
Abstract
We propose a Forward-Backward Truncated-Newton method (FBTN) for minimizing the sum of two convex functions, one of which smooth. Unlike other proximal Newton methods, our approach does not involve the employment of variable metrics, but is rather based on a reformulation of the original problem as the unconstrained minimization of a continuously differentiable function, the forward-backward envelope (FBE). We introduce a generalized Hessian for the FBE that symmetrizes the generalized Jacobian of the nonlinear system of equations representing the optimality conditions for the problem. This enables the employment of conjugate gradient method (CG) for efficiently solving the resulting (regularized) linear systems, which can be done inexactly. The employment of CG prevents the computation of full (generalized) Jacobians, as it requires only (generalized) directional derivatives. The resulting algorithm is globally (subsequentially) convergent, Q-linearly under an error bound condition, and up to Q-superlinearly and Q-quadratically under regularity assumptions at the possibly non-isolated limit point.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others



Keywords
- Forward-backward splitting
- Linear Newton approximation
- Truncated-Newton method
- Backtracking linesearch
- Error bound
- Superlinear convergence
AMS 2010 Subject Classification
15.1 Introduction
In this work we focus on convex composite optimization problems of the form
where \(f:\mathbb {R}^n\rightarrow \mathbb {R}\) is convex, twice continuously differentiable and with L f-Lipschitz-continuous gradient, and \(g:\mathbb {R}^n\rightarrow \mathbb {R}\cup \{\infty \}\) has a cheaply computable proximal mapping [51]. To ease the notation, throughout the chapter we indicate

Problems of the form (15.1) are abundant in many scientific areas such as control, signal processing, system identification, machine learning, and image analysis, to name a few. For example, when g is the indicator of a convex set then (15.1) becomes a constrained optimization problem, while for \(f(x)=\frac 12\|Ax-b\|{ }^2\) and g(x) = λ∥x∥1 it becomes the ℓ 1-regularized least-squares problem (lasso) which is the main building block of compressed sensing. When g is equal to the nuclear norm, then (15.1) models low-rank matrix recovery problems. Finally, conic optimization problems such as linear, second-order cone, and semidefinite programs can be brought into the form of (15.1), see [31].
Perhaps the most well-known algorithm for problems in the form (15.1) is the forward-backward splitting (FBS) or proximal gradient method [16, 40], that interleaves gradient descent steps on the smooth function and proximal steps on the nonsmooth one, see Section 15.3.1. Accelerated versions of FBS, based on the work of Nesterov [5, 54, 77], have also gained popularity. Although these algorithms share favorable global convergence rate estimates of order O(ε −1) or O(ε −1∕2) (where ε is the solution accuracy), they are first-order methods and therefore usually effective at computing solutions of low or medium accuracy only. An evident remedy is to include second-order information by replacing the Euclidean norm in the proximal mapping with that induced by the Hessian of f at x or some approximation of it, mimicking Newton or quasi-Newton methods for unconstrained problems [6, 32, 42]. However, a severe limitation of the approach is that, unless Q has a special structure, the computation of the proximal mapping becomes very hard. For example, if φ models a lasso problem, the corresponding subproblem is as hard as the original problem.
In this work we follow a different approach by reformulating the nonsmooth constrained problem (15.1) into the smooth unconstrained minimization of the forward-backward envelope (FBE) [57], a real-valued, continuously differentiable, exact penalty function for φ. Although the FBE might fail to be twice continuously differentiable, by using tools from nonsmooth analysis we show that one can design Newton-like methods to address its minimization, that achieve Q-superlinear asymptotic rates of convergence under nondegeneracy and (generalized) smoothness conditions on the set of solutions. Furthermore, by suitably interleaving FBS and Newton-like iterations the proposed algorithm also enjoys good complexity guarantees provided by a global (non-asymptotic) convergence rate. Unlike the approaches of [6, 32], where the corresponding subproblems are expensive to solve, our algorithm only requires the inexact solution of a linear system to compute the Newton-type direction, which can be done efficiently with a memory-free CG method.
Our approach combines and extends ideas stemming from the literature on merit functions for variational inequalities (VIs) and complementarity problems (CPs), specifically the reformulation of a VI as a constrained continuously differentiable optimization problem via the regularized gap function [23] and as an unconstrained continuously differentiable optimization problem via the D-gap function [79] (see [19, §10] for a survey and [38, 58] for applications to constrained optimization and model predictive control of dynamical systems).
15.1.1 Contributions
We propose an algorithm that addresses problem (15.1) by means of a Newton-like method on the FBE. Differently from a direct application of the classical Newton method, our approach does not require twice differentiability of the FBE (which would impose additional properties on f and g), but merely twice differentiability of f. This is possible thanks to the introduction of an approximate generalized Hessian which only requires access to ∇2 f and to the generalized (Clarke) Jacobian of the proximal mapping of g, as opposed to third-order derivatives and classical Jacobian, respectively. Moreover, it allows for inexact solutions of linear systems to compute the update direction, which can be done efficiently with a truncated CG method; in particular, no computation of full (generalized) Hessian matrices is necessary, as only (generalized) directional derivatives are needed. The method is thus particularly appealing when the Clarke Jacobians are sparse and/or well structured, so that the implementation of CG becomes extremely efficient. Under an error bound condition and a (semi)smoothness assumption at the limit point, which is not required to be isolated, the algorithm exhibits asymptotic Q-superlinear rates. For the reader’s convenience we collect explicit formulas of the needed Jacobians of the proximal mapping for a wide range of frequently encountered functions, and discuss when they satisfy the needed semismoothness requirements that enable superlinear rates.
15.1.2 Related Work
This work is a revised version of the unpublished manuscript [59] and extends ideas proposed in [57], where the FBE is first introduced. Other FBE-based algorithms are proposed in [69, 71, 75]; differently from the truncated-CG type of approximation proposed here, they all employ quasi-Newton directions to mimic second-order information. The underlying ideas can also be extended to enhance other popular proximal splitting algorithms: the Douglas Rachford splitting (DRS) and the alternating direction method of multipliers (ADMM) [74], and for strongly convex problems also the alternating minimization algorithm (AMA) [70].
The algorithm proposed in this chapter adopts the recent techniques investigated in [71, 75] to enhance and greatly simplify the scheme in [59]. In particular, Q-linear and Q-superlinear rates of convergence are established under an error bound condition, as opposed to uniqueness of the solution. The proofs of superlinear convergence with an error bound pattern the arguments in [82, 83], although with less conservative requirements.
15.1.3 Organization
The work is structured as follows. In Section 15.2 we introduce the adopted notation and list some known facts on generalized differentiability needed in the sequel. Section 15.3 offers an overview on the connections between FBS and the proximal point algorithm, and serves as a prelude to Section 15.4 where the forward-backward envelope function is introduced and analyzed. Section 15.5 deals with the proposed truncated-Newton algorithm and its convergence analysis. In Section 15.6 we collect explicit formulas for the generalized Jacobian of the proximal mapping of a rich list of nonsmooth functions, needed for computing the update directions in the proposed algorithm. Finally, Section 15.7 draws some conclusions.
15.2 Preliminaries
15.2.1 Notation and Known Facts
Our notation is standard and follows that of convex analysis textbooks [2, 8, 28, 63]. For the sake of clarity we now properly specify the adopted conventions, and briefly recap known definitions and facts in convex analysis. The interested reader is referred to the above-mentioned textbooks for the details.
Matrices and Vectors
The n × n identity matrix is denoted as In, and the \(\mathbb {R}^n\) vector with all elements equal to 1 is as 1 n; whenever n is clear from context we simply write I or 1, respectively. We use the Kronecker symbol δ i,j for the (i, j)-th entry of I. Given \(v\in \mathbb {R}^n\), with \(\operatorname {diag} v\) we indicate the n × n diagonal matrix whose i-th diagonal entry is v i. With \(\operatorname {S}(\mathbb {R}^n)\), \(\operatorname {S}_+(\mathbb {R}^n)\), and \(\operatorname {S}_{++}(\mathbb {R}^n)\) we denote respectively the set of symmetric, symmetric positive semidefinite, and symmetric positive definite matrices in \(\mathbb {R}^{n\times n}\).
The minimum and maximum eigenvalues of \(H\in \operatorname {S}(\mathbb {R}^n)\) are denoted as λ min(H) and λ max(H), respectively. For \(Q,R\in \operatorname {S}(R^n)\) we write Q ≽ R to indicate that \(Q-R\in \operatorname {S}_+(\mathbb {R}^n)\), and similarly Q ≻ R indicates that \(Q-R\in \operatorname {S}_{++}(\mathbb {R}^n)\). Any matrix \(Q\in \operatorname {S}_+(\mathbb {R}^n)\) induces the semi-norm ∥⋅∥Q on \(\mathbb {R}^n\), where \(\|x\|{ }_Q^2\mathrel{\mathop:}= \langle {}x{},{}Qx{}\rangle \); in case Q = I, that is, for the Euclidean norm, we omit the subscript and simply write ∥⋅∥. No ambiguity occurs in adopting the same notation for the induced matrix norm, namely \(\|M\|\mathrel{\mathop:}= \max \{{\|Mx\|} \vert x\in \mathbb {R}^n,~\|x\|=1\vert \}\) for \(M\in \mathbb {R}^{n\times n}\).
Topology
The convex hull of a set \(E\subseteq \mathbb {R}^n\), denoted as \(\operatorname {conv} E\), is the smallest convex set that contains E (the intersection of convex sets is still convex). The affine hull \(\operatorname {aff} E\) and the conic hull \(\operatorname {cone} E\) are defined accordingly. Specifically,

The closure and interior of E are denoted as \( \operatorname *{\mathrm {cl}} E\) and \(\operatorname {int} E\), respectively, whereas its relative interior, namely the interior of E as a subspace of \(\operatorname {aff} E\), is denoted as \(\operatorname {relint} E\). With  and
and  we indicate, respectively, the open and closed balls centered at x with radius r.
we indicate, respectively, the open and closed balls centered at x with radius r.
Sequences
The notation  represents a sequence indexed by elements of the set K, and given a set E we write
represents a sequence indexed by elements of the set K, and given a set E we write  to indicate that a
k ∈ E for all indices k ∈ K. We say that
to indicate that a
k ∈ E for all indices k ∈ K. We say that  is summable if ∑k ∈ K∥a
k∥ is finite, and square-summable if
is summable if ∑k ∈ K∥a
k∥ is finite, and square-summable if  is summable. We say that the sequence converges to a point \(a\in \mathbb {R}^n\) superlinearly if either a
k = a for some \(k\in {\mathbb N}\), or ∥a
k+1 − a∥∕∥a
k − a∥→ 0; if ∥a
k+1 − a∥∕∥a
k − a∥q is bounded for some q > 1, then we say that the sequence converges superlinearly with order q, and in case q = 2 we say that the convergence is quadratic.
is summable. We say that the sequence converges to a point \(a\in \mathbb {R}^n\) superlinearly if either a
k = a for some \(k\in {\mathbb N}\), or ∥a
k+1 − a∥∕∥a
k − a∥→ 0; if ∥a
k+1 − a∥∕∥a
k − a∥q is bounded for some q > 1, then we say that the sequence converges superlinearly with order q, and in case q = 2 we say that the convergence is quadratic.
Extended-Real Valued Functions
The extended-real line is  . Given a function \(h:\mathbb {R}^n\rightarrow [-\infty ,\infty ]\), its epigraph is the set
. Given a function \(h:\mathbb {R}^n\rightarrow [-\infty ,\infty ]\), its epigraph is the set

while its domain is

and for \(\alpha \in \mathbb {R}\) its α-level set is

Function h is said to be lower semicontinuous (lsc) if \( \operatorname *{\mathrm {epi}} h\) is a closed set in \(\mathbb {R}^{n+1}\) (equivalently, h is said to be closed); in particular, all level sets of an lsc function are closed. We say that h is proper if h > −∞ and \( \operatorname {{\mathrm {dom}}} h\neq \emptyset \), and that it is level bounded if for all \(\alpha \in \mathbb {R}\) the level set \(\operatorname {lev}_{\leq \alpha }h\) is a bounded subset of \(\mathbb {R}^n\).
Continuity and Smoothness
A function \(G:\mathbb {R}^n\rightarrow \mathbb {R}^m\) is 𝜗-Hölder continuous for some 𝜗 > 0 if there exists L ≥ 0 such that
for all x, x′. In case 𝜗 = 1 we say that G is (L-)Lipschitz continuous. G is strictly differentiable at \(\bar x\in \mathbb {R}^n\) if the Jacobian matrix \( JG(\bar x) {}\mathrel{\mathop:}= {} \big (\frac {\partial G_i}{\partial x_j}(\bar x)\big )_{i,j} \) exists and

The class of functions \(h:\mathbb {R}^n\rightarrow \mathbb {R}\) that are k times continuously differentiable is denoted as \(C^k(\mathbb {R}^n)\). We write \(h\in C^{1,1}(\mathbb {R}^n)\) to indicate that \(h\in C^1(\mathbb {R}^n)\) and that ∇h is Lipschitz continuous with modulus L h. To simplify the terminology, we will say that such an h is L h -smooth. If h is L h-smooth and convex, then for any \(u,v\in \mathbb {R}^n\)

Moreover, having \(h\in C^{1,1}(\mathbb {R}^n)\) and μ h-strongly convex is equivalent to having
for all \(u,v\in \mathbb {R}^n\).
Set-Valued Mappings
We use the notation \(H:\mathbb {R}^n\rightrightarrows \mathbb {R}^m\) to indicate a point-to-set function \(H:\mathbb {R}^n\rightarrow \mathcal P(\mathbb {R}^m)\), where \(\mathcal P(\mathbb {R}^m)\) is the power set of \(\mathbb {R}^m\) (the set of all subsets of \(\mathbb {R}^m\)). The graph of H is the set

while its domain is

We say that H is outer semicontinuous (osc) at \(\bar x\in \operatorname {{\mathrm {dom}}} H\) if for any ε > 0 there exists δ > 0 such that  for all
for all  . In particular, this implies that whenever
. In particular, this implies that whenever  converges to x and
converges to x and  converges to y with y
k ∈ H(x
k) for all k, it holds that y ∈ H(x). We say that H is osc (without mention of a point) if H is osc at every point of its domain or, equivalently, if \(\operatorname {gph} H\) is a closed subset of \(\mathbb {R}^n\times \mathbb {R}^m\) (notice that this notion does not reduce to lower semicontinuity for a single-valued function H).
converges to y with y
k ∈ H(x
k) for all k, it holds that y ∈ H(x). We say that H is osc (without mention of a point) if H is osc at every point of its domain or, equivalently, if \(\operatorname {gph} H\) is a closed subset of \(\mathbb {R}^n\times \mathbb {R}^m\) (notice that this notion does not reduce to lower semicontinuity for a single-valued function H).
Convex Analysis
The indicator function of a set \(S\subseteq \mathbb {R}^n\) is denoted as \(\operatorname {\delta }_S:\mathbb {R}^n\rightarrow \overline {\mathbb {R}}\), namely

If S is nonempty closed and convex, then \(\operatorname {\delta }_S\) is proper convex and lsc, and both the projection \(\operatorname {\mathscr P}_S:\mathbb {R}^n\rightarrow \mathbb {R}^n\) and the distance \(\operatorname {dist}({}\cdot {},S):\mathbb {R}^n\rightarrow [0,\infty )\) are well-defined functions, given by \(\operatorname {\mathscr P}_S(x)= \operatorname *{\mathrm {argmin}} \nolimits _{z\in S}\|z-x\|\) and \(\operatorname {dist}(x,S)=\min _{z\in S}\|z-x\|\), respectively.
The subdifferential of h is the set-valued mapping \(\partial h:\mathbb {R}^n\rightrightarrows \mathbb {R}^n\) defined as

