
Abstract
In recent years, fault diagnosis of rotating equipment based on vibration signals is receiving much importance due to its vital role as part of the Conditional Based Monitoring (CBM). Classical methods of fault diagnosis are based on features extracted from signal such as mean, standard deviation, kurtosis etc. But, signals still carry abundant information that shows their unique characteristics. Therefore, in this research work, a new approach is being proposed for bearing fault diagnosis based on Ensemble Machine learning algorithms like Random Forest (RF) and eXtreme Gradient Boosting (XGB) by extracting Mel Frequency Cepstral Coefficients(MFCC) features from vibration signals. Both RF and XGB classification models accept MFCCs as input features and then these models are trained and tested for diagnosis of 12 different fault types under varying machine conditions. The experimental application of the proposed methodology is based on vibration signals collected from the bearing data center of Case Western Reserve University (CWRU). This research work also focusses on tuning the hyper parameters of the fault diagnosis models to optimize their performance. RF and XGB models have demonstrated an accuracy of 98.17% and 98.08% respectively in predicting the various 12 different types of bearing fault conditions. The performance of the proposed algorithms for fault diagnosis is also compared with Support Vector Machine based method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Roller bearing (RB) is one of the most critical component in any rotating equipment as it plays a significant role in many industrial systems that involves rotation. It prevents direct metal to metal contact between two elements that are in relative motion to avoid friction, heat generation and ultimately, the wear and tear of parts. It is certain that these components suffer from a sequence of physical effects such as machine-driven stress and mechanical wear, which causes distortion and corrosion of the bearings. Due to which the working performance of the machine results in the degradation over a period. So, there’s an unexpected machine breakdown and catastrophic failure occurs because of the failure of roller bearing. Therefore, in modern industrial production, fault diagnosis of rotating machinery and condition monitoring is a major concern. Hence timely detection and condition monitoring of roller bearing is essential to avoid financial losses and personnel safety accidents.
It is very difficult for humans to identify the fault of a roller bearing accurately through physical observation or interpretation. Hence, there’s a need of Machine Learning (ML) technique, which is one of the important and growing field of data science. ML algorithms are used to make a prediction or classification by uncovering key insights within data that subsequently drive decision making within various applications and businesses. ML algorithms identify the hidden patterns or unique features in the vibration data so that they can potentially diagnose the bearing fault. There are two significant factors that motivates the use of these effective applications which are: (1) Usage of statistical models that capture the complex data dependencies and (2) Scalable learning models that learn the pattern of interest from large datasets. Various Machine Learning (ML) and Deep Learning (DL) algorithms for fault diagnosis are summarized and compared their performance by utilizing CWRU dataset [1]. The applications of ML include Speech Recognition, Customer Service, Medical Diagnosis, Computer Vision, Recommendation Engines, Automated stock trading and many more.
2 Related work
In the recent researches, a combination of vibration-based analysis with Machine Learning has attracted more attention in fault diagnosis of roller bearing due to it’s very effective results in identifying the various faults. Raw vibration data may contain some noise and outliers so that it may become unusable for diagnosing the faults accurately. Pankaj Gupta et al. summarized the various types of defects, sources of vibration and vibration measurement techniques to assess the fault in a bearing through signal analysis in different domains [2]. Literature survey reveals that extracting accurate features from vibration signals is a challenging task. So, various feature extraction methods were employed in time-domain, frequency-domain and time–frequency domain in order to extract the relevant features from vibration data [3, 4]. Wahyu Caesarendra et al. [5] reviewed several feature extraction methods by considering six categories such as time-domain features extraction, frequency-domain features extraction, time–frequency representation, phase-space dissimilarity measurement, complexity measurement and other features as well for vibration data acquired from slew bearings which are naturally degraded and operating at very low rotational speed.
Many researchers have proven that the fault diagnosis of rolling bearing based on Time–Frequency domain analysis is more effective because of non-linear characteristics of a vibration signal which involves the process of extracting Mel-Frequency Cepstrum Coefficient (MFCC) features from vibration signals. MFCC of a signal represents a small set of features which concisely describe the overall shape of a spectral envelope. A combination of Gaussian Mixture Model with MFCC features have shown the performance enhancement in classifying the faults by choosing the MFCCs with frame length of 1024 and 2048 samples from the pre-processed signals [6]. Based on convolutional neural networks (CNNs), a new bearing fault classification method was presented by extracting MFCC and delta cepstrum features using feature arrangement method to transfer feature vectors to feature images by providing these images as feature inputs to CNN with satisfactory performance in classifying the faults [7].
