
Abstract
Deep networks involve a huge amount of computation during the training phase and are prone to over-fitting. To ameliorate these, several conventional techniques such as DropOut, DropConnect, Guided Dropout, Stochastic Depth, and BlockDrop have been proposed. These techniques regularize a neural network by dropping nodes, connections, layers, or blocks within the network. However, these conventional regularization techniques suffers from limitation that, they are suited either for fully connected networks or ResNet-based architectures. In this research, we propose a novel regularization technique LayerOut to train deep neural networks which stochastically freeze the trainable parameters of a layer during an epoch of training. This technique can be applied to both fully connected networks and all types of convolutional networks such as VGG-16, ResNet, etc. Experimental evaluation on multiple dataset including MNIST, CIFAR-10, and CIFAR-100 demonstrates that LayerOut generalizes better than the conventional regularization techniques and additionally reduces the computational burden significantly. We have observed up to 70\(\%\) reduction in computation per epoch and up to 2\(\%\) improvement in classification accuracy as compared to the baseline networks (VGG-16 and ResNet-110) on above datasets. Codes are publically available at https://github.com/Goutam-Kelam/LayerOut.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The recent trend in the deep learning community is to use deeper neural networks (DNN) [8, 27] to solve real-life problems such as image classification [17, 26], language translation [19, 29], object detection [5, 21], speech recognition [2, 6], etc. However, deeper neural networks have been empirically found to display the undesirable characteristic of being prone to over-fitting. Further, the computational load of training a deeper network is by no means trivial. This makes the deployment of deeper models in real-time environment such as interactive applications on mobile devices, autonomous driving, etc. a challenging task.
In the literature, there are multiple techniques to reduce over-fitting in DNNs such as data augmentation which increases the number of training samples; semi-supervised learning [10] which additionally uses large amount of unsupervised data to train the DNNs; transfer learning [4, 15] which additionally uses models pre-trained on large amount of supervised data. The regularization techniques such as L2 weight normalization and local response normalization (LRN) [22] reduce the variance in the DNNs while training, hence avoiding over-fitting.
An efficient solution to reduce variance and thereby over-fitting would be to use an ensemble of architectures for decision-making. However, explicit ensembling adds to computational burden. Some of the popular methods such as DropOut [28], DropConnect [31], Guided Dropout [14], Stochastic Depth [9], and BlockDrop [32] were introduced that performed implicit ensembling by randomly dropping nodes, connections, layers, or blocks within the network during each training iteration. They address over-fitting effectively and reduce the computational overload. Main limitation of DropOut, Guided Dropout and DropConnect is that they can be used only for fully connected neural networks; whereas, Stochastic Depth and BlockDrop are applicable only in ResNet [8] kind of architectures. This motivated us to develop a regularization technique that can be applied in all kinds of neural networks.
In this work, we propose a novel regularization technique called LayerOut that is modeled along the lines of the above mentioned techniques. LayerOut stochastically freezes the layers of the neural network instead of dropping the nodes, connections, layers or blocks. The proposed technique is presented in Sect. “Proposed Method—LayerOut”. The main advantage of Layerout is its applicability in both fully connected and Convolutional neural networks(CNNs). It also reduces the computational cost during training. We demonstrate using LayerOut a considerable improvement in generalization capability of the architecture on the popular benchmark datasets MNIST [18], CIFAR-10, and CIFAR-100 [16].
The rest of the paper is structured as follows: Section “Related Work” presents the relevant works done to reduce over-fitting using regularization. In Section “Motivation”, we discuss about the shortcomings of the existing methods and the motivation for our research. Our proposed method and its effectiveness is presented in Sect. “Proposed Method—LayerOut”. Section “Experimental Details”, discusses about the experimentation and implementation details. The results of our proposed regularization method are reported in Sect. “Results and Analysis”. The conclusion and future works are listed in Sect. “Conclusion and Future Work”.
Related Work
The principle behind LayerOut draws inspiration from the following works: DropOut [28], Guided Dropout [14], DropConnect [31], Stochastic Depth [9], and BlockDrop [32].
