
Abstract
The form of a verbal response allows for reinforcement mediation and language transmission across cultures. Reinforcement, in turn, plays a decisive role in learning verbal forms. The present work addresses methodological limitations of previous studies, providing further evidence of the role of automatic reinforcement in achieving parity with vocal models. In the first experiment, 4 preschool-age children heard the experimenter describe drawings of different actions in the passive voice. Participants were then asked to describe analogous drawings. They used the passive voice after the model was presented and continued to do so even when preferred explicit consequences followed diverging descriptions (i.e., in the active voice). To further investigate the effects of explicit reinforcement and of the passive-voice model, in Experiment 2, we altered the number of trials with explicit reinforcement and with the model. Three of four participants used the passive voice to describe the drawings, despite greater exposure to explicit consequences following descriptions diverging from the model.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Listeners are often unaware of the controlling variables of speakers’ behaviors. A scream for help can be under the control of very different stimuli, from a painful wound, to a robbery. Nonetheless, listeners can infer the controlling variables from the form of the response and mediate reinforcement (e.g., by imagining possible explanations and calling 911). The set of conventional forms that comprise the shared and shaped verbal practices of a community constitutes language (Vargas, 2013). Form allows for reinforcement mediation in a verbal community and the transmission of language across cultures (Palmer, 2007).
The role of reinforcement in learning conventional verbal forms is still a subject of debate. On one hand, nativists and interactionists argue that genetic endowment is the main force driving language development (Chomsky, 2005; for a review, see Schoneberger, 2010; for an empirical approach, see Greer & Yuan, 2008). On the other hand, Palmer (1996), drawing on Skinner (1957, p. 164), argues that, although it is not reasonable to assume that explicit reinforcement is responsible for all language learning, achieving parity with vocal models may be a strong automatic reinforcerFootnote 1 when learning conventional verbal forms. This is a plausible argument especially because when the vocal stimuli produced by a speaker reaches all listeners and the speaker, there is immediate feedback for converging with or diverging from the models (Donahoe & Palmer, 1994; Greer & Du, 2015). According to Palmer, “achieving parity is a conceptually awkward sort of reinforcer. It is not a stimulus. It is a particular kind of response, a recognition that one has conformed” (1996, p. 290). When speaker and listener repertoires are integratedFootnote 2 and models are stable in the verbal community, parity can be achieved not only by responses with point-to-point correspondence with the models (also named hear-say correspondence; Greer & Du, 2015) but also by responses that conform partially to the models (e.g., Skinner, 1957, p. 164), as is the case of intraverbal frames. For instance, by using the passive-voice frame “Z is being Y-ed by X,” the variable elements (Z, Y, X) will differ on each utterance depending on one’s particular context, but the fixed elements will achieve parity with verbal community practices, thus allowing for automatic reinforcement of the frame. Intraverbal control maintains the frame’s stability, despite its internal variability (Palmer, 1998).
To test possible effects of achieving parity, one can contrast the expected automatic reinforcing consequences of conforming to models with explicit consequences for diverging. Wright (2006), building on Whitehurst, Ironsmith, and Goldfein (1974), presented English-speaking children (3- to 5-year-olds) drawings of different animal interactions (e.g., a cat brushing a dog) and described each drawing in the passive voice. Following each description, participants were asked to describe an analogous drawing (e.g., a dog brushing a cat). Participants’ descriptions in the passive voice, which conformed to the model, were followed by a new trial, whereas active-voice descriptions were followed by praise, stickers, and toys. Despite such explicit consequences and despite describing drawings only in active voice during baseline, all participants used passive voice with increased frequency after repetitive exposure to the model. Østvik, Eikeseth, and Klintwall (2012) replicated Wright’s (2006) findings with Norwegian-speaking children (3- to 5-year-olds).
Wright (2006) and Østvik et al. (2012) thus provide empirical support for the reinforcing effects of achieving parity. However, they did not conduct systematic preference assessments of explicit consequences (Tullis et al., 2011), and the interval between trials was not standardized, considering that the next trial was presented immediately after a conforming description. Thus, participants conforming to the model completed the experiment more rapidly than those diverging from the model. Finally, the age variability between participants (up to 2 years) may be an extraneous variable that might have introduced variability in the data, possibly making the experimental effects less clear, especially considering the fact that the age range of the participants is a period of rapid verbal development (Horne & Lowe, 1996).
