
Abstract
In this work, we develop efficient solvers for linear inverse problems based on randomized singular value decomposition (RSVD). This is achieved by combining RSVD with classical regularization methods, e.g., truncated singular value decomposition, Tikhonov regularization, and general Tikhonov regularization with a smoothness penalty. One distinct feature of the proposed approach is that it explicitly preserves the structure of the regularized solution in the sense that it always lies in the range of a certain adjoint operator. We provide error estimates between the approximation and the exact solution under canonical source condition, and interpret the approach in the lens of convex duality. Extensive numerical experiments are provided to illustrate the efficiency and accuracy of the approach.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
MSC:
1 Introduction
This work is devoted to randomized singular value decomposition (RSVD) for the efficient numerical solution of the following linear inverse problem
where \(A\in \mathbb {R}^{n\times m}\), \(x\in \mathbb {R}^m\) and \(b\in \mathbb {R}^n\) denote the data formation mechanism, unknown parameter and measured data, respectively. The data b is generated by \(b = b^\dag + e,\) where \(b^\dag = Ax^\dag \) is the exact data, and \(x^\dag \) and e are the exact solution and noise, respectively. We denote by \(\delta =\Vert e\Vert \) the noise level.
Due to the ill-posed nature, regularization techniques are often applied to obtain a stable numerical approximation. A large number of regularization methods have been developed. The classical ones include Tikhonov regularization and its variant, truncated singular value decomposition, and iterative regularization techniques, and they are suitable for recovering smooth solutions. More recently, general variational type regularization methods have been proposed to preserve distinct features, e.g., discontinuity, edge and sparsity. This work focuses on recovering a smooth solution by Tikhonov regularization and truncated singular value decomposition, which are still routinely applied in practice. However, with the advent of the ever increasing data volume, their routine application remains challenging, especially in the context of massive data and multi-query, e.g., Bayesian inversion or tuning multiple hyperparameters. Hence, it is still of great interest to develop fast inversion algorithms.
In this work, we develop efficient linear inversion techniques based on RSVD. Over the last decade, a number of RSVD inversion algorithms have been developed and analyzed [10, 11, 20, 26, 31]. RSVD exploits the intrinsic low-rank structure of A for inverse problems to construct an accurate approximation efficiently. Our main contribution lies in providing a unified framework for developing fast regularized inversion techniques based on RSVD, for the following three popular regularization methods: truncated SVD, standard Tikhonov regularization, and Tikhonov regularization with a smooth penalty. The main novelty is that it explicitly preserves a certain range condition of the regularized solution, which is analogous to source condition in regularization theory [5, 13], and admits interpretation in the lens of convex duality. Further, we derive error bounds on the approximation with respect to the true solution \(x^\dag \) in Sect. 4, in the spirit of regularization theory for noisy operators. These results provide guidelines on the low-rank approximation, and differ from existing results [1, 14, 30, 32, 33], where the focus is on relative error estimates with respect to the regularized solution.
Now we situate the work in the literature on RSVD for inverse problems. RSVD has been applied to solving inverse problems efficiently [1, 30, 32, 33]. Xiang and Zou [32] developed RSVD for standard Tikhonov regularization and provided relative error estimates between the approximate and exact Tikhonov minimizer, by adapting the perturbation theory for least-squares problems. In the work [33], the authors proposed two approaches based respectively on transformation to standard form and randomized generalized SVD (RGSVD), and for the latter, RSVD is only performed on the matrix A. There was no error estimate in [33]. Wei et al [30] proposed different implementations, and derived some relative error estimates. Boutsidis and Magdon [1] analyzed the relative error for truncated RSVD, and discussed the sample complexity. Jia and Yang [14] presented a different way to perform truncated RSVD via LSQR for general smooth penalty, and provided relative error estimates. See also [16] for an evaluation within magnetic particle imaging. More generally, the idea of randomization has been fruitfully employed to reduce the computational cost associated with regularized inversion in statistics and machine learning, under the name of sketching in either primal or dual spaces [2, 22, 29, 34]. All these works also essentially exploit the low-rank structure, but in a different manner. Our analysis may also be extended to these approaches.
The rest of the paper is organized as follows. In Sect. 2, we recall preliminaries on RSVD, especially implementation and error bound. Then in Sect. 3, under one single guiding principle, we develop efficient inversion schemes based on RSVD for three classical regularization methods, and give the error analysis in Sect. 4. Finally we illustrate the approaches with some numerical results in Sect. 5. In the appendix, we describe an iterative refinement scheme for (general) Tikhonov regularization. Throughout, we denote by lower and capital letters for vectors and matrices, respectively, by I an identity matrix of an appropriate size, by \(\Vert \cdot \Vert \) the Euclidean norm for vectors and spectral norm for matrices, and by \((\cdot ,\cdot )\) for Euclidean inner product for vectors. The superscript \(^*\) denotes the vector/matrix transpose. We use the notation \(\mathscr {R}(A)\) and \(\mathscr {N}(A)\) to denote the range and kernel of a matrix A, and \(A_k\) and \(\tilde{A}_k\) denote the optimal and approximate rank-k approximations by SVD and RSVD, respectively. The notation c denotes a generic constant which may change at each occurrence, but is always independent of the condition number of A.
2 Preliminaries
Now we recall preliminaries on RSVD and technical lemmas.
2.1 SVD and Pseudoinverse
Singular value decomposition (SVD) is one of most powerful tools in numerical linear algebra. For any matrix \(A\in \mathbb {R}^{n\times m}\), SVD of A is given by
where \(U=[u_1,\ u_2, \ \ldots , \ u_n] \in \mathbb {R}^{n\times n}\) and \(V=[v_1, v_2, \ldots , v_m]\in \mathbb {R}^{m\times m}\) are column orthonormal matrices, with the vectors \(u_i\) and \(v_i\) being the left and right singular vectors, respectively, and \(V^*\) denotes the transpose of V. The diagonal matrix \(\varSigma =\mathrm {diag}(\sigma _i)\in \mathbb {R}^{n\times m}\) has nonnegative diagonal entries \(\sigma _i\), known as singular values (SVs), ordered nonincreasingly:
where \(r=\mathrm {rank}(A)\) is the rank of A. Let \(\sigma _i(A)\) be the ith SV of A. The complexity of the standard Golub-Reinsch algorithm for computing SVD is \(4n^2m + 8m^2n + 9m^3\) (for \(n\ge m\)) [8, p. 254]. Thus, it is expensive for large-scale problems.
Now we can give the optimal low-rank approximation to A. By Eckhardt-Young theorem, the optimal rank-k approximation \(A_k\) of A (in spectral norm) is given by
where \(U_k\in \mathbb {R}^{n\times k}\) and \(V_k\in \mathbb {R}^{m\times k}\) are the submatrix formed by taking the first k columns of the matrices U and V, and \(\varSigma _k=\mathrm {diag}(\sigma _1,\ldots ,\sigma _k)\in \mathbb {R}^{k\times k}\). The pseudoinverse \(A^\dag \in \mathbb {R}^{m\times n}\) of \(A \in \mathbb {R}^{n\times m}\) is given by
We have the following properties of the pseudoinverse of matrix product.
