
Abstract
In this study, several mathematical, soft computing, and machine learning modeling tools are used to develop a dependable model for forecasting the compressive strength of cement mortar modified with metakaolin (MK) additive and predicting the effect of MK and a maximum diameter of the fine aggregate (MDA) on the compressive strength of the mortar. In this regard, 230 datasets were collected from literature with a wide-ranging mix of proportion and curing time. Water to binder ratio (w/b) ranged between 0.36 and 0.6 (by the weight of dry cement), sand to binder ratio 2 to 3, metakaolin content 0–30%, and curing time up to 90 days. Multivariate regression spline (MARS), multiexpression programming (MEP), nonlinear regression (NLR), and artificial neural network (ANN) models were used. Several assessment tools were utilized to quantify the performance of the proposed models, such as coefficient of determination (R2), root mean squared error (RMSE), mean absolute error (MAE), scatter index (SI), and Taylor diagram. Based on the modeling result, the performance of the MARS model is better than MEP, NLR, and ANN models with high R2 and low RMSE and MAE. The MARS, MEP, and ANN excellently predicted the compressive strength based on the scatter index. The parametric analysis of MK and MDA revealed that the ANN model successfully predicted the influence of the mentioned model inputs and optimum MK content for improving long- and short-term compressive strength.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Supplementary cementitious material (SCM) can be used in cement mortar and concrete to substitute some of the cement and produce low-cost building materials [1]. Replacing cement with a binder agent in mortar and concrete is essential, since some of those replacing materials positively impact the mechanical properties of concrete or mortar and reduce the negative effect of cement production on the surrounding environment [2]. Cement manufacturing plants use many natural resources, require more energy, and emit a large carbon dioxide (CO2) content into the atmosphere [3,4,5].
Metakaolin (MK) is one of the mineral admixtures, which is a high pozzolanic reactive material; silicon oxide (SiO2) and aluminum oxide (Al2O3) are mainly included in its chemical composition. The reaction of SiO2 and Al2O3 with calcium hydroxide (Ca(OH)2) produces calcium silicate hydrate (C–S–H) [6,7,8] and improves the mechanical properties of the produced compound. MK has small particle sizes when used to replace portland cement (PC). During mortar production, the voids and gaps inside the cement mortar are reduced; hence density is increased, further improving strength [9,10,11]. Considering vast quantities of concrete predicted to be manufactured in the following years to achieve our infrastructure needs, different concrete production options with PC alternatives must be investigated. These alternatives are typically used to replace PC and aggregates in part or whole inside mortar or concrete [12].
Typically, MK is produced by calcinating kaolin clay at a temperature of 600–800 °C [13]. The kaolinite clay structure collapses when the water is driven off during the calcination process, resulting in an amorphous aluminum silicate. The following equation shows the process: \(A{l}_{2}{O}_{3}\cdot 2Si{O}_{2}\cdot 2{H}_{2}O\to A{l}_{2}{O}_{3}\cdot 2Si{O}_{2}+\uparrow 2{H}_{2}O\). Numerous research projects have focused on the thermal conversion of kaolinite. It was discovered that heating temperature, heating time and rate, cooling rate, and environmental conditions are the primary factors that greatly affect the dehydroxylation process [14, 15].
Badogiannis et al. [16] investigated the optimization of kaolin calcination to utilize the metakaolin produced as a supplemental cementitious material. A high purity commercialized kaolin and inferior Greek kaolin (Milos island) were tested. Different temperatures and periods were used to heat the samples. DTA-TG and XRD study of raw and thermally treated kaolin samples, pozzolanic activity assessment of metakaolin, and finally strength improvement analysis of cement–metakaolin combinations were used to investigate the optimization of the calcination conditions. This method demonstrated that calcination of kaolin with minimal alunite concentration for 3 h results in highly reactive metakaolin. However, for kaolin with a significant alunite content, a 