
Abstract
This work is an example driven overview article of recent works on the connection of multiple zeta values, modular forms and q-analogues of multiple zeta values given by multiple Eisenstein series.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
We study a specific connection of multiple zeta values and modular forms given by multiple Eisenstein series. This work is an example driven overview article and summary of the results obtained in the works [3, 6, 7, 9].
Multiple zeta values are real numbers that are natural generalizations of the Riemann zeta values. These are defined for integers \(s_1 \ge 2\) and \(s_2,\dots ,s_l \ge 1\) by
Such real numbers were already studied by Euler in the \(l=2\) case in the 18th century. Because of its occurrence in various fields of mathematics and theoretical physics these real numbers had a comeback in the mathematical and physical research community in the late 1990s due to works by several people such as D. Broadhurst, F. Brown, P. Deligne, H. Furusho, A. Goncharov, M. Hoffman, M. Kaneko, D. Zagier et al.. Denote the  -vector space of all multiple zeta values of weight k by
-vector space of all multiple zeta values of weight k by

and write \({{\,\mathrm{\mathscr {Z}}\,}}\) for the space of all multiple zeta values. One of the main interests is to understand the  -linear relations between these numbers. The first one is given by \(\zeta (2,1) = \zeta (3)\) and there are several different ways to prove this relation [11]. Using the representation of multiple zeta values as an ordered sum, their product can be written as a linear combination of multiple zeta values of the same weight, i.e. the space \({{\,\mathrm{\mathscr {Z}}\,}}\) has the structure of a
-linear relations between these numbers. The first one is given by \(\zeta (2,1) = \zeta (3)\) and there are several different ways to prove this relation [11]. Using the representation of multiple zeta values as an ordered sum, their product can be written as a linear combination of multiple zeta values of the same weight, i.e. the space \({{\,\mathrm{\mathscr {Z}}\,}}\) has the structure of a  -algebra. For example it is
-algebra. For example it is
This way to express the product, which will be studied in Section 1 in more detail, is called the stuffle product (also named harmonic product). Besides this, a representation of multiple zeta values as iterated integrals yields another way to express the product of two multiple zeta values, which is called the shuffle product. For the above examples, this is given by
Since (1) and (3) are two different expressions for the product \(\zeta (2) \cdot \zeta (3)\) we obtain the linear relation \(\zeta (5) = 2 \zeta (3,2) + 6 \zeta (4,1)\). These relations are called the double shuffle relations. Conjecturally all  -linear relations between multiple zeta values can be proven by using an extended version of these types of relations [24]. Often relations between multiple zeta values are not proven by using double shuffle relations, since there are easier ways to prove them in some cases. The relation \(\zeta (4) = \zeta (2,1,1)\) for example, has an easy proof using the iterated integral expressions for multiple zeta values. A famous result by Euler is, that every even zeta value \(\zeta (2k)\) is a rational multiple of \(\pi ^{2k}\) and in particular we have, for example,
-linear relations between multiple zeta values can be proven by using an extended version of these types of relations [24]. Often relations between multiple zeta values are not proven by using double shuffle relations, since there are easier ways to prove them in some cases. The relation \(\zeta (4) = \zeta (2,1,1)\) for example, has an easy proof using the iterated integral expressions for multiple zeta values. A famous result by Euler is, that every even zeta value \(\zeta (2k)\) is a rational multiple of \(\pi ^{2k}\) and in particular we have, for example,
The relations (5) can also be proven with the double shuffle relations, but for general k there is no explicit proof of Eulers relations using only double shuffle relations so far.
Since the double shuffle relations just give relations in a fixed weight it is conjectured that the space \({{\,\mathrm{\mathscr {Z}}\,}}\) is a direct sum of the \({{\,\mathrm{\mathscr {Z}}\,}}_k\), i.e. there are no relations between multiple zeta values with different weight.
Surprisingly there are several connections of these numbers to modular forms for the full modular group. Recall, modular forms are holomorphic functions in the complex upper half-plane fulfilling certain functional equations. One of the most famous connection is the Broadhurst-Kreimer conjecture.
Conjecture 1
(Broadhurst-Kreimer conjecture [15]) The generating series of for the dimension  of weight k multiple zeta values of length l modulo lower lengths can be written as
of weight k multiple zeta values of length l modulo lower lengths can be written as

where
The connection to modular forms arises here, since
is the generating function of the dimensions of cusp forms for the full modular group. In the formula of the Broadhurst-Kreimer conjecture one can see, that cusp forms give rise to relations between double zeta values, i.e. multiple zeta values in the length \(l=2\) case. For example in weight 12, the first weight where non-trivial cusp forms exist, there is the following famous relation
Even though we are not focused on this conjecture, the concept of obtaining relations of multiple zeta values by cusp forms also appears in our context of multiple Eisenstein series and q-analogues of multiple zeta values. It is known that every modular form for the full modular group can be written as a polynomial in classical Eisenstein series. These are for even \(k>0\) given by
where \(\tau \in \mathbb {H}\) is an element in the upper half-plane, \(q=\exp (2\pi i \tau )\) and \(\sigma _k(n) = \sum _{d | n} d^k\) denotes the classical divisor-sum. In [19] the authors introduced a direct connection of modular forms to double zeta values following ideas of Don Zagier introduced in [37]. They defined double Eisenstein series \(G_{s_1,s_2} \in \mathbb {C}[\![q]\!]\) which are a length two generalization of classical Eisenstein series and which are given by a double sum over ordered lattice points. These functions have a Fourier expansion given by sums of products of multiple zeta values and certain q-series with the double zeta value \(\zeta (s_1,s_2)\) as their constant term. In [2] the author treated the multiple cases and calculated the Fourier expansion of multiple Eisenstein series \(G_{s_1,\dots ,s_l} \in \mathbb {C}[\![q]\!]\). The result of [2] was that the Fourier expansion of multiple Eisenstein series is again a \({{\,\mathrm{\mathscr {Z}}\,}}\)-linear combination of multiple zeta values and the q-series \(g_{t_1,\dots ,t_m} \in \mathbb {C}[\![q]\!]\) defined by \(g_{t_1,\dots ,t_m}(\tau ) := (-2\pi i)^{t_1+\dots +t_m} [t_1,\dots ,t_m]\) with \(q=e^{2\pi i \tau }\) and
Theorem 2
([2]) For \(s_1,\dots ,s_l \ge 2\) the \(G_{s_1,\dots ,s_l}\) can be written as a \({{\,\mathrm{\mathscr {Z}}\,}}\)-linear combination of the above functions \(g_{t_1,\dots ,t_m}\).
For example:
The starting point of the thesis [4] was the fact that there are more multiple zeta values than multiple Eisenstein series, since \(\zeta (s_1,\dots ,s_l)\) exists for all \(s_1 \ge 2, s_2, \dots , s_l \ge 1\) and the \(G_{s_1,\dots ,s_l}\) just exists when all \(s_j \ge 2\). The main objective was to answer the following question.
Question 1
What is a “good” definition of a “regularized” multiple Eisenstein series, such that for each multiple zeta value \(\zeta (s_1,\dots ,s_l)\) with \(s_1>1\), \(s_2,\dots ,s_l \ge 1\) there is a q-series
with this multiple zeta value as the constant term in its Fourier expansion and which equals the multiple Eisenstein series in the cases \(s_1,\dots ,s_l \ge 2\)?
By “good” we mean that these regularized multiple Eisenstein series should have the same, or at least as close as possible, algebraic structure similar to multiple zeta values. Our answer to this question was approached in several steps which will be described in the following (i)–(iii). First (i) the algebraic structure of the functions g was studied. During this investigation it turned out, that these objects, or more precisely the q-series \([s_1,\dots ,s_l]\) are very interesting objects in their own rights. It turned out that in order to understand their algebraic structure it was necessary to study a more general class of q-series, called bi-brackets in (ii). The results on bi-brackets and brackets then were used, together with a beautiful connection of the multiple Eisenstein series to the coproduct structure of formal iterated integrals, to answer the above question in (iii).
(i) To answer Question 1 the algebraic structure of the functions g or more precisely the algebraic structure of the q-series \([s_1,\dots ,s_l]\) was studied in [6]. It turned out that these q-series, whose coefficients are given by weighted sums over partitions of n, are, independently to their appearance in the Fourier expansion of multiple Eisenstein series, very interesting objects. We will denote the  -vector space spanned by all these brackets and 1 by \({{\,\mathrm{\mathscr {MD}}\,}}\). Since we also include the rational numbers, the normalized Eisenstein series \(\widetilde{G}_k(\tau ) := (-2\pi i)^{-k}G_k(\tau )\) are contained in \({{\,\mathrm{\mathscr {MD}}\,}}\). For example we have
-vector space spanned by all these brackets and 1 by \({{\,\mathrm{\mathscr {MD}}\,}}\). Since we also include the rational numbers, the normalized Eisenstein series \(\widetilde{G}_k(\tau ) := (-2\pi i)^{-k}G_k(\tau )\) are contained in \({{\,\mathrm{\mathscr {MD}}\,}}\). For example we have
The algebraic structure of the space \({{\,\mathrm{\mathscr {MD}}\,}}\) was studied in [6] and one of the main result was the following
Theorem 3
([6]) The  -vector space spanned by all brackets equipped with the usual multiplication of formal q-series is a
-vector space spanned by all brackets equipped with the usual multiplication of formal q-series is a  -algebra, with the algebra of modular forms with rational coefficients as a subalgebra.
-algebra, with the algebra of modular forms with rational coefficients as a subalgebra.
In fact, the product fulfills a quasi-shuffle product and the notion of quasi-shuffle products will be made precise in Sect. 4.1. Roughly speaking, this means that the product of two brackets can be expressed as a linear combination of brackets similar to the stuffle product (1), (2) of multiple zeta values. For example we will see that
i.e. up to the lower weight term \(- \frac{1}{12} [3]\) and \(\frac{1}{12}[2,2]-\frac{1}{2}[2,3]-\frac{1}{12}[3,1]\) this looks exactly like (1) and (2). One might ask if there is also something which corresponds to the shuffle product (3) of multiple zeta values. It turned out that for the lowest length case, this has to do with the differential operator \( {\text {d}}= q \frac{d}{dq}\). In [6] it was shown that
which, again up to the term \(- 3[4] + {\text {d}}[3]\), looks exactly like the shuffle product (3) of multiple zeta values. In particular it follows that \( {\text {d}}[3]\) is again in the space \({{\,\mathrm{\mathscr {MD}}\,}}\) and in general it was shown that
Theorem 4
([6]) The operator \( {\text {d}}= q \frac{d}{dq}\) is a derivation on \({{\,\mathrm{\mathscr {MD}}\,}}\).
(ii) Equation (7) above was the motivation to study a larger class of q-series, which will be called bi-brackets. While the quasi-shuffle product of brackets also exists in higher length, the second expression for the product, corresponding to the shuffle product, does not appear in higher length if one just allows derivatives as “error terms”. The bi-brackets can be seen as a generalization of the derivative of brackets. For \(s_1,\dots ,s_l \ge 1\), \(r_1,\dots ,r_l \ge 0\) we define these bi-brackets by
In the case \(r_1=\dots =r_l=0\) these are just ordinary brackets. The products of these seemingly larger class of q-series have two representations similar to the stuffle and shuffle product of multiple zeta values in arbitrary length. For our example, the analogue of the shuffle product (4) for brackets can now be expressed as
We will see in Sect. 5.2 that these double shuffle structure can be described, using the so called partition relation, in a nice combinatorial way. This gives a large family of linear relations between bi-brackets. In fact numerical calculations show, that there are so many relations, that we have the following surprising conjecture.
Conjecture 5
([3]) Every bi-bracket can be written in terms of brackets, i.e.
Using the algebraic structure of the space of bi-brackets we now review the definition of shuffle brackets  and stuffle \([s_1,\dots ,s_l]^*\) version of the ordinary brackets as certain linear combination of bi-brackets as introduced in [3]. These objects fulfill the same shuffle and stuffle products as multiple zeta values respectively. Both constructions use the theory of quasi-shuffle algebras first developed by Hoffman in [21] and later generalized in [22]. We summarize the results in the following Theorem.
and stuffle \([s_1,\dots ,s_l]^*\) version of the ordinary brackets as certain linear combination of bi-brackets as introduced in [3]. These objects fulfill the same shuffle and stuffle products as multiple zeta values respectively. Both constructions use the theory of quasi-shuffle algebras first developed by Hoffman in [21] and later generalized in [22]. We summarize the results in the following Theorem.
Theorem 6
([3])
-
(i)
The space \({{\,\mathrm{\mathscr {BD}}\,}}\) spanned by all bi-brackets \( \genfrac[]{0.0pt}{}{s_1, \dots , s_l}{r_1,\dots ,r_l}\) forms a
 -algebra with the space of (quasi-)modular forms and the space \({{\,\mathrm{\mathscr {MD}}\,}}\) of brackets as subalgebras. There are two ways to express the product of two bi-brackets which correspond to the stuffle and shuffle product of multiple zeta values.
-algebra with the space of (quasi-)modular forms and the space \({{\,\mathrm{\mathscr {MD}}\,}}\) of brackets as subalgebras. There are two ways to express the product of two bi-brackets which correspond to the stuffle and shuffle product of multiple zeta values. -
(ii)
There are two subalgebras
 and \({{\,\mathrm{\mathscr {MD}}\,}}^*\subset {{\,\mathrm{\mathscr {MD}}\,}}\) spanned by elements
and \({{\,\mathrm{\mathscr {MD}}\,}}^*\subset {{\,\mathrm{\mathscr {MD}}\,}}\) spanned by elements  and \([s_1,\dots ,s_l]^*\) which fulfill the shuffle and stuffle products, respectively, and which are in the length one case given by the bracket \([s_1]\).
and \([s_1,\dots ,s_l]^*\) which fulfill the shuffle and stuffle products, respectively, and which are in the length one case given by the bracket \([s_1]\).
 -algebra with the space of (quasi-)modular forms and the space
-algebra with the space of (quasi-)modular forms and the space  and
and  and
and For example, similarly to the relation between multiple zeta values above we have

(iii) A particular reason for studying the  is due to their use in the regularization of multiple Eisenstein series, i.e. they are needed in the answer of the original Question 1. This was implicitly done in [9] by proving an explicit connection of the Fourier expansion of multiple Eisenstein series to the coproduct on formal iterated integrals introduced by Goncharov in [20]. This connection was already known to the authors of [19] in the length two case. Without knowing this connection it was then rediscovered independently by the authors of [9] during a research stay of the second author at the DFG Research training Group 1670 at the University of Hamburg in 2014. The result of this research stay was the work [9], in which the authors used this connection to give a definition of the shuffle regularized multiple Eisenstein series. Later, the present author combined the result of [9] and the algebraic structure of bi-brackets to give a more explicit definition of shuffle regularized multiple Eisenstein series using bi-brackets in [3].
is due to their use in the regularization of multiple Eisenstein series, i.e. they are needed in the answer of the original Question 1. This was implicitly done in [9] by proving an explicit connection of the Fourier expansion of multiple Eisenstein series to the coproduct on formal iterated integrals introduced by Goncharov in [20]. This connection was already known to the authors of [19] in the length two case. Without knowing this connection it was then rediscovered independently by the authors of [9] during a research stay of the second author at the DFG Research training Group 1670 at the University of Hamburg in 2014. The result of this research stay was the work [9], in which the authors used this connection to give a definition of the shuffle regularized multiple Eisenstein series. Later, the present author combined the result of [9] and the algebraic structure of bi-brackets to give a more explicit definition of shuffle regularized multiple Eisenstein series using bi-brackets in [3].
Formal iterated integrals are symbols \(I(a_0; a_1, \dots , a_n; a_{n+1})\) with \(a_j \in \{ 0, 1 \}\) that fulfill identities like real iterated integrals. We will write I(3, 2) for I(1; 00101; 0) and we will see that the elements of the form \(I(s_1,\dots ,s_l)\), obtained in the same way as I(3, 2), form a basis of the space of formal iterated integrals in which we are interested. The space of these integrals has a Hopf algebra structure with the multiplication given by the shuffle product and the coproduct \(\varDelta \) given by an explicit formula which we will review in Sect. 6.1. For example it is
Compare this with the Fourier expansion of the double Eisenstein series \(G_{3,2}\)
Since \(\varDelta (I(s_1,\dots ,s_l))\) exists for all \(s_1,\dots ,s_l \ge 1\) this comparison suggested a definition of shuffle regularized multiple Eisenstein series  by sending the first component of the coproduct of \(I(s_1,\dots ,s_l)\) to a \((-2\pi i)\)-multiple of the shuffle bracket and the second component to shuffle regularized multiple zeta values. In [9] it was proven that this construction gives back the original multiple Eisenstein series in the cases \(s_1,\dots ,s_l \ge 2\). Together with the results on the shuffle brackets in [3] we obtain the following
by sending the first component of the coproduct of \(I(s_1,\dots ,s_l)\) to a \((-2\pi i)\)-multiple of the shuffle bracket and the second component to shuffle regularized multiple zeta values. In [9] it was proven that this construction gives back the original multiple Eisenstein series in the cases \(s_1,\dots ,s_l \ge 2\). Together with the results on the shuffle brackets in [3] we obtain the following
Theorem 7
([3, 9]) For all \(s_1,\ldots ,s_l\ge 1\) there exist shuffle regularized multiple Eisenstein series  with the following properties:
with the following properties:
-
(i)
They are holomorphic functions on the upper half-plane (by setting \(q=\exp (2\pi i \tau )\)) having a Fourier expansion with the shuffle regularized multiple zeta values as the constant term.
-
(ii)
They fulfill the shuffle product.
-
(iii)
They can be written as a linear combination of multiple zeta values, powers of \((-2\pi i)\) and shuffle brackets
 .
. -
(iv)
For integers \(s_1,\ldots ,s_l\ge 2\) they equal the multiple Eisenstein series

and therefore they fulfill the stuffle product in these cases.
 .
.
We now study the  -algebra spanned by the
-algebra spanned by the  and its relation to multiple zeta values. Theorem 7 (iv) gives a subset of the double shuffle relations between the
and its relation to multiple zeta values. Theorem 7 (iv) gives a subset of the double shuffle relations between the  , since the stuffle product is just fulfilled for the case \(s_1,\dots ,s_l \ge 2\). A natural question is, if they also fulfill the stuffle product when some indices \(s_j\) are equal to 1. For some cases this was proven in [3]. For example it was shown, that
, since the stuffle product is just fulfilled for the case \(s_1,\dots ,s_l \ge 2\). A natural question is, if they also fulfill the stuffle product when some indices \(s_j\) are equal to 1. For some cases this was proven in [3]. For example it was shown, that

