
Abstract
Accurate delineation of watershed and drainage networks is crucial for hydrological and geomorphological models, water resource management, change of floodplains, flood risk management, and surface water mapping. Since high-resolution digital elevation models (DEMs) are often not available, it is necessary to evaluate open source products. Various statistical measures were used to estimate the vertical accuracy of these freely available DEMs. Moreover, DEM products from Shuttle Radar Topography Mission (SRTM), Advanced Thermal Emission and Reflection Radiometer (ASTER), and Cartosat data were also compared. The study areas are located in the Vadodara district of Gujarat State of India. A comparison of SRTM-, ASTER-, and Cartosat-derived DEMs allowed a qualitative assessment of the vertical component of the error, whereas statistical measurements were used to estimate their vertical accuracy. In order to compare the frequency histograms of the elevation distributions in the DEMs in the study area, skewness and kurtosis were determined. Further, to obtain the degree of relationship between the DEMs, scatterplots, as well as correlation coefficients, were used. The results showed that all DEMs have imperfections in the delineation of a small river like Vishwamitri, and the comparison showed that SRTM 30 m and ASTER 30 m failed to delineate proper main drainage for the river. Cartosat 30 m DEM exhibited better results. The root mean square error (RMSE) was calculated as 7.21 m for ASTER and 3.24 m for SRTM. The correlation value of 0.94 indicates the existence of a strong positive linear correlation between SRTM and Cartosat. The study shows that for the study area ASTER elevation data were highly underestimated, whereas SRTM elevation data were slightly overestimated.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
A naturally occurring geohydrological unit draining to a common point by a system of natural streams/drains is defined as a watershed. The drainage divide of a watershed starts at the highest points on the landscape, like mountain peaks. The imaginary line that connects these high points is called the ridgeline. Precipitation that falls inside the watershed divide flows down to the water body (like a river or a lake) at the lowest point in that landscape. The point on the surface at which water flows out of an area is called the outlet or the pour point. Moreover, the outlet is the lowest point along the boundary of a watershed.
For various hydrological and geomorphological models, the digital elevation model is applied as inputs. A set of morphometric parameters, which are used to construct relationships between hydrological features and morphometric properties, can be used to deterministically identify terrain features. The study of Sharma and Tiwari (2014) shows noteworthy contrasts in hydrological properties of the two contemplated DEMs considering vertical accuracy assessment, hydrological simulation, empirical USLE model, and physical SWAT model. ArcSWAT simulation results uncover runoff predictions that are less sensitive to the selection of the DEMs. To delineate the drainage network that causes a significant effect on hydrological or hydraulic modeling and the comprehension of fluvial processes, Persendt and Gomez (2016) selected different progressive flow accumulation threshold values. Ficklin et al. (2015) concluded that the DEM source and DEM resampling techniques (nearest neighbor, bilinear interpolation, cubic convolution, and majority) are less sensitive parameters as compared to DEM resolution in the SWAT model. Guth (2010) compared the GDEM with SRTM 3 arcsecond data and computed the elevation, slope distributions, and geomorphometric parameters. Furthermore, they determined that the ASTER GDEM is essentially equivalent to SRTM 3 arcsecond data. In addition, they also reported that GDEM contains data anomalies or inconsistencies that corrupt its utilization for most applications. However, many studies have demonstrated that the outputs of hydrological models are influenced by DEM resolution (Chaplot 2014; Wolock and Price 1994), DEM source (Wang et al. 2012), and DEM resampling technique. In order to simulate streamflow, nitrate–nitrogen, and total phosphorus (TP) in the Moores Creek watershed, AR, USA, Chaubey et al. (2005) investigated the impact of DEM resolution (from 30 to 1000 m) within the SWAT model. Furthermore, they observed that a finer DEM resolution resulted in a higher amount of stream flow and NO3–N, whereas TP showed an inconsistent trend with DEM resolution. The sensitivity of original and resampled DEMs on streamflow simulated by SWAT in the Charlie Creek Basin, FL, USA, was evaluated by Ficklin et al. (2015). Furthermore, they concluded that the accuracy of streamflow is significantly different for the original 90 m DEM and the resampled 90 m DEM as compared to a 30 m DEM.
DEMs, however, contain local “pits” or “sinks” due to data errors in observation density, spatial sampling, interpolation process, data entry, or observer bias (Martz and Garbrecht 1998; Martz and Garbrecht 1999; Qian et al. 1990). As all surrounding cells are higher than a local sink cell, such local pits can cause biased extraction of flow directions and stream networks from DEMs. Therefore, there will be no outflow from the sink, resulting in internal drainage or storage (McCormack et al. 1993; Nikolakopoulos et al. 2006; Winter and LaBaugh 2006). Thus, to enable processing of flow directions and watershed delineation, only pit-free DEMs can be used in the Hydrology and ArcHydro tools of ArcGIS. Thus, filling pits are considered as the first step before processing watershed flow directions (Li et al. 2011; Lindsay & Creed 2006).
A DEM’s horizontal accuracy may range from a few meters to hundreds of meters as reported in many previous studies. For understanding and interpreting the vertical accuracy, the horizontal accuracy is considered important. For various GDEM and SRTM versions in different regions of the world, horizontal accuracy assessments have been provided. To evaluate the horizontal and vertical components of the error by comparing SRTM- and ASTER-derived DEMs, Nikolakopoulos et al. (2006) used qualitative assessment. Furthermore, the root mean square error (RMSE) was used to evaluate the elevation difference between SRTM and ASTER products.
The accuracy of Río Illangama watershed boundaries derived from three different sources was evaluated by Pryde et al. (2007). Moreover, it was determined that the difference between the manually delineated and the SRTM-based boundaries was small, whereas the ASTER-based boundaries vary largely from the manually delineated one. Later, to obtain a new watershed boundary with almost no difference with the boundaries delineated from detailed topographic data, the ASTER-DEM was corrected and processed.
The evaluation of lower resolution data such as the Shuttle Radar Topography Mission (SRTM) and Advanced Thermal Emission and Reflection Radiometer (ASTER) was carried out by Jarihani et al. (2015)—using the hydrodynamic models by (i) assessing the point accuracy and geometric co-registration error of the original DEMs, (ii) quantifying the effects of DEM preparation methods (vegetation smoothed and hydrologically corrected) on hydrodynamic modeling relative accuracy, and (iii) quantifying the effect of the grid size (30–2000 m) of the digital elevation hydrodynamic model and the associated relative computational costs (run time) on relative accuracy in model outputs. The study highlights the important impact of the quality of the underlying DEM and, in particular, how sensitive hydrodynamic models are to preparation methods and how important vegetation smoothing and hydrological correction of the base topographic data are for modeling floods in low gradient and multichannel environments.
