
Abstract
Liquid biopsies represent novel promising tools to determine the impact of clonal heterogeneity on clinical outcomes with the potential to identify novel therapeutic targets in cancer patients. We developed a low-coverage whole-genome sequencing approach in order to noninvasively establish copy number aberrations in plasma DNA from metastasized cancer patients. Using plasma-Seq we were able to monitor genetic evolution including the acquirement of novel copy number changes, such as focal amplifications and chromosomal polysomies. The big advantage of our approach is that it can be performed on a benchtop sequencer, speed, and cost-effectiveness. Therefore, plasma-Seq represents an easy, fast, and affordable tool to provide the urgently needed genetic follow-up data. Here we describe our method including plasma DNA extraction, library preparation, and bioinformatic analyses.
Access provided by CONRICYT – Journals CONACYT. Download protocol PDF
Similar content being viewed by others


Key words
- Cell-free DNA
- Circulating tumor DNA
- Plasma DNA
- Copy number aberrations
- Low-coverage whole-genome sequencing
- Plasma-Seq
1 Introduction
The analysis of cell-free circulating tumor DNA from plasma, often referred to as “liquid biopsy” has recently gained considerable interest. Cell-free DNA is released from tumor and normal cells by different mechanisms including necrosis and apoptosis making it a challenging analyte owing to its high degree of fragmentation [1, 2]. Nevertheless, ctDNA is released from multiple tumor locations and therefore it reflects the entire tumor genome. Many recent studies have shown the feasibility of ctDNA analysis using next-generation sequencing based methods, thereby allowing the monitoring of tumor genomes by noninvasive means [3–14]. As the trend of optimal therapy management is towards decisions based on the current status of the entire tumor genome, the use of ctDNA as a liquid biopsy may help to obtain the urgently needed genetic follow-up data.
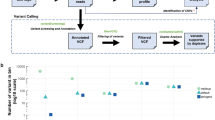
Generally, there are two approaches for the analysis of plasma DNA, (1) targeted approaches, which include the analysis of known genetic changes from the primary tumor or frequently occurring driver mutations, and (2) untargeted approaches like whole-genome sequencing, exome sequencing, or targeted resequencing of large gene panels. The main advantage of untargeted approaches is that they do not rely on recurrent genetic changes. Therefore, these methods are applicable to all patients including those who were diagnosed with synchronous metastases, where only limited tumor material is available. Furthermore, these methods can identify novel changes that were not present in the primary tumor, which makes them useful for monitoring tumor evolution and the identification of resistance mechanisms and newly occurring therapy targets. Given that chromosomal copy number changes occur frequently in human cancer, we developed an approach allowing the mapping of tumor-specific copy number aberrations from plasma DNA employing next generation sequencing . Therefore, we use shallow sequencing depth with a benchtop high-throughput instrument (Illumina MiSeq; Illumina, Inc., San Diego, CA, USA) to examine the tumor genomes of patients with metastasized cancer at reasonable costs. This so-called plasma-Seq brings the power of whole-genome analysis to a more routine clinical benchtop setting [8, 11]. Using plasma-Seq we were able to monitor genetic evolution including the acquirement of novel copy number changes, such as focal amplifications and chromosomal polysomies in colorectal cancer patients as a response to anti-EGFR therapy [13]. Here we describe our methods for the noninvasive establishment of tumor-specific copy number changes beginning with the blood draw, plasma DNA extraction, library preparation, and sequencing to the bioinformatic analysis. The analysis workflow is displayed in Fig. 1.

Analysis workflow of plasma-Seq
2 Materials
2.1 Blood Sampling
-
1.
1 EDTA Vacutainer tube (9 ml) for plasma DNA isolation (BD Biosciences).
-
2.
Syringe with 0.225 ml of 10 % neutral-buffered solution containing formaldehyde (NBF) (Sigma-Aldrich).
2.2 Extraction of Free Circulating DNA from Plasma
-
1.
QIAamp DNA Mini Kit (Qiagen).
-
2.
QIAGEN Proteinase K stock solution (store at room temperature, 15–25 °C).
-
3.
Buffer AL (store at room temperature, 15–25 °C): Mix Buffer AL thoroughly by shaking before use. Buffer AL is stable for 1 year when stored at room temperature. If a precipitate has formed in Buffer AL, dissolve by incubating at 56 °C.
-
4.
Buffer AW1* (store at room temperature, 15–25 °C): Buffer AW1 is supplied as a concentrate. Before using for the first time, add the appropriate amount of ethanol (96–100 %) to Buffer AW2 concentrate as indicated on the bottle. Buffer AW1 is stable for 1 year when stored closed at room temperature.
-
5.
Buffer AW2* (store at room temperature, 15–25 °C): Buffer AW2 is supplied as a concentrate. Before using for the first time, add the appropriate amount of ethanol (96–100 %) to Buffer AW2 concentrate as indicated on the bottle. Buffer AW2 is stable for 1 year when stored closed at room temperature.
-
6.
Nuclease-free water.
-
7.
Water bath or heating block at 56 °C.
-
8.
Speed Vac centrifuge (Eppendorf).
-
9.
2100 Bioanalyzer (Agilent).
-
10.
Agilent DNA High Sensitivity Kit.
2.3 Quantification of Free Circulating DNA from Plasma with Qubit
-
1.
Qubit® 3.0 Fluorometer (Life Technologies).
-
2.
Qubit® dsDNA HS Assay Kit (Life Technologies).
-
3.
Thin-wall, clear 0.5 ml PCR tubes.
2.4 Library Preparation
-
TruSeq® Nano DNA Sample Preparation kit (Illumina).
2.4.1 End Repair
-
End Repair Mix 2 (ERP2).
-
Resuspension buffer (RSB).
-
Sample Purification Beads (AMPure XP beads) (SPB).
-
1.5 ml microcentrifuge tubes.
-
0.2 ml PCR tubes.
-
Freshly prepared 80 % ethanol (EtOH).
2.4.2 A-Tailing
-
A-Tailing Mix.