Lemma 1
For any \(A\in \mathbb {R}^{m\times n}\), \(B\in \mathbb {R}^{n\times l}\), the identity \((AB)^\dag = B^\dag A^\dag \) holds, if one of the following conditions is fulfilled: (i) A has orthonormal columns; (ii) B has orthonormal rows; (iii) A has full column rank and B has full row rank.
The next result gives an estimate on matrix pseudoinverse.
Lemma 2
For symmetric semipositive definite \(A,B\in \mathbb {R}^{m\times m}\), there holds
Proof
Since A is symmetric semipositive definite, we have \(A^\dag = \lim _{\mu \rightarrow 0^+}(A+\mu I)^{-1}.\) By the identity \(C^{-1}-D^{-1}=C^{-1} (D-C)D^{-1}\) for invertible \(C,D\in \mathbb {R}^{m\times m}\),
Now the estimate follows from the matrix spectral norm estimate.\(\square \)
Remark 1
The estimate for general matrices is weaker than the one in Lemma 2: for general \(A,B\in \mathbb {R}^{n\times m}\) with \(\mathrm {rank}(A)=\mathrm {rank}(B)<\min (m,n)\), there holds [25]
The rank condition is essential, and otherwise, the estimate may not hold.
Last, we recall the stability of SVs ([12, Corollary 7.3.8], [27, Sect. 1.3]).
Lemma 3
For \(A,B\in \mathbb {R}^{n\times m}\), there holds
2.2 Randomized SVD
Traditional numerical methods to compute a rank-k SVD, e.g., Lanczos bidiagonalization and Krylov subspace method, are especially powerful for large sparse or structured matrices. However, for many discrete inverse problems, there is no such structure. The prototypical model in inverse problems is a Fredholm integral equation of the first kind, which gives rise to unstructured dense matrices. Over the past decade, randomized algorithms for computing low-rank approximations have gained popularity. Frieze et al. [6] developed a Monte Carlo SVD to efficiently compute an approximate low-rank SVD based on non-uniform row and column sampling. Sarlos [23] proposed an approach based on random projection, using properties of random vectors to build a subspace capturing the matrix range. Below we describe briefly the basic idea of RSVD, and refer readers to [11] for an overview and to [10, 20, 26] for an incomplete list of recent works.
RSVD can be viewed as an iterative procedure based on SVDs of a sequence of low-rank matrices to deliver a nearly optimal low-rank SVD. Given a matrix \(A\in \mathbb {R}^{n\times m}\) with \(n\ge m\), we aim at obtaining a rank-k approximation, with \(k\ll \min ( m,n)\). Let \(\varOmega \in \mathbb {R}^{m\times (k+p)}\), with \(k+p\le m\), be a random matrix, with its entries following an i.i.d. Gaussian distribution N(0, 1), and the integer \(p\ge 0\) is an oversampling parameter (with a default value \(p=5\) [11]). Then we form a random matrix Y by
where the exponent \(q\in \mathbb {N}\cup \{0\}\). By SVD of A, i.e., \(A=U\varSigma V^*\), Y is given by
Thus \(\varOmega \) is used for probing \(\mathscr {R}(A)\), and \(\mathscr {R}(Y)\) captures \(\mathscr {R}(U_k)\) well. The accuracy is determined by the decay of \(\sigma _i\)s, and the exponent q can greatly improve the performance when \(\sigma _i\)s decay slowly. Let \(Q\in \mathbb {R}^{n\times (k+p)}\) be an orthonormal basis for \(\mathscr {R}(Y)\), which can be computed efficiently via QR factorization or skinny SVD. Next we form the (projected) matrix
Last, we compute SVD of B
with \(W\in \mathbb {R}^{(k+p)\times (k+p)}\), \(S\in \mathbb {R}^{(k+p)\times (k+p)}\) and \(V\in \mathbb {R}^{m\times (k+p)}\). This again can be carried out efficiently by standard SVD, since the size of B is much smaller. With 1 : k denoting the index set \(\{1,\ldots ,k\}\), let \(\tilde{U}_k = QW(1:n,1:k)\in \mathbb {R}^{n\times k}\), \(\tilde{\varSigma }_k = S(1:k,1:k)\in \mathbb {R}^{k\times k}\) and \(\tilde{V}_k =V(1:m,1:k)\in \mathbb {R}^{m\times k}\). The triple \((\tilde{U}_k,\tilde{\varSigma }_k,\tilde{V}_k)\) defines a rank-k approximation \(\tilde{A}_k\):
The triple \((\tilde{U}_k,\tilde{\varSigma }_k,\tilde{V}_k)\) is a nearly optimal rank-k approximation to A; see Theorem 1 below for a precise statement. The approximation is random due to range probing by \(\varOmega \). By its very construction, we have
where \(\tilde{P}_k=\tilde{U}_k\tilde{U}_k^*\in \mathbb {R}^{n\times n}\) is the orthogonal projection into \(\mathscr {R}(\tilde{U}_k)\). The procedure for RSVD is given in Algorithm 1. The complexity of Algorithm 1 is about \(4(q+1)nmk\), which can be much smaller than that of full SVD if \(k\ll \min (m,n)\).

Remark 2
The SV \(\sigma _i\) can be characterized by [8, Theorem 8.6.1, p. 441]:
Thus, one may estimate \(\sigma _i(A)\) directly by \(\tilde{\sigma }_i(A) = \Vert A^* \tilde{U}(:,i)\Vert \), and refine the SV estimate, similar to Rayleigh quotient acceleration for computing eigenvalues.
The following error estimates hold for RSVD \((\tilde{U}_k,\tilde{\varSigma }_k,\tilde{V}_k)\) given by Algorithm 1 with \(q=0\) [11, Corollary 10.9, p. 275], where the second estimate shows how the parameter p improves the accuracy. The exponent q is in the spirit of a power method, and can significantly improve the accuracy in the absence of spectral gap; see [11, Corollary 10.10, p. 277] for related discussions.
Theorem 1
For \(A\in \mathbb {R}^{n\times m}\), \(n\ge m\), let \(\varOmega \in \mathbb {R}^{m\times (k+p)}\) be a standard Gaussian matrix, \(k+p\le m\) and \(p\ge 4\), and Q an orthonormal basis for \(\mathscr {R}(A\varOmega )\). Then with probability at least \(1-3p^{-p}\), there holds
and further with probability at least \(1-3e^{-p}\), there holds
The next result is an immediate corollary of Theorem 1. Exponentially decaying SVs arise in, e.g., backward heat conduction and elliptic Cauchy problem.
Corollary 1
Suppose that the SVs \(\sigma _i\) decay exponentially, i.e., \(\sigma _j=c_0c_1^{j}\), for some \(c_0>0\) and \(c_1\in (0,1)\). Then with probability at least \(1-3p^{-p}\), there holds
and further with probability at least \(1-3e^{-p}\), there holds
So far we have assumed that A is tall, i.e., \(n\ge m\). For the case \(n<m\), one may apply RSVD to \(A^*\), which gives rise to Algorithm 2.

The efficiency of RSVD resides crucially on the truly low-rank nature of the problem. The precise spectral decay is generally unknown for many practical inverse problems, although there are known estimates for several model problems, e.g., X-ray transform [18] and magnetic particle imaging [17]. The decay rates generally worsen with the increase of the spatial dimension d, at least for integral operators [9], which can potentially hinder the application of RSVD type techniques to high-dimensional problems.
