
Abstract
Pre harvest prediction of sugarcane and sugar production is essential for obtaining the objectives of the national food security mission. Traditional field experimentation results are not reliable and are biased. Improvement in the accuracy and timeliness of crop yield estimation by blending of ancillary data and remotely sensed data in the temporal domain is indispensable. Ratoon sugarcane and planted sugarcane are the two prevalent agricultural practices in India. Ratoon sugarcane crop is suitable both from economic and production consideration. Identification of ratoon sugarcane and monitoring of its growth has been poorly studied. The objective of this study is to extract the information related to the ratoon sugarcane using remote sensing data. The present study proposed NDVIT, an index based on temporal values of NDVI data of Landsat 8 for monitoring and discrimination of ratoon sugarcane. This index has been found to provide 91% accuracy when tested on the ground in the Himalayan foothills region of Uttarakhand. Study indicated that the best period for discrimination of ratoon sugarcane crop is during the first week of April and last week of August to the end of September. This matches with the start of tillering stage and during the period of grand growth stage of the sugarcane.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
India covers only 2.4% of the earth’s geographical area, whereas it caters about one fifth of world population. Food grain demand is gradually increasing due to escalating population, improved socioeconomic conditions and food habits. A prognostic study indicates that in approaching 30 years the food grain production has to be doubled to meet out the growing need whereas cultivated land and water resources are continuously decreasing. Timely and accurate crop yield estimation will be essential to support decision making related to the crop production in order to meet future food needs and ensure food security [1].
The Sugarcane plant offers a huge potential, not only as the sucrose of a very important food but also as a source of energy and valuable commercial products from fermentation and chemical synthesis. Sugarcane occupies a very prominent position on the agricultural map of India. Sugarcane is known to be thriving well in Brazil, India, Australia, Cuba, USA, Philippines, USSR and Indonesia. India ranks second in the world, after Brazil, in terms of area and sugarcane production [2]. In India, the sugar industry is the second largest industry next to the textile industry that is playing a vital role in the socioeconomic transformation of the country.
The sugarcane industry and the Government have to rely on the traditional mechanism for the estimation of sugarcane. These traditional methods are based on the data collected and compiled from the fields manually by the analysts. These manual estimates of sugarcane production many a times have been found to be significantly far from reality [3]. Consequently, it is observed that sometimes sugarcane production is higher and another time lower than what had been estimated at the beginning or grand growth stage of the crop. This may lead to the inappropriate planning, strategies and course of action at the producer, consumer, industry and the Government level. It is worth mentioning that such estimates are associated with many impediments due to the heterogeneity of cropping practices and the multitude of plots, which are often smaller than a hectare.
Under these circumstances need is pushed towards reliable estimation of the sugarcane production. This in turn will help in formulating appropriate policies and feasible course of action to handle surpluses or shortages as the case may be, well in time. A study in the Punjab province explored that improvement in the accuracy and timeliness of crop yield estimation can be achieved through a suitable blending of ancillary data as well as multitemporal remotely sensed data [4]. The crop information so generated coupled with sophisticated statistical techniques lead to the effective and optimized decision making [5].
In Bharat, two types of sugarcane farming practices are prevalent. One is plantation, in which fresh seeding is done. Many a times forced by economic constraints the cane grower prefers to regrow the sugarcane from the existing roots of the sugarcane after harvesting. Commonly this is known as Ratoon sugarcane. The growth cycle of sugarcane plantation is generally twelve months. The sugarcane ratoon generally takes nine months to reach to maturity stage. As a result the Ratoon sugarcane is harvested and available for crushing early as compared to planted sugarcane. Sugarcane mills of the area purchase the sugarcane from the peasants for the crushing. Field traversing and discussions with sugarcane growers it has been observed that the sugar content in the ratoon sugarcane is higher. This continues up to two cycles of growth. Therefore ratoon sugarcane plays significant role to each and every one associated with sugarcane production.
