
Abstract
Supervised Descent Method (SDM) is an efficient and accurate approach for facial landmark locating and face alignment. In the training phase, it requires a large amount of training samples to learn the descent directions and get the corresponding regressors. Then in the test phase, it uses the corresponding regressors to estimate the descent directions and locate the facial landmarks. However, when the facial expression or direction changes too much, generally SDM cannot obtain good performance due to the large variation between the initial shape (the initial shape of SDM is the mean shape of the training samples) and the target shape. Therefore, we propose a coarse-to-fine SDM (CFSDM) method to improve the accuracy of the test results. This method predicts the approximate coordinates of the facial landmarks with a simple CNN (Convolutional Neural Network) network (here we introduce the channel-wise attention mechanism, which can predict the coordinates of the landmarks more accurately with a relatively simple structure) in advance, and then SDM will take the coordinates as its initial shape’s coordinates, which reduces the distance between the initial shape and the target shape, thereby solving the problem that SDM cannot achieve good results when the facial expression or direction changes greatly.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Face alignment means that the key feature points (such as the eyes, the tip of the nose, the corners of the mouth, the eyebrows, and so on) of the face are automatically located according to the input face image, as shown in the Fig. 1. It is widely used in many facial analysis tasks, such as face recognition [1], expression analysis [2], face tracking, face animation [3] and facial attributes analysis [4]. Face alignment still faces many challenges due to many factors, like different poses, expressions, lighting, and occlusion.

The task of face alignment.
SDM (Supervised Descent Method) [5] is a very representative method based on cascaded regression model. It evolved from Newton Descent Method with high efficiency and precision. The SDM starts with the initial shape (the mean shape of the training samples) and iterates through a series of regressors to bring the initial shape closer to the true shape. One of the drawbacks of the cascaded regression model is that its final result is highly dependent on its initial shape. When in simple conditions, SDM can often achieve better results due to its superior performance, but when under extreme conditions, such as a large head pose, or a facial expression is too exaggerated, the initial is too different from the true shape, at this time, it is very difficult to make the initial shape approximate to the true shape by several iterations.
After 2013, the methods based on deep learning began to be widely used in face alignment and achieved remarkable results. These methods generally do not rely on initialization. But under the premise of achieving high precision, they often show a complex structure and a time-consuming process.
To solve the above problems, we propose a coarse-to-fine SDM (CFSDM) method. We first use a simple CNN (Convolutional Neural Network) network (we added the channel-wise attention mechanism to the CNN network, so that the position of the landmarks will be predicted more accurately with a relatively simple structure) to predict the approximate location of the facial landmarks, and the resulting coordinates of the landmarks are assigned to SDM as its average face coordinate (i.e., the initial shape at the time of testing), thus the initialization of SDM will be optimized. This method provides a good initialization for SDM and is not easy to fall into local optimum, thus improves the results.
2 Related Work
2.1 Face Alignment
Traditional Methods
Traditional face alignment methods include ASM [6], AAM [7], CLM [8], etc. ASM is an active shape model, it model the facial landmarks labeled in the training set, and then search for the best matching points on the test set and locate the facial landmarks. AAM is an active appearance model. AAM is based on ASM, it further statistical model the texture, and merge the two statistical models of shape and texture into appearance models. CLM inherits the advantages of ASM and AAM respectively, it gets a balance between the efficiency of ASM and the accuracy of AAM, and models the patch of the local texture around the facial landmarks on the basis of ASM rather than the global texture method of AAM.
Recently, the cascade shape regression model has made a major breakthrough in face alignment task. These methods use a regression model to learn the mapping function directly from the appearance of the face to the shape of the face (or the parameters of the face shape model), then establish a correspondence from the appearance to the shape. Such methods do not require complex face shape and appearance, and achieve good results in controllable scenes (human faces collected under laboratory conditions) and non-controllable scenes (network face images, etc.). In 2010, Dollar proposed CPR (Cascaded Pose Regression) [9], CPR gradually refines a specified initial prediction value through a series of regressors. ESR [10] adopted boosted regression and two-level cascade regression. CFSS [11] began with a coarse search over a shape space that contains diverse shapes, and employs the coarse solution to constrain subsequent finer search of shapes. LBF (Regressing Local-Binary Features) [12] learned sparse binary features in local regions based on random forest regression model. SDM [5] used supervised gradient descent method to solve non-Linear least squares problem, and learns a series of regressors for locating facial landmarks. In general, the cascade shape regression methods are very sensitive to the starting point of the regression process.
