We now generalize the concept of continued fraction algorithm defined in Sect. 3.2.2 and introduce generalized continued fraction algorithms. Standard references for these objects are Brentjes [58] and Schweiger [119]. Also Labbé’s Cheat Sheets [95] for 3-dimensional continued fraction algorithms are highly recommended. For discussions of generalized continued fraction algorithms in a context similar to ours we refer e.g. to [11, 19, 21, 41].
Definition 3.4.3 (Generalized Continued Fraction Algorithm)
For d ≥ 2 let X be a closed subset of the projective space \(\mathbb {P}^{d-1}\) and let {X i}i ∈ I be a partition of X (up to a set of measure 0) indexed by a countable set I. Let \(\mathcal {M}=\{M_i\,:\, i\in I\}\) be a set of unimodular d × d integer matrices (that act on \(\mathbb {P}^{d-1}\) by homogeneity) satisfying \(M_i^{-1}X_i \subset X\) and let \(M:X\to \mathcal {M}\) given by M(x) = M i whenever x ∈ X i. The generalized continued fraction algorithm associated with this data is given by the mapping
If I is a finite set, the algorithm given by F is called additive, otherwise it is called multiplicative.
Note that F is defined only almost everywhere since {X i}i ∈ I in general is only a partition up to measure zero. We confine ourselves to unimodular matrices. Thus the algorithms in Definition 3.4.3 are sometimes called unimodular algorithms. Interesting examples of nonunimodular continued fraction algorithms are provided by the N-continued fraction algorithm introduced by Burger et al. [60] and by the Reverse algorithm, a certain “completion” of the Arnoux-Rauzy algorithm studied in [19, Section 4].
We illustrate the definition of generalized continued fraction algorithms by a classical example: Brun’s continued fraction algorithm.
Example 3.4.4 (Brun’s Algorithm)
The linear version of Brun’s algorithm is defined on the subset
It maps a vector [w 1 : w 2 : w 3] to sort[w 1 : w 2 : w 3 − w 2], i.e., it subtracts the second largest entry from the largest one and sorts the resulting entries in ascending order. By a straightforward calculation we see that \(\mathcal {M}=\{M_{1},M_{2},M_{3}\}\) with
and that the partition X = X 1 ∪ X 2 ∪ X 3 is given by Fig. 3.10.

The partition of X induced by Brun’s continued fraction algorithm
With this data the linear Brun continued fraction mapping can be defined according to Definition 3.4.3 by
Since M 1, M 2, and M 3 are unimodular, Brun’s algorithm is a unimodular continued fraction algorithm. As we did for the classical continued fraction algorithm in Sect. 3.2.2, we can define a projective version also in the case of Brun’s algorithm. This projective version is the original version of this algorithm and goes back to Brun [59]. It is defined on the set
by
To see that f B is the projective version of F B we use the same reasoning as in the classical case in Sect. 3.2.2.
We refer to Example 3.5.12 where we provide S-adic sequences associated with Brun’s algorithm.
Other well-known generalized continued fraction algorithms include the Jacobi-Perron algorithm [109] and the Selmer algorithm [120].
3.5 The Importance of Primitivity and Recurrence
As indicated in Sect. 3.3 it is not possible to generalize the results of Sect. 3.2 to higher dimensions (or, equivalently, to alphabets of cardinality greater than two) without additional conditions on the sequence of substitutions σ. In this section we will discuss two natural conditions that we will have to impose on our sequences of substitutions. The first one is primitivity, the second one is recurrence. Both of them will have important consequences for the underlying S-adic system: primitivity will imply minimality, and if we assume recurrence on top of primitivity, the system will be uniquely ergodic.
3.5.1 Primitivity and Minimality
In the following definition a matrix is called nonnegative if each of its entries is greater than or equal to zero. In a positive matrix each entry is greater than zero.
Definition 3.5.1 (Primitivity)
A sequence M = (M n)n≥0 of nonnegative integer matrices is primitive if for each \(m\in \mathbb {N}\) there is n > m such that M [m,n) is a positive matrix. A sequence σ of substitutions is primitive if its associated sequence of incidence matrices is primitive.
Note that primitivity of (M n)n≥0 implies primitivity of the “shifted” sequence (M n+k)n≥0 for each \(k\in \mathbb {N}\). The same applies for primitive sequences of substitutions.
Our definition of primitivity is taken from [52, Section 2.2]. It coincides with the notion of weak primitivity introduced in [44, Definition 5.1] and with the notion of nonstationary primitivity defined in [81, p. 339]. The more restrictive property of strong primitivity which is also introduced in [44, Definition 5.1] requires that the integer n in Definition 3.5.1 can be chosen in a way that the difference n − m is uniformly bounded in m. In other papers, this stronger property is called primitivity (see e.g. [71,72,73]).
As we will see in the first result of this section, the assumption of primitivity entails minimality of the associated S-adic systems. We recall the definition of this basic concept.
Definition 3.5.2 (Minimality)
Let (X, T) be a topological dynamical system. (X, T) is called minimal if the orbit of each point is dense in X, i.e., if \(\overline {\{T^nx\,:\;n\in \mathbb {N}\}}=X\) holds for each x ∈ X.
The following lemma summarizes the consequences of primitivity for an S-adic system. It is proved for instance in [20, Proposition 2.1 and 2.2]; the minimality assertion can already be found in [71, Lemma 7].
Proposition 3.5.3
If σ is a primitive sequence of substitutions, the following properties hold.
-
(i)
There exists at least one and at most \(|\mathcal {A}|\)limit sequences forσ.
-
(ii)
Let w, w ′be two S-adic sequences with directive sequenceσ. Then the dynamical systems (X w, Σ) and \((X_{w'},\varSigma )\)are equal.
-
(iii)
For a limit sequence w ofσthe S-adic system (X w, Σ) is minimal.
Proof
To show (i) let σ = (σ n) and for each \(n\in \mathbb {N}\) let \(\mathcal {A}_n\) be the set of all first letters occurring in the family \(\sigma _{[0,n)}(\mathcal {A})\) of words. Then \((\mathcal {A}_n)\) is a decreasing sequence of nonempty subsets of \(\mathcal {A}\). Hence, there is \(a\in \bigcap _{n\ge 0}\mathcal {A}_n\). By construction there is a sequence (a n) with a 0 = a such that a n is the first letter of σ n(a n+1). Moreover, σ [0,n)(a n) is a prefix of σ [0,n+1)(a n+1). By primitivity, the lengths of these words tend to infinity which implies that w =limn→∞σ [0,n)(a na n…) converges.Footnote 6 By the same reasoning (here we use that primitivity also holds for “shifted” sequences), we see that w (m) =limn→∞σ [m,n)(a na n…) converges as well and the sequence (w (m)) satisfies the conditions of Definition 3.4.1. Thus w = w (0) is an S-adic sequence with directive sequence σ.
If w is an S-adic sequence with directive sequence σ, by Definition 3.4.1 we can associate a sequence (w (n)) with it. For \(n\in \mathbb {N}\) let a n be the first letter of w (n). Primitivity implies that |σ [0,n)(a n)|→∞ for n →∞ and, hence, the sequence w is determined by the sequence (a n). In particular, we can write w =limn→∞σ [0,n)(a na n…). Since a n uniquely determines a p for each p < n, there are at most \(|\mathcal {A}|\) possible different choices for such a sequence.
To prove (ii) let w and w ′ be two S-adic sequences with directive sequence σ. Associate the sequences (a n) and \((a_n^{\prime })\), respectively, with them as above. If u is a factor of w then u is a factor of σ [0,m)(a m) for some m. By primitivity, there exists n > m such that a m occurs in \(\sigma _{[m,n)}(a_n^{\prime })\). Thus σ [0,m)(a m) and a fortiori also u is a factor of w ′ and, hence, L(w) ⊆ L(w′). Exchanging the roles of w and w ′ we can therefore conclude that L(w) = L(w′) which implies that \(X_w=X_{w'}\).
It remains to prove (iii). This follows if we can show that L(v) = L(w) for each v ∈ X w. This in turn holds if each factor of w occurs infinitely often in w with bounded gaps, which we will now prove. Let u be a factor of w and let (a n) be the sequence of letters associated to w as above. Then u is a factor of σ [0,m)(a m) for some m. By primitivity, there exists n > m such that u is a factor of σ [0,n)(a) for each \(a\in \mathcal {A}\). Since w is an S-adic sequence, w = σ [0,n)(w (n)) holds for some \(w^{(n)}\in \mathcal {A}^{\mathbb {N}}\). Thus u occurs in w infinitely often with gaps bounded by \(2\max \{|\sigma _{[0,n)}(a)| \,:\, a\in \mathcal {A}\}\). □
If σ is a primitive sequence of substitutions, assertion (ii) of this proposition implies that X σ = X w and, hence, (X σ, Σ) = (X w, Σ) for w being an arbitrary S-adic sequence with directive sequence σ. Since we will assume primitivity throughout the remaining part of the paper we will always work with X σ.
3.5.2 Recurrence, Weak Convergence, and Unique Ergodicity
The next concept we introduce is recurrence. Let S be a finite set of substitutions. If we take a random sequence of substitutions \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\) whose elements are taken from a finite set S we will almost always (w.r.t. any natural measure on the space \(S^{\mathbb {N}}\)) get a sequence σ each of whose patterns occurs infinitely often. This infinite repetition of patterns is made precise in the following definition.
Definition 3.5.4 (Recurrence)
A sequence M = (M n) of integer matrices is called recurrent if for each \(m\in \mathbb {N}\) there is n ≥ 1 such that (M 0, …, M m−1) = (M n, …, M n+m−1). A sequence σ = (σ n) of substitutions is called recurrent if for each \(m\in \mathbb {N}\) there is n ≥ 1 such that (σ 0, …, σ m−1) = (σ n, …, σ n+m−1).
Note that recurrence of a sequence of substitutions σ implies that each block of substitutions that occurs once in σ must occur infinitely often (the same is true for sequences of matrices). Thus recurrence of \((\sigma _n)_{n\in \mathbb {N}}\) implies recurrence of \((\sigma _{m+n})_{n\in \mathbb {N}}\) for each \(m\in \mathbb {N}\) and an analogous statement holds for sequences of matrices. We also emphasize that a nonrecurrent sequence of substitutions may well have a recurrent sequence of incidence matrices. This is due to the fact that two different substitutions can have the same incidence matrix.
We now study consequences of primitivity and recurrence. We start with the following result which follows from contraction properties of the Hilbert metric, a metric on projective space that goes back to Birkhoff [55] and Furstenberg [84, pp. 91–95] (we mention [81, Appendix A] and [125, Chapter 26] as more recent references). A special case of this result is stated in Sect. 3.2, see (3.14).
Proposition 3.5.5
LetM = (M n) be a primitive and recurrent sequence of nonnegative integer matrices. Then there is a vector \(\mathbf {u}\in \mathbb {R}^d_{> 0}\)satisfying
Proof
To prove this result we define a metric on the space \(\mathcal {W}=\{\mathbb {R}_{+}\mathbf {w} \,:\, \mathbf {w}\in \mathbb {R}^d_{\ge 0}\setminus \{\mathbf {0}\}\}\) of nonnegative rays through the origin by (see [81, Appendix A])
where v = (v 1, …, v d) and w = (w 1, …, w d). It can be checked by direct calculation that this is a metric on \(\mathcal {W}\) which is the so-called Hilbert Metric (cf. e.g. [81, Lemma A.5] or [125, Chapter 26]). Let \(\mathrm {diam}_{\mathcal {W}}(A)\) be the diameter of a set \(A\subset \mathcal {W}\) w.r.t. this metric. Then \(\mathrm {diam}_{\mathcal {W}}(\mathcal {W})=\infty \) and \(\mathrm {diam}_{\mathcal {W}}(M\mathcal {W})<\infty \) for every positive matrix M. It follows from the definitions that a nonnegative matrix M is nonexpanding in the sense that \(d_{\mathcal {W}}(M\mathbb {R}_+\mathbf {v},M\mathbb {R}_+\mathbf {w})\le d_{\mathcal {W}}(\mathbb {R}_+\mathbf {v},\mathbb {R}_+\mathbf {w})\) for all \(\mathbb {R}_+\mathbf {v},\mathbb {R}_+\mathbf {w}\in \mathcal {W}\). Moreover, one can show that each positive matrix M is a contraction, i.e., there is κ < 1 (depending on M) such that \(d_{\mathcal {W}}(M\mathbb {R}_+\mathbf {v},M\mathbb {R}_+\mathbf {w})\le \kappa \, d_{\mathcal {W}}(\mathbb {R}_+\mathbf {v},\mathbb {R}_+\mathbf {w})\) for all \(\mathbb {R}_+\mathbf {v},\mathbb {R}_+\mathbf {w}\in \mathcal {W}\) (see for instance [55] or [125, Proposition 26.3] for a proof of this).
We now apply these contraction properties to our setting. Since M is primitive and recurrent, there exists a positive matrix B and an integer h > 0 such that \(B=M_{[m_i,m_i+h)}\) for a sequence of positive integers (m i)i≥0 satisfying m i + h ≤ m i+1. By the preceding paragraph we get that \(\mathrm {diam}_{\mathcal {W}}(B\mathcal {W})= \gamma \) for some γ > 0 and that B is a contraction with some contraction factor κ < 1. Thus for each m ∈{m i + h, m i+1 + h − 1} we have
Since κ < 1 and i →∞ for m →∞ this yields the result. Positivity of the entries of u follows from the primitivity of M. □
This result motivates the following definition.
Definition 3.5.6 (Weak Convergence and Generalized Right Eigenvector)
If a sequence of nonnegative integer matrices satisfies (3.26) for some \(\mathbf {u}\in \mathbb {R}^d_{\ge 0}\setminus \{\mathbf {0}\}\) we say that M is weakly convergent to u. In this case we call u a generalized right eigenvector of M. If a sequence σ of substitutions has a sequence of incidence matrices M which is weakly convergent to u, we say that σ is weakly convergent to u and call u a generalized right eigenvector of σ.
Our next goal is to establish unique ergodicity of S-adic systems with primitive and recurrent directive sequences. We start with a fundamental definition (and refer to [126, §6.5] for background material on this).
Definition 3.5.7 (Unique Ergodicity)
A topological dynamical system (X, T) on a compact space X is said to be uniquely ergodic if there is a unique T-invariant Borel probability measure on X.
By a theorem of Krylov and Bogoliubov (see e.g. [126, Corollary 6.9.1]) there always exists an invariant probability measure on (X, T) if X is compact.
A uniquely ergodic dynamical system is ergodic (thus the name) since otherwise there would be a T-invariant set E with μ(E) ∈ (0, 1) which could be used to define a second T-invariant Borel probability measure \(\nu (B)=\frac {\mu (B\cap E)}{\mu (E)}\) on X. Unique ergodicity is equivalent to the fact that each point is generic in the sense that Birkhoff’s ergodic theorem holds everywhere (cf. [126, Theorem 6.19]). Roughly speaking, this is true since nongeneric points (as for instance periodic points) could be used to construct a second invariant measure.
We note that unique ergodicity is close to minimality in the sense that there are many dynamical systems that either enjoy both or none of the two properties. If (X, T) is uniquely ergodic with T-invariant measure μ having full support then minimality follows. However, there are examples of systems that have only one of these two properties. For a discussion of such examples in a context similar to ours see [78] and the references given there. What happens for these examples is that although we have a primitive sequence of matrices (leading to minimality) this primitivity is so weak that it does not make the positive cone converge to a single line as in (3.26). This entails that no letter frequencies exist which permits to construct many invariant measures (see also [53, 54, 81]).
It has been mentioned already in Sect. 3.2 that the existence of uniform frequencies of letters and words in a shift (X w, Σ) entail unique ergodicity. We want to give the elegant proof of this result here before we use it in order to establish unique ergodicity of primitive and recurrent S-adic systems. To this matter we need the following definition (see Lemma 3.2.9 for the special case of Sturmian sequences).
Definition 3.5.8 (Uniform Word and Letter Frequencies)
Let \(w=w_0w_1\ldots \in \mathcal {A}^{\mathbb {N}}\) be given and for each \(k,\ell \in \mathbb {N}\) and each \(v\in \mathcal {A}^*\) let |w k…w k+ℓ−1|v be the number of occurrences of v in w k…w k+ℓ−1. We say that w has uniform word frequencies if for each \(v\in \mathcal {A}^*\) the ratio |w k…w k+ℓ−1|v∕ℓ tends to a limit f v(w) (which does not depend on k) for ℓ →∞ uniformly in k. It has uniform letter frequencies if this is true for each \(v\in \mathcal {A}\).
Proposition 3.5.9 (See [82, Proposition 5.1.21])
Let \(w \in \mathcal {A}^{\mathbb {N}}\)be a sequence with uniform word frequencies and let \(X_w=\overline {\{\varSigma ^kw\,:\, k\in \mathbb {N}\}}\)be the shift orbit closure of w. Then (X w, Σ) is uniquely ergodic.
Proof
For every factor v of w = w
0w
1… let [v] be the cylinder of all sequences in X
w that have v as a prefix. Define a function μ on these cylinders by μ([v]) = μ(Σ
−n[v]) = f
v(w). Since cylinders generate the topology on X
w this defines a Borel measure μ on X
w. Our goal is to show that every element of X
w is generic in the sense of Birkhoff’s ergodic theorem. To this end note first that (here  denotes the characteristic function of a set Y ⊂ X
w)
denotes the characteristic function of a set Y ⊂ X
w)