The present study addresses these methodological limitations, extending the investigation to Brazilian Portuguese-speaking children. This extension may further demonstrate the generality of the effects of achieving parity across cultures, but it can also reveal effects on more complex passive constructions. Whereas all of Wright’s (2006) and Østvik et al.’s (2012) passives took the form of “The Z is being Y-ed by the X,”Footnote 3 in Portuguese, nouns have gender markings that require different definite articles.Footnote 4 The most frequent frame used in the present study was “O Z-o está sendo Y-o pelo X-o,” with Z and X being male characters. However, if Z and X were female characters, the frame would be “A Z-a está sendo Y-a pela X-a,” and if Z was male and X was female, the frame would be “O Z-o está sendo Y-o pela X-a,” and vice versa. Furthermore, some verbs from English do not have correspondent verbs in Brazilian Portuguese (e.g., tickle/cócegas, which only functions as a noun); thus, other auxiliaries are needed rather than is being / está sendo (e.g., receiving/recebendo). For instance, the English phrase “The Z is being tickled by the X” was translated as “O Z-o está recebendo Y pelo X-o.”
Experiment 1
Method
Participants
Four children (Mage = 4.71 years, SD = 0.27 years), three girls (P1 to P3) and one boy (P4), participated in the experiment. All participants were native Brazilian Portuguese speakers with no reported developmental or language delays. Three additional children began the experiment, but two did not meet the experimental criteria to continue the experiment and one dropped out.
Setting and stimuli
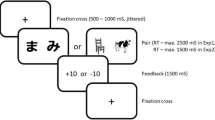
The experiment was conducted in a room at the school where participants were recruited. Sixty drawings, organized in three sets of 10 pairs each and based on the features established by Wright (2006) and Østvik et al. (2012), were used. In each pair, one drawing displayed animal X doing something to animal Y, and the other drawing showed the same animals playing the reverse roles (Slobin, 1966; Fig. 1). With one exception, animals and actions were not repeated across trials. Animals always moved to the right, and the descriptions included regular verbs (Budwig, 1990; Ferreira, 1994). The drawings were black and white and 15 cm long, and the width varied from 7 to 14 cm.

A pair of drawings used in the experimental condition. Drawing A would be described in the active voice as “The elephant is pulling the rat,” and in the passive voice as “The rat is being pulled by the elephant.” Drawing B would be described in the active voice as “The rat is pulling the elephant,” and in the passive voice as “The elephant is being pulled by the rat.” All descriptions were delivered in Brazilian Portuguese
Explicit consequences and noninteracting intervals
A paired-choice assessment (Fisher et al., 1992) was used to identify individual preferences for eight cartoons (e.g., Peppa Pig, Scooby-Doo). At least three cartoons, exhibiting high or medium preference, were selected for use as explicit consequences. Each presentation of the cartoon lasted 10 s. Following participants’ descriptions diverging from the model (e.g., active voice), the experimenter presented one cartoon and provided praise (“You rock!” etc.). Noninteracting 10-s intervals followed descriptions conforming to the model (i.e., passive voice) in order to guarantee equal time intervals between trials and to avoid subtle reinforcement (Greenspoon, 1955). During intervals, the experimenter ignored participants’ presence and utterances.
Procedure
We conducted the procedure in two conditions: a preexperimental condition and an experimental condition. The entire procedure comprised five daily sessions of 20 min each. In order to maintain a sufficient level of participants’ engagement in the task, at the end of each experimental session, the experimenter and child played and talked for 10 min. During this period, the experimenter always used the active voice. Table 1 shows all phases, independent variables, stimuli sets, and the number of trials per phase.
Preexperimental condition
This condition began with 20 min of playtime (e.g., bowling, playing cards). Next, speaker and listener repertoires were tested. The experimenter placed two common objects (e.g., pencil, eraser) on a table. He then pointed to one of them and asked, “What’s that?” After the child provided the correct answer, the experimenter removed the objects and asked, “What did you just tell me?” Finally, two objects were placed on the table with the instruction “Give me [object].” The procedure was repeated six times, using new combinations for each trial (Lowe, Horne, Harris, & Randle, 2002, p. 531). Correct responses (tact, self-echoic, selection) provided evidence that participants could act as both speakers and listeners.
