
Abstract
In developing countries, where urbanization rates are high, urban sprawl is a significant contributor of the land use change. However, characterizing sprawl has become a contentious issue with numerous arguments both for and against the phenomenon. Meanwhile, effective metrics to characterize sprawl in India are required to characterize this. We have attempted to capture urban sprawl over the landscape and hence adopt landscape metrics, entropy and principal component analysis for characterizing sprawling process. The measurement and monitoring of land-use changes in these areas are crucial to government officials and city planners who urgently need updated information for planning and management purposes. This paper examines the use of landscape metrics and entropy in the measurement and monitoring of urban sprawl by the integration of remote sensing and GIS techniques. The advantages of the entropy method are its simplicity and easy integration with GIS. The measurement of entropy is devised based on locational factors-distances from central business district and reveal spatial patterns of urban sprawl. The entropy space can be conveniently used to differentiate various kinds of urban growth patterns. The application of the method in the Bhubaneswar Metropolitan Area, one of the fastest growing and planned cities in India, has demonstrated that it is very useful and effective for the monitoring of urban sprawl. It provides a useful tool for the quantitative measurement that is much needed for rapidly growing regions in identifying the spatial dynamics, variations and changes of urban sprawl patterns.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Sprawl is surrounded by controversy. The phenomenon is abhorred by many and is the bane of city planning agencies trying to curb its spread. Sprawl is obviously popular, however, and there is little doubt that lots of people want to live in sprawling suburbs, whether policy-makers consider it prudent for them to do so or not. Discord is also present in our understanding of the phenomenon. Characterization of sprawl is often descriptive with strong differences of opinion as to how sprawl manifests on the ground. Difficulties in translating these textual descriptions into practice present a formidable barrier to evaluating their efficacy as exemplars. Some excellent work has already been undertaken to measure sprawl. Nevertheless, contradictory results are often reported for the same cities when examination of sprawl is quantitative. This is a by-product of sprawl’s multi-attribute nature and challenges in measuring the phenomenon, with the result that “smart growth” measures to target sprawl lack the strongest empirical foundation and potential costs and benefits are difficult to gauge. The literature characterizing sprawl is voluminous. Sprawl is often defined in cost terms (Benfield et al. 1999; Burchell et al. 1998; James Duncan and Associates et al. 1989). Definitions based on benefits are comparatively rare (Bae and Richardson 1994; Gordon and Richardson 1997a, b). Some key distinguishing features do reappear in the literature, however: growth; social and aesthetic attributes; decentralization; accessibility; density characteristics; fragmentation; loss of open space; and dynamics. These attributes serve as the subject matter for our analysis.
Aesthetic preferences often flavor characterization of sprawl. Sprawl is widely met with disapproval and distaste on the grounds of design and morphology (Calthorpe et al. 2001; Duany et al. 2001). These complaints often relate to ribbon sprawl (Burchell et al. 1998; Hasse and Lathrop 2003a), dominance of commercial land-use and parking along roads. Exit-parasitic retail development is an associated component: the clustering of hotels, gas stations, fast food restaurants, and so forth close to highway exit ramps. Assumption of decentralization from a central core to the urban periphery is often fundamental to sprawl’s characterization (Ewing et al. 2002; Galster et al. 2001). Sprawl is commonly linked to economic suburbanization, with an assertion that jobs and development follow population to the fringe and that businesses chase perceived discounts in development costs and greater access to highways there. Indeed, job creation has traditionally been more active, and office space more available, in suburban areas in the USA (OTA 1995). Accessibility is a related issue (Ewing 1997; Sultana and Weber 2007). Suburban households in the US drive more per year, on average, than those in central cities (HUD 1999). Sprawl’s accessibility characteristics are among the most frequently measured. The examples include measures of accessibility for given urban designs (Ewing et al. 2002); access to urban resources (Ewing et al. 2002; Hasse 2004); and opportunity diversity in land-use mix (Burchell et al. 1998; Ewing et al. 2002; Hasse and Lathrop 2003a; Malpezzi 1999).
Density characteristics are chief among sprawl’s attributes. Sprawl is commonly regarded as a low density phenomenon, although there is debate as to whether this characterization is appropriate (Ewing 1997; Gordon and Richardson 1997a, b; Lang 2003; Peiser 1989). Low density is considered to be problematic because buildings that need to be supplied with services are further away from central service nodes and from each other than might be expected in denser developments. Lower densities also contribute to accessibility problems, as opportunities take more time to walk and drive to than in densely-settled areas. Impermeable surface grows as development footprints grow, with associated problems of runoff-related pollution and urban heat islands (Alberti 1999). There are benefits, however, in dispersing air pollutants (Bae and Richardson 1994). It remains unclear as to which variables should be used to measure density: housing units (Real Estate Research Corporation 1974), development (Burchell et al. 1998), population (El Nasser and Overberg 2001; Ledermann 1967), employment, or combinations of these attributes (Galster et al. 2001). There is also disagreement regarding the scale of observation that should be used: all land (gross density) (Ewing et al. 2002), urban area (Ewing et al. 2002; Pendall 1999), developable area (Galster et al. 2001), urban fringe (Burchell et al. 1998; Lang 2003), or smaller subsets, say all area save that in which people could not possibly reside (net density). Scattering is another important attribute that is often used to characterize sprawl as tracts of developed land that sit in isolation from other undeveloped tracts (Lessinger 1962). A wide variety of techniques are employed in measuring sprawl scatter, including design measures over urban grids (Galster et al. 2001) and distance from previously-urbanized settlements (Hasse and Lathrop 2003a). Differentiating scattered sprawl from economically-efficient discontinuous development can be difficult, however (Ewing 1994, 1997). Erosion of open space under sprawl is another popular characteristic of the phenomenon. Open space has featured in measurement of sprawl, generally (Sierra Club 1998); however, consideration of land cover relates, for the most part, to remote sensing analyses of sprawl (Burchfield et al. 2006; Clapham 2003; Hasse and Lathrop 2003b; Sudhira et al. 2003). Ribbon sprawl may restrict access to nearby open space. Leapfrogging development leaves open space but it is generally held in private hands and it is often worth too much money to be used as farmland (Ewing 1994).