In order to improve the accuracy of the estimated topography, Pham et al. (2018) developed an approach by combining two complementary DEMs (ASTER GDEM 1 arcsecond and SRTM DEM 1 arcsecond) in regions of missing reference data. Moreover, the combination approach was based on formulating relationships between slopes and weights in sites with reference data. Then, to determine the combined weight of each DEM without using reference data, the developed relationships were applied to sites with similar geomorphology. When compared with the SRTM and ASTER GDEM products, the results indicate that combined DEMs offer significant improvements of 47% and 20% in mean bias over a mountainous site, and 16% and 58% at a low-relief site, respectively. DEM-derived drainages were also found to be more accurate for the combined DEMs as compared to the near-global DEMs in areas where reference data are not available. Furthermore, more accurate river networks can be derived by using higher resolution DEMs, but the best results may not be necessarily offered by the highest resolution data (Li and Wong 2010).
In addition, DEM spatial resolution may have minor impacts on flood simulation results, but inundation areas from flood simulation vary significantly across different DEM sources. The caveats on using DEM-derived river network data for hydrologic applications and the difficulties in reconciling differences among elevation data from various sources and different resolutions are highlighted by flood simulation results. Moreover, much time and effort are required to be devoted to the identification and manual delineation of channel networks from maps or aerial photographs.
A close agreement has not always been shown between automatically delineated channel networks and manually delineated networks. A comparative analysis is demonstrated between a drainage network automatically extracted from a gridded digital elevation model and a drainage network manually delineated from stereographic pairs of aerial photographs by Garcia and Camarasa (1999). The comparison results of manual and automated network extraction in the Carraixet catchment suggest that the automatic extraction technique can be improved by using different parameters for each of the geomorphological units within the catchment. Similarly, by dividing the basin into geomorphological sectors and using a different threshold in each sector, automated extraction can also be improved. According to the analysis, the automatic extraction technique may be adequate for catchment headwaters, but it is inappropriate for the middle and lower basins, especially for alluvial fans and calcareous platforms.
The accuracy and quality of the reference data should be at least one order better as compared to the data to be evaluated. The ASTER GDEM, Cartosat, and SRTM data with 11 DGPS-derived GCPs were evaluated by Mukherjee et al. (2013). The RMS error was calculated to be 6.08 m and 9.2 m with a mean error of − 2.58 m and − 2.94 m for the ASTER and SRTM, respectively. In both cases, the error is less as compared to the error specification reported by the nodal agency (8.86 m for ASTER and 16 m for SRTM). This could be due to the GCPs that are taken in the flat terrain because of the accessibility of the field work. The average vertical error is determined to be 3.2 m (calculated from absolute difference), RMSE is determined to be 3.64 m, and the mean bias is determined to be − 0.42 m for Cartosat. The assessment of a DEM surface is not found to be good enough considering a few sample points. As a result, a surface-to-surface comparison of ASTER and SRTM with Cartosat DEM was carried out. It has been observed that a perfect elevation model is not rendered by Cartosat. However, Cartosat DEM is considerably more accurate as compared to ASTER and SRTM. Hence, Cartosat DEM is considered appropriate as reference data.
A statistical similarity between sample sets is measured by Jaccard similarity, also known as the Jaccard index. It is defined as the cardinality of the intersection divided by the cardinality of the union of the sample sets for two sets. For the classification of ecological species, the Jaccard similarity measure has been used (Jaccard 1912). Similarly, in biology, anthropology, taxonomy, image retrieval, text retrieval, geology, and chemistry, binary similarity measures were applied. Recently, for solving the identification of fingerprints, iris picture problems, and the recognition of manuscripts characters, these similarity measures were actively used. Their properties and characteristics are discussed in many articles (Hubalek 1982). Hidayatullah et al. (2012) used the Jaccard similarity index to measure the similarity between the actual and the detected license number for automatic license plate recognition using optical character recognition (OCR).
To demonstrate a comparative assessment of discrepancy in the hydrological behavior of the DEMs in terms of terrain representation at the catchment scale is the main objective of this study. Hydrological research on watersheds in developing countries is considered a relatively new field. Therefore, for the development of mathematical watershed models that can simulate and evaluate the existing and proposed management scenarios, the application of hydrologic data is considered necessary. Thus, the evaluation of the accuracy of watershed boundaries derived from different sources of elevation data becomes necessary. This study reports that DEMs from different sources are more likely to produce inconsistent results. To evaluate the sensitivity of data sources and their vertical accuracies, two hydrologic applications, watershed boundary and river network extraction, were used along with various statistical measures. Hydrologic applications are selected because they heavily rely on DEM data.
To apply DEM data within a GIS environment, many tools, models (SWAT, HEC-RAS, HEC-HMS, etc.), and algorithms have been developed for hydrological modeling. The results of our analysis may be of great value to a large number of GIS users as many researchers are using these tools in the geographic information system to perform hydrologic applications.
Study area and data collection
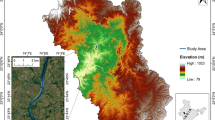
The study area is located in the Vadodara district of Gujarat State of India. In this work, the Viswamitri Watershed has been selected as the study area. The Vadodara district area, which is located south of the Tropic of Cancer and in the transition zone of heavy rainfall areas of South Gujarat and arid areas of North Gujarat plains, has a subtropical climate with moderate humidity. The Vadodara district forms a part of the great Gujarat plain. The eastern portion of the district is hilly terrain with several ridges, plateaus, and isolated relict hills that have an elevation in the range of 150–481 m above the mean sea level. The southeastern plateau has the highest peaks of the district—Amba Dungar and Mandai Dongar 637 m above the mean sea level. The Vishwamitri river, which falls in the Vadodara taluka, is considered as a major tributary of the Dhadhar river. The Vishwamitri river originates from the hills of Pavagadh, which is 43 km northeast of Vadodara. The Pavagadh hill is made of trappean rocks that emerge abruptly 830 m above the mean sea level. The Viswamitri river has a channel length of around 70 km and 58 km of this channel length flows through the Vadodara District. It meets the Dhadhar river at Pingalwada in the Vadodara District. Figure 1 shows the geographical location of the study area.

