
Abstract
Prediction of construction waste is one of the successful techniques to reduce the amount of waste generation at source. Estimation of construction waste at each stage or phase of project is very essential to accurately compute and predict the total waste generation. The study aims to quantify the amount of construction waste at different stages of construction project so as to develop a machine learning model to accurately predict the amount of generated waste at various stages and from variable sources. About 134 construction sites were inspected to collect the generated waste data. As the construction activities are very dynamic in nature, it is very important to precisely compute the waste generation, to analyze the data prediction model, and enable to predict the sources and the amount of waste likely to generate. The decision tree and the K-nearest neighbors algorithm are used for analyzing, and the neural networks performance was studied by providing gross floor area and material estimation. The results indicate that an appreciable amount of waste is generated at every stage of project having considerable high cost, and a particular pattern has been observed for waste materials at typical stages of projects. The model has average RSME values of 0.49 which indicates the accuracy of model is satisfactory for use to perform the predictions. The combined average accuracy of the decision tree and KNN was found to be 88.32 and 88.51, respectively. These findings can provide basic data support and reference for the management and utilization of construction waste.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
One of the main contributors to the environmental burden and consuming the appreciable amount non-renewable resources as well as causing waste streams is the construction and infrastructural industry. The industry plays paramount role in economical contribution as well as the social development world-wide but also responsible for diminution about 40% natural resources, greenhouse gas emission of 18% and global waste of 25% (Ali and Rahmat 2010; Suk et al., 2016). The residential building sector uses a significant amount of resources and thus it is one of the biggest contributors to the environmental deterioration. Management of construction waste has become a critical issue around the globe due to rapid urbanization in living areas. (Coskuner et al., 2020) Construction waste is primarily generated at each stage of construction project; the amount of the generated waste mainly depends upon the type of project, quantum of work, degree of complexity, accuracy of design, adopted working methodology, communication and the quality of workmanship (Markandeya Raju et al., 2015; Parsamehr et al., 2022). Residential construction project mostly generates the waste between 0.95 and 1.15 kg of solid waste per square foot. In particular, the amount of construction waste generation is steadily increasing with respect to forward transition of construction stages (Ruibo et al., 2021). The reduction of such high rate of waste generation is very essential to curtail the overall cost of project as well as the environmental damage caused by construction waste materials (Elshaboury et al., 2022; Aravindh et al., 2022; Coffie et al., 2019). India has the relevant set of rules and regulations for the management of construction waste, but due to the improper enforcement by the authorities, unawareness among the construction agencies, complexity in agenda, communication barriers and lack of monitoring within the system make the waste management plans less efficient for the infrastructural projects (Kolaventi et al., 2019).
Estimation of construction waste at each stage or phase of project is very essential to accurately compute the total waste generation (Bekr 2014). The waste quantification is required to be done at each phase of any construction project, but it very difficult to do so, as preciseness is needed for exact computation of waste as well as ability to identify the characteristics of the generated waste is essential (Hassan et. al., 2020). The segregation of construction waste needs to be done veraciously so as to get correct amount of generated waste. Due to highly dynamic nature of construction activity, it is arduous to identify and quantify the exact amount of construction waste. (Quiñones et al., 2022). Due to paucity of documentation particularly for the amount of generated waste, data collection on construction waste management is formidable. At various stages of construction project, the composition as well as the quantity of generated waste varies. The variation in quantity will also depend on accurate adoption and implementation of waste management policies at site. Without preciseness, ability to identify the characteristics as well as proper segregation, it would be very difficult to accurately track, monitor and quantify the total amount of generated waste (Zezhou et. al., 2014). To benchmark the waste management practices at any construction site, this computed waste quantity acts as a significant indicator. However, this waste generation pattern can be predicable (Foo et al., 2013).
The amount of waste produced by the construction projects can be skillfully calculated using proper estimation and perdition technique, and the exact estimation involves calculating the historical quantity of waste, whereas the prediction determines the future production of waste based on previous data (Abou Rizk 2010). It is very essential to predict the output of future construction waste for better planning, strategic waste treatment and proper resource utilization for projects (Li et al., 2016). To minimize the amount of waste at the subsequent stages, waste predictions at primary stages are very crucial for residential projects. An emerging area having a huge potential of transformation is the machine learning, which provides a robust platform for the development of prediction model (Ram et al., 2017). With a prodigious potentiality for the transformation of many management and science areas including industrial information processing, machine learning is pivotal (Gavali and Halder 2020).
Quantification of construction waste
Waste quantification can be defined as the act of measuring and counting the total amount of waste generated from particular project at various levels and expressed in terms of statistical dataset. The waste quantification is one of the performance indicators for the waste management implementation plan as well as can be used for monitoring the overall effectuation of project undertaken. For accurate strategic development and prediction model, the exact quantified data of waste is a key factor. The relevant data on estimated and actual consumption of basic and major materials items, such as Cement, Reinforcement steel, Bricks, Sand and Coarse Aggregate, required for studied projects are collected and analyzed. For each project, negative variance or wastage is worked out. This carried-out wastage affects the productivity of project. Such type of analysis helps carry out the amount of wastage for any particular construction material as well as identification of such item so as to curtail the rate of waste generation (Fig. 1).