3 Efficient Regularized Linear Inversion with RSVD
Now we develop efficient inversion techniques based on RSVD for problem (1) via truncated SVD (TSVD), Tikhonov regularization and Tikhonov regularization with a smoothness penalty [5, 13]. For large-scale inverse problems, this can be expensive, since they either involve full SVD or large dense linear systems. We aim at reducing the cost by exploiting the inherent low-rank structure for inverse problems, and accurately constructing a low-rank approximation by RSVD. This idea has been pursued recently [1, 14, 30, 32, 33]. Our work is along the same line in of research but with a unified framework for deriving all three approaches and interpreting the approach in the lens of convex duality.
The key observation is the range type condition on the approximation \(\tilde{x}\):
with the matrix B is given by
where L is a regularizing matrix, typically chosen to the finite difference approximation of the first- or high-order derivatives [5]. Similar to (4), the approximation \(\tilde{x}\) is assumed to live in \(\mathrm {span}(\{v_i\}_{i=1}^k)\) in [34] for Tikhonov regularization, which is slightly more restrictive than (4). An analogous condition on the exact solution \(x^\dag \) reads
for some \(w\in \mathbb {R}^n\). In regularization theory [5, 13], (5) is known as source condition, and can be viewed as the Lagrange multiplier for the equality constraint \(Ax^\dag =b^\dag \), whose existence is generally not ensured for infinite-dimensional problems. It is often employed to bound the error \(\Vert \tilde{x}-x^\dag \Vert \) of the approximation \(\tilde{x}\) in terms of the noise level \(\delta \). The construction below explicitly maintains (4), thus preserving the structure of the regularized solution \(\tilde{x}\). We will interpret the construction by convex analysis. Below we develop three efficient computational schemes based on RSVD.
3.1 Truncated RSVD
Classical truncated SVD (TSVD) stabilizes problem (1) by looking for the least-squares solution of
Then the regularized solution \(x_k \) is given by
The truncated level \(k\le \mathrm {rank}(A)\) plays the role of a regularization parameter, and determines the strength of regularization. TSVD requires computing the (partial) SVD of A, which is expensive for large-scale problems. Thus, one can substitute a rank-k RSVD \((\tilde{U}_k,\tilde{\varSigma }_k,\tilde{V}_k)\), leading to truncated RSVD (TRSVD):
By Lemma 3, \(\tilde{A}_k=\tilde{U}_k\tilde{\varSigma }_k\tilde{V}_k^*\) is indeed of rank k, if \(\Vert A-\tilde{A}_k\Vert <\sigma _k\). This approach was adopted in [1]. Based on RSVD, we propose an approximation \(\tilde{x}_k\) defined by
By its construction, the range condition (4) holds for \(\tilde{x}_k\). To compute \(\tilde{x}_k\), one does not need the complete RSVD \((\tilde{U}_k,\tilde{\varSigma }_k,\tilde{V}_k)\) of rank k, but only \((\tilde{U}_k,\tilde{\varSigma }_k)\), which is advantageous for complexity reduction [8, p. 254]. Given the RSVD \((\tilde{U}_k,\tilde{\varSigma }_k)\), computing \(\tilde{x}_k\) by (6) incurs only \(O(nk+nm)\) operations.
3.2 Tikhonov Regularization
Tikhonov regularization stabilizes (1) by minimizing the following functional
where \(\alpha >0\) is the regularization parameter. The regularized solution \(x_\alpha \) is given by
The latter identity verifies (4). The cost of the step in (7) is about \(nm^2+\frac{m^3}{3}\) or \(mn^2+\frac{n^3}{3}\) [8, p. 238], and thus it is expensive for large scale problems. One approach to accelerate the computation is to apply the RSVD approximation \(\tilde{A}_k =\tilde{U}_k\tilde{\varSigma }_k\tilde{V}_k^*\). Then one obtains a regularized approximation [32]
To preserve the range property (4), we propose an alternative
For \(\alpha \rightarrow 0^+\), \(\tilde{x}_\alpha \) recovers the TRSVD \(\tilde{x}_k\) in (6). Given RSVD \((\tilde{U}_k,\tilde{\varSigma }_k)\), the complexity of computing \(\tilde{x}_\alpha \) is nearly identical with the TRSVD \(\tilde{x}_k\).
3.3 General Tikhonov Regularization
Now we consider Tikhonov regularization with a general smoothness penalty:
where \(L\in \mathbb {R}^{\ell \times m}\) is a regularizing matrix enforcing smoothness. Typical choices of L include first-order and second-order derivatives. We assume \(\mathscr {N}(A)\cap \mathscr {N}(L)=\{0\}\) so that \(J_\alpha \) has a unique minimizer \(x_\alpha \). By the identity
if \(\mathscr {N}(L)=\{0\}\), the minimizer \(x_\alpha \) to \(J_\alpha \) is given by (with \(\varGamma =L^{\dag }L^{\dag *}\))
The \(\varGamma \) factor reflects the smoothing property of \(\Vert Lx\Vert ^2\). Similar to (9), we approximate \(B:=AL^\dag \) via RSVD: \( \tilde{B}_k= U_k\varSigma _kV_k^*\), and obtain a regularized solution \(\tilde{x}_\alpha \) by
It differs from [33] in that [33] uses only the RSVD approximation of A, thus it does not maintain the range condition (19). The first step of Algorithm 1, i.e., \(AL^{-1}\varOmega \), is to probe \(\mathscr {R}(A)\) with colored Gaussian noise with covariance \(\varGamma \).
Numerically, it also involves applying \(\varGamma \), which can be carried out efficiently if L is structured. If L is rectangular, we have the following decomposition [4, 32]. The A-weighted pseudoinverse \(L^\#\) [4] can be computed efficiently, if \(L^\dag \) is easy to compute and the dimensionality of W is small.
Lemma 4
Let W and Z be any matrices satisfying \(\mathscr {R}(W)=\mathscr {N}(L)\), \(\mathscr {R}(Z)=\mathscr {R}(L)\), \(Z^*Z=I\), and \(L^\#=(I-W(AW)^\dag A)L^\dag \). Then the solution \(x_\alpha \) to (10) is given by
where the variable \(\xi _\alpha \) minimizes \(\frac{1}{2}\Vert AL^\#Z\xi -b\Vert ^2 + \frac{\alpha }{2} \Vert \xi \Vert ^2\).
Lemma 4 does not necessarily entail an efficient scheme, since it requires an orthonormal basis Z for \(\mathscr {R}(L)\). Hence, we restrict our discussion to the case:
It arises most commonly in practice, e.g., first-order or second-order derivative, and there are efficient ways to perform standard-form reduction. Then we can let \(Z=I_\ell \). By slightly abusing the notation \(\varGamma = L^\#L^{\#*}\), by Lemma 4, we have
The first term is nearly identical with (12), with \(L^\#\) in place of \(L^\dag \), and the extra term \(W(AW)^\dag b\) belongs to \(\mathscr {N}(L)\). Thus, we obtain an approximation \(\tilde{x}_\alpha \) defined by
where \(\tilde{B}_k\) is a rank-k RSVD to \(B\equiv AL^\#\). The matrix B can be implemented implicitly via matrix-vector product to maintain the efficiency.