Experimental condition
This condition began with familiarization with the stimuli display. The experimenter presented two drawings (one at a time), which were similar to the experimental stimuli and said, “Look! There are two animals here. Can you see that they are playing?” The familiarization was followed by five experimental phases: pretest (PRE), model (MOD), model and explicit consequence (MOD-CON), posttest (POST), and generalized audience test (GEN).
Pre
This phase served as a baseline of passive-voice use, prior to the introduction of the model. Ten drawings, the first in each pair from Set 1, were presented with the following instruction: “Tell me about this drawing.” When participants only labeled the animals, the experimenter asked, “What are they doing?” Participants’ descriptions were followed by removal of the drawing and a 10-s noninteracting interval.
Mod
The experimenter informed the participants that they would take turns describing the drawings (Set 2). Next, he described the first drawing in the first pair using the passive voice (Fig. 1a); after a 2-s interval, the experimenter presented the second drawing (Fig. 1b) and said, “This is your turn now! Tell me about this drawing.” A noninteracting interval followed participants’ descriptions. This procedure was repeated until the end of Set 2.
The main objective of this experiment was to contrast the effects of achieving parity and explicit consequences for participants’ descriptions. For participants to advance to the next phase, they had to describe at least three drawings overall in the passive voice. If this criterion was not met, the procedure was repeated. If the participant failed to meet the criterion a second time, the participant’s participation was terminated. As previously noted, that was the case for two participants.
Mod-con
This phase was similar to the previous one, MOD. However, explicit consequences followed descriptions made in the active voice or any kind of description not made in the passive voice (e.g., saying “Cat!”). Descriptions in the passive voice were still followed by a noninteracting interval (Set 3).
POST and GEN
These last two phases were similar to the PRE phase. However, during the POST phase, the second drawing in each pair from Set 1 was used. During GEN, a different experimenter (unfamiliar to the child) conducted the trials.
Data analysis and interobserver agreement
Participant descriptions were coded as passive, active, or other.Footnote 5 An independent observer, naive to the experimental conditions, also analyzed the recordings of all P1 and P3 sessions, coding the voice used in each description and verifying procedural integrity using a procedural script. The interobserver agreement rate was 100%.
Results and discussion
Figure 2 depicts the number of descriptions in the passive voice across experimental phases for all participants. No participants used the passive voice in PRE. However, after being exposed to the model during MOD, all participants used the passive voice. Only P4 had to repeat the MOD phase. He described only two drawings in the passive voice the first time but described five in the passive voice the second time. When explicit consequences followed descriptions diverging from the model (MOD-CON), participants continued to use the passive voice, with increasing frequency for P1 and P2. When model and consequences were withdrawn (POST), the use of passive voice by participants decreased. During GEN, three participants continued to describe the drawings in the passive voice, but two did so less frequently. Performance in POST and GEN suggests that effects of the model faded over time. The decrease in the rate of passive-voice descriptions in the last four trials of POST and GEN, when compared to the same trials of MOD and MOD-CON, further corroborate this finding (Fig. 3).

Number of passive-voice descriptions in the pretest (PRE), model (MOD), model and explicit consequences (MOD-CON), posttest (POST), and generalized audience test (GEN) experimental phases for all participants. The asterisk indicates that P4 did not describe any drawings during GEN

Rate of passive-voice use by all participants during the last four trials of the model (MOD), model and explicit consequences (MOD-CON), posttest (POST), and generalized audience test (GEN) experimental phases
The present results are consistent with the findings of Wright (2006) and Østvik et al. (2012). However, it is possible that the experimental sequence used in these two previous studies and in the present experiment created a sequence effect between MOD and MOD-CON (Sidman, 1960). If achieving parity with the model is automatically reinforcing, then such reinforcement was available during the 20 trials of MOD and MOD-CON. On the other hand, the reinforcing effects of explicit consequences were available only during the 10 trials of MOD-CON. This sequence may have increased the reinforcing effects of achieving parity while decreasing the reinforcing effects of the explicit consequences. To investigate a possible sequence effect, we conducted a second experiment.
Experiment 2
In Experiment 2, the number of trials in which explicit consequences were available was doubled, and the number of trials in which the model was presented was reduced to half, reversing the scenario in Experiment 1. The setting, stimuli, consequences, and data analysis were identical to those of Experiment 1.
