
Abstract
Speaker recognition systems have shown good performance in noise-free environments, but the performance will severely deteriorate in the presence of noises. At the front end of the systems, Mel-Frequency Cepstral Coefficient (MFCC), or a relatively noise-robust feature Gammatone Frequency Cepstral Coefficients (GFCC), is commonly used as time-frequency feature. To further improve the noise-robustness of GFCC, signal processing techniques, such as DC removal, pre-emphasis and Cepstral Mean Variance Normalization (CMVN), are investigated in the extraction of GFCC. Being aware the advantages and disadvantages of MFCC and GFCC, an adaptive strategy was proposed to make feature selection based on the quality of speech. Experiments were conducted on TIMIT dataset to evaluate our approach. Compared with ordinary GFCC and MFCC features, our method significantly reduced the EER in speech data with miscellaneous SNRs.
This work is supported by the Natural Science Foundation of Jiangsu Province for Excellent Young Scholars (BK20180080).
X. Zhang is working for a master degree at the Lab of Intelligent Information Processing of PLA Army Engineering University. His research topic is speaker recognition.
X. Zou is now an associate professor at the Lab of Intelligent Information Processing of PLA Army Engineering University. His research interest is speech signal processing.
M. Sun is now a researcher at the Lab of Intelligent Information Processing of PLA Army Engineering University. His research interests are speech processing, unsupervised/semi-supervised machine learning and sequential pattern recognition.
P. Wu is working for a master degree at the Lab of Intelligent Information Processing of PLA Army Engineering University. His research topic is speech signal processing.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
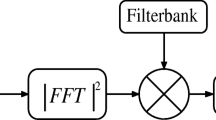

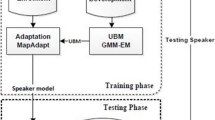
References
Dehak, N., Kenny, P.J., Dehak, R., Dumouchel, P., Ouellet, P.: Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 19(4), 788–798 (2011)
Burget, L., Plchot, O., Cumani, S., Glembek, O., Matějka, P., Brümmer, N.: Discriminatively trained Probabilistic Linear Discriminant Analysis for speaker verification. In: IEEE International Conference on Acoustics, Speech and Signal Processing, vol. 125, pp. 4832–4835. IEEE (2011)
Zhao, X., Shao, Y., Wang, D.L.: Casa-based robust speaker identification. IEEE Trans. Audio Speech Lang. Process. 20(5), 1608–1616 (2012)
Shao, Y., Srinivasan, S., Wang, D.L.: Incorporating auditory feature uncertainties in robust speaker identification. In: IEEE International Conference on Acoustics, Speech and Signal Processing, vol. 4, pp. IV-277–IV-280. IEEE (2007)
Das, P., Bhattacharjee, U.: Robust speaker verification using GFCC and joint factor analysis. In: International Conference on Computing, Communication and Networking Technologies, pp. 1–4. IEEE (2014)
Shi, X., Yang, H., Zhou, P.: Robust speaker recognition based on improved GFCC. In: IEEE International Conference on Computer and Communications, pp. 1927–1931. IEEE (2017)
Jeevan, M., Dhingra, A., Hanmandlu, M., Panigrahi, B.K.: Robust speaker verification using GFCC based i-vectors. In: Proceedings of the International Conference on Signal, Networks, Computing, and Systems, pp. 85–91. Springer India (2017)
Zhao, X., Wang, D.: Analyzing noise robustness of MFCC and GFCC features in speaker identification. In: IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 7204–7208. IEEE (2013)
Reynolds, D.A., Quatieri, T.F., Dunn, R.B.: Speaker verification using adapted gaussian mixture models. Dig. Signal Process. 10, (1–3), 19–41 (2000)
Zhiyi, L.I., Liang, H.E., Zhang, W., Liu, J.: Speaker recognition based on discriminant i-vector local distance preserving projection. J. Tsinghua Univ. (Sci. Technol.) 52(5), 598–601 (2012)
Lamel, L.: Speech database development: design and analysis of the acoustic-phonetic corpus. In: Proceedings of DARPA Speech Recognition Workshop (1986)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, X., Zou, X., Sun, M., Wu, P. (2020). Robust Speaker Recognition Using Improved GFCC and Adaptive Feature Selection. In: Yang, CN., Peng, SL., Jain, L. (eds) Security with Intelligent Computing and Big-data Services. SICBS 2018. Advances in Intelligent Systems and Computing, vol 895. Springer, Cham. https://doi.org/10.1007/978-3-030-16946-6_13
Download citation
DOI: https://doi.org/10.1007/978-3-030-16946-6_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-16945-9
Online ISBN: 978-3-030-16946-6
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)