Hinton et al. [28] introduced a regularization technique known as Dropout to avoid over-fitting the neural networks. The idea of dropout is to drop the nodes in the network along with their connections randomly during the training phase. This random dropping of the nodes during the forward propagation prevents the weights of the layers to converge to an identical position, thus reducing the interdependent learning among the nodes. Dropout forces the nodes in the network to learn better robust features independently. Assuming the model has H hidden nodes, then with dropout, there are \({2}^{{ H}}\) possible models while training as each node is capable of being dropped out. During the train phase, the nodes are kept with probability \(\mathbf{p}\) and the nodes are dropped with probability \({(1-p)}\). During the test phase, the entire model is considered, but to account for the number of dropped nodes, each activation is compensated by a factor of p.
Keshari et al., in their work Guided Dropout [14] generalized the Dropout technique. In contrast to Dropout where the nodes are dropped randomly from the hidden layers, Guided Dropout measures the strength of each node during the training and drops the nodes having high strength. Guided Dropout hypothesize that when nodes with high strength are dropped, then nodes having low strength can train better, thus improving their strength and contribute to the performance of a model. Guided Dropout, thus, prevents co-adaptation of the features across the hidden layers and strengthens each node in the hidden layers to improve the accuracy of the model.
Wan et al. [31] improvised on the dropout technique by dropping the connections of the nodes with the probability of \({(1-p)}\) instead of dropping the nodes. Dropconnect makes the fully connected network a sparsely connected network by dropping the connections between the nodes randomly. Dropconnect helps to train many models during training compared to dropout since the number of connections will always be more than the number of nodes in the model. Since only a subset of the connections is dropped, almost all the nodes of the network are partially active during the training phase, in contrast to dropout where most of the nodes become inactive. In summary, we can say that Dropout makes any fully connected network thinner and Dropconnect makes it sparse.
However, in the recent studies conducted, it was observed that Dropout and Dropconnect fail to generalize well beyond fully connected neural networks [12]. The reason for this is Dropout and Dropconnect were designed to be used with fully connected networks. However, with the success of CNNs [17] which share weights across different layers and reduces the number of parameters to be trained, newer architectures started replacing fully connected networks with large number of convolutional layers. Both Dropout and Dropconnect were primarily implemented for fully connected layers and as a result, the modern network did not reap many benefits out of these techniques. In case of convolutional layers, the number of parameters is less, so they need a small regularization as such and that is provided using batch normalization [11].
Huang et al. [9] introduced Stochastic Depth which allow training a shallow network during the train phase and a deeper network during the test phase. In this technique, during training, a subset of layers are randomly dropped/bypassed using identity connections. The deeper networks have two major concerns. The first is that of vanishing gradients [3] where the gradients become very small during the backward propagation and the earlier layers learn very slow. The second problem is analogous to the vanishing gradient problem, known as diminishing feature reuse [13] during forward propagation. The features computed by the earlier layers start getting washed out as we progress deeper during the forward propagation due to repeated convolutions with weight matrices. This makes learning better features by later layers difficult. These problems were eliminated by ResNets [8] using their skip connections. These skip connections make ResNets a better option for stochastic depth. Training the models using the stochastic depth reduces the test error and the training time. The reason for the reduction in test error could be attributed to the fact that the network trained using stochastic depth behaves as an ensemble network where the networks are of different depths and the reduction in depth of the network helps in avoiding both vanishing gradient and diminishing feature reuse problems. The reason for the reduction in training time can be attributed to the fewer number of computations to be performed during forward and backward propagation due to the dropping of layers.
Nagarajan et al. [32] introduced BlockDrop as a reinforcement learning technique. In this paper, they used a pretrained ResNet-110 model and trained a policy network which outputs the probabilities for making a binary decision of keeping or dropping the blocks of the pretrained ResNet model. The policy network is trained using curriculum learning where the policy network is rewarded if it uses fewer blocks of the pretrained ResNet model while maintaining the accuracy produced by the ResNet model. Unlike stochastic depth where layer dropping happens only during training, in BlockDrop, blocks of ResNet are also dropped during test phase. BlockDrop naturally reduces computational burden.
