
Abstract
Deep learning (DL) based autoencoder (AE) has been proposed recently as a promising, and potentially disruptive Physical Layer (PHY) design for beyond-5G communication systems. Compared to a traditional communication system with a multiple-block structure, the DL based AE provides a new PHY paradigm with a pure data-driven and end-to-end learning based solution. However, significant challenges are to be overcome before this approach becomes a serious contender for practical beyond-5G systems. One of such challenges is the robustness of AE under interference channels. In this paper, we first evaluate the performance and robustness of an AE in the presence of an interference channel. Our results show that AE performs well under weak and moderate interference condition, while its performance degrades substantially under strong and very strong interference condition. We further propose a novel online adaptive deep learning (ADL) algorithm to tackle the performance issue of AE under strong and very strong interference, where level of interference can be predicted in real time for the decoding process. The performance of the proposed algorithm for different interference scenarios is studied and compared to the existing system using a conventional DL-assist AE through an offline learning method. Our results demonstrate the robustness of the proposed ADL-assist AE over the entire range of interference levels, while existing AE fail to perform in the presence of strong and very strong interference. The work proposed in this paper is an important step towards enabling AE for practical 5G and beyond communication systems with dynamic and heterogeneous interference.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Communication networks and services are becoming more intelligent with the novel advancements and unprecedented levels of computational capacity that is available for processing locally or in the cloud. AI, including machine learning (ML) and deep learning (DL), has been widely used for the design and management of communication systems, and has been shown to significantly enhance the system performance and reduce the operational cost, hence has raised great interest in standard [1], as well as in research. There has been a number of examples of using AI in communication systems in the literature, for example, for channel estimation [2], complex multiple-input and multiple-output (MIMO) detection [3], channel decoding [4], joint channel estimation and detection [5], joint channel encoding and source encoding [6].

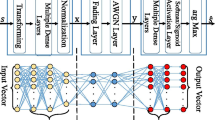
System block diagram of an ADL algorithm based AE for a wireless communication interference channel with m-user
In a conventional communication system, the channel propagation is often modeled mathematically, which may not correctly reflect the channel in practical scenarios and the dynamic nature of the changing. DL based approaches demonstrate a useful and insightful way of fundamentally rethinking the communication system design problem and hold the promise for performance enhancement in complex scenarios that are difficult to characterize with tractable mathematical models. Compared to a traditional communication system with a structure consisting multiple functional blocks, autoencoder provides a new paradigm with a pure data-driven and end-to-end learning based solution. For example, a DL based AE is proposed in [7], where the deep neural networks (DNNs) based reconstruction transceiver block jointly optimizes all the functions in a single process. The work in [8] presents end-to-end learning of a communications system without a channel model. In [9], authors propose a deep reinforcement learning approach for training a link with noisy feedback, for both additive white Gaussian noise (AWGN) and Rayleigh block-fading (RBF) channels. Also, two practical DL-based systems are implemented in [10] and [11].
All the work above provided great insights of the potential performance of applying AE for interference-free channels. However, it is also revealed in [12] that AE can be vulnerable to adversarial and jamming attacks, compared to conventional coding schemes. While [13] shows that such drawbacks can be mitigated through adversarial training, it is not clear how AE will behave under a multi-user interference channel, with which performance of a multi-user system is often impaired [14, 15]. The study in [7] considers a two-user link with interference for AE. However, offline training is used and there is no adaptive training for different levels of interference. Other studies on AE, MIMO channel learning [16], channel estimation in an OFDM system [17], and learning to optimize for interference management [18], are all based on offline learning, therefore does not cope well with the situation when interference is dynamic, can be from different sources, and can vary in real time.
In this work, we characterize the tolerance of a conventional AE under a Gaussian interference channel, with respective to different interference levels. Our results demonstrate that although the offline trained AE approach has reasonable robustness for noisy to moderate interference channel, performance of AE suffers substantially under a strong or very strong interference channel. To date, there has been little work on DL-based AE in the presence of an interference channel with a variety of interference strengths, even less so to address the issue for allowing AE in practical dynamic and heterogamous interference scenarios. In this paper, we proposed an adaptive deep learning (ADL) algorithm based AE. The interference strength is predicted through an adaptive deep learning process, where real time online learning is performed to obtain the knowledge of the real time interference level for the subsequent decoding process, through an updated DNNs layer. We demonstrate that the proposed AE works robustly for all interference levels. In particular, the performance improvement compared to conventional AE [7] is more notable for the strong and very strong interference scenarios.