-
Resuspension buffer (RSB).
-
RNase/DNase-free strip tubes.
2.4.3 Adapter Ligation
-
DNA Adapter Indices A or B.
-
Ligation mix 2 (LIG2).
-
Resuspension buffer (RSB) 1.
-
Sample Purification Beads (AMPure XP beads) (SPB).
-
Stop ligation buffer.
-
0.2 ml PCR tubes or stripes.
-
Freshly prepared 80 % ethanol (EtOH), 800 μl per sample.
2.4.4 Enrichment
-
Enhanced PCR mix (EPM).
-
PCR primer cocktail (PPC).
-
Sample Purification Beads (AMPure XP beads) (SPB).
-
RSB.
-
PCR tubes.
2.4.5 Validation
-
Bioanalyzer Agilent.
-
Agilent DNA 7500 Kit.
2.4.6 Quantification
-
Fast SYBR® Green Master Mix (Life Technology).
-
LibQuant_F: 5′ AATGATACGGCGACCACCGAGAT 3′.
-
LibQuant_R: 5′ CAAGCAGAAGACGGCATACGA 3′.
-
Real-time PCR instrument.
2.4.7 Pooling of Libraries and Sequencing
-
MiSeq (Illumina).
-
MiSeq Reagent Kit v3 (150 cycles).
-
HT1 (hybridization buffer), thawed and pre-chilled.
-
1.0 N NaOH, molecular biology grade.
-
Tris-Cl 10 mM, pH 8.5 with 0.1 % Tween 20 (General lab supplier).
2.4.8 Bioinformatics
-
Basic Linux system.
-
Python scripts from Baslan et al. [15].
-
bwa (http://bio-bwa.sourceforge.net/) [16].
-
samtools (http://samtools.sourceforge.net/) [17].
-
R (http://www.r-project.org/) [18].
-
R-package CGHweb (http://compbio.med.harvard.edu/CGHweb/Rpackage.html) [19] including the R-packages needed by CGHweb: waveslim, quantreg, snapCGH, cghFLasso, FASeg, GLAD, GDD, gplots.
3 Methods
3.1 Blood Sampling
-
1.
After blood sampling 0.225 ml NBF should be immediately added to the blood in the EDTA tube to stabilize cell membranes and to impede additional cell lysis that might further dilute free circulating DNA with “normal DNA” from these cells (see Notes 1 and 2 ).
-
2.
Samples should be gently inverted, stored at RT, and further processed within 2 h. As soon as the samples arrive at the laboratory, plasma isolation should be started immediately.
3.2 Plasma Extraction from Whole Blood
-
1.
Fill the whole blood into a 15 ml tube.
-
2.
Centrifuge tubes at 200 × g for 10 min.
-
3.
Perform a subsequent centrifugation step at 1600 × g for 10 min (see Note 4 ).
-
4.
Collect the supernatant (plasma without any cells) and transfer it to a new 15 ml tube and spin at 1600 × g for 10 min (see Note 4 ).
-
5.
Carefully transfer plasma to a new sterile 1.5 ml Eppendorf by aliquoting to 1 ml and store at −80 °C for future use (see Note 3 ).
3.3 Extraction of Free Circulating DNA from Plasma
Plasma DNA extraction is performed using QIAamp DNA Mini Kit, Qiagen. The protocol is slightly modified from “QIAamp® DNA Mini Kit and QIAamp DNA Blood Mini Kit Handbook.”
-
1.
Isolate plasma DNA either from 1 ml freshly prepared plasma or from 1 ml of stored plasma. In the latter case thaw plasma on room temperature and proceed immediately after thawing.
-
2.
For the extraction of 1 ml plasma pipet 50 μl QIAGEN Proteinase K into the bottom of two 2 ml microcentrifuge tubes (see Note 5 ).
-
3.
Add 500 μl plasma to each of the microcentrifuge tubes.
-
4.
Add 500 μl Buffer AL to the samples. Mix by pulse-vortexing for 15 s.
-
5.
Incubate at 56 °C for 10 min. (DNA yield reaches a maximum after lysis for 10 min at 56 °C. Longer incubation times have no effect on yield or quality of the purified DNA.)
-
6.
Briefly centrifuge the microcentrifuge tube to remove drops from the inside of the lid.
-
7.
Add 500 μl ethanol (96–100 %) to the samples, and mix again by pulse-vortexing for 15 s. After mixing, briefly centrifuge the tube to remove drops from the inside of the lid.
-
8.
Carefully apply 700 μl of the mixture from step 6 to the QIAamp Mini spin column (in a 2 ml collection tube) without wetting the rim. Close the cap, and centrifuge at 6000 × g (8000 rpm) for 1 min. Remove flow-through, apply the remaining volume of the mixture to the column, and repeat centrifugation.
-
9.
Repeat step 7 until the mixture from both tubes from step 6 has been transferred to the spin column.
-
10.
Place the QIAamp Mini spin column in a clean 2 ml collection tube, and discard the tube containing the filtrate (see Note 6 ).
-
11.
Carefully open the QIAamp Mini spin column and add 500 μl Buffer AW1 without wetting the rim. Close the cap and centrifuge at 6000 × g (8000 rpm) for 1 min. Place the QIAamp Mini spin column in a clean 2 ml collection tube, and discard the collection tube containing the filtrate.
-
12.
Open the QIAamp Mini spin column and add 500 μl Buffer AW2 without wetting the rim. Close the cap and centrifuge at full speed (20,000 × g; 14,000 rpm) for 3 min (see Note 7 ).
-
13.
Place the QIAamp Spin Column in a new 2 ml collection tube (not provided) and discard the collection tube with the filtrate. Centrifuge at full speed for 1 min.
-
14.
Place the QIAamp Mini spin column in a clean 1.5 ml microcentrifuge tube and discard the collection tube containing the filtrate. Carefully open the QIAamp Mini spin column and add 60–90 μl of nuclease-free water. Incubate at room temperature (15–25 °C) for 5 min and then centrifuge at 6000 × g (8000 rpm) for 1 min.
