
Abstract
Introduction
Post-marketing safety surveillance primarily relies on data from spontaneous adverse event reports, medical literature, and observational databases. Limitations of these data sources include potential under-reporting, lack of geographic diversity, and time lag between event occurrence and discovery. There is growing interest in exploring the use of social media (‘social listening’) to supplement established approaches for pharmacovigilance. Although social listening is commonly used for commercial purposes, there are only anecdotal reports of its use in pharmacovigilance. Health information posted online by patients is often publicly available, representing an untapped source of post-marketing safety data that could supplement data from existing sources.
Objectives
The objective of this paper is to describe one methodology that could help unlock the potential of social media for safety surveillance.
Methods
A third-party vendor acquired 24 months of publicly available Facebook and Twitter data, then processed the data by standardizing drug names and vernacular symptoms, removing duplicates and noise, masking personally identifiable information, and adding supplemental data to facilitate the review process. The resulting dataset was analyzed for safety and benefit information.
Results
In Twitter, a total of 6,441,679 Medical Dictionary for Regulatory Activities (MedDRA®) Preferred Terms (PTs) representing 702 individual PTs were discussed in the same post as a drug compared with 15,650,108 total PTs representing 946 individual PTs in Facebook. Further analysis revealed that 26 % of posts also contained benefit information.
Conclusion
Social media listening is an important tool to augment post-marketing safety surveillance. Much work remains to determine best practices for using this rapidly evolving data source.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Social media and Internet forums contain untapped safety and benefit information. |
Methods exist to reduce noise and make the data suitable for post-marketing safety surveillance. |
Additional research is needed to better understand the strengths, limitations, and best practices. |
1 Introduction
Pharmacovigilance, or drug safety surveillance, is the science related to the collection, detection, assessment, monitoring, and prevention of adverse effects with pharmaceutical products [1]. This discipline has advanced rapidly since the early 1960s when the world experienced the infamous disaster of phocomelia caused by thalidomide use during pregnancy. This discovery, along with several other high-profile safety issues, led to the call for and realization of a number of advances in the science of pharmacovigilance.
Prior to approval and marketing, a drug undergoes several stages of clinical trials to assess its safety and efficacy within a controlled environment. However, once the drug is marketed, the number of people exposed to it can increase exponentially. The controlled environment of strict inclusion and exclusion criteria does not necessarily hold in the marketed environment. Real-world use can expand beyond the strict interpretation of the label, although updates to the label remain a major avenue for communication of emerging safety concerns with healthcare providers. As a result, it is important that pharmaceutical companies and regulatory agencies have robust post-marketing safety surveillance processes that can provide information about real-world drug use.
A key source of post-marketing data is spontaneous adverse event (AE) reports. Regulatory agencies and industry stakeholders worldwide have mandatory reporting systems for certain adverse drug reactions (ADRs), medication errors, and quality problems, as well as systems for voluntary reporting of any concerns. Although spontaneous reports provide a valuable source of data, they have many limitations, including, but not limited to, significant under-reporting of events, incomplete data quality for clinical evaluation, and a lack of geographic diversity in reporting (e.g., most reports are from the USA and Europe).
In the USA, the Food and Drug Administration Amendments Act of 2007 (FDAAA 2007) mandated the development of new pharmacovigilance technologies focused on observational data (e.g., medical records, insurance claims databases) [2]. Several initiatives are underway that further explore ways in which observational data can be best utilized for post-marketing safety surveillance [3–6]. Limitations of observational data include a time delay (e.g., most publicly available data sources have a lag time of 9–12 months), a lack of geographic diversity (e.g., most data sources are from the USA or Europe), and insufficient information to determine the probability that the drug was a causative factor of the event.
One potential new source of drug safety data may be social media. A recent survey showed that nearly 90 % of the US adult population uses the Internet, and 72 % of those users had searched online for information about health issues [7]. Furthermore, between 3 and 4 % of Internet users have posted about their experiences with healthcare service providers or treatments on social media sites [7]. Much of the data posted by these patients are publicly available on the Internet, depending on the individual’s use of privacy settings when posting.
Because the Internet is already being used to communicate medical information, social listening—the process of learning from public conversations on the Internet [8]—is worthy of further exploration for several reasons, including those investigated by others [9–17]. First, it may unlock a large data source that has been previously untapped for pharmacovigilance. Second, it introduces the voice of the patient directly into the conversation about drug safety, using his or her own words, which may prove valuable to our understanding of real-world medication use. Third, the worldwide utilization of social media and rapid availability of data may offer real-time access to geographically diverse data without a significant temporal lag between an event’s occurrence and its discovery by the pharmacovigilance community. These social listening attributes could help overcome some of the limitations of other data sources.
