
Abstract
After a brief overview of existing models in software reliability in Sects. 25.1 and 25.2 discusses a generalized nonhomogeneous Poisson process model that can be used to derive most existing models in the software reliability literature. Section 25.3 describes a generalized random field environment (RFE) model incorporating both the testing phase and operating phase in the software development cycle for estimating the reliability of software systems in the field. In contrast to some existing models that assume the same software failure rate for the software testing and field operation environments, this generalized model considers the random environmental effects on software reliability. Based on the generalized RFE model, Sect. 25.4 describes two specific RFE reliability models, the γ-RFE and β-RFE models, for predicting software reliability in field environments. Section 25.5 illustrates the models using telecommunication software failure data. Some further considerations based on the generalized software reliability model are also discussed.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
- Reliability prediction
- Software testing
- Software reliability
- Software development process
- Software failure, Model criteria
Many software reliability models have been proposed to help software developers and managers understand and analyze the software development process, estimate the development cost, and assess the level of software reliability. Among these software reliability models, models based on the nonhomogeneous Poisson process (NHPP) have been successfully applied to model the software failure processes that possess certain trends such as reliability growth or deterioration. NHPP models seem to be useful to predict software failures and software reliability in terms of time and to determine when to stop testing and release the software [1].
Currently most existing NHPP software reliability models have been carried out through the fault intensity rate function and the mean-value functions (MVF) m(t) within a controlled operating environment [2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55]. Obviously, different models use different assumptions and therefore provide different mathematical forms for the mean-value function m(t). Table 25.1 shows a summary of several existing models appearing in the software reliability engineering literature [14]. Generally, these models are applied to software testing data and then to make predictions of software failures and reliability in the field. The underlying assumption for this application is that the field environments are the same as, or close to, a testing environment; this is valid for some software systems that are only used in one environment throughout their entire lifetime. However, this assumption is not valid for many applications where a software program may be used in many different locations once it is released.
The operating environments for the software in the field are quite different. The randomness of the field environment will affect software failure and software reliability in an unpredictable way. Yang and Xie [15] mentioned that the operational reliability and testing reliability are often different from each other, but they assumed that the operational failure rate is still close to the testing failure rate, and hence that the difference between them is that the operational failure rate decreases with time, while the testing failure rate remains constant. Zhang et al. [16] proposed an NHPP software reliability calibration model by introducing a calibration factor. This calibration factor, K, obtained from software failures in both the testing and field operation phases will be a multiplier to the software failure intensity. This calibrated software reliability model can be used to assess and adjust the predictions of software reliability in the operation phase.
Instead of relating the operating environment to the failure intensity λ, in this chapter we assume that the effect of the operating environment is to multiply the unit failure-detection rate b(t) achieved in the testing environment using the concept of the proportional hazard approach suggested by Cox [56]. If the operating environment is more liable to software failure, then the unit fault-detection rate increases by some factor η greater than 1. Similarly, if the operating environment is less liable to software failure, then the unit fault-detection rate decreases by some positive factor η less than 1.
This chapter describes a model based on the NHPP model framework for predicting software failures and evaluating the software reliability in random field environments. A generalized random field environment (RFE) model incorporating both the testing phase and operating phase in the software development cycle with Vtub-shaped fault-detection rate is discussed. An explicit solution of the mean value function for this model is derived. Numerical results of some selected NHPP models are also discussed based on existing criteria such as mean squared error (MSE), predictive power, predictive-ratio risk, and normalized criteria distance from a set of software failure data.
Based on this model, developers and engineers can further develop specific software reliability models customized to various applications.