The method to prove this was to introduce stuffle regularized multiple Eisenstein series \(G^*_{s_1,\dots ,s_l}\), which fulfill by construction the stuffle product and which equal the classical multiple Eisenstein series in the \(s_1,\dots ,s_l \ge 2\) cases. Since both \(G^*\) and  can be written in terms of multiple zeta values and bi-brackets it was possible to compare these two regularization. It was shown that all
can be written in terms of multiple zeta values and bi-brackets it was possible to compare these two regularization. It was shown that all  appearing in (31) equal the \(G^*\) ones, from which this equation followed. In contrast to the shuffle regularized multiple Eisenstein series the stuffle regularized ones could not be defined for all \(s_1,\dots ,s_l \ge 1\), but we have the following results:
appearing in (31) equal the \(G^*\) ones, from which this equation followed. In contrast to the shuffle regularized multiple Eisenstein series the stuffle regularized ones could not be defined for all \(s_1,\dots ,s_l \ge 1\), but we have the following results:
Theorem 8
([3]) For all \(s_1,\dots ,s_l \ge 1\) and \(M \ge 1\) there exists \(G_{s_1,\dots ,s_l}^{*,M} \in \mathbb {C}[\![q]\!]\) with the following properties
-
(i)
They are holomorphic functions on the upper half-plane (by setting \(q=\exp (2\pi i \tau )\)) having a Fourier expansion with the stuffle regularized multiple zeta values as the constant term.
-
(ii)
They fulfill the stuffle product.
-
(iii)
In the case where the limit \(G^*_{s_1,\dots ,s_l} := \lim _{M\rightarrow \infty } G_{s_1,\dots ,s_l}^{*,M}\) exists, the functions \(G^*_{s_1,\dots ,s_l}\) are a linear combination of multiple zeta values, powers of \((-2\pi i)\) and bi-brackets.
-
(iv)
For \(s_1,\dots ,s_l \ge 2\) the \(G^*_{s_1,\dots ,s_l}\) exist and equal the classical multiple Eisenstein series
$$\begin{aligned} G_{s_1,\dots ,s_l}(\tau ) = G^*_{s_1,\dots ,s_l}(\tau ) \,. \end{aligned}$$
It is still an open question which extended double shuffle relations of multiple zeta values are also fulfilled for the  . Or equivalently, under what circumstances the product of two
. Or equivalently, under what circumstances the product of two  can be expressed using the stuffle product formula. Clearly there are some double shuffle relations which can’t be fulfilled by multiple Eisenstein series. For example not all of the Euler relations (5) are fulfilled since \(G_2^2\) is not a multiple of \(G_4\) as \(G_2\) is not modular and \(G_6^2\) is not a multiple of \(G_{12}\) as there are cusp forms in weight 12. In Sect. 6.3 we will explain this failure in terms of the double shuffle relations which are fulfilled by multiple Eisenstein series.
can be expressed using the stuffle product formula. Clearly there are some double shuffle relations which can’t be fulfilled by multiple Eisenstein series. For example not all of the Euler relations (5) are fulfilled since \(G_2^2\) is not a multiple of \(G_4\) as \(G_2\) is not modular and \(G_6^2\) is not a multiple of \(G_{12}\) as there are cusp forms in weight 12. In Sect. 6.3 we will explain this failure in terms of the double shuffle relations which are fulfilled by multiple Eisenstein series.
After the discussion above, we believe that Question 1 got a satisfying answer given by the regularized multiple Eisenstein series  and \(G^*\). To go back from multiple Eisenstein series to multiple zeta values one can consider the projection to the constant term. But there is another direct connection of brackets, and therefore also of the subalgebra of modular forms, to multiple zeta values. The brackets can be seen as a q-analogue of multiple zeta values. A q-analogue of multiple zeta values is said to be a q-series which gives back multiple zeta values in the case \(q \rightarrow 1\). Define for \(k\in \mathbb {N}\) the map
and \(G^*\). To go back from multiple Eisenstein series to multiple zeta values one can consider the projection to the constant term. But there is another direct connection of brackets, and therefore also of the subalgebra of modular forms, to multiple zeta values. The brackets can be seen as a q-analogue of multiple zeta values. A q-analogue of multiple zeta values is said to be a q-series which gives back multiple zeta values in the case \(q \rightarrow 1\). Define for \(k\in \mathbb {N}\) the map  by
by
Proposition 9
([6, Proposition 6.4]) For \(s_1\ge 2\) and \(s_2,\dots ,s_l\ge 1\) the map \(Z_k\) sends a bracket to the corresponding multiple zeta value, i.e.
Since every relation of multiple zeta values in a given weight k is, by Proposition 9, in the kernel of the map \(Z_k\), this kernel was studied in [6] with the following result.
Theorem 10
([6, Theorem 1.13])
-
(i)
For any \(f\in {{\,\mathrm{\mathscr {MD}}\,}}\) which can be written as a linear combination of brackets with weight \(\le k-2\) we have \( {\text {d}}f \in \ker Z_k\).
-
(ii)
Any cusp form for \({{\,\mathrm{SL}\,}}_2(\mathbb {Z})\) of weight k is in the kernel of \(Z_k\).
We give an example for Theorem 10 (ii): Using the theory of brackets (Corollary 4.13) we can prove for the cusp form \(\varDelta = q\prod _{n>0} \left( 1-q^n \right) ^{24} \in S_{12}({{\,\mathrm{SL}\,}}_2(\mathbb {Z}))\) the representation
Letting \(Z_{12}\) act on both sides of (9) one obtains a new proof for the relation (6), i.e.,
Another reason for studying the enlargement of the brackets given by the bi-brackets is the following: In weight 4 one has the following relation of multiple zeta values \(\zeta (4) = \zeta (2,1,1)\), i.e. it is \([4] - [2,1,1] \in \ker Z_4\). But this element can’t be written as a linear combination of cusp forms, lower weight brackets or derivatives. But one can show, by using the double shuffle relations of bi-brackets, that
and \( \genfrac[]{0.0pt}{}{2,1}{1,0} \in \ker Z_4\). To describe the kernel of the map \(Z_k\) was in fact our first motivation to study the bi-brackets. Equation (10) is also an example for the above mentioned Conjecture 5, since it shows that the bi-bracket \(\genfrac[]{0.0pt}{}{2,1}{1,0}\) can be written as brackets and therefore is an element in \({{\,\mathrm{\mathscr {MD}}\,}}\).
2 Outlook and Related Work
In the following paragraphs (a)–(g) we want to mention some related works and give an outlook to open questions.
(a) There are still a lot of open questions concerning multiple Eisenstein series as well as the space of (bi-)brackets. After the above mentioned works [3, 6, 9] we now have a good definition of regularized multiple Eisenstein series given by the  . For the structure of the space spanned by these series there are still several open questions.
. For the structure of the space spanned by these series there are still several open questions.
-
(i)
What exactly is the failure of the stuffle product for the
 and when does it hold?
and when does it hold? -
(ii)
For which indices \(s_1,\dots ,s_l \in \mathbb {N}\) do we have
 ? Is there an explicit connection between these two regularizations similar to the regularized multiple zeta values given by the map \(\rho \) in [24]?
? Is there an explicit connection between these two regularizations similar to the regularized multiple zeta values given by the map \(\rho \) in [24]? -
(iii)
What is the dimension of the space of (shuffle) regularised multiple Eisenstein series? Is there an explicit basis similar to the Hoffman basis of multiple zeta values (Which is given by all multiple zeta values \(\zeta (s_1,\dots ,s_l)\) with \(s_j \in \{2,3\}\))?
-
(iv)
Which linear combinations of multiple Eisenstein series are modular forms for \({{\,\mathrm{SL}\,}}_2(\mathbb {Z})\)? Is there an explicit way to describe the modular defect?
-
(v)
Is the space of multiple Eisenstein series closed under the derivative \( {\text {d}}= q \frac{d}{dq}\) ? Meanwhile this question was also already addressed in [5].
-
(vi)
What is the kernel of the projection to the constant term? Does it consist of more than derivatives and cusp forms?
-
(vii)
Is there a general theory behind the connection of the Fourier expansion of multiple Eisenstein series and the Goncharov coproduct? Can we equip the space of multiple Eisenstein series with a coproduct structure in an useful way?
 and when does it hold?
and when does it hold? ? Is there an explicit connection between these two regularizations similar to the regularized multiple zeta values given by the map
? Is there an explicit connection between these two regularizations similar to the regularized multiple zeta values given by the map Especially the last questions seems to be interesting since the connection to the coproduct of formal iterated integrals is quite mysterious and it seems that there might be a geometric interpretation for this connection.
(b) Several q-analogues of multiple zeta values were studied in recent years. The first works on this area are [14, 28, 31, 38]. Possible double shuffle structures are discussed for example in [18, 32, 33, 39], where the last one gives also a nice overview of various different q-analogue models. Often these q-analogues have a product structure similar to the stuffle product of multiple zeta values. To obtain something which corresponds to the shuffle product one usually needs to modify the space and add extra elements (like derivatives) or consider index sets \((s_1,\dots ,s_r)\) with \(s_j \in \mathbb {Z}\) or \(s_j \ge 0\). The picture is similar for bi-brackets, where we consider double indices \( \genfrac[]{0.0pt}{}{s_1, \dots , s_l}{r_1,\dots ,r_l}\) to obtain an analogue for both products in a very natural way. This gives a lot of linear relations similar to the double shuffle relations. Numerical experiments suggest, that every bi-bracket can be written as a linear combination of brackets and therefore (conjecturally) every relation of bi-brackets gives rise to relations between multiple zeta values by applying the map \(Z_k\).
(c) In the case of multiple zeta values one way to give upper bounds for the dimension is to study the double shuffle space [24, 25]. Similarly, one can study the partition shuffle space

for bi-brackets, where \(|_P\) is the involution given by the partition relation (see Sect. 5.1, (23)) and \(|_{{\text {Sh}}_j}\) is given by the sum of all shuffles of type j similar to the one in [25]. Counting the number of these polynomials it is possible to give upper bounds for the dimensions of the space of bi-brackets. This approach therefore enabled us to prove the conjecture \({{\,\mathrm{\mathscr {MD}}\,}}={{\,\mathrm{\mathscr {BD}}\,}}\) up to weight 7 in a current work in progress [8]. Therefore, considering the space \(\mathbb {PS}(k-l,l)\) in more detail might be crucial to understand the structure of bi-brackets.
(d) In this work we were interested in modular forms for the full modular group and therefore studied the level 1 case. In [26] the authors studied double Eisenstein series and double zeta values of level 2. They also derive the Fourier expansion of these series which involves similar calculation as in the level 1 case. One result is, that they derive the dimension of the space of double Eisenstein series and give also an upper bound for the dimension of double zeta values of level 2, which involves the dimension of the spaces of cusp forms of level 2. Beside the work on Level 2 double Eisenstein series there are also work for level N double Eisenstein series of Yuan and Zhao in [34]. Later these authors also considered a level N version of the brackets in [35].
(e) At the end of [26] the authors give a proof for an upper bound of the dimension of double zeta values in even weight. We want to recall this result, since the presented results in the present work might be able to use these ideas for higher lengths. Consider the space spanned by all normalized double Eisenstein series \((-2\pi i)^{-r-s} G_{r,s}(\tau )\) in even weight \(k=r+s\). Denote by \(\pi _i\) the projection of this space to the imaginary part. Using the Fourier expansion of double Eisenstein series the authors can write down the matrix representation of \(\pi _i\) explicitly. Together with well known results on period polynomials they obtain

Due to the Broadhurst-Kreimer Conjecture 1 it is conjectured that this is actually an equality. The key fact here is, that it is possible to write down an explicit basis of the imaginary part and the matrix representation of \(\pi _i\). To also obtain upper bounds for the dimensions of multiple zeta values in higher lengths, one might try to use the exact same method as in the length two case. The imaginary part of the (again normalized with the factor \((-2\pi i)^{-k}\)) multiple Eisenstein series is more complicated since it involves the functions g in different length, where it is known that they are not linearly independent anymore. But the algebraic structure of the g or more precisely of the brackets [..] are subject of the current work. It is quite possible that the results on the brackets enable one to study the projection of the imaginary part of multiple Eisenstein series to obtain upper bounds for the Broadhurst-Kreimer conjecture.
(f) The multiple Eisenstein series and the bi-brackets itself also have connections to counting problems in enumerative geometry:
-
(i)
In [1, 30] the author studies q-series
 which arises in counting certain types of hyperelliptic curves. One of the results is, that the \(A_k(q)\) are contained in the ring of quasi-modular forms. The connection to the brackets is given by the fact that \(A_k(q) = [\underbrace{2,\dots ,2}_k]\). The results of [1] can also be obtained by using an explicit calculation of the Fourier expansion of \(G_{2,\dots ,2}\).
which arises in counting certain types of hyperelliptic curves. One of the results is, that the \(A_k(q)\) are contained in the ring of quasi-modular forms. The connection to the brackets is given by the fact that \(A_k(q) = [\underbrace{2,\dots ,2}_k]\). The results of [1] can also be obtained by using an explicit calculation of the Fourier expansion of \(G_{2,\dots ,2}\). -
(ii)
In [27, 29] the authors connect certain q-analogues of multiple zeta values to Hilbert schemes of points on surfaces. These q-analogues are just particular linear combinations of brackets as explained in [7] and Sect. 7.2.
-
(iii)
The coefficients of bi-brackets also occur naturally when counting flat surfaces [40], i.e. certain covers of the torus.
 which arises in counting certain types of hyperelliptic curves. One of the results is, that the
which arises in counting certain types of hyperelliptic curves. One of the results is, that the (g) There also exists different “multiple”-versions of classical Eisenstein series. One of them is treated in [10], where the authors discuss the series defined by
for \(r\in \mathbb {N}_{\ge 2}\) and \(p_1,\ldots ,p_r\in \mathbb {N}\) and prove (Theorem 2) that for \(r\in \mathbb {N}_{\ge 2}\) and \(p_1,\ldots ,p_r\in \mathbb {N}\),
The methods used to prove these statements are similar to the methods used in the calculation of the Fourier expansion of multiple Eisenstein series. But besides this there does not seem to be a direct connection to the multiple Eisenstein series presented here.
3 Multiple Eisenstein Series
In this section we are going to introduce multiple zeta values and present the multiple Eisenstein series and their Fourier expansion. Especially the construction of the Fourier expansion of multiple Eisenstein series in Sect. 3.2 was rewritten for this survey. It will be a shortened version of the construction given in [2] using results by Bouillot obtained in [12]. This section is not part of the works [6, 7, 9]. Before we discuss multiple Eisenstein series, we give a short review of multiple zeta values and their algebraic structure given by the stuffle and shuffle product. In order to describe these two products we will use quasi-shuffle algebras, introduced by Hofmann in [21], which will also be needed later when we deal with the generating series of multiple divisor-sums (brackets) and their generalizations given by the bi-brackets.
3.1 Multiple Zeta Values and Quasi-shuffle Algebras
Multiple zeta values are natural generalizations of the Riemann zeta values that are definedFootnote 1 for integers \(s_1 > 1\) and \(s_i \ge 1\) for \(i>1\) by
We denote the  -vector space of all multiple zeta values of weight k by
-vector space of all multiple zeta values of weight k by

It is well known that the product of two multiple zeta values can be written as a linear combination of multiple zeta values of the same weight by using the stuffle or shuffle relations (See for example [24, 42]). Thus they generate a  -algebra \({{\,\mathrm{\mathscr {Z}}\,}}\). There are several connections of these numbers to modular forms for the full modular group. In the smallest length the stuffle product reads
-algebra \({{\,\mathrm{\mathscr {Z}}\,}}\). There are several connections of these numbers to modular forms for the full modular group. In the smallest length the stuffle product reads
For length 1 times length 2 the same argument gives
The second expression for the product, the shuffle product, comes from the iterated integral expression of multiple zeta values. For example it is
Multiplying two of these integrals one obtains again a linear combination of multiple zeta values as for example
More generally the smallest length case is given by
To describe these two product structures precisely we will use the language of quasi-shuffle algebras as introduced in [21, 22].
Definition 3.1
Let A (the alphabet) be a countable set of letters,  the
the  -vector space generated by these letters and
-vector space generated by these letters and  the noncommutative polynomial algebra over
the noncommutative polynomial algebra over  generated by words with letters in A. For a commutative and associative product
generated by words with letters in A. For a commutative and associative product  on
on  , \(a,b \in A\) and
, \(a,b \in A\) and  we define on
we define on  recursively a product by \(1 \odot w=w \odot 1=w\) and
recursively a product by \(1 \odot w=w \odot 1=w\) and
By a result of Hoffman [22, Theroem 2.1]  is a commutative
is a commutative  -algebra which is called a quasi-shuffle algebra.
-algebra which is called a quasi-shuffle algebra.
To describe the stuffle and the shuffle product for multiple zeta values we need to deal with two different alphabets \(A_{xy}\) and \(A_z\). The first alphabet is given by \(A_{xy} := \{ x,y \}\) and we set  and
and  , with 1 being the empty word. It is easy to see that \(\mathfrak H^1\) is generated by the elements \(z_j = x^{j-1} y\) with \(j \in \mathbb {N}\), i.e.
, with 1 being the empty word. It is easy to see that \(\mathfrak H^1\) is generated by the elements \(z_j = x^{j-1} y\) with \(j \in \mathbb {N}\), i.e.  with the second alphabet \(A_z := \{ z_1,z_2, \dots \}\). Additionally, we define
with the second alphabet \(A_z := \{ z_1,z_2, \dots \}\). Additionally, we define  .
.
-
(i)
On \(\mathfrak H^1\) we have the following quasi-shuffle product with respect to the alphabet \(A_z\), called the stuffle product. We denote it by \(*\) and define it as the quasi-shuffle product with \(z_j \diamond z_i = z_{j+i}\). For \(a,b \in \mathbb {N}\) and \(w,v \in \mathfrak H^1\) we therefore have:
$$\begin{aligned} \begin{aligned} z_a w *z_b v&= z_a(w *z_b v) + z_b(z_a w *v) + z_{a+b}( w *v) \,. \end{aligned} \end{aligned}$$By \((\mathfrak H^1, *)\) we denote the corresponding
 -algebra.
-algebra. -
(ii)
On the alphabet \(A_{xy}\) we define the shuffle product as the quasi-shuffle product with \(\diamond \equiv 0\), and by
 we denote the corresponding
we denote the corresponding 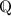 -algebra.
-algebra.
 -algebra.
-algebra. we denote the corresponding
we denote the corresponding 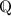 -algebra.
-algebra.It is easy to check that \(\mathfrak H^0\) is closed under both products \(*\) and  and therefore we have also the two algebras \((\mathfrak H^0,*)\) and
and therefore we have also the two algebras \((\mathfrak H^0,*)\) and  .
.
By the definition of multiple zeta values as an ordered sum and by the iterated integral expression one obtains algebra homomorphisms \(Z: (\mathfrak H^0, *) \rightarrow {{\,\mathrm{\mathscr {Z}}\,}}\) and  by sending \(w=z_{s_1} \dots z_{s_l} \) to \(\zeta (w) = \zeta (s_1,\dots ,s_l)\), since the words in \(\mathfrak H^0\) correspond exactly to the indices for which the multiple zeta values are defined. It is a well known fact, that these algebra homomorphisms can be extended to \(\mathfrak H^1\):
by sending \(w=z_{s_1} \dots z_{s_l} \) to \(\zeta (w) = \zeta (s_1,\dots ,s_l)\), since the words in \(\mathfrak H^0\) correspond exactly to the indices for which the multiple zeta values are defined. It is a well known fact, that these algebra homomorphisms can be extended to \(\mathfrak H^1\):
Proposition 3.2
([24, Proposition 1]) There exist algebra homomorphisms

which are uniquely determined by  for \(w\in \mathfrak H^0\) and by their images on the word \(z_1\), which we set 0 here, i.e.
for \(w\in \mathfrak H^0\) and by their images on the word \(z_1\), which we set 0 here, i.e.  .
.
3.2 Multiple Eisenstein Series and the Calculation of Their Fourier Expansion
The Riemann zeta values appear as the constant term in the Fourier expansion of classical Eisenstein series. These series are defined for \(\tau \in \mathbb {H}\) by
where \(k>2\) is the called the weight. Splitting the summation into the parts \(m=0\) and \(m \in \mathbb {Z}\backslash {0}\) we obtain for even k
To calculate the Fourier expansion of the sum on the right, one uses the well known Lipschitz summation formula (\(q=e^{2\pi i \tau }\))
which is valid for \(k>1\). With (14) we obtain
where \(\sigma _k(n) = \sum _{d | n} d^k\) denote the divisor-sum. Formula (15) also makes sense for odd k but does not give a modular form, since there are no non trivial modular forms of odd weight. The sum in (13) vanishes for odd k, therefore instead of summing over the whole lattice, we restrict the summation to the positive lattice points, with positivity coming from an order on the lattice \(\mathbb {Z}\tau + \mathbb {Z}\). This in turn will also enable us to give an multiple version of the Eisenstein series in an obvious way.
Let \(\varLambda _\tau = \mathbb {Z}\tau + \mathbb {Z}\) be a lattice with \(\tau \in \mathbb {H}:= \left\{ x+iy \in \mathbb {C}\mid y>0 \right\} \). An order \(\succ \) on \(\varLambda _\tau \) is defined by setting (see [19])
for \(\lambda _1,\lambda _2 \in \varLambda _\tau \) and the following set P, which we call the set of positive lattice points