Study area
Study area
Nagpur is the third largest city of Maharashtra state of India, it is also the winter capital, proposed smart city and the geographical center of the country. By population, it stands fourteenth largest. The city has one of the highest potentials for the development as all the required resources are available within. The city has total area of 227.36 km2, due to its unsurpassable geographical location, and it is one of the leading cities for investment in infrastructural projects. Many residential projects have currently been in process and many other are in line. Due to larger area, Nagpur is growing horizontally as well as vertically, people from various sectors are investing in various projects in Nagpur, suitable to their pockets. From the single dwelling unit to the high-rise residential projects, Nagpur currently encompasses all possible types of residential projects. Due to the best-quality public transports like metro rail, the city is developing in all possible directions. This enables the growth of residential sector in all parts of the city i.e., from the centrally business development to outskirts area of the city.
Population and sample
Total 153 numbers of construction projects were visited to identify and collect the construction waste data. 134 out of 153 project data were used for analysis purpose (Acceptance rate is 87.58%). About 19 site data as discarded. (Discarding rate is 12.42%). As construction activities as well as project are very dynamic in nature having short and variable compilation period, a simultaneous approach of waste investigation is adopted to maintain consistency and accuracy of data collection. Almost equal characteristic proportions are maintained, as the projects are divided into three specific categories i.e., small, medium and large residential projects. All the selected projects were at different stages of construction as data collected was from substructural, superstructural and finishing stage.
Data collection and analysis for construction waste
The data on estimated material required for the particular project and actual consumption of basic and major materials items, such as Cement, Reinforcement steel, Bricks, Sand, Coarse Aggregate, floor finishes and wall finishes, required for studied projects are collected and analyzed. For each project, negative variance or wastage of significant materials is worked out. The floor area of each project is also calculated from the main building plan to substantiate the estimated material. All the generated waste is compartmentalized for maintaining fastidious approach for quantification. The quantification of the generated waste has been carried out at each stage of construction project. The total amount of wastage of any particular item is calculated using Eq. 1.
A proper effectiveness of all relevant measures of waste management is termed as wastivity, and it is measured as a ratio of generated waste material from a particular project to the estimated material consumption. To improve the productivity of any project, it is important to curtail the wastivity%age. Wastivity has been calculated using the following mathematical Eq. 2.
The wastivity has been calculated in each phase of construction project, and a cumulative amount of wastage has been calculated for each relative phase. The cost of construction is a cardinal factor and a decision-making parameter. The overall cost of construction project proliferates with the increment in the waste generation rate. Cost associated with generated waste has been calculated using following equation. {Current SSR Rate × Amount of wastage}.
Prediction model
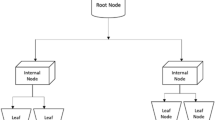
The prediction model is developed using the machine learning techniques to predict the amount of wastage generated at each stage of construction projects. Predictive models are generally categorized as on the basis of Decision trees and K-Nearest Neighbor (KNN) Algorithm. Prediction algorithms perform a certain level of data mining and a statistical analysis to determine the patterns and trends in the data (Cha et al., 2021; Al Mamari et al., 2022). To accurately predict the amount of waste at each respective stage of construction, machine learning and statistical algorithms are employed. Decision trees-based algorithms are comparatively simple and powerful for dealing with multi-variable analysis, which identifies various ways to split the data in branch-like structures. A decision tree is non-parametric supervised learning algorithm, which is used for the classification and regression task. It is particularly a hierarchical tree structure which includes branches, root node, internal node and leaf node. The main grail of using the decision tree is to create the precise training model that can be used to predict the value of the target variable by learning simple decision rule theorized from actual collected data (Ali et al, 2012). Fig. 2 shows the hierarchical structure of the decision tree algorithm. The k-nearest neighbors (KNN) algorithm is a simple, easy-to-implement supervised machine learning algorithm that can be used to solve both classification and regression problems. Co-relation analysis was done to remove the items with similar features. Both the prediction algorithms were used for prediction (Golbaz et al., 2019). The k-value for the dataset was kept 3 using elbow method. KNN is also a supervised learning classifier, uses a proximity for prediction about the grouping of an individual data point. The Euclidean distance has been computed using Eq. 3.