Motivation
Dropout, Guided Dropout and Dropconnect are primarily useful for fully connected layers. Stochastic depth and BlockDrop assume that underlying architecture is a ResNet architecture. They leverage on the idea that unrolling ResNet enumerates a plethora of paths from input to output and, some of them may be redundant. The redundant ones are dropped thereby minimizing over-fitting and reducing computational load. These techniques regularizes the neural network by dropping nodes, connections, layers, and blocks in the network. However, these approaches suffer from their structural dependence on the DNNs. DropOut, Guided Dropout and DropConnect can only be applied to fully connected networks, and Stochastic Depth and BlockDrop can only be applied to ResNet-based architectures; thus, the development of highly available regularization method that can be applied to all variation of DNNs has been a challenge.
The above-mentioned shortcoming of the existing regularization approach motivated us to develop a regularization technique that can be applied on all variant of DNN architectures. We propose a novel method called LayerOut which achieves regularization by stochastically freezing the learnable parameters of a certain layer during a learning epoch.
LayerOut stands out from the existing regularization techniques due to following reasons:
-
During the testing phase, there is no need to scale the activations as all of the layers participate in the forward propagation.
-
LayerOut can be used for both convolutional layer as well as a fully connected layer.
-
LayerOut also reduces computational cost during training as it does not compute gradients for the frozen layers during the backpropagation.
In the following section, we describe the LayerOut technique in detail.
Proposed Method—LayerOut
LayerOut proposes a simple modification to the backpropagation algorithm by requiring that only a few randomly chosen layers be updated. For a given architecture and a given epoch during train phase, a uniform random vector of probabilities is sampled wherein the \(i\mathrm{th}\) component represents the probability of binary decision to freeze or update layer i of the architecture. When a decision to freeze a layer is made, the parameters corresponding to that layer are omitted from being updated during the backpropagation. We refer to these decisions as freezing strategy.
Formal Framework
Let K be the number of layers in a given architecture. Let \(v = (v_1,v_2,\ldots ,v_i,\ldots ,v_K)\) be a random vector, where \(v_{i}\)s are independently sampled from uniform distribution over [0, 1]. We call v as freeze probability vector. Let \(s = (s_1,s_2,\ldots ,s_i,\ldots ,s_K)\) be a Bernoulli random vector where \(s_{i}\) denote whether layer i is frozen or updated. \(s_{i}\) assume value 1 (i.e layer i is frozen) with probability \(v_{i}\). Let \(\pi\) denote the joint probability distribution of \(s_1\), \(s_2\), ..., \(s_K\). Then,
Here, \(\pi (s)\) is the joint probability of freezing K layers in the architecture in an epoch during training. \(\pi (s_i)\) is the probability of layer i being frozen without any parameter update. In other words, \(1-\pi (s_i)\) is the probability that layer i is updated in an epoch during training. During the forward propagation, the entire network is fully functional but during the backward propagation, only those layers which are not frozen are updated. Figure 1 illustrates the weight update during backpropagation while training a Neural Network(NN) with different variants of LayerOut. Figure 1a illustrates training the NN without LayerOut; thus, all the layers get updated. Figure 1b illustrates training a NN with LayerOut using random generation of probability vector. Figure 1c illustrates training a NN with LayerOut using generation of probability vector in increasing order such that the later layers get frozen more often than the earlier layers. Figure 1d illustrates training a NN with LayerOut using generation of probability vector in decreasing order such that the earlier layers get frozen more often than the later layers. In addition, Algorithm 1 summarizes the procedure for training using LayerOut.

Illustration of backpropagation in Neural Network a Without LayerOut, b Layerout with random probability vector, c dFreeze (with probability vector in increasing order), d eFrreze (with probability vector in decreasing order)
Let \(W_e^{[i]}\) denote the weight matrix in layer i of the network in the beginning of an epoch e during training. Then,
where
Here, \(W_{e-1}^{[i]}\) is the weight matrix in layer i at the end of epoch \(e-1\) during training. Further, \(\alpha\) is the learning rate and \(\bigtriangledown W_{e-1}^{[i]}\) is the loss gradient with respect to \(W_{e-1}^{[i]}\). Since the realization of \(W_e^{[i]}\) in epoch e is random, the realization of hidden activation (Eq. 4) in layer i in epoch \(e+1\) denoted by \(h_{e+1}^{[i]}\) is random. That is, assuming bias vector is zero,

Why LayerOut Should Work?
