
Abstract
As of late, the need for biometric security framework is elevated for giving safety and security against frauds, theft, and so on. Face recognition has gained a significant position among all biometric-based systems. It can be used for authentication and surveillance to prove the identity of a person and detect individuals, respectively. In this paper, a point-by-point outline of some imperative existing strategies which are accustomed to managing the issues of face recognition has been introduced along with their face recognition accuracy and the factors responsible to degrade the performance of the study. In the first section of this paper, different factors that degrade the facial recognition accuracy have been investigated like aging, pose variation, partial occlusion, illumination, facial expressions, and so on. While in the second section, different techniques have been discussed that worked to mitigate the effect of discussed factors.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Face detection and recognition is one of the pivotal authentication systems based on biometric which can be used for the authentication process as well as surveillance. With the rapid increase in frauds day by day, face recognition is becoming a crucial system for us. Various applications of an efficient face recognition system are forensics, identification of criminals, surveillance, fraud exclusion, etc. A lot of research has been done on both national and international levels, but even after continuous research, a truly resilient and efficacious system is not available that can perform well in both normal and real-time conditions. Facial recognition has always been a very complex and challenging task. Its actual test lies in outlining an automated framework which parallels the human capacity to perceive faces. Be that as it may, there is confinement to the human capacity when it manages a lot of obscure appearances. Consequently, a programmed automatic electronic framework with relatively higher recognition accuracy and fast processing is required.
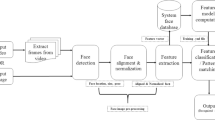
Face detection and recognition process consists of three steps in Fig. 1 [1]:

Steps of face detection and recognition
-
1.
Face detection: To identify the faces in an image or video using landmark points on the face like eyes, nose, mouth, etc.
-
2.
Feature extraction: Alignment, normalization of the faces for better recognition exactitude.
-
3.
Face recognition: To recognize a particular person in an image or video by matching with the database.
This paper is divided into five major sections. The first section gives the brief introduction of face detection and recognition. In the second section, different factors that degrade the facial recognition accuracy have been discussed. The third section gives a brief introduction of methods involved in face detection and recognition along with its importance. The next section gives a brief review of the algorithms used till now for the appearance-based, feature-based, and hybrid method with their recognition accuracy. Lastly, it concludes with the findings from this research.
2 Factors Affecting Face Recognition Accuracy
Face recognition from images and videos is a formidable task. A lot of research has been done to achieve 100% precision, but still we are not getting satisfactory results in view of the various factors confronting this framework. It has been found that the factors that degrade the accuracy of the face recognition systems are: occlusion, low resolution, noise, illumination, pose variation, expressions, aging, and plastic surgery [2,3,4]. These factors can be classified into two categories: intrinsic and extrinsic factors [2]. Intrinsic components incorporate the physical state of the human face like aging, facial expression, plastic surgery, and so on, influencing the system, while extrinsic factors are responsible to change the appearance of the face like occlusion, low resolution, noise, illumination, and pose variation given in Fig. 2.

Categories of factors affecting face recognition accuracy
2.1 Occlusion
Partial occlusion is one of the major challenges of face recognition. It would be difficult to recognize a face if some part of the face is missing. For example, sunglasses and specs can hide eyes, earrings and hairs can hide ears, scarfs can hide half face, mustaches, and beard of boys can hide half of the face, and so on which can be shown in Fig. 3. These factors can deteriorate the performance of the system. Different approaches are being proposed by the researchers to overcome these problems [5].

Partial occlusion in the face [6]
2.2 Low Resolution
The pictures taken from surveillance video cameras comprise small faces; thus, its resolution is low as shown in Fig. 4. To compare the low-resolution query image with the high-resolution gallery image is a challenging task. Such a low-resolution picture comprises exceptionally constrained data as the greater part of the points of interest are lost. This can drastically degrade the recognition rate. Distinctive methodologies are being proposed by the researchers to tackle with this issue [5, 7].

Frame from surveillance video. a video, b captured face [7]
2.3 Noise
Digital images are inclined to various types of noise. This noise leads to poor detection and recognition accuracy. Noise can be introduced in images via different ways that are dependent on image creation. The pre-handling is an imperative factor in the general face detection and recognition framework [8]. Figure 5b illustrates the salt-and-pepper noise present in an image.

