
Abstract
Internet of things (IoT) emerged as a promising technology in the last decade and predicted to be ascendant in the next. Its application in the producer side of the healthcare industry is still in the nascent stage but expected to increase manifold in the near future. The purpose of this chapter is twofold; first, illuminate on the IoT applications on the pharmaceutical manufacturing and supply chain practices with real examples, and second elaborate the wide avenue of the opportunity of IoT it has in the drug discovery. Where most of the previous works argue the prospect of IoT in the conceptual or theoretical manner, we, however, intend to show the utility of automatic information processing in the context of computational drug design, which is an integral part of the drug discovery process. We integrate quantitative structure relationships with activity (QSAR), property (QSPR), and toxicity (QSTR) by utilizing an optimization technique to come up with a combined decision model. Numerical analysis has been performed with the developed optimization model considering three different cases using a simple chemical structure to test the model. Results suggest that the developed mathematical model can successfully be able to integrate QSAR, QSPR, and QSTR parameters which in terms of aid in automatic information and data capturing and lessen human efforts. This automatization can help in generating “optimal” drug candidates by considering all necessary facets. The present chapter also discusses other aspects of the healthcare producers where IoT can be proven beneficial in the near future.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others



Keywords
1 IoT in the Producer Side of Health Care: Introduction
Healthcare industry functions through three main stakeholders. We can refer to them as “pillars” of the healthcare sector. These “pillars” are payers, providers, and producers [1]. Payers are the segment who are directly or indirectly responsible for the payment for the cost incurred while availing a healthcare service or affording a healthcare product. Payers can be insurance companies, public or governmental bodies, or patients in case of out of pocket expenditures. Where payers are responsible to “pay” the fee of the healthcare services or products, providers and producers are responsible for delivering them, respectively. Providers are the organizations that deliver healthcare services to the patients. Providers can vary from a small 20-bed small health clinic to an 800-bed multispecialty hospital. When producers, on the other hand, not standing on the front end of health service delivery but indispensable part of healthcare services as without required supply of products, healthcare personnel (HCP) will not be able to serve the patients in the hour of the need. Producers consist of mainly pharmaceutical, diagnostics, and medical device manufacturers.
“Internet of things” (IoT) is a much recent but popular construct in today’s media and management consulting firm reports. While this book addresses IoT from multiple angles, this chapter explores the applicability of IoT concepts in the healthcare producer context, specifically in the case of the pharmaceutical industry. At the early stages of adoption of IoT in the healthcare industry, the main application was limited to the patient-centric mobility devices or wearables. Today, however, it extends to real-time patient monitoring, patient compliance or medication adherence, and HCP reporting. But practitioners still believe that the application of IoT is still in the nascent stage as a technology in the healthcare sector. Healthcare producers especially pharmaceutical companies can leverage the benefits of IoT to a great extent in the upcoming years [2].
Pharmaceutical companies retain a high-profit margin and thus has a low incentive to change. However, the situation is changing rapidly due to competition and the advent of personalized medicines. In the second case, companies need to produce a small batch of medicine which has a much low economy of scale. Currently, there is a media report suggesting that due to a $3500 broken vacuum pump, an American Pharma company lost products worth $20 million and to cater such unforeseen events in the future, the firm decided to install IoT sensors to its vacuum pumps [3]. Such an application is a classic example of how IoT can benefit pharmaceutical production environment by predicting failures way ahead. Apotex, a Canadian Pharmaceutical manufacturer, utilizes IoT-based technology to improve its solid dosage form manufacturing plant which resulted in increased productivity and improving bottom lines. Manufacturing plant floor control automation has been achieved for the Apotex due to real-time visibility of the pharmaceutical manufacturing automation and process flow tracking [4]. IoT has also benefitting pharmaceutical supply chain practices to a great extent. Drug counterfeiting is one of the main concerns for the pharmaceutical firms and to a major point for the integrity of the pharmaceutical supply chain. UK-based Eurosoft Systems Ltd. (ESL) has developed SMARTpack, an IoT-enabled product which aid to stop counterfeit of medicines by ensuring smart packaging and tracking [5].
A diverse range of IoT applications thus has the potential to alter the current healthcare system to a more accessible, quality-driven healthcare system, although proponents of the iron triangle of health care [6] can argue that this accessibility and quality probably comes with their competing issue: cost, which is the cost of the technology. We, however, need to understand that the implementation of the IoT-based mechanisms not only change the pharmaceutical manufacturing operations or supply chains but also has a much greater impact on the drug discovery process. IoT’s capability to enhance R&D activities and clinical development of drug molecules is mostly unexplored and holds the potential to save financial resources to a good extent in the near future.
2 Drug Discovery Process: Current Scenario
The traditional or de novo drug discovery is a costly and time-consuming process that often contributes to the exorbitant price of a newly patented drug molecule. De novo drug discovery process contains several steps: drug target identification, screening and discovery of the molecule, optimization of the lead molecule which has the best potential to become a successful drug, testing for its in vivo properties (absorption–distribution–metabolism–excretion/ADME), preclinical and clinical trial process, and finally regulatory process. It takes 10–17 year to develop a successful drug [7], and millions of dollars were spent on the process. From the first step to final drug development, probability success is only 10% [8].