Decision tree hierarchical structure
where (x11, y11) are the coordinates of one point. (x 22, y22) are the coordinates of the other point. d is the distance between (x11, y11) and (x22, y22). The higher value of K leads to lower variance. Figure 3 portrays the structure of KNN algorithm.

KNN structure
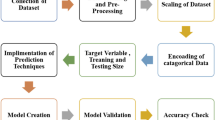
Fig. 4 communicates the detailed flow chart of the steps involved in machine learning prediction. Dataset in machine learning is collection of data pieces for analyzing and prediction purposes that are treated as a single unit by computer. The collected data is in a way that it is understandable by the machine. Here the dataset is collected from various construction projects with similar characteristics and materials used for construction process. The collected dataset are raw data collected from 153 construction sites. The dataset includes the data of amount of waste generated at three precise levels of project i.e., substructure stage, superstructure stage and finishing stage. The selection of appropriate machine learning algorithms was very climacteric as independent variables affecting the model outcome were substantially categorical data. Data cleaning is done to eliminate the duplication and error in dataset. To fit the data into a specific scale, transformation of data has been done. The model is trained by particular dataset collected using supervised learning method. About 70% data are used for training purpose. The model is run with a trained dataset that produces a result which is then compared with target, with each input vector in training data set. While employing the models’ hypermeters, the validation accoutres the clear evaluation. Finally, the hold-out dataset provides unprejudiced evaluation of final model fit on training dataset. The test dataset has been decided 30% of the total data. At the tertiary stage, the accuracy is found out; the flowchart of decision tree and the KNN algorithm is presented by Figs. 5 and 6, respectively. ANN-based models are very useful for the prediction and computing the waste generation rate, particularly back-propagation method for training, and testing is very useful in prediction of waste at the execution stage of project (Kaveh & Khalegi, 1998; Kaveh & Servati, 2001). For opting the best exploration of the desired results, it is very important to decide the appropriate type of the network, and according to it, selection of layers is appropriate when using the ANN-based algorithms for prediction (Kaveh et al., 2008). ANN has a great potential of self-learning and a fairly good accuracy in mapping nonlinear relationships even though if the relationships are complex one (Kaveh & Rahimi Bondarabady, 2004). However, the input parameters, framework, algorithm, data and partition, hidden layers and performance evaluation mainly depend on the size of the data set. The larger the set, the more accurate is the prediction model. Smaller data set may have more deviations as compared to the larger dataset.

