
Abstract
Music elements have been widely used to influence the audiences’ emotional experience by its music grammar. However, these domain knowledge, has not been thoroughly explored as music grammar for music emotion analyses in previous work. In this paper, we propose a novel method to analyze music emotion via utilizing the domain knowledge of music elements. Specifically, we first summarize the domain knowledge of music elements and infer probabilistic dependencies between different main musical elements and emotions from the summarized music theory. Then, we transfer the domain knowledge to constraints, and formulate affective music analysis as a constrained optimization problem. Experimental results on the Music in 2015 database and the AMG1608 database demonstrate that the proposed music content analyses method outperforms the state-of-the-art performance prediction methods.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
We are surrounded by digital music collections due to the popularity of the Internet and the proliferation of user friendly MP3 players. Since almost every piece of music is created to convey emotion, naturally, music emotion recognition has attracted increasing attention in recent years. Automatic emotion recognition from music pieces has wide potential application in both music creation and music distribution.

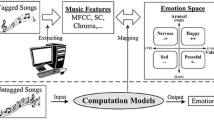
Music elements used by composers to communicate emotions to audiences
The framework of current research into music emotion recognition mainly consists of feature extraction and classification. First, various features, including timbre, rhythm and harmony, are extracted from music pieces. Then, a classifier, such as support vector machine, is used to classify music pieces into several discrete emotion categories, or a regressor, such as support vector regression, is adopted to predict continuous emotional dimensions, such as valence and arousal. An extensive review of emotion recognition from music can be found in [18].
Although various discriminative features and classifiers have been developed, automatic emotion recognition from music pieces is still a very challenging task due to the complexity and subjectivity of human emotions, and the rich variety of music content.
Almost all the current work on music emotion recognition focuses on developing discriminative features and classifiers. This kind of data-driven approach does not successfully exploit the domain knowledge of emotion and music, i.e. the inherent psychological relationship between human emotion and music, which carries crucial information for music emotion recognition.
Specifically, main musical dimensions, i.e., rhythm, tonality, timbre, dynamics and pitch are often used to affect users’ emotional experience. The tempo, mode, brightness, loudness and pitch can represent the five main musical dimensions respectively [10]. Figure 1 [15] summarized the relations between music elements and emotions. From Fig. 1, we can find that fast tempo is usually utilized to result in the arousal atmosphere, while the slow tempo is utilized to generate quiet environment [5,6,7,8]. Major mode can be used to induce happiness and excitement, and minor mode can create a more tense and sad music [13]. Brightness is related to arousal [6]. Higher brightness can be used to induce excitement and astonishment, while lower brightness can be used to induce sadness and softness. As for loudness, higher loudness can be used to induce anger, fear and excitement, and lower loudness can create a more relaxed and quiet music [6]. High pitch may lead to happiness, anger and fear, while low pitch may induce sadness [6]. Such inherent dependencies between music elements and emotions can be leveraged for emotion recognition from music, but have not been explored yet.
Therefore, in this paper, we propose a novel method to analyze musical emotion through exploring domain knowledge. As a primary study to explore music theory for music emotion analysis, this paper utilize main musical dimensional elements to demonstrate the superiority of the proposed music emotion analyses method enhanced via domain knowledge. Specifically, summarized in music theory, we first infer probabilistic relations between main musical dimensional elements and emotions. Then we transfer this probabilistic dependencies based on domain knowledge as a constrained optimization problem. In order to demonstrate the superiority of the proposed method, we conduct our experiments on two benchmark databases.
2 Domain Knowledge
Rhythm, tonality, timbre, dynamics are often used by composers to invoke emotions to audiences, which constitute musical main dimensions, audiences [9]. In this section, we introduce the dependencies between musical elements and emotions from the summarized music theory.