holds uniformly in \(j \in \mathbb {N}\) for every \(v\in \mathcal {A}^*\) by the existence of uniform word frequencies for w. Since continuous functions are monotone limits of simple functions this extends to
uniformly in \(j\in \mathbb {N}\) for each g ∈ C(X w). By this uniform convergence, in (3.27) we may choose j = n k with any sequence (n k) and (3.27) holds uniformly in k. Since each u ∈ X w is the limit of \((\varSigma ^{n_k}w)\) for some sequence (n k) this implies that
holds for each g ∈ C(X w) and each u ∈ X w. Thus each point is generic in the sense of Birkhoff’s ergodic theorem which is equivalent to unique ergodicity (by [126, Theorem 6.19] which was already mentioned above). □
We now show that the conditions we introduced so far imply unique ergodicity of S-adic systems. In view of Proposition 3.5.9 we will establish the following lemma (see also [44, Theorem 5.7]).
Lemma 3.5.10
Letσbe a sequence of substitutions with associated sequence of incidence matricesM. IfMis primitive and recurrent then each sequence w ∈ X σhas uniform word frequencies.
Proof
Let w = w 0w 1… ∈ X σ be given. We follow the proof of [44, Theorem 5.7] to establish that w has uniform word frequencies.
Part 1: Uniform Letter Frequencies
Since M satisfies the conditions of Proposition 3.5.5, it admits a generalized right eigenvector u. Let u∕∥u∥1 = (u 1, u 2, …, u d)t. Since w ∈ X σ, for all \(k,\ell ,n\in \mathbb {N}\) we can write
for some \(p,v,s\in \mathcal {A}^*\), where the lengths of p, s are bounded by the number \(\max \{|\sigma _{[0,n)}(a)|\,:\,a\in \mathcal {A}\}\). Now for each \(a\in \mathcal {A}\)
By the convergence of the positive cone to u in Proposition 3.5.5 we know that |σ [0,n)(b)|a∕|σ [0,n)(b)| is close to u a for all \(a,b\in \mathcal {A}\) if n is large. Thus for each ε > 0 there is \(N\in \mathbb {N}\) such that whenever ℓ ≥ N we can choose n in a way that |p|, |s|≤ εℓ and ||σ [0,n)(b)|a −|σ [0,n)(b)|u a| < ε|σ [0,n)(b)| for all letters a and b. This proves that the right hand side of (3.28) is bounded by 3ε and, hence, limℓ→∞|w k…w k+ℓ−1|a∕ℓ = u a uniformly in k. Thus w has uniform letter frequencies.
Part 2: Uniform Word Frequencies
For \(m\in \mathbb {N}\) let u (m) be a right eigenvector of the shifted sequence \({\boldsymbol {\sigma }}^{(m)}=(\sigma _{m+n})_{n\in \mathbb {N}}\) and set \({\mathbf {u}}^{(m)}/\Vert {\mathbf {u}}^{(m)}\Vert _1=(u_1^{(m)},\ldots ,u_d^{(m)})\). Such an eigenvector exists by Proposition 3.5.5 since the shifted sequence σ (m) has a primitive and recurrent sequence of incidence matrices as well.
Fix \(v\in \mathcal {L}_{\boldsymbol {\sigma }}\). We claim that for each \(m\in \mathbb {N}\) and each \(w^{(m)}=w_0^{(m)}w_1^{(m)}\ldots \in X_{{\boldsymbol {\sigma }}^{(m)}}\) we have
uniformly in \(q\in \mathbb {N}\). This claim follows because, since w (m) has uniform letter frequencies \((u_1^{(m)},\ldots ,u_d^{(m)})\) by Part 1, we get that
uniformly in \(q\in \mathbb {N}\).
Now we proceed similarly to Part 1. First define
and observe that primitivity of σ implies that both of these quantities tend to ∞ for n →∞. For each \(n\in \mathbb {N}\) choose a fixed \(w^{(n)}=w^{(n)}_0w^{(n)}_1\ldots \in X_{{\boldsymbol {\sigma }}^{(n)}}\). As w ∈ X σ, for all \(k,\ell \in \mathbb {N}\) we can write
for some \(q,r\in \mathbb {N}\), where the lengths of \(p,s\in \mathcal {A}^*\) are bounded by \(m_{n}^+\). There are three possibilities for an occurrence of v in w k…w k+ℓ−1. Firstly, v can overlap with p or s. This can happen at most \(2m_{n}^+\) times. Secondly, v can have nonempty overlap with the images \(\sigma _{[0,n)}(w_i^{(n)})\) and \(\sigma _{[0,n)}(w_{i+1}^{(n)})\) of two consecutive letters \(w^{(n)}_{i}\) and \(w^{(n)}_{i+1}\) of \(w^{(n)}_q\ldots w^{(n)}_{q+r-1}\). This can happen at most \(|v|(r-1)\le |v|\frac {\ell }{m_{n}^-}\) times. Thirdly, v can occur as a factor of \(\sigma _{[0,n)}(w^{(n)}_{i})\) for some i ∈{q, …, q + r − 1} which happens exactly \(\sum _{i=q}^{q+r-1}|\sigma _{[0,n)}(w^{(n)}_{i})|{ }_v\) times. Each of these three possibilities contributes one of the summands of the right hand side of the estimate
Letting ℓ →∞ and using (3.29) for the third term on the right this yields that
Since for n →∞ the quantity \(\frac {|w_k\dots w_{k+\ell -1}|{ }_v}{\ell }\) does not change while \(\frac {|v|}{m_{n}^-} \to 0\) we conclude from (3.31) that \((g(v,n))_{n\in \mathbb {N}}\) is a Cauchy sequence converging to the frequency f v(w) of v in w. Since \(\frac {|v|}{m_{n}^-}\) does not depend on k and the convergence in (3.29) is uniform in q, the estimate (3.30) implies that \(\frac {|w_k\dots w_{k+\ell -1}|{ }_v}{\ell }\to f_v(w)\) for ℓ →∞ uniformly in k and the proof is finished. □
The following main result of this section is an immediate consequence of Propositions 3.5.3, 3.5.9, and Lemma 3.5.10.
Theorem 3.5.11
Letσbe a sequence of substitutions with associated sequence of incidence matricesM. IfMis primitive and recurrent then (X σ, Σ) is minimal and uniquely ergodic.
A proof of a similar result as Theorem 3.5.11 is sketched in Berthé and Delecroix [44]. Moreover, we refer to Fisher [81] and Bezuglyi et al. [53, 54], where theorems of this flavor are proved in the context of Bratteli-Vershik systems.
Example 3.5.12
We associate substitutions with the matrices M 1, M 2, and M 3 that came up in (3.23) during the definition of Brun’s continued fraction algorithm. Indeed, the substitutions
are called Brun substitutions (see [52, Sections 3.3 and 9.2] where also the relation between these substitutions and a slightly different set of “Brun substitutions” studied in [42] is discussed).
It is immediate that M 1M 2M 1M 2 is a strictly positive matrix. Thus we get the following result.
Proposition 3.5.13
Let S = {σ 1, σ 2, σ 3} be the set of Brun substitutions and \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\). Ifσis recurrent and contains the block (σ 1, σ 2, σ 1, σ 2) then the associated S-adic system (X σ, Σ) is minimal and uniquely ergodic.
Proof
Since σ is recurrent it contains the block (σ 1, σ 2, σ 1, σ 2) infinitely often. Thus σ is primitive and the result follows from Theorem 3.5.11. □
3.6 The Importance of Balance and Algebraic Irreducibility
Let σ be a sequence of unimodular substitutions over an alphabet \(\mathcal {A}=\{1,2,\ldots ,d\}\) and let (X σ, Σ) be the S-adic system defined by it. At the end of Sect. 3.2.4 we gave some rough idea on how we want to prove that (X σ, Σ) is measurably conjugate to a rotation on \(\mathbb {T}^{d-1}\). Indeed, we wish to project the broken line (see (3.17) for an example) associated with a limit sequence w ∈ X σ to a hyperplane in \(\mathbb {R}^d\) not containing the frequency vector u of the sequences in X σ. On a natural subdivision \(\mathcal {R}(1),\ldots ,\mathcal {R}(d)\) of the closure \(\mathcal {R}\) of this projection we want to define a domain exchange and a rotation. This is possible only if the sets \(\mathcal {R}(i)\), \(i\in \mathcal {A}\), have suitable topological properties and the mentioned subdivision has no essential overlaps.
In the present section we will define these sets \(\mathcal {R}\) and \(\mathcal {R}(i)\), \(i\in \mathcal {A}\), and discuss basic properties of them. Besides primitivity and recurrence, the crucial conditions we will have to impose on σ in order to get suitable properties of the sets \(\mathcal {R}\) and \(\mathcal {R}(i)\) will be algebraic irreducibility of the sequence of incidence matrices of σ and balance of the language \(\mathcal {L}_{\boldsymbol {\sigma }}\). Both of these conditions will be defined and first consequences of them will be discussed. This paves the way to obtain deeper topological and measure theoretic properties of \(\mathcal {R}\) and \(\mathcal {R}(i)\) in Sect. 3.7. The theory we will outline in the present as well as in the forthcoming sections is mainly due to Berthé et al. [52] and we refer to this paper for rigorous proofs of the statements we give.
3.6.1 S-adic Rauzy Fractals
Following Berthé et al. [52, Section 2.9] we will now define S-adic Rauzy fractals. As mentioned before, on these objects we will be able to “see” the rotations to which we want to (measurably) conjugate our S-adic systems. In the definition we will use the following notations. For a vector \(\mathbf {w}\in \mathbb {R}^d\setminus \{ \mathbf {0} \}\) we write w ⊥ for the hyperplane orthogonal to w, i.e., \({\mathbf {w}}^{\bot }=\{\mathbf {x}\in \mathbb {R}^d\,:\, \langle \mathbf {x},\mathbf {w}\rangle =0 \}\) with 〈⋅, ⋅〉 being the dot product on \(\mathbb {R}^d\), and we equip the space w ⊥ with the (d − 1)-dimensional Lebesgue measure λ w. Since its orthogonal hyperplane will be of special interest later we introduce the vector 1 = (1, …, 1)t.
For vectors \(\mathbf {u},\mathbf {w} \in \mathbb {R}^d\setminus \{\mathbf {0}\}\) satisfying u∉w
⊥ we denote the projection along u to w
⊥ by  .
.
Definition 3.6.1 (S-adic Rauzy Fractal and Subtiles)
Let σ be a sequence of unimodular substitutions over the alphabet \(\mathcal {A}\) and assume that σ is weakly convergent to a generalized right eigenvector \(\mathbf {u}\in \mathbb {R}^d_{>0}\). The S-adic Rauzy fractal in the representation space w ⊥, \(\mathbf {w}\in \mathbb {R}_{\ge 0}^{d}\setminus \{\mathbf {0}\}\), associated with σ is the set

The set \(\mathcal {R}_{\mathbf {w}}\) can be covered by the subtiles

For convenience we will use the notation \(\mathcal {R}(i)=\mathcal {R}_{\mathbf {1}}(i)\) and \(\mathcal {R}=\mathcal {R}_{\mathbf {1}}\).
The prototype of a Rauzy fractal goes back to Rauzy [114] and was used there in order to show that a certain substitutive dynamical system is measurably conjugate to a rotation on the torus, see Example 3.6.2 below. In the meantime there exists a vast literature on Rauzy fractals. For constant sequences σ = (σ) with σ being a Pisot substitution fundamental properties of Rauzy fractals were studied for instance by Ito and Kimura [89], Holton and Zamboni [86], Arnoux and Ito [18], Canterini and Siegel [61], Sirvent and Wang [124], Hubert and Messaoudi [88], and Ito and Rao [91]. Akiyama [2, 3] and Messaoudi [103, 104] consider versions of Rauzy fractals for β-numeration, in Siegel [122], Minervino and Thuswaldner [106], and Minervino and Steiner [105] Rauzy fractals with \(\mathfrak {p}\)-adic factors are related to nonunimodular substitutions. For versions of Rauzy fractals corresponding to substitutions with reducible incidence matrices (whose most prominent representative is the so-called “Hokkaido Fractal” studied by Akiyama and Sadahiro [5]) we refer to [3, 75, 100]. A case of a non-Pisot substitution is treated in [16]. Surveys containing information on Rauzy fractals are provided in [51, 123] (see also [4] for their relation to the Pisot substitution conjecture). An easily accessible treatment of Rauzy fractals intended for a broad audience is given in [17].
Recently, Boyland and Severa [57] considered a particular family of S-adic sequences associated with the so-called infimaxS-adic family over three letters. These sequences do not fit into our framework. Indeed, they have two “expanding directions” which entails that the authors have to project on a 1-dimensional subspace of \(\mathbb {R}^3\) in order to obtain compact Rauzy fractals. Their Rauzy fractals turn out to be Cantor sets which can be subdivided naturally into three subtiles whose convex hulls are intervals that intersect on their boundary points. This fact is used to show that the infimax S-adic systems can be geometrically represented as 3-interval exchange transformations.
In what follows, instead of “S-adic Rauzy fractal” we will often just say “Rauzy fractal”. This will cause no confusion. To give the reader a feeling for a Rauzy fractal and its importance in the remaining part of this chapter we provide an example.
Example 3.6.2 (Tribonacci Substitution)
We explain the definition of a Rauzy fractal for the constant sequence \({\boldsymbol {\sigma }}=(\sigma )_{n\in \mathbb {N}}\) with σ being the Tribonacci substitution introduced in (3.20). The sequence σ is easily checked to be primitive and obviously it is recurrent. Thus it admits a generalized right eigenvector u which is just the Perron-Frobenius eigenvector of M σ. Since each of the words σ(1), σ(2), and σ(3) begins with 1 the only limit sequence of (σ) is given by
and, hence,  for \(\mathbf {w}\in \mathbb {R}_{\ge 0}^{d}\setminus \{\mathbf {0}\}\). In Fig. 3.11 we illustrate the definition of \(\mathcal {R}_{\mathbf {u}}\) and its subtiles (we choose w = u in this case so the occurring projection
for \(\mathbf {w}\in \mathbb {R}_{\ge 0}^{d}\setminus \{\mathbf {0}\}\). In Fig. 3.11 we illustrate the definition of \(\mathcal {R}_{\mathbf {u}}\) and its subtiles (we choose w = u in this case so the occurring projection  is an orthogonal projection). As mentioned before, this famous prototype of a Rauzy fractal first appears in Rauzy [114].
is an orthogonal projection). As mentioned before, this famous prototype of a Rauzy fractal first appears in Rauzy [114].

The broken line and its projection to u ⊥ defining the Rauzy fractal \(\mathcal {R}_{\mathbf {u}}\) for the case of the Tribonacci substitution (note that only the vertices of the broken line are projected; not the whole edges). Each of the three subtiles \(\mathcal {R}_{\mathbf {u}}(i)\) is shaded differently. The shaded triangle represents a part of the plane u ⊥ in which \(\mathcal {R}_{\mathbf {u}}\) is situated
For this example it is known since Rauzy [114] that one can define a rotation on the Rauzy fractal using the broken line. This can be used to prove that the substitutive system (X (σ), Σ) is measurably conjugate to a rotation on \(\mathbb {T}^2\). We want to give an idea on how this works without going into the details. To this end it is convenient to work with \(\mathcal {R}=\mathcal {R}_{\mathbf {1}}\) and its subtiles. It was shown in [114] that each of the three subtiles \(\mathcal {R}(i)\), i ∈{1, 2, 3}, is a compact subset of the space 1 ⊥ which is equal to the closure of its interior and has a boundary of λ 1-measure 0. Moreover, it is proved that these subtiles are pairwise disjoint apart from overlaps on their boundaries. Thus we can almost everywhere define a “domain exchange” E in the following way. If we set

we see from the definition of \(\mathcal {R}(i)\) that  (recall that w is the only limit sequence of σ). As the Lebesgue measure λ
1 doesn’t change under translation and we still have that \(\mathcal {R}=\tilde {\mathcal {R}}(1)\cup \tilde {\mathcal {R}}(2)\cup \tilde {\mathcal {R}}(3)\) also the translated pieces only overlap on a set of measure 0. The domain exchange
(recall that w is the only limit sequence of σ). As the Lebesgue measure λ
1 doesn’t change under translation and we still have that \(\mathcal {R}=\tilde {\mathcal {R}}(1)\cup \tilde {\mathcal {R}}(2)\cup \tilde {\mathcal {R}}(3)\) also the translated pieces only overlap on a set of measure 0. The domain exchange

is thus well defined almost everywhere and it moves \(\mathcal {R}(i)\) to \(\tilde {\mathcal {R}}(i)\) for each i ∈{1, 2, 3}. By what was said above, E is an almost everywhere bijective symmetry. The effect of E on the points of \(\mathcal {R}\) is illustrated in Fig. 3.12. As in the Sturmian case discussed in Sect. 3.2.4, each step on the broken line performs the domain exchange on \(\mathcal {R}\).

The domain exchange on the classical Rauzy fractal associated with the Tribonacci substitution: the bright domain \(\mathcal {R}(1)\) is translated by  , the darker domain \(\mathcal {R}(2)\) is translated by
, the darker domain \(\mathcal {R}(2)\) is translated by  , and finally the darkest domain \(\mathcal {R}(3)\) is translated by
, and finally the darkest domain \(\mathcal {R}(3)\) is translated by  . The union of the translated domains gives \(\mathcal {R}\) again
. The union of the translated domains gives \(\mathcal {R}\) again
The problem that remains is the transition from the domain exchange to the rotation. In the Sturmian case this was achieved by identifying the endpoints of an interval. Here things become more complicated as intervals are replaced by fractals and we have to make identifications on \(\partial \mathcal {R}\).
To settle this, Rauzy [114] proved that \(\mathcal {R}\) forms a fundamental domain of the lattice

i.e., it forms a tiling of 1
⊥ when translated by elements of Λ. Thus \(\mathcal {R}\) can be seen as a subset of the 2-torus 1
⊥∕Λ and since it is a fundamental domain of Λ it covers the torus without overlaps (apart from the boundary). This gives the desired identifications on \(\partial \mathcal {R}\). If we look at the domain exchange on this torus we see that  holds for i, j ∈{1, 2, 3}. Thus on this torus all the translations performed by the domain exchange E become the same and, hence, on the torus the mapping E induces a rotation by
holds for i, j ∈{1, 2, 3}. Thus on this torus all the translations performed by the domain exchange E become the same and, hence, on the torus the mapping E induces a rotation by  . One can show (by defining a suitable “representation map” for the elements of X
(σ) on the torus 1
⊥∕Λ) that (X
(σ), Σ) is measurably conjugate to
. One can show (by defining a suitable “representation map” for the elements of X
(σ) on the torus 1
⊥∕Λ) that (X
(σ), Σ) is measurably conjugate to  , which is a rotation on the 2-torus. We also refer to [52, Section 8] where rigorous arguments are given in a general context (a sketch of these arguments is provided in Sect. 3.9.2 below).
, which is a rotation on the 2-torus. We also refer to [52, Section 8] where rigorous arguments are given in a general context (a sketch of these arguments is provided in Sect. 3.9.2 below).
In the preceding example various properties of the Rauzy fractal were needed in order to get the measurable conjugacy between the substitutive system and the rotation. Our aim is to establish these conditions for S-adic Rauzy fractals under a set of natural conditions. Since tiling properties of S-adic Rauzy fractals will play an important role we will now define some collections of Rauzy fractals that will later be shown to provide tilings in the following sense.
Definition 3.6.3 (Multiple Tiling and Tiling)
A collection \(\mathcal {K}\) of subsets of a Euclidean space \(\mathcal {E}\) is called a multiple tiling of \(\mathcal {E}\) if each element of \(\mathcal {K}\) is a compact set which is equal to the closure of its interior, and if there is \(m\in \mathbb {N}\) such that almost every point (w.r.t. Lebesgue measure) of \(\mathcal {E}\) is contained in exactly m elements of \(\mathcal {K}\). If m = 1 then a multiple tiling is called a tiling.
The collections of tiles we need in our setting are defined in terms of so-called discrete hyperplanes . These objects were first defined and studied in the context of theoretical computer science (see [115] and later [7, 93]) and have interesting connections to generalized continued fraction algorithms (cf. e.g. [45, 79, 80, 90, 92]). The formal definition reads as follows. Pick \(\mathbf {w}\in \mathbb {R}^d_{\ge 0}\setminus \{\mathbf {0}\}\), then (setting e i = l(i) for \(i\in \mathcal {A}\))
This has a geometrical meaning: if we interpret the symbol \([\mathbf {x},i]\in \mathbb {Z}^d\times \mathcal {A}\) as the hypercube or “face”
the set Γ(w) turns into a “stepped hyperplane” that approximates w ⊥ by hypercubes. In Fig. 3.13 this is illustrated for two cases: for a rational vector w, which leads to a periodic pattern and for an irrational vector w which yields an aperiodic one. A finite subset of a discrete hyperplane will often be called a patch.

Examples of stepped planes. On the left hand side the stepped plane Γ(1), on the right hand side Γ(u) with u as in Example 3.6.2. Since 1 is rational the stepped plane Γ(1) is periodic, while the irrationality of u leads to an aperiodic structure in Γ(u)
Using the concept of discrete hyperplane we define the following collections of Rauzy fractals. Let σ be a sequence of substitutions with generalized right eigenvector \(\mathbf {u}\in \mathbb {R}_{> 0}^d\) and choose \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\). Then, following [52, Section 2.10], we set

As mentioned above, we will see that each of these collections forms a tiling of the space w ⊥ under natural conditions. A special role will be played by the collection \(\mathcal {C}_{\mathbf {1}}\) which will give rise to a periodic tiling of 1 ⊥ by lattice translates of the Rauzy fractal \(\mathcal {R}\).
3.6.2 Balance, Algebraic Irreducibility, and Strong Convergence
Let (X σ, Σ) be an S-adic system. As we mentioned already, the associated Rauzy fractals can be used to prove that (X σ, Σ) is measurably conjugate to a rotation on a torus provided that they have suitable properties. In the present section we will discuss two conditions that have to be imposed on σ in order to guarantee that each of the associated Rauzy fractals \(\mathcal {R}_{\mathbf {w}}\), \(\mathbf {w}\in \mathbb {R}_{\ge 0}\setminus \{\mathbf {0}\}\), as well as each of their subtiles \(\mathcal {R}_{\mathbf {w}}(i)\), \(i\in \mathcal {A}\), is a compact set that is the closure of its interior and has a boundary of zero measure λ w.
The first property is balance and as we will see immediately it entails compactness of \(\mathcal {R}_{\mathbf {w}}\) and its subtiles (see e.g. [1, 44] or [52, Section 2.4] for similar definitions).
Definition 3.6.4 (Balance)
Let \(\mathcal {A}\) be an alphabet and consider a pair of words \((u,v)\in \mathcal {A}^*\times \mathcal {A}^*\) of the same length. If there is C > 0 such that ||v|i −|u|i| ≤ C holds for each letter \(i\in \mathcal {A}\), the pair (u, v) is called C-balanced. A language \(\mathcal {L}\subset \mathcal {A}^*\) is called C-balanced if each pair \((u,v)\in \mathcal {L}\times \mathcal {L}\) with |u| = |v| is C-balanced. It is called finitely balanced if it is C-balanced for some C > 0.
In Definition 3.2.3 and in Sect. 3.3.2 we defined balance of an infinite sequence and applied this notion to Sturmian sequences as well as to Arnoux-Rauzy sequences. For a general S-adic system (X σ, Σ) it is more convenient to look at balance of the associated language \(\mathcal {L}_{\boldsymbol {\sigma }}\) since there might be more than one limit sequence associated with the given directive sequence σ. Of course, by Proposition 3.5.3(ii) primitivity of σ implies that each of these limit sequences has the language \(\mathcal {L}_{\boldsymbol {\sigma }}\) of factors.
The following result goes back essentially to [1, Proposition 7] and, in the form we present it here, is contained in [52, Lemma 4.1] (in fact, the conditions that are imposed on σ in that paper are slightly weaker than ours).
Proposition 3.6.5
Let σ be a primitive and recurrent sequence of unimodular substitutions. Then \(\mathcal {R}_{\mathbf {w}}\) and each of its subtiles is compact for each \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\) if and only if \(\mathcal {L}_{\boldsymbol {\sigma }}\) is finitely balanced.
Proof
Since \(\mathcal {R}_{\mathbf {w}}\) as well as each of its subtiles is closed by definition it suffices to prove that
We start with proving (3.36) for the case w = 1 and follow [52]. Let u be a generalized right eigenvector for σ which exists by Proposition 3.5.5.
If \(\mathcal {R}\) is bounded then there is C > 0 such that  for each prefix of a limit sequence of σ. Let \(u,v\in \mathcal {L}_{\boldsymbol {\sigma }}\) be of equal length. Then, by primitivity these words are factors of a limit sequence which entails that
for each prefix of a limit sequence of σ. Let \(u,v\in \mathcal {L}_{\boldsymbol {\sigma }}\) be of equal length. Then, by primitivity these words are factors of a limit sequence which entails that  . As l(u) −l(v) ∈1
⊥ this yields
. As l(u) −l(v) ∈1
⊥ this yields  and, hence, \(\mathcal {L}_{\boldsymbol {\sigma }}\) is 4C-balanced.
and, hence, \(\mathcal {L}_{\boldsymbol {\sigma }}\) is 4C-balanced.
Assume now that \(\mathcal {L}_{\boldsymbol {\sigma }}\) is C-balanced and let w be a limit sequence of σ. Let p be a prefix of w and write w = v
0v
1… where \(v_k\in \mathcal {A}^{*}\) with |v
k| = |p| for each k ≥ 0. By C-balance,  for each \(k\in \mathbb {N}\) and, hence,
for each \(k\in \mathbb {N}\) and, hence,  for each \(n\in \mathbb {N}\). By Lemma 3.5.10 (see proof of Part 1), the letter frequencies of w are given by the entries of the vector u∕∥u∥1 which implies that
for each \(n\in \mathbb {N}\). By Lemma 3.5.10 (see proof of Part 1), the letter frequencies of w are given by the entries of the vector u∕∥u∥1 which implies that  and thus
and thus