NextGen cloud-based architecture is an example that aims to reduce the cost of drug discovery by utilizing IoT concepts [2]. It intends to reduce the human effort in the process. It might seem confusing how to find a suitable drug candidate or “lead molecule” after initial screening. Here, we propose an optimization model that can reduce human effort by the help of automatic identification and data capturing (AIDC) concepts for identifying new chemical entities (NCE). Automatic identification of NCE by optimization of chemical structures for different chemical groups can aid us to automate the drug design process and opens new avenues of opportunity for finding NCE that can be prospective “lead” or drug molecules.
3 An Optimization Model for Identification of NCE
Identification of NCE or potential drug molecules can be done by various screening techniques; among them, computational drug design is a popular method of NCE screening. We try to develop an optimization model that can be integrated into the computational drug design process for automatic data serialization for identifying NCE.
3.1 Computational Drug Design for NCE Identification
Computational drug design is a three-dimensional puzzle where the drug or the “chemical molecule with the medicinal property” has been computationally designed by keeping the binding site of the biological target of the human body in mind. The drug, only with the association of the targeted biomolecule, can produce a desired therapeutic effect that alleviates a disease present in the patient body [9]. This chemical entity or drug is termed as “ligand” by the scientists. In order to come up with a successful drug, it is essential to decipher the functional groups and elements attaching to the core chemical structure of the drug [10]. The advent of computers and the use of quantitative techniques helped us to solve the enigma of finding a suitable chemical structure with all attached functional groups within a practically feasible time span [11, 12].
Quantitative structure–activity relationship (QSAR) models are quite popular and widely used techniques in the computational drug design domain. QSAR is contingent upon the assumption that the ligand molecule has several positions around its core chemical structure, and the presence of different elements/functional groups in those positions affects the activity of the ligand. With proper quantitative exercise with functional groups, researchers can suggest if a ligand can turn out to be a successful drug. However, the rationale behind a successful drug is mainly determined as the biological activity exhibited by a structure. The core structure has a certain number of elements/groups in certain positions, i.e., “most suitable” elements in “most suitable” positions of the ligand. The outcomes are represented as a numerical value, and multivariate modeling techniques are used to come up with a QSAR model for that “potential” drug molecule [13, 14]. While a desired biological or therapeutic activity is a necessary criterion to be considered as a potential drug molecule, it has to be seen that the newly designed molecule should have possessed certain necessary physicochemical properties when entering inside a human body to turn out to be a good candidate [15]. Instead of the wide popularity of QSAR models [16], consideration of physicochemical properties that affects absorption in the body, distribution throughout the body, metabolism, and excretion of the drug (ADME properties) eventually attracts the attention of the researchers. This leads to a quantitative structure–property relationship (QSPR) studies that essentially capture the relation between molecular structure and physicochemical or ADME properties of the drug molecule [17, 18]. However, even ensuring optimal biological activity and calibrated physicochemical properties does not help us to ensure the feasibility of a “good drug.” As drug discovery is a costly process, initial screening has to consider one of the most important parameters of any chemical entity, i.e., toxicity produced by the chemical molecule inside the human body. Researchers conducted quantitative structure–toxicity relationship (QSTR) studies to determine how the combination of functional groups/elements in a chemical structure can determine its toxicity potential in the environment [19, 20] and inside the human body [21]. QSTR has been also adopted by other researchers to determine the toxicity profile of any new chemical molecule even if it is not a drug and just a solvent [22] of novel material [23] to bolster greener practices of the planet.
Initially, researchers tried to use QSPR as a validation of QSAR model before finalizing the multilinear regression model [24] and some researchers conducted QSTR studies in parallel with the QSAR studies. Later, many researchers advocated the need for a model that considers activity, property, and toxicity together [25]. A correct form of model that ensures optimal biological/therapeutic activity, ensures desired physicochemical or ADME properties, and confirms toxicity to be under the specified level is absent in the current literature. This motivated us to develop a model ensuring all the three main parameters of a suitable drug candidate using mathematical optimization technique. The objective of this chapter is to consider QSAR, QSPR, and QSTR parameters and come up with a combined quantitative structure relationship model for a chemical structure.