In the study area, it is observed that the proportion of the plantation sugarcane and the ratoon sugarcane is 1:3. Therefore, merely 25% of the whole area under sugarcane is plantation. On the other hand, a major part of the study area is cultivated with ratoon sugarcane. Subsequently, more care and attention is essential to augment the productivity of ratoon sugarcane leading to more sugar production. Peasants of the study area are found to give less attention to ratoon sugarcane crop in terms of nutrient and pest management. As result sugar production from the ratoon sugarcane is many a times lower. This may be attributed to ignorance, poor economy and poor management practices adopted by the growers. From growers perspective, it may be reasonable. However, with proper intervention of farming practices the sugar production from ratoon may be significantly enhanced. Therefore, for better production from ratoon sugarcane there is burning need of its proper and timely monitoring its growth and thereby adopting appropriate measures to optimize the growth leading to higher production [6]. Till recently information about crop areas is collected through field traversing and experimentation which are expensive and time consuming and full of bias. However the use of geoinformatics tools to extract crop monitoring information has been found to be reliable, economic and near real time [7].
In this area, it has also been observed that intercropping and mixed cropping is common. Therefore, knowledge of associated crops in the area is equally relevant for precise estimates of specific crop of interest. Prevalent farming practices indicate that crops are grown in the close vicinity. As a result the spectral signature of many crops on a particular day or band may overlap. Under these circumstances crop discrimination may be erroneous [8]. The feasible solution to this is the use of the spectral behaviour of a crop using temporal resolution of remotely sensed data. Successful investigations have been conducted in Cuttack district of Orissa State in India using temporal data analysis for crop discrimination [9].
For accurate and reliable crop estimation proper attention is to be given to mixed pixels. This can be solved by selecting an suitable approach such as Linear Mixture Models, Fuzzy classification, Clustering, Neural Networks or even data fusion [10]. The present work is being premeditated to the optimized use of the recent expansion of satellite based remote sensing tools for acquisition of consistent and near real time information associated to the crops status in spatial and temporal domain. A study in the Sao Paulo State of Brazil demonstrated that computerised data storage, analysis and modelling which are essential for evolving optimal strategy for farm yield [11]. An experimental work in KCP Sugar factory zones of Vuyyuru and Lakshmipuram of Andhra Pradesh proved that sugarcane identification and estimation using multi temporal vegetation indices will go a long way in supporting the Indian food security on sustainable basis [12].
The discrimination of the specific crops may be fruitful in the prediction of crop yield, area under the crop, and monitoring of the crop growth [13, 14]. The aim of the proposed study is to discriminate the ratoon and plant sugarcane based on the multi temporal remotely sensed data. Temporal profile of Normalized Difference Vegetation Index (NDVI) have been used as an efficient and reliable indicator to discriminate the specific crop at the field scale or global scale [15].
2 Study area and the data used
The most common data for projects related to earth resources management are satellite derived data. They become very popular in recent years because of their better spatial and spectral resolutions and their capacity to generate multi temporal products more cheaply than aerial photographs. Limited ground truth formed the important information.
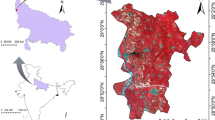
The study has been carried out in a small experimental area in the Himalayan foothills (Fig. 1). The area is dominated by agricultural practices around Bhadarabad region, Haridwar district, Uttarakhand State, India. The area is enveloped by \(29^{\circ } 55{'}35^{\prime\prime}\)N–\(29^{\circ }56^{\prime}10^{\prime\prime}\)N latitude and \(77^{\circ }57^{\prime}40^{\prime\prime}\)E–\(77^{\circ }58^{\prime}5^{\prime\prime}\)E longitude. The area has a fair network of irrigation canals with more than a century old Upper Ganga canal as a main canal with highly fertile lands. Under this canal two distributaries, Bhadarabad and Ahmadpur carry irrigation water. The experimental area is part of the the Northern Division Ganga Canal (NDGC) command area. It spreads over the Khedli minor command. This minor passes through a small village Khedli and provides irrigation to about 200 ha. The agricultural fields not getting canal water are irrigated by ground water. The soil texture of the area found to be mainly sandy loam, which is suitable for all types of crops. Major crops grown in the area are Wheat and Sugarcane in Rabi season and Sugarcane and Paddy in Kharif season. Other minor crops are Urd, Gram, Mustard and Soyabean.

