
Abstract
This paper uses nonparametric method to study the relationship between economic growth and the level of pollution. The results indicate that as income increases the level of PM10 pollution rises and falls for low- and middle-income countries, respectively. Countries with GDP per capita above $32,000 experience an increased pollution level. Statistical tests show that nonparametric result provides better analysis than cubic specification, which dominates research works. Among the control variables in semiparametric setting, the higher the proportion of urban population, the higher is the level of pollutions while coal consumption and trade openness have no effect on PM10 pollution.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Damage to the environment, both in terms of quality and quantity, has recently been experienced to a greater extent than ever before (IPCC 2013). Acres of forest destroyed, amount of soil and organic matter eroded, number of wildlife lost and extent of biodiversity threatened are part of everyday news around the world (Hayward 2005; Weber and Kunzelman 2012). Reduction in air quality, emission of dangerous pollutants, apparent global warming and other environmental confrontations are often mentioned as a result of uncontrolled human interactions with environment. These interactions are diverse, but most importantly, they are the results of activities experienced at different stages of economic growth.
As described by Selden and Song (1994), agricultural modernization and industrialization, typical characteristics of the “take-off ” stage of economic growth, may initially lead to increased air and water pollution. On the other hand, a host of other favorable factors such as positive income elasticity for environmental quality, changes in the composition of production and consumption, higher levels of education and environmental awareness, and more open political systems would cause eventual reduction in certain pollutants. As the same time, it is recognized that it is possible to grow economically without experiencing environmental problems (Shafik and Bandyopadhyay 1992).
More specifically, accumulation of hazardous agricultural and industrial wastes and by-products, such as Particulate Matter 10 (PM10), is growing at an unprecedented rate in developing world (Panyacosit 2000; Guo et al. 2008). This is due to extensive use of agricultural chemicals, machines and equipments that are outdated which release more emissions than the standards; tax and resource incentives to transfer these technologies to developing countries; and less preference and hence lower investment to environment, to mention few factors (Wheeler 2001; Dinda 2004). In this respect, developing countries could hurt the environment on their way to economic growth. On the other hand, extensive use of vehicle for transportation and coal in generating electricity are often blamed for high volume of PM10 in developed countries. Negative environmental externalities associated with intensified agriculture, for instance, have been major policy issues in industrialized countries. There is no guarantee that environmental problems will subside once countries advance to industrialized stage (Lee et al. 2001).
The relationship between economic growth and environmental quality and quantity has been broadly explored in recent years. This relationship also has an important implication in crafting appropriate joint economic and environmental policy, depending on whether there is a negative or a positive impact of economic growth on environmental quality and quantity (Azomahou et al. 2006). One widely applied tool used to understand this relationship is the environmental Kuznets curve (EKC) hypothesis.Footnote 1
The main notion of EKC is that at initial stage of economic growth, pressure on environment increases until a country reaches a certain level of GDP per capita (usually called a threshold level of income). When the intrinsic values of environmental goods and amenities exceed the value of goods and services they used to produce, stress on environment diminishes at a certain pace. In other words, after attaining a certain threshold level of income, effort is given to restore damaged resources and conserve existing amenities.
Empirical studies on EKC hypothesis are generally based on parametric specifications, the popular forms are quadratic and cubic polynomials, for few pollutants (such as sulfur dioxide, carbon dioxide and nitrogen oxide) with little attention paid to model robustness (Grossman and Krueger 1993; Selden and Song 1994; Holtz-Eakin and Selden 1995; Carson et al. 1997; List and Gallet 1999; Shin and Hashimoto 2004; Hayward 2005; Auffhammer and Carson 2008). In such specifications, the perceived income-environment interactions have been aggregated and averaged to satisfy strict assumptions with minor or no effort to understand each and every interaction as it presides. In addition, different parametric specification could lead to different conclusion and ultimately inconsistent policy recommendation. In using parametric models, it is apparent that functional misspecification problems are likely to occur.