4 The Mathematical Model
We present the summarized table of notations below:
Notation | Description |
|---|---|
\(n\) | Number of elements/groups to be tested for the structure |
\(N\) | Number of positions in the structure |
\(X_{Ni}\) | Choice of ith element in the Nth position (Decision Variables) |
\(A\) | Therapeutic property of the drug (Parameter) |
\(B\) | Toxicity property of the drug (Parameter) |
\(M\) | Physicochemical/ADME property of the drug (Parameter) |
\(\alpha\) | Lower permissible bound for therapeutic property (Parameter) |
\(\beta\) | Upper permissible bound for toxicity property (Parameter) |
\(NU\) | The net utility of the drug |
The mathematical problem shown below is the mathematical model to determine the optimal mix of elements in the chemical structure subject to the therapeutic and toxicity parameter of the drug. We also incorporate the physicochemical/ADME property into our mathematical model. ADME is an acronym in pharmacology for “absorption, distribution, metabolism, and excretion,” thereby explaining the kinetics and pharmacological traits of the compound as a drug. The ADME property is represented by M, and the values range from 0 and 1 to capture the proportion of ADME property in the given chemical composition. We assume that there are N positions in the structure where n elements can be placed as a chemical bond to enhance the net utility of the drug. It is therefore important to incorporate a model which simultaneously decides the positions of n elements in N positions of the chemical structure. Additionally, the model incorporates that a particular element can sit in different positions of the structure to enhance the net utility. To enhance the relevance of the model, the lower and upper bounds of therapeutic and toxicity property, respectively, have been incorporated. In addition, the model ensures that no element is being considered where the utility, i.e., the difference between therapeutic and toxicity, is always positive. Non-negativity constraints have been ensured as per the practical relevance. The given model is a binary integer programming model, where the decision is to fix the choice of n elements in N positions, given that the individual properties (parameters) in each combination are known to the user.
subject to
5 Numerical Validation of the Model
We provide empirical validation of our model by testing the same with different parametric values. To ensure the flexibility of the model, we tested the same in e different cases. Case 1 represents a balanced problem where there are six positions in the chemical structure (N = 6) and there are six elements which need to be tested for each position (n = 6). The results, shown in Table 1, ensure that the model works N x n cases where both N is equal to n. In each of the models, we assumed α ≥ 20 and β ≤ 40. However, the structural model holds for different values of α and β. Values of different parameters have been taken in such a fashion where there are elements with both high and low ADMEs, therapeutic and toxicity property in order to test the model in different scenarios. A careful examination reveals that the designated second element is favorable for position 6 and substantiated the earlier claim that the same element can be bonded at different positions to improve the net utility. The same logic is applicable for the third element which sits on both positions 2 and 5.
Case 2 represents a scenario where the number of elements is less than the vacant positions in the structure. We present the results in Table 2. Here, we purposefully eliminated element 6 from the previous case to observe the changes in the structure as element 6 was the optimal choice for position 1 in the previous case. We observe that the revised optimal solution suggests that element 4 is most suitable for position 1 given the absence of element 6. A different perspective can be brought in with regard to the elimination strategies of the elements. If we start decreasing the gap between therapeutic and toxicity parameter bounds (α and β), automatically desirable elements will be removed from the model and revised optimal solutions will start appearing.
Similar results are shown for Case 3 in Table 3 where an additional element has been introduced from Case 1 with relatively higher ADME structure. We observe that due to high ADME parameter values, the newly inserted element is the optimal choice for positions 1, 2, 3, and 4, respectively, indicating the relevance of chemical structure with high ADME quotient.
It takes a huge amount of financial resources and scientific efforts to come up with a potential drug candidate. As an optimal therapeutic activity, the correct set of physicochemical properties or ADME properties and low toxicity profile are the characteristics of a drug molecule that cannot be compromised under any circumstances; a drug design study focused only on the QSAR, QSPR, or QSTR model, is likely to generate huge amount of drug candidates that can turn out to be erroneous, and is the synthesis and testing phase. Utilizing this mathematical model ensures “best” choice drug candidate and most preferable element/functional group choice for each position in the chemical structure. This reduces the chances of occurrences of false positive drug candidates.
This study although explained each possible scenario or cases hypothetically is consistent with the literature which suggests that we need to maintain one structure for testing. As a proper validation of a known core chemical structure, studies on QSAR, QSPR, and QSTR have to be completed under the same “testing” condition. This is to test how this optimization model helps us to come up with a suitable new chemical entity with a new incoming chemical group. We took simplistic aromatic ring, i.e., benzene where entry of the new element is restricted for six positions of the carbon and numerical analysis is done for cases where five, six, and seven new elements entered into the structure. This shows that this model is capable to handle number if new entrant groups are less, equal, and more than the available position.
For the readers of the chapter, we provide a separate tutorial section at the end of the chapter as appendices so that one can cross-verify their own optimization model with the current one in a step-by-step manner.
6 Discussion on the Scope of Optimization in Automatic NCE Identification
The previous section of the chapter contributes to the application of the mathematical optimization technique in the domain of computational chemistry. Till now, the computational design of drugs mainly utilizes statistical techniques like regression to come up with a successful model. However, in this study, we demonstrate why a regression model considering only QSAR or QSPR or QSTR parameters is not a good model to proceed with chemical experimentation. Rather, using the optimization technique, we can come with a more accurate and theoretically correct model. Numerical analysis of a simple six-carbon core structure shows the utility of the model in realistic scenarios with a different number of entrant groups in the core structure. This study contributes to the novel application of optimization in a completely new domain which has a lot of opportunities to explore further by future researchers.