This finishes the proof of (3.36) for the case w = 1. The full statement (3.36) follows from this because  , which implies that \(\mathcal {R}\) is bounded if and only if \(\mathcal {R}_{\mathbf {w}}\) is bounded for each \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\). □
, which implies that \(\mathcal {R}\) is bounded if and only if \(\mathcal {R}_{\mathbf {w}}\) is bounded for each \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\). □
Our next aim is to make sure that \(\mathcal {R}_{\mathbf {w}}(i)\) has nonempty interior for each \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\) and each \(i\in \mathcal {A}\). This will require much more work. In a first step observe that we have no hope to get nonempty interior if u has coordinates which are rationally dependent, i.e., if there is \(\mathbf {x}\in \mathbb {Z}^d\) such that 〈x, u〉 = 0. Indeed, in this case the set \(\mathcal {R}_{\mathbf {w}}\) is contained in a finite union of proper affine subspaces of w ⊥. We wish to exclude this case first. This is related to an irreducibility property (going back to [52, Section 2.2]) of the underlying set of incidence matrices which we define now.
Definition 3.6.6 (Algebraic Irreducibility)
Let M = (M n) be a sequence of nonnegative integer matrices. We say that M is algebraically irreducible if for each \(m\in \mathbb {N}\) there is n > m such that the characteristic polynomial of M [m,ℓ) is irreducible for each ℓ ≥ n.
A sequence σ of substitutions is called algebraically irreducible if it has a sequence of incidence matrices which is algebraically irreducible.
Remark 3.6.7
For our purposes we can replace algebraic irreducibility by the weaker condition that for each \(m\in \mathbb {N}\) the matrix M m is regular and there is n > m such that M [m,ℓ) does not have 1 as eigenvalue for each ℓ ≥ n. This condition is easier to check than algebraic irreducibility.
However, since we will always have to assume balance in our setting all but the dominant eigenvalue of large blocks M [m,ℓ) should be inside the closed unit disk anyway (cf. also the definition of the Pisot condition in (3.59)). Thus this new condition is not essentially weaker than algebraic irreducibility. For this reason we work with algebraic irreducibility in the sequel.
Together with other properties, algebraic irreducibility of σ implies rational independence of the right eigenvector. We announce this in the following lemma, whose elegant proof is taken from [52, Lemma 4.2].
Lemma 3.6.8
Let σ be an algebraically irreducible sequence of substitutions with finitely balanced language \(\mathcal {L}_{\boldsymbol {\sigma }}\) that admits a generalized right eigenvector \(\mathbf {u}\in \mathbb {R}_{\ge 0}^{d}\setminus \{\mathbf {0}\}\) . Then u has rationally independent coordinates.
Proof
The proof is done by contradiction. Assume that u has rationally dependent coordinates. Then there is \(\mathbf {x}\in \mathbb {Z}^d\setminus \{\mathbf {0}\}\) such that 〈x, u〉 = 0. This implies that  is uniformly bounded in \(i\in \mathcal {A}\) and \(n\in \mathbb {N}\) by balance of \(\mathcal {L}_{\boldsymbol {\sigma }}\). Thus \((M_{[0,n)})^t\mathbf {x} \in \mathbb {Z}^d\) is bounded and, hence, there exists an integer k and infinitely many ℓ > k with (M
[0,k))tx = (M
[0,ℓ))tx. Multiplying by ((M
[0,k))t)−1 we see that x is an eigenvector of (M
[k,ℓ))t with eigenvalue 1. Since ℓ can be chosen arbitrarily large this contradicts algebraic irreducibility. □
is uniformly bounded in \(i\in \mathcal {A}\) and \(n\in \mathbb {N}\) by balance of \(\mathcal {L}_{\boldsymbol {\sigma }}\). Thus \((M_{[0,n)})^t\mathbf {x} \in \mathbb {Z}^d\) is bounded and, hence, there exists an integer k and infinitely many ℓ > k with (M
[0,k))tx = (M
[0,ℓ))tx. Multiplying by ((M
[0,k))t)−1 we see that x is an eigenvector of (M
[k,ℓ))t with eigenvalue 1. Since ℓ can be chosen arbitrarily large this contradicts algebraic irreducibility. □
In Definition 3.5.6 the concept of weak convergence of a sequence of matrices is introduced. In what follows, we will need a stronger form of convergence, viz. strong convergence. If we look back to Lemma 3.2.12 we see that the cascade of inductions we perform on the interval leads to smaller and smaller intervals (that are blown up by renormalization) whose lengths tend to 0. To get an analogous behavior on S-adic Rauzy fractals we need to introduce a certain subdivision on them whose pieces have a diameter that tends to zero. It will turn out that strong convergence is the right condition to guarantee this behavior. We thus recall the definition of strong convergence which is well known in the theory of generalized continued fraction algorithms (see e.g. [119, Definition 19]) and then derive it from the conditions we introduced so far.
Definition 3.6.9 (Strong Convergence)
We say that a sequence M = (M n) of nonnegative integer matrices is strongly convergent to \(\mathbf {u}\in \mathbb {R}_{\ge 0}^{d}\setminus \{\mathbf {0}\}\) if

If σ has a strongly convergent sequence of incidence matrices we say that σ is strongly convergent.
The difference between weak and strong convergence is explained and illustrated in Fig. 3.14: while weak convergence of vectors can be seen on the unit ball, strong convergence takes place at their end points.

The sequence M = (M n) of matrices is weakly convergent, if the intersections of M [0,n)e i with the unit ball converge to the intersection of the generalized right eigenvector u with the unit ball. It is strongly convergent, if the minimal distance of the point M [0,n)e i to the ray \( \mathbb {R}_+\mathbf {u}\) converges to zero for each \(i\in \mathcal {A}\). Summing up: weak convergence takes place on the unit ball while strong convergence concerns the end points of the vectors
The following result on strong convergence will be needed in the sequel. It is the content of [52, Proposition 4.3].
Proposition 3.6.10
Let σ be a primitive, algebraically irreducible, and recurrent sequence of substitutions with finitely balanced language \(\mathcal {L}_{\boldsymbol {\sigma }}\) . Then

By primitivity this implies that σ is strongly convergent.
The proof of this result is quite tricky. We give a sketch to illustrate the ideas and refer to [52, Proposition 4.3] for details.
Proof (Sketch)
Let w be a limit sequence of σ. By primitivity we may apply Proposition 3.5.3(ii) to the shifted sequence (σ n, σ n+1, σ n+2, …). Thus the language \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n)}\) is equal to the language L(w (n)) of factors of the nth “desubstitution” w (n) of w (see (3.22)), i.e., each \(v\in \mathcal {L}_{\boldsymbol {\sigma }}^{(n)}\) satisfies l(v) = l(p) −l(q), where p and q are prefixes of w (n). Thus it suffices to prove

Let (i
n) be the sequence of first letters of w
(n) and choose ε > 0 arbitrary. Define the sets  and
and  .
.
Then \(\mathcal {S}_n \to \tilde {\mathcal {R}}\) for n →∞ in Hausdorff metric. Since, on the other hand,  holds for each \(p\in \mathcal {A}^*\) such that pi
n is a prefix w
(n) we obtain
holds for each \(p\in \mathcal {A}^*\) such that pi
n is a prefix w
(n) we obtain

for each \(p\in \mathcal {A}^*\) such that pi n is a prefix w (n) for a large enough n. We have to prove (3.38) for arbitrary prefixes p of w (n). If \(N(p)=\{n\in \mathbb {N}\,:\, pi_n \mbox{ is a prefix of } w^{(n)}\}\) is infinite then (3.38) yields

Using algebraic irreducibility and balance by some tricky arguments it is now possible to find a set P of prefixes of w such that the abelianizations l(P) contain a basis of \(\mathbb {R}^d\) and N(P) =⋂p ∈ PN(p) is an infinite set (moreover, the elements of P can by “synchronized” in a certain way by using the recurrence of σ). This implies that (3.39) is true for each p ∈ P when N(p) is replaced by N(P), i.e.,

Since l(P) contains a basis of \(\mathbb {R}^d\) we gain

Using primitivity and recurrence again, Eq. (3.37) can be obtained using (3.38) and (3.40). This again requires some work and we omit the details. □
3.7 Properties of S-adic Rauzy Fractals
Based on the results of the previous section we will now study deeper properties of S-adic Rauzy fractals. In particular, the present section is devoted to the illustration of the proof of the following result from Berthé et al. [52, Theorem 3.1 (ii)].
Theorem 3.7.1
Let S be a finite set of unimodular substitutions over a finite alphabet \(\mathcal {A}\)and letσ = (σ n) be a primitive and algebraically irreducible sequence of substitutions taken from the set S. Assume that there is C > 0 such that for every \(\ell \in \mathbb {N}\)there exists n ≥ 1 such that (σ n, …, σ n+ℓ−1) = (σ 0, …, σ ℓ−1) and the language \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n+\ell )}\)is C-balanced.
Then each subtile \(\mathcal {R}(i)\), \(i\in \mathcal {A}\), of the Rauzy fractal \(\mathcal {R}\)is a nonempty compact set which is equal to the closure of its interior and has a boundary whose Lebesgue measure λ 1is zero.
Remark 3.7.2
-
(i)
We can see that the assumptions of this theorem contain all the properties we discussed in the previous subsections. We could have used the stronger assumption that σ is primitive, recurrent, algebraically irreducible, and has C-balanced language \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n)}\) for each \(n\in \mathbb {N}\). However, although this assumption is more handy and holds for many natural examples it would lead to a measure zero subset of the set of “all” sequences σ. The conditions we give in Theorem 3.7.1 will turn out to be “generic” in the sense that they are true for “almost all” sequences σ. All this will be made precise when we develop a metric counterpart of our theory in Sect. 3.9.3.
-
(ii)
Let σ be a substitution on the alphabet \(\mathcal {A}\). It is easy to prove that for each C > 0 there is C′ > 0 such that σ(w) is C ′-balanced for each C-balanced sequence \(w\in \mathcal {A}^{\mathbb {N}}\). Applying this to the substitution σ = σ [0,n+ℓ) for some n, ℓ with balanced language \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n+\ell )}\) we see that we can choose the constant C in Theorem 3.7.1 in a way that also \(\mathcal {L}_{\boldsymbol {\sigma }}\) is C-balanced. We will always assume that C is chosen in this way in the sequel.
-
(iii)
We confine ourselves to finite sets S of substitutions to keep things as simple as possible. With a bit more effort it is possible to generalize Theorem 3.7.1 to infinite sets S. This is of interest because infinite sets S correspond to multiplicative continued fraction algorithms like the important Jacobi-Perron algorithm or an acceleration of the Arnoux-Rauzy algorithm proposed recently by Avila et al. [30]. This more general setting is treated in [52].
Theorem 3.7.1 will enable us to study tiling properties of \(\mathcal {R}_{\mathbf {w}}\) and its subtiles which will finally lead to the measurable conjugacy of (X σ, Σ) to a rotation.
The proof of Theorem 3.7.1 is quite long and technical and we refer to [52, Section 6] for details. Our aim here is to illustrate the main ideas in a way that is hopefully more accessible to a broader readership than the original research paper. First we will establish a set equation for the subtiles \(\mathcal {R}_{\mathbf {w}}(i)\), \(i\in \mathcal {A}\), of \(\mathcal {R}_{\mathbf {w}}\) that governs certain subdivisions of \(\mathcal {R}_{\mathbf {w}}(i)\). Using this set equation we will be able to establish the properties of S-adic Rauzy fractals stated in Theorem 3.7.1.
Theorem 3.7.1 has a number of predecessors. For instance, Lagarias and Wang [96] proved that each self-affine tile \(\mathcal {T}\) is the closure of its interior and \(\partial \mathcal {T}\) has Lebesgue measure zero. For substitutive Rauzy fractals the according result was proved by Sirvent and Wang [124]. However, in all these cases the sets have strong self-affinity properties which are no longer present in our setting. We therefore need new ideas and more efforts to get the desired results (in particular, the proof of the fact that the boundary of an S-adic Rauzy fractal has measure zero will need quite some work).
3.7.1 Set Equations for S-adic Rauzy Fractals and Dual Substitutions
The first important tool in the proof of Theorem 3.7.1 will be a set equation for the subtiles \(\mathcal {R}_{\mathbf {w}}(i)\), \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\) and \(i\in \mathcal {A}\), of a sequence σ of unimodular substitutions as well as for related subtiles associated with “shifts” of σ. This set equation equips the sets \(\mathcal {R}_{\mathbf {w}}(i)\) with a subdivision structure that is governed by σ. We now give an idea on how this works.
Let σ = (σ n) be a primitive and recurrent sequence of unimodular substitutions over the alphabet \(\mathcal {A}\) with generalized right eigenvector \(\mathbf {u}\in \mathbb {R}_{> 0}^d\) and choose \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\). In all what follows, keep in mind the definition of the subtile \(\mathcal {R}_{\mathbf {w}}(i)\) from (3.33). We choose a limit sequence w of σ and associate with it the sequence (w (n)) of its “desubstitutions” according to (3.22).
Consider the set  and observe that by the definition of a limit sequence each \(p\in \mathcal {A}^*\) for which pi is a prefix of w can be written as p = σ
0(p′)p
0 with p
0i a prefix of σ
0(j) for some \(j\in \mathcal {A}\) and p′j some prefix of w
(1). Using this decomposition of p we obtain the decomposition
and observe that by the definition of a limit sequence each \(p\in \mathcal {A}^*\) for which pi is a prefix of w can be written as p = σ
0(p′)p
0 with p
0i a prefix of σ
0(j) for some \(j\in \mathcal {A}\) and p′j some prefix of w
(1). Using this decomposition of p we obtain the decomposition

From (3.21) we see that lσ
0(p′) = M
0l(p′). Moreover, direct calculation (see [52, Lemma 5.2]) yields that  . Inserting this in (3.41) we gain
. Inserting this in (3.41) we gain

Taking the union over all (finitely many, by Proposition 3.5.3) limit sequences of σ and taking the closure we obtain by (3.33) that

We now inspect the closures in the union in (3.42). Looking at the definition of subtiles in (3.33) we see that these are subtiles of the Rauzy fractal corresponding to the shifted sequence (σ n+1)n≥0 of σ. Indeed, it follows from Proposition 3.5.5 that \(M_0^{-1}\mathbf {u}\) is the right eigenvector of this shifted sequence. This motivates the following definitions.
For \(k\in \mathbb {N}\) let

denote the subtiles of the shifted sequence of substitutions \((\sigma _{n+k})_{n\in \mathbb {N}}\) which live in the hyperplane \((M_{[0,k)}^{t}\mathbf {w})^\bot \) by

and set \(\mathcal {R}_{\mathbf {w}}^{(k)}=\bigcup _{i\in \mathcal {A}}\mathcal {R}_{\mathbf {w}}^{(k)}(i)\). Together with these notations (3.42) can be generalized by using similar arguments as we used in its proof. The generalized form of (3.42) reads as follows (for a detailed proof see [52, Proposition 5.6]).
Proposition 3.7.3 (The Set Equation)
Letσbe a primitive and recurrent sequence of unimodular substitutions with generalized right eigenvectoru. Then for each \([\mathbf {x},i]\in \mathbb {Z}^d\times \mathcal {A}\)and every \(k,\ell \in \mathbb {N}\)with k < ℓ we have

where
The elements in the union on the right hand side of (3.45) are called the level (ℓ − k) subtiles of  . The collection of all the elements in the union is called the (ℓ − k)-th subdivision of
. The collection of all the elements in the union is called the (ℓ − k)-th subdivision of  . This will often be applied for the case k = 0. In Fig. 3.16 the set equation is illustrated for the situation discussed in Example 3.7.8.
. This will often be applied for the case k = 0. In Fig. 3.16 the set equation is illustrated for the situation discussed in Example 3.7.8.
The dual geometric realization \(E_1^*(\sigma )\) of a substitution σ defined in (3.46) will turn out to be useful when we define so-called coincidence conditions in Sect. 3.8.2. If we regard the pairs [x, i] as hypercubes as we did in (3.34) this dual also has a geometric meaning. We explain this in the following example.
Example 3.7.4
Let σ be the Tribonacci substitution defined in (3.20). Then by direct computation we see that \(E_1^*(\sigma )\) is given by
together with the obvious fact that \(E_1^*(\sigma )[\mathbf {x},i]=M_\sigma ^{-1}\mathbf {x}+E_1^*(\sigma )[\mathbf {0},i]\). One can extend the definition of \(E_1^*(\sigma )\) to subsets of \(Y\subset \mathbb {Z}^d\times \mathcal {A}\) in a natural way by setting
Using this extension we can then iterate \(E_1^*(\sigma )\). The geometric interpretation of \(E_1^{*}(\sigma )^{12}[\mathbf {0},1]\) is depicted in Fig. 3.15. It is not by accident that this image is a good approximation of (an affine image of) the classical Rauzy fractal corresponding to σ depicted in Fig. 3.12. In fact, \(E_1^{*}(\sigma )\) can even be used to give an alternative definition of \(\mathcal {R}\), see for example [18, 51].

An approximation of \(\mathcal {R}\) using \(E_1^*(\sigma )\)

Illustration of the set equation. (a) shows a patch P 0 of the collection \(\mathcal {C}_{ \mathbb {\mathbf {w}}}=\mathcal {C}^{(0)}_{ \mathbb {\mathbf {w}}}\), (b) shows a patch P 1 of \(\mathcal {C}^{(1)}_{\mathbf {w}}\). In (c) P 0 and P 1 are drawn together to illustrate that they lie in different planes. In (d) the matrix M 0 is applied to P 1: the image M 0P 1 is located in the same plane as P 0 and forms a subdivision of tiles of P 0. The subdivision of P 0 in patches of \(M_0\mathcal {C}^{(1)}_{ \mathbb {\mathbf {w}}}\) is shown in (e) for the whole patch P 0
The dual \(E_1^*(\sigma )\) and its higher dimensional generalizations have been investigated thoroughly in connection with the study of substitutive dynamical systems and their Rauzy fractals (see [18, 51, 74, 91, 100, 117]). We need a result of Fernique [79] that shows how \(E_1^*(\sigma )\) behaves with respect to discrete hyperplanes. Before we state it we introduce some notation. Let σ be a sequence of substitutions with generalized right eigenvector \(\mathbf {u}\in \mathbb {R}^d_{>0}\) and let a fixed vector \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\) be given (such that the Rauzy fractal \(\mathcal {R}_{\mathbf {w}}\) can be defined). Then, motivated by the projections (3.43) we needed in the formulation of the set equation we set
Lemma 3.7.5
Letσ = (σ n) be a sequence of unimodular substitutions. Then for all k < ℓ the following assertions hold.
-
(i)
M [k,ℓ)(w (ℓ))⊥ = (w (k))⊥,
-
(ii)
\(E_1^*(\sigma _{[k,\ell )})\varGamma ({\mathbf {w}}^{(k)})=\varGamma ({\mathbf {w}}^{(\ell )})\),
-
(iii)
for distinct pairs [x, i], [x ′, i′] ∈ Γ(w (k)) the images \(E_1^*(\sigma _{[k,\ell )})[\mathbf {x},i]\)and \(E_1^*(\sigma _{[k,\ell )})[{\mathbf {x}}^{\prime },i']\)are disjoint patches of Γ(w (ℓ)).
Proof
Assertion (i) is an immediate consequence of the definition of w (k), assertions (ii) and (iii) are the content of [79, Theorem 1]. Their proof is a bit tedious, however, it just uses the definition of discrete hyperplane and checks the required conditions (assertion (iii) is essentially already contained in [18, Lemma 3]). □
Combining Proposition 3.7.3 and Lemma 3.7.5 we get the following result in which we use the notation

for the collection of subtiles associated with the shifted sequence \((\sigma _{n+k})_{n\in \mathbb {N}}\) of σ.
Proposition 3.7.6
Letσbe a primitive and recurrent sequence of unimodular substitutions with generalized right eigenvectoru. Then for each \([\mathbf {x},i]\in \mathbb {Z}^d\times \mathcal {A}\)and every \(k,\ell \in \mathbb {N}\)with k < ℓ we have