In recent years, however, nonparametric (NP) and semiparametric (SP) methods have been introduced for detecting the relationship between environment and economic growth (Taskin and Zaim 2000; Millimet et al. 2003; Bertinelli and Strobl 2005; Azomahou et al. 2006; Zapata et al. 2008; Nguyen-Van 2010). One essential advantage of these methods is that interaction can be found at the local level, with minimal assumptions and with no advance specified functional forms (Pagan and Ullah 1999). In addition, the interaction of the occurrence of events (for instance, the likelihood of low GDP per capita and low or high PM10 level) can be studied by finding a smoothing function with minimal pre-established assumptions. More specifically, NP model is better in capturing neglected nonlinearities in data that can facilitate flexibility in analyzing relationship. Another advantage of NP method is that its result can be used to identify appropriate counterpart parametric models.
This is one of a few studies that deal with the relationship between economic growth, measured using GDP per capita in purchasing power parity (PPP), and the level of pollution, measured using PM10, in NP method at a country level. In addition, we present SP and parametric specification analyses and results that help understand the resulting relationship based on different model specification.
The paper is organized as follows. The next section specifies NP estimation and model testing methods. “Data” section illustrates the main data and their descriptive statistics. In “Result and Discussion” section, NP and SP results are presented along with their analysis and interpretation. Finally, a Conclusion summarizes the main findings of the study.
Method
Estimation
Pagan and Ullah (1999) stated the potential advantages of NP econometric in applied research, owing to the method’s ability to adapt many unknown features of data. NP regression is performed without imposing a specific functional form a priori to capture unknown and nonlinear effects of the determinate on the dependent variable. The method also helps to find a smooth representation of the prevailing dynamics within data. In addition, structural changes in analyzing the relationship can easily be captured by employing appropriate NP methods.
The NP panel model for the relationship between PM10 pollution for country i in period t, \(({ PM}_{it} )\), and the country’s GDP per capita measured in purchasing power parity in the same period, \(({ GDP}_{it})\) can be represented by
where \(f_t \) is an unspecified smoothing functional form that makes the regression estimate NP. The random effect \(u_{it}\) is assumed to be i.i.d with zero mean, infinite variance and independent of \({ GDP}_{it}\) for all i and t. In addition, a country-specific effect i is allowed to be correlated with \({ GDP}_{it}\) with unknown correlation structure which completes fixed effect specification.
A common empirical approach to eliminate a country-specific effect, \(\mu _i\), is to take the first difference of Eq. (1). The new specification becomes
Taking the expectation of Eq. (2) and assuming that the expectation of the first difference of the error term is zero, \(E[ {u_{it} -u_{i,t-1} }]=0\), the remaining first difference can be further specified as
where \({\mathbf {x}}_{{\mathbf {it}}} = ({ GDP}_{it} , { GDP}_{i, t-1} )^{\prime }\); and \(\mathbf{PM} =\left( {{ PM}_{it} - { PM}_{i,t-1} } \right) \) with dimension \(N\left( {T-1} \right) \).
For estimating the NP model, we follow the procedure described in Azomahou et al. (2006). Let \(\mathbf{X}^{*}\) is a \(N\left( {T-1} \right) X2 \) matrix organized in the same way as \(\mathbf{PM}\) with \({\mathbf {x}}_{it}^{\prime } =\left( {x_{i1, \ldots , } x_{it} } \right) ^{\prime }\) as typical row. With \(\ell \) a \(N\left( {T-1} \right) \) vector of 1, let \(\mathbf{X}= \left( {\ell , \mathbf{X}^{*}} \right) \). Let \( K_h (.)\) be a bivariate kernel, smoothing function with bandwidth \(h = \left( {h_1 , h_2 } \right) ^{\prime }\) corresponding to \({ GDP}_{it} \) and \({ GDP}_{i, t-1} \), respectively. The bandwidth parameter could be determined by ad-hoc, plugin or cross-validation methods, depending on the smoothness of the fitted relationship.
The next step is designing the estimation procedure for the item described in the LHS of Eq. (3), \({\Psi }_t\left( {{\mathbf {x}}_{{\mathbf {it}}} } \right) \). This can be done by formulating a local linear kernel estimator, \({\widehat{{\Psi }}}_{x_o }\), given by
where
and \(x_o \) is a point of interest. The kernel function needs to satisfy some conditions before it can be used for smoothing purpose. One of the important features is that kernel is a density estimator that integrates to one.Footnote 2
Let \( \left( {\frac{\mathbf{X}^{*}_{\mathbf{it}} -\hbox {x}_{\mathrm{o}} }{\hbox {h}}} \right) ={ \Psi }\), the standard normal kernel, \(\hbox {K}\left( {\Psi } \right) ,\) can be defined as
The rationale for using kernel regression is that the function gives more weight to observations that are closer to the point of interest, \(x_o\), but the weight is decreasing for further tails within a particular window of bandwidth. The objective of this functional specification is to get a smooth depicting relationship between the two variables in all evaluation points without a particular local or global restriction. This is in contrast to, for instance, parametric specification on which quadratic function allows one turning point as a global restriction.