A vector v ∈ ∂h(x) is called a subgradient of h at x. It holds that \( \operatorname {{\mathrm {dom}}}\partial h\subseteq \operatorname {{\mathrm {dom}}} h\), and if h is proper and convex, then \( \operatorname {{\mathrm {dom}}}\partial h\) is a nonempty convex set containing \(\operatorname {relint} \operatorname {{\mathrm {dom}}} h\), and ∂h(x) is convex and closed for all \(x\in \mathbb {R}^n\).
A function h is said to be μ-strongly convex for some μ ≥ 0 if \(h-\tfrac \mu 2\|{}\cdot {}\|{ }^2\) is convex. Unless differently specified, we allow for μ = 0 which corresponds to h being convex but not strongly so. If μ > 0, then h has a unique (global) minimizer.
15.2.2 Generalized Differentiability
Due to its inherent nonsmooth nature, classical notions of differentiability may not be directly applicable in problem (15.1). This subsection contains some definitions and known facts on generalized differentiability that will be needed later on in the chapter. The interested reader is referred to the textbooks [15, 19, 65] for the details.
Definition 15.2.1 (Bouligand and Clarke Subdifferentials)
Let \(G:\mathbb {R}^n\rightarrow \mathbb {R}^m\) be locally Lipschitz continuous, and let \(C_G\subseteq \mathbb {R}^n\) be the set of points at which G is differentiable (in particular  has measure zero). The B-subdifferential (also known as Bouligand or limiting Jacobian) of G at \(\bar x\) is the set-valued mapping \( \partial _BG:\mathbb {R}^n\rightrightarrows \mathbb {R}^{m\times n} \) defined as
has measure zero). The B-subdifferential (also known as Bouligand or limiting Jacobian) of G at \(\bar x\) is the set-valued mapping \( \partial _BG:\mathbb {R}^n\rightrightarrows \mathbb {R}^{m\times n} \) defined as

whereas the (Clarke) generalized Jacobian of G at \(\bar x\) is \( \partial _CG:\mathbb {R}^n\rightrightarrows \mathbb {R}^{m\times n} \) given by
If \(G:\mathbb {R}^n\rightarrow \mathbb {R}^m\) is locally Lipschitz on \(\mathbb {R}^n\), then ∂ C G(x) is a nonempty, convex, and compact subset of \(\mathbb {R}^{m\times n}\) matrices, and as a set-valued mapping it is osc at every \(x\in \mathbb {R}^n\). Semismooth functions [60] are precisely Lipschitz-continuous mappings for which the generalized Jacobian (and consequently the B-subdifferential) furnishes a first-order approximation.
Definition 15.2.2 (Semismooth Mappings)
Let \(G:\mathbb {R}^n\rightarrow \mathbb {R}^m\) be locally Lipschitz continuous at \(\bar x\). We say that G is semismooth at \(\bar x\) if

We say that G is 𝜗-order semismooth for some 𝜗 > 0 if the condition can be strengthened to

and in case 𝜗 = 1 we say that G is strongly semismooth.
To simplify the notation, we adopt the small-o and big-O convention to write expressions as (15.11a) in the compact form \( G(x)+H(\bar x-x)-G(\bar x) {}={} o(\|x-\bar x\|) \), and similarly (15.11b) as \( G(x)+H(\bar x-x)-G(\bar x) {}={} O(\|x-\bar x\|{ }^{1+\vartheta }) \). We remark that the original definition of semismoothness given by [49] requires G to be directionally differentiable at x. The definition given here is the one employed by [25]. It is also worth remarking that ∂ C G(x) can be replaced with the smaller set ∂ B G(x) in Definition 15.2.2. Fortunately, the class of semismooth mappings is rich enough to include many functions arising in interesting applications. For example, piecewise smooth (PC 1 ) mappings are semismooth everywhere. Recall that a continuous mapping \(G:\mathbb {R}^n\rightarrow \mathbb {R}^m\) is PC 1 if there exists a finite collection of smooth mappings \(G_i:\mathbb {R}^n\rightarrow \mathbb {R}^m\), i = 1, …, N, such that

The definition of PC 1 mapping given here is less general than the one of, e.g., [66, §4] but it suffices for our purposes. For every \(x\in \mathbb {R}^n\) we introduce the set of essentially active indices

In other words, \(I_G^e(x)\) contains only indices of the pieces G i for which there exists a full-dimensional set on which G agrees with G i. In accordance with Definition 15.2.1, the generalized Jacobian of G at x is the convex hull of the Jacobians of the essentially active pieces, i.e., [66, Prop. 4.3.1]

The following definition is taken from [19, Def. 7.5.13].
Definition 15.2.3 (Linear Newton Approximation)
Let \(G:\mathbb {R}^n\rightarrow \mathbb {R}^m\) be continuous on \(\mathbb {R}^n\). We say that G admits a linear Newton approximation (LNA) at \(\bar x\in \mathbb {R}^n\) if there exists a set-valued mapping \(\mathcal H:\mathbb {R}^n\rightrightarrows \mathbb {R}^{m\times n}\) that has nonempty compact images, is outer semicontinuous at \(\bar x\), and

If for some 𝜗 > 0 the condition can be strengthened to

then we say that \(\mathcal H\) is a 𝜗-order LNA, and if 𝜗 = 1 we say that \(\mathcal H\) is a strong LNA.
Functions G as in Definition 15.2.3 are also referred to as \(\mathcal H\)-semismooth in the literature, see, e.g., [78], however we prefer to stick to the terminology of [19] and rather say that \(\mathcal H\) is a LNA for G. Arguably the most notable example of a LNA for semismooth mappings is the generalized Jacobian, cf. Definition 15.2.1. However, semismooth mappings can admit LNAs different from the generalized Jacobian. More importantly, mappings that are not semismooth may also admit a LNA.
Lemma 15.2.4 ([19, Prop. 7.4.10])
Let \(h\in C^1(\mathbb {R}^n)\) and suppose that \(\mathcal H:\mathbb {R}^n\rightrightarrows \mathbb {R}^{n\times n}\) is a LNA for ∇h at \(\bar x\) . Then,

We remark that although [19, Prop. 7.4.10] assumes semismoothness of ∇h at \(\bar x\) and uses ∂ C(∇h) in place of \(\mathcal H\); however, exactly the same arguments apply for any LNA of ∇h at \(\bar x\) even without the semismoothness assumption.
15.3 Proximal Algorithms
15.3.1 Proximal Point and Moreau Envelope
The proximal mapping of a proper closed and convex function \(h:\mathbb {R}^n\rightarrow \overline {\mathbb {R}}\) with parameter γ > 0 is \(\operatorname {prox}_{\gamma h}:\mathbb {R}^n\rightarrow \mathbb {R}^n\), given by

The majorization model \(\mathcal M_\gamma ^h(x;{}\cdot {})\) is a proper and strongly convex function, and therefore has a unique minimizer. The value function, as opposed to the minimizer, defines the Moreau envelope \(h^\gamma :\mathbb {R}^n\rightarrow \mathbb {R}\), namely

which is real valued and Lipschitz differentiable, despite the fact that h might be extended-real valued. Properties of the Moreau envelope and the proximal mapping are well documented in the literature, see, e.g., [2, §24]. For example, \(\operatorname {prox}_{\gamma h}\) is nonexpansive (Lipschitz continuous with modulus 1) and is characterized by the implicit inclusion
For the sake of a brief recap, we now list some other important known properties. Theorem 15.3.1 provides some relations between h and its Moreau envelope h γ, which we informally refer to as sandwich property for apparent reasons, cf. Figure 15.1. Theorem 15.3.2 highlights that the minimization of a (proper, lsc and) convex function can be expressed as the convex smooth minimization of its Moreau envelope.

Moreau envelope of the function \(\varphi (x) = \tfrac 13x^3+x^2-x+1+\operatorname {\delta }_{[0,\infty )}(x)\) with parameter γ = 0.2. At each point x, the Moreau envelope φ γ is the minimum of the quadratic majorization model \(\mathcal M_\gamma ^\varphi =\varphi + \frac {1}{2\gamma }({}\cdot {}-x)^2\), the unique minimizer being, by definition, the proximal point \(\hat x\mathrel{\mathop:}= \operatorname {prox}_{\gamma \varphi }(x)\). It is a convex smooth lower bound to φ, despite the fact that φ might be extended-real valued. Function φ and its Moreau envelope φ γ have same \(\inf \) and \( \operatorname *{\mathrm {argmin}}\); in fact, the two functions agree (only) on the set of minimizers. In general, φ γ is sandwiched as \(\varphi \circ \operatorname {prox}_{\gamma \varphi }\leq \varphi ^\gamma \leq \varphi \)
Theorem 15.3.1 (Moreau Envelope: Sandwich Property [2, 12])
For all γ > 0 the following hold for the cost function φ:
-
(i)
 for all
\(x\in \mathbb {R}^n\)
where
\(\hat x\mathrel{\mathop:}= \operatorname {prox}_{\gamma \varphi }(x)\)
;
for all
\(x\in \mathbb {R}^n\)
where
\(\hat x\mathrel{\mathop:}= \operatorname {prox}_{\gamma \varphi }(x)\)
;
-
(ii)
 for all
\(x\in \mathbb {R}^n\)
where
\(\hat x\mathrel{\mathop:}= \operatorname {prox}_{\gamma \varphi }(x)\)
;
for all
\(x\in \mathbb {R}^n\)
where
\(\hat x\mathrel{\mathop:}= \operatorname {prox}_{\gamma \varphi }(x)\)
;
-
(iii)
 iff \( x\in \operatorname *{\mathrm {argmin}}\varphi \).
iff \( x\in \operatorname *{\mathrm {argmin}}\varphi \).
 for all
for all
 for all
for all
 iff
iff Proof
-
•
15.3.1(i) . This fact is shown in [12, Lem. 3.2] for a more general notion of proximal point operator; namely, the square Euclidean norm appearing in (15.16) and (15.17) can be replaced by arbitrary Bregman divergences. In this simpler case, since \(\tfrac 1\gamma (x-\hat x)\) is a subgradient of φ at \(\hat x\), cf. (15.18), we have
 (15.19)
(15.19)The claim now follows by subtracting \(\tfrac {1}{2\gamma }\|x-\hat x\|{ }^2\) from both sides.
-
•
15.3.1(ii) . Follows by definition, cf. (15.16) and (15.17).
-
•
15.3.1(iii) . See [2, Prop. 17.5]. □

□
Theorem 15.3.2 (Moreau Envelope: Convex Smooth Minimization Equivalence [2])
For all γ > 0 the following hold for the cost function φ:
-
(i)
φ γ is convex and smooth with \(L_{\varphi ^\gamma }=\gamma ^{-1}\) and \( \nabla \varphi ^\gamma (x) {}={} \gamma ^{-1}\big (x-\operatorname {prox}_{\gamma \varphi }(x)\big ) \) ;
-
(ii)
\( \inf \varphi =\inf \varphi ^\gamma \) ;
-
(iii)
\( x_\star \in \operatorname *{\mathrm {argmin}}\varphi \) iff \( x_\star \in \operatorname *{\mathrm {argmin}}\varphi ^\gamma \) iff ∇φ γ(x ⋆) = 0.
Proof
- •
-
•
15.3.2(ii) . See [2, Prop. 12.9(iii)].
-
•
15.3.2(iii) . See [2, Prop. 17.5]. □
□
As a consequence of Theorem 15.3.2, one can address the minimization of the convex but possibly nonsmooth and extended-real-valued function φ by means of gradient descent on the smooth envelope function φ γ with stepsize \(0<\tau <{2}/{L_{\varphi _\gamma }}=2\gamma \). As first noticed by Rockafellar [64], this simply amounts to (relaxed) fixed-point iterations of the proximal point operator, namely
where λ = τ∕γ ∈ (0, 2) is a possible relaxation parameter. The scheme, known as proximal point algorithm (PPA) and first introduced by Martinet [45], is well covered by the broad theory of monotone operators, where convergence properties can be easily derived with simple tools of Fejérian monotonicity, see, e.g., [2, Thm.s 23.41 and 27.1]. Nevertheless, not only does the interpretation as gradient method provide a beautiful theoretical link, but it also enables the employment of acceleration techniques exclusively stemming from smooth unconstrained optimization, such as Nesterov’s extrapolation [26] or quasi-Newton schemes [13], see also [7] for extensions to the dual formulation.
15.3.2 Forward-Backward Splitting
While it is true that every convex minimization problem can be smoothened by means of the Moreau envelope, unfortunately it is often the case that the computation of the proximal operator (which is needed to evaluate the envelope) is as hard as solving the original problem. For instance, evaluating the Moreau envelope of the cost of modeling a convex QP at one point amounts to solving another QP with same constraints and augmented cost. To overcome this limitation there comes the idea of splitting schemes, which decompose a complex problem in small components which are easier to operate onto. A popular such scheme is the forward-backward splitting (FBS), which addresses minimization problems of the form (15.1).
Given a point \(x\in \mathbb {R}^n\), one iteration of forward-backward splitting (FBS) for problem (15.1) with stepsize γ > 0 and relaxation λ > 0 consists in

where

is the forward-backward operator, characterized as

as it follows from (15.18). FBS interleaves a gradient descent step on f and a proximal point step on g, and as such it is also known as proximal gradient method. If both f and g are (lsc, proper and) convex, then the solutions to (15.1) are exactly the fixed points of the forward-backward operator T γ. In other words,

where

is the forward-backward residual.Footnote 1 FBS iterations (15.21) are well known to converge to a solution to (15.1) provided that f is smooth and that the parameters are chosen as γ ∈ (0, 2∕L f) and λ ∈ (0, 2 − γL f∕2) [2, Cor. 28.9] (λ = 1, which is always feasible, is the typical choice).
15.3.3 Error Bounds and Quadratic Growth
We conclude the section with some inequalities that will be useful in the sequel.
Lemma 15.3.3
Suppose that \(\mathcal X_\star \) is nonempty. Then,
Proof
From the subgradient inequality it follows that for all \(x_\star \in \mathcal X_\star \) and v ∈ ∂φ(x) we have
and the claimed inequality follows from the arbitrarity of x ⋆ and v. □
Lemma 15.3.4
Suppose that \(\mathcal X_\star \) is nonempty. For all \(x\in \mathbb {R}^n\) and γ > 0 the following holds:

Proof
Let  . The characterization (15.23) of
. The characterization (15.23) of  implies that
implies that

After trivial rearrangements the sought inequality follows. □
Further interesting inequalities can be derived if the cost function φ satisfies an error bound, which can be regarded as a generalization of strong convexity that does not require uniqueness of the minimizer. The interested reader is referred to [3, 17, 43, 55] and the references therein for extensive discussions.
Definition 15.3.5 (Quadratic Growth and Error Bound)
Suppose that \(\mathcal X_\star \neq \emptyset \). Given μ, ν > 0, we say that
-
1.
φ satisfies the quadratic growth with constants (μ, ν) if
 (15.30)
(15.30) -
2.
φ satisfies the error bound with constants (μ, ν) if
 (15.31)
(15.31)


In case ν = ∞ we say that the properties are satisfied globally.
Theorem 15.3.6 ([17, Thm. 3.3])
For a proper convex and lsc function, the quadratic growth with constants (μ, ν) is equivalent to the error bound with same constants.
Lemma 15.3.7 (Globality of Quadratic Growth)
Suppose that φ satisfies the quadratic growth with constants (μ, ν). Then, for every ν′ > ν it satisfies the quadratic growth with constants (μ′, ν′), where

Proof
Let ν′ > ν be fixed, and let \(x\in \operatorname {lev}_{\leq \varphi _\star +\nu '}\) be arbitrary. Since μ′≤ μ, the claim is trivial if φ(x) ≤ φ ⋆ + ν; we may thus suppose that φ(x) > φ ⋆ + ν. Let z be the projection of x onto the (nonempty closed and convex) level set \(\operatorname {lev}_{\leq \varphi _\star +\nu }\), and observe that φ(z) = φ ⋆ + ν. With Lemma 15.3.3 and Theorem 15.3.6 we can upper bound ν as

Moreover, it follows from [28, Thm. 1.3.5] that there exists a subgradient v ∈ ∂φ(z) such that 〈v, x − z〉 = ∥v∥∥x − z∥. Then,

By subtracting φ(z) from the first and last terms we obtain

which implies

Thus,

using the quadratic growth at z and the inequality (15.36)

By using the fact that \(a^2+b^2\geq \frac 12(a+b)^2\) for any \(a,b\in \mathbb {R}\) together with the triangular inequality \(\operatorname {dist}(x,\mathcal X_\star )\leq \|x-z\|+\operatorname {dist}(z,\mathcal X_\star )\), we conclude that \( \varphi (x) {}-{} \varphi _\star {}\geq {} \tfrac {\mu '}{2} \operatorname {dist}(x,\mathcal X_\star )^2 \), with μ′ as in the statement. Since μ′ depends only on μ, ν, and ν′, from the arbitrarity of \(x\in \operatorname {lev}_{\leq \varphi _\star +\nu '}\) the claim follows. □
Theorem 15.3.8 ([17, Cor. 3.6])
Suppose that φ satisfies the quadratic growth with constants (μ, ν). Then, for all γ ∈ (0, 1∕L f) and \(x\in \operatorname {lev}_{\leq \varphi _\star +\nu }\varphi \) we have