The collection \(M_{[k,\ell )}\mathcal {C}_{\mathbf {w}}^{(\ell )}\) is a refinement of \(\mathcal {C}_{\mathbf {w}}^{(k)}\) in the sense that each element of the latter is a finite union of elements of the former.
The following lemma shows that the set equation subdivides Rauzy fractals into sets whose diameter eventually tends to zero (see [52, Lemma 5.5]).
Lemma 3.7.7
Let \(\boldsymbol {\sigma } = (\sigma _n)\in S^{\mathbb {N}}\) be a primitive, algebraically irreducible, and recurrent sequence of unimodular substitutions with balanced language \(\mathcal {L}_{\boldsymbol {\sigma }}\) , and let \(\mathbf {w} \in \mathbb {R}_{\ge 0}^d \setminus \{\mathbf {0}\}\) . Then
Proof
As  and
and  , we conclude that
, we conclude that  for all \(v\in \mathcal {L}_{\boldsymbol {\sigma }}^{(n)}\). Now, the result follows from Proposition 3.6.10 and the definition of \(\mathcal {R}^{(n)}_{\mathbf {w}}\) in (3.44). □
for all \(v\in \mathcal {L}_{\boldsymbol {\sigma }}^{(n)}\). Now, the result follows from Proposition 3.6.10 and the definition of \(\mathcal {R}^{(n)}_{\mathbf {w}}\) in (3.44). □
We explain the concepts and results of this section in the next example.
Example 3.7.8
Recall the definition of the Arnoux-Rauzy substitutions σ 1, σ 2, σ 3 from (3.18) and consider a sequence
where the dots “…” mean that the sequence is continued in a way that σ is primitive and recurrent.
If we start with three blocks of the form σ 1, σ 2, σ 3 it turns out that \(\mathcal {R}_{\mathbf {w}}\) is close to the classical Rauzy fractal studied in Example 3.6.2 in Hausdorff metric, which, of course, doesn’t say anything about its topological properties or tiling properties; we just did it this way to get nice pictures in Fig. 3.16.
In Fig. 3.16a we show a patch P 0 of the collection \(\mathcal {C}_{\mathbf {w}}\) (for some convenient vector \(\mathbf {w}\in \mathbb {R}^3_{\ge 0}\setminus \{\mathbf {0}\}\)) of subtiles associated with σ, while Fig. 3.16b shows a patch P 1 of the collection \(\mathcal {C}_{\mathbf {w}}^{(1)}\) associated with the shifted sequence
Note that, since w and w (1) are not collinear, these patches live in two different planes which is illustrated in Fig. 3.16c.
In this setting, the set equation in Proposition 3.7.3 says that each element of the collection \(\mathcal {C}_{\mathbf {w}}\) can be viewed as the union of elements from \(M_0\mathcal {C}_{\mathbf {w}}^{(1)}\). In other words, if we take the patch P 1 depicted in Fig. 3.16b and apply the linear mapping M 0 to it, the resulting patch M 0P 1 lies in the same plane w ⊥ as the collection \(\mathcal {C}_{\mathbf {w}}\) and some elements of P 0 are unions of elements from M 0P 1. In Fig. 3.16d this is illustrated: the image of the patch P 1 from Fig. 3.16b under the mapping M 0 is subdividing some parts of P 0. Figure 3.16e illustrates that, according to Proposition 3.7.6, each element of \(\mathcal {C}_{\mathbf {w}}\) is a union of elements from \(M_0\mathcal {C}_{\mathbf {w}}^{(1)}\).
Note that in Fig. 3.16 the collections \(\mathcal {C}_{\mathbf {w}}\) and \(\mathcal {C}^{(1)}_{\mathbf {w}}\) are depicted as tilings and the patches of \(M_0\mathcal {C}^{(1)}_{\mathbf {w}}\) subdivide the elements of \(\mathcal {C}_{\mathbf {w}}\) without overlap. This is the situation we “dream” of. So far, we only know that elements of \(\mathcal {C}_{\mathbf {w}}\) are unions of elements of \(M_0\mathcal {C}^{(1)}_{\mathbf {w}}\). To realize this ideal situation we need to work more.
3.7.2 An S-adic Rauzy Fractal Is the Closure of Its Interior
The present section is devoted to the interior of the subtiles. We start with a covering result taken from [52, Proposition 6.2]. In its statement we use the following terminology. Let \(\mathcal {K}\) be a collection of subsets of a set D. The covering degree of \(\mathcal {K}\) (in D) is the largest number m having the property that each x ∈ D is contained in at least m elements of \(\mathcal {K}\).
Lemma 3.7.9
Letσbe a sequence of unimodular substitutions and \(\mathbf {w}\in \mathbb {R}_{\ge 0}\setminus \{\mathbf {0}\}\). Ifσis primitive, recurrent, algebraically irreducible, and has finitely balanced language \(\mathcal {L}_{\boldsymbol {\sigma }}\)then \(\mathcal {C}_{\mathbf {w}}^{(n)}\)covers (w (n))⊥with finite covering degree for each \(n\in \mathbb {N}\). The covering degree of \(\mathcal {C}_{\mathbf {w}}^{(n)}\)increases monotonically with n.
Proof
We prove the covering property for \(\mathcal {C}_{\mathbf {w}}\). The covering property for \(\mathcal {C}_{\mathbf {w}}^{(n)}\) as well as the monotonicity of the covering degree follow from this by the set equation in Proposition 3.7.3.
By Proposition 3.7.6 with the choices k = 0 and ℓ = n ≥ n 0 we know that

holds for each \(n_0\in \mathbb {N}\). Because \(\mathcal {C}_{\mathbf {w}}\) is a locally finite collection of compact sets it suffices to show that \(\bigcup _{T\in \mathcal {C}_{\mathbf {w}}}T\) is dense in w ⊥. To prove this we show that the right hand side of (3.48) is dense in w ⊥ for each \(n_0\in \mathbb {N}\). To see this note that by the definition of the discrete hyperplane Γ(w (n)) the set of translates in this union satisfies (recall from (3.47) that w (n) = (M [0,n))tw)

As u has rationally independent coordinates by Lemma 3.6.8, the set

is dense in w ⊥. Since \(\max _{i\in \mathcal {A}}\langle M_{[0,n)}{\mathbf {e}}_i, \mathbf {w} \rangle \to \infty \) for n →∞ by primitivity, this yields that

is dense in w ⊥ for each \(n_0\in \mathbb {N}\). Because n 0 was arbitrary, and the limit \(\lim _{n\to \infty } M_{[0,n)}\mathcal {R}_{\mathbf {w}}^{(n)}(i)=\{\mathbf {0}\}\) by Lemma 3.7.7 this implies that the right hand side of (3.48) is dense in w ⊥ for each \(n_0\in \mathbb {N}\) and we are done. □
From this result we get the assertion on the interiors of S-adic Rauzy fractals.
Proposition 3.7.10
Letσbe a sequence of unimodular substitutions over the alphabet \(\mathcal {A}\)and \(\mathbf {w}\in \mathbb {R}_{\ge 0}\setminus \{\mathbf {0}\}\). Ifσis primitive, recurrent, algebraically irreducible, and has finitely balanced language \(\mathcal {L}_{\boldsymbol {\sigma }}\), then \(\mathcal {R}(i)\)is the closure of its interior for each \(i\in \mathcal {A}\).
Proof
Choose some \(\mathbf {w}\in \mathbb {R}_{\ge 0}\setminus \{\mathbf {0}\}\). By Lemma 3.7.9 the collection \(\mathcal {C}_{\mathbf {w}}^{(n)}\) is a locally finite covering of (w (n))⊥ by compact sets for each \(n\in \mathbb {N}\). Thus by Baire’s theorem for each \(n\in \mathbb {N}\) there is \(i_n\in \mathcal {A}\) such that \(\mathrm {int}(\mathcal {R}^{(n)}_{\mathbf {w}}(i_n))\neq \emptyset \). By primitivity of σ the set equation in Proposition 3.7.3 implies that each \(\mathcal {R}^{(n)}_{\mathbf {w}}(i)\) contains \(\mathcal {R}^{(k)}_{\mathbf {w}}(i_k)\) for some k > n. Thus for each \(n\in \mathbb {N}\) and each \(i\in \mathcal {A}\) we have \(\mathrm {int}(\mathcal {R}^{(n)}_{\mathbf {w}}(i))\neq \emptyset \).
For each \(i\in \mathcal {A}\) and each \(n\in \mathbb {N}\), Proposition 3.7.3 yields a subdivision of \(\mathcal {R}_{\mathbf {w}}(i)\) in translates of sets of the form \(M_{[0,n)}\mathcal {R}_{\mathbf {w}}^{(n)}(j)\), \(j\in \mathcal {A}\). The diameters of these sets tend to 0 by Lemma 3.7.7. Since they all contain inner points, the set of inner points of \(\mathcal {R}_{\mathbf {w}}(i)\) is dense in \(\mathcal {R}_{\mathbf {w}}(i)\). In other words, \(\mathcal {R}_{\mathbf {w}}(i)\) is the closure of its interior. The result now follows by taking w = 1. □
3.7.3 The Generalized Left Eigenvector
Let σ be a primitive and recurrent sequence of unimodular substitutions. If we look at the set equation in Proposition 3.7.3 for k = 0 and ℓ = n we see that it subdivides the sets \(\mathcal {R}_{\mathbf {w}}(i)\), \(i\in \mathcal {A}\), into translates of sets of the form \(\mathcal {R}_{\mathbf {w}}^{(n)}(j)\), \(j\in \mathcal {A}\). In the well-studied substitutive case \(\mathcal {R}_{\mathbf {w}}^{(n)}(i)=\mathcal {R}_{\mathbf {w}}(i)\) holds for each n, i.e., the sets \(\mathcal {R}_{\mathbf {w}}(i)\) are subdivided into small copies of themselves. This fact is crucial in most of the proofs of properties of substitutive Rauzy fractals (see e.g. [123]). In our case, in general the sets \(\mathcal {R}_{\mathbf {w}}^{(n)}\) are not only different for each \(n\in \mathbb {N}\), but also live in different hyperplanes (w (n))⊥ of \(\mathbb {R}^n\).
In what follows we want to deal with this problem by choosing a strictly increasing sequence (n k) of integers such that \(\mathcal {R}_{\mathbf {w}}^{(n_k)}(i)\) is at least getting closer and closer to \(\mathcal {R}_{\mathbf {w}}(i)\) in Hausdorff metric when k →∞.
To this matter let σ be a sequence of substitutions that satisfies the assumptions of Theorem 3.7.1. We now successively choose subsequences of the integers to get the desired properties.
-
(a)
Consider the set equation in Proposition 3.7.3 for the choices k = 0, ℓ = m and k = n, ℓ = n + m. Look at the subdivision of \(\mathcal {R}_{\mathbf {w}}(i)\) and \(\mathcal {R}_{\mathbf {w}}^{(n)}(i)\). We can hope to get \(\mathcal {R}_{\mathbf {w}}(i)\) and \(\mathcal {R}_{\mathbf {w}}^{(n)}(i)\) close to each other in Hausdorff metric if they have the same subdivision structure. From Proposition 3.7.3 we see that these subdivision structures are the same if (σ 0, …, σ m−1) = (σ n, …, σ n+m−1). Since σ is recurrent, there exist strictly increasing sequences (n k) and (ℓ k) such that
$$\displaystyle \begin{aligned} (\sigma_0,\ldots,\sigma_{\ell_k-1}) = (\sigma_{n_k},\ldots,\sigma_{n_k+\ell_k-1}).\end{aligned} $$(3.50)By recurrence and primitivity it is possible to choose (n k) and (ℓ k) in a way that there is some h such that \(M_{[\ell _k-h,\ell _k)}\) is the same primitive matrix for all \(k\in \mathbb {N}\).
-
(b)
We know that \(M_{[0,\ell _k)}\mathcal {R}_{\mathbf {w}}^{(\ell _k)}(j)\) tends to {0} in Hausdorff metric for k →∞ by Lemma 3.7.7 so that the subdivision corresponding to the choice k = 0, ℓ = ℓ k in the set equation gives a subdivision of \(\mathcal {R}_{\mathbf {w}}(j)\) into sets whose diameter tends to 0 for k →∞. However, if we consider \(\mathcal {R}_{\mathbf {w}}^{(n_k)}(i)\), there is no reason for \(M_{[n_k,n_k+\ell _k)}\mathcal {R}_{\mathbf {w}}^{(n_k+\ell _k)}(j)=M_{[0,\ell _k)}\mathcal {R}_{\mathbf {w}}^{(n_k+\ell _k)}(j)\) to tend to {0} unless \(\mathcal {R}_{\mathbf {w}}^{(n_k+\ell _k)}(j)\) is bounded uniformly in k. To this end we need to assume that \(\mathcal {L}_{{\boldsymbol {\sigma }}}^{(n_k+\ell _k)}\) is C-balanced as this implies that \(\mathcal {R}_{\mathbf {w}}^{(n_k+\ell _k)}(j)\) is indeed bounded by Proposition 3.6.5. In view of the conditions imposed on σ in Theorem 3.7.1 it is, however, possible to change the sequence (n k) and (ℓ k) chosen in (a) in a way that also \(\mathcal {L}_{{\boldsymbol {\sigma }}}^{(n_k+\ell _k)}\) is C-balanced for \(C\in \mathbb {N}\) not depending on k.
-
(c)
Still (a) and (b) give us no reason for \(\mathcal {R}_{\mathbf {w}}^{(n_k)}\) living in a hyperplane \({\mathbf {w}}^{(n_k)}\) close to w which is needed in order to get \(\mathcal {R}_{\mathbf {w}}^{(n_k)}\) close to \(\mathcal {R}_{\mathbf {w}}\) in Hausdorff metric. By the compactness of the space of directions in \(\mathbb {R}^d\), using the Hilbert metric from Proposition 3.5.5 it is possible to exhibit a vector \(\mathbf {v}\in \mathbb {R}_{\ge 0}\setminus \{\mathbf {0}\}\) for which there exists subsequences of (n k) and (ℓ k) (called (n k) and (ℓ k) again) such that \(\lim _{k\to \infty }{\mathbf {v}}^{(n_k)}/\Vert {\mathbf {v}}^{(n_k)}\Vert _1=\mathbf {v}/\Vert \mathbf {v}\Vert _1\). Here we set v (n) = (M [0,n))tv.
Summing up, if the conditions of Theorem 3.7.1 are in force we can choose sequences (n k) and (ℓ k) satisfying (a), (b), and (c). The vector v defined in (c) deserves special attention.
Definition 3.7.11 (Generalized Left Eigenvector)
A vector v as in (c) is called a generalized left eigenvector of σ.
Sequences (n k) and (ℓ k) associated with σ in the above way will just be called associated sequences for σ in the sequel (they are related to the property PRICE of [52, Definition 5.8]). It turns out that associated sequences are suitable for our purposes. In particular, we get the following result (we refer to [52, Proposition 5.12] for details).
Proposition 3.7.12
Letσbe a sequence of substitutions that admits associated sequences (n k) and (ℓ k) and has a generalized left eigenvectorv. Then for each \(i\in \mathcal {A}\)
in Hausdorff metric.
Proof (Sketch)
By (3.50) in (a) the sets \(\mathcal {R}_{\mathbf {v}}(i)\) and \(\mathcal {R}^{(n_k)}_{\mathbf {v}}(i)\) have the same subdivision structure governed by \(E_1^{*}(\sigma _{[0,\ell _k)})\) for \(k\in \mathbb {N}\). More precisely,

By Proposition 3.6.10 the sets \(M_{[0,\ell _k)}\mathcal {R}_{\mathbf {v}}^{(\ell _k)}(j)\) tend to {0} in Hausdorff metric for k →∞. With more effort, using the balance conditions of (b) and the convergence properties of (c), one can also show that the sets \(M_{[0,\ell _k)}\mathcal {R}_{\mathbf {v}}^{(n_k+\ell _k)}(j)\) tend to {0} in Hausdorff metric for k →∞. So replacing all these sets by {0} on the right hand side of (3.51) changes the sets on the left hand side of (3.51) only very little in Hausdorff metric for large \(k\in \mathbb {N}\). Thus for large \(k\in \mathbb {N}\) the Hausdorff distance between \(\mathcal {R}_{\mathbf {v}}^{(n_k)}(i)\) and \(\mathcal {R}_{\mathbf {v}}(i)\) is (up to an error tending to 0 for k →∞) bounded by

One can now show that the latter maximum tends to 0 for k →∞. Here one uses that by the definition of the generalized left eigenvector in (c) the hyperplanes \(({\mathbf {v}}^{(n_k)})^{\bot }\) converge to v ⊥. □
3.7.4 An S-adic Rauzy Fractal Has a Boundary of Measure Zero
We now turn to the boundary of an S-adic Rauzy fractal. We start with a result on level ℓ subtiles contained in the interior of a given subtile whose detailed proof is contained in [52, Lemma 6.6].
Lemma 3.7.13
Letσbe a sequence of unimodular substitutions that satisfies the properties of Theorem 3.7.1and let associated sequences (n k), (ℓ k), and a generalized left eigenvectorvbe given.
Then there is \(\ell \in \mathbb {N}\) such that for each \(i,j\in \mathcal {A}\) there is \([\mathbf {y},j]\in E_1^*(\sigma _{[0,\ell )})[\mathbf {0},i]\) such that
-
(i)
 ,
, -
(ii)
 for each sufficiently large
\(k\in \mathbb {N}\).
for each sufficiently large
\(k\in \mathbb {N}\).
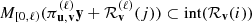 ,
,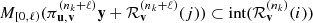 for each sufficiently large
for each sufficiently large
Moreover, the covering degree of \(\mathcal {C}_{\mathbf {v}}^{(n)}\) does not depend on n.
Proof (Sketch)
Since the conditions in the lemma imply that \(\mathrm {int}(\mathcal {R}_{\mathbf {v}}(i) ) \neq \emptyset \) (see Proposition 3.7.10) and that the diameter of \(M_{[0,\ell )}\mathcal {R}_{\mathbf {v}}^{(\ell )}(j)\) becomes arbitrarily small for large ℓ (see Lemma 3.7.7), assertion (i) follows easily from primitivity.
The fact that ℓ and y can be chosen in a way that (i) and (ii) hold simultaneously is more difficult to prove. By Proposition 3.7.12 we get that \(\mathcal {R}^{(n_k)}_{\mathbf {v}}(i) \to \mathcal {R}_{\mathbf {v}}(i)\) in Hausdorff metric. Moreover, \(\mathcal {R}_{\mathbf {v}}(i)\) and \(\mathcal {R}^{(n_k)}_{\mathbf {v}}(i)\) have the same subdivision structure for ℓ k steps. This implies that the “inner structure” of these tiles is similar for large k. However, as inner points are not respected by the Hausdorff metric, technical difficulties occur and also the “outer structure”, i.e., the structure of the collections \(\mathcal {C}_{\mathbf {v}}\) and \(\mathcal {C}^{(n_k)}_{\mathbf {v}}\) has to be exploited. One can show that if a patch P occurs in a discrete hyperplane Γ(w), then translates of P occur relatively densely in each discrete hyperplane \(\varGamma (\tilde {\mathbf {w}})\) provided that \(\Vert \mathbf {w}-\tilde {\mathbf {w}}\Vert _\infty \) is small enough. In particular, containment of translates of a patch P is an open property of discrete hyperplanes. Thus, if k is large then at level n k there is a translation \({\mathbf {y}}_k\in \mathbb {Z}^d\) such that the sets Γ(v) and \(\varGamma ({\mathbf {v}}^{(n_k)})-{\mathbf {y}}_k\) have a large patch around the origin in common.
Summing up, this means that the collections  convergeFootnote 7 to \(\mathcal {C}_{\mathbf {v}}\) for k →∞. This implies that the covering degree of
convergeFootnote 7 to \(\mathcal {C}_{\mathbf {v}}\) for k →∞. This implies that the covering degree of  is less than or equal to the covering degree of \(\mathcal {C}_{\mathbf {v}}=\mathcal {C}_{\mathbf {v}}^{(0)}\) for k large enough. Since the covering degree of \(\mathcal {C}^{(n)}_{\mathbf {v}}\) is monotonically increasing in n by Lemma 3.7.9, the last assertion of the lemma follows.
is less than or equal to the covering degree of \(\mathcal {C}_{\mathbf {v}}=\mathcal {C}_{\mathbf {v}}^{(0)}\) for k large enough. Since the covering degree of \(\mathcal {C}^{(n)}_{\mathbf {v}}\) is monotonically increasing in n by Lemma 3.7.9, the last assertion of the lemma follows.
The fact that the collections  converge to \(\mathcal {C}_{\mathbf {v}}\) and have the same covering degree can now be used to show that inner points of elements of \(\mathcal {C}_{\mathbf {v}}\) are close to inner points of elements of
converge to \(\mathcal {C}_{\mathbf {v}}\) and have the same covering degree can now be used to show that inner points of elements of \(\mathcal {C}_{\mathbf {v}}\) are close to inner points of elements of  for large k. Using this together with the fact that \(\mathcal {R}_{\mathbf {v}}(i)\) and \(\mathcal {R}^{(n_k)}_{\mathbf {v}}(i)\) have the same subdivision structure for ℓ
k steps, one can show that (i) and (ii) holds simultaneously as claimed. □
for large k. Using this together with the fact that \(\mathcal {R}_{\mathbf {v}}(i)\) and \(\mathcal {R}^{(n_k)}_{\mathbf {v}}(i)\) have the same subdivision structure for ℓ
k steps, one can show that (i) and (ii) holds simultaneously as claimed. □
After these preparations we can also prove the result on the measure of the boundary of S-adic Rauzy fractals announced in Theorem 3.7.1.
Proposition 3.7.14
Letσbe a sequence of unimodular substitutions over the alphabet \(\mathcal {A}\)that satisfies the assertions of Theorem 3.7.1. Then the Lebesgue measure \(\lambda _{\mathbf {1}}(\partial \mathcal {R}(i))\)is zero for each \(i\in \mathcal {A}\).
Proof (Sketch)
Choose \(\ell \in \mathbb {N}\) and the sequences (n
k) and (ℓ
k) as in Lemma 3.7.13 and consider \(\mathcal {R}_{\mathbf {v}}(i)\) for some \(i\in \mathcal {A}\) (see Fig. 3.17a), where v is a generalized left eigenvector of σ. Then subdivide \(\mathcal {R}_{\mathbf {v}}(i)\) into its level ℓ subtiles as shown in Fig. 3.17b. According to Lemma 3.7.13(i) there is at least one level ℓ subtile  which is a subset of \(\mathrm {int}(\mathcal {R}_{\mathbf {v}}(i))\); this is indicated with a black boundary in Fig. 3.17b. Letting \(m_{ij}=\lambda _{\mathbf {v}}(M_{[0,\ell )}\mathcal {R}_{\mathbf {v}}^{(\ell )}(j))/\lambda _{\mathbf {v}}(\mathcal {R}_{\mathbf {v}}(i))\) and \(m=\min \{m_{ij}\,:\, i,j\in \mathcal {A}\}\) we therefore gain
which is a subset of \(\mathrm {int}(\mathcal {R}_{\mathbf {v}}(i))\); this is indicated with a black boundary in Fig. 3.17b. Letting \(m_{ij}=\lambda _{\mathbf {v}}(M_{[0,\ell )}\mathcal {R}_{\mathbf {v}}^{(\ell )}(j))/\lambda _{\mathbf {v}}(\mathcal {R}_{\mathbf {v}}(i))\) and \(m=\min \{m_{ij}\,:\, i,j\in \mathcal {A}\}\) we therefore gain
Now we subdivide all level ℓ subtiles of \(\mathcal {R}_{\mathbf {v}}(i)\) apart from  in level n
k subtiles where k is chosen in a way that n
k ≥ ℓ. This is illustrated in Fig. 3.17c.
in level n
k subtiles where k is chosen in a way that n
k ≥ ℓ. This is illustrated in Fig. 3.17c.