Flow chart of steps for ML prediction

Flow chart for Decision tree algorithm

Flow chart for KNN algorithm
Model verification and performance evaluation
Root mean square error (RMSE)
The RMSE represents the square root of the second sample moment of the differences between predicted values and observed values or the quadratic mean of these differences. The standard deviation of the residuals is root mean square error (RMSE), a measure of how far regression line data points are the residuals and a measure of how unfurled these residuals are the root mean square error. For a precise dataset to analogize forecasting error of various models, RMSE measures the accuracy. It is invariably a non-negative value, the lower the value, the best fit is to the data (Sama Azadi et al., 2015). The RMSE is calculated using Eq. 4.
where Σ is a symbol that means “sum”. Pi is the predicted value for the ith observation in the dataset. Oi is the observed value for the ith observation in the dataset. n is the sample size.
As model is built and developed, it is very essential to assess the validity of the model. A preliminary study involves inspection of values of models with the point of blueprint of experiment. The criterion is applied to test the fit between observed and predicted model to find the accuracy of models. RMSE values reflecting between 0.2 and 0.5 represent that model can predict the data accurately, the value more than 0.75 indicates the higher accuracy.
Mean absolute% error (MAPE)
The absolute% error in context to the machine learning approach refers to the eminence of difference between true observed value and the predicted values from the model. A magnitude of error for the selected group is measured for predicted and the actual observed values by taking the average of absolute error (Ujong et al., 2022). MAPE is a precise quantifiable measurement of error particularly for the regression problem, it helps to formulate learning problem into optimization problem and also uses as loss function for the regression problems. The resultant accuracy is also known as scale-dependent accuracy as error is calculated during observation taken on same scale. For the regression model in machine learning, MAPE is particularly used as the evaluation matrix. Mean Absolute% Error is a model evaluation metric used with regression models. The mean absolute error of a model with respect to a test set is the mean of the absolute values of the individual prediction errors on overall instances in the test set. Each prediction error is the difference between the true value and the predicted value for the instance. MAPE is calculated by adopting Eq. 5 and the accuracy is computed using Eq. 6.
where, Σ: summation. yi: actual observed value for the ith observation. xi calculated value for the ith observation. n total number of observations.
Results and discussion
Wastivity
The following results represent the average amount of wastage generated from all the three phases of construction project. The substructure is the primary phase of project execution. This phase generally includes major activity related to casting of foundation, plinth and column till ground. The results are for the all-nature project i.e., small, medium and large types. The amount of bricks wastage ranges from 12 to 14%, the wastage of aggregates ranges from 11 to 13.5%, for the sand the wastage% is from 10 to 14.5%, the range for the cement wastage is 10–12.6%, and the wastage of steel reinforcement is 4–8.5%.
The representation beneath also represents the wastage generated during the superstructure stage. This is the second phase of studied construction project, which embraces the activity like casting of structural elements including beam, column and slab, and it also includes brickwork. This stage is responsible for generating maximal amounts of waste. The average wastivity for bricks ranges from 12 to 12.25%. At this stage, the wastivity of aggregate ranges from 11 to 12.25%, the wastivity of sand ranges from 10 to 11.5%, cement wastivity range is from 12 to 12.2%, and the steel reinforcement has the wastivity range of 6–6.2%. The tertiary stage is the finishing stage which also contributes significantly to the wastivity. This is the last stage of execution phase of the project and includes the major activities like plastering, wall finishes and floor finishes. The cement has the wastivity of 11–13.7%. The amount of wastivity for sand is 10–12.4. The wastivity of internal and external wall finishes are 10–11.3% and 10–11.80% respectively. The wastage generated by the floor finishes is 9–10.3%.
Fig. 7 represents the waste generation from construction projects at the substructure stage for small medium and large projects. In small projects, about 12% of cement waste was generated, sand was about 14.5%, bricks are around 14%, aggregates are 13.5% and reinforcement about 8.5% is wasted. In medium projects, the wastage for cement was 12.5%, for sand it was 13.7% for bricks it was 15%, for aggregates 11%, and for reinforcement, wastivity is about 6.7%. Considering larger projects, the wastivity of cement is 10.6%, for sand it is 10.7%, and for bricks, aggregates and reinforcement, it was 12.7, 11 and 5%, respectively.

Average wastivity % for projects in substructure stage
Figure 8 portrays the wastivity generated at superstructure stage, and for the small project, the generated wastage of the bricks was about 12.19%; wastage for sand and coarse aggregate, it was 11.4 and 12%; and for cement and reinforcement, the wastage statistics are 12.1 and 6.1% of the total material estimated. For the medium projects, the generated wastage for the bricks is 12.06%; wastage for the aggregates was 10.8 and 12.2%; the wastage observed for the cement and reinforcement was 12.06 and 6.01, respectively. For the large-scale projects, the wastivity observed was 12.2% for bricks, 11.49 and 11.47 for sand and coarse aggregates. The wastage for cement and steel reinforcement was 10.6 and 4.9%.