Noise in face image [8]
2.4 Illumination
The variations in illumination can drastically degrade the performance of the face recognition system. The reasons for these variations could be background light, shadow, brightness, contrast, etc. The images taken in different lighting conditions are shown in Fig. 6. Different approaches related to illumination are being discussed in [9,10,11,12,13,14].

Effect of illumination in face images [14]
2.5 Pose Variation
Different pose distribution is also one of the major concerns of the face recognition system. Frontal face reconstruction is required to match the profile face with the gallery face [15]. This reconstruction is required because a database image consists of frontal view and non-frontal profile face can generate faulty results. Different approaches proposed by the researchers to convert the non-frontal face to frontal face could increase the recognition accuracy [15, 16]. How pose variation degrades the performance of the algorithm dramatically is being discussed by researchers in the proposed approaches [11, 17]. Different pose distributions of an individual are shown in Fig. 7.

Pose variations [18]
2.6 Expressions
With the help of facial expressions, we can express our feelings as shown in Fig. 8. It changes the geometry of the face. A small variation in the face can create vagueness for face recognition system. Facial expression is a rapid signal that is easily affected due to the contraction of muscles and changes the facial features like eyebrows, cheeks, mouth, etc. Continuous research is being done for face recognition by taking facial expression into consideration [9, 13].

Different facial expressions [3]
2.7 Aging
Aging is one of the natural components affecting face recognition systems as it swings to be a wreck for an algorithm. The face is a mix of skin tissues, facial muscles, and bones. At the point, when muscles contract, they result in the twisting of facial highlights. Be that as it may, maturing causes critical changes in facial appearances of an individual, e.g., facial surface (wrinkles and so forth) and face shape with the progression of time. The face recognition frameworks ought to be sufficiently skilled in considering this requirement [13, 19, 20]. Different texture of faces of the same person at different ages is given in Fig. 9.

Aging variations [20]
2.8 Plastic Surgery
It is also a major concerned factor that affects the face recognition accuracy. Many incidents happened that because of accidents, numerous people have experienced plastic surgery and their faces will be unknown to the existing face recognition framework. Mostly criminals adopt the idea of plastic surgery to bury their identity. So, as discussed in [21], we need an identification system that is capable of recognizing faces even after reconstructive surgery. The effect of plastic surgery is shown in Fig. 10.

Surgery effects [21]
3 Classification of Face Recognition Methods
Face recognition methods can be classified into the following three categories [22]:
-
(i)
Appearance-based Methods
-
(ii)
Feature-based Matching Methods
-
(iii)
Hybrid Methods
The classification of face recognition methods and the algorithms used in the above-discussed methods is shown in Fig. 11.

Classification of face recognition algorithms
3.1 Appearance-Based Methods
Appearance-based methods are also known as the holistic method where a whole face is matched with the gallery face. The advantages offered by holistic approach are:
-
(i)
They concentrate on only limited regions or points of interest without destroying any of the information in images.
-
(ii)
No knowledge of geometry and reflectance of faces is required.
-
(iii)
Recognition is simple as compared to other matching approaches.
-
(iv)
Fast and easy to implement.
But, they are quite prone to the limitations caused by facial variations such as illumination, pose, and expressions. Also, recognition accuracy is low in an unconstrained environment.
3.2 Feature-Based Matching Methods
In feature-based matching methods, matching of probe face with gallery face has done using local features of the face like nose, eyes, and mouth. The location and local statistics of the extracted features has fed into the structural classifier to recognize the face.
In feature-based matching methods, recognition accuracy is better than appearance-based approaches. However, high memory usage is required in these methods and also a large amount of clean and labeled data for training.
3.3 Hybrid Methods
Hybrid methods are a combination of both appearance-based methods and feature-based matching methods. Both appearance-based and feature-based methods are amalgamated to increase the recognition rate. However, this method is complex and difficult to implement as it is the combination of both feature- and appearance-based approaches.