2.1 Rhythm
Tempo is one of the most import musical elements to affect the mood of audiences [5,6,7,8]. Generally, tempo express the rhythm and fluency of the music [9]. By changing the tempo, the composers can fully put the emotions into their music. Especially, as mentioned in [6], fast tempo is usually used to generate the exaggerated mood, which result in high arousal atmospheres. On the other hand, the slow tempo is utilized to generate quiet mood, which result in low arousal atmospheres.
From the perspective of the audiences, the perceived music tempo can well influence their feelings. Specifically, when receiving fast music tempo signals, people will intuitively associate with activity/excitement, happiness/joy/pleasantness, potency, surprise, flippancy, anger, uneasiness and fear. However, when perceiving slow-tempo music, people may be associated with calmness/serenity, peace, sadness, dignity/solemnity, tenderness, longing, boredom and disgust [6]. Thus the fast tempo music can induce high arousal from audiences, while slow tempo music can invoke low arousal from audiences.
Normally, the tempo are categorized into Largo (40–60 bpm), Adagio (66–76 bpm), Andante (76–10 bpm), Moderato (108–120 bpm) and Allegro (120–168) as shown in Table 1 [13]. Since the difference between slow tempo and intermediate tempo are not obvious, we adopt the 108 bpm as the threshold and categorize the tempo as fast tempo and slow tempo.
2.2 Tonality
In the composers’ perspective, musical tonality is one of the most important musical elements for music presentation. Since mode is a system of musical tonality involving a type of scale coupled with a set of characteristic melodic behaviors [13], composers control the musical tonality by adjusting the mode. Generally, the mode is scaled in to a heptationic scale, in which the first, third, and fifth scale degrees play important roles. As stated in [13], the mode is categorized into two groups: major mode and minor mode. Specifically, the major mode is constructed by adjusting the first, third, and fifth scale degrees with a major triad, while the minor mode is constructed by adjusting the first, third, and fifth scale degrees with a minor triad. In hands of the composers, they intend to present an audio of grace with major mode, while present an audio of anxiety and sad with minor mode. Thus, major mode is used for invoking high valence from the audiences, and minor mode is used to induce low valence. From the perspective of the audiences, studies also show that major mode is strongly correlated to grace, serene, and solemn, while minor mode is strongly correlated to dreamy, dignified, tension, disgust, and anger [8].
In this paper, we extract the mode features with the MIR toolbox, which ranges between −1 and +1. After obtaining the mode features, we adopt the median mode value as the threshold and categorized the audio clips into major mode and minor mode. Specifically, audio clips whose mode values are above the median are assigned as major mode while audio clips whose mode values are below the median are assigned as minor mode.
2.3 Timbre
Musical timbre denoted as brightness [17] is a powerful component in constructing the music piece. The composer usually express their music emotion with the audiences via different musical instruments and equalizer. Normally, in order to show joyful, angry or thrill atmosphere, the composer compose the music using a bright tone, while with depression or tender, compose the music with dull sound [6]. Thus, dull sound is utilized to deliver low valence while bright sound is utilized for delivering high valence. From the perspective of the psychology, while perceiving bright sound, the audience is more likely to feel the arousal emotion [16], e.g. excitement and astonishment. On the other hand, they feel sadness or softness after hearing dull sound.
In this paper, we extract the brightness features via measures the proportion of high frequency (over 1500 HZ) in the music piece. The formulation is shown as below:
where \(X_{above}\) represents component whose the energy above 1500 Hz, and \( X_{total}\) represents the total energy of the music.
2.4 Dynamics
In music, the dynamics of a piece is the variation in loudness between notes or phrases, which usually used by musicians to deliver dynamic in a music piece instrumentalist and Singers playing a song to express their emotion and create atmosphere through the loudness. As stated in [6], the volume of the music can strongly influence arousal. Specifically, great joy, surprise, excitement and anger are often invoked by Loud sound while peaceful mood, tender and sadness associated with soft sound [6]. Thus, the loudness can well influence the audiences. Specifically, audiences tend to feel high arousal mood while listening high loudness songs, and tend to feel low arousal mood while listening low loudness songs.