Dynamics are also important to sprawl characterization (Lopez and Hynes 2003). Today’s sprawl could turn into compact and sustainable development in later years as the pace of urban extension drives developers to fill-in previously undeveloped sites (Peiser 1989). Understanding of sprawl dynamics requires examination of change in the space–time distribution of each of the characteristics discussed thus far. Commonly, this is achieved by proxy, tracking characteristics by temporal cross-section across several cities (El Nasser and Overberg 2001; Lang 2003; Pendall 1999). Significant progress has been made in quantifying sprawl, but challenges remain. Methodologies are highly variable and are often data-driven rather than having a foundation in theory or practice. Different lenses are used to study sprawl. The bulk of existing studies focus on one or two characteristics for a single city or across a number of cities. Measurement is often focused on the city as a unit. Some studies have treated cities on an intra-urban basis, but work has rarely been done at multiple scales. A distinction between core and periphery is seldom made. Moreover, metrics designed to work at one scale do not always function at another. Sprawl is a dynamic phenomenon, yet work on sprawl often focuses on a single temporal snapshot or disjointed snapshots, rather than following longitudinally in synchrony with urban evolution. The methodology most commonly employed in analysis relies heavily on descriptive and multivariate statistics that are prone to unreliable results owing to spatial autocorrelation (Berry 1993; Fotheringham et al. 2000; Moran 1950). Use of geospatial metrics to avoid spatial autocorrelation problems (usually a fatal roadblock when encountered in analysis) is exceptional when measuring sprawl. Moreover, many of the studies and the dataware at their foundation suffer from problems of ecological fallacy and modifiable areal units (Openshaw 1983), due to an over-reliance on Census data that are reported at aggregate spatio-temporal units. On an operational level, measurement of sprawl is generally tabular in form; and efforts to map and visualize the problem-space of the phenomenon have been few and far between. In this analysis knowledge of the spatio-temporal pattern of the urbanization is important to understand the size and functional changes in the landscape. Spatial metrics were computed to quantify the patterns of urban dynamics, that aid in understanding spatial patterns of various land cover features in the city (McGarigal and Marks 1995). Quantifying the landscape pattern and its change is essential for monitoring and assessing the urbanization process and its ecological consequences (Luck and Wu 2002; Herold et al. 2002; Zhao et al. 2006; Sha et al. 2008). Spatial metrics have been widely used to study the structure, dynamic pattern with the underlying social, economic and political processes of urbanization (Jenerette and Potere 2010). This has provided useful information for implementing holistic approaches in the regional land-use planning (Simoniello et al. 2006) reviews the spatial characteristics of metropolitan growth including analysis (Alberti and Waddell 2000) the study of urban landscapes. Applications of landscape metrics include landscape ecology (number of patches, mean patch size, total edge, total edge and mean shape), geographical applications by taking advantage of the properties of these metrics (Gibert and Sànchez-Marrè 2011) and measurement of ecological sustainability (Renetzedera et al. 2010).
Study area
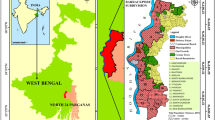
Bhubaneswar city (Latitude 20°12′–20°25′N Longitude 85°44–85°55′E) is the name which has been given to a notified area covering 91.94 sq.km (Fig. 1). It has a population of 113,095 on the 1st April of 1971. It covers 28 villages or rather mauzas (small administrative unit) which are revenue units. Bhubaneswar is one of the main mouzas among 28 U. The city is developed from centre to towards its surrounding area. The total metropolis area of the city is 135 sq.km, and the metro area is covered 393.57 sq.km of its surrounding area of the city centre. The Bhubaneswar Municipal Corporation is bounded by (a) North-Raghunathpur and Patia; (b) South-Daya river, Mohanpur, Dihapur, Erabanga, Kukudaghai, Papada; (c) East-Bhimpur, Jannejayapur, Jaganathpur, Saleswar, Andilo, Kesura and (d) West-Naugan, Malipad, Andharua, Jaganthprasad, Sundarpur, Sampur. After the independence, Bhubaneswar region has gone through a lot of expansion and growth. Administrative and institutional activities have contributed to the increase in the volume of trade and commerce activity. The population of Bhubaneswar has been increased from 16,512 in 1951 to 881,988 in 2011 (Census of India 2011). A proper look at its demographic and socio-cultural activities reveals that this state is one of the least urbanized among the major states of India (13.5 % of the state population resides in urban areas). 69 % of the state population is involved in agribusiness. Nevertheless, the state has the third lowest population growth rate in the country. The literacy rate is marginally lower than the national mark. Modern Bhubaneswar is a well-planned city with wide roads and many parks and gardens. The framework was made by Otto H. Koenigsberger. Though part of the city has remained as planned, it has developed speedily over the decades and has made the planning process clumsy.
Materials and method
This work is an amalgamation of landscape cum micro level analysis by selecting patches from sprawling areas. The remote sensing data obtained from GLCF (http://glcf.umd.edu/data) are initially processed to quantify the land use/land cover of Bhubaneswar city. Satellite images MSS of 1972 and LANDSAT 8 of 2014 were analysed for Land use/land cover categories found in Bhubaneswar area. Patches of different land use were drawn on open source images to analyse the distribution, fragmented nature of landscape and metrics of urban sprawling. These patches were analysed using FRAGSTAT metrics software for different landscape metrics. The change in entropy can be used to identify whether land development is toward a more dispersed (sprawl) or compact pattern. The analysis was discussed how to use the entropy method to measure rapid urban sprawl in one of the fastest growing city with the integration of remote sensing and GIS. Along with this a micro level study has also been done through randomly selected 14 sprawling micro zones; out of 9 areas are presented. Data collected from households residing in these areas on type of residential unit, type of family, monthly income of the household, age of the house and operating costs (Annual municipal tax, Residential tap water connection cost, electricity bill etc.), transport facilities, transport cost, infrastructure facilities, economic and non-economic factors etc. At the same time secondary data collected from different published books, reports, research papers etc. Different offices like Bhubaneswar Municipal Corporation, Bhubaneswar Development Authority (BDA) were visited for collecting information. This information was examined through principal component analysis (PCA) to find out the factors responsible for sprawling in the selected areas as well as zones.
Data processing
The data quality limitations of the imageries have to be considered in this analysis. A number of image-processing steps were required (Herold et al. 2002). The data were geometrically corrected, geo-referenced to cover the whole study area. To transform image spectral response into thematic information, the images were individually classified using an unsupervised approach for class delineation with a manual visual reclassification into ‘vegetation’ and ‘built-up’ thematic classes. Some inconsistencies were identified in the multi temporal image classification (Herold et al. 2002). These resulted from seasonal differences in the sun illumination conditions and in the vegetation cover between the various dates of air photograph acquisition and from radiometric distortions caused by vignetting effects in the imageries. The classification problems resulting from the spectral limitations of the imageries and from the different sun illumination effects were reduced by assigning just two land cover classes: built up and vegetation. These two classes are spatially and spectrally clearly separable in the air photographs and represent the dominant land-cover categories found in urbanized or residential areas (Sadler et al. 1991; Ridd 1995). Errors caused by seasonal changes in vegetation cover were minimized by including images in the analyses as they are from a similar season. Resultant errors in the image classification could not be quantified because of a lack of ground truth information, a general problem in historical remote sensing data analysis. The generally clear spectral and spatial separation of the land-cover classes allows for the derivation of multi temporal binary land-cover maps of sufficient accuracy to introduce and evaluate the proposed approach. Resultant classification errors do not significantly change the general pattern of spatial land-cover structure and urban growth (Herold et al. 2002).

Geographical location of Greater Bhubaneswar city area with dominant type of land conversion for residential development in urban out growths around city
Land use pattern
The fast growing population is creating sprawl effect in the adjacent agricultural and others vacant land. Thus the city is experiencing haphazard growth and leads to increasing pressure on open land, agricultural lands and urban infrastructural facilities. The demand for land within the fringe areas and Periurban areas of Bhubaneswar Municipal Corporation (BMC) is growing as more and people prefer to live in the areas adjacent to the main city. As a result land value is gradually getting higher. It is also observed that the nature of land use is mixed in general in most part of the city. The functions like trade and commerce, open spaces, recreational areas, agriculture and industries etc. are encroaching upon the existing areas of residential and other such purposes (Fig. 2a–i).