Testing
The Li and Wang (1998) test, or sometimes called NP consistent model specification test, will be used to check whether or not parametric models can be rejected against NP model. The test is based on the residuals of the parametric model. The null hypothesis is the first-difference version of parametric models and the alternative is NP specification shown in Eq. (1). The statistic for this one-sided test has an asymptotic standard normal distribution under the null of correct specification of parametric model (Azomahou et al. 2006). Kernel regression significance test will be performed for a consistence test for the significance of the explanatory variable in NP regression setting that is similar to a simple t test in a parametric regression setting. This test is based on Hayfield and Racine (2008).
Finally, statistical test of poolability specified by Racine (2009) will be conducted. The basic framework of this method is to introduce an unordered categorical variable \(\delta _i \) for \(i=1,2,\ldots ,N\) and nonparametrically estimate \(E\left( {{ PM}_{it} \big |{ GDP}_{it} ,\delta _i } \right) =\hat{{f}}\left( {{ GDP}_{it} ,\delta _i } \right) \) using mixed categorical method described in Hayfield and Racine (2008). Let \(\hat{{\tau }}\) denotes the cross-validation smoothing parameter associated with i. If \(\hat{{\tau }}=1\), the data is then poolable for estimation. Under the assumption of poolability, the functional form can be written as \({ PM}_{it} =f\left( {{ GDP}_{it} } \right) + \mu _i +u_{it} \) or \(f\left( . \right) \) which does not change over time. If \(\hat{{\tau }}=0\) or close to 0, then the data is nonpoolable and effectively estimated using Eq. (1). Finally, if \(0<{\hat{{\tau }}}>1\) one may interpret this as a case in which the data is partially poolable.
Data
Panel data for 158 countries from 1991 to 2010 is collected from different sources. PM10 country level (the urban-population weighted PM10 levels in residential areas of cities with more than 100,000 residents), the proportion of urban population, total population, and GDP per capita based on purchasing power parity (PPP) in constant 2005 international $ are obtained from the World Bank (The World Bank 2013). Trade openness at 2005 constant prices (%) is collected from Penn World Table Version 7.1 (Heston et al. 2012). In addition, coal consumption (in thousand short tons) is collected from the Energy Information Administration (EIA) and converted to coal consumption per capita for analysis (EIA 2013).
The level of PM10 pollution varied from 6 micrograms per cubic meter \((\upmu \hbox {g/m}^{3})\), the level of pollution in Equatorial Guinea and Belarus in the late 2000s, to \(367 \,\upmu \hbox {g/m}^{3}\), in Armenia in the early 1990s, with a global average of \(59\, \upmu \hbox {g/m}^{3}\), as shown in Table 1.Footnote 3 GDP per capita PPP was recorded from $102 (measured in constant 2005 international $ in Liberia in 1995) to $74,021 (in Luxembourg in 2007) with the global average of $10,865.
In addition to income per capita-pollution variables, this study includes trade openness, coal consumption per capita and proportion of urban population as control variables in SP setting. Singapore with trade openness value of 440 % was the most open economy, while Sudan (9.5 %) was the least open economy. The world’s average international trade openness was about 83 %. The highest coal consumption per capita (7.9 short tons per capita) was recorded in Czech Republic in 1993, while the global average was around 1 short ton per capita. Finally, 53 % the world population lived in urban areas.
Result and Discussion
NP Result
The NP regression significance test described in Hayfield and Racine (2008) is performed for the explanatory variable. It is found that GDP per capita is significant at all conventional levels (where \(\hbox {p}\,<\,0.001\)) for the local linear NP model with plugin bandwidth selection method.Footnote 4 For the Li and Wang (1998) NP model consistence specification test, the test statistics is 24.30 for cubic pooled estimate. This result reveals that the null hypothesis of correct parametric specification is rejected for cubic models. Hence, the two tests show that NP model is better than the parametric specifications for studying the relationship between PM10 and GDP per capita.