CNN Based Methods
Deep learning has been widely used in the field of computer vision [24, 25], face alignment methods based on deep learning have also achieved remarkable results. Sun et al. [13] used CNN for face alignment for the first time, they proposed a three-layer network structure, and each layer contains multiple independent CNN models, which are responsible for predicting some or all key points. Wu et al. [14] found that the cnn network is hierarchical, and the deeper network extracted features can reflect the position of the facial landmarks more accurately, so they proposed TCNN (Twaned Convolutional Neural Networks). MTCNN [15] used three CNN cascades to simultaneously perform face detection and face alignment. SAN [16] predicted facial landmarks by simultaneously inputting the original face image and the style aggregate image, and solves the problem caused by the change of the image’s style. LAB [17] used a network to extract boundary of the face and fuses the information of boundary into face alignment. TCDCN [18] used multi-task learning to optimize facial landmark locating with a set of related tasks. In summary, in order to achieve accuracy, the deep learning methods generally use a cascaded depth model to gradually improve the estimation, which leads to more complicated calculations.
We propose a coarse-to-fine SDM (SDM) method, which takes advantage of the fact that the deep learning methods do not depend on initialization, reduces the complexity of the cnn structure, optimizes the initialization of SDM, and improves the final result.
2.2 Attention Mechanism
In recent years, the study of deep learning has become more and more extensive, and many breakthroughs have been made in various fields. Neural networks based on the attention mechanism have become a hot topic in recent neural network research. Mnih et al. [19] used the attention mechanism on the RNN model for image classification. Bahdanau et al. [20] first proposed the application of the attention mechanism to the NLP field. In order to make the i-th channel only related to the position of the i-th landmark, We use a channel-wise attention module which proposed in [21] in our method.
3 Method
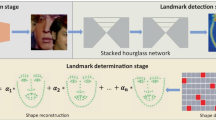
During the test phase, SDM starts with the initial shape (the average shape of the training samples) and iterates with a series of regressors to gradually approximate the initial shape to the true shape. It is easy to find that its final result is very dependent on the initial shape. When the facial expression or the head pose changes too much, since the variation between the initial shape and the real shape is too large, generally SDM cannot obtain good performance. So we propose a coarse-to-fine SDM (CFSDM) method. We utilize a simple CNN network (the channel wise attention mechanism is introduced here) to predict the approximate position of the facial landmarks in advance, and then the obtained coordinates are given to SDM as its initial shape coordinates, which optimize the initialization of SDM, and then the initial shape will be closer to the real shape through the regressors that be learned. The overall process of the method is shown in Fig. 2.

The overall process of our CFSDM. The coarse shape is estimated by CNN network, and it is the initial shape of SDM during test phase.
3.1 Coarse Localization Based on CNN
Architecture of CNN Network
Figure 3 shows the detailed structure of CNN network. We take the first 13 layers of VGG-16 [22] as our backbone. VGG is simple and practical, and it performs very well in both image classification and object detection. The size of convolutional filters’ receptive field is \( 3 \times 3 \), which is the smallest size to capture the left/right, up/down and center. The stride of the convolution is fixed to 1 pixel. The padding of the convolution layer is used to maintain the spatial resolution of the image after convolution. The second, the fourth, the seventh and the tenth convolutional layer are followed with a max-pooling layer respectively. Max-pooling is performed over a \( 2 \times 2 \) pixel window, with stride 2.

The structure of CNN network.
It is well known that the bottleneck of VGG-16 is that there are too many parameters in the fully connected layer, and the speed is very slow, so we give up the fully connected layer of VGG-16. We adopt a structure with fewer parameters and higher efficiency, that is, a deconvolution layer. We revert the obtained CNN feature maps to the input size through the deconvolution layer. Each channel of the final output is equivalent to a probability map that predicts where a landmark is most likely to exist. For example, to predict the location of 68 landmarks for a face image in Helen dataset, the final output of our network contains also 68 channels. In order to make the i-th channel only related to the position of the i-th landmark, we have added the channel-wise attention module. We will introduce the specific structure of channel-wise attention module in Sect. 3.1.
Our CNN network is trained with an end-to-end manner. We take the mean square error as the loss function,
where \( x_{i} \) and \( y_{i} \) are the ground truth coordinate of the i-th landmark, \( x_{i}^{{\prime }} \) and \( y_{i}^{{\prime }} \) are the predicted coordinate of the i-th landmark.