3-h heat treatment at 850 °C is required to remove unwanted SO3. Pure kaolin has been proven to be effective in developing highly reactive metakaolin. Vu et al. [17] studied the effect of calcined kaolin (metakaolin) on the fresh properties, mechanical behavior, and durability of cement mortar; they tested nearly 150 samples; the ratio of metakaolin to cement ranged between 0 and 0.3 in 0.05 increment, water to binder ratio from 40 to 53% by weight of the binder, and superplasticizer as 0, 0.5, and 1.4% of the total binder. The result revealed that the setting time affected when cement was replaced by metakaolin was more than 20%; below that point, the effect was insignificant. Also, the influence of metakaolin on the strength of the later ages (7–28 days) was more significant than early age strength.
Moreover, increasing the replacement ratio resulted in higher strength for mature mortars. The samples with metakaolin modification cured at MgSO4 solution showed improved performance in the solution environment. Courard et al. [18] also tested the durability of cement mortar with metakaolin. They concluded the same result for durability enhancement and revealed that the optimum replacement of cement by metakaolin was between 10 and 15%. Parande et al. [19] observed an increase in MK-modified cement mortar compressive strength up to 15% (MK/binder by weight). Beyond that, a decrease in strength was noted. Sumasree and Sajja [20] mixed fiber with metakaolin in cement mortar, and the mechanical properties improved when cera-fiber was 0.75 and 25% of cement replaced with metakaolin. Increasing cera-fiber to 0.8% decreased the replacement ratio to 20%. Batis et al. [21] studied the effect of replacing cement and sand with metakaolin on the corrosion resistance of the mortar, compressive strength, and mass loss. They reached the optimum replacement of 10% for cement and 20% for sand (by weight).
As highlighted in the literature, machine learning models are successfully utilized in engineering and material science [22]. Multiple regressions, M5P-tree, and neural networks (ANN) are all recently created technologies that can be used to model material characteristics [23,24,25,26]. M5P-tree model, ANN, and nonlinear multiple regression were used by Mohammed et al. [17] to forecast the compressive strength of modified cement-based mortar with fly ash. The evaluation of the developed models showed that those models could be utilized well to predict the CS with high R2 and RMSE. Armaghani and Asteris [22] utilized ANN and adaptive neuro-fuzzy inference (ANFIS) to predict the compressive strength of cement mortar. The result showed good performance of both the models in the testing phase. However, overfitting was observed for the ANFIS model, but validated with the experimental result. Another soft computing technique forecaster is the multiexpression programming (MEP) model that was utilized and resulted in good performance after training with optimizable parameters [27,28,29].
In this study, different soft computing techniques and machine learning models such as Multivariate Adaptive Regression Spline (MARS), Multi-expression Programming (MEP), Nonlinear (NLR), and Artificial Neural Network (ANN) models were used to predict the compressive strength of cement mortar modified with metakaolin. The effect of metakaolin content and maximum fine aggregate diameter on the compressive strength was also investigated. Finally, the proposed model was characterized using assessment tools such as R2, RMSE, and SI.
This study objectives can be summarized as follows: (a) data collection and analysis of the mixture proportions of metakaolin-modified cement mortar, (b) finding the effect of the mixture ingredients on the compressive strength of the mortar, (c) using different nonlinear modeling techniques to predict the compressive strength of cement mortar modified by MK at different curing ages, (d) predicting the effect of the maximum size of fine aggregate on the CS of cement-based mortar, and (e) choosing the best model based on statistical assessment tools.
2 Methodology and materials
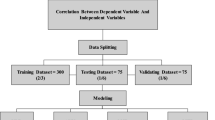
Figure 1 summarizes the methodology of the present study. The elements of the entire procedure can be seen on the graph from data collection to the last step of the model construction. Finally, the most influential parameter affecting the CS was found using sensitivity analysis.