15.4 Forward-Backward Envelope
There are clearly infinite ways of representing the (proper, lsc and) convex function φ in (15.1) as the sum of two convex functions f and g with f smooth, and each of these choices leads to a different FBS operator T γ. If f = 0, for instance, then T γ reduces to \(\operatorname {prox}_{\gamma \varphi }\), and consequently FBS (15.21) to the PPA (15.20). A natural question then arises, whether a function exists that serves as “envelope” for FBS in the same way that φ γ does for \(\operatorname {prox}_{\gamma \varphi }\). We will now provide a positive answer to this question by reformulating the nonsmooth problem (15.1) as the minimization of a differentiable function. To this end, the following requirements on f and g will be assumed throughout the chapter without further mention.
Assumption I (Basic Requirements) In problem (15.1),
-
(i)
\(f:\mathbb {R}^n\rightarrow \mathbb {R}\) is convex, twice continuously differentiable and L f -smooth;
-
(ii)
 is lsc, proper, and convex.
is lsc, proper, and convex.
 is lsc, proper, and convex.
is lsc, proper, and convex.
Compared to the classical FBS assumptions, the only additional requirement is twice differentiability of f. This ensures that the forward operator  is differentiable; we denote its Jacobian as \(Q_\gamma :\mathbb {R}^n\rightarrow \mathbb {R}^{n\times n}\), namely
is differentiable; we denote its Jacobian as \(Q_\gamma :\mathbb {R}^n\rightarrow \mathbb {R}^{n\times n}\), namely

Notice that, due to the bound  (which follows from L
f-smoothness of f, see [53, Lem. 1.2.2]) Q
γ(x) is invertible (in fact, positive definite) whenever γ < 1∕L
f. Moreover, due to the chain rule and Theorem 15.3.2(i)
we have that
(which follows from L
f-smoothness of f, see [53, Lem. 1.2.2]) Q
γ(x) is invertible (in fact, positive definite) whenever γ < 1∕L
f. Moreover, due to the chain rule and Theorem 15.3.2(i)
we have that

Rearranging,

we obtain the gradient of a real-valued function, which we define as follows.
Definition 15.4.1 (Forward-Backward Envelope) The forward-backward envelope (FBE) for the composite minimization problem (15.1) is the function \(\varphi _\gamma :\mathbb {R}^n\rightarrow \mathbb {R}\) defined as

In the next section we discuss some of the favorable properties enjoyed by the FBE.
15.4.1 Basic Properties
We already verified that the FBE is differentiable with gradient

In particular, for γ < 1∕L f one obtains that a FBS step is a (scaled) gradient descent step on the FBE, similarly as the relation between Moreau envelope and PPA; namely,
To take the analysis of the FBE one step further, let us consider the equivalent expression of the operator T γ as

Differently from the quadratic model \(\mathcal M_\gamma ^\varphi \) in (15.16), \(\mathcal M_\gamma ^{f,g}\) replaces the differentiable component f with a linear approximation. Building upon the idea of the Moreau envelope, instead of the minimizer T γ(x) we consider the value attained in the subproblem (15.42), and with simple algebra one can easily verify that this gives rise once again to the FBE:

Starting from this expression we can easily mirror the properties of the Moreau envelope stated in Theorems 15.3.1 and 15.3.2. These results appeared in the independent works [54] and [57], although the former makes no mention of an “envelope” function and simply analyzes the majorization-minimization model \(\mathcal M_\gamma ^{f,g}\).
Theorem 15.4.2 (FBE: Sandwich Property)
Let γ > 0 and \(x\in \mathbb {R}^n\) be fixed, and denote  . The following hold:
. The following hold:
-
(i)
 ;
;
-
(ii)
\( \varphi _\gamma (x) {}-{} \frac {1}{2\gamma }\|x-\bar x\|{ }^2 {}\leq {} \varphi (\bar x) {}\leq {} \varphi _\gamma (x) {}-{} \frac {1-\gamma L_f}{2\gamma }\|x-\bar x\|{ }^2 \).
 ;
;
In particular,
-
(i)
 iff \( x_\star \in \operatorname *{\mathrm {argmin}}\varphi \).
iff \( x_\star \in \operatorname *{\mathrm {argmin}}\varphi \).
 iff
iff In fact, the assumption of twice continuous differentiability of f can be dropped.
Proof
-
•
15.4.2(i) Since the minimum in (15.43) is attained at \(w=\bar x\), cf. (15.42), we have
 (15.44)
(15.44)where in the inequality we used the fact that \(\tfrac 1\gamma (x-\bar x)-\nabla f(x)\in \partial g(\bar x)\), cf. (15.23).
-
•
15.4.2(ii) Follows by using (15.5) (with h = f, u = x and \(v=\bar x\)) in (15.44).
-
•
15.4.2(i) Follows by 15.4.2(i) and the optimality condition (15.24). □

□
Notice that by combining Theorems 15.4.2(i) and 15.4.2(ii) we recover the “sufficient decrease” condition of (convex) FBS [54, Thm. 1], that is

holding for all \(x\in \mathbb {R}^n\) with  .
.
Theorem 15.4.3 (FBE: Smooth Minimization Equivalence)
For all γ > 0
-
(i)
\(\varphi _\gamma \in C^1(\mathbb {R}^n)\) with
 .
.
 .
.Moreover, if γ ∈ (0, 1∕L f) then the following also hold:
-
(i)
\( \inf \varphi =\inf \varphi _\gamma \) ;
-
(ii)
\( x_\star \in \operatorname *{\mathrm {argmin}}\varphi \) iff \( x_\star \in \operatorname *{\mathrm {argmin}}\varphi _\gamma \) iff ∇φ γ(x ⋆) = 0.
Proof
-
•
15.4.3(i) . Since \(f\in C^2(\mathbb {R}^n)\) and \(g^\gamma \in C^1(\mathbb {R}^n)\) (cf. Theorem 15.3.2(i) ), from the definition (15.39) it is apparent that φ γ is continuously differentiable for all γ > 0. The formula for the gradient was already shown in (15.40).
Suppose now that γ < 1∕L f.
-
•
15.4.3(i) .
 .
. -
•
15.4.3(ii) . We have
 (15.46)
(15.46)where the second equivalence follows from the invertibility of Q γ.
Suppose now that \(x_\star \in \operatorname *{\mathrm {argmin}}\varphi _\gamma \). Since \(\varphi _\gamma \in C^1(\mathbb {R}^n)\) the first-order necessary condition reads ∇φ γ = 0, and from the equivalence proven above we conclude that \( \operatorname *{\mathrm {argmin}}\varphi _\gamma \subseteq \operatorname *{\mathrm {argmin}}\varphi \). Conversely, if \(x_\star \in \operatorname *{\mathrm {argmin}}\varphi \), then
 (15.47)
(15.47)proving \(x_\star \in \operatorname *{\mathrm {argmin}}\varphi _\gamma \), hence the inclusion \( \operatorname *{\mathrm {argmin}}\varphi _\gamma \supseteq \operatorname *{\mathrm {argmin}}\varphi \). □
 .
.

□
Proposition 15.4.4 (FBE and Moreau Envelope [54, Thm. 2])
For any γ ∈ (0, 1∕L f), it holds that
Proof
We have

Using the upper bound in (15.5) instead yields the other inequality. □
Since φ γ is upper bounded by the γ −1-smooth function φ γ with which it shares the set of minimizers \(\mathcal X_\star \), from (15.5) we easily infer the following quadratic upper bound.
Corollary 15.4.5 (Global Quadratic Upper Bound)
If \(\mathcal X_\star \neq \emptyset \) , then

Although the FBE may fail to be convex, for γ < 1∕L f its stationary points and minimizers coincide and are the same as those of the original function φ (Figure 15.2). That is, the minimization of φ is equivalent to the minimization of the differentiable function φ γ. This is a clear analogy with the Moreau envelope, which in fact is the special case of the FBE corresponding to f ≡ 0 in the decomposition of φ. In the next result we tighten the claims of Theorem 15.4.3(i) when f is a convex quadratic function, showing that in this case the FBE is convex and smooth and thus recover all the properties of the Moreau envelope.

FBE of the function φ as in Figure 15.1 with same parameter γ = 0.2, relative to the decomposition as the sum of f(x) = x 2 + x − 1 and \(g(x) = \tfrac 13x^3+\operatorname {\delta }_{[0,\infty )}(x)\). For γ < 1∕L f (L f = 2 in this example) at each point x the FBE φ γ is the minimum of the quadratic majorization model \(\mathcal M_\gamma ^{f,g}({}\cdot {},x)\) for φ, the unique minimizer being the proximal gradient point \(\bar x=T_\gamma (x)\). The FBE is a differentiable lower bound to φ and since f is quadratic in this example, it is also smooth and convex (cf. Theorem 15.4.6). In any case, its stationary points and minimizers coincide, and are equivalent to the minimizers of φ
Theorem 15.4.6 (FBE: Convexity & Smoothness for Quadratic f [24, Prop. 4.4])
Suppose that f is convex quadratic, namely f(x) = 〈x, Hx〉 + 〈h, x〉 for some \(H\in \operatorname {S}_+(\mathbb {R}^n)\) and \(h\in \mathbb {R}^n\) . Then, for all γ ∈ (0, 1∕L f] the FBE φ γ is convex and smooth, with

where L f = λ max(H) and μ f = λ min(H). In particular, when f is μ f -strongly convex the strong convexity of φ γ is maximized for \(\gamma =\frac {1}{\mu _f+L_f}\) , in which case

Proof
Letting Q: = I − γH, we have that Q
γ ≡ Q and  . Therefore,
. Therefore,

From the firm nonexpansiveness of \(\operatorname {prox}_{\gamma g}\) (see [2, Prop.s 4.35(iii) and 12.28]) it follows that
By combining with the previous inequality, we obtain

Since λ min(Q) = 1 − γL f and λ max(Q) = 1 − γμ f, from Lemma 2 we conclude that
with \(\mu _{\varphi _\gamma }\) and \(L_{\varphi _\gamma }\) as in the statement, hence the claim, cf. (15.6). □
Lemma 15.4.7
Suppose that φ has the quadratic growth with constants (μ, ν), and let \(\varphi _\star \mathrel{\mathop:}= \min \varphi \) . Then, for all γ ∈ (0, 1∕L f] and \(x\in \operatorname {lev}_{\leq \varphi _\star +\nu }\varphi _\gamma \) it holds that

Proof
Fix \(x\in \operatorname {lev}_{\leq \varphi _\star +\nu }\varphi _\gamma \) and let  . We have
. We have

and since \(\bar x\in \operatorname {lev}_{\leq \varphi _\star +\nu }\varphi \) (cf. Theorem 15.4.2(ii) ), from Theorem 15.3.8 we can bound the quantity \(\operatorname {dist}(\bar x,\mathcal X_\star )\) in terms of the residual as

The proof now follows from the inequality  , see [4, Thm. 10.12], after easy algebraic manipulations. □
, see [4, Thm. 10.12], after easy algebraic manipulations. □
15.4.2 Further Equivalence Properties
Proposition 15.4.8 (Equivalence of Level Boundedness)
For any γ ∈ (0, 1∕L f), φ has bounded level sets iff φ γ does.
Proof
Theorem 15.4.2 implies that \( \operatorname {lev}_{\leq \alpha }\varphi \subseteq \operatorname {lev}_{\leq \alpha }\varphi _\gamma \) for all \(\alpha \in \mathbb {R}\), therefore level boundedness of φ
γ implies that of φ. Conversely, suppose that φ
γ is not level bounded, and consider  with ∥x
k∥→∞. Then from Theorem 15.4.2 it follows that \( \varphi (\bar x_k) {}\leq {} \varphi _\gamma (x_k)-\tfrac {1}{2\gamma }\|x_k-\bar x_k\|{ }^2 {}\leq {} \alpha -\tfrac {1}{2\gamma }\|x_k-\bar x_k\|{ }^2 \), where
with ∥x
k∥→∞. Then from Theorem 15.4.2 it follows that \( \varphi (\bar x_k) {}\leq {} \varphi _\gamma (x_k)-\tfrac {1}{2\gamma }\|x_k-\bar x_k\|{ }^2 {}\leq {} \alpha -\tfrac {1}{2\gamma }\|x_k-\bar x_k\|{ }^2 \), where  . In particular,
. In particular,  . If
. If  is bounded, then \(\inf \varphi =-\infty \); otherwise, \(\operatorname {lev}_{\leq \alpha }\varphi \) contains the unbounded sequence
is bounded, then \(\inf \varphi =-\infty \); otherwise, \(\operatorname {lev}_{\leq \alpha }\varphi \) contains the unbounded sequence  . Either way, φ cannot be level bounded. □
. Either way, φ cannot be level bounded. □
Proposition 15.4.9 (Equivalence of Quadratic Growth)
Let γ ∈ (0, 1∕L f) be fixed. Then,
-
(i)
if φ satisfies the quadratic growth condition with constants (μ, ν), then so does φ γ with constants (μ′, ν), where \( \mu ' {}\mathrel{\mathop:}= {} \tfrac {1-\gamma L_f}{(1+\gamma L_f)^2} \tfrac {\mu \gamma }{(2+\gamma \mu )^2} \mu \) ;
-
(ii)
conversely, if φ γ satisfies the quadratic growth condition, then so does φ with same constants.
Proof
Since φ and φ γ have same infimum and minimizers (cf. Theorem 15.4.3), 15.4.9(ii) is a straightforward consequence of the fact that φ γ ≤ φ (cf. Theorem 15.4.2(i) ).
Conversely, suppose that φ satisfies the quadratic growth with constants (μ, ν). Then, for all \( x {}\in {} \operatorname {lev}_{\leq \varphi _\star +\nu }\varphi _\gamma \) we have that  , therefore
, therefore

where in the last inequality we discarded the term \(\varphi (\bar x)-\varphi _\star \geq 0\) and used Theorem 15.3.8 to lower bound  . □
. □
Corollary 15.4.10 (Equivalence of Strong Minimality)
For all γ ∈ (0, 1∕L f), a point x ⋆ is a (locally) strong minimizer for φ iff it is a (locally) strong minimizer for φ γ.
Lastly, having showed that for convex functions the quadratic growth can be extended to arbitrary level sets (cf. Lemma 15.3.7), an interesting consequence of Proposition 15.4.9 is that, although φ γ may fail to be convex, it enjoys the same property.
Corollary 15.4.11 (FBE: Globality of Quadratic Growth)
Let γ ∈ (0, 1∕L f) and suppose that φ γ satisfies the quadratic growth with constants (μ, ν). Then, for every ν′ > ν there exists μ′ > 0 such that φ γ satisfies the quadratic growth with constants (μ′, ν′).
15.4.3 Second-Order Properties
Although φ γ is continuously differentiable over \(\mathbb {R}^n\), it fails to be C 2 in most cases; since g is nonsmooth, its Moreau envelope g γ is hardly ever C 2. For example, if g is real valued, then g γ is C 2 (and \(\operatorname {prox}_{\gamma g}\) is C 1) if and only if g is C 2 [33]. Therefore, we hardly ever have the luxury of assuming continuous differentiability of ∇φ γ and we must resort to generalized notions of differentiability stemming from nonsmooth analysis. Specifically, our analysis is largely based on generalized differentiability properties of \(\operatorname {prox}_{\gamma g}\) which we study next.
Theorem 15.4.12
For all \(x\in \mathbb {R}^n\) , \(\partial _C(\operatorname {prox}_{\gamma g})(x)\neq \emptyset \) and any \(P\in \partial _C(\operatorname {prox}_{\gamma g})(x)\) is a symmetric positive semidefinite matrix that satisfies ∥P∥≤ 1.
Proof
Nonempty-valuedness of \(\partial _C(\operatorname {prox}_{\gamma g})\) is due to Lipschitz continuity of \(\operatorname {prox}_{\gamma g}\). Moreover, since g is convex, its Moreau envelope is a convex function as well, therefore every element of ∂ C(∇g γ)(x) is a symmetric positive semidefinite matrix (see, e.g., [19, §8.3.3]). Due to Theorem 15.3.2(i) , we have that \( \operatorname {prox}_{\gamma g}(x) {}={} x-\gamma \nabla g^\gamma (x) \), therefore
The last relation holds with equality (as opposed to inclusion in the general case) due to the fact that one of the summands is continuously differentiable. Now, from (15.57) we easily infer that every element of \(\partial _C(\operatorname {prox}_{\gamma g})(x)\) is a symmetric matrix. Since ∇g γ(x) is Lipschitz continuous with Lipschitz constant γ −1, using [15, Prop. 2.6.2(d)], we infer that every H ∈ ∂ C(∇g γ)(x) satisfies ∥H∥≤ γ −1. Now, according to (15.57) it holds that
Therefore, for every \(d\in \mathbb {R}^n\) and \(P\in \partial _C(\operatorname {prox}_{\gamma g})(x)\),
On the other hand, since \(\operatorname {prox}_{\gamma g}\) is Lipschitz continuous with Lipschitz constant 1, using [15, Prop. 2.6.2(d)] we obtain that ∥P∥≤ 1 for all \(P\in \partial _C(\operatorname {prox}_{\gamma g})(x)\). □
We are now in a position to construct a generalized Hessian for φ γ that will allow the development of Newton-like methods with fast asymptotic convergence rates. An obvious route to follow would be to assume that ∇φ γ is semismooth and employ ∂ C(∇φ γ) as a generalized Hessian for φ γ. However, this approach would require extra assumptions on f and involve complicated operations to evaluate elements of ∂ C(∇φ γ). On the other hand, what is really needed to devise Newton-like algorithms with fast local convergence rates is a linear Newton approximation (LNA), cf. Definition 15.2.3, at some stationary point of φ γ, which by Theorem 15.4.3(ii) is also a minimizer of φ, provided that γ ∈ (0, 1∕L f).
The approach we follow is largely based on [72], [19, Prop. 10.4.4]. Without any additional assumptions we can define a set-valued mapping \(\hat \partial ^2\varphi _\gamma :\mathbb {R}^n\rightrightarrows \mathbb {R}^{n\times n}\) with full domain and whose elements have a simpler form than those of ∂
C(∇φ
γ), which serves as a LNA for ∇φ
γ at any stationary point x
⋆ provided \(\operatorname {prox}_{\gamma g}\) is semismooth at  . We call it approximate generalized Hessian of φ
γ and it is given by
. We call it approximate generalized Hessian of φ
γ and it is given by