-
15.
Proceed with quantification or store samples at −20 °C.
3.4 Quantification of Plasma DNA Using Qubit dsDNA HS Assay Kit
-
1.
Set up the number of 0.5 ml tubes you will need for two standards and the number of samples that are measured, and label the tubes.
-
2.
Prepare the Qubit™ working solution by diluting the Qubit™ dsDNA HS reagent 1:200 in Qubit™ dsDNA HS buffer. Use a clean plastic tube (and no glass container) each time you make the working solution (see Note 8 ).
-
3.
Note: The final volume for measuring is 200 μl. Each of the two standard tubes will require 190 μl of working solution, and each sample tube will require 195 μl. Prepare sufficient working solution to accommodate all standards and samples.
-
4.
Preparing of the standards: Pipet 190 μl of working solution into each of the tubes used for standards and add 10 μl of each Qubit™ standard to the appropriate tube and mix by vortexing 2–3 s, being careful not to create bubbles.
-
5.
Preparing the samples: Load 5 μl of your samples and add 195 ml of working solution to the tube. Mix by vortexing for 2–3 s (see Note 9 ).
-
6.
Incubate tubes at room temperature for 2 min.
-
7.
On the Home Screen of the Qubit® 2.0 Fluorometer, press DNA, and then select dsDNA High Sensitivity as the assay type.
-
8.
Press “Read new standard” to run a new calibration and follow the instructions on the screen. Insert the tube containing Standard #1, close the lid, and press “Read.” Then remove Standard #1 and insert the tube containing Standard #2, close the lid, and press “Read.” Remove Standard #2.
-
9.
Insert a sample tube into the Qubit 2.0 Fluorometer, close the lid, and press “Read.”
-
10.
Upon completion of the sample measurement, press “Calculate Stock Conc.” The Dilution Calculator Screen containing the volume roller wheel is displayed. Select the volume of your original sample (5 μl) that you have added to the assay tube. When you stop scrolling, the Qubit® 2.0 Fluorometer calculates the original sample concentration based on the measured assay concentration.
-
11.
Select the unit for your original sample concentration by touching the desired unit in the unit selection pop-up window. To close the unit selection pop-up window, touch anywhere on the screen outside.
-
12.
Insert the next sample, and “Read Next Sample.”
-
13.
Repeat sample readings until all samples have been read.
3.5 Assessment of DNA Integrity on an Agilent Bioanalyzer
For comparable results the amount of cfDNA should be normalized before loading the Bioanalyzer chip. 800 pg seems to be the optimal amount for analyzing the DNA integrity of cfDNA since healthy controls show only one peak at 160 bp with this amount whereas tumor patients often show an additional peak at 320 bp. However, for samples with very low concentration the Bioanalyzer may be omitted. Examples for Bioanalyzer profiles of a monophasic and biphasic size distribution are shown in Fig. 2.

Examples of size distribution of plasma DNA. (a) An enrichment of fragments in the range of 160 bp can be observed representing a monophasic size distribution. (b) Biphasic size distribution with an additional peak in the range of 320 bp. (c) Fragments larger than 100 bp indicate contamination with normal DNA from blood cells
-
1.
Calculate the volume of your sample that contains 1600 pg.
-
2.
Concentrate the volume to 2 μl in a SpeedVac Eppendorf centrifuge (Program V-AQ, room temperature) and load 1 μl corresponding to a High Sensitivity Bioanalyzer chip.
-
3.
Analyze the chip on a 2100 Agilent Bioanalyzer.
-
4.
You should observe at least one peak with a maximum of approximately 160 bp (monophasic size distribution). In some samples further peaks corresponding to multiples of 160 bp might be observed (biphasic size distribution) (see Fig. 1 and Note 10 ).
3.6 Library Preparation
Library preparation is performed using the TruSeq Nano DNA Sample Preparation kit. However, our protocol includes several changes (see Note 11 ).
3.6.1 End Repair
-
1.
Use 5–10 ng of DNA as input amount; adjust the volume to 60 μl with RSB in a 200 μl PCR-tube.
-
2.
Centrifuge the thawed end repair mix 2 tube to 600 × g for 5 s.
-
3.
Add 40 μl of end repair mix 2 to the tube containing the fragmented DNA and mix by gently pipetting the entire volume up and down ten times.
-
4.
Incubate the tube at 30 °C for 30 min in a thermal cycler. Choose with preheat lid option and set to 100 °C. Hold at 4 °C.
-
5.
Remove the tube at 4 °C.
-
6.
Dilute AMPure Beads (Sample Purification Beads) (see Note 12 ). Determine the amount of Sample Purification Beads and PCR-grade water needed to combine to prepare a diluted bead mixture: Sample Purification Beads: # of samples × 160 μl × 0.85 = μl Sample Purification Beads. PCR-grade water: # of samples × 160 μl × 0.15 = μl PCR-grade water.
-
7.
Add 160 μl of the diluted bead mixture to a 1.5 ml Eppendorf tube and add 100 μl of End Repair Mix. Gently pipette the entire volume up and down ten times to mix thoroughly.
-
8.
Incubate at room temperature for 10 min.
-
9.
Place the tube on a magnetic stand at room temperature until the liquid appears clear (approximately 5–10 min).
-
10.
Remove and discard the supernatant.
-
11.
Leave the tube on the magnetic stand and add 200 μl of freshly prepared 80 % EtOH to each tube without disturbing the beads.
-
12.
Incubate at room temperature for 30 s, then remove, and discard all of the supernatant from each tube. Take care not to disturb the beads.
-
13.
Repeat steps 8 and 9 once for a total of two 80 % EtOH washes.
-
14.
Leave the tube on the magnetic stand and dry it at room temperature for 15 min to dry.
-
15.
Remove the tube from the magnetic stand and resuspend the dried pellet with 17.5 μl RSB.
-
16.
Incubate tube at room temperature for 2 min.
-
17.
Place the tube back on the magnetic stand at room temperature for 5 min or until the liquid appears clear.