Study area
Cartosat-DEM
With the prime objective of delivering high-resolution satellite data of 2.5 m in-track stereo, Indian Space Research Organization (ISRO) launched Cartosat –1 on May 5, 2005 (Crespi et al. 2008). The quality verification process is performed by panning and draped visualization in order to demarcate distortions. The DEM is referenced to WGS84.
SRTM-DEM
The SRTM data are projected in a geographic (lat./long.) projection taking into consideration the WGS84 horizontal datum and the EGM96 vertical datum. It is considered global DEM with 1-arcsecond resolution (approximately 30 m at the equator). Two different C-band and X-band interferometric radar images of the same area are captured by two antennas that are about 60 m apart. C-RADAR Vertical reference and Polarization are EGM96 geoid and HH VV, respectively, whereas X-RADAR Vertical reference and Polarization are WGS84 ellipsoid and VV, respectively. Elevation data are obtained after processing interferograms.
ASTER GDEM
ASTER GDEM was generated by using the stereo-correlation of more than 1.5 million along-track stereo images of 15 m horizontal resolution, which are obtained by the visible and near-infrared (VNIR) sensor covering land surfaces between 83° N and 83° S. Initially, ASTER (GDEM-V1) with 30 m horizontal resolution and absolute vertical accuracy of 20 m (95% confidence interval) were made open for public use (ASTER GDEM Validation Team 2009) (Jain et al. 2018). The data are referenced to WGS84 and EGM96 vertical datum.
Methodology
Datum transformation
The ellipsoidal height of terrain (in meters), with WGS84 ellipsoid as a horizontal and a vertical datum, in Geographic Projection System (i.e., X and Y in terms of latitude and longitude) is provided by Cartosat DEM. The 27,4476 elevation values extracted from Cartosat DEM have been reprojected by using the Vdatum transformation tool provided by NOAA’s National Ocean Service in a Geographic (lat./long.) projection, with WGS84 as a horizontal datum and EGM96 as a vertical datum. SRTM and ASTER data are referenced to WGS84 and EGM96 vertical datum.
Statistical comparison
Several descriptive statistic measures were employed to describe and compare the elevation distributions in each DEM. The RMSE, a typical proportion of measuring vertical exactness in DEMs, was computed for DEMs. The elevation of each ASTER and SRTM DEM pixel was compared with that of the respective Cartosat DEM pixel. The RMSE was calculated directly from data.
In addition, skewness and kurtosis were determined for DEMs (Hopkins and Weeks 1990; Cain et al. 2017). The degree of asymmetry of a distribution around its mean is measured by skewness. The range of skewness is considered to be from minus infinity (−∞) to positive infinity (+∞). A distribution with a tail extending out to the right is called positively skewed distribution, whereas a distribution with an asymmetric tail extending out to the left is called negatively skewed (see Fig. 2).