Methodology flowchart of the current study
2.1 Data collection
A database for cement mortar was created. A total of 230 datasets were collected from previous research to propose analytical models to predict the compressive strength of cement mortar modified with metakaolin. The collected data are summarized in Table 1. The input variables are water to binder ratio (w/b), sand to binder ratio (s/b), metakaolin content (MK, %), maximum diameter of fine aggregate (MDA, mm), superplasticizer content (SP, %), and curing ages (t, days). At the same time, the target value is the compressive strength (CS, MPa).
2.1.1 Sample sizes
The collected data consist of two different sample sizes (S1 = 40 × 40 mm and S2 = 50 × 50 mm), as shown in Fig. 2. All the data are used together to train the models. Then, based on statistical assessment tools, the performance of the developed models to predict the compressive strength of varied sizes is measured, and the best model is selected.

Summary of the sample sizes in the training and testing datasets
2.2 Statistical analysis
In this section, the collected data are presented to see the model inputs’ relationship and variation and provide adequate evidence of a good correlation between independent and dependent variables. If there is a strong relationship between one predictor and the target, the modeling techniques are not required, and a simple correlation equation can solve the problem. For determination of the distribution and variation in the input variables, different statistical parameters are used, such as mean, standard deviation (SD), variance (Var), kurtosis (Kur), and skewness. Standard deviation and variance show the dispersion of numbers from their mean. Kurtosis and skewness indicate the tail of the distribution: the positive value of skewness indicates the right tail, and the negative value is for the left tail; kurtosis specifies the longer or shorter distribution tail, with positive for longer and negative value for shorter tail. The details of the summary of statistical analysis on the input and target are shown in Table 1. The input variation with target value is shown in Fig. 3. The histogram for CS is provided in Fig. 4 with the kernel distribution function and a boxplot to show the compressive strength range of the mortar modified with metakaolin from 1 to 90 days of curing.



Marginal plot with histogram for relationship between compressive strength and a w/b, b s/b, c MK, d MDA e SP, and f t

Histogram for compressive strength of metakaolin-modified cement mortar from 1 to 90 days of curing
2.3 Modeling
From the correlation matrix (Fig. 5), a strong correlation between model parameters and the target value is not observed. Therefore, different modeling approaches are used to construct predictive models to forecast the compressive effect of cement mortar modified by metakaolin. The collected data are randomly divided between training and testing sets (70/30), 70% of the data for training the models, and the remaining 30% for testing model prediction on the data that is not used in training. In the next subsections, details about the used modeling tools are provided.

Correlation matrix for the target and input variables
2.3.1 Multiadaptive regression splines model (MARS)
Friedman introduced the MARS model [17] as a nonlinear and nonparametric regression approach. It is implemented using a set of splines (piecewise polynomials) with variable gradients to describe nonlinear interactions between a system of input and output. This system does not require a persistent assumption regarding the significant underlying correlation between input and output variables. The nodes are the segment end point; a node defines the end point of one data region and the start of another data area. The resulting splines (known as base functions) give the model more flexibility in curvatures, thresholds, and other linear function deviations. A two-step procedure is used to implement MARS models. The initial step is to build up functions and find probabilistic nodes for performance improvement, resulting in a model with precise curve fitting. The second is the removal of real minimal terms. If y is the function of multiple independent variables (x), then the following is the response function:
where e is the error value, and n is the number of input variables. Basis function (BF) is employed in the MARS modeling algorithm to function approximation, which refers to the splines; BF includes piecewise-linear and piecewise-cubic functions.
In this study piecewise-linear function is used, and the following is the explanation of the function:
The MARS model linearly combines the BFs, which can be expressed as follows:
where N is the total number of observations, β are the coefficients, and γk (x) is the function that includes one or more spline functions.
2.3.2 Multiexpression programming model (MEP)
The genetic algorithm (GA) is a state-of-the-art intelligent algorithm based on evolutionary concepts [30]. The gene was expressed with decimals or binary numbers in the early theory of GA, which caused it to fail in various complex areas. Ferreira [31] proposed a novel genetic method, genetic expression programming (GEP), in which the gene was encoded as a binary tree that could be translated to a mathematical equation. This breakthrough increased the chromosome’s ability to express itself and might be utilized to anticipate time series [32]. Due to its success, the GEP has been extended to multiexpression programming (MEP) [34, 34]. Individuals in the MEP contained more than one gene, allowing them to express not only one, but numerous mathematical expressions. This addition makes the GEP more adaptable and efficient. The model requires several fitting parameters, which can be found by the trial and error me27thod [].
2.3.3 Nonlinear model (NLR)
Equation 4 is the general formula for a nonlinear model that can be used to predict the properties of a material. The equation shows a nonlinear relationship between the target (dependent variable) and predictors (independent variables). The model was trained using the least square method by minimizing the squared error between the measured and predicted target values.
where a, b, c, …, j, and k are model parameters. CS, w/b, s/b, MK, MDA, SP, and t are compressive strength (MPa), water to binder ratio, sand to binder ratio, metakaolin content (%), maximum diameter of fine aggregate (mm), superplasticizer content (%), and curing ages (days), respectively.
2.3.4 Artificial neural network model (ANN)
The artificial neural network (ANN) is a computing system that resembles the human brain and its information analysis. In addition, this model is a machine learning system employed in construction engineering for various numerical forecasts and difficulties. ANN consists of three layers: input, hidden, and output layers; these layers are connected through biases and weights. The behavior of an ANN network is influenced by the connections of neurons pattern, which also determines the class of the network. It is possible to train a network to enhance network performance. In more technical terms, the topology of the network and connection weights change repeatedly such that the error at each output layer node is minimized [32]. This study designed a multilayer feedforward network with mortar composition (w/b, s/b, MK, MDA, SP, and t) as input and CS as output. A log sigmoid activation function is used in the hidden layers and a pure linear activation function at the output layer.
The following equation is the mean-squared error function which measures the error at the output node:
where Yp, Ym, and N are the output value of the model, actual measured value, and total observation in the training datasets, respectively.
Several parameters affect the final model result, such as the training algorithm, number of hidden layers and neurons, and transfer function [22]. The ANN structure can be found using the trial and error method to tune the required parameters. In back-propagation (BP), the procedure includes two stages: forward and backward phases. While training, the signals move toward the output node, and each node’s errors (biases) and weights are calculated. Then in the backward stage, the bias, inputs, and layer weights are corrected. In other words, back-propagation aims to minimize the cost function through fine-tuning the network’s weights and biases. [35]. Equation 6 can be considered as a general formula for the calculation of an ANN output with only one node:
where Nd1 is the weight value for the output from Node 1, and the threshold is the error of the output layer. Bias, p, x, and w are the error of the hidden layer, number of predictors (independent variables), predictor value, and the corresponding weight for the specific predictor from the input layer, as shown in Fig. 6.