4 A Review of Face Recognition Methods Used in Different Studies
4.1 Appearance-Based Approaches
A lot of research has been done under this category. The main algorithms used for these methods are SIFT algorithm [17], PCA algorithm [10, 23,24,25,26], AdaBoost, LDA, elastic bunch graph matching algorithms [24], Fisherface, and SVD techniques [25].
Khan et al. [23] proposed an automatic face recognition system. In the proposed system, the PCA eigenface algorithm has been used for face recognition. Experimental results demonstrate that the proposed approach achieved 86% recognition accuracy in a constrained environment and 80% recognition accuracy in an unconstrained environment. The limitations of the proposed system are that it does not provide better results for low-resolution videos and large pose variations [23].
In Chawla and Trivedi [24], a comparison between AdaBoost, PCA, LDA, and elastic bunch graph matching algorithms for face recognition has been illustrated with their drawbacks, benefits, success rate, and other factors. After the comparative study, it has been found that PCA has the highest success rate (85–95%) but it is not suitable for video datasets. All the discussed algorithms are suitable only for smaller or simple databases.
Abdullah et al. [10] proposed an application of face recognition approach for criminal detection. In the proposed method, principal component analysis has been used to recognize the criminal faces. The results showed 80% recognition accuracy, but a lot of testing is needed for the proposed work.
Dhameja et al. [25] used a combination of PCA, Fisherface, and SVD techniques for face recognition. The proposed system was tested on AT&T face database and achieved approximately 99.5% recognition rate by the leaving-one-out method and 93.92% by the hold-out method.
Kavitha and Mirnalinee [15] proposed an algorithm to frontalize the non-frontal faces. Fitting, mirroring, and stretching operations are done to obtain the frontal face. Experiments are done on FERET, HP, LFW, and PUB-FIG datasets to prove the proposed approach reconstruction accuracy. The proposed approach can handle only up to ±22.5° pose variation.
In Gao and Jong [17], the authors proposed a face recognition algorithm which is based on multiple virtual views and alignment error. In the proposed work, Lucas Kanade algorithm and SIFT algorithm were used. FERET dataset has been used to evaluate the performance of the proposed approach. The proposed approach reported approximately 38% improvement in the performance when compared with the results obtained from other face recognition algorithms. But the proposed approach can handle only up to ±60° pose distribution. Also, recognition accuracy is poor beyond 40°. Time complexity is high in comparison with other comparing algorithms.
The work proposed by Ahonen et al. [13] used Local binary pattern to represent the face. The method was applied on FERET dataset. The results showed that the proposed approach achieved 97% accuracy for images with different facial expressions but did not perform well for other factors [13].
In [2], a comparative research has been done by Sharif et al. [2] on different approaches and applications of face recognition used till 2014. Different approaches discussed in this paper are based on eigenface, Gabor wavelet, neural network, and hidden Markov model. In this review paper, it has been concluded that (i) eigenface-based methods work well only for frontal faces, (ii) Gabor wavelet-based methods do not provide better recognition accuracy due to redundancy in Gabor filters, (iii) neural network-based methods improve the recognition accuracy, but it requires a large amount of time for the training purpose, (iv) support vector machine is slow in classification, but in combination with other approaches it generates good results.
4.2 Feature-Based Approaches
The following algorithms such as face recognition through geometric features, elastic bunch graph matching, hidden Markov model, convolutional neural networks, and active appearance model are rooted in this classification [23].
Luo et al. [9] proposed unsupervised deep adaptation methods. They adopted a deep unsupervised domain adaptation neural network. They explained that the training dataset for supervised learning methods should be labeled and cleaned. The study reported approximately 17% improvement in the performance when compared with the results obtained from different face recognition algorithms. The method was applied to GBU and FERET datasets. CASIA-Webface was used to train the DCNN. But, the results presented were not sufficiently detailed for video datasets. The proposed research focused only on different illumination, expression, and age.
The key thought of the study by Zhou and Lam [19] was to provide an age-invariant face recognition model. The algorithm works on three steps: local feature extraction, identity subspace, and feature fusion using canonical correlation analysis (CCA) for face matching. Experimental results were conducted on FGNET, MORPH, and CACD datasets to present the efficacy of the proposed approach. They achieved approximately 51% improvement in recognition accuracy when applied on FGNET dataset and 13% improvement on CACD and MORPH datasets.