Channel-Wise Attention
The different channels of the feature maps are essentially features extracted by different filters, and the different filters may extract different emphases. It is possible that one filter extracts more features of the tip of the nose, and another filter extracts more features of the eye. So it is required a weight, that is, channel-wise weight. To a certain extent, channel-wise attention can be seen as semantic attention which focuses on different objects in the image. Figure 4 shows the structure of channel-wise attention module.

The structure of channel-wise attention module.
At first, the feature maps \( {\mathbf{V}} \) which extracted from our convolutional filters are reshaped to get the channel-wise vectors,
where \( {\mathbf{u}}_{i} \in {\mathbb{R}}^{{{\text{W}} \times {\text{H}}}} \) is the i-th channel of feature maps and \( c \) is the number of the CNN feature channels. Then the average pooling is performed on each channel to obtain the vector
which characterizes the information of different channels. And the final weight calculation is expressed as:
where \( {\mathbf{W}}_{c} \), \( {\mathbf{W}}_{i} \) are transformation matrices we prepared to learn, and \( \otimes \) represents the outer product of vectors, \( b_{c} \), \( {\text{b}}_{i} \) are bias terms and \( \odot \) donate that each channel of \( {\mathbf{V}} \) is multiplied by \( \upbeta \).
3.2 Fine Localization Based on SDM
SDM is a commonly used method to solve complex Non-linear Least Squares (NLS) problems. SDM gets a initial shape after training, and it uses the initial shape as the staring point of the test, see Fig. 5. The initial shape of SDM is obtained by averaging the coordinates of all the training samples. But in our CFSDM, the initial shape is estimated by the CNN network. Such initialization is more beneficial to the results.

The initial shape of SDM (the above is the training phase, and the following is the test phase).
Let us review the derivation of SDM. Given an image \( {\mathbf{d}} \in {\mathbb{R}}^{m \times 1} \) of m pixels, \( {\mathbf{d}}\left( {\mathbf{x}} \right) \in {\mathbb{R}}^{p \times 1} \) represents p landmarks in the image. \( {\mathbf{h}} \) is a nonlinear feature extraction function, such as \( {\mathbf{h}}\left( {{\mathbf{d}}\left( {\mathbf{x}} \right)} \right) \in {\mathbb{R}}^{128p \times 1} \) can denote the SIFT features extracted from p landmarks. Given the initial shape \( x_{0} \), the goal is to make \( x_{0} \) more and more close to the correct shape \( x_{*} \) of the face by regression. In order to achieve this goal, it is required to find the \( \Delta x \) that minimizes the following function
where \( \varPhi_{*} = {\mathbf{h}}\left( {{\mathbf{d}}\left( {x_{\varvec{*}} } \right)} \right) \) represents the SIFT values in the manually labeled landmarks of the face. Of course, the above is the target of testing. We only have the initial \( x_{0} \) in the prediction, and we do not know \( \Delta x \) and \( \varPhi_{*} \).
In training phase, the \( \Delta x \) and \( \varPhi_{*} \) are known, and the good regressors need to be trained from the training samples, so that it can return the initial \( x_{0} \) step by step to the correct unknown shape. In general, the initial \( x_{0} \) is the mean shape of the true shape of all known samples.
For regressing the same initial shape of each image to the true shape of there face, we extracted different SIFT features from different images. Although the initial shape is same, the SIFT features extracted from different images are completely different, that is \( \varPhi_{0} \) is different. This allows the initial shape to be regressed to the true shape through regressors. This can also be seen in Eq. 7.
The next thing to do is to get a series of regressors that can be used to regress an initial shape to a real shape, that is to learn the correct regressors to get the best \( \Delta x \). Of course, if you want to regress the initial shape to the real shape step by step, it is generally impossible to do it by only one \( \Delta x \), because it is very difficult to achieve the final goal in just one step. So we have to learn to get a series of different regressors, they will regress in turn, and a series of \( \Delta x \) will be learned, so \( x_{0} \) will converge to \( x_{*} \) in the training data by \( x_{k + 1} = x_{k} + \Delta x_{k} \) (k is the number of regressors or iterations).