Method
Participants
Four children (Mage = 4.50 years, SD = 0.19 years), three girls (P5 to P7) and one boy (P8), participated in the experiment. All participants were native Brazilian Portuguese speakers with no reported developmental or language delays, and none had participated in Experiment 1.
Procedure
The preexperimental condition was the same as that of Experiment 1 with all participants attaining correct responses in all tasks. Following familiarization with stimuli structure, four experimental phases were conducted: PRE, explicit consequences (CON), MOD-CON, and POST. The PRE, MOD-CON, and POST phases were the same as those used in Experiment 1. CON was similar to PRE, with the exception that the second drawing in each pair from Set 2 was used with explicit consequences following descriptions that were not made in the passive voice. Table 2 depicts all phases, independent variables, stimuli sets, and number of trials per phase. The entire procedure was comprised of four daily sessions of 20 min each.
Interobserver agreement
As in Experiment 1, an independent observer, naive to the experimental conditions, analyzed the recordings of all P5 and P8 sessions. The agreement was 97% (range 94%–100%) for verbal voice coding (with one disagreement regarding an active-voice description) and 100% for procedural integrity.
Results and discussion
Figure 4 illustrates the number of descriptions using the passive voice by all participants in all experimental phases. No drawings were described in the passive voice during PRE and CON. Thus, all descriptions in CON were followed by explicit consequences. Nonetheless, three participants used the passive voice when the model was presented (MOD-CON), despite the presence of explicit consequences for diverging from the model and their analogous experience in CON. Additionally, participants did not use the passive voice during POST.

Number of passive-voice descriptions under the pretest (PRE), explicit consequences (CON), model and explicit consequences (MOD-CON), and posttest (POST) experimental phases for all participants
These results suggest that automatic reinforcement arising from achieving parity with vocal models can control the form of descriptions even when explicit consequences are abundant for diverging forms. However, the data also indicate that the amount of exposure to the models and to the explicit consequences modulates the duration of automatic reinforcing effects.
General discussion
The present study offers further evidence of automatic reinforcing effects of achieving parity with vocal models. It addresses methodological limitations of previous studies and expands the investigation to a new verbal community, whose language includes more complex passive constructions. Our results indicate that, even when contrasted with powerful competing reinforcers, achieving parity with the verbal practices of an adult is an important reinforcer for children around the age of 4 years. Furthermore, our findings suggest that the amount of exposure to the models and to explicit consequences can modulate such effects.
Nonetheless, the data presented in the study should be interpreted with caution. Although our findings are consistent with previous studies (Østvik et al., 2012; Wright, 2006), generality cannot be assumed due to the limited number of participants and to the observed lack of convergence with the model in three individuals. Future studies should use a more stringent criterion for ensuring that participants converge with the model in the modeling (MOD) condition, for instance, by requiring three consecutive rather than three cumulative passives. Additionally, the effects of instructional history might be better controlled by a multiple-probe design, and any possible extraneous order effect might be better controlled by counterbalancing the drawing sets across conditions and randomizing the order of the drawings’ presentation across participants. These modifications will require a greater number of participants, which may represent a good opportunity to further test the generality of the phenomenon under investigation.
Future research should also examine the contingencies that establish the reinforcing effects of achieving parity with verbal community practices. Research on the importance of conditioned reinforcers for complex verbal development (Greer & Du, 2015) and stimulus-stimulus pairing procedures might be particularly informative (Shillingsburg, Hollander, Yosick, Bowen, & Muskat, 2015; Smith, Michael, & Sundberg, 1996). Finally, future research should extend the investigation to different grammatical constructs.Footnote 6
An operant explanation of how linguistic regularity is learned has the potential to advance the behavioral and linguistic analysis of human language. The present findings represent a step forward in this direction.
Notes
The equivalent in Norwegian was “Z blir Y-t av X” (Østvik, 2009).
For a list with all the descriptions in Brazilian Portuguese and the correspondent English translations, please contact the first author.
Detailed analysis of each occurrence can be requested from the first author.
During pilot studies, we found that participants started describing single-subject actions using the uncommon object-subject-verb construct after the experimenter’s model (dubbed the Yoda model).
References
Budwig, N. (1990). The linguistic marking of nonprototypical agency: An exploration into children’s use of passives. Linguistics, 28(6), 1221–1252. https://doi.org/10.1515/ling.1990.28.6.1221
Chomsky, N. (2005). Three factors in language design. Linguistic Inquiry, 36(1), 1–22. https://doi.org/10.1162/0024389052993655
Donahoe, J. W., & Palmer, D. C. (1994). Learning and complex behavior. Boston, MA: Allyn & Bacon.
