
Abstract
It is a known fact that the precipitation characteristics will become irregular as a result of climate change resulting from global warming. Trend analysis is one of the most effective methods of observing the effects of climate change on precipitation. This study compares the changes in precipitation with traditional trend analysis methods and graphical method (divided into subcategories using the Z-Score Index). Some preliminary analyzes (missing data estimation, homogeneity check, autocorrelation, and removal of the autocorrelation), which are lacking in many studies in the literature, have been performed. In this context, the monthly total precipitation data of the precipitation stations belonging to the Coruh Basin, one of the most important basins of Turkey, for the period 1972–2011 were used. As a result of the study, it was determined that all the stations’ data were homogeneous, and 92% of them were at the Class A level. While 100% trend is determined in Innovative Trend Analysis in total annual precipitation, this rate was just 40% at Mann–Kendall and Spearman's rho at 95% confidence. An increasing trend was determined in the “high” group of total spring precipitation at all stations.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Since the 1750s, there has been a significant increase in the concentrations of carbon dioxide (CO2), methane (CH4) and nitrous oxide (N2O) in the atmosphere (40%, 150% and 20%, respectively) (IPCC 2014). This increase in greenhouse gas emissions causes the changes in climate on hydrometeorological events to be experienced more clearly through global warming (Guclu 2018). This situation usually causes more precipitation in rainy areas and more dryness in dry areas. (Dore 2005; Toride et al. 2018). The severity, frequency, and duration of droughts and floods that occur are related to the precipitation characteristics of the study area (Oztopal and Sen 2017). Therefore, in the design, maintenance, and operation of future water structures, and the management of drainage basins, it is necessary to define these trends occurring in precipitation and take into account the stochastic characteristics of extreme events (Guclu 2020). Recent studies on climate change also indicate that the spatial and temporal distributions of precipitation are important factors to be examined (Vincent et al. 2005; Li et al. 2013). Therefore, to address climate change objectively, it should be determined whether trends in hydrometeorological time series are increasing, decreasing, or neutral (Oztopal and Sen 2017). In this context, determining trends in various climatic elements using statistical methods has been an active research area for many years. Generally, Mann–Kendall (Mann 1945; Kendall 1975) and Spearman’s rho from nonparametric methods and linear regression analysis (Haan 1977) from the parametric method are used in defining trends. Río et al. (2011) applied the Mann–Kendall test, which is one of the classic trend determination methods, to precipitation data obtained from Spanish weather stations. Nalley et al. (2013) examined the trends in average surface air temperature of the southern parts of Canada–Ontario and Quebec–using the Mann–Kendall and sequential Mann–Kendall test. In another study, Gocic and Trajkovic (2014) determined the trend in evapotranspiration data using both parametric and nonparametric methods. Adarsh and Janga Reddy (2014) long-term precipitation trends in the regions of Kerala, Tamil Nadu, North Interior Karnataka, and Telangana, four subdivisions of South India, were analyzed using linear regression, Mann–Kendall, and Sen’s slope estimator methods. Zarei and Eslamian (2017) examined the trends in precipitation and Standard Precipitation Index (SPI) using linear regression, Mann–Kendall, and Spearman’s rho tests. Bacanli (2017) annual and monthly time series trends of Aegean were investigated by applying the Mann–Kendall and Spearman’s rho test. Forootan (2019) conducted trend analysis on temperature, precipitation, flow, humidity, evaporation, and wind speed data using nonparametric methods.
Although trend analysis is one of the most effective methods for observing and interpreting the effects of climate change on precipitation, Mann–Kendall and Spearman’s rho, which are the most widely used nonparametric tests, have some advantages and disadvantages. These advantages; the Mann–Kendall test allows for missing data (Yu et al. 1993), the Mann–Kendall test is highly resistant to the effects of outliers (Isioma 2018), does not require data to be normally distributed (Jaiswal et al. 2015), likewise Spearman’s rho (Gauthier 2001). The disadvantages are as follows; since it is sensitive to intrinsic dependence, autocorrelation control should be done before applying Mann–Kendall (Partal 2003). The Mann–Kendall test gives a holistic monotonic trend without any categorization of the time series (Dabanlı et al. 2016) likewise the Spearman’s rho test (Yilmaz and Tosunoglu 2019). Although the nonparametric methods mentioned above are frequently used in determining the trend, the 1:1 straight line (45°) Innovative trend analysis method was proposed by Sen (2012). Unlike classical trend methods such as Mann–Kendall and Spearman’s rho, the main advantages of the Innovative Trend Analysis method do not mention monotonous trends and do not contain restrictive elements such as data length, independent structure of time series, and normality (Kisi 2015). The Innovative Trend Analysis method has been used frequently in recent studies and has been compared with classical trend analysis methods. Sonali and Nagesh Kumar (2013) determined the trend in temperature time series in India using the Innovative Trend Analysis method and classical methods. Alifujiang et al. (2020) comparatively analyzed the trend of precipitation in the Lake Issyk-Kul basin (respectively) using Mann–Kendall and Innovative Trend Analysis (ITA) method.