Machine Learning algorithms such as Support Vector Machine (SVM), Naïve Bayes (NB), Decision Tree (DT), k-Nearest Neighbor (kNN), Artificial Neural Networks (ANN) etc. were surveyed to understand the practical implication of these algorithms to diagnose the fault in roller bearing [8]. Ensemble Learning (EL) algorithms such as Random Forest (RF) and Extreme Gradient Boosting (XGBoost) have shown the promising results with an accuracy of 99% in classifying different types of faults in Induction Motors by extracting statistical features from the current signal using Discrete Wavelet Transform method [9]. Priyanka et al. [10] demonstrated an application of EL methods by combining RF, AdaBoost, Gradient Boosting (GB), XGBoost, Extra tree and Majority Voting for fault diagnosis of bearing through extraction of four statistical features such as kurtosis, Root Mean Square, shape factor and peak to peak from the captured signal. To recognize the degradation state of RB such as healthy, early, recession and failure state, K-Means clustering algorithm was used by extracting few statistical and MFCC features from vibration data and then in order to eliminate the interference brought by human factors the Convolution Neural Networks (CNN) model was built which takes the bearing vibration as input, and outputs the degradation state category [11].
An implementation of many ML algorithms for fault classification on Vehicle Power Transmission System based on MFCC features has shown higher accuracy by acquiring the acoustic signals of the vehicle [12]. A Cost-Efficient Fault Detection and Isolation method for Electromagnetic pumps was proposed by extracting MFCCs, the first-order and the second-order differentials by selecting features based on rank through recursive feature elimination (RFE) and classified the faults using Gaussian kernel SVM algorithm [13]. Daihee Park et al. employed SVM algorithm to detect and diagnose faults in railway condition monitoring systems by extracting MFCC from audio data of Railway Point Machines [14]. An application of Gaussian Mixture model was demonstrated by combining MFCC with Kurtosis features to show an improvement in classification rate up to 99% in bearing fault classification [15]. kNN and RF algorithms were experimented for multi-class fault diagnosis in paper [16] by selecting most appropriate features from feature ranking methods such as Relief algorithm, Chi-Square, and Information Gain by validating 5 databases. A comparative study of supervised ML techniques such as ANN, logistic regression and SVM was presented for the fault diagnosis of cylindrical roller bearing by applying wavelet analysis for feature selection and the results showed that Logistic Regression was found more accurate in comparison with the ANN and SVM [17]. In [18], Xgboost algorithm was used to rank the important features by obtaining the time domain and time–frequency domain features and then these features were input into the SVM to observe the fault diagnosis accuracy improvement after applying Xgboost.
Motivated by the fact that Ensemble based machine learning methods perform better in fault diagnosis by aggregating the predictions of all the base learners. In this research work, two such algorithms namely, RF and XGB are implemented to predict 12 different types of bearing faults. These algorithms are trained using the MFCC features which are extracted from the vibration signals of roller bearing and also hyperparameter tuning is done in order to achieve accurate results. Section 3 illustrates the proposed methodology. Followed by that, an experimental setup is discussed in Sect. 4 and results are analysed in Sect. 5.
3 Proposed methodology
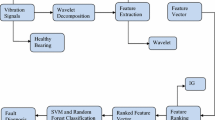
The proposed method aims at developing a multi-class fault diagnostic model for roller bearing under various running conditions. Figure 1 shows the proposed fault diagnostic method. Vibration signals are collected from CWRU dataset by acquiring data from a set of ball bearings containing localized faults. The goal is to identify the different types of faults using MFCC based feature extraction method and ensemble learning techniques. Firstly, the acquired vibration signals are segmented into suitable number of sub-samples. Then, MFCC features are extracted from every segment of the signal and the most appropriate features are selected. Finally, every sample acquired from different faulty bearings is processed and dataset is prepared for different supervised ML models. They are trained and tested to diagnose the different faults with improved diagnostic capability of the classifiers.

