
Abstract
Increasing urban demand and population growth in cities have led to an increase in demand for developing new ways. Parchin–Pasdaran Road, which runs from the heart of Khojir National Park, is a big threat to this park. Despite these environmental threats, the development and creation of new highways is unavoidable. This research was carried out to study the effect of the road on Smith–Wilson evenness index and Simpson diversity index in Khojir National Park. The Land Management Units were created using the ArcGIS software. Using appropriate algorithm in artificial neural network structure and linear regression of species evenness and diversity was modelled. For modelling of species evenness and diversity, factors like bulk density, particle density, moisture content, porosity and distance from the road were used. Finally, considering that the amount of R2 in artificial neural network method was statistically significant for Smith–Wilson and Simpson (0.54), (0.71) and in the regression method, respectively (0.25), (0.75), was obtained, the neural network model was selected as the optimal model. Based on the analysis of sensitivity analysis, humidity factors at 5 and 10 cm from the soil surface, the actual 5 cm particle density on the Smith–Wilson index and the porosity at 10 cm from the soil surface had the most effect on the Russian Simpson index.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Today, the need for road construction is one of the main infrastructures for land development. On the other hand, the development of the transport system has a negative effect on the natural environment, wildlife habitats and sensitive ecosystems in national parks. Roads have unacceptable ecological impacts on the plants and the surrounding environment due to physical and chemical disruptions which have been caused along road construction, roadside maintenance and greenhouse gas emissions (Lama and Job 2014). Numerous Protected Areas (PAs) in the Amazon region have been recognized as “default protection” that is because of remoteness and unavailability issues (Adeney et al. 2009; Barber et al. 2012; Joppa et al. 2008). Hence, national parks were explicitly analysed under solid impact from an acknowledged primary driver of deforestation, nearness to transportation networks, to assess their versatility and the moderating impacts (Barber et al. 2014).
Evaluating the ecological impacts of roads on land vegetation, as one of the national parks management tools, has been generalized in the most PAs since the last three decades. Today, the recognition of roads impacts is one of the key tools for sustainable development and environmental management specially in national parks where the protective aims are the first priority. In this matter, when we need quantitative values for decision making, modelling is an applicable method in quantitative impact assessment (Jahani et al. 2016). To reduce the risk of decision making in national park management plans, artificial intelligence approaches such as neural network models lead to the discovery of relationships between ecosystem elements, quantification and relations with ecosystem degradation as a decision supporting system. Artificial neural networks (ANN) and regression models have been used in extensive environmental studies where the quantitative assessments were unavoidable (Jahani 2019b; Jahani and Mohamadi Fazel 2016; Jahani et al. 2016; Maier et al. 2010; vali et al. 2012).
Discovering the relationships between ecosystem components, quantification and providing models for decision making in the environment are considered as the main applications of neural networks (Jahani and Mohamadi Fazel 2016). Also, regression analysis as one of the traditional techniques in artificial intelligence has been widely applied in the model generations (Chopra et al. 2014; Nuruddin et al. 2015). Lama and Job, 2014 conducted a research on road development in protected area. They concluded that road construction boosts tourism and sales of agricultural products. As a result, road construction leads to the reduction of land integrity, vegetation change and pressure on natural resources (Lama and Job 2014). Johnston and Johnston (2004) found that road edge and road with drainage areas had less organic matter, useful material and acidic and higher rate of coarse material in comparison with natural soil. Also, exotic species decreased in the road edge with only a small percentage of native species. Centario et al. (2018) access the environmental impact of touristic activities in 3 natural protected areas. They got the result that some touristic activities polluted soil and water, removed plant cover, caused soil erosion by wheels or by urbanization or human treading and biodiversity perturbation. Also, their result showed that tourism can be a threat to conservation because it includes the rise of pollution, urbanization and using natural resources and alters land use and land cover (Drumm and Moore 2005; Cañada and Gascón 2007; Canteriro et al. 2018; Leondes 1998; Marion et al. 2016).
Gerrard et al. (1992) found that the distribution of bald eagle territories far from a new starting point of human activity many years after the activity was created. Akinyemi and Kayaode (2010) discovered human activities in Old Oyo National Park, Nigeria, like hunting, planting, keeping cattle, effect animal’s habitat, loss of genetic diversity and migration of wildlife. Their result showed that animals like ungulates migrate to core zone of the park, because they have better protection and undisturbed ecosystem there.
The purpose of this study is to compare regression and ANN methods in predicting and modelling ecological impacts of road construction on plants diversity to determine the most accurate model as a decision support system in national parks management.
Materials and methods
Study area
Khojir national park is one of the nearest neighbouring national parks in the Tehran metropolis. This is Tehran’s breathing lung, while it has been severely invaded by various types of urban pollutions. The construction of the Parchin–Pasdaran Road in the centre of the Khojir National Park, the existence of the centre for animal husbandry research, the focal points of human activities, the construction of the Mamlu Dam, the fire, hunting, unauthorized fishing and the degradation of land by the troops have been the major threats to the park. Khojir National Park is considered as one of the most important environmentally sensitive areas of Iran in terms of richness in biodiversity. The impact of human intervention in this ecosystem is undeniable. One of the most important processes that affect this disaster can be the construction and development of roads and consequently the increase of human traffic with vehicles, greenhouses, uneven development of Khojir village and military garrison.
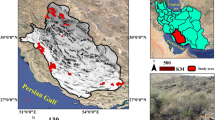
This research was carried out in Khojir National Park with an area of 11,570 hectares (Fig. 1 ). The area is located between 35° and 45′, to 35° and 36′ north latitude and 51° and 40′ to 51° and 49′ east longitude. The Parchin–Pasdaran road has been constructed in this region with 11,230 m length. The road was built with the purpose of accessing the villagers to the residential area, the construction of the Mamlu dam and military activities in 1982. Due to military activities, access to this road is not possible for the public who are not familiar with this region.

