
Abstract
The rapid development and wide application of Online Social Network (OSN) has produced a large amount of social data. How to effectively use these data to recommend interesting relationships to users is a hot topic in social network mining. At present, the user relationship recommendation algorithm relies on similarity, and the user’s influence is insufficiently considered. Aiming at this problem, this paper proposes a new user influence evaluation model, and on this basis, a new user relationship recommendation algorithm (SIPMF) is proposed by combining similarity and dynamic influence. 2522366 Sina Weibo data were crawled to build an experimental data set for experiment. Compared with the typical relational recommendation algorithms SoRec, PMF, and FOF, the SIPMF algorithm improved 4.9%, 7.9%, and 10.3% in accuracy and recall respectively. And 2.6%, 4.2%, 6.6%, can recommend for users more interested in the relationship.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
An online social network is a collection of thousands of network users that form a relational connection based on social networking sites in a self-organizing manner [1]. Online social networks are essentially a mapping of real-world social networks in the Internet [2].
Social networking sites allow users to express themselves, display their social networks, and establish or maintain contact with others [3]. Domestic Sina Weibo (hereinafter referred to as Weibo), Tencent, Renren, and foreign countries such as Facebook and Twitter have rapidly emerged. As of September 2017, Weibo monthly active users totaled 376 million, and daily active users reached 165 million [4]. In the first quarter of 2018, the number of Facebook monthly active users in the world’s largest social networking site reached 2.20 billion, an increase of 13% over the same period last year [5]. The huge user base in online social networks and the self-organizing relationship structure have spawned a complex social network, resulting in a huge amount of social data. These massive social data on the one hand increase user stickiness, but at the same time it also creates information overload problems. Therefore, how to find out the interested relationship for the target user group from the massive Weibo user group becomes a research hotspot. As a method that can effectively relieve information overload, the user recommendation system has received increasing attention [6].
Research on user recommendation algorithms in social networks can be divided into two categories, content recommendation [7] and social relationship recommendation [8, 9]. The content recommendation is to recommend the content of interest to the user from a large amount of data [7]. Social relationships are the link between users in social networks and are important foundations for the dissemination of social network information. Social relationship recommendation is to predict and recommend the unknown relationship between users in social networks [2]. User relationship recommendation algorithms in online social networks can be divided into three types, link-based recommendation algorithms, content-based recommendation algorithms, and hybrid recommendation algorithms. The link-based recommendation algorithm is to transform the relationship recommendation problem into a link prediction problem in a graph composed of a social network topology. For the link-based recommendation algorithm, Lin et al. defined the similarity between nodes and used it to predict new links [10]. Yin et al. used the Non-negtive Matrix Factorization (NMF) method based on social relations to mine the hidden information in microblog social relationships [11]. However, relying solely on the explicit network structure information of microblog users will encounter data sparsity problems and affect the accuracy of the recommendation results. For content-based recommendation algorithms, Xu et al. proposed a variety of user-based attribute information (background information, micro The similarity calculation method of Bo text) and the fusion of these similarity information to achieve recommendation [12]. However, since the Weibo text information is relatively short and mixed with various picture information, it is time-consuming and labor-intensive to handle and the accuracy rate is not high. For the hybrid recommendation algorithm, Chen et al. also use the blog content and social structure information to calculate the similarity between users. Degrees, resulting in a list of mixed recommendations [13]. The hybrid recommendation algorithm can make better use of social relationship information, user attribute information and blog content information, but it also has computational efficiency problems.
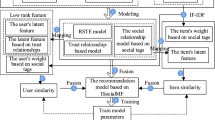
Currently proposed social network user recommendation algorithms have problems such as sparse data and insufficient consideration of dynamic changes in user relationships. In response to these deficiencies, this paper builds a user’s dynamic impact assessment model based on implicit network information (likes, forwards, comments) among users, and adds explicit network information between users’ friends (followers and fans). A matrix decomposition algorithm (SIPMF) that combines similarity and influence is proposed. When recommending new relationships for users, the algorithm considers both the explicit network information between users and the dynamic influence of implicit network information. It obtains similarities and dynamic influences, and uses similarity to constrain dynamic influences. The method of matrix decomposition is introduced to reduce the dynamic influence between users, so as to obtain the potential characteristics of influence among users, and then to predict the relationship between target users.