Land use/land cover pattern in selected areas. a Bapujinagar, b Bhoumanagar, c Jagannathbihar, d Kalinganagar, e Joydevbihar, f Kalingabihar, g Kesharinagar, h Naragoda and i Nathapur. Sample areas are selected on the basis of their location at different distance away from CBD
The land use map of 1972 and 2014 (Fig. 3a, b) visualise the drastic change in land use pattern. The open land of the western part decreased drastically and the built up areas in the entire city area has been increased noticeably.

General land use/land cover pattern in Bhubaneswar city. a 1972 and b 2014
To understand the pattern of urban built up area the gradient approach is adopted for a circular region of 9 km radius from the centre dividing it into concentric zones of incrementing radii of 1 km (Fig. 4). This visualise the land use changes at every 1 km distance. This also helped in identifying the causal factors and the degree of urbanization (in response to the economic, social and political forces) at local levels and visualizing the forms of urban sprawl. The spatial built up density in each circle is monitored through regression analysis for the year 2014.

Gradient approach adopted for concentric zones with 1 km width to understand spatial variability in built up area around CBD for built up class
Landscape metrics
Landscape metrics or indices can be defined as quantitative indices to describe structures and pattern of a landscape (McGarigal and Marks 1994; O’Neill et al. 1988). The development of landscape metrics is based on information-theory measures and fractal geometry. Their use for describing natural and geographic phenomena is described by De Cola and Lam (1993), Mandelbrot (1983), and Xia and Clarke (1997). Important applications of landscape metrics include the detection of landscape pattern, biodiversity, and habitat fragmentation (Gardner et al. 1993; Keitt et al. 1997), the description of changes in landscapes (Dunn et al. 1991; Frohn et al. 1996), and the investigation of scale effects in describing landscape structures (O’Neill et al. 1996; Turner et al. 1989). Related investigations usually focus on the structural analysis of patches, defined as spatially consistent areas with similar thematic features as basic homogeneous entities, in describing or representing a landscape (McGarigal and Marks 1994). Based on the work of O’Neill et al. (1988), a number of different metrics were developed, modified, and investigated (for example, Li and Reynolds 1993; McGarigal and Marks 1994). The most commonly used metrics are the used in this analysis (Table 1).
Shannon’s entropy
The entropy is used to measure the extent of urban sprawl with the integration of remote sensing and GIS. The measurement is directly carried out within a GIS facilitate access to its spatial database. In the past few years, significant research has been carried out on the use of satellite data and GIS for measuring urban growth patterns using Shannon entropy approach (Sudhira et al. 2004; Joshi et al. 2006; Sun et al. 2007; Sarvestani et al. 2011). Shannon’s entropy is based on information theory. Shannon’s entropy acts as an indicator of spatial concentration or dispersion and can be applied to investigate any geographical units. It is a metric calculation technique whereby spatial variation and temporal changes of growth areas are taken into account statistically to measures urban sprawl patterns (Yeh and Li 1998). It can also specify the degree of urban expansion by examining whether the land development is dispersed or compact (Lata et al. 2001). The review of the literature also found that the entropy method is the most reliable and robust metric among the available urban sprawl measurement indices. In this study, the entropy method has been applied to serve two purposes: firstly, to overcome the limitation of demonstrated indices and to obtain a reliable result by using the most widely used metric; secondly, to evaluate the results obtained by applying other indices, especially the newly proposed and modified indices.
Shannon’s entropy (H) can be used to measure the degree of spatial concentration or dispersion of a geographical variable (x i ) among zones (Thomas 1981). Entropy is calculated by
where, P i is the proportion of a phenomenon occurring in the ith zone \( \left( {P_{i} = \frac{{x_{i} }}{{\sum\nolimits_{i = 1}^{n} {x_{i} } }}} \right) \), x i is the observed value of the phenomena occurring in the ith zone, and n is the total number of zones. The value of entropy ranges from 0 to log e (n). A value of 0 indicates that the distribution of built-up areas is very compact, while values closer to log e (n) reveal that the distribution of built-up areas is dispersed. Higher values of entropy indicate the occurrence of sprawl. Half-way mark of log e (n) is generally considered as threshold. If the entropy value crosses this threshold the city is considered as sprawled.
Relative entropy can be used to scale the entropy value into a value that ranges from 0 to 1. As Thomas (1981) demonstrated, relative entropy (H 1) for n number of zones can be calculated as
In this instance 0.5 (for whole area) is considered as threshold. Values higher than this generally considered as sprawl.
In the present study, built-up areas within each zone have been calculated. If we calculate the entropy from these built-up data, we can get the entropy values for the each zone. This model is robust, because it can identify the sprawl as a pattern for each built-up area. The threshold, that can determine whether the city is sprawled or compact, can also be determined mathematically.
The change in entropy can be used to identify whether the land development is becoming more dispersed (sprawled). However, as mentioned that entropy is suffered from modifiable areal unit problem (MAUP). Relative entropy can mitigate the scale effect of MAUP. But, zone effect can only be overcome by decomposition of entropy.
Following the research of Thomas (1981), let us now apply entropy decomposition theorem in this study to overcome the problem associated with zone effect. As a preliminary decomposition analysis, zoning systems must be delimited for the different scales of analysis. The proportion of built-up area can then be calculated as
where, i ∊ j denotes the value of i which is the first element (∊) of set j, and n j is the value of i which forms the last element of set j. P j is the proportion of built-up in a delimited zone and P j (i) is the proportion in a zone before delimitation.
The entropy decomposition theorem states that the entropy should be calculated in terms of both the proportions P j (i) and P j . Hence, the formula of entropy can be written as (Thomas 1981)
where, k is the total number of delimited zones.
Equation 5 is composed of two expression on either side of the addition (+) sign. The expression on the left-hand side is termed the between region entropy and is denoted by H k , while the expression in right-hand side is termed the within region average entropy and is denoted by H n/k . This terminology allows that entropy decomposition Eq. (3) to be written simply as
Notice that, taken together, the entropies associated with maximum dispersion satisfy the decomposition theorem in Eq. 5, because
Therefore, the relative between-region entropy has been calculated as
Relative-within region average entropy has been calculated as
These relative entropies should be interpreted separately since they can reveal opposite conclusion (as presented by Thomas 1981).
Principal component analysis
Principle Component Analysis (PCA) is mathematically defined as an orthogonal linear transformation that transforms the data to a new coordinate system such that the greatest variance by some projection of the data comes to lie on the first coordinate (called the first principal component), the second greatest variance on the second coordinate, and so on. In this analysis, urban environmental data matrix x, with column-wise zero empirical means (the sample mean of each column has been shifted to zero), where each of the n rows represents a different repetition of the experiment, and each of the p columns gives a particular kind of datum (say, the results from a particular sensor). Mathematically, the transformation is defined by a set of p dimensional vectors of weights or loadings w k = (w 1…w p )(k) that map each row vector x i of x to a new vector of principal component scorest (i) = (t 1…t p )(i), given by t k(i) = x (i) w (k) in such a way that the individual variables of t considered over the data set successively inherit the maximum possible variance from x, with each loading vector w constrained to be a unit vector.
First component
The first loading vector w i thus has to satisfy
Equivalently, writing this in matrix form gives
Since w i has been defined to be a unit vector, it equivalently also satisfies
The quantity to be maximised can be recognised as a Rayleigh quotient. A standard result for a symmetric matrix such as x T x is that the quotient’s maximum possible value is the largest eigenvalues of the matrix, which occurs when w is the corresponding eigenvector.