Ferreira, F. (1994). Choice of passive voice is affected by verb type and animacy. Journal of Memory and Language, 33(6), 715–736. https://doi.org/10.1006/jmla.1994.1034
Fisher, W., Piazza, C. C., Bowman, L. G., Hagopian, L. P., Owens, J. C., & Slevin, I. (1992). A comparison of two approaches for identifying reinforcers for persons with severe and profound disabilities. Journal of Applied Behavior Analysis, 25(2), 491–498. https://doi.org/10.1901/jaba.1992.25-491
Greenspoon, J. (1955). The reinforcing effect of two spoken sounds on the frequency of two responses. American Journal of Psychology, 68(3), 409–416. https://doi.org/10.2307/1418524
Greer, R. D., & Du, L. (2015). Identification and establishment of reinforcers that make the development of complex social language possible. International Journal of Behavior Analysis & Autism Spectrum Disorders, 1(1), 13–34.
Greer, R. D., & Speckman, J. (2009). The integration of speaker and listener responses: A theory of verbal development. The Psychological Record, 59, 449–488. https://doi.org/10.1007/BF03395674
Greer, R. D., & Yuan, L. (2008). How kids learn to say the darnedest things: The effect of multiple exemplar instruction on the emergence of novel verb usage. The Analysis of Verbal Behavior, 24, 103–121. https://doi.org/10.1007/BF03393060
Horne, P. J., & Lowe, C. F. (1996). On the origins of naming and other symbolic behavior. Journal of the Experimental Analysis of Behavior, 65(1), 185–241. https://doi.org/10.1901/jeab.1996.65-185
Kennedy, C. H. (1994). Automatic reinforcement: Oxymoron or hypothetical construct? Journal of Behavioral Education, 4(4), 387–395. https://doi.org/10.1007/BF01539540
Lowe, C. F., Horne, P. J., Harris, F. D., & Randle, V. R. L. (2002). Naming and categorization in young children: Vocal tact training. Journal of the Experimental Analysis of Behavior, 78(3), 527–549. https://doi.org/10.1901/jeab.2002.78-527
Østvik, L. (2009). Language acquisition and verbal behavior in normally developing children (unpublished master’s thesis). Norway: University of Oslo.
Østvik, L., Eikeseth, S., & Klintwall, L. (2012). Grammatical constructions in typical developing children: Effects of explicit reinforcement, automatic reinforcement and parity. The Analysis of Verbal Behavior, 28(1), 73–82. https://doi.org/10.1007/BF03393108
Palmer, D. C. (1996). Achieving parity: The role of automatic reinforcement. Journal of the Experimental Analysis of Behavior, 65(1), 289–290. https://doi.org/10.1901/jeab.1996.65-289
Palmer, D. C. (1998). The speaker as listener: The interpretation of structural regularities in verbal behavior. The Analysis of Verbal Behavior, 15(1), 3–16. https://doi.org/10.1007/BF03392920
Palmer, D. C. (2007). Verbal behavior: What is the function of structure? European Journal of Behavior Analysis, 8(2), 161–175. https://doi.org/10.1080/15021149.2007.11434280
Schoneberger, T. (2010). Three myths from the language acquisition literature. The Analysis of Verbal Behavior, 26, 107–131. https://doi.org/10.1007/BF03393086
Shillingsburg, M. A., Hollander, D. L., Yosick, R. N., Bowen, C., & Muskat, L. R. (2015). Stimulus-stimulus pairing to increase vocalizations in children with language delays: A review. The Analysis of Verbal Behavior, 31(2), 215–235. https://doi.org/10.1007/s40616-015-0042-2
Sidman, M. (1960). Tactics of scientific research: Evaluating experimental data in psychology. New York, NY: Basic Books.