Illustration of the proof of Proposition 3.7.14. In (a) a subtile \(\mathcal {R}_{\mathbf {v}}(i)\), \(i\in \mathcal {A}\), is shown. In (b) we see the ℓth subdivision of \(\mathcal {R}_{\mathbf {v}}(i)\). The level ℓ subtile contained in \(\mathrm {int}(\mathcal {R}_{\mathbf {v}}(i))\) has black boundary. In (c) all other level ℓ subtiles are further subdivided in level n k subtiles. Each of them contains a level n k + ℓ subtile in its interior. These level n k + ℓ subtiles, which a fortiori are also contained in \(\mathrm {int}(\mathcal {R}_{\mathbf {v}}(i))\), are depicted in (d) also with black boundary
We iterate this procedure: each level n k subtile \(R_{n_k}\) we got in this way is subdivided in level n k + ℓ subtiles. By Lemma 3.7.13(ii) one of these level n k + ℓ subtiles lies in the interior of \(R_{n_k}\) (see Fig. 3.17d for an illustration of this) and, a fortiori, in the interior of \(\mathcal {R}_{\mathbf {v}}(i).\) If we set
(note that the last equation follows from recurrence of σ if k is chosen large enough) and \(m^{(n_k)}=\min \{m^{(n_k)}_{ij}\,:\, i,j\in \mathcal {A}\}\) we obtain
Iterating this further we get for some infinite set \(K\subset \mathbb {N}\) that
One can show that \(m^{(n_k)}\) is uniformly bounded away from 0. To this end one needs Proposition 3.7.12 and the fact that ℓ k is chosen in a way that there is some h such that \(M_{[\ell _k-h,\ell _k)}\) is the same primitive matrix for all \(k\in \mathbb {N}\) (see (a) in Sect. 3.7.3). Now (3.52) yields \(\lambda _{\mathbf {v}} (\partial \mathcal {R}_{\mathbf {v}}(i))=0\) and, hence, \(\lambda _{\mathbf {1}} (\partial \mathcal {R}(i))=0\). □
3.8 Tilings, Coincidence Conditions, and Combinatorial Issues
We now turn to tiling conditions of Rauzy fractals. Already in the substitutive case combinatorial conditions like the strong coincidence condition (see e.g. [18]) or the super coincidence condition and its variants (cf. [36, 51, 91]) have to be imposed in order to gain all the tiling results on Rauzy fractals required for our purposes. Here we discuss an S-adic version of these concepts and establish a variety of tiling results. For detailed proofs we refer again to Berthé et al. [52]. As before, our aim is to discuss the main ideas and to make these ideas understandable without going into all the technical details.
3.8.1 Multiple Tiling and Inner Subdivision of the Subtiles
In this section we prove tiling properties of Rauzy fractals that hold without further combinatorial conditions. Our first result contains a multiple tiling property of the collections of Rauzy fractals \(\mathcal {C}_{\mathbf {v}}\) defined in (3.35).
Proposition 3.8.1
Letσ = (σ n) be a primitive and algebraically irreducible sequence of unimodular substitutions. Assume that there is C > 0 such that for every \(\ell \in \mathbb {N}\)there exists n ≥ 1 such that (σ n, …, σ n+ℓ−1) = (σ 0, …, σ ℓ−1) and the language \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n+\ell )}\)is C-balanced.
Ifvis a generalized left eigenvector ofσthen the collection \(\mathcal {C}_{\mathbf {v}}\)forms a multiple tiling of the hyperplanev ⊥.
Proof (Sketch)
Let (ℓ k) and (n k) be associated sequences for σ. We subdivide the proof in seven observations. In the sequel B X(x, ε) denotes an open ball in a metric space X centered at x with radius ε.
-
(i)
Let \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\). As mentioned in the proof of Lemma 3.7.13 one can show that each patch P ⊂ Γ(w) is repetitive in the following sense: there exists δ P > 0 and a radius r P > 0 such that for each \(\tilde {\mathbf {w}}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\) with \(\Vert \tilde {\mathbf {w}}- \mathbf {w}\Vert _\infty <\delta _P\) and each z with \([\mathbf {z},i]\in \varGamma (\tilde {\mathbf {w}})\) a translate of P occurs in \(\varGamma (\tilde {\mathbf {w}})\cap B_{\mathbb {R}^n}(\mathbf {z},r_P)\). This means that each patch occurring in a discrete hyperplane \(\mathcal {D}\) occurs uniformly repetitively in each hyperplane \(\mathcal {D}^{\prime }\) which is close enough to \(\mathcal {D}\). This general property of discrete hyperplanes is proved in [52, Lemma 6.5].
-
(ii)
Let m be the covering degree of \(\mathcal {C}_{\mathbf {v}}\). Then each point x ∈v ⊥ which is covered exactly m times by elements of \(\mathcal {C}_{\mathbf {v}}\) is not contained in the boundary of any element of \(\mathcal {C}_{\mathbf {v}}\). Suppose this was wrong and let \(R_1, \ldots , R_m \in \mathcal {C}_{\mathbf {v}}\) be the elements containing x. Since \(\mathcal {C}_{\mathbf {v}}\) is a locally finite union of compact sets there is ε > 0 such that \(B_{{\mathbf {v}}^{\bot }}(\mathbf {x},\varepsilon )\) doesn’t intersect any \(R\in \mathcal {C}_{\mathbf {v}} \setminus \{R_1, \ldots , R_m \}\). By assumption x ∈ ∂R i for some 1 ≤ i ≤ m. Thus there is \(\mathbf {y}\in B_{{\mathbf {v}}^{\bot }}(\mathbf {x},\varepsilon )\) with y∉R i and, hence, y is covered by at most m − 1 elements of \(\mathcal {C}_{\mathbf {v}}\), a contradiction.
-
(iii)
Choose x which is covered exactly m times by elements of \(\mathcal {C}_{\mathbf {v}}\). Since the elements of \(\mathcal {C}_{\mathbf {v}}\) are uniformly bounded, the set of elements of \(\mathcal {C}_{\mathbf {v}}\) which contain x is contained in a set
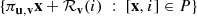 , where P is a patch of Γ(v) which is chosen so large that, regardless of how the elements of Γ(v) continue outside P, they will not contribute elements of \(\mathcal {C}_{\mathbf {v}}\) containing x because they are bounded and located “too far away” from x. Thus, whenever we encounter a translate P + t of P in Γ(v), the point
, where P is a patch of Γ(v) which is chosen so large that, regardless of how the elements of Γ(v) continue outside P, they will not contribute elements of \(\mathcal {C}_{\mathbf {v}}\) containing x because they are bounded and located “too far away” from x. Thus, whenever we encounter a translate P + t of P in Γ(v), the point 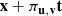 will be covered m times by elements of \(\mathcal {C}_{\mathbf {v}}\) as well. Thus by (i) and (ii) there exist r
m and \(r^{\prime }_m\) such that in each ball of radius \(r_m^{\prime }\) the hyperplane v
⊥ contains a ball of radius r
m that is covered by exactly m elements of \(\mathcal {C}_{\mathbf {v}}\).
will be covered m times by elements of \(\mathcal {C}_{\mathbf {v}}\) as well. Thus by (i) and (ii) there exist r
m and \(r^{\prime }_m\) such that in each ball of radius \(r_m^{\prime }\) the hyperplane v
⊥ contains a ball of radius r
m that is covered by exactly m elements of \(\mathcal {C}_{\mathbf {v}}\). -
(iv)
\(\mathcal {C}^{(n_k)}_{\mathbf {v}}\) converges to \(\mathcal {C}_{\mathbf {v}}\) in a sense described in the proof of Lemma 3.7.13. Thus by (i) the radii r m and \(r^{\prime }_m\) in (iii) can be chosen in a way that in each ball of radius \(r_m^{\prime }\) the hyperplane \(({\mathbf {v}}^{(n_k)})^\bot \) contains a ball of radius r m that is covered by exactly m elements of \(\mathcal {C}^{(n_k)}_{\mathbf {v}}\) for k large enough.
-
(v)
Suppose that \(\mathcal {C}_{\mathbf {v}}\) is not a multiple tiling. Then there is a set X ⊂v ⊥ with λ v(X) > 0 which is covered at least m + 1 times. Since the boundaries of the elements of \(\mathcal {C}_{\mathbf {v}}\) have measure 0 by Proposition 3.7.14, there is x, which is covered a least m + 1 times and which is not contained in the boundary of any element of \(\mathcal {C}_{\mathbf {v}}\). Thus there is ε > 0 such that \(B_{{\mathbf {v}}^{\bot }}(\mathbf {x},\varepsilon )\) is covered at least m + 1 times.
-
(vi)
Suppose that \(\mathcal {C}_{\mathbf {v}}\) is not a multiple tiling. By analogous arguments as in (iii), by (v) there exist r m+1 and \(r^{\prime }_{m+1}\) such that in each ball of radius \(r_{m+1}^{\prime }\) the hyperplane v ⊥ contains a ball of radius r m+1 that is covered by at least m + 1 elements of \(\mathcal {C}_{\mathbf {v}}\).
-
(vii)
By Proposition 3.7.6 each element of \(\mathcal {C}_{\mathbf {v}}\) can be subdivided into elements of \(M_{[0,n_k)}\mathcal {C}^{(n_k)}_{\mathbf {v}}\). The diameters of the elements of \(M_{[0,n_k)}\mathcal {C}^{(n_k)}_{\mathbf {v}}\) tend to 0 for k →∞ by Lemma 3.7.7 and the balls of radius \(r_{m}^{\prime }\) occurring in (iv) are shrunk by \(M_{[0,n_k)}\) to ellipsoids contained in balls of radius less than r m+1. Thus by (iv) we can chose k so large that in each ball of radius r m+1 in v ⊥ there are points which are covered exactly m times by \(M_{[0,n_k)}\mathcal {C}^{(n_k)}_{\mathbf {v}}\). Thus, by Proposition 3.7.6, in each ball of radius r m+1 there are points which are covered at most m times by \(\mathcal {C}_{\mathbf {v}}\). This contradicts (vi) and the result follows.
□
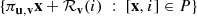 , where P is a patch of Γ(v) which is chosen so large that, regardless of how the elements of Γ(v) continue outside P, they will not contribute elements of
, where P is a patch of Γ(v) which is chosen so large that, regardless of how the elements of Γ(v) continue outside P, they will not contribute elements of 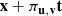 will be covered m times by elements of
will be covered m times by elements of This result can be generalized to \(\mathcal {C}_{\mathbf {w}}\) for arbitrary \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\). To establish this generalization one needs to show first that the measures of the subtiles of \(\mathcal {R}_{\mathbf {v}}\) are determined by

where m is the covering degree of the multiple tiling \(\mathcal {C}_{\mathbf {v}}\). This can be proved along similar lines as in the substitutive case, see [91, Lemma 2.3]. Using this, measure theoretical considerations lead to the following generalization of Proposition 3.8.1.
Proposition 3.8.2
Letσ = (σ n) be a primitive and algebraically irreducible sequence of unimodular substitutions. Assume that there is C > 0 such that for every \(\ell \in \mathbb {N}\)there exists n ≥ 1 such that (σ n, …, σ n+ℓ−1) = (σ 0, …, σ ℓ−1) and the language \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n+\ell )}\)is C-balanced.
Then for each \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\)the collection \(\mathcal {C}_{\mathbf {w}}\)forms a multiple tiling of the hyperplanew ⊥.
It remains to show that this multiple tiling is actually a tiling. As we will see later, additional assumptions are needed to prove this. However, there is one tiling result which holds without additional assumptions. This result, which concerns the “inner tiling” of \(\mathcal {R}_{\mathbf {w}}(i)\) by the set equation (3.45) will be proved next.
Proposition 3.8.3
Letσ = (σ n) be a primitive and algebraically irreducible sequence of unimodular substitutions. Assume that there is C > 0 such that for every \(\ell \in \mathbb {N}\)there exists n ≥ 1 such that (σ n, …, σ n+ℓ−1) = (σ 0, …, σ ℓ−1) and the language \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n+\ell )}\)is C-balanced.
Then the unions in the set equation (3.45) of Proposition 3.7.3are disjoint in measure.
Proof
From Proposition 3.8.2 we know that \(\mathcal {C}_{\mathbf {w}}\) is a multiple tiling for each \(\mathbf {w}\in \mathbb {R}_{\ge 0}^d\setminus \{\mathbf {0}\}\) with multiplicity m not depending on w. Together with Proposition 3.7.6 this implies that the (ℓ − k)th subdivisions of all the tiles in the multiple tiling \(\mathcal {C}_{{\mathbf {w}}^{(k)}}\) form a multiple tiling \(M_{[k,\ell )}\mathcal {C}_{{\mathbf {w}}^{(\ell )}}\) of the same covering degree (for all \(k,\ell \in \mathbb {N}\) with k < ℓ). This is possible only if each tile of \(\mathcal {C}_{{\mathbf {w}}^{(k)}}\) is tiled without overlaps by elements of \(M_{[k,\ell )}\mathcal {C}_{{\mathbf {w}}^{(\ell )}}\). This proves the result. □
3.8.2 Coincidence Conditions and Tiling Properties
Let σ be a sequence of unimodular substitutions over an alphabet \(\mathcal {A}\). In view of Example 3.6.2 in order to prove that (X σ, Σ) is measurably conjugate to a rotation on a torus we need two properties of the associated Rauzy fractal \(\mathcal {R}\). Firstly, the subtiles \(\mathcal {R}(i)\), \(i\in \mathcal {A}\), need to be disjoint in measure and secondly, the Rauzy fractal itself has to be a fundamental domain of a (well-chosen) torus. The latter property is equivalent to the fact that \(\mathcal {R}\) admits a lattice tiling of v ⊥. Setting w = 1 in Proposition 3.8.2 we obtain that \(\mathcal {C}_{\mathbf {1}}\) is a multiple tiling of 1 ⊥. Since the discrete hyperplane Γ(1) can be written as \(\varGamma (\mathbf {1}) = \{[\mathbf {x},i] \,:\, \langle \mathbf {x}, \mathbf {1}\rangle =0,\ i\in \mathcal {A} \}\) we see that

Thus \(\mathcal {R}\) is a covering of 1 ⊥ w.r.t. the lattice \(\{\mathbf {x} \in \mathbb {Z}^d\,:\, \langle \mathbf {x}, \mathbf {1}\rangle =0\}\) and we have to prove that the elements of the union on the right hand side are measure disjoint to get tiling properties of \(\mathcal {R}\).
We have therefore three types of unions which we want to be disjoint in measure:
-
(i)
The unions of subtiles on the right hand side of the set equation (3.45).
-
(ii)
The union \(\mathcal {R} = \mathcal {R}(1)\cup \dots \cup \mathcal {R}(d)\).
-
(iii)
The union
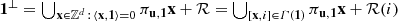 .
.
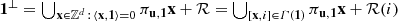 .
.The elements of the unions in (i) are disjoint in measure by Proposition 3.8.3. One can use this fact in order to prove that the unions in (ii) are disjoint in measure as well. However, to make this proof work we need an additional assumption on σ.
Definition 3.8.4 (Strong Coincidence Condition)
A sequence σ of substitutions over an alphabet \(\mathcal {A}\) satisfies the strong coincidence condition if there is \(\ell \in \mathbb {N}\) such that for each pair \((j_1,j_2)\in \mathcal {A}^2\) there are \(i\in \mathcal {A}\) and \(p_1,p_2\in \mathcal {A}^*\) with l(p 1) = l(p 2) such that \(\sigma _{[0,\ell )}(j_1)\in p_1i\mathcal {A}^*\) and \(\sigma _{[0,\ell )}(j_2)\in p_2i\mathcal {A}^*\).
This definition has an easy geometric meaning: it says that the broken lines associated with σ [0,ℓ)(j 1) and σ [0,ℓ)(j 2) have at least one line segment in common for each pair \((j_1,j_2)\in \mathcal {A}^2\).
Example 3.8.5
Figure 3.18 shows that the strong coincidence condition is satisfied for the constant sequence σ = (σ) with σ(1) = 121, σ(2) = 21. Because we are in a case with a two letter alphabet we only have to deal with the instance (j 1, j 2) = (1, 2).

The broken lines associated with i, σ [0,1)(i), and σ [0,2)(i) for i ∈{1, 2}. Coincidence is indicated by the bold line
Using the strong coincidence condition we get the following result.
Proposition 3.8.6
Letσ = (σ n) be a primitive and algebraically irreducible sequence of unimodular substitutions. Assume that there is C > 0 such that for every \(\ell \in \mathbb {N}\)there exists n ≥ 1 such that (σ n, …, σ n+ℓ−1) = (σ 0, …, σ ℓ−1) and the language \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n+\ell )}\)is C-balanced.
If the strong coincidence condition holds then the subtiles \(\mathcal {R}(i)\), \(i\in \mathcal {A}\), are disjoint in measure.
Proof (Sketch)
Let (n k) and (ℓ k) be the associated sequences of σ. Let \(\mathcal {R}(j_1)\) and \(\mathcal {R}(j_2)\) be two subtiles with \(j_1,j_2\in \mathcal {A}\) distinct and assume that the strong coincidence condition holds with \(\ell \in \mathbb {N}\). By the definition of the dual \(E_1^*\) in (3.46) this implies that for k satisfying n k ≥ ℓ there is \({\mathbf {z}}_k\in \mathbb {Z}^d\) and a letter \(i\in \mathcal {A}\) such that \([{\mathbf {z}}_k,j_1],[{\mathbf {z}}_k,j_2]\in E_1^*(\sigma _{[0,n_k)})[\mathbf {0},i]\). Thus the set equation

