
Abstract
The bag-of-words model is widely used in many AI applications. In this paper, we propose the task of hierarchical conceptual labeling (HCL), which aims to generate a set of conceptual labels with a hierarchy to represent the semantics of a bag of words. To achieve it, we first propose a denoising algorithm to filter out the noise in a bag of words in advance. Then the hierarchical conceptual labels are generated for a clean word bag based on the clustering algorithm of Bayesian rose tree. The experiments demonstrate the high performance of our proposed framework.
This paper was supported by National Natural Science Foundation of China under No. 61732004.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others
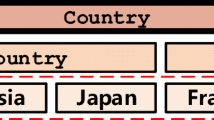


1 Introduction
The bag-of-words model is widely used in many natural language processing tasks. There are lots of mature technologies to generate a bag of words (BoW) [4]. However, a BoW is just a collection of scattered words and it is difficult to be understood by machines or human beings without explicit semantic analysis. The conceptualization-based methods, i.e., conceptual labeling (CL), aim to generate conceptual labels for a BoW to explicitly represent its semantics. In [3, 5, 6], a BoW is first divided into multiple groups according to their semantic relevance and then each group is labeled with a concept that can specifically summarize the explicit semantics. We present two examples as follows.
In this paper we propose the task of hierarchical conceptual labeling (HCL), which represents the semantics of a BoW by hierarchical conceptual labels (i.e., a label set with different granularities). For example, given a BoW {China,Japan,France,Germany,Russia\(\}\), the hierarchical conceptual labels can be {Asian country, EU State} and {country}. In general, the hierarchical labels contain more information, which allows real applications to select labels with different abstractness according to their real requirements.
We consider the hierarchical cluster algorithm: Bayesian rose tree (BRT) [1] as our framework to generate hierarchical conceptual labels, where the candidate concepts are derived from the knowledge base: Microsoft concept graph (MCG) [8]. Besides, we also propose a simple but effective method to delete the noise before the conceptualization operation.
2 Framework
We first present how to filter out the noise words in a BoW. Then we elaborate on the generation process of hierarchical conceptual labels.
2.1 Filtering Out Noise
The basic idea is: if a word in a BoW is hard to be semantically clustered with any other word, i.e., difficult to be tagged with the same conceptual label as any other word, then we take it as noise and remove it from the BoW.
Specifically, let \(\mathcal {D}\) be the input BoW, and \(d_i\) (\(d_j\)) be the i-th (j-th) instanceFootnote 1 in \(\mathcal {D}\). We take \(p(c|{d_i},{d_j})\) to measure how well the concept c conceptualizes the semantics of two instances \(d_i, d_j\). We use Bayesian rule to compute \(p(c|{d_i},{d_j})\) as follows:
Then \(p(c|d_i, d_j) = \frac{1}{\tilde{p}^2}p(d_i|c)p(d_j|c)p(c)\). The prior probability p(c) measures the popularity of c. Intuitively, a larger \(p(c|d_i, d_j)\) indicates c can summarize \(d_i\) and \(d_j\) well, so \(d_i\) and \(d_j\) have strong semantic relevance. \(p(d_k|c)\) and p(c) are estimated using knowledge in MCG [8]. Let \(\mathcal {C}_{i}\) and \(\mathcal {C}_{j}\) be the concept sets of \(d_i\) and \(d_j\) in MCG, respectively. \(\mathcal {C}_{i,j} = \mathcal {C}_{i}\cap \mathcal {C}_{j}\) denotes the shared concept set of \(d_i\) and \(d_j\). We describe the denoising algorithm as follows.
Consider the word \({d_i\in \mathcal {D}}\), for any other word \(d_j\in \mathcal {D}\) (\(d_j\ne d_i\)), if we cannot find an appropriate concept in \(\mathcal {C}_{i,j}\) to conceptualize \(d_i\) and \(d_j\), i.e.,
then \(d_i\) is treated as noise. \(\delta \) is a hyperparameter.
2.2 Hierarchical Conceptual Labeling
Next, we describe how to generate hierarchical conceptual labels for a BoW. The basic idea is: clustering a BoW \(\mathcal {D}\) hierarchically based on BRT [1], and for each cluster \(\mathcal {D}_m\) an appropriate conceptual label will be generated. We present the pseudo code in Algorithm 1.

Estimation of f(\(\mathcal {D}_m\)) and p(\(D_m|T_m\)). \(f(\mathcal {D}_m)\) qualifies the probability that all the words in \({\mathcal {D}_m}\) belong to the same cluster and it further helps us to estimate \(p(D_m|T_m)\). Similar to [7], we consider that \({\mathcal {D}_m}\) with more shared concepts in MCG is more inclined to belong to the same cluster. For each \(c \in \mathcal {C}_m\) (the shared concepts of \({\mathcal {D}_m}\)), the probability that \({\mathcal {D}_m}\) belongs to the same cluster is computed as
When considering all the concepts in \(\mathcal {C}_m\), \(f(\mathcal {D}_m)\) is computed by \(f(\mathcal {D}_m) = {\sum \nolimits _{{c} \in {\mathcal {C}_m}} {p\left( {{c}} \right) p\left( {{\mathcal {D}_m}\left| {{c}} \right. } \right) }}\). Based on \(f(\mathcal {D}_m)\), the probability \(p(D_m|T_m)\) can be recursively calculated by \(p\left( {{\mathcal {D}_m}\left| {{T_m}} \right. } \right) = {\pi _m}f(\mathcal {D}_m) + \left( {1 - {\pi _m}} \right) \mathop \prod \nolimits _{{T_k} \in \hbox {ch}(T_m)} p\left( {{D_k}\left| {{T_k}} \right. } \right) \).
