
Abstract
This chapter introduces permutation methods for the analysis of contingency tables. Included in this chapter are six example analyses illustrating computation of permutation methods for goodness-of-fit tests, analysis of contingency tables composed of two nominal-level (categorical) variables, analysis of contingency tables composed of two ordinal-level (ranked) variables, analysis of contingency tables composed of one nominal-level variable and one ordinal-level variable, analysis of contingency tables composed of one nominal-level variable and one interval-level variable, and analysis of contingency tables composed of one ordinal-level variable and one interval-level variable. Included in this chapter are permutation versions of Pearson chi-squared goodness-of-fit test, Pearson’s chi-squared test of independence, Cramér’s symmetrical measure of nominal association, Goodman and Kruskal’s τ a and τ b asymmetric measures of association for two categorical variables, Goodman and Kruskal’s G measure of association for two ranked variables, Somers’ d yx and d xy asymmetric measures of association for two ranked variables, Freeman’s θ measure of association for a categorical independent variable and a ranked dependent variable, Pearson’s point-biserial correlation coefficient for one dichotomous variable and one interval-level variable, and Jaspen’s correlation coefficient for one ranked variable and one interval-level variable.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

This chapter introduces exact and Monte Carlo permutation statistical methods for selected measures of relationship among nominal-, ordinal-, and interval-level variables, commonly called contingency table analysis. The analysis of contingency tables with their associated measures of effect size and tests of significance constitutes a substantial portion of nonparametric statistical methods.
In this last chapter, exact and Monte Carlo permutation statistical methods for the analysis of contingency tables are illustrated with six types of analyses. The first section of the chapter considers permutation statistical methods applied to conventional goodness-of-fit tests; for example, Pearson’s chi-squared goodness-of-fit test. The second section is devoted to permutation statistical methods for analyzing contingency tables composed of two cross-classified nominal-level (categorical) variables; for example, Pearson’s symmetric chi-squared test of independence for two categorical variables and Goodman and Kruskal’s t a and t b asymmetric measures of association for two categorical variables. The third section utilizes permutation statistical methods for analyzing contingency tables composed of two cross-classified ordinal-level (ranked) variables; for example, Goodman and Kruskal’s symmetric G measure of association for two ranked variables and Somers’ d yx and d xy asymmetric measures of association for two ranked variables. The fourth section is the first of three sections utilizing permutation statistical methods for analyzing contingency tables composed of two cross-classified mixed-level variables. In this fourth section permutation statistical methods are utilized for analyzing contingency tables composed of one nominal-level (categorical) variable cross-classified with one ordinal-level (ranked) variable; for example, Freeman’s θ measure for one categorical independent variable and one ranked dependent variable. The fifth section utilizes permutation statistical methods for analyzing contingency tables composed of one nominal-level variable cross-classified with one interval-level variable; for example, Pearson’s point-biserial correlation coefficient for one dichotomous variable and one interval-level variable. The sixth section utilizes permutation statistical methods for analyzing contingency tables composed of one ordinal-level variable cross-classified with one interval-level variable; for example, Jaspen’s correlation coefficient for one ranked variable and one interval-level variable. Footnote 1
There exist a vast array of measures of association and correlation. The few measures described here illustrate the application of permutation statistical methods to the analysis of two-way contingency tables at various levels of measurement and were selected for their popularity in the research literature and inclusion in various introductory textbooks. For a more comprehensive treatment of permutation statistical methods applied to measures of association and correlation see a 2018 book on The Measurement of Association by the authors [2].
11.1 Goodness-of-Fit Tests
Goodness-of-fit tests are essential for determining how well observed data conform to hypothetical models. When at all reasonable, exact goodness-of-fit tests are preferred over asymptotic tests. More specifically, goodness-of-fit tests are designed to compare the observed values in k discrete, unordered categories with values that are expected to occur under chance conditions. For example, for a fair coin the expectation for 100 independent trials is 50 heads and 50 tails over many, many trials of 100 tosses. The observed values, say 60 heads and 40 tails, are then compared with expected values under the null hypothesis, H 0: p(H) = p(T) = 0.50.
The most popular goodness-of-fit test for k discrete, unordered categories is Pearson’s chi-squared test, although Wald’s likelihood-ratio test is occasionally encountered in the contemporary literature. Utilizing the conventional notation presented in many introductory textbooks, Pearson’s chi-squared goodness-of-fit test for k discrete, unordered categories is given by
where O i and E i denote the observed and expected frequency values, respectively, for i = 1, …, k. Under the Neyman–Pearson null hypothesis, H 0: O i = E i for i = 1, …, k, χ 2 is asymptotically distributed as Pearson’s χ 2 with k − 1 degrees of freedom, under the assumption of normality.Footnote 2
Consider the random assignment of N objects to k discrete, unordered categories where the probability that any one of the N objects occurs in the ith category is p i > 0 for i = 1, …, k. Then the probability that O i objects occur in the ith category for i = 1, …, k is the multinomial probability given by
where
11.1.1 Example 1
Two example analyses will serve to illustrate the permutation approach to goodness-of-fit-tests. For the first analysis under the Neyman–Pearson population model of statistical inference, consider a small example set of data with k = 3 unordered categories, N = 6 total objects, O 1 = 5 objects in the first category, O 2 = 1 object in the second category, and O 3 = 0 objects in the third category. The observed and expected frequencies along with the associated theoretical proportions are listed in Table 11.1. For the example data listed in Table 11.1 with N = 6 observations, Pearson’s chi-squared goodness-of-fit test statistic is
Under the Neyman–Pearson null hypothesis, H 0: O i = E i for i = 1, …, k, χ 2 is asymptotically distributed as Pearson’s χ 2 with k − 1 degrees of freedom. With k − 1 = 3 − 1 = 2 degrees of freedom, the asymptotic probability value of χ 2 = 7.00 is P = 0.0302, under the assumption of normality.
11.1.2 An Exact Permutation Analysis
For the example data listed in Table 11.1 under the Fisher–Pitman permutation model of statistical inference there are exactly
possible, equally-likely arrangements in the reference set of all permutations of the example data listed in Table 11.1. Table 11.2 lists the M = 28 arrangements of the observed data, the associated χ 2 values, and the multinomial point probability values to six decimal places, ordered by the χ 2 values from lowest (\(\chi _{1}^{2} = 0.00\)) to highest (\(\chi _{28}^{2} = 12.00\)). The exact probability value of χ 2 = 7.00 is the sum of the multinomial point probability values associated with values of χ 2 that are equal to or greater than the observed χ 2 value. There are only nine arrangements of the observed data with χ 2 test statistic values that are equal to or greater than the observed value of χ 2 = 7.00: six values of χ 2 = 7.00 and three values of χ 2 = 12.00, all in rows indicated with asterisks in Table 11.2. Thus if all M arrangements of the N = 6 observations listed in Table 11.1 occur with equal chance under the Fisher–Pitman null hypothesis, the exact probability value of χ 2 = 7.00 computed on the M = 28 possible arrangements of the observed data with k = 4 categories preserved for each arrangement is
There is a substantial difference between the exact probability value of P = 0.0535 and the asymptotic probability value of P = 0.0302; that is,
With the sparse data given in Table 11.1 there are only M = 28 possible arrangements of cell frequencies given the marginal frequency totals and it would be unreasonable to expect a continuous mathematical function such as Pearson’s χ 2 to fit such a small discrete distribution consisting of only six different values with any precision.