Block diagram of the proposed fault diagnosis method
Details of each step are in the following subsections.
3.1 Data acquisition
Bearing vibration data is obtained from the CWRU bearing data set [19]. This repository is made available to access it for conducting the research work. It consists of both normal and faulty ball bearings vibration data. Motor bearings were induced with faults using electro-discharge machining (EDM) and the acceleration data was measured at locations near to and remote using a 2 horsepower(hp) Reliance Electric motor. Faults were introduced at the Inner Race (IR), Rolling Element (i.e. Ball) and Outer Race (OR) with diameters ranging from 0.007 to 0.040 inches. Vibration data was collected for motor loads of 0–3 hp with motor speeds of 1797–1720 Rotations Per Minute (RPM) by reinstalling faulted bearings into the test motor.
The vibration measurement is considered for three operating conditions:
-
1.
Baseline—no fault, sampling rate of 12 kHz with rotations of 1797 per minute.
-
2.
Outer race fault—Sampling rate of 12 kHz with rotations of 1797 per minute.
-
3.
Inner race fault—Sampling rate of 12 kHz with rotations of 1797 per minute.
3.2 MFCC for feature extraction
Mel Frequency Cepstral Coefficients (MFCCs) is a feature extraction method which is widely and successfully used in automatic speech recognition. MFCC is noticed as a best feature extraction (FE) technique for speech signal among many FE methods [3]. Therefore, MFCC features with time and frequency information presents the unique feature of a signal.
Initially, the vibration data is segmented into small frames and windowed. From each frame, the frequency spectrum is obtained by applying the short-time Fourier transform (STFT). The short frame spectrum is separated by Mel frequency scale to highlight the features or characteristics of signal. Finally, spectral feature is reduced to a lower dimension feature from the frequency spectrum by dividing it by discrete cosine transform (DCT). These spectral features are called as MFCC features.
The conversion between actual frequency and Mel scale of a signal ‘f’ is given in (1):
The MFCC feature extraction process is shown in Fig. 2. It involves the transformation of the signal from time domain to frequency domain and then mapping of the transformed signal in hertz, onto Mel scale.

MFCC feature extraction process
The following steps are used for the calculation of MFCCs:
-
Pre-emphasis filtering.
-
Framing and Windowing.
-
Take the absolute value of the STFT.
-
Wrapping of auditory frequency scale.
-
Take the DCT of the log auditory-spectrum.
-
Obtain the MFCCs.
Pre-emphasis filtering is a type of finite impulse response (FIR) that compensate the fluctuation of the spectrum energy between low frequencies and high frequencies.
Let x[n] be the raw vibration signal at sample n and s[n] be the signal after the high-pass filtering which is given as:
where ‘α’ is a parameter which is set between 0.95 and 1 and it controls how much signal is to be filtered.
Then, next step is to apply Short Time Fourier Transformation to transform the signal from time domain to frequency domain by combining it with a window function as mentioned in (3).
where wa(n) is the window function and i is an imaginary part. wa(n) is a zero valued function everywhere except inside the window. To keep the frames continuous, Hamming window is preferred. The window function is:
where α = 0.54, β = 1 − α = 0.46, 0 ≤ n ≤ N.
Human hearing ability is between 20 and 1000 Hz and it is less effective to assign a signal with the same scale at high frequencies as lower frequencies. So, an adjustment needs to be done by mapping the data from Hertz-scale onto Mel-scale. The mapping function is given by:
In addition, its inverse is computed as shown in (6).
For an input window frame xa[k] and given the STFT, then filter bank with M filters (m = 1,2…M) which are linear on Mel scale and nonlinear on Hertz scale. The filter bank calculation is given by:
where m is triangular filter, N is the length of the filter. These filters which are linear on Mel scale are converted back to Hertz scale. Then, the log-energy of each filter is calculated as given below:
The discrete cosine transform of ‘M’ filter outputs as Mel-frequency cepstrum coefficients is given in (9):
3.3 Ensemble learning algorithms used in the proposed model for fault diagnosis
As seen in the literature, many ML algorithms have been employed for fault diagnosis of roller bearings. But, selection of an efficient ML algorithm is a challenging task for fault diagnosis. Among all, Ensemble learning algorithms such as Random Forest (RF) and eXtreme Gradient Boosting (XGB) methods have demonstrated very accurate results in fault classification [7]. In ensemble learning, multiple base learners are combined to produce a better model to achieve higher accuracy. XGBoost algorithm has achieved promising accuracy in diagnosing the fault of roller bearing by showing the importance of each feature as discussed in [18]. In this research, two ensemble learning techniques known as Random Forest and XGBoost are examined for fault classification of roller bearings.