The paper authored by Gosavi et al. [27] dealt with the review of different feature extraction techniques. Different feature extraction approaches like geometric-based feature extraction, appearance-based feature extraction, template-based feature extraction, and artificial neural networks for face recognition are reviewed in this study. Among discussed approaches, template-based feature extraction provides more recognition accuracy. Backpropagation neural network and convolutional neural network are more efficient than other feature extraction approaches based on neural network. It has concluded that the discussed approaches were not as much as efficient [27].
In the work proposed by Fu et al. [5], a deep learning model based on guided CNN has been used for cross-resolution and occluded image recognition. The proposed system consists of two sub-models: one is used as a guide which is already trained with high-resolution images and the other is used as a learner for low-resolution input images. CASIA-Webface dataset and LFW dataset were used for training and testing purposes, respectively. This procedure accurately recognizes the cross-resolution and partially occluded images. They achieved 9% improvement in case of cross-resolution images and 4% improvement in case of partially occluded images. The proposed approach requires a lot of training as for each image in the database; the system needs to be trained for corresponding low-resolution image.
Bhavani et al. [28] used sparse representation technique for the recognition of faces in a video. Viola–Jones algorithm was used to detect the faces in an image. All the experiments have done on a real-time dataset. They achieved 75–80% recognition accuracy. However, they can work only for frontal face images.
Kakkar and Sharma [29] provided an adequate face recognition system for criminal identification by using Haar feature-based cascade classifier and local binary pattern histogram. The drawback of their system is that it can recognize only frontal faces [29].
The research done by Harsing et al. [30] proposed a new approach called entropy-based volume SIFT (EV-SIFT) for the recognition of surgery faces. The system was evaluated for the following surgeries: blepharoplasty, brow lift, liposhaving, malar augmentation, mentoplasty, otoplasty, rhinoplasty, rhytidectomy, and skin peeling. They achieved different recognition rate for the different types of plastic surgeries [30].
The contemplation in the work proposed by Sameem et al. [31] was to provide an efficient face detection and recognition system using Viola–Jones algorithm and MSAC algorithm. To perform experiments, Graz 01 dataset was used. Recognition accuracy of the proposed approach was compared with the approach proposed by Hong et al. [32] and achieved a 10% improvement in the recognition rate. It has been concluded that the proposed system is capable of handling images in an unconstrained environment.
Gaikawad and Sonawane [33] provided a different perspective on face detection and recognition from video surveillance. They have not implemented their approach to evaluate the algorithm on the dataset. However, it has been accomplished that the suggested method can cope with illumination, pose, shape, resolution, and plastic surgery.
Ding and Tao [34] proposed a framework based on convolutional neural networks (CNN) to cope with the challenges/issues related to video-based face recognition. Trunk-Branch Ensemble CNN (TBE-CNN) model has been used to confront the pose and occlusion variations. Mean distance regularized triplet loss (MDR-TL) function has been used to train TBE-CNN. The success of the proposed method was evaluated not only on single dataset but also for multiple video datasets like COX face, PaSC, and YouTube faces. They achieved approximately 95% recognition accuracy on YouTube faces database, 96% recognition accuracy on PaSC dataset and 99.33% accuracy for V2V, 98.96% for V2S, and 95.74% for S2V on COX database. In BTAS 2016 Video Person Recognition Evaluation, their approach acquired the first position. The proposed approach efficiently handles the problems like blur, partial occlusion, and poses variations.
Ding et al. [11] deduced a pose-invariant face recognition model by using multi-task feature transformation learning scheme to train the transformation dictionary for each patch. Experimental results showed that the proposed method achieved 100% recognition accuracy for ±44° yaw angle on CMU-PIE dataset, 98% accuracy for +65° on FERET dataset, approximately 87.75% recognition accuracy for ±60° pose angle with illumination on MULTI-PIE dataset, 98% recognition accuracy for ±45° pose angle with recording session on MULTI-PIE dataset, 91.78% accuracy on LFW challenging dataset. It has been concluded that the proposed approach outperforms single-task-based methods. They were the first to use multi-task learning in pose-invariant face recognition.