Some of the studies in the literature are briefly mentioned above. The literature review shows that most of the studies are based on the comparative analysis of different trend analysis methods. Recently, some studies have investigated trend analysis of index values with ITA by applying the Standard Precipitation Index (SPI) to precipitation data (Caloiero 2018; Mehr and Vaheddoost 2020). This study, has novelty in terms of performing comparative analyzes with different trend analysis methods and applying the Z-Score index in reverse to create subcategories in ITA and grouping raw precipitation data instead of the index value. In addition, four bands, ± 10% and ± 20%, were added to determine the range of the trend slope in the ITA graphics. To the best of our knowledge, there is no study using the Z-Score index in the creation of ITA subcategories. For this reason, the mentioned index was used in the present study to fill this gap in the literature. It is aimed to determine the critical precipitation values that can cause drought and wetness by applying this method in reverse. In this way, it is planned that the data obtained as a result of grouping raw precipitation data with ITA will be used directly by water resources planners and officials. The remainder of this study is organized as follows. In Sect. 2, the study area and data are presented. The methodology is described in Sect. 3. The results and discussion are given in Sect. 4. Finally, the conclusion part is presented in Sect. 5.
2 Study Area and Data
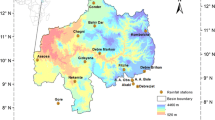
Located in Northeastern Turkey Coruh Basin covers approximately 2.53% of the country with a 19,748 km2 area (Tosunoglu 2017). With an average annual precipitation of up to 480 mm, the land elevation of the basin varies between 30 and 2200 m according to sea level (Yerdelen et al. 2010). The water potential of the basin is approximately 6.50 million m3 (Süme and Türüt 2018). Due to its location, the Coruh Basin (Fig. 1) is located between the continental climate of the Eastern Anatolia Region and the climate behind the Black Sea, so the transition zone has climatic characteristics. The presence of water resource structures and hydroelectric power plants under construction or completed in the Coruh Basin has further increased the economic importance of the basin from the point of view of Turkey.

Study area and station locations (Akpınar et al. 2009)
Therefore, examining the changes occurring in the basin, especially in precipitation, has become even more important for water resource planners and managers today. For this reason, the data of all stations operated by the Turkish State Meteorological Service (TSMS) in the Coruh Basin, which is determined as a study area, and which are known to have sufficient records in statistical analyses, were used in this study. To plan water resources according to basin-based needs, the basin water potential should be analyzed very well. In addition, for these analyses to be accurate and reliable, hydrometeorological data of the basin must be complete. However, most of the time, incomplete data can be found in the examined hydrometeorological time series due to measurement errors and interruption of measurements. These missing data can be complemented by using convincing statistical inferences of some techniques so that near-reality planning of water resources can be made. However, the percentage of missing in the hydrometeorological series is directly related to the reliability of statistical inference. Tosunoglu (2014) accepted this missing as 2.5% to make reliable inferences. The missing data rates of the stations used in this study; range between 0.42% and 1.39%, and there is no missing data at the Artvin station. The linear regression model (LR), recommended by TSMS (TSMS 2020) and used in many studies (Bárdossy and Pegram 2014; Khosravi et al. 2015; Sattari et al. 2017; Aieb et al. 2019) along with other methods, was used to estimate incomplete data in precipitation series. In the selection of the independent variable to be used in the regression model, the station with the highest correlation with the station to be estimated was taken into account.
The location information of the observation stations used in this study is presented in Table 1. The mentioned stations are located in the provinces of Artvin, Bayburt, and Erzurum, which are located within the boundaries of the basin. Artvin and Bayburt are the central observation stations, and Ispir, Oltu, and Tortum are the stations on the borders of Erzurum. The following factors were effective in the selection of these stations; (I) their representation of three provinces, (ii) their geographical distribution in the basin (east–west, north–south), and (iii) they have long-term and relatively few or no missing data. Although new observation stations in the basin have been put into operation recently, these stations were not used in the study because they did not have sufficient data length.
3 Methodology
In this study, a comparative analysis of the trend in the seasonal and annual total precipitation time series of the Coruh Basin in Turkey is presented with classic methods (MK and SR) and an innovative approach (ITA). Before applying trend analysis methods to precipitation data, change points should be considered for homogeneity. If there is a sudden change point, it may not trend before and after the change point (Sagarika et al. 2014). In this study, the homogeneity of stations was examined by applying Von Neumann (1941), Pettitt (1979), Buishand (1982), and Standard Normal Homogeneity (Alexandersson 1986) methods before trend analysis was performed. In addition, before MK was applied, it was investigated whether the data were intrinsically dependent, and the time series in which autocorrelation was detected removed autocorrelation using the trend-free pre-whitening (TFPW) method. Afterward, trend analyses were conducted as seasonal and annual by using MK, SR, and ITA methods. This study is one of the first examples of a new approach in which subcategories are created using the Z-Skore Index (ZSI) in the ITA method. Accordingly, precipitation that may cause drought is categorized as “low”, normal condition “medium” and precipitation that may cause wetness as “high”. In addition, information about the trend slope is provided thanks to the ( ±) 10% and ( ±) 20% trend bands created in the ITA method. The methodological main flow chart followed is presented in Fig. 2.

