
Abstract
Video modeling has been shown to be effective in teaching a number of skills to learners diagnosed with autism spectrum disorders (ASD). In this study, we taught two young men diagnosed with ASD three different activities of daily living skills (ADLS) using point-of-view video modeling. Results indicated that both participants met criterion for all ADLS. Participants did not maintain mastery criterion at a 1-month follow-up, but did score above baseline at maintenance with and without video modeling.
• Point-of-view video models may be an effective intervention to teach daily living skills.
• Video modeling with handheld portable devices (Apple iPod or iPad) can be just as effective as video modeling with stationary viewing devices (television or computer).
• The use of handheld portable devices (Apple iPod and iPad) makes video modeling accessible and possible in a wide variety of environments.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Video modeling is a teaching procedure that involves an individual viewing a videotaped sample of a model performing a specific, scripted activity or task. Immediately following having viewed the video-based model, the individual is directed to perform the activity or script he or she observed in the video (e.g., MacDonald, Clark, Garrigan, & Vangala, 2005). Bellini and Akullian (2007) conducted a meta-analysis of 23 studies that used video modeling or video self-modeling (VSM) with participants diagnosed with autism spectrum disorders (ASD) and found that both procedures were effective in developing skill acquisition in participants, and the effects maintained over time. Thus, previous research suggests that video modeling is a highly effective intervention for a variety of behaviors in ASD (Bellini & Akullian, 2007).
Empirical research supports video modeling as an effective pedagogical procedure that may produce quick skill acquisition (Allen, Wallace, Renes, Bowen, & Burke, 2010; Bidwell & Rehfeldt, 2004). Further, video modeling has been used to teach a variety of different skills including daily living skills (Shipley-Benamou, Lutzker, & Taubman, 2002), task analyses (Bellini & Akullian, 2007), social skills (Apple, Billingsley, & Schwartz, 2005; Maione & Mirenda, 2006), and vocational skills in young adults with ASD (Kellems & Morningstar, 2012). Teaching activities of daily living skills (ADLS) typically requires that the learner perform the behavior in the natural environment. One consideration is how the learner could acquire a skill and perform it in the natural environment with limited prompting. However, these skills also need to be maintained over time. Research has supported video modeling as a prompting procedure that can maintain skills over time (Burke, Allen, Howard, Downey, Matz, & Bowen, 2013). Further, video modeling has proven successful in increasing complex response sequences (e.g., D’Ateno, Mangiapanello, & Taylor, 2003; Shipley-Benamou et al., 2002). More recently, video modeling has been demonstrated to serve as an effective prompt within the natural environment with the use of portable devices such as iPods and tablets (e.g., Burke et al., 2013; Kellems & Morningstar, 2012).
The purpose of the study was to replicate and extend the study of Kellems and Morningstar (2012) and to address one of their self-imposed limitations by “collecting data on the amount of prompts needed to use the technology to determine if this impacts the effectiveness of the intervention” (p. 165). In this study, we taught two young men with ASD three ADLS using point-of-view video modeling and evaluated the number of prompts needed to produce performance on a step in a task.
Method
Participants, Setting, and Activities
Two male adolescents, 18 years of age and previously diagnosed with ASD participated in this study. Researchers selected participants based upon age, diagnosis (record review), the need for improved daily living skills to become independent, and parental consent to participate.
Each participant’s residence served as the setting for this study. The location of each session varied depending on the task that was being performed. The settings in which the participants performed tasks were in the kitchen, bathroom, and laundry room. A Board Certified Behavior Analyst (BCBA), a BCBA candidate, and an ABA therapist conducted sessions for participant 1, and the BCBA and BCBA candidate conducted sessions for participant 2.
Researchers identified three ADL tasks for each participant through a collaborative interview process with each participant’s parents. These tasks included skills that the family reported that the participants performed below expectation. Tasks for participant 1 included cooking, setting the table, and folding jeans. Tasks for participant 2 included setting the table and cleaning the bathroom sink/counter and mirror.