The conventional regularization techniques achieves generalization of any DNNs by preventing the hidden layers to co-adapt to certain specific features. In LayerOut when the layers are frozen, the hidden nodes are not activated non-deterministically. The implicit source of randomness or noise means that every layer has to learn to be more robust to a lot of variation in its input thus preventing the co-adaptation of hidden layers to specific features. This implies LayerOut acts as a regularizer. This is an argument similar to why batch normalization [11] is considered as a regularizer.
Further, because layers are randomly frozen and hence do not participate consistently in backpropagation, the amount of computation time during backpropagation significantly falls down. This reduces computational burden during training.
For example, in Fig. 1b, the first and the third hidden layers of the fully connected network (FC) are frozen simultaneously. Thus, all the layers participate during the forward propagation but during the backpropagation, the gradients for the first and the third hidden layers are not computed. As a result, these layers are not updated. Note that the concept of freezing the layers can be applied to any of the deep neural networks (CNN and FC).
Experimental Details
Datasets
-
1.
MNIST [18] dataset consists of grayscale images of handwritten digits of size \(28 \times 28\). The dataset contains 60,000 training images and 10,000 test images belonging to 10 classes, i.e., digits from 0 to 9.
-
2.
CIFAR-10 dataset [16] consists of \(32 \times 32\) color images from 10 classes, where each class has 5000 training images and 1000 test images. In total, CIFAR-10 consists of 50000 images for training and 10000 images for testing.
-
3.
CIFAR-100 dataset [16] consists of \(32 \times 32\) RGB images from 100 classes, where each class has 500 train images and 100 test images. The dataset consists of 50000 images for training and 10000 images for testing.
Experimental Protocol
To evaluate the proposed technique, we designed the following experiments:
-
1.
Train baseline without LayerOut
-
2.
LayerOut since start
-
3.
LayerOut after warm-up with random generation of freeze probability vector v
-
4.
LayerOut after warm-up with manual fixing of probability vector v
The first experiment refers to baseline model without LayerOut, i.e., no layers of the model are frozen. In the second experiment, LayerOut is incorporated from the first epoch, i.e., for every epoch, a freeze probability vector is generated which decides which layers must be frozen for that particular epoch. The third and fourth experiments train the baseline model for a warm-up period to 20 epochs. Once the model is trained for 20 epochs, we start training the network using LayerOut. The third and fourth experiments differ in the way freeze probability vector v is generated: randomly in the former case and manually in the latter case. It is to be noted that in the second experiment, we report results only for random v since, in general, LayerOut after warm-up performed better than LayerOut since start with or without random generation of v. The goal of all these experiments is to demonstrate that LayerOut influences performance positively and also significantly reduces training time. We do not consider a complete LayerOut of all layers as this would freeze all parameters resulting in zero learning and wasted forward computations.
Implementation Details
All implementations are carried out in PyTorch [20]. We set weight decay to \(5 \times 10^{-4}\), momentum to 0.9 and stochastic gradient descent (SGD) [23] as the optimizer. Further, the input data are augmented using the following techniques:
-
Pad by 4 pixels on all the sides
-
Random crop
-
Random Horizontal Flip
-
Standard normalization
During test phase, we only adopted standard normalization. Specific details of experiments conducted on different datasets along with implementation details are described next.