Typical ANN calculation
2.4 Evaluation criteria for the developed models’ comparison
The developed models are characterized and compared based on the different assessment tools such as R2, RMSE, MAE, and Taylor diagram. The formulas for calculation of those mentioned parameters are shown in the following equations:
where \(\mathrm{CSP}, \overline{\mathrm{CSP} },\mathrm{ CSM},\overline{\mathrm{ CSM },}\) and n are predicted compressive strength, mean of predicted compressive strength, measured compressive strength, measured compressive strength, and several instances in the related dataset. The optimal value for all the above evaluation tools is zero; except for R2, the best value is 1. The model performance is considered excellent if SI < 0.1, good if 0.1 < SI < 0.2, fair if 0.2 < SI < 0.3, and poor performance if SI > 0.3 [36].
3 Results and output analysis
3.1 Variation of measured and predicted compressive strength
3.1.1 MARS model
The relationship between the actual measured CS and the output of the MARS model is shown in Fig. 7. The model is performed well for both training and testing datasets with high R2 and low RMSE values of 0.99 and 2.08 MPa, and 0.97 and 2.5 MPa for training and testing, respectively. The figure shows the error limit of ±10%, indicating that 90% of the data lie in the predicted CS/measured CS range from 0.9 to 1.1. The details of the MARS model training parameters are provided in Table 2. Equation 8 is the formula of the MARS model that can be used for prediction purpose, and the basis functions (BFs) given in Eq. 12 can be gathered from Table 3.

Relationship between measured and predicted CS for the MARS model
No. of training data = 161, R2 = 0.99, RMSE = 2.08 MPa.
3.1.2 MEP model
Table 4 provides the required training parameters used in the MEP development process. Figure 8 shows the variation of measured CS with forecasted CS from the MEP model and an error limit of ±20%. The R2 and RMSE for training and testing are 0.96 and 3.71 MPa, 0.94 and 3.72 MPa, respectively. The MEP model’s formula to predict CS is shown in Eq. (13).

Relationship between measured and predicted CS for the MEP model
No. of training data = 161, R2 = 0.96, RMSE = 3.71 MPa, where a, b, c, …, and f are water to binder ratio (w/b), sand to binder ratio (s/b), metakaolin content (MK, %), the maximum diameter of fine aggregate (MDA, mm), superplasticizer content (SP, %), and curing ages (t, days).
3.1.3 NLR model
Equation 14 is the final form of the NLR model. The relationship between measured and predicted compressive strength is shown in Fig. 9; the figure contained a ±20% error limit, and overestimation was observed; therefore, it shows less performance of this model than MARS and MEP models, since lower R2 and higher RMSE are obtained for the NLR model. The R2 and RMSE are 0.93 and 5.1 MPa, and 0.89 and 5 MPa for the training and testing phases. From the model parameters, s/b affects the CS more than other input factors, and MDA positively affects the CS of the mortar.