Estimation of \(\pi _m\). \(\pi _m\) is a hyperparameter denoting the prior probability that the leaves under \(T_m\) are kept in one cluster rather than subdivided by the recursive partitioning process. We simply set \(\pi _m = 0.5\) in this paper.
Label Generation. To generate hierarchical conceptual labels for a BoW, we need to select an appropriate conceptual label to well conceptualize each cluster \(\mathcal {D}_m\). The following criterion is used to select the most appropriate conceptual label:
Likelihood Ratio \(\gamma \). In most cases, a BoW is hard to be semantically merged into one cluster, so the cluster operation should be stopped when there is no appropriate label. We take a likelihood ratio \(\gamma \), and stop clustering when \(L\left( {{T_m}} \right) < \gamma \).
3 Experiments
We evaluate the generated hierarchical conceptual labels. In all experiments, \(\delta = 5 \times {10^{ - 8}}\) and \(\gamma = 0.8\) are used.
Dataset. The dataset in [7] is used, which contains two subsets: Flickr and Wikipedia. We sample \(b = 500\) BoWs from each dataset for evaluation.
Baselines. To the best of our knowledge, there is no work to deal with the task of HCL, so we present two strong baselines constructed by ourselves. (1) Bayesian hierarchical clustering-based model (BHC). We first cluster a BoW using Bayesian hierarchical clustering [2]. Each node in the hierarchy is equipped with a concept to conceptualize the corresponding cluster, where the candidate concepts are also from MCG. (2) Maximal clique segmentation-based model (MCS). We first construct a semantic graph for a BoW, where the vertex corresponds to a word. Then we take the maximal clique segmentation [5] to split the graph into several subgraphs given a similarity threshold. Finally, we select one conceptual label for each graph, thus generating a flat conceptual label set for a BoW. Furthermore, when considering multiple similarity thresholds, we will get the multiple label sets with different granularities for a BoW.
Metric. We evaluate the models and consider the two cases: with (without) denoising algorithm. We recruit \(v=5\) volunteers to evaluate the labeling results by scoring (\(0\le score \le 3\)), where the scoring criteria are motivated by [7]. The average score is computed by \(\frac{1}{bv}\sum _{i=1}^{v}\sum _{j=1}^{b}{s_{i,j}}\), where \(s_{i,j}\) is the score of the j-th BoW by volunteer i, b is number of BoWs in each dataset and v is the number of volunteers.
Results and Analysis. The results are presented in Table 1. We conclude that (1) the scores with the denoising algorithm are higher than these without it for all models, which proves the effectiveness of the denoising method. (2) The proposed model outperforms the other two baselines. In particular, BHC only considers the binary branching structures in the hierarchy and cannot generate multi-branching structures that frequently appear in the BoW clustering. MCS only clusters BoWs into multi-level label sets without hierarchy.
4 Conclusion
This paper first proposes the task of HCL, which aims to generate conceptual labels with different granularities for BoWs. To achieve it, we propose the BRT-based approach with high performance. Besides, we also propose a denoising algorithm to effectively filter out the noise in advance.
Notes
- 1.
In this paper, the words in BoWs are also called instances.
References
Blundell, C., Teh, Y.W., Heller, K.A.: Bayesian rose trees. In: UAI (2010)
Heller, K.A., Ghahramani, Z.: Bayesian hierarchical clustering. In: ICML 21 (2005)
Hua, W., Wang, Z., Wang, H., Zheng, K.: Short text understanding through lexical-semantic analysis. In: IEEE International Conference on Data Engineering, pp. 495–506 (2015)
Pay, T.: Totally automated keyword extraction. In: 2016 IEEE International Conference on Big Data (Big Data), pp. 3859–3863 (2016)
Song, Y., Wang, H., Wang, H.: Open domain short text conceptualization: a generative + descriptive modeling approach. In: International Conference on Artificial Intelligence, pp. 3820–3826 (2015)
Song, Y., Wang, H., Wang, Z., Li, H., Chen, W.: Short text conceptualization using a probabilistic knowledge base. In: IJCAI, pp. 2330–2336 (2011)
Sun, X., Xiao, Y., Wangy, H., Wang, W.: On conceptual labeling of a bag of words. In: IJCAI, pp. 1326–1332 (2015)
Wu, W., Li, H., Wang, H., Zhu, K.Q.: Probase: a probabilistic taxonomy for text understanding. In: SIGMOD, pp. 481–492 (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Jiang, H. et al. (2019). Hierarchical Conceptual Labeling. In: Li, G., Yang, J., Gama, J., Natwichai, J., Tong, Y. (eds) Database Systems for Advanced Applications. DASFAA 2019. Lecture Notes in Computer Science(), vol 11448. Springer, Cham. https://doi.org/10.1007/978-3-030-18590-9_18
Download citation
DOI: https://doi.org/10.1007/978-3-030-18590-9_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-18589-3
Online ISBN: 978-3-030-18590-9
eBook Packages: Computer ScienceComputer Science (R0)