With w (1) found, the first component of a data vector x i can then be given as a score t 1(i) = x (i) w (1) in the transformed co-ordinates, or as the corresponding vector in the original variables, {x (i) w (1)}w (1).
Further components
The kth component can be found by subtracting the first k − 1 principal components from x,
and then finding the loading vector which extracts the maximum variance from this new data matrix
It turns out that this gives the remaining eigenvectors of x T x, with the maximum values for the quantity in brackets given by their corresponding eigenvalues. Thus the loading vectors are eigenvectors of x T x.
The kth component of a data vector x (i) can therefore be given as a score t k(1) = x (i) w (k) in the transformed co-ordinates, or as the corresponding vector in the space of the original variables, {x (i) w (k)}w k , where w (k) is the kth eigenvector of x T x.
The full principal components decomposition of x can therefore be given as
where, w is a p-by-p matrix whose columns are the eigenvectors of x T x of urban environmental data.
Results and discussion
Spatial pattern of urban sprawling by landscape metrics
Characterising landscape properties at the landscape level involves calculating the fragmentation, patchiness, porosity, patch density, interspersion and juxtaposition, relative richness, diversity and dominance in terms of structure, function, and change (ICIMOD 1999). Characterising pattern involves detecting and quantifying it with appropriate scales and summarising it statistically. There are scores of metrics now available to describe landscape pattern. The only major components that were considered for this study are composition and structure. The landscape pattern metrics are generally used in studying forest patches (Trani and Giles 1999). But here we apply the concept for the analysis of land use patches inform of road, settled area, water body, open land, built up area, agricultural land and waste land etc. Landscape metrics provide quantitative description of the composition and configuration of urban landscape. These metrics were computed for each circle, zone wise using classified land use data at the landscape level with the help of FRAGSTATS (Meeus 1995). Urban dynamics is characterised by 10 spatial metrics chosen based on complexity, centrality and compactness criteria. The metrics include the patch area, shape, size; dispersion and interspersion is listed in Table 2. Table 2 shows the land use/land cover wise patch analysis of whole area and its further extension portrayed on zone wise for specific class. For the purpose of sprawling analysis, we have selected only built up class in terms of its dynamic characters and analyse regression model with 95 % confidence level.
Interspersion and Juxtaposition Index
Interspersion and Juxtaposition Index (IJI) equals minus the sum of the length (m) of each unique edge type divided by the total landscape edge (m), multiplied by the logarithm of the same quantity, summed over each unique edge type; divided by the logarithm of the number of patch types times the number of patch types minus 1 divided by 2; multiplied by 100 (to convert to a percentage) and the observed interspersion over the maximum possible interspersion for the given number of patch types. Note, IJI considers all patch types present on an image, including any present in the landscape border, if a border was included. All background edge segments are ignored, as are landscape boundary segments if a border is not provided, because adjacency information for these edge segments is not available. IJI approaches 0 when the distribution of adjacencies among unique patch types becomes increasingly uneven. IJI = 100 when all patch types are equally adjacent to all other patch types (i.e., maximum interspersion and juxtaposition. IJI is undefined and reported as “NA” in the “basename”. full file and a dot “.” in the “basename”. Land file if the number of patch types is less than 3 and IJI 0 ≤ IJI ≤ 100. IJI highlights that the centre of the city is more compact in 2014 with more clumpiness and aggregation in different directions. In 2014 it is observed that large urban patches are located closely almost forming a single patch especially at the centre and urbanization of city is growing towards north (Patia to Raghunathpur), south-east (old town to Nathapur and Gangotri Nagar) and southwest (Khandagiri to Patrapada) direction. The present town has extended maximum towards north, i.e., about 22.5 km towards village Patia, its extension towards northwest is about 14.5 km, west 11 km, southwest 8 km, south 6.5 km, and east 9.5 km. The present township sprawls over 233 sq km comprising a total number of 2312 revenue villages. For zone-2 and 6 urban patches diversity exceeds the predicted or existing tendency away from the city centre and more clumpiness and aggregation in this direction. In 2014 it is observed that large urban patches are located closely almost forming a single patch especially at the centre and urbanization of city is growing towards north in Fig. 5a.


Plots of regression trend in different landscape metrics with 95 % confidence level for built-up areas vs. distance from CBD. a interspersion and juxtaposition index, b Shannon’s diversity index, c area-weighted mean patch fractal dimension, d mean patch fractal dimension, e area-weighted mean shape index, f mean shape index, g mean patch size (hec), h number of patches (#), i total landscape area (hec) and j class area (hec)
Shannon’s Diversity Index
Shannon’s Diversity Index (SHDI) equals minus the sum, across all patch types, of the proportional abundance of each patch type multiplied by that proportion. SHDI = 0 when the landscape contains only 1 patch (i.e., no diversity). SHDI increases as the number of different patch types (i.e., patch richness, PR) increases and/or the proportional distribution of area among patch types become more equitable and SHDI ≥ 0, without limit. Bhubaneswar city is experiencing the sprawl in all directions as diversity index values are closer to the threshold value 0.50. Lower diversity index values of 0.62 of zone-1 shows an aggregated growth as most of urbanization was concentrated at CBD with landscape contains greater than 60 % patches. However, the region experienced dispersed growth and reaching higher values 1.06 in zone-9. The diversity computed for the city shows the sprawl phenomenon at outskirts. However, diversity values are comparatively lower when buffer region is considered. Shannon’s diversity values of recent time confirms of minimal fragmented dispersed urban growth in the city in Fig. 5b. This also illustrates and establishes the influence of drivers of urbanization in various zones. For zone-2 and 6 land use diversity exceeds the predicted or existing trend away from the CBD. It means in this zone built up area is yet to consume other land use type to maintain the existing spatial trend of urban development as a function of distance from the CBD. Land utilization is still diversified in this zone. Urban development prompts conversion of land into built up areas as the expense of other land use types. As such, urbanization leads to more homogenization in the pattern of land use. Therefore, land use diversity is expected to increase with increasing distance from the city centre. A spatial trend in this land use homogenization is established for Bhubaneswar city. The zone-2 (between 1 and 2 km) exhibits aberration to this spatial trend.
Area-Weighted Mean Shape Index
Area-Weighted Mean Shape Index (AWMSI) equals the sum, across all patches, of each patch perimeter (m) divided by the square root of patch area (m2), adjusted by a constant to adjust for a circular standard (vector) or square standard (raster), multiplied by the patch area (m2) divided by total landscape area. In other words, AWMSI equals the average shape index (SHAPE) of patches, weighted by patch area so that larger patches weigh more than smaller ones. AWMSI = 1 when all patches in the landscape are circular (vector) or square (raster); AWMSI increases without limit as the patch shapes become more irregular and AWMSI ≥ 1, without limit. Results indicate that there were low AWMSI values (2.40) in as there were minimal urban areas which were aggregated at the centre and values 4.28; AWMSI increases without limit as the patch shapes become more irregular without limit. The city has been experiencing dispersed growth in all direction and circles, towards 2014 it shows aggregating trend as the value reaches. For zone-1 and 3 AWMSI increases without limit as the patch shapes become more irregular and AWMSI ≥ 1exceeds the predicted or existing tendency away from the city centre and patch area so that larger one in Fig. 5c.