3.4 Dual Interpretation
Now we give an interpretation of (13) in the lens of Fenchel duality theory in Banach spaces (see, e.g., [3, Chap. 2.4]). Recall that for a functional \(F:X\rightarrow \overline{\mathbb {R}}:=\mathbb {R}\cup \{\infty \}\) defined on a Banach space X, let \(F^*:X^*\rightarrow \overline{\mathbb {R}}\) denote the Fenchel conjugate of F given for \(x^*\in X^*\) by
Further, let \(\partial F(x):=\{x^*\in X^*: \langle x^*,\tilde{x}-x\rangle _{X^*,X}\le F(\tilde{x})-F(x)\ \ \forall \tilde{x}\in X\}\) be the subdifferential of the convex functional F at x, which coincides with Gâteaux derivative \(F'(x)\) if it exists. The Fenchel duality theorem states that if \(F:X\rightarrow \overline{ \mathbb {R}}\) and \(G:Y\rightarrow \overline{\mathbb {R}}\) are proper, convex and lower semicontinuous functionals on the Banach spaces X and Y, \(\varLambda :X\rightarrow Y\) is a continuous linear operator, and there exists an \(x_0\in W\) such that \(F(x_0)<\infty \), \(G(\varLambda x_0)<\infty \), and G is continuous at \(\varLambda x_0\), then
Further, the equality is attained at \((\bar{x}, \bar{y}^*)\in X\times Y^*\) if and only if
hold [3, Remark 3.4.2].
The next result indicates that the approach in Sects. 3.2–3.3 first applies RSVD to the dual problem to obtain an approximate dual \(\tilde{p}_\alpha \), and then recovers the optimal primal \(\tilde{x}_\alpha \) via duality relation (17). This connection is in the same spirit of dual random projection [29, 34], and it opens up the avenue to extend RSVD to functionals whose conjugate is simple, e.g., nonsmooth fidelity.
Proposition 1
If \(\mathscr {N}(L)=\{0\}\), then \(\tilde{x}_\alpha \) in (13) is equivalent to RSVD for the dual problem.
Proof
For any symmetric positive semidefinite Q, the conjugate functional \(F^*\) of \(F(x) = \frac{\alpha }{2}x^*Qx\) is given by \(F^*(\xi ) =-\frac{1}{2\alpha }\xi ^*Q^\dag \xi \), with its domain being \(\mathscr {R}(Q)\). By SVD, we have \((L^*L)^\dag =L^\dag L^{\dag *}\), and thus \(F^*(\xi )=-\frac{1}{2\alpha }\Vert L^{\dag *}\xi \Vert ^2\). Hence, by Fenchel duality theorem, the conjugate \(J_\alpha ^*(\xi )\) of \(J_\alpha (x)\) is given by
Further, by (17), the optimal primal and dual pair \((x_\alpha ,\xi _\alpha )\) satisfies
Since \(\mathscr {N}(L)=\{0\}\), \(L^*L\) is invertible, and thus \(x_\alpha = \alpha ^{-1} (L^*L)^{-1} A^*\xi _\alpha = \alpha ^{-1} \varGamma A^*\xi _\alpha \). The optimal dual \(\xi _\alpha \) is given by \(\xi _\alpha = \alpha (AL^{\dag }L^{*\dag } A^*+\alpha I)^{-1}b\). To approximate \(\xi _\alpha \) by \(\tilde{\xi }_\alpha \), we employ the RSVD approximation \(\tilde{B}_k\) to \(B=AL^\dag \) and solve
We obtain an approximation via the relation \(\tilde{x}_\alpha = \alpha ^{-1}\varGamma A^*\tilde{\xi }_\alpha \), recovering (13).\(\square \)
Remark 3
For a general regularizing matrix L, one can appeal to the decomposition in Lemma 4, by applying first the standard transformation and then approximating the regularized part via convex duality.
4 Error Analysis
Now we derive error estimates for the approximation \(\tilde{x}\) with respect to the true solution \(x^\dag \), under sourcewise type conditions. In addition to bounding the error, the estimates provide useful guidelines on constructing the approximation \(\tilde{A}_k\).
4.1 Truncated RSVD
We derive an error estimate under the source condition (5). We use the projection matrices \(P_k=U_kU_k^*\) and \(\tilde{P}_k= \tilde{U}_k\tilde{U}_k^*\) frequently below.
Lemma 5
For any \(k\le r\) and \(\Vert A-\tilde{A}_k\Vert \le \sigma _k/2\), there holds \(\Vert A^* (\tilde{A}_k^*)^\dag \Vert \le 2.\)
Proof
It follows from the decomposition \(A=\tilde{P}_k A + (I-\tilde{P}_k)A=\tilde{A}_k + (I-\tilde{P}_k)A\) that
Now the condition \(\Vert A-\tilde{A}_k\Vert \le \sigma _k/2\) and Lemma 3 imply \(\tilde{\sigma }_k\ge \sigma _k-\Vert A-\tilde{A}_k\Vert \ge \sigma _k/2\), from which the desired estimate follows.\(\square \)
Now we can state an error estimate for the approximation \(\tilde{x}_k\).
Theorem 2
If Condition (5) holds and \(\Vert A-\tilde{A}_k\Vert \le \sigma _k/2\), then for the estimate \(\tilde{x}_k\) in (6), there holds
Proof
By the decomposition \(b=b^\dag + e\), we have (with \(P_k^\perp =I-P_k\))
The source condition \(x^\dag = A^*w\) in (5) implies
By the triangle inequality, we have
It suffices to bound the three terms separately. First, for the term \(\mathrm{I}_1\), by the identity \((\tilde{A}_k\tilde{A}_k^*)^\dag = (\tilde{A}_k^*)^\dag \tilde{A}_k^\dag \) and Lemma 5, we have
Second, for \(\mathrm{I}_2\), by Lemmas 5 and 2 and the identity \((\tilde{A}_k\tilde{A}_k^*)^\dag = (\tilde{A}_k^*)^\dag \tilde{A}_k^\dag \), we have
since \(\Vert \tilde{A}_k\tilde{A}_k^*-A_kA_k^*\Vert \le \Vert \tilde{A}_k-A_k\Vert (\Vert \tilde{A}_k\Vert +\Vert A_k^*\Vert )\le 2\Vert A\Vert \Vert \tilde{A}_k-A_k\Vert \) and \(\Vert (A_kA_k^*)^\dag AA^*\Vert \le 1\). By Lemma 3, we can bound the term \(\Vert (\tilde{A}_k^*)^\dag \Vert \) by
Last, we can bound the third term \(\mathrm{I}_3\) directly by \(\mathrm{I}_3 \le \Vert P_k^\perp A^*\Vert \Vert w\Vert \le \sigma _{k+1}\Vert w\Vert \). Combining these estimates yields the desired assertion.\(\square \)
Remark 4
The bound in Theorem 2 contains three terms: propagation error \(\sigma _k^{-1}\delta \), approximation error \(\sigma _{k+1}\Vert w\Vert \), and perturbation error \(\sigma _k^{-1}\Vert A\Vert \Vert A-\tilde{A}_k\Vert \Vert w\Vert \). It is of the worst-case scenario type and can be pessimistic. In particular, the error \(\Vert A^*(\tilde{A}_k\tilde{A}_k^*)^{-1}e\Vert \) can be bounded more precisely by
and \(\Vert \tilde{A}_k^\dag e\Vert \) can be much smaller than \(\tilde{\sigma }_k^{-1}\Vert e\Vert \), if e concentrates in the high-frequency modes. By balancing the terms, it suffices for \(\tilde{A}_k\) to have an accuracy \(O(\delta )\). This is consistent with the analysis for regularized solutions with perturbed operators.