-
18.
Transfer 15 μl of the clear supernatant from each tube to a new 0.2 ml PCR tube.
3.6.2 Adenylate 3′ Ends
-
1.
Thaw the A-Tailing Mix and centrifuge the tube to 600 × g for 5 s.
-
2.
Add 12.5 μl of thawed A-Tailing Mix to each tube containing the samples from the end repair and mix gently by pipetting the entire volume up and down ten times.
-
3.
Place the tube on a pre-programmed thermal cycler and run the program as follows: Choose the preheat lid option and set to 100 °C, 37 °C for 30 min, 70 °C for 5 min, 4 °C for 5 min, and hold at 4 °C.
-
4.
When the thermal cycler temperature has been at 4 °C for 5 min, remove the tube from the thermal cycler and briefly spin down the liquid. Proceed immediately to adapter ligation.
3.6.3 Adapter Ligation
-
1.
Thaw the adapter tubes and centrifuge the thawed tubes to 600 × g for 5 s.
-
2.
Centrifuge the stop ligation buffer tube to 600 × g for 5 s.
-
3.
Add 2.5 μl of RSB to tube with the adenlyated samples.
-
4.
Add 2.5 μl of ligation mix 2 to each tube.
-
5.
Add 2.5 μl of the appropriate thawed DNA Adapter Index to tube and mix by gently pipetting the entire volume up and down ten times.
-
6.
Briefly spin down the tube on a pre-programmed thermal cycler and run the program as follows: Choose the thermal cycler pre-heat lid option and set to 100 °C, 30 °C for 10 min, Hold at 4 °C.
-
7.
Remove the tube from the thermal cycler and add 5 μl of stop ligation buffer. Mix gently pipetting the entire volume up and down ten times.
-
8.
Vortex the Sample Purification Beads for at least 1 min or until they are well dispersed, then add 42.5 μl of the Sample Purification Beads to tube mix by gently pipetting the entire volume up and down ten times.
-
9.
Incubate at room temperature for 5 min.
-
10.
Place the tube on the magnetic stand at room temperature for 5 min or until the liquid appears clear.
-
11.
Remove and discard 80 μl of the supernatant from tube and take care not to disturb the pellet.
-
12.
With the tube remaining on the magnetic stand, add 200 μl of freshly prepared 80 % EtOH to each well without disturbing the beads.
-
13.
Incubate at room temperature for 30 s, then remove, and discard all of the supernatant. Take care not to disturb the beads.
-
14.
Repeat steps 12 and 13 once for a total of two 80 % EtOH washes.
-
15.
With the tube remaining on the magnetic stand, let the samples air dry at room temperature for 5 min. Remove and discard any remaining EtOH with a 10 μl pipette.
-
16.
Add 52.5 μl of RSB to the tube and remove tube from the magnetic stand.
-
17.
Resuspend the beads by repeatedly dispensing the RSB over the bead pellet until it is immersed in the solution, and then gently pipette the entire volume up and down ten times to mix thoroughly.
-
18.
Incubate at room temperature for 2 min.
-
19.
Place the tube back on the magnetic stand at room temperature for 5 min or until the liquid appears clear.
-
20.
Transfer 50 μl of the clear supernatant from each tube to a new 1.5 ml Eppendorf tube. Take care not to disturb the beads.
-
21.
Vortex the Sample Purification Beads until they are well dispersed.
-
22.
Add 50 μl of mixed Sample Purification Beads to each tube for a second clean up, mix and incubate at room temperature for 5 min.
-
23.
Place the tube on the magnetic stand at room temperature for 5 min or until the liquid appears clear.
-
24.
Remove and discard 95 μl of the supernatant. Take care not to disturb the beads.
-
25.
Add 200 μl of freshly prepared 80 % EtOH to each well and incubate at room temperature for 30 s. Take care not to disturb the beads.
-
26.
Remove and discard all of the supernatant.
-
27.
Repeat steps 24 and 25 once for a total of two 80 % EtOH washes.
-
28.
With the tube remaining on the magnetic stand, let the samples air-dry at room temperature for 5 min.
-
29.
Remove and discard any remaining EtOH with a 10 μl pipette.
-
30.
Add 27.5 μl of RSB to each tube and then remove tubes from the magnetic stand.
-
31.
Resuspend the beads by repeatedly dispensing the RSB over the bead pellet until it is immersed in the solution, and then gently pipette the entire volume up and down ten times to mix thoroughly.
-
32.
Incubate at room temperature for 2 min.
-
33.
Place the tube on the magnetic stand at room temperature for 5 min or until the liquid appears clear.
-
34.
Transfer 25 μl of the clear supernatant to a new 0.2 ml PCR tube.
3.6.4 Enrich DNA Fragments
-
1.
Add 5 μl thawed PCR primer cocktail to each tube from the adapter ligation.
-
2.
Add 20 μl thawed enhanced PCR Mix to each well of the PCR plate and mix gently by pipetting the entire volume up and down ten times to mix.
-
3.
Close the tubes and place them into a pre-programmed thermal cycler.
-
4.
Run the following program:
-
(a)
Choose the preheat lid option and set to 100 °C.
-
(b)
95 °C for 3 min.
-
(c)
25 cycles of:
-
98 °C for 20 s.
-
60 °C for 15 s.
-
72 °C for 30 s.
-
-
(d)
72 °C for 5 min.
-
(e)
Hold at 4 °C.
-
(a)
-
5.
Remove tubes from thermal cycler and spin down the liquid and transfer to a 1.5 ml tube.
-
6.
Vortex the Sample Purification Beads until they are well dispersed.
-
7.
Add 50 μl mixed Sample Purification Beads to each tube 5 containing 50 μl of the PCR amplified library and mix well mix gently by pipetting the entire volume up and down ten times to mix.
-
8.
Incubate the PCR plate at room temperature for 5 min.
-
9.
Place the tubes on the magnetic stand at room temperature for 5 min or until the liquid is clear.
-
10.