Notice that if f is quadratic, then \(\hat \partial ^2\varphi _\gamma \equiv \partial _C\nabla \varphi _\gamma \); more generally, the key idea in the definition of \(\hat \partial ^2\varphi _\gamma \), reminiscent of the Gauss-Newton method for nonlinear least-squares problems, is to omit terms vanishing at x ⋆ that contain third-order derivatives of f.
Proposition 15.4.13
Let \(\bar x\in \mathbb {R}^n\) and γ > 0 be fixed. If \(\operatorname {prox}_{\gamma g}\) is (𝜗-order) semismooth at  (and ∇2
f is 𝜗-Hölder continuous around \(\bar x\)
), then
(and ∇2
f is 𝜗-Hölder continuous around \(\bar x\)
), then

is a (𝜗-order) LNA for  at \(\bar x\).
at \(\bar x\).
Proof
We shall prove only the 𝜗-order semismooth case, as the other one is shown by simply replacing all occurrences of O(∥⋅∥1+𝜗) with o(∥⋅∥) in the proof. Let  be the forward operator, so that the forward-backward operator
be the forward operator, so that the forward-backward operator  can be expressed as
can be expressed as  . With a straightforward adaptation of the proof of [19, Prop. 7.2.9] to include the 𝜗-Hölderian case, it can be shown that
. With a straightforward adaptation of the proof of [19, Prop. 7.2.9] to include the 𝜗-Hölderian case, it can be shown that
Moreover, since ∇f is Lipschitz continuous and thus so is q γ, we also have
Let  be arbitrary; then, there exists
be arbitrary; then, there exists  such that \( U_x {}={} \gamma ^{-1}(\mathrm {I}-P_xQ_\gamma (x))(\bar x-x) \). We have
such that \( U_x {}={} \gamma ^{-1}(\mathrm {I}-P_xQ_\gamma (x))(\bar x-x) \). We have

due to 𝜗-order semismoothness of \(\operatorname {prox}_{\gamma g}\) at \(q_\gamma (\bar x)\),

where in the last equality we used the fact that ∥P x∥≤ 1, cf. Theorem 15.4.12. □
Corollary 15.4.14
Let γ ∈ (0, 1∕L
f) and \(x_\star \in \mathcal X_\star \)
. If \(\operatorname {prox}_{\gamma g}\) is (𝜗-order) semismooth at  (and ∇2
f is locally 𝜗-Hölder continuous around x
⋆
), then \(\hat \partial ^2\varphi _\gamma \) is a (𝜗-order) LNA for ∇φ
γ at x
⋆.
(and ∇2
f is locally 𝜗-Hölder continuous around x
⋆
), then \(\hat \partial ^2\varphi _\gamma \) is a (𝜗-order) LNA for ∇φ
γ at x
⋆.
Proof
Let  , so that H
x = Q
γ(x)U
x for some \(U_x\in \mathcal R_\gamma (x)\). Then,
, so that H
x = Q
γ(x)U
x for some \(U_x\in \mathcal R_\gamma (x)\). Then,
where in the equalities we used the fact that ∇φ γ(x ⋆) = R γ(x ⋆) = 0, and in the inequality the fact that ∥Q γ∥≤ 1. Since \(\mathcal R_\gamma \) is a (𝜗-order) LNA of R γ at x ⋆, the last term is o(∥x − x ⋆∥) (resp. O(∥x − x ⋆∥1+𝜗)). □
As shown in the next result, although the FBE is in general not convex, for γ small enough every element of \(\hat \partial ^2\varphi _\gamma (x)\) is a (symmetric and) positive semidefinite matrix. Moreover, the eigenvalues are lower and upper bounded uniformly over all \(x\in \mathbb {R}^n\).
Proposition 15.4.15
Let γ ≤ 1∕L f and \(H\in \hat \partial ^2\varphi _\gamma (x)\) be fixed. Then, \(H\in \operatorname {S}_+(\mathbb {R}^n)\) with

where μ f ≥ 0 is the modulus of strong convexity of f.
Proof
Fix \(x\in \mathbb {R}^n\) and let Q: = Q
γ(x). Any \(H\in \hat \partial ^2\varphi _\gamma (x)\) can be expressed as H = γ
−1
Q(I − PQ) for some  . Since both Q and P are symmetric (cf. Theorem 15.4.12), it follows that so is H. Moreover, for all \(d\in \mathbb {R}^n\)
. Since both Q and P are symmetric (cf. Theorem 15.4.12), it follows that so is H. Moreover, for all \(d\in \mathbb {R}^n\)

On the other hand, since P ≽ 0 (cf. Theorem 15.4.12) and thus QPQ ≽ 0, we can upper bound (15.65) as
□
The next lemma links the behavior of the FBE close to a solution of (15.1) and a nonsingularity assumption on the elements of \(\hat \partial ^2\varphi _\gamma (x_\star )\). Part of the statement is similar to [19, Lem. 7.2.10]; however, here ∇φ γ is not required to be locally Lipschitz around x ⋆.
Lemma 15.4.16
Let \(x_\star \in \operatorname *{\mathrm {argmin}}\varphi \) and γ ∈ (0, 1∕L
f). If \(\operatorname {prox}_{\gamma g}\) is semismooth at  , then the following conditions are equivalent:
, then the following conditions are equivalent:
-
(a)
x ⋆ is a locally strong minimum for φ (or, equivalently, for φ γ );
-
(b)
every element of \(\hat \partial ^2\varphi _\gamma (x_\star )\) is nonsingular.
In any such case, there exist δ, κ > 0 such that

for any  and \( H\in \hat \partial ^2\varphi _\gamma (x) \).
and \( H\in \hat \partial ^2\varphi _\gamma (x) \).
Proof
Observe first that Corollary 15.4.14 ensures that \(\hat \partial ^2\varphi _\gamma \) is a LNA of ∇φ γ at x ⋆, thus semicontinuous and compact valued (by definition). In particular, the last claim follows from [19, Lem. 7.5.2].
-
•
15.4.16(a) ⇒ 15.4.16(b) It follows from Corollary 15.4.10 that there exists μ, δ > 0 such that \( \varphi _\gamma (x)-\varphi _\star {}\geq {} \tfrac \mu 2\|x-x_\star \|{ }^2 \) for all
 . In particular, for all \(H\in \hat \partial ^2\varphi _\gamma (x_\star )\) and
. In particular, for all \(H\in \hat \partial ^2\varphi _\gamma (x_\star )\) and  we have
we have  (15.67)
(15.67)Let v min be a unitary eigenvector of H corresponding to the minimum eigenvalue λ min(H). Then, for all ε ∈ (−δ, δ) the point x ε = x ⋆ + εv min is δ-close to x ⋆ and thus
 (15.68)
(15.68)where the last inequality holds up to possibly restricting δ (and thus ε). The claim now follows from the arbitrarity of \(H\in \hat \partial ^2\varphi _\gamma (x_\star )\).
-
•
15.4.16(a) ⇐ 15.4.16(b) Easily follows by reversing the arguments of the other implication. □
 . In particular, for all
. In particular, for all  we have
we have 

□
15.5 Forward-Backward Truncated-Newton Algorithm (FBTN)
Having established the equivalence between minimizing φ and φ γ, we may recast problem (15.1) into the smooth unconstrained minimization of the FBE. Under some assumptions the elements of \(\hat \partial ^2\varphi _\gamma \) mimic second-order derivatives of φ γ, suggesting the employment of Newton-like update directions d = −(H + δI)−1∇φ γ(x) with \(H\in \hat \partial ^2\varphi _\gamma (x)\) and δ > 0 (the regularization term δI ensures the well definedness of d, as H is positive semidefinite, see Proposition 15.4.15). If δ and ε are suitably selected, under some nondegeneracy assumptions updates x + = x + d are locally superlinearly convergent. Since such d’s are directions of descent for φ γ, a possible globalization strategy is an Armijo-type linesearch. Here, however, we follow the simpler approach proposed in [71, 75] that exploits the basic properties of the FBE investigated in Section 15.4.1. As we will discuss shortly after, this is also advantageous from a computational point of view, as it allows an arbitrary warm starting for solving the underlying linear system.
Let us elaborate on the linesearch. To this end, let x be the current iterate; then, Theorem 15.4.2 ensures that  . Therefore, unless
. Therefore, unless  , in which case x would be a solution, for any \(\sigma \in (0,\gamma \frac {1-\gamma L_f}{2})\) the strict inequality
, in which case x would be a solution, for any \(\sigma \in (0,\gamma \frac {1-\gamma L_f}{2})\) the strict inequality  is satisfied. Due to the continuity of φ
γ, all points sufficiently close to
is satisfied. Due to the continuity of φ
γ, all points sufficiently close to  will also satisfy the inequality, thus so will the point
will also satisfy the inequality, thus so will the point  for small enough stepsizes τ. This fact can be used to enforce the iterates to sufficiently decrease the value of the FBE, cf. (15.70), which straightforwardly implies optimality of all accumulation points of the generated sequence. We defer the details to the proof of Theorem 15.5.1. In Theorems 15.5.4 and 15.5.5 we will provide conditions ensuring acceptance of unit stepsizes so that the scheme reduces to a regularized version of the (undamped) linear Newton method [19, Alg. 7.5.14] for solving ∇φ
γ(x) = 0, which, under due assumptions, converges superlinearly.
for small enough stepsizes τ. This fact can be used to enforce the iterates to sufficiently decrease the value of the FBE, cf. (15.70), which straightforwardly implies optimality of all accumulation points of the generated sequence. We defer the details to the proof of Theorem 15.5.1. In Theorems 15.5.4 and 15.5.5 we will provide conditions ensuring acceptance of unit stepsizes so that the scheme reduces to a regularized version of the (undamped) linear Newton method [19, Alg. 7.5.14] for solving ∇φ
γ(x) = 0, which, under due assumptions, converges superlinearly.
Algorithm 15.1 (FBTN) Forward-Backward Truncated-Newton method

In order to ease the computation of d k, we allow for inexact solutions of the linear system by introducing a tolerance ε k > 0 and requiring ∥(H k + δ kI)d k + ∇φ γ(x k)∥≤ ε k.
Algorithm 15.2 (CG) Conjugate Gradient for computing the update direction

Since H k + δ kI is positive definite, inexact solutions of the linear system can be efficiently retrieved by means of CG (15.2) , which only requires matrix-vector products and thus only (generalized) directional derivatives, namely, (generalized) derivatives (denoted as \(\frac {\partial }{\partial \lambda }\)) of the single-variable functions \( t\mapsto \operatorname {prox}_{\gamma g}(x+t\lambda ) \) and t↦∇f(x + tλ), as opposed to computing the full (generalized) Hessian matrix. To further enhance computational efficiency, we may warm start the CG method with the previously computed direction, as eventually subsequent update directions are expected to have a small difference. Notice that this warm starting does not ensure that the provided (inexact) solution d k is a direction of descent for φ γ; either way, this property is not required by the adopted linesearch, showing a considerable advantage over classical Armijo-type rules. Putting all these facts together we obtain the proposed FBE-based truncated-Newton algorithm FBTN (15.1) for convex composite minimization.
Remark 15.1 (Adaptive Variant When L f Is Unknown)
In practice, no prior knowledge of the global Lipschitz constant L f is required for FBTN . In fact, replacing L f with an initial estimate L > 0, the following instruction can be added at the beginning of each iteration, before step 1:

Moreover, since positive definiteness of H k + δ kI is ensured only for γ ≤ 1∕L f where L f is the true Lipschitz constant of ∇φ γ (cf. Proposition 15.4.15), special care should be taken when applying CG in order to find the update direction d k. Specifically, CG should be stopped prematurely whenever 〈p, z〉≤ 0 in step 6, in which case γ ← γ∕2, L ← 2L and the iteration should start again from step 1.
Whenever the quadratic bound (15.5) is violated with L in place of L f, the estimated Lipschitz constant L is increased, γ is decreased accordingly, and the proximal gradient point \(\bar x^k\) with the new stepsize γ is evaluated. Since replacing L f with any L ≥ L f still satisfies (15.5), it follows that L is incremented only a finite number of times. Therefore, there exists an iteration k 0 starting from which γ and L are constant; in particular, all the convergence results here presented remain valid starting from iteration k 0, at latest. Moreover, notice that this step does not increase the complexity of the algorithm, since both \(\bar x^k\) and ∇f(x k) are needed for the evaluation of φ γ(x k).
15.5.1 Subsequential and Linear Convergence
Before going through the convergence proofs let us spend a few lines to emphasize that FBTN is a well-defined scheme. First, that a matrix H k as in line 1 exists is due to the nonemptyness of \(\hat \partial ^2\varphi _\gamma (x^k)\) (cf. Section 15.4.3). Second, since δ k > 0 and H k ≽ 0 (cf. Proposition 15.4.15) it follows that H k + δ kI is (symmetric and) positive definite, and thus CG is indeed applicable at line 3.
Having clarified this, the proof of the next result falls as a simplified version of [75, Lem. 5.1 and Thm. 5.6]; we elaborate on the details for the sake of self-inclusiveness. To rule out trivialities, in the rest of the chapter we consider the limiting case of infinite accuracy, that is ε = 0, and assume that the termination criterion  is never met. We shall also work under the assumption that a solution to the investigated problem (15.1) exists, thus in particular that the cost function φ is lower bounded.
is never met. We shall also work under the assumption that a solution to the investigated problem (15.1) exists, thus in particular that the cost function φ is lower bounded.
Theorem 15.5.1 (Subsequential Convergence)
Every accumulation point of the sequence  generated by
FBTN
(15.1) is optimal.
generated by
FBTN
(15.1) is optimal.
Proof
Observe that

and that  as τ
k → 0. Continuity of φ
γ ensures that for small enough τ
k the linesearch condition (15.70) is satisfied, in fact, regardless of what d
k is. Therefore, for each k the stepsize τ
k is decreased only a finite number of times. By telescoping the linesearch inequality (15.70) we obtain
as τ
k → 0. Continuity of φ
γ ensures that for small enough τ
k the linesearch condition (15.70) is satisfied, in fact, regardless of what d
k is. Therefore, for each k the stepsize τ
k is decreased only a finite number of times. By telescoping the linesearch inequality (15.70) we obtain

and in particular  . Since
. Since  is continuous we infer that every accumulation point x
⋆ of
is continuous we infer that every accumulation point x
⋆ of  satisfies
satisfies  , hence \(x_\star \in \operatorname *{\mathrm {argmin}}\varphi \), cf. (15.24). □
, hence \(x_\star \in \operatorname *{\mathrm {argmin}}\varphi \), cf. (15.24). □
Remark 15.2
Since FBTN is a descent method on φ γ, as ensured by the linesearch condition (15.70), from Proposition 15.4.8 it follows that a sufficient condition for the existence of cluster points is having φ with bounded level sets or, equivalently, having \( \operatorname *{\mathrm {argmin}}\varphi \) bounded (cf. Lemma 1).
As a straightforward consequence of Lemma 15.4.7, from the linesearch condition (15.70) we infer Q-linear decrease of the FBE along the iterates of FBTN provided that the original function φ has the quadratic growth property. In particular, although the quadratic growth is a local property, Q-linear convergence holds globally, as described in the following result.
Theorem 15.5.2 (Q-Linear Convergence of FBTN Under Quadratic Growth)
Suppose that φ satisfies the quadratic growth with constants (μ, ν). Then, the iterates of FBTN (15.1) decrease Q-linearly the value of φ γ as

where

Proof
Since
FBTN
is a descent method on φ
γ, it holds that  with α = φ
γ(x
0). It follows from Lemma 15.3.7 that φ satisfies the quadratic growth condition with constants (μ′, φ
γ(x
0)), with μ′ is as in the statement. The claim now follows from the inequality ensured by linesearch condition (15.70) combined with Lemma 15.4.7. □
with α = φ
γ(x
0). It follows from Lemma 15.3.7 that φ satisfies the quadratic growth condition with constants (μ′, φ
γ(x
0)), with μ′ is as in the statement. The claim now follows from the inequality ensured by linesearch condition (15.70) combined with Lemma 15.4.7. □
15.5.2 Superlinear Convergence
In this section we provide sufficient conditions that enable superlinear convergence of FBTN . In the sequel, we will make use of the notion of superlinear directions that we define next.
Definition 15.5.3 (Superlinear Directions)
Suppose that \(\mathcal X_\star \neq \emptyset \) and consider the iterates generated by
FBTN
(15.1). We say that  are superlinearly convergent directions if
are superlinearly convergent directions if