Mean Shape Index
Mean Shape Index (MSI) equals the sum of the patch perimeter (m) divided by the square root of patch area (m2) for each patch of the corresponding patch type, adjusted by a constant to adjust for a circular standard (vector) or square standard (raster), divided by the number of patches of the same type; in other words, MSI equals the average shape index of patches of the corresponding patch type. MSI = 1 when all patches of the corresponding patch type are circular (vector) or square (raster); MSI increases without limit as the patch shapes become more irregular and MSI ≥ 1, without limit. Results show that the landscape had a highly fragmented urban class, which became further fragmented and started assemblage to form a single square in 2014 especially in northeast and northwest direction in all zones and few inner zones in southeast and southwest directions, conforming and advocacy to other landscape metrics in Fig. 5d. For zone-1 mean shape exceeds the predicted or existing trend away from the CBD. It means in this zone built up area is hitherto to devour other land use type to maintain the existing spatial trend of mean shape as a function of distance from the CBD and values increased to 4.3.
Mean Patch Fractal Dimension
Mean patch fractal dimension (MPFD) equals the sum of 2 times the logarithm of patch perimeter (m) divided by the logarithm of patch area (m2) for each patch in the landscape, divided by the number of patches; the raster formula is adjusted to correct for the bias in perimeter (Li et al. 2006). A fractal dimension greater than 1 for a 2-dimensional landscape mosaic indicates a departure from a Euclidean geometry (i.e., an increase in patch shape complexity). MPFD approaches 1 for shapes with very simple perimeters such as circles or squares, and approaches 2 for shapes with highly convoluted, plane filling perimeters and 1 ≤ MPFD ≤ 2. Results indicate of shapes with very simple perimeters such as squares (indicating clumping of specific classes. The value approaches greater than 1 in 2014 indicating aggregation leading to clumped region of urban land use in Fig. 5e. For zone-1 mean patch fractal dimension exceeds the predicted or existing trend away from the CBD. It means in this zone built up area is yet to get through other land use type to maintain the existing spatial trend of mean patch areas as a function of distance from the CBD and values augmented to 1.20.
Area-Weighted Mean Patch Fractal Dimension
Area-weighted mean patch fractal dimension (AWMPFD) equals the sum, across all patches, of 2 times the logarithm of patch perimeter (m) divided by the logarithm of patch area (m2), multiplied by the patch area (m2) divided by total landscape area; the raster formula is adjusted to correct for the bias in perimeter (Li et al. 2006). In other words, AWMPFD equals the average patch fractal dimension (FRACT) of patches in the landscape, weighted by patch area. A fractal dimension greater than 1 for a 2-dimensional landscape mosaic indicates a departure from a Euclidean geometry (i.e., an increase in patch shape complexity). AWMPFD approaches 1 for shapes with very simple perimeters such as circles or squares, and approaches 2 for shapes with highly convoluted, plane-filling perimeters and 1 ≤ AWMPFD ≤ 2. The area weighted mean patch fractal dimension (AWMPFD) measures a different dimension of urban land-use structure. This metric is a measure of the fragmentation of each built-up patch, and not for the whole homogeneous urban patches, as is measured by the contagion metric (Herold et al. 2002). The highest values (1.21) are found in the High-density built-up residential areas in Fig. 5f. High-density built-up residential areas patches consist of spatially aggregated parcels and buildings of small size along a regular street pattern, resulting in a highly fragmented patch structure. The patches of the low-density built-up residential areas regions are not coherent and show a more compact shape, which leads to a lower fractal dimension (1.13). Approximately the same AWMPFD values can be found for the commercial and industrial areas regions, whose small patch fragmentation result from their large size and compact structure as well as the domination of one land-cover type which prevents a detection of single houses. An analysis of the metric values also indicates that the different metrics are individually sensitive to different characteristics of the urban landscape. The combination of different spatial information (such as the percentage of landscape, the spatial aggregation of built-up areas, or the mean parcel and building size) suggests that a functional separation among the three regions is possible by utilizing selected landscape metric measures. The different landscape metrics may thus be considered as `landscape metric signatures’ (LMSs) for the various urban land-use categories in the study area. These signatures can be used to develop and define indices as aggregated information for land-use structures. For zone-1 and 6 AWMPFD increases without limit as the patch shapes turn out to be more uneven and AWMPFD ≥ 1exceeds the predicted or existing propensity away from the city centre and patch area so that larger one.
Mean Patch Size
Mean patch size (MPS) equals the sum of the areas (m2) of all patches of the corresponding patch type, divided by the number of patches of the same type, divided by 10,000 (to convert to hectares). The range in MPS is limited by the grain and extent of the image and the minimum patch size in the same manner as patch area (AREA) and MPS > 0, without limit. Figure 6a illustrates that the city is becoming clumped patch at the centre, while outskirts are relatively fragmented. Clumped patches are more prominent in northwest and southwest directions and patches are agglomerating to a single urban patch. Largest patch highlights that the city’s landscape is fragmented in all direction due to heterogeneous landscapes, transformed a homogeneous single patch in 2014 in Fig. 5g. The patch sizes highlights that there were small urban patches in all directions and the increase in the index values implies increased urban patches during 2014 in the northeast and southeast. A higher value at the CBD indicates the aggregation at the centre and in the verge of forming a single urban patch largest patches were found in northeast and southeast direction. For zone-1 MPS increases without limit as the patch size turn out to be more patchy and MPS > 0, without limit, exceeds the predicted or existing predisposition away from the CBD centre and patch size so that larger one.

Density gradient measure. a best curve fitting with second order polynomial, b gradient of average density of development from CBD
Number of Patches
Number of patches (NP) equals the number of patches of the corresponding patch type (class). NP = 1 when the landscape contains only 1 patch of the corresponding patch type; that is, when the class consists of a single patch and NP ≥ 1, without limit in Fig. 5h. For zone-5 and 6 patches diversity exceeds the predicted or existing trend away from the CBD. It means in this zone built up area is yet to consume other patch type to maintain the existing spatial trend of patch development as a function of distance from the CBD. Patch development is still diversified in this zone. Urban development prompts conversion of land into built up areas as the expense of other land use types. As such, development leads to more number of patches in terms of land use conversion. Therefore, patches diversity is expected to increase with increasing distance from the city centre. A spatial trend in this patches diversity is established for Bhubaneswar city.
Landscape Area
Total Landscape area (TA) equals the area (m2) of the landscape, divided by 10,000 (to convert to hectares). TA excludes the area of any background patches within the landscape and TA > 0, without limit in Fig. 4i. For zone-9 TA increases without limit as the patch size turn out to be more patchy and TA > 0, without limit, exceeds the predicted or existing predisposition away from the CBD centre and landscape area so that larger one.
Class Area
Class area (CA) equals the sum of the areas (m2) of all patches of the corresponding patch type, divided by 10,000 (to convert to hectares); that is, total class area. CA approaches 0 as the patch type become increasing rare in the landscape. CA = TA when the entire landscape consists of a single patch type; that is, when the entire image is comprised of a single patch and CA ≥ 0, without limit. For zone-5 and 6 CA increases without limit as the patch size of built up area turn out to be more patchy and CA ≥ 0, without limit, exceeds the predicted or existing predisposition away from the CBD centre and class area so that larger for this built up area in Fig. 5j.