Relationship between measured and predicted CS for the NLR model
No. of training data = 161, R2 = 0.93, RMSE = 5.1 MPa.
3.1.4 ANN model
The ANN model is trained with two hidden layers and eight neurons, as shown in Fig. 10. The logistic sigmoid activation function is used for hidden layers, and the pure linear activation function is used for the output layer with the Levenberg–Marquardt optimization algorithm. The final gradient and Mu are 0.1096 and 1 × 10–4 after training at epoch 1000. The result for bias and weights for input, hidden layer, and output layer is provided in the followings matrices:

Selected ANN structure
No. of training data = 161, R2 = 0.997, RMSE = 1.05 MPa.
The relationship between measured and predicted CS is shown in Fig. 11; the figure has an error limit of ±12%, while R2 and RMSE are 0.997 and 1.05 MPa, and 0.966 and 2.74 MPa for training and testing, respectively.

Relationship between the measured and predicted CS for the ANN model
3.2 Evaluating the performance of proposed models
Figure 12 compares the developed models based on SI; as displayed in the figure, ANN model performance based on SI is better than that of other models in the training phase. However, the MARS model is better than MEP, NLR, and ANN models in the testing phase. The comparison between the proposed models based on R2, RMSE, MAE, and Taylor diagram is shown in Figs. 13 and 14. The R2 for the MARS model for both training and testing is greater than 0.95, while for the MEP model, the R2 is greater than 0.95 for training and smaller than 0.94; the R2 of the ANN model also indicates the best performance in the training stage, and lesser performance of the NLR model is observed in comparison to other models. Correspondingly, based on RMSE, the best is the MARS model at the testing phase. According to all the criteria, the best model is the ANN model in the training phase and the MARS model in the testing phase. Moreover, the MEP model is better than the NLR model.

Performance evaluation of the developed models based on scatter index

Comparison between the proposed models based on a R2, b RMSE, and c MAE

Evaluation of the proposed models using Taylor diagram based on standard deviation and correlation coefficient between the measured and predicted compressive strength
The Taylor diagram for comparing the proposed models based on a standard deviation of the predicted compressive strength and measured compressive strength and correlation coefficient (R) is shown in Fig. 14. Taylor diagram shows the variation of predicted and measured compressive strength. The result of the Taylor diagram revealed that according to standard deviation, MARS and MEP models’ predicted standard deviations are close to experimental standard deviation. However, R and standard deviation show the excellent performance of the MARS and ANN models.
3.3 The efficacy of the proposed model in predicting different strength ranges
The training and testing datasets are divided into strength ranges from 1 to 105 by 15 MPa increment; for compressive strength of different curing ages (i.e., 1–90 days), the very low strengths are referred to as the early age compressive strength. The performance of the developed models is measured based on RMSE and R, as summarized in Tables 5 and 6. In the training stage, the ANN model predicts the compressive strength for all the strength ranges better than MARS, MEP, and NLR models, whereas the MEP model prediction for strength range of 1–15 MPa in the testing phase is better than that of another developed model. The strength ranges of 30–45 MPa and 45–60 MPa ANN model is better than those of the other proposed models. The MARS model forecasted the compressive in 15–30, 60–75, and 75–90 MPa better than other models.
3.4 Performance of the developed models to predict different sample size’s compressive strength
As summarized in Table 7, the training dataset is divided based on the tested sample size; after training the models on the training datasets, the performance of the developed models is measured for different sample sizes. As can be seen in Fig. 2, it was not applicable to test the developed models to predict the compressive strength of a sample size of S2 (50 × 50 mm) in the testing dataset, since only one data was available for testing. Therefore, only the training dataset is considered. Based on the prediction of the developed models, the ANN model predicts the compressive strength for samples S1 and S2 better than other developed models in the training dataset.
3.5 The effect of MK and MDA on the CS
Parametric analysis was done to determine the effect of MK on the mortar. First, a database with a fixed mixture composition was created, and the MK changed from 0 to 30% while other compositions remained unchanged, and the mixture composition was decided based on the standard EN196-1 [37]. All the models are used to forecast the CS. Based on the results, the ANN model predicted the CS comprising the ranges and optimum content for MK as mentioned in the literature; the optimum MK is up to 10% and covers all the curing ages and improves the compressive strength of the mortar, as shown in Fig. 15.

