
Abstract
In this paper, we focus on classifying cardiac arrhythmias. The MIT-BIH database is used with 14 original classes of labeling which is then mapped into 5 more general classes, using the Association for the Advancement of Medical Instrumentation standard. Three types of features were selected with a focus on the time–frequency aspects of ECG signal. After using the Wigner–Ville distribution the time–frequency plane is split into 9 windows considering the frequency bandwidth and time duration of ECG segments and peaks. The summation over these windows are employed as pseudo-energy features in classification. The “subject-oriented” scheme is used in classification, meaning the train and test sets include samples from different subjects. The subject-oriented method avoids the possible overfitting issues and guaranties the authenticity of the classification. The overall sensitivity and positive predictivity of classification is 99.67 and 98.92%, respectively, which shows a significant improvement over previous studies.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Cardiac arrhythmias are group of heart conditions in which the electrical activities of the heart become irregular. Arrhythmias usually occur as a result of a malfunction in the conduction system or when a pulse is originated from where it wasn’t supposed to. Some arrhythmias can be extremely dangerous and some of them can happen in an everyday life of a healthy person. However, studies show that about 80% of sudden cardiac death is the result of ventricular arrhythmias. Thus, the early and accurate detection of arrhythmias is crucial [1].
Electrocardiogram (ECG) is the recording of the electrical activity of the heart which occurs almost periodically through each heartbeat. Thus, the ECG signal is an excellent source to identify arrhythmias. Some arrhythmias don’t show any persistent trace in the ECG signal and consequently a continuous monitoring of ECG is necessary for some cases. Detection and classification of different abnormalities in ECG has long been investigated by researchers in the field of biomedical signal processing. Our goal in this paper is to introduce a new prospective in cardiac arrhythmia detection and help to improve the classification process.
Notable works has been done in analyzing the time-domain features of ECG signal which include RR intervals, QT segments, QRS complexes and other morphological features [2,3,4]. On the other hand, the spectral domain offers a different insight and its parameters give a distinctive representation of signal which can be used for better diagnosis. Besides the subtle time-domain changes of some arrhythmias will have an evident impact on the ECG spectrum.
The most well-known tool for investigating a signal in frequency domain is the Fourier Transform (FT), which in spite of a detailed frequency information, provides no link to the time domain. Meaning, one wouldn’t know when different frequencies of signal occur. Each arrhythmia is triggered in a specific part of the heart’s conduction system and each part of the ECG signal corresponds to a specific part of depolarization or repolarization, FT can’t provide the sufficient information for an accurate detection. This problem can be solved with the help of time–frequency (TF) techniques. Short-time Fourier transform (STFT) is a popular TF technique, could be used to compute the energy distribution of the ECG signal; the features are then extracted from the energy distribution and used in classification algorithms. There is a tradeoff in time and frequency resolutions in STFT, limiting authenticity of the features [5]. Wavelets resolve this issue by employing a time-scale resolution scheme for signal analysis. Papers adopting STFT and wavelet techniques for ECG signal processing and arrhythmia classifications report significant improvements compared to single domain studies [6,7,8,9].
As a supervised classification problem, many machine learning algorithms have been proposed in literature. Support vector machine (SVM) [7, 10, 11], self-organizing map (SOP) [12], artificial neural networks (ANNs) [6, 13], linear discriminant analysis (LDA) [2, 14], conditional random filed (CRF) [15], decision trees [16]. Using the same dataset and exploring various features and dimensionality reduction algorithms helps in forming a fast-evolving field for ECG arrhythmia classification.
In this paper, we propose the use of time–frequency windowing for pseudo-energy feature extraction and then employ an ensemble of decision trees for classification. The results show that our proposed method is a more effective method in the analysis and classification of ECG signals.
The paper is organized as follows; Sect. 2 has the background materials, in Sect. 3 we introduce our method. Section 4 provides the classification results and the paper is concluded in Sect. 5.
2 Background
2.1 Higher order statistics
The conventional lower (first and second) order statistics are well-known in the field of bio-signal processing. However, for nonlinear signals the lower order statistics are not sufficient for a proper representation. Hence the third and fourth order statistics respectively known as skewness and kurtosis are proven to be useful by many papers [9, 10, 16, 17].
For a random variable, \( \varvec{x} \), the third and fourth order statistics are defined as,
in which \( E \) denoted the expected value. Skewness provides a measurement of the lopsidedness of the distribution and kurtosis gives a relative measurement of the signal’s distribution with a Gaussian distribution of the same variance. These higher order statistics can be estimated as,
where \( x_{i} \)’s are realizations of the random variable \( \varvec{x} \) and \( \hat{m} \) and \( \hat{\sigma } \) are the estimates of the mean