Definition 3.3
For \(s_1 \ge 3, s_2,\dots ,s_l \ge 2\) the multiple Eisenstein series is defined by
With \(k=s_1 + \dots + s_l\) we denote the weight and with l its length.
It is easy to see that these are holomorphic functions in the upper half-plane and that they fulfill the stuffle product, i.e. for example
By definition it is \(G_{s_1,\dots ,s_l}(\tau + 1) = G_{s_1,\dots ,s_l}(\tau )\), i.e. there exists a Fourier expansion of \(G_{s_1,\dots ,s_l}\) in \(q=e^{2\pi i \tau }\). To write down the Fourier expansion of multiple Eisenstein series we need to introduce the following q-series which will be studied in detail in Sect. 4.1. For \(s_1,\dots ,s_l \ge 1\) we define

and write \(g_{s_1,\dots ,s_l}(\tau ) := (-2\pi i)^{s_1+\dots +s_l} [s_1,\dots ,s_l]\), which is an holomorphic function in the upper half-plane by setting \(q=e^{2\pi i \tau }\).
Theorem 3.4
([2], Fourier expansion) For \(s_1\ge 3, s_2,\dots ,s_l \ge 2\) the \(G_{s_1,\dots ,s_l}(\tau )\) can be written as a \({{\,\mathrm{\mathscr {Z}}\,}}\)-linear combination of the functions g. More precisely there are rational numbers  , for \(r=(r_1,\dots ,r_l)\) and \(1\le j \le l-1\), such that (with \(k=s_1+\dots +s_l\))
, for \(r=(r_1,\dots ,r_l)\) and \(1\le j \le l-1\), such that (with \(k=s_1+\dots +s_l\))
Even though the proof of this statement is the main result of [2] we will give a shortened version of it in the following.
The condition \(s_1\ge 3\) is necessary for the absolute convergence of the sum. Nevertheless we can also allow the case \(s_1 = 2\) by using the Eisenstein summation as it was done in [9] Definition 2.1. This corresponds to the usual way of defining the quasi-modular form \(G_2\) in length one. Since the construction of the Fourier expansion described below uses exactly this Eisenstein summation the Theorem 3.4 is also valid for \(s_1 \ge 2\).
For example the triple Eisenstein series \(G_{3,2,2}\) can be written as
To derive the Fourier expansion we introduce the following functions, that can be seen as a multiple version of the term \(\sum _{n \in \mathbb {Z}} \frac{1}{(x+n)^k}\) appearing in the calculation of the Fourier expansion of classical Eisenstein series.
Definition 3.5
For \(s_1,\dots ,s_l \ge 2\) we define the multitangent function of length l by
In the case \(l=1\) we also refer to these as monotangent function.
These functions were introduced and studied in detail in [12]. One of the main results there, which is crucial for the calculation of the Fourier expansion presented here, is the following theorem which reduces the multitangent functions into monotangent functions.
Theorem 3.6
([12, Theroem 3], Reduction of multitangent into monotangent functions) For \(s_1,\dots ,s_l \ge 2\) and \(k=s_1+\dots +s_l\) the multitangent function can be written as a \({{\,\mathrm{\mathscr {Z}}\,}}\)-linear combination of monotangent functions, more precisely there are \(c_{k,h} \in {{\,\mathrm{\mathscr {Z}}\,}}_{k-h}\) such that
Proof
An explicit formula for the coefficients \(c_k\) is given in Theorem 3 in [12]. The proof uses partial fraction and a non trivial relation between multiple zeta values to argue that the sum starts at \(h=2\). For example in length two it is
The connection between the functions g and the monotangent functions is given by the following
Proposition 3.7
For \(s_1,\dots ,s_r \ge 2\) the functions g can be written as an ordered sum of monotangent functions
Proof
This follows directly from the Lipschitz formula (14) and the definition of the functions g.
Preparation for the Proof of Theorem 3.4: We will now recall the construction of the Fourier expansion of multiple Eisenstein series introduced in [2], in order to prove Theorem 3.4. To calculate the Fourier expansion we rewrite the multiple Eisenstein series as
We decompose the set of tuples of positive lattice points \(P^l\) into the \(2^l\) distinct subsets \(A_1 \times \dots \times A_l \subset P^l\) with \(A_i \in \{R,U\}\) and write
this gives the decomposition
In the following we identify the \(A_1 \dots A_l\) with words in the alphabet \(\{R,U\}\). In length \(l=1\) we have \(G_{k}(\tau ) =G_k^R(\tau ) + G_k^U(\tau )\) and
where \(\varPsi _k\) is the monotangent function given by
To calculate the Fourier expansion of \(G_k^U\) one uses the Lipschitz formula (14). In general the \(G^{U^l}_{s_1,\dots ,s_l}\) can be written as
The other special case \(G^{R^l}_{s_1,\dots ,s_l}\) can also be written down explicitly:
In length 2 we have \( G_{s_1,s_2} = G^{RR}_{s_1,s_2}+G^{UR}_{s_1,s_2} +G^{RU}_{s_1,s_2}+G^{UU}_{s_1,s_2}\) and
In the case \(G^{UR}\) we saw that we could write it as \(G^U\) multiplied with a zeta value. In general, having a word w of length l ending in the letter R, i.e. there is a word \(w'\) ending in U with \(w = w' R^r\) and \(1 \le r \le l\) we can write
Example: \(G^{RUURR}_{3,4,5,6,7} = G^{RUU}_{3,4,5} \cdot \zeta ( 6,7)\)
Hence one can concentrate on the words ending in U when calculating the Fourier expansion of a multiple Eisenstein series. Let w be a word ending in U then there are integers \(r_1,\dots ,r_j \ge 0\) with \(w = R^{r_1} U R^{r_2} U \dots R^{r_j} U\). With this one can write
Example: \(w=RURRU\)

Proof of Theorem 3.4: For \(s_1,\dots ,s_l \ge 2\) the Fourier expansion of the multiple Eisenstein series \(G_{s_1,\dots ,s_l}\) can be computed in the following way
-
(i)
Split up the summation into \(2^l\) distinct parts \(G^w_{s_1,\dots ,s_l}\) where w are a words in \(\{R,U\}\).
-
(ii)
For w being a word ending in R one can write \(G^w_{s_1,\dots ,s_l}\) as \(G^{w'}_{s_1,\dots } \cdot \zeta (\dots ,s_l)\) with a word \(w'\) ending in U.
-
(iii)
For w being a word ending in U one can write \(G^w_{s_1,\dots ,s_l}\) as
$$\begin{aligned} G^w_{s_1,\dots ,s_l}(\tau ) = \sum _{m_1> \dots> m_l >0} \varPsi _{s_1,\dots }(m_1\tau ) \dots \varPsi _{\dots ,s_l}(m_l \tau ) \,. \end{aligned}$$ -
(iv)
Using the Theorem 3.6 we can write the multitangent functions in (iii) as a \({{\,\mathrm{\mathscr {Z}}\,}}\)-linear combination of monotangents. We therefore just have \({{\,\mathrm{\mathscr {Z}}\,}}\)-linear combinations with sums of the form
$$\begin{aligned} \sum _{m_1> \dots> m_j >0} \varPsi _{k_1}(m_1 \tau ) \dots \varPsi _{k_j}(m_j \tau )= g_{k_1,\dots ,k_j}(\tau ) = (-2 \pi i)^{k_1+\dots +k_j} [k_1,\dots ,k_j] \,. \end{aligned}$$
\(\square \)
An explicit formula for the Fourier expansion of the multiple Eisenstein series for arbitrary length can be found in [9] Proposition 2.4. (with a reversed order of indices). Here we just give the Fourier expansion for the length 2 and 3. For this we define for \(n_1,n_2,k > 0\) the numbers \(C_{n_1,n_2}^k\) by
Proposition 3.8
-
(i)
([2, 9, 19, Formula (52)]) For \(s_1,s_2 \ge 2\) the Fourier expansion of the double Eisenstein series is given by
$$\begin{aligned} G_{s_1,s_2}(\tau ) = \zeta (s_1,s_2) + \zeta (s_2) g_{s_1}(\tau ) + \sum _{\begin{array}{c} k_1+k_2 = s_1+s_2 \\ k_1,k_2 \ge 2 \end{array}} C^{k_2}_{s_1,s_2} \zeta (k_2) g_{k_1}(\tau ) + g_{s_1,s_2}(\tau ) \,. \end{aligned}$$ -
(ii)
([2, 9]) For \(s_1,s_2,s_3 \ge 2\) and \(k=s_1+s_2+s_3\) the Fourier expansion of the triple Eisenstein series can be written as
$$\begin{aligned} G_{s_1,s_2,s_3}(\tau )&= \zeta (s_1,s_2,s_3) + \zeta (s_2,s_3) g_{s_1}(\tau ) + \zeta (s_3) g_{s_1,s_2}(\tau ) + g_{s_1,s_2,s_3}(\tau ) \\&+\zeta (s_3) \sum _{k_1+k_2 = s_1 + s_2} C_{s_1,s_2}^{k_1} \zeta (k_1) g_{k_2}(\tau ) \\&+\sum _{ k_1+k_2 = s_1 + s_2} C_{s_1,s_2}^{k_2} \zeta (k_2) g_{k_1,s_3}(\tau )+\sum _{ k_1+k_2 = s_2 + s_3} C_{s_2,s_3}^{k_2} \zeta (k_2) g_{s_1,k_1}(\tau ) \\&+\sum _{k_1+k_2+k_3 = k} (-1)^{s_2+s_3} \left( {\begin{array}{c}k_2-1\\ s_2-1\end{array}}\right) \left( {\begin{array}{c}k_3-1\\ s_3-1\end{array}}\right) \zeta (k_3,k_2) g_{k_1}(\tau ) \\&+\sum _{k_1+k_2+k_3 = k}(-1)^{s_1+s_2+k_2+k_3} \left( {\begin{array}{c}k_2-1\\ k_3-1\end{array}}\right) \left( {\begin{array}{c}k_3-1\\ s_2-1\end{array}}\right) \zeta (k_3,k_2) g_{k_1}(\tau ) \\&+(-1)^{s_1+s_3}\sum _{k_1+k_2+k_3 = k} (-1)^{k_2} \left( {\begin{array}{c}k_2-1\\ s_1-1\end{array}}\right) \left( {\begin{array}{c}k_3-1\\ s_3-1\end{array}}\right) \zeta (k_3) \zeta (k_2) g_{k_1}(\tau ) \,, \end{aligned}$$where in the sums we sum over all \(k_i \ge 2\).
We finish this section with a closer look at the stuffle product of two Eisenstein series. Since the product of multiple Eisenstein series can be written in terms of the stuffle product it is \(G_2 \cdot G_3 = G_{2,3} + G_{3,2} + G_5\). On the other hand we have
and by Proposition 3.8 it is
In conclusion, we obtain a relation for the product of the g’s namely \(g_2 \cdot g_3 = g_{3,2} + g_{2,3} + g_5 + 2 \zeta (2) g_3\) and dividing out \((-2\pi i)^5\) we get
We conclude that a product of the q-series  has an expression similar to the stuffle product and that conversely, a product structure on these q-series could be used, together with the Fourier expansion, to explain the stuffle product for multiple Eisenstein series.
has an expression similar to the stuffle product and that conversely, a product structure on these q-series could be used, together with the Fourier expansion, to explain the stuffle product for multiple Eisenstein series.
One might now ask, if the multiple Eisenstein series also “fulfill” the shuffle product. As we saw above the shuffle product of \(\zeta (2)\) and \(\zeta (3)\) reads
and since there is no definition of \(G_{4,1}\) this question does not make sense when replacing \(\zeta \) by G in (17). We will see that the understanding of the product structure of the brackets, explained in the next two sections, together with the Fourier expansion of multiple Eisenstein series will help to answer this question. This will be done by introducing shuffle regularized multiple Eisenstein series  in Sect. 6.2. There we will see that we can replace the \(\zeta \) in (17) by
in Sect. 6.2. There we will see that we can replace the \(\zeta \) in (17) by  and that the
and that the  are given by the original G, for the cases in which they are defined.
are given by the original G, for the cases in which they are defined.
4 Multiple Divisor-Sums and Their Generating Functions
The classical divisor-sums \(\sigma _r(n) = \sum _{d|n} d^r\) have a long history in number theory. They are well-known examples for multiplicative functions and appear in the Fourier expansion of Eisenstein series. This section is devoted to a larger class of functions, that can be seen as a multiple version of the divisor-sums and are therefore called multiple divisor-sums. For natural numbers \(r_1,\dots ,r_l \ge 0\) they are defined by
Even though the definition of these arithmetic functions is not complicated and somehow canonical, the author could not find any results on these functions before he started studying them in his master thesis [2]. As mentioned in the introduction, the motivation to study them was due to their appearance in the Fourier expansion of multiple Eisenstein series, but as it turned out later in [6], they are very nice and interesting objects in their own rights. Similar to multiple zeta values they fulfill a lot of relations. For example it is
Having objects of this type it is natural to consider their generating functions, which we denote by
and which are, just for the sake of short notations, called brackets. The factorial factors and the “shift” of \(-1\) are natural if one thinks about the Fourier expansion of Eisenstein series. With this notation the relation (19) reads as
which can be seen as a counterpart of the relation \(\zeta (3) = \zeta (2,1)\) between multiple zeta values.Footnote 2
In this section, we want to focus on the algebraic structure of the space spanned by all brackets, which we will denote by \({{\,\mathrm{\mathscr {MD}}\,}}\). This algebraic structure was studied in [6]. We will see that the space \({{\,\mathrm{\mathscr {MD}}\,}}\) has the structure of a  -algebra and that the product of two brackets can be expressed in terms of brackets in a way that looks similar to the stuffle product of multiple zeta values. The operator \( {\text {d}}= q \frac{d}{dq}\) which appears in (20) plays an important role in the theory of (quasi-)modular forms. We will see that the space \({{\,\mathrm{\mathscr {MD}}\,}}\) is closed under this operator and that this gives a second way of expressing the product of two brackets in length one similarly to the shuffle product of multiple zeta values. This second product expression in higher length will be discussed in Sect. 5.
-algebra and that the product of two brackets can be expressed in terms of brackets in a way that looks similar to the stuffle product of multiple zeta values. The operator \( {\text {d}}= q \frac{d}{dq}\) which appears in (20) plays an important role in the theory of (quasi-)modular forms. We will see that the space \({{\,\mathrm{\mathscr {MD}}\,}}\) is closed under this operator and that this gives a second way of expressing the product of two brackets in length one similarly to the shuffle product of multiple zeta values. This second product expression in higher length will be discussed in Sect. 5.
4.1 Brackets
Definition 4.1
For any integers \(s_1,\dots ,s_l>0\) we define the generating function for the multiple divisor sum \(\sigma _{s_1-1,\dots ,s_l-1}\) by the formal power series