Since validation with the real-life experimental data for computationally developed QSAR models is an integral part for scientific robustness [26, 27] which is absent in this chapter, a practical example for the validation is the main limitation and a potential future direction for this study. Future academicians may opt to “validate” this model with different core chemical structures and can come up with the findings that for what type of structure relationships this mathematical model holds correct and illuminate on the limitation of the model with the experimental data.
Scope of optimization in automated NCE identification is immense as it can aid to reduced human effort, effective discovery process handling, and the reduced timeline for the development of the new drug molecule.
7 IoT: The Road Ahead for Healthcare Producers
It is clear that standing in the era of Industry 4.0, the utility of IoT technologies will increase exponentially over the coming decade as IoT can both contribute to cost-cutting and increased productivity in the context of healthcare producers [5].
The following are the avenues of implementation of IoT-based technologies for a healthcare producer firm:
-
Application of radio-frequency identification (RFID) technologies may aid us to real-time monitoring of the medicines that drastically reduce drug counterfeiting, managing quality inventory, and improving production planning and distribution mechanism by using itemized data obtained from the sensor.
-
Item-wise automatic traceability will be the advantage for the pharmaceutical supply chain managers while making any decision. IoT helps us to develop this context-aware RFID-based drug-tracing mechanism [28, 29].
-
IoT-based technologies can help us to identify if any combination of medicines has any interactions or if the patient condition (e.g., pregnancy, liver, or renal disease) is not suitable for any medicines to be prescribed and delivered accordingly. Item-wise medicine data aid the prescription for any patients [30, 31].
-
Identification of medicine interaction reduces malaise in patients due to the avoidance of all medicine combination that has an interaction. This improves patient compliance with medicine [31]. Also, IoT technologies are implemented to deliver medicines in an intelligent box (iMedBox), which, like a personal pharmacist, aid a patient for the dose and medicines [32]. IoT-based wearables have immense potential for delivering patient-centric care as well [33].
-
Real-time diagnostics with the help of IoT technologies have been explored by the Sysmex, a global leader in the diagnostics services [4].
Where it is clear that IoT technologies have immense prospect to emerge as a dominant adoption concept in the upcoming years, it also has limitations. First, the security of itemized data for the pharmaceutical supply chain must be protected data security practices; otherwise, it can be traced by the illegal people/organization who might be interested in some specific chemical item to produce illegal substances such as narcotic substances. Second, the advent of IoT-based manufacturing may further automate the pharmaceutical manufacturing process which might lead to unemployment of semiskilled or skilled workers. Social impact of the same must be kept in mind before implementing the IoT-based automation practices.
Despite the limitation, it is evident that IoT-based technologies will reduce cost, improve productivity, and generate new avenues of employment in the future.
8 Conclusion
This chapter is intended to emphasize the application of IoT in the healthcare producer side. First, it introduces the IoT applications in pharmaceutical manufacturing and supply chain management with real-life contexts. Next, it describes how the introduction of IoT-based technologies has the promise to revolutionize the pharmaceutical drug development procedure and reduce the involvement human efforts, and thus significantly bolster efficient discovery of designed drug candidate within a lesser time span. However, in order to achieve profuse usage of IoT, we must be able to conceptualize the aspects of the drug discovery where IoT can be utilized. Computational drug design seemed to be a relevant context where automatic identification and data capturing principles can be helpful. We deduce a simplistic linear mathematical optimization model that will integrate the principles of current computational drug design concepts such as QSAR and QSPR and can be tested through a simplistic chemical structure to verify the prowess of suggested mathematical model. Finally, the chapter discussed the utility of such models to build a cost-effective and the potential IoT for the healthcare producers. The chapter concludes with the current state of developments with relevant references and challenges such as security of data generated by RFID-based itemization in a pharmaceutical firm.
In a nutshell, the chapter elaborates the impact that IoT can bring to the producer side of the healthcare industry, point out the present state of developments, and provide a mathematical model with numerical validation to bolster the argument that use of IoT in the pharmaceutical drug discovery process is beneficial. Then, it explains the current challenges and future avenues of IoT on the producer side.