2 System Model
2.1 System Description
The proposed ADL algorithm based AE system for a wireless communication interference channel with m-user is shown in Fig. 1. It has three main blocks: transmitter, channel, and receiver. Compared to a conventional communication system with a number of blocks, this proposed diagram recast the block diagram as an end-to-end optimization task and represent the system as a simplified AE system by using a DL based neural network (NN) layer. For basics of DNN, an introduction is given in [24]. The NN layer stacks one on top of another. In general, the NN layers considered in this work transform an input data \(l_{\text {in}}\) into an output \(l_{\text {out}}\) as follows:
where w and b are weights and trainable parameters and f(.) is a non-linear function [24]. The weights of the whole layers are optimized jointly. Let \({\varvec{{s}}}\) as the input, and the training set contains all the possible values of \({\varvec{{s}}}\). In an AE during the training, the targets values are equal to the inputs ie \(\hat{s}_i=s_i\), where \(s_i\) is a realization of \({\varvec{{s}}}\). The network is trained to optimize the reconstruction error, which is given:
The reconstruction error here is the cross entropy loss, which is given [24]:
where \(\hat{s}(k)=P(s(k)=1|\hat{s})\). s(k) stands for bit k of s and \(\hat{s}(k)\) stands for bit k of \(\hat{s}\). The training of the network is performed by solving the following optimization problem:
where P is denote the set of trainable parameters. N and \(\theta \) are generated noise and phase by the channel layer each time it is used.
For the transmitter side, the transmitted messages \({\varvec{{s}}}\) is reconstructed, and \(s_i\in M=\{1,2, \ldots ,M\}\), where \(M=2^{k}\) is the dimension of M with k being the number of bits per message. The message is passed to the transmitter. The transmitter applies a transformation by a DNN layer \(f:M \rightarrow \) \(\mathbb {R}^{2n}\) to the message \(s_i\) to generate the transmitted signal \(x=f(s_i)\in \mathbb {R}^{2n}\). Note that the output of the transmitter is an n-dimensional complex vector which is transformed to a 2n real vector. We use ’one-hot vector’ with size of M to reconstruct \(s_i\) for DNN layer. Following the similar definition in [7], the transmitter is constrained by an average power: \({{\,\mathrm{\mathbb {E}}\,}}{[|x_i^{2}|]}\le 0.5\, \forall \, i\). In this work, we use a m-user interference channel with AWGN.
2.2 Model of Interference Channel with m-user
In Fig. 1, a m-user Gaussian AWGN interference channel is illustrated within the dashed-line rectangle block. The interference channel has m transmitter-receiver pairs that simultaneously communicate in blocks of size m. Each transmitter communicates to its own receiver a message \(s \in m =\{1, 2, \dots , m \}\). Let \(x^{n}\) and \(y^{n}\) denote the input and output signal of the \(n\,th\) user, respectively. \(N^n \sim CN(0, 1)\) is independent and identically distributed Gaussian noise that impairs receiver n. Each \(x_n\) has an associated average power constraint \(P^n\) so that \(\frac{1}{m}\sum _{n=1}^{m} |x^{n}_{m}|^{2}\le P^n\). Receiver n observes \(\hat{y}^n\) and estimates the transmitted message \(\hat{x}^n\). The average probability of error for user n is \(\epsilon ^{n}_{m}={{\,\mathrm{\mathbb {E}}\,}}[P(\hat{s}^n \ne s^n)]\), where expectation is over the random choice of message. The channel output at each receiver is a noisy linear combination of its desired signal and the sum of the interfering terms, of the form [19]:

where \(y^n\) and \(N^n\) are the channel output and AWGN respectively, at the \(n\,th\) receiver and the \(x^n\) is the channel input symbol at the \(n\,th\) transmitter. All symbols are real and the channel coefficients are fixed. The AWGN is normalized to have zero mean and unit variance and the input power constraint is given by [19]:
The INR is defined through the parameter \(\alpha \) [19]:
Note that the definition of INR ignores the fact that there are m-1 interferers observed at each receiver. This is for two reasons. First, this definition parallels that of the two-user case [20], which will make it easier to compare the two rate regions. Second, the receivers will often be able to treat the interference as stemming from a single effective transmitter, via interference alignment. This is not the case when the receiver treats the interference as noise. In this work, the introduced parameter \(\alpha >0\) defined by \(\text {INR}=\text {SNR}^{\alpha }\); this coupling parameter \(\alpha \) is used to specify the corresponding linear deterministic model in [21].