In the first section, we saw that these series, by setting \(q= \exp (2\pi i \tau )\), appear in the Fourier expansion of the multiple Eisenstein series but in this section we just view them as formal power series. We refer to these generating functions of multiple divisor sums as brackets and define the vector space \({{\,\mathrm{\mathscr {MD}}\,}}\) to be the  vector space generated by
vector space generated by  and all brackets \([s_1,\dots ,s_l]\). It is important to notice that we also include the constants in the space \({{\,\mathrm{\mathscr {MD}}\,}}\).
and all brackets \([s_1,\dots ,s_l]\). It is important to notice that we also include the constants in the space \({{\,\mathrm{\mathscr {MD}}\,}}\).
Example 4.2
We give a few examples:
Notice that the first non vanishing coefficient of \(q^n\) in \([s_1,\dots ,s_l]\) appears at \(n = \frac{l (l+1)}{2}\), because it belongs to the “smallest” possible partition
i.e. \(u_j= j\) and \(v_j = 1\) for \(1 \le j \le l\). The number \(k=s_1+\dots +s_l\) is called the weight of \([s_1,\dots ,s_l]\) and l denotes the length.
We want to show that the brackets are closed under multiplication by proving that their product structure is an example for a quasi-shuffle product. To do this we first introduce some notations and quote some results which are needed for this.
Recall that for \(s,z \in \mathbb {C}\), \(|z|<1\) the polylogarithm \({\text {Li}}_s(z)\) of weight s is given by \({\text {Li}}_s(z) = \sum _{n>0} \frac{z^n}{n^s}\). For \(s \in \mathbb {N}\) the \({\text {Li}}_{-s}(z)\) are rational functions in z with a pole in \(z=1\). More precisely for \(|z|<1\) they can be written as
where \(P_s(z)\) is the s-th Eulerian polynomial. Such a polynomial is given by
where the Eulerian numbers \(A_{s,n}\) are defined by
For our purpose we write
Lemma 4.3
([6, Lemma 2.5]) For \(s_1,\dots ,s_l \in \mathbb {N}\) we have
Remark 4.4
-
(i)
The second expression in terms of Eulerian Polynomials will be important for the interpretation of these series as q-analogues of multiple zeta values in Sect. 7.
-
(ii)
This representation is also used for a fast implementation of these q-series in Pari GP. By doing so, the authors in [6] were able to give various results on the dimensions of the (weight and length filtered) spaces of \({{\,\mathrm{\mathscr {MD}}\,}}\). These results can be found in Sect. 5 of [6].
The product of \([s_1]\) and \([s_2]\) can thus be written as
In order to prove that this product is an element of \({{\,\mathrm{\mathscr {MD}}\,}}\) the product \(\widetilde{{\text {Li}}}_{1-s_1}\left( q^n\right) \widetilde{{\text {Li}}}_{1-s_2}\left( q^n\right) \) must be a rational linear combination of \(\widetilde{{\text {Li}}}_{1-j}\left( q^n\right) \) with \(1 \le j \le s_1+s_2\). We therefore need the following
Lemma 4.5
For \(a,b \in \mathbb {N}\) we have
where the coefficient  for \(1 \le j \le a\) is given by
for \(1 \le j \le a\) is given by
with \(B_k\) being the k-th Bernoulli number.Footnote 3
Proof
We prove this by using the generating function
With this one can see by direct calculation that
By the definition of the Bernoulli numbers
this can be written as
The statement then follows by calculating the coefficient of \(X^{a-1}Y^{b-1}\) in this equation.
Now we are able to interpret the product structure of brackets as an example for a quasi-shuffle product. We equip \(\mathfrak H^1\) with a third product, beside the stuffle product \(*\) and the shuffle product  . This product will be denoted
. This product will be denoted  , since it can be seen as a “bracket version” of the stuffle product \(*\). For \(a,b \in \mathbb {N}\) and \(w,v \in \mathfrak H^1\) we define recursively the product
, since it can be seen as a “bracket version” of the stuffle product \(*\). For \(a,b \in \mathbb {N}\) and \(w,v \in \mathfrak H^1\) we define recursively the product

where the coefficients  are the same as in Lemma 4.5. We equip \({{\,\mathrm{\mathscr {MD}}\,}}\) with the usual multiplication of formal q-series and obtain the following:
are the same as in Lemma 4.5. We equip \({{\,\mathrm{\mathscr {MD}}\,}}\) with the usual multiplication of formal q-series and obtain the following:
Theorem 4.6
([6, Prop 2.10]) For the linear map  defined on the generators \(w=z_{s_1}\dots z_{s_l}\) by \([w] := [s_1,\dots ,s_l]\) we have
defined on the generators \(w=z_{s_1}\dots z_{s_l}\) by \([w] := [s_1,\dots ,s_l]\) we have

and therefore \({{\,\mathrm{\mathscr {MD}}\,}}\) is a  -algebra and \([\, . \, ]\) an algebra homomorphism.
-algebra and \([\, . \, ]\) an algebra homomorphism.
Example 4.7
The first products of brackets are given by
We end this section by some notations which are needed for the rest of this paper.
Definition 4.8
On \({{\,\mathrm{\mathscr {MD}}\,}}\) we have the increasing filtration \( {\text {Fil}}^{{\text {W}}}_{\bullet }\) given by the weight and the increasing filtration \( {\text {Fil}}^{{\text {L}}} _{\bullet }\) given by the length. For a subset \(A\subset {{\,\mathrm{\mathscr {MD}}\,}}\) we writeFootnote 4

If we consider the length and weight filtration at the same time, we use the short notation \( {\text {Fil}}^{{\text {W}},{\text {L}}}_{k,l} := {\text {Fil}}^{{\text {W}}}_k {\text {Fil}}^{{\text {L}}} _l\).
Remark 4.9
As it can be seen by Theorem 4.6, the multiplication of two brackets respects these filtrations, i.e.
4.2 Derivatives and Subalgebras
In this section we want to give an overview of interesting subalgebras of the space \({{\,\mathrm{\mathscr {MD}}\,}}\) and discuss the differential structure with respect to the differential \( {\text {d}}=q \frac{d}{dq}\). One of the main results in [6] is the following
Theorem 4.10
([6, Theroem 1.7]) The operator \( {\text {d}}= q \frac{d}{dq}\) is a derivation on \({{\,\mathrm{\mathscr {MD}}\,}}\), it maps \( {\text {Fil}}^{{\text {W}},{\text {L}}}_{k,l}({{\,\mathrm{\mathscr {MD}}\,}})\) to \( {\text {Fil}}^{{\text {W}},{\text {L}}}_{k+2,l+1}({{\,\mathrm{\mathscr {MD}}\,}})\).
The proof of Theorem 4.10 uses generating functions of the brackets. It gives explicit formulas for the derivatives \( {\text {d}}[s_1,\dots ,s_l]\) for all l which we omit here, since they are complicated. For example we have
In the following we give a list of subalgebras and review the results on whether they are also closed under \( {\text {d}}\) or not.
(i) (quasi-)modular forms: Next to the connection to modular forms due to their appearance in the Fourier expansion of multiple Eisenstein series, the brackets have a direct connection to quasi-modular forms for \({{\,\mathrm{SL}\,}}_2(\mathbb {Z})\) with rational coefficients. In the case \(l=1\) we get the divisor sums \(\sigma _{k-1}(n) = \sum _{d | n} d^{k-1}\) and
These simple brackets appear in the Fourier expansion of classical Eisenstein series with rational coefficients \(\widetilde{G}_k(\tau ):= (-2\pi i)^{-k}G_k(\tau )\) since we also included the rational numbers in \({{\,\mathrm{\mathscr {MD}}\,}}\). For example we have
Denote by  and
and  the algebras of modular forms and quasi-modular forms with rational coefficients.
the algebras of modular forms and quasi-modular forms with rational coefficients.
It is a well-known fact that the space  is closed under the operator \( {\text {d}}= q \frac{d}{dq}\).
is closed under the operator \( {\text {d}}= q \frac{d}{dq}\).
(ii) Admissible brackets: We define the set of all admissible brackets \({{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}\) as the span of all brackets \([s_1,\dots ,s_l]\) with \(s_1 > 1\) and 1. This space is a subalgebra of \({{\,\mathrm{\mathscr {MD}}\,}}\) [6, Theorem 2.13] and every bracket can be written as a polynomial in the bracket [1] with coefficients in \({{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}\):
Theorem 4.11
([6, Theorem 2.14, Proposition 3.14])
-
(i)
We have \({{\,\mathrm{\mathscr {MD}}\,}}= {{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}[\,[1]\,]\).
-
(ii)
The algebra \({{\,\mathrm{\mathscr {MD}}\,}}\) is a polynomial ring over \({{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}\) with indeterminate [1], i.e. \({{\,\mathrm{\mathscr {MD}}\,}}\) is isomorphic to \({{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}[\,T\,]\) by sending [1] to T.
-
(iii)
The space \({{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}\) is closed under \( {\text {d}}\).
The elements in \({{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}\) are the ones, where the corresponding multiple zeta values exist. It will be reviewed in more detail in Sect. 7, when we consider the brackets as q-analogues of multiple zeta values.
(iii) Even brackets and brackets with no 1’s: Denote by \({{\,\mathrm{\mathscr {MD}^\text {even}}\,}}\) the space spanned by 1 and all \([s_1,\dots ,s_l]\) with \(s_j\) even for all \(0 \le j \le l\) and by  the space spanned by 1 and all \([s_1,\dots ,s_l]\) with \(s_j>1\). Both spaces \({{\,\mathrm{\mathscr {MD}^\text {even}}\,}}\) and
the space spanned by 1 and all \([s_1,\dots ,s_l]\) with \(s_j>1\). Both spaces \({{\,\mathrm{\mathscr {MD}^\text {even}}\,}}\) and  are subalgebras of \({{\,\mathrm{\mathscr {MD}}\,}}\) [6, Proposition 2.15]. It is expected, that the space \({{\,\mathrm{\mathscr {MD}^\text {even}}\,}}\) is not closed under \( {\text {d}}\), since numerical calculation suggest, that for example \( {\text {d}}[4,2] \notin {{\,\mathrm{\mathscr {MD}^\text {even}}\,}}\). Whether the space
are subalgebras of \({{\,\mathrm{\mathscr {MD}}\,}}\) [6, Proposition 2.15]. It is expected, that the space \({{\,\mathrm{\mathscr {MD}^\text {even}}\,}}\) is not closed under \( {\text {d}}\), since numerical calculation suggest, that for example \( {\text {d}}[4,2] \notin {{\,\mathrm{\mathscr {MD}^\text {even}}\,}}\). Whether the space  is closed under this operator is an open and interesting question. In [7] it is shown, that this is actually equivalent to one part of Conjecture 1 in [27] given by Okounkov.
is closed under this operator is an open and interesting question. In [7] it is shown, that this is actually equivalent to one part of Conjecture 1 in [27] given by Okounkov.
To summarize, we have the following inclusion of  -algebras
-algebras

The dashed arrows indicate the conjectured behavior of the map \( {\text {d}}\), whereas the other arrows are all known to be correct.
Though in length \(l=1\) we derive not just one but several expressions for \( {\text {d}}[s]\) given by the following Proposition.
Proposition 4.12
([6, Proposition 3.3]) For \(s_1,s_2\) with \(s_1+s_2>2\) and \(s=s_1+s_2-2\) we have the following expression for \( {\text {d}}[s]\):
If you compare this formula with the shuffle product of multiple zeta values (11) in the length one times length one case you notice that Proposition 4.12 basically states that the brackets fulfill the shuffle product up to the term \(\left( {\begin{array}{c}s\\ s_1-1\end{array}}\right) \frac{ {\text {d}}[s]}{s} - \left( {\begin{array}{c}s\\ s_1-1\end{array}}\right) [s+1]\).
We end this section by using these formulas to prove the following identity
Proposition 4.13
The unique normalized cusp form \(\varDelta \) in weight 12 can be written as
Proof
With the Eisenstein series \(\widetilde{G}_6\) and \(\widetilde{G}_{12}\) given by
the cusp form \(\varDelta \) can be written as \(\varDelta = -3316800 G_6^2 + 3432000 G_{12}\). Using quasi-shuffle product of brackets one can derive
and therefore
Using Proposition 4.12 for \((s_1,s_2) = (4,8), (5,7), (6,6)\) we get the following three expressions for \( {\text {d}}[10]\)
Summing them up as \(0 = -504 {\text {d}}[10] +1890 {\text {d}}[10] -1386 {\text {d}}[10]\) we get
Combining (22) and (21), in order to eliminate the occurrence of [6, 6], we obtain the desired identity.
5 Bi-Brackets and a Second Product Expression for Brackets
In the previous section we have seen that the space \({{\,\mathrm{\mathscr {MD}}\,}}\) of brackets has the structure of a  -algebra and that there is an explicit formula to express the product of two brackets as a linear combination of brackets similarly to the stuffle product of multiple zeta values. In this section we want to present a larger class of q-series, called bi-brackets. The quasi-shuffle product of brackets extend to this larger class and therefore the space of bi-brackets is also a
-algebra and that there is an explicit formula to express the product of two brackets as a linear combination of brackets similarly to the stuffle product of multiple zeta values. In this section we want to present a larger class of q-series, called bi-brackets. The quasi-shuffle product of brackets extend to this larger class and therefore the space of bi-brackets is also a  -algebra. The beautiful feature of bi-brackets is, that there is a relation, which we call partition relation, which enables one to express the product of two bi-brackets in a second different way. These two product expressions then give a large class of linear relations, similar to the double shuffle relations of multiple zeta values. A variation of the bi-brackets were also studied in [41]. Later, the bi-brackets will be used to define regularized multiple Eisenstein series in Sect. 6. All results in this section were studied and introduced in [3].
-algebra. The beautiful feature of bi-brackets is, that there is a relation, which we call partition relation, which enables one to express the product of two bi-brackets in a second different way. These two product expressions then give a large class of linear relations, similar to the double shuffle relations of multiple zeta values. A variation of the bi-brackets were also studied in [41]. Later, the bi-brackets will be used to define regularized multiple Eisenstein series in Sect. 6. All results in this section were studied and introduced in [3].
5.1 Bi-Brackets and Their Generating Series
As motivated in the introduction of this section we want to study the following q-series:
Definition 5.1
For \(r_1,\dots ,r_l \ge 0\), \(s_1,\dots ,s_l > 0\) and we define the following q-series

which we call bi-brackets of weight \(r_1+\dots +r_k+s_1+\dots +s_l\), upper weight \(s_1+\dots +s_l\), lower weight \(r_1+\dots +r_l\) and length l. By \({{\,\mathrm{\mathscr {BD}}\,}}\) we denote the  -vector space spanned by all bi-brackets and 1.
-vector space spanned by all bi-brackets and 1.
The factorial factors in the definition of bi-brackets will become natural when considering generating functions of bi-brackets and the connection to multiple zeta values.
For \(r_1=\dots =r_l=0\) the bi-brackets are just the brackets
as defined in Sect. 4. Similarly to the Definition 4.8 of the filtration for the space \({{\,\mathrm{\mathscr {BD}}\,}}\) we write for a subset \(A\in {{\,\mathrm{\mathscr {BD}}\,}}\)

and again if we consider the length and weight filtration at the same time we use the short notation \( {\text {Fil}}^{{\text {W}},{\text {L}}}_{k,l} := {\text {Fil}}^{{\text {W}}}_k {\text {Fil}}^{{\text {L}}} _l\) and similar for the other filtrations.
Proposition 5.2
([3, Proposition 4.2]) Let \( {\text {d}}:= q \frac{d}{dq}\), then we have
and therefore \( {\text {d}}\left( {\text {Fil}}^{{\text {W}},{\text {D}},{\text {L}}}_{k,d,l}({{\,\mathrm{\mathscr {BD}}\,}}) \right) \subset {\text {Fil}}^{{\text {W}},{\text {D}},{\text {L}}}_{k+1,d+1,l}({{\,\mathrm{\mathscr {BD}}\,}}) \).
Proof
This is an easy consequence of the definition of bi-brackets and the fact that \( {\text {d}}\sum _{n>0} a_n q^n = \sum _{n>0} n a_n q^n\).
Proposition 5.2 suggests that the bi-brackets can be somehow viewed as partial derivatives of the brackets with total differential \( {\text {d}}\).
In the following we now want to discuss the algebra structure of the space \({{\,\mathrm{\mathscr {BD}}\,}}\). For this we extend the quasi-shuffle product  of \(\mathfrak H^1\) to a larger space of words. Since we have double indices we replace the alphabet \(A_z = \{z_1, z_2,\dots \}\) by \(A^{\text {bi}}_{z} := \{z_{s,r} \mid s\ge 1\,, r\ge 0\}\).
of \(\mathfrak H^1\) to a larger space of words. Since we have double indices we replace the alphabet \(A_z = \{z_1, z_2,\dots \}\) by \(A^{\text {bi}}_{z} := \{z_{s,r} \mid s\ge 1\,, r\ge 0\}\).
We consider on  the commutative and associative product
the commutative and associative product

and on  the commutative and associative quasi-shuffle product
the commutative and associative quasi-shuffle product

where the the numbers  for \(1 \le j \le a\) are the same as before, i.e.
for \(1 \le j \le a\) are the same as before, i.e.
Theorem 5.3
([3, Theroem 3.6]) The map  given by
given by
fulfills  and therefore \({{\,\mathrm{\mathscr {BD}}\,}}\) is a
and therefore \({{\,\mathrm{\mathscr {BD}}\,}}\) is a  -algebra.
-algebra.
Definition 5.4
For the generating function of the bi-brackets we write
These are elements in the ring \({{\,\mathrm{{{\,\mathrm{\mathscr {BD}}\,}}_{gen}}\,}}=\varinjlim _j {{\,\mathrm{\mathscr {BD}}\,}}[[X_1,\dots ,X_j,Y_1,\dots ,Y_j]]\) of all generating series of bi-brackets.
To derive relations between bi-brackets we will prove functional equations for their generating functions. The key fact for this is that there are two different ways of expressing these given by the following Theorem.
Theorem 5.5
([3, Theroem 2.3]) For \(n\in \mathbb {N}\) set

Then for all \(l\ge 1\) we have the following two different expressions for the generating functions:
(with \(X_{l+1} := 0\)). In particular the partition relationsFootnote 5 holds:
Remark 5.6
A nice combinatorial explanation for the partition relation (23) is the following: By a partition of a natural number n with l parts we denote a representation of n as a sum of l distinct natural numbers, i.e. \(15 = 4 + 4 + 3 + 2 + 1 + 1\) is a partition of 15 with the 4 parts given by 4, 3, 2, 1. We identify such a partition with a tuple \((u,v) \in \mathbb {N}^l \times \mathbb {N}^l\) where the \(u_j\)’s are the l distinct numbers in the partition and the \(v_j\)’s count their appearance in the sum. The above partition of 15 is therefore given by the tuple \((u,v) = ((4,3,2,1),(2,1,1,2))\). By \(P_l(n)\) we denote all partitions of n with l parts and hence we set
On the set \(P_l(n)\) one has an involution given by the conjugation \(\rho \) of partitions which can be obtained by reflecting the corresponding Young diagram across the main diagonal (Fig. 1).

The conjugation of the partition \(15 = 4 + 4 + 3 + 2 + 1 + 1\) is given by \(\rho ( ((4,3,2,1),(2,1,1,2)) ) = ((6,4,3,2),(1,1,1,1))\) which can be seen by reflection the corresponding Young diagram at the main diagonal
On the set \(P_l(n)\) the conjugation \(\rho \) is explicitly given by \(\rho ( (u,v) ) = (u',v')\) where \(u'_j = v_1 + \dots + v_{l-j+1}\) and \(v'_j = u_{l-j+1}-u_{l-j+2}\) with \(u_{l+1} := 0\), i.e.
By the definition of the bi-brackets its clear that with the above notation they can be written as
The coefficients are given by a sum over all elements in \(P_l(n)\) and therefore it is invariant under the action of \(\rho \). As an example, consider [2, 2] and apply \(\rho \) to the sum. Then we obtain
This is exactly the relation one obtains by using the partition relation.
Corollary 5.7
([3, Corollary 2.5]) (Partition relation in length one and two) For \(r,r_1,r_2 \ge 0\) and \(s,s_1,s_2 > 0\) we have the following relations in length one and two
Remark 5.8
-
(i)
If we replace in the generating series in Definition 5.4 the bi-brackets by the corresponding bi-words in and enforce the partition relation (23) for this power series, we obtain an involution

By Corollary 5.7 it is for example \(P(z_{s,r}) = z_{r+1,s-1}\). This will be needed to describe the second product structure in the next section.
-
(ii)
In [41] the author introduces multiple q-zeta brackets \(\mathfrak {Z}\genfrac[]{0.0pt}{}{s_1,\dots ,s_r}{r_1,\dots ,r_l}\), which can be written in terms of bi-brackets and vice versa. For these objects the partition relation has the nice form
$$\begin{aligned} \mathfrak {Z}\genfrac[]{0.0pt}{}{s_1,\dots ,s_r}{r_1,\dots ,r_l} = \mathfrak {Z}\genfrac[]{0.0pt}{}{r_l,\dots ,r_1}{s_l,\dots ,s_1}\,, \end{aligned}$$which can be interpreted in terms of duality. This is also used in [41] to describe the second product structure for the \(\mathfrak {Z}\). Similarly in [17] the authors use a duality by Zhao [39] to describe a second product structure for another model of q-analogues.