In this paper, we use root-mean-square amplitude (rms) to calculate loudness. Rms can be extacted with the MIR toolbox with its values from 0 to 1. We calculate the median value as the threshold to categorize the rms and divide loudness into high loudness and llow loudness. In conclusion, the dependencies between emotions and main musical dimensions including rhythm, tonality, timbre and dynamics discussed above are shown in Table 2.
3 Proposed Method
3.1 Problem Statement
Denote three tuple \(S=\{(x_i,h_i,y_i)|i=1,...,N\}\), where \(x_i\) represents D-dimensional features, \(h_i=(h_i^t,h_i^m,h_i^b,h_i^l)\in \{0,1\}\) represents the binarized tempo values, mode values, brightness values and loudness values respectively, \(y_i\in \{y_i^v,y_i^a|-1\le y_i^v,y_i^a\le 1\}\) represents continuous valence and arousal values, and N is the number of training samples. The goal is to learn a classifier \(\mathrm {f}(x,w)\) as follows:
where \(\alpha \) and \(\beta \) are the coefficients, \(\ell (f_{\theta }(x_i),y_i)\) represents the basic loss function, and \(L(x_i,h_i,y_i)\) captures the domain knowledge between music elements h and the emotion values y. The first section denotes the basic loss function. The second section denotes the regularization term associating domain knowledge.
For the first term, any loss function can be used. In this paper, we adopt the support vector regression as the basic loss function:
where the function \(\ell _\epsilon (z)\) satisfy the below:
where \(\epsilon \) is a constant which defines the maximum deviation allowed for a prediction to be considered as correct; \(\alpha \) is used as a trade-off between the model complexity and regression loss.
As for the second term, the relations between music elements and emotions as domain knowledge, can be exploited to build better emotion classifiers from music. In this paper, domain knowledge of four music elements, i.e., tempo, mode brightness and loudness are discussed, with respect to dynamic, rhythm, timbre and tonality of the music dimension.
3.2 Representation of Domain Knowledge
Domain Knowledge in Arousal Space. From Table 2, tempo, brightness and loudness have the strong relationship with musical emotion in the arousal space. Fast tempo features, high brightness and high loudness are more possible to express high arousal mood of audiences, while the slow tempo features, low brightness and low loudness are more likely to deliver the low arousal of the audiences. Thus the probabilistic dependencies between tempo and arousal emotion shown as:
where \(p(\hat{y^a}\ge 0|h^{\{t,b,l\}}=1)\) and \(p(\hat{y^a}<0|h^{\{t,b,l\}}=1)\) indicate the probabilities of high arousal and low arousal respectively, when observing fast tempo, high brightness and loudness. \(p(\hat{y^a}<0|h^{\{t,b,l\}}=0)\) and \(p(\hat{y^a}\ge 0|h^{\{t,b,l\}}=0)\) show the probabilities of low arousal and high arousal respectively, when given slow tempo, low brightness and low loudness.
ReLU function is adopt in our method to penalize the samples violating the domain knowledge. The corresponding penalty \(l_i^{\{ta,ba,la\}}(x_i,h_i,\hat{y_i})\) from the domain knowledge according to Eq. 5 is encoded as below:
where \([\cdot ]=max(\cdot ,0)\).
Since there is no obvious relationship between mode and arousal, we treat the major mode and minor equal important. In other words, major mode and minor mode have equal chances to invoke low arousal mood or high arousal mood from audiences. Hence, mode information is not used in arousal space.
Domain Knowledge in Valence Space. From Table 2, major mode (high-value mode) features are more possible to invoke high valence mood from audiences, while the minor mode (low-value mode) features are more likely to invoke the low valence of the audiences in the valence space. Thus we can infer the probabilistic dependencies between mode and valence emotion as:
Thus the corresponding constraint \(l_i^{mv}(x_i,h_i,\hat{y_i})\) for valence according to Eq. 7 is encoded as below:
Since there is no obvious relationship between valence and another elements, e.g. tempo, brightness, loudness, the information of tempo, brightness and loudness is not used in valence space.