Remove and discard 95 μl of the supernatant from each tube.
-
11.
With the PCR plate on the magnetic stand, add 200 μl freshly prepared 80 % EtOH to each tube without disturbing the beads.
-
12.
Incubate at room temperature for 30 s, and then remove and discard all of the supernatant.
-
13.
Repeat steps 8 and 9 one time for a total of two 80 % EtOH washes.
-
14.
With the tube on the magnetic stand, let the samples air-dry at room temperature for 5 min. Remove and discard any remaining EtOH from each tube with a 10 μl pipette.
-
15.
With the tube on the magnetic stand, add 32.5 μl RSB to each well of the PCR plate.
-
16.
Remove tubes from the magnetic stand.
-
17.
Resuspend the beads by repeatedly dispensing the RSB over the bead pellet until it is immersed in the solution. Mix gently by pipetting the entire volume up and down ten times to mix.
-
18.
Incubate at room temperature for 2 min.
-
19.
Place the tube on the magnetic stand at room temperature for 5 min or until the liquid is clear.
-
20.
Transfer 30 μl of the clear supernatant from to a new tube.
-
21.
Proceed to library validation or store the library at −15 to −25 °C.
3.6.5 Validate Library
-
1.
Run 1 μl of the library on a Bioanalyzer for qualitative purposes only. Proceed to library validation or store the library at −15 to −25 °C. Examples for successful library preparations are shown in Fig. 3.
Fig. 3 
Examples of library preparations form plasma DNA. Due to its fragmentation plasma DNA libraries do not show a normal size distribution of DNA fragments as it would be expected for shotgun libraries from high-molecular-weight DNA after fragmentation

3.6.6 Quantification of Libraries
To achieve the highest data quality on the Illumina MiSeq accurate quantification is of utmost interest. Although you can use fluorometric quantification methods that use dsDNA binding, qPCR is the most accurate methods in order to achieve optimized cluster densities across every lane of a flow cell. As a standard we use a library that achieved optimal cluster density in a MiSeq run. Alternatively you can use the PhiX control library or commercially available kits.
-
1.
Prepare a 2× serial dilution of your standard (PhiX or exciting library from a previous run) starting from 50 to 1.56 pM.
-
2.
Based on the Bioanalyzer result, prepare a 10 nM working dilution of your library.
-
3.
For qPCR quantification dilute the library 1:500, 1:1000, and 1:2000.
-
4.
Prepare a 96-well reaction plate and configure the plate for three replicates of each of the standard and library dilutions and calculate the number of reaction needed for the qPCR. A possible plate configuration for quantification 6 libraries is displayed in Fig. 4.
Fig. 4 
Example of a plate configuration for quantification of plasma DNA libraries using qPCR. A total of six libraries can be concomitantly analyzed in one plate.S standard,U unknown samples
-
5.
Prepare a master mix according to the number of samples of 10 μl of Fast SYBR® Green Master Mix (2×) and 0.5 μl of the 10 μM primers LibQuant_F and LibQuant_R and 7 μl PCR-grade water.
-
6.
Transfer 18 μl of the master mix to each well of the 96-well plate.
-
7.
Add 2 μl of your samples to the wells.
-
8.
In your real-time software program choose “Absolute Quantification.”
-
9.
Define the number and ratios of you standard dilutions and assign them to the wells containing the standard samples. Then define the targets (libraries to be quantified) and assign them to the wells in the reaction plate.
-
10.
Run the reaction plate on a qPCR instrument using the following program:
-
(a)
95 °C for 20 s.
-
(b)
40 cycles of:
-
Denature 95 °C for 3 s.
-
Anneal/extend 60 °C for 30 s.
-
-
(a)
-
11.
When the run is complete, check the NTC wells for any amplification. There should be no amplification.
-
12.
Check for any outliers in you replicates are >0.5 Ct and omit these from you analysis.
-
13.
Check whether all library dilutions are within the range of the standard curve. In case a dilution is out of range omit these samples from the analysis.
-
14.
Check the threshold and adjust it in case it is not set appropriately.
-
15.
Export the analysis results and calculate a mean concentration of your samples by taking the original dilution into account (1:500, 1:1000, 1.2000).

3.7 Pooling and Preparing Libraries for the Sequencing
-
1.
Dilute the libraries according to the concentrations from the qPCR 4 nM.
-
2.
Pool a total of six libraries by transferring 5 μl of each library into a 1.5 ml tube (see Note 13 ).
-
3.
Prepare 1 ml of 0.2 N NaOH (800 μl laboratory-grade water + 200 μl 1.0 N NaOH) (see Note 14 ).
-
4.
For denaturation transfer 5 μl of your library pool to a fresh 1.5 ml tube and add 5 μl freshly diluted 0.2 N NaOH.
-
5.
Vortex briefly to mix spin down the sample solution.
-
6.
Incubate for 5 min at room temperature.
-
7.
Add 990 μl of the pre-chilled HT1 buffer to the tube. Your library is now concentrated to 20 pM in 1 mM NaOH.
-
8.
Place the denatured library pool on ice until you are ready to proceed to final dilution.
-
9.
The final dilution should be adjusted to our sequencing instrument. Based on our experience a final dilution of 8–12 pM results in optimal cluster density for a MiSeq Reagent Kit v3 (150 cycle V3) run (see Note 15 ).
3.8 Bioinformatics
For the analysis of Plasma-Seq , a depth-of-coverage algorithm is most appropriate. That is, we count the amount of reads in previously specified genomic regions (often called bins, or windows). These raw read counts must be normalized since several factors (such as GC-count) may introduce a bias in the results. Our analysis algorithm is based on the procedure described by Baslan et al. [15], who used this approach to detect copy-numbers from single-nucleus sequencing experiments [20].
Firstly, the pseudo-autosomal region of the chromosome Y is masked, since it is impossible to differentiate between the copy on the chromosome Y and the corresponding part on chromosome X [15]. We divide the genome into 50,000 regions of an average length of about 56 kbp, with each region containing the same amount of mappable positions. This was done by generating synthetic 150 bp reads from the hg19 genome for each position and mapping them back to check whether a perfect match coming from that position would yield an alignment [15]. Hence, some genomic windows (e.g., regions containing repeats, segmental duplications) are larger than average.