Geographical location of the Khojir National Park in Iran
Methods
In this study, Land Management Units (LMUs) were formed in the area regarding ecological features of the land. LMUs were planned based on Ian McHarg’s overlay method McHarg (1969) using ARC GIS 10.3 software. The maps of ecological components were overlaid, and the new map with boundaries of the particular ecological factor classes (classes of altitude, slope, aspect, vegetation type and soil type) was created. It implies that ecological factor classes of an LMU vary from ecological factor classes of adjacent LMUs (at least in one ecological element class) (Jahani et al. 2016). Ecological variables, which impact vulnerability of ecosystem, have been distinguished by the scientific literature review (Makhdoum 2002; Potter et al. 2005).
In the first step, the mapping of homogeneous LMUs in the region was carried out. The goal of creating homogeneous LMUs is to achieve map units with almost identical conditions. In these homogeneous LMUs, considering the same ecological conditions at each unit level, the environmental effects of road construction were investigated using Smith–Wilson and Simpson’s model index. The LMUs were selected to be completely similar in terms of slope, direction, altitude, vegetation and soil. The only difference between LMUs was the distance from the road as the target human activity. With regard to this fact that road construction causes direct effects on the soil and surrounding vegetation and makes changes in the plants species richness index, the operation of sampling of vegetation and soil was carried out. To determine the effect of roads on plant diversity, we selected three areas for sampling which were near the road, 25 m distance from the road and far from the road in restricted area of national park (but same in ecological condition in same LMUs) (Fig. 2). In sampling process, 5 samples in a rectangular plot with a 2 × 2 aspect ratio were taken along the 200-m transect. For sampling in a restricted area along two 200-m transects perpendicular to each other, 5 samples were taken in a rectangular plot with a 2 × 2 aspect ratio. After the field sampling, statistical characteristics and frequency of plant species were recorded in each LMU.