3.3 Proposed Model
We propose to learn classifier with the objectives as below:
where w is the parameter of the classifier, \(\alpha \), \(\beta ^t\), \(\beta ^m\), \(\beta ^b\) and \(\beta ^l\) are coefficients. We use \(f(x,w)=w\cdot \phi (x)\) as our function where \(\phi (x)\) maps the features space into the kernel space. According to the property of logistic regression, we apply sigmoid function to replace the probabilistic dependencies between audio elements and emotion labels as follow:
where \(sigmoid(x)=\frac{1}{1+e^{-x}}\).
In order to solve the optimization we adopt the stochastic gradient descent (SGD) to solve the problem. The updating rule is shown as follows:
where t and \(\eta \) are the number of iterations and the learning rate differently.
The gradient of loss function to the weight can be computed as below:
where the specific gradient of loss function to the weight is computed as:

Gradients of \(\ell _i^{ta}\), \(\ell _i^{mv}\), \(\ell _i^{ba}\) and \(\ell _i^{la}\) can be computed as Eq. 14 similarly.
The learning algorithm is shown in Algorithm 1.

After training, the proposed approach can evaluate the predicted emotion value for testing samples according to function f(x, w).
4 Experiments
4.1 Experimental Conditions
We conduct experiments on two benchmark databases: the Music Emotion in 2015 database [1] and the All Music Guide 1608 database (AMG1608) [3].
The Music Emotion in 2015 database consists of royalty-free music, with diverse genres of rock, classical, pop, jazz, country, folk, rap etc. [2]. The database is divided into two subsets: the development set and the test set. Specifically, the development set consists of 430 clips of 45 s, and the test set is comprised of 58 complete music pieces with an average duration of \(234 \pm 105.7\) s. We use 260 low-level feature set provided by [1], which are extracted using openSMILE features. The 260 dimensional feature set represent the music from 65 dimensional mean deviation, 65 dimensional standard deviation, and their first-order derivatives from acoustic descriptors. We also extract tempo, mode, brightness, loudness with MIR toolbox.
The AMG1608 database consists of 1608 preview clips of Western songs, collected from a popular music stream service named 7 digit. Each preview clips is 30-second long. For experiments, we adopt the four-fold cross-validation on the database. We use the public feature set provided by [3], including MFCC, Tonal, Spectral and Temporal. We also extract tempo, mode, brightness, loudness with MIR toolbox.
To further demonstrate the effectiveness of domain knowledge, we conduct the following experiments in the arousal space: music audio emotion analysis ignoring all domain knowledge (none), music audio emotion analysis only exploiting single domain knowledge (tempo, brightness, loudness), music audio emotion analysis exploiting two of domain knowledge(tempo+brightness, tempo+loudness, brightness+loudness) and music audio emotion analysis exploiting all domain knowledge (tempo+brightness+loudness). In the valence space, since mode is the only musical elements that affects the valence, we conduct experiments as: music audio emotion analysis ignoring all domain knowledge (none), and music audio emotion analysis exploiting mode (mode). We also conduct experiments using music audio emotion analysis fusing the musical elements as features (fusion).
Root-Mean-Square Error (RMSE) and Pearson Correlation (R) is adopted to evaluate the effectiveness of the proposed method.
During training phrase, we use grid search to select our hyper parameter. Specifically, we first initialize small random number as weights, then through grid search, we choose the hyper parameter \(\alpha \), \(\beta ^t\), \(\beta ^m\), \(\beta ^b\) and \(\beta ^l\) ranging from {0.1, 1, 10, 20, 50}. On the Music Emotion in 2015 database, a fixed split of training/validation/testing 400/30/58 is adapted. On the AMG1608 database, we adopt 4-fold cross-validation.
