
Abstract
Nonparametric structural models facilitate the analysis of counterfactuals without making use of parametric assumptions. Such methods make use of the behavioural and equilibrium assumptions specified in economic models to define a mapping between the distribution of the observable variables and the primitive functions and distributions that are used in the model. Using these methods, one can infer elements of the model, such as utility and production functions, that are not directly observed. We review some of the latest works that have dealt with the identification and estimation of nonparametric structural models.
Access provided by CONRICYT-eBooks. Download reference work entry PDF
Similar content being viewed by others


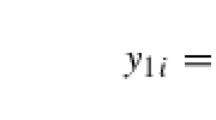
Keywords
- Additivity
- Average derivative methods
- Control functions
- Convergence
- Curse of dimensionality
- Endogeneity
- Estimation
- Identification
- Instrumental variables
- Maximum likelihood
- Nonadditivity
- Nonparametric structural models
- Nonseparable models
- Observable and unobservable explanatory variables
- Partial integration methods
- Quantile structural functions
- Simultaneous equations
JEL Classifications
The interplay between economic theory and econometrics comes to its full force when analysing structural models. These models are used in industrial organization, marketing, public finance, labour economics and many other fields in economics. Structural econometric methods make use of the behavioural and equilibrium assumptions specified in economic models to define a mapping between the distribution of the observable variables and the primitive functions and distributions that are used in the model. Using these methods, one can infer elements of the model, such as utility and production functions, that are not directly observed. This allows one to predict behaviour and equilibria outcomes under new environments and to evaluate the welfare of individuals and profits of firms under alternative policies, among other benefits.
To provide an example, suppose that one would like to predict the demand for a new product. Since the product has not previously been available, no direct data exists. However, one could use data on the demand for existent products together with a structural model, as shown and developed by McFadden (1974). Characterize the new product and the existent competing products by vectors of common attributes. Assume that consumers derive utility from the observable and unobservable attributes of the products, and that each chooses the product that maximizes his or her utility of those attributes among the existent products. Then, from the choice of consumers among existent products, one can infer their preferences for the attributes, and then predict what the choice of each of them would be in a situation when a new vector of attributes, corresponding to the new product, is available. Moreover, one could get a measure of the differences in the welfare of the consumers when the new product is available.
Economic theory seldom has implications regarding the parametric structures that functions and distributions may possess. The behavioural and equilibrium specifications made in economic models typically imply shape restrictions, such as monotonicity, concavity, homogeneity, weak separability, and additive separability, and exclusion restrictions, but typically not parametric specifications, such as linearity of conditional expectations, or normal distributions for unobserved variables. Nonparametric methods, which do not require specification of parametric structures for the functions and distributions in a model, are ideally fitted, therefore, to analyse structural models, using as few a priori restrictions as possible. Nonparametric techniques have been applied to many models, such as discrete choice models, tobit models, selection models, and duration models. We will concentrate here, however, on the basic models and on those, indicate some of the latest works that have dealt with identification and estimation.
Nonparametric Structural Econometric Models
As with parametric models, a nonparametric econometric model is characterized by a vector X of variables that are determined outside the model and are observable, a vector ε of variables that are determined outside the model and are unobservable, a vector ϒ of outcome variables, which are determined within the model and are unobservable, and a vector Y of outcome variables that are determined within the model and are observable. These variables are related by functional relationships, which determine the causal structure by which ϒ and Y are determined from X and ε. The functional relationships are characterized by some functions that are known and some that are unknown. Similarly, some distributions may be known, some are unknown, and the others should be derived from the functional relationships and the known and unknown functions and distributions. Let h* denote the vector of all the unknown functions in the model, F* denote the vector of all unknown distributions, and ζ* = (h*, F*)-In contrast to parametric models, in nonparametric models, none of the coordinates of ζ* is assumed known up to a finite dimensional parameter.
Only restrictions such as continuity or values of the conditional expectations are assumed. The specification of the model should be such that from any vector ζ = (h, F), satisfying those same restrictions that ζ* is assumed to satisfy, one is able to derive a distribution for the observable variables, FYX(·, ζ).