Sampling location in two roadside (a) and restricted area without road effect (b)
Then, Smith–Wilson and Simpson’s index was calculated using Ecological Methodology 6 software. In this research, a ring with a diameter of 7 cm and a height of 5 cm was used. Samples were taken at the beginning and at the end of the transects from depths of 0–5 and from a depth of 5–10 cm. The samples were then transferred to the Soil Laboratory for physical changes investigation due to the road and placed at 105 degrees of centigrade for 24 h. Using the size of the cylindrical metal and the soil bulk density, its bulk density was determined (Eq. 1).
where db, dry soil bulk density; Ws, solid particle weight; vs, volume occupied by solid particles of soil; va, volumes occupied by air in the soil; and vw, volumes occupied by water in the soil.
Then, some soil was tamped and placed in an oven for 24 h at 105° C, then weighed it. Adds the amount of weighed soil into a graduated cylinder, which already had a predetermined amount of water, and increase in volume is calculated and the amount of particle density is derived from the formula (Eq. 2).
where ws, solid particle weight and vs, volume that is occupied by solid particles of soil.
By replacing the soil bulk density in relation (Eq. 3), the porosity was calculated.
where F, soli porosity; db, soil bulk density; and ds, soil particle density.
In the following, by obtaining the difference between the weight of dry soil and wet soil and by placing in (Eq. 4) the soil moisture content was obtained. Then, soil porosity was calculated using soil bulk density.
where M, percentage of soil moisture content; Ww, weight of water in the soil; and Ws, dry mass of solid particles.
Multiple regression model
We used 9 independent variables to predict Smith–Wilson and Simpson indices. We divided total samples (60 samples) into 2 subdivisions haphazardly. Training data subdivision contained 80% of total samples, and test data subdivision contained 20% of total samples. After calculating the soil indicators such as dry soil bulk density (db), particle density (Pd), moisture content (M) and porosity (P), we recorded distance from the road (D) in three classes (1: restricted area–2: 25 m distance from the road–3: near the road) and the regression linear model was developed in SPSS 25 software.
ANN modelling
An ANN is regarded as a computer program that can learn from samples without requiring earlier knowledge of the parameter relationships (Callan 1999). By adapting the strength of its interconnections (weights) properly, ANN learns to resolve the issue (Nasr et al. 2012). By learning more, it easily adjusts to new situations, ambiguous or probabilistic data (Lee et al. 2012). Biological nervous systems promoted the concept of ANN (Picton 2000). Neural networks are in fact an effort to create systems that function in a manner comparable to the human brain. The human brain is tightly interconnected with dozens of billions of neurons. An ANN’s role is to use obtained inputs to generate an output model. Output signals transmitted to other units, together with connections (approved as weights) that stimulate or prevent the signal connected. Learning is the method of adjusting the weights of the connection to the stimulus displayed at the inputs and optionally to the outputs. Learning in this scenario is called “supervised learning.” ANN comprises of units with restricted computation capacity, and if many units are connected together, the whole network has the capacity to resolve very complex problems. In general, the input layer, the hidden layer and the output layer are contained in an ANN architecture. The data are processed in a hidden layer and may have a design perspective depending on at least one sub-layer.
An attempt was made to evaluate the impact of road construction on the evenness and diversity factor of species using artificial neural network modelling to determine the most effective factors in increasing the diversity and evenness, because the artificial neural network, by pattern recognition, establishes the best relationship between inputs or predictive variables (even if too much) and outputs. Also, due to the parallel processing of data in comparison with other patterns, there is less error than the error in the input data. In our study, architecture of an ANN contains the input layer, 2 hidden layers and the output layer (Fig. 3).