The estimated results for nonparametric and comparable parametric regressions are shown in Fig. 1 and Table 2. For low-income countries,Footnote 5 with GDP per capita less than $1000 (PPP in constant 2005 international $), the level of pollution rises as these countries experience economic growth, which is in line with EKC hypothesis. For middle-income countries, with GDP per capita between $1000 and $12,000, the level of pollution declines as these countries grow, as supported by EKC hypothesis. For many high-income countries, with GDP per capita between $12,000 and $32,000, the level of pollution declines as these countries grow, as supported by EKC hypothesis. For some high-income countries with GDP per capita more than $32,000, however, the trend shows that the level of pollution increases as income rises. Unlike for low- and middle-income countries, the result for high-income countries is inconsistent with EKC hypothesis. Therefore, the estimated result with pooled-data setting indicates an “N-shaped” relationship between PM10 pollution level and the level of economic growth, instead of an inverted “U-shaped”.

Nonparametric and parametric estimate using pooled and panel data
The challenge for complete existence of EKC comes from a situation that a decline in the level of pollution for middle-income countries is followed by unprecedented pollution surge for countries with GDP per capita above $32,000. For some high-income countries and more importantly for oil-producing high-income countries (such as United Arab Emirates, Kuwait, Brunei and Qatar) the trend for the level of pollution is exceptionally higher than what is normally expected from EKC hypothesis.
In a nonpooled data setting, Fig. 2 shows the pattern of pollution for different time period along the income level. Low-income countries experience a consistent increase in the level of pollution as they grow, but the level of pollution in the late 2000s is lower than what was recorded in the early 1990s. On the income side, low-income countries have higher income in the late 2000s than in the early 1990s. Middle-income countries experience a decreased level of pollution as they grow. In addition, they emit lower level of pollution in the late 2000s than in the early 1990s.

Nonparametric estimate using panel data
For high-income countries, the pattern of pollution varies for different time period. These countries experience an increased and a decreased level of pollution in the 1990s and in the late 2000s, respectively. Generally, in the late 2000s, high-income countries release low level of pollution than the other two income groups. Hence, seeing from different time perspective, an inverted U-shaped relationship between pollution and economic growth, which is postulated by EKC hypothesis, has happened at the most recent time periods.
With the adjusted R-squared values shown in Table 2, NP regression with panel data (nonpooled) estimate provides better result than other regression estimates. This can also be confirmed through statistical test of poolability specified by Racine (2009). The cross-validated smoothing parameter associated with individual country dummy is calculated and the value of the bandwidth is very close to zero (0.00034); hence, the data is nonpoolable. That means the given countries’ variable of interest is not stable over time, as also seen from Fig. 2. Consequently, the unspecified functional form of NP regression is not generalized using a single setting or constant functional form. Figure 2, which presents the level of pollution at different time period, is a better representation for the relationship between economic growth and the level of pollution.
Another advantage of NP results is to provide a functional relationship for the variables under consideration. Cubic regression is found to better represent the relationship using parametric specification than other polynomials. Both parametric-panel between and ordinary least square (OLS) estimates represent alternative to nonparametric estimate as seen in Table 2. More importantly, the estimated coefficients indicate that the level of pollution increases as income rises, as seen from the coefficient of GDP per capita (11.054 for between and 8.641 for OLS) but at a decreasing rate (\(-\)3.087 for between and \(-\)2.431 for OLS).
On the other hand, parametric-within estimate (fixed effect) provides a decreasing trend in the level of pollution as income per capita grows, as shown in Fig. 1. Nevertheless, the coefficients for this estimate are statistically insignificant. As shown in both Fig. 1 and Table 2, this functional relationship depicts completely different story and may lead to a different policy formulation than the other estimates. Hence, NP estimate can correct the misspecification error and suggest a corrected alternative that explains the existing relationship in parametric settings.
SP Result
Even though NP method has potential benefits of providing set of flexible tools for analyzing unknown regression relationships, it is not free from shortcomings. One of the challenges of embracing NP method is that it is rather difficult to account for more explanatory variables at the same time (Cooper 2002). An alternative approach is to use SP method.