3.3.1 Random Forest
The Random forest (RF) is an ensemble learning algorithm. It is a collection of multiple weak base learners or decision trees which are constructed in parallel. Each tree in this collection is trained individually by arbitrarily selecting samples from training dataset. Here, each input dataset is sampled separately for each tree such that the distribution rate will remain same for all the trees. Then, the trees are obtained by combining the bootstrap samples with the subsets of features for splitting at each node. Selection of random subsets of features for the individual base learners will help to reduce the correlation. Finally, after combining all the base learners, RF outcomes in low bias and low variance for the trained model. The tree which receives majority voting from the base learners is selected for decision making. The RF can overcome the overfitting problem by hyperparameter tuning.
The hyperparameters for the RF model are number of trees, features in each split, samples at leaf nodes and maximum depth. RF uses a bagging method, in which a subset of features is selected randomly at each time to train a single base learner. Then, it aggregates the outcome of an each base learner to determine the final predicted output. Thus, it avoids overfitting of the model.
The RF algorithm working principle—For each base learner in the forest of trees, we select ith bootstrap sample i.e. S(i) from S. A modified decision-tree learning algorithm is learnt as follows: At each node of the tree, we randomly choose subsets of features in spite of considering all the possible feature-splits i.e. f \(\subseteq\) F, where F is the set of features. Then, the node splits at the best feature in f. The pseudocode is illustrated below.

3.3.2 eXtreme Gradient Boosting
eXtreme Gradient Boosting (XGB) is an effective ensemble learning algorithm for supervised machine learning problems. The decision trees which are the base learners are trained sequentially. Each successive base learner aims to reduce the prediction errors of the preceding learner. Each base learner learns from its predecessors and the residual errors are updated accordingly. Hence, the tree grows in sequence by learning from an updated version of the residuals of the previous learner.
The algorithm produces a prediction model through ensemble of weak prediction models by constructing it recursively, typically decision trees. Xgboost applies a second order Taylor expansion of the loss function. A regular term is also added to the loss function to optimize the overall solution. So, this addition of the regular term helps to understand the decline of the loss function and also the complexity of the model to avoid model overfitting. The main reason for choosing XGBoost is that it does automatic parallel computation on a single machine and can be run on a cluster so that efficiency can be increased.
Pseudocode of XGBoost Algorithm:
-
(1)
Suppose a model has K decision trees, then classification result of this model can be shown as:
$$ \widehat{yi} = \mathop \sum \limits_{k = 1}^{K} f_{k} \left( {x_{i} } \right) $$(10) -
(2)
The objective function at t-th step is:
$$ obj^{\left( t \right)} = \mathop \sum \limits_{i = 1}^{N} L\left( {y_{i} , y^{{ \wedge^{\left( t \right)} }} } \right) + \mathop \sum \limits_{i = 1}^{t} \Omega \left( {f_{i} } \right) $$(11)where Ω represents regularization term that prevents overfitting. It’s given as:
$$ \Omega = \gamma T + \frac{1}{2} \lambda \mathop \sum \limits_{j = 1}^{T} w_{j}^{2} $$(12)where T- Number of leaves wj-weight score on j-th leaf.
-
(3)
Next, second order derivative of Taylor expansion is computed as:
$$ obj^{\left( t \right)} \cong \mathop \sum \limits_{i = 1}^{N} \left[ {L\left( {y_{i} , y^{{ \wedge \left( {t - 1} \right)}} } \right) + g_{i} f_{t} \left( {x_{i} } \right) + \frac{1}{2}h_{i} f_{t}^{2} \left( {x_{i} } \right)} \right] + \sum\limits_{(i = 1)}^{t} {\Omega (f_{i} )} $$(13)where \(g_{i} = grad = \partial_{{y^{{ \wedge \left( {t - 1} \right)}} }} L\left( {y_{i} , y^{{ \wedge \left( {t - 1} \right)}} } \right)\) and \(h_{i} = hess = \partial^{2}_{{y^{{ \wedge \left( {t - 1} \right)}} }} L\left( {y_{i} , y^{{ \wedge \left( {t - 1} \right)}} } \right)\).