Structure of artificial neural network
In this research, sampling of soil and vegetation cover in the same LMUs was done in Khojir National Park. Artificial neural network input layer included bulk density, particle density, moisture content, porosity, distance from the road and output layer included Smith–Wilson and Simpson’s index. Then, a multi-layer perceptron network was used to simulate the data with the help of the intelligent neural network tool. The MATLAB 2018 software was used to design and evaluate various artificial neural networks. To train the network, 60 samples were randomly divided into 3 groups: network training (60%), validation (20%) and network testing (20%). The characteristics tested to achieve the best neural network model are illustrated in Table 1.
By comparing the output of the model and the calculated indices including the coefficient of explanation (R2), the mean absolute error (MAE) and the mean square error (MSE), model validity was estimated (Eqs. 5–7).
Results
In this study, each variables average in the form of the input matrix is presented in Table 2. Also, 30 LMUs were determined and soil and vegetation data were recorded in each of them (Fig. 4). Regarding the aim of the study, for determining the species diversity and evenness, the Smith–Wilson and Simpson’s index of each LMUs was estimated.

LMUs in Khojir National Park
Regression model
In the regression model, we use the enter method, and finally, the regression models for Smith–Wilson and Simpson’s index prediction are defined in Eqs. (8, 9):
The results of Smith–Wilson and Simpson’s index prediction by regression model were compared with the target values in Figs. 5 and 6. We tested the model accuracy with 20% of the data which are not used in training process.

Comparison of real Smith–Wilson and Smith–Wilson predicted regression

Comparison of real Simpson and Simpson predicted regression
In the linear regression model, the values of R2 and RMSE in the test data set prediction for Smith–Wilson and Simpson indices were 0.15, 0.23 and 0.04, 0.06, respectively (Table 3), while we found the more accuracy in training data set.
ANN modelling
Nine variables as input variables, and Smith–Wilson and Simpson indices as outputs, were summarized in the MATLAB software to design the most accurate structure of ANN. The collected data of 9 variables were used to train the feedforward neural networks. The recorded data contain 9 variables as input data sets in the designed ANN and Smith–Wilson and Simpson indices as output data sets.
Figures 7 and 8 illustrate the difference between the target (real) and predicted (output) Smith–Wilson and Simpson’s indices by artificial neural network model in 4 series of data. All 4 figures indicate the almost high accuracy of the artificial neural network in predicting Smith–Wilson and Simpson’s index.

The actual Smith–Wilsons index difference and Smith–Wilsons index predicted by artificial neural network in a all data, b test data c validation data and d training data

The actual Simpson index difference and Simpson index predicted by artificial neural network in a all data, b test data, c validation data, d training data
In Table 4, the coefficient of determination and error of the two diversity indices were reported.
The scatter plot will be applicable to illustrate the correlation between variables (Fernandez et al. 2009). Figures 9 and 10 show the scatter plot of ANN output values of the Smith–Wilson and Simpson indices for training, validation, test and total data.

Correlation between the ANN (estimated) outputs and actual Smith–Wilson outputs

Correlation between the ANN (estimated) outputs and actual Simpson outputs
Sensitivity analysis of Smith–Wilson and Simpson’s index
Also, the results of the sensitivity analysis of the components which have been conducted in the artificial neural network modelling prove that distance from the road variable has the most impact on the changes in the Smith–Wilson index (Fig. 11).

The results of sensitivity analysis of Smith–Wilson index
Also, Fig. 12 indicate that the value of distance is the most significant variable on the changes in the Simpson index.