Methodological main flow chart of the study
3.1 Homogeneity Tests
In climate change studies, the use of homogeneous series is very important (Zaifoglu et al. 2017). Changes in homogeneous series are due to changes in climate and weather (Conrad and Pollak 1950). Changing the location of measuring stations, exposure to environmental factors, and tool and adjustment errors affect homogeneity in climate data (Peterson et al. 1998). In this study, homogeneity was investigated by Pettitt, Buishand, Von Neumann Ratio, and Standard Normal Homogeneity tests. The critical values of the homogeneity tests used in this study, depending on the sample size at a 99% confidence level, are presented in Table 2. In all tests, homogeneity is controlled by the null hypothesis (H0), if H0 is accepted, the series is homogeneous. Test results Wijngaard et al. (2003) classified as below.
-
(1)
Class A/Useful: No more than one of four tests rejects the H0 hypothesis status. Under this class, series are grouped homogeneously and can be used for further analysis.
-
(2)
Class B/Doubtful: It is the case that two out of four tests reject the H0 hypothesis. In this class, the series has an inhomogeneous signal and must be critically examined before further analysis can be performed.
-
(3)
Class C/Suspect: When three or all tests reject the H0, the series falls into this category. Time series in this category be deleted or ignored without further analysis.
If the values obtained from the related tests exceed the critical values given in Table 2 (for Pettitt, Buishand, and SNHT)/do not exceed (for Von-Neumann), it means that the precipitation series are not homogeneous. An inhomogeneous station may show sudden jumps compared to the average of the data in the neighboring station. Wijngard noted in his study that only very large trends from precipitation belonging to the "Suspect" group can be associated with a climate signal (Wijngard et al. 2003). Therefore, trend results of inhomogeneous precipitation data may not be realistic, and inhomogeneous precipitation series should either be excluded from the study or homogenized. In this context, Double-Mass Curves Analysis (DM) is one of the common methods used to detect the long-term systematic shift of precipitation data. The DM approach is used to check the consistency of many types of hydrological data by comparing the precipitation records for a single station with that of a model consisting of data from several other stations in the region (Searcy et al. 1960). All the details of the method can be found in the study proposed by Searcy et al. (1960).
3.1.1 Pettitt Test
The Pettitt test developed by Pettitt (1979) is a nonparametric test that does not require any assumptions about the distribution of data. This nonparametric test is used to determine the homogeneity of climate records. The H0 of this test is that data are independent and randomly distributed. This means that data follow the same distribution. A brief description of the methodology is as follows:
Y1, Y2, Y3, …,Yn values are sequenced as r1, r2, r3, …,rn
where \({\text{r}}_{{\text{i}}}\) is the rank of the data, n is the number of observations, \(X_{k}\) is the test statistics, \(X_{E}\) is the critical value.
3.1.2 Buishand Test
This test is based on the adjusted partial sums or cumulative deviations from the mean (Buishand 1982). The adjusted partial sum is calculated as:
where \(\overline{Y}\) is the mean of time series,\(Y_{i}\) is the observation values, n is the number of observations, and S is the standard deviation.
The H0 is accepted when the value of \(\mathrm{R}\surd \mathrm{n}\) is less than the critical values given by Buishand (1982).
3.1.3 Von Neumann Ratio Test
The Von Neumann ratio N is defined as the ratio of the mean square successive (year to year) difference to the variance (Von Neumann, 1941):
where \(\overline{Y}\) is the mean of time series, \(Y_{i}\) is the observation values, and n is the number of observations.
3.1.4 Standard Normal Homogeneity Test (SNHT)
The standard normal homogeneity test (SNHT) developed by Alexandersson (1986) has been used in many hydrological studies. The T(k) is computed as:
where n is the number of observations,\(\overline{Y}\) and s are the mean and standard deviation of the series, \(Y_{i}\) is the observation values. The year k consisted of a break if the value of T is maximum. The test statistic (To)
3.2 Serial Correlation Analysis
The series correlation structure in a dependent time series will affect the capability of MK. More clearly, the presence of a positive series correlation in time series increases the chance of giving a significant trend, even in the absence of a trend in the series (Hamed and Rao 1998; Yilmaz and Tosunoglu 2019). Therefore, the serial correlation structure of the series should be checked before the MK test is applied. If there is a significant series correlation in a data series, the calculation of the test statistics should be modified or a preliminary method should be used to eliminate the effect of this correlation. In this study, the trend-free pre-whitening method (TFPW) proposed by Yue et al. (2002) was used. The steps to implement this method are as follows (Akçay 2018);
Step 1: The first autocorrelation coefficient (ri) is calculated as:
where \(x_{i}\) is the serial values, \(\overline{x}\) is the mean of the series, n is the number of observations, k is the number of shifts, and 1 is taken.
Step 2 │r1│ > \({{1.96} \mathord{\left/ {\vphantom {{1.96} {\sqrt N }}} \right. \kern-\nulldelimiterspace} {\sqrt N }}\) there is an internal dependency in the series, and its effect should be eliminated (α = 0.05 significance level).