Nonparametric Identification
When specifying an econometric model, we may be interested in testing it, or we may be interested in estimating ζ* = (h*, F*) or some feature of ζ*, such as only one of the elements of h*, or even the value of that element at one point. Suppose that interest lies on estimating a particular feature, ψ(ζ*) of ζ*. The first question one must answer is whether that feature is identified. Let Ω denote the set of all possible values that ψ(ζ) may attain, when ζ is restricted to satisfy the properties that ζ* is assumed to satisfy. Given ψ ∈ Ω, define ΓY,X(ψ) to be the set of all probability distributions of (Y, X) that are consistent with ψ. This is the set of all distributions that can be generated by a ζ, satisfying the properties that ζ* is assumed to satisfy, and with ψ(ζ) = ψ. We say that two values ψ, ψ′∈ Ω are observationally equivalent if
that is, they are observationally equivalent if there exist a distribution of the observable variables that could have been generated by two vectors ζ and ζ′ with ψ(ζ) = ψ and ψ(ζ′) = ψ′. The feature ψ* = ψ (ζ*) is said to be identified if there is no ψ ∈ Ω such that ψ ≠ ψ* and ψ is observationally equivalent to ψ*. That is, ψ* = ψ (ζ*) is identified if a change from ψ* to ψ ≠ ψ* cannot be compensated by a change in other unknown elements of ζ, so that a same distribution of observable variables could be generated by both, vectors ζ* and ζ with ψ* = ψ (ζ*) and ψ = ψ (ζ).
When ψ* can be expressed as a continuous functional of the distribution of observable variables (Y, X) one can typically estimate ψ* nonparametrically by substituting the distribution by a nonparametric estimator for it.
Additive and Nonadditive Models with Exogenous Explanatory Variables
The current literature on nonparametric econometrics methods considers additive and nonadditive models. In additive models, the unobservable exogenous variables ε are specified as affecting the value of Y though an additive function. Hence, for some functions m and v and some unobservable η
In these models, the object of interest is typically the function m. Depending on the restrictions that one may impose on η, m may denote a conditional expectation, a conditional quantile, or some other function. Many methods exist to estimate conditional means and conditional quantiles nonparametrically. Prakasa Rao (1983), Härdle and Linton (1994), Matzkin (1994, 2007b), Pagan and Ullah (1999), Koenker (2005), and Chen (2007), among others, survey parts of this literature. Some nonparametric tests for these models include Wooldridge (1992), Yatchew (1992), Hong and White (1995), and Fan and Li (1996).
In nonadditive models, one is interested in analysing the interaction between the unobservable and observable explanatory variables. These models are specified, for some function m as
Nonparametric identification and estimation in models of this type was studied in Roehrig (1988), Olley and Pakes (1996), Brown and Matzkin (1998), Matzkin (1999, 2003, 2004, 2005, 2006), Chesher (2003), Imbens and Newey (2003), and Athey and Imbens (2006), among others.
Dependence Between Observable and Unobservable Explanatory Variables
In econometric models, it is often the case that in an equation of interest, some of the explanatory variables are endogenous; they are not distributed independently of the unobservable explanatory variables in that same equation. This typically occurs when restrictions such as agent’s optimization and equilibrium conditions generate interrelationships among observable variables and unobservable variables, ε, that affect a common observable outcome variable, Y. In such cases, the distribution of the observable outcome and observable explanatory variables does not provide enough information to recover the causal effect of those explanatory variables on the outcome variable, since changes in those explanatory variables do not leave the value of ε fixed. A typical example of this is when Y denotes quantity demanded for a product, X denotes the price of the product, and ε is an unobservable demand shifter. If the price that will make firms produce a certain quantity increases with quantity, this change in ε will generate an increment in the price X. Hence, the observable effect of a change in price in demanded quantity would not correspond to the effect of changing the value of price when the value ε stays constant. Another typical example arises when analysing the effect of years of education on wages. An unobservable variable, such as ability, affects wages and also affects the decision about years of education.