Effect of metakaolin content on the CS of mortar (w/b = 0.5, s/b = 3, MDA = 2)
Additionally, the effect of MDA on the CS is analyzed similarly to that of MK. MDA was changed, whereas the other mixture composition was fixed based on the highest replication of those parameters in the literature and the EN196-1. The result revealed that the compressive strength of the mortar increased with increase in the maximum diameter of the fine aggregate, as displayed in Fig. 16. It is worth mentioning that studies are conducted on the effect of maximum aggregate size (MAS) on the compressive strength of concrete, while increasing MAS increases the compressive strength of normal strength concrete (Fig. 17). Conversely, the compressive strength of high-strength concrete decreased with MAS [38]. This result should be validated with experimental work using different sand with varied MAS.

Effect of the maximum diameter of fine aggregate on the CS of mortar at a 7 and b 28 days of curing and different metakaolin content

Contribution percentage of the input parameters in the prediction of compressive strength
From the figure, it is clear for a larger diameter of the fine aggregate from the prediction of the developed models that a higher replacement ratio could be utilized; for smaller particles of fine aggregate, the replacement ratio of cement by MK is reduced, and the result of ANN model is used to illustrate the effect of the maximum diameter of the aggregate, since it has a good performance in predicting the MK effect on the compressive strength of the mortar and determining the optimum content of metakaolin.
4 Sensitivity analysis
To determine the effect of each model input variable on the final prediction of the CS and find the most valuable parameter which cannot be eliminated while predicting the CS of the mortar and has a great influence on the forecast of the CS, several databases with removed input parameters were created. After that, the model is trained on the combination of the remaining input parameters. After training, the final error of the model is recorded. A removed parameter from the trial with high error is the most influential predictor. According to the result of the analysis, curing time is the most important factor in predicting CS, than the maximum diameter of fine aggregate.
5 Conclusions
It is important to use artificial intelligence modeling tools, since they are time saving and cost-effective. In this study, the experimental results of the previous research were collected, analyzed, and used to construct a predictive model to forecast the compressive strength of metakaolin-modified cement mortar. Referring to the collected data and result of the modeling, the following can be concluded:
-
1.
Metakaolin additive produced through calcination of kaolin clay at 600–850 °C can be used as supplementary cementitious material and improve the mechanical properties of the cement mortar.
-
2.
According to the literature’s collected data, cement replacement with metakaolin is from 0 to 30% by weight of cementitious material, and the water to binder ratio ranges between 0.36 and 0.6.
-
3.
The modeling result indicates that the mortar’s compressive strength increased with increasing metakaolin content up to 10% and covered all the curing ages, improving the compressive strength of the mortar. This result is confirmed by previous literature.
-
4.
According to statistical assessment tools (i.e., R2, RMSE, MAE, and SI), the MARS model is better than MEP, NLR, and ANN models, since it has low RMSE, MAE, and high R2 in the testing phase.
-
5.
Based on the Taylor diagram, the standard deviation of the predicted compressive values from the MEP model is near the standard deviation of the actual compressive strength.
-
6.
The ANN model outperformed other developed models in predicting the optimum metakaolin content.
-
7.
According to the modeling result, the maximum diameter of the sand positively affected the compressive strength of the cement mortar modified with metakaolin, and the replacement ratio for larger size of sand was higher.
-
8.
Based on sensitivity analysis, curing time is more influential than other model input factors on the compressive strength of mortar. The maximum diameter of fine aggregate is the second most important.