Remark 5
The condition \(\Vert A-\tilde{A}_k\Vert <\sigma _k/2\) in Theorem 2 requires a sufficiently accurate low-rank RSVD approximation \((\tilde{U}_k,\tilde{\varSigma }_k,\tilde{V}_k)\) to A, i.e., the rank k is sufficiently large. It enables one to define a TRSVD solution \(\tilde{x}_k\) of truncation level k.
Next we give a relative error estimate for \(\tilde{x}_k\) with respect to the TSVD approximation \(x_k\). Such an estimate was the focus of a few works [1, 30, 32, 33]. First, we give a bound on \(\Vert \tilde{A}_k\tilde{A}_k^*(A_k^*)^\dag -A_k\Vert \).
Lemma 6
The following error estimate holds
Proof
This estimate follows by direct computation:
since \(\Vert \tilde{A}_k\Vert = \Vert \tilde{P}_kA\Vert \le \Vert A\Vert =\sigma _1\). Then the desired assertion follows directly.\(\square \)
Next we derive a relative error estimate between the approximations \(x_k\) and \(\tilde{x}_k\).
Theorem 3
For any \(k<r\), and \(\Vert A-\tilde{A}_k\Vert <\sigma _{k}/2\), there holds
Proof
We rewrite the TSVD solution \(x_k\) as
By Lemma 3 and the assumption \(\Vert A-\tilde{A}_k\Vert <\sigma _{k}/2\), we have \(\tilde{\sigma }_{k} >0.\) Then \(x_k-\tilde{x}_k = A^*((A_kA_k^*)^{\dag }-(\tilde{A}_k\tilde{A}_k^*)^{\dag })b\). By Lemma 2,
It follows from the identity \((A_kA_k^*)^\dag =(A_k^*)^\dag A_k^\dag \) and (18) that
Thus, we obtain
By Lemma 3, we bound the term \(\Vert \tilde{A}_k^\dag \Vert \) by \(\Vert \tilde{A}_k^\dag \Vert \le 2\sigma _k^{-1}.\) Combining the preceding estimates with Lemmas 5 and 6 completes the proof.\(\square \)
Remark 6
The relative error is determined by k (and in turn by \(\delta \) etc). Due to the presence of the factor \(\sigma _k^{-2}\), the estimate requires a highly accurate low-rank approximation, i.e., \(\Vert A_k-\tilde{A}_k\Vert \ll \sigma _k(A)^{-2}\), and hence it is more pessimistic than Theorem 2. The estimate is comparable with the perturbation estimate for the TSVD
Modulo the \(\alpha \) factor, the estimates in [30, 32] for Tikhonov regularization also depend on \(\sigma _k^{-2}\) (but can be much milder for a large \(\alpha \)).
4.2 Tikhonov Regularization
The following bounds are useful for deriving error estimate on \(\tilde{x}_\alpha \) in (9).
Lemma 7
The following estimates hold
Proof
It follows from the identity
and the inequality \(\Vert \tilde{A}_k\Vert =\Vert \tilde{P}_kA\Vert \le \Vert A\Vert \) that
Next, by the triangle inequality,
This, together with the identity \(AA^*-\tilde{A}_k\tilde{A}_k^*=A(A^*-\tilde{A}_k^*)+(A-\tilde{A}_k)A_k^*\) and the first estimate, yields the second estimate, completing the proof of the lemma.\(\square \)
Now we can give an error estimate on \(\tilde{x}_\alpha \) in (9) under condition (5).
Theorem 4
If condition (5) holds, then the estimate \(\tilde{x}_\alpha \) satisfies
Proof
First, with condition (5), \(x^\dag \) can be rewritten as
The identity (11) implies \(x^\dag = A^*(AA^*+\alpha I)^{-1}(b^\dag +\alpha w)\). Consequently,
Let \(\tilde{I} =(AA^*+\alpha I)(\tilde{A}_k\tilde{A}_k^*+\alpha I)^{-1}\). Then by the identity (11), there holds
and taking inner product with \(\tilde{x}_\alpha -x^\dag \) yields
By Young’s inequality \(ab\le \frac{1}{4}a^2+b^2\) for any \(a,b\in \mathbb {R}\), we deduce
By Lemma 7 and the identity \( b^\dag =AA^*w\), we have
Combining the preceding estimates yield the desired assertion.\(\square \)
Remark 7
To maintain the error \(\Vert \tilde{x}_\alpha -x^\dag \Vert \), the accuracy of \(\tilde{A}_k\) should be of \(O(\delta )\), and \(\alpha \) should be of \(O(\delta )\), which gives an overall accuracy \(O(\delta ^{1/2})\). The tolerance on \(\Vert A-\tilde{A}_k\Vert \) can be relaxed for high noise levels. It is consistent with existing theory for Tikhonov regularization with noisy operators [19, 21, 28].
Remark 8
The following relative error estimate was shown [32, Theorem 1]:
with \(\theta =\sin ^{-1}\frac{(\Vert b-Ax_\alpha \Vert ^2+\alpha \Vert x_\alpha \Vert ^2)^{\frac{1}{2}}}{\Vert b\Vert }\) and \(\kappa = (\sigma _1^2+\alpha )(\frac{\alpha ^\frac{1}{2}}{\sigma _n^2+\alpha }+\max _{1\le i\le n}\frac{\sigma _i}{\sigma _i^2 +\alpha })\). \(\kappa \) is a variant of condition number. Thus, \(\tilde{A}_k\) should approximate accurately A in order not to spoil the accuracy, and the estimate can be pessimistic for small \(\alpha \) for which the estimate tends to blow up.
4.3 General Tikhonov Regularization
Last, we give an error estimate for \(\tilde{x}_\alpha \) defined in (13) under the following condition
where \(\mathscr {N}(L)=\{0\}\), and \(\varGamma =L^\dag L^{*\dag }\). Also recall that \(B=A\varGamma ^\dag \).
Theorem 5
If Condition (19) holds, then the regularized solution \(\tilde{x}_\alpha \) in (13) satisfies
Proof
First, by the source condition (19), we rewrite \(x^\dag \) as
Now with the identity \((A^*A+\alpha L^*L)^{-1}A^* = \varGamma A^*(A\varGamma A^*+\alpha I)^{-1},\) we have
Thus, upon recalling \(B=AL^\dag \), we have
It follows from the identity
that
with \(\tilde{I} =(BB^*+\alpha I)(\tilde{B}_k\tilde{B}_k^*+\alpha I)^{-1}\). Taking inner product with \(x_\alpha -x^\dag \) and applying Cauchy-Schwarz inequality yield
Young’s inequality implies \(\alpha ^\frac{1}{2} \Vert L(\tilde{x}_\alpha -x^\dag )\Vert \le 2^{-1}(\Vert \tilde{I}e\Vert +\Vert (\tilde{I}-I)b^\dag \Vert + \alpha \Vert w\Vert )\). The identity \(b^\dag = Ax^\dag = AL^{\dag }L^{\dag *}A^*w=BB^*w\) from (19) and Lemma 7 complete the proof.\(\square \)
5 Numerical Experiments and Discussions
Now we present numerical experiments to illustrate our approach. The noisy data b is generated from the exact data \(b^\dag \) as follows
where \(\delta \) is the relative noise level, and the random variables \(\xi _i\)s follow the standard Gaussian distribution. All the computations were carried out on a personal laptop with 2.50 GHz CPU and 8.00G RAM by MATLAB 2015b. When implementing Algorithm 1, the default choices \(p=5\) and \(q=0\) are adopted. Since the TSVD and Tikhonov solutions are close for suitably chosen regularization parameters, we present only results for Tikhonov regularization (and the general case with L given by the first-order difference, which has a one-dimensional kernel \(\mathscr {N}(L)\)).