EKC reflects an unconditional account of how the level of pollution changes with economic growth of a country. To the same extent, economic and noneconomic factors could affect the level of pollution as a country progresses. Along with economic growth, there are, however, other factors that could influence the level of pollution. These factors could have a direct and/or an indirect impact on the interaction between the level of pollution and economic growth. Therefore, by following some previous research works and by relying on economic theory about the level of pollution and economic growth, we have included few additional controls to investigate how their presence affect EKC hypothesis. The specification presented in Eq. (1) is modified to SP specification with additional controls, \(Z_{it} \). SP specification becomes
where \(\varepsilon _{it} \) are random disturbances, \(\varepsilon _{it} = \mu _i + u_{it} \) and \(E[ {\varepsilon _{it} \big |{\mathbf {x}}_{{\mathbf {it}}} } ]=0\). Equation (6) can be estimated by using a method developed by Verardi and Debarsy (2011).
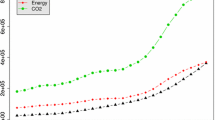
Since a seminal work by Kraft and Kraft (1978), energy becomes another nexus on the analysis of EKC. One of the controls in this case is coal consumption per capita where its main by-product is PM10 (Guo et al. 2008). In this study, coal consumption per capita, that is, a country’s total coal consumption divided by total population at a given time, is used as a control in SP setting. The result is shown in Fig. 3a and Table 3 (Model a).

Semiparametric estimate results
With the inclusion of coal consumption per capita, the relationship resembles NP nonpooled data result, partially supports the existence of EKC for GDP per capita less than $32,000. Another important finding is an inverse relationship between coal consumption per capita and the level of PM10 pollution, keeping GDP per capita constant, as shown in Table 3 (Model (a) negative and statistically significant coefficients). Hence, it can be inferred that more coal consumption per capita is not directly associated with high level of PM10, keeping GDP per capita constant.
Another control is country’s openness to international trade (Frazer 2006). The effect of trade openness on environmental quality has attracted the attention of policy makers and been dealt with different settings and institutional frameworks since the original paper of Grossman and Krueger (1991). For instance, Dinda (2004) stated that international trade is one of the most important factors that explain EKC. Managi et al. (2009) investigated whether trade could improve environmental quality and found that the beneficial effect varies depending on the pollution and the country under consideration. For instance, trade is beneficial in improving the environment of OECD countries. The result of SP specification is given in Fig. 3b and Table 3 (Model b), the level of pollution decreases as trade openness increases, keeping GDP per capita constant. This is relatively similar with the finding that trade openness exhibits a negative, statistically significant relationship with pollution (Cole 2004).
PM10 pollution is mostly ubiquitous in urban areas. The economic activities of urban population (such as vehicle exhaust) are among the major sources of PM10 (Fischer et al. 2000). As seen in Fig. 3c and Table 3 (Model c), there is a direct relationship between the proportion of urban population and PM10 while maintaining comparable EKC results with NP nonpooled data results.
SP regression result with all the control variables is shown in Fig. 3d and Table 3 (Model d). It has all the features of individual SP result: coal consumption and trade openness have statistically significant and indirect effect on the level of PM10 pollution; while the proportion of urban population has statistically insignificant but direct effect on the level of PM10 pollution, keeping GDP per capita constant. Hence, it can be inferred that SP specification reveals similar GDP per capita-PM10 relationship found in NP model.
Conclusion
When it comes to the extent of economic growth and pollution, the first assumption that least developed countries start to pollute the environment when they begin to grow economically is found to be valid using both NP and SP results. After reaching a certain threshold level of income, however, low-income countries released lesser level of PM10 pollution. This phase is followed by a declined level of pollution for middle- and many high-income countries.
For some oil-producing high-income countries the trend for the level of pollution is exceptionally higher than what is normally expected from EKC hypothesis. These countries experience an increased level of pollution during the 1990s, but a diminished level around the late 2000s as their income grows. This result is not consistent with ECK hypothesis.
Model significance test reveal that NP method provides statistically better estimate for the relationship between GDP per capita and PM10. In addition, the relationship can be expressed in cubic parametric specifications, widely used in previous studies. Adding more control variables in SP setting provides similar results with NP ones. Among the control variables, it is found that the higher the proportion of urban population, the higher is the level of pollutions, keeping GDP per capita constant.