If for some q > 1 the condition can be strengthened to

then we say that  are superlinearly convergent directions with order q.
are superlinearly convergent directions with order q.
We remark that our definition of superlinear directions extends the one given in [19, §7.5] to cases in which \(\mathcal X_\star \) is not a singleton. The next result constitutes a key component of the proposed methodology, as it shows that the proposed algorithm does not suffer from the Maratos’ effect [44], a well-known obstacle for fast local methods that inhibits the acceptance of the unit stepsize. On the contrary, we will show that whenever the directions  computed in
FBTN
are superlinear, then indeed the unit stepsize is eventually always accepted, and the algorithm reduces to a regularized version of the (undamped) linear Newton method [19, Alg. 7.5.14] for solving ∇φ
γ(x) = 0 or, equivalently,
computed in
FBTN
are superlinear, then indeed the unit stepsize is eventually always accepted, and the algorithm reduces to a regularized version of the (undamped) linear Newton method [19, Alg. 7.5.14] for solving ∇φ
γ(x) = 0 or, equivalently,  , and \(\operatorname {dist}(x^k,\mathcal X_\star )\) converges superlinearly.
, and \(\operatorname {dist}(x^k,\mathcal X_\star )\) converges superlinearly.
Theorem 15.5.4 (Acceptance of the Unit Stepsize and Superlinear Convergence)
Consider the iterates generated by
FBTN
(15.1). Suppose that φ satisfies the quadratic growth (locally) and that  are superlinearly convergent directions (with order q). Then, there exists \(\bar k\in {\mathbb N}\) such that
are superlinearly convergent directions (with order q). Then, there exists \(\bar k\in {\mathbb N}\) such that

In particular, eventually the iterates reduce to x k+1 = x k + d k , and \(\operatorname {dist}(x^k,\mathcal X_\star )\) converges superlinearly (with order q).
Proof
Without loss of generality we may assume that  and
and  belong to a region in which quadratic growth holds. Denoting \(\varphi _\star \mathrel{\mathop:}= \min \varphi \), since φ
γ also satisfies the quadratic growth (cf. Proposition 15.4.9(i)
) it follows that
belong to a region in which quadratic growth holds. Denoting \(\varphi _\star \mathrel{\mathop:}= \min \varphi \), since φ
γ also satisfies the quadratic growth (cf. Proposition 15.4.9(i)
) it follows that

for some constant μ′ > 0. Moreover, we know from Lemma 15.4.7 that

for some constants c, c′ > 0, where in the second inequality we used Lipschitz continuity of  (Lemma 3) together with the fact that
(Lemma 3) together with the fact that  for all points \(x_\star \in \mathcal X_\star \). By combining the last two inequalities, we obtain
for all points \(x_\star \in \mathcal X_\star \). By combining the last two inequalities, we obtain

Moreover,

Thus,
and since t k → 0, eventually it holds that \( t_k {}\leq {} 1-\frac {2\sigma }{\gamma (1-\gamma L_f)} {}\in {} (0,1) \), resulting in

□
Theorem 15.5.5
Consider the iterates generated by
FBTN
(15.1). Suppose that φ satisfies the quadratic growth (locally), and let x
⋆ be the limit point of  .Footnote 2 Then,
.Footnote 2 Then,  are superlinearly convergent directions provided that
are superlinearly convergent directions provided that
-
(i)
either
 is strictly differentiable at x
⋆
Footnote 3 and there exists D > 0 such that ∥d
k∥≤ D∥∇φ
γ(x
k)∥ for all k’s,
is strictly differentiable at x
⋆
Footnote 3 and there exists D > 0 such that ∥d
k∥≤ D∥∇φ
γ(x
k)∥ for all k’s,
-
(ii)
or
 and \(\operatorname {prox}_{\gamma g}\) is semismooth at
and \(\operatorname {prox}_{\gamma g}\) is semismooth at  . In this case, if \(\operatorname {prox}_{\gamma g}\) is 𝜗-order semismooth at
. In this case, if \(\operatorname {prox}_{\gamma g}\) is 𝜗-order semismooth at  and ∇2
f is 𝜗-Hölder continuous close to x
⋆
, then the order of superlinear convergence is at least
and ∇2
f is 𝜗-Hölder continuous close to x
⋆
, then the order of superlinear convergence is at least  .
.
 is strictly differentiable at x
⋆
is strictly differentiable at x
⋆
 and
and  . In this case, if
. In this case, if  and ∇2
f is 𝜗-Hölder continuous close to x
⋆
, then the order of superlinear convergence is at least
and ∇2
f is 𝜗-Hölder continuous close to x
⋆
, then the order of superlinear convergence is at least  .
.Proof
Due to Proposition 15.4.9 and Theorem 15.5.2, if  then the sequence
then the sequence  converges to x
⋆. Otherwise, the hypothesis ensure that
converges to x
⋆. Otherwise, the hypothesis ensure that

from which we infer that  is R-linearly convergent, hence that
is R-linearly convergent, hence that  is a Cauchy sequence, and again we conclude that the limit point x
⋆ indeed exists. Moreover, in light of Proposition 15.4.9 we have that
is a Cauchy sequence, and again we conclude that the limit point x
⋆ indeed exists. Moreover, in light of Proposition 15.4.9 we have that  is contained in a level set of φ
γ where φ
γ has quadratic growth. To establish a notation, let e
k: = [H
k + δ
kI]d
k + ∇φ
γ(x
k) be the error in solving the linear system at line 3, so that
is contained in a level set of φ
γ where φ
γ has quadratic growth. To establish a notation, let e
k: = [H
k + δ
kI]d
k + ∇φ
γ(x
k) be the error in solving the linear system at line 3, so that
(cf. line 1), and let H
k = Q
γ(x
k)U
k for some  , see (15.61). Let us now analyze the two cases separately.
, see (15.61). Let us now analyze the two cases separately.
-
•
15.5.5(i) Let \(x^k_\star \mathrel{\mathop:}= \operatorname {\mathscr P}_{\mathcal X_\star }x^k\), so that \(\operatorname {dist}(x^k,\mathcal X_\star )=\|x^k-x^k_\star \|\). Recall that
 and that (1 − γL
f)I ≼ Q
γ ≼I. Since
and that (1 − γL
f)I ≼ Q
γ ≼I. Since  , from Lemma 3 and Theorem 15.3.8 we infer that there exist r
1, r
2 > 0 such that
, from Lemma 3 and Theorem 15.3.8 we infer that there exist r
1, r
2 > 0 such that 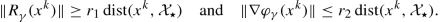 (15.82)
(15.82)In particular, the assumption on d k ensures that \(\|d^k\|=O\big (\operatorname {dist}(x^k,\mathcal X_\star )\big )\). We have

As to quantity (a), we have

where we used strict differentiability and the fact that
 [15, Prop. 2.2.4] which implies U
k → JR(x
⋆). In order to bound (b), recall that δ
k = ζ∥∇φ
γ(x
k)∥ν (cf. line 1). Then,
[15, Prop. 2.2.4] which implies U
k → JR(x
⋆). In order to bound (b), recall that δ
k = ζ∥∇φ
γ(x
k)∥ν (cf. line 1). Then,
and we conclude that \(\operatorname {dist}(x^k+d^k,\mathcal X_\star )\leq \text{(a)}+\text{(b)}\leq o\big (\operatorname {dist}(x^k,\mathcal X_\star )\big )\).
-
•
15.5.5(ii) In this case \(\operatorname {dist}(x^k,\mathcal X_\star )=\|x^k-x_\star \|\) and the assumption of (𝜗-order) semismoothness ensures through Proposition 15.4.13 that
 is a (𝜗-order) LNA for
is a (𝜗-order) LNA for  at x
⋆. Moreover, due to Lemma 15.4.16 there exists c > 0 such that ∥[H
k + δ
kI]−1∥≤ c for all k’s. We have
at x
⋆. Moreover, due to Lemma 15.4.16 there exists c > 0 such that ∥[H
k + δ
kI]−1∥≤ c for all k’s. We have 
Since
 is a LNA at x
⋆, it follows that the quantity emphasized in the bracket is a o(∥x
k − x
⋆∥), whereas in case of a (𝜗-order) LNA the tighter estimate O(∥x
k − x
⋆∥1+𝜗) holds. Combined with the fact that δ
k = O(∥x
k − x
⋆∥ν) and ∥e
k∥ = O(∥x
k − x
⋆∥1+ρ), we conclude that
is a LNA at x
⋆, it follows that the quantity emphasized in the bracket is a o(∥x
k − x
⋆∥), whereas in case of a (𝜗-order) LNA the tighter estimate O(∥x
k − x
⋆∥1+𝜗) holds. Combined with the fact that δ
k = O(∥x
k − x
⋆∥ν) and ∥e
k∥ = O(∥x
k − x
⋆∥1+ρ), we conclude that  are superlinearly convergent directions, and with order at least
are superlinearly convergent directions, and with order at least  in case of 𝜗-order semismoothness. □
in case of 𝜗-order semismoothness. □
 and that (1 − γL
f)I ≼ Q
γ ≼I. Since
and that (1 − γL
f)I ≼ Q
γ ≼I. Since  , from Lemma
, from Lemma 


 [
[
 is a (𝜗-order) LNA for
is a (𝜗-order) LNA for  at x
⋆. Moreover, due to Lemma
at x
⋆. Moreover, due to Lemma 
 is a LNA at x
⋆, it follows that the quantity emphasized in the bracket is a o(∥x
k − x
⋆∥), whereas in case of a (𝜗-order) LNA the tighter estimate O(∥x
k − x
⋆∥1+𝜗) holds. Combined with the fact that δ
k = O(∥x
k − x
⋆∥ν) and ∥e
k∥ = O(∥x
k − x
⋆∥1+ρ), we conclude that
is a LNA at x
⋆, it follows that the quantity emphasized in the bracket is a o(∥x
k − x
⋆∥), whereas in case of a (𝜗-order) LNA the tighter estimate O(∥x
k − x
⋆∥1+𝜗) holds. Combined with the fact that δ
k = O(∥x
k − x
⋆∥ν) and ∥e
k∥ = O(∥x
k − x
⋆∥1+ρ), we conclude that  are superlinearly convergent directions, and with order at least
are superlinearly convergent directions, and with order at least  in case of 𝜗-order semismoothness. □
in case of 𝜗-order semismoothness. □□
Problems where the residual is (𝜗-order) semismooth are quite common. For instance, piecewise affine functions are everywhere strongly semismooth, as it is the case for the residual in lasso problems [67]. On the contrary, when the solution is not unique the condition ∥d
k∥≤ D∥∇φ
γ(x
k)∥ (or, equivalently,  ) is trickier. As detailed in [82, 83], this bound on the directions is ensured if ρ = 1 and for all iterates x
k and points x close enough to the limit point the following smoothness condition holds:
) is trickier. As detailed in [82, 83], this bound on the directions is ensured if ρ = 1 and for all iterates x
k and points x close enough to the limit point the following smoothness condition holds:

for some constant c > 0. This condition is implied by and closely related to local Lipschitz differentiability of  and thus conservative. We remark that, however, this can be weakened by requiring ρ ≥ ν, and a notion of 𝜗-order semismoothness at the limit point with some degree of uniformity on the set of solutions \(\mathcal X_\star \), namely
and thus conservative. We remark that, however, this can be weakened by requiring ρ ≥ ν, and a notion of 𝜗-order semismoothness at the limit point with some degree of uniformity on the set of solutions \(\mathcal X_\star \), namely

for some 𝜗 ∈ [ν, 1]. This weakened requirement comes from the observation that point x in (15.83) is in fact \(x^k_\star \), the projection of x
k onto \(\mathcal X_\star \), set onto which  is constant (equal to 0). To see this, notice that (15.84) implies that
is constant (equal to 0). To see this, notice that (15.84) implies that  for some c > 0. In particular, mimicking the arguments in the cited references, since H
k ≽ 0 and ∥Q
γ∥≤ 1, observe that
for some c > 0. In particular, mimicking the arguments in the cited references, since H
k ≽ 0 and ∥Q
γ∥≤ 1, observe that
and
Therefore,

which is indeed O(∥∇φ
γ(x
k)∥) whenever  . Some comments are in order to expand on condition (15.84).
. Some comments are in order to expand on condition (15.84).
-
(i)
If
 is a singleton, then x′ is fixed to x
⋆ and the requirement reduces to 𝜗-order semismoothness at x
⋆.
is a singleton, then x′ is fixed to x
⋆ and the requirement reduces to 𝜗-order semismoothness at x
⋆. -
(ii)
This notion of uniformity is a local property: for any ε > 0 the set \(\mathcal X_\star \) can be replaced by
 .
. -
(iii)
The condition
 in the limit can be replaced by
in the limit can be replaced by  , since
, since  .
.
 is a singleton, then x′ is fixed to x
⋆ and the requirement reduces to 𝜗-order semismoothness at x
⋆.
is a singleton, then x′ is fixed to x
⋆ and the requirement reduces to 𝜗-order semismoothness at x
⋆. .
. in the limit can be replaced by
in the limit can be replaced by  , since
, since  .
. In particular, by exploiting this last condition it can be easily verified that if  is piecewise 𝜗-Hölder differentiable around x
⋆, then (15.84) holds, yet the stronger requirement (15.83) in [82, 83] does not.
is piecewise 𝜗-Hölder differentiable around x
⋆, then (15.84) holds, yet the stronger requirement (15.83) in [82, 83] does not.
15.6 Generalized Jacobians of Proximal Mappings
In many interesting cases \(\operatorname {prox}_{\gamma g}\) is PC 1 and thus semismooth. Piecewise quadratic (PWQ) functions comprise a special but important class of convex functions whose proximal mapping is PC 1. A convex function g is called PWQ if \( \operatorname {{\mathrm {dom}}} g\) can be represented as the union of finitely many polyhedral sets, relative to each of which g(x) is given by an expression of the form \(\frac 12\langle {}x{},{}Hx{}\rangle +\langle {}q{},{}x{}\rangle +c\) (\(H\in \mathbb {R}^{n\times n}\) must necessarily be symmetric positive semidefinite) [65, Def. 10.20]. The class of PWQ functions is quite general since it includes e.g., polyhedral norms, indicators and support functions of polyhedral sets, and it is closed under addition, composition with affine mappings, conjugation, inf-convolution and inf-projection [65, Prop.s 10.22 and 11.32]. It turns out that the proximal mapping of a PWQ function is piecewise affine (PWA) [65, 12.30] (\(\mathbb {R}^n\) is partitioned in polyhedral sets relative to each of which \(\operatorname {prox}_{\gamma g}\) is an affine mapping), hence strongly semismooth [19, Prop. 7.4.7]. Another example of a proximal mapping that is strongly semismooth is the projection operator over symmetric cones [73].
A big class with semismooth proximal mapping is formed by the semi-algebraic functions. We remind that a set \(A\subseteq \mathbb {R}^n\) is semi-algebraic if it can be expressed as