Notations | |
|---|---|
R(t) | Software reliability function |
η | Random environmental factor |
G(η) | Cumulative distribution function of η |
γ | Shape parameter of gamma distributions |
θ | Scale parameter of gamma distributions |
α, β | Parameters of beta distributions |
N(t) | Counting process which counts the number of software failures discovered by time t |
m(t) | Expected number of software failures detected by time t, m(t) = E[N(t)] |
a(t) | Expected number of initial software faults plus introduced faults by time t |
m1(t) | Expected number of software failures in testing by time t |
m2(t) | Expected number of software failures in the field by time t |
a1(t) | Expected number of initial software faults plus introduced faults discovered in the testing by time t |
a | Number of initial software faults at the beginning of testing phase, is a software parameter that is directly related to the software itself |
T | Time to stop testing and release the software for field operations |
aF | Number of initial software faults in the field (at time T) |
b(t) | Failure detection rate per fault at time t, is a process parameter that is directly related to testing and failure process |
p | Probability that a fault will be successfully removed from the software |
q | Error introduction rate at time t in the testing phase |
MLE | Maximum likelihood estimation |
RFE-model | Software reliability model subject to a random field environment |
γ-RFE | Software reliability model with a gamma distributed field environment |
β-RFE | Software reliability model with a beta distributed field environment |
NHPP | Nonhomogeneous Poisson process |
SRGM | Software reliability growth model |
HD | Hossain–Ram |
PNZ | Pham–Nordman–Zhang |
G–O | Goel–Okumoto |
MLE | Maximum likelihood estimation |
RFE | Random field environment |
1 A Generalized NHPP Software Reliability Model
A generalized NHPP model studied by Zhang et al. [7] can be formulated as follows:
where m(t) is the number of software failures expected to be detected by time t. If the marginal conditions are given as m(0) = 0 and a(0) = a, then for a specific environmental factor η, the solutions to (25.1) and (25.2) are, given in [7], as follows
This is the generalized form of the NHPP software reliability model. When p = 1, η = 1, and q = 0, then for any given function a(t) and b(t), all the functions listed in Table 25.1 can easily be obtained.
2 Generalized Random Field Environment (RFE) Model
The testing environment is often a controlled environment with much less variation compared to the field environments, which may be quite different for the field application software. Once a software program is released, it may be used in many different locations and various applications in industries. The operating environments for the software are quite different. Therefore, the randomness of the field environment will affect the cumulative software failure data in an unpredictable way.
Figure 25.1 shows the last two phases of the software life cycle: in-house testing and field operation [18]. If T is the time to stop testing and release the software for field operations, then the time period 0 ≤ t ≤ T refers to the time period ofsoftware testing, while the time period T ≤ t refers to the postrelease period – field operation.

Testing versus field environment where T is the time to stop testing and release the software
The environmental factor η is used to capture the uncertainty about the environment and its effects on the software failure rate. In general, software testing is carried out in a controlled environment with very small variations, which can be used as a reference environment where η is constant and equals to 1. For the field operating environment, the environmental factor η is assumed to be a non-negative random variable (RV) with probability density function (PDF) f(η), that is,
If the value of η is less than 1, this indicates that the conditions are less favorable to fault detection than that of testing environment. Likewise, if the value of η is greater than 1, it indicates that the conditions are more favorable to fault detection than that of the testing environment.
From (25.3) and (25.5), the mean-value function and the function a1(t) during testing can be obtained as
For the field operation where t ≥ T, the mean-value function can be represented as
where aF is the number of faults in the software at time T. Using the Laplace transform formula, the mean-value function can be rewritten as
where F*(s) is the Laplace transform of the PDF f(x) and
or, equivalently,
Notice that \( {F}^{\ast }(0)={\int}_{\!\!0}^{\infty }{\mathrm{e}}^{-0x}f(x)\mathrm{d}x=1 \), so
The expected number of faults in the software at time T is given by
The generalized RFE model can be obtained as
The model in (25.8) is a generalized software reliability model subject to random field environments. The next section presents specific RFE models for the gamma and beta distributions of the random field environmental factor η.
3 RFE Software Reliability Models
Obviously, the environmental factor η must be non-negative. Any suitable non-negative distribution may be used to describe the uncertainty about η. In this section, we present two RFE models. The first model is a γ-RFE model, based on the gamma distribution, which can be used to evaluate and predict software reliability in field environments where the software failure-detection rate can be either greater or less than the failure detection rate in the testing environment. The second model is a β-RFE model, based on the beta distribution, which can be used to predict software reliability in field environments where the software failure detection rate can only be less than the failure detection rate in the testing environment.
3.1 γ-RFE Model
In this model, we use the gamma distribution to describe the random environmental factor η. This model is called the γ-RFE model.