The Taylor expansion of the objective function Eq. 7 is described as:
where \( {\mathbf{J}}_{f} \left( {x_{0} } \right) \) and \( {\mathbf{H}}\left( {x_{0} } \right) \) are the Jacobian and Hessian matrices of f evaluated at \( x_{0} \). Differentiating Eq. 8 with respect to \( \Delta x \) and setting it to 0 gives us the first update for x,
where \( \varPhi_{0} = {\mathbf{h}}\left( {{\mathbf{d}}\left( {x_{0} } \right)} \right) \) denotes the SIFT features extracted from the initial shape \( x_{0} \). Let \( {\text{R}}_{0} = - 2{\mathbf{H}}^{ - 1} {\mathbf{J}}_{h}^{\text{T}} \), and \( \varPhi_{*} \) is unknown but fixed during the test stage, so Eq. 9 can be rewritten as follows:
where \( {\mathbf{R}}_{0} \) is a descent direction, \( b_{0} \) is a bias term, and they can be learned from the training samples.
Usually the task cannot be completed in just one step and requires multiple steps, so SDM will learn a series of descent directions \( \left\{ {{\mathbf{R}}_{k} } \right\} \) and bias terms \( \left\{ {{\mathbf{b}}_{k} } \right\} \),
where \( x_{k} \) will converge to \( x_{*} \) step by the Eq. 11.
During training phase, \( \left\{ {{\mathbf{R}}_{k} } \right\} \) and \( \left\{ {{\mathbf{b}}_{k} } \right\} \) can be learned by minimizing this function:
where \( \Delta x_{*}^{ki} = x_{*}^{i} - x_{k}^{i} \), and i indicates the number of landmarks.
During test stage, the initial shape \( x_{0} \) is determined by CNN network, and it will be more and more close to the true shape \( x_{k} \) through the learned \( \left\{ {{\mathbf{R}}_{k} } \right\} \) and \( \left\{ {{\mathbf{b}}_{k} } \right\} \).
4 Experiment
In this section, we evaluate the performance of the proposed method and compare it with several existing state-of-the-art methods on four datasets: LFPW, Helen, IBUG, and 300W.
-
LFPW (68 landmarks) contains 1432 face images, in which 1132 are for training and 300 are for testing. Since only image URLs are available and some links disappeared as time passed, we used a reduced version of 1035 images (each annotated with 68 landmarks), 811 of which are for training and the rest 224 for testing. The challenges are Large variations in illuminations, expressions, poses and occlusion.
-
Helen (68 landmarks) contains 2330 high resolution and accurately labeled face images, 2000 of which are for training and 330 are for testing. The challenges are large variations in expressions, poses and occlusion.
-
IBUG (68 landmarks) contains 135 accurately labeled face images. The challenges are extremely large variations in illuminations, expressions, poses and occlusion.
-
Multiple (68 landmarks) contains 150 people, and 10 facial expressions for each person. Each image is annotated with 68 landmarks. We select 225 images as training set, and 100 images as test set.
We use the Normalized Mean Error (NME) as a metric to measure the shape estimation error
It computes the euclidean distance between the ground-truth and estimated landmark positions normalized by \( d_{i} \). Table 1 shows the face alignment performance of our CFSDM and those of several excellent methods: LBF [12], CFAN [23], SDM [5] as well. From Table 1, it can be seen that our CFSDM outperforms the other methods, and it has a great improvement compared with SDM, especially in challenging datasets like IBUG and Multiple. Figure 6 plots the curves of percentage of images versus normalized error, it shows that our CFSDM performs the best on most of the test images. Some example results of SDM and our CFSDM are displayed in Fig. 7.

The curves of percentage of test images vs normalized error of various approaches on four datasets: LFPW, Helen, IBUG, and 300W.

Some example results of SDM and our CFSDM. The first and third row of images are our experimental results, and the second and fourth row of images are experimental results of SDM.
In order to prove that the CNN network and the channel-wise attention module are both beneficial for the improvement of the final result, we performed an ablation experiment, see Table 2.
5 Conclusion
In this paper, we propose a coarse-to-fine SDM (CFSDM) method. We utilize a CNN network with a channel-wise attention module to optimize the initialization of SDM, which reduces the distance between the initial shape and the real shape in the test phase of SDM. It solves the problem that SDM can’t achieve good results when the facial expression or direction changes greatly. The evaluation on four datasets shows that our CFSDM improves the accuracy of traditional SDM method and outperforms some other excellent methods.