Implementation Details on MNIST
We designed a baseline shallow network for experimenting on the MNIST dataset. This network consists of 5 convolution layers and 2 fully connected layers. We omitted the use of any pooling layer and compensated for it by performing a strided convolution on \(2\mathrm{nd}\) and \(4\mathrm{th}\) layer. The activation function, ReLU [1] is used after every layer. The architecture of the shallow network is shown in Fig. 2. The model was trained for 100 epochs with the learning rate as 0.01. The weights were initialized using Xavier initialization. With regard to experiment 4, we consider two cases: (1) fixing v in decreasing order as \(v=(0.9,0.7,0.6,0.5,0.4,0.3,0.1)\) and (2) fixing v in increasing order as \(v=(0.1, 0.3, 0.4, 0.5, 0.6, 0.7, 0.9)\). In the former case, earlier layers are more likely to be frozen than the deeper layers. The latter case is the counterpart of the former case. To differentiate between these two cases, we name them as LayerOut-efreeze and LayerOut-dfreeze, respectively. Our implementations of experiments on MNIST dataset are available at MNIST code.Footnote 1

Shallow network architecture used to train on MNIST dataset
Implementation details on CIFAR-10 and CIFAR-100
CIFAR-10: We consider VGG-16 and ResNet-110 as our baseline architectures. In our implementation of VGG-16, we have modified 7 \(\times\) 7 convolutions in first fully connected layer to 1 \(\times\) 1 convolutions. With abuse of nomenclature, we still call the modified VGG-16 as VGG-16 for convenience. Apart from aforesaid data augmentations, we also used random erasing [33].For both baseline architectures, weights were initialized using He initialization [7]. Relu [1] was the preferred activation function. VGG-16 model was trained for 300 epochs with the initial learning rate as 0.1. The learning rate was reduced by a factor of 10 on the \(150\mathrm{th}\) and the \(225\mathrm{th}\) epoch. The ResNet-110 model was trained for 164 epochs. The initial learning rate for ResNet-110 was set to 0.01 and after training for 4 epochs, it was changed to 0.1 and then it was reduced by a factor of 10 during \(82 \mathrm{nd}\) and \(123\mathrm{rd}\) epoch. The other hyperparameters chosen for ResNet-110 are the same as those defined in [8]. The batch size for VGG-16 and ResNet-110 was fixed to be 128 and 32, respectively. We consider two cases here for experiment 4 as in MNIST. The freeze probability vectors for LayerOut-efreeze and LayerOut-dfreeze with regard to baseline VGG-16 were set to v = (0.9, 0.8, 0.8, 0.7, 0.7, 0.6, 0.6, 0.5, 0.5, 0.4, 0.4, 0.3, 0.3, 0.2, 0.2, 0.1) and its reverse, respectively. In case of ResNet-110 we randomly generated the probability vector v, as manual fixation of probabilities was practically infeasible. Our implementations of experiments on CIFAR-10 dataset are available at CIFAR-10 code.Footnote 2
CIFAR-100: The experimental setup for CIFAR-100 dataset is exactly the same as in case of CIFAR-10 dataset. Our implementations of experiments on CIFAR-100 dataset are available at this CIFAR-100 code.Footnote 3
Results and Analysis
In Tables 1, 2, 3, 4, 5, the last column denotes the percentage of parameters frozen per epoch on an average during training and best performance is shown in bold.
Evaluation on MNIST
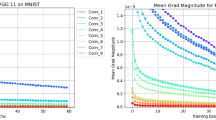
In Table 1, the performance of LayerOut against the baseline shallow network in terms of accuracy and percentage of reduction in trainable parameters is presented. Clearly, LayerOut after warmup (rows 3, 4 and 5 in the table) outperforms baseline and LayerOut since start significantly. Specifically, Layerout-efreeze dominates over all other cases with 99.08% accuracy. Though LayerOut-dfreeze also exhibits a relatively good performance, we see that it does not generalize as well as LayerOut-efreeze. We interpret this as being evidence of the undesirability of freezing the learning for more complex features in the data that might require a continuous learning.
Further, the number of trainable parameters in our shallow network is about 0.49 million. LayerOut-dfreeze freezes on average about 0.17 million parameters (34.9%) per epoch and LayerOut-efreeze freezes on average about 0.11 million parameters (22.3%) per epoch. This is a significant reduction which demonstrates that LayerOut eases training and improves accuracy.