While public health research efforts have typically relied on traditional data sources, social media is gaining as a viable data source that can be used to analyze and forecast epidemiologic trends. HealthMap, developed by the Computational Epidemiology Group at Boston Children’s Hospital, is a publicly available online surveillance system designed to detect infectious disease outbreaks from news media reports. Recently, HealthMap identified the earliest public signals of an initial Ebola outbreak in Guinea dating back to March 2014. Within 6 months of the outbreak, more than 13,000 alerts were aggregated, classified, and visualized, enabling researchers to visualize a projected spread of the disease and high-risk areas of transmission. HealthMap’s Ebola data were used to support outbreak surveillance by the Centers for Disease Control and Prevention, Department of Homeland Security, Department of Health and Human Services, and the World Health Organization (WHO) [18].
Another study, conducted by Merck and the Computational Epidemiology Group at Boston Children’s Hospital, investigated whether Twitter data could be of use in research on sleep issues. Using data acquired from public Twitter posts, the authors created cohorts of patients to characterize and compare individuals apparently experiencing sleep issues compared with those who were not. The authors concluded that social media provided a cost-effective and efficient source of valuable data that could contribute to research on sleep issues [19].
Overall, we hypothesize that by capturing publicly available data on social media sites and Internet forums, we might meaningfully and positively impact current pharmacovigilance processes. In this paper, we describe and evaluate one applied approach to social media listening for pharmacovigilance and identify whether any benefit information was also present.
2 Methods
After acquisition of publicly available Facebook and Twitter data using these sites’ public Application Programming Interfaces (APIs), which are commercially available from authorized data resellers, the following steps were performed by a third-party vendor:
-
Translation: standardization of drug names and vernacular symptom/event descriptions.
-
Filtering: highlighting of relevant posts and data cleaning (removal of duplicates and noise).
-
De-identification: removal of personally identifying information.
-
Supplementation: addition of other data sources to assist with interpretation.
2.1 Translation
After data were collected, posts underwent an automated classification process to interpret the wording used to describe drug and medical condition concepts. Natural language processing (NLP) software, which refers to the development and use of computer systems to recognize and interpret natural human language [20], reviewed each post and matched the text against a vernacular-to-regulatory language translation dictionary. At the time of our research, the dictionary contained over 5,000 phrases linked to approximately 1,500 Medical Dictionary for Regulatory Activities (MedDRA®) Preferred Terms (PTs). The process of identifying PTs by tagging verbatim text was conducted in an entirely automated fashion (e.g., “I looked like a lobster” would be mapped to “erythema”).
In addition to standardizing medical concepts, we also standardized drug names based on the Anatomical Therapeutic Chemical (ATC) classification system for drugs. All individual product search terms were mapped to the fifth level of the ATC system hierarchy, with the ability to group product data at the substance level. If a single post were to refer to more than one product, human curation would be used to attribute each symptom to the appropriate product, where verbatim descriptions made attribution possible. WHO’s published guidelines for ATC classification and defined daily dose (DDD) assignment were followed for mapping combination products. Products with more than one ATC code were mapped to multiple hierarchies. We used a proprietary dictionary that maps vernacular terms for drugs, including common misspellings. At the time of our research, about 1,000 distinct drug concepts existed in the dictionary. For the purpose of this paper, the term ‘drug’ may represent a range of pharmaceutical products (e.g., prescription medicines, over-the-counter products, vaccines, etc.).
2.2 Filtering
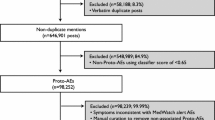
The next step was to identify which posts were relevant for drug safety. To achieve this, a Bayesian probabilistic model was developed through statistical machine learning computation, based on Robinson’s approach to eliminating spam emails [21], also described in detail elsewhere [20]. The dataset to train the model was developed by manually coding more than 100,000 posts using a custom curation interface built specifically for reviewing and labeling posts. Curators were certified MedDRA® coders and trained in pharmacovigilance, and adhered to standard assessment practices whereby a priori assumptions of causality did not influence curation. Analysts labeled the posts as either a post in which a potential AE is discussed, or not, according to standard protocol, and coded all symptoms present in the text according to MedDRA® coding guidelines. The resulting data were then reviewed for concordance with labeled AEs as well as with spontaneous report data received by the FDA [20]. Using the Bayesian probabilistic model, each post was assigned an indicator score on a scale of 0–1 by the algorithm. A score close to 0 meant there was a low probability that the post was related to an AE discussion, whereas a score close to 1 indicated a high probability that the post was related to an AE discussion. The indicator scores, combined with the drug/condition mappings previously discussed, were used to categorize posts into one of the following four categories (Fig. 1):

Schematic representation for classification of social media posts into relevant categories for drug safety. This figure depicts the logical progression of classification questions used to categorize social media posts from Twitter and Facebook. If a post did not contain a valid product name, it was considered junk. If it contained a valid product, and if it did not describe a proto-adverse event, it was considered a ‘mention’. Proto-adverse events were then further dichotomized based on the presence of interaction with the clinical healthcare delivery system. AE adverse event, HSI health system interaction
-
Junk: spam (e.g., questionable internet pharmacy advertisements).