11.1.3 Example 2
Gregor Mendel (1822–1884) is notable for his studies of hybridization utilizing the common garden pea while he resided in the Augustinian monastery of St. Thomas at Brünn in Austrian Silesia.Footnote 3 , Footnote 4 In one of his many studies of garden peas, Mendel crossed hybrid plants producing round yellow peas with hybrid plants producing wrinkled green peas. To produce his hybrids, Mendel carefully brushed the pollen of one pea plant onto the pistils of another plant. The first generation, as expected, produced all round yellow peas—both dominant characteristics. However, the second generation yielded four varieties of peas: round yellow, wrinkled yellow, round green, and wrinkled green.Footnote 5
Figure 11.1 displays the different varieties of peas in a Punnett square where RY denotes round yellow peas, Ry denotes round green peas, rY denotes wrinkled yellow peas, and ry denotes wrinkled green peas.Footnote 6 In the Punnett diagram in Fig. 11.1, the round-yellow hybrids, RYRY, RYRy, RYrY, RYry, RyRY, RyrY, rYRY, rYRy, and ryRY, are indicated by nine black circles ([black,fill=black] (0,0) circle (0.6ex);), the round-green hybrids, RyRy, Ryry, and ryRy, are indicated by three dark gray circles ([gray,fill=gray] (0,0) circle (0.6ex);), the wrinkled-yellow hybrids, rYrY, rYry, and ryrY, are indicated by three light gray circles ([lightgray,fill=lightgray] (0,0) circle (0.6ex);), and the single wrinkled-green ryry hybrid is indicated by a white circle ([black,fill=white] (0,0) circle (0.6ex);).

Punnett square depicting RYRY, RYRy, RYrY, RYry, RyRY, RyrY, rYRY, rYRy, and ryRY hybrids with nine black circles, RyRy, Ryry, and ryRy hybrids with three dark gray circles, rYrY, rYry, and ryrY hybrids with three light gray circles, and the sole ryry hybrid with a single white circle
Mendel’s 15 double-hybrid plants produced a sample of N = 556 peas. Mendel’s data for the N = 556 second-generation hybrids are listed in Table 11.3, along with the expected values which approximate the ratios 9:3:3:1.
For Mendel’s hybridization data listed in Table 11.3, Pearson’s chi-squared goodness-of-fit test statistic is
Under the Neyman–Pearson null hypothesis, H 0: O i = E i for i = 1, …, k, χ 2 is asymptotically distributed as Pearson’s χ 2 with k − 1 degrees of freedom. With k − 1 = 4 − 1 = 3 degrees of freedom, the asymptotic probability value of χ 2 = 0.4700 is P = 0.9254, under the assumption of normality.
In a 1936 paper published in Annals of Science, R.A. Fisher , Galton Professor of Eugenics at University College, London, re-examined Mendel’s hybridization data, questioned Mendel’s recording of his observations, and concluded that the very close agreement between Mendel’s observed and expected series was unlikely to have arisen by chance [4]. Fisher submitted his paper at Christmas time in 1936 to Annals of Science with a comment to the editor, Dr. Douglas McKie:
I had not expected to find the strong evidence which has appeared that the data had been cooked. This makes my paper far more sensational than ever I had intended…(quoted in Box [3, p. 297]).
11.1.4 An Exact Permutation Analysis
Under the Fisher–Pitman permutation model, the exact probability value of an observed chi-squared value of χ 2 = 7.00 is given by the sum of the multinomial point probability values associated with the values of χ 2 that are equal to or greater than the observed χ 2 value. For the Mendel hybridization data listed in Table 11.3 under the permutation model there are
possible, equally-likely arrangements in the reference set of all permutations of Mendel’s hybridization data listed in Table 11.3, making an exact permutation analysis feasible. If all M arrangements of the N = 556 observations listed in Table 11.3 occur with equal chance under the Fisher–Pitman null hypothesis, the exact probability value of the observed chi-squared value of χ 2 = 0.4700 computed on the M = 28, 956, 759 possible arrangements of the observed data with k = 4 categories preserved for each arrangement is P = 0.9381; that is, the sum of the multinomial probability values associated with values of χ 2 = 0.4700 or greater.
11.1.5 A Measure of Effect Size
A chi-squared test of goodness-of-fit and its associated probability value provide no information as to the closeness of the fit between the observed and theoretical values, only whether they are statistically significant under the Neyman–Pearson population-model null hypothesis. Measures of effect size are essential in such cases as they index the magnitude of the fit between the observed and expected frequencies and indicate the practical significance of the research. A maximum-corrected measure of effect size is easily specified for a chi-squared goodness-of-fit test [1].
Define
for k disjoint, unordered categories. Then with q determined, the maximum value of χ 2 is given by
and a maximum-corrected measure of effect size for Pearson’s chi-squared goodness-of-fit test is given by
where \(\chi _{\text{o}}^{2}\) denotes the observed value of χ 2 [8].
For Mendel’s hybridization data listed in Table 11.3, the minimum expected frequency value is
and the maximum possible Pearson’s χ 2 test statistic value given k = 4, q = 34.75, and N = 556 is
To illustrate the function of Eq. (11.1) imagine that all N = 556 observations are concentrated in the one category with the smallest expected value and the remaining k − 1 categories contain zero observations. In this case all N = 556 observations are concentrated in the last category with the minimum expected value of E 4 = 34.75, such as depicted in Table 11.4. Then the maximum value of Pearson’s chi-squared goodness-of-fit test statistic is
and the maximum-corrected measure of effect size is
indicating that the observed value of χ 2 = 0.4700 is an insignificantly small proportion of the maximum possible χ 2 value, given the expected values E 1 = 312.75, E 2 = 104.25, E 3 = 104.25, and E 4 = 34.75.
11.2 Contingency Measures: Nominal by Nominal
The most popular test for the cross-classification of two nominal-level (categorical) variables is Pearson’s chi-squared test of independence, which is presented in every introductory textbook. Utilizing the conventional notation presented in many introductory textbooks for a contingency table with r rows and c columns, Pearson’s chi-squared test statistic is given by
where O ij denotes the observed frequency in the ith row and jth column for i = 1, …, r and j = 1, …, c, R i denotes a row marginal frequency total for i = 1, …, r, C j denotes a column marginal frequency total for j = 1, …, c, and N denotes the total number of values in the observed contingency table.
11.2.1 Example 1
Two examples will serve to illustrate Pearson’s chi-squared test of independence for an r×c contingency table. For an analysis under the Neyman–Pearson population model, consider the sparse example data given in Table 11.5 with r = 3 rows, c = 3 columns, and N = 9 observations. Under the Neyman–Pearson population model, the chi-squared test statistic value for the example data given in Table 11.5 is
Under the Neyman–Pearson null hypothesis, H 0: O ij = E ij for i = 1, …, r and j = 1, …, c, where the expected cell values are given by
for i = 1, …, r and j = 1, …, c, χ 2 is asymptotically distributed as Pearson’s χ 2 with (r − 1)(c − 1) degrees of freedom. With (r − 1)(c − 1) = (3 − 1)(3 − 1) = 4 degrees of freedom, the asymptotic probability value of χ 2 = 11.2500 is P = 0.0239, under the assumption of normality.