-
(4)
Rewriting the (13) by substituting Ω from (12),
we will get:
$$ \begin{aligned} obj^{\left( t \right)} & = \mathop \sum \limits_{i = 1}^{N} \left[ {g_{i} f_{t} \left( {x_{i} } \right) + \frac{1}{2}h_{i} f_{t}^{2} \left( {x_{i} } \right)} \right] \\ & + \gamma T + \frac{1}{2} \lambda \mathop \sum \limits_{j = 1}^{T} w_{j}^{2} \\ \end{aligned} $$(14)where \(w_{j} = Leaf score = - \frac{{\mathop \sum \nolimits_{{i \in I_{j} }} g_{i} }}{{\mathop \sum \nolimits_{{i \in I_{j} }} h_{i } + \lambda }}\) and Index set assigned at j-th leaf is: \(I_{j} = \left\{ {i\left| {q\left( {x_{i } } \right)} \right. = j } \right\}\).
-
(5)
Find the best split by optimizing the objective function as given below:
$$ obj^{\left( t \right)} = - \frac{1}{2} \frac{{\left( {\mathop \sum \nolimits_{{i \in I_{j} }} g_{i} } \right)^{2} }}{{\mathop \sum \nolimits_{{i \in I_{j} }} h_{i } + \lambda }}/\!\!\!\!\! - \gamma $$(15) -
(6)
Let IL and IR be the index set assigned to left and right node. Then, gain of the split is:
$$ Gain = \frac{1}{2}\left[ {\frac{{\left( {\mathop \sum \nolimits_{{i \in I_{L} }} g_{i} } \right)^{2} }}{{\mathop \sum \nolimits_{{i \in I_{L} }} h_{i } + \lambda }} + \frac{{\left( {\mathop \sum \nolimits_{{i \in I_{R} }} g_{i} } \right)^{2} }}{{\mathop \sum \nolimits_{{i \in I_{R} }} h_{i } + \lambda }} + \frac{{\left( {\mathop \sum \nolimits_{i \in I} g_{i} } \right)^{2} }}{{\mathop \sum \nolimits_{i \in I} h_{i } + \lambda }}} \right] $$(16)
To construct a tree, the best splitting point is recursively computed until the maximum depth is reached. Finally, the nodes are pruned with a negative gain in a bottom-up manner.
3.3.3 Performance metrics for the fault diagnosis models
When a Machine Learning model is built, various performance metrics are used to check its quality by evaluating the performance of a model. For classification models, metrics such as Accuracy, Confusion Matrix, Classification report i.e. Accuracy, Precision, Recall, F1 score are used.
Confusion Matrix It is a performance evaluating matrix for ML based classification problems. It describes the performance of a classification model in the form of a table consisting of predicted and actual values as shown in Table 1. It is extremely useful for measuring Accuracy, Precision, Recall, AUC-ROC curve and also other performance indicators.
Elements of confusion Matrix are explained below.
True Positive (TP) The number of test samples which are actually positive and are predicted positive.
False Positive (FP) The number of test samples which are actually negative but wrongly predicted as positive.
False Negative (FN) The number of test samples which are actually positive but wrongly predicted as negative.
True Negative (TN) The number of test samples which are actually negative and are predicted negative. The other performance metrics are calculated as shown in Table 2.
4 Experimental setup
An experimental set-up of CWRU dataset [19] for the bearing data collection is shown in Fig. 3. It consists of 2 hp motor, a torque transducer, a dynamometer, control electronics and the bearings used in the experiment are part of the motor shaft. Using electro-discharge machining (EDM), single point faults of various diameters 7 mils, 14 mils, 21 mils, 28 mils, and 40 mils (1 mil = 0.001 inches) were introduced to the test bearings. The bearing faults of diameters 7, 14 and 21 mils are of SKF bearing types. The bearing faults of diameters 28 and 40 mils are of NTN bearing type.