-
Mention: post in which a drug is discussed.
-
Proto-AE: post in which a potential event is discussed within the context of drug use and an indicator score of at least 0.7.
-
Health System Interaction (HSI): a Proto-AE that also describes a health system interaction (e.g., “saw my doctor,” “went to the emergency room,” etc.)
After the automated categorization, the team manually reviewed and classified approximately 10,000 proto-AEs and mentions as AEs or non-AEs, using an annotation tool developed in-house specifically for this purpose. The annotation tool allowed the team to modify the post classification (e.g., re-classify a post in the event of a false positive) and disambiguate the product–event pairs mentioned in posts. Subsequently, the indicator scores for these posts were stratified into ten equal strata and evaluated.
The software platform, from data acquisition to visualization, was undergoing GxP validation during the analysis. Final certification of GxP validation was not completed until the analysis was complete.
2.3 De-Identification
The next step was to remove personally identifiable information (PII), such as screen names, user names, first and last names, and addresses, as well as any uninformative vulgar content. A hybrid automated–manual process was used for removing first and last names. Using a ‘PII dictionary’ containing a few hundred thousand names from a global database of values, the software removed from the posts any names that were contained in the dictionary. In addition, text-based pattern matching was used to remove URLs and other structured information that could lead to individual identification. Additionally, any geographic information included in the post was either removed, made less specific, or otherwise obfuscated (e.g., truncating five-digit US postal codes to only the first three digits allows for patient anonymity while preserving sufficient geographical resolution to conduct geospatial analysis). For the purpose of this research project, the following additional steps were taken to protect privacy:
-
Once the data had been de-identified by the vendor, no attempt was made to re-identify the person making the post. As a result, no attempt was made to obtain follow-up information about potential AEs.
-
Posts from the same person were not linked.
2.4 Supplementation
Once posts were categorized, the data were supplemented with other sources of information to help the review process. Supplemental data included:
-
Mentions and sales data to be used as denominators in frequency calculations.
-
The European Medicines Agency (EMA) Important Medical Event (IME) terms list.
-
Drug labeling to identify which events are currently listed in the drug’s label and which are not.
-
Spontaneous AE data from the FDA AE Reporting System (FAERS) for comparison purposes.
2.5 Statistical Methods
Disproportionality was calculated using the proportional reporting ratio (PRR) at the drug–event pair level and multiplicate copies were consolidated. For the sake of brevity, a single product (salbutamol/albuterol) was chosen for PRR calculations.
PRR was calculated as \( \left( {\frac{{a/\left( {a + b} \right)}}{{c/\left( {c + d} \right)}}} \right) \), where, for a given drug X and event Y pair, a is the number of proto-AEs involving drug X and event Y, b is the number of proto-AEs involving drug X and NOT event Y, c is the number of proto-AEs involving NOT drug X and event Y, d is the number of proto-AEs involving NOT drug X and NOT event Y.
Multiplicate copies were accounted for in two ways. First, literal duplicates were identified and consolidated using verbatim matches. For Twitter data, the system further identified duplicate posts according to characteristics such as the phrase ‘RT’ (used in Twitter to denote a ‘retweet’). Second, a rule-based approach was developed to consider fuzzy matches as duplicates using increased computation power. If a post was nearly identical to another post, but had a number of characters that were distinct, then it was marked as a duplicate. This character length was customizable, and was set at 50 characters. The duplicate removal process was developed based on a Bloom filter [22], a computationally efficient algorithm used to determine set membership. This method allows for a 100 % recall rate (i.e., all duplicates would be captured), while the probability of finding a false positive was set at 0.001 % (i.e., there is a 0.001 % chance that a post would be falsely marked as a duplicate). Multiplicate copy reduction was conducted only using empirical textual approaches, and did not include attempts to reduce conceptually redundant posts as has been undertaken with spontaneous report data [23].
2.6 Data Analysis
Two analysis datasets were created. All publicly available English-language posts from Facebook and Twitter from October 2012 to October 2014 were collected and analyzed to understand the general characteristics of the data.
A second dataset was created from 15 GlaxoSmithKline drugs with varying characteristics (different dosage forms, acute vs. chronic, prescription vs. non-prescription, older vs. newer agents, larger vs. smaller target patient populations). This dataset contained 15,490 posts, collected and processed using the previously described methodology. All proto-AEs were manually reviewed along with a similar number of mentions that were randomly selected from publicly available, English-language posts on Facebook and Twitter from 01 September 2013 to 31 August 2014. If a single post referred to more than one product, manual curation was used to attribute each event to the appropriate product, when verbatim descriptions made such attribution possible. The manual review was conducted by experienced pharmacovigilance staff members (curation team) who assessed a range of attributes.
The following analyses were performed on the second dataset:
-
Distribution of indicator scores for ‘adverse event’ and ‘non-adverse event’ posts.
-
Summary of post classifications (see Fig. 1).