11.2.2 A Measure of Effect Size
The fact that a chi-squared statistical test produces a low probability value indicates only that there are differences among the response measurement scores between the two variables that (possibly) cannot be attributed to error. The obtained probability value does not indicate whether these differences are of any practical value. Measures of effect size express the practical or clinical significance of an obtained chi-squared value, as contrasted with the statistical significance of a chi-squared value. The most popular measure of effect size for Pearson’s chi-squared test of independence is Cramér’s V given by
For the example data given in Table 11.6 with χ 2 = 11.2500, Cramér’s measure of effect size is
For a critical evaluation of Cramér’s V measure of effect size, see a discussion in The Measurement of Association by the authors [2, pp. 80–82].
Occasionally in the contemporary literature, Cohen’s measure of effect size for a chi-squared test of independence is encountered. Cohen’s measure is given by
For the example data given in Table 11.5, Cohen’s measure of effect size is
11.2.3 An Exact Permutation Analysis
Given the observed marginal frequency totals for the example data, there are only M = 39 possible, equally-likely arrangements of cell frequencies in the reference set of all permutations of the N = 9 observations given in Table 11.5, making an exact permutation analysis possible. Table 11.6 lists the M = 39 arrangements of cell frequencies, the associated chi-squared test statistic values, and the hypergeometric point probability values given by
Because the observed marginal frequency totals are fixed, Table 11.6 lists only cell frequencies O 11, O 12, O 21, and O 22, as the remaining five cell frequencies can be determined from the observed marginal frequency totals.
Under the Fisher–Pitman permutation model, the exact probability value of χ 2 = 11.2500 is the sum of the hypergeometric point probability values associated with the chi-squared values that are equal to or greater than the observed chi-squared value. For the results listed in Table 11.6, there are four chi-squared test statistic values that are equal to or greater than the observed value of χ 2 = 11.2500: \(\chi _{1}^{2} = 18.0000\), \(\chi _{2}^{2} = 14.0625\), \(\chi _{3}^{2} = 13.0000\), and \(\chi _{4}^{2} = 11.2500\), in rows 1, 2, 3, and 4, respectively, and indicated by asterisks. Thus the exact probability value of χ 2 = 11.2500 is
There is a substantial difference between the exact probability value of P = 0.0111 and the asymptotic probability value of P = 0.0239; that is,
With such sparse data as given in Table 11.5 there are only M = 39 possible arrangements of cell frequencies given the marginal frequency totals with only 25 different chi-squared values and it would be unreasonable to expect a continuous mathematical function such as Pearson’s χ 2 to fit such a small discrete distribution with any precision.
11.2.4 Example 2
For a second example of a chi-squared analysis of a nominal-nominal contingency table, consider the 3×5 contingency table with cell frequencies given in Table 11.7. Following Eq. (11.2), Pearson’s chi-squared test statistic for the frequency data given in Table 11.7 is
Under the Neyman–Pearson null hypothesis the chi-squared test statistic is asymptotically distributed as Pearson’s χ 2 with (r − 1)(c − 1) degrees of freedom. With (r − 1)(c − 1) = (3 − 1)(5 − 1) = 8 degrees of freedom, the asymptotic probability value of χ 2 = 16.6279 is P = 0.0342, under the assumption of normality.
11.2.5 A Measure of Effect Size
For the frequency data given in Table 11.7, Cramér’s measure of effect size is
and Cohen’s measure of effect size is
11.2.6 An Exact Permutation Analysis
Given the observed marginal frequency totals for the example data, there are M = 11, 356, 797 possible, equally-likely arrangements of the cell frequencies in the reference set of all permutations of the N = 63 observations given in Table 11.7, making an exact permutation analysis possible. Under the Fisher–Pitman permutation model, the exact probability of χ 2 = 16.6279 is the sum of the hypergeometric point probability values associated with the chi-squared values calculated on all M possible arrangements of the cell frequencies, given the observed marginal frequency totals. For the frequency data given in Table 11.7, there are M = 11, 356, 797 possible, equally-likely arrangements of the cell frequencies given the observed marginal frequency totals, of which 10,559,996 chi-squared test statistic values are equal to or greater than the observed chi-squared value of χ 2 = 16.6279, yielding an exact hypergeometric probability value of P = 0.0306. Note that with M = 11, 356, 797 possible arrangements of the data given in Table 11.7, the asymptotic χ 2 probability value of P = 0.0342 closely approximates the exact hypergeometric probability value of P = 0.0306.
11.2.7 Goodman–Kruskal’s t a and t b Measures
While all measures of association based on Pearson’s chi-squared are symmetric measures, Goodman and Kruskal’s two asymmetric proportional-reduction-in-error measures (t a and t b) allow researchers to specify an independent and a dependent variable. Consider two cross-classified, unordered polytomies, A and B, with variable A the dependent variable and variable B the independent variable. Table 11.8 provides notation for the cross-classification, where a j for j = 1, …, c denotes the c categories for dependent variable A, b i for i = 1, …, r denotes the r categories for independent variable B, N denotes the total of cell frequencies in the table, n i. denotes a marginal frequency total for the ith row, i = 1, …, r, summed over all columns, n .j denotes a marginal frequency total for the jth column, j = 1, …, c, summed over all rows, and n ij denotes a cell frequency for i = 1, …, r and j = 1, …, c.
Goodman and Kruskal’s t a test statistic is a measure of the relative reduction in prediction error where two types of errors are defined. The first type is the error in prediction based solely on knowledge of the distribution of the dependent variable, termed “errors of the first kind” (E 1) and consisting of the expected number of errors when predicting the c dependent variable categories (a 1, …, a c) from the observed distribution of the marginals of the dependent variable (n .1, …, n .c). The second type is the error in prediction based on knowledge of the distributions of both the independent and dependent variables, termed “errors of the second kind” (E 2) and consisting of the expected number or errors when predicting the c dependent variable categories (a 1, …, a c) from knowledge of the r independent variable categories (b 1, …, b r).
To illustrate the two error types, consider predicting category a 1 only from knowledge of its marginal distribution, n .1, …, n .c. Clearly, n .1 out of the N total cases are in category a 1, but exactly which n .1 of the N cases is unknown. The probability of incorrectly identifying one of the N cases in category a 1 by chance alone is given by
Since there are n .1 such classifications required, the number of expected incorrect classifications is
and, for all c categories of variable A, the number of expected errors of the first kind is given by
Likewise, to predict n 11, …, n 1c from the independent category b 1, the probability of incorrectly classifying one of the n 1. cases in cell n 11 by chance alone is
Since there are n 11 such classifications required, the number of incorrect classifications is
and, for all cr cells, the number of expected errors of the second kind is given by
Goodman and Kruskal’s t a statistic can then be defined as
An efficient computation form for Goodman and Kruskal’s t a test statistic is given by
A computed value of t a indicates the proportional reduction in prediction error given knowledge of the distribution of independent variable B over and above knowledge of only the distribution of dependent variable A. As defined, t a is a point estimator of Goodman and Kruskal’s population parameter τ a for the population from which the sample of N cases was obtained. If variable B is considered the dependent variable and variable A the independent variable, then Goodman and Kruskal’s test statistic t b and associated population parameter τ b are analogously defined.