Skewness
The degree to which a distribution is more or less peaked than a normal distribution is measured by excess kurtosis. Kurtosis is a unitless measure that indicates how sharp the data peak is. A kurtosis value of > 0 indicates a peaked distribution, whereas a kurtosis value of < 0 indicates a flat distribution (see Fig. 3).

Kurtosis
The main difference between skewness and kurtosis is that the former measures the degree of symmetry, whereas the latter measures the degree of peakedness in the frequency distribution. Data can be distributed in different ways, such as spread out more on left or on the right or evenly spread. A distribution is called the normal distribution when the data are scattered uniformly at the central point. The normal distribution is a perfectly symmetric bell-shaped curve, i.e., both the sides are equal, and it is not skewed on any sides.
By analyzing the respective scatter plots, the correlation between Cartosat-, SRTM-, and ASTER-derived elevation values were estimated. A measure of linear association between quantitative variables is called the correlation coefficient (r). The value of the correlation coefficient ranges from 1 (indicating the perfect positive correlation) to − 1 (indicating the perfect negative correlation). Pearson’s correlation between variables a and b is determined by
Moreover, the normality tests have also been performed over the datasets. For instance, The Kolmogorov–Smirnov (K–S) sample test is a nonparametric test with null hypothesis indicating that the data have been derived from a normal distribution.
Similarly, the Wilcoxon signed-rank test is a nonparametric statistical hypothesis test that is used to compare two related samples in order to assess whether their population mean ranks differ (i.e., it is a paired difference test). When the population data are not normally distributed, the Wilcoxon test can be used as an alternative to the paired Student’s t test (also known as “t test for matched pairs” or “t test for dependent samples”). The related-sample Wilcoxon signed-rank test conducted with the null hypothesis indicates that the median of differences between the data equals 0.
In order to compare the mean and standard deviation and to verify whether the data are underestimated or overestimated, an error map was developed for ASTER and SRTM by subtracting their elevation values from the respective Cartosat values.
Visual comparison
The aim of visual comparison was to detect changes between the results, such as streams and watershed derived from the different DEMs by using the shaded relief map and the high-resolution satellite imagery. The Cartosat watershed was selected for comparison between the slope map generated by ASTER, SRTM, and Cartosat DEMs taking into consideration heterologous comparisons of the ridgeline and stream.
The maximum rate of change of the elevation of the plane (the angle that the plane makes with a horizontal surface) is called the slope gradient. A declivity map with a pixel size of 30 m was created for analyzing the influence of the terrain slope on the models. Based on the Brazilian Agricultural Research Corporation standards, the slope values were classified. The Brazilian Agricultural Research Corporation (Embrapa), which is a state-owned research corporation, is affiliated with the Brazilian Ministry of Agriculture.
Watershed delineation was performed by GIS software by importing DEMs. A pixel or a set of spatially connected pixels whose flow direction cannot be assigned to one of the eight valid values in a raster of the flow direction is called a sink. In order to remove small imperfections in the data, the Fill Sink tool was used. Sinks must be filled to ensure a proper delineation of basins and streams. A derived drainage network may be discontinuous if the sinks are not filled.
A raster of the flow direction from each pixel to its downslope neighbors is created by the flow-direction tool. The accumulated flow as the accumulated weight of all pixels flowing into each downslope pixel in the output raster is calculated by the flow accumulation tool. Pixels with a high flow accumulation are termed as areas of concentrated flow, which may be used for identifying stream channels. Similarly, pixels with a flow accumulation of 0 are termed as local topographic highs, which may be used for identifying ridges.
A stream network can be delineated by applying a threshold value to the flow accumulation raster. A user-defined and important parameter, which is known as the stream threshold, directly affects the drainage network and basin boundaries that would be obtained by hydrological analysis. In this study, the stream threshold has been considered as 1% of the maximum flow accumulation value. The point on the surface at which water flows out of an area is called the outlet or the pour point. The outlet is the lowest point along the boundary of a watershed. Figure 4 shows the methodology adopted for watershed delineation.