Step 3: \(x = b_{0} + b_{1} t\) The relationship between line equation, observation values (x) and time values (up to.
t = 1,2,..,nth years) is established by regression, and the slope of the line (b1) is calculated.
Step 4 In Eq. 10, the trend is removed from the series, the properties of the original series do not change. The trend is considered to be linear.
Step 5 The intrinsic dependence in the remaining series in Eq. 11 is removed.
Step 6 In Eq. 12, the trend is added to the series again, and the internal dependency is eliminated. One year missing (first year) data set is obtained. Finally, the MK test is applied to the new Yt'' time series.
3.3 Trend Analysis
3.3.1 Mann–Kendall (MK) Test
The nonparametric Mann–Kendall (MK) test, which was developed by Mann (1945) and Kendall (1975), is most commonly used in trend analysis studies. This test is less sensitive to gaps in the data series. According to the H0 hypothesis, series data are similar and independent scattered variables. According to the H1 hypothesis, the distribution of the sequential data ordered by time is not similar, and there is a trend in the time series. The MK test statistic (S) can be computed as:
where S is MK statistic, and sgn is the signum function. The application of the trend test is made to a time series yi that is ranked from i = 1, 2,………n-1 and yj, which is ranked from j = i + 1, 2,……….n. If the data length in the time series is n > 10, it is assumed that the data are distributed normally, and the variance is calculated as in Eq. (15).
where n is the number of data, k is the number of connected groups of the series, and ti shows the number of elements in observation subsets whose numerical value is equal. Then, the standardized MK test statistic (Z) can be defined as:
The Ho hypothesis is rejected if the absolute value of the calculated z value calculated as the result of Eq. (16) is greater than the z value determined at the α sense level, namely, there is a significant trend in the time series. If it is low, the Ho hypothesis is accepted, meaning that there is no significant trend in time series.
3.3.2 Spearman’s Rho (SR) Test
The Spearman’s rho (SR) test is also a nonparametric test, like the MK test, and is used to determine the monotonic trend in the time series. According to the H0 hypothesis, the data in the series are uniform, meaning that there is no trend in the series. The SR correlation coefficient (rs) and its test statistic (Z) for trend evaluation are defined as follows:
where R(xi) is the i. sequence number of value, i is the order of observation of data, and n is the data length. For n > 30, normal distribution tables are used since the rs distribution approaches normal. If the Z value at the α significance level is greater than the Zα/2 value determined from the standard normal distribution tables, the H0 hypothesis is rejected, and it is concluded that there is a certain trend.
3.3.3 Innovative Trend Analysis (ITA)
There are some limitations in the methods used to determine the trends of hydrometeorological variables, such that the data are serially independent, normally distributed, and the data are of a certain length. For the Innovative Trend Analysis (ITA) method developed by Sen (2012), there is no limitation in data length, and it can be applied to any time series. Step by step implementation of this method is as follows:
Step 1 The time series is first divided into two equal parts, and the separated series are ordered from the smallest to the largest.
Step 2 The first half of the time series is placed on the x-axis and the second half on the y-axis.
Step 3. These series placed in the coordinate system are mutually marked. As in Fig. 3, it is concluded that if points remain above the 1:1 (45°) line, there is an increasing trend in the time series, if they are below the line, there is a decreasing trend if they remain on the line, there is no trend.

Graph showing the ITA method
The Z-Score does not need any transformation of index data such as gamma distributions or Type III Pearson distribution (Jain et al. 2015; Mahmoudi et al. 2019). Because of its simple calculation and efficiency, the Z-Score Index (ZSI) has been used in many drought studies (Komuscu 1999; Morid et al. 2006; Akhtari et al. 2009; Akşan and Bacanlı 2021). Dry periods, as well as wet periods, can be monitored with the help of an index calculated based on only precipitation values. In this study, while researching trends with the ITA method, classification was made with the ZSI. In this context, three main categories were created while classifying with ZSI (Table 3). ZSI was applied in reverse and precipitation that could cause drought was classified as “low”, normal “medium” and precipitation that could cause wetness “high”.
where \(X\) is observed precipitation, \(\overline{X}\) is mean precipitation, and \(S\) is the standard deviation.
This integration of ITA and ZSI offers some advantages in trend interpretation. In this way, it allows preliminary interpretations against two extreme events, such as flood and drought, in which precipitation plays a leading role. For example, while the precipitation in the low group increases, the decrease in the precipitation in the medium and high group may increase the drought pressure in the region. This situation will make itself felt in many areas, from product productivity in agricultural activities to industry, environment, and irrigation. On the other hand, the presence of an increasing trend in precipitation in the high group, especially during a period when rapid snowmelt increases, such as the spring season, may lead to a flood event in the region.
4 Results and Discussion
4.1 Homogeneity Test Results and Serial Correlation Analysis
Absolute homogeneity tests were performed at the stations to determine whether there were any non-climatic changes over time. The critical values obtained from these test results and the results obtained by the classification specified under the heading methodology are presented in Table 4. When the related table is examined, it has been determined that the total precipitation in Artvin/summer season and Oltu/spring season is doubtful. Within the scope of the study, these values were examined in detail, and it was concluded that they did not exceed the critical values in high amounts and continued to be used in the study.