Evaluation on CIFAR-10
Table 2 and Table 3 tabulate the performance of LayerOut against the baseline VGG-16 and ResNet-110 on CIFAR-10, respectively. As in the case of MNIST, LayerOut improves the baseline network’s accuracies. Specifically in VGG-16, LayerOut-efreeze achives 94.07% accuracy with random erasing and 94.02% accuracy without random erasing. For the baseline ResNet-110, manual setting of freeze probabilities is infeasible. Hence, we report results only with respect to first three experiments. LayerOut after warm-up achieves the best accuracy of 95.27% without random erasing.
The total number of learnable parameters in our VGG-16 implementation for CIFAR-10 is about 33.64 million. LayerOut-efreeze and LayerOut-dfreeze achieve 53.66% and 69.91% reduction in number of trainable parameters, respectively. Similarly, ResNet-110 has about 1.70 million trainable parameters and LayerOut on an average achieves a reduction by 48.23% per epoch.
Evaluation on CIFAR-100
Tables 4 and 5 tabulate the performance of LayerOut against the baseline VGG-16 and ResNet-110 on CIFAR-100 respectively. LayerOut clearly outperforms baseline’s accuracies. Specifically in VGG-16, LayerOut-efreeze achieves the best accuracy of 73.81% with random erasing. For baseline ResNet-110, LayerOut after warm-up achieves the best accuracy of 77.57% with and without random erasing.
The total number of learnable parameters in our VGG-16 implementation for CIFAR-100 is about 34 million. LayerOut-efreeze and LayerOut-dfreeze achieve 53.90% and 70.05% reduction in number of trainable parameters, respectively. Similarly, ResNet-110 has about 1.70 million trainable parameters and LayerOut on an average achieves a reduction by 48.87% per epoch.
The above report emphasizes the fact that (1) LayerOut generalizes much better than the baseline and (2) requires far fewer backward computations, thereby achieving a significant reduction in number of trainable parameters on an average in an epoch.
Comparative Analysis
We also compared LayerOut with ResNet-110, BlockDrop and Stochastic Depth. Table 6 tabulates these comparison and illustrates that LayerOut overwhelms these state-of-the-art models on CIFAR-10 and CIFAR-100 datasets. A parallel can be drawn to explain the improvement in accuracy of the ResNet architecture while using LayerOut. Guided Dropout [14] proved that some nodes have more strength to represent a feature compared to others and randomly dropping the nodes may not improve the generalization capability of the entire model. In the similar way, BlockDrop and Stochastic Depth either drops the entire block or subset of the layers randomly and, thus, does not allow all the nodes to participate in the forward propagation, thus reducing the strength of the entire network. LayerOut allows every node to participate in the forward propagation and update the nodes which are not frozen. It allows all the nodes to be more robust to the features and, thus, generalizing the model better compared to BlockDrop and Stochastic Depth.
Conclusion and Future Work
In this work, we proposed LayerOut, a simple yet effective method that freezes the layers randomly at every epoch during the training. It generalizes well and eases computational burden. In comparison to recent techniques like DropOut, DropConnect, Stochastic Depth, BlockDrop, LayerOut reports better accuracy and significant reduction in number of trainable parameters during training. LayerOut can be incorporated for both fully connected networks and various type of convolutional networks. The freeze probabilities can be set randomly or manually. We observed that freezing deeper layers degrades accuracy. This is because deeper layers extract complex features in a hierarchical way and hence require more continual learning. The proposed method is tested on standard benchmark datasets such as MNIST, CIFAR-10 and CIFAR-100. We would like to extend our work to other useful applications like ImageNet, face recognition that need very deep networks [24, 25, 30]. In this scenario, our work can definitely ease training and maintain accuracy. Further, we would like to inspect the effectiveness of our proposed method on sequential models, such as multi-layered LSTM and GRU. Sequential models are hard to train and more so if it is multi-layered. Layer freezing can simplify training multilayered sequence models
References
Agarap AF. Deep learning using rectified linear units (relu). 2018. arXiv preprint arXiv:1803.08375
Bahdanau D, Chorowski J, Serdyuk D, Brakel P, Bengio Y. End-to-end attention-based large vocabulary speech recognition. In: Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on IEEE; 2016, pp. 4945–4949.
Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans Neural Netw. 1994;5(2):157–66.
Caruana R. Learning many related tasks at the same time with backpropagation. Adv Neural Inf Process Syst. 1995;1995:657–64.
Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2014. pp. 580–587.
Graves A, Mohamed A-R, Hinton G. Speech recognition with deep recurrent neural networks. In: Acoustics, speech and signal processing (icassp), 2013 IEEE international conference on, 2013; pp. 6645–6649. IEEE.
He K, Zhang X, Ren S, Sun J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In: Proceedings of the IEEE international conference on computer vision; 2015. pp. 1026–1034.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2016, pp. 770–778.
Huang G, Sun Y, Liu Z, Sedra D, Weinberger KQ. Deep networks with stochastic depth. In: European Conference on Computer Vision. Springer; 2016. pp. 646–661.
Ian G, Jean P-A, Mehdi M, Bing X, David W-F, Sherjil O, Aaron C, Yoshua B. Generative adversarial nets. In: Advances in neural information processing systems; 2014. pp. 2672–2680.
Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167; 2015.
Jansma H. Don’t use dropout in convolutional networks; 2018.
Kumar SR, Greff K, Schmidhuber J. Highway networks. arXiv preprint arXiv:1505.00387; 2015.
Keshari R, Singh R, Vatsa M. Guided dropout. Proc AAAI Conf Artif Intell. 2019;33:4065–72.
Koch G, Zemel R, Salakhutdinov R. Siamese neural networks for one-shot image recognition. In: ICML deep learning workshop, vol. 2. Lille; 2015.
Krizhevsky A, Hinton G. Learning multiple layers of features from tiny images. In: Citeseer: Technical report; 2009.
Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst. 2012;2012:1097–105.
LeCun Y. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/; 1998.
Luong M-T, Pham H, Manning CD. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025; 2015.
Paszke A, Gross S, Chintala S, Chanan G, Yang E, DeVito Z. Zeming Lin. Alban Desmaison: Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch; 2017.
Ren S, He K, Girshick R, Sun J. Faster r-cnn: towards real-time object detection with region proposal networks. In: Advances in neural information processing systems; 2015, pp. 91–99.
Robinson AE, Hammon PS, de Sa VR. Explaining brightness illusions using spatial filtering and local response normalization. Vis Res. 2007;47(12):1631–44.
Ruder S. An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747; 2016.
Russakovsky O, Zhiheng S, Karpathy A, et al. Imagenet large scale visual recognition challenge. Int J Comput Vis. 2015;115(3):211–52.
Schroff F, Kalenichenko D, Philbin J. Facenet: a unified embedding for face recognition and clustering. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2015, pp. 815–823.
Sermanet P, Eigen D, Zhang X, Mathieu M, LeCun Y. Overfeat: integrated recognition, localization and detection using convolutional networks. arXiv preprint arXiv:1312.6229; 2013.
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556; 2014.
Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res. 2014;15(1):1929–58.
Sutskever I, Vinyals O, Le Quoc V. Sequence to sequence learning with neural networks. Adv Neural Inf Process Syst. 2014;2014:3104–12.
Taigman Y, Yang M, Ranzato MA, Wolf L. Deepface: closing the gap to human-level performance in face verification. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2014, pp. 1701–1708.
Wan L, Zeiler M, Zhang S, Cun YL, Fergus R. Regularization of neural networks using dropconnect. Int Conf Mach Learn. 2013;2013:1058–66.
Wu Z, Nagarajan T, Kumar A, et al. Blockdrop: dynamic inference paths in residual networks. Proc IEEE Conf Comput Vis Pattern Recogn. 2018;2018:8817–26.
Zhong Z, Zheng L, Kang G, Li S, Yang Y. Random erasing data augmentation. arXiv preprint arXiv:1708.04896; 2017.
Acknowledgements
We dedicate this work to our Revered Founder Chancellor, Bhagawan Sri Sathya Sai Baba and the Department of Mathematics and Computer Science, SSSIHL for providing us with the necessary resources needed to conduct our research.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Goutam, K., Balasubramanian, S., Gera, D. et al. LayerOut: Freezing Layers in Deep Neural Networks. SN COMPUT. SCI. 1, 295 (2020). https://doi.org/10.1007/s42979-020-00312-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-020-00312-x