11.2.8 An Example Analysis for t a
To illustrate Goodman and Kruskal’s t a measure of nominal-nominal association, consider the contingency table given in Table 11.9 with r = 3 rows, c = 4 columns, and N = 110 cross-classified ordered observations. Following Eq. (11.3), the observed value of Goodman and Kruskal’s t a test statistic is
Under the Neyman–Pearson null hypothesis, H 0: τ a = 0, t a(N − 1)(r − 1) is asymptotically distributed as Pearson’s χ 2 with (r − 1)(c − 1) degrees of freedom. With (r − 1)(c − 1) = (3 − 1)(4 − 1) = 6 degrees of freedom, the asymptotic probability value of t a = 0.2797 is P = 0.2852×10−10, under the assumption of normality.
11.2.9 An Exact Permutation Analysis for t a
Under the Fisher–Pitman permutation model, the exact probability value of an observed value of Goodman and Kruskal’s t a is given by the sum of the hypergeometric point probability values associated with t a test statistic values that are equal to or greater than the observed value of t a = 0.2797. For the frequency data given in Table 11.9, there are M = 26, 371, 127 possible, equally-likely arrangements in the reference set of all permutations of cell frequencies given the observed row and column marginal frequency distributions, {37, 35, 38} and {25, 25, 27, 33}, respectively, making an exact permutation analysis possible. There are exactly 1,523,131 t a test statistic values that are equal to or greater than the observed value of t a = 0.2797. The exact probability value of the observed t a value under the Fisher–Pitman null hypothesis is P = 0.0578; that is, the sum of the hypergeometric point probability values associated with values of t a = 0.2797 or greater.
11.2.10 An Example Analysis for t b
Now consider variable B as the dependent variable. A convenient computing formula for t b is
Thus, for the frequency data given in Table 11.9 the observed value of t b is
Under the Neyman–Pearson null hypothesis, H 0: τ b = 0, t b(N − 1)(c − 1) is asymptotically distributed as Pearson’s χ 2 with (r − 1)(c − 1) degrees of freedom. With (r − 1)(c − 1) = (3 − 1)(4 − 1) = 6 degrees of freedom, the asymptotic probability value of t b = 0.4428 is P = 0.9738×10−28, under the assumption of normality.
11.2.11 An Exact Permutation Analysis for t b
Under the Fisher–Pitman permutation model, the exact probability value of an observed value of Goodman and Kruskal’s t b is given by the sum of the hypergeometric point probability values associated with t b test statistic values that are equal to or greater than the observed value of t b = 0.4428. For the frequency data given in Table 11.9, there are M = 26, 371, 127 possible, equally-likely arrangements in the reference set of all permutations of cell frequencies given the observed row and column marginal frequency distributions, {37, 35, 38} and {25, 25, 27, 33}, respectively, making an exact permutation analysis possible. There are exactly 991,488 t b test statistic values that are equal to or greater than the observed value of t b = 0.4428. The exact probability value of the observed t b value under the Fisher–Pitman null hypothesis is P = 0.0376; that is, the sum of the hypergeometric point probability values associated with values of t b = 0.4428 or greater.
11.2.12 The Relationships Among t a, t b, and χ 2
While no general equivalence exists between Goodman and Kruskal’s t a and t b measures of nominal-nominal association and Pearson’s χ 2 test of independence, certain relationships hold among t a, t b, and χ 2 under some limited conditions. Four of the relationships can easily be specified.
First, if n i. = N∕r for i = 1, …, r, then χ 2 = N(r − 1)t b and t b = χ 2∕N(r − 1). To illustrate the relationship between Goodman and Kruskal’s t b asymmetric measure of nominal-nominal association and Pearson’s χ 2 test of independence when n i. = N∕r for i = 1, …, r, consider the frequency data given in Table 11.10 with r = 3 rows, c = 3 columns, N = 30 cross-classified observations, and n i. = N∕r = 10 for i = 1, …, r. For the frequency data given in Table 11.10 with N = 30 observations,
and
Then the observed value of Pearson’s χ 2 test statistic with respect to the observed value of Goodman and Kruskal’s t b test statistic is
and the observed value of Goodman and Kruskal’s t b test statistic with respect to the observed value of Pearson’s χ 2 test statistic is
Second, if n .j = N∕c for j = 1, …, c, then χ 2 = N(c − 1)t a and t a = χ 2∕N(c − 1). To illustrate the relationship between Goodman and Kruskal’s t a measure of nominal-nominal association and Pearson’s χ 2 test of independence when n .j = N∕c for j = 1, …, c, consider the frequency data given in Table 11.11 with r = 2 rows, c = 4 columns, N = 40 cross-classified observations, and n .j = N∕c = 10 for j = 1, …, c. For the frequency data given in Table 11.11 with N = 40 observations,
and
Then the observed value of Pearson’s χ 2 test statistic with respect to the observed value of Goodman and Kruskal’s t a test statistic is
and the observed value of Goodman and Kruskal’s t a test statistic with respect to the observed value of Pearson’s χ 2 test statistic is
Third, if r = 2, then χ 2 = Nt a and t a = χ 2∕N, which is Pearson’s ϕ 2 coefficient of contingency. Also, if c = 2, then χ 2 = Nt b and t b = χ 2∕N. Thus, if r = c = 2, then χ 2 = Nt a = Nt b. To illustrate the relationships between Goodman and Kruskal’s t a and t b measures of nominal-nominal association and Pearson’s χ 2 test of independence with r = c = 2, consider the frequency data given in Table 11.12 with r = 2 rows, c = 2 columns, and N = 90 cross-classified observations. For the frequency data given in Table 11.12 with N = 90 observations,
and
Then the observed value of Pearson’s χ 2 test statistic with respect to the observed value of Goodman and Kruskal’s t a test statistic is
and the observed value of Goodman and Kruskal’s t a test statistic with respect to the observed value of Pearson’s χ 2 test statistic is
Also, the observed value of Pearson’s χ 2 test statistic with respect to Goodman and Kruskal’s t b test statistic is
and the observed value of Goodman and Kruskal’s t b test statistic with respect to the observed value of Pearson’s χ 2 test statistic is
Fourth, if n i. = N∕r and n .j = N∕c for i = 1, …, r and j = 1, …, c, then χ 2 = N(c − 1)t a = N(r − 1)t b. To illustrate the relationships between Goodman and Kruskal’s t a and t b asymmetric measures of nominal association and Pearson’s χ 2 test of independence with n i. = N∕r = 12 for i = 1, …, r and n .j = N∕c = 9 for j = 1, …, c, consider the frequency data given in Table 11.13 with r = 3 rows, c = 4 columns, and N = 36 cross-classified observations. For the frequency data given in Table 11.13 with N = 36 observations,
and
Then the observed value of Pearson’s χ 2 test statistic with respect to the observed value of Goodman and Kruskal’s t a test statistic is
and the observed value of Goodman and Kruskal’s t a test statistic with respect to the observed value of Pearson’s χ 2 test statistic is
Also, the observed value of Pearson’s χ 2 test statistic with respect to Goodman and Kruskal’s t b test statistic is
and the observed value of Goodman and Kruskal’s t b test statistic with respect to the observed value of Pearson’s χ 2 test statistic is
11.2.13 The Relationships Among t b, δ, and \(\Re \)
Goodman and Kruskal’s t b measure of nominal-nominal association is directly related to the permutation test statistic δ and, hence, to the permutation-based, chance-corrected \(\Re \) measure of effect size. To illustrate the relationships among test statistics t b, δ, and \(\Re \), consider the frequency data given in Table 11.9 on p. 426, replicated in Table 11.14 for convenience. The conventional notation for an r×c contingency table is given in Table 11.8 on p. 423 where the row marginal frequency totals are denoted by n i. for i = 1, …, r, the column marginal frequency totals are denoted by n .j for j = 1, …, c, the cell frequencies are denoted by n ij for i = 1, …, r and j = 1, …, c, and
Then for the frequency data given in Table 11.14, Goodman and Kruskal’s t b test statistic is
In 1971 Richard Light and Barry Margolin developed test statistic R 2, based on an analysis of variance technique for categorical response variables [6]. Light and Margolin were unaware that R 2 was identical to Goodman and Kruskal’s t b test statistic and that they had asymptotically solved the long-standing problem of testing the null hypothesis that the population parameter corresponding to Goodman and Kruskal’s t b was zero; that is, H 0: τ b = 0. The identity between R 2 and t b was first recognized by Särndal in 1974 [9] and later discussed by Margolin and Light [7], where they showed that t b(N − 1)(c − 1) was distributed as Pearson’s chi-squared with (r − 1)(c − 1) degrees of freedom.