The level of pollution is higher in low-income countries than in both middle- and high-income countries. Most of the world population continues to live in urban areas; and in countries with higher proportion of urban population, the level of PM10 pollution is found to be high. Hence, economic and demographic intervention and policies would be designed to address the problem of PM10 pollution. In addition, some high-income countries may experience an increased level of pollution as their income grows. This finding indicates that high level of PM10 pollution may occur in countries where environmental amenities and institutions are well-developed. The general hypothesis that pollution decreases as countries reach a certain threshold level of income may not be acceptable for all countries.
Notes
This is a direct analog to Simon Kuznets’s work on the relationship between income distribution and economic fortune of US (Kuznets 1955). EKC is an inverted U-shaped relationship between the fortune (GDP per capita) and level of environmental quality or ambient pollution level.
Once \({\widehat{{\Psi }}}_{x_o } \) is obtained, the RHS of Eq. (3) or the individual functional form, \(f_t \) and \(f_{t-1} \) can be retrieved using marginal integration method described by Linton and Nielsen (1995). The choice of a kernel is determined by computational cost, simplicity and the speed of convergence of the density estimator (Pagan and Ullah 1999).
The health-based national air quality standard for PM-10 is \(50\,\upmu \hbox {g/m}^{3}\) (measured as an annual mean) and \(150\, \upmu \hbox {g/m}^{3}\) (measured as a daily concentration) (EPA 2013).
Plugin method was found to be superior in representing a smooth relationship between the two variables.
This is based on the World Bank classification of countries (for detailed explanations refer to http://data.worldbank.org/about/country-classifications).
References
Auffhammer, M., and R.T. Carson. 2008. Forecasting the path of China’s \(\text{ CO }_2\) emissions using province-level information. Journal of Environmental Economics and Management 55(3): 229–247.
Azomahou, T., F. Laisney, and P.N. Van. 2006. Economic development and \(\text{ CO }_2\) emissions: A nonparametric panel approach. Journal of Public Economics 90(6–7): 1347–1363.
Bertinelli, L., and E. Strobl. 2005. The environmental Kuznets curve semi-parametrically revisited. Economics Letters 88(3): 350–357.
Carson, R., Y. Jeon, and D. McCubbin. 1997. The relationship between air pollution emissions and income: US Data. Environment and Development Economics 2: 433–450.
Cole, M.A. 2004. Trade, the pollution haven hypothesis and the environmental Kuznets curve: Examining the linkages. Ecological Economics 48(1): 71–81.
Cooper, J. 2002. Flexible functional form estimation of willingness to pay using dichotomous choice data. Journal of Environmental Economics and Management 43: 267–279.
Dinda, S. 2004. Environmental Kuznets curve hypothesis: A survey. Ecological Economics 49(4): 431–455.
EIA. 2013. Coal consumption, http://www.eia.gov/cfapps/ipdbproject. Accessed 15 Dec 2013.
EPA. 2013. PM-10, http://www.epa.gov/airtrends/aqtrnd95/pm10.html/. Accessed 15 Dec 2013.
Frazer, G. 2006. Inequality and development across and within countries. World Development 34(9): 1459–1481.
Fischer, P.H., G. Hoek, H. van Reeuwijk, D.J. Briggs, E. Lenret, J.H. van Wijnen, S. Kingham, and P.E. Elliott. 2000. Traffic-related differences in outdoor and indoor concentrations of particles and volatile organic compounds in Amsterdam. Atmospheric Environment 34: 3713–3722.
Grossman, G., and A. Krueger. 1991. Environmental impacts of a North American free trade agreement, Working Paper 3914, National Bureau of Economic Research Inc.
Grossman, G., and A. Krueger. 1993. Environmental impacts of a North American free trade agreement. In The Mexico—U.S. free trade agreement, ed. Peter M. Garber. Cambridge: MIT Press Cambridge.
Guo, X., D. Chen, and Chu-Guang Zheng. 2008. Experimental study on emission characteristics of PM10-fracture in coal-fired boilers. Asia-Pacific Journal of Chemical Engineering 3: 514–520.
Hayfield, T., and J.S. Racine. 2008. Nonparametric econometrics: The np package. Journal of Statistical Software 27(5): 1–32.
Hayward, S. 2005. The China syndrome and the environmental Kuznets curve, environmental policy outlook. Washington: American Enterprise Institute for Public Policy Research.
Heston, A., R. Summers, and B. Aten. 2012. Penn World Table Version 7.1. Center for International Comparisons of Production, Income and Prices. University of Pennsylvania, Philadelphia.