Availability of data and materials
The data supporting the conclusions of this article are included in the article.
References
John N. Strength properties of metakaolin admixed concrete. Int J Sci Res Publ. 2013;3(6):1–7.
Torres A, Bartlett L, Pilgrim C. Effect of foundry waste on the mechanical properties of Portland Cement Concrete. Constr Build Mater. 2017;135:674–81.
Damtoft JS, Lukasik J, Herfort D, Sorrentino D, Gartner EM. Sustainable development and climate change initiatives. Cem Concr Res. 2008;38(2):115–27.
Gustavsson L, Sathre R. Variability in energy and carbon dioxide balances of wood and concrete building materials. Build Environ. 2006;41(7):940–51.
Gartner E. Industrially interesting approaches to “low-CO2” cements. Cem Concr Res. 2004;34(9):1489–98.
Nehdi ML, Suleiman AR, Soliman AM. Investigation of concrete exposed to dual sulfate attack. Cem Concr Res. 2014;64:42–53.
Wianglor K, Sinthupinyo S, Piyaworapaiboon M, Chaipanich A. Effect of alkali-activated metakaolin cement on compressive strength of mortars. Appl Clay Sci. 2017;141:272–9.
Zhang YJ, Wang YC, Li S. Mechanical performance and hydration mechanism of geopolymer composite reinforced by resin. Mater Sci Eng, A. 2010;527(24–25):6574–80.
Abdalla AA, Salih Mohammed A. Theoretical models to evaluate the effect of SiO2 and CaO contents on the long-term compressive strength of cement mortar modified with cement kiln dust (CKD). Arch Civ Mech Eng. 2022;22(3):1–21.
Mahmood LJ, Rafiq SK, Mohammed AS. A review study of eggshell powder as cement replacement in concrete (2022) SJES. 2022;9(1).
Qian X, Wang J, Wang L, Fang Y. Enhancing the performance of metakaolin blended cement mortar through in-situ production of nano to sub-micro calcium carbonate particles. Constr Build Mater. 2019;196:681–91.
Mahmood W, Mohammed AS, Sihag P, Asteris PG, Ahmed H. Interpreting the experimental results of compressive strength of hand-mixed cement-grouted sands using various mathematical approaches. Arch Civ Mech Eng. 2022;22(1):1–25.
Ilić BR, Mitrović AA, Miličić LR. Thermal treatment of kaolin clay to obtain metakaolin. Hem Ind. 2010;64(4):351–6.
Biljana I, Aleksandra M, Ljiljana M. Thermal treatment of kaolin clay to obtain metakaolin. Hem Ind. 2010;64(4):351–6.
Shvarzman A, Kovler K, Grader GS, Shter GE. The effect of dehydroxylation/amorphization degree on pozzolanic activity of kaolinite. Cem Concr Res. 2003;33(3):405–16.
Badogiannis E, Kakali G, Tsivilis S. Metakaolin as supplementary cementitious material: optimization of kaolin to metakaolin conversion. J Therm Anal Calorim. 2005;81(2):457–62.
Mohammed A, Rafiq S, Sihag P, Kurda R, Mahmood W, Ghafor K, Sarwar W. ANN, M5P-tree and nonlinear regression approaches with statistical evaluations to predict the compressive strength of cement-based mortar modified with fly ash. J Market Res. 2020;9(6):12416–27.
Courard L, Darimont A, Schouterden M, Ferauche F, Willem X, Degeimbre R. Durability of mortars modified with metakaolin. Cem Concr Res. 2003;33(9):1473–9.
Parande AK, Babu BR, Karthik MA, Kumaar KKD, Palaniswamy N. Study on strength and corrosion performance for steel embedded in metakaolin blended concrete/mortar. Constr Build Mater. 2008;22(3):127–34.
Sumasree C, Sajja S. Effect of metakaolin and cerafibermix on mechanical and durability properties of mortars. Int J Sci Eng Technol. 2016;4(3):501–6.
Batis G, Pantazopoulou P, Tsivilis S, Badogiannis E. The effect of metakaolin on the corrosion behavior of cement mortars. Cement Concr Compos. 2005;27(1):125–30.
Armaghani DJ, Asteris PG. A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. Neural Comput Appl. 2021;33(9):4501–32.
Mahmood W, Mohammed A. New Vipulanandan pq model for particle size distribution and groutability limits for sandy soils. J Test Eval. 2019;48(5):3695–712. https://doi.org/10.1520/JTE20180606.
Qadir W, Ghafor K, Mohammed A. Evaluation the effect of lime on the plastic and hardened properties of cement mortar and quantified using Vipulanandan model. Open Eng. 2019;9(1):468–80. https://doi.org/10.1515/eng-2019-0055.