-
Calculation and evaluation of PRRs for one drug (albuterol) using a reference database developed for this purpose that contained approximately 300 drugs.
-
Evaluation of benefit information.
3 Results
3.1 Medical Events
In Twitter, a total of 6,441,679 events (at the PT level, representing 702 unique PTs) were discussed in the same post as a drug; 15,650,108 total PTs representing 946 unique PTs were similarly discussed in Facebook. The five most common PTs discussed were pain, altered state of consciousness, headache, malaise, and drug ineffective (Table 1).
3.2 Medical Products
Among the medical products studied, those with the most events on Twitter and Facebook were diphenhydramine, influenza vaccine, dextroamphetamine, codeine, and morphine (Table 2).
3.3 Indicator Scores
Posts with indicator scores of ≥0.7 had a positive predictive value of approximately 0.5 (i.e., five of every ten posts would be relevant for drug safety), while keeping almost 92 % of the true AE posts (2291 of 2496) (Table 3). Note that a true positive was defined as a post that is identified as an AE by a member of the curation team. On the other hand, posts with indicator scores of <0.7 had a positive predictive value of approximately 0.04 (i.e., fewer than one in every ten posts would be relevant for drug safety).
3.4 Post Classification
The distribution of post classifications by social media source varied considerably among drugs. The percent of posts with proto-AEs varied from 11 to 51 % for prescription drugs (Table 4), and were generally lower for over-the-counter products, ranging from 3 to 34 % (Table 5). The highest volume prescription drug (drug E) had 3,104 posts (all mentions in Facebook and Twitter combined) during the study period, 1,467 of which were proto-AEs. The lowest volume prescription drug (drug D) had only 63 posts (all mentions in Facebook and Twitter combined), with only seven proto-AEs identified.
3.5 Disproportionality Analysis
The proto-AEs with the highest PRRs observed for salbutamol (albuterol) were mostly known side effects (ADRs) of the drug or events related to the respiratory diseases for which the drug is indicated, including tremor (PRR 40.1), chronic obstructive pulmonary disease (39.2), wheezing (38.7), bronchitis (14.6), and pallor (13.9) (Table 6).
3.6 Benefit Discussions
Of 15,490 total posts reviewed (representing all tagged proto-AEs and a random sample of an equal number of mentions), 3976 (26 %) discussed benefits of the drug. Of the benefit discussions, 524 (13.2 %) went on to contextualize benefits with respect to AEs, other treatment options, cost, and/or product complaints. See Fig. 2 for more details (post text has been paraphrased and/or altered in non-meaningful ways to protect the privacy of individuals).

Description of types of benefit discussions and contextualization observed in social media data. Distributions of types of product contextualization are presented, alongside exemplary quotations from social media. Indication was often given among posts with any contextualization or benefit information. Full or partial benefits followed, and time-to-onset and duration of benefit were rarely specified. Among contextualization information, benefits were often presented alongside adverse events. Patients regularly made comparisons between products and offered advice. Cost and product quality complaints were also documented. Verbatim post text has been paraphrased and/or altered in non-meaningful ways to protect patient identity and prevent unmasking using Internet search engines
4 Discussion
In this paper, we describe a methodology by which raw social listening data can be effectively transformed into a usable format for routine post-marketing safety surveillance. The methodology includes collection of raw data, standardization of vocabularies, identification of informative posts, and reduction of noise. Additionally, we have described how the data can be supplemented with other sources of information (e.g., product label, sales data) to facilitate the review process and contextualize the results. Although this process is a promising method of unlocking the potential of social listening for routine post-marketing safety surveillance, it is only a starting point, and several limitations exist. Additional research is needed to better understand the strengths and limitations of the method we describe, as well as to identify other methods that might be used. Since social media is a relatively new data source, more work remains to determine how the data can be efficiently leveraged and incorporated into an overall pharmacovigilance strategy.
Other studies have examined the use of social media data in pharmacovigilance from a hypothetical or research standpoint [9–17]. These studies have mostly focused on investigating the availability of AE information in social media sources and the necessary technology and methods for processing it. Academic studies that have proposed alternative methodological approaches to social listening in pharmacovigilance were also evaluated in the conduct of the research presented here [20, 24–29]. In addition, many case studies have been published documenting specific drug–event associations, Internet-based tools for soliciting patient reports of AEs, and disease-related discussions that also mention AEs [30–45]. Finally, there are studies that articulate general text mining approaches in pharmacovigilance, including from published literature [46, 47]. In contrast, this paper aims to provide practical information from an industry perspective on how social media data may be used to support specific pharmacovigilance efforts—both through a technical description of our methods and a discussion of how we addressed challenges such as individuals’ privacy protection.