Average wastivity % for projects in superstructure stage
Figure 9 illustrates the wastivity generated at finishing stage of the project; this is the last stage at construction project. The amount of wastivity for the smaller project generated by wastage of cement and sand was 13.6 and 12.3%, the observed wastage for wall finishes was 11.5 for external and 9.7 for internal wall finishes; the wastage generated by the floor finishes was 9.7%. For the medium-scale project, the wastivity generated by the cement and sand was 12.4 and 10.8, respectively. The generation of the waste by the wall finishes both internal and external 11.2 and 10.8%, the amount of wastivity generated by the floor finishes was 10.2%. For the large-scale projects, the wastivity generated by cement and sand was 11.9 and 11.7%; the waste generated by the internal and external wall finishes was 10.8 and 11.7%, respectively. The generated wastage by the floor finishes at the terminal stage was 10.07%.

Average wastivity % for projects in finishing stage
Cost of wastage
Cost is among the very crucial parameter when decision and strategy making are concerned (Abu Hammad et.al., 2008; Venkatesh and Aarthy 2012). The following cost is computed by multiplying the total amount of wastivity that is generated at respective stages i.e., substructure, superstructure and finishing stage by the major civil engineering materials by the current state scheduled rates of the study area for year 2022 for all smaller-, medium- and the large-scale infrastructural residential projects.
Fig. 10 renders the cost for the wastivity generated at substructure stage for smaller, medium and large infrastructural projects. For the substructure stage of smaller projects, the cost wastage was around 6% of the total project material cost. While for the medium project, the cost of wastage at substructure stage was 5.8% of the cost of project. For the large-scale projects, the cost of wastage for the substructure stage was 5%.

Average cost of wastage for projects in substructure stage
Fig. 11 delineates the cost of generated waste amount at superstructure stage for all smaller, medium and large construction projects. At the superstructure stage, the cost of wastage for smaller project was approximately about 8% of the total project material cost, the cost of wastage for superstructure stage for medium-scale project is 7.5%, and for large-scale projects, the cost of wastage for the superstructure stage is 7% of the total project material cost.

Average cost of wastage for projects in superstructure stage
Fig. 12 depicts the cost of generated waste at finishing stage for all smaller, medium and large construction projects. At the finishing stage for the small-scale projects, the cost of wastage is 4.5% of total project cost, for the medium-scale projects at finishing stage, cost of wastage is 4% approximately, and for the large-scale projects, the cost of wastage for the finishing stage is 4% to the total cost of material of the project.

Average cost of wastage for projects in finishing stage
Waste prediction
On the substratum of the estimated amount of construction waste of the study area, the decision tree and the k-nearest neighbor algorithm for prediction have been used to predict the generated amount of construction waste at various phases of construction project. The resemblance between the actual values collected from site and the predicted values has been shown in following graphs for each selected stage of construction projects. The X-axis displays the total number of projects and the Y-axis shows the observed wastage of the particular material at the respective construction site. The results manifest that the predicted values of the waste generation are exceedingly close to the actual values obtained from the projects. The average root mean square error value RMSE = 0.49 < 1 shows that the models’ accuracy is high. Overall accuracy level of the models is satisfactory and can be used for the prediction of construction waste. The Decision tree and KNN are very suitable for the short-term prediction, and the accuracy maintained is on higher side, but for the long-term prediction, the accuracy level is bit too low.
Preceding Fig. 13 proclaims the observed and the predicted waste generated at substructure stage for the basic civil engineering construction materials i.e., cement, bricks, coarse aggregates, sand and steel reinforcement. The average root mean square error for the substructure stage by KNN is 0.63 and decision tree algorithm is 0.60. Fig. 14 conveys the observed and predicted values for superstructure stage where average root mean square error for KNN and decision tree are 0.48 and 0.50, respectively.

Waste prediction for substructure stage

Waste Prediction for superstructure stage
Figure 15 evinces the observed and predicted wastage generated particularly at the finishing stage of the construction project, where the average root mean square error for the KNN is 0.36, and for decision tree, it was 0.40. For all the materials, the predicted values and the observed values are forming the accurate pattern, resembling that the accuracy is considerable.