In [35], Hu et al. investigated the reason for the promising performance of convolutional neural network in face recognition. They proposed 3 CNN architectures of different sizes: CNN-S (Small), CNN-M (Medium), and CNN-L (Large). The experimental results showed that the proposed approach is better than some existing approaches but also provides worse result than other existing state-of-the-art approaches. In last, they concluded that network fusion can greatly enhance the performance of face recognition systems. Metric learning is also responsible to boost the face recognition accuracy.
Huang et al. [36] introduced a video database for face recognition called COX face database. They showed the effectiveness of the introduced database in comparison with other existing video datasets. They also proposed a point-to-set correlation learning (PSCL) method to prove the face recognition accuracy on proposed COX face database. Experimental results showed that the proposed approach achieves higher accuracy in comparison with other existing approaches on COX database. In last, it has been concluded that video-based face recognition is more complex when compared to image-based face recognition. More efforts can be done to improve the recognition accuracy of the proposed approach.
To authenticating the user for mobile payments, Wang et al. [12] have introduced face recognition approach based on deep reinforcement learning with convolutional neural networks. The proposed method provides 100% recognition accuracy when the gamma correction value is 1. In conclusion, the proposed approach outperforms other existing CNN-based approaches. Q-table learning was incorporated in the presented approach to fine-tune the previous model in different lighting conditions.
4.3 Hybrid Approach
Hybrid approach is an amalgamation of both the appearance- and feature-based methods.
Banerjee et al. [16] contended that deep learning techniques for facial recognition. They also explained the question of whether to train the system for multiple poses is beneficial or to frontalize the profile face is propitious. They also compared the face recognition accuracy using their proposed frontalization algorithm with existing Hassner and Enbar [37] frontalization algorithm and simple 2D alignment (i.e., no frontalization) on PaSC video dataset and CW image dataset. Viola–Jones algorithm was used for face detection. Generic 3D face model was used to frontalize the profile image. Image correction and postprocessing was done to obtain the final frontalized image. They used a supervised learning approach for face recognition pipeline. CMU multi-PIE dataset with the combination of different facial landmarking algorithms was used to calculate the frontalization success rate. With the help of experimental results, they concluded that all the discussed frontalization methods along with facial landmarking algorithms experienced high failure rates beyond 40° yaw angle. It has also been concluded that the usefulness of frontalization is dependent on the facial recognition system used and may not always provide better results.
Fathima et al. [38] proposed a hybrid approach using Gabor wavelet and linear discriminant analysis for face recognition. AT&T, MIT-India, and Faces94 datasets are used to evaluate the recognition rate of the proposed approach. They achieved 88% recognition accuracy on AT&T, 88.125% on MIT-India, and 94.02% on Faces94 datasets. Results showed that the proposed approach provides better results in comparison with Gabor and efficient for the unconstrained environment.
In [39], Lei et al. [39] proposed an efficacious face detection system. The system works in two phases: detection phase and the recognition phase. In the detection phase, they used modest AdaBoost algorithm that maintains a low computational cost. Improved independent component analysis approach was used in the recognition phase. Hausdorff distance was used in the recognition phase to calculate the similarity measure between the face and other objects present in an image. An experiment has done on CMU-MIT face database to evaluate the detection rate of the algorithm. Experimental results showed that the proposed approach provides better detection rate in comparison with other existing face detection algorithms. The proposed approach can be used for other object detection and recognition tasks.
Research gaps of some of the above-discussed approaches are listed in Table 1.
5 Conclusion
After two decades of continuous research, it has been observed that a lot of research is going on in face detection and recognition area but still we are not getting satisfactory recognition accuracy and results. The classifications are broadly classified on appearance-based approaches, feature-based approaches, and hybrid approaches. All the approaches have their own advantages and disadvantages depending upon their area of application and datasets used.
Appearance-based methods do not provide better results for low-resolution video and pose variation. The method in which a supervised learning approach is used provides satisfactory results, but it requires a large amount of clean and labeled training data to train the system for the recognition stage.
Most of the methods do not perform well for non-frontal faces, i.e., faces with different pose distribution. In addition, the factors such as aging, occlusion, and plastic surgery also affect the recognition accuracy of the system.