Study area
Satellite images from Landsat 8 (OLI-Operational Land Imager) for the year 2015 have been collected for the study. The collected data was put into preliminary analysis followed by detailed analysis. Finally, the collected remotely sensed data was used to create NDVI profile in the multitemporal domain. The bands used in the study are presented in the Table 1.
A variety of ancillary data, the farming practice, crop growth, crop yield, agricultural management practices and meteorological information is essential for carrying out this study. Sugarcane is the main preferred cash crop by the peasant of the area. Historical sugarcane growth and yield data have been collected from the State Agriculture Department, Sugarcane Industries and interaction with farmers. In addition, the sowing and harvesting periods of the different crops grown in the study area have been collected. The synthesized crop calendar is shown in Fig. 2.

Crop calendar of the study area
3 Methodology
Ground truth data at regular intervals have been collected to extract the information related to the crop growth cycle of the study area. The growth cycle of the sugarcane is divided into four stages, viz (1) Germination stage, (2) Tillering stage, (3) Grand growth period and (4) Ripening stage. These stages are diagrammatically represented by the Fig. 3.

Growth stages of the sugarcane
Based on these stages, satellite images for the entire year 2015 have been collected for the study. The details of the available cloud free data for the year 2015 is given in Table 2. These satellite images after the preprocessing operations are further used to generate the NDVI images. Open source software QGIS have been used to obtain the NDVI temporal profile. The methodology adopted in the present study is given by Fig. 4.

Flow diagram of the methodology
3.1 Conversion of DN values to reflectance values
Conversion of numerical values of Digital Numbers (DN) to actual reflectance values is very crucial to perform the quantitative analysis [16]. Reflectance values represent the actual spectral response of the targets [17]. As we used image time series, the digital counts needed to be converted into reflectance [18]. To do this, we used the following equation: A normalization formula has been used to convert the DN values to reflectance values (physical measurements of the part of the solar energy reflected by earth features) based on the Landsat 8 radiance rescaling factors available in the metadata (MTL) file (http://landsat.usgs.gov/Landsat8_Using_Product.php; [19]). Mathematically, this transformation without incorporating adjustments for sun angle is expressed as:
where \(\rho \lambda ^{'}\), Top of Atmosphere (TOA) planetary reflectance; \(M_{\rho }\), Band-specific multiplicative rescaling factor; \(A_{\rho }\), Band-specific additive rescaling factor; \(Q_{cal}\), Quantized and calibrated standard product pixel values (DN).
It is important to mention here that \(\rho \lambda ^{'}\) does not contain a correction for the sun angle. Band-specific multiplicative rescaling factor (\(M_{\rho }\)) is obtained from the metadata file using the variable: REFLECTANCE_MULT_BAND_x and Band-specific additive rescaling factor (\(A_{\rho }\)) is obtained from the metadata file using the variable: REFLECTANCE_ADD_BAND_x, where x is the band number.
The Numerical value of reflectance was calculated using Eq. 1, and is then corrected for the sun angle using:
where \(\rho \lambda\), Sun angle corrected TOA planetary reflectance; \(sin(\theta _{SE})\), Local sun elevation angle; \(sin(\theta _{SZ})\), Local solar zenith angle.
3.2 Vegetation indices
Vegetation indices such as NDVI have been established as reliable tool to discriminate the crop, monitor crop growth and assess its maturity [20]. These indices have been proven to be very sensitive to variation in the biomass and leaf area index (LAI) [21]. Crop classification and discrimination of specific crops based on temporal observation has been preferred than single data observation due to the spectral similarity of the different features and objects [22]. Different types of Vegetation Indices generated from remote sensing data proven to be very effective in qualitative and quantitative measures of growth parameters, vegetation cover and vigor [23].
Simplest ration based vegetation index known as Simple Ratio (SR) or Ratio Vegetation Index (RVI) based on the characteristic of vegetation that it absorb the red band signal and reflect the near infra red signal of electromagnetic energy spectrum is used. This index is more useful for the assessment of biomass [24]. Mathematically, it is given as :
where NIR represents the reflectance in the near infrared band (0.85–\(0.88\,\upmu\)m)while R is the red band (0.64–0.67\(\,\upmu\)m) reflectance. A computed value of simple ratio less than one is considered as non vegetation whereas, the computed value of the ration greater than one is taken as the vegetation. The major drawback of this index is the generation of infinite values for the pixels with zero values in red band.