Waste prediction for finishing stage
Particularly both prediction models i.e., decision tree and K-nearest neighbors (KNN) algorithms are most effective on small datasets. The Decision trees can handle small datasets well because they do not require a lot of data to build the tree, also the decision tree can handle both continuous and categorical data, so they can be used with a variety of dataset types. The decision tree provides interpretable results, which can be useful when working with small datasets where it may be important to understand the predictions. In case of KNN, it does not make assumptions about the underlying data distribution, so it can be a good choice for datasets that may not fit a particular model. KNN can also handle both continuous and categorical data. Some of the reasons that KNN is a better choice than other prediction techniques for small datasets include ease of implementation, no need for extensive training, and does not have a complex network of weights and biases for optimization. KNN can be particularly useful for small datasets where it may be difficult to train a more complex model. KNN can perform well even with a small number of examples, as long as the examples are representative of the overall population.
Verification and performance evaluation
Figure 16 shows the stage-wise average root mean square values for all the three stages of construction. The substructure stage is having the average RMSE value of 0.62, the average RMSE value of superstructure was computed 0.49, and the RMSE value at finishing stage of construction is 0.38. The lower the RMSE value, the better is the accuracy of the prediction models.

Average RMSE values at all stages
Above Figs. 17 and 18 portray the accuracy of decision tree and KNN model, respectively, at all three stages of construction project collectively for all the construction materials for the particular stage. The particular prediction trend has been observed for the stages of construction as well as the respective materials. Mean Absolute% Error shows that the accuracy for prediction of cement sand and the aggregate are higher for both the models as they are proportional to each other. Both the models show an appreciable depletion in predicating accuracy of reinforcement as it falls in the supreme category, and the quantified requirement is low as compared to the other construction material. The quantified brick requirement is fair enough, and the prediction pattern by both the models for bricks is in the higher quartile. At the finishing stage, the prediction for the floor and the internal wall finishes is at higher side as compared to external wall finish. The average accuracy for decision tree model is found to be 87.94%, whereas the accuracy percentage for KNN was computed 87.17% at substructure stage, and for superstructure stage, average accuracy for decision tree model is found to be 88.84%, whereas the accuracy percentage for KNN was computed 88.94%. At finishing stage, the average accuracy for decision tree model is found to be 87.94% and the accuracy percentage for KNN was computed 87.17%.

Accuracy by decision tree model for all stages

Accuracy by KNN model for all stages
Figure 19 precisely shows the combined average accuracy of both the models for substructure, superstructure and finishing stage of the construction projects. The combined average accuracy for decision tree model was obtained as 88.32%, and for the KNN model, it was obtained as 88.51%. Both the model accuracy is fair to predict the generated waste for the construction infrastructural project at various stages of project during execution phase. In present study, the data set is small as it was collected from the actual construction sites. There is no synthetic dataset of similar nature which is available for many construction projects. The study region is also restricted due the geographical constraints. While referring to the overfitting, highly complicated tree can be created by decision tree learning, but it does not generalize the input well. Sometimes the precise sorting of nodes makes the algorithm more expansive. As far as the KNN is concerned, the prediction stage may get slow when the size of the dataset increases. The requirement of the system memory also increases to store all the data for training and testing purposes.