Following Light and Margolin in the context of a completely-randomized analysis of variance for the frequency data given in Table 11.14, the sum-of-squares total is
the sum-of-squares between treatments is
the sum-of-squares within treatments is
and Light and Margolin’s test statistic is
which is identical to Goodman and Kruskal’s t b = 0.4428.
The essential factors, sums of squares (SS), degrees of freedom (df), mean squares (MS), and variance-ratio test statistic (F) are summarized in Table 11.15 where df Between = c − 1 = 4 − 1 = 3, df Within = N − c = 110 − 4 = 106, and df Total = N − 1 = 110 − 1 = 109. Under the Neyman–Pearson null hypothesis, H 0: n ij = n i.∕c for i = 1, …, r and j = 1, …, c, where each of the c treatment groups possesses the same multinomial probability structure, test statistic F is asymptotically distributed as Snedecor’s F with ν 1 = r − 1 and ν 2 = N − r degrees of freedom. With ν 1 = r − 1 = 4 − 1 = 3 and ν 2 = N − r = 110 − 4 = 106 degrees of freedom, the asymptotic probability value of F = 28.0835 is P = 0.1917×10−12, under the assumptions of normality and homogeneity.
For the frequency data given in Table 11.14, the permutation test statistic is
the exact expected value of test statistic δ under the Fisher–Pitman null hypothesis is
and Mielke and Berry’s chance-corrected measure of effect size is
indicating approximately 43% agreement between variables A and B above what is expected by chance.
Alternatively, in terms of a completely-randomized analysis of variance model the chance-corrected measure of effect size is
Then the observed value of test statistic δ with respect to the observed value of Goodman and Kruskal’s t b test statistic is
and the observed value of Goodman and Kruskal’s t b test statistic with respect to the observed value of test statistic δ is
The observed value of test statistic δ with respect to the observed value of Fisher’s F-ratio test statistic is
and the observed value of Fisher’s F-ratio test statistic with respect to the observed value of test statistic δ is
The observed value of Goodman and Kruskal’s t b test statistic with respect to the observed value of Mielke and Berry’s \(\Re \) measure of effect size is
and the observed value of Mielke and Berry’s \(\Re \) measure of effect size with respect to Goodman and Kruskal’s t b test statistic is
The observed value of Mielke and Berry’s \(\Re \) measure of effect size with respect to the observed value of Fisher’s F-ratio test statistic is
and the observed value of Fisher’s F-ratio test statistic with respect to the observed value of Mielke and Berry’s \(\Re \) measure of effect size is
11.3 Contingency Measures: Ordinal by Ordinal
There exist numerous measures of association for the cross-classification of two ordinal (ranked) variables. Three popular measures of ordinal-ordinal association are Goodman and Kruskal’s symmetric measure of ordinal association denoted by G and two asymmetric measures of ordinal association by Somers denoted by d yx and d xy.Footnote 7 These three measures and several others are based on the numbers of concordant and discordant pairs present in the observed contingency table. To illustrate the calculation of concordant and discordant pairs, consider the 3×5 contingency table given in Table 11.16 with N = 63 observations.
For any ordered contingency table there are five types of pairs to be considered: concordant pairs (C), discordant pairs (D), pairs that are tied on variable x but not tied on variable y (T x), pairs tied on variable y but not tied on variable x (T y), and pairs tied on both variable x and variable y (T xy). Together they sum to the number of possible pairs in the table; that is,
To demonstrate the calculation of concordant (C) and discordant (D) pairs, consider the two sets of rank scores listed in Table 11.17, where there are no tied ranks. Consider the first pair of objects: Objects 1 and 2. For Object 1, x 1 = 1 and y 1 = 3, and for Object 2, x 2 = 3 and y 2 = 4. Since x 1 < x 2 and y 1 < y 2 (1 < 3 and 3 < 4), the pair is considered to be concordant. Now consider a second pair of objects: Objects 1 and 3. For Object 1, x 1 = 1 and y 1 = 3, and for Object 3, x 3 = 2 and y 3 = 1. Since x 1 < x 3 and y 1 > y 3 (1 < 2 and 3 > 1), the pair is considered to be discordant. For the untied rank data listed in Table 11.17, the number of concordant pairs is C = 23 and the number of concordant pairs is D = 5. The
concordant (C) and discordant (D) pairs for the rank-score data listed in Table 11.17 are listed in Table 11.18.
To illustrate the calculation of the T x, T y, and T xy tied pairs, consider the two sets of rank scores listed in Table 11.19, where there are multiple tied rank scores on both variable x and variable y. For the rank scores listed in Table 11.19, N = 6, the number of concordant pairs is C = 8, the number of discordant pairs is D = 2, the number of pairs tied on variable x is T x = 1, the number of pairs tied on variable y is T y = 2, and the number of pairs tied on both variable x and variable y is T xy = 2. Table 11.20 lists the
paired differences: concordant pairs (C), discordant pairs (D), pairs tied on variable x (T x), pairs tied on variable y (T y), and pairs tied on both variable x and variable y (T xy).
11.3.1 An Example Analysis for G
For the example rank data given in Table 11.16 on p. 438 with N = 63 observations, the number of concordant pairs is
the number of discordant pairs is
and Goodman and Kruskal’s measure of ordinal-ordinal association is
Under the Neyman–Pearson null hypothesis, H 0: γ = 0, Goodman and Kruskal’s G measure of ordinal-ordinal association is asymptotically distributed N(0, 1) as N →∞ with a standard error given by
For the frequency data given in Table 11.16,
yielding an asymptotic upper-tail N(0, 1) probability value of P = 0.1252, under the assumption of normality.