for some polynomial functions \(P_{ij},Q_{ij}:\mathbb {R}^n\rightarrow \mathbb {R}\), and that a function \(h:\mathbb {R}^n\rightarrow \overline {\mathbb {R}}{ }^m\) is semi-algebraic if \(\operatorname {gph} h\) is a semi-algebraic subset of \(\mathbb {R}^{n+m}\).
Proposition 15.6.1
If \(g:\mathbb {R}^n\rightarrow \overline {\mathbb {R}}\) is semi-algebraic, then so are g γ and \(\operatorname {prox}_{\gamma g}\) . In particular, g γ and \(\operatorname {prox}_{\gamma g}\) are semismooth.
Proof
Since g
γ and \(\operatorname {prox}_{\gamma g}\) are both Lipschitz continuous, semismoothness will follow once we show that they are semi-algebraic [11, Rem. 4]. Every polynomial is clearly semi-algebraic, and since the property is preserved under addition [10, Prop. 2.2.6(ii)], the function \((x,w)\mapsto g(w)+\tfrac {1}{2\gamma }\|w-x\|{ }^2\) is semi-algebraic. Moreover, since parametric minimization of a semi-algebraic function is still semi-algebraic (see, e.g., [1, §2]), it follows that the Moreau envelope g
γ is semi-algebraic and therefore so is \( h(x,w) {}\mathrel{\mathop:}= {} g(w)+\tfrac {1}{2\gamma }\|w-x\|{ }^2-g^\gamma (x) \). Notice that  , therefore
, therefore

is a semi-algebraic set, since the interval (−∞, 0] is clearly semi-algebraic and thus so is h −1((−∞, 0]) [10, Prop. 2.2.7]. □
In fact, with the same arguments it can be shown that the result still holds if “semi-algebraic” is replaced with the broader notion of “tame”, see [11]. Other conditions that guarantee semismoothness of the proximal mapping can be found in [46,47,48, 50]. The rest of the section is devoted to collecting explicit formulas of \(\partial _C\operatorname {prox}_{\gamma g}\) for many known useful instances of convex functions g.
15.6.1 Properties
-
a.
Separable functions.
Whenever g is (block) separable, i.e., \(g(x)=\sum _{i=1}^N g_i(x_i)\), \(x_i\in \mathbb {R}^{n_i}\), \(\sum _{i=1}^N n_i=n\), then every \(P\in \partial _C(\operatorname {prox}_{\gamma g})(x)\) is a (block) diagonal matrix. This has favorable computational implications especially for large-scale problems. For example, if g is the ℓ 1 norm or the indicator function of a box, then the elements of \(\partial _C\operatorname {prox}_{\gamma g}(x)\) (or \(\partial _B\operatorname {prox}_{\gamma g}(x)\)) are diagonal matrices with diagonal elements in [0, 1] (or in
 ).
). -
b.
Convex conjugate.
With a simple application of the Moreau’s decomposition [2, Thm. 14.3(ii)], all elements of \(\partial _C\operatorname {prox}_{\gamma g^\ast }\) are readily available as long as one can compute \(\partial _C\operatorname {prox}_{\nicefrac g\gamma }\). Specifically,
$$\displaystyle \begin{aligned} \partial_C(\operatorname{prox}_{\gamma g^\ast})(x) {}={} \mathrm{I}-\partial_C(\operatorname{prox}_{\nicefrac g\gamma})(\nicefrac x\gamma). \end{aligned} $$(15.87) -
c.
Support function.
The support function of a nonempty closed and convex set D is the proper convex and lsc function σ D(x): =supy ∈ D〈x, y〉. Alternatively, σ D can be expressed as the convex conjugate of the indicator function δ D, and one can use the results of Section §15.6.1b to find that
$$\displaystyle \begin{aligned} \partial_C(\operatorname{prox}_{\gamma g})(x) {}={} \mathrm{I}-\partial_C(\operatorname{\mathscr P}_D)(\nicefrac x\gamma). \end{aligned} $$(15.88)Section 15.6.2 offers a rich list of sets D for which a closed form expression exists.
-
d.
Spectral functions.
The eigenvalue function \(\lambda :\operatorname {S}(\mathbb {R}^{n\times n})\rightarrow \mathbb {R}^n\) returns the vector of eigenvalues of a symmetric matrix in nonincreasing order. Spectral functions are of the form
 (15.89)
(15.89)where \(h:\mathbb {R}^n\rightarrow \overline {\mathbb {R}}\) is proper, lsc, convex, and symmetric, i.e., invariant under coordinate permutations [35]. Such G inherits most of the properties of h [36, 37]; in particular, its proximal mapping is [56, §6.7]
 (15.90)
(15.90)where
 is the spectral decomposition of X (Q is an orthogonal matrix). If, additionally, $$\displaystyle \begin{aligned} h(x)=g(x_1)+\cdots+g(x_N) \end{aligned} $$(15.91)
is the spectral decomposition of X (Q is an orthogonal matrix). If, additionally, $$\displaystyle \begin{aligned} h(x)=g(x_1)+\cdots+g(x_N) \end{aligned} $$(15.91)for some \(g:\mathbb {R}\rightarrow \overline {\mathbb {R}}\), then
$$\displaystyle \begin{aligned} \operatorname{prox}_{\gamma h}(x) {}={} (\operatorname{prox}_{\gamma g}(x_1),\ldots,\operatorname{prox}_{\gamma g}(x_N)), \end{aligned} $$(15.92)and therefore the proximal mapping of G can be expressed as
 (15.93)
(15.93)[9, Chap. V], [29, Sec. 6.2]. Now we can use the theory of nonsmooth symmetric matrix-valued functions developed in [14] to analyze differentiability properties of \(\operatorname {prox}_{\gamma G}\). In particular, \(\operatorname {prox}_{\gamma G}\) is (strongly) semismooth at X iff \(\operatorname {prox}_{\gamma g}\) is (strongly) semismooth at the eigenvalues of X [14, Prop. 4.10]. Moreover, for any \(X\in \operatorname {S}(\mathbb {R}^{n\times n})\) and \(P\in \partial _B(\operatorname {prox}_{\gamma G})(X)\) we have [14, Lem. 4.7]
 (15.94)
(15.94)where ⊙ denotes the Hadamard product and for vectors \(u,v\in \mathbb {R}^n\) we defined \(\varOmega ^{\gamma g}_{u,v}\) as the n × n matrix
 (15.95)
(15.95) -
e.
Orthogonally invariant functions. A function \(G:\mathbb {R}^{m\times n}\rightarrow \overline {\mathbb {R}}\) is called orthogonally invariant if
 for all \(X\in \mathbb {R}^{m\times n}\) and orthogonal matrices \(U\in \mathbb {R}^{m\times m}\), \(V\in \mathbb {R}^{n\times n}\).Footnote 4
for all \(X\in \mathbb {R}^{m\times n}\) and orthogonal matrices \(U\in \mathbb {R}^{m\times m}\), \(V\in \mathbb {R}^{n\times n}\).Footnote 4
A function \(h:\mathbb {R}^q\rightarrow \overline {\mathbb {R}}\) is absolutely symmetric if h(Qx) = h(x) for all \(x\in \mathbb {R}^q\) and any generalized permutation matrix Q, i.e., a matrix \(Q\in \mathbb {R}^{q\times q}\) that has exactly one nonzero entry in each row and each column, that entry being ± 1 [34]. There is a one-to-one correspondence between orthogonally invariant functions on \(\mathbb {R}^{m\times n}\) and absolutely symmetric functions on \(\mathbb {R}^q\). Specifically, if G is orthogonally invariant, then
$$\displaystyle \begin{aligned} G(X)=h(\sigma(X)) \end{aligned} $$(15.96)for the absolutely symmetric function \(h(x)=G(\operatorname {diag}(x))\). Here, for \(X\in \mathbb {R}^{m\times n}\) and
 the spectral function \(\sigma :\mathbb {R}^{m\times n}\rightarrow \mathbb {R}^q\) returns the vector of its singular values in nonincreasing order. Conversely, if h is absolutely symmetric, then G(X) = h(σ(X)) is orthogonally invariant. Therefore, convex analytic and generalized differentiability properties of orthogonally invariant functions can be easily derived from those of the corresponding absolutely symmetric functions [34]. For example, assuming for simplicity that m ≤ n, the proximal mapping of G is given by [56, Sec. 6.7]
the spectral function \(\sigma :\mathbb {R}^{m\times n}\rightarrow \mathbb {R}^q\) returns the vector of its singular values in nonincreasing order. Conversely, if h is absolutely symmetric, then G(X) = h(σ(X)) is orthogonally invariant. Therefore, convex analytic and generalized differentiability properties of orthogonally invariant functions can be easily derived from those of the corresponding absolutely symmetric functions [34]. For example, assuming for simplicity that m ≤ n, the proximal mapping of G is given by [56, Sec. 6.7]  (15.97)
(15.97)where
 is the singular value decomposition of X. If we further assume that h has a separable form as in (15.91), then
is the singular value decomposition of X. If we further assume that h has a separable form as in (15.91), then  (15.98)
(15.98)where \(\varSigma _g(X)=\operatorname {diag}(\operatorname {prox}_{\gamma g}(\sigma _1(X)),\ldots ,\operatorname {prox}_{\gamma g}(\sigma _n(X)))\). Functions of this form are called nonsymmetric matrix-valued functions. We also assume that g is a non-negative function such that g(0) = 0. This implies that \(\operatorname {prox}_{\gamma g}(0)=0\) and guarantees that the nonsymmetric matrix-valued function (15.98) is well defined [80, Prop. 2.1.1]. Now we can use the results of [80, §2] to draw conclusions about generalized differentiability properties of \(\operatorname {prox}_{\gamma G}\).
For example, through [80, Thm. 2.27] we have that \(\operatorname {prox}_{\gamma G}\) is continuously differentiable at X if and only if \(\operatorname {prox}_{\gamma g}\) is continuously differentiable at the singular values of X. Furthermore, \(\operatorname {prox}_{\gamma G}\) is (strongly) semismooth at X if \(\operatorname {prox}_{\gamma g}\) is (strongly) semismooth at the singular values of X [80, Thm. 2.3.11].
For any \(X\in \mathbb {R}^{m\times n}\) the generalized Jacobian \(\partial _B(\operatorname {prox}_{\gamma G})(X)\) is well defined and nonempty, and any \(P\in \partial _B(\operatorname {prox}_{\gamma G})(X)\) acts on \(H\in \mathbb {R}^{m\times n}\) as [80, Prop. 2.3.7]
 (15.99)
(15.99)where V = [V 1 V 2],
 ,
,  and matrices Ω are as in (15.95).
and matrices Ω are as in (15.95).
 ).
).

 is the spectral decomposition of X (Q is an orthogonal matrix). If, additionally,
is the spectral decomposition of X (Q is an orthogonal matrix). If, additionally, 


 for all
for all  the spectral function
the spectral function 
 is the singular value decomposition of X. If we further assume that h has a separable form as in (
is the singular value decomposition of X. If we further assume that h has a separable form as in (

 ,
,  and matrices Ω are as in (
and matrices Ω are as in (15.6.2 Indicator Functions
Smooth constrained convex problems
can be cast in the composite form (15.1) by encoding the feasible set D with the indicator function \(g=\operatorname {\delta }_D\). Whenever \(\operatorname {\mathscr P}_D\) is efficiently computable, then algorithms like the forward-backward splitting (15.21) can be conveniently considered. In the following we analyze the generalized Jacobian of some of such projections.
-
a.
Affine sets.
 for some \(A\in \mathbb {R}^{m\times n}\) and \(b\in \mathbb {R}^m\).
for some \(A\in \mathbb {R}^{m\times n}\) and \(b\in \mathbb {R}^m\).In this case, \(\operatorname {\mathscr P}_D(x)=x- A^\dagger (Ax-b)\) where A † is the Moore-Penrose pseudoinverse of A. For example, if A is surjective (i.e., it has full row rank and thus m ≤ n), then
 , whereas if it is injective (i.e., it has full column rank and thus m ≥ n), then A
† = (A
⊤
A)−1
A
⊤. Obviously \(\operatorname {\mathscr P}_D\) is an affine mapping, thus everywhere differentiable with
, whereas if it is injective (i.e., it has full column rank and thus m ≥ n), then A
† = (A
⊤
A)−1
A
⊤. Obviously \(\operatorname {\mathscr P}_D\) is an affine mapping, thus everywhere differentiable with  (15.101)
(15.101) -
b.
Polyhedral sets.
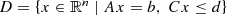 , for some \(A\in \mathbb {R}^{p\times n}\), \(b\in \mathbb {R}^p\), \(C\in \mathbb {R}^{q\times n}\) and \(d\in \mathbb {R}^q\).
, for some \(A\in \mathbb {R}^{p\times n}\), \(b\in \mathbb {R}^p\), \(C\in \mathbb {R}^{q\times n}\) and \(d\in \mathbb {R}^q\).It is well known that \(\operatorname {\mathscr P}_D\) is piecewise affine. In particular, let
 (15.102)
(15.102)Then, the faces of D can be indexed with the elements of \(\mathcal I\) [66, Prop. 2.1.3]: for each \(I\in \mathcal I_D\) let

be the I-th face of D,

be the hyperplane containing the I-th face of D,

be the normal cone to any point in the relative interior of F I [66, Eq. (2.44)],5 and
$$\displaystyle \begin{aligned} R_I {}\mathrel{\mathop:}={} & F_I+N_I. \end{aligned} $$Footnote 5 We then have
 , i.e., \(\operatorname {\mathscr P}_D\) is a piecewise affine function. The affine pieces of \(\operatorname {\mathscr P}_D\) are the projections on the corresponding affine subspaces S
I (cf. Section §15.6.2a). In fact, for each x ∈ R
I we have \(\operatorname {\mathscr P}_D(x)=\operatorname {\mathscr P}_{S_I}(x)\), each R
I is full dimensional and \(\mathbb {R}^n=\bigcup _{I\in \mathcal I_D}R_I\) [66, Prop.s 2.4.4 and 2.4.5]. For each \(I\in \mathcal I_D\) let $$\displaystyle \begin{aligned} P_I {}\mathrel{\mathop:}={} \nabla\operatorname{\mathscr P}_{S_I} {}={} \mathrm{I}-{\binom{A}{C_I}}^\dagger\binom{A}{C_I}, \end{aligned} $$(15.103)
, i.e., \(\operatorname {\mathscr P}_D\) is a piecewise affine function. The affine pieces of \(\operatorname {\mathscr P}_D\) are the projections on the corresponding affine subspaces S
I (cf. Section §15.6.2a). In fact, for each x ∈ R
I we have \(\operatorname {\mathscr P}_D(x)=\operatorname {\mathscr P}_{S_I}(x)\), each R
I is full dimensional and \(\mathbb {R}^n=\bigcup _{I\in \mathcal I_D}R_I\) [66, Prop.s 2.4.4 and 2.4.5]. For each \(I\in \mathcal I_D\) let $$\displaystyle \begin{aligned} P_I {}\mathrel{\mathop:}={} \nabla\operatorname{\mathscr P}_{S_I} {}={} \mathrm{I}-{\binom{A}{C_I}}^\dagger\binom{A}{C_I}, \end{aligned} $$(15.103)and for each \(x\in \mathbb {R}^n\) let
 (15.104)
(15.104)Then,
 (15.105)
(15.105)Therefore, an element of \(\partial _B\operatorname {\mathscr P}_D(x)\) is P I as in (15.103) where
 is the set of active constraints of \(\bar x=\operatorname {\mathscr P}_D(x)\). For a more general analysis we refer the reader to [27, 39].
is the set of active constraints of \(\bar x=\operatorname {\mathscr P}_D(x)\). For a more general analysis we refer the reader to [27, 39]. -
c.
Halfspaces.
 for some \(a\in \mathbb {R}^n\) and \(b\in \mathbb {R}\).
for some \(a\in \mathbb {R}^n\) and \(b\in \mathbb {R}\).Then, denoting the positive part of \(r\in \mathbb {R}\) as
 ,
, 
and
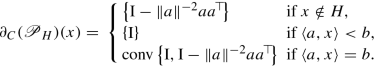
-
d.
Boxes.
 for some ℓ, u ∈ [−∞, ∞]n.
for some ℓ, u ∈ [−∞, ∞]n.We have

and since the corresponding indicator function δ D is separable, every element of \(\partial _C(\operatorname {\mathscr P}_D)(x)\) is diagonal with (cf. Section §15.6.1a)