(see (3.45)) contains \(M_{[0,n_k)}({\mathbf {z}}_k + \mathcal {R}^{(n_k)}(j_1))\) and \(M_{[0,n_k)}({\mathbf {z}}_k + \mathcal {R}^{(n_k)}(j_2))\) in the union on the right hand side. Proposition 3.8.3 now implies that \(\mathcal {R}^{(n_k)}(j_1)\) and \(\mathcal {R}^{(n_k)}(j_2)\) are disjoint in measure. Since this is true for arbitrarily large k, using results along the line of Proposition 3.7.12 (in particular, [52, Lemma 6.8]) this implies that \(\mathcal {R}(j_1)\) and \(\mathcal {R}(j_2)\) are disjoint in measure as well. □
What we did in the proof of Proposition 3.8.6 can be explained in a simple way. If the strong coincidence condition holds, each intersection of the subtiles \(\mathcal {R}(j_1) \cap \mathcal {R}(j_2)\) can be realized as an intersection of two elements in the union on the right hand side of the set equation (3.45). Since we know that the elements in the union of the set equation are measure disjoint, the same is true for \(\mathcal {R}(j_1)\) and \(\mathcal {R}(j_2)\). More briefly: in case of strong coincidence the elements in the union in (ii) are special cases of the elements in some union in (i).
The same strategy can be used in order to prove that the unions in (iii) are measure disjoint. To this end we need another type of coincidence condition.
Definition 3.8.7 (Geometric Coincidence Condition)
A sequence σ of unimodular substitutions over an alphabet \(\mathcal {A}\) satisfies the geometric coincidence condition if the following is true. For each r > 0 there is \(n_0\in \mathbb {N}\) such that for each n ≥ n 0 the set \(E_1^*(\sigma _{[0,n)})[\mathbf {0},i_n]\) contains a ball of radius r of the discrete hyperplane Γ((M [0,n))t1) for some \(i_n\in \mathcal {A}\).
Along similar lines as Proposition 3.8.6 one can prove the following tiling criterion for Rauzy fractals (see [52, Proposition 7.9]).
Proposition 3.8.8
Letσ = (σ n) be a primitive and algebraically irreducible sequence of unimodular substitutions. Assume that there is C > 0 such that for every \(\ell \in \mathbb {N}\)there exists n ≥ 1 such that (σ n, …, σ n+ℓ−1) = (σ 0, …, σ ℓ−1) and the language \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n+\ell )}\)is C-balanced. Then the following assertions are equivalent.
-
(i)
The collection \(\mathcal {C}_{\mathbf {1}}\)forms a tiling of1 ⊥.
-
(ii)
The sequenceσsatisfies the geometric coincidence condition.
-
(iii)
The sequenceσsatisfies the strong coincidence condition and for each r > 0 there exists \(n_0 \in \mathbb {N}\)such that \(\bigcup _{i\in \mathcal {A}} E_1^*(\sigma _{[0,n)})[\mathbf {0},i]\)contains a ball of radius r of Γ((M [0,n))t1) for all n ≥ n 0.
-
(iv)
The sequenceσsatisfies the following effective condition: There are \(n \in \mathbb {N}\), \(i \in \mathcal {A}\), and \(\mathbf {z} \in \mathbb {R}^d\), such that
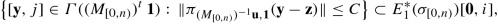
where \(C \in \mathbb {N}\)is chosen in a way that \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n)}\)is C-balanced.
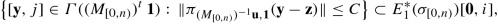
An (essentially) more restrictive condition than the geometric coincidence condition and its variants in Proposition 3.8.8 is the following one.
Definition 3.8.9 (Geometric Finiteness Property)
A sequence σ of unimodular substitutions over an alphabet \(\mathcal {A}\) satisfies the geometric finiteness property if for each r > 0 there is \(n_0\in \mathbb {N}\) such that \(\bigcup _{i\in \mathcal {A}} E_1^*(\sigma _{[0,n)})[\mathbf {0},i]\) contains the ball {[x, i] ∈ Γ((M [0,n))t1) : ∥x∥≤ r} for all n ≥ n 0.
The geometric finiteness property implies that \(\bigcup _{i\in \mathcal {A}} E_1^*(\sigma _{[0,n)})[\mathbf {0},i]\) generates a whole discrete plane for n →∞, and that 0 is an inner point of the Rauzy fractal \(\mathcal {R}\) (as is proved in [52, Proposition 7.10]). It is immediate that together with the strong coincidence condition the geometric finiteness property is more restrictive than the condition in Proposition 3.8.8(iii). The name geometric finiteness property comes from the fact that it is related to certain finiteness properties in number representations w.r.t. positional number systems (see for instance Barat et al. [31] for a survey on these objects). By Proposition 3.8.8(iii) strong coincidence plus geometric finiteness imply that \(\mathcal {C}_{\mathbf {1}}\) forms a tiling of 1 ⊥.
3.8.3 How to Check Geometric Coincidence and Geometric Finiteness?
In most cases it is easy to check strong coincidence of a sequence σ = (σ n) of substitutions over an alphabet \(\mathcal {A}\). For instance, this property trivially holds if σ 0(i) starts with the same letter for each \(i\in \mathcal {A}\). However, it is a priori not so clear how to check geometric coincidence or geometric finiteness and although there is an effective criterion for geometric coincidence contained in Proposition 3.8.8(iv) this is only suitable for checking single instances. Geometric coincidence asserts that a large piece of a discrete hyperplane can be generated by the dual substitution \(E_1^*(\sigma _{[0,n)})\) acting on [0, i n] if n is large. If geometric finiteness holds, even a whole discrete hyperplane can be generated by the patches \(E_1^*(\sigma _{[0,n)})\bigcup _{i\in \mathcal {A}}[\mathbf {0},i]\) for n →∞. The idea of generating discrete hyperplanes in this way using sequences of substitutions coming from generalized continued fraction algorithms goes back to Ito and Ohtsuki [90]. More recently, Berthé et al. [42, 48] provide a systematic study on how to check geometric coincidence as well as geometric finiteness. While [48] concentrates on Arnoux-Rauzy substitutions, the more general treatment in [42] uses substitutions related to the Brun as well as the Jacobi-Perron algorithm as guiding examples. In this section we give a brief discussion of their ideas which are centered around an “annulus property” of stepped hyperplanes generated by \(E_1^*(\sigma _{[0,n)})\).
Let σ = (σ n) be a sequence of unimodular substitutions over an alphabet \(\mathcal {A}\) and let \(S=\{\sigma _n\,:\, n\in \mathbb {N}\}\). The fact that σ satisfies the geometric coincidence condition in Definition 3.8.7 roughly says that the patch \(E_1^*(\sigma _{[0,n)})[\mathbf {0},i_n]\) contains a larger and larger ball when n is growing. In this section, for the sake of simplicity, we will deal with the geometric finiteness property. Indeed, we will assume that this ball is centered at the origin and instead of [0, i n] we will use \(\mathcal {U}=\bigcup _{i\in \mathcal {A}}[\mathbf {0},i]\) as our “seed”. So we want to show that for each R > 0 there is \(n_0 \in \mathbb {N}\) such that \( E_1^*(\sigma _{[0,n)})\mathcal {U}\) contains the ball {[x, i] ∈ Γ((M [0,n))t1) : ∥x∥≤ R} for all n ≥ n 0.
Following [42] we shall reformulate the geometric finiteness property in a more combinatorial way. Let P be a patch of a discrete hyperplane containing \(\mathcal {U}\) and interpret its elements as faces as in (3.34). Then the minimal combinatorial radius rad(P) of P is equal to the length ℓ of the shortest sequence of faces [x 1, j 1], …, [x ℓ, j ℓ] ∈ P satisfying \([{\mathbf {x}}_1,j_1]\in \mathcal {U}\), [x ℓ, j ℓ] contains a part of the boundary of P (regarded as a topological manifold), and [x k, j k] ∩ [x k+1, j k+1] ≠ ∅ for 1 ≤ k ≤ ℓ − 1. Intuitively, rad(P) is the minimal distance between 0 and the boundary of P. For instance, one easily checks that the minimal combinatorial radius of the patch on the left hand side of Fig. 3.13 is equal to six. Clearly a sequence σ enjoys the geometric finiteness property if and only if \(\mathrm {rad}\left (E_1^*(\sigma _{[0,n)})\mathcal {U} \right )\) tends to ∞ for n →∞.
Let \(P_{[m,n)}=E_1^*(\sigma _{[m,n)})\mathcal {U}\). We have to show that the minimal combinatorial radii of the patches P [0,n) tend to ∞ for n →∞. Since the patches P [0,n) can have complicated shapes there is no obvious way to do this. One approach to prove this property goes back to Ito and Ohtsuki [90] and makes use of “annuli”. Let ℓ < m < n and suppose that \(\mathcal {U}\subset E_1^*(\sigma )\mathcal {U}\) holds for each σ ∈ S (this is not a crucial assumption and, if it is not true, can often be gained by blocking the substitutions of the sequence σ). Then P [m,n) ⊂ P [ℓ,n) holds by the definition of \(E_1^*(\sigma )\) (note in particular that \(E_1^*(\tau )E_1^*(\sigma )=E_1^*(\sigma \tau )\) for σ, τ ∈ S). The idea is to make sure that whenever (σ ℓ, …, σ m−1) is of a certain shape then P [ℓ,n) ∖ P [m,n) contains an annulus of positive width. One can then show that if (σ 0, …, σ n) contains the block (σ ℓ, …, σ m−1) for k times, the patch P [0,n) contains k “concentric” annuli and has a minimal combinatorial radius greater than or equal to k.
To achieve this we first search for a block (σ 0, …, σ m−1) such that \(A=P_{[0,m)}\setminus \mathcal {U}\) contains an annulus of positive width, i.e., \(\partial P_{[0,m)} \cap \mathcal {U}=\emptyset \). If σ is recurrent, the block (σ 0, …, σ m−1) occurs infinitely often in σ. Let (n j) with n 0 = 0 and n j ≥ n j−1 + m be an increasing sequence such that \((\sigma _{n_j},\ldots ,\sigma _{n_j+m-1})=(\sigma _0,\ldots ,\sigma _{m-1})\). Fix \(k\in \mathbb {N}\) and set \(A_0=P_{[0,n_k+m)}\setminus P_{[m,n_k+m)}\) and \(A_j:= P_{[n_{j-1}+m,n_k+m)} \setminus P_{[n_j+m,n_k+m)}\) for j ≥ 1. Then
Because
for j ≥ 1 (the last step comes from the recurrence property; the case j = 0 follows along similar lines) each A j contains some image of A under \(E_1^*\). If the annulus A has certain “covering properties” that are described in detail in [42, 48], one can show that images of A under \(E_1^*\) are annuli of positive width as well. Thus such an annulus of positive width is contained in each of the pairwise disjoint subsets A 0, …, A k of \(P_{[0,n_k+m)}\) and therefore (3.53) implies that the patch \(P_{[0,n_k+m)}\) contains a “concentric” annulus for each of the k + 1 (non overlapping) occurrence of the block (σ 0, …, σ m−1) in \((\sigma _0,\ldots ,\sigma _{n_k+m-1})\). Since an application of \(E_1^*\) maps disjoint annuli to disjoint annuli also \(P_{[0,n)}=E_1^*(\sigma _{[n_k+m,n)})P_{[0,n_k+m)}\) with n k + m ≤ n < n k+1 + m contains k + 1 such “concentric” annuli. Thus if n →∞, the number of such annuli in P [0,n) tends to ∞. Since the above-mentioned covering properties of A imply that \(A_0 \cup \dots \cup A_k\cup \mathcal {U}=P_{[0,n_k+m)}\) is simply connected for each \(k\in \mathbb {N}\) and that the same is true for all the patches P [0,n) (see [48]), we gain that the minimal combinatorial radii of the patches P [0,n) tend to ∞ for n →∞.
The following example shows that this method can be used in order to prove geometric finiteness for large classes of sequences of substitutions.
Example 3.8.10
We want to illustrate the construction of the annulus A around \(\mathcal {U}\) for the case of sequences of Arnoux-Rauzy substitutions σ = (σ n) (all details for this case can be found in [48]). Suppose that σ is a recurrent sequence of Arnoux-Rauzy substitutions which contains each of the three Arnoux-Rauzy substitutions (3.18). Then, by recurrence, σ contains a block (σ 0, …, σ m−1) in which each Arnoux Rauzy substitution occurs at least twice. In the graph depicted in Fig. 3.19 the action of \(E_1^*\) on \(\mathcal {U}\) is illustrated.Footnote 8 The vertices of this graph are patches and there is an edge \(P_1\xrightarrow {i} P_2\) if \(P_2\subset E_1^*(\sigma _i)P_1\). Thus each vertex has an outgoing edge for each i ∈{1, 2, 3} (loops and outgoing edges of patches that contain an annulus of positive width around \(\mathcal {U}\) are suppressed). Examining the graph we see that \(E_1^*(\sigma _{[k,n)})\mathcal {U}\) contains an annulus around \(\mathcal {U}\) of positive width whenever the block (σ k, …, σ n−1) contains at least two occurrences of each Arnoux-Rauzy substitution. Thus, P [0,m) is a patch which contains \(\mathcal {U}\) together with an annulus A of positive width around it.

An illustration of the annulus property for sequences of Arnoux-Rauzy substitutions
If one proves that the annulus A has the above-mentioned covering properties (which was done in [48]) one can iterate this procedure as indicated above and prove that P [0,n) is simply connected and contains a growing number of “concentric” annuli for growing n. Thus the minimal combinatorial radius of P [0,n) tends to ∞ for n →∞ and, hence, σ has the geometric finiteness property.
Summing up, in Example 3.8.10 we have sketched a proof of the following result.
Proposition 3.8.11
Let σ be a sequence of Arnoux-Rauzy substitutions. If σ is recurrent and contains each of the three Arnoux-Rauzy substitutions then σ satisfies the geometric finiteness property.
3.9 S-adic Systems and Torus Rotations
Let σ be a sequence of unimodular substitutions over an alphabet \(\mathcal {A}\) with d letters. In the past sections we proved a variety of properties of Rauzy fractals. Using all these results makes Rauzy fractals suitable to “see” a rotation on the torus \(\mathbb {T}^{d-1}\) acting on them. This rotation turns out to be measurably conjugate to the underlying S-adic system (X σ, Σ). In this section we prove the according results which form special cases of the main results of [52] and provide some examples.
In Sect. 3.9.1 we state Theorem 3.9.4, a result that gives the measurable conjugacy between (X σ, Σ) and a torus rotation together with some of its consequences under a set of natural conditions. Section 3.9.2 is devoted to the proof of this result. In Sect. 3.9.3 we formulate a metric version of Theorem 3.9.4. In particular, for a finite set S of substitutions we consider the shiftFootnote 9 \((S^{\mathbb {N}},\varSigma ,\nu )\) acting on all infinite sequences of substitutions taken from S. The measure ν is chosen in a way that this shift becomes ergodic. We prove that the conditions of Theorem 3.9.4 are “generic” w.r.t. the measure ν if the Pisot condition (3.59) on the Lyapunov exponents associated with a linear cocycle of \((S^{\mathbb {N}},\varSigma ,\nu )\) is in force. Thus under this Pisot condition we gain that ν-almost all \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\) give rise to an S-adic system (X σ, Σ) that is measurably conjugate to a torus rotation. This result is the content of Theorem 3.9.5. Section 3.9.4 is devoted to the proof of this result. Finally, Sect. 3.9.5 gives examples for S-adic systems associated with Arnoux-Rauzy and Brun substitutions. This shows that the Pisot condition is satisfied in many natural situations.
3.9.1 Statement of the Conjugacy Result
Before we state the first main result of this survey we give some terminology. We start with a spectral property of a measurable dynamical system that is “the opposite” of continuous spectrum (see Sect. 3.3.3; we refer to this section also for the definition of an eigenfunction).
Definition 3.9.1 (Pure Discrete Spectrum, see [126, Defintion 3.2])
An ergodic dynamical system (X, T, μ) on a probability space X has pure discrete spectrum if there exists an orthonormal basis of L 2(μ) which consists of eigenfunctions of T.
It is well known that an ergodic dynamical system on a probability space that has pure discrete spectrum is measurably conjugate to a rotation on a compact abelian group. On the other hand, each ergodic rotation on a compact abelian group has pure discrete spectrum (see for instance [126, Theorems 3.5 and 3.6]; these results can be proved by using character theory and Pontryagin duality for compact abelian groups).
The notion of natural coding came up already in Sects. 3.2.4 and 3.3.2 in the framework of Sturmian sequences and Arnoux-Rauzy sequences. Sloppily speaking a natural coding is a coding of a torus rotation that induces translations on the atoms of the partition that was used to define the coding. We give a precise general definition of this concept.
Definition 3.9.2 (Coding and Natural Coding)
Let Λ be a full-rank lattice in \(\mathbb {R}^d\) and \(T_{\mathbf {t}}: \mathbb {R}^d/\varLambda \to \mathbb {R}^d/\varLambda \), x↦x + t a rotation on the torus \(\mathbb {R}^d/\varLambda \). Let \(\varOmega \subset \mathbb {R}^d\) be a fundamental domain for the lattice Λ and \(\tilde T_{\mathbf {t}}:\varOmega \to \varOmega \) the mapping induced by T t on Ω. Assume that Ω = Ω 1 ∪⋯ ∪ Ω k is a (measure theoretic w.r.t. the Lebesgue measure) partition of Ω.
A sequence \(w=w_0w_1\ldots \in \{1,\ldots ,k\}^{\mathbb {N}}\) is the coding of a point x ∈ Ω with respect to this partition if \(\tilde T_{\mathbf {t}}^j(\mathbf {x})\in \varOmega _{w_j}\) holds for each \(j\in \mathbb {N}\). If, in addition, for each 1 ≤ i ≤ k the restriction \(\tilde T_{\mathbf {t}}|{ }_{\varOmega _i}\) is given by the translation x↦x + t i for some \({\mathbf t}_i\in \mathbb {R}^d\) we call w a natural coding of T t.
For the sake of completeness we give the definition of bounded remainder set.
Definition 3.9.3 (Bounded Remainder Set)
Let Λ be a full-rank lattice in \(\mathbb {R}^d\). A subset A of \(\mathbb {R}^d/\varLambda \) is called a bounded remainder set for the rotation \(T_{\mathbf {t}}: \mathbb {R}^d/\varLambda \to \mathbb {R}^d/\varLambda \), x↦x + t if there exist γ, C > 0 such that, for a.e. \(\mathbf {x} \in \mathbb {R}^d/\varLambda \),
holds for all \(N \in \mathbb {N}\).
The following result gives sufficient conditions for an S-adic system (X σ, Σ) to be measurably conjugate to an irrational rotation on a torus. The subtiles \(\mathcal {R}(i)\) of the Rauzy fractal \(\mathcal {R}\) turn out to be bounded remainder sets for this rotation and induce natural codings of the elements of (X σ, Σ).
Theorem 3.9.4 (See [52, Theorem 3.1])
Let S be a finite set of unimodular substitutions over a finite alphabet \(\mathcal {A}=\{1,2,\ldots ,d\}\)and letσ = (σ n) be a primitive and algebraically irreducible sequence of substitutions taken from the set S. Assume that there is C > 0 such that for every \(\ell \in \mathbb {N}\)there exists n ≥ 1 such that (σ n, …, σ n+ℓ−1) = (σ 0, …, σ ℓ−1) and the language \(\mathcal {L}_{\boldsymbol {\sigma }}^{(n+\ell )}\)is C-balanced.
If the collection \(\mathcal {C}_{\mathbf {1}}\) forms a tiling of 1 ⊥ then the following results hold.
-
1.
The S-adic shift (X σ, Σ, μ), with μ being the unique Σ-invariant Borel probability measure on X σ, is measurably conjugate to a rotation T on the torus \(\mathbb {T}^{d-1}\); in particular, its measure-theoretic spectrum is purely discrete.
-
2.
Each element of X σis a natural coding of the torus rotation T with respect to the partition \(\{\mathcal {R}(i):\,i \in \mathcal {A}\}\)of the fundamental domain \(\mathcal {R}\).
-
3.
The subtile \(\mathcal {R}(i)\)is a bounded remainder set for the torus rotation T for each \(i\in \mathcal {A}\).
For the special case of two letter alphabets the tiling condition does not have to be assumed. It can be derived from the remaining assumptions of Theorem 3.9.4. The corresponding result is proved in [50] and generalizes an analogous result for substitutive systems from [34].
3.9.2 Proof of the Conjugacy Result
In this section we illustrate the proof of Theorem 3.9.4 given in [52]. We assume throughout this section that the sequence σ satisfies the conditions of Theorem 3.9.4. The main part is the proof of the measurable conjugacy between (X σ, Σ, μ) and a rotation on the torus \(\mathbb {T}^{d-1}\), where d is the cardinality of the underlying alphabet. Here μ is the unique Σ-invariant Borel probability measure on X σ (see Theorem 3.5.11).
Our first aim is to set up the representation map from X σ to the Rauzy fractal. We define this map using a nested sequence of the subsets

of the Rauzy fractal \(\mathcal {R}\). In particular, we set
To show that φ is a well-defined continuous surjection one has to prove that the intersection on the right-hand side of (3.54) is a single point. Using the minimality of (X σ, Σ) and the strong convergence property from Proposition 3.6.10 this is done in [52, Section 8].
In the next step one proves that (X σ, Σ, μ) is measurably conjugate to the domain exchange \((\mathcal {R},E,\lambda _{\mathbf {1}})\), where E is given by

which is illustrated in Fig. 3.12. Since \(\mathcal {C}_{\mathbf {1}}\) is a tiling, the overlaps of the subtiles \(\mathcal {R}(i)\) have measure 0 and, hence, E is well defined a.e. w.r.t. the measure λ 1 on \(\mathcal {R}\). To prove the asserted conjugacy, we have to show that φ is bijective μ-a.e. and that the diagram

commutes. Since
follows easily by direct calculation it remains to prove the bijectivity assertion. This runs as follows (all statements are true up to measure zero). First observe that, for all \(i \in \mathcal {A}\), E satisfies

Therefore, we have \(\bigcup _{i\in \mathcal {A}} E(\mathcal {R}(i)) = \mathcal {R}\) and, hence, E is a surjective piecewise isometry. Therefore, E is bijective. Since the subtiles \(\mathcal {R}(i)\), \(i\in \mathcal {A}\), are disjoint in measure and
the injectivity of E implies that also the elements of the collection of “length n subtiles”Footnote 10 \(\mathcal {K}_{n}=\{\mathcal {R}(u)\,:\, u\in \mathcal {L}_{{\boldsymbol {\sigma }}} \mbox{ with } |u|=n\}\) are disjoint in measure. By (3.56) the measure λ 1 ∘ φ is a shift invariant probability measure on X σ. As by Theorem 3.5.11 there is only one such measure, μ = λ 1 ∘ φ. Now, essential disjointness of the elements of \(\mathcal {K}_{n}\) implies that φ(x)≠φ(y) for all distinct x, y satisfying \(\varphi (\mathbf {x}),\varphi (\mathbf {y} ) \in \mathcal {R} \setminus \bigcup _{n\in \mathbb {N}, K\in \mathcal {K}_n} \partial K\). As, by (3.57) and Theorem 3.7.1, λ 1(∂K) = μ(φ −1(∂K)) = 0 for all \(K\in \mathcal {K}_n\), \(n\in \mathbb {N}\), the map φ is μ-a.e. injective. Since surjectivity follows from the definition of φ this proves μ-a.e. bijectivity. Finally, using (3.56), the commutativity of the diagram (3.55) follows from the bijectivity of φ.
Since \(\mathcal {C}_{\mathbf {1}}\) forms a tiling of 1
⊥ by assumption, the Rauzy fractal \(\mathcal {R}\) is a fundamental domain of the lattice \(\varLambda = {\mathbf {1}}^\bot \cap \mathbb {Z}^d\) spanned by e
1 −e
i, \(i \in \mathcal {A} \setminus \{1\}\). But as  holds for each \(i\in \mathcal {A}\), the canonical projection of E onto the torus \({\mathbf {1}}^\bot / \varLambda \simeq \mathbb {T}^{d-1}\) is equal to the rotation
holds for each \(i\in \mathcal {A}\), the canonical projection of E onto the torus \({\mathbf {1}}^\bot / \varLambda \simeq \mathbb {T}^{d-1}\) is equal to the rotation  . Thus, if we denote by \(\overline {\varphi }\) the canonical projection of φ to the torus 1
⊥∕Λ, the diagram
. Thus, if we denote by \(\overline {\varphi }\) the canonical projection of φ to the torus 1
⊥∕Λ, the diagram