In this work, we address the interference scenarios including noisy, weak, moderate, strong, and very strong interferences. The definition of the classification for the interference is proposed in [19]. The degrees-of-freedom (GDoF) of the symmetric m-user interference channel is identical to that of the multiple-user channel, except for a singularity at \(\alpha \) = 1, as follows:

2.3 ADL Algorithm at Receiver Blocks
As shown in Fig. 1, at the receiver side, y(n) is the received signal after propagating through an AWGN channel, which includes the original transmitted signal, the channel response, AWGN noise as well as the interference from other sources. Here, the received n-dimensional signal y(n) noised by a channel represented as a conditional probability density function p(y|x), and the DNNs receiver subsequently learns it with multiple dense layers. The last layer of the receiver is a Softmax activation layer that outputs an M-dimensional probability vector \({\varvec{{p}}}\), in which the sum of its elements is equal to 1. The receiver first applies the transformation \(f:\mathbb {R}^{2n} \rightarrow M\) to decode the signal, creating a signal \(\hat{s}_i\) to recover the original transmitted signal \(s_i\).
To enable the comparability of the results implemented in different scenarios, we set n = 4 and k = 4 throughout this work. For other setups of the AE, to allow a benchmark for comparison, we use the similar AE structure and settings as in [7], which are based on a multi-layer perceptron (MLP) AE. The specifications are listed in Table 1. We train the AE in an end-to-end manner using the Adam optimizer, on the set of all possible messages \(s_i \in M\), using the cross-entropy loss function. ReLU and Softmax are used in DNNs layer.
As shown in Fig. 1, we design and propose an adaptive learning processing, integrating with the DNNs based receiver block, named ADL algorithm, to estimate the interference coupling parameter \(\alpha \). With the Predicted \(\alpha \), we obtain an updated channel function, according to Eqs. (5) to (7). Then the DNN layer is updated with this knowledge by substituting \(\alpha \) into Eq. (5). This process includes two stages. Firstly, we utilize multiple group of pilot signals for online DNN training to predict the real-time \(\alpha \). Then with the knowledge of the channel, we update the interference channel function, decode signals with DNN layers.
It assumes that the signals consist of two parts. The first part is pilot signal, as the training data set. The second part is the transmitted signal, which has the same structure as it’s in a DL based OFDM system [17]. However, we utilize the pilot signals here for both estimating interference and the DNN training. We introduce and explain our proposed ADL algorithm in Algorithm 1. At the initialization stage, we set the specifications of an (n = 4, k = 4) AE and load the input training data set. Then, the DNN layer encodes the data for propagating through an AWGN channel. The DNNs based receiver block first captures a group of signals, and then the reinforcement block starts to train the pilots simultaneously. By process of reward computation, the block normalizes the reward regarding different guessing values of \(\alpha \). Then we determines the optimum \(\alpha \) range with regarding the a predefined confidence interval. Based on the plot of the reward according to the guessing values of \(\alpha \). We compute the mean, as the predicted \(\alpha \). Next, the estimated \(\alpha \) is substituted back into the DNNs block for the decoding process with an updated DNNs layer. For this prediction process based on the reward performance, we will give more details in the Section of Numerical Evaluation. In this work, the normalized reward is defined as follows:
where
\(R_i\) is defined as the reciprocal of the mean bit error rate (BER) value for i pilots signals.