Skinner, B. F. (1947). A psychological analysis of verbal behavior. Transcription by R. Hefferline of Skinner’s course on verbal behavior at Columbia University, New York. Available at http://www.bfskinner.org/archives/unpublished-works/
Skinner, B. F. (1948). Verbal behavior: William James lectures. Available at http://www.bfskinner.org/archives/unpublished-works/
Skinner, B. F. (1957). Verbal behavior. East Norwalk, CT: Appleton-Century-Crofts. https://doi.org/10.1037/11256-000
Slobin, D. I. (1966). Grammatical transformations and sentence comprehension in childhood and adulthood. Journal of Verbal Learning and Verbal Behavior, 5(3), 219–227. https://doi.org/10.1016/S0022-5371(66)80023-3
Smith, R., Michael, J., & Sundberg, M. L. (1996). Automatic reinforcement and automatic punishment in infant vocal behavior. The Analysis of Verbal Behavior, 13(1), 39–48. https://doi.org/10.1007/BF03392905
Tullis, C. A., Cannella-Malone, H. I., Basbigill, A. R., Yeager, A., Fleming, C. V., Payne, D., & Wu, P. F. (2011). Review of the choice and preference assessment literature for individuals with severe to profound disabilities. Education and Training in Autism and Developmental Disabilities, 46(4), 576–595.
Vargas, E. A. (2013). The importance of form in Skinner’s analysis of verbal behavior and a further step. The Analysis of Verbal Behavior, 29(1), 167–183. https://doi.org/10.1007/BF03393133
Vaughan, M., & Michael, J. L. (1982). Automatic reinforcement: An important but ignored concept. Behaviorism, 10(2), 217–227.
Whitehurst, G. J., Ironsmith, M., & Goldfein, M. (1974). Selective imitation of the passive construction through modeling. Journal of Experimental Child Psychology, 17(2), 288–302. https://doi.org/10.1016/0022-0965(74)90073-3
Wright, A. N. (2006). The role of modeling and automatic reinforcement in the construction of the passive voice. The Analysis of Verbal Behavior, 22, 153–169. https://doi.org/10.1007/BF03393036
Funding
The authors wish to thank So-Young Yoon, formerly of the F. S. Keller School in Yonkers, New York, for drawing the first and second sets of pictures used in the present and previous studies and Dr. Svein Eikeseth for sharing these sets; Karina C. Cinel for drawing the third set of stimuli; Lívia Benatti, Fanny Silveira, André Ferreira, and Fernanda Calixto for assistance during data collection and analysis; and São Paulo Research Foundation for its financial support through a master’s scholarship for the first author (no. 13/24761-0). A portion of this article is based on a thesis submitted by the first author, under the supervision of the second author, to the graduate program in psychology of the Universidade Federal de São Carlos in partial fulfillment of the requirements for the master’s degree in psychology.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Rodrigo Dal Ben and Celso Goyos conceived the study and were involved in experimental design. Rodrigo Dal Ben acquired and analyzed the data, with interpretation help from Celso Goyos. Rodrigo Dal Ben drafted the article, with revisions contributed by Celso Goyos. The manuscript has not been submitted to any other journal and has not been published previously.
Conflict of interest
There are no potential conflicts of interests, financial or not, regarding the research. Rodrigo Dal Ben declares that he has no conflict of interest. Celso Goyos declares that he has no conflict of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards. The institutional research ethics committee of the Universidade Federal de São Carlos approved the research (approval no. 31644714.2.0000.5504).
Informed consent
Parents provided informed consent authorizing the participation of their children, who agreed to take part at the onset of each experimental session.
Ethical statement
Concerning the manuscript “Further evidence of automatic reinforcement effects on verbal form”, the authors declare that:
1. Rodrigo Dal Ben and Celso Goyos conceived the study and were involved in experimental design. Rodrigo Dal Ben acquired and analyzed the data, with interpretation help from Celso Goyos. Rodrigo Dal Ben drafted the paper, with revisions contributed by Celso Goyos.
2. The manuscript has not been submitted to any other journal;
3. The manuscript has not been published previously;
4. There are no potential conflicts of interests, financial or not, regarding the research:
Rodrigo Dal Ben declares that he has no conflict of interest;
Celso Goyos declares that he has no conflict of interest;
5. All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
6. The institutional research ethics committee of the Universidade Federal de São Carlos approved the research (approval number 31644714.2.0000.5504) and parents signed an informed consent authorizing the participation of their children, who agreed to take part at the onset of each experimental session.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Dal Ben, R., Goyos, C. Further evidence of automatic reinforcement effects on verbal form. Analysis Verbal Behav 35, 74–84 (2019). https://doi.org/10.1007/s40616-018-0104-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40616-018-0104-3