Methodology adopted for watershed delineation
Map algebra that determines where the Fill tool had filled the sinks was used to investigate the cause of the errors in the streams network. Depressions can be corrected by applying diverse algorithms, known as the acronym of Fill or Filling. In this method, all depressions in DEMs are considered to be errors caused by the underestimation of elevation at a certain point. To permit overflow continuity, the correction fills the sinks. The widely used commercial ArcGIS and the open source, Unix-based GRASS, were used to implement this procedure. Fill has become a reference for comparing newly developed approaches and a standard for scientific and practical applications as a result of large diffusion and availability (Jenson and Domingue 1988).
Currently, most depression filling algorithms are based on the one-dimensional (1D) single flow direction. For example, the algorithm developed by Jenson and Domingue (1988) is a widely used one and has been implemented in many GIS and hydrological software, such as Arc Hydro Tools, GRASS, and HEC GEO-HMS. All of these software packages have been proved to be quite effective in 1D surface runoff models. Nevertheless, the sinks or depression filling algorithms have not been considered important for removing the sinks completely (Zhu et al. 2013; Lindsay 2016). Moreover, better DEMs have been used in conjunction to improve the efficiency of identifying and filling surface depressions in DEMs. A large number of sinks around the actual river have considerably contributed in the deviation of the DEM-derived stream from the actual stream.
It was observed that the sinks greater than 3 m in ASTER and 5 m in SRTM were the principal causes of misalignment of the DEM-derived stream from the actual stream. In order to manage the filling surface depression issues in DEMs, a threshold of 3 m and 5 m was selected to remove the anomalies associated with ASTER data and SRTM data, respectively, that reduces the amount of sinks present and also reduces the overall RMSE of ASTER data and SRTM data.
The ASTER DEM was corrected by using the following rules: if the absolute difference between ASTER and Cartosat is more than 3 m, it is replaced by the mean value of SRTM and Cartosat; if not, then the ASTER value is used. Cartosat and SRTM possess a small number of sinks as compared to ASTER data. Moreover, Cartosat and SRTM are closely correlated to each other with a correlation value of 0.94 and a coefficient of determination of 88.36%, which are the basis of selecting SRTM and Cartosat in conjunction.
The SRTM DEM was corrected by using the following rules: if the absolute difference between SRTM and Cartosat is more than 5 m, it is replaced by the mean value of SRTM and Cartosat; if not, then the SRTM value is used (see Fig. 4).
- Con:
-
Performs a conditional if/else evaluation on each of the input cells of an input raster
- Abs:
-
Raster function that calculates the absolute value of each pixel in the raster.
Jaccard index or Jaccard similarity coefficient
The Jaccard index or the Jaccard similarity coefficient was computed between the Cartosat and corrected ASTER watershed boundaries and the Cartosat and corrected SRTM boundaries. The statistical similarity between the sample sets was measured by the Jaccard similarity coefficient, also known as the Jaccard index. For two sample sets, the Jaccard similarity coefficient is defined as the cardinality of the intersection divided by the cardinality of the union of the sample sets. Moreover, the tolerance limit of 500 m was selected considering the fact that the original DEMs contain errors because the accuracy of the DEM data varies with different sources, such as collection techniques, active airborne sensors, photogrammetric methods, and field surveying. Furthermore, the interpolation methods for DEM generation and the characteristics of the terrain surface are considered as the other sources of errors. The Cartosat watershed boundary, corrected ASTER watershed boundary, and corrected SRTM watershed boundary were converted to binary images in order to calculate the Jaccard similarity coefficient. The Jaccard similarity coefficient of 1 means that the segmentation between the two images has a perfect match and 0 means the segmentation has no match. Mathematically, Jaccard similarity coefficient is given as
where
- J(C, A):
the Jaccard similarity coefficient between Cartosat watershed boundary and Corrected ASTER watershed boundary
- J(C, S):
the Jaccard similarity coefficient between Cartosat watershed boundary and Corrected SFRRTM watershed boundary
- C:
Cartosat watershed boundary
- A:
Corrected ASTER watershed boundary
- S:
Corrected SRTM watershed boundary
- ∩:
Intersection
- ∪:
Union
Likewise, the dissimilarity between two sets is measured by a similar statistic, known as the Jaccard distance. Basically, the complement of the Jaccard index is termed as the Jaccard distance, which can be calculated by subtracting the Jaccard index from 100%.
The Jaccard distance is expressed as follows:
where
- D(C, A):
the Jaccard dissimilarity coefficient between Cartosat watershed boundary and Corrected ASTER watershed boundary
- D(C, S):
the Jaccard dissimilarity coefficient between Cartosat watershed boundary and Corrected SRTM watershed boundary
- C:
Cartosat watershed boundary
- A:
Corrected ASTER watershed boundary
- S:
Corrected SRTM watershed boundary
Results
Statistical comparison
In order to provide evidence of the statistical significance of the results, the amount of data (274,476 pixels) from all three DEMs was used. The absolute difference between the mean value of SRTM and Cartosat is 1.55 m and between the mean value of ASTER and Cartosat was found to be 5.38 m as shown in Table 1. The standard deviation showed that the Cartosat dataset was less spread out as compared to the other two datasets, which was also confirmed by the difference between the upper and lower quartiles (interquartile range). For the samples, the positive value of skewness showed that the distributions of the data were positively skewed or skewed right, i.e., the right tail of the distribution was longer as compared to the left tail of the distribution. For ASTER, the value of kurtosis was 0.02, which showed that the distribution is leptokurtic, i.e., its tails are longer and fatter. For SRTM and Cartosat, the negative value of kurtosis showed that the distribution is platykurtic, i.e., its tails are shorter and thinner.
In addition, the normality test was conducted over the datasets. For instance, the K–S sample test is a nonparametric test with the null hypothesis, which demonstrates that the data were obtained from a normal distribution as shown in Table 2. The criteria used to reject or accept the null hypothesis is that if the p value is smaller than the significance level α = 0.05, the null hypothesis is rejected. Moreover, there are sufficient pieces of evidence that the data are not normally distributed. For instance, the null hypothesis was rejected (the significance level is 0.05) in all the above three cases. The p value (0.00) of less than 0.05 showed that there is not enough evidence to prove that the data are normal. The histograms of the ASTER, SRTM, and Cartosat sample data are shown in Fig. 5a–c, respectively.