5.2 Double Shuffle Relations for Bi-Brackets
The partition relation together with the quasi-shuffle product can be used to obtain a second expression for the product of two bi-brackets. Before giving the general explanation this second product expression we illustrate it in two examples.
Example 5.9
-
(i)
We want to given a second product expression for the product \([2] \cdot [3]\). By the partition relation we know that \([2] = \genfrac[]{0.0pt}{}{1}{1}\), \([3] = \genfrac[]{0.0pt}{}{1}{2}\) and using the quasi-shuffle product we have
$$\begin{aligned} \genfrac[]{0.0pt}{}{1}{1} \cdot \genfrac[]{0.0pt}{}{1}{2}&=\genfrac[]{0.0pt}{}{1,1}{1,2} + \genfrac[]{0.0pt}{}{1,1}{2,1} -3 \genfrac[]{0.0pt}{}{1}{3} + 3 \genfrac[]{0.0pt}{}{2}{3} \,. \end{aligned}$$The partition relations for the length two bi-brackets on the right is given by
$$\begin{aligned} \genfrac[]{0.0pt}{}{1,1}{1,2}&=\genfrac[]{0.0pt}{}{3,2}{0,0}+3 \genfrac[]{0.0pt}{}{4,1}{0,0} = [3,2] + 3 [4,1]\,,\\ \genfrac[]{0.0pt}{}{1,1}{2,1}&=\genfrac[]{0.0pt}{}{2,3}{0,0}+2\genfrac[]{0.0pt}{}{3,2}{0,0}+ 3 \genfrac[]{0.0pt}{}{4,1}{0,0} = [2,3] + 2 [3,2] + 3 [4,1]\,. \end{aligned}$$Combining all of this we obtain
$$\begin{aligned} \genfrac[]{0.0pt}{}{2}{0} \cdot \genfrac[]{0.0pt}{}{3}{0}&= \genfrac[]{0.0pt}{}{1}{1} \cdot \genfrac[]{0.0pt}{}{1}{2} \\&=\genfrac[]{0.0pt}{}{1,1}{1,2} + \genfrac[]{0.0pt}{}{1,1}{2,1} -3 \genfrac[]{0.0pt}{}{1}{3} + 3 \genfrac[]{0.0pt}{}{2}{3} \\&=[2,3] + 3[3,2] + 6 [4,1]+ 3\genfrac[]{0.0pt}{}{4}{1} - 3 [4] \,. \end{aligned}$$Compare this to the shuffle product of multiple zeta values
$$\begin{aligned} \zeta (2)\zeta (3)= \zeta (2,3) + 3 \zeta (3,2) + 6\zeta (4,1) \,. \end{aligned}$$Since \( {\text {d}}[3] = 3 \genfrac[]{0.0pt}{}{4}{1}\) this example exactly coincides with the formula in Proposition 4.12 for the derivative \( {\text {d}}[k]\).
-
(ii)
In higher length, expressing the product of two bi-brackets in a similar way as in i) becomes interesting, since then the extra terms can’t be expressed with the operator \( {\text {d}}\) anymore. Doing the same calculation for the product \([3] \cdot [2,1]\), i.e. using the partition relation, the quasi-shuffle product and again the partition relation we obtain
$$\begin{aligned}{}[3] \cdot [2,1]&= \genfrac[]{0.0pt}{}{1}{2} \cdot \genfrac[]{0.0pt}{}{1,1}{0,1} \\&= \genfrac[]{0.0pt}{}{1,1,1}{2,0,1}+\genfrac[]{0.0pt}{}{1,1,1}{0,2,1}+\genfrac[]{0.0pt}{}{1,1,1}{0,1,2}+3 \genfrac[]{0.0pt}{}{1,2}{0,3}+\genfrac[]{0.0pt}{}{2,1}{2,1}-3 \genfrac[]{0.0pt}{}{1,1}{0,3}-\genfrac[]{0.0pt}{}{1,1}{2,1}\\&= [2,1,3]+[2,2,2]+2[2,3,1]+2[3,1,2]+5[3,2,1]+9[4,1,1]\\&+\genfrac[]{0.0pt}{}{2,3}{0,1} + 2 \genfrac[]{0.0pt}{}{3,2}{0,1} + 3 \genfrac[]{0.0pt}{}{4,1}{1,0} - [2,3] - 2 [3,2] -6[4,1]\,. \end{aligned}$$
This product can be seen as the analogue of the shuffle product
Here the bi-brackets, which are not given as brackets, can not be written in terms of the operator \( {\text {d}}\) in an obvious way.
This works for arbitrary lengths and yields a natural way to obtain the second product expression for bi-brackets. To be more precise, denote by  the involution defined in Remark 5.8. Using this convention the second product expression for bi-brackets can be written in
the involution defined in Remark 5.8. Using this convention the second product expression for bi-brackets can be written in  for two words
for two words  as
as  , i.e. the two product expressions of bi-brackets which correspond to the stuffle and shuffle product of multiple zeta values are given by
, i.e. the two product expressions of bi-brackets which correspond to the stuffle and shuffle product of multiple zeta values are given by

In contrast to multiple zeta values these two product expression are the same for some cases, as one can check for the example \([1] \cdot [1,1]\). In the smallest length case, we have the following explicit formulas for the two products expressions.
Proposition 5.10
([2, Proposition 3.3]) For \(s_1,s_2 > 0\) and \(r_1,r_2 \ge 0\) we have the following two expressions for the product of two bi-brackets of length one:
-
(i)
(“Stuffle product analogue for bi-brackets”)
$$\begin{aligned} \genfrac[]{0.0pt}{}{s_1}{r_1} \cdot \genfrac[]{0.0pt}{}{s_2}{r_2}&=\genfrac[]{0.0pt}{}{s_1,s_2}{r_1,r_2} + \genfrac[]{0.0pt}{}{s_2,s_1}{r_2,r_1} + \left( {\begin{array}{c}r_1+r_2\\ r_1\end{array}}\right) \genfrac[]{0.0pt}{}{s_1+s_2}{r_1+r_2} \\&+\left( {\begin{array}{c}r_1+r_2\\ r_1\end{array}}\right) \sum _{j=1}^{s_1} \frac{(-1)^{s_2-1} B_{s_1+s_2-j}}{(s_1+s_2-j)!} \left( {\begin{array}{c}s_1+s_2-j-1\\ s_1-j\end{array}}\right) \genfrac[]{0.0pt}{}{j}{r_1+r_2} \\&+\left( {\begin{array}{c}r_1+r_2\\ r_1\end{array}}\right) \sum _{j=1}^{s_2} \frac{(-1)^{s_1-1} B_{s_1+s_2-j}}{(s_1+s_2-j)!} \left( {\begin{array}{c}s_1+s_2-j-1\\ s_2-j\end{array}}\right) \genfrac[]{0.0pt}{}{j}{r_1+r_2} \end{aligned}$$ -
(ii)
(“Shuffle product analogue for bi-brackets”)
$$\begin{aligned} \genfrac[]{0.0pt}{}{s_1}{r_1} \cdot \genfrac[]{0.0pt}{}{s_2}{r_2}&= \sum _{\begin{array}{c} 1 \le j \le s_1 \\ 0 \le k \le r_2 \end{array}} \left( {\begin{array}{c}s_1+s_2-j-1\\ s_1-j\end{array}}\right) \left( {\begin{array}{c}r_1+r_2-k\\ r_1\end{array}}\right) (-1)^{r_2-k} \genfrac[]{0.0pt}{}{s_1+s_2-j, j}{k,r_1+r_2-k} \\&+\sum _{\begin{array}{c} 1\le j \le s_2 \\ 0 \le k \le r_1 \end{array}} \left( {\begin{array}{c}s_1+s_2-j-1\\ s_1-1\end{array}}\right) \left( {\begin{array}{c}r_1+r_2-k\\ r_1-k\end{array}}\right) (-1)^{r_1-k} \genfrac[]{0.0pt}{}{s_1+s_2-j, j}{k,r_1+r_2-k}\\&+\left( {\begin{array}{c}s_1+s_2-2\\ s_1-1\end{array}}\right) \genfrac[]{0.0pt}{}{s_1+s_2-1}{r_1+r_2+1} \\&+\left( {\begin{array}{c}s_1+s_2-2\\ s_1-1\end{array}}\right) \sum _{j=0}^{r_1} \frac{(-1)^{r_2} B_{r_1+r_2-j+1}}{(r_1+r_2-j+1)!} \left( {\begin{array}{c}r_1+r_2-j\\ r_1-j\end{array}}\right) \genfrac[]{0.0pt}{}{s_1+s_2-1}{j} \\&+\left( {\begin{array}{c}s_1+s_2-2\\ s_1-1\end{array}}\right) \sum _{j=0}^{r_2} \frac{(-1)^{r_1} B_{r_1+r_2-j+1}}{(r_1+r_2-j+1)!} \left( {\begin{array}{c}r_1+r_2-j\\ r_2-j\end{array}}\right) \genfrac[]{0.0pt}{}{s_1+s_2-1}{j} \end{aligned}$$
Having these two expressions for the product of bi-brackets we obtain a large family of linear relations between them. Computer experiments suggest that actually every bi-bracket can be written in terms of brackets and that motivates the following surprising conjecture.
Conjecture 5.11
The algebra \({{\,\mathrm{\mathscr {BD}}\,}}\) of bi-brackets is a subalgebra of \({{\,\mathrm{\mathscr {MD}}\,}}\) and in particular we have
The results towards this conjecture, beside the computer experiments which have been done up to weight 8, are the following
Proposition 5.12
([3, Proposition 4.4]) For \(l=1\) the Conjecture 5.11 is true.
In [8] it will be shown, that Conjecture 5.11 is also true for all length up to weight 7. For higher weights and lengths there are no general statements. The only general statement for the length two case is given by the following Proposition.
Proposition 5.13
([3, Proposition 5.9]) For all \(s_1,s_2 \ge 1\) it is
5.3 The Shuffle Brackets
We now want to define a q-series which is an element in \({{\,\mathrm{\mathscr {BD}}\,}}\) and whose products can be written in terms of the “real” shuffle product of multiple zeta values. For \(e_1,\dots ,e_l \ge 1\) we generalize the generating function of bi-brackets to the following
In particular for \(e_1 = \dots = e_l=1\) these are the generating functions of the bi-brackets. To show that the coefficients of these series are in \({{\,\mathrm{\mathscr {BD}}\,}}\) for arbitrary \(e_j\) we need to define the differential operator \(\mathscr {D}^Y_{e_1,\dots ,e_l} := D_{Y_1,e_1} D_{Y_2,e_2} \dots D_{Y_l,e_l}\) with
where we set \(\frac{\partial }{\partial Y_{l+1}}=0\).
Lemma 5.14
Let \(\mathscr {A}\) be an algebra spanned by elements \(a_{s_1,\dots ,s_l}\) with \(s_1,\dots , s_l \in \mathbb {N}\), let \(H(X_1,\dots ,X_l) = \sum _{s_j} a_{s_1,\dots ,s_l} X_1^{s_1-1} \dots X_1^{s_l-1}\) be the generating functions of these elements and define for 
Then the following two statements are equivalent.
-
(i)
The map
 given by \(z_{s_1} \dots z_{s_j} \mapsto a_{s_1,\dots ,s_l}\) is an algebra homomorphism.
given by \(z_{s_1} \dots z_{s_j} \mapsto a_{s_1,\dots ,s_l}\) is an algebra homomorphism. -
(ii)
For all \(r,s \in \mathbb {N}\) it is

where \(sh_r^{(r+s)} = \sum _{\sigma \in \Sigma (r,s)}\sigma \) in the group ring \(\mathbb {Z}[\mathfrak {S}_{r+s}]\) and the symmetric group \(\mathfrak {S}_r\) acts on
 by \((f\big |\sigma )(X_1,\ldots ,X_r)= f(X_{\sigma ^{-1}(1)},\ldots ,X_{\sigma ^{-1}(r)})\).
by \((f\big |\sigma )(X_1,\ldots ,X_r)= f(X_{\sigma ^{-1}(1)},\ldots ,X_{\sigma ^{-1}(r)})\).
 given by
given by 
 by
by Proof
This can be proven by induction over l together with Proposition 8 in [23].
Theorem 5.15
([3, Theroem 5.7]) For \(s_1,\dots ,s_l\in \mathbb {N}\) define  as the coefficients of the following generating function
as the coefficients of the following generating function

Then we have the following two statements
-
i)
The
 fulfill the shuffle product, i.e.
fulfill the shuffle product, i.e. 
-
ii)
For \(s_1\ge 1,\, s_2,\dots ,s_l \ge 2\) we have
 .
.
 fulfill the shuffle product, i.e.
fulfill the shuffle product, i.e. 
 .
.For low lengths we obtain the following examples:
Corollary 5.16
It is  and for \(l=2,3,4\) the
and for \(l=2,3,4\) the  are given byFootnote 6
are given byFootnote 6
-
(i)

-
(ii)

-
(iii)
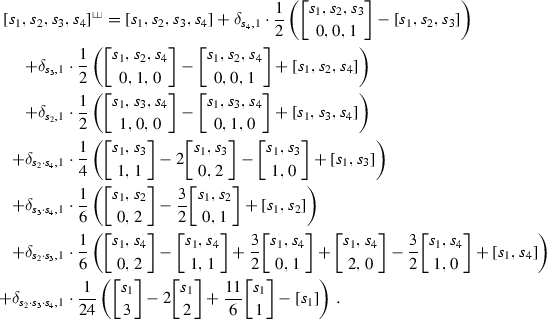


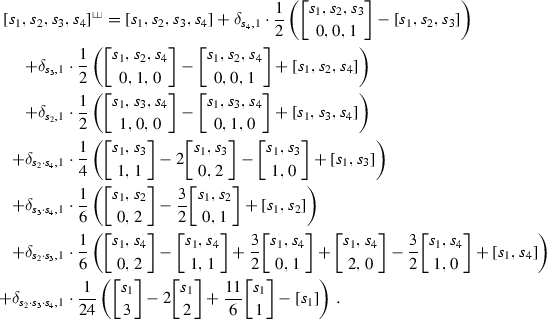
Proof
This follows by calculating the coefficients of the series  in Theorem 5.15.
in Theorem 5.15.
The shuffle brackets will be used to define shuffle regularized multiple Eisenstein series in the next section.
6 Regularizations of Multiple Eisenstein Series
This section is devoted to Question 1 in the introduction, which was to find a regularization of the multiple Eisenstein series. We want to present two type of regularization: The shuffle regularized multiple Eisenstein series [3, 9] and stuffle regularized multiple Eisenstein series [3].
The definition of shuffle regularized multiple Eisenstein series uses a beautiful connection of the Fourier expansion of multiple Eisenstein series and the coproduct of formal iterated integrals. The other regularization, the stuffle regularized multiple Eisenstein series uses the construction of the Fourier expansion of multiple Eisenstein series together with a result on regularization of multitangent functions by Bouillot [12].
We start by reviewing the definition of formal iterated integrals and the coproduct defined by Goncharov. An explicit example in length two will make the above mentioned connection of multiple Eisenstein series and this coproduct clear. After doing this, we give the definition of shuffle and stuffle regularized multiple Eisenstein series as presented in [3, 9]. At the end of this section we compare these two regularizations with a help of a few examples.
6.1 Formal Iterated Integrals
Following Goncharov (Sect. 2 in [20]) we consider the algebra \({\mathscr {I}}\) generated by the elements
together with the following relations
-
(i)
For any \(a,b\in \{0,1\}\) the unit is given by \(\mathbb {I}(a;b):=\mathbb {I}(a;\emptyset ;b)=1\).
-
(ii)
The product is given by the shuffle product
 $$\begin{aligned}&\mathbb {I}(a_0;a_1,\ldots ,a_M;a_{M+N+1}) \mathbb {I}(a_0;a_{M+1},\ldots ,a_{M+N};a_{M+N+1})\\&=\sum _{\sigma \in sh_{M,N}} \mathbb {I}(a_0;a_{\sigma ^{-1}(1)},\ldots ,a_{\sigma ^{-1}(M+N)};a_{M+N+1}), \end{aligned}$$
$$\begin{aligned}&\mathbb {I}(a_0;a_1,\ldots ,a_M;a_{M+N+1}) \mathbb {I}(a_0;a_{M+1},\ldots ,a_{M+N};a_{M+N+1})\\&=\sum _{\sigma \in sh_{M,N}} \mathbb {I}(a_0;a_{\sigma ^{-1}(1)},\ldots ,a_{\sigma ^{-1}(M+N)};a_{M+N+1}), \end{aligned}$$where \(sh_{M,N}\) is the set of \(\sigma \in \mathfrak {S}_{M+N}\) such that \(\sigma (1)<\cdots <\sigma (M)\) and \(\sigma (M+1)<\cdots <\sigma (M+N)\).
-
(iii)
The path composition formula holds: for any \(N\ge 0\) and \(a_i,x\in \{0,1\}\), one has
$$\begin{aligned} \mathbb {I}(a_0;a_1,\ldots ,a_N;a_{N+1}) = \sum _{k=0}^N \mathbb {I}(a_0;a_1,\ldots ,a_k;x) \mathbb {I}(x;a_{k+1},\ldots ,a_N;a_{N+1}). \end{aligned}$$ -
(iv)
For \(N\ge 1\) and \(a_i,a\in \{0,1\}\) it is \(\mathbb {I} (a;a_1,\ldots ,a_N;a)=0\).
-
(v)
The path inversion is satisfied:
$$\begin{aligned} \mathbb {I}(a_0;a_1,\ldots ,a_N;a_{N+1}) = (-1)^N \mathbb {I}(a_{N+1};a_N,\ldots ,a_1;a_0)\,. \end{aligned}$$

Definition 6.1
(Coproduct) Define the coproduct \(\varDelta \) on \({\mathscr {I}}\) by
where the sum on the right runs over all \(i_0=0<i_1<\cdots<i_k<i_{k+1}=N+1\) with \(0\le k \le N\).
Proposition 6.2
([20, Proposition 2.2]) The triple  is a commutative graded Hopf algebra over
is a commutative graded Hopf algebra over  .
.
To calculate \(\varDelta \left( \mathbb {I}(a_0;a_1,\dots ,a_8;a_{9}) \right) \) one sums over all possible diagrams of the following form (Fig. 2).