After the literature review, it has been concluded that despite continuous research, an efficient face recognition system is required that can perform well in constrained as well as the unconstrained environment.
References
Yu, S., Lu, Y., Zhou, J.: A survey of face detection, extraction and recognition. J. Comput. Inf. 22, 163–195 (2003)
Sharif, M., Naz, F., Yasmin, M., Shahid, M.A., Rehman, A.: Face recognition: a survey. J. Eng. Sci. Technol. Rev. 10(2), 166–177 (2017)
Patel, R., Rathod, N., Shah, A.: Comparative analysis of face recognition approaches: a survey. Int. J. Comput. Appl. 57(17), 50–61 (2012)
Khade, B.S., Gaikwad, H.M., Aher, A.S., Patil, K.K.: Face recognition techniques: a survey. Int. J. Comput. Sci. Mob. Comput. 5(11), 65–72 (2016)
Fu, T., Chiu, W., Wang, Y.F.: Learning guided convolutional neural networks for cross-resolution face recognition. In: 2017 IEEE 27th International Workshop on Machine Learning for Signal Processing (MLSP) (2017)
Zhang, W., Shan, S., Chen, X., Gao, W.: Local Gabor binary patterns based on Kullback–Leibler divergence for partially occluded face recognition. IEEE Sig. Process. Lett. 14(11), 875–878 (2007)
Zou, W.W.W., Yuen, P.C.: Very low resolution face recognition problem. IEEE Trans. Image Process. 21(1), 327–340 (2012)
Tin, H.H.K.: Removal of noise by median filtering in image processing. In: 6th Parallel and Soft Computing (PSC 2011) Removal (2011)
Luo, Z., Hu, J., Deng, W., Shen, H.: Deep unsupervised domain adaptation for face recognition. In: 13th IEEE International Conference on Automatic Face & Gesture Recognition, pp. 453–457 (2018)
Abdullah, N.A., et al.: Face recognition for criminal identification: an implementation of principal component analysis for face recognition. In: The 2nd International Conference on Applied Science and Technology 2017 (ICAST’17) (2017)
Ding, C., Member, S., Xu, C., Tao, D.: Multi-task pose-invariant face recognition. IEEE Trans. Image Process. 24(3), 980–993 (2015)
Wang, P., Lin, W., Chao, K.-M., Lo, C.-C.: A face-recognition approach using deep reinforcement learning approach for user authentication. In: Fourteenth IEEE International Conference on e-Business Engineering, pp. 183–188 (2017)
Ahonen, T., Hadid, A., Pietika, M.: Face description with local binary patterns: application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 28(12), 2037–2041 (2006)
Li, S.Z., Member, S., Chu, R., Liao, S., Zhang, L.: Using near-infrared images. IEEE Trans. Pattern Anal. Mach. Intell. 29(4), 627–639 (2007)
Kavitha, J., Mirnalinee, T.T.: Automatic frontal face reconstruction approach for pose invariant face recognition. In: Proceedings of the 4th International Conference on Recent Trends in Computer Science & Engineering, Elsevier, vol. 87, pp. 300–305 (2016)
Banerjee, S., et al.: To frontalize or not to frontalize: do we really need elaborate pre-processing to improve face recognition ? In: IEEE Winter Conference on Applications of Computer Vision, pp. 20–29 (2018)
Gao, Y., Jong, H.: Cross-pose face recognition based on multiple virtual views and alignment error. Pattern Recognit. Lett. 65, 170–176 (2015)
Singh, R., Vatsa, M.: A mosaicing scheme for pose-invariant face recognition. IEEE Trans. Syst. Man Cybern. B Cybern. 37(5), 1212–1225 (2007)
Zhou, H., Lam, K.: Age-invariant face recognition based on identity inference from appearance age. J. Pattern Recognit. 76, 191–202 (2018)
Li, Z., Park, U., Jain, A.K.: A discriminative model for age invariant face recognition. IEEE Trans. Inf. Forensics Secur. 6(3), 1028–1037 (2011)
Mun, M., Deorankar, P.A.: Implementation of plastic surgery face recognition using multimodal biometric features. Int. J. Comput. Sci. Inf. Technol. 5(3), 3711–3715 (2014)
Dass, R., Rani, R., Kumar, D.: Face recognition techniques: a review. Int. J. Eng. Res. Dev. 4(7), 70–78 (2012)