Experimental set-up of CWRU bearing data collection
5 Results and discussion
The vibration data is collected from CWRU dataset for three different bearing conditions. The details of the bearing data used in this research work is described in Table 3. The table shows the different types of faults and the number of samples for each fault category that is collected from the experimental setup.
The time-domain characteristics of the raw vibration signals collected for different bearing faults are shown in Fig. 4a–d.

a Time-domain characteristics for Normal Bearing. b Time-domain characteristics for Outer Race Fault. c Time-domain characteristics for Inner Race Fault. d Time-domain characteristics for Ball Fault
Once the vibration data is pre-processed, twenty MFCC features are extracted from each sample in time–frequency domain. The extracted MFCC features are given as inputs to both of the ensemble learning classifiers i.e. Random Forest and eXtreme Gradient Boosting for diagnosing various bearing faults. The MFCC features for each type of the fault are shown in Fig. 5a–d.

a MFCC features for Normal Bearing. b MFCC features for Outer Race fault. c MFCC features for Inner Race fault. d MFCC features for Ball fault
The Ensemble learning methods namely RF and XGB are implemented using the Sklearn [20] library of Python’s ML package.
Hyperparameter tuning for the Ensemble Models Many ML algorithms have some parameters known as hyperparameters that are external to the model. These are the parameters that control the learning process and helps in identifying the best value of the model’s parameters by the end of the learning process. Hence tuning these hyperparameters help in optimizing the performance of the trained model.
In this work, the hyperparameters of RF and XGB are tuned using the “GridSearchCV”, API of Sklearn by applying k-fold cross validation for each independent set. For both classifiers, a range of parameters are tested and also fivefold cross validation is applied to enhance the reliability of the output. The two hyperparameters of XGB that are tuned include max_depth and n_estimators. Max_depth indicates the maximum depth of the tree, a parameter that controls overfitting. N_estimators indicates the number of parallel threads that are used to run the algorithm. As seen in Fig. 6, GridSearchCV predicts the optimal values of these parameters as max_depth value = 5 and n_estimators = 9 based on accuracy as the scoring metric.

Hyperparameter Tuning for RF based Fault Diagnosis
Figures 6 and 7 illustrates the parameter tuning process of RF and XGB algorithm for its hyperparameters namely n_estimators and Max_depth. The optimal value for both the parameters is 9 as seen in the plot.

Hyperparameter Tuning for XGB based Fault Diagnosis
The optimum parameters found after the GridSearchCV method of the two ensemble models for fault diagnosis are listed in Table 4.
The proposed model is tested with 4118 vibration signal samples in order to verify the feasibility and reliability of the model. The various categories of faults and its description is given in Table 5.
The RF model is trained using fivefold cross validation method and obtained the confusion matrix is shown in Fig. 8. In total, 4041 out of 4118 samples are recognized correctly, so the accuracy reached to 98.17%, which indicates that the RF classifier performed well in fault classification of the rolling bearing on the test set. Similarly, the confusion matrix for XGB-based model is shown in Fig. 9. The XGBoost classifier demonstrated an accuracy of 98.08% by classifying 4038 out of 4118 samples correctly. The performance of these algorithms is compared with Support Vector Machine(SVM) classifier.

Confusion Matrix of RF Based Fault Diagnosis

Confusion Matrix of XGB Based Fault Diagnosis
The performance matrix for ensemble learning classifiers and SVM classifier is given in Table 6. It includes Fault classification accuracy, recall, precision and F1-score for 12 different types of faults.
Feature Importance graph of XGBoost It can be seen from Fig. 10 that the Xgboost algorithm can improve the accuracy of fault diagnosis by ranking the relevant MFCC features for fault diagnosis. Visualization of importance of each feature as a bar graph involves counting the number of times each feature is split on across all boosting rounds in the model. The graph depicts the order of importance of features from highest to lowest i.e. MFCC features 1, 2, 3 and 11 are having highest importance compared to all other features as shown in Feature Importance graph.