One challenge posed by this data source is that it is ever-changing, particularly in terms of its availability. This is a significant factor because, for this study, only public data from Facebook and Twitter were used, to both respect individuals’ privacy and comply with site-specific terms of use agreements. During the study period, individual account holders on Facebook were able to designate a post to be private or public, and only the latter were used. Approximately 25 % of profiles on Facebook [48] and 90 % of Twitter feeds [49] are believed to be completely public, although the availability of these data is subject to unanticipated change due to personal user settings, modifications made to APIs, and other site-wide limitations. While only including public posts signifies that the reports are only coming from a select number of social media users, similar biases exist in spontaneous data sources, in which AE reports are submitted by patients on a voluntary basis.
One important task is to understand when and how to access the various disparate social media data sources and how best to evaluate newly emerging data sources in the context of pharmacovigilance. Because of the unique nature of each data source, we anticipate significant variation in the potential applications for drug safety. For example, the character restriction of Twitter limits the extent of discussion of very complex safety issues. Also, certain disease-specific websites, such as http://www.lupus.org, focus only on a particular patient population. There is also a need to understand where the pockets of high-yield data exist. For example, which data sources provide the most information for certain disease states (e.g., asthma, diabetes) and which data sources work well for certain medical conditions (e.g., pregnancy).
In addition to understanding these aspects of the data, much work needs to be done in the field of ontology (formal vocabularies). For example, we need to understand how vernacular terminology is used to represent medical concepts, how this might vary from site to site, and how this might vary from one geographic region to another. As communication methods and styles continue to evolve, there is an increasing need to be aware of new terminology, colloquialisms, acronyms, and abbreviations. We also need to develop data-mining capabilities to capture posts in multiple languages around the world. Although we currently have a vernacular-to-regulatory language translation dictionary (e.g., mapping “feeling bad” to ‘malaise’), there are opportunities for improvement as well as a need for ongoing maintenance.
Similarly, more work is needed to determine how our current process can be further automated. Our method relies on human skill to further train the classifier and remove false positives, a process that increases the overall positive predictive value to nearly 100 %. While our current understanding of social media discussion is that its highly nuanced nature warrants this type of manual review, additional work in ontology and data-mining could ultimately help us reduce the amount of human effort required.
Because we opted to not link posts from the same person in order to protect individuals’ privacy, it is possible that duplicative—but distinct—posts describing a single AE may have been captured and included in the analysis. We do not believe that the likelihood of these types of duplicates occurring in social media data would be much different from that of duplicates occurring in other, more traditional data sources or that this would affect overall results [23].
Further investigation of ways to appropriately and efficiently leverage quantitative techniques will also help improve our understanding of the data. We have described a way of calculating frequencies and disproportionality, for example, but other methodologies could be tested and new techniques may emerge over time. It will also be important to understand how to utilize the quantitative aspects, such as quantitative signal detection. For example, rates of AE discussions are likely to have a baseline rate and a peak rate that may be stimulated by reports on health conditions in the media. Informal content analysis of the results suggest that the baseline rate may be more relevant for quantitative signal detection, since peak rates were observed to be stimulated by news media coverage, as has been noted in previous studies conducted by our group [50–53]. Further research is needed to determine how best to use these rates and whether a statistical threshold for quantitative signal detection may be appropriate.
Other methodological areas also need further exploration. Moving beyond identifying a simple drug–event relationship to include other elements of sentences in online posts may help to identify the true essence of the discussion (we call this ‘topic identification’). For example, in previous published work from our group, we observed peaks in news media discussion around drug abuse with opioid analgesics, but applying topic identification methods revealed that the discussions centered on a famous person who had overdosed rather than on patients discussing their own experiences [53]; content analysis of social media posts displayed the same characteristic, a phenomenon known as intermedia convergence [54]. Topic identification offers the potential to distill a large amount of data very quickly and can provide key learnings to safety staff in an efficient manner.
In addition to the methodological work outlined above, there is a need to understand how to best utilize the data for signal detection. It would be helpful to know whether these data are best suited for specific drugs and events or whether they can be used more broadly. Based on the events shown in Table 1, the following areas may be worth exploring in the future:
-
Dependence, drug abuse: these terms might be used to better understand the abuse potential of drugs.
-
Overdose: this might be used to better understand exaggerated pharmacologic effects typically seen in overdose cases.
-
Pregnancy: using this term could identify discussions of drug use in pregnancy.
We also need to understand what, if any, additional data elements exist within posts that might contribute to our understanding of potential events of interest. For example, concomitant drugs and medical history information might enable a more accurate clinical assessment of events of interest. Demographic information, such as sex and age, might allow better generalization of results, and natural language processing technology may evolve where these characteristics can be inferred based on the usage of language.
5 Conclusions
Our research suggests that social media listening is an important tool to augment the post-marketing safety surveillance process. Not only can it contextualize real-world drug use, but it also offers the potential to help identify safety concerns. Social listening also offers additional data not traditionally seen with existing data sources, such as benefit discussions. Much work remains to better understand best practices for using these new and rapidly evolving data sources. As practical experience is obtained, best practices will start to emerge and should be shared among all stakeholders. It will take collaboration across a range of internal and external stakeholders to answer many of the questions we have raised.