SER versus SNR performance of an AE (4, 4): no interference, interference \(\alpha \) = (0.2 0.8) with blind training, \(\alpha \) = 0.2 with knowledge of \(\alpha \).

SER versus SNR performance of an AE (4, 4): weak interference \(\alpha =0.5\) (at training) with offset up to \(\alpha _{\text {off}}\,=\,2.5\) (received).
3 Numerical Results and Discussion
In this section, numerical simulation is carried out under the environment of Python 3.0, with the libraries of PyTorch, TorchNet and TQDM. Training was done at a fixed value of \(E_b/N_0\) = 7 dB using Adam [22] with a learning rate of 0.001. Activation functions rectified linear units (ReLU) [23] and Softmax are used in our DNNs layer. The details are listed in Table 1. Detailed explanation of these can be found in [24]. The pilot symbol ratio we used in our simulation is 0.01. The group number of the bit streams is 30, which is used for jointly training and estimating the interference \(\alpha \).
3.1 Comparsion with and Without Interference
A DL based AE with different settings of (n, k) (n is the number of channel use, and k is the bits of the signal) are studied and evaluated in [7]. It compares the performance between the M-QAM modulation and AE with similar settings. It demonstrates that the AE (4, 4) and (4, 8) outperforms the 4-QAM and 16-QAM. To enable a benchmark for comparison, we choose the setting (4, 4) throughout all scenarios. However, we evaluate the performance according to our proposed interference model, as shown in Eqs. 5–8. We verify our algorithm through an example of a two-user interference channel case. For other multi-user case, the methodology is similar, and the enhancement is more significant.
In the proposed DL based system, the AE reconstruct and compressed the data with ‘one hot vector’ format for the NN layer. For a fair comparison to a conventional system with other modulation schemes, we study the symbol error rate (SER) for evaluating the system performance. We first simulate an AE (4, 4) system in an ideal channel without taking any interference, as a reference point. The plot is illustrated in Fig. 2. It shows that without the interference, the system works well, even under a low SNR. Then we evaluate a blind training with interference. The blind training is defined as that the system does not have any knowledge that it is an interference channel. Therefore the system trains a model without interference \(\alpha \). However, the true received signal has a certain value of \(\alpha \). We evaluate the system from \(\alpha =0.2\) to \(\alpha =0.8\), in Fig. 2. The results show that with a blind training, the AE has some robustness even without any knowledge of the channel. However, when \(\alpha \) increases beyond 0.6, then the AE doesn’t work well. We also plot the case with the knowledge of \(\alpha \) for comparison. When \(\alpha =0.2\), we could achieve SER \(\sim \) \(10^{-3}\) at \(E_b/N_0 =\,\) \(\sim \) \(7\) dB, and this is assuming that we know the exact \(\alpha \) for training. The comparison in Fig. 2 indicates that it is possible to overcome the interference effect if we have an efficient approach to predict the interference parameter \(\alpha \).
3.2 Robustness of an AE for Different Interference Strengths
We demonstrate that the AE approach has some robustness when it applies in an interference channel. However, we also want to characterize the robustness for difference interference strengths. It assumes that the system knows the interference channel generalized formula (Eq. 5) and it applies a DL training for the decoder. We train the model with a predetermined \(\alpha \). However, we assume that \(\alpha \) may change dynamically in a real time scenario and we want to evaluate how robust of the decoder when \(\alpha \) has some offset, denote as \(\alpha _\text {off}\).
Following the definition in Eqs. 5 to 8 , we simulate for weak (\(\alpha =0.5\)) and very strong interference (\(\alpha =2\)) respectively. Results are plotted in Figs. 3 and 4. It shows that the AE approach is quite robust for a weak interference. The system works even under a very large offset: 3 times of the training \(\alpha \). However, the situation is slightly different for very strong interference, where \(\alpha =2\). The result in Fig. 4 indicates that the system is quite sensitive to the offset under a very strong interference channel. For this scenario, it does require a technique to deal with the interference. To address this, we apply the proposed ADL algorithm and the performance evaluation is given in the next section.