Feature importance graph of XGBoost
6 Conclusion
In this paper, a novel approach for fault diagnosis of rotating machinery is proposed with the experimental results of the same. A combination of MFCC feature extraction method with Ensemble Machine Learning technique is applied to diagnose multiple faults of roller bearing. Both RF and XGB classifier models demonstrate very promising results in terms of accuracy and other accepted and f1 score. Random Forest has achieved an accuracy of 98.17% and XGBoost with 98.08%. In future, the performance of the Ensemble Models for Fault Diagnosis will be analyzed by combining statistical and performance indicators such as precision, Recall MFCC features extracted from the vibration signals of roller bearings for different fault conditions.
References
Zhang S, Zhang S, Wang B, Habetler TG (2020) Deep learning algorithms for bearing fault diagnostics—a comprehensive review. IEEE Access 8:29857–29881
Gupta P, Pradhan MK (2017) Fault detection analysis in rolling element bearing: a review. Mater Today Proc 4(2):2085–2094
Singh S, Vishwakarma M (2015) A review of vibration analysis techniques for rotating machines. Int J Eng Res Technol 4(03):757–761
Yang H, Mathew J, Ma L (2003) Vibration feature extraction techniques for fault diagnosis of rotating machinery: a literature survey. In: Asia-Pacific Vibration Conference, no. 42460, pp 801-807
Caesarendra W, Tjahjowidodo T (2017) A review of feature extraction methods in vibration-based condition monitoring and its application for degradation trend estimation of low-speed slew bearing. Machines 5(4):21
Atmani Y, Rechak S, Mesloub A, Hemmouche L (2020) Enhancement in bearing fault classification parameters using Gaussian mixture models and mel frequency cepstral coefficients features. Arch Acoust 45(2):283–295
Jiang Q, Chang F, Sheng B (2019) Bearing fault classification based on convolutional neural network in noise environment. IEEE Access 7:69795–69807
Liu R, Yang B, Zio E, Chen X (2018) Artificial intelligence for fault diagnosis of rotating machinery: a review. Mech Syst Signal Process 108:33–47
Nishat Toma R, Kim J-M (2020) Bearing fault classification of induction motors using discrete wavelet transform and ensemble machine learning algorithms. Appl Sci 10(15):5251
Patil PS, Patil MS, Tamhankar SG, Patil SS (2020) Ensembles of ensemble machine learning approach for fault detection of bearing. Solid State Technol 63(6):14442–14455
Zhou Q, Shen H, Zhao J, Liu X, Xiong X (2019) Degradation state recognition of rolling bearing based on K-means and CNN algorithm. Shock Vib 2019:2–4
Gong C-SA, Su C-SA, Tseng K-H (2020) Implementation of machine learning for fault classification on vehicle power transmission system. IEEE Sens J 20(24):15163–15176
Akpudo UE, Hur J-W (2021) A cost-efficient MFCC-based fault detection and isolation technology for electromagnetic pumps. Electronics 10(4):439
Lee J, Choi H, Park D, Chung Y, Kim H-Y, Yoon S (2016) Fault detection and diagnosis of railway point machines by sound analysis. Sensors 16(4):549
Nelwamondo FV, Marwala T (2006) Faults detection using Gaussian mixture models, Mel-frequency cepstral coefficients and kurtosis. In: 2006 IEEE International Conference on systems, man and cybernetics, vol. 1, pp 290–295. IEEE, 2006
Sanchez R-V, Lucero P, Vásquez RE, Cerrada M, Macancela J-C, Cabrera D (2018) Feature ranking for multi-fault diagnosis of rotating machinery by using random forest and KNN. J Intell Fuzzy Syst 34(6):3463–3473
Parmar U, Pandya DH (2021) Comparison of the supervised machine learning techniques using WPT for the fault diagnosis of cylindrical roller bearing. Int J Eng Sci Technol 13(2):50–56
Xingang WANG, Chao WANG (2019) Application of Xgboost feature extraction in fault diagnosis of rolling bearing. Mech Eng Sci 1(2):3–6
Available at https://engineering.case.edu/bearingdatacenter. Accessed 16 Sep 2021
Available at https://scikit-learn.org/stable/. Accessed 16 Sep 2021
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Choudakkanavar, G., Mangai, J.A. & Bansal, M. MFCC based ensemble learning method for multiple fault diagnosis of roller bearing. Int. j. inf. tecnol. 14, 2741–2751 (2022). https://doi.org/10.1007/s41870-022-00932-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41870-022-00932-x