References
Burns LR (2014) India’ s healthcare industry: innovation in delivery, financing, and manufacturing. Cambridge University Press, Cambridge
Shrivastava A (2015) NextGen pharma takes “smart” strides with internet of things
Meek T (2018) How IoT is revolutionizing the pharma industry. https://samsungnext.com/whats-next/iot-pharma-biotech/
Maroto F (2019) Is the internet of things changing manufacturing? In: Datafloq. https://datafloq.com/read/internet-of-things-changing-manufacturing/1057. Accessed 7 July 2019
Sridhar A, Varia H (2016) The healthcare industry could have a lot riding on IoT. Indiatimes
Kissick WL (1994) Medicine’s dilemmas: infinite needs versus finite resources. Yale University Press
Ashburn TT, Thor KB (2004) Drug repositioning: identifying and developing new uses for existing drugs. Nat Rev Drug Discov 3:673–683. https://doi.org/10.1038/nrd1468
European Bioinformatics Institute (2018) Train online: drug discovey. https://www.ebi.ac.uk/training/online/course/functional-genomics-i-introduction-and-designing-e/functional-genomics-case-studies/drug-disc. Accessed 13 June 2019
Liljefors T, Krogsgaard-Larsen P, Madsen U (2002) Textbook of drug design and discovery. CRC Press
Güner FO (2000) Pharmacophore perception, development, and use in drug design, vol 2. Internat’l University Line
Cohen CN (1996) Guidebook on molecular modeling in drug design. Elsevier
Brown FK (1998) Chemoinformatics: what is it and how does it impact drug discovery. Annu Rep Med Chem 33:375–384
Verma J, Khedkar V, Coutinho E (2010) 3D-QSAR in Drug Design—a review. Curr Top Med Chem 10:95–115. https://doi.org/10.2174/156802610790232260
Foye WO (2008) Foye’s principles of medicinal chemistry. Lippincott Williams & Wilkins
Scior T, Medina-Franco J, Do Q-T et al (2009) How to recognize and workaround pitfalls in QSAR studies: a critical review. Curr Med Chem 16:4297–4313. https://doi.org/10.2174/092986709789578213
Dudek a Z, Arodz T, Gálvez J (2006) Computational methods in developing quantitative structure-activity relationships (QSAR): a review. Comb Chem High Throughput Screen 9:213–228. https://doi.org/10.2174/138620706776055539
Katritzky A, Lobanov V, Karelson M (1995) QSPR: the correlation and quantitative prediction of chemical and physical properties from structure. Chem Soc Rev 24:279–287. https://doi.org/10.1039/cs9952400279
Karelson M, Lobanov VS, Katritzky AR (1996) Quantum-chemical descriptors in QSAR/QSPR studies. Chem Rev 96:1027–1043. https://doi.org/10.1021/cr950202r
Carlsen L, Kenessov BN, Batyrbekova SY (2008) A QSAR/QSTR study on the environmental health impact by the rocket fuel 1,1-dimethyl hydrazine and its transformation products. Environ Health Insights 1:11–20. https://doi.org/10.1016/j.etap.2009.01.005
Cronin MTD, Dearden JC (1995) QSAR in toxicology: 1.-prediction of aquatic toxicity. Quant Struct Relationsh 14:1–7
Garg D, Gandhi T, Gopi Mohan C (2008) Exploring QSTR and toxicophore of hERG K+ channel blockers using GFA and HypoGen techniques. J Mol Graph Model 26:966–976. https://doi.org/10.1016/j.jmgm.2007.08.002
Das RN, Roy K (2013) Advances in QSPR/QSTR models of ionic liquids for the design of greener solvents of the future. Mol Divers 17:151–196. https://doi.org/10.1007/s11030-012-9413-y
Kleandrova VV, Luan F, González-Díaz H et al (2014) Computational tool for risk assessment of nanomaterials: novel QSTR-perturbation model for simultaneous prediction of ecotoxicity and cytotoxicity of uncoated and coated nanoparticles under multiple experimental conditions. Environ Sci Technol 48:14686–14694. https://doi.org/10.1021/es503861x
Rücker C, Rücker G, Meringer M (2007) Y-randomization and its variants in QSPR/QSAR. J Chem Inf Model 47:2345–2357
Yee LC, Wei YC (2012) Current modeling methods used in QSAR/QSPR. In: Statistical modelling of molecular descriptors in QSAR/QSPR, pp 1–31. https://doi.org/10.3390/ijms10051978
Gramatica P (2007) Principles of QSAR models validation: internal and external. QSAR Comb Sci 26:694–701. https://doi.org/10.1002/qsar.200610151
Tropsha A, Gramatica P, Gombar VK (2003) The importance of being earnest: validation is the absolute essential for successful application and interpretation of QSPR models. QSAR Comb Sci 22:69–77. https://doi.org/10.1002/qsar.200390007
Barchetti U, Bucciero A, De Blasi M et al (2010) RFID, EPC and B2B convergence towards an item-level traceability in the pharmaceutical supply chain. In: Proceedings of 2010 IEEE international conference on RFID-technology and applications. IEEE, pp 194–199
Chamekh M, El Asmi S, Hamdi M, Kim TH (2017) Context aware middleware for RFID based pharmaceutical supply chain. In: 2017 13th international wireless communications and mobile computing conference (IWCMC). IEEE, pp 1915–1920
Jara AJ, Alcolea AF, Zamora MA, et al (2010) Drugs interaction checker based on IoT. In: 2010 internet things. IEEE, pp 1–8. https://doi.org/10.1109/IOT.2010.5678458
Jara AJ, Zamora MA, Skarmeta AF (2014) Drug identification and interaction checker based on IoT to minimize adverse drug reactions and improve drug compliance. Pers Ubiquitous Comput 18:5–17. https://doi.org/10.1007/s00779-012-0622-2
Yang G, Xie L, Mäntysalo M et al (2014) A health-IoT platform based on the integration of intelligent packaging, unobtrusive bio-sensor, and intelligent medicine box. IEEE Trans Ind Inform 10:2180–2191. https://doi.org/10.1109/TII.2014.2307795
Roy SN, Srivastava SK, Gururajan R (2018) Integrating wearable devices and recommendation system: towards a next generation healthcare service delivery. J Inf Technol 19:4–30
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix: Tutorial for Building Optimization Model in Excel Solver
Appendix: Tutorial for Building Optimization Model in Excel Solver
We have provided a step-by-step procedure to prepare the excel solver input–output analysis for solving the linear optimization model. After each step, readers are advised to check their formulated model in the excel file with the figures provided for the proper reproducibility. However, it is a better approach to build own model first and then cross-verify with the tutorial figures for a complete understanding.