Materials
Researchers created video models using Apple iPad iOS software. Similar to Bellini and Akullian (2007), researchers filmed videos from the perspective of the viewer and portrayed the arms and hands of the model performing the task. Family members served as models. The entire task was filmed with a verbal description of each step as it was being performed in the participant’s home setting. The materials used were the same materials used during teaching sessions. The length of the videos and number of steps varied for each task. The length of the videos ranged from 1.5 to 6 min. A video showed nine steps for folding jeans, 23 steps for cooking, 15 and 17 steps for setting the table, 14 steps for cleaning the sink and the counter, and 13 steps for cleaning the mirror.
Experimental Design
A multiple-probe design across behaviors was used to evaluate the effects of video modeling on ADLS. For each participant, researchers introduced an intervention to a second target behavior following the participant reaching mastery criterion on the first target behavior, and the intervention was introduced to the third target behavior when mastery criterion was reached with the second.
Dependent Variables
The dependent variables were the percentage of task analysis steps performed correctly and the number of prompts delivered to the participant during the intervention. A correct response was defined as a response that matched the behavior depicted in the video model and was performed within 10 s of the instruction or previous behavior. To be scored as correct, a participant had to perform a step in the exact order described by the task analysis. If a step had multiple components, it was scored as one response. If the participant had to re-watch the video, performed an incorrect behavior, or did not respond within 10 s, researchers scored the response as incorrect. The percentage was calculated by the correct number of responses divided by the total number of steps in the task analysis, multiplied by 100. A prompt was defined as a single occurrence of a gestural prompt.
Interobserver Agreement
Interobserver agreement (IOA) was calculated by dividing the smaller count by the larger count and multiplying by 100. The IOA was calculated for 100 % of the baseline sessions, 50 % of the probe condition sessions, and 24 % of the sessions during intervention for participant 1. The overall mean of agreement was 99 % (range 95–100 %). The IOA for prompt data during the intervention condition was 83 % (range 50–100 %). The IOA was calculated for 100 % of the baseline condition, 100 % of the probe condition, and 45 % of the intervention condition for participant 2. The overall mean of agreement was 96 % (range 72–100 %). The IOA for prompt data during the intervention condition was 70 % (range 0–100 %).
Procedures
Baseline
Sessions were conducted in the natural environment (i.e., forks were in drawers, tortellini was in the freezer, jeans were in a dyer, multipurpose spray was in the closet). To begin a trial, a researcher provided a discriminative stimulus to begin the task. No feedback or prompting was provided during baseline or probe sessions.
Pre-teaching
This phase involved teaching prerequisite skills for the ADL. Prerequisite skills included setting a timer and turning on/off the stove for participant 1. The researchers taught the prerequisite skills to participant 1 by providing verbal instructions.
Intervention
During the intervention phase, participants watched the entire video and the researcher then asked the participant to perform the ADL. For each incorrect response, the researcher reset the video and the participant reviewed the segment in the video that modeled the response; the participant was then given the opportunity to perform that behavior. If an incorrect response or no response occurred after the participant reviewed the video segment, the researcher provided a gestural prompt. If a correct response did not occur, the participant re-watched the video segment of the step in which an incorrect or no response occurred up to two more times before moving on to the next step. A gestural prompt was considered part of the error correction procedure only if the participant did not perform the step correctly after re-watching the video the first time and did not always occur during the error correction procedure. With participant 1, the researchers provided no feedback on correct responses. With participant 2, the researchers praised correct setting of the table at the end of the task. During sessions in which caregivers observed, they often provided verbal praise and edible reinforcers to participant 2 after he performed the task. During the intervention phase with setting the table, participant 2 did not correctly follow the video direction to place the napkin and cup on the left side of the plate and, at that point, the researchers terminated the sessions and began to teach directional concepts receptively in isolation until the participant mastered the skill.