Based on Scrapy’s breadth-first strategy, the Weibo crawler was designed to collect microblog data in a continuous time interval. After preprocessing, an experimental data set composed of user relationship data and interaction behavior data (approximately 2522366) was obtained. Compared with the typical relational recommendation algorithms SoRec, PMF, and FOF, the algorithm improved by 4.9%, 7.9%, 10.3%, and 2.6%, 4.2%, and 6.6% in terms of accuracy and recall. The validity of the SIPMF algorithm is proved and the user’s interested relationship can be more accurately recommended.
The Sect. 2 introduces the calculation of user similarity and the evaluation model of dynamic influence. The Sect. 3 is the introduction of data sources and the analysis of the results of the experiment; the last is the summary of the full text.
2 Matrix Decomposition Method Combining Similarity and Influence
2.1 User Similarity
The phenomenon of homogeneity is reflected in many aspects of social life. Nearly all people are red and black is a good example. The same is true in social networks, and the formation of a concern between users is often influenced by whether there is a common interest or hobby among users. In Weibo relationship prediction, a good method is to find users similar to the recommended users, sort them according to similarity, and select TopN users to recommend. Therefore, in the microblog relationship prediction, a primary problem is to find a user similar to the recommended user, that is, how to solve the problem of measuring the similarity of the microblog user. Currently, mainstream microblog user similarity measurement algorithms can be divided into three categories: (1) Krishnamurthy et al. [14] represent users based on attention and fan relationships, and establish network topologies based on user relationships. And to calculate the similarity between users. (2) Considering the number of common neighbors between users, the greater the number of common neighbors, the higher the similarity of users. The CN (Common Neighbors) method, the Jaccard method, and the Cosine method are all based on this idea. The difference is that different methods have different choices for the proportion of common neighbors [15]. (3) Ma et al. [9] viewed Weibo as an undirected weighted graph, and added various user background information, social information, etc. to the nodes in the graph to calculate user similarity.
In Weibo, there are two kinds of relationships between users. If user vu is follow vc, then vc is said to be the follower of vu and vu is a follower of vc. The Weibo network topology structure built on the basis of attention and fan relations is a directed graph. The attention relation is the out-edge of the node in the graph, and the fan relationship is the edge of the node in the graph. Therefore, when calculating the similarity of Weibo users, it is necessary to comprehensively consider the relationship between attention and fans, that is, the outbound and inbound edges in the microblog network topology. The SimRank algorithm considers these two relationships well. The calculation of the two similarities is shown in Eqs. (1) and (2).
Among them, c \( \in \) (0,1) is the damping coefficient, usually taking 0.6~0.8, I(vu) is the set of all vu neighbors (fans) and O(vu) is the set of vu neighbors (follow). In Weibo network topology, the contributions of outbound and inbound to the similarity are not consistent. The number of fans of Weibo V is much larger than the number of concerns. Relatively speaking, the importance of outbound similarity is more important than the similarity of incoming edges. Sex, so a linear weighted combination of two similarities. The formula for calculating the similarity is shown in (3).
Among them, λ is the weight of fan similarity.
2.2 Dynamic User Influence
In Weibo, users do not exist in isolation. Yin et al. [16] studied the formation mechanism of the attention relationship in Weibo. The experimental results show that about 90% of new links are formed by two-hop relations. This shows that the formation of the vast majority of new concerns in Weibo is formed between friends (friends who have concerns or fan relationships). For example, vu and vi are related to each other, and vi is focused on vc. If the impact of vi is large enough, vu is likely to focus on vc. In addition, if vu, vi, and vj are related to each other and vi and vj are focused on vc, vu may be affected by vi and vj. Follow vc. For a microblog of vc, the user’s vu likes, comments, or forwards represent different degrees of recognition of vu for the microblog vc, and further, vu The behavior of vc Weibo is also a manifestation of the influence of vc. Therefore, the higher the likes, comments, and frequency of vu posts on the vc blog post, the stronger the influence of vc on x. The following definitions are made for the three impact factors.
Among them, Like (vu, vc) is the number of likes between vu and vc, and \( {\text{U}}_{{{\text{v}}_{\text{c}} }}^{\text{l}} \) and \( {\text{U}}_{{{\text{v}}_{\text{c}} }}^{\text{l}} \) are shown with \( {\text{v}}_{\text{u}} \) and vc respectively is a bit like the collection of users where the behavior occurred.
The influence between user pairs is constantly changing, but within a relatively short period of time, the change is small. Therefore, the interval can be divided according to the time sequence of microblog posting, and the influence of the current interval can be considered as a local influence.