We then map the resulting reads to the hg19 genome and count reads within each of the 50,000 genomic regions. Since the amount of reads within each genomic region depends not only on the copy number but on the GC content of that region, we correct for GC content of each genomic region using LOWESS-smoothing. Moreover, GC-corrected read counts are corrected using the mean read counts of non-tumor controls (raw sequencing data of a set of 20 controls without any sign of malignant disease are available at EBI-EGA https://www.ebi.ac.uk/ega/home under the accession number EGAS00001000451 [11]).
In a further step, regions having similar read counts are grouped using existing segmentation algorithms and means of each copy number segments are calculated. To reliably identify segments with aberrant copy numbers and to increase sensitivity we calculate z-scores for each segment by subtracting the mean read counts of healthy controls and dividing by the standard-deviation (SD). We define a significant change in the regional representation of plasma DNA as > 3 SDs from the mean representation of the healthy controls for the bins in the corresponding segment.
3.8.1 Setup
You can skip the preparation step if you already have files containing the bin boundaries and the corresponding GC contents. Bin boundaries for synthetic 150 bp reads using BWA for alignment are available on request from the authors.
-
1.
Download the hg19 reference genome (e.g.:http://hgdownload.cse.ucsc.edu/goldenPath/hg19/bigZips/chromFa.tar.gz).
-
2.
Mask the pseudo-autosomal region of the chromosome Y using the script provided in [15]: (hg19.chrY.psr.py).
-
3.
Combine the FASTA files to a single multi-entry FASTA files. Make sure to use the PAR-masked chromosome Y file.
cat chr1.fa chr2.fa chr3.fa chr4.fa chr5.fa chr6.fa chr7.fa chr8.fa chr9.fa chr10.fa chr11.fa chr12.fa chr13.fa chr14.fa chr15.fa chr16.fa chr17.fa chr18.fa chr19.fa chr20.fa chr21.fa chr22.fa chrX.fa chrY.fa > hg19.fa
-
4.
Create an index for bwa using the PAR masked multi-entry FASTA file.
bwa index -p hg19_par_masked hg19.fa
-
5.
Generate synthetic 150 bp reads for each position on the hg19 genome using the script provided in [15]: (hg19.generate.reads.k50.py; modify to output 150 bp reads). This script generates FASTQ files, each containing 150 million reads.
-
6.
Align the synthetic 150 bp reads back to the PAR-masked hg19 genome.
bwa aln -f <SAI File> hg19_par_masked <FASTQ File>
bwa samse -f <SAM File> hg19_par_masked <SAI File> <FASTQ File>
-
7.
Create a list of chromosome sizes using the script provided in [15] (hg19.chrom.sizes.py).
-
8.
Create the “goodzones” file: i.e., create a list of contiguous blocks, of which every position can be aligned back to the original position with bwa (hg19.bowtie.goodzones.k50.py).
-
9.
Count the number of mappable positions on each chromosome using the script provided in [15]hg19.chrom.mappable.bowtie.k50.py.
-
10.
Compute the bin boundaries for 50,000 genomic bins (hg19.bin.boundaries.50k.py).
-
11.
Sort the bin boundaries and compute GC-content for each bin (hg19.varbin.gc.content.50k.bowtie.k50.py).
3.8.2 Analysis
-
1.
Align FASTQ files to PAR-masked hg19 genome using bwa. Replace the text within the parentheses with the appropriate file names.
bwa aln -f <SAI File> hg19_par_masked <FASTQ File>
bwa samse -f <SAM File> hg19_par_masked <SAI File> <FASTQ File>
-
2.
Convert Text-based SAM file to BAM file.
samtools view -S -b -o <BAM File> <SAM File>
-
3.
Remove PCR duplicates using samtools rmdup and convert back to SAM.
samtools rmdup -s <BAM File> <RMDUP BAM File>
samtools sort <RMDUP BAM File> <Sorted RMDUP BAM File>
samtools view <Sorted RMDUP BAM File> > <Sorted RMDUP SAM File>
-
4.
Count reads in bins (varbin.50k.sam.py from [15]). The output of this script is a text-based file containing bin positions, raw read counts per bin and read counts normalized by the median read count (to account for varying sequencing yields per sample).
varbin.50k.sam.py <Sorted RMDUP SAM File> <Bincounts File> <Statistics File>
-
5.
Postprocessing and normalization in R (modified from SRR054616.cbs.r script from Baslan [15]), Load R
R
-
6.
Load library CGH Web.
library("CGHweb")
-
7.
Define lowess function to correct for GC-content.
lowess.gc <- function(jtkx, jtky) {
jtklow <- lowess(jtkx, log(jtky), f=0.05)
jtkz <- approx(jtklow$x, jtklow$y, jtkx)
return(exp(log(jtky) - jtkz$y))
}
-
8.
Define postprocess function.