Maintenance
The maintenance phase began after mastery criterion was met during the skill acquisition phase. For participant 1, procedures for maintenance were identical to baseline. For participant 2, tasks 1 and 2 occurred at least 3–4 weeks after task acquisition, whereas a maintenance probe was conducted for task 3 within a day of reaching mastery criteria. For participant 2, maintenance procedures were identical to baseline for one of each task and identical to intervention for one of each task.
Results
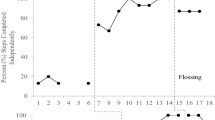
The top portion of Fig. 1 displays the results for participant 1. During baseline, he responded with low accuracy with the cooking task (M = 4 %), setting the table (M = 0 %), and folding his jeans (M = 0 %). With the introduction of video modeling, the participant’s accuracy increased immediately and he mastered the three tasks in 11, 5, and 9 sessions, respectively. Coupled with video modeling, participant 1 required an average of 3, 0.4, and 0.2 prompts per session to acquire the cooking task, setting the table, and folding his jeans, respectively. During maintenance sessions, participant 1 responded with accuracy that was higher than baseline and just below mastery criterion for all three behaviors. His percentage of steps performed correctly was 74, 72, and 89 % for tasks 1, 2, and 3, respectively.

Percentage of steps performed correctly for participant 1 (top portion of figure) with making tortellini (top panel), setting the table (middle panel), and folding jeans (bottom panel) and participant 2 (bottom portion of figure) with setting the table, cleaning the counter and sink, and cleaning the mirror
The bottom portion of Fig. 1 displays the results for participant 2. During baseline, he responded with low accuracy with the setting the table task (M = 0 %), cleaning the sink and counter (M = 0 %), and cleaning the mirror (M = 15 %). With the introduction of video modeling, his accuracy increased immediately and he mastered the three tasks in 11, 30, and 15 sessions, respectively. Coupled with video modeling, participant 2 required an average of 4, 2, and 1.5 prompts per session to acquire the setting the table, cleaning the counter and sink, and cleaning the mirror tasks, respectively. During maintenance sessions, participant 2 responded with accuracy that was higher than baseline and just below mastery criterion for all three behaviors. Additionally, participant 2 responded with higher accuracy when the video was shown than without the use of video modeling. Specifically, his percentage of steps performed correctly on maintenance probes without the video was 76, 43, and 46 % with tasks 1, 2, and 3, respectively; maintenance probes with the video were 94, 50, and 77 % with tasks 1, 2, and 3, respectively.
Discussion
The overall findings from this study suggested a functional relation between the use of video modeling utilizing the iPad/iPod and the percentage of steps correctly performed by the participants during the targeted ADLS tasks. This study extends the work of Kellems and Morningstar (2012) in several notable ways. First, we employed a more stringent mastery criterion. Second, we measured the number of prompts and found that (a) prompts were needed for some of the steps in a task, but not all, and (b) there was a decrease in the number of needed prompts across sessions as the percentage of steps performed correctly increased.
This study also explored whether task acquisition could be maintained over time with (participant 2) and without (participant 1) the use of the video modeling during maintenance trials. For participant 2, the results suggested that participant 2 performed better with maintenance probes in which the video was shown. Participant 1’s overall performance was maintained without the use of video modeling; however, it was not maintained at the mastery criterion level.