Intrinsic dependence, or serial correlation, is an important problem to consider in the analysis of hydrological time series. Internal dependence can be called the state in which successive values in the time series affect each other. Since this situation affects the ability of the Mann–Kendall test, autocorrelation coefficients were calculated for the seasonal and annual total precipitation data of the stations, as shown in Table 5. The results of this study indicated 1 series out of 25 series that found to be serially correlated. The trend-free pre whitening (TFPW) method was used in this study to eliminate the intrinsic dependency in the Artvin/autumn precipitation series. After applying the TFPW method to the autocorrelated Artvin/autumn precipitation, the autocorrelation coefficient rk was recalculated using Eq. 9. It was determined that the rk value (0.018) of the Artvin/Autumn precipitation obtained after TFPW was less than the critical value (0.310) corresponding to the 95% confidence level, that is, autocorrelation was eliminated. Then, the MK test was applied to the new precipitation series, which was free from serial correlation.
4.2 Comparison of ITA, MK, and SR Test Results
ITA, MK, and SR trend analysis methods are applied to each precipitation series as described in the “Sect. 3.3 Trend Analysis”. As is known, MK and SR are based on a monotonous holistic trend without any grouping. On the other hand, ITA is based on categorical trend behavior by clustering time series. In this study, the time series in the ITA scatter diagram is divided into three groups (Table 3). The boundaries of this grouping are determined by ZSI. These groups are formed by the reverse application of the ZSI formula (Eq. 19), precipitation that may cause drought is named as “low”, normal “medium” and precipitation that may cause wet as “high”. Figure 4 shows how the grouping of stations subject to scattering diagrams is applied to the total annual precipitation. It is clear that there is an increasing trend for all groups in most of the precipitation stations in Fig. 4 When the ITA graph of the total annual precipitation of Artvin station (Fig. 4a) is examined, it is seen that the series is generally distributed between the 1:1 line and the 20% ( +) band. Similarly, an increasing trend is observed in all groups at Bayburt except for the peak value station (Fig. 4b). Ispir (Fig. 4c) station, there is a partially increasing trend in the medium group data (385–567 mm), low group data (< 385 mm), and high group data (> 567 mm) show an increasing trend in the 1:1 line and 10% ( +) band. Oltu (Fig. 4d) although an increasing trend was observed in all groups at the station, it was determined that as the values of high group data increased, the trend increase slope also increased. An increasing trend is also observed in all groups at the Tortum station (Fig. 4e). MK and SR trend analysis results of the same stations are summarized in Table 6. Contrary to expectations, an increasing trend was observed at only 2 (Artvin and Bayburt) out of 5 stations in MK testing and SR tests.

Results of ITA for total annual precipitation a Artvin, b Bayburt, c Ispir, d Oltu, e Tortum
The trend analysis results of total seasonal precipitation according to MK, SR, and ITA are presented in Table 7 comparatively in order not to take up much space in the article. As can be seen from the corresponding table, MK and SR produced completely parallel results. According to these results, while there was a statistically increasing trend in 4 of the total seasonal precipitation series (5*4 = 20 stations /season in total) according to both MK and SR methods, no significant trend was observed in the remaining 16 series. In light of the definitions found in Table 7, the corresponding table is self-explanatory. In the last column in the table, short expressions on the ITA method are included. Some important comparative results of trend analysis methods are as follows; an increasing trend can be mentioned for all methods in the total precipitation of the Artvin/summer season. Here the zcritic values for MK and SR are 2.924 and 2.923, respectively. MK and SR zcritic values are 1.911 and 1.216, respectively, in total precipitation of Artvin/autumn season. While an increasing trend was observed in ITA in general, if the MK was at 90% confidence level (zcritic = 1.645), it would be determined that there was an increasing trend in MK. An increasing trend can be mentioned for all methods (except the low group for ITA) in the total precipitation of the Bayburt/spring season. Here the zcritic values for MK and SR are 2.505 and 2.470, respectively. As the size of the values in the medium and high group increases in the total precipitation of the Ispir/winter season, the decreasing tendency also increases. All methods show an increasing trend in total precipitation in the Oltu/spring season. Here MK and SR zcritic value are 3.283 and 3.195, respectively. For the total spring and summer seasonal precipitation of the Tortum station, ITA detected increasing trends in the medium and high classification, although there was no significant trend according to the MK and SR test.
According to the MK and SR test results applied to the seasonal and annual total precipitation records of 5 precipitation stations in the Coruh Basin, whose data length is equal to or longer than 36 years, the decreasing trend in seasonal and annual total precipitation was not observed. However, the data of annual total precipitation only 2 (Artvin and Bayburt) showed a significant increasing trend at the α = 0.05 significance level. Again, an increasing trend was observed at only 4 stations /season α = 0.05 significance level. In the ITA method, in many cases where MK and SR do not determine a significant trend, it has determined a neutral, increasing, or decreasing trend in the grouping field with “low”, “medium”, and “high” in both seasonal and annual total precipitation. Although MK and SR are quantitative methods that give numerical results, there are some limitations mentioned in the introduction of the article. However, ITA is not subject to such restrictions as a graphical method. Moreover, it allows the creation of any number of categories with ITA. This situation facilitates studies that can be done on extreme events such as drought and flood, which are indirect consequences of climate change. Trend analysis studies in the literature are statistically interpreted as quantitative results, while ITA has verbal definitions and inferences. In this study, grouping in the ITA method was performed by applying ZSI in reverse and taking into account precipitation values instead of index values.