Assume that η follows a gamma distribution with a probability density function as follows:
The gamma distribution has sufficient flexibility and has desirable qualities with respect to computations [18]. Figure 25.2 shows an example of the gamma density probability function. The gamma function seems to be reasonable to describe a software failure process in those field environments where the software failure-detection rate can be either greater (i.e., η > 1) or less than (i.e., η < 1) the failure-detection rate in the testing environment.

A gamma density function
The Laplace transform of the probability density function in (25.9) is
Assume that the error-detection rate function b(t) is given by
where b is the asymptotic unit software-failure detection rate and c is the parameter defining the shape of the learning curve, then from (25.8) the mean-value function of the γ-RFE model can be obtained as follows
3.2 β-RFE Model
This section presents a model using the beta distribution that describes the random environmental factor η, called the β-RFE model.
The beta PDF is
Figure 25.3 shows an example of the beta density function. It seems that the β-RFE model is a reasonable function to describe a software failure process in those field environments where the software failure-detection rate can only be less than the failure-detection rate in the testing environment. This is not uncommon in the software industry because, during software testing, the engineers generally test the software intensely and conduct an accelerated test on the software in order to detect most of the software faults as early as possible.

A PDF curve of the beta distribution
The Laplace transform of the PDF in (25.13) is
where HG([β], [α + β], s) is a generalized hypergeometric function such that
Therefore,
where the Poisson PDF is given by
Using the same error-detection rate function in (25.11) and replacing F*(s) by Fβ*(s), the mean-value function of the β-RFE model is
where
The next section will discuss the parameter estimation and illustrate the applications of these two RFE software reliability models using software failure data.
4 Parameter Estimation
4.1 Maximum Likelihood Estimation (MLE)
We use the MLE method to estimate the parameters in these two RFE models. Let yi be the cumulative number of software faults detected up to time ti, i = 1, 2,…, n. Based on the NHPP, the likelihood function is given by
The logarithmic form of the above likelihood function is
In this analysis, the error-removal efficiency p is given. Each model has five unknown parameters. For example, in the γ-RFE model, we need to estimate the following five unknown parameters: a, b, q, γ, and θ. For the β-RFE model, we need to estimate: a, b, q, α, and β. By taking derivatives of (25.17) with respect to each parameter and setting the results equal to zero, we can obtain five equations for each RFE model. After solving all those equations, we obtain the maximum likelihood estimates (MLEs) of all parameters for each RFE model.
Table 25.2 shows a set of failure data from a telecommunication software application during software testing [16]. The column “Time” shows the normalized cumulative time spent in software testing for this telecommunication application, and the column “Failures” shows the normalized cumulative number of failures occurring in the testing period up to the given time.
The time to stop testing is T = 0.0184. After the time T, the software is released for field operations. Table 25.3 shows the field data for this software release. Similarly, the column “Time” shows the normalized cumulative time spent in the field for this software application, and the time in Table 25.3 is continued from the time to stop testing T. The column “Failures” shows the normalized cumulative number of failures found after releasing the software for field operations up to the given time. The cumulative number of failures is the total number of software failures since the beginning of software testing.
To obtain a better understanding of the software development process, we show the actual results of the MLE solutions instead of the normalized results. In this study, let us assume that testing engineers have a number of years of experience of this particular product and software development skills and therefore conducted perfect debugging during the test. In other word, p = 1. The maximum likelihood estimates of all the parameters in the γ-RFE model are obtained as shown in Table 25.4.
Similarly, set p = 1, the MLE of all the parameters in the β-RFE model are obtained as shown in Table 25.5.
For both RFE models, the MLE results can be used to obtain more insightful information about the software development process. In this example, at the time to stop testing the software T = 0.0184, the estimated number of remaining faults in the system is aF = a − (p − q)m(T) = 55.
4.2 Mean-Value Function Fits
After we obtain the MLEs for all the parameters, we can plot the mean-value function curve fits for both the γ-RFE and β-RFE models based on the MLE parameters against the actual software application failures.
Table 25.6 shows the mean-value function curve fits for both the models where the columns mγ(t) and mβ(t) show the mean-value function for the γ-RFE model and the β-RFE model, respectively.
The γ-RFE and β-RFE models yield very close fits and predictions on software failures. Figure 25.4 shows the mean-value function curve fits for both the γ-RFE model and β-RFE model. Both models appear to be a good fit for the given data set. Since we are particularly interested in the fits and the predictions for software failure data during field operation, we also plot the detailed mean-value curve fits for both the γ-RFE model and the β-RFE model in Fig. 25.5.