a Histogram of ASTER data. b Histogram of SRTM data. c Histogram of Cartosat data. d Quantile–quantile plot of ASTER data. e Quantile–quantile plot of SRTM data. f Quantile–quantile plot of Cartosat data. g Detrended normal Q-Q plot of ASTER data. h Detrended normal Q-Q plot of SRTM data. i Detrended normal Q-Q plot of Cartosat data
The normal quantile–quantile (Q-Q) plot and the detrended normal Q-Q plot were also drawn to support or refute the claim of normality. The Q-Q plot is shown in Fig. 5d–f, which compares the observed quantiles of the data with those of the normally distributed data. The observed quantiles of the data are depicted as circles, whereas the quantiles of data that we would expect to see if the data were normally distributed are depicted as a solid line. The data are approximately normally distributed, if the points are on or close to the line. Similarly, the sample data are not normally distributed if the points are not clustered on the 45° line or they, in fact, follow a curve. Moreover, the detrended normal Q-Q plot provides the same information as the normal Q-Q plot, but in a different way. In the detrended plot, the horizontal line at the origin represents the quantiles if the data were normally distributed, whereas the dots represent the magnitude and direction of deviation in the observed quantiles. Each dot is calculated by subtracting the expected quantile from the observed quantile. Figure 5 g–i also show the detrended normal Q-Q plot.
The related-sample Wilcoxon signed rank test was conducted (significance level 0.05) by using the null hypothesis: the median of differences between Cartosat and SRTM equals 0 and the decision of the test was used to retain the null hypothesis as the p value (1.00) was more than 0.05. Likewise, the same test was also conducted by using the null hypothesis: the median of differences between Cartosat and ASTER equals to 0 and the decision of the test was used to reject the null hypothesis as the p value (0.00) was less than 0.05. The results also showed that 9.12% and 65.65% data in ASTER and SRTM, respectively, have more elevation than the Cartosat data, the 86.68% and 23.33% data in ASTER and SRTM, respectively, have less elevation than the Cartosat data, and 4.19% and 11.01% data in ASTER and SRTM, respectively, have the same elevation as the Cartosat data. Figures 6 a and b and Table 3 demonstrate the corresponding results.

a Related-samples Wilcoxon signed rank test for ASTER. b Related-samples Wilcoxon signed rank test for SRTM
In order to assess the level of correlation between the DEMs, the correlation scatterplots were drawn as shown in Fig. 7 a and b. It was difficult to create a scatterplot from each pixel in a DEM as each DEM contains over a million pixels. However, a total of 274,476 pixels were used for the analysis. As shown in Table 4, the correlation coefficient of 0.83, 0.94, and 0.85 was obtained by Pearson’s correlation analysis between the ASTER and Cartosat, SRTM and Cartosat, and ASTER and SRTM, respectively (correlation is found to be significant at the level of 0.01). For instance, the correlation value of 0.94 indicates a strong positive linear correlation between SRTM and Cartosat. Similarly, the simple linear regression analysis is demonstrated by means of scatterplots. In this case, the analysis of the determination coefficients (R2) of the regression line shows that the Cartosat DEM is considered adequate for describing the ASTER DEM in 68.9% and the SRTM DEM in 87.9%.

a Scatterplot showing linear regression of ASTER-derived elevation vs Cartosat-derived elevation. b Scatterplot showing linear regression of SRTM-derived elevation vs Cartosat-derived elevation
Considering Cartosat as the reference DEM, the RMSE calculated was used for evaluating the vertical accuracy of the ASTER DEM and the SRTM DEM. For ASTER, the RMSE was calculated to be 7.21 m, whereas for SRTM, the RMSE was calculated to be 3.24 m.
Error maps for ASTER and SRTM were produced by subtracting their elevation values from the respective Cartosat values as shown in Fig. 8 a and c. For the ASTER error map, the mean value and standard deviation were found to be 5.39 m and 4.79 m, respectively. The corresponding frequency histograms indicate that the ASTER elevation data were highly underestimated as shown in Fig. 8b. For the SRTM error map, the mean value and standard deviation were found to be − 1.55 m and 2.85 m, respectively. The corresponding frequency histograms indicate that the SRTM elevation data were slightly overestimated as shown in Fig. 8d.

a Error map for ASTER. b Histogram of error map of ASTER. c Error map for SRTM. d Histogram of error map of SRTM
Slope gradients classes
Moreover, six classes of slope were established for a better understanding of terrain as shown in Table 5. As shown in Fig. 9 and Table 5, the slope values were classified according to the Brazilian Agricultural Research Corporation standards (Medeiros et al. 2016; Morais et al. 2017). According to the SRTM and Cartosat, the result showed that the maximum area in watershed belongs to flat relief with a declivity value (in %) between 0 and 2.99. According to the ASTER, however, the maximum area belongs to smooth relief with a declivity value (in %) between 3 and 7.99.