Among them, \( Like_{i} \left( {v_{u} ,v_{c} } \right) \) is the number of vc in \( \left[ {\left( {i - 1} \right)*k,i*k} \right) \) like vu, \( U_{{v_{u} }}^{I} \) represents the point A collection of users who like vu, \( U_{{v_{c} }}^{O} \) represents a collection of users who like vc.
Define the user’s forwarding influence and comment influence in the same way. Finally, the user’s local influence on the ith interval is obtained.
Among them, the parameters \( \upalpha_{1} \), \( \upalpha_{2} \), \( \upalpha_{3} \) are the weighting factors for the likes, comments, and forwarding behaviors, respectively, and \( 0 \le\upalpha_{1} \le 1 \), \( 0 \le\upalpha_{2} \le 1 \), \( 0 \le\upalpha_{3} \le 1\square \)\( \alpha_{1} + \alpha_{2} + \alpha_{3} = 1\square \) Construct a weight function.
Dynamic Influence of vu on vc:
\( I_{i} \left( {v_{u} ,v_{c} } \right) \) is the local influence of vu on vc in the ith interval.
2.3 Matrix Factorization
In Weibo, building an adjacency matrix based on user concerns and fan relationships is the simplest binary matrix. The user vu follows vc, then \( R\left( {v_{u} ,v_{c} } \right) = 1 \), otherwise \( R\left( {v_{u} ,v_{c} } \right) = 0 \). In such a scoring matrix, it is necessary to predict whether the relationship of \( R\left( {v_{u} ,v_{c} } \right) = 0 \) is based on existing relationships and social information. Changes occur in the later period. For m users, the rating matrix \( R^{m \times n} \) for n recommended objects, each element of the matrix \( r_{{v_{i} ,v_{j} }} \) represents vj for vj Scoring, this value is 0 or 1 in the binary score matrix. \( W \in R^{m \times k} \) and \( H \in R^{k \times n} \) means that the decomposed user is associated with the recommended user k-dimensional feature matrix, its column vector \( W_{{v_{u} }} \) and the row vector \( H_{{v_{j} }} \) represents the corresponding potential feature vector respectively. However, because of system noise, \( R^{m \times n} \) cannot be perfectly decomposed into \( W^{T} H \). So get an approximation \( \hat{R} \) of R.
At the same time, in order to prevent over-fitting, you need to constrain W and H. In the Probabilistic Matrix Factorization (PMF), it is assumed that the observation noise \( \delta = |R - \hat{R}| \) obeys the mean \( {\text{W}}^{\text{T}} {\text{H}} \) and the variance is a Gaussian distribution of \( \sigma \). The probability density function of the scoring matrix is shown in Eq. (10).
Assume that both W and H obey a mean of 0 and the variances are Gaussian distributions of \( \sigma_{W} \) and \( \sigma_{H} \), respectively. As shown in Eqs. (11) and (12).
Formula (13) can be obtained by using the posterior probability formula.
2.4 SIPMF
In the scoring matrix, not only need to consider the explicit structure information between users, but also need to consider the user’s similarity and mutual influence between users, take these two together to get a new scoring matrix.
Among them, \( \beta \) is the weight coefficient of the user’s similarity.
A SIPMF model was proposed after the similarity and influence were combined. After the fusion, the logarithm of the posterior probability formula satisfies formula (15).
To simplify the calculation, let \( \sigma_{W} = \sigma_{H} \). Maximizing the posterior probability is equal to minimizing the objective function E(W, H).
SIPMF algorithm design: First, user similarity is calculated based on the user relationship; then, an evaluation model of dynamic influence is established based on the interaction behavior; the two are integrated into the PMF model through adaptive weight wij; and the user relationship is obtained by gradient descent algorithm Feature vector.
Input: initial influence matrix I, similarity matrix S, number of recommend user m, number of recommended user n, learnrate, Output: precision, recall, F1-measure

3 Experimental Results and Analysis
3.1 Experimental Data Set
For the Weibo user recommendation issue, there is currently no publicly available Chinese standard data set. The experimental data in this article comes from a set of Sina Weibo user data collected by a self-developed Weibo crawler (acquisition started in October 2017). Weibo acquisition adopts a breadth-first strategy, first select 10 users, crawl 10 users’ attention and fan list, get user set U (total 464), and then use user set U as a basis to expand one layer outward. Catch these user’s attention and fan list to get more users (27362 total). At the same time, collect the microblog information of these users, as well as users who like, comment, and forward these microblogs (Table 1).