-
STEP 1: Writing the decision variable and parameters row-wise so as to ensure that multiplication and addition between variables and parameters turn out to be easy when we formulate the objective function. For all the six positions in the structure, we prepare the excel for ADME property, therapeutic value, toxicity value, and the decision variable line, i.e., choice of ith element in the Nth position. We then provide the value for the parameters and set the value of the cells under decision variables to zero. Figure 1 is the screenshot for further understanding.
Fig. 1 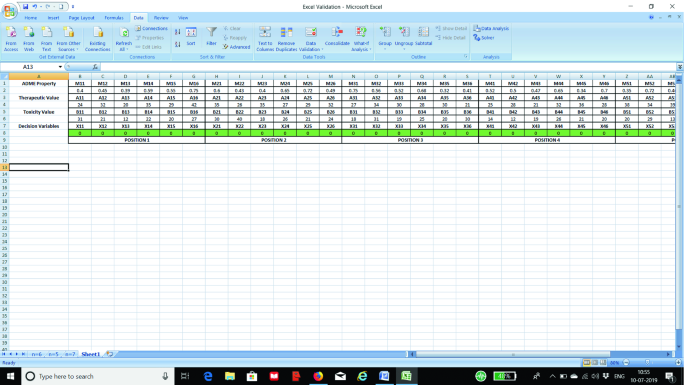
Preparing the excel for decision variables and parameters input for solver analysis
-
STEP 2: Next, we prepare and formulate the objective function with the help of STEP 1 where we prepared the entire input matrix of decision variables and parameters. Therefore, we first prepare the multiplicative operations, i.e., ADME Property * (Therapeutic Value – Toxicity Value) * Decision Variable. We then add all such cells for each of the cells prepared from the input matrix. Please refer Fig. 2a, b for further clarity in this regard.
Fig. 2 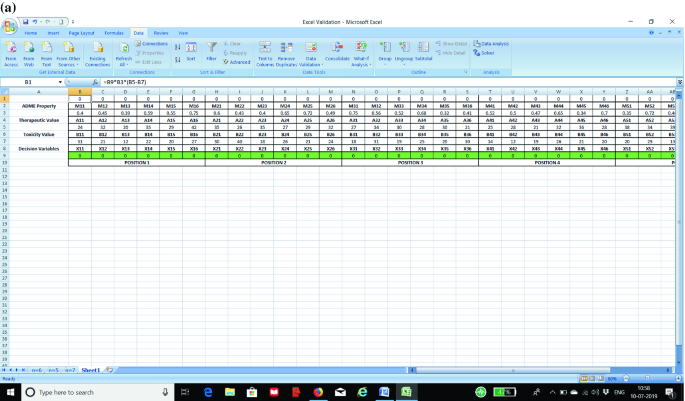
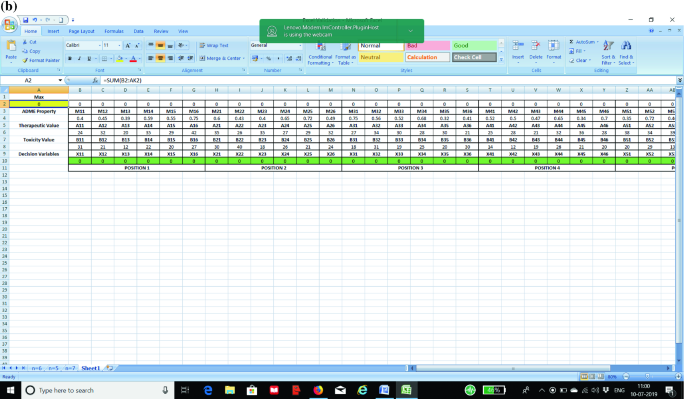
a Formulating the objective function in line with the input matrix formed from decision variables and parameters. b Formulating the objective function in line with the input matrix formed from decision variables and parameters
-
STEP 3: Now we prepare the constraints in the excel sheet. The first constraint is to ensure that all the values as entered in STEP 2 are greater than or equal to zero. In the absence of this constraint, the excel solver may assume negative values for a particular cell. The next set of constraints (one constraint for each position) is to ensure that only one element is fixed to a position. We show the formula for each constraint in separate screenshots as shown in Fig. 3a–g for the purpose of clarity to the students.