Slope classes
Stream comparison
When the delineated streams are overlaid over high-resolution imagery, the Cartosat-generated network is much closer to the actual river network followed by the SRTM-derived drainage network as shown in Fig. 10. It has been observed that the drainage network delineated by ASTER is highly misleading. Moreover, sinks around the actual river have considerably contributed to the deviation of ASTER DEM- and SRTM DEM-derived streams.

Map showing ASTER-, SRTM-, and Cartosat-derived river deviation from the actual river
Watershed comparison
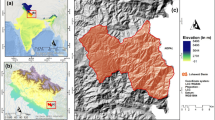
The area enclosed by the watershed generated by SRTM and ASTER is comparatively much larger than that generated by Cartosat as shown in Figs. 11 and 12. The area of the watershed delineated by Cartosat is 1285.4 km2, whereas the area of the watershed delineated by ASTER is 1624.8 km2 (26.40% larger). Moreover, the SRTM-based watershed area is 2026.3 km2, which is 56.63% larger than the Cartosat boundary. The perimeter of the watershed delineated by Cartosat is 209.9 km, whereas the perimeter of the watershed delineated by ASTER is 315.4 km (50.26% larger). Moreover, the SRTM-based watershed perimeter is 294.9 km, which is 40.5% larger than the Cartosat watershed perimeter.

Delineated watershed boundaries from ASTER, SRTM, and Cartosat data

Area and perimeter of delineated watersheds
Ridgeline inspection over relief map
The relief map used in the cartographic relief depiction shows the shape of the terrain in a realistic fashion and also demonstrates the three-dimensional surface that is illuminated from a point light source. Moreover, the watersheds overlaid over the relief map and satellite imagery show that the watersheds delineated by ASTER and SRTM could not follow the ridgeline, and hence, they have encompassed the Dhadhar river in them. As shown in Fig. 13, the highlighted yellow circles show the locations where the ASTER watershed and the SRTM watershed encompass the Dhadhar river. Clearly, it can also be observed that the Cartosat-derived boundary follows the actual ridgeline.

Visual inspection of watersheds derived from ASTER, SRTM, and Cartosat over the shaded relief map and satellite imagery
In the flow-direction process, a depressionless DEM is considered to be the desired input. An erroneous flow-direction raster may be resulted in the presence of sinks. Moreover, there may be legitimate sinks in the data in some of the cases. By taking into consideration the flow networks associated with each type of elevation data, the cause of the difference in the watershed boundaries can be found. It has been observed that the flow networks generated from the ASTER- and SRTM-based DEM had several errors. Map algebra was used to find where the Fill tool had filled the sinks in order to determine the cause of the errors in the streams network.
As shown in Fig. 14, it was found that the errors in the stream network occurred where filling greater than 3 m in ASTER and 5 m in SRTM along the actual river had occurred. Moreover, in the deviation of ASTER DEM- and SRTM DEM-derived streams from the actual stream, a large number of sinks around the actual river have considerably contributed. Such error indicates that there were probably residual and artifactual anomalies that most certainly degraded the overall accuracy of ASTER and SRTM DEMs. As a result of underestimating the elevation at certain points, pit, and depressions are considered false in the Fill method as mentioned above. Therefore, the depressions are filled, and thus raising the elevation until it reaches the lower neighbor. As a result, the larger the number of continuously affected pixels, the more the result of the flow-direction assignment is affected.

a Filled sinks in ASTER. b Filled sinks in Cartosat. c Filled sinks in SRTM
Figure 14 a–c shows that ASTER data contain a large number of depressions or pits followed by the SRTM data, whereas the Cartosat data contain the least amount of depressions or pits.
In order to obtain a new watershed boundary, the corrected DEMs were again processed. The results are presented in Figs. 15 and 16. The area enclosed by the watershed generated by the corrected SRTM and the corrected ASTER is approximately equal to the watershed generated by Cartosat. The area of the watershed delineated by Cartosat is 1285.4 km2, whereas the area of the watershed delineated by the corrected ASTER is 1279.59 km2 (0.45% smaller). Moreover, the corrected SRTM-based watershed area is 1272.83 km2, which is 0.97% smaller than the Cartosat boundary. The perimeter of the watershed delineated by Cartosat is 209.9 km, whereas the perimeter of the watershed delineated by the corrected ASTER is 221.50 km (5.52% larger). Moreover, the corrected SRTM-based watershed perimeter is 235.15 km, which is 12.02% larger than the Cartosat watershed perimeter.

Delineated watersheds from ASTER, SRTM, and Cartosat data after correction

Area and perimeter of delineated watersheds from corrected DEMs
In order to compare the elevations pre- and post-correction, random samples along the red-encircled ridgeline were used to extract the elevation values as shown in Fig. 17. The precorrection elevation profile of SRTM and ASTER DEMs of the random samples along the selected part of the ridgeline elevations demonstrates a noisy pattern, whereas the post-correction elevation profile of the corrected SRTM and the corrected ASTER DEMs demonstrates a less noisy pattern.