The results of sensitivity analysis of Simpson index
Comparison of two regression and neural network models
By comparing regression and artificial neural network for both indices, it was concluded that due to the high R2 value for Smith–Wilson and Simpson Indices (0.54) (0.71) than the regression (0.25) (0.75), for Smith–Wilson index artificial neural network has a better ability to model the indices, but the result of the regression test is low in the training and the accuracy of the test data is higher for Simpson index. Therefore, the model does not have sufficient credit.
Discussion
In the present study, using the soil physical properties factors, the Smith–Wilson evenness and the Simpson diversity index were simulated by two methods of artificial intelligence modelling including multiple regression and artificial neural network. A review of studies has proved the accurate results of modelling with artificial neural network in natural environments such as water resources management (Arsene et al. 2012; Fernandez et al. 2009; Iliadis and Maris 2007; Maier et al. 2010), environmental assessment and urban green space management (Jahani and Mohamadi Fazel 2016). In our study, according to ANN results for Smith–Wilson and Simpson index (R2 = 0.54 and R2 = 0.71, respectively) in comparison with multiple regression results (R2 = 0.25 and R2 = 0.75), ANN is clearly superior method for modelling Smith–Wilson and Simpson indices prediction. Jahani (2019a) used 2 predictive models in a research, multiple regression and ANN model, for comparing results in FLAQM prediction. He concludes that the results of research proved the capability of ANN in the quantification of forest landscape aesthetic quality after forest project implementation.
The sensitivity analysis of Smith–Wilson and Simpson indices illustrated that there is a strong relation between distance and evenness and diversity. It means that by getting far from the road specially in national parks the amount of evenness and diversity increase because of restricted areas which are far from the roads. Johnston and Johnston (2004) showed that road disturbance reduces organic matter and natural vegetation in terms of number and diversity in the road verge. Soil in road disturbance cannot support a rich, diverse number of vegetation types with high percentage. It also dominated by exotic species and decrease both frequency and abundance (Joppa et al. 2008). Jahani et al. (2016) used an environmental decision support system (called OFDM) to assess the effects of a forestry plan in a study that was based on an artificial neural network optimized forest degradation model. In their study, which had the same results with the results of this research, various factors, including road construction, were investigated for degradation factors, but in this study merely road construction was considered as a destructive factor. Barber et al. (2014) examined the effects of roads on deforestation on protected areas in the Amazon, which indicate that deforestation was much higher near roads and rivers than elsewhere in the Amazon; nearly 95% of all deforestation occurred within 5.5 km of roads or 1 km of rivers. Protected areas near roads and rivers had much lower deforestation (10.9%) than did unprotected areas near roads and rivers (43.6%). Protected forests experienced less forest loss than did unprotected lands at all distances from roads and navigable rivers. All protected area types mitigated deforestation risk and had four times less deforestation than unprotected areas even when highly accessible. They also concluded that deforestation would be lower as the distance from the road increases.
The model presented in this study will also be used as a decision support system for future road construction projects in similar areas (ecologically) and is an example of applied modelling to reduce the environmental impacts of development projects in the natural areas.
References
Adeney JM, Christensen NL Jr, Pimm SL (2009) Reserves protect against deforestation fires in the Amazon’. PLoS ONE 4:e5014
Akinyemi AF, Kayaode IB (2010) Impact of human activities on the distribution of ungulates in Old Oyo National Park, Nigeria. Obeche J 28(2):106–111
Arsene CTC, Gabrys B, Al-Dabass D (2012) Decision support system for water distribution systems based on neural networks and graphs theory for leakage detection. Expert Syst Appl 39:13214–13224
Barber CP, Cochrane MA, Souza CM Jr, Veríssimo A (2012) Dynamic performance assessment of protected areas. Biol Conserv 149:6–14
Barber CP, Cochrane MA, Souza CM Jr, Laurance WF (2014) Roads, deforestation, and the mitigating effect of protected areas in the Amazon. Biol Conserv 177:203–209