commutes. Note that \(\overline {\varphi }\) is m to 1 onto, where m is the covering degree of \(\mathcal {C}_1\), and, hence, a bijection as \(\mathcal {C}_1\) forms a tiling. This proves the first assertion of Theorem 3.9.4.
The second assertion of Theorem 3.9.4 follows from the definition of a natural coding because the rotation T was defined in terms of an exchange of domains. Finally, due to [1, Proposition 7], the C-balance of \(\mathcal {L}_{\boldsymbol {\sigma }}\) implies that \(\mathcal {R}(i)\) is a bounded remainder set for each \(i \in \mathcal {A}\), which also proves the last assertion.
3.9.3 A Metric Result
As mentioned already in Remark 3.7.2(i), the assumptions of Theorems 3.7.1 and 3.9.4 allow for a metric version of these results. To be more precise, let S be a finite set of substitutions and consider the full shift \((S^{\mathbb {N}}, \varSigma , \nu )\), where ν is an ergodic Σ-invariant probability measure satisfying some mild conditions. Our aim is to state a version of Theorems 3.5.11, 3.7.1, and 3.9.4 that is valid for ν-a.e. \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\). This second main result of the present survey is also a special case of a result from Berthé et al. [52].
To state our result we need to introduce some new concepts. Let S be a finite set of substitutions over the alphabet \(\mathcal {A}=\{1,2,\ldots ,d\}\) and consider the shift \((S^{\mathbb {N}},\varSigma ,\nu )\), where ν is some Σ-invariant probability measure on \(S^{\mathbb {N}}\). With each σ = (σ n)n≥0 we associate the linear cocycle operatorA(σ) = (M 0)t (recall that M 0 is the incidence matrix of σ 0) and define the Lyapunov exponents𝜗 1, …, 𝜗 d of \((S^{\mathbb {N}},\varSigma ,\nu )\) iteratively by
for 1 ≤ k ≤ d, where ∧k denotes the k-fold wedge product. We say that \((S^{\mathbb {N}},\varSigma ,\nu )\) satisfies the Pisot condition if
(cf. [44, §6.3]). Using these definitions we get the following metric version of Theorems 3.5.11, 3.7.1, and 3.9.4.
Theorem 3.9.5 (See [52, Theorem 3.3])
Let S be a finite set of unimodular substitutions and assume that the shift \((S^{\mathbb {N}},\varSigma ,\nu )\) is ergodic and satisfies the Pisot condition. Assume further that ν assigns positive measure to every cylinder and that there exists a cylinder corresponding to a substitution with positive incidence matrix. Then, for ν-almost every \(\boldsymbol {\sigma } \in S^{\mathbb {N}}\) the following assertions hold.
-
1.
(X σ, Σ) is minimal and uniquely ergodic (denote the unique Σ-invariant measure by μ).
-
2.
Each subtile \(\mathcal {R}(i)\), \(i\in \mathcal {A}\), is equal to the closure of its interior and satisfies \(\lambda _{\mathbf {1}}(\partial \mathcal {R}(i))=0\).
-
3.
If the collection \(\mathcal {C}_{\mathbf {1}}\)associated withσforms a tiling of1 ⊥then (X σ, Σ, μ) is measurably conjugate to a rotation T on \(\mathbb {T}^{d-1}\), each element of X σis a natural coding of T w.r.t. the partition \(\{\mathcal {R}(i)\,:\, i\in \mathcal {A}\}\)of \(\mathcal {R}\), and each \(\mathcal {R}(i)\), \(i\in \mathcal {A}\), is a bounded remainder set for T.
3.9.4 Proof of the Metric Result
In the present section we give a quite complete proof of Theorem 3.9.5. The idea is to show that each of the conditions posed in Theorem 3.9.4 is generic. A prominent tool in this proof is the Multiplicative Ergodic Theorem (also called Oseledec Theorem; see for instance [8, 3.4.1 Theorem]). Also the famous Poincaré Recurrence Theorem (cf. e.g. [126, Theorem 1.4]), which states that a.e. orbit in a measurable dynamical system (X, T, μ) starting in a set of positive measure E hits E infinitely often, will be used. In our setting, the Oseledec theorem has the following consequence.
Proposition 3.9.6
Let S be a finite set of unimodular substitutions over the alphabet \(\mathcal {A}=\{1,2,\ldots ,d\}\)and assume that the shift \((S^{\mathbb {N}},\varSigma ,\nu )\)is ergodic with Lyapunov exponents 𝜗 1, …, 𝜗 dsatisfying the Pisot condition (3.59). Assume further that ν assigns positive measure to every cylinder and that there exists a cylinder corresponding to a substitution with positive incidence matrix. Then for ν-a.e. \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\)the following assertions hold.
-
(i)
The sequenceσis primitive and recurrent, thus the letter frequency vectoru = u(σ) exists.
-
(ii)
For each ε > 0 there exists n 0 = n 0(ε, σ) such that the sequence of incidence matricesM = (M n) = (M n(σ)) satisfies Footnote 11
$$\displaystyle \begin{aligned} \Vert (M_{[0,n)})^t\vert_{{\mathbf{u}}^\bot} \Vert_2 < e^{(\vartheta_2+\varepsilon)n} \end{aligned}$$for each n ≥ n 0.
Proof
Since ν puts positive mass on each cylinder, ν-a.e. σ is recurrent by Poincaré recurrence. Together with the fact that there is a cylinder corresponding to a positive incidence matrix Poincaré recurrence also implies primitivity for ν-a.e. σ. Thus ν-a.e. σ has a letter frequency vector u by Proposition 3.5.5. This proves (i).
In order to apply the Multiplicative Ergodic Theorem [8, 3.4.1 Theorem] we need to assure log-integrability of the cocycle which, in our case, means that
Since S finite, the quantity \(\max \{0, \log \Vert M_0({\boldsymbol {\sigma }})\Vert _2\}\) is bounded and therefore (3.60) always holds. Thus, because 𝜗 1 is a simple Lyapunov exponent, [8, 3.4.1 Theorem] implies that for ν-a.e. σ there is a hyperplane \(\mathcal {H}=\mathcal {H}({\boldsymbol {\sigma }})\subset \mathbb {R}^d\) such that \(\lim _{n\to \infty } \frac 1n \log \Vert M_{[0,n)}({\boldsymbol {\sigma }})^t|{ }_{\mathcal {H}} \Vert _2 \le \vartheta _2\). This implies that for each ε > 0 there is n 0 = n 0(ε, σ) such that
holds for n ≥ n 0. It remains to show that \(\mathcal {H}={\mathbf {u}}^\bot \). However, this follows because for x∉u ⊥ we have that 〈M [0,n)(σ)tx, 1〉 = 〈x, M [0,n)(σ)1〉 is unbounded because for large n the vector M [0,n)(σ)1 is a large vector close to the line \(\mathbb {R}_+\mathbf {u}\). Thus the only hyperplane for which (3.61) can possibly hold is \(\mathcal {H}={\mathbf {u}}^\bot \) and (ii) follows. □
Proposition 3.9.6 is now used in order to show that balance is generic for elements of a shift \((S^{\mathbb {N}},\varSigma ,\nu )\) satisfying the Pisot condition.
Lemma 3.9.7
Let S be a finite set of unimodular substitutions over the alphabet \(\mathcal {A}=\{1,2,\ldots ,d\}\)and assume that the shift \((S^{\mathbb {N}},\varSigma ,\nu )\)is ergodic and satisfies the Pisot condition (3.59). Assume further that ν assigns positive measure to every cylinder and that there exists a cylinder corresponding to a substitution with positive incidence matrix. Then the sets
satisfy
i.e., balance of \(\mathcal {L}_{\boldsymbol {\sigma }}\)is a generic property of \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\).
Proof
By Proposition 3.9.6 we see that for ν-a.e. \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\) the sequence is primitive and recurrent, and for the letter frequency vector u = (u 1, …, u d)t (with ∥u∥1 = 1) we have
We assume that \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\) has all these properties and follow the proof of [44, Theorem 5.8]. Let w ∈ X σ be arbitrary. Since by the proof of Proposition 3.5.3(iii) each element of X σ has the same language, each factor v of w is a factor of a limit sequence of σ and, hence, by (3.4.1) can be written as
where p n and s n is a prefix and a suffix of σ n(i) for some \(i\in \mathcal {A}\), respectively, for each 0 ≤ n ≤ N − 1 and x is a factor of σ N(i) for some \(i\in \mathcal {A}\). To make the notation easier we set p N = x and s N = ε. We mention that (3.63) is the Dumont-Thomas decomposition of v which was first introduced in [70]. Using (3.63) and denoting by e 1, …, e d the standard basis vectors of \(\mathbb {R}^d\) we have
for each \(i\in \mathcal {A}\). Since u 1 + ⋯ + u d = 1 we see that e i − u i(e 1 + ⋯ + e d) ∈u ⊥. This can be used to get
Since S is a finite set, the quantity ∥M n∥2 is uniformly bounded in n. Thus, using (3.62) this implies that w is finitely balanced. Since σ was taken from a set of full measure ν of \(S^{\mathbb {N}}\) this finishes the proof. □
Before we can put everything together we need to deal with the genericness of algebraic irreducibility. This has been done in [52, Lemma 8.7] in the following fashion.
Lemma 3.9.8
Let S be a finite set of unimodular substitutions over the alphabet \(\mathcal {A}=\{1,2,\ldots ,d\}\)and assume that the shift \((S^{\mathbb {N}},\varSigma ,\nu )\)is ergodic and satisfies the Pisot condition (3.59). If ν-a.e. sequence \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\)is primitive then ν-a.e. sequence \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\)is algebraically irreducible.
Proof (Sketch)
Let σ be a generic sequence with sequence of incidence matrices M = (M n) and fix \(k\in \mathbb {N}\). Then for ℓ →∞ the matrix M [k,ℓ) maps the unit sphere into an ellipse whose largest semiaxis tends to infinity and all of whose other semiaxes tend to zero by the Pisot condition. We prove that for ℓ large enough there can be only one eigenvalue λ with |λ|≥ 1.
Indeed, if ℓ is large enough then M [k,ℓ) is strictly positive, thus there is a dominant Perron-Frobenius eigenvalue λ 0 > 1. It corresponds to an eigenvector w 0 with strictly positive entries. Suppose that there is another real eigenvalue λ with |λ|≥ 1 and corresponding eigenvector w. Since the image of the unit sphere under M [k,ℓ) is an ellipse with the above mentioned properties, the corresponding eigenvector has to have a direction close to w 0 for ℓ large, because otherwise its length would be shrunk by the application of M [k,ℓ) as can be seen in Fig. 3.20. Thus, if ℓ is large enough then w must have strictly positive entries. However, such an eigenvector has to belong to the Perron-Frobenius eigenvalue, a contradiction. The case of nonreal eigenvalues can be treated similarly. Thus M [k,ℓ) has only one eigenvalue of modulus greater than or equal to 1. Since M [k,ℓ) is an unimodular integer matrix, it cannot have 0 as an eigenvalue. This implies that the characteristic polynomial of M [k,ℓ) is irreducible and, hence, σ is algebraically irreducible. Indeed, we even proved that the characteristic polynomial of M [k,ℓ) is the minimal polynomial of the Pisot number λ 0. □