One diagram for the calculation of \(\varDelta \left( \mathbb {I}(a_0;a_1,\dots ,a_8;a_{9}) \right) \). It gives the term \(I(a_0;a_1,a_4,a_7;a_9) \otimes I(a_0;a_1)I(a_1;a_2,a_3;a_4)I(a_4;a_5,a_6;a_7)I(a_7;a_8;a_9)\)
For our purpose it will be important to consider the quotient spaceFootnote 7
Let us denote by
an image of \(\mathbb {I}(a_0;a_1,\ldots ,a_N;a_{N+1})\) in \(\mathscr {I}^1\). The quotient map \(\mathscr {I} \rightarrow \mathscr {I}^1\) induces a Hopf algebra structure on \(\mathscr {I}^1\), but for our application we just need that for any \(w_1,w_2\in \mathscr {I}^1\), one has  . The coproduct on \(\mathscr {I}^1\) is given by the same formula as before by replacing \(\mathbb {I}\) with I. For integers \(n\ge 0,s_1,\ldots ,s_r\ge 1\), we set
. The coproduct on \(\mathscr {I}^1\) is given by the same formula as before by replacing \(\mathbb {I}\) with I. For integers \(n\ge 0,s_1,\ldots ,s_r\ge 1\), we set
In particular, we writeFootnote 8 \(I(s_1,\ldots ,s_r)\) to denote \(I_0(s_1,\ldots ,s_r)\).
Proposition 6.3
([9, Eqs. (3.5), (3.6) and Proposition 3.5])
-
(i)
We have \(I_n(\emptyset )=0\) if \(n\ge 1\) or 1 if \(n=0\).
-
(ii)
For integers \(n\ge 0,s_1,\ldots ,s_r\ge 1\),
$$\begin{aligned} I_{n}(s_1,\ldots ,s_r) = (-1)^n \sum ^*\bigg (\prod _{j=1}^{r}\left( {\begin{array}{c}k_j-1\\ s_j-1\end{array}}\right) \bigg ) I (k_1,\ldots ,k_r) \,, \end{aligned}$$where the sum runs over all \(k_1+\cdots +k_r=s_1+\cdots +s_r+n\) with \(k_1,\ldots ,k_r\ge 1\).
-
(iii)
The set \(\{I(s_1,\ldots ,s_r)\mid r\ge 0,s_i\ge 1\}\) forms a basis of the space \(\mathscr {I}^1\).
We give an example for ii): In \(\mathscr {I}^1\) it is \(I(1;0;0)=0\) and therefore
which gives \(I_1(2) = -2 I(3) = (-1)^1 \left( {\begin{array}{c}2\\ 1\end{array}}\right) I(3)\).
Remark 6.4
Statement (iii) in Proposition 6.3 basically states that we can identify \(\mathscr {I}^1\) with \(\mathfrak H^1\) by sending \(I(s_1,\dots ,s_l)\) to \(z_{s_1}\dots z_{s_l}\). In other words we can equip \(\mathfrak H^1\) with the coproduct \(\varDelta \). Instead of working with I we will use this identification in the next section, when defining the shuffle regularized multiple Eisenstein series.
Example 6.5
In the following we are going to calculate \(\varDelta (I(3,2)) = \varDelta (I(1;0,0,1,0,1;0))\). Therefore we have to determine all possible markings of the diagram

where the corresponding summand in the coproduct does not vanish. For simplicity we draw \(\circ \) to denote a 0 and \(\bullet \) to denote a 1. We will consider the \(4 = 2^2\) ways of marking the two \(\bullet \) in the top part of the circle separately. As mentioned in the introduction, we want to compare the coproduct to the Fourier expansion of multiple Eisenstein series. Therefore, in this case we also calculate the expansion of \(G_{3,2}(\tau )\) using the construction described in Sect. 3.2. Recall that we also had the 4 different parts \(G^{RR}_{3,2}\), \(G^{UR}_{3,2}\), \(G^{RU}_{3,2}\) and \(G^{UU}_{3,2}\). We will see that the number and positions of the marked \(\bullet \) correspond to the number and positions of the letter U in the word w of \(G^w\).
-
(i)
Diagrams with no marked \(\bullet \):

Corresponding sum in the coproduct:
$$\begin{aligned} I(0;\emptyset ;1) \otimes I(1;0,0,1,0,1;0) = 1 \otimes I(3,2) \,. \end{aligned}$$The part of the Fourier expansion of \(G_{3,2}\) which is associated to this, is the one with no U “occurring”, i.e. \(G^{RR}_{3,2}(\tau ) = \zeta (3,2)\).
-
(ii)
Diagrams with the first \(\bullet \) marked:

Corresponding sum in the coproduct:
$$\begin{aligned} I(1;0,0,1;0) \otimes \big ( I(1;0) \cdot I(0;0) \cdot I(0;1) \cdot I(1;0,1;0) \big ) = I(3) \otimes I(2) \,. \end{aligned}$$The associated part of the Fourier expansion of \(G_{3,2}\) is \(G^{UR}_{3,2}(\tau ) = g_3(\tau ) \cdot \zeta (2)\).
-
(iii)
Diagrams with the second \(\bullet \) marked:

Corresponding sum in the coproduct:
$$\begin{aligned}&I(1;0,1;0) \otimes \big ( I(1;0,0,1;0) \cdot I(0;1) \cdot I(1;0)\big ) \\ +&I(1;0,1;0) \otimes \big ( I(1;0) \cdot I(0;0,1,0;1) \cdot I(1;0)\big ) \\ +&I(1;0,0,1;0) \otimes \big ( I(1;0) \cdot I(0;0) \cdot I(0;1,0;1) \cdot I(1;0)\big ) \\&= I(2) \otimes I(3) - I(2) \otimes I_1(2) + I(3) \otimes I(2) \,, \end{aligned}$$where we used \(I(0,0,1,0;1)=-I_1(2)\) and \(I(0;1,0;1) = (-1)^2 I(1;0,1;0) = I(2)\). Together with \(I_1(2) = -2 I(3)\) this gives
$$\begin{aligned} 3 I(2) \otimes I(3) + I(3) \otimes I(2) \,. \end{aligned}$$Also the associated part of the Fourier expansion is the most complicated one. We had \(G^{RU}_{3,2}(\tau ) = \sum _{m>0} \varPsi _{3,2}(m\tau )\) and with (16) we derived \(\varPsi _{3,2}(x) = 3 \varPsi _2(x) \cdot \zeta (3) + \varPsi _3(x) \cdot \zeta (2)\), i.e.
$$\begin{aligned} G^{RU}_{3,2}(\tau ) = 3 g_2(\tau ) \cdot \zeta (3) + g_3(\tau ) \cdot \zeta (2) \,. \end{aligned}$$ -
(iv)
Diagrams with both \(\bullet \) marked:

Corresponding sum in the coproduct: \( I(3,2) \otimes 1\). The associated part of the Fourier expansion of \(G_{3,2}\) is \(G^{UU}_{3,2}(\tau ) = g_{3,2}(\tau )\).




Summing all 4 parts together we obtain for the coproduct
and for the Fourier expansion of \(G_{2,3}(\tau )\):
This shows that the left factors of the terms in the coproduct corresponds to the functions g and the right factors side to the multiple zeta values. We will use this in the next section to define shuffle regularized multiple Eisenstein series.
6.2 Shuffle Regularized Multiple Eisenstein Series
In this section we present the definition of shuffle regularized multiple Eisenstein series as it was done in [9] together with the simplification developed in [3]. We use the observation of the section before and use the coproduct \(\varDelta \) of formal iterated integrals to define these series. As mentioned in Remark 6.4 we can equip the space \(\mathfrak H^1\) with the coproduct \(\varDelta \) instead of working with the space \(\mathscr {I}^1\). Denote by \({{\,\mathrm{\mathscr {MZB}}\,}}\subset \mathbb {C}[\![q]\!]\) the space of all formal power series in q which can be written as a  -linear combination of products of multiple zeta values, powers of \((-2\pi i)\) and bi-brackets. In the following, we set \(q=\exp (2\pi i \tau )\) with \(\tau \) being an element in the upper half-plane. Since the coefficient of bi-brackets just have polynomials growth, the elements in \({{\,\mathrm{\mathscr {MZB}}\,}}\) and \({{\,\mathrm{\mathscr {BD}}\,}}\) can be viewed as holomorphic functions in the upper half-plane with this identification.
-linear combination of products of multiple zeta values, powers of \((-2\pi i)\) and bi-brackets. In the following, we set \(q=\exp (2\pi i \tau )\) with \(\tau \) being an element in the upper half-plane. Since the coefficient of bi-brackets just have polynomials growth, the elements in \({{\,\mathrm{\mathscr {MZB}}\,}}\) and \({{\,\mathrm{\mathscr {BD}}\,}}\) can be viewed as holomorphic functions in the upper half-plane with this identification.
In analogy to the map  of shuffle regularized multiple zeta values (Proposition 3.2), the map
of shuffle regularized multiple zeta values (Proposition 3.2), the map  defined on the generators \(z_{t_1} \dots z_{t_l}\) by
defined on the generators \(z_{t_1} \dots z_{t_l}\) by

is also an algebra homomorphism by Theorem 5.15.
With this notation we can recall the definition of  from [3] (which is a variant of the definition in [9], where the authors did not use bi-brackets and the shuffle bracket).
from [3] (which is a variant of the definition in [9], where the authors did not use bi-brackets and the shuffle bracket).
Definition 6.6
For integers \(s_1,\ldots ,s_l\ge 1\), define the functions  , called shuffle regularized multiple Eisenstein series, as
, called shuffle regularized multiple Eisenstein series, as

where m denotes the multiplication given by \(m: a \otimes b \mapsto a\cdot b\) and  denotes the map for shuffle regularized multiple zeta values given in Proposition 3.2.
denotes the map for shuffle regularized multiple zeta values given in Proposition 3.2.
We can view  as an algebra homomorphism
as an algebra homomorphism  such that the following diagram commutes
such that the following diagram commutes

Theorem 6.7
([3, Theroem 6.5 ], [9, Theroem 1.1, 1.2]) For all \(s_1,\ldots ,s_l\ge 1\) the shuffle regularized multiple Eisenstein series  have the following properties:
have the following properties:
-
(i)
They are holomorphic functions on the upper half-plane having a Fourier expansion with the shuffle regularized multiple zeta values as the constant term.
-
(ii)
They fulfill the shuffle product.
-
(iii)
For integers \(s_1,\ldots ,s_l\ge 2\) they equal the multiple Eisenstein series

and therefore they fulfill the stuffle product in these cases.

Parts (i) and (ii) in this theorem follow directly by definition. The important part here is (iii), which states that the connection of the Fourier expansion and the coproduct, as illustrated in Example 6.5, holds in general. It also proves that the shuffle regularized multiple Eisenstein series fulfill the stuffle product in many cases. Though the exact failure of the stuffle product of these series is unknown so far.
6.3 Stuffle Regularized Multiple Eisenstein Series
Motivated by the calculation of the Fourier expansion of multiple Eisenstein series described in Sect. 3.2 we consider the following construction.
Construction 6.8
Given a  -algebra \((A,\cdot )\) and a family of homomorphism
-algebra \((A,\cdot )\) and a family of homomorphism
from \((\mathfrak H^1, *)\) to \((A,\cdot )\), we define for \(w \in \mathfrak H^1\) and \(M \in \mathbb {N}\)
where l(w) denotes the length of the word w and \(w_1 \dots w_k = w\) is a decomposition of w into k words in \(\mathfrak H^1\).
Proposition 6.9
([3, Proposition 6.8]) For all \(M \in \mathbb {N}\) the assignment \(w \mapsto F_w(M)\), described above, determines an algebra homomorphism from \((\mathfrak H^1, *)\) to \((A,\cdot )\). In particular \(\left\{ w \mapsto F_w(m) \right\} _{m \in \mathbb {N}}\) is again a family of homomorphism as used in Construction 6.8.
For a word \(w=z_{s_1} \dots z_{s_l} \in \mathfrak H^1\) we also write in the following \(f_{s_1,\dots ,s_l}(m):=f_w(m)\) and similarly \( F_{s_1,\dots ,s_l}(M):=F_w(M)\).
Example 6.10
Let \(f_w(m)\) be as in Construction 6.8. In small lengths the \(F_w\) are given by
and one can check directly by the use of the stuffle product for the \(f_w\) that
Let us now give an explicit example for maps \(f_w\) in which we are interested. Recall (Definition 3.5) that for integers \(s_1,\dots ,s_l \ge 2\) we defined the multitangent function by
In [12], where these functions were introduced, the author uses the notation \(\mathscr {T}e^{s_1,\ldots ,s_l}(z)\) which corresponds to our notation \(\varPsi _{s_1,\ldots ,s_l}(z)\). It was shown there that the series \(\varPsi _{s_1,\ldots ,s_l}(z)\) converges absolutely when \(s_1,\ldots ,s_l\ge 2\). These functions fulfill (for the cases they are defined) the stuffle product. As explained in Sect. 3.2 the multitangent functions appear in the calculation of the Fourier expansion of the multiple Eisenstein series \(G_{s_1,\dots ,s_l}\), for example in length two it is
One nice result of [12] is a regularization of the multitangent function to get a definition of \(\varPsi _{s_1,\ldots ,s_l}(z)\) for all \(s_1,\dots ,s_l \in \mathbb {N}\). We will use this result together with the above construction to recover the Fourier expansion of the multiple Eisenstein series.
Theorem 6.11
([12]) For all \(s_1,\dots ,s_l \in \mathbb {N}\) there exist holomorphic functions \(\varPsi _{s_1,\dots ,s_l}\) on \(\mathbb {H}\) with the following properties
-
(i)
Setting \(q=e^{2\pi i \tau }\) for \(\tau \in \mathbb {H}\) the map \(w \mapsto \varPsi _w(\tau )\) defines an algebra homomorphism from \((\mathfrak H^1, *)\) to \((\mathbb {C}[\![q]\!],\cdot )\).
-
(ii)
In the case \(s_1,\dots ,s_l \ge 2\) the \(\varPsi _{s_1,\dots ,s_l}\) are given by the multitangent functions in Definition 3.5.
-
(iii)
The monotangents functions have the q-expansion given by
$$\begin{aligned} \varPsi _1(\tau )&= \frac{\pi }{\tan (\pi \tau )} = (-2 \pi i)\left( \frac{1}{2} + \sum _{n>0} q^n \right) \end{aligned}$$and for \(k\ge 2\) by
$$\begin{aligned} \varPsi _k(\tau )&= \frac{(-2\pi i)^k}{(k-1)!} \sum _{n>0} n^{k-1} q^n\,. \end{aligned}$$ -
(iv)
(Reduction into monotangent function) Every \(\varPsi _{s_1,\dots ,s_l}(\tau )\) can be written as a \({{\,\mathrm{\mathscr {Z}}\,}}\)-linear combination of monotangent functions. There are explicit \(\epsilon ^{s_1,\dots ,s_l}_{i,k} \in {{\,\mathrm{\mathscr {Z}}\,}}\) s.th.
$$\begin{aligned} \varPsi _{s_1,\dots ,s_l}(\tau ) = \delta ^{s_1,\dots ,s_l} + \sum _{i=1}^l \sum _{k=1}^{s_i} \epsilon ^{s_1,\dots ,s_l}_{i,k} \varPsi _k(\tau ) \,, \end{aligned}$$where \( \delta ^{s_1,\dots ,s_l} = \frac{(\pi i)^l}{l!}\) if \(s_1=\dots =s_l=1\) and l even and \(\delta ^{s_1,\dots ,s_l} = 0\) otherwise. For \(s_1>1\) and \(s_l>1\) the sum on the right starts at \(k=2\), i.e. there are no \(\varPsi _1(\tau )\) appearing and therefore there is no constant term in the q-expansion.
Proof
This is just a summary of the results in Section 6 and 7 of [12]. The last statement (iv) is given by Theorem 6 in [12].
Due to iv) in the Theorem the calculation of the Fourier expansion of multiple Eisenstein series, where ordered sums of multitangent functions appear, reduces to ordered sums of monotangent functions. The connection of these sums to the brackets, i.e. to the functions g, is given by the following fact which can be seen by using iii) of the above Theorem. For \(n_1,\dots ,n_r \ge 2\) it is
For \(w \in \mathfrak H^1\) we now use the Construction 6.8 with \(A=\mathbb {C}[\![q]\!]\) and the family of homomorphism \(\{ w \mapsto \varPsi _w(n \tau ) \}_{n\in \mathbb {N}}\) (see Theorem 6.11 (i) ) to define
From Proposition 6.9 it follows that for all \(M\in \mathbb {N}\) the map \(\mathfrak {g}^{*,M}\) is an algebra homomorphism from \((\mathfrak H^1,*)\) to \(\mathbb {C}[\![q]\!]\).
To define stuffle regularized multiple Eisenstein series we need the following: For an arbitrary quasi-shuffle algebra  define the following coproduct for a word w
define the following coproduct for a word w
Then it is known due to Hoffman ([21]) that the space  has the structure of a bialgebra. With this we try to mimic the definition of the
has the structure of a bialgebra. With this we try to mimic the definition of the  and use the coproduct structure on the space \((\mathfrak H^1, *, \varDelta _H)\) to define for \(M\ge 0\) the function \(G^{*,M}\) and then take the limit \(M\rightarrow \infty \) to obtain the stuffle regularized multiple Eisenstein series. For this we consider the following diagram
and use the coproduct structure on the space \((\mathfrak H^1, *, \varDelta _H)\) to define for \(M\ge 0\) the function \(G^{*,M}\) and then take the limit \(M\rightarrow \infty \) to obtain the stuffle regularized multiple Eisenstein series. For this we consider the following diagram

with the above algebra homomorphism \(\mathfrak {g}^{*,M} : (\mathfrak H^1, *) \rightarrow \mathbb {C}[\![q]\!]\) and the map \(Z^*\) for stuffle regularized multiple zeta values given in Proposition 3.2.
Definition 6.12
For integers \(s_1,\ldots ,s_l\ge 1\) and \(M \ge 1\), we define the q-series \(G^{*,M}_{s_1,\ldots ,s_r}\in \mathbb {C}[\![q]\!]\) as the image of the word \(w= z_{s_1}\dots z_{s_l} \in \mathfrak H^1\) under the algebra homomorphism \((\mathfrak {g}^{*,M} \otimes Z^{*})\circ \varDelta _H\):
For \(s_1,\dots ,s_l \ge 2\) the limit
exists and we have  ([3, Proposition 6.13]).
([3, Proposition 6.13]).
Remark 6.13
The open question is for what general \(s_1,\dots ,s_l\) the limit in (28) exists. It is believed that this is exactly the case for \(s_1\ge 2\) and \(s_2,\dots ,s_l\ge 1\) as explained in Remark 6.14 in [3]. This would be the case if \(\varPsi _{1,\dots ,1}\) are the only multitangent functions with a constant term in the decomposition of Theorem 6.11 (iv). That this is the case is remarked, without a proof, in [13] in the last sentence of page 3.
Theorem 11
([3]) For all \(s_1,\dots ,s_l \in \mathbb {N}\) and \(M \in \mathbb {N}\) the \(G_{s_1,\dots ,s_l}^{*,M} \in \mathbb {C}[\![q]\!]\) have the following properties:
-
(i)
Their product can be expressed in terms of the stuffle product.
-
(ii)
In the case where the limit \(G^*_{s_1,\dots ,s_l} := \lim _{M\rightarrow \infty } G_{s_1,\dots ,s_l}^{*,M}\) exists, the functions \(G^*_{s_1,\dots ,s_l}\) are elements in \({{\,\mathrm{\mathscr {MZB}}\,}}\).
-
(iii)
For \(s_1,\dots ,s_l \ge 2\) the \(G^*_{s_1,\dots ,s_l}\) exist and equal the classical multiple Eisenstein series
$$\begin{aligned} G_{s_1,\dots ,s_l}(\tau ) = G^*_{s_1,\dots ,s_l}(\tau ) \,. \end{aligned}$$
6.4 Double Shuffle Relations for Regularized Multiple Eisenstein Series
By Theorem 6.7 we know that the product of two shuffle regularized multiple Eisenstein series  with \(s_1,\dots ,s_l \ge 1\) can be expressed by using the shuffle product formula. This means we can for example replace every \(\zeta \) by
with \(s_1,\dots ,s_l \ge 1\) can be expressed by using the shuffle product formula. This means we can for example replace every \(\zeta \) by  in the shuffle product (4) of multiple zeta values and obtain
in the shuffle product (4) of multiple zeta values and obtain