Fig. 3 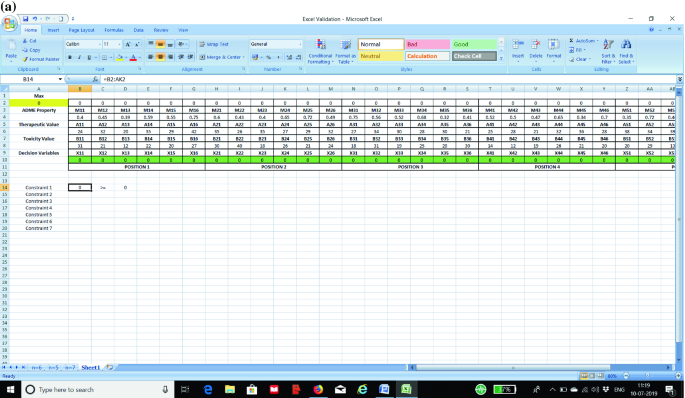
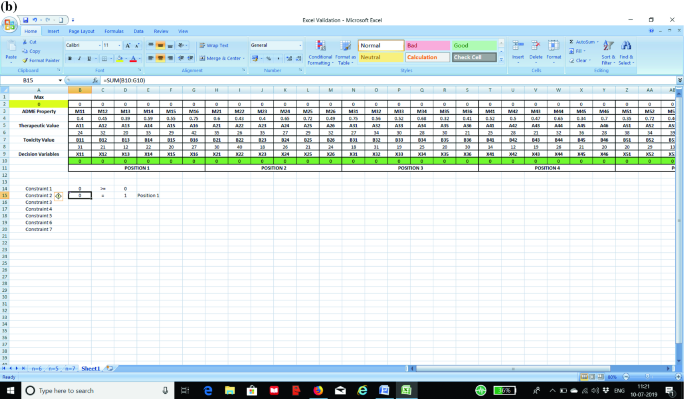
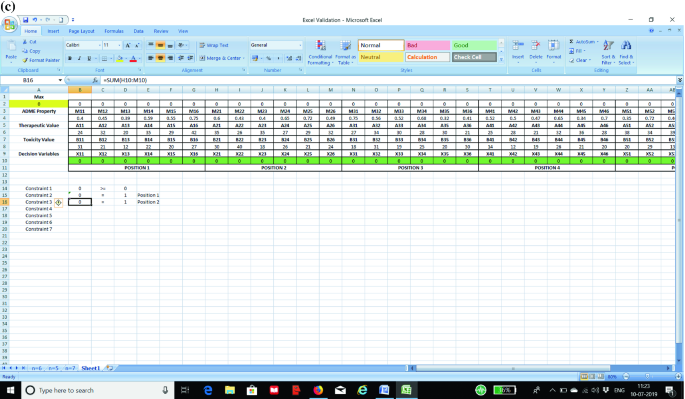
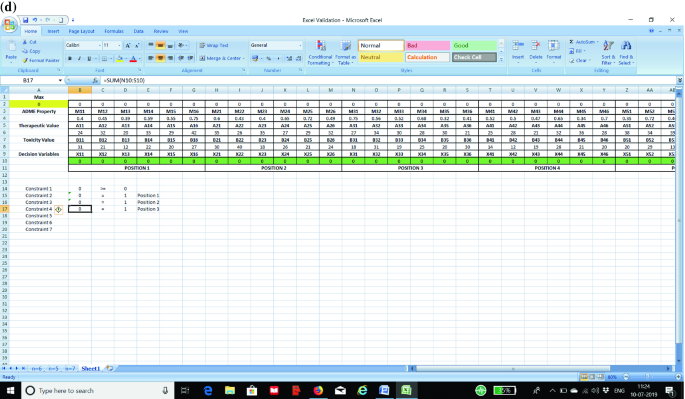
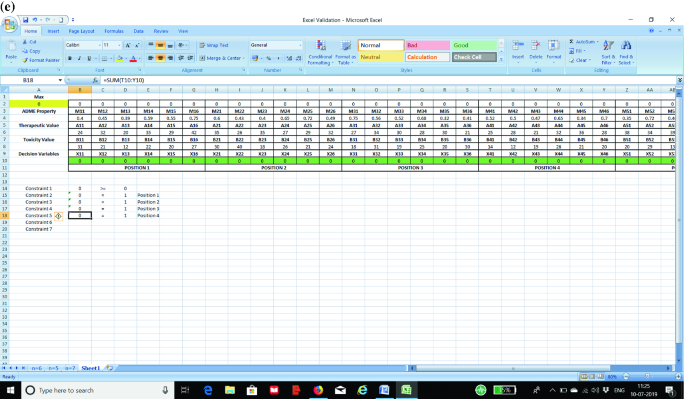
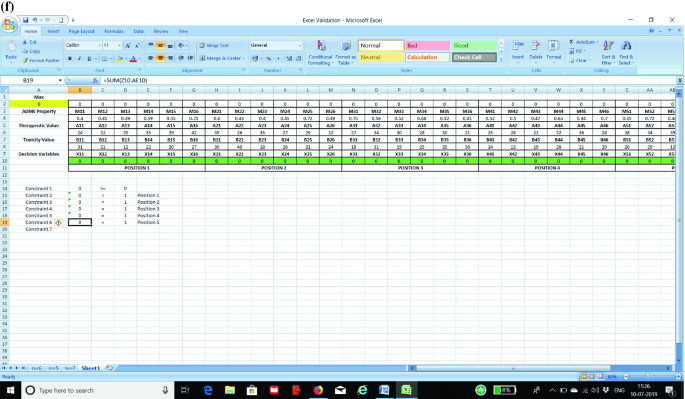
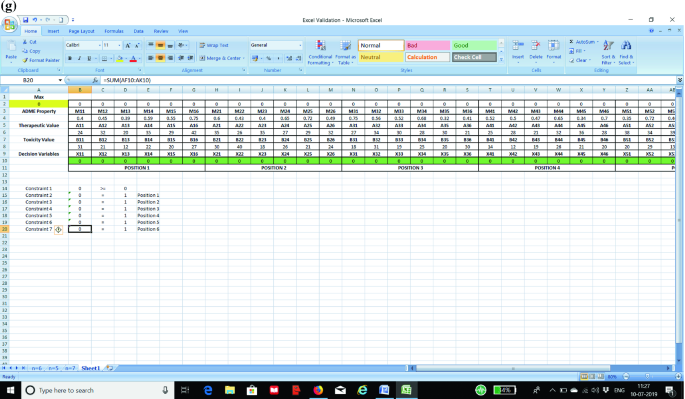
a Screenshot for Constraint 1 in the optimization model. b Screenshot for Constraint 2 in the optimization model. c Screenshot for Constraint 3 in the optimization model. d Screenshot for Constraint 4 in the optimization model. e Screenshot for Constraint 5 in the optimization model. f Screenshot for Constraint 6 in the optimization model. g Screenshot for Constraint 7 in the optimization model
-
STEP 4: Next we prepare the optimization algorithm by initiating the solver function in excel. Students should first go to the “Data” tab and at the right-hand most corners, EXCEL SOLVER will be present. Students are advised to first click the button. A pop-up screen will appear. Students will just need to select the (A) objective function, (B) maximization or minimization option, (C) select the decision variables, and (D) select the constraints. Please note that in addition to the constraints explained in STEP 3, we have also