Huete [25] proposed an index known as Soil Adjusted Vegetation Index (SAVI) again based on NIR and RED bands. This index is advantageous to lessen the effect of background soil on the spectral properties of vegetation. Mathematically, it is represented as:
where NIR represents the reflectance in the near infrared band (0.85–\(0.88\,\upmu\)m) while R is the red band (0.64–\(0.67\,\upmu\)m) reflectance. Parameter L is soil and canopy adjustment value. While using the SAVI for agricultural applications the value of L is generally taken as 0.5.
The Normalized Difference Vegetation Index (NDVI) [26] was computed with the formula:
where NIR represents the reflectance in the near infrared band (0.85–\(0.88\,\upmu\)m) while R is the red band (0.64–\(0.67\,\upmu\)m) reflectance. The values of this index varies between \(-\,1\) and \(+\,1\). Generally, the negative values and values close to zero are specific to soil devoid of vegetation or sparse vegetation, whereas the surfaces covered by dense and healthy vegetation have the values 0.7–1.0. The generated temporal NDVI profile of agricultural fields containing different varieties of sugarcane in the study area for the year 2015 is shown in Fig. 5.
The visual analysis of Fig. 5 in conjunction with general crop growth information pertaining to the study area confirms the belief that some of the computed values are contaminated. Field traversing, ground truth information revealed that the contamination of NDVI values is due to presence of integrated noise popping up as the cumulative effect of cloud cover and other climatic variations. There is a need to reconstruct the NDVI temporal profile due to the presence of these contaminated factors. It is worth mentioning that the growth and yield information about the plants and crops can be more accurately ascertain from the reconstructed NDVI temporal profile.

NDVI temporal profile of sugarcane fields. a P1, b P2, c P3, d P4, e P5
3.3 Reconstruction of temporal data
A review of available literature revealed that the NDVI is the nucleus of land cover related information. Consequently, temporal and spatial variations in the numerical values of the NDVI may be successfully used to study the land cover change dynamics and crop growth monitoring [27]. An early and advanced information about the crop growth leads to the cost effective and reliable scheduling of the cane supply [28]. A crop simulation model based on Leaf Area Index (LAI) has been proposed to extract the crop information [29]. Vegetation indices have a significant relationship with the yield but direct use of these indices may not produce reliable results. The research work given by [30] explored the noticeable NDVI distinction flanked by vegetated and non vegetated areas in addition to the demonstration of the superior capability of Landsat 8 OLI NDVI for agricultural applications such as crop growth monitoring. The authors of [31] conducted a study for the land cover classification and deduced that the performance of Landsat 8 OLI bands is much better than that of Landsat 7 ETM+ bands. Nevertheless, satellite derived NDVI information may be contaminated by a variety of factors, for example, atmospheric effects, geometric errors, snow and the clouds. These causative factors considerably affect the crop growth monitoring process using satellite based information. In turn, these errors always reduce the consistency, reliability and applicability of satellite data, especially for the agricultural applications [32, 33].
The method of reconstruction of the NDVI temporal profile is based on the running medians and moving average. Besides the streamline of the observed NDVI time series, the filter have been used to preserve the general crop growth trend of NDVI profile. Reconstructed information delivers the near real time growth curve which may be effectively used for the agricultural applications. The streamlining process is decomposed into following three modules:
-
Module 1: Running medians streamlining
$$\begin{aligned} Z_t=P{\mathrm {median}}(NDVI_{t-2},NDVI_{t-1},NDVI_t,NDVI_{t+1},NDVI_{t+2}) \end{aligned}$$(6)Where \(NDVI_t\) represents the original time series data.