Estimation Techniques for Additive and Nonadditive Functions of Endogenous Variables
The estimation techniques that have been developed to estimate nonparametric models with endogenous explanatory variables typically make use of additional information, which provides some exogenous variation on either the value of the endogenous variable or on the value of the unobservable variable. The common procedures are based on conditional independence methods and on instrumental variable methods. In the first set of procedures, independence between the unobservable and observable explanatory variables in a model is typically achieved by either conditioning on observable variables, or conditioning on unobservable variables. A control function approach (Heckman and Robb 1985) models the unobservable as a function, so that conditioning on that function purges the dependence between the explanatory observable and unobservable variables in the model. Instrumental variable methods derive identification from an independence condition between the unobservable and an external variable (an instrument) or function, which is correlated with the endogenous variable and which might be estimable.
Conditioning on unobservable variables often requires the estimation of those unobservable variables. Two-step procedures, where they are first estimated, and then used as additional regressors in the model of interest have been developed for additive models by Ng and Pinkse (1995), Pinkse (2000), and Newey et al. (1999), among others. Two-step procedures for nonadditive models have been developed by Altonji and Matzkin (2001), Blundell and Powell (2003), Chesher (2003), and Imbens and Newey (2003), among others. Conditional moment estimation methods or quasi-maximum likelihood estimation methods can also be used (see, for example, Ai and Chen 2003). Altonji and Ichimura (2000), Altonji and Matzkin (2001, 2005), and Matzkin (2004), among others, considered conditioning on observables for estimation of nonadditive models with endogenous explanatory variables. Matzkin (2004) provides insight into the sources of exogeneity that are generated when conditioning on either observables or unobservables, and which allow identification and estimation in nonadditive models. In particular, if Y = m(X, ε), with m strictly increasing in ε, and ε is independent of X conditional on W, she shows that there exists functions s(W,η) and r(W, δ) such that δ is independent η conditional on W, X = s(W, η) and ε = r(W, δ). Hence,
Instrumental variable methods for additive models were considered by Newey and Powell (1989, 2003), Ai and Chen (2003), Darolles et al. (2003), and Hall and Horowitz (2003), among others. To develop estimators for m in the model
they use the moment condition
which depends on the conditional expectation E[Y1|Z = z] and the conditional density \( {f}_{Y_2\mid Z=z}\left({y}_2\right) \), which can be estimated nonparametrically. For nonadditive models, of the form
where m is strictly increasing in ε, Chernozhukov and Hansen (2005) and Chernozhukov et al. (2007) developed estimation methods using the moment condition that for al τ
from which m can be estimated using the conditional moment restriction
Matzkin (2006) considered the model
where Z is distributed independently of (ε, η). She established restrictions on the functions m1 and m2 and on the distribution of (ε, η, Z) under which
can be expressed as a function of the conditional density \( {{f_{Y_1}}_{,{Y}_2}}_{\mid Z={z}^{\ast }}\left({y}_1,{y}_2\right) \), where r1 is the inverse of m1 with respect to ε, and the value z* of the instrument Z is easily identified (see also Matzkin 2005, 2007a, b).
Estimation of Averages and Average Derivatives
Nonparametric estimators are notorious by their slow rate of convergence, which worsens as the dimension of the number of arguments of the nonparametric function increases. A remedy for this is to consider averages of the nonparametric function. The average derivative method in Powell et al. (1989) and the partial integration methods of Newey (1994) and Linton and Nielsen (1995), for example, show how rates of convergence can increase by averaging a nonparametric function or its derivatives. This approach has been extended to cases where the explanatory variables are endogenous, using additional variables to deal with the endogeneity, and averaging over them. Examples are Blundell and Powell’s (2003) average structural function, Imbens and Newey’s (2003) average quantile function, and Altonji and Matzkin’s (2001, 2005) local average response function.