Throughout, the regularization parameter \(\alpha \) is determined by uniformly sampling an interval on a logarithmic scale, and then taking the value attaining the smallest reconstruction error, where approximate Tikhonov minimizers are found by either (9) or (16) with a large k (\(k=100\) in all the experiments).
5.1 One-Dimensional Benchmark Inverse Problems
First, we illustrate the efficiency and accuracy of proposed approach, and compare it with existing approaches [32, 33]. We consider seven examples (i.e., deriv2, heat, phillips, baart, foxgood, gravity and shaw), taken from the popular public-domain MATLAB package regutools (available from http://www.imm.dtu.dk/~pcha/Regutools/, last accessed on January 8, 2019), which have been used in existing studies (see, e.g., [30, 32, 33]). They are Fredholm integral equations of the first kind, with the first three examples being mildly ill-posed (i.e., \(\sigma _i\)s decay algebraically) and the rest severely ill-posed (i.e., \(\sigma _i\)s decay exponentially). Unless otherwise stated, the examples are discretized with a dimension \(n=m=5000\). The resulting matrices are dense and unstructured. The rank k of \(\tilde{A}_k\) is fixed at \(k=20\), which is sufficient to for all examples.
The numerical results by standard Tikhonov regularization and two randomized variants, i.e., (8) and (9), for the examples are presented in Table 1. The accuracy of the approximations, i.e., the Tikhonov solution \(x_\alpha \), and two randomized approximations \(\hat{x}_\alpha \) (cf. (8), proposed in [32]) and \(\tilde{x}_\alpha \) (cf. (9), the proposed in this work), is measured in two different ways:
where the methods are indicated by the subscripts. That is, \(\tilde{e}_{xz}\) and \(\tilde{e}_{ij}\) measure the accuracy with respect to the Tikhonov solution \(x_\alpha \), and e, \(e_{xz}\) and \(e_{ij}\) measure the accuracy with respect to the exact one \(x^\dag \).
The following observations can be drawn from Table 1. For all examples, the three approximations \(x_\alpha \), \(\tilde{x}_\alpha \) and \(\hat{x}_\alpha \) have comparable accuracy relative to the exact solution \(x^\dag \), and the errors \(e_{ij}\) and \(e_{xz}\) are fairly close to the error e of the Tikhonov solution \(x_\alpha \). Thus, RSVD can maintain the reconstruction accuracy. For heat, despite the apparent large magnitude of the errors \(\tilde{e}_{xz}\) and \(\tilde{e}_{ij}\), the errors \(e_{xz}\) and \(e_{ij}\) are not much worse than e. A close inspection shows that the difference of the reconstructions are mostly in the tail part, which requires more modes for a full resolution. The computing time (in seconds) for obtaining \(x_\alpha \) and \(\tilde{x}_\alpha \) and \(\hat{x}_\alpha \) is about 6.60, 0.220 and 0.220, where for the latter two, it includes also the time for computing RSVD. Thus, for all the examples, with a rank \(k=20\), RSVD can accelerate standard Tikhonov regularization by a factor of 30, while maintaining the accuracy, and the proposed approach is competitive with the one in [32]. Note that the choice \(k=20\) can be greatly reduced for severely ill-posed problems; see Sect. 5.2 below for discussions.
The preceding observations remain largely valid for general Tikhonov regularization; see Table 2. Since the construction of the approximation \(\hat{x}_\alpha \) does not retain the structure of the regularized solution \(x_\alpha \), the error \(\tilde{e}_{xz}\) can potentially be much larger than \(\tilde{e}_{ij}\), which can indeed be observed. The errors e, \(e_{xz}\) and \(e_{ij}\) are mostly comparable, except for deriv2. For deriv2, the approximation \(\hat{x}_\alpha \) suffers from grave errors, since the projection of L into \(\mathscr {R} (Q)\) is very inaccurate for preserving L. It is expected that the loss occurs whenever general Tikhonov penalty is much more effective than the standard one. This shows the importance of structure preservation. Note that, for a general L, \(\tilde{x}_\alpha \) takes only about 1.5 times the computing time of \(\hat{x}_\alpha \). This cost can be further reduced since L is highly structured and admits fast inversion. Thus preserving the range structure of \(x_\alpha \) in (4) does not incur much overhead.

Last, we present some results on the computing time for deriv2 versus the problem dimension, and at two truncation levels for RSVD, i.e., \(k=20\) and \(k=30\). The numerical results are given in Fig. 1. The cubic scaling of the standard approach and quadratic scaling of the approach based on RSVD are clearly observed, confirming the complexity analysis in Sects. 2 and 3. In both (9) and (16), computing RSVD represents the dominant part of the overall computational efforts, and thus the increase of the rank k from 20 to 30 adds very little overheads (compare the dashed and solid curves in Fig. 1). Further, for Tikhonov regularization, the two randomized variants are equally efficient, and for the general one, the proposed approach is slightly more expensive due to its direct use of L in constructing the approximation \(\tilde{B}_k\) to \(B:=AL^\#\). Although not presented, we note that the results for other examples are very similar.
5.2 Convergence of the Algorithm
There are several factors influencing the quality of \(\tilde{x}_\alpha \) the regularization parameter \(\alpha \), the noise level \(\delta \) and the rank k of the RSVD approximation. The optimal truncation level k should depend on both \(\alpha \) and \(\delta \). This part presents a study with deriv2 and shaw, which are mildly and severely ill-posed, respectively.

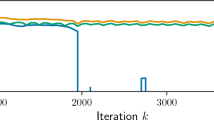
The convergence of the error \(e_{ij}\) with respect to the rank k for deriv2 (top) and shaw (bottom) with \(\delta =1\%\) and different regularization parameters
First, we examine the influence of \(\alpha \) on the optimal k. The numerical results for three different levels of regularization are given in Fig. 2. In the figure, the notation \(\alpha ^*\) refers to the value attaining the the smallest error for Tikhonov solution \(x_\alpha \), and thus \(10\alpha ^*\) and \(\alpha ^*/10\) represent respectively over- and under-regularization. The optimal k value decreases with the increase of \(\alpha \) when \(\alpha \gg \alpha ^*\). This may be explained by the fact that a too large \(\alpha \) causes large approximation error and thus can tolerate large errors in the approximation \(\tilde{A}_k\) (for a small k). The dependence can be sensitive for mildly ill-posed problems, and also on the penalty. The penalty influences the singular value spectra in the RSVD approximation implicitly by preconditioning: since L is a discrete differential operator, the (weighted) pseudoinverse \(L^\#\) (or \(L^\dag \)) is a smoothing operator, and thus the singular values of \(B=AL^\#\) decay faster than that of A. In all cases, the error \(e_{ij}\) is nearly monotonically decreasing in k (and finally levels off at e, as expected). In the under-regularized regime (i.e., \(\alpha \ll \alpha ^*\)), the behavior is slightly different: the error \(e_{ij}\) first decreases, and then increases before eventually leveling off at e. This is attributed to the fact that proper low-rank truncation of A induces extra regularization, in a manner similar to TSVD in Sect. 3.1. Thus, an approximation that is only close to \(x_\alpha \) (see e.g., [1, 30, 32, 33]) is not necessarily close to \(x^\dag \), when \(\alpha \) is not chosen properly.