Combined average accuracy of prediction model for all stages
Conclusions
Waste generation is observed on each stage of construction project i.e., substructure, superstructure and finishing stage for all types of construction projects. Wastage pattern is almost similar for all residential type construction projects. In substructure stage, sand and bricks waste generation is predominant as compared to cement, aggregates and reinforcement. In superstructure stage, generation of waste from cement and bricks is relative to the higher value than the rest of materials, but in finishing stage, waste generation from cement and external wall finishes is more than other materials taken into consideration. The cost of wastage is approximately 15% to total cost of material for the project. The prediction model i.e., Decision tree and KNN predicts the amount of waste accurately. The RMSE value for Decision tree in multistage varies from 0.17 to 0.9, and for KNN, it varies from 0.19 to 0.8, showing that models are predicting accurately and getting better as transitioning toward finishing stages. The average combined accuracy of models is nearly 90% portraying that both the models are predicting the waste generation stage-wise accurately. The harnessed methods for prediction really work accurately for small data. The results show that the considerable amount of material is getting waste and cost associated with it is also directly proportional. The prediction model will help predict the wastage, also raise awareness among the managers to take precautionary measures to mitigate the problems and provide conclusive solutions. A higher accuracy in prediction has been observed for proportionate materials like cement sand and aggregate, and a particular depiction has been seen in the accuracy of the prediction of reinforcement for the substructure and superstructure stages, and at the finishing stage, accuracy for internal wall finishes as well as floor finishes is inclining toward higher side as compared to external wall finishes.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Abou Rizk, S. (2010). Role of simulation in construction engineering and management. Journal of Construction Engineering and Management, 136, 1140–1153.
Abu Hammad, A., Alhaj Ali, S., Sweis, G., & Bashir, A. (2008). Prediction model for construction cost and duration in Jordan. Jordan Journal of Civil Engineering, 2(3), 250–266.
Al Mamari, A. H. S., Al Ghafri, R. S. H. H., Aravind, N., et al. (2022). Experimental study and development of machine learning model using random forest classifier on shear strength prediction of RC beam with externally bonded GFRP composites. Asian Journal of Civil Engineering. https://doi.org/10.1007/s42107-022-00502-3
Ali, A. S., & Rahmat, I. (2010). The performance measurement of construction projects managed by ISO-certified contractors in Malaysia. Journal of Retail and Leisure Property, 9(1), 25–35. https://doi.org/10.1057/RLP.2009.20/TABLES/3
Ali, J., Khan, R., Ahmad, N., & Maqsood, I. (2012). Random forests and decision trees. International Journal of Computer Science, 9(5), 272–278.
Aravindh, M. D., Nakkeeran, G., Krishnaraj, L., et al. (2022). Evaluation and optimization of lean waste in construction industry. Asian Journal of Civil Engineering, 23, 741–752. https://doi.org/10.1007/s42107-022-00453-9
Bekr, G. A. (2014). Study of the causes and magnitude of wastage of materials on construction sites in Jordan. Journal of Construction Engineering, 2014, 1–6. https://doi.org/10.1155/2014/283298
Cha, G.-W., Moon, H. J., Kim, Y.-M., Hong, W.-H., Hwang, J.-H., Park, W.-J., & Kim, Y.-C. (2021). Development of a prediction model for demolition waste generation using a random forest algorithm based on small data sets. International Journal of Environmental Research and Public Health, 17(19), 6997.
Coffie, G. H., Aigbavboa, C. O., & Thwala, W. D. (2019). Modelling construction completion cost in Ghana public sector building projects. Asian Journal of Civil Engineering, 20, 1063–1070. https://doi.org/10.1007/s42107-019-00165-7
Coskuner, G., Jassim, M. S., Zontul, M., & Karateke, S. (2020). Application of artificial intelligence neural network modeling to predict the generation of domestic, commercial and construction wastes. Waste Management & Research: THe Journal for a Sustainable Circular Economy, 39(3), 499–507.
Elshaboury, N., Al-Sakkaf, A., Abdelkader, E. M., & Alfalah, G. (2022). Construction and demolition waste management research: A science mapping analysis. International Journal of Environmental Research and Public Health, 19(8), 4496.
Foo, L. C., Rahman, I. A., Asmi, A., Nagapan, S., & Khalid, K. I. (2013). Classification and quantification of construction waste at housing project site. International Journal of Zero Waste Generation, 1(1), 1–7.
Gavali, A., & Halder, S. (2020). Identifying critical success factors of ERP in the construction industry. Asian Journal of Civil Engineering, 21, 311–329. https://doi.org/10.1007/s42107-019-00192-4