Mean-value function curve fits for both RFE models

Mean-value function fitting comparisons
For the overall fitting of the mean-value function against the actual software failures, the MSE is 23.63 for the γ-RFE model fit and is 23.69 for the β-RFE model. We can also obtain the fits and predictions for software failures by applying some existing NHPP software reliability models to the same set of failure data. Since all these existing models assume a constant failure-detection rate throughout both the software testing and operation periods, we only apply the software testing data to the software models and then predict the software failures in the field environments.
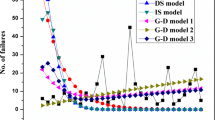
Figure 25.6 shows the comparisons of the mean-value function curve fits between the two RFE models and some existing NHPP software reliability models. It appears that the two models that include consideration of the field environment on the software failure-detection rate perform better in terms of the predictions for software failures in the field.

Model comparisons
4.3 Software Reliability
Once the MLEs of all the parameters in (25.12) and (25.14) are obtained, the software reliability within (t, t + x) can be determined as
Let T = 0.0184, and change x from 0 to 0.004, then we can compare the reliability predictions between the two RFE models and some other NHPP models that assume a constant failure-detection rate for both software testing and operation. The reliability prediction curves are shown in Fig. 25.7. From Fig. 25.7, we can see that the NHPP models without consideration of the environmental factor yield much lower predictions for software reliability in the field than the two proposed RFE software reliability models.

Reliability prediction comparisons
4.4 Confidence Interval
4.4.1 γ-RFE Model
To see how good the reliability predictions given by the two RFE models are, in this section we describe how to construct confidence intervals for the prediction of software reliability in the random field environments. From Tables 25.4 and 25.5, the MLEs of c and q are equal to zero and, if p is set to 1, then the model in (25.12) becomes
This model leads to the same MLE results for the parameters a, b, γ, and θ and also yields exactly the same mean-value function fits and predictions as the model in (25.12). To obtain the confidence interval for the reliability predictions for the γ-RFE model, we derive the variance–covariance matrix for all the maximum likelihood estimates as follows.
If we use xi, i = 1, 2, 3, and 4, to denote all the parameters in the model, or
The Fisher information matrix H can be obtained as
where
where L is the log-likelihood function in (25.18).
If we denote z(tk) = m(tk) − m(tk–1) and Δyk = yk − yk–1, k = 1, 2,…, n, then we have
Then we can obtain each element in the Fisher information matrixH. For example,
The variance matrix, V, can also be obtained
The variances of all the estimate parameters are given by
The actual numerical results for the γ-RFE model variance matrix are
4.4.2 β-RFE Model
The model in (25.14) can also be simplified given that the estimates of both q and c are equal to zero and p is set to 1. The mean-value function becomes
This model leads to the same MLE results for the parameters a, b, α, and β and also yields exactly the same mean-value function fits and predictions. To obtain the confidence interval for the reliability predictions for the β-RFE model, we need to obtain the variance–covariance matrix for all the maximum likelihood estimates.
If we use xi, i = 1, 2, 3, and 4, to denote all the parameters in the model, or
and go through similar steps as for the γ-RFE model, the actual numerical results for the β-RFE model variance matrix can be obtained as
4.4.3 Confidence Interval of the Reliability Predictions
If we define a partial derivative vector for the reliability R(x | t) in (25.18) as
then the variance of R(x | t) in (25.18) can be obtained as
Assume that the reliability estimation follows a normal distribution, then the 95% confidence interval for the reliability predictionR(x | t) is
Figures 25.8 and 25.9 show the 95% confidence interval of the reliability predicted by the γ-RFE and β-RFE models, respectively.

γ-RFE model reliability growth curve and its 95% confidence interval

β-RFE model reliability growth prediction and its 95% confidence interval
We plot the reliability predictions and their 95% confidence interval for both the γ-RFE model and the β-RFE model in Fig. 25.10. For this given application data set, the reliability predictions for the γ-RFE model and the β-RFE model are very close to each other, as are their confidence intervals. Therefore, it would not matter too much which one of the two RFE models was used to evaluate the software reliability for this application. However, will these two RFE models always yield similar reliability predictions for all software applications? or which model should one choose for applications if they are not always that close to each other? We will try to answer these two questions in the next section. Figure 25.11 shows the 95% confidence interval for the mean-value function fits and predictions from the γ-RFE model.