11.3.2 An Exact Permutation Analysis for G
Under the Fisher–Pitman permutation model, the exact probability value of an observed value of Goodman and Kruskal’s G measure of ordinal-ordinal association is given by the sum of the hypergeometric point probability values associated with values of test statistic G that are equal to or greater than the observed value of G = +0.2741. For the frequency data given in Table 11.16 with N = 63 observations, there are M = 11, 356, 797 possible, equally-likely arrangements in the reference set of all permutations of cell frequencies given the observed row and column marginal frequency distributions {21, 25, 17} and {7, 11, 16, 21, 8}, respectively, making an exact permutation analysis feasible. The exact probability value of the observed value of test statistic G is P = 0.0336; that is, the sum of the hypergeometric point probability values associated with values of G = +0.2741 or greater.
11.3.3 The Relationship Between Statistics G and δ
The functional relationships between test statistic δ and Goodman and Kruskal’s G measure of ordinal-ordinal association are given by
For the frequency data given in Table 11.16, the observed value of test statistic δ with respect to the observed value of Goodman and Kruskal’s G measure of ordinal-ordinal association is
and the observed value of Goodman and Kruskal’s G measure of ordinal-ordinal association with respect to the observed value of test statistic δ is
11.3.4 Somers’ d yx and d xy Measures
While Goodman and Kruskal’s G measure of ordinal-ordinal association is a symmetric measure, Somers’ two asymmetric proportional-reduction-in-error (PRE) measures (d yx and d xy) allow researchers to specify an independent and a dependent variable. For Somers’ d yx, the dependent variable is typically the column variable labeled y and for Somers’ d xy, the dependent variable is typically the row variable labeled x. The two asymmetric measures are given by
where C is the number of concordant pairs, D is the number of discordant pairs, T x is the number of pairs tied on the row variable, and T y is the number of pairs tied on the column variable. As is evident in Eq. (11.4), Somers included in the denominators of d yx and d xy the number of tied pairs on the dependent variable: T y for d yx and T x for d xy. The rationale for including the tied pairs is simply that when variable y is the dependent variable (d yx), then if two values of the independent variable x differ, but the corresponding two values of the dependent variable y do not differ (are tied), there is evidence of a lack of association and the ties on dependent variable y (T y) should be included in the denominator where they act to decrease the value of d yx. The same rationale holds for Somers’ d xy where the ties on dependent variable x (T x) are included in the denominator.
11.3.5 An Example Analysis for d yx
For the frequency data given in Table 11.16 on p. 438, replicated in Table 11.21 for convenience, the number of concordant pairs is
the number of discordant pairs is
the number of pairs tied on variable x is
the number of pairs tied on dependent variable y is
and Somers’ d yx asymmetric measure of ordinal-ordinal association is
For an r×c contingency table, d yx is asymptotically distributed N(0, 1) under the Neyman–Pearson null hypothesis as N →∞ with a standard error given by
For the frequency data given in Table 11.21,
yielding an asymptotic upper-tail N(0, 1) probability value of P = 0.0133, under the assumption of normality.
11.3.6 An Exact Permutation Analysis for d yx
Under the Fisher–Pitman permutation model, the exact probability value of an observed value of Somers’ d yx is given by the sum of the hypergeometric point probability values associated with values of test statistic d yx that are equal to or greater than the observed value of d yx = +0.2150. For the frequency data given in Table 11.21, there are M = 11, 356, 797 possible, equally-likely arrangements in the reference set of all permutation of cell frequencies given the observed row and column marginal frequency distributions {21, 25, 17} and {7, 11, 16, 21, 8}, respectively, making an exact permutation analysis feasible. The exact probability value of d yx = +0.2150 is P = 0.0331; that is, the sum of the hypergeometric point probability values associated with values of d yx = +0.2150 or greater.
11.3.7 The Relationship Between Statistics d yx and δ
The functional relationships between test statistic δ and Somers’ d yx asymmetric measure of ordinal-ordinal association are given by
For the frequency data given in Table 11.21, the observed value of test statistic δ with respect to the observed value of Somers’ d yx measure of ordinal-ordinal association is
and the observed value of Somers’ d yx measure of ordinal-ordinal association with respect to the observed value of test statistic δ is
11.3.8 An Example Analysis for d xy
For the frequency data given in Table 11.21, the number of concordant pairs is C = 653, the number of discordant pairs is D = 372, the number of pairs tied on dependent variable x is T x = 494, and Somers’ d xy asymmetric measure of ordinal-ordinal association is
For an r×c contingency table, d yx is asymptotically distributed N(0, 1) under the Neyman–Pearson null hypothesis as N →∞ with a standard error given by
For the frequency data given in Table 11.21,
yielding an asymptotic upper-tail N(0, 1) probability value of P = 0.0123, under the assumption of normality.
11.3.9 An Exact Permutation Analysis for d xy
Under the Fisher–Pitman permutation model, the exact probability value of an observed value of Somers’ d xy is given by the sum of the hypergeometric point probability values associated with values of test statistic d xy that are equal to or greater than the observed value of d xy = +0.1850. For the frequency data given in Table 11.21, there are M = 11, 356, 797 possible, equally-likely arrangements in the reference set of all permutation of cell frequencies given the observed row and column marginal frequency distributions {21, 25, 17} and {7, 11, 16, 21, 8}, respectively, making an exact permutation analysis feasible. The exact probability value of d xy = +0.1850 is P = 0.0331; that is, the sum of the hypergeometric point probability values associated with values of d xy = +0.1850 or greater.
11.3.10 The Relationship Between d xy and δ
The functional relationships between test statistic δ and Somers’ d xy asymmetric measure of ordinal-ordinal association are given by
For the frequency data given in Table 11.21, the observed value of test statistic δ with respect to the observed value of Somers’ d xy measure of ordinal-ordinal association is
and the observed value of Somers’ d xy measure of ordinal association with respect to the observed value of test statistic δ is
11.3.11 Probability Values for d yx and d xy
It may appear inconsistent that while Somers’ two measures of effect size differ (d yx = +0.2150 and d xy = 0.1850), they both yield the same probability value of P = 0.0331. It follows from the fact that the denominators of d yx and d xy (C + D + T y and C + D + T x, respectively) can be computed from just the marginal frequency distributions, which are fixed for all possible arrangements of cell frequencies and are, therefore, invariant under permutation.
It is easily shown that C + D + T y can be obtained from N and the row marginal frequency distribution. Recall that for the frequency data listed in Table 11.21 on p. 443, the number of concordant pairs is C = 653, the number of discordant pairs is D = 372, the number of pairs tied on variable y is T y = 282, and C + D + T y = 653 + 372 + 282 = 1307. Then with N = 63,
In such manner C + D + T x can be obtained from N and the column marginal frequency distribution. For the frequency data listed in Table 11.21, the number of concordant pairs is C = 653, the number of discordant pairs is D = 372, the number of pairs tied on variable x is T x = 494, and C + D + T x = 653 + 372 + 494 = 1519. Then with N = 63,
11.4 Contingency Measures: Nominal by Ordinal
There exist any number of measures of association for which the standard error is unknown. Permutation statistical methods do not rely on knowledge of standard errors and therefore provide much-needed probability values for a number of otherwise very useful measures of association. One measure without a known standard error is Freeman’s θ measure of nominal-ordinal association [5, pp. 108–119].