4.2 Experimental Results and Analysis
Tables 3 and 4 show the music audio analyses results on the Music Emotion in 2015 database and the AMG1608 database in the valence space and arousal space. From Tables 3 and 4, we observe as follows:
First, the proposed method exploiting all domain knowledge has the best performance among all methods with the lowest RMSE and highest Pearson correlation. Specifically, compared with music audio analyses ignoring all domain knowledge, the proposed method achieves 0.039 and 0.021 decrement of RMSE, and 0.032 and 0.076 increment of Pearson correlation, with respect to the Music Emotion in 2015 database and the AMG1608 database in the valence space. In the arousal space, the proposed method decrease the RMSE of 0.036 and 0.027, and increase the Pearson correlation of 0.223 and 0.101 on the Music Emotion in 2015 database and the AMG1608 database respectively. The method ignoring domain knowledge is totally data-driven method, which only learns the mapping from the extracted features to the predictions and it ignores the well-established music knowledge. On the contrary, our method capture the relations between domain knowledge and training data, and thus achieves better performance.
Second, the methods utilizing more domain knowledge have better performance than that using less domain knowledge. Specifically, in the arousal space, the methods with one domain knowledge is worse than the methods leveraging two domain knowledge. Since temp, brightness, and loudness describes the music from different aspects, the effects of these musical elements on the music emotion analyses are complementary. Thus, the methods using more domain knowledge can build more relations between music elements and emotion, and achieves better prediction.
4.3 Comparison with Related Work
In this section, we aim to evaluate the effectiveness of the proposed method. We compared the proposed method with the state-of-the-art methods.
On the Music Emotion in 2015 database, we compare the proposed method with Aljanaki’s [1], Liu’s [11], Chin’s [4], Markor’s [12], and Patra’s [14]. Specifically, Aljanaki et al. provided the baseline for MediaEval 2015. Liu et al. proposed Arousal-Valence Similarity Preserving Embedding (AV-SPE) to extract the intrinsic features embedded in music signal, and train the SVR which takes the extracted features as the input and the emotion values as labels; Chin et al. adopted deep recurrent neural network to predict the valence and arousal for each moment of a song; Markor et al. used Kernel Bayes Filter (KBF) for predicting the valence and arousal. Patra et al. proposed the music emotion recognition system consisting of feed-forward neural networks, which predicts the dynamic valence and arousal values continuously. The comparisons are given in Table 5. As we can see from the table, we conclude that:
Compared with the others’ works, our method achieves best performance in most cases. The state-of-the-art method only learns the maps from the features, and makes prediction of the music emotion. On the contrary, the proposed method not only learns the mapping from the features, but also captures the dependencies between musical elements and emotions through domain knowledge. Thus the proposed capture more information, and achieves better performance.
Rare work is conducted on the AMG1608 database. Thus, we only compare the proposed method with the baseline methods provided in [3]. In [3], Chen et al. adopted the Music emotion recognition (MER) system to recognize music emotion on the AMG1608 database. We adapted the Average Euclidean Distance (AED) and Pearson correlation as evaluation. The comparison is shown in Table 4. From the table, we observe as follows:
Compared with baseline method, the proposed method achieve better performance of AED and Pearson correlation. Since the proposed method captures the more information by constraints of domain knowledge, it is reasonable that the proposed method achieves better performance.
Taking the comparisons above into consideration, the proposed method has an excellent generalization ability with respect to affective audio music analysis. This demonstrates our approach successfully achieves higher music emotion prediction supported by domain knowledge.
5 Conclusion
This paper has proposed to analyze music emotion recognition by exploring domain knowledge. Probabilistic dependencies is used for music emotion recognition between emotions and music elements, i.e., tempo, mode, brightness and loudness. Then we model such probabilistic dependencies to the domain knowledge constraints in order to regularize our objective function. Experimental results on the Music emotion in 2015 database and the AMG1608 database demonstrate that our model outperforms the state-of-the-art approaches. This further demonstrates the importance of the domain knowledge to music emotion recognition.