On the basis of these already obtained data, a preliminary screening of the data was conducted. The screening was mainly based on the user’s activity on Weibo, and the number of followers and the number of followers was greater than 10 for screening. At the same time, users who have fewer than 10 microblogs are further screened. The purpose of these screenings is to remove inactive users.
3.2 Experimental Evaluation Index
In this paper, Precision rate, Recall rate and F1 measure are used as evaluation indicators of experiment results.
The accuracy rate refers to the ratio between the predicted number of relations Nt and the total number of predictions Na in the predicted relationship. The accuracy rate is proportional to the ratio, and the higher the ratio, the better the prediction result. The accuracy formula is:
The recall rate refers to the ratio between the predicted relationship number Nt and the total relationship number Nb in the predicted relationship. The recall rate is proportional to the ratio, and the larger the ratio, the better the prediction result. The formula for the recall rate is as follows:
The F1 measure is the evaluation index of the comprehensive accuracy and recall rate. The larger the value, the more accurate the prediction result. The F1 measure calculation results are as follows:
3.3 Experimental Parameters
For the user’s attention similarity and the user’s fan similarity weight parameter \( \lambda \), rely on fans and attention relations for Top-5 recommendation, parameters \( \lambda \) value from 0.1 to 1, according to the similarity recommendation, get the recommendation accurately Rate line chart for the parameter \( \lambda \).
The Fig. 1 shows that the recommended accuracy is the highest when the parameter λ = 0.7.

Parameter \( \lambda \) line chart of accuracy
The parameters \( \upalpha_{1} \), \( \upalpha_{2} \), and \( \upalpha_{3} \) are calculated using the analytic hierarchy process. The hierarchical weight matrix of the three types of interaction information for commenting, forwarding, and praising is shown in Table 2. The final parameters \( \alpha_{1} \), \( \alpha_{2} \), and \( \alpha_{3} \) are set to 0.14, 0.33, and 0.53, respectively.
3.4 Analysis of Results
In order to evaluate the effectiveness of the proposed algorithm proposed in this paper, the SIPMF algorithm is based on a friend-based recommendation algorithm FOF [17], PMF algorithm (Probabilistic Matrix Factorization, PMF) [18], and SoRec [19] algorithm (Social Recommendation Using Probabilistic Matrix). Factorization, SoRec compares the captured microblogging dataset. Among them, the PMF algorithm only considers the relationship matrix between users, and considers the relationship between all users to be equal. SoRec integrates the user’s static influence on the basis of the user relationship matrix.
From the real microblogging data crawled, 30% were randomly selected as the test set and 70% were used as the training set. The important parameter settings are shown in Sect. 3.3. The friend recommendation performances of Top-2, Top-4, Top-6, and Top-8 are respectively compared in the feature dimension k = 5. The accuracy, recall rate, and F1 value are shown in Figs. 2, 3, and 4, respectively. As can be seen from the figure, the SIPMF algorithm is more effective than other algorithms in terms of recommendation accuracy, recall rate, and F1 metrics. This shows that the user’s dynamic influence has a significant impact on the recommendation effect. This also proves the effectiveness of the method of fusion dynamic influence and similarity under matrix decomposition.

Precesion of Top-k

Recall rate of Top-k

F1 measure of Top-k
From Figs. 2, 3 and 4, it can be seen that as the length of the recommendation list continues to increase, the recommendation accuracy rate and the recommendation recall rate of these four recommendation algorithms are affected to varying degrees, but the SIPMF algorithm is recommended in different recommended lengths. On the other hand, relatively good recommendations can be obtained.
3.5 Influence of Parameters on Recommendation Accuracy
Under the premise that the other parameters are not changed, the impact on the accuracy of top-4 recommendation is affected when the dimension of the hidden feature k = 5, k = 10, and k = 15, respectively.
From the Fig. 5, we can find that with the increase of feature dimensions, the algorithm’s recommendation accuracy has been improved, but the increase is not large, so the experimental dimension of the experiment is 5 in this paper.