Consider an r×c contingency table where the r rows are a nominal-level (categorical) independent variable (x) and the c columns are an ordinal-level (ranked) dependent variable (y). For Freeman’s θ it is necessary to calculate the absolute sum of the number of concordant pairs and number of discordant pairs for all combinations of the nominal-level independent variable (rows) considered two at a time. Assuming that the column ordered variable (y) is underlying continuous and that ties in ranking result simply from a crude classification of the continuous variable, Freeman’s nominal-ordinal measure of association is given by
11.4.1 An Example Analysis for θ
To illustrate the calculation of Freeman’s θ measure of nominal-ordinal association, consider the 4×5 contingency table given in Table 11.22 with N = 40 observations. For the frequency data given in Table 11.22 with N = 40 observations, the number of concordant pairs is
the number of discordant pairs is
the number of pairs tied on variable y is
the concordant and discordant pairs for the r = 4 rows considered two at a time are
and Freeman’s θ is
11.4.2 An Exact Permutation Analysis for θ
Under the Fisher–Pitman permutation model, the exact probability value of an observed value of θ = 0.7486 is given by the sum of the hypergeometric point probability values associated with the values of test statistic θ calculated on all M possible arrangements of the cell frequencies that are equal to or greater than the observed value of θ = 0.7486. For the frequency data given in Table 11.22, there are only M = 6, 340, 588 possible arrangements in the reference set of all permutations of cell frequencies consistent with the observed row and column marginal frequency distributions, {10, 20, 5, 5} and {11, 7, 12, 6, 4}, respectively, making an exact permutation analysis feasible.
If all M possible arrangements of the observed data occur with equal chance, the exact probability value of Freeman’s θ under the Fisher–Pitman null hypothesis is the sum of the hypergeometric point probability values associated with the arrangements of cell frequencies with values of θ that are equal to or greater than the observed value of θ = 0.7486. Based on the underlying hypergeometric probability distribution, the exact probability value of θ = 0.7486 is P = 0.2105×10−10.
11.5 Contingency Measures: Nominal by Interval
Pearson’s point-biserial correlation coefficient, denoted by r pb, measures the association between a nominal-level (categorical) variable with two categories and an interval-level variable. Pearson’s point-biserial correlation coefficient is an important measure in fields such as education and educational psychology where it is typically used to measure the correlation between test questions scored as correct (1) or incorrect (0) and the overall score on the test for N test takers. A low or negative point-biserial correlation coefficient indicates that the test takers with the highest scores on the test answered the question incorrectly and the test takers with the lowest scores on the test answered the question correctly, alerting the instructor to the possibility that the question failed to discriminate properly and may be faulty.
11.5.1 An Example Analysis for r pb
To illustrate the calculation of Pearson’s point-biserial correlation coefficient, consider the dichotomous data listed in Table 11.23 for N = 20 observations where variable x is the dichotomous variable and variable y is an unspecified interval-level variable. The point-biserial correlation coefficient is often expressed as
where n 0 and n 1 denote the number of y values coded 0 and 1, respectively, N = n 0 + n 1, \(\bar {y}_{0}\) and \(\bar {y}_{1}\) denote the means of the y values coded 0 and 1, respectively, and s y is the sample standard deviation of the y values given by
For the data listed in Table 11.23, n 0 = n 1 = 10,
and Pearson’s point-biserial correlation coefficient is
Alternatively, with
Pearson’s point-biserial correlation coefficient is simply the product-moment correlation between dichotomous variable x and interval-level variable y. Thus,
The conventional test of significance for Pearson’s point-biserial correlation coefficient is
Under the Neyman–Pearson null hypothesis, H 0: ρ pb = 0, test statistic t is asymptotically distributed as Student’s t with N − 2 degrees of freedom. With N − 2 = 20 − 2 = 18 degrees of freedom, the asymptotic two-tail probability value of t = −1.9743 is P = 0.0639, under the assumption of normality. For a critical evaluation of the point-biserial correlation coefficient, see a discussion in The Measurement of Association by the authors [2, pp. 417–424].
11.5.2 An Exact Permutation Analysis for r pb
For the bivariate observations listed in Table 11.23, there are only
possible, equally-likely arrangements in the reference set of all permutations of the observed scores, making an exact permutation analysis possible. Under the Fisher–Pitman permutation model, the exact probability of an observed value of Pearson’s |r pb| is the proportion of |r pb| values calculated on all possible arrangements of the observed data that are equal to or greater than the observed value of |r pb| = 0.4219. There are exactly 11,296 |r pb| values that are equal to or greater than the observed value of |r pb| = 0.4219. If all arrangements of the N = 20 observed scores occur with equal chance, the exact probability value of |r pb| = 0.4219 computed on the M = 184, 756 possible arrangements of the observed data with n 0 = n 1 = 10 preserved for each arrangement is

where  denotes the observed absolute value of test statistic r
pb and M is the number of possible, equally-likely arrangements of the N = 20 bivariate observations listed in Table 11.23.
denotes the observed absolute value of test statistic r
pb and M is the number of possible, equally-likely arrangements of the N = 20 bivariate observations listed in Table 11.23.
11.6 Contingency Measures: Ordinal by Interval
The best-known and most-widely reported measure of ordinal-by-interval association is Jaspen’s multiserial correlation coefficient, which is simply the Pearson product-moment correlation coefficient between an interval-level variable, Y , and a transformation of an ordinal-level variable, X. Given N values on the interval variable and k disjoint, ordered categories on the ordinal variable, the mean standard score of the underlying scale for a given category is given by
where \(Y_{L_{j}}\) and \(Y_{U_{j}}\) are the lower and upper ordinates of the segment of the N(0, 1) distribution corresponding to the jth ordered category, and where p j is the proportion of cases in the jth of k ordered categories. Given the obtained values of \(\bar {Z}_{j}\), j = 1, …, k, and the original N values of the interval-level variable, a standard Pearson product-moment correlation between the Y and \(\bar {Z}\) values yields the multiserial correlation coefficient.
11.6.1 An Example Analysis for 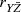
To illustrate the calculation of Jaspen’s multiserial correlation coefficient, consider the small set of data given in Table 11.24 where N = 32 interval-level variables are listed in k = 4 disjoint, ordered categories: A, B, C, and D. Table 11.25 illustrates the calculation of Jaspen’s multiserial correlation coefficient. The first column, headed X in Table 11.25, lists the k = 4 ordered categories of variable X. The second column, headed n, lists the number of observations in each of the k ordered categories. The third column, headed p, lists the proportion of observations in each of the k ordered categories. The fourth column, headed P, lists the cumulative proportion of observations in each of the k ordered categories. The fifth column, headed z, lists the standard score that defines the cumulative proportion from the fourth column under the unit-normal distribution for each of the k ordered categories. For example, for category A the standard score that defines the lowest (left-tail) of the normal distribution with proportion P = 0.1250 is z = −1.1503. The sixth column, headed Y L, lists the height of the ordinate at the standard score listed in the fifth column below the specified segment of the unit-normal distribution. For example, for category A,
The seventh column, headed Y U, lists the height of the ordinate at the standard score listed in the fifth column above the specified segment of the unit-normal distribution. For example, for category C,
The last column, headed \(\bar {Z}\), lists the average standard scores for the k ordered categories. For example, for category B,
Jaspen’s
multiserial correlation coefficient
is the Pearson
product-moment correlation between the Y interval-level values given in Table 11.24 and the transformed \(\bar {Z}\) values given in Table 11.25. Table 11.26 lists the Y , \(\bar {Z}\), Y
2, \(\bar {Z}^{2}\), and  values, along with the corresponding sums.
values, along with the corresponding sums.