References
World Health Organization. The importance of PV: safety monitoring of medical products. World Health Organization, United Kingdom. 2002. http://apps.who.int/medicinedocs/pdf/s4893e/s4893e.pdf. Accessed 7 Dec 2015.
Food and Drug Administration Amendments Act of 2007. 2007. http://www.fda.gov/RegulatoryInformation/Legislation/SignificantAmendmentstotheFDCAct/FoodandDrugAdministrationAmendmentsActof2007/FullTextofFDAAALaw/default.htm. Accessed 16 Sept 2015.
Patadia VK, Coloma P, Schuemie MJ, Herings R, Gini R, Mazzaglia G, et al. Using real-world healthcare data for PV signal detection—the experience of the EU-ADR project. Expert Rev Clin Pharmacol. 2015;8(1):95–102. doi:10.1586/17512433.2015.992878.
Trifiro G, Coloma PM, Rijnbeek PR, Romio S, Mosseveld B, Weibel D, et al. Combining multiple healthcare databases for postmarketing drug and vaccine safety surveillance: why and how? J Intern Med. 2014;275(6):551–61. doi:10.1111/joim.12159.
Stang PE, Ryan PB, Racoosin JA, Overhage JM, Hartzema AG, Reich C, et al. Advancing the science for active surveillance: rationale and design for the Observational Medical Outcomes Partnership. Ann Intern Med. 2010;153(9):600–6. doi:10.7326/0003-4819-153-9-201011020-00010.
McClure DL, Raebel MA, Yih WK, Shoaibi A, Mullersman JE, Anderson-Smits C, et al. Mini-Sentinel methods: framework for assessment of positive results from signal refinement. Pharmacoepidemiol Drug Saf. 2014;23(1):3–8. doi:10.1002/pds.3547.
Pew Research Internet Project. Health Fact Sheet: Highlights of the Pew Internet Project’s research related to health and healthcare. http://www.pewinternet.org/fact-sheets/health-fact-sheet. Accessed 7 Aug 2015.
Nair M. Understanding and measuring the value of social media. J Corp Acc Finance. 2011;22(3):45–51.
Ghosh R, Lewis D. Aims and approaches of Web-RADR: a consortium ensuring reliable ADR reporting via mobile devices and new insights from social media. Expert Opin Drug Saf. 2015:1–9. doi:10.1517/14740338.2015.1096342.
Golder S, Norman G, Loke YK. Systematic review on the prevalence, frequency and comparative value of adverse events data in social media. Br J Clin Pharmacol. 2015;80(4):878–88. doi:10.1111/bcp.12746.
Lardon J, Abdellaoui R, Bellet F, Asfari H, Souvignet J, Texier N, et al. Adverse drug reaction identification and extraction in social media: a scoping review. J Med Internet Res. 2015;17(7):e171. doi:10.2196/jmir.4304.
Sloane R, Osanlou O, Lewis D, Bollegala D, Maskell S, Pirmohamed M. Social media and PV: a review of the opportunities and challenges. Br J Clin Pharmacol. 2015;80(4):910–20. doi:10.1111/bcp.12717.
Sarker A, Ginn R, Nikfarjam A, O’Connor K, Smith K, Jayaraman S, et al. Utilizing social media data for PV: a review. J Biomed Inform. 2015;54:202–12. doi:10.1016/j.jbi.2015.02.004.
Noren GN. PV for a revolving world: prospects of patient-generated data on the internet. Drug Saf. 2014;37(10):761–4. doi:10.1007/s40264-014-0205-4.
White RW, Harpaz R, Shah NH, DuMouchel W, Horvitz E. Toward enhanced PV using patient-generated data on the internet. Clin Pharmacol Ther. 2014;96(2):239–46. doi:10.1038/clpt.2014.77.
Masoni M, Guelfi MR, Conti A, Gensini GF. PV and use of online health information. Trends Pharmacol Sci. 2013;34(7):357–8. doi:10.1016/j.tips.2013.05.001.
Edwards IR, Lindquist M. Social media and networks in PV: boon or bane? Drug Saf. 2011;34(4):267–71. doi:10.2165/11590720-000000000-00000.
Majumder MS, Kluberg S, Santillana M, Mekaru S, Brownstein JS. ebola outbreak: media events track changes in observed reproductive number. PLoS Curr. 2014;2015:7. doi:10.1371/currents.outbreaks.e6659013c1d7f11bdab6a20705d1e865.
McIver DJ, Hawkins JB, Chunara R, Chatterjee AK, Bhandari A, Fitzgerald TP, et al. Characterizing sleep issues using twitter. J Med Internet Res. 2015;17(6):e140. doi:10.2196/jmir.4476.
Freifeld CC, Brownstein JS, Menone CM, Bao W, Filice R, Kass-Hout T, et al. Digital drug safety surveillance: monitoring pharmaceutical products in twitter. Drug Saf. 2014;37(5):343–50. doi:10.1007/s40264-014-0155-x.