postprocess <- function(indir, outdir, bad.bins, varbin.gc, varbin.data, sample.name, alt.sample.name, alpha, nperm, undo.SD, min.width) {
gc <- read.table(varbin.gc, header=T)
bad <- read.table(bad.bins, header=F)
chrom.numeric <- substring(gc$bin.chrom, 4)
chrom.numeric[which(gc$bin.chrom == "chrX")] <- "23"
chrom.numeric[which(gc$bin.chrom == "chrY")] <- "24"
chrom.numeric <- as.numeric(chrom.numeric)
thisRatio <- read.table(paste(indir, varbin.data, sep="/"), header=F)
names(thisRatio) <- c("chrom", "chrompos", "abspos", "bincount", "ratio")
thisRatio$chrom <- chrom.numeric
a <- thisRatio$bincount + 1
thisRatio$ratio <- a / mean(a)
thisRatio$gc.content <- gc$gc.content
thisRatio$lowratio <- lowess.gc(thisRatio$gc.content, thisRatio$ratio)
a <- quantile(gc$bin.length, 0.985)
thisRatioNobad <- thisRatio[which(bad[, 1] == 0),]
write.table(thisRatio,file=paste(sample.name, ".corrected.bincounts", sep=""), sep="\t", row.names=FALSE)
# replace <Mean control read counts> with actual filepath
controlsRatio <-read.table(<Mean control read counts>, header=F)
controlsRatio$ratio<-controlsRatio$V5
controlsRatio$ratio[which(controlsRatio$ratio == 0)] <- 0.001
controlsRatio$lowratio<- lowess.gc(thisRatio$gc.content, controlsRatio$ratio)
thisRatio$normlowratio <- thisRatio$lowratio / controlsRatio$lowratio
printDataframe <- data.frame(chrom=thisRatio$chrom, pos=thisRatio$chrompos,gc=thisRatio$gc.content, ratio = thisRatio$ratio, lowratio=thisRatio$lowratio, controlRatio = controlsRatio$lowratio, normratio = thisRatio$normlowratio)
#cghweb analysis
CGHweb_ratios<-data.frame(ProbeID=(1:length(thisRatio$chrom)),Chromosome=thisRatio$chrom,LogRatio=log(thisRatio$normlowratio, 2),Position=thisRatio$chrompos)
runCGHAnalysis(CGHweb_ratios, BioHMM = FALSE, UseCloneDists = FALSE, Lowess = FALSE, Lwidth = 15, Wavelet = FALSE, Wlevels = 3, Runavg = FALSE,Rwidth = 5, CBS = TRUE, alpha = 0.05, Picard = FALSE, Km = 20,S = -0.5, FusedLasso = FALSE, fluv = FALSE, FDR = 0.5,rsm = FALSE, GLAD = TRUE, qlambda = 0.999,FASeg = FALSE, sig = 0.025, delta = 0.1, srange = 50, fineTune = FALSE, Quantreg = FALSE, lambda = 1,minLR = -2, maxLR = 2, Threshold = 0.2,genomeType = "HG19", tempDir = getwd(), resultDir = "CGHResults")
}
-
9.
Call postprocess function (replace brackets (<>) with actual filepaths). CGHWeb creates a directory (CGHResults) containing plots and a text file (Table_of_aCGH_smoothed_profiles.txt) containing the segmented bin counts.
postprocess(indir=".", outdir=".", bad.bins=<BAD BINS>, varbin.gc=<GC Content File>, varbin.data=<Bincounts File>, sample.name=<Sample name>, alt.sample.name="", alpha=0.05, nperm=1000, undo.SD=1.0, min.width=5)
-
10.
Extract copy number segment boundaries and mean log2-ratios from Table_of_aCGH_smoothed_profiles.txt using Perl. The first command-line argument is the Table_of_aCGH_smoothed_profiles.txt and the s argument is the output (text) file containing Segment boundaries and mean log2-ratios. The script is available on request from the authors.
-
11.
For each segment z-scores are calculated by summing up GC-corrected bincounts of bins within that segment for the sample and each of the controls. The mean of the sums of the controls are subtracted from the sample bincount sum and divided by the standard deviation of sums of the controls. The script and corrected bincounts of controls are available on request from the authors.
-
12.
Results can be plotted using R. Specify the output file in <Output File>.(see Note 16 )
ratio<-read.table(“Table_of_aCGH_smoothed_profiles.txt”, header=TRUE);
png(filename = <Output File>, width = 2280, height = 218,
units = "px", pointsize = 20, bg = "white", res = NA)
par(mar=c(4,0,0,0))
count<-1
widths<-vector(length=24)
for (i in c(1:24)) {
ch <- which(ratio$Chromosome==i)
widths[count]<-max(ratio$Position[ch])
count<-count+1
}
nf <- layout(matrix(c(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24), 1, 24, byrow=TRUE), widths=widths)
for (i in c(1:24)) {
chrom <- which(ratio$Chromosome==i)
if (length(chrom)>0) {
plot(ratio$Position[chrom],ratio$LogRatio[chrom],ylim = c(-2,2),yaxt="n",xlab = paste ("chr",i),ylab = "log2-ratios",pch = ".",col = colors()[201])
points(ratio$Position[chrom],ratio$Summary[chrom], pch = ".", col = colors()[88],cex=3)
chrom <- which(ratio$Chromosome==i& ratio$Summary > 0.2)
points(ratio$Position[chrom],ratio$Summary[chrom], pch = ".", col = colors()[136],cex=3)
chrom <- which(ratio$Chromosome==i& ratio$Summary < -0.2)
points(ratio$Position[chrom],ratio$Summary[chrom], pch = ".", col = colors()[461],cex=3)
abline(h=0)
}
}
dev.off()
4 Notes
-
1.
Blood tubes should be inverted the tube several times in order to prevent coagulation and to preserve blood cells from bursting that might dilute the fraction of circulating tumor DNA.
-
2.
High-molecular-weight DNA on a Bioanalyzer profile indicates contamination with DNA from blood cells (see Fig. 2c).
-
3.
Hemolysis and released haem may interfere with subsequent amplification methods. Therefore, presence of hemolysis should be documented for troubleshooting.
-
4.
All centrifugation steps for plasma extraction should be done with the brake and acceleration powers set to zero.
-
5.
QIAamp Mini kit: do not add QIAGEN Protease or proteinase K directly to Buffer AL.
-
6.
QIAamp Mini kit: Close each spin column in order to avoid aerosol formation during centrifugation. Centrifugation at full speed will not affect the yield or purity of the DNA. If the lysate has not completely passed through the column after centrifugation, centrifuge again at higher speed until the QIAamp Mini spin column is empty.
-
7.
QIAamp Mini kit: Residual Buffer AW2 in the eluate may cause problems in downstream applications. Therefore, an additional centrifugation step may be performed to eliminate buffer residuals.
-
8.
Qubit: Use only thin-wall, clear 0.5 ml PCR tubes.