References
Aljanaki, A., Yang, Y.H., Soleymani, M.: Emotion in music task at mediaeval 2015. In: Working Notes Proceedings of the MediaEval 2015 Workshop (2015)
Bittner, R.M., Salamon, J., Tierney, M., Mauch, M., Cannam, C., Bello, J.P.: MedleyDB: a multitrack dataset for annotation-intensive MIR research. In: ISMIR, pp. 155–160 (2014)
Chen, Y.A., Yang, Y.H., Wang, J.C., Chen, H.: The AMG1608 dataset for music emotion recognition. In: 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 693–697. IEEE (2015)
Chin, Y.H., Wang, J.C.: Mediaeval 2015: recurrent neural network approach to emotion in music tack. In: Working Notes Proceedings of the MediaEval 2015 Workshop (2015)
Fernández-Sotos, A., Fernández-Caballero, A., Latorre, J.M.: Influence of tempo and rhythmic unit in musical emotion regulation. Front. Comput. Neurosci. 10, 80 (2016)
Gabrielsson, A., Lindström, E.: The role of structure in the musical expression of emotions. In: Handbook of Music and Emotion: Theory, Research, Applications, pp. 367–400 (2010)
Gomez, P., Danuser, B.: Relationships between musical structure and psychophysiological measures of emotion. Emotion 7(2), 377–387 (2007)
Husain, G., Thompson, W.F., Schellenberg, E.G.: Effects of musical tempo and mode on arousal, mood, and spatial abilities. Music Percept.: Interdisc. J. 20(2), 151–171 (2002)
Lartillot, O.: Mirtoolbox 1.3. 4 user’s manual. Finnish Centre of Excellence in Interdisciplinary Music Research, University of Jyväskylä, Finland (2011)
Lartillot, O., Toiviainen, P.: A Matlab toolbox for musical feature extraction from audio. In: International Conference on Digital Audio Effects, pp. 237–244 (2007)
Liu, Y., Liu, Y., Gu, Z.: Affective feature extraction for music emotion prediction (2015)
Markov, K., Matsui, T.: Dynamic music emotion recognition using kernel Bayes’ filter (2015)
Miller, M.: The Complete Idiot’s Guide to Music Theory. Penguin, New York (2005)
Patra, B.G., Maitra, P., Das, D., Bandyopadhyay, S.: Mediaeval 2015: music emotion recognition based on feed-forward neural network. In: MediaEval (2015)
Sloboda, J.: Handbook of Music and Emotion: Theory, Research, Applications. Oxford University Press, Oxford (2011)
Trochidis, K., Lui, S.: Modeling affective responses to music using audio signal analysis and physiology. In: Kronland-Martinet, R., Aramaki, M., Ystad, S. (eds.) CMMR 2015. LNCS, vol. 9617, pp. 346–357. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46282-0_22
Wessel, D.L.: Timbre space as a musical control structure. Comput. Music J. 3, 45–52 (1979)
Yang, Y.H., Chen, H.H.: Machine recognition of music emotion: a review. ACM Trans. Intell. Syst. Technol. (TIST) 3(3), 40 (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Shu, Y., Xu, G. (2019). Emotion Recognition from Music Enhanced by Domain Knowledge. In: Nayak, A., Sharma, A. (eds) PRICAI 2019: Trends in Artificial Intelligence. PRICAI 2019. Lecture Notes in Computer Science(), vol 11670. Springer, Cham. https://doi.org/10.1007/978-3-030-29908-8_10
Download citation
DOI: https://doi.org/10.1007/978-3-030-29908-8_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-29907-1
Online ISBN: 978-3-030-29908-8
eBook Packages: Computer ScienceComputer Science (R0)