-
e.
Unit simplex.
 .
.By writing down the optimality conditions for the corresponding projection problem, one can easily see that
$$\displaystyle \begin{aligned} \operatorname{\mathscr P}_D(x)=[x-\lambda\mathbf{1}]_+, \end{aligned} $$(15.106)where λ solves 〈1, [x − λ 1]+〉 = 1. Since the unit simplex is a polyhedral set, we are dealing with a special case of Section §15.6.2b, where
 , b = 1, C = −I, and d = 0. Therefore, in order to calculate an element of the generalized Jacobian of the projection, we first compute \(\operatorname {\mathscr P}_D(x)\) and then determine the set of active indices
, b = 1, C = −I, and d = 0. Therefore, in order to calculate an element of the generalized Jacobian of the projection, we first compute \(\operatorname {\mathscr P}_D(x)\) and then determine the set of active indices  . An element \(P\in \partial _B(\operatorname {\mathscr P}_D)(x)\) is given by
. An element \(P\in \partial _B(\operatorname {\mathscr P}_D)(x)\) is given by  (15.107)
(15.107)where |J| denotes the cardinality of the set J. Notice that P is block diagonal after a permutation of rows and columns.
-
f.
Euclidean unit ball.
 .
.We have

and

where w: = x∕∥x∥.
-
g.
Second-order cone.
 .
.Let \(x\mathrel{\mathop:}= (x_0,\bar x)\), and for \(w\in \mathbb {R}^n\) and \(\alpha \in \mathbb {R}\) define
 (15.108)
(15.108)Then, \( \partial _C(\operatorname {\mathscr P}_{\mathcal K})(x) {}={} \operatorname {conv}(\partial _B(\operatorname {\mathscr P}_{\mathcal K})(x)) \) where, for \(\bar w\mathrel{\mathop:}= {\bar x}/{\|\bar x\|}\) and \(\bar \alpha \mathrel{\mathop:}= -{x_0}/{\|\bar x\|}\), we have [30, Lem. 2.6]
 (15.109)
(15.109) -
h.
Positive semidefinite cone. \(\mathcal S_+=\operatorname {S}_+(\mathbb {R}^{n\times n})\).
For any symmetric matrix M it holds that
 (15.110)
(15.110)where
 is any spectral decomposition of M. This coincides with (15.93), as \(\operatorname {\delta }_{\mathcal S_+}\) can be expressed as in (15.89), where h has the separable form (15.91) with \(g=\delta _{\mathbb {R}_+}\), so that for \(r\in \mathbb {R}\) we have
is any spectral decomposition of M. This coincides with (15.93), as \(\operatorname {\delta }_{\mathcal S_+}\) can be expressed as in (15.89), where h has the separable form (15.91) with \(g=\delta _{\mathbb {R}_+}\), so that for \(r\in \mathbb {R}\) we have  (15.111)
(15.111)An element of \(\partial _B\operatorname {\mathscr P}_{\operatorname {S}_+(\mathbb {R}^{n\times n})}(X)\) is thus given by (15.94).
 for some
for some  , whereas if it is injective (i.e., it has full column rank and thus m ≥ n), then A
† = (A
⊤
A)−1
A
⊤. Obviously
, whereas if it is injective (i.e., it has full column rank and thus m ≥ n), then A
† = (A
⊤
A)−1
A
⊤. Obviously 
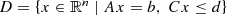 , for some
, for some 



 , i.e.,
, i.e., 

 is the set of active constraints of
is the set of active constraints of  for some
for some  ,
, 
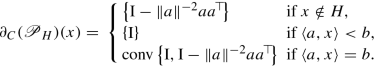
 for some ℓ, u ∈ [−∞, ∞]n.
for some ℓ, u ∈ [−∞, ∞]n.

 .
. , b = 1, C = −I, and d = 0. Therefore, in order to calculate an element of the generalized Jacobian of the projection, we first compute
, b = 1, C = −I, and d = 0. Therefore, in order to calculate an element of the generalized Jacobian of the projection, we first compute  . An element
. An element 
 .
.

 .
.


 is any spectral decomposition of M. This coincides with (
is any spectral decomposition of M. This coincides with (
15.6.3 Norms
-
a.
ℓ 1 norm. g(x) = ∥x∥1.
The proximal mapping is the well-known soft-thresholding operator
$$\displaystyle \begin{aligned} (\operatorname{prox}_{\gamma g}(x))_i {}={} \operatorname{{\mathrm{sign}}}(x_i)[|x_i|-\gamma]_+, \quad i=1,\ldots,n. \end{aligned} $$(15.112)Function g is separable, and thus every element of \(\partial _B(\operatorname {prox}_{\gamma g})\) is a diagonal matrix, cf. Section §15.6.1a. Specifically, the nonzero elements are
 (15.113)
(15.113)We could also arrive to the same conclusion by applying the Moreau decomposition of Section §15.6.1b to the function of Section §15.6.2d with u = −ℓ = 1 n, since the ℓ 1 norm is the conjugate of the indicator of the ℓ ∞-norm ball.
-
b.
ℓ ∞ norm. g(x) = ∥x∥∞.
Function g is the convex conjugate of the indicator of the unit simplex D analyzed in Section §15.6.2e. From the Moreau decomposition, see Section §15.6.1b, we obtain
$$\displaystyle \begin{aligned} \partial_C(\operatorname{prox}_{\gamma g})(x) {}={} \mathrm{I}-\partial_C(\operatorname{\mathscr P}_D)(\nicefrac x\gamma). \end{aligned} $$(15.114)Then, \( \operatorname {\mathscr P}_D(\nicefrac x\gamma ) {}={} [\nicefrac x\gamma -\lambda \mathbf {1}]_+ \) where \(\lambda \in \mathbb {R}\) solves 〈1, [x∕γ − λ 1]+〉 = 1. Let
 , then an element of \(\partial _B(\operatorname {prox}_{\gamma g})(x)\) is given by
, then an element of \(\partial _B(\operatorname {prox}_{\gamma g})(x)\) is given by  (15.115)
(15.115) -
c.
Euclidean norm. g(x) = ∥x∥.
The proximal mapping is given by
 (15.116)
(15.116)Since \(\operatorname {prox}_{\gamma g}\) is a PC 1 mapping, its B-subdifferential can be computed by simply computing the Jacobians of its smooth pieces. Specifically, denoting w = x∕∥x∥ we have
 (15.117)
(15.117) -
d.
Sum of Euclidean norms. \(g(x)=\sum _{s\in \mathcal S}\|x_s\|\), where \(\mathcal S\) is a partition of
 .
.Differently from the ℓ 1-norm which induces sparsity on the whole vector, this function serves as regularizer to induce group sparsity [81]. For \(s\in \mathcal S\), the components of the proximal mapping indexed by s are
$$\displaystyle \begin{aligned} (\operatorname{prox}_{\gamma g}(x))_s {}={} (1-\gamma\|x_s\|{}^{-1})_+x_s.\end{aligned} $$(15.118)Any \(P\in \partial _B(\operatorname {prox}_{\gamma g})(x)\) is block diagonal with the s-block equal to
 (15.119)
(15.119) -
e.
Matrix nuclear norm. G(X) = ∥X∥⋆ for \(X\in \mathbb {R}^{m\times n}\).
The nuclear norm returns the sum of the singular values of a matrix \(X\in \mathbb {R}^{m\times n}\), i.e., \(G(X)=\sum _{i=1}^m\sigma _i(X)\) (for simplicity we are assuming that m ≤ n). It serves as a convex surrogate for the rank, and has found many applications in systems and control theory, including system identification and model reduction [20,21,22, 41, 61]. Other fields of application include matrix completion problems arising in machine learning [62, 68] and computer vision [52, 76], and nonnegative matrix factorization problems arising in data mining [18].
The nuclear norm can be expressed as G(X) = h(σ(X)), where h(x) = ∥x∥1 is absolutely symmetric and separable. Specifically, it takes the form (15.91) with g = |⋅|, for which g(0) = 0 and 0 ∈ ∂g(0), and whose proximal mapping is the soft-thresholding operator. In fact, since the case of interest here is x ≥ 0 (because σ i(X) ≥ 0), we have \(\operatorname {prox}_{\gamma g}(x)=[x-\gamma ]_+\), cf. (15.116). Consequently, the proximal mapping of ∥X∥⋆ is given by (15.98) with
$$\displaystyle \begin{aligned} \varSigma_g(X)=\operatorname{diag}([\sigma_1(X)-\gamma]_+,\ldots,[\sigma_m(X)-\gamma]_+).\end{aligned} $$(15.120)For \(x\in \mathbb {R}_+\) we have that
 (15.121)
(15.121)then \(\partial _B(\operatorname {prox}_{\gamma G})(X)\) takes the form as in (15.99).

 , then an element of
, then an element of 


 .
.