SER versus SNR performance of an AE (4, 4): very strong interference \(\alpha =2\) (at training) with offset up to \(\alpha =2.5\) (received).

Normalized reward versus predicted \(\alpha \): strong interference \(\alpha =1.5\) and very strong interference \(\alpha =2\).

SER versus SNR: comparison for strong and very strong interference channel, with and without the proposed ADL algorithm.
3.3 Evaluation with the Proposed Learning Algorithm
Recall the proposed ADL algorithm in sect. 2. We evaluate the ADL algorithm to estimate \(\alpha \) in different interference strengths. We also carried more groups of study as in section B, and we found that for strong (\(\alpha =1.5\)) and very strong (\(\alpha =2\)) interference, the offset of \(\alpha \) becomes more critical. Therefore, we address this and implement our algorithm for these cases. With the same setting in Figs. 3 and 4, we plot the normalized reward versus a predicted \(\alpha \) (different values at training), in Fig. 5. for \(\alpha =1.5\) and \(\alpha =2\), respectively. We can see that the peak value of the normalized reward appears around 1.5 (actual value), and it reduces gradually to both sides of the actual value. By contrast, for the very strong interference, where \(\alpha =2\), we can also found out the peak value of the normalized reward appears around the real value of \(\alpha \). However, it decreases rapidly towards both sides of the actual value, which agree with the achievement that it’s more sensitive to the offset. As the fluctuation is quite large in Fig. 5, here we define 40% offset as the confidence interval of the reward, to estimate \(\alpha \). We use the mean \(\alpha \) for evaluating the performance, as we introduced in Sect. 2. Furthermore, the reward is computed according to the instant SNR condition. For this simulation, we use \(E_b/N_0 = 7\) dB as an example. To evaluate the performance with and without applying the proposed ADL algorithm, we plot the SER performance for weak, strong and very strong interference channels for comparison, as shown in Fig. 6. In this simulation, we take a large interference effect as an example, \(\alpha _{\text {off}}=2\alpha \), to demonstrate the improvement achieved by our algorithm. Two groups of data are highlighted in Fig. 6. We can see that the SER significantly degrades due to the large offset of \(\alpha \). In particular, for the strong and very strong interference cases, the system does not work without the knowledge of \(\alpha \). However, with applying the ADL algorithm, the result shows that with an efficient interference prediction, the ADL algorithm based AE is capable of robust performance over the entire range of interference levels, even for the worst case in a very strong interference channel.
4 Conclusion
An ADL algorithm based AE is proposed for interference channel with unknown interference. With the proposed online learning, interference can be estimated and predicted, which is then subsequently used for decoding of the signals using DNN. The proposed algorithm is shown to significantly enhance the robustness of the interference channel, and provides an AE system that is adaptable to real-time interference, for the entire range of interference levels. The enhancement is more notable for strong and very strong interference scenarios, compared to performance of conventional AE with offline learning.
We believe that our proposed approach is an important step towards enabling AE for 5G and beyond communication systems with dynamic and heterogeneous interference. Our future work aims at improving computational efficiency of our online learning scheme, and the implementation on real-life platforms.