5 Conclusions
In studies focusing on climate change, it is very important to interpret the possible change in the hydrometeorological parameters that affect the climate, which is precipitation in this study, in a certain time series. In this study, MK and SR, which are the classical trend analysis methods, and ITA were applied to the precipitation records of 5 precipitation stations in the Coruh Basin, and the results were analyzed comparatively. The results may be summarized as follows:
-
(1)
The absolute homogeneity tests applied to both seasonal and annual total precipitation of the precipitation stations were investigated and classified. As a result of these tests, most of the stations (92%) were found to be homogeneous at the Class A level.
-
(2)
Before applying the MK, the internal dependence in the precipitation data was examined by serial correlation analysis and the data with internal dependency were purified by the TFPW method. This step is often overlooked in most trend analysis studies.
-
(3)
MK and SR test results reveal an increasing trend in total annual precipitation at two stations. Increasing trends were determined in four of the total seasonal precipitation.
-
(4)
As precipitation series in the ITA method is divided into three clusters (low, medium, and high), trending behaviors have been studied in more detail. This new approach has led ITA to produce detailed results when MK and SR methods do not set trends.
-
(5)
The present in this study, in which three different methods are discussed comparatively, revealed that the ITA method has some advantages relative to the MK and SR methods. One of its main advantages is that it does not have any assumptions (e.g. serial correlation, non-normality, data length, etc.) as in MK and SR methods. Another important advantage is that low, medium, and high data trends can be easily determined with ITA. Determining a categorical tendency instead of a monotonic tendency will enable the implementation of projects that better respond to the needs.
-
(6)
Thanks to this study, The fact that the ITA is grouped for a specific cause (ZSI), and the study of changes in this grouping can provide valuable information to authorities in the investigation of extreme events such as drought and floods, management of water resources, operation, and planning. Especially in basins with internationally important rivers crossing the border of countries such as Coruh (Turkey-Georgia), it is very important to examine the change in precipitation with this type of new approach.
Availability of data and material
Not applicable.
References
Adarsh S, Janga Reddy M (2014) Trend analysis of rainfall in four meteorological subdivisions of southern India using nonparametric methods and discrete wavelet transforms. Int J Climatol 35:1107–1124. https://doi.org/10.1002/joc.4042
Aieb A, Madani K, Scarpa M, Bonaccorso B, Lefsih K (2019) A new approach for processing climate missing databases applied to daily rainfall data in Soummam watershed, Algeria. Heliyon. https://doi.org/10.1016/j.heliyon.2019.e01247
Akçay F (2018) Trend analysis for the monthly and yearly mean flows of the Eastern Black Sea Basin. MS Thesis, The Graduate school of natural and applied sciences, Civil Engineering Graduate Program, Karadeniz Technical University, Trabzon, Turkey
Akhtari R, Morid S, Mahdian MH, Smakhtin V (2009) Assessment of areal interpolation methods for spatial analysis of SPI and EDI drought indices. Int J Climatol 29:135–145
Akpınar A, Kömürcü İM, Kankal M, Filiz MH (2009) Çoruh Havzası’ndaki küçük hidroelektrik santrallerin durumu. V. Yenilenebilir Enerji Kaynakları Sempozyumu, ss. 249–254. Diyarbakır, Türkiye
Akşan GN, Bacanli ÜG (2021) Comparison of the meteorological drought indices according to the parameter (s) used in the Southeastern Anatolia Region, Turkey. Environ Res Technol 4:230–243. https://doi.org/10.35208/ert.912990
Alexandersson H (1986) A homogeneity test applied to precipitation data. J Climatol 6:661–675. https://doi.org/10.1002/joc.3370060607
Alifujiang Y, Abuduwaili J, Maihemuti B, Emin B, Groll M (2020) Innovative trend analysis of precipitation in the Lake Issyk-Kul Basin. Kyrgyzstan Atmos. https://doi.org/10.3390/atmos11040332
Bacanli UG (2017) Trend analysis of precipitation and drought in the Aegean region, Turkey. Meteorol Appl 24:239–249. https://doi.org/10.1002/met.1622
Bárdossy A, Pegram G (2014) Infilling missing precipitation records–a comparison of a new copula-based method with other techniques. J Hydrol 519:1162–1170. https://doi.org/10.1016/j.jhydrol.2014.08.025