-
Module 2: Moving average streamlining
$$\begin{aligned} M_t=\frac{NDVI_{t-1}+NDVI_t+NDVI_{t+1}}{3} \end{aligned}$$(7) -
Module 3: Selection of the optimal values
$$\begin{aligned} SNVI_t={\mathrm {max}}(NDVI_t,Z_t,M_t) \end{aligned}$$(8)This step is applied just to preserve the key points and peaks of the NDVI profile.
3.4 Feature selection
Classification accuracy may increase, though not necessarily, by employing several spectral bands. It has been found that accuracy starts falling (decreasing) by increasing the number of bands after a certain number or by using all the combinations. The problem of selection of certain such optimal bands which provide the maximum accuracy and economy is called ’feature selection’. The solution of this problem requires prediction of performance of the classifier based on the statistical separability between the various classes, i.e. the manipulation of variances and class means. Increasing the separation of the means decreases the probability of the error, whereas the probability of error increase by increasing the variance.
Transformed divergence [34] is used in this study for the feature selection. Mathematical expression for the transformed divergence is:
where x and y are the signatures of the features. Divergence \(D_{xy}\) is given by:
where \(Cov_x\) and \(Cov_y\) are the covariance matrices of the classes x and y respectively, tr is trace function, \(u_x\) and \(u_y\) are the mean vectors of the classes x and y and T is transpose of matrix.
3.5 Clustering technique
In order to discriminate a specific crop and to overcome the problems due to the mixed pixels, a classification technique known as PCM (Possibilistic c-Means) may be used effectively for single class of interest [35]. This technique is primarily based on the distance between distributions. It is evident from the computer generated histograms that more of the measurement vectors tend to occur in a particular region than in adjoining regions. This means that these measurement vectors tend to ’cluster’ near the mode. The cluster analysis of a set of measurement vectors to detect their inherent tendency to form clusters in multidimensional space is called cluster analysis or clustering. The analysis includes the determination of the distance between points in the feature space. There are many ways to measure distance between points. Generally used, most familiar one is Euclidean Distance (ED) which can be mathematically expressed as:
where n is the number of bands and \(a_i\) and \(b_i\) are the DN values of pixels a and pixel b in band i.
All the steps of the proposed methodology may be implemented with the help of the following algorithm:
Algorithm 1: Proposed Algorithm | |
|---|---|
Step 1: Initialization: | |
Collection and Compilation of relevant data: meteorological, Landsat images, ancillary data, and ground truth | |
Step 2: Pre-processing: | |
Generation and Analysis the Metadata Files: Checking of data sufficiency, discarding the images with cloud cover more than 30 % and planning field data collection program wherever necessary | |
-Creation of the layer stack for all the temporal images | |
-Conversion of DN values to reflectance values [Equation (1) and Equation (2)] | |
-Generation of NDVI profile for obtained reflectance values [Equation (5)] | |
Step 3: Temporal Analysis: | |
-Mean NDVI values are calculated for all the pixels obtained in Step 2 | |
-Scatter plot for the temporal NDVI profile is created | |
-Streamlining based on Running Medians [Equation (6)] | |
-Further Enhancement using Moving Point Average [Equation (7)] | |
-Selection of the best values [Equation (8)] | |
-Generation of NDVIT | |
Step 4: Error Analysis: | |
-Assessment based on the Field Experimentation | |
-Analysis based on obtained results |
4 Results and discussion
This study has been carried out in an experimental area containing a variety of crops including sugarcane. Field traversing and interaction with the farmers and ground truth for the experimental area has been conducted for the year 2015. This has been done twice a month, more or less synchronizing with the LANDSAT 8 overpass on the area. Therefore, meteorological data on daily basis pertaining to the study area have been collected for the year 2015. Preliminary investigations of the data revealed that the average temperature varies between 2.40 and \(42.60\,^{\circ }{\mathrm{C}}\), Relative Humidity have been found to vary between 11 and 100%, Average Vapour pressure have been found to vary between 5.6 and 27.7 mm, Monthly Rainfall have been found to vary between 0.0 and \(134.8\,{\mathrm{mm}}\), Evaporation have been found to vary between 0.2 and \(10\,{\mathrm{mm/day}}\), whereas the wind velocity have been found to vary between 0.4 and \(5.9\,{\mathrm{km/h}}\). These meteorological parameters reconfirms that the study area is suitable for a variety of crops from meteorological consideration.