Sihag P, Jain P, Kumar M. Modelling of impact of water quality on recharging rate of storm water filter system using various kernel function based regression. MESE. 2018;4(1):61–8. https://doi.org/10.1007/s40808-017-0410-0.
Vipulanandan C, Mohammed A. Magnetic field strength and temperature effects on the behavior of oil well cement slurry modified with iron oxide nanoparticles and quantified with vipulanandan models. J Test Eval. 2019;48(6):4516–37. https://doi.org/10.1520/JTE20180107.
Shah MI, Amin MN, Khan K, Niazi MSK, Aslam F, Alyousef R, Javed MF, Mosavi A. Performance evaluation of soft computing for modeling the strength properties of waste substitute green concrete. Sustainability. 2021;13(5):2867. https://doi.org/10.3390/su13052867.
Abdalla AA, Mohammed AS, Rafiq S, Noaman R, Qadir WS, Ghafor K, Hind ALD, Fairs R. Microstructure, chemical compositions, and soft computing models to evaluate the influence of silicon dioxide and calcium oxide on the compressive strength of cement mortar modified with cement kiln dust. Constr Build Mater. 2022;341: 127668.
Abdalla A, Salih Mohammed A. Surrogate models to predict the long-term compressive strength of cement-based mortar modified with fly ash. Arch Comput Methods Eng. 2022. p. 1–26.
Zhiyuan G, Yongxian W, Lan N (2000) Genetic algorithms based on bintree structure encoding. J Tsinghua Univ. 2000;40(10):125-128.
Ferreira C. Function finding and the creation of numerical constants in gene expression programming. In: Advances in soft computing. Springer; 2003. p. 257–65.
Lopes HS, Weinert WR. A gene expression programming system for time series modeling. In: Proceedings of XXV Iberian Latin American Congress on Computational methods in Engineering (CILAMCE), vol 10. Recife: Brazil; 2004. pp. 1-13.
Oltean M, Dumitrescu D. Multi expression programming. J Genet Program Evolvable Mach. 2022. https://doi.org/10.21203/rs.3.rs-853086/v1
Searson DP, Leahy DE, Willis MJ. GPTIPS: an open source genetic programming toolbox for multigene symbolic regression. In: Proceedings of the International multi conference of engineers and computer scientists, vol 1. Citeseer; 2010. pp. 77–80.
Mohamad ET, Hajihassani M, Armaghani DJ, Marto A. Simulation of blasting-induced air overpressure by means of artificial neural networks. Int Rev Model Simul. 2012;5(6):2501–6.
Despotovic M, Nedic V, Despotovic D, Cvetanovic S. Evaluation of empirical models for predicting monthly mean horizontal diffuse solar radiation. Renew Sustain Energy Rev. 2016;56:246–60. https://doi.org/10.1016/j.rser.2015.11.058.
En BS (2005) 196–1.(2005). Methods of testing cement. Determination of strength. British Standards Institute.
Meddah MS, Zitouni S, Belâabes S. Effect of content and particle size distribution of coarse aggregate on the compressive strength of concrete. Constr Build Mater. 2010;24(4):505–12.
Kadri E-H, Kenai S, Ezziane K, Siddique R, De Schutter G. Influence of metakaolin and silica fume on the heat of hydration and compressive strength development of mortar. Appl Clay Sci. 2011;53(4):704–8.
Mardani-Aghabaglou A, Sezer Gİ, Ramyar K. Comparison of fly ash, silica fume and metakaolin from mechanical properties and durability performance of mortar mixtures view point. Constr Build Mater. 2014;70:17–25.
Potgieter-Vermaak SS, Potgieter JH. Metakaolin as an extender in South African cement. J Mater Civ Eng. 2006;18(4):619–23.
Acknowledgements
The University of Sulaimani, College of Engineering—Civil Engineering Department, and Gazin Cement Co. supported this work.
Funding
This work had no funding.
Author information
Authors and Affiliations
Contributions
AA and ASM: collected data, planned, and wrote the article; AA: contributed to results and analysis; ASM and AA: contributed to conclusions and editing.
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that they have no competing interests.
Ethics approval and consent to participate
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Abdalla, A., Mohammed, A.S. Hybrid MARS-, MEP-, and ANN-based prediction for modeling the compressive strength of cement mortar with various sand size and clay mineral metakaolin content. Archiv.Civ.Mech.Eng 22, 194 (2022). https://doi.org/10.1007/s43452-022-00519-0
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s43452-022-00519-0