Robinson G. A statistical approach to the spam problem. Linux J. 2003;2003(107):3.
Bloom B. Space/time trade-offs in hash coding with allowable errors. Commun ACM. 1970;13(7):422–6. doi:10.1145/362686.362692.
Hauben M, Reich L, DeMicco J, Kim K. ‘Extreme duplication’ in the US FDA adverse events reporting system database. Drug Saf. 2007;30(6):551–4.
Nikfarjam A, Sarker A, O’Connor K, Ginn R, Gonzalez G. PV from social media: mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. J Am Med Inform Assoc. 2015;22(3):671–81. doi:10.1093/jamia/ocu041.
Yang M, Kiang M, Shang W. Filtering big data from social media–Building an early warning system for adverse drug reactions. J Biomed Inform. 2015;54:230–40. doi:10.1016/j.jbi.2015.01.011.
Sarker A, Gonzalez G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. J Biomed Inform. 2015;53:196–207. doi:10.1016/j.jbi.2014.11.002.
Sarntivijai S, Abernethy DR. Use of internet search logs to evaluate potential drug adverse events. Clin Pharmacol Ther. 2014;96(2):149–50. doi:10.1038/clpt.2014.115.
O’Connor K, Pimpalkhute P, Nikfarjam A, Ginn R, Smith KL, Gonzalez G. PV on twitter? Mining tweets for adverse drug reactions. AMIA Annu Symp Proc. 2014;2014:924–33.
Wu H, Fang H, Stanhope SJ. Exploiting online discussions to discover unrecognized drug side effects. Methods Inf Med. 2013;52(2):152–9. doi:10.3414/ME12-02-0004.
Abou Taam M, Rossard C, Cantaloube L, Bouscaren N, Roche G, Pochard L, et al. Analysis of patients’ narratives posted on social media websites on benfluorex’s (Mediator(R)) withdrawal in France. J Clin Pharm Ther. 2014;39(1):53–5. doi:10.1111/jcpt.12103.
Chary M, Genes N, McKenzie A, Manini AF. Leveraging social networks for toxicovigilance. J Med Toxicol. 2013;9(2):184–91. doi:10.1007/s13181-013-0299-6.
Coloma PM, Becker B, Sturkenboom MC, van Mulligen EM, Kors JA. Evaluating social media networks in medicines safety surveillance: two case studies. Drug Saf. 2015;38(10):921–30. doi:10.1007/s40264-015-0333-5.
Dyar OJ, Castro-Sanchez E, Holmes AH. What makes people talk about antibiotics on social media? A retrospective analysis of Twitter use. J Antimicrob Chemother. 2014;69(9):2568–72. doi:10.1093/jac/dku165.
Harmark L, van Puijenbroek E, van Grootheest K. Intensive monitoring of duloxetine: results of a web-based intensive monitoring study. Eur J Clin Pharmacol. 2013;69(2):209–15. doi:10.1007/s00228-012-1313-7.
Pages A, Bondon-Guitton E, Montastruc JL, Bagheri H. Undesirable effects related to oral antineoplastic drugs: comparison between patients’ internet narratives and a national PV database. Drug Saf. 2014;37(8):629–37. doi:10.1007/s40264-014-0203-6.
Palosse-Cantaloube L, Lacroix I, Rousseau V, Bagheri H, Montastruc JL, Damase-Michel C. Analysis of chats on French internet forums about drugs and pregnancy. Pharmacoepidemiol Drug Saf. 2014;23(12):1330–3. doi:10.1002/pds.3709.
Schroder S, Zollner YF, Schaefer M. Drug related problems with Antiparkinsonian agents: consumer internet reports versus published data. Pharmacoepidemiol Drug Saf. 2007;16(10):1161–6. doi:10.1002/pds.1415.
Simmering JE, Polgreen LA, Polgreen PM. Web search query volume as a measure of pharmaceutical utilization and changes in prescribing patterns. Res Social Adm Pharm. 2014;10(6):896–903. doi:10.1016/j.sapharm.2014.01.003.
White RW, Tatonetti NP, Shah NH, Altman RB, Horvitz E. Web-scale PV: listening to signals from the crowd. J Am Med Inform Assoc. 2013;20(3):404–8. doi:10.1136/amiajnl-2012-001482.
Shutler L, Nelson LS, Portelli I, Blachford C, Perrone J. Drug use in the twittersphere: a qualitative contextual analysis of tweets about prescription drugs. J Addict Dis. 2015;34(4):303–10. doi:10.1080/10550887.2015.1074505.
Lee JL, DeCamp M, Dredze M, Chisolm MS, Berger ZD. What are health-related users tweeting? A qualitative content analysis of health-related users and their messages on twitter. J Med Internet Res. 2014;16(10):e237. doi:10.2196/jmir.3765.