Elevation of the random samples along the selected part of the ridgeline elevations a pre-correction and b post-correction
The Jaccard index or the Jaccard similarity coefficient was computed between the Cartosat and corrected ASTER watershed boundaries and the Cartosat and corrected SRTM boundaries. The horizontal accuracy of a DEM may range from a few meters to hundreds of meters as reported in many previous studies. Moreover, the tolerance limit of 500 m has been selected considering the fact that the original DEMs contain errors because the accuracy of the DEM data varies with different sources, such as collection techniques, active airborne sensors, photogrammetric methods, and field surveys. Furthermore, the interpolation methods for DEM generation and the characteristics of the terrain surface are considered as the other sources of errors. In addition, the computed Jaccard similarity coefficient shows that Cartosat and corrected ASTER watershed boundaries demonstrate 69.28% of similarity or the overlap and Cartosat and corrected SRTM boundaries demonstrate 56.68% of similarity or the overlap as shown in Fig. 18. However, the calculated Jaccard distance shows that Cartosat and corrected ASTER watershed boundaries demonstrate 30.72% of dissimilarity and Cartosat and corrected SRTM boundaries demonstrate 43.32% of dissimilarity.

a Binary intersection of the Cartosat watershed boundary and corrected ASTER watershed boundary. b Binary union of the Cartosat watershed boundary and corrected ASTER watershed boundary. c Binary intersection of Cartosat watershed boundary and corrected SRTM watershed. d Binary union of Cartosat watershed boundary and corrected SRTM watershed boundary
Conclusion
This paper evaluates watershed delineation considering DEMs of different sources. The accuracy of the watershed delineation significantly depends on the accuracy and good quality of the digital elevation model available. The results show that all the DEMs have imperfections for the delineation of the small river like Vishwamitri. Moreover, a comparison shows that SRTM 30 m and ASTER 30 m failed to delineate proper main drainage for the Vishwamitri river.
However, Cartosat 30 m DEM exhibited better results. It has been shown that information contained in the Cartosat DEM is much superior to the rest of the DEMs used in the study. The Cartosat-generated network is much closer to the actual river network followed by the SRTM-derived drainage network.
Furthermore, it has been observed that the drainage network delineated by ASTER is highly misleading. In addition, watersheds delineated by ASTER and SRTM could not follow the ridgeline, and hence, they have encompassed the Dhadhar river in them. The RMSE was calculated at a value of 7.21 m and 3.24 m for ASTER and SRTM, respectively. For instance, the correlation value of 0.94 indicates a strong positive linear correlation between SRTM and Cartosat.
For the selected study area, the mean value and standard deviation were found to be 5.39 m and 4.79 m, respectively, for the ASTER error map. However, the corresponding frequency histograms of the ASTER error map indicated that the ASTER elevation data were highly underestimated. For the SRTM error map, the mean value and standard deviation were found to be − 1.55 m and 2.85 m, respectively. However, the corresponding frequency histograms of the SRTM error map indicated that the SRTM elevation data were slightly overestimated.
According to the SRTM and Cartosat, the maximum area in the watershed belongs to flat relief with a declivity value (in %) between 0 and 2.99. According to the ASTER, however, the maximum area belongs to smooth relief with a declivity value (in %) between 3 and 7.99. Moreover, the computed Jaccard similarity coefficient shows that a fusion of DEMs by using different sources (optics and radar) leads to improved results. Finally, it can be concluded that for hydrological studies the Cartosat DEM should be given first preference followed by the SRTM DEM for the areas where the relief class belongs to a flat relief.
References
Cain MK, Zhang Z, Yuan KH (2017) Univariate and multivariate skewness and kurtosis for measuring nonnormality: prevalence, influence and estimation. Behav Res Methods 49(5):1716–1735. https://doi.org/10.3758/s13428-016-0814-1
Chaplot V (2014) Impact of spatial input data resolution on hydrological and erosion modeling: recommendations from a global assessment. Phys Chem Earth 67–69:23–35. https://doi.org/10.1016/j.pce.2013.09.020
Chaubey I, Cotter AS, Costello TA, Soerens TS (2005) Effect of DEM data resolution on SWAT output uncertainty. Hydrol Process 19(3):621–628. https://doi.org/10.1002/hyp.5607
Crespi M, De Vendictis L, Poli D, Wolff K, Colosimo G, Gruen A, Volpe F (2008) Radiometric quality and DSM generation analysis of CartoSat-1 stereo imagery. Int Arch Photogramm Remote Sens Spat Inf Sci 37(3):1349–1355
Ficklin DL, Tan ML, Chaplot V, Dixon B, Ibrahim AL, Yusop Z (2015) Impacts of DEM resolution, source, and resampling technique on SWAT-simulated streamflow. Appl Geogr 63:357–368. https://doi.org/10.1016/j.apgeog.2015.07.014
Garcia MJL, Camarasa A (1999) Use of geomorphological units to improve network extraction from a DEM drainage Comparison between automated extraction and photointerpretation methods in the Carraixet catchment (Valencia, Spain). Int J Appl Earth Obs Geoinf 1(3):187–195
Guth PL (2010). Geomorphometric comparison of ASTER GDEM and SRTM. In A sspecial joint symposium of ISPRS Technical Commission IV & AutoCarto in conjunction with ASPRS/CaGIS.
Hidayatullah P, Syakrani N, Suhartini I, Muhlis W (2012) Optical character recognition improvement for license plate recognition in Indonesia. In 2012 Sixth UKSim/AMSS European Symposium on Computer Modeling and Simulation. IEEE:249–254
Hopkins K, Weeks D (1990) Tests for normality and measures of skewness and kurtosis: their place in research reporting. Educ Psychol Meas 50(4):717–729. https://doi.org/10.1177/0013164490504001
Hubalek Z (1982) Coefficients of association and similarity, based on binary (presence-absence) data: an evaluation. Biol Rev 57(4):669–689
Jaccard P (1912) The distribution of the flora in the alpine zone. New Phytologist, 11(2):37–50. Retrieved from https://doi.org/10.1111/j.1469-8137.1912.tb05611.x
Jain AO, Thaker T, Chaurasia A, Patel P, Singh AK (2018) Vertical accuracy evaluation of SRTM-GL1, GDEM-V2, AW3D30 and CartoDEM-V3. 1 of 30-m resolution with dual frequency GNSS for lower Tapi Basin India. Geocarto Int 33(11):1237–1256
Jarihani AA, Callow JN, Mcvicar TR, Van Niel TG, Larsen JR (2015) Satellite-derived digital elevation model (DEM) selection, preparation and correction for hydrodynamic modelling in large, low-gradient and data-sparse catchments. J Hydrol 524:489–506. https://doi.org/10.1016/j.jhydrol.2015.02.049
Jenson SK, Domingue JO (1988) Extracting topographic structure from digital elevation data for geographic information system analysis. Photogramm Eng Remote Sens 54(11):1593–1600
Li S, MacMillan RA, Lobb DA, McConkey BG, Moulin A, Fraser WR (2011) Lidar DEM error analyses and topographic depression identification in a hummocky landscape in the prairie region of Canada. Geomorphology 129(3–4):263–275. https://doi.org/10.1016/j.geomorph.2011.02.020
Li J, Wong DWS (2010) Computers, environment and urban systems effects of DEM sources on hydrologic applications. Comput Environ Urban Syst 34(3):251–261. https://doi.org/10.1016/j.compenvurbsys.2009.11.002
Lindsay JB (2016) Efficient hybrid breaching-filling sink removal methods for flow path enforcement in digital elevation models. Hydrol Process 30(6):846–857. https://doi.org/10.1002/hyp.10648
Lindsay JB, Creed IF (2006) Distinguishing actual and artefact depressions in digital elevation data. Comput Geosci 32(8):1192–1204. https://doi.org/10.1016/j.cageo.2005.11.002
Martz LW, Garbrecht J (1998) The treatment of flat areas and depressions in automated drainage analysis of raster digital elevation models. Hydrol Process 12(6):843–855. https://doi.org/10.1002/(SICI)1099-1085(199805)12:6<843::AID-HYP658>3.0.CO;2-R
Martz LW, Garbrecht J (1999) An outlet breaching algorithm for the treatment of closed depressions in a raster DEM. Comput Geosci 25(7):835–844. https://doi.org/10.1016/S0098-3004(99)00018-7
McCormack JE, Gahegan MN, Roberts SA, Hogg J, Hoyle BS (1993) Feature-based derivation of drainage networks. Int J Geogr Inf Syst 7(3):263–279. https://doi.org/10.1080/02693799308901956
Medeiros G. de O. R., Giarolla A., Sampaio G., & Marinho M. de A. (2016). Estimates of annual soil loss rates in the state of São Paulo, Brazil. Revista Brasileira de Ciencia Do Solo, 40(November). https://doi.org/10.1590/18069657rbcs20150497
Morais JD, Faria TS, Elmiro MAT, Nero MA, Silva AA, Nobrega RAA (2017) Altimetry assessment of aster GDEM v2 and SRTM v3 digital elevation models: A case study in urban area of Belo Horizonte, MG, Brazil. Boletim de Ciencias Geodesicas 23(4):654–668. https://doi.org/10.1590/S1982-21702017000400043
Mukherjee S, Joshi PK, Mukherjee S, Ghosh A, Garg RD, Mukhopadhyay A (2013) Evaluation of vertical accuracy of open source digital elevation model (DEM). Int J Appl Earth Obs Geoinf 21:205–217
Nikolakopoulos KG, Kamaratakis EK, Chrysoulakis N (2006) SRTM vs ASTER elevation products. Comparison for two regions in Crete, Greece. Int J Remote Sens 27(21):4819–4838. https://doi.org/10.1080/01431160600835853
Persendt FC, Gomez C (2016) Assessment of drainage network extractions in a low-relief area of the Cuvelai Basin (Namibia) from multiple sources: LiDAR, topographic maps, and digital aerial orthophotographs. Geomorphology 260:32–50. https://doi.org/10.1016/j.geomorph.2015.06.047
Pham HT, Marshall L, Johnson F, Sharma A (2018) A method for combining SRTM DEM and ASTER GDEM2 to improve topography estimation in regions without reference data. Remote Sens Environ 210:229–241
Pryde JK, Osorio J, Wolfe ML, Heatwole C, Benham B, & Cardenas, . (2007). Comparison of watershed boundaries derived from SRTM and ASTER digital elevation datasets and from a digitized topographic map
Qian J, Ehrich RW, Campbell JB (1990) DNESYS-an expert system for automatic extraction of drainage networks from digital elevation data. IEEE Trans Geosci Remote Sens 28(1):29–45. https://doi.org/10.1109/36.45743
Sharma A, Tiwari KN (2014) A comparative appraisal of hydrological behavior of SRTM DEM at catchment level. J Hydrol 519:1394–1404. https://doi.org/10.1016/j.jhydrol.2014.08.062
Wang W, Yang X, Yao T (2012) Evaluation of ASTER GDEM and SRTM and their suitability in hydraulic modelling of a glacial lake outburst flood in Southeast Tibet. Hydrol Process 26(2):213–225. https://doi.org/10.1002/hyp.8127
Winter TC, LaBaugh JW (2006) Hydrologic considerations in defining isolated wetlands. Wetlands 23(3):532–540. https://doi.org/10.1672/0277-5212(2003)023[0532:hcidiw]2.0.co;2
Wolock DM, Price CV (1994) Effects of digital elevation model map scale and data resolution on a topography-based watershed model. Water Resour Res 30(11):3041–3052
Zhu D, Ren Q, Xuan Y, Chen Y, Cluckie ID (2013) An effective depression filling algorithm for DEM-based 2-D surface flow modelling. Hydrol Earth Syst Sci 17(2):495–505. https://doi.org/10.5194/hess-17-495-2013
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Rana, V.K., Suryanarayana, T.M.V. Visual and statistical comparison of ASTER, SRTM, and Cartosat digital elevation models for watershed. J geovis spat anal 3, 12 (2019). https://doi.org/10.1007/s41651-019-0036-z
Published:
DOI: https://doi.org/10.1007/s41651-019-0036-z