-
9.
If plasma DNA concentration is below the detection limit of Qubit, either use larger volumes of plasma DNA or concentrate the sample in a speed Vac. The sample can be anywhere in the range of 1 and 20 μl. Add working solution so that the final volume in each tube after adding sample is 200 μl.
-
10.
Based on our experience the likelihood of identifying copy number aberrations is higher in samples with a biphasic size distribution on a Bioanalyzer.
-
11.
During library preparation there several save stopping points. Samples can be stored at −15 to −25 °C for up to 7 days after end repair, adapter ligation, PCR amplification, and validation.
-
12.
In the Protocol AMPure Beads are referred to as “Sample Purification Beads.” Before use remove SPB from 2 to 8 °C storage and let stand for at least 30 min to bring them to room temperature.
-
13.
When pooling six libraries in one run be aware that only libraries with different indices can be pooled in one run.
-
14.
Always prepare freshly diluted NaOH for library denaturation.
-
15.
When using a MiSeq Reagent 150 cycle kit you should obtain a cluster density of 1200–1400 kg/mm2. Based on our experience approximately 85–95 % of clusters should pass the filters and more than 90 % of reads should be above Q30 (Fig. 5a, b). Pooling should result in the same amount of reads for all samples (Fig. 5c, d).
Fig. 5 
Quality parameters of pooling and sequencing on an Illumina MiSeq. (a) Distribution of quality scores of all reads. (b) Heat map of quality scores. (c,d) Distribution of reads across all samples
-
16.
Exemplary copy number profiles are displayed in Fig. 6.
Fig. 6 
Example of copy number profiles established with the plasma-Seq approach. (a) Copy number profile of a male control shows no copy number changes across the genome. (b) Copy number profiles of two plasma DNA samples from breast cancer patients. A variety of copy number changes including focal amplifications that are frequently detected in breast cancer can be observed. Even in samples with lower amount of tumor DNA (lower panel) copy number changes can be observed. (c) Copy number profiles of two plasma DNA samples from prostate cancer patients


References
Jung M, Klotzek S, Lewandowski M et al (2003) Changes in concentration of DNA in serum and plasma during storage of blood samples. Clin Chem 49:1028–1029
Lui YY, Chik KW, Chiu RW et al (2002) Predominant hematopoietic origin of cell-free DNA in plasma and serum after sex-mismatched bone marrow transplantation. Clin Chem 48:421–427
Bettegowda C, Sausen M, Leary RJ et al (2014) Detection of circulating tumor DNA in early- and late-stage human malignancies. Sci Transl Med 6:22ra424
Chan KC, Jiang P, Chan CW et al (2013) Noninvasive detection of cancer-associated genome-wide hypomethylation and copy number aberrations by plasma DNA bisulfite sequencing. Proc Natl Acad Sci U S A 110:18761–18768
Chan KC, Jiang P, Zheng YW et al (2013) Cancer genome scanning in plasma: detection of tumor-associated copy number aberrations, single-nucleotide variants, and tumoral heterogeneity by massively parallel sequencing. Clin Chem 59:211–224
Diehl F, Schmidt K, Choti MA et al (2008) Circulating mutant DNA to assess tumor dynamics. Nat Med 14:985–990
Forshew T (2012) Noninvasive identification and monitoring of cancer mutations by targeted deep sequencing of plasma DNA. Sci Transl Med 4:136ra68
Heidary M, Auer M, Ulz P et al (2014) The dynamic range of circulating tumor DNA in metastatic breast cancer. Breast Cancer Res 16:421
Heitzer E, Auer M, Hoffmann EM et al (2013) Establishment of tumor-specific copy number alterations from plasma DNA of patients with cancer. Int J Cancer 133:346–356
Heitzer E, Auer M, Ulz P et al (2013) Circulating tumor cells and DNA as liquid biopsies. Genome Med 5:73
Heitzer E, Ulz P, Belic J et al (2013) Tumor-associated copy number changes in the circulation of patients with prostate cancer identified through whole-genome sequencing. Genome Med 5:30
Heitzer E, Ulz P, Geigl JB (2014) Circulating tumor DNA as a liquid biopsy for cancer. Clin Chem 61:112
Mohan S, Heitzer E, Ulz P et al (2014) Changes in colorectal carcinoma genomes under anti-egfr therapy identified by whole-genome plasma DNA sequencing. PLoS Genet 10:e1004271
Murtaza M (2013) Non-invasive analysis of acquired resistance to cancer therapy by sequencing of plasma DNA. Nature 497:108–112
Baslan T, Kendall J, Rodgers L et al (2012) Genome-wide copy number analysis of single cells. Nat Protoc 7:1024–1041
Li H, Durbin R (2009) Fast and accurate short read alignment with burrows-wheeler transform. Bioinformatics 25:1754–1760
Li H, Handsaker B, Wysoker A et al (2009) The sequence alignment/map format and samtools. Bioinformatics 25:2078–2079
R:. R: A language and environment for statistical computing. http://www.R-project.org
Lai W, Choudhary V, Park PJ (2008) Cghweb: a tool for comparing DNA copy number segmentations from multiple algorithms. Bioinformatics 24:1014–1015
Navin N, Kendall J, Troge J et al (2011) Tumour evolution inferred by single-cell sequencing. Nature 472:90–94
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer Science+Business Media New York
About this protocol
Cite this protocol
Ulz, P., Auer, M., Heitzer, E. (2016). Detection of Circulating Tumor DNA in the Blood of Cancer Patients: An Important Tool in Cancer Chemoprevention. In: Strano, S. (eds) Cancer Chemoprevention. Methods in Molecular Biology, vol 1379. Humana Press, New York, NY. https://doi.org/10.1007/978-1-4939-3191-0_5
Download citation
DOI: https://doi.org/10.1007/978-1-4939-3191-0_5
Publisher Name: Humana Press, New York, NY
Print ISBN: 978-1-4939-3190-3
Online ISBN: 978-1-4939-3191-0
eBook Packages: Springer Protocols