References
Wang, Y., et al.: Network management and orchestration using artificial intelligence: overview of ETSI ENI. IEEE Commun. Stand. Mag. 2(4), 58–65 (2018)
Farsad, N., Goldsmith, A.: Neural network detection of data sequences in communication systems. IEEE Trans. Signal Process. 66(21), 5663–5678 (2018)
Huang, H., Yang, J., Huang, H., Song, Y., Gui, G.: Deep learning for super-resolution channel estimation and DOA estimation based massive MIMO system. IEEE Trans. Veh. Technol. 67(9), 8549–8560 (2018)
Nachmani, E., Be’ery, Y., Burshtein, D.: Learning to decode linear codes using deep learning. In: 54th Annual Allerton Conference on IEEE Communication, Control, and Computing, pp. 341–34, Allerton (2016)
Ye, H., Li, G.Y., Juang, B.-H.: Power of deep learning for channel estimation and signal detection in OFDM systems. IEEE Wirel. Commun. Lett. 7(1), 114–117 (2018)
Farsad, N., Rao, M., Goldsmith, A.: Deep learning for joint source-channel coding of text, arXiv preprint arXiv:1802.06832 (2018)
O’Shea, T., Hoydis, J.: An introduction to deep learning for the physical layer. IEEE Trans. Cognit. Commun. Netw. 3(4), 563–575 (2017)
Aoudia, F.A., Hoydis, J.: End-to-end learning of communications systems without a channel model, arXiv preprint arXiv:1804.02276 (2018)
Goutay, M., Aoudia, F.A., Hoydis, J.: Deep reinforcement learning autoencoder with noisy feedback, arXiv preprint arXiv:1810.05419 (2018)
Dörner, S., Cammerer, S., Hoydis, J., Brink, S.: Deep learning based communication over the air. IEEE J. Sel. Top. Signal Process. 12(1), 132–143 (2018)
O’Shea, T.J., Roy, T., West, N., Hilburn, B.C.: Physical layer communications system design over-the-air using adversarial networks, arXiv preprint arXiv:1803.03145 (2018)
Sadeghi, M., Larsson, E.G.: Physical adversarial attacks against end-to-end autoencoder communication systems. IEEE Commun. Lett. 23(5), 847–850 (2019)
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples, arXiv (2018)
Gomadam, K., Cadambe, V.R., Jafar, S.A.: A distributed numerical approach to interference alignment and applications to wireless interference networks. IEEE Trans. Inf. Theory 57(6), 3309–3322 (2011)
Geng, C., Naderializadeh, N., Avestimehr, A.S., Jafar, S.A.: On the optimality of treating interference as noise. IEEE Trans. Inf. Theory 61(4), 1753–1767 (2015)
Erpek, T., O’Shea, T.J., Clancy, T.C.: Learning a physical layer scheme for the MIMO interference channel. In: 2018 IEEE International Conference on Communications (ICC), pp. 1–5 (2018)
Balevi, E., Andrews, J.G.: One-bit OFDM receivers via deep learning. IEEE Trans. Commun. 67(6), 4326–4336 (2019)
Sun, H., Chen, X., Shi, Q., Hong, M., Fu, X., Sidiropoulos, N.D.: Learning to optimize: training deep neural networks for interference management. IEEE Trans. Signal Process. 66(20), 5438–5453 (2018)
Jafar, S.A., Vishwanath, S.: Generalized degrees of freedom of the symmetric Gaussian K user interference channel. IEEE Trans. Inf. Theory 56(7), 3297–3303 (2010)
Etkin, R.H., David, N., Wang, H.: Gaussian interference channel capacity to within one bit. IEEE Trans. Inf. Theory 54(12), 5534–5562 (2008)
Ordentlich, O., Erez, U., Nazer, B.: The approximate sum capacity of the symmetric Gaussian \( K \)-user interference channel. IEEE Trans. Inf. Theory 60(6), 3450–3482 (2014)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization (2014), arXiv preprint arXiv:1412.6980
Jin, X., Xu, C., Feng, J., Wei, Y., Xiong, J., Yan, S.: Deep learning with S-shaped rectified linear activation units. In: AAAI, vol. 3, no. 2, p. 3.2 (2016)
Goodfellow, I., Bengio, Y., Courville, A., Bengio, Y.: Deep Learning. MIT Press, Cambridge (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 IFIP International Federation for Information Processing
About this paper

Cite this paper
Wu, D., Nekovee, M., Wang, Y. (2020). An Adaptive Deep Learning Algorithm Based Autoencoder for Interference Channels. In: Boumerdassi, S., Renault, É., Mühlethaler, P. (eds) Machine Learning for Networking. MLN 2019. Lecture Notes in Computer Science(), vol 12081. Springer, Cham. https://doi.org/10.1007/978-3-030-45778-5_23
Download citation
DOI: https://doi.org/10.1007/978-3-030-45778-5_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-45777-8
Online ISBN: 978-3-030-45778-5
eBook Packages: Computer ScienceComputer Science (R0)