Reliability growth prediction curves and their 95% confidence intervals for the γ-RFE model and the β-RFE model

Mean-value function curve fit and its 95% confidence intervals for the γ-RFE mode
4.5 Concluding and Remarks
Table 25.7 shows all the maximum likelihood estimates of all the parameters and other fitness measures. The maximum likelihood estimates (MLEs) on common parameters, such as a – the initial number of faults in the software and b – the unit software failure-detection rate during testing, are consistent for both models. Both models provide very close predictions for software reliability and also give similar results for the mean and variance of the random environment factor η.
The underlying rationale for this phenomenon is the similarity between the gamma and beta distributions when the random variable η is close to zero. In this application, the field environments are much less liable to software failure than the testing environment. The random field environmental factor, η, is mostly much less than 1 with mean (η) ≈ 0.02.
Figure 25.12 shows the PDF curves of the environmental factorη based on the MLEs of all the parameters for both the γ-RFE model and the β-RFE model. We observe that the PDF curves for the beta and gamma distributions are also very close to each other. The two RFEs models give similar results because this software application is much less likely to fail in the field environment, with mean (η) = 0.02. If the mean (η) is not so close to 0, then we would expect to have different prediction results from the γ-RFE model and the β-RFE model.

PDF curves comparison for the environmental factor η
We suggest the following criteria as ways to select between the two models discussed in this chapter for predicting the software reliability in the random field environments:
-
1.
Software less liable to failure in the field than in testing, that is, η ≤ 1
In the γ-RFE model, the random field environmental factor, η following a gamma distribution, ranges from 0 to +∞. For the β-RFE model, the random field environmental factor, η following a beta distribution, ranging from 0 to 1. Therefore, the β-RFE model will be more appropriate for describing field environments in which the software application is likely to fail than in the controlled testing environment.
For this given application, we notice that when the field environmental factor η is much less than 1 [mean(η) = 0.02], the γ-RFE model yields similar results to the β-RFE model. However, we also observe that the γ-RFE model does not always yield similar results to the β-RFE model when η is not close to 0. In this case, if we keep using the γ-RFE model instead of the β-RFE model, we would expect to see a large variance in the maximum likelihood estimates for all the unknown parameters, and hence a wider confidence interval for the reliability prediction.
-
2.
Smaller variance of the RFE factor η
A smaller variance of the random environmental factor η will generally lead to a smaller confidence interval for the software reliability prediction. It therefore represents a better prediction in the random field environments.
-
3.
Smaller variances for the common parameters a and b
The software parameter a and the process parameter b are directly related to the accuracy of reliability prediction. They can also be used to investigate the software development process. Smaller variances of a and b would lead, in general, to smaller confidence intervals for the mean-value function predictions and reliability predictions.
-
4.
Smaller MSE of the mean-value function fits
A smaller MSE for the mean-value function fits means a better fit of the model to the real system failures. This smaller MSE will usually lead to a better prediction of software failures in random field environments.
The above criteria can be used with care to determine which RFE model should be chosen in practice. They may sometime provide contradictory results. In the case of contradictions, practitioners can often consider selecting the model with the smaller confidence interval for the reliability prediction.
5 A RFE Model with Vtub-Shaped Fault-Detection Rate
In this section, we present a specific RFE model with Vtub-shaped fault-detection rate. Numerical results of some selected NHPP models based on MSE, predictive power, predictive-ratio risk, and normalized criteria distance from a set of software failure data are discussed.
Here we assume that a detected fault will be 100% successfully removed from the software during the software testing period and the software fault-detection rate per unit time, h(t), with a Vtub-shaped function [22], is as follows:
We also assume that the random variable η as defined in (25.1) has a gamma distribution with parameters α and β, that is, η ∼ gamma(α, β) where the PDF of η is given by
From Eq. (25.1), we can obtain the expected number of software failures detected by time t subject to the uncertainty of the environments as follows:
where N is the expected number of faults that exists in the software before testing.