Golbaz, S., Nabizadeh, R., & Sajadi, H. S. (2019). Comparative study of predicting hospital solid waste generation using multiple linear regression and artificial intelligence. Journal of Environmental Health Science and Engineering, 17(1), 41–51. https://doi.org/10.1007/s40201-018-00324-z
Hassan, S. H., Aziz, H. A., Daud, N. M., Keria, R., Noor, S. M., Johari, I., & Shah, S. M. R. (2020). The methods of waste quantification in the construction sites (a review). Advances in Civil Engineering and Science Technology, AIP Conference Proceedings, 2020, 020056-1–020056-6.
Kaveh, A., & Khalegi, A. (1998). Prediction of strength for concrete specimens using Artificial Neural Networks. In: 1st International Conference on Engineering Computational Technology/4th International Conference on Computational Structures Technology, pp 165–171, WOS:000077305500020
Kaveh, A., & Servati, H. (2001). Design of double layer grids using back-propagation neural networks. Computers and Structures, 79, 1561–1568. https://doi.org/10.1016/S0045-7949(01)00034-7
Kaveh, A., Gholipour, Y., & Rahami, H. (2008). Optimal design of transmission towers using genetic algorithm and neural networks. International Journal of Space Structures, 1(23), 1–19. https://doi.org/10.1260/026635108785342073
Kaveh, A., & Rahimi Bondarabady, H. A. (2004). Wavefront reduction using graphs, neural networks and genetic algorithm. International Journal for Numerical Methods in Engineering, 60, 1803–1815. https://doi.org/10.1002/nme.1023
Kolaventi, S. S., Tezeswi, T. P., & Siva Kumar, M. V. N. (2019). An assessment of construction waste management in India: A statistical approach. Waste Management & Research, 38(4), 444–459. https://doi.org/10.1177/0734242X19867754
Li, Y., Zhang, X., Ding, G., & Feng, Z. (2016). Developing a quantitative construction waste estimation model for building construction projects. Resources, Conservation and Recycling, 106, 9–20. https://doi.org/10.1016/j.resconrec.2015.11.001
Markandeya Raju, P., & Kameswari, L. (2015). Construction and demolition waste management—a review. International Journal of Advanced Science and Technology, 84, 19–46.
Parsamehr, M., Perera, U. S., Dodanwala, T. C., et al. (2022). A review of construction management challenges and BIM-based solutions: Perspectives from the schedule, cost, quality, and safety management. Asian Journal of Civil Engineering. https://doi.org/10.1007/s42107-022-00501-4
Quiñones, R., Llatas, C., Montes, M. V., & Cortés, I. (2022). Quantification of construction waste in early design stages using bim-based tool. Recycling, 7(5), 63. https://doi.org/10.3390/recycling7050063
Ram, V. G., & Kalidindi, S. N. (2017). Estimation of construction and demolition waste using waste generation rates in Chennai, India. Waste Management & Research: THe Journal for a Sustainable Circular Economy, 35(6), 610–617. https://doi.org/10.1177/0734242X17693297
Ruibo, H., Chen, K., Chen, W., Wang, Q., & Luo, H. (2021). Estimation of construction waste generation based on an improved on-site measurement and SVM-based prediction model: A case of commercial buildings in China. Waste Management, 126, 791–799.
Sama, A., & AyoubKarimi, J. (2015). Verifying the performance of artificial neural network and multiple linear regression in predicting the mean seasonal municipal solid waste generation rate: A case study of Fars province Iran. Waste Management, 48, 14–23. https://doi.org/10.1016/j.wasman.2015.09.034
Suk, S. J., Chi, S., Mulva, S. P., Caldas, C. H., & An, S. H. (2016). Quantifying combination effects of project management practices on cost performance. KSCE Journal of Civil Engineering. https://doi.org/10.1007/s12205-016-0499-0
Ujong, J. A., Mbadike, E. M., & Alaneme, G. U. (2022). Prediction of cost and duration of building construction using artificial neural network. Asian Journal of Civil Engineering, 23, 1117–1139. https://doi.org/10.1007/s42107-022-00474-4
Venkatesh, J., & Aarthy, C. (2012). Emerging erp systems—exemplary for the construction industry. EXCEL International Journal of Multidisciplinary Management Studies, 2(6), 24–31.
Zezhou, W., Yu, A. T. W., Shen, L., & Liu, G. (2014). Quantifying construction and demolition waste: An analytical review. Waste Management, 34(9), 1683–1692.
Acknowledgements
The research work supported by the Lovely Professional University, Punjab, India and G H Raisoni College of Engineering, Maharashtra, India. The authors thankfully acknowledge the funding agencies for the support.
Funding
The authors have not disclosed any funding.
Author information
Authors and Affiliations
Contributions
Credit Author Statement AG: conceptualization, methodology, validation, formal analysis, investigation, resources, data curation, writing – original draft, writing – review & editing, visualization. RLS: conceptualization, writing – review & editing, supervision. PB: writing – review & editing, supervision.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Gulghane, A., Sharma, R.L. & Borkar, P. Quantification analysis and prediction model for residential building construction waste using machine learning technique. Asian J Civ Eng 24, 1459–1473 (2023). https://doi.org/10.1007/s42107-023-00580-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42107-023-00580-x