To carry out the experimental work, five agricultural fields containing sugarcane (P1, P2, P3, P4 and P5) has been identified and selected. The selection of the dates to generate the temporal profile has been performed by calculating the transformed divergence for all the possible date combinations. The transformed divergence values between 1900 and 2000 may be treated as good to achieve the high classification accuracy [36]. The final selection of the temporal data has been focused around the saturation value 2000 as well as the growth stages of the sugarcane.
The scatter plots of original temporal NDVI are shown in Fig. 5. Close analysis of Fig. 5 indicates the presence of contaminated values, particularly in the initial stage of the crop growth. The contaminated values have been detected due to the presence of abnormal decrease in NDVI, and the numerical value of NDVI at these points does not fit into the general crop growth model. Whereas field traversing brought out the fact that during this period the general crop growth was normal. Therefore, there is need to streamline the temporal variation of NDVI values so as to monitor and predict the crop growth in an appropriate manner. Figure 6 shows the streamlined scatter plot of mean NDVI for all the sugarcane agricultural fields. The phenological attributes of vegetation or crops has been parametrized based on the variance, phase, mean and the number and time period of peaks in the cropping season. The main characteristics of each type are given in Table 3.

Scatter plot of mean NDVI for the fields P1, P2, P3, P4 and P5
Cavernous study of Fig. 6 indicates the there are two different growth patterns. The NDVI values are initially low in case of plants P1 and P2 whereas the initial values of NDVI remain high in the case of plants P3, P4 and P5. The NDVI values of all the plants almost coincide near the 150 days after the plantation. Immediately after the tillering period is over the NDVI values of the plants P3, P4 and P5 shoots up while there is a steady increase in the NDVI values in case of P1 and P2. At the ripening stage the values again coincided with each other. This temporal profile clearly exploits all the stages of the growth and further the numerical values of NDVI represent the general crop growth. Therefore the temporal variation of NDVI values can be used to monitor the crop growth in an appropriate manner.
Variation of NDVI values during the sugarcane growth periods have been used for the discrimination. A temporal variation index NDVIT has been used for the analysis, which is mathematically given as:
where \(NDVI_{t_1}\) and \(NDVI_{t_2}\) are the mean NDVI values of those sugarcane growth periods where the separation of ratoon and plantation sugarcane is maximum. Close analysis of the Fig. 6 indicated that the maximum seperability is during the initial 50–150 days (NDVIT050150) and during 150–250 (NDVIT150250) days. Field experimentation confirms the fact that the greenness of the sugarcane have a maximum variation between Tillering stage and Grand growth stage. This variation factor can be used to discriminate the type of sugarcane as well as sugarcane varieties. Stages of the sugarcane growth based on the temporal values of NDVI in all the five selected field has been given by Fig. 6. The accuracy analysis and measurement of NDVI temporal profile have been conducted based on the on-field survey and training sample data collected from the different fields of sugarcane.
A total of 55 pixels have been chosen to measure the classification accuracy. Table 4 revealed that 50 of 55 pixels were classified with an overall accuracy of 90.91%. The value of the Kappa Coefficient was 0.80 which signifies that the approach may be used effectively for the discrimination of ratoon sugarcane from plantation.
5 Conclusions
The present study demonstrated that temporal vegetation indices may be effectively used for the discrimination of ratoon sugarcane from the plantation. The preliminarily analysis and the streamlining of the temporal profile of NDVI was required to extract the potential sugarcane pixels from the NDVI images. Quantitative and qualitative analysis based on the collected data was presented to deduce the suitability and interpretations. In spite of the fact that the present study is based on data for one single year it is reasonable to deduce that the observed accuracy of the proposed method is most suitable and operational in achieving the global normal accuracy in Himalayan Foothills areas having diverse agricultural practice. The proposed approach may be explored and implemented in other similar areas.
References
Mutanga, S., Ramoelo, A., & Gonah, T. (2013). Trend analysis of small scale commercial sugarcane production in post resettlement areas of Mkwasine Zimbabwe, using hyper-temporal satellite imagery. Advances in Remote Sensing, 2, 29–34.