Suppose, for example, that the model of interest is
and W is such that Y2 and ε are independent conditional on W. Then, the Blundell and Powell (2003) average structural function is
which can be derived from a nonparametric estimator for the distribution of (Y1, Y2, W) as
Imbens and Newey’s (2003) quantile structural function is defined for the τ-th quantile of ε, qε(τ), as
which can be estimated by
Altonji and Matzkin’s (2001, 2005) local average response function is
which can be derived from a nonparametric estimator for the distribution of (Y1, Y2, W) as
Conclusions
The literature on nonparametric structural models has been rapidly developing in recent years. The new methods allow one to analyse counterfactuals without making use of parametric assumptions. Estimation of some features of the model rather than the functions themselves may reduce the curse of dimensionality, therefore providing improved properties and reducing the need for large data-sets.
Bibliography
Ai, C., and X. Chen. 2003. Efficient estimation of models with conditional moments restrictions containing unknown functions. Econometrica 71: 1795–1843.
Altonji, J.G., and H. Ichimura. 2000. Estimating derivatives in nonseparable models with limited dependent variables. Mimeo, Northwestern University.
Altonji, J.G., and R.L. Matzkin. 2001. Panel data estimators for nonseparable models with endogenous regressors. NBER Working paper T0267.
Altonji, J.G., and R.L. Matzkin. 2005. Cross section and panel data estimators for nonseparable models with endogenous regressors. Econometrica 73: 1053–1102.
Athey, S., and G. Imbens. 2006. Identification and inference in nonlinear difference-in-differences models. Econometrica 74: 431–497.
Blundell, R., and J.L. Powell. 2003. Endogeneity in nonparametric and semiparametric regression models. In Advances in economics and econometrics, theory and applications, eighth world congress, ed. M. Dewatripont, L.P. Hansen, and S.J. Turnovsky, vol. 2. Cambridge: Cambridge University Press.
Brown, D.J, and R.L. Matzkin. 1998. Estimation of nonparametric functions in simultaneous equations models, with an application to consumer demand. Discussion paper no. 1175, Cowles Foundation, Yale University.
Chen, X. 2007. Large sample sieve estimation of semi-nonparametric models. In Handbook of econometrics, ed. E. Leamer and J.J. Heckman, vol. 6. Amsterdam: North-Holland.
Chernozhukov, V., and C. Hansen. 2005. An IV model of quantile treatment effects. Econometrica 73: 245–261.
Chernozhukov, V., G. Imbens, and W. Newey. 2007. Instrumental variable estimation of nonseparable models. Journal of Econometrics 139: 4–14.
Chesher, A. 2003. Identification in nonseparable models. Econometrica 71: 1404–1441.
Darolles, S., J.P. Florens, and E.Renault. 2003. Nonparametric instrumental regression. IDEI Working paper no. 228.
Fan, Y., and Q. Li. 1996. Consistent model specification tests: Omitted variables and semiparametric functional forms. Econometrica 64: 4.
Florens, J.P. 2003. Inverse problems and structural econometrics: The example of instrumental variables. In Advances in economics and econometrics, theory and applications, ed. M. Dewatripont, L.P. Hansen, and S. Turnovsky, vol. 2. Cambridge: Cambridge University Press.
Hall, P., and J.L. Horowitz. 2003. Nonparametric methods for inference in the presence of instrumental variables. Working paper no. 102/03, CMMD.
Härdle, W., and O. Linton. 1994. Applied nonparametric methods. In Handbook of econometrics, ed. R.F. Engel and D.F. McFadden, vol. 4. Amsterdam: North-Holland.
Heckman, J.J., and R. Robb. 1985. Alternative methods for evaluating the impact of interventions. In Longitudinal analysis of labor market data, ed. J.J. Heckman and B. Singer. Cambridge: Cambridge University Press.
Hong, Y., and H. White. 1995. Consistent specification testing via nonparametric series regression. Econometrica 63: 1133–1159.
Imbens, G.W., and W.K. Newey. 2003. Identification and estimation of triangular simultaneous equations models without additivity. Mimeo, Massachusetts Institute of Technology.
Koenker, R.W. 2005. Quantile regression. Cambridge: Cambridge University Press.