incorporated the binary constraint for the decision variable. Then, we have to click the options button and then click “Assume Non-Negative” and “Assume Linear Model” to ensure that the optimization model is a linear programming problem and all the decision variables are non-negative. Then, we click solve to get our answer. Refer Fig. 4a, b for further understanding.
Fig. 4 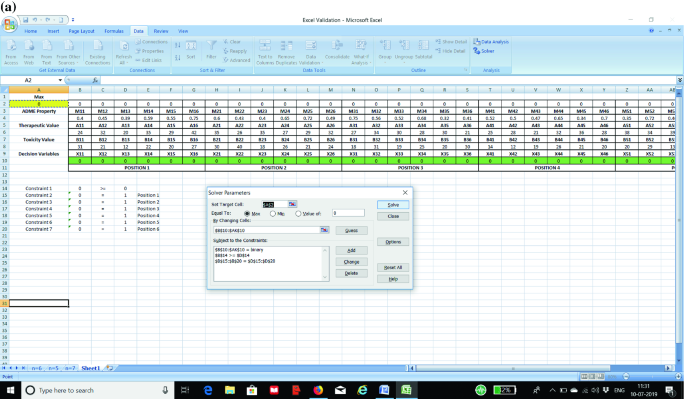
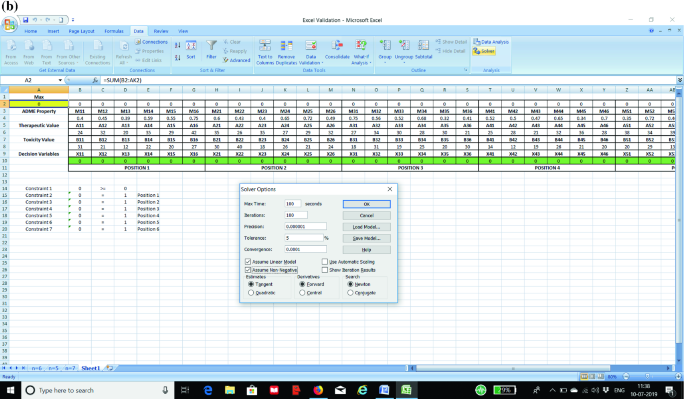
a Initiating the solver function in the Excel and incorporating the constraints, decision variables, and objective function. b Incorporating linearity and non-negativity in the optimization model












Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Roy, S.N., Sengupta, T. (2020). Impact of IoT on the Healthcare Producers: Epitomizing Pharmaceutical Drug Discovery Process. In: Raj, P., Chatterjee, J., Kumar, A., Balamurugan, B. (eds) Internet of Things Use Cases for the Healthcare Industry. Springer, Cham. https://doi.org/10.1007/978-3-030-37526-3_6
Download citation
DOI: https://doi.org/10.1007/978-3-030-37526-3_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-37525-6
Online ISBN: 978-3-030-37526-3
eBook Packages: Computer ScienceComputer Science (R0)