References
Chen, C., Dantcheva, A., Ross, A., et al.: Automatic facial makeup detection with application in face recognition. In: International Conference on Biometrics, pp. 1–8 (2013)
Ashraf, A.B., Lucey, S., Cohn, J.F., et al.: The painful face - pain expression recognition using active appearance models. Image Vis. Comput. 27(12), 1788–1796 (2009)
Thies, J., Zollhofer, M., Stamminger, M., et al.: Face2Face: real-time face capture and reenactment of RGB videos. In: Computer Vision and Pattern Recognition, pp. 2387–2395 (2016)
Datta, A., Feris, R., Vaquero, D.: Hierarchical ranking of facial attributes. In: Face and Gesture 2011, pp. 36–42. IEEE (2011)
Xiong, X., De la Torre, F.: Supervised descent method and its applications to face alignment. In: Computer Vision and Pattern Recognition, pp. 532–539 (2013)
Cootes, T.F., Taylor, C.J., Cooper, D.H., et al.: Active shape models—their training and application. Comput. Vis. Image Underst. 61(1), 38–59 (1995)
Cootes, T.F., Edwards, G.J., Taylor, C.J., et al.: Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 23(6), 681–685 (2001)
Cristinacce, D., Cootes, T.F.: Feature detection and tracking with constrained local models. In: British Machine Vision Conference, pp. 929–938 (2006)
Dollar, P., Welinder, P., Perona, P., et al.: Cascaded pose regression. In: Computer Vision and Pattern Recognition, pp. 1078–1085 (2010)
Cao, X., Wei, Y., Wen, F., et al.: Face alignment by explicit shape regression. Int. J. Comput. Vis. 107(2), 177–190 (2014)
Zhu, S., Li, C., Loy, C.C., et al.: Face alignment by coarse-to-fine shape searching. In: Computer Vision and Pattern Recognition, pp. 4998–5006 (2015)
Ren, S., Cao, X., Wei, Y., et al.: Face alignment at 3000 FPS via regressing local binary features. In: Computer Vision and Pattern Recognition, pp. 1685–1692 (2014)
Sun, Y., Wang, X., Tang, X., et al.: Deep convolutional network cascade for facial point detection. In: Computer Vision and Pattern Recognition, pp. 3476–3483 (2013)
Wu, Y., Hassner, T., Kim, K., et al.: Facial landmark detection with tweaked convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 40(12), 3067–3074 (2018)
Zhang, K., Zhang, Z., Li, Z., et al.: Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 23(10), 1499–1503 (2016)
Dong, X., Yan, Y., Ouyang, W., et al.: Style aggregated network for facial landmark detection. In: Computer Vision and Pattern Recognition, pp. 379–388 (2018)
Wu, W., Qian, C., Yang, S., et al.: Look at boundary: a boundary-aware face alignment algorithm. In: Computer Vision and Pattern Recognition, pp. 2129–2138 (2018)
Zhang, Z., Luo, P., Loy, C.C., Tang, X.: Facial landmark detection by deep multi-task learning. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8694, pp. 94–108. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10599-4_7
Mnih, V., Heess, N., Graves, A., et al.: Recurrent models of visual attention. In: Neural Information Processing Systems, pp. 2204–2212 (2014)
Bahdanau, D., Cho, K., Bengio, Y., et al.: Neural machine translation by jointly learning to align and translate. In: International Conference on Learning Representations (2015)
Chen, L., Zhang, H., Xiao, J., et al.: SCA-CNN: spatial and channel-wise attention in convolutional networks for image captioning. In: Computer Vision and Pattern Recognition, pp. 6298–6306 (2017)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations (2015)
Zhang, J., Shan, S., Kan, M., Chen, X.: Coarse-to-fine auto-encoder networks (CFAN) for real-time face alignment. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8690, pp. 1–16. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10605-2_1
Zhao, Z.Q., Zheng, P., Xu, S., Wu, X.: Object detection with deep learning: a review. IEEE Trans. Neural Netw. Learn. Syst. (2018). https://doi.org/10.1109/tnnls.2018.2876865
Zhao, Z.Q., Hu, J., Tian, W., Ling, N.: Cooperative adversarial network for accurate super resolution. In: Asian Conference on Computer Vision (ACCV) (2018)
Acknowledgments
This research was supported by the National Natural Science Foundation of China (No. 61672203), and AnHui Natural Science Funds for Distinguished Young Scholar (No. 170808J08).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhu, X., Zhao, ZQ., Tian, W. (2019). Coarse-to-Fine Supervised Descent Method for Face Alignment. In: Huang, DS., Bevilacqua, V., Premaratne, P. (eds) Intelligent Computing Theories and Application. ICIC 2019. Lecture Notes in Computer Science(), vol 11643. Springer, Cham. https://doi.org/10.1007/978-3-030-26763-6_17
Download citation
DOI: https://doi.org/10.1007/978-3-030-26763-6_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-26762-9
Online ISBN: 978-3-030-26763-6
eBook Packages: Computer ScienceComputer Science (R0)