Linton, O.B., and J.B. Nielsen. 1995. A kernel method of estimating structured nonparametric regression based on marginal integration. Biometrika 82: 93–100.
Matzkin, R.L. 1994. Restrictions of economic theory in nonparametric methods. In Handbook of econometrics, ed. R.F. Engel and D.L. McFadden, vol. 4. Amsterdam: North-Holland.
Matzkin, R.L. 1999. Nonparametric estimation of nonadditive random functions. Mimeo, Northwestern University.
Matzkin, R.L. 2003. Nonparametric estimation of nonadditive random functions. Econometrica 71: 1339–1375.
Matzkin, R.L. 2004. Unobservable instruments. Mimeo, Northwestern University.
Matzkin, R.L. 2005. Identification in nonparametric simultaneous equations. Mimeo, Northwestern University.
Matzkin, R.L. 2006. Estimation of nonparametric simultaneous equations. Mimeo, Northwestern University.
Matzkin, R.L. 2007a. Heterogenous choice. Invited lecture, ninth world congress of the econometric society. In Advanced in economics and econometrics, theory and applications, ninth world congress, ed. R. Blundell, W. Newey, and T. Persson, vol. 3. Cambridge: Cambridge University Press.
Matzkin, R.L. 2007b. Nonparametric identification. In Handbook of econometrics, ed. E. Leamer and J.J. Heckman, vol. 6. Amsterdam: North-Holland.
McFadden, D. 1974. Conditional logit analysis of qualitative choice behavior. In Frontiers in econometrics, ed. P. Zarembka. New York: Academic Press.
Newey, W.K. 1994. Kernel estimation of partial means and a general variance estimator. Econometric Theory 10: 233–253.
Newey, W., and J. Powell. 1989. Instrumental variables estimation of nonparametric models. Mimeo, Princeton University.
Newey, W., and J. Powell. 2003. Instrumental variables estimation of nonparametric models. Econometrica 71: 1565–1578.
Newey, W.K., J.L. Powell, and F. Vella. 1999. Nonparametric estimation of triangular simultaneous equations models. Econometrica 67: 565–603.
Ng, S., and J. Pinkse. 1995. Nonparametric two-step estimation of unknown regression functions when the regressors and the regression error are not independent. Mimeo, CIREQ.
Olley, G.S., and A. Pakes. 1996. The dynamics of productivity in the telecommunications equipment industry. Econometrica 64: 1263–1297.
Pagan, A., and A. Ullah. 1999. Nonparametric econometrics. Cambridge: Cambridge University Press.
Pinkse, J. 2000. Nonparametric two-step regression estimation when regressors and errors are dependent. Canadian Journal of Statistics 28: 289–300.
Powell, J.L., J.H. Stock, and T.M. Stoker. 1989. Semiparametric estimation of index coefficients. Econometrica 51: 1403–1430.
Prakasa Rao, B.L.S. 1983. Nonparametric functional estimation. New York: Academic Press.
Roehrig, C.S. 1988. Conditions for identification in nonparametric and parametric models. Econometrica 56: 433–447.
Wooldridge, J. 1992. Nonparametric regression tests based on an infinite dimensional least squares procedure. Econometric Theory 8: 435–451.
Yatchew, A.J. 1992. Nonparametric regression tests based on an infinite dimensional least squares procedure. Econometric Theory 8: 435–451.
Author information
Authors and Affiliations
Editor information
Copyright information
© 2018 Macmillan Publishers Ltd.
About this entry

Cite this entry
Matzkin, R.L. (2018). Non-parametric Structural Models. In: The New Palgrave Dictionary of Economics. Palgrave Macmillan, London. https://doi.org/10.1057/978-1-349-95189-5_2163
Download citation
DOI: https://doi.org/10.1057/978-1-349-95189-5_2163
Published:
Publisher Name: Palgrave Macmillan, London
Print ISBN: 978-1-349-95188-8
Online ISBN: 978-1-349-95189-5
eBook Packages: Economics and FinanceReference Module Humanities and Social SciencesReference Module Business, Economics and Social Sciences