The influence of feature dimension on recommendation precision
4 Conclusion
The existing social network recommendation algorithm based on user influence evaluates the user’s static influence according to historical records, and does not fully consider the dynamic influence of the user. This article aims at this issue, put forward the user’s dynamic influence evaluation model. At the same time, the fusion of user similarity restricts the user’s dynamic influence. A social network user recommendation method that combines dynamic influence model and user similarity is proposed. The effectiveness of the algorithm is verified by experiments.
In order to highlight the problem itself, this article only considers the user’s network structure information and interactive information between the recommended objects, while ignoring the impact of other background information between the recommended objects on the recommendation results, such as the user’s blog content, user tags, etc. In the future work, we will study how to better integrate the user’s background information into the recommendation method in order to further improve the effectiveness of the recommendation.
References
Fang, P.: Research of community detection’s algorithm based on friends similarity from online social networks. HuaZhong University, Wuhan (2013)
Zhao, S., Liu, X., Duan, Z., et al.: A survey on social ties mining. Chin. J. Comput. 40(3), 535–555 (2017)
Ellison, N.B., Steinfield, C., Lampe, C.: The benefits of Facebook “friends”: social capital and college students’ use of online social network sites. J. Comput. Med. Commun. 12(4), 1143–1168 (2007)
Sina Weibo: 2017 Weibo User Development Report [EB/OL]. (2018-00-00). http://data.weibo.com/report/reportDetail?id=404. Accessed 27 May 2018
Facebook: Facebook 2018 first quarter earnings [EB/OL]. (2018-00-00). https://www.sec.gov/Archives/edgar/data. Accessed 27 May 2018
Liu, H.F., Jing. L.P., Jian, Y.U.: Survey of matrix factorization based recommendation methods by integrating social information. J. Soft. (2018)
Chen, J., Liu, X., Li, B., et al.: Personalized microblogging recommendation based on dynamic interests and social networking of users. Acta Electron. Sin. 45(4), 898–905 (2017)
Wang, R., An, W., Fen, Y., et al.: Important micro-blog user recommendation algorithm based on label and pagerank. Comput. Sci. 45(2), 276–279 (2018)
Ma, H., Jia, M., Zhang, D., et al.: Microblog recommendation based on tag correlation and user social relation. Acta Electron. Sin. 1, 112–118 (2017)
Lin, D.: An information-theoretic definition of similarity. In: Fifteenth International Conference on Machine Learning, pp. 296–304. Morgan Kaufmann Publishers Inc. (1998)
Yin, D., Hong, L., Davison, B.D.: Structural link analysis and prediction in microblogs, pp. 163–1168 (2011)
Xu, Z., Li, D., Liu, T., et al.: Measuring similarity between microblog users and its application. Chin. J. Comput. 37(1), 207–218 (2014)
Chen, H., Jin, H., Cui, X.: Hybrid followee recommendation in microblogging systems. Sci. China Inf. Sci. 60(1), 012102 (2016)
Krishnamurthy, B., Phillipa, G. et al.: A few chirps about twitter. In: Proceedings of the First Workshop on Online Social Networks, pp. 19–24. ACM (2008)
Liben-Nowell, D., Kleinberg, J.: The Link-Prediction Problem for Social Networks. Wiley, New York (2007)
Yin, D., Hong, L., Xiong, X., et al.: Link formation analysis in microblogs, pp. 1235–1236 (2011)
Chen, J., Geyer, W., Dugan, C., et al.: Make new friends, but keep the old: recommending people on social networking sites. In: Sigchi Conference on Human Factors in Computing Systems, pp. 201–210. ACM(2009)
Salakhutdinov, R., Mnih, A.: Probabilistic matrix factorization. In: International Conference on Neural Information Processing Systems, pp. 1257–1264. Curran Associates Inc. (2007)
Ma, H., Yang, H., Lyu, M.R., et al.: SoRec: social recommendation using probabilistic matrix factorization. Comput. Intell. 28(3), 931–940 (2008)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Xiong, X., Zhang, M., Zheng, J., Liu, Y. (2018). Social Network User Recommendation Method Based on Dynamic Influence. In: Meng, X., Li, R., Wang, K., Niu, B., Wang, X., Zhao, G. (eds) Web Information Systems and Applications. WISA 2018. Lecture Notes in Computer Science(), vol 11242. Springer, Cham. https://doi.org/10.1007/978-3-030-02934-0_42
Download citation
DOI: https://doi.org/10.1007/978-3-030-02934-0_42
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-02933-3
Online ISBN: 978-3-030-02934-0
eBook Packages: Computer ScienceComputer Science (R0)