5.1 Model Criteria
We briefly discuss some common criteria such as MSE, predictive-ratio risk (PRR), and predictive power (PP) that will be used to compare the performance of some selected models from Table 25.1 to illustrate the modeling analysis.
The MSE measures the difference between the estimated values and the actual observation and is defined as:
where yi = total number of actual failures at time ti; \( \hat{m}\left({t}_i\right) \) = the estimated cumulative number of failures at time ti for i = 1, 2,…, n; and n and k = number of observations and number of model parameters, respectively.
The predictive-ratio risk (PRR) measures the distance of model estimates from the actual data against the model estimate and is defined as [22]:
The predictive power (PP) measures the distance of model estimates from the actual data against the actual data [22]:
For all these three criteria – MSE, PRR, and PP – the smaller the value, the better the model fits.
Pham [28] discussed a normalized criteria distance, or NCD criteria, to determine the best model from a set of performance criteria. The NCD criteria is defined as follows:
where s and d are the total number of models and criteria, respectively.
-
wj = the weight of the jth criteria for j = 1, 2, ... ,d
-
\( k=\left\{\begin{array}{ll}1& \mathrm{represent}\, \mathrm{criteria}\, j\, \mathrm{value}\\ {}2& \mathrm{represent}\, \mathrm{criteria}\, j\, \mathrm{ranking}\end{array}\right\} \)
-
Cij1 = the ranking based on specified criterion of model i with respect to (w.r.t.) criteria j
-
Cij2 = criteria value of model i w.r.t. criteria j where i = 1, 2, ..., s and j = 1, 2, ... ,d
Obviously the smaller the NCD value, Di, it represents the better rank.
5.2 Model Analysis
A set of system test data which is referred to as Phase 2 data set [22] is used to illustrate the model performance in this subsection. In this data set, the number of faults detected in each week of testing is found and the cumulative number of faults since the start of testing is recorded for each week. This data set provides the cumulative number of faults by each week up to 21 weeks.
Table 25.8 summarizes the result as well as the ranking of nine selected models from Table 25.1 based on MSE, PRR, PP, and NCD criteria. It is worth to note that one can use the NCD criterion to help in selecting the best model from among model candidates. Table 25.8 shows the NCDs and its corresponding ranking for w1 = 2, w2 = 1.5, and w3 = 1 with respect to MSE, PRR, and PP, respectively.
Based on the results as shown in Table 25.8, the Vtub-shaped fault-detection rate model seems to provide the best fit based on the normalized criteria distance method.
References
Pham, H., Zhang, X.: A software cost model with warranty and risk costs. IEEE Trans. Comput. 48, 71–75 (1999)
Pham, H., Normann, L., Zhang, X.: A general imperfect debugging NHPP model with S-shaped fault detection rate. IEEE Trans. Reliab. 48, 169–175 (1999)
Goel, A.L., Okumoto, K.: Time-dependent error-detection rate model for software and other performance measures. IEEE Trans. Reliab. 28, 206–211 (1979)
Ohba, M.: Software reliability analysis models. IBM J. Res. Dev. 28, 428–443 (1984)
Pham, H.: Software Reliability. Springer, London (2000)
Yamada, S., Ohba, M., Osaki, S.: S-shaped reliability growth modeling for software error detection. IEEE Trans. Reliab. 33, 475–484 (1984)
Zhang, X., Teng, X., Pham, H.: Considering fault removal efficiency in software reliability assessment. IEEE Trans. Syst. Man Cybern. A. 33, 114–120 (2003)
Pham, H., Zhang, X.: NHPP software reliability and cost models with testing coverage. Eur. J. Oper. Res. 145, 443–454 (2003)
Zhang, X., Pham, H.: Predicting operational software availability and its applications to telecommunication systems. Int. J. Syst. Sci. 33(11), 923–930 (2002)
Pham, H., Wang, H.: A quasi renewal process for software reliability and testing costs. IEEE Trans. Syst. Man Cybern. A. 31, 623–631 (2001)