Due to Theorem 6.7 (iii) we know that  whenever \(s_1,\dots ,s_l \ge 2\). Since the product of two multiple Eisenstein series \(G_{s_1,\dots ,s_l}\) can be expressed using the stuffle product formula we also have
whenever \(s_1,\dots ,s_l \ge 2\). Since the product of two multiple Eisenstein series \(G_{s_1,\dots ,s_l}\) can be expressed using the stuffle product formula we also have

Combining (29) and (30) we obtain the relation  . In the following we will call these relations, i.e. the relations obtained by writing the product of two
. In the following we will call these relations, i.e. the relations obtained by writing the product of two  with \(s_1,\dots ,s_l \ge 2\) as the stuffle and shuffle product, restricted double shuffle relations.
with \(s_1,\dots ,s_l \ge 2\) as the stuffle and shuffle product, restricted double shuffle relations.
We know that multiple zeta values fulfill even more linear relations, in particular we can express the product of two multiple zeta values \(\zeta (s_1,\dots ,s_l)\) in two different ways whenever \(s_1\ge 2\) and \(s_2,\dots ,s_l\ge 1\). A natural question therefore is, in which cases the  also fulfill these additional relations. The answer to this question is that some are satisfied and some are not, as the following will show.
also fulfill these additional relations. The answer to this question is that some are satisfied and some are not, as the following will show.
In [3, Example 6.15] it is shown that  ,
,  ,
,  and
and  . Since the product of two \(G^*\) can be expressed using the stuffle product we obtain
. Since the product of two \(G^*\) can be expressed using the stuffle product we obtain

Using also the shuffle product to express  we obtain a linear relation in weight 5 which is not covered by the restricted double shuffle relations. This linear relation was numerically observed in [9] but could not be proven there. So far it is not known exactly which products of the
we obtain a linear relation in weight 5 which is not covered by the restricted double shuffle relations. This linear relation was numerically observed in [9] but could not be proven there. So far it is not known exactly which products of the  can be written in terms of stuffle products.
can be written in terms of stuffle products.
We end this section by comparing different versions of the double shuffle relations and explain, why multiple Eisenstein series can’t fulfill every double shuffle relation of multiple zeta values. For this we write for words \(u,v \in \mathfrak H^1\)

Recall that by \(\mathfrak H^0\) we denote the algebra of all admissible words, i.e.  . Additionally we set
. Additionally we set  to be the span of all words in \(\mathfrak H^1\) with no \(z_1\) occurring, i.e. the words for which the multiple Eisenstein series G exists. These are also the words for which the product of two multiple Eisenstein series can be expressed as the shuffle and stuffle product by Theorem 6.7. Denote by \(|w| \in \mathfrak H^1\) the length of the word w with respect to the alphabet \(\{x , y\}\) and define
to be the span of all words in \(\mathfrak H^1\) with no \(z_1\) occurring, i.e. the words for which the multiple Eisenstein series G exists. These are also the words for which the product of two multiple Eisenstein series can be expressed as the shuffle and stuffle product by Theorem 6.7. Denote by \(|w| \in \mathfrak H^1\) the length of the word w with respect to the alphabet \(\{x , y\}\) and define
Also set \({{\,\mathrm{\textsf {eds}}\,}}= \bigcup _{k>0} {{\,\mathrm{\textsf {eds}}\,}}_k\) and similarly \({{\,\mathrm{\textsf {fds}}\,}}\) and \({{\,\mathrm{\textsf {rds}}\,}}\). These spaces can be seen as the words in \(\mathfrak H^0\) corresponding to the extendedFootnote 9-, finite- and the restricted double shuffle relations. We have the inclusions
View \(\zeta \) as a map \(\mathfrak H^0 \rightarrow {{\,\mathrm{\mathscr {Z}}\,}}\) by sending the word \(z_{s_1} \dots z_{s_l}\) to \(\zeta (s_1,\dots ,s_l)\). It is known ([24, Theroem 2]), that \({{\,\mathrm{\textsf {eds}}\,}}_k\) is in the kernel of the map \(\zeta \) and it is expected (Statement (3) after Conjecture 1 in [24]) that actually \({{\,\mathrm{\textsf {eds}}\,}}_k = \ker (\zeta )\). Viewing  in a similar way as a map \(\mathfrak H^0 \rightarrow {{\,\mathrm{\mathscr {MZB}}\,}}\), we know that \({{\,\mathrm{\textsf {rds}}\,}}_k\) is contained in the kernel of this map (Theorem 6.7 (iv)). But due to (31) we also have
in a similar way as a map \(\mathfrak H^0 \rightarrow {{\,\mathrm{\mathscr {MZB}}\,}}\), we know that \({{\,\mathrm{\textsf {rds}}\,}}_k\) is contained in the kernel of this map (Theorem 6.7 (iv)). But due to (31) we also have  which is not an element of \({{\,\mathrm{\textsf {rds}}\,}}_5\). In [2] Example 6.15 ii) it is shown that there are also elements in \({{\,\mathrm{\textsf {fds}}\,}}_k \subset {{\,\mathrm{\textsf {eds}}\,}}_k\), that are not in the kernel of
which is not an element of \({{\,\mathrm{\textsf {rds}}\,}}_5\). In [2] Example 6.15 ii) it is shown that there are also elements in \({{\,\mathrm{\textsf {fds}}\,}}_k \subset {{\,\mathrm{\textsf {eds}}\,}}_k\), that are not in the kernel of  . We therefore expect
. We therefore expect

and the above examples show, that it seems to be crucial to understand for which indices we have  to answer these questions.
to answer these questions.
We now discuss applications of the extended double shuffle relations to the classical theory of (quasi-)modular forms. As we have seen in the introduction it is known due to Euler that
In the following, we want to show how to prove these relations using extended double shuffle relations and argue why for multiple Eisenstein series the second is fulfilled but the first and the last equation of (32) are not.
-
(i)
The relation \(\zeta (2)^2 = \frac{5}{2} \zeta (4)\) can be proven in the following way by using double shuffle relations. It is \(z_2 *z_2 = 2 {{\,\mathrm{ds}\,}}(z_3,z_1) - \frac{1}{2} {{\,\mathrm{ds}\,}}(z_2,z_2) + \frac{5}{2} z_4\), since
$$\begin{aligned} {{\,\mathrm{ds}\,}}(z_3, z_1)&= z_3 z_1 + z_2 z_2 - z_4\,,\\ {{\,\mathrm{ds}\,}}(z_2, z_2)&= 4 z_3 z_1 - z_4 \,,\\ z_2 *z_2&= 2 z_2 z_2 + z_4\,. \end{aligned}$$Applying the map \(\zeta \) we therefore deduce
$$\begin{aligned} \zeta (2)^2 = \zeta (z_2 *z_2) = \zeta \left( 2 {{\,\mathrm{ds}\,}}(z_3,z_1) - \frac{1}{2} {{\,\mathrm{ds}\,}}(z_2,z_2) + \frac{5}{2} z_4\right) = \frac{5}{2}\zeta (4) \,. \end{aligned}$$This relation is not true for Eisenstein series. Though \({{\,\mathrm{ds}\,}}(z_2,z_2)\) is in the kernel of
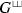 the element \({{\,\mathrm{ds}\,}}(z_3,z_1)\) is not. In fact, using the explicit formula for the Fourier expansion of
the element \({{\,\mathrm{ds}\,}}(z_3,z_1)\) is not. In fact, using the explicit formula for the Fourier expansion of  and
and  together with Proposition 4.12 for \( {\text {d}}[2]\) we obtain
together with Proposition 4.12 for \( {\text {d}}[2]\) we obtain  , where as before \( {\text {d}}= q \frac{d}{dq}\). Using this we get
, where as before \( {\text {d}}= q \frac{d}{dq}\). Using this we get 
This is a well-known fact in the theory of quasi-modular forms ([36]).
-
(ii)
Similarly to the above example one can prove the relation \( \zeta (4)^2 = \frac{7}{6} \zeta (8)\) by checking that
$$\begin{aligned} z_4 *z_4 = \frac{2}{3} {{\,\mathrm{ds}\,}}(z_4,z_4) - \frac{1}{2} {{\,\mathrm{ds}\,}}(z_3,z_5) + \frac{7}{6} z_8 \end{aligned}$$and since
 we also derive \({G_4}^2 = \frac{7}{6} G_8\) by applying the map
we also derive \({G_4}^2 = \frac{7}{6} G_8\) by applying the map  to this equation.
to this equation. -
(iii)
To prove the relation \(\zeta (6)^2 = \frac{715}{691} \zeta (12)\) in addition to the double shuffles of the form \({{\,\mathrm{ds}\,}}(z_a,z_b)\) double shuffles of the form \({{\,\mathrm{ds}\,}}(z_a z_b, z_c)\) are needed as well. This follows indirectly from the results obtained in [19]. Using the computer one can check that
$$\begin{aligned} z_6 *z_6 = 2 z_6 z_6 + z_{12} =\frac{715}{691} z_{12} + \frac{1}{2^2 \cdot 19 \cdot 113 \cdot 691} \cdot (R + E) \end{aligned}$$with \(R \in {{\,\mathrm{\textsf {rds}}\,}}_{12}\) and \(E \in {{\,\mathrm{\textsf {eds}}\,}}_{12} \backslash {{\,\mathrm{\textsf {rds}}\,}}_{12}\) being the quite complicated elements
$$\begin{aligned} R&= \,2005598{{\,\mathrm{ds}\,}}(z_6,z_6)-8733254{{\,\mathrm{ds}\,}}(z_7,z_5)+8128450{{\,\mathrm{ds}\,}}(z_8,z_4)+5121589{{\,\mathrm{ds}\,}}(z_9,z_3)\\&+16364863{{\,\mathrm{ds}\,}}(z_{10},z_2)+2657760{{\,\mathrm{ds}\,}}(z_2 z_8, z_2)+5220600{{\,\mathrm{ds}\,}}(z_3 z_7, z_2)\\&+12711531{{\,\mathrm{ds}\,}}(z_4 z_6 , z_2)+10460184{{\,\mathrm{ds}\,}}(z_5 z_5, z_2)+18601119{{\,\mathrm{ds}\,}}(z_6 z_4, z_2)\\&+33877826{{\,\mathrm{ds}\,}}(z_7 z_3 , z_2)+39496002{{\,\mathrm{ds}\,}}(z_8 z_2, z_2)-13288800{{\,\mathrm{ds}\,}}(z_2 z_2, z_8)\\&-5220600{{\,\mathrm{ds}\,}}(z_2 z_7 , z_3)-5734750{{\,\mathrm{ds}\,}}(z_3 z_6 , z_3)-84659{{\,\mathrm{ds}\,}}(z_4 z_5 , z_3)\\&+2820467{{\,\mathrm{ds}\,}}(z_5 z_4, z_3)-5486485{{\,\mathrm{ds}\,}}(z_6 z_3 , z_3)+8462489{{\,\mathrm{ds}\,}}(z_7 z_2 , z_3)\\&-6067131{{\,\mathrm{ds}\,}}(z_2 z_6 , z_4)-7532671{{\,\mathrm{ds}\,}}(z_3 z_5 , z_4)-10879336{{\,\mathrm{ds}\,}}(z_4 z_3 , z_5)\\&-5151234{{\,\mathrm{ds}\,}}(z_4 z_4, z_4)+3440519{{\,\mathrm{ds}\,}}(z_5 z_3 , z_4)-1458819{{\,\mathrm{ds}\,}}(z_6 z_2 , z_4)\\&+2259096{{\,\mathrm{ds}\,}}(z_5 z_2, z_5)-4319105{{\,\mathrm{ds}\,}}(z_3 z_4 , z_5)-778598{{\,\mathrm{ds}\,}}(z_5 z_2 , z_5)\\&+7609581{{\,\mathrm{ds}\,}}(z_2 z_4, z_6)+13064898{{\,\mathrm{ds}\,}}(z_3 z_3 , z_6)-1281420{{\,\mathrm{ds}\,}}(z_3 z_2, z_7) \,, \\ E&= -22681134 {{\,\mathrm{ds}\,}}(z_{11},z_1)+10631040{{\,\mathrm{ds}\,}}(z_3 z_8, z_1)+4241200{{\,\mathrm{ds}\,}}(z_7 z_1, z_4) \\&+31893120{{\,\mathrm{ds}\,}}(z_4 z_7, z_1)+58185960{{\,\mathrm{ds}\,}}(z_5 z_6, z_1)+78309000{{\,\mathrm{ds}\,}}(z_6 z_5, z_1)\\&+77976780{{\,\mathrm{ds}\,}}(z_7 z_4, z_1)+44849700{{\,\mathrm{ds}\,}}(z_8 z_3, z_1)-13288800{{\,\mathrm{ds}\,}}(z_9 z_2, z_1)\\&-15946560{{\,\mathrm{ds}\,}}(z_{10} z_1, z_1)+75052824{{\,\mathrm{ds}\,}}(z_9 z_1 , z_2)+19477164{{\,\mathrm{ds}\,}}(z_8 z_1 , z_3)\\&-12951740{{\,\mathrm{ds}\,}}(z_6 z_1 , z_5)-10631040{{\,\mathrm{ds}\,}}(z_2 z_1 , z_9) \, \end{aligned}$$Here the elements E and R are in the kernel of \(\zeta \) but E, in contrast to R, is not in the kernel of
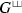 . The defect here is given by the cusp form \(\varDelta \) in weight 12 as one can derive
. The defect here is given by the cusp form \(\varDelta \) in weight 12 as one can derive 
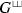 the element
the element  and
and  together with Proposition
together with Proposition  , where as before
, where as before 
 we also derive
we also derive  to this equation.
to this equation.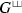 . The defect here is given by the cusp form
. The defect here is given by the cusp form 
It is still an open problem how to derive these Euler relations in general by using double shuffle relations. The last example shows that this also seems to be very complicated. But as the examples above show, this might be of great interest to understand the connection of modular forms and multiple zeta values. This together with the question which double shuffle relations are fulfilled by multiple Eisenstein series will be considered in upcoming works by the author.
7 q-Analogues of Multiple Zeta Values
In general, a q-analogue of an mathematical object is a generalization involving a new parameter q that returns the original object in the limit as \(q\rightarrow 1\). The easiest example of such an generalization is the q-analogue of a natural number \(n \in \mathbb {N}\) given by
Clearly this gives back the original number n as \(\lim _{q \rightarrow 1} [n]_q = n\).
Several different models for q-analogues of multiple zeta values have been studied in recent years. A good overview of them can be found in [39]. There are different motivations to study q-analogues of multiple zeta values.
That our brackets can be seen as q-analogue of multiple zeta values somehow occurred by accident since their original motivation was their appearance in the Fourier expansion of multiple Eisenstein series. But as turned out, seeing them as q-analogues gives a direct connection to multiple zeta values. In this section we first show how the brackets can be seen as a q-analogue of multiple zeta values and then discuss how one can obtain relations between multiple zeta values using the results obtained in [6]. The second section will be devoted to connecting the brackets to other q-analogues.
7.1 Brackets as q-Analogues of MZV and the Map \(Z_k\)
Define for \(k\in \mathbb {N}\) the map  by
by
Since we have seen that the brackets can be written as
and using \(P_{k-1}(1) = (k-1)!\) and interchanging the summation and the limit we derive ([6, Proposition 6.4]), that for \(s_1>1\), i.e. \([s_1,\dots ,s_l] \in {{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}\)
Due to \({{\,\mathrm{\mathscr {MD}}\,}}= {{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}[\,[1]\,]\) (Theorem 4.11) we can define a well-defined mapFootnote 10 on the whole space \({{\,\mathrm{\mathscr {MD}}\,}}\) by
where \(g_j \in {\text {Fil}}^{{\text {W}}}_{j}({{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}})\).
Every relation between multiple zeta values of weight k is contained in the kernel of the map \(Z_k\). Therefore the kernel of \(Z_k\) was studied in [6].
Theorem 7.1
([6, Theroem 1.13]) For the kernel of \(Z^{alg}_k \in {\text {Fil}}^{{\text {W}}}_{k}({{\,\mathrm{\mathscr {MD}}\,}})\) we have
-
(i)
If for \([s_1,\dots ,s_l]\) it holds \(s_1+\dots +s_l<k\), then \(Z_k^{alg}[s_1,\dots , s_l]=0\).
-
(ii)
For any \(f \in {\text {Fil}}^{{\text {W}}}_{k-2}({{\,\mathrm{\mathscr {MD}}\,}}) \) we have \(Z_k^{alg} {\text {d}}(f)=0\), i.e., \( {\text {d}} {\text {Fil}}^{{\text {W}}}_{k-2}({{\,\mathrm{\mathscr {MD}}\,}})\subseteq \ker Z_k\).
-
(iii)
If \(f \in {\text {Fil}}^{{\text {W}}}_{k}({{\,\mathrm{\mathscr {MD}}\,}})\) is a cusp form for \({{\,\mathrm{SL}\,}}_2(\mathbb {Z})\), then \(Z_k^{alg}(f)=0\).
Example 7.2
We illustrate some applications for Theorem 7.1. For this we recall identities for the derivatives and relations of brackets as they were given in [6]. All of them can be obtained by using the results explained in Sect. 4.
Using Theorem 7.1 as immediate consequences and without any difficulties we recover the following well-known identities for multiple zeta values.
-
(i)
If we apply \(Z_3\) to (33) we deduce \(\zeta (3)=\zeta (2,1)\).
-
(ii)
If we apply \(Z_4\) to (34) and (35) we deduce \(\zeta (4)= 4 \zeta (3,1) = \frac{4}{3} \zeta (2,2)\).
-
(iii)
The identity (36) reads in \({{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}[\,[1]\,]\) as
$$ {\text {d}}[1,1]= \left( [3]-[2,1]+\frac{1}{2}[2]\right) \cdot [1] + 2 [3,1] - \frac{1}{2}[4] - \frac{1}{2}[2,1] - \frac{1}{2}[3] + \frac{1}{3}[2]\,.\,$$Applying \(Z^{alg}_4\) we deduce again the two relations \(\zeta (3)=\zeta (2,1)\) and \(4\zeta (3,1)=\zeta (4)\), since by Theorem 7.1 we have
$$\begin{aligned} Z^{alg}_4( {\text {d}}[1,1])=\left( \zeta (3) - \zeta (2,1) \right) T - \frac{1}{2}\zeta (4) + 2 \zeta (3,1) = 0 \,. \end{aligned}$$ -
(iv)
If we apply \(Z_8\) to (37) we deduce \(\zeta (8)= 12 \zeta (4,4)\).
-
(v)
As we have seen in Proposition 4.13 the cusp form \(\varDelta \) can be written as
$$\begin{aligned} -\frac{1}{2^6\cdot 5 \cdot 691} \varDelta&= 168 [5,7]+150 [7,5]+28 [9,3] \nonumber \\&+\frac{1}{1408} [2] - \frac{83}{14400}[4] +\frac{187}{6048} [6] - \frac{7}{120} [8] - \frac{5197}{691} [12] \,. \end{aligned}$$(38)Letting \(Z_{12}\) act on both sides of (38) one obtains the relation (6)
$$\begin{aligned} \frac{5197}{691} \zeta (12) = 168 \zeta (5,7)+150 \zeta (7,5) + 28 \zeta (9,3) \,. \end{aligned}$$
But as mentioned in the introduction there are also elements in the kernel of \(Z_k\) that are not covered by Theorem 7.1. In weight 4 one has the following relation of multiple zeta values \(\zeta (4) = \zeta (2,1,1)\), i.e. it is \([4] - [2,1,1] \in \ker Z_4\). But this element can’t be written as a linear combination of cusp forms, lower weight brackets or derivatives. But using the double shuffle relations for bi-brackets described in Sect. 5.2 one can proveFootnote 11 that
Another way to see that many of the bi-brackets of weight k are in the kernel of the map \(Z_k\) is the following. Assume that \(s_1 > r_1+1\) and \(s_j \ge r_j + 1\) for \(j=2, \dots , l\), then using again the representation with the Eulerian polynomials (See also Proposition 1 [41]) we get
and in particular with this assumption it is \(\genfrac[]{0.0pt}{}{s_1,\dots ,s_l}{r_1,\dots ,r_l} \in \ker Z_{s_1+\dots +s_l+1}\).
The study of the kernel \(Z_k\) is of great interest since it contains every relation of weight k. We expect that every element in the kernel of \(Z_k\) can be described using bi-brackets of a “certain kind” and it seems to be a really interesting question to specify this “certain kind” explicitly. To determine which bi-brackets are exactly in the kernel of the map \(Z_k\) and also which bi-brackets can be written in terms of brackets in \({{\,\mathrm{q\mathscr {M}\mathscr {Z}}\,}}\) is an open problem. The naive guess, that exactly the bi-brackets \(\genfrac[]{0.0pt}{}{s_1,\dots ,s_l}{r_1,\dots ,r_l}\) where at least one \(r_j >0\) are elements in the kernel of \(Z_{s_1+\dots +s_l+r_1+\dots +r_l}\) is wrong, since for example
7.2 Connection to Other q-Analogues
In [39] the author gives an overview over several different q-analogues of multiple zeta values. Here we complement his work and focus on aspects related to our brackets. To compare the brackets to other q-analogues we first generalize the notion of a q-analogue of multiple zeta values as it was done in [7]. This notion of a q-analogue does cover many but not all q-analogues described in [39].
In the following we fix a subset \(S \subset \mathbb {N}\), which we consider as the support for index entries, i.e. we assume \(s_1,\dots ,s_l \in S\). For each \(s\in S\) we let  be a polynomial with \(Q_s(0)=0\) and \(Q_s(1) \ne 0\). We set \(Q = \left\{ Q_s(t) \right\} _{s\in S}\). A sum of the form
be a polynomial with \(Q_s(0)=0\) and \(Q_s(1) \ne 0\). We set \(Q = \left\{ Q_s(t) \right\} _{s\in S}\). A sum of the form
with polynomials \(Q_s\) as before, defines a q-analogue of a multiple zeta-value of weight \(k=s_1+ \dots +s_l\) and length l. Observe only because of \(Q_{s_1}(0)=0\) this defines an element of  . That these objects are in fact a q-analogue of a multiple zeta-value is justified by the following calculation.
. That these objects are in fact a q-analogue of a multiple zeta-value is justified by the following calculation.
Here we used that \( \lim \limits _{q \rightarrow 1}{ (1-q)^{s}/(1-q^{n})^{s} = 1/n^s }\) and with the same arguments as in [6] Proposition 6.4, the above interchange of the limit with the sum can be justified for all \((s_1,...,s_l)\) with \(s_1 > 1\). Related definitions for q-analogues of multiple zeta values are given in [14, 28, 33, 42]. It is convenient to define \(Z_Q(\emptyset )=1\) and then we denote the vector space spanned by all these elements by