Next we examine the influence of the noise level \(\delta \); see Fig. 3. With the optimal choice of \(\alpha \), the optimal k increases as \(\delta \) decreases, which is especially pronounced for mildly ill-posed problems. Thus, RSVD is especially efficient for the following two cases: (a) highly noisy data (b) severely ill-posed problem. These observations agree well with Theorem 4: a low-rank approximation \(\tilde{A}_k\) whose accuracy is commensurate with \(\delta \) is sufficient, and in either case, a small rank is sufficient for obtaining an acceptable approximation. For a fixed k, the error \(e_{ij}\) almost increases monotonically with the noise level \(\delta \).
These empirical observations naturally motivate developing an adaptive strategy for choosing the rank k on the fly so as to effect the optimal complexity. This requires a careful analysis of the balance between k, \(\delta \), \(\alpha \), and suitable a posteriori estimators. We leave this interesting topic to a future work.

The convergence of the error \(e_{ij}\) with respect to the rank k for deriv2 (top) and shaw (bottom) at different noise levels
5.3 Electrical Impedance Tomography
Last, we illustrate the approach on 2D electrical impedance tomography (EIT), a diffusive imaging modality of recovering the electrical conductivity from boundary voltage measurement. This is one canonical nonlinear inverse problem. We consider the problem on a unit circle with sixteen electrodes uniformly placed on the boundary, and adopt the complete electrode model [24] as the forward model. It is discretized by the standard Galerkin FEM with conforming piecewise linear basis functions, on a quasi-uniform finite element mesh with 2129 nodes. For the inversion step, we employ ten sinusoidal input currents, unit contact impedance and measure the voltage data (corrupted by \(\delta =0.1\%\) noise). The reconstructions are obtained with an \(H^1(\varOmega )\)-seminorm penalty. We refer to [7, 15] for details on numerical implementation. We test the RSVD algorithm with the linearized model. It can be implemented efficiently without explicitly computing the linearized map. More precisely, let F be the (nonlinear) forward operator, and \(\sigma _0\) be the background (fixed at 1). Then the random probing of the range \(\mathscr {R}(F'(\sigma _0))\) of the linearized forward operator \(F'(\sigma _0)\) (cf. Step 4 of Algorithm 1) can be approximated by
and it can be made very accurate by choosing a small variance for the random vector \(\omega _i\). Step 6 of Algorithm 1 can be done efficiently via the adjoint technique.
The numerical results are presented in Fig. 4, where linearization refers to the reconstruction by linearizing the nonlinear forward model at the background \(\sigma _0\). This is one of the most classical reconstruction methods in EIT imaging. The rank k is taken to be \(k=30\) for \(\tilde{x}_\alpha \), which is sufficient given the severe ill-posed nature of the EIT inverse problem. Visually, the RSVD reconstruction is indistinguishable from the conventional approach. Note that contrast loss is often observed for EIT reconstructions obtained by a smoothness penalty. The computing time (in seconds) for RSVD is less than 8, whereas that for the conventional method is about 60. Hence, RSVD can greatly accelerate EIT imaging.

Numerical reconstructions for EIT with \(0.1\%\) noise
6 Conclusion
In this work, we have provided a unified framework for developing efficient linear inversion techniques via RSVD and classical regularization methods, building on a certain range condition on the regularized solution. The construction is illustrated on three popular linear inversion methods for finding smooth solutions, i.e., truncated singular value decomposition, Tikhonov regularization and general Tikhonov regularization with a smoothness penalty. We have provided a novel interpretation of the approach via convex duality, i.e., it first approximates the dual variable via randomized SVD and then recovers the primal variable via duality relation. Further, we gave rigorous error bounds on the approximation under the canonical sourcewise representation, which provide useful guidelines for constructing a low-rank approximation. We have presented extensive numerical experiments, including nonlinear tomography, to illustrate the efficiency and accuracy of the approach, and demonstrated its competitiveness with existing methods.

References
Boutsidis, C., Magdon-Ismail, M.: Faster SVD-truncated regularized least-squares. In: 2014 IEEE International Symposium on Information Theory, pp. 1321–1325 (2014). https://doi.org/10.1109/ISIT.2014.6875047
Chen, S., Liu, Y., Lyu, M.R., King, I., Zhang, S.: Fast relative-error approximation algorithm for ridge regression. In: Proceedings of the 31st Conference on Uncertainty in Artificial Intelligence, pp. 201–210 (2015)
Ekeland, I., Témam, R.: Convex Analysis and Variational Problems. SIAM, Philadelphia, PA (1999). https://doi.org/10.1137/1.9781611971088
Eldén, L.: A weighted pseudoinverse, generalized singular values, and constrained least squares problems. BIT 22(4), 487–502 (1982). https://doi.org/10.1007/BF01934412
Engl, H.W., Hanke, M., Neubauer, A.: Regularization of Inverse Problems. Kluwer, Dordrecht (1996). https://doi.org/10.1007/978-94-009-1740-8
Frieze, A., Kannan, R., Vempala, S.: Fast Monte-Carlo algorithms for finding low-rank approximations. J. ACM 51(6), 1025–1041 (2004). https://doi.org/10.1145/1039488.1039494
Gehre, M., Jin, B., Lu, X.: An analysis of finite element approximation in electrical impedance tomography. Inverse Prob. 30(4), 045,013,24 (2014). https://doi.org/10.1088/0266-5611/30/4/045013
Golub, G.H., Van Loan, C.F.: Matrix Computations, 3rd edn. Johns Hopkins University Press, Baltimore, MD (1996)
Griebel, M., Li, G.: On the decay rate of the singular values of bivariate functions. SIAM J. Numer. Anal. 56(2), 974–993 (2018). https://doi.org/10.1137/17M1117550
Gu, M.: Subspace iteration randomization and singular value problems. SIAM J. Sci. Comput. 37(3), A1139–A1173 (2015). https://doi.org/10.1137/130938700
Halko, N., Martinsson, P.G., Tropp, J.A.: Finding structure with randomness: probabilistic algorithms for constructing approximate matrix decompositions. SIAM Rev. 53(2), 217–288 (2011). https://doi.org/10.1137/090771806
Horn, R.A., Johnson, C.R.: Matrix Analysis. Cambridge University Press, Cambridge (1985). https://doi.org/10.1017/CBO9780511810817
Ito, K., Jin, B.: Inverse Problems: Tikhonov Theory and Algorithms. World Scientific Publishing Co. Pte. Ltd., Hackensack, NJ (2015)