Zhang, X., Shin, M.-Y., Pham, H.: Exploratory analysis of environmental factors for enhancing the software reliability assessment. J. Syst. Softw. 57, 73–78 (2001)
Pham, L., Pham, H.: A Bayesian predictive software reliability model with pseudo-failures. IEEE Trans. Syst. Man Cybern. A. 31(3), 233–238 (2001)
Zhang, X., Pham, H.: Comparisons of nonhomogeneous Poisson process software reliability models and its applications. Int. J. Syst. Sci. 31(9), 1115–1123 (2000)
Pham, H.: Software reliability and cost models: perspectives, comparison and practice. Eur. J. Oper. Res. 149, 475–489 (2003)
Yang, B., Xie, M.: A study of operational, testing reliability in software reliability analysis. Reliab. Eng. Syst. Safety. 70, 323–329 (2000)
Zhang, X., Jeske, D., Pham, H.: Calibrating software reliability models when the test environment does not match the user environment. Appl. Stoch. Model. Bus. Ind. 18, 87–99 (2002)
Li, Q., Pham, H.: A generalized software reliability growth model with consideration of the uncertainty of operating environments. IEEE Access. 7 (2019)
Teng, X., Pham, H.: A software cost model for quantifying the gain with considerations of random field environment. IEEE Trans. Comput. 53, 3 (2004)
Kapur, P.K., Pham, H., Aggarwal, A.G., Kaur, G.: Two dimensional multi-release software reliability modeling and optimal release planning. IEEE Trans. Reliab. 61(3), 758–768 (2012)
Kapur, P.K., Pham, H., Anand, S., Yadav, K.: A unified approach for developing software reliability growth models in the presence of imperfect debugging and error generation. IEEE Trans. Reliab. 60(1), 331–340 (2011)
Li, Q., Pham, H.: NHPP software reliability model considering the uncertainty of operating environments with imperfect debugging and testing coverage. Appl. Math. Model. 51(11), 68–85 (2017)
Pham, H.: System Software Reliability. Springer (2006)
Pham, H.: Software reliability assessment: imperfect debugging and multiple failure types in software development. EG&G-RAAM-10737; Idaho National Engineering Laboratory (1993)
Pham, H.: A software cost model with imperfect debugging, random life cycle and penalty cost. Int. J. Syst. Sci. 27(5), 455–463 (1996)
Pham, H., Zhang, X.: An NHPP software reliability model and its comparison. Int. J. Reliab. Qual. Saf. Eng. 4(3), 269–282 (1997)
Pham, H.: An imperfect-debugging fault-detection dependent-parameter software. Int. J. Autom. Comput. 4(4), 325–328 (2007)
Pham, H.: A software reliability model with vtub-shaped fault-detection rate subject to operating environments. In: Proc. 19th ISSAT Int’l Conf. on Reliability and Quality in Design, Hawaii (2013)
Pham, H. (2014), "A new software reliability model with Vtub-shaped fault-detection rate and the uncertainty of operating environments," Optimization, v 63, p. 1481–1490
Pham, H., Pham, D. H., Pham, H. (2014), “A new mathematical logistic model and its applications,” Int. J. Inform.Manag. Sci., v, 25, no. 2, p. 79–99
Pham, H.: Loglog fault-detection rate and testing coverage software reliability models subject to random environments. Vietnam J. Comput. Sci. 1(1) (2014)
Pham, L., Pham, H.: Software reliability models with time-dependent hazard function based on Bayesian approach. IEEE Trans. Syst. Man Cybern. A. 30(1), 25–35 (2000)
Pham, H.: A generalized fault-detection software reliability model subject to random operating environments. Vietnam J. Comput. Sci. 3(3), 145–150 (2016)
Sgarbossa, F., Pham, H.: A cost analysis of systems subject to random field environments and reliability. IEEE Trans. Syst. Man Cybern. C. 40(4), 429–437 (2010)
Zhang, X., Pham, H.: Software field failure rate prediction before software deployment. J. Syst. Softw. 79, 291–300 (2006)
Zhu, M., Pham, H.: A two-phase software reliability modeling involving with software fault dependency and imperfect fault removal. Comput. Lang. Syst. Struct. 53(2018), 27–42 (2018)
Lee, D.H., Chang, I.-H., Pham, H.: Software reliability model with dependent failures and SPRT. Mathematics. 8, 2020 (2020)
Zhu, M., Pham, H.: A generalized multiple environmental factors software reliability model with stochastic fault detection process. Ann. Oper. Res. (2020) (in print)