Khan, A., et al.: Forensic video analysis: passive tracking system for automated Person of Interest (POI) localization. IEEE Access 6, 43392–43403 (2018)
Chawla, D., Trivedi, M.C.: A comparative study on face detection techniques for security surveillance. In: Advances in Computer and Computational Sciences, pp. 531–541 (2018)
Dhamija, J., Choudhary, T., Kumar, P., Rathore, Y.S.: An advancement towards efficient face recognition using live video feed. In: International Conference on Computational Intelligence and Networks (CINE), pp. 53–56 (2017)
Baykara, M., Daş, R.: Real time face recognition and tracking system. In: International Conference on Electronics, Computer and Computation, pp. 159–163 (2013)
Gosavi, V.R., Sable, G.S., Deshmane, A.K.: Evaluation of feature extraction techniques using neural network as a classifier: a comparative review for face recognition. Int. J. Sci. Res. Sci. Technol. 4(2), 1082–1091 (2018)
Bhavani, K., et al.: Real time face detection and recognition in video surveillance. Int. Res. J. Eng. Technol. 4(6), 1562–1565 (2017)
Kakkar, P., Sharma, V.: Criminal identification system using face detection and recognition. Int. J. Adv. Res. Comput. Commun. Eng. 7(3), 238–243 (2018)
Harsing, A., Talbar, S.N., Amarsing, H.: Recognition of plastic surgery faces and the surgery types: an approach with entropy based scale invariant features. J. King Saud Univ. Comput. Inf. Sci. 1–7 (2017)
Sameem, M.S.I., Qasim, T., Bakhat, K.: Real time recognition of human faces. In: International Conference on Open Source Systems & Technologies, pp. 62–65 (2016)
Hong, Y., Li, Q., Jiang, J., Tu, Z.: Learning a mixture of sparse distance metrics for classification and dimensionality reduction. In: IEEE International Conference on Computer Vision, pp. 906–913 (2011)
Gaikawad, P.A.D., Sonawane, P.P.D.: An efficient video surveillance system using video based face recognition on real world data. Int. J. Sci. Eng. Technol. Res. 5(4), 1245–1250 (2016)
Ding, C., Tao, D.: Trunk-branch ensemble convolutional neural networks for video-based face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 40(4), 1002–1014 (2018)
Hu, G., et al.: When face recognition meets with deep learning: an evaluation of convolutional neural networks for face recognition. In: IEEE International Conference on Computer Vision Workshops, pp. 384–392 (2015)
Huang, Z., et al.: A benchmark and comparative study of video-based face recognition on COX face database. IEEE Trans. Image Process. 24(12), 5967–5981 (2015)
Hassner, T., Enbar, R.: Effective face frontalization in unconstrained images. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 4295–4304 (2015)
Fathima, A.A., Ajitha, S., Vaidehi, V., Hemalatha, M., Karthigaiveni, R., Kumar, R.: Hybrid approach for face recognition combining gabor wavelet and linear discriminant analysis. In: IEEE International Conference on Computer Graphics, Vision and Information Security, pp. 220–225 (2015)
Lei, Z., Wang, C., Wang, Q., Huang, Y.: Real-time face detection and recognition for video surveillance applications. In: 2009 World Congress on Computer Science and Information Engineering Real-time, pp. 168–172 (2009)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Anwarul, S., Dahiya, S. (2020). A Comprehensive Review on Face Recognition Methods and Factors Affecting Facial Recognition Accuracy. In: Singh, P., Kar, A., Singh, Y., Kolekar, M., Tanwar, S. (eds) Proceedings of ICRIC 2019 . Lecture Notes in Electrical Engineering, vol 597. Springer, Cham. https://doi.org/10.1007/978-3-030-29407-6_36
Download citation
DOI: https://doi.org/10.1007/978-3-030-29407-6_36
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-29406-9
Online ISBN: 978-3-030-29407-6
eBook Packages: EngineeringEngineering (R0)