Rudorff, B. F. T., Aguiar, D. A., Silva, W. F., Sugawara, L. M., Adami, M., & Moreira, M. A. (2010). Studies on the rapid expansion of sugarcane for ethanol production in Sao Paulo State (Brazil) using Landsat data. Remote Sensing, 2(4), 1057–1076.
Simões, M. S., Rocha, J. V., & Lamparelli, R. A. C. (2005). Spectral variables, growth analysis and yield of sugarcane. Scientia Agricola, 62(3), 199–207.
Dempewolf, J., Adusei, B., Becker-Reshef, I., Hansen, M., Potapov, P., Khan, A., et al. (2014). Wheat yield forecasting for Punjab province from vegetation index time series and historic crop statistics. Remote Sensing, 6(10), 9653–9675.
Pupin Mello, M., Atzberger, C., & Formaggio, A. (2014). Near real time yield estimation for sugarcane in Brazil combining remote sensing and official statistical data. In 2014 IEEE International, Geoscience and Remote Sensing Symposium (IGARSS) (pp. 5064–5067).
Dev, C. M., Meena, R. N., Kumar, A., & Mahajan, G. (2011). Earthing up and nitrogen levels in sugarcane ratoon under subtropical Indian condition. Indian Journal of Sugarcane Technology, 26(1), 1–5.
Mulianga, B., Bgu, A., Simoes, M., & Todoroff, P. (2013). Forecasting regional sugarcane yield based on time integral and spatial aggregation of MODIS NDVI. Remote Sensing, 5(5), 2184–2199.
Masialeti, I., Egbert, S., & Wardlow, B. D. (2010). A comparative analysis of phenological curves for major crops in Kansas. GIScience & Remote Sensing, 47(2), 241–259.
Panigrahy, R. K., Ray, S. S., & Panigrahy, S. (2009). Study on the utility of IRS-P6 AWiFS SWIR band for crop discrimination and classification. Journal of the Indian Society of Remote Sensing, 37(2), 325–333.
Dadhwal, V., Singh, R., Dutta, S., & Parihar, J. (2002). Remote sensing based crop inventory: A review of indian experience. Tropical Ecology, 43(1), 107–122.
Chen, S. C., & Spiguel, M. C. R. V. (1984). Evaluation of the possibility of using landsat mss data for sugarcane yield estimation. In N. d. J. Parada (Ed.), Anais... Brazilian Symposium on Remote Sensing, 3. (SBSR), National Institute of Space Research (INPE), São José dos Campos.
Rao, P., Rao, V., & Venkataratnam, L. (2002). Remote sensing: A technology for assessment of sugarcane crop acreage and yield. Sugar Tech, 4(3–4), 97–101.
Morel, J., Todoroff, P., Bgu, A., Bury, A., Martin, J. F., & Petit, M. (2014). Toward a satellite-based system of sugarcane yield estimation and forecasting in smallholder farming conditions: A case study on Reunion Island. Remote Sensing, 6(7), 6620–6635.
Dangwal, N., Patel, N., Kumari, M., & Saha, S. (2016). Monitoring of water stress in wheat using multispectral indices derived from Landsat-TM. Geocarto International, 31(6), 682–693.
Silleos, N. G., Alexandridis, T. K., Gitas, I. Z., & Perakis, K. (2006). Vegetation Indices: Advances made in biomass estimation and vegetation monitoring in the last 30 years. Geocarto International, 21(4), 21–28.
Thenkabail, P. S., Smith, R. B., & Pauw, E. D. (2002). Evaluation of narrowband and broadband vegetation indices for determining optimal hyperspectral wavebands for agricultural crop characterization. Photogrammetric Engineering & Remote Sensing, 68(6), 607–621.
Fortes, C., & Demattae, J. A. M. (2006). Discrimination of sugarcane varieties using Landsat 7 ETM+ spectral data. International Journal of Remote Sensing, 27(7), 1395–1412.
Begue, A., Lebourgeois, V., Bappel, E., Todoroff, P., Pellegrino, A., Baillarin, F., et al. (2010). Spatio-temporal variability of sugarcane fields and recommendations for yield forecast using NDVI. International Journal of Remote Sensing, 31(20), 5391–5407.