Buishand TA (1982) Some methods for testing the homogeneity of rainfall records. J Hydrol 58:11–27. https://doi.org/10.1016/0022-1694(82)90066-X
Caloiero T (2018) SPI trend analysis of New Zealand applying the ITA technique. Geosciences. https://doi.org/10.3390/geosciences8030101
Conrad VA, Pollak LW (1950) Methods in climatology. Harvard University Press, London
Dabanlı İ, Şen Z, Yeleğen MÖ, Şişman E, Selek B, Güçlü YS (2016) Trend assessment by the Innovative-Şen Method. Water Resour Manage 30:5193–5203. https://doi.org/10.1007/s11269-016-1478-4
Dore MH (2005) Climate change and changes in global precipitation patterns: what do we know? Environ Int 31:1167–1181. https://doi.org/10.1016/j.envint.2005.03.004
Forootan E (2019) Analysis of trends of hydrologic and climatic variables. Soil Water Res 14:163–171. https://doi.org/10.17221/154/2018-SWR
Gauthier TD (2001) Detecting trends using Spearman’s rank correlation coefficient. Environ Forensics 2:359–362. https://doi.org/10.1080/713848278
Gocic M, Trajkovic S (2014) Analysis of trends in reference evapotranspiration data in a humid climate. Hydrol Sci J 59:165–180. https://doi.org/10.1080/02626667.2013.798659
Guclu YS (2018) Multiple Şen-innovative trend analyses and partial Mann-Kendall test. J Hydrol 566:685–704. https://doi.org/10.1016/j.jhydrol.2018.09.034
Guclu YS (2020) Improved visualization for trend analysis by comparing with classical Mann Kendall test and ITA. J Hydrol. https://doi.org/10.1016/j.jhydrol.2020.124674
Haan CT (1977) Statistical methods in hydrology. The Iowa State University Press, Ames, Iowa
Hamed KH, Rao AR (1998) A modified Mann-Kendall trend test for autocorrelated data. J Hydrol 204:182–196. https://doi.org/10.1016/S0022-1694(97)00125-X
Intergovernmental Panel on Climate Change (IPCC) (2014) Intergovernmental panel on climate change 2014 Synthesis report. Switzerland, Geneva
Isioma NI, Rudolph II, Omena AL (2018) Non-parametric Mann-Kendall test statistics for rainfall trend analysis in some selected states within the Coastal Region of Nigeria. J Civil, Constr Environ Eng 3:17–28. https://doi.org/10.11648/j.jccee.20180301.14
Jain VK, Pandey RP, Jain MK, Byun HR (2015) Comparison of drought indices for appraisal of drought characteristics in the Ken River Basin. Weather and Climate Extremes 8:1–11. https://doi.org/10.1016/j.wace.2015.05.002
Jaiswal RK, Lohani AK, Tiwari HL (2015) Statistical analysis for change detection and trend assessment in climatological parameters. Environmental Processes 2:729–749. https://doi.org/10.1007/s40710-015-0105-3
Kendall MG (1975) Rank correlation method. Charless Griffin, London
Khosravi G, Nafarzadegan AR, Nohegar A, Fathizadeh H, Malekian A (2015) A modified distance-weighted approach for filling annual precipitation gaps: application to different climates of Iran. Theoret Appl Climatol 119:33–42. https://doi.org/10.1007/s00704-014-1091-5
Kisi O (2015) An innovative method for trend analysis of monthly pan evaporations. J Hydrol 527:1123–1129. https://doi.org/10.1016/j.jhydrol.2015.06.009
Komuscu AU (1999) Using the SPI to analyze spatial and temporal patterns of drought in Turkey. Drought network news (1994–2001). Paper 49:7–13
Li L, Ngongondo CS, Xu CY, Gong L (2013) Comparison of the global TRMM and WFD precipitation datasets in driving a large-scale hydrological model in southern Africa. Hydrol Res 44:770–788. https://doi.org/10.2166/nh.2012.175
Mahmoudi P, Rigi A, Kamak MM (2019) A comparative study of precipitation-based drought indices with the aim of selecting the best index for drought monitoring in Iran. Theoret Appl Climatol 137:3123–3138. https://doi.org/10.1007/s00704-019-02778-z
Mann HB (1945) Nonparametric tests against trend. Econometrica 13:245–259
Mehr AD, Vaheddoost B (2020) Identification of the trends associated with the SPI and SPEI indices across Ankara, Turkey. Theoret Appl Climatol 139:1531–1542. https://doi.org/10.1007/s00704-019-03071-9
Morid S, Smakhtin V, Moghaddasi M (2006) Comparison of seven meteorological indices for drought monitoring in Iran. Int J Climatol 26:971–985. https://doi.org/10.1002/joc.1264
Nalley D, Adamowski J, Khalil B, Ozga-Zielinski B (2013) Trend detection in surface air temperature in Ontario and Quebec, Canada during 1967–2006 using the discrete wavelet transform. Atmos Res 132:375–398. https://doi.org/10.1016/j.atmosres.2013.06.011
Oztopal A, Sen Z (2017) Innovative trend methodology applications to precipitation records in Turkey. Water Resour Manage 31:727–737. https://doi.org/10.1007/s11269-016-1343-5