Jia, Z., Yang, Y.: Modified truncated randomized singular value decomposition (MTRSVD) algorithms for large scale discrete ill-posed problems with general-form regularization. Inverse Prob. 34(5), 055,013,28 (2018). https://doi.org/10.1088/1361-6420/aab92d
Jin, B., Xu, Y., Zou, J.: A convergent adaptive finite element method for electrical impedance tomography. IMA J. Numer. Anal. 37(3), 1520–1550 (2017). https://doi.org/10.1093/imanum/drw045
Kluth, T., Jin, B.: Enhanced reconstruction in magnetic particle imaging by whitening and randomized SVD approximation. Phys. Med. Biol. 64(12), 125,026,21 (2019). https://doi.org/10.1088/1361-6560/ab1a4f
Kluth, T., Jin, B., Li, G.: On the degree of ill-posedness of multi-dimensional magnetic particle imaging. Inverse Prob. 34(9), 095,006,26 (2018). https://doi.org/10.1088/1361-6420/aad015
Maass, P.: The x-ray transform: singular value decomposition and resolution. Inverse Prob. 3(4), 729–741 (1987). http://stacks.iop.org/0266-5611/3/729
Maass, P., Rieder, A.: Wavelet-accelerated Tikhonov-Phillips regularization with applications. In: Inverse Problems in Medical Imaging and Nondestructive Testing (Oberwolfach, 1996), pp. 134–158. Springer, Vienna (1997)
Musco, C., Musco, C.: Randomized block Krylov methods for stronger and faster approximate singular value decomposition. In: NIPS 2015 (2015)
Neubauer, A.: An a posteriori parameter choice for Tikhonov regularization in the presence of modeling error. Appl. Numer. Math. 4(6), 507–519 (1988). https://doi.org/10.1016/0168-9274(88)90013-X
Pilanci, M., Wainwright, M.J.: Iterative Hessian sketch: fast and accurate solution approximation for constrained least-squares. J. Mach. Learn. Res. 17, 38 (2016)
Sarlos, T.: Improved approximation algorithms for large matrices via random projections. In: Foundations of Computer Science, 2006. FOCS ’06. 47th Annual IEEE Symposium on (2006). https://doi.org/10.1109/FOCS.2006.37
Somersalo, E., Cheney, M., Isaacson, D.: Existence and uniqueness for electrode models for electric current computed tomography. SIAM J. Appl. Math. 52(4), 1023–1040 (1992). https://doi.org/10.1137/0152060
Stewart, G.W.: On the perturbation of pseudo-inverses, projections and linear least squares problems. SIAM Rev. 19(4), 634–662 (1977). https://doi.org/10.1137/1019104
Szlam, A., Tulloch, A., Tygert, M.: Accurate low-rank approximations via a few iterations of alternating least squares. SIAM J. Matrix Anal. Appl. 38(2), 425–433 (2017). https://doi.org/10.1137/16M1064556
Tao, T.: Topics in Random Matrix Theory. AMS, Providence, RI (2012). https://doi.org/10.1090/gsm/132
Tautenhahn, U.: Regularization of linear ill-posed problems with noisy right hand side and noisy operator. J. Inverse Ill-Posed Probl. 16(5), 507–523 (2008). https://doi.org/10.1515/JIIP.2008.027
Wang, J., Lee, J.D., Mahdavi, M., Kolar, M., Srebro, N.: Sketching meets random projection in the dual: a provable recovery algorithm for big and high-dimensional data. Electron. J. Stat. 11(2), 4896–4944 (2017). https://doi.org/10.1214/17-EJS1334SI
Wei, Y., Xie, P., Zhang, L.: Tikhonov regularization and randomized GSVD. SIAM J. Matrix Anal. Appl. 37(2), 649–675 (2016). https://doi.org/10.1137/15M1030200
Witten, R., Candès, E.: Randomized algorithms for low-rank matrix factorizations: sharp performance bounds. Algorithmica 72(1), 264–281 (2015). https://doi.org/10.1007/s00453-014-9891-7
Xiang, H., Zou, J.: Regularization with randomized SVD for large-scale discrete inverse problems. Inverse Prob. 29(8), 085,008,23 (2013). https://doi.org/10.1088/0266-5611/29/8/085008
Xiang, H., Zou, J.: Randomized algorithms for large-scale inverse problems with general Tikhonov regularizations. Inverse Prob. 31(8), 085,008,24 (2015). https://doi.org/10.1088/0266-5611/31/8/085008
Zhang, L., Mahdavi, M., Jin, R., Yang, T., Zhu, S.: Random projections for classification: a recovery approach. IEEE Trans. Inform. Theory 60(11), 7300–7316 (2014). https://doi.org/10.1109/TIT.2014.2359204
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix A: Iterative refinement
Appendix A: Iterative refinement
Proposition 1 enables iteratively refining the inverse solution when RSVD is not sufficiently accurate. This idea was proposed in [29, 34] for standard Tikhonov regularization, and we describe the procedure in a slightly more general context. Suppose \(\mathscr {N}(L)=\{0\}\). Given a current iterate \(x^j\), we define a functional \(J_\alpha ^j(\delta x)\) for the increment \(\delta x\) by
Thus the optimal correction \(\delta x_\alpha \) satisfies
i.e.,
with \(B=AL^\dag \). However, its direct solution is expensive. We employ RSVD for a low-dimensional space \(\tilde{V}_k\) (corresponding to B), parameterize the increment \(L\delta x\) by \(L\delta x=\tilde{V}_k^*z\) and update z only. That is, we minimize the following functional in z
Since \(k\ll m\), the problem can be solved efficiently. More precisely, given the current estimate \(x^j\), the optimal z solves
It is the Galerkin projection of (20) for \(\delta x_\alpha \) onto the subspace \(\tilde{V}_k\). Then we update the dual \(\xi \) and the primal x by the duality relation in Sect. 6:
Summarizing the steps gives Algorithm 3. Note that the duality relation (17) enables A and \(A^*\) to enter into the play, thereby allowing progressively improving the accuracy. The main extra cost lies in matrix-vector products by A and \(A^*\).
The iterative refinement is a linear fixed-point iteration, with the solution \(x_\alpha \) being a fixed point and the iteration matrix being independent of the iterate. Hence, if the first iteration is contractive, i.e., \(\Vert x^1-x_\alpha \Vert \le c\Vert x^0-x_\alpha \Vert \), for some \(c\in (0,1)\), then Algorithm 3 converges linearly to \(x_\alpha \). It can be satisfied if the RSVD approximation \((\tilde{U}_k,\tilde{\varSigma }_k,\tilde{V}_k)\) is reasonably accurate to B.
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Ito, K., Jin, B. (2020). Regularized Linear Inversion with Randomized Singular Value Decomposition. In: Beilina, L., Bergounioux, M., Cristofol, M., Da Silva, A., Litman, A. (eds) Mathematical and Numerical Approaches for Multi-Wave Inverse Problems. CIRM 2019. Springer Proceedings in Mathematics & Statistics, vol 328. Springer, Cham. https://doi.org/10.1007/978-3-030-48634-1_5
Download citation
DOI: https://doi.org/10.1007/978-3-030-48634-1_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-48633-4
Online ISBN: 978-3-030-48634-1
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)