An illustration of the elliptic image of the unit circle under M [k,ℓ). The dashed lines are the axes of the ellipse, the largest axis being the direction of the Perron-Frobenius eigenvector w 0. If the indicated vector w is an eigenvector of M [k,ℓ) for another eigenvalue, its direction has to be far from the direction of w 0 (because not all of its entries can be positive). This entails that its length is less than 1 and so it can only correspond to an eigenvalue less than 1 in modulus
We now have all the necessary ingredients to finish the proof of Theorem 3.9.5.
Proof (Conclusion of the Proof of Theorem 3.9.5)
We show that the conditions of Theorem 3.9.4 are satisfied for ν-a.e. \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\). To keep things simple we give the proof only for ν being a Bernoulli measure. Primitivity and algebraic irreducibility hold ν-a.e. by Proposition 3.9.6(i) and Lemma 3.9.8, respectively.
It remains to deal with the condition involving recurrence and balance. We claim that there is \(C\in \mathbb {N}\) such that
Indeed, since ν is a Bernoulli measure, [σ 0, …, σ ℓ−1] is independent from Σ −ℓS(C). Thus we have
and the claim (3.64) follows because ν([σ 0, …, σ ℓ−1]) > 0 by assumption and ν(S(C)) > 0 for C large enough by Lemma 3.9.7. By another application of Poincaré recurrence (3.64) yields that for ν-a.e. \({\boldsymbol {\sigma }} \in S^{\mathbb {N}}\) and for every \(\ell \in \mathbb {N}\) there is n > 0 such that Σ nσ ∈ [σ 0, …, σ ℓ−1] and Σ n+ℓσ ∈ S(C).
Summing up we see that the assumptions of Theorem 3.9.4 are satisfied for ν-a.e. \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\). Thus Theorem 3.9.5 (1) follows from Theorem 3.5.11, Theorem 3.9.5 (2) follows from Theorem 3.7.1, and Theorem 3.9.5 (3) follows from Theorem 3.9.4. □
Remark 3.9.9
With small amendments in the conclusion of the proof of Theorem 3.9.5 it is possible to prove Theorem 3.9.5 for sofic subshifts (X, Σ, ν) of \((S^{\mathbb {N}},\varSigma ,\nu )\). Even the case of infinitely many substitutions (i.e., |S| = ∞) can be treated provided that the log-integrability condition (3.60) is satisfied. In this case one has to deal with the S-adic graph introduced in [44]. As mentioned above, the general result is contained in [52].
3.9.5 Corollaries for Arnoux-Rauzy and Brun Systems
We now want to apply the two main theorems to Arnoux-Rauzy as well as Brun S-adic systems. Since these systems and their related generalized continued fraction algorithms have been studied quite well in the literature this will yield unconditional results on measurable conjugacy to a torus rotation, natural codings, and bounded remainder sets.
We start with the case of Arnoux-Rauzy systems. Let S = {σ 1, σ 2, σ 3} be the set of Arnoux-Rauzy substitutions defined in (3.18). First we give a version of Theorem 3.9.5 for the S-adic sequences taken from \(S^{\mathbb {N}}\).
Corollary 3.9.10 (See [52, Theorem 3.8])
Let S be the set of Arnoux-Rauzy substitutions defined in (3.18) and consider the full shift \((S^{\mathbb {N}},\varSigma , \nu )\)equipped with an ergodic invariant measure ν that assigns positive mass to each cylinder. Then ν-a.e. \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\)defines an S-adic system (X σ, Σ) that is measurably conjugate to a rotation T on the 2-torus \(\mathbb {T}^2\). Moreover, each element of X σforms a natural coding of T w.r.t. the partition \(\{\mathcal {R}_i\,:\, i\in \mathcal {A}\}\)defined by the subtiles of the Rauzy fractal \(\mathcal {R}\). Each of these subtiles is a bounded remainder set of T.
Proof (Sketch)
It is easy to see that each cylinder containing each of the three substitutions has positive incidence matrix. Thus the result follows from Theorem 3.9.5 if we can establish that \((S^{\mathbb {N}},\varSigma ,\nu )\) satisfies the Pisot condition and that for ν-a.e. \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\) the associated collection \(\mathcal {C}_{\mathbf {1}}\) of Rauzy fractals forms a tiling. The fact that the Pisot condition holds was proved by Avila and Delecroix [28]. The tiling property is a consequence of Proposition 3.8.8. Indeed, assertion (iii) of this proposition holds by the following results. Firstly, strong coincidence follows from [37, Proposition 4] (or [52, Section 9] where “negative coincidence” was used). The other assertion from Proposition 3.8.8(iii) is a weaker form of the geometric finiteness property which holds by Proposition 3.8.11 (see also [48, Theorem 4.7]). □
With help of the balance properties of Arnoux-Rauzy sequences proved in [43] it is possible to use Theorem 3.9.4 in order to show results for concrete Arnoux-Rauzy systems. For instance it is proved in [52, Corollary 3.9] that any linearly recurrent Arnoux-Rauzy sequence with recurrent directive sequence generates an S-adic system (X σ, Σ) that is measurably conjugate to a rotation on a 2-torus.
For the second class of examples let S = {σ 1, σ 2, σ 3} be the set of Brun substitutions defined in (3.32). In this case a version of Theorem 3.9.5 completely analogous to Corollary 3.9.10 holds.
Corollary 3.9.11 (See [52, Theorem 3.10])
Let S be the set of Brun substitutions defined in (3.32) and consider the full shift \((S^{\mathbb {N}},\varSigma , \nu )\)equipped with an ergodic invariant measure ν that assigns positive mass to each cylinder. Then ν-a.e. \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\)defines an S-adic system (X σ, Σ) that is measurably conjugate to a rotation T on the 2-torus \(\mathbb {T}^2\). Moreover, each element of X σforms a natural coding of T w.r.t. the partition \(\{\mathcal {R}_i\,:\, i\in \mathcal {A}\}\)defined by the subtiles of the Rauzy fractal \(\mathcal {R}\). Each of these subtiles is a bounded remainder set of T.
Proof (Sketch)
First observe that σ 1σ 2σ 1σ 2 has positive incidence matrix. One uses again [28] to ensure that the Pisot condition holds (see also [83, 102, 118] for similar results). The tiling property follows from geometric coincidence which is established in [42] for the Brun class. □
Contrary to the Arnoux-Rauzy continued fraction algorithm, the Brun algorithm can be performed for all elements (x 1, x 2) ∈ Δ with Δ as in (3.24). Thus, using Brun systems we get natural codings for a.a. torus rotations \(\mathbf {t}\in \mathbb {T}^2\).
Corollary 3.9.12 (See [52, Corollary 3.12])
Let S be the set of Brun substitutions defined in (3.32). Then for almost every \(\mathbf {t}\in \mathbb {T}^2\)(w.r.t. the Haar measure on \(\mathbb {T}^2\)) there is \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\)such that the shift (X σ, Σ) is measurably conjugate to the rotation T tbyton \(\mathbb {T}^2\). Moreover, the sequences in X σform natural codings of the rotation T t.
To create concrete examples of Brun S-adic shifts being measurably conjugate to a rotation, one can use Theorem 3.9.4 together with the balance results established in [68].
3.10 Concluding Remarks: Natural Extensions, Flows, and Their Poincaré Sections
It remains to extend the ideas and results presented in Sect. 3.2.5 to generalized continued fraction algorithms and S-adic systems on d letters. This is the subject of the ongoing paper by Arnoux et al. [12].
It is possible to study natural extensions of generalized continued fraction algorithms (see for instance [19, 21]). In the way we do it in [12], the analogs of the L-shaped regions of Sect. 3.2.5 are “Rauzy-Boxes” which are defined as suspensions of S-adic Rauzy fractals. They were introduced in the S-adic setting in [52, Section 2.9] but have been studied earlier in the substitutive case, see for instance Ito and Rao [91]. These Rauzy boxes allow nonstationary Markov partitions for so-called “mapping families” in the sense studied by Arnoux and Fisher [15] that can be visualized by restacking S-adic Rauzy fractals in a suitable way.
Also Artin’s idea of viewing continued fraction algorithms as Poincaré sections of the geodesic flow on \(\mathrm {SL}_2(\mathbb {Z})\backslash \mathrm {SL}_2(\mathbb {R})\) can be generalized. In this generalization the role of the geodesic flow is played by the Weyl Chamber Flow, a diagonal \(\mathbb {R}^{d-1}\)-action on the space \(\mathrm {SL}_d(\mathbb {Z})\backslash \mathrm {SL}_d(\mathbb {R})\) of d-dimensional lattices. It turns out that each coordinate direction of this \(\mathbb {R}^{d-1}\)-action has a Poincaré section which is arithmetically coded by a generalized continued fraction algorithm. Geometrically, this is visualized by deforming a given Rauzy box (one for each coordinate) by the action of the Weyl Chamber Flow and restacking it accordingly as soon as a Poincaré section is reached.
Details of all this will be contained in [12].
Notes
- 1.
This implies that u and v have Σx and Σy in their orbit where x and y are the two limit sequences of σ. This interesting fact, which is not needed in this proof, should be proved by the reader.
- 2.
We could also have started with writing out 1 and going to the right from the origin. This would have produced the second limit sequence of (σ) which coincides with w save for the first two letters.
- 3.
A sequence is called linearly recurrent if there is a constant K such that each of its factors u occurs infinitely often in the sequence with gaps bounded by K|u|.
- 4.
A sequence is called uniformly recurrent if each of its factors occurs infinitely often in the sequence with bounded gaps.
- 5.
If we impose the additional property of primitivity on the coding sequence of a sequence \(w\in \mathcal {A}^{\mathbb {N}}\) it turns out that X w depends only on the directive sequence σ defining the S-adic sequence w and we have X σ = X w. This will be worked out precisely in Sect. 3.5.
- 6.
Only the first letter a n in the argument of σ [0,n) is relevant for the limit. However, since we use the topology on \(\mathcal {A}^{\mathbb {N}}\) and \(\sigma _{[0,n)}(a_{n})\not \in \mathcal {A}^{\mathbb {N}}\) we have to write σ [0,n)(a na n…).
- 7.
In [111] a space of tilings is equipped with a topology by saying that two tilings are close to each other if their tiles are close to each other in Hausdorff metric inside a large ball around the origin. Although \(\mathcal {C}_{\mathbf {v}}\) and \(\mathcal {C}^{(n_k)}_{\mathbf {v}}\) are no tilings, an analogous topology can be used here: \(\mathcal {C}_{\mathbf {v}}\) and
 are said to be close to each other if Γ(v) and \(\varGamma ({\mathbf {v}}^{(n_k)})-{\mathbf {y}}_k\) coincide inside a large ball B around the origin and the tiles associated to an element of [y, i] ∈ Γ(v) ∩ B in each of these two collections are close to each other in Hausdorff metric.
are said to be close to each other if Γ(v) and \(\varGamma ({\mathbf {v}}^{(n_k)})-{\mathbf {y}}_k\) coincide inside a large ball B around the origin and the tiles associated to an element of [y, i] ∈ Γ(v) ∩ B in each of these two collections are close to each other in Hausdorff metric. - 8.
- 9.
Note that there are two kinds of shifts: the one just defined acts on the sequence of substitutions \(S^{\mathbb {N}}\), the other one (the S-adic shift) acts on the set of sequences X σ which is defined in terms of a single sequence of substitutions \({\boldsymbol {\sigma }}\in S^{\mathbb {N}}\). It should cause no confusion that both of these shift mappings are denoted by Σ.
- 10.
Not to be confused with the level n subtiles introduced in Sect. 3.7.1.
- 11.
Here ∥⋅∥2 is the operator norm w.r.t. the Euclidean norm on \(\mathbb {R}^d\).
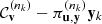 are said to be close to each other if Γ(v) and
are said to be close to each other if Γ(v) and References
B. Adamczewski, Balances for fixed points of primitive substitutions. Theor. Comput. Sci. 307(1), 47–75 (2003). Words
S. Akiyama, Self affine tilings and Pisot numeration systems, in Number Theory and Its Applications, ed. by K. Győry, S. Kanemitsu (Kluwer, Dordrecht, 1999), pp. 1–17
S. Akiyama, On the boundary of self affine tilings generated by Pisot numbers. J. Math. Soc. Japan 54(2), 283–308 (2002)
S. Akiyama, M. Barge, V. Berthé, J.Y. Lee, A. Siegel, On the Pisot substitution conjecture, in Mathematics of Aperiodic Order. Progr. Math., vol. 309 (Birkhäuser/Springer, Basel, 2015), pp. 33–72
S. Akiyama, T. Sadahiro, A self-similar tiling generated by the minimal Pisot number, in Proceedings of the 13th Czech and Slovak International Conference on Number Theory (Ostravice, 1997), vol. 6 (1998), pp. 9–26
J.P. Allouche, J. Shallit, Automatic Sequences: Theory, Applications, Generalizations. (Cambridge University Press, Cambridge, 2003)
A. Andres, R. Acharya, C. Sibata, Discrete analytical hyperplanes. Graph. Model. Image Process. 59, 302–309 (1997)
L. Arnold, Random Dynamical Systems. Springer Monographs in Mathematics (Springer, Berlin, 1998)
P. Arnoux, Un exemple de semi-conjugaison entre un échange d’intervalles et une translation sur le tore. Bull. Soc. Math. France 116(4), 489–500 (1989) (1988)
P. Arnoux, Le codage du flot géodésique sur la surface modulaire. Enseign. Math. (2) 40(1-2), 29–48 (1994)
P. Arnoux, Continued fractions: natural extensions and invariant measures, in Natural Extension of Arithmetic Algorithms and S-adic System. RIMS Kôkyûroku Bessatsu, vol. B58 (Res. Inst. Math. Sci. (RIMS), Kyoto, 2016), pp. 19–32
P. Arnoux, V. Berthé, M. Minervino, W. Steiner, J. Thuswaldner, Nonstationary Markov partitions, flows on homogeneous spaces, and continued fractions (2018, in preparation)
P. Arnoux, S. Ferenczi, P. Hubert, Trajectories of rotations. Acta Arith. 87(3), 209–217 (1999)
P. Arnoux, A.M. Fisher, The scenery flow for geometric structures on the torus: the linear setting. Chinese Ann. Math. Ser. B 22(4), 427–470 (2001)
P. Arnoux, A.M. Fisher, Anosov families, renormalization and non-stationary subshifts. Ergodic Theory Dyn. Syst. 25(3), 661–709 (2005)
P. Arnoux, M. Furukado, E. Harriss, S. Ito, Algebraic numbers, free group automorphisms and substitutions on the plane. Trans. Am. Math. Soc. 363(9), 4651–4699 (2011)
P. Arnoux, E. Harriss, What is …a Rauzy fractal? Not. Am. Math. Soc. 61(7), 768–770 (2014)
P. Arnoux, S. Ito, Pisot substitutions and Rauzy fractals. Bull. Belg. Math. Soc. Simon Stevin 8(2), 181–207 (2001). Journées Montoises d’Informatique Théorique (Marne-la-Vallée, 2000)
P. Arnoux, S. Labbé, On some symmetric multidimensional continued fraction algorithms. Ergodic Theory Dyn. Syst. 38, 1601–1626 (2018)
P. Arnoux, M. Mizutani, T. Sellami, Random product of substitutions with the same incidence matrix. Theor. Comput. Sci. 543, 68–78 (2014)
P. Arnoux, A. Nogueira, Mesures de Gauss pour des algorithmes de fractions continues multidimensionnelles. Ann. Sci. École Norm. Sup. (4) 26(6), 645–664 (1993)
P. Arnoux, G. Rauzy, Représentation géométrique de suites de complexité 2n + 1. Bull. Soc. Math. France 119(2), 199–215 (1991)
P. Arnoux, T.A. Schmidt, Cross sections for geodesic flows and α-continued fractions. Nonlinearity 26(3), 711–726 (2013)
P. Arnoux, T.A. Schmidt, Commensurable continued fractions. Discrete Contin. Dyn. Syst. 34(11), 4389–4418 (2014)
P. Arnoux, Š. Starosta, The Rauzy gasket, in Further Developments in Fractals and Related Fields. Trends Mathematics (Birkhäuser/Springer, New York, 2013), pp. 1–23
E. Artin, Ein mechanisches System mit quasiergodischen Bahnen. Abh. Math. Sem. Univ. Hamburg 3(1), 170–175 (1924)
J. Auslander, Minimal Flows and Their Extensions. North-Holland Mathematics Studies, vol. 153. (North-Holland Publishing Co., Amsterdam, 1988). Notas de Matemática [Mathematical Notes], 122
A. Avila, V. Delecroix, Some monoids of Pisot matrices (2015). Preprint, http://arxiv.org/abs/1506.03692
A. Avila, P. Hubert, A. Skripchenko, Diffusion for chaotic plane sections of 3-periodic surfaces. Invent. Math. 206(1), 109–146 (2016)
A. Avila, P. Hubert, A. Skripchenko, On the Hausdorff dimension of the Rauzy gasket. Bull. Soc. Math. France 144(3), 539–568 (2016)
G. Barat, V. Berthé, P. Liardet, J. Thuswaldner, Dynamical directions in numeration. Ann. Inst. Fourier (Grenoble) 56(7), 1987–2092 (2006). Numération, pavages, substitutions
M. Barge, The Pisot conjecture for β-substitutions. Ergodic Theory Dyn. Syst. 38(2), 444–472 (2016)
M. Barge, Pure discrete spectrum for a class of one-dimensional substitution tiling systems. Discrete Contin. Dyn. Syst. 36(3), 1159–1173 (2016)
M. Barge, B. Diamond, Coincidence for substitutions of Pisot type. Bull. Soc. Math. France 130(4), 619–626 (2002)
M. Barge, J. Kellendonk, Proximality and pure point spectrum for tiling dynamical systems. Mich. Math. J. 62(4), 793–822 (2013)
M. Barge, J. Kwapisz, Geometric theory of unimodular Pisot substitutions. Amer. J. Math. 128(5), 1219–1282 (2006)
M. Barge, S. Štimac, R.F. Williams, Pure discrete spectrum in substitution tiling spaces. Discrete Contin. Dyn. Syst. 33(2), 579–597 (2013)
A.Y. Belov, G.V. Kondakov, I.V. Mitrofanov, Inverse problems of symbolic dynamics, in Algebraic Methods in Dynamical Systems. Banach Center Publ., vol. 94 (Polish Acad. Sci. Inst. Math., Warsaw, 2011), pp. 43–60
J. Bernoulli, Sur une nouvelle espece de calcul. Recueil pour les Astronomes, Berlin, vol. 1 (1772), pp. 255–284
J. Berstel, Transductions and context-free languages, Leitfäden der Angewandten Mathematik und Mechanik [Guides to Applied Mathematics and Mechanics], vol. 38 (B. G. Teubner, Stuttgart, 1979)
V. Berthé, Multidimensional Euclidean algorithms, numeration and substitutions. Integers 11B, A2 (2011)
V. Berthé, J. Bourdon, T. Jolivet, A. Siegel, A combinatorial approach to products of Pisot substitutions. Ergodic Theory Dyn. Syst. 36(6), 1757–1794 (2016)
V. Berthé, J. Cassaigne, W. Steiner, Balance properties of Arnoux-Rauzy words. Int. J. Algebra Comput. 23(4), 689–703 (2013)
V. Berthé, V. Delecroix, Beyond substitutive dynamical systems: S-adic expansions. RIMS Lecture Note ‘Kôkyûroku Bessatsu’ B46, 81–123 (2014)
V. Berthé, E. Domenjoud, D. Jamet, X. Provençal, Fully subtractive algorithm, tribonacci numeration and connectedness of discrete planes, in Numeration and Substitution 2012. RIMS Kôkyûroku Bessatsu, vol. B46 (Res. Inst. Math. Sci. (RIMS), Kyoto, 2014), pp. 159–174
V. Berthé, S. Ferenczi, L.Q. Zamboni, Interactions between dynamics, arithmetics and combinatorics: the good, the bad, and the ugly, in Algebraic and Topological Dynamics. Contemp. Math., vol. 385 (American Mathematical Society, Providence, RI, 2005), pp. 333–364
V. Berthé, C. Holton, L.Q. Zamboni, Initial powers of Sturmian sequences. Acta Arith. 122(4), 315–347 (2006)
V. Berthé, T. Jolivet, A. Siegel, Substitutive Arnoux-Rauzy sequences have pure discrete spectrum. Unif. Distrib. Theory 7(1), 173–197 (2012)
V. Berthé, S. Labbé, Factor complexity of S-adic words generated by the Arnoux-Rauzy-Poincaré algorithm. Adv. Appl. Math. 63, 90–130 (2015)
V. Berthé, M. Minervino, W. Steiner, J. Thuswaldner, The S-adic Pisot conjecture on two letters. Topology Appl. 205, 47–57 (2016)
V. Berthé, A. Siegel, J.M. Thuswaldner, Substitutions, Rauzy fractals, and tilings, in Combinatorics, Automata and Number Theory. Encyclopedia of Mathematics and its Applications, vol. 135 (Cambridge University Press, Cambridge, 2010)
V. Berthé, W. Steiner, J.M. Thuswaldner, Geometry, dynamics, and arithmetic of S-adic shifts. Ann. Inst. Fourier (Grenoble) 69(3), 1347–1409 (2019)
S. Bezuglyi, J. Kwiatkowski, K. Medynets, B. Solomyak, Invariant measures on stationary Bratteli diagrams. Ergodic Theory Dyn. Syst. 30(4), 973–1007 (2010)
S. Bezuglyi, J. Kwiatkowski, K. Medynets, B. Solomyak, Finite rank Bratteli diagrams: structure of invariant measures. Trans. Am. Math. Soc. 365(5), 2637–2679 (2013)
G. Birkhoff, Extensions of Jentzsch’s theorem. Trans. Am. Math. Soc. 85, 219–227 (1957)
M. Boshernitzan, A unique ergodicity of minimal symbolic flows with linear block growth. J. Anal. Math. 44, 77–96 (1984/85)
P. Boyland, W. Severa, Geometric representation of the infimax S-adic family. Fundam. Math. 240(1), 15–50 (2018)
A.J. Brentjes, Multidimensional continued fraction algorithms, Mathematical Centre Tracts, vol. 145 (Mathematisch Centrum, Amsterdam, 1981)
V. Brun, Algorithmes euclidiens pour trois et quatre nombres, in Treizième congrès des mathèmaticiens scandinaves, tenu à Helsinki 18-23 août 1957 (Mercators Tryckeri, Helsinki, 1958), pp. 45–64
E.B. Burger, J. Gell-Redman, R. Kravitz, D. Walton, N. Yates, Shrinking the period lengths of continued fractions while still capturing convergents. J. Number Theory 128(1), 144–153 (2008)
V. Canterini, A. Siegel, Geometric representation of substitutions of Pisot type. Trans. Am. Math. Soc. 353(12), 5121–5144 (2001)
J. Cassaigne, S. Ferenczi, A. Messaoudi, Weak mixing and eigenvalues for Arnoux-Rauzy sequences. Ann. Inst. Fourier (Grenoble) 58(6), 1983–2005 (2008)
J. Cassaigne, S. Ferenczi, L.Q. Zamboni, Imbalances in Arnoux-Rauzy sequences. Ann. Inst. Fourier (Grenoble) 50(4), 1265–1276 (2000)
J. Cassaigne, S. Labbé, J. Leroy, A set of sequences of complexity 2n + 1, in Combinatorics on Words. Lecture Notes in Comput. Sci., vol. 10432 (Springer, Cham, 2017), pp. 144–156
J. Cassaigne, F. Nicolas, Factor complexity, in: Combinatorics, Automata and Number Theory. Encyclopedia Math. Appl., vol. 135 (Cambridge University Press, Cambridge, 2010), pp. 163–247
M.I. Cortez, F. Durand, B. Host, A. Maass, Continuous and measurable eigenfunctions of linearly recurrent dynamical Cantor systems. J. Lond. Math. Soc. (2) 67(3), 790–804 (2003)
E.M. Coven, G.A. Hedlund, Sequences with minimal block growth. Math. Systems Theory 7, 138–153 (1973)
V. Delecroix, T. Hejda, W. Steiner, Balancedness of Arnoux-Rauzy and Brun words, in WORDS. Lecture Notes in Computer Science, vol. 8079, pp. 119–131 (Springer, Berlin, 2013)
R. DeLeo, I.A. Dynnikov, Geometry of plane sections of the infinite regular skew polyhedron {4, 6∣4}. Geom. Dedicata 138, 51–67 (2009)
J.M. Dumont, A. Thomas, Systemes de numeration et fonctions fractales relatifs aux substitutions. Theor. Comput. Sci. 65(2), 153–169 (1989)
F. Durand, Linearly recurrent subshifts have a finite number of non-periodic subshift factors. Ergodic Theory Dyn. Syst. 20, 1061–1078 (2000)
F. Durand, Corrigendum and addendum to: “Linearly recurrent subshifts have a finite number of non-periodic subshift factors” [Ergodic Theory Dynam. Systems 20 (2000), no. 4, 1061–1078]. Ergodic Theory Dyn. Syst. 23, 663–669 (2003)
F. Durand, J. Leroy, G. Richomme, Do the properties of an S-adic representation determine factor complexity? J. Integer Seq. 16(2), Article 13.2.6, 30 pp. (2013)
H. Ei, Some properties of invertible substitutions of rank d, and higher dimensional substitutions. Osaka J. Math. 40(2), 543–562 (2003)
H. Ei, S. Ito, H. Rao, Atomic surfaces, tilings and coincidences. II. Reducible case. Ann. Inst. Fourier (Grenoble) 56(7), 2285–2313 (2006). Numération, pavages, substitutions
M. Einsiedler, T. Ward, Ergodic Theory with a View Towards Number Theory. Graduate Texts in Mathematics, vol. 259 (Springer, London, 2011)
S. Ferenczi, Rank and symbolic complexity. Ergodic Theory Dyn. Syst. 16(4), 663–682 (1996)
S. Ferenczi, A.M. Fisher, M. Talet, Minimality and unique ergodicity for adic transformations. J. Anal. Math. 109, 1–31 (2009)
T. Fernique, Multidimensional Sturmian sequences and generalized substitutions. Int. J. Found. Comput. Sci. 17(3), 575–599 (2006)
T. Fernique, Generation and recognition of digital planes using multi-dimensional continued fractions, in Discrete Geometry for Computer Imagery. Lecture Notes in Comput. Sci., vol. 4992 (Springer, Berlin, 2008)
A.M. Fisher, Nonstationary mixing and the unique ergodicity of adic transformations. Stochastics Dyn. 9(3), 335–391 (2009)
N.P. Fogg, Substitutions in Dynamics, Arithmetics and Combinatorics. Lecture Notes in Mathematics, vol. 1794 (Springer, Berlin, 2002)
T. Fujita, S. Ito, M. Keane, M. Ohtsuki, On almost everywhere exponential convergence of the modified Jacobi-Perron algorithm: a corrected proof. Ergodic Theory Dyn. Syst. 16(6), 1345–1352 (1996)
H. Furstenberg, Stationary Processes and Prediction Theory. Annals of Mathematics Studies, No. 44 (Princeton University Press, Princeton, NJ, 1960)
P.R. Halmos, Lectures on Ergodic Theory (Chelsea Publishing Co., New York, 1960)
C. Holton, L.Q. Zamboni, Geometric realizations of substitutions. Bull. Soc. Math. France 126(2), 149–179 (1998)
J.E. Hopcroft, J.D. Ullman, Introduction to Automata Theory, Languages, and Computation. Addison-Wesley Series in Computer Science (Addison-Wesley Publishing Co., Reading, MA, 1979).
P. Hubert, A. Messaoudi, Best simultaneous Diophantine approximations of Pisot numbers and Rauzy fractals. Acta Arith. 124(1), 1–15 (2006)
S. Ito, M. Kimura, On Rauzy fractal. Japan J. Ind. Appl. Math. 8(3), 461–486 (1991)
S. Ito, M. Ohtsuki, Parallelogram tilings and Jacobi-Perron algorithm. Tokyo J. Math. 17(1), 33–58 (1994)
S. Ito, H. Rao, Atomic surfaces, tilings and coincidence. I. Irreducible case. Israel J. Math. 153, 129–155 (2006)
D. Jamet, N. Lafrenière, X. Provençal, Generation of digital planes using generalized continued-fractions algorithms, in Discrete Geometry for Computer Imagery. Lecture Notes in Comput. Sci., vol. 9647, pp. 45–56 (Springer, Cham, 2016)
D. Jamet, J.L. Toutant, On the connectedness of rational arithmetic discrete hyperplanes, in Discrete Geometry for Computer Imagery. Lecture Notes in Comput. Sci., vol. 4245, (Springer, Berlin, 2006), pp. 223–234
A. Katok, Interval exchange transformations and some special flows are not mixing. Israel J. Math. 35(4), 301–310 (1980)
S. Labbé, 3-dimensional continued fraction algorithms cheat sheets (2015). http://arxiv.org/abs/1511.08399
J. Lagarias, Y. Wang, Self-affine tiles in \(\mathbb {R}^n\). Adv. Math. 121, 21–49 (1996)
J. Leroy, Some improvements of the S-adic conjecture. Adv. Appl. Math. 48(1), 79–98 (2012)
J. Leroy, An S-adic characterization of minimal subshifts with first difference of complexity 1 ≤ p(n + 1) − p(n) ≤ 2. Discrete Math. Theor. Comput. Sci. 16(1), 233–286 (2014)
G. Levitt, La dynamique des pseudogroupes de rotations. Invent. Math. 113(3), 633–670 (1993)
B. Loridant, M. Minervino, Geometrical models for a class of reducible Pisot substitutions. Discrete Comput. Geom. 60, 981–1028 (2018)
M. Lothaire, Algebraic Combinatorics on Words. Encyclopedia of Mathematics and its Applications, vol. 90 (Cambridge University Press, Cambridge, 2002). A collective work by J. Berstel, D. Perrin, P. Seebold, J. Cassaigne, A. De Luca, S. Varricchio, A. Lascoux, B. Leclerc, J.-Y. Thibon, V. Bruyere, C. Frougny, F. Mignosi, A. Restivo, C. Reutenauer, D. Foata, G.-N. Han, J. Desarmenien, V. Diekert, T. Harju, J. Karhumaki and W. Plandowski, with a preface by J. Berstel and D. Perrin
R. Meester, A simple proof of the exponential convergence of the modified Jacobi-Perron algorithm. Ergodic Theory Dyn. Syst. 19(4), 1077–1083 (1999)
A. Messaoudi, Frontière du fractal de Rauzy et système de numération complexe. Acta Arith. 95(3), 195–224 (2000)
A. Messaoudi, Propriétés arithmétiques et topologiques d’une classe d’ensembles fractales. Acta Arith. 121(4), 341–366 (2006)
M. Minervino, W. Steiner, Tilings for Pisot beta numeration. Indag. Math. (N.S.) 25(4), 745–773 (2014)
M. Minervino, J.M. Thuswaldner, The geometry of non-unit Pisot substitutions. Ann. Inst. Fourier (Grenoble) 64(4), 1373–1417 (2014)
M. Morse, G.A. Hedlund, Symbolic dynamics II. Sturmian trajectories. Am. J. Math. 62, 1–42 (1940)
H. Nakada, S. Ito, S. Tanaka, On the invariant measure for the transformations associated with some real continued-fractions. Keio Eng. Rep. 30(13), 159–175 (1977)
O. Perron, Grundlagen für eine Theorie des Jacobischen Kettenbruchalgorithmus. Math. Ann. 64(1), 1–76 (1907)
M. Queffélec, Substitution Dynamical Systems—Spectral Analysis. Lecture Notes in Mathematics, vol. 1294, 2nd edn. (Springer, Berlin, 2010)
C. Radin, M. Wolff, Space tilings and local isomorphism. Geom. Dedicata 42(3), 355–360 (1992)
G. Rauzy, Une généralisation du développement en fraction continue, in Séminaire Delange-Pisot-Poitou, 18e année: 1976/77, Théorie des nombres, Fasc. 1, pp. Exp. No. 15, 16 (Secrétariat Math., Paris, 1977)
G. Rauzy, échanges d’intervalles et transformations induites. Acta Arith. 34(4), 315–328 (1979)
G. Rauzy, Nombres algébriques et substitutions. Bull. Soc. Math. France 110(2), 147–178 (1982)
J.P. Reveillès, Géométrie discrète, calculs en nombres entiers et algorithmes. Ph.D. thesis, Université Louis Pasteur, Strasbourg (1991)
V.A. Rohlin, Exact endomorphism of a Lebesgue space. Magyar Tud. Akad. Mat. Fiz. Oszt. Közl. 14, 443–474 (1964)
Y. Sano, P. Arnoux, S. Ito, Higher dimensional extensions of substitutions and their dual maps. J. Anal. Math. 83, 183–206 (2001)
B.R. Schratzberger, The exponent of convergence for Brun’s algorithm in two dimensions. Österreich. Akad. Wiss. Math.-Natur. Kl. Sitzungsber. II 207, 229–238 (1999) (1998)
F. Schweiger, Multidimensional Continued Fractions Oxford Science Publications (Oxford University Press, Oxford, 2000)
E.S. Selmer, Continued fractions in several dimensions. Nordisk Nat. Tidskr. 9, 37–43, 95 (1961)
C. Series, The modular surface and continued fractions. J. London Math. Soc. (2) 31(1), 69–80 (1985)
A. Siegel, Représentation des systèmes dynamiques substitutifs non unimodulaires. Ergodic Theory Dyn. Syst. 23(4), 1247–1273 (2003)
A. Siegel, J.M. Thuswaldner, Topological properties of Rauzy fractals. Mém. Soc. Math. Fr. (N.S.) 118, 144pp (2009)
V.F. Sirvent, Y. Wang, Self-affine tiling via substitution dynamical systems and Rauzy fractals. Pac. J. Math. 206(2), 465–485 (2002)
M. Viana, Ergodic theory of interval exchange maps. Rev. Mat. Complut. 19(1), 7–100 (2006)
P. Walters, An Introduction to Ergodic Theory. Graduate Texts in Mathematics, vol. 79 (Springer, New York, 1982)
Acknowledgements
I warmly thank Shigeki Akiyama and Pierre Arnoux for inviting me to contribute to this volume. I very much appreciate their constant encouragement and support, and the many discussions I had with them. Moreover, I am indebted to Valérie Berthé, Sébastien Labbé, and Wolfgang Steiner for their suggestions.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 The Editor(s) (if applicable) and The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Thuswaldner, J.M. (2020). S-adic Sequences: A Bridge Between Dynamics, Arithmetic, and Geometry. In: Akiyama, S., Arnoux, P. (eds) Substitution and Tiling Dynamics: Introduction to Self-inducing Structures. Lecture Notes in Mathematics, vol 2273. Springer, Cham. https://doi.org/10.1007/978-3-030-57666-0_3
Download citation
DOI: https://doi.org/10.1007/978-3-030-57666-0_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-57665-3
Online ISBN: 978-3-030-57666-0
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)