Holtz-Eakin, D., and M. Selden. 1995. Stoking the fires? \(\text{ CO }_2\) emissions and economic growth. Journal of Public Economics 57: 85–101.
IPCC. 2013. Climate change 2013: The physical science basis, Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change. Cambridge: Cambridge University Press.
Kraft, J., and A. Kraft. 1978. Relationship between energy and GDP. Journal of Energy and Development 3(2): 401–403.
Kuznets, S. 1955. Growth and economic inequality. American Economic Review 45(1): 1–28.
Lee, D.R., C.B. Barrett, P. Hazell, and D. Southgate. 2001. Assessing tradeoffs and synergies among agricultural intensification, economic development and environmental goals: Conclusions and implications for policy. In Tradeoffs or synergies? Agricultural intensification, economic development and the environment, ed. D.R. Lee, and C.B. Barrett, 451–464. New York: CAB International.
Li, Q., and S.J. Wang. 1998. A simple consistent bootstrap test for a parametric regression function. Journal of Econometrics 87(1): 145–165.
Linton, O., and J.P. Nielsen. 1995. A Kernel-method of estimating structured Nonparametric regression-based on marginal integration. Biometrika 82(1): 93–100.
List, J.A., and C.A. Gallet. 1999. The environmental Kuznets curve: Does one size fit all? Ecological Economics 31: 409–423.
Managi, S., A. Hibiki, and T. Tsurumi. 2009. Does trade openness improve environmental quality? Journal of Environmental Economics and Management 58: 346–363.
Millimet, D.L., J.A. List, and T. Stengos. 2003. The environmental Kuznets curve: Real progress or misspecified models? Review of Economics and Statistics 85: 138–1047.
Nguyen-Van, P. 2010. Energy consumption and income: A semiparametric panel data analysis. Energy Economics 32(3): 557–563.
Pagan, A., and A. Ullah. 1999. Nonparametric econometrics. Cambridge: Cambridge University Press.
Panyacosit, Lily. 2000. A review of particulate matter and health: Focus on developing countries. Laxenburg: International Institute for Applied Systems Analysis.
Racine, J.S. 2009. Nonparametric and semiparametric methods in R. In Advances in econometrics nonparametric econometric methods, ed. Q. Li, and J.S. Racine, 335–375. Bingley: Emerald Group Publishing Limited.
Selden, T., and D. Song. 1994. Environmental-quality and development—Is there a Kuznets curve for air-pollution emissions. Journal of Environmental Economics and Management 27: 147–162.
Shafik, N., and S. Bandyopadhyay. 1992. Economic growth and environmental quality: Time series and cross-country evidence, Working Paper WPS 904, The World Bank, Washington, DC.
Shin, J., and Y. Hashimoto. 2004. Environmental Kuznets curve on country level: Evidence from China. Discussion Paper 04-09. Osaka: Graduate School of Economics and Osaka School of International Public Policy.
Taskin, F., and O. Zaim. 2000. Searching for a Kuznets curve in environmental efficiency using Kernel estimation. Economics Letters 68(2): 217–223.
The World Bank. 2013. Data, http://data.worldbank.org/. Accessed 15 Dec 2013.
Verardi, V., and N. Debarsy. 2011. Robinson’s square root of N consistent semiparametric regression estimator in Stata. The Stata Journal 12(4): 726–735.
Weber, H.R., and M. Kunzelman. 2012. Environmental damages remain issue after BP deal. http://www.msnbc.msn.com/. Accessed 07 Mar 2012.
Wheeler, D. 2001. Racing to the bottom? Foreign investment and air pollution in developing countries. Journal of Environment & Development 1(10): 225–245.
Zapata, H., K. Paudel, and C. Moss. 2008. Functional form of the environmental Kuznets curve. In Advances in econometrics, Vol. 25(1), ed. Q. Li, and J.S. Racine. Bingley: Emerald Group Publishing Limited.
Acknowledgments
The views expressed are those of the authors and do not necessarily reflect the views of the Economic Research Service or the U.S. Department of Agriculture.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Nigatu, G. The Level of Pollution and the Economic Growth Factor: A Nonparametric Approach to Environmental Kuznets Curve. J. Quant. Econ. 13, 147–159 (2015). https://doi.org/10.1007/s40953-015-0009-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40953-015-0009-0