Zhu, M., Pham, H.: A novel system reliability modeling of hardware, software, and interactions of hardware and software. Mathematics. 7(11), 2019 (2019)
Song, K.Y., Chang, I.-H., Pham, H.: A testing coverage model based on NHPP software reliability considering the software operating environment and the sensitivity analysis. Mathematics. 7(5) (2019). https://doi.org/10.3390/math7050450
Sharma, M., Pham, H., Singh, V.B.: Modeling and analysis of leftover issues and release time planning in multi-release open source software using entropy based measure. Int. J. Comput. Syst. Sci. Eng. 34(1) (2019)
Pham, T., Pham, H.: A generalized software reliability model with stochastic fault-detection rate. Ann. Oper. Res. 277(1), 83–93 (2019)
Zhu, M., Pham, H.: A software reliability model incorporating martingale process with gamma-distributed environmental factors. Ann. Oper. Res. (2019). https://doi.org/10.1007/s10479-018-2951-7
Chatterjee, S., Shukla, A., Pham, H.: Modeling and analysis of software fault detectability and removability with time variant fault exposure ratio, fault removal efficiency, and change point. J. Risk Reliab. 233(2), 246–256 (2019)
Pham, H.: A logistic fault-dependent detection software reliability model. J. Univ. Comput. Sci. 24(12), 1717–1730 (2018)
Song, K.Y., Chang, I.-H., Pham, H.: Optimal release time and sensitivity analysis using a new NHPP software reliability model with probability of fault removal subject to operating environments. Appl. Sci. 8(5), 714–722 (2018)
Sharma, M., Singh, V.B., Pham, H.: Entropy based software reliability analysis of multi-version open source software. IEEE Trans. Softw. Eng. 44(12), 1207–1223 (2018)
Zhu, M., Pham, H.: A multi-release software reliability modeling for open source software incorporating dependent fault detection process. Ann. Oper. Res. 269 (2017). https://doi.org/10.1007/s10479-017-2556-6
Song, K.Y., Chang, I.-H., Pham, H.: An NHPP software reliability model with S-shaped growth curve subject to random operating environments and optimal release time. Appl. Sci. 7(12), 2017 (2017)
Song, K.Y., Chang, I.-H., Pham, H.: A software reliability model with a Weibull fault detection rate function subject to operating environments. Appl. Sci. 7(10), 983 (2017)
Li, Q., Pham, H.: A testing-coverage software reliability model considering fault removal efficiency and error generation. PLoS One. (2017). https://doi.org/10.1371/journal.pone.0181524
Zhu, M., Pham, H.: Environmental factors analysis and comparison affecting software reliability in development of multi-release software. J. Syst. Softw. 132, 72–84 (2017)
Lee, S.W., Chang, I.-H., Pham, H., Song, K.Y.: A three-parameter fault-detection software reliability model with the uncertainty of operating environment. J. Syst. Sci. Syst. Eng. 26(1), 121–132 (2017)
Zhu, M., Pham, H.: A software reliability model with time-dependent fault detection and fault-removal. Vietnam J. Comput. Sci. 3(2), 71–79 (2016)
Zhu, M., Zhang, X., Pham, H.: A comparison analysis of environmental factors affecting software reliability. J. Syst. Softw. 109, 150–160 (2015)
Chang, I.-H., Pham, H., Lee, S.W., Song, K.Y.: A testing-coverage software reliability model with the uncertainty of operating environments. Int. J. Syst. Sci. 1(4), 220–227 (2014)
Cox, D.R.: Regression models and life tables (with discussion). J.~R. Stat. Soc. Ser. B. 34, 133–144 (1972)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 Springer-Verlag London Ltd., part of Springer Nature
About this chapter

Cite this chapter
Pham, H., Teng, X. (2023). Software Reliability Modeling and Prediction. In: Pham, H. (eds) Springer Handbook of Engineering Statistics. Springer Handbooks. Springer, London. https://doi.org/10.1007/978-1-4471-7503-2_25
Download citation
DOI: https://doi.org/10.1007/978-1-4471-7503-2_25
Published:
Publisher Name: Springer, London
Print ISBN: 978-1-4471-7502-5
Online ISBN: 978-1-4471-7503-2
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)