McGregor F, Somner JE, Bourne RR, Munn-Giddings C, Shah P, Cross V. Social media use by patients with glaucoma: what can we learn? Ophthalmic Physiol Opt. 2014;34(1):46–52. doi:10.1111/opo.12093.
Harmark L, Puijenbroek E, Grootheest K. Longitudinal monitoring of the safety of drugs by using a web-based system: the case of pregabalin. Pharmacoepidemiol Drug Saf. 2011;20(6):591–7. doi:10.1002/pds.2135.
Greene JA, Choudhry NK, Kilabuk E, Shrank WH. Online social networking by patients with diabetes: a qualitative evaluation of communication with Facebook. J Gen Intern Med. 2011;26(3):287–92. doi:10.1007/s11606-010-1526-3.
Cobert B, Silvey J. The Internet and drug safety: what are the implications for PV? Drug Saf. 1999;20(2):95–107.
Avillach P, Dufour JC, Diallo G, Salvo F, Joubert M, Thiessard F, et al. Design and validation of an automated method to detect known adverse drug reactions in MEDLINE: a contribution from the EU-ADR project. J Am Med Inform Assoc. 2013;20(3):446–52. doi:10.1136/amiajnl-2012-001083.
Oliveira JL, Lopes P, Nunes T, Campos D, Boyer S, Ahlberg E, et al. The EU-ADR Web Platform: delivering advanced PV tools. Pharmacoepidemiol Drug Saf. 2013;22(5):459–67. doi:10.1002/pds.3375.
Brown D. Cool Facts About Social Media. 2012. http://dannybrown.me/2012/06/06/52-cool-facts-social-media-2012/. Accessed 16 Oct 2015.
Beevolve. An Exhaustive Study of Twitter Users Around the World. 2012. http://temp.beevolve.com/twitter-statistics/-c1. Accessed 6 Oct 2015.
Schwind JS, Wolking DJ, Brownstein JS, Consortium P, Mazet JA, Smith WA. Evaluation of local media surveillance for improved disease recognition and monitoring in global hotspot regions. PLoS One. 2014;9(10):e110236. doi:10.1371/journal.pone.0110236.
Scales D, Zelenev A, Brownstein JS. Quantifying the effect of media limitations on outbreak data in a global online web-crawling epidemic intelligence system, 2008–2011. Emerg Health Threats J. 2013;6:21621. doi:10.3402/ehtj.v6i0.21621.
Chunara R, Andrews JR, Brownstein JS. Social and news media enable estimation of epidemiological patterns early in the 2010 Haitian cholera outbreak. Am J Trop Med Hyg. 2012;86(1):39–45. doi:10.4269/ajtmh.2012.11-0597.
Dasgupta N, Mandl KD, Brownstein JS. Breaking the news or fueling the epidemic? Temporal association between news media report volume and opioid-related mortality. PLoS One. 2009;4(11):e7758. doi:10.1371/journal.pone.0007758.
Reese S, Danielian L. Intermedia influence and the drug issue: converging on cocaine. In: Shoemaker P, editor. Communication campaigns about drugs: government, media and the public. Hillsdale: L. Erlbaum Associates; 1989.
Acknowledgments
The authors thank many curators who have contributed to training the classifier, including Chi Bahk, Wenjie Bao, Anne Czernek, Michael Gilbert, Melissa Jordan, Christopher Menone, and Carly Winokur.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Funding
GlaxoSmithKline paid for the research presented in this paper, including responding to reviewer comments during manuscript preparation. All work was conducted by the authors listed. Development of the social listening platform was funded in part by the US FDA under contract with Epidemico, Inc. prior to initiation and continuing throughout this research. Additional development funds for the social listening platform are provided to Epidemico, Inc. through a public–private partnership, but were not used to directly support the specific content of this research. This collaborative effort is provided via the WEB-RADR project, which is supported by the Innovative Medicines Initiative Joint Undertaking (IMI JU) under Grant Agreement No. 115632, resources of which are composed of financial contributions from the European Union’s Seventh Framework Programme (FP7/2007-2013) and EFPIA companies’ in kind contribution. Neither the FDA, WEB-RADR, nor IMI JU had any role in this research.
Conflict of interest
Gregory Powell, Harry Seifert, Tjark Reblin, Phil Burstein, James Blowers, Alan Menius, Jeffery Painter, Michele Thomas, and Heidi Bell were employees of or contractors to GlaxoSmithKline during the study. Carrie Pierce, Harold Rodriguez, John Brownstein, Clark Freifeld, and Nabarun Dasgupta are employees of or contractors to Epidemico, Inc., a technology company intending to commercialize the software platform used in this research.
Rights and permissions
About this article

Cite this article
Powell, G.E., Seifert, H.A., Reblin, T. et al. Social Media Listening for Routine Post-Marketing Safety Surveillance. Drug Saf 39, 443–454 (2016). https://doi.org/10.1007/s40264-015-0385-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40264-015-0385-6