There are several limitations identified in this study. One limitation to the study is that both of the observers did not observe every prompt, due to physical positioning, and therefore, the agreement coefficient for participant 2’s prompt data was relatively low. If a gestural prompt was used, it was difficult at times for the second observer to see the prompt. For example, if there were two prompts provided and one observer recorded one prompt, a 50 % agreement resulted which lowered the IOA percentage considerably. The second potential limitation is the fact that the verbal description in the video may have effectively chained the task, aiding in performance in the tasks for participant 2. While watching the videos, we observed that participant 2 engaged in a self-echoic prompt and stated the steps before he was about to perform them. However, while cleaning the mirror, participant 2 was observed to engage in facial distortion (contraction and release of facial musculature) as well as vocalizations. These behaviors may have interrupted the behavior chain leading to a slower rate of skill acquisition. The third limitation is that sessions occurred only 1–2 days out of the week which may have affected the rate of task acquisition. Elapsed time between sessions could have slowed down the rate of acquisition. The fourth potential limitation in the study was that we were not able to conduct maintenance probes on a consistent schedule due to participant availability and access to the home setting due to schedule conflicts. The final limitation in this study is the lack of maintenance data for participant 1 with the use of video modeling. Future research should consider a fixed schedule of maintenance probes with and without the use of video on maintenance probes over time.
Video modeling may be an effective tool for instructing learners diagnosed with ASD to perform activities of daily living skills resulting in an increase in independence which can lead to a better quality of life. Video models can be created in a short period of time and of various skills. In this study, point-of-view video models depicted the steps to be performed in an ADL task along with a verbal description of each step. The data in this study support Kellems and Morningstar (2012) and previous video-modeling research in which the use of video modeling has been shown to be effective with teaching ADLS and other skills such as vocational, social, and transitional skills.
References
Allen, K. D., Wallace, D. P., Renes, D., Bowen, S. L., & Burke, R. V. (2010). Use of video modeling to teach vocational skills to adolescents and young adults with autism spectrum disorders. Education and Treatment of Children, 33, 339–349.
Apple, A. L., Billingsley, F., & Schwartz, I. S. (2005). Effects of video modeling alone and with self-management on compliment-giving behaviors of children with high-functioning ASD. Journal of Positive Behavior Interventions, 7, 33–46.
Bellini, S., & Akullian, J. (2007). A meta-analysis of video modeling and video self-modeling interventions for children and adolescents with autism spectrum disorders. Exceptional Children, 73, 264–287.
Bidwell, M. A., & Rehfeldt, R. A. (2004). Using video modeling to teach a domestic skill with an embedded social skill to adults with severe mental retardation. Behavioral Interventions, 19, 263–274.
Burke, R. V., Allen, K. D., Howard, M. R., Downey, D., Matz, M. G., & Bowen, S. L. (2013). Tablet- based video modeling and prompting in the workplace for individuals with autism. Journal of Vocational Rehabilitation, 38(1), 1–14.
D’Ateno, P., Mangiapanello, K., & Taylor, B. A. (2003). Using video modeling to teach complex play sequences to a preschooler with autism. Journal of Positive Behavior Interventions, 5, 5–11.
Kellems, R. O., & Morningstar, M. E. (2012). Using video modeling delivered through iPods to teach vocational tasks to young adults with autism spectrum disorders. Career Development and Transition for Exceptional Individuals, 35, 155–167.
MacDonald, R., Clark, M., Garrigan, E., &Vangala, M. (2005) Using video modeling to teach pretend play to children with autism. Behavioral Interventions, 20, 225-238.
Maione, L., & Mirenda, P. (2006). Effects of video modeling and video feedback on peer-directed social language skills of a child with autism. Journal of Positive Behavior Interventions, 8, 106–118.
Shipley-Benamou, R. S., Lutzker, J. R., & Taubman, M. (2002). Teaching daily living skills to children with autism through instructional video modeling. Journal of Positive Behavior Interventions, 4, 165–175.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Funding
This study did not receive funding.
Conflict of Interest
The authors declare that they have no conflict of interest.
Ethical Approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed Consent
Informed consent was obtained from all individual participants included in the study.
Rights and permissions
About this article

Cite this article
Aldi, C., Crigler, A., Kates-McElrath, K. et al. Examining the Effects of Video Modeling and Prompts to Teach Activities of Daily Living Skills. Behav Analysis Practice 9, 384–388 (2016). https://doi.org/10.1007/s40617-016-0127-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40617-016-0127-y