Callan R (1999) The essence of neural networks. Prentice Hall, Upper Saddle River
Cañada E, Gascón J (2007) Gascón.Turismo y desarrollo. herramientas para una mirada crítica (laed.) Managua.Enlace
Canteriro M, Cordova-Tapia F, Brazeiro A (2018) Tourism impact assessment: a tool to evaluate the environmental impact of touristic activities in natural protected areas. Tour Manag Perspect 28:220–227
Chopra P, Sharma RK, Kumar M (2014) Regression models for the prediction of compressive strength of concrete with & without fly ash. Int J Latest Trends Eng Technol 3:400–406
Drumm A, Moore A (2005) Desarrollo del Ecoturismo Un manual para los profesionales de la conservación. Volumen 1, Segunda Edición Copyright © 2005 por The Nature Conservancy, Arlington, Virginia, USA
Fernandez F, Seco J, Ferrer A, Rodrigo MA (2009) Use of neuro fuzzy networks to improve wastewater flow-rate forecasting. Environ Model Softw 24:686–693
Gerrard JM, Gerrard PN, Bortolotti GR, Dzus EH (1992) A 24-year study of bald eagles on Besnard Lake, Saskatchewan. J Raptor Res 26:159–166
Iliadis LS, Maris F (2007) An artificial neural network model for mountainous water- resources management: the case of Cyprus mountainous watersheds. Environ Model Softw 22:1066–1072
Jahani A (2019a) Forest landscape aesthetic quality model (FLAQM): a comparative study on landscape modelling using regression analysis and artificial neural networks. J Forest Sci 65:61–69
Jahani A (2019b) Sycamore failure hazard classification model (SFHCM): an environmental decision support system (EDSS) in urban green spaces. Int J Environ Sci Technol 16:955–964
Jahani A, Feghhi J, Makhdoum M, Omid M (2016) Optimized forest degradation model (OFDM): an environmental decision support system for environmental impact assessment using an artificial neural network. J Environ Plan Manag 59(2):222–244
Jahani A, Mohamadi Fazel A (2016) Aesthetic quality modelling of landscape in urban green space using artificial neural network. J Nat Environ (Iran J Nat Resour) 69(4):951–963
Johnston FM, Johnston SW (2004) Impacts of road disturbance on soil properties and on exotic plant occurrence in subalpine areas of the Australian Alps. Arct Antarct Alp Res 36(2):201–207
Joppa LN, Bane SR, Pimm SL (2008) On the protection of protected areas. Proc Natl Acad Sci USA 105:6673–6678
Lama AK, Job H (2014) Protected areas and road development: sustainable development discourses in the Annapurna conservation areas, Nepal. Erdkunde 68(4):229–250
Lee MA, Davies L, Power SA (2012) Effects of roads on adjacent plant community composition and ecosystem function: an example from three calcareous ecosystems. Environ Pollut 163:273–280
Leondes C (1998) Fuzzy logic and expert systems applications. Academic Press, Los Angeles
Maier H, Jain RA, Dany GC, Sudhear KP (2010) Methods use for the development of neural networks for the prediction of water resource variables in river systems: current status and future direction. Environ Model Softw 25(8):891–909
Makhdoum MF (2002) Degradation model: a quantitative EIA instrument, acting as a decision support system (DSS) for environmental management. Environ Manag 30(1):151–156
Marion JL, Leung YF, Eagleston H, Burroughs K (2016) A review and synthesis of recreation ecology research findings on visitor impacts to wilderness and protected natural areas. J Forest 114(3):352–362
McHarg I (1969) Design with nature. Natural History Press, New York
Nasr M, Moustafa M, Seif H, ElKobrosy G (2012) Application of artificial neural network (ANN) for the prediction of ELAGAMY wastewater treatment plant performance-EGYPT. Alex Eng J 51(1):37–43
Nuruddin MF, Ullah Khan S, Shafiq N, Ayub T (2015) Strength prediction models for PVA fiber-reinforced high-strength concrete. J Mater Civ Eng 27:2–16
Picton P (2000) Neural networks, 2nd edn. Palgrave, New York
Potter KM, Cubbage FW, Schaberg RH (2005) Multiple-scale landscape predictors of benthic macroinvertebrate community structure in North Carolina. Landsc Urban Plan 71:77–90
Vali A, Ramesht MH, Seif A, Ghazavi R (2012) An assessment of the artificial neural networks technique to geomorphologic modelling sediment yield (case study Samandegan river system). Geogr Environ Plan J 44(4):5–9
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Pourmohammad, P., Jahani, A., Zare Chahooki, M.A. et al. Road impact assessment modelling on plants diversity in national parks using regression analysis in comparison with artificial intelligence. Model. Earth Syst. Environ. 6, 1281–1292 (2020). https://doi.org/10.1007/s40808-020-00799-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40808-020-00799-6