Degree of urban sprawl by Shannan’s entropy: dispersed or compact
Entropy can be used to indicate the degree of urban sprawl by examining whether land development in a city is dispersed or compact (Gar-On Yeh and Li 2001). If it has a large value, then urban sprawl has occurred. The buffer function of a GIS can be used to define distance or zones from CBD and the density of land development in each of 9 concentric zones can be used to calculate the entropy. The results show that there is substantial variation in the patterns of urban sprawl among the places of the study area by fitting second order polynomial curve (R 2 = 0.893). In general, urban sprawl is quite obvious in the whole city. The entropy of urban sprawl from CBD was 0.949 (the threshold 0.5). Some places witnessed quite unusual sprawl of land development, as can be seen from their entropy values. In 2014, the top five localities with the highest entropy from places were Joydevbihar (0.920), Jaganathbihar (0.892), Bhoumanagar (0.849), Bapujinagar (0.845), and Kalingabihar (0.846The spatial relationship between urban sprawl and the distance variables can be more clearly identified by using the two-dimensional entropy space (Fig. 6a).
Distance decay functions of land development can be observed in the scatter plots of the average density of land development in the distance zones of the city proper (Fig. 6b). The density of land development declines rapidly as the distance from CBD increases. It can be seen from Fig. 6b that the density of land development sharply increases to a peak in a short distance and then declines away from the town centre. The relationships between average densities of land development and distances from town centres can be summarized by the following regression equations and city has an unusually high degree of urban sprawl due to land speculation. Distance from CBD given by:
where r is distance in km away from the CBD and \( \bar{D}_{(r)} \) is the average density of land development at distance r. It is found that, on average, the density of land development increases steadily from the town centres to around 5 km and then declines gradually with increasing distance from the CBD. The decline in the density of land development was much faster from CBD centre.
Relative entropy of the CBD buffers density of land development in 2014 was calculated. Relative entropy of buffer distance is used to measure the degree of urban sprawl and monitor its change with time. It is calculated by Eq. 2. Urban sprawl from town centres will produce a higher value of relative entropy; it is found that different urban growth patterns can be identified from entropy spaces. It is interesting to note that the towns of Jagannathbihar have quite distinctive growth patterns according to their entropy values. This can help government officials and planners to identify the towns that have irrational development patterns. In Fig. 6b, the city that fall within region 2 km have quite dispersed patterns because their entropy is high for the distance variables. Their highly dispersed patterns of urban sprawl should be of major concern to the city government. The entropy decomposition theorem can be used to identify different component the entropy that are related to different zone sizes in collecting the data (Batty 1976; Thomas 1981). The application of the method reveals that the study area has experienced severe urban sprawl in the 2014 with the lack of proper development control and management. Some areas in the study area it can be seen from Fig. 6b that land development usually occurs around existing built-up areas. In order to examine the influences of locational factors on the spatial pattern of land development, the buffer function of a GIS was used to create distance zones around CBD in order to calculate the density of land development in each distance zone (Fig. 6b). The distance zones have a width of 12.5 km. Too wide distance will cause the loss of information due to aggregation. The overlay of the urban land-use images on the buffer images was carried out to find the densities of land development, which is the amount of land development divided by the land area in each distance zone. The distribution of land development densities over the distance zones was obtained using the summary function of ERDAS Imagine 11. The summary function will overlay the distance layer on top of the urban land development layer and find the number (or hectares) and percentage of urban land development pixels for each distance buffer zone.
Spatial factors of urban sprawling by principal component analysis
10 variables related to dwelling and living environment have been considered for PCA (Table 3; Fig. 7a). Average Rank has been assigned to each of the variables on the basis of perception of the local people. Data were collected by interviewing more than 50 persons from each of the surveyed localities located at different distances from the city core are.

Plots of factor score, a principal component-1 versus principal component-2/3, b variable rotated component-1 versus variable rotated component-2/3
The data were passed through PCA applying varimax rotation method (Table 4; Fig. 7b). The analysis has grouped the variables into three categories each of which is associated with a Principal Component (PC).
The PCs with eigenvalues > 1 have been retained. As such, three PCs have been obtained. The First Principal Component (PC-1) primarily involves those variables which are more related to infrastructural facilities (drainage, educational, health services, recreational and disposal of refuse facilities). These variables has higher loading on PC-1. This PC-1 explains 40.63 % of variation in the data. The second Principal Component (PC-2) takes variables (noise level, average space between buildings and over all environmental quality) into its fold. The variables underlying the PC-2 represent the status of physical environment. PC-2 explains 19.23 % variation in the data. The Third Principal Component (PC-3) includes two facilities (Transport and Sewerage). The three PCs together explain about 74.44 % variation in the data. The scores of each PC for each of the selected localities have also been calculated. High score of PC-1 for a locality (e.g., Raghunathpur, Bijipur etc.) suggests that the locality enjoys good status with respect to the variables that underlie PC-1 i.e., drainage, educational, health services, recreational and disposal of refuse. Expansions of these facilities in areas located away from the city core have been instrumental in augmenting the sprawling process. The localities (like Kalinganagar) with higher PC-2 score are preferred by people for residence due to aesthetic qualities even if the areas are located away from city proper and transport and other facilities are yet to develop to the desired level.
Conclusion
From the field observation and analysis of land use metrics in Greater Bhubaneswar city area, it is found that the trend of urban sprawl is happening towards peripheral zones from CBD. It is rapidly spreading up in a non-contiguous way. Except the core area, the most of the residential areas are randomly distributed around the centre. In the north-eastern and south-eastern parts of CBD, a large number of new built-up is located. The most of the vacant lands are altered to residential area day-by-day. Besides, the cost of land is increased in both core areas and the surrounding areas. The process of urban sprawl is still active in Bhubaneswar city and its surrounding area. Local urban and rural planners need to put forward effective implementable adaptive plans to improve basic amenities in the sprawl localities. Spatial land use analysis along with urban density gradient different directions has helped in visualizing the growth along with the cultural and industrial evolution. An important future research objective will be the further evaluation of different spatial metrics as well as the aggregation of metric information (spatial urban indices) to develop robust measurements of urban morphological structures. Spatial measurements allow a very robust characterization of urban form (Banister et al. 1997; Longley and Mesev 2000) and are useful for representing urban processes and functionality and contributing to urban models. The issue of the input remote sensing datasets is also of importance. Digitized satellite images were utilized in this study and such imagery is available to almost every local or regional planning agency. New, high-spatial resolution satellite data are also now commercially available. These datasets can undoubtedly serve as input data for the types of analysis described here. Our future research will seek to test such applications. We are encouraged by the results of this study and are confident that high-resolution satellite data will also prove useful in such analysis. The following findings have been point out here:
-
The metrics include the patch area, shape, size; dispersion and interspersion provides urbanization of Bhubaneswar is growing towards North (Patia to Raghunathpur), south-east (old town to Nathapur and Gangotri Nagar) and south-west (Khandagiri to Patrapada) direction. The present city has extended maximum towards north, i.e., about 22.5 km towards village Patia, its extension towards northwest is about14.5 km, west 11 km, southwest 8 km, south 6.5 km, and east 9.5 km. The present township sprawls over 233 sq km comprising a total number of 2312 revenue villages. The western part of the city is more urbanized than the eastern part. The urban development in Bhubaneswar is random and going in an unplanned manner. A decrease in agricultural areas and increase of the residential areas has been found in the sprawling areas;
-
Entropy measure shows that there is substantial variation in the patterns of urban sprawl among the places of the study area by fitting second order polynomial curve (R2 = 0.893). In general, urban sprawl is quite obvious in the whole city. The average entropy of urban sprawl from CBD was 0.949 (the threshold 0.5). Some places witnessed quite unusual sprawl of land development, as can be seen from their entropy values. In 2014, the top five localities with the highest entropy from places were Joydevbihar (0.920), Jagannathbihar (0.892), Bhoumanagar (0.849), Bapujinagar (0.845), and Kalingabihar (0.846 The spatial relationship between urban sprawl and the distance variables can be more clearly identified by using the two-dimensional entropy space. Relative entropy value also shows that the city that fall within region 2 km have quite dispersed patterns because their entropy is high for the distance variables.