For the summations given in Table 11.26, the Pearson product-moment correlation between the Y and \(\bar {Z}\) values is

Jaspen’s multiserial correlation coefficient is known to be biased. The bias is due to the grouping of the values into k categories. When k is small, the bias can be pronounced. For the example data listed in Table 11.24, the correction for grouping is
and the corrected multiserial correlation coefficient is

Jaspen’s
 is asymptotically distributed
as Student’s
t
under the Neyman–Pearson null hypothesis
with N − 2 degrees of freedom.
If the population parameter, ρ
c, is assumed to be zero, then for the observed data in Table 11.24,
is asymptotically distributed
as Student’s
t
under the Neyman–Pearson null hypothesis
with N − 2 degrees of freedom.
If the population parameter, ρ
c, is assumed to be zero, then for the observed data in Table 11.24,

and with N − 2 = 32 − 2 = 30 degrees of freedom the asymptotic
two-tail probability value of  is P = 0.1308×10−2, under the assumption of normality.
is P = 0.1308×10−2, under the assumption of normality.
11.6.2 A Monte Carlo Permutation Analysis for 

Because there are
possible, equally-likely arrangements
in the reference set of all permutations
of the observed values listed in Table 11.24, an exact permutation analysis is not possible and a Monte Carlo analysis is mandated.
Let  indicate the observed value of r
c. Based on L = 1, 000, 000 randomly-selected arrangements
of the observed data, there are 3069 |r
c| values that are equal to or greater than
indicate the observed value of r
c. Based on L = 1, 000, 000 randomly-selected arrangements
of the observed data, there are 3069 |r
c| values that are equal to or greater than  , yielding a Monte Carlo probability value of
, yielding a Monte Carlo probability value of

where  denotes the observed value of r
c and L is the number of randomly-selected, equally-likely arrangements of the ordinal-interval data listed in Table 11.24.
denotes the observed value of r
c and L is the number of randomly-selected, equally-likely arrangements of the ordinal-interval data listed in Table 11.24.
11.7 Summary
Under the Neyman–Pearson model of statistical inference, this chapter examined various measures of nominal-nominal, ordinal-ordinal, nominal-ordinal, nominal-interval, and ordinal-interval association. Asymptotic probability values were provided under either Pearson’s χ 2 probability distribution, Student’s t distribution, Snedecor’s F distribution, or the N(0, 1) probability distribution. Under the Fisher–Pitman permutation model of statistical inference, procedures for both exact and Monte Carlo probability values were developed.
Six sections provided examples and illustrative analyses of permutation statistical methods for contingency tables. In the first section, goodness-of-fit measures for k discrete, mutually-exclusive categories were described and permutation methods were utilized to obtain exact probability values. A measure of effect size for the chi-squared goodness-of-fit test was presented and illustrated.
The second section illustrated the use of permutation statistical methods for analyzing contingency tables in which two nominal-level variables have been cross-classified. Three well-known and widely-used measures of nominal-nominal association were introduced and analyzed with permutation methods: Cramér’s symmetric V measure, based on Pearson’s chi-squared test statistic, and Goodman and Kruskal’s t a and t b asymmetric measures, based on the differences between concordant and discordant pairs of observations. The relationships between Pearson’s χ 2 test statistic and Goodman and Kruskal’s t a and t b measures were described.
The third section illustrated the use of permutation statistical methods for analyzing contingency tables in which two ordinal-level variables have been cross-classified. Three popular measures of ordinal-ordinal association were introduced and analyzed with permutation methods: Goodman and Kruskal’s G symmetric measure of ordinal-ordinal association and Somers’ d yx and d xy asymmetric measures of ordinal-ordinal association.
The fourth section illustrated the use of permutation statistical methods for analyzing contingency tables in which a nominal-level variable was cross-classified with an ordinal-level variable. Freeman’s θ measure of association for a nominal-level independent variable and an ordinal-level dependent variable was described and illustrated with exact permutation statistical methods.
The fifth section illustrated the use of permutation statistical methods for analyzing contingency tables in which a nominal-level variable was cross-classified with an interval-level variable. Pearson’s point-biserial correlation coefficient for a dichotomous nominal-level variable and a continuous interval-level variable was described and analyzed with exact permutation statistical methods.
The sixth section illustrated the use of permutation statistical methods for analyzing contingency tables in which an ordinal-level variable was cross-classified with an interval-level variable. Jaspen’s multi-serial correlation coefficient for ordinal-interval association was described and analyzed with Monte Carlo permutation methods.
Notes
- 1.
There is never any reason to relate a higher-level independent variable with a lower-level dependent variable due to the loss of information from the independent variable.
- 2.
Pearson’s χ 2 test statistic is one of several test statistics that utilizes a lower-case Greek letter for both the sample test statistic and the population parameter.
- 3.
Presently the region of Silesia is located largely in Poland with smaller parts in the Czech Republic and in Germany.
- 4.
Mendel’s birth name was Johann, but he adopted the name Gregor when he entered the monastery in 1843 at the age of 21.
- 5.
Mendel was elected abbot of the monastery in 1868 at the age of 46, the administrative duties of which precluded any further research. Mendel passed away in 1884 at the age of 62.
- 6.
More technically, RY denotes round and yellow, Ry denotes round and not yellow, rY denotes not-round and yellow, and ry denotes not-round and not-yellow.
- 7.
Goodman and Kruskal’s G measure of ordinal association is oftentimes denoted by the lower-case Greek letter γ. In this section γ denotes the population parameter and G denotes the sample test statistic.
References
Berry, K.J., Johnston, J.E., Mielke, P.W.: Exact goodness-of-fit tests for unordered equiprobable categories. Percept. Motor Skill. 98, 909–918 (2004)
Berry, K.J., Johnston, J.E., Mielke, P.W.: The Measurement of Association: A Permutation Statistical Approach. Springer, Cham (2018)
Box, J.F.: R. A. Fisher: The Life of a Scientist. Wiley, New York (1978)
Fisher, R.: Has Mendel’s work been rediscovered? Ann. Sci. 1, 115–137 (1936)
Freeman, L.C.: Elementary Applied Statistics. Wiley, New York (1965)
Light, R.J.: Measures of response agreement for qualitative data: some generalizations and alternatives. Psychol. Bull. 76, 365–377 (1971)
Margolin, B.H., Light, R.J.: An analysis of variance for categorical data, II: small sample comparisons with chi square and other competitors. J. Am. Stat. Assoc. 69, 755–764 (1974)
Mielke, P.W., Berry, K.J.: Exact goodness-of-fit probability tests for analyzing categorical data. Educ. Psychol. Meas. 53, 707–710 (1993)
Särndal, C.E.: A comparative study of association measures. Psychometrika 39, 165–187 (1974)
Author information
Authors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Berry, K.J., Johnston, J.E., Mielke, P.W. (2019). Contingency Tables. In: A Primer of Permutation Statistical Methods. Springer, Cham. https://doi.org/10.1007/978-3-030-20933-9_11
Download citation
DOI: https://doi.org/10.1007/978-3-030-20933-9_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-20932-2
Online ISBN: 978-3-030-20933-9
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)