Chander, G., Markham, B. L., & Helder, D. L. (2009). Summary of current radiometric calibration coefficients for landsat MSS, TM, ETM+, and EO-1 ALI sensors. Remote Sensing of Environment, 113(5), 893–903.
Wang, J., Rich, P. M., & Price, K. P. (2003). Temporal responses of NDVI to precipitation and temperature in the central Great Plains, USA. International Journal of Remote Sensing, 24(11), 2345–2364.
Turner, D. P., Cohen, W. B., Kennedy, R. E., Fassnacht, K. S., & Briggs, J. M. (1999). Relationships between Leaf Area Index and landsat TM spectral vegetation indices across three temperate zone sites. Remote Sensing of Environment, 70(1), 52–68.
Townshend, J. R. G., Goff, T. E., & Tucker, C. J. (1985). Multitemporal dimensionality of images of normalized difference vegetation index at continental scales. IEEE Transactions on Geoscience and Remote Sensing, GE–23(6), 888–895.
Xue, J., & Su, B. (2017). Significant remote sensing vegetation indices: A review of developments and applications. Journal of Sensors, 2017(1353691), 17.
Hatfield, J. L., & Prueger, J. H. (2010). Value of using different vegetative indices to quantify agricultural crop characteristics at different growth stages under varying management practices. Remote Sensing, 2(2), 562–578.
Huete, A. R. (1988). A soil-adjusted vegetation Index SAVI. Remote Sensing of Environment, 25, 295–309.
Rouse, J. W., Haas, H. R., Schell, A. J., & Deering, D. W. (1974). Monitoring vegetation systems in the great plains with ERTS. In Proceedings of the Third Earth Resources Technology Satellite-1 Symposium (pp. 301–317).
Tucker, C. J., Townshend, J. R., & Goff, T. E. (1985). African land-cover classification using satellite data. Science, 227(4685), 369–375.
Gers, C. (2003). Relating remotely sensed multi-temporal Landsat 7 ETM+ imagery to sugarcane characteristics. In Proc S Afr Sug Technol Ass (p. 7).
Chatwachirawong, P., Kitaura, A., Srinives, P., & Nawata, E. (2012). Construction of a simple yield estimation model for productivity prediction in sugarcane. Tropical Agriculture and Development, 56(3), 113–116.
Ke, Y., Im, J., Lee, J., Gong, H., & Ryu, Y. (2015). Characteristics of Landsat 8 OLI-derived NDVI by comparison with multiple satellite sensors and in-situ observations. Remote Sensing of Environment, 164, 298–313.
Jia, K., Wei, X., Gu, X., Yao, Y., Xie, X., & Li, B. (2014). Land cover classification using Landsat 8 operational land imager data in Beijing, China. Geocarto International, 29(8), 941–951.
Mulianga, B., Bégué, A., Clouvel, P., & Todoroff, P. (2015). Mapping cropping practices of a sugarcane-based cropping system in Kenya using remote sensing. Remote Sensing, 7(11), 14428–14444.
Wei, W., Wu, W., Li, Z., Yang, P., & Zhou, Q. (2015). Selecting the optimal NDVI time-series reconstruction technique for crop phenology detection. Intelligent Automation & Soft Computing, 22(2), 237–247.
Haack, B., Bryant, N., & Adams, S. (1987). An assessment of Landsat MSS and TM data for urban and near-urban land-cover digital classification. Remote Sensing of Environment, 21(2), 201–213.
Kumar, A., Ghosh, S. K., & Dadhwal, V. K. (2010). ALCM: Automatic land cover mapping. Journal of the Indian Society of Remote Sensing, 38(2), 239–245.
Jensen, J. R. (1986). Introductory digital image processing: A remote sensing perspective (3rd ed.). New York, NJ: Prentice Hall.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Singla, S.K., Garg, R.D. & Dubey, O.P. Sugarcane ratoon discrimination using LANDSAT NDVI temporal data. Spat. Inf. Res. 26, 415–425 (2018). https://doi.org/10.1007/s41324-018-0184-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41324-018-0184-0