-
Distance decay functions of land development that, on average, the density of land development increases steadily from the town centres to around 5 km and then declines gradually with increasing distance from the CBD. The decline in the density of land development was much faster from CBD centre;
-
High score of PC-1 for a locality (e.g., Raghunathpur, Bijipur etc.) suggests that the locality enjoys good status with respect to the variables that underlie PC-1 i.e., drainage, educational, health services, recreational and disposal of refuse. Expansions of these facilities in areas located away from the city core have been instrumental in augmenting the sprawling process. The localities (like Kalinganagar) with higher PC-2 score are preferred by people for residence due to aesthetic qualities even if the areas are located away from city proper and transport and other facilities are yet to develop to the desired level.
References
Alberti M (1999) Modeling the urban ecosystem: a conceptual framework. Environ Plan B 26(4):605–630
Alberti M, Waddell P (2000) An integrated urban development and ecological simulation model. Int Assess 1:215–227
Bae C-HC, Richardson HW (1994) Automobiles, the environment and metropolitan spatial structure. Lincoln Institute of Land Policy, Cambridge
Banister D, Watson S, Wood C (1997) Sustainable cities: transport, energy, and urban form. Environ Plan B 24:125–144
Batty M (1976) Entropy in spatial aggregation. Geograph Anal 8(1):1–21
Benfield FK, Raimi MD, Chen DDT (1999) Once there were Greenfields: how urban sprawl is undermining America’s environment, economy, and social fabric. Natural Resources Defence Council, New York, Washington
Berry WD (1993) Understanding regression assumptions. Sage, Newbury Park
Burchell RW, Shad NA, Lisotkin D, Phillips H, Downs A, Seskin S et al (1998) The costs of sprawl revisited. National Academy Press, Washington
Burchfield M, Overman HG, Puga D, Turner M (2006) Causes of sprawl: a portrait from space. Q J Econ 121(2):587–633
Calthorpe P, Fulton W, Fishman R (2001) The regional city: planning for the end of sprawl. Island Press, Washington
Census of India, Odisha State (2011) Office of the Registrar General and Census Commissioner, India 2/A, Man Singh Road, New Delhi-110011, India
Clapham WB Jr (2003) Continuum-based classification of remotely sensed imagery to describe urban sprawl on the watershed scale. Remote Sens Environ 86:322–340
Club Sierra (1998) Sprawl: the dark side of the American dream. Challenge to Sprawl Campaign, College Park
De Cola L, Lam NNS (1993) Introduction to fractals in geography, in Fractals in Geography. Prentice-Hall, Englewood, pp 3–22
Duany A, Speck J, Plater-Zyberk E (2001) Smart growth: new urbanism in American communities. McGraw-Hill, New York
Dunn CP, Sharpe DM, Guntensbergen GR, Stearns F, Yang Z (1991) Methods for analyzing temporal changes in landscape pattern. In: Turner MG, Gardner RH (eds) Quantitative methods in landscape ecology: the analysis and interpretation of landscape heterogeneity. Springer, New York, pp 173–198
El Nasser H, Overberg P (2001) A comprehensive look at sprawl in America. USA Today, February 22
Ewing R (1994) Causes, characteristics, and effects of sprawl: a literature review. Environ Urban Issues 21(2):1–15
Ewing R (1997) Is Los Angeles-style sprawl desirable? J Am Plan Assoc 63(1):107–126
Ewing R, Pendall R, Chen DDT (2002) Measuring sprawl and its impact. Smart Growth Americax, Washington
Fotheringham AS, Brunsdon C, Charlton M (2000) Quantitative geography: perspectives on spatial data analysis. Sage, London
Frohn RC, Mcgwire KC, Dale VH, Estes JE (1996) Using satellite remote sensing analysis to evaluate a socio-economic and ecological model of deforestation in Rondonia, Brazil. Int J Remote Sens 17:3233–3255
Galster G, Hanson R, Ratcliffe MR, Wolman H, Coleman S, Freihage J (2001) Wrestling sprawl to the ground: defining and measuring an elusive concept housing policy. Debate 12(4):681–717
Gardner RH, O’Neill RV, Turner MG (1993) Ecological implications of landscape fragmentation. In: Pickett STA, McDonnell MJ (eds) Humans as components of ecosystems; subtle human effects and the ecology of populated areas. Springer, New York, pp 208–226
Gibert K, Sànchez-Marrè M (2011) Outcomes from the iEMSs data mining in the environmental sciences work shop series. Environ Model Softw 26(7):983–985
Gordon P, Richardson HW (1997a) Are compact cities a desirable planning goal? J Am Plan Assoc 63(1):95–106
Gordon P, Richardson HW (1997b) Where’s the sprawl? J Am Plan Assoc 63(2):275–278
Hasse J (2004) A geospatial approach to measuring new development tracts for characteristics of sprawl. Landsc J 23(1):52–67
Hasse JE, Lathrop RG (2003a) Land resource impact indicators of urban sprawl. Appl Geogr 23:159–175
Hasse J, Lathrop RG (2003b) A housing-unit-level approach to characterizing residential sprawl. Photogramm Eng Remote Sens 69(9):1021–1030
Herold M, Scepan J, Clarke KC (2002) The use of remote sensing and landscape metrics to describe structures and changes in urban land uses. Environ Plann A 34:1443–1458
HUD (1999) The state of the cities. US Departmet of Housing and Urban Development, Washington
ICIMOD (1999) Integration of GIS, remote sensing and ecological methods for biodiversity inventory and assessment. In: Issues in Mountain Development
James Duncan & Associates, Van Horn GA, Ivey B, Harris, Walls, Inc., Wade-Trim I (1989) The search for efficient urban growth patterns: a study of the fiscal impacts of development in Florida. Presented to the Governor’s Task Force on Urban Growth Patterns and the Florida Department of Community Affairs, July 1989
Jenerette GD, Potere D (2010) Global analysis and simulation of land-use change associated with urbanization. Landsc Ecol 25(5):657–670
Joshi H, Guhathakurta S, Konjevod G, Crittenden J, Li K (2006) Simulating the effect of light rail on urban growth in Phoenix: an application of the UrbanSim modeling environment. J Urban Technol 13(2):91–111
Keitt TH, Urban DL, Milne BT (1997) Detecting critical scales in fragmented landscapes. Conserv Ecol (online) 1(1) 4. www.consecol.org/vol1/iss1/art4
Lang RE (2003) Open spaces, bounded places: Does the American West’s arid landscape yield dense metropolitan growth? Hous Policy Debate 13(4):755–778