Note by the above convention we have, that  is contained in this space.
is contained in this space.
Lemma 7.3
([7, Lemma 2.1]) If for each \(r,s \in S\) there exists numbers  such that
such that
then the vector space Z(Q, S) is a  -algebra.
-algebra.
Theorem 7.4
([7, Theroem 2.4]) Let \(Z(Q,\mathbb {N}_{>1})\) be any family of q-analogues of multiple zeta values as in (41), where each \(Q_s(t) \in Q\) is a polynomial with degree at most \(s-1\), then
where \({{\,\mathrm{\mathscr {MD}}\,}}^\sharp \) was the in Sect. 4.2 defined subalgebra of \({{\,\mathrm{\mathscr {MD}}\,}}\) spanned by all brackets \([s_1,\dots ,s_l]\) with \(s_j \ge 2\). Therefore, all such families of q-analogues of multiple zeta values are  -subalgebras of \({{\,\mathrm{\mathscr {MD}}\,}}\).
-subalgebras of \({{\,\mathrm{\mathscr {MD}}\,}}\).
The following proposition allows one to write an arbitrary element in \(Z(Q,\mathbb {N}_{>1})\) as an linear combination of \([s_1,\dots ,s_l] \in {{\,\mathrm{\mathscr {MD}}\,}}^\sharp \).
Proposition 7.5
([7, Proposition 2.5]) Assume \(k\ge 2\). For \(1 \le i,j \le k-1\) define the numbers  by
by
With this it is for \(1 \le i \le k-1\) and \(Q^E_{j}(t) = \frac{1}{(j-1)!} t P_j(t)\)
We give some examples of q-analogues of multiple zeta values, with some being of the above type.
(i) To write the brackets in the above way we choose \(Q^E_s(t) = \frac{1}{(s-1)!} t P_{s-1}(t)\), where the \(P_s(t)\) are the Eulerian polynomials defined earlier by
for \(s\ge 0\). With this we have for all \(s_1,\dots ,s_l \in \mathbb {N}\)
and \({{\,\mathrm{\mathscr {MD}}\,}}= Z( \{Q^E_s(t))\}_{s},\mathbb {N})\).
(ii) The polynomials \(Q_s^T(t) = t^{s-1}\) are considered in [33, 42] and sums of the form (40) with \(s_1>1\) and \(s_2, \dots ,s_l \ge 1\) are studied there. Using Proposition 7.5 every q-analogue of this type can be written explicitly in terms of brackets.
(iii) Okounkov chooses the following polynomials in [27]
and defines for \(s_1,\dots ,s_l \in S=\mathbb {N}_{>1}\)
We write for the space of the Okounkov q-multiple zetas
Due to Theorem 7.4 we have \({{\,\mathrm{\textsf {qMZV}}\,}}= {{\,\mathrm{\mathscr {MD}}\,}}^\sharp \). In [27] Okounkov conjectures, that the space \({{\,\mathrm{\textsf {qMZV}}\,}}\) is closed under the operator \( {\text {d}}\). In length 1 this is proven in Proposition 2.9 [7].
(iv) There are also q-analogues which are not of the type as in (40). For example, the model introduced in [28] and further studied in [18]. For \(s_1,\dots ,s_l\ge 1\) they are define by
It is easy to see, that every \(\mathfrak {z}_q(s_1,\dots ,s_l)\) can be written in terms of bi-brackets. For example
Similarly one can prove \(\mathfrak {z}_q(2,1,1) = [2,1,1]-2[2,1]+ \genfrac[]{0.0pt}{}{2,1}{1,0} + \genfrac[]{0.0pt}{}{2}{2} - \frac{3}{2} \genfrac[]{0.0pt}{}{2}{1} + [2]\). For higher weights this also works as illustrated in the following
Using again Proposition 7.5 it becomes clear for arbitrary weights \(s_1,\dots ,s_l \ge 2\) we can write \(\mathfrak {z}_q(s_1,\dots ,s_l)\) in terms of bi-brackets.
Writing any q-analogue in terms of bi-brackets enables us to use the double shuffle structure explained in Sect. 5 to obtain linear relations for all of these q-analogues. Though it might be difficult to compare our double shuffle relations to the double shuffle relations of other models. For example in the case of \(\mathfrak {z}_q(s_1,\dots ,s_l)\) the authors in [18] consider \(s_1,\dots ,s_l \in \mathbb {Z}\) to describe their double shuffle relations. See [8] for further details on the comparison between different models of q-analogues and bi-brackets.
Notes
- 1.
Some authors use the opposite convention \(0< n_1<\dots < n_l\) in the definition of multiple zeta values. This is in particular the case for the work [9], where this opposite convention is used for multiple zeta values and multiple Eisenstein series.
- 2.
- 3.
For convenience we recall that the Bernoulli numbers \(B_k\) are defined by \(\frac{X}{e^X-1} =: \sum _{k\ge 0} \frac{B_k}{k!}X^k\).
- 4.
We set \([s_1,\dots ,s_l] =1\) for \(l=0\).
- 5.
- 6.
Here \(\delta _{a,b}\) denotes the Kronecker delta, i.e \(\delta _{a,b}\) is 1 for \(a=b\) and 0 otherwise.
- 7.
If one likes to interpret the integrals as real integrals, then the passage from \(\mathscr {I}\) to \(\mathscr {I}^1\) regularizes these integrals such that “\(-\log (0) = \int _{1> t > 0} \frac{dt}{t} := 0\)”.
- 8.
This notion fits well with the iterated integral expression of multiple zeta values. Recall that
$$\begin{aligned} \zeta (2,3) = \int _{{\small 1> t_1> \dots> t_5 > 0}} \underbrace{\frac{dt_1}{t_1} \cdot \frac{dt_2}{1-t_2}}_{2} \cdot \underbrace{ \frac{dt_3}{t_3}\cdot \frac{dt_4}{t_4} \cdot \frac{dt_5}{1-t_5}}_{3} \,. \end{aligned}$$This corresponds to I(2, 3) (but is of course not the same since the I are formal symbols).
- 9.
In [24] the authors introduced the notion of extended double shuffle relations. We use this notion here for smaller subset of these relations given there as the relations described in statement (3) on page 315.
- 10.
- 11.
That the last term \(\genfrac[]{0.0pt}{}{2,1}{1,0}\) in (39) is in the kernel of \(Z_4\) can be proven in the following way: In Proposition 7.2 [6] it is shown, that an element \(f = \sum _{n>0} a_n q^n\) with \(a_n = O(n^m)\) and \(m<k-1\) is in the kernel of \(Z_k\). Here we have
$$\begin{aligned} \genfrac[]{0.0pt}{}{2,1}{1,0} = \sum _{\begin{array}{c} u_1> u_2> 0\\ v_1 , v_2> 0 \end{array}} v_1 u_1 q^{v_1 u_1 + v_2 u_2} < \sum _{\begin{array}{c} u_1,u_1 0\\ v_1 , v_2 > 0 \end{array}} v_1 u_1 q^{v_1 u_1 + v_2 u_2} = {\text {d}}[1] \cdot [1]\,, \end{aligned}$$where the < is meant to be coefficient wise. Since the coefficients of \( {\text {d}}[1] \cdot [1]\) grow like \(n^2 \log (n)^2\) we conclude \(\genfrac[]{0.0pt}{}{2,1}{1,0} \in \ker Z_4\).
References
Andrews, G., Rose, S.: MacMahon’s sum-of-divisors functions, Chebyshev polynomials, and Quasi-modular forms. J. Reine Angew. Math. 676, 97–103 (2013)
Bachmann, H.: Multiple Zeta-Werte und die Verbindung zu Modulformen durch multiple Eisensteinreihen. Master thesis, Hamburg University (2012). http://www.henrikbachmann.com
Bachmann, H.: The algebra of bi-brackets and regularized multiple Eisenstein series. J. Number Theory 200, 260–294 (2019)
Bachmann, H.: Multiple Eisenstein series and \(q\)-analogues of multiple zeta values. Thesis, Hamburg University (2015). http://www.henrikbachmann.com
Bachmann, H.: Double shuffle relations for q-analogues of multiple zeta values, their derivatives and the connection to multiple Eisenstein series. RIMS Kôyûroku 2017, 22–43 (2015)
Bachmann, H., Kühn, U.: The algebra of generating functions for multiple divisor sums and applications to multiple zeta values. Ramanujan J. 40(3), 605–648 (2016)
Bachmann, H., Kühn, U.: A short note on a conjecture of Okounkov about a \(q\)-analogue of multiple zeta values. arXiv:1309.3920 [math.NT]
Bachmann, H., Kühn, U.: A dimension conjecture for \(q\)-analogues of multiple zeta values. In This Volume
Bachmann, H., Tasaka, K.: The double shuffle relations for multiple Eisenstein series. Nagoya Math. J. 230, 1–33 (2017)
Bachmann, H., Tsumura, H.: Multiple series of Eisenstein type. Ramanujan J. 42(2), 479–489 (2017)
Borwein, J., Bradley, D.: Thirty-two Goldbach variations. Int. J. Number Theory 02, 65–103 (2006)
Bouillot, O.: The algebra of multitangent functions. J. Algebra 410, 148–238 (2014)
Bouillot, O.: Table of reduction of multitangent functions of weight up to 10 (2012). http://www-igm.univ-mlv.fr/~bouillot/Tables_de_multitangentes.pdf
Bradley, D.M.: Multiple q-zeta values. J. Algebra 283, 752–798 (2005)
Broadhurst, D., Kreimer, D.: Association of multiple zeta values with positive knots via Feynman diagrams up to 9 loops. Phys. Lett. B 393, 403–412 (1997)
Ecalle, J.: The flexion structure and dimorphy: flexion units, singulators, generators, and the enumeration of multizeta irreducibles. In: Asymptotics in Dynamics, Geometry and PDEs, Generalized Borel Summation, vol. II, pp. 27–211 (2011)
Ebrahimi-Fard, K., Manchon, D., Singer, J.: Duality and (q-)multiple zeta values. Adv. Math. 298, 254–285 (2016)
Ebrahimi-Fard, K., Manchon, D., Medina, J.C.: Unfolding the double shuffle structure of q-multiple zeta values. Bull. Austral. Math. Soc. 91(3), 368–388 (2015)
Gangl, H., Kaneko, M., Zagier, D.: Double zeta values and modular forms. Automorphic Forms and Zeta Functions, pp. 71–106. World Science Publisher, Hackensack, NJ (2006)
Goncharov, A.B.: Galois symmetries of fundamental groupoids and noncommutative geometry. Duke Math. J. 128(2), 209–284 (2005)
Hoffman, M.E.: Quasi-shuffle products. J. Algebraic Combin. 11(1), 49–68 (2000)
Hoffman, M.E., Ihara, K.: Quasi-shuffle products revisited. J. Algebra 481, 293–326 (2017)
Ihara, K.: Derivation and double shuffle relations for multiple zeta values, joint work with M. Kaneko, D. Zagier. RIMS Kôyûroku 1549, 47–63
Ihara, K., Kaneko, M., Zagier, D.: Derivation and double shuffle relations for multiple zeta values. Compos. Math. 142, 307–338 (2006)
Ihara, K., Ochiai, H.: Symmetry on linear relations for multiple zeta values. Nagoya Math. J. 189, 49–62 (2008)
Kaneko, M., Tasaka, K.: Double zeta values, double Eisenstein series, and modular forms of level 2. Math. Ann. 357(3), 1091–1118 (2013)
Okounkov, A.: Hilbert schemes and multiple \(q\)-zeta values. Funct. Anal. Appl. 48, 138–144 (2014)
Ohno, Y., Okuda, J., Zudilin, W.: Cyclic \(q\)-MZSV sum. J. Number Theory 132(1), 144–155 (2012)
Qin, Z., Yu, F.: On Okounkov’s conjecture connecting Hilbert schemes of points and multiple q-zeta values. Int. Math. Res. Not. 2, 321–361 (2018)
Rose, S.: Quasi-modularity of generalized sum-of-divisors functions. Res. Number Theory 1, Art. 18, 11 pp (2015)
Schlesinger, K.-G.: Some remarks on q-deformed multiple polylogarithms. arXiv:math/0111022 [math.QA]
Singer, J.: On q-analogues of multiple zeta values. Funct. Approx. Comment. Math. 53(1), 135–165 (2015)
Takeyama, Y.: The algebra of a q-analogue of multiple harmonic series. SIGMA Symmetry Integrability Geom. Methods Appl. 9, Paper 061 (2013)
Yuan, H., Zhao, J.: Double shuffle relations of double zeta values and double Eisenstein series of level N. J. Lond. Math. Soc. (2) 92(3), 520–546 (2015)
Yuan, H., Zhao, J.: Multiple Divisor Functions and Multiple Zeta Values at Level N. arXiv:1408.4983 [math.NT]
Zagier, D.: Elliptic modular forms and their applications. The 1-2-3 of Modular Forms, pp. 1–103. Universitext Springer, Berlin (2008)
Zagier, D.: Periods of modular forms, traces of Hecke operators, and multiple zeta values. RIMS Kôyûroku 843, 162–170 (1993)
Zhao, J.: Multiple q-zeta functions and multiple q-polylogarithms. Ramanujan J. 14(2), 189–221 (2007)
Zhao, J.: Uniform approach to double shuffle and duality relations of various q-analogs of multiple zeta values via Rota-Baxter algebras. arXiv:1412.8044 [math.NT]
Zorich, A.: Flat surfaces. Frontiers in Number Theory, Physics, and Geometry, vol. I, Springer (2006)
Zudilin, W.: Multiple \(q\)-zeta brackets. Math. 3:1, Spec. Issue Math. Phys. 119–130 (2015)
Zudilin, W.: Algebraic relations for multiple zeta values, (Russian. Russian summary) Uspekhi Mat. Nauk 58 (2003)
Acknowledgements
This paper has served as the introductory part of my cumulative thesis written at the University of Hamburg. First of all I would like to thank my supervisor Ulf Kühn for his continuous, encouraging and patient support during the last years. Besides this I also want to thank several people for supporting me during my PhD project by whether giving me suggestion and ideas, letting me give talks on conferences and seminars, proof reading papers or having general discussions on this topic with me. A big “thank you” goes therefore to Olivier Bouillot, Kathrin Bringmann, David Broadhurst, Kurusch Ebrahimi-Fard, Herbert Gangl, José I. Burgos Gil, Masanobu Kaneko, Dominique Manchon, Nils Matthes, Martin Möller, Koji Tasaka, Don Zagier, Jianqiang Zhao and Wadim Zudilin. Finally I would like to thank the referee for various helpful comments and remarks.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Bachmann, H. (2020). Multiple Eisenstein Series and q-Analogues of Multiple Zeta Values. In: Burgos Gil, J., Ebrahimi-Fard, K., Gangl, H. (eds) Periods in Quantum Field Theory and Arithmetic. ICMAT-MZV 2014. Springer Proceedings in Mathematics & Statistics, vol 314. Springer, Cham. https://doi.org/10.1007/978-3-030-37031-2_8
Download citation
DOI: https://doi.org/10.1007/978-3-030-37031-2_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-37030-5
Online ISBN: 978-3-030-37031-2
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)