15.7 Conclusions
A forward-backward truncated-Newton method ( FBTN ) is proposed that minimizes the sum of two convex functions one of which Lipschitz continuous and twice continuously differentiable. Our approach is based on the forward-backward envelope (FBE), a continuously differentiable tight lower bound to the original (nonsmooth and extended-real valued) cost function sharing minima and minimizers. The method requires forward-backward steps, Hessian evaluations of the smooth function and Clarke Jacobians of the proximal map of the nonsmooth term. Explicit formulas of Clarke Jacobians of a wide variety of useful nonsmooth functions are collected from the literature for the reader’s convenience. The higher-order operations are needed for the computation of symmetric and positive semidefinite matrices that serve as surrogate for the Hessian of the FBE, allowing for a generalized (regularized, truncated-) Newton method for its minimization. The algorithm exhibits global Q-linear convergence under an error bound condition, and Q-superlinear or even Q-quadratic if an additional semismoothness assumption at the limit point is satisfied.
Notes
- 1.
Due to apparent similarities with gradient descent iterations, having
 in FBS,
in FBS,  is also referred to as (generalized) gradient mapping, see, e.g., [17]. In particular, if g = 0, then
is also referred to as (generalized) gradient mapping, see, e.g., [17]. In particular, if g = 0, then  whereas if f = 0 then
whereas if f = 0 then  . The analogy will be supported by further evidence in the next section where we will see that, up to a change of metric, indeed
. The analogy will be supported by further evidence in the next section where we will see that, up to a change of metric, indeed  is the gradient of the forward-backward envelope function.
is the gradient of the forward-backward envelope function. - 2.
As detailed in the proof, under the assumptions the limit point indeed exists.
- 3.
From the chain rule of differentiation it follows that
 is strictly differentiable at x
⋆ if \(\operatorname {prox}_{\gamma g}\) is strictly differentiable at
is strictly differentiable at x
⋆ if \(\operatorname {prox}_{\gamma g}\) is strictly differentiable at 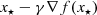 (strict differentiability is closed under composition).
(strict differentiability is closed under composition). - 4.
In case of complex-valued matrices, functions of this form are known as unitarily invariant [34].
- 5.
Consistently with the definition in [66], the polyhedron P can equivalently be expressed by means of only inequalities as
 , resulting indeed in
, resulting indeed in  .
.
 in FBS,
in FBS,  is also referred to as (generalized) gradient mapping, see, e.g., [
is also referred to as (generalized) gradient mapping, see, e.g., [ whereas if f = 0 then
whereas if f = 0 then  . The analogy will be supported by further evidence in the next section where we will see that, up to a change of metric, indeed
. The analogy will be supported by further evidence in the next section where we will see that, up to a change of metric, indeed  is the gradient of the forward-backward envelope function.
is the gradient of the forward-backward envelope function. is strictly differentiable at x
⋆ if
is strictly differentiable at x
⋆ if 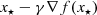 (strict differentiability is closed under composition).
(strict differentiability is closed under composition). , resulting indeed in
, resulting indeed in  .
.References
Attouch, H., Bolte, J., Svaiter, B.F.: Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods. Mathematical Programming 137(1), 91–129 (2013). DOI 10.1007/s10107-011-0484-9
Bauschke, H.H., Combettes, P.L.: Convex analysis and monotone operator theory in Hilbert spaces. CMS Books in Mathematics. Springer (2017). DOI 10.1007/978-3-319-48311-5
Bauschke, H.H., Noll, D., Phan, H.M.: Linear and strong convergence of algorithms involving averaged nonexpansive operators. Journal of Mathematical Analysis and Applications 421(1), 1–20 (2015)
Beck, A.: First-Order Methods in Optimization. Society for Industrial and Applied Mathematics, Philadelphia, PA (2017). DOI 10.1137/1.9781611974997
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM Journal on Imaging Sciences 2(1), 183–202 (2009). DOI 10.1137/080716542
Becker, S., Fadili, J.: A quasi-Newton proximal splitting method. In: Advances in Neural Information Processing Systems, pp. 2618–2626 (2012)
Bertsekas, D.P.: Constrained optimization and lagrange multiplier methods. Computer Science and Applied Mathematics, Boston: Academic Press, 1982 (1982)
Bertsekas, D.P.: Convex Optimization Algorithms. Athena Scientific (2015)
Bhatia, R.: Matrix Analysis. Graduate Texts in Mathematics. Springer New York (1997)
Bochnak, J., Coste, M., Roy, M.F.: Real Algebraic Geometry. Ergebnisse der Mathematik und ihrer Grenzgebiete. 3. Folge / A Series of Modern Surveys in Mathematics. Springer Berlin Heidelberg (2013)
Bolte, J., Daniilidis, A., Lewis, A.: Tame functions are semismooth. Mathematical Programming 117(1), 5–19 (2009). DOI 10.1007/s10107-007-0166-9
Chen, G., Teboulle, M.: Convergence analysis of a proximal-like minimization algorithm using Bregman functions. SIAM Journal on Optimization 3(3), 538–543 (1993). DOI 10.1137/0803026
Chen, X., Fukushima, M.: Proximal quasi-Newton methods for nondifferentiable convex optimization. Mathematical Programming 85(2), 313–334 (1999). DOI 10.1007/s101070050059
Chen, X., Qi, H., Tseng, P.: Analysis of nonsmooth symmetric-matrix-valued functions with applications to semidefinite complementarity problems. SIAM Journal on Optimization 13(4), 960–985 (2003). DOI 10.1137/S1052623400380584
Clarke, F.H.: Optimization and Nonsmooth Analysis. Society for Industrial and Applied Mathematics (1990). DOI 10.1137/1.9781611971309
Combettes, P.L., Pesquet, J.C.: Proximal Splitting Methods in Signal Processing, pp. 185–212. Springer New York, New York, NY (2011). DOI 10.1007/978-1-4419-9569-8_10
Drusvyatskiy, D., Lewis, A.S.: Error bounds, quadratic growth, and linear convergence of proximal methods. Mathematics of Operations Research (2018)
Eldén, L.: Matrix Methods in Data Mining and Pattern Recognition. Society for Industrial and Applied Mathematics (2007). DOI 10.1137/1.9780898718867
Facchinei, F., Pang, J.S.: Finite-dimensional variational inequalities and complementarity problems, vol. II. Springer (2003)
Fazel, M.: Matrix rank minimization with applications. Ph.D. thesis, Stanford University (2002)
Fazel, M., Hindi, H., Boyd, S.P.: A rank minimization heuristic with application to minimum order system approximation. In: Proceedings of the 2001 American Control Conference, vol. 6, pp. 4734–4739 (2001). DOI 10.1109/ACC.2001.945730
Fazel, M., Hindi, H., Boyd, S.P.: Rank minimization and applications in system theory. In: Proceedings of the 2004 American Control Conference, vol. 4, pp. 3273–3278 vol.4 (2004). DOI 10.23919/ACC.2004.1384521
Fukushima, M.: Equivalent differentiable optimization problems and descent methods for asymmetric variational inequality problems. Mathematical Programming 53(1), 99–110 (1992). DOI 10.1007/BF01585696
Giselsson, P., Fält, M.: Envelope functions: Unifications and further properties. Journal of Optimization Theory and Applications (2018). DOI 10.1007/s10957-018-1328-z
Gowda, M.S.: Inverse and implicit function theorems for H-differentiable and semismooth functions. Optimization Methods and Software 19(5), 443–461 (2004). DOI 10.1080/10556780410001697668
Güler, O.: New proximal point algorithms for convex minimization. SIAM Journal on Optimization 2(4), 649–664 (1992). DOI 10.1137/0802032
Han, J., Sun, D.: Newton and quasi-Newton methods for normal maps with polyhedral sets. Journal of Optimization Theory and Applications 94(3), 659–676 (1997). DOI 10.1023/A:1022653001160
Hiriart-Urruty, J.B., Lemaréchal, C.: Fundamentals of Convex Analysis. Grundlehren Text Editions. Springer Berlin Heidelberg (2004)
Horn, R.A., Horn, R.A., Johnson, C.R.: Topics in Matrix Analysis. Cambridge University Press (1994)
Kanzow, C., Ferenczi, I., Fukushima, M.: On the local convergence of semismooth Newton methods for linear and nonlinear second-order cone programs without strict complementarity. SIAM Journal on Optimization 20(1), 297–320 (2009). DOI 10.1137/060657662
Lan, G., Lu, Z., Monteiro, R.D.C.: Primal-dual first-order methods with O(1∕ε) iteration-complexity for cone programming. Mathematical Programming 126(1), 1–29 (2011). DOI 10.1007/s10107-008-0261-6
Lee, J.D., Sun, Y., Saunders, M.: Proximal Newton-type methods for minimizing composite functions. SIAM Journal on Optimization 24(3), 1420–1443 (2014). DOI 10.1137/130921428
Lemaréchal, C., Sagastizábal, C.: Practical aspects of the Moreau-Yosida regularization: Theoretical preliminaries. SIAM Journal on Optimization 7(2), 367–385 (1997). DOI 10.1137/S1052623494267127
Lewis, A.S.: The convex analysis of unitarily invariant matrix functions. Journal of Convex Analysis 2(1), 173–183 (1995)
Lewis, A.S.: Convex analysis on the Hermitian matrices. SIAM Journal on Optimization 6(1), 164–177 (1996). DOI 10.1137/0806009
Lewis, A.S.: Derivatives of spectral functions. Mathematics of Operations Research 21(3), 576–588 (1996)
Lewis, A.S., Sendov, H.S.: Twice differentiable spectral functions. SIAM Journal on Matrix Analysis and Applications 23(2), 368–386 (2001). DOI 10.1137/S089547980036838X
Li, W., Peng, J.: Exact penalty functions for constrained minimization problems via regularized gap function for variational inequalities. Journal of Global Optimization 37(1), 85–94 (2007). DOI 10.1007/s10898-006-9038-8
Li, X., Sun, D., Toh, K.C.: On the efficient computation of a generalized Jacobian of the projector over the Birkhoff polytope. ArXiv e-prints (2017)
Lions Lions, P.L., Mercier, B.: Splitting algorithms for the sum of two nonlinear operators. SIAM Journal on Numerical Analysis 16(6), 964–979 (1979). DOI 10.1137/0716071
Liu, Z., Vandenberghe, L.: Interior-point method for nuclear norm approximation with application to system identification. SIAM Journal on Matrix Analysis and Applications 31(3), 1235–1256 (2010). DOI 10.1137/090755436
Lu, Z.: Randomized block proximal damped Newton method for composite self-concordant minimization. SIAM Journal on Optimization 27(3), 1910–1942 (2017). DOI 10.1137/16M1082767
Luo, Z.Q., Tseng, P.: Error bounds and convergence analysis of feasible descent methods: a general approach. Annals of Operations Research 46(1), 157–178 (1993). DOI 10.1007/BF02096261
Maratos, N.: Exact penalty function algorithms for finite dimensional and control optimization problems (1978)
Martinet, B.: Brève communication. Régularisation d’inéquations variationnelles par approximations successives. Revue française d’informatique et de recherche opérationnelle. Série rouge 4(R3), 154–158 (1970)
Meng, F.: Moreau-Yosida regularization of Lagrangian-dual functions for a class of convex optimization problems. Journal of Global Optimization 44(3), 375 (2008). DOI 10.1007/s10898-008-9333-7
Meng, F., Sun, D., Zhao, G.: Semismoothness of solutions to generalized equations and the Moreau-Yosida regularization. Mathematical Programming 104(2), 561–581 (2005). DOI 10.1007/s10107-005-0629-9
Meng, F., Zhao, G., Goh, M., De Souza, R.: Lagrangian-dual functions and Moreau-Yosida regularization. SIAM Journal on Optimization 19(1), 39–61 (2008). DOI 10.1137/060673746
Mifflin, R.: Semismooth and semiconvex functions in constrained optimization. SIAM Journal on Control and Optimization 15(6), 959–972 (1977). DOI 10.1137/0315061
Mifflin, R., Qi, L., Sun, D.: Properties of the Moreau-Yosida regularization of a piecewise C 2 convex function. Mathematical Programming 84(2), 269–281 (1999). DOI 10.1007/s10107980029a
Moreau, J.J.: Proximité et dualité dans un espace hilbertien. Bulletin de la Société Mathématique de France 93, 273–299 (1965)
Morita, T., Kanade, T.: A sequential factorization method for recovering shape and motion from image streams. IEEE Transactions on Pattern Analysis and Machine Intelligence 19(8), 858–867 (1997). DOI 10.1109/34.608289
Nesterov, Y.: Introductory lectures on convex optimization: A basic course, vol. 87. Springer (2003)
Nesterov, Y.: Gradient methods for minimizing composite functions. Mathematical Programming 140(1), 125–161 (2013). DOI 10.1007/s10107-012-0629-5
Pang, J.S.: Error bounds in mathematical programming. Mathematical Programming 79(1), 299–332 (1997). DOI 10.1007/BF02614322
Parikh, N., Boyd, S.: Proximal algorithms. Found. Trends Optim. 1(3), 127–239 (2014). DOI 10.1561/2400000003
Patrinos, P., Bemporad, A.: Proximal Newton methods for convex composite optimization. In: IEEE Conference on Decision and Control, pp. 2358–2363 (2013)
Patrinos, P., Sopasakis, P., Sarimveis, H.: A global piecewise smooth Newton method for fast large-scale model predictive control. Automatica 47(9), 2016–2022 (2011)
Patrinos, P., Stella, L., Bemporad, A.: Forward-backward truncated Newton methods for convex composite optimization. ArXiv e-prints (2014)
Qi, L., Sun, J.: A nonsmooth version of Newton’s method. Mathematical Programming 58(1), 353–367 (1993). DOI 10.1007/BF01581275
Recht, B., Fazel, M., Parrilo, P.A.: Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Review 52(3), 471–501 (2010). DOI 10.1137/070697835
Rennie, J.D.M., Srebro, N.: Fast maximum margin matrix factorization for collaborative prediction. In: Proceedings of the 22Nd International Conference on Machine Learning, ICML ’05, pp. 713–719. ACM, New York, NY, USA (2005). DOI 10.1145/1102351.1102441
Rockafellar, R.: Convex analysis (1970)
Rockafellar, R.T.: Monotone operators and the proximal point algorithm. SIAM Journal on Control and Optimization 14(5), 877–898 (1976). DOI 10.1137/0314056
Rockafellar, R.T., Wets, R.J.B.: Variational analysis, vol. 317. Springer Science & Business Media (2011)
Scholtes, S.: Piecewise Differentiable Functions, pp. 91–111. Springer New York, New York, NY (2012). DOI 10.1007/978-1-4614-4340-7_4
Sopasakis, P., Freris, N., Patrinos, P.: Accelerated reconstruction of a compressively sampled data stream. In: 2016 24th European Signal Processing Conference (EUSIPCO), pp. 1078–1082 (2016). DOI 10.1109/EUSIPCO.2016.7760414
Srebro, N.: Learning with matrix factorizations. Ph.D. thesis, Cambridge, MA, USA (2004)
Stella, L., Themelis, A., Patrinos, P.: Forward-backward quasi-Newton methods for nonsmooth optimization problems. Computational Optimization and Applications 67(3), 443–487 (2017). DOI 10.1007/s10589-017-9912-y
Stella, L., Themelis, A., Patrinos, P.: Newton-type alternating minimization algorithm for convex optimization. IEEE Transactions on Automatic Control (2018). DOI 10.1109/TAC.2018.2872203
Stella, L., Themelis, A., Sopasakis, P., Patrinos, P.: A simple and efficient algorithm for nonlinear model predictive control. In: 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pp. 1939–1944 (2017). DOI 10.1109/CDC.2017.8263933
Sun, D., Fukushima, M., Qi, L.: A computable generalized Hessian of the D-gap function and Newton-type methods for variational inequality problems. Complementarity and Variational Problems: State of the Art, MC Ferris and JS Pang (eds.), SIAM, Philadelphia, PA pp. 452–472 (1997)
Sun, D., Sun, J.: Semismooth matrix-valued functions. Mathematics of Operations Research 27(1), 150–169 (2002). DOI 10.1287/moor.27.1.150.342
Themelis, A., Patrinos, P.: Douglas-Rachford splitting and ADMM for nonconvex optimization: tight convergence results. ArXiv e-prints (2017)
Themelis, A., Stella, L., Patrinos, P.: Forward-backward envelope for the sum of two nonconvex functions: Further properties and nonmonotone linesearch algorithms. SIAM Journal on Optimization 28(3), 2274–2303 (2018). DOI 10.1137/16M1080240
Tomasi, C., Kanade, T.: Shape and motion from image streams under orthography: a factorization method. International Journal of Computer Vision 9(2), 137–154 (1992). DOI 10.1007/BF00129684
Tseng, P.: On accelerated proximal gradient methods for convex-concave optimization. Tech. rep. (2008)
Ulbrich, M.: Optimization Methods in Banach Spaces, pp. 97–156. Springer Netherlands, Dordrecht (2009). DOI 10.1007/978-1-4020-8839-1_2
Yamashita, N., Taji, K., Fukushima, M.: Unconstrained optimization reformulations of variational inequality problems. Journal of Optimization Theory and Applications 92(3), 439–456 (1997). DOI 10.1023/A:1022660704427
Yang, Z.: A study on nonsymmetric matrix-valued functions. Master’s thesis, National University of Singapore (2009)
Yuan, M., Lin, Y.: Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society. Series B (Statistical Methodology) 68(1), 49–67 (2006)
Zhou, G., Qi, L.: On the convergence of an inexact Newton-type method. Oper. Res. Lett. 34(6), 647–652 (2006). DOI 10.1016/j.orl.2005.11.001
Zhou, G., Toh, K.C.: Superlinear convergence of a Newton-type algorithm for monotone equations. Journal of Optimization Theory and Applications 125(1), 205–221 (2005). DOI 10.1007/s10957-004-1721-7
Acknowledgements
This work was supported by the Research Foundation Flanders (FWO) research projects G086518N and G086318N; KU Leuven internal funding StG/15/043; Fonds de la Recherche Scientifique—FNRS and the Fonds Wetenschappelijk Onderzoek—Vlaanderen under EOS Project no 30468160 (SeLMA).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix: Auxiliary Results
Appendix: Auxiliary Results
Lemma 1
Any proper lsc convex function with nonempty and bounded set of minimizers is level bounded.
Proof
Let h be such function; to avoid trivialities we assume that \( \operatorname {{\mathrm {dom}}} h\) is unbounded. Fix \(x_\star \in \operatorname *{\mathrm {argmin}} h\) and let R > 0 be such that  . Since \( \operatorname {{\mathrm {dom}}} h\) is closed, convex, and unbounded, it holds that h attains a minimum on the compact set \(\operatorname {bdry} B\), be it m, which is strictly larger than h(x
⋆) (since \(\operatorname {dist}( \operatorname *{\mathrm {argmin}} h,\operatorname {bdry} B)>0\) due to compactness of \( \operatorname *{\mathrm {argmin}} h\) and openness of B). For x∉B, let \(s_x=x_\star +R\tfrac {x-x_\star }{\|x-x_\star \|}\) denote its projection onto \(\operatorname {bdry} B\), and let \(t_x\mathrel{\mathop:}= \tfrac {\|x-x_\star \|}{R}\geq 1\). Then,
. Since \( \operatorname {{\mathrm {dom}}} h\) is closed, convex, and unbounded, it holds that h attains a minimum on the compact set \(\operatorname {bdry} B\), be it m, which is strictly larger than h(x
⋆) (since \(\operatorname {dist}( \operatorname *{\mathrm {argmin}} h,\operatorname {bdry} B)>0\) due to compactness of \( \operatorname *{\mathrm {argmin}} h\) and openness of B). For x∉B, let \(s_x=x_\star +R\tfrac {x-x_\star }{\|x-x_\star \|}\) denote its projection onto \(\operatorname {bdry} B\), and let \(t_x\mathrel{\mathop:}= \tfrac {\|x-x_\star \|}{R}\geq 1\). Then,
where in the first inequality we used the fact that t x ≥ 1. Since m − h(x ⋆) > 0 and t x →∞ as ∥x∥→∞, we conclude that h is coercive, and thus level bounded. □
Lemma 2
Let \(H\in \operatorname {S}_+(\mathbb {R}^n)\) with λ max(H) ≤ 1. Then \(H-H^2\in \operatorname {S}_+(\mathbb {R}^n)\) with

Proof
Consider the spectral decomposition  for some orthogonal matrix S and diagonal D. Then,
for some orthogonal matrix S and diagonal D. Then,  where \(\tilde D=D-D^2\). Apparently, \(\tilde D\) is diagonal, hence the eigenvalues of H − H
2 are exactly
where \(\tilde D=D-D^2\). Apparently, \(\tilde D\) is diagonal, hence the eigenvalues of H − H
2 are exactly  . The function λ↦λ − λ
2 is concave, hence the minimum in \(\operatorname {eigs}(\tilde H)\) is attained at one extremum, that is, either at λ = λ
min(H) or λ = λ
max(H), which proves the claim. □
. The function λ↦λ − λ
2 is concave, hence the minimum in \(\operatorname {eigs}(\tilde H)\) is attained at one extremum, that is, either at λ = λ
min(H) or λ = λ
max(H), which proves the claim. □
Lemma 3
For any γ ∈ (0, 2∕L
f) the forward-backward operator  (15.22) is nonexpansive (in fact, \(\frac {2}{4-\gamma L_f}\)
-averaged), and the residual
(15.22) is nonexpansive (in fact, \(\frac {2}{4-\gamma L_f}\)
-averaged), and the residual  is Lipschitz continuous with modulus \(\frac {4}{\gamma (4-\gamma L_f)}\).
is Lipschitz continuous with modulus \(\frac {4}{\gamma (4-\gamma L_f)}\).
Proof
By combining [2, Prop. 4.39 and Cor. 18.17] it follows that the gradient descent operator  is γL
f∕2-averaged. Moreover, since the proximal mapping is 1∕2-averaged [2, Prop. 12.28] we conclude from [2, Prop. 4.44] that the forward-backward operator T
γ is α-averaged with \(\alpha =\frac {2}{4-\gamma L_f}\), thus nonexpansive [2, Rem. 4.34(i)]. Therefore, by definition of α-averagedness there exists a 1-Lipschitz continuous operator S such that \(T_\gamma =(1-\alpha )\operatorname {id}+\alpha S\) and consequently the residual
is γL
f∕2-averaged. Moreover, since the proximal mapping is 1∕2-averaged [2, Prop. 12.28] we conclude from [2, Prop. 4.44] that the forward-backward operator T
γ is α-averaged with \(\alpha =\frac {2}{4-\gamma L_f}\), thus nonexpansive [2, Rem. 4.34(i)]. Therefore, by definition of α-averagedness there exists a 1-Lipschitz continuous operator S such that \(T_\gamma =(1-\alpha )\operatorname {id}+\alpha S\) and consequently the residual  is (2α∕γ)-Lipschitz continuous. □
is (2α∕γ)-Lipschitz continuous. □
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Themelis, A., Ahookhosh, M., Patrinos, P. (2019). On the Acceleration of Forward-Backward Splitting via an Inexact Newton Method. In: Bauschke, H., Burachik, R., Luke, D. (eds) Splitting Algorithms, Modern Operator Theory, and Applications. Springer, Cham. https://doi.org/10.1007/978-3-030-25939-6_15
Download citation
DOI: https://doi.org/10.1007/978-3-030-25939-6_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-25938-9
Online ISBN: 978-3-030-25939-6
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)