Lata KM, Sankar Rao CH, Krishna Prasad V, Badrinath KVS, Raghavaswamy V (2001) Measuring urban sprawl: a case study of Hyderabad. GIS Dev 5(12):8–13
Ledermann RC (1967) The city as a place to live. In: Gottmann J, Harpe RA (eds) Metropolis on the move: geographers look at urban sprawl. Wiley, New York
Lessinger J (1962) The cause for scatteration: some reflections on the National Capitol Region plan for the year 2000. J Am Inst Plan 28(3):159–170
Li H, Reynolds JF (1993) A new contagion index to quantify spatial patterns of landscapes. Landsc Ecol 8:155–162
Li Y, Zhao S, Zhao K, Xie P, Fang J (2006) Land-cover changes in an urban lake watershed in a mega-city, central China. Environ Monit Assess 115:349–359
Longley PA, Mesev V (2000) On the measurement and generalization of urban form. Environ Plan A 32(3):473–488
Lopez R, Hynes HP (2003) Sprawl in the 1990s: measurement, distribution, and trends. Urban Affairs Rev 38(3):325–355
Luck M, Wu JG (2002) A gradient analysis of urban landscape pattern: a case study from the Phoenix metropolitan region, Arizona, USA. Landsc Ecol 17:327–339
Malpezzi S (1999) Estimates of the measurement and determinants of urban sprawl in US metropolitan areas. University of Wisconsin Center for Urban Land Economics Research, Madison
Mandelbrot BB (1983) The fractal geometry of nature. W H Freeman, New York
McGarigal L, Marks BJ (1994) FRAGSTATS manual: spatial pattern analysis program for quantifying landscape structure. ftp.fsl.orst.edu/pub/fragstats.2.0
McGarigal K, Marks BJ (1995) FRAGSTATS: spatial pattern analysis program for quantifying landscape structure. USDA Forest Service General Technical Report PNW-351. www.umass.edu/landeco/research/fragstats/fragstats.html
Meeus JHA (1995) Pan-European landscapes. Landsc Urban Plan 31(1):57–79
Moran PAP (1950) Notes on continuous stochastic phenomena. Biometrika 37:17–23
O’Neill RV, Krummel JR, Gardner RH, Sugihara G, Jackson B, Deangelis DL, Milne BT, Turner MG, Zygmunt B, Christensen SW, Dale VH, Graham RH (1988) Indices of landscape pattern. Landsc Ecol 1:113–153
O’Neill RV, Hunsaker CT, Timmins SP, Jackson KB, Ritters KH, Wickham JD (1996) Scale problems in reporting landscape pattern at regional scale. Landsc Ecol 11:169–180
Openshaw S (1983) The modifiable areal unit problem, CATMOG 38. GeoBooks, Norwich
OTA (1995) The technological reshaping of Metropolitan America. DCUS Congress Office of Technology Assessment, Washington
Peiser R (1989) Density and urban sprawl. Land Econ 65(3):193–204
Pendall R (1999) Do land-use controls cause sprawl? Environ Plan B 26:555–571
Real Estate Research Corporation (1974) The costs of sprawl: environmental and economic costs of alternative residential patterns at the Urban Fringe. US Government Printing Office, Washington
Renetzedera C, Schindlera S, Peterseila J, Prinza MA, Mücherc S, Wrbka T (2010) Can we measure ecological sustainability? Landscape pattern as an indicator for naturalness and land use intensity at regional, national and European level. Ecol Indic 10:39–48
Ridd MK (1995) Exploring a VIS (vegetation-impervious-surface-soil) model for urban ecosystem analysis through remote sensing: comparative anatomy for cities. Int J Remote Sens 16:2165–2185
Sadler GJ, Barnsley MJ, Barr SL (1991) Information extraction from remotely sensed images for urban land analysis. In: Proceeding of the 2nd European conference on geographical information systems (EGIS’91). Brussels, Belgium, April (EGIS Foundation, Utrecht), pp 955–96
Sarvestani MS, Ibrahim AL, Kanaroglou P (2011) Three decades of urban growth in the city of Shiraz, Iran: a remote sensing and geographic information systems application. Cities 28(4):320–329
Sha Z, Bai Y, Xie Y, Yu M, Zhang L (2008) Using a hybrid fuzzy classifier (HFC) to map typical grassland vegetation in Xilin River Basin, Inner Mongolia, China. Int J Remote Sens 29:2317–2337
Simoniello T, Carone MT, Coppola R, Grippa A, Lanfredi M, Liberti M, Macchiato M (2006) Preliminary study to monitor land degradation phenomena through landscape metrics. In: 2nd Workshop of the EARSeL SIG on land use and land cover. Center for Remote Sensing of Land Surfaces, Bonn, pp 408–414
Sudhira HS, Ramachandra TV, Jagadish KS (2003) Urban sprawl pattern recognition and modeling using GIS. In: Paper read at Map India Conference 2003
Sudhira HS, Ramachandra TV, Jagadish KS (2004) Urban sprawl: metrics, dynamics and modelling using GIS. Int J Appl Earth Obs Geoinf 5(1):29–39
Sultana S, Weber J (2007) Journey-to-work patterns in the age of sprawl: evidence from two midsize southern Metropolitan Areas. Prof Geogr 59(2):193–208
Sun H, Forsythe W, Waters N (2007) Modeling urban land use change and urban sprawl: Calgary, Alberta, Canada. Netw Spat Econ 7(4):353–376
Thomas RW (1981) Information statistics in geography. Geo Abstr, Norwich
Trani MK, Giles RH Jr (1999) An analysis of deforestation: metrics used to describe pattern change. For Ecol Manage 114(2):459–470
Turner MG, O’Neill RV, Gardner RH, Milne BT (1989) Effects of changing spatial scale on the analysis of landscape pattern. Landsc Ecol 3:153–162
Xia ZG, Clarke KC (1997) Approaches of scaling geo-spatial data. In: Quattrochi DA, Goodchild MF (eds) Scale in Remote Sensing and GIS. CRC Lewis, Boca Raton, pp 309–360
Yeh AGO, Li X (1998) Sustainable land development model for rapid growth areas using GIS. Int J Geogr Inf Sci 12(2):169–189
Yeh Anthony Gar-On, Li Xla (2001) Measurement and monitoring of urban sprawl in a rapidly growing region using entropy. Photogramm Eng Remote Sens 1(2001):83–90
Zhao S, Da L, Tang Z, Fang H, Song K, Fang J (2006) Ecological consequences of rapid urban expansion: Shanghai, China. Frontiers Ecol Environ 4(7):341–346
Acknowledgments
The authors are most grateful to the valuable comments from the anonymous referees in helping us to improve the paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Das Chatterjee, N., Chatterjee, S. & Khan, A. Spatial modeling of urban sprawl around Greater Bhubaneswar city, India. Model. Earth Syst. Environ. 2, 14 (2016). https://doi.org/10.1007/s40808-015-0065-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40808-015-0065-7