Partal T (2003) Trend analysis in Turkey precipitation data. MS. Thesis, Institute of science, Hydraulics and water resources engineering program, Istanbul technical university, Istanbul, Turkey
Peterson TC et al (1998) Homogeneity adjustments of in Situ atmospheric climate data: a review. Int J Climatol 18:1493–1517. https://doi.org/10.1002/(SICI)1097-0088(19981115)18:13%3c1493::AID-JOC329%3e3.0.CO;2-T
Pettitt AN (1979) A Non-Parametric approach to the change-point problem. Appl Stat 28:126–135. https://doi.org/10.2307/2346729
Río SD, Herrero L, Fraile R, Penas A (2011) Spatial distribution of recent rainfall trends in Spain (1961–2006). Int J Climatol 31:656–667. https://doi.org/10.1002/joc.2111
Sagarika S, Kalra A, Ahmad S (2014) Evaluating the effect of persistence on long-term trends and analyzing step changes in streamflows of the continental United States. J Hydrol 517:36–53. https://doi.org/10.1016/j.jhydrol.2014.05.002
Sattari MT, Rezazadeh-Joudi A, Kusiak A (2017) Assessment of different methods for estimation of missing data in precipitation studies. Hydrol Res 48:1032–1044. https://doi.org/10.2166/nh.2016.364
Searcy JK, Hardison CH (1960) Double-mass curves. USGS Publications Warehouse Web. https://pubs.usgs.gov/wsp/1541b/report.pdf. Accessed 8 November 2021
Sen Z (2012) Innovative trend analysis methodology. J Hydrol Eng 17:1042–1046. https://doi.org/10.1061/(ASCE)HE.1943-5584.0000556
Sonali P, Kumar Nagesh D (2013) Review of trend detection methods and their application to detect temperature changes in India. J Hydrol 476:212–227. https://doi.org/10.1016/j.jhydrol.2012.10.034
Süme V, Türüt R (2018) Aşağı Çoruh'ta bulunan barajların hidroelektrik potansiyeli ve çevresel etkileri. Türk Hidrolik Dergisi 2:12–18
Toride K, Cawthorne DL, Ishida K, Kavvas ML, Anderson ML (2018) Long-term trend analysis on total and extreme precipitation over Shasta Dam watershed. Sci Total Environ 626:244–254. https://doi.org/10.1016/j.scitotenv.2018.01.004
Tosunoglu F (2017) Trend analysis of daily maximum rainfall series in Coruh Basin, Turkey. J Inst Sci Technol 7:195–205
Tosunoglu F (2014) Investigating the relationship between atmospheric oscillations and meteorological and hydrological droughts in Turkey. PhD thesis, Graduate school of natural and applied sciences, Department of Civil Engineering, Ataturk University, Erzurum, Turkey
TSMS.(2020)Hydrometeorology.[online].https://www.mgm.gov.tr/FILES/genel/kitaplar/hidrometeoroloji.pdf. Accessed 4 November 2020. (in Turkish)
Vincent LA et al (2005) Observed trends in indices of daily temperature extremes in South America 1960–2000. J Clim 18:5011–5023. https://doi.org/10.1175/JCLI3589.1
Von Neumann J (1941) Distribution of the ratio of the mean square successive difference to the variance. Ann Math Stat 12:367–395. https://doi.org/10.1214/aoms/1177731677
Wijngaard JB, Klein Tank AMG, Konnen GP (2003) Homogeneity of 20th century European daily temperature and precipitation series. Int J Climatol 23:679–692. https://doi.org/10.1002/joc.906
Yerdelen C, Karimi Y, Kahya E (2010) Frequency analysis of mean monthly stream flow in Coruh Basin, Turkey. Fresenius Environ Bull 19:1300–1311
Yilmaz M, Tosunoglu F (2019) Trend assessment of annual instantaneous maximum flows in Turkey. Hydrol Sci J 64:820–834. https://doi.org/10.1080/02626667.2019.1608996
Yu YS, Zou S, Whittemore D (1993) Non-parametric trend analysis of water quality data of rivers in Kansas. J Hydrol 150:61–80. https://doi.org/10.1016/0022-1694(93)90156-4
Yue S, Pilon P, Phinney B, Cavadias G (2002) The influence of autocorrelation on the ability todetect trend in hydrological series. Hydrol Process 16:1807–1829. https://doi.org/10.1002/hyp.1095
Zaifoglu H, Akintug B, Yanmaz AM (2017) Quality control, homogenity analysis and trends of extreme precipitation indices in Northern Cyprus. J Hydrol Eng. https://doi.org/10.1061/(ASCE)HE.1943-5584.0001589
Zarei AR, Eslamian S (2017) Trend assessment of precipitation and drought index (SPI) using parametric and non-parametric trend analysis methods (case study: arid regions of southern Iran). Int J Hydrol Sci Technol 7:12–38. https://doi.org/10.1504/IJHST.2017.080957
Funding
No funding to declare.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There are no conflicts of interest to declare.
Rights and permissions
About this article

Cite this article
Hırca, T., Eryılmaz Türkkan, G. Comparison of Statistical Methods to Graphical Method in Precipitation Trend Analysis, A Case Study: Coruh Basin, Turkey. Iran J Sci Technol Trans Civ Eng 46, 4605–4617 (2022). https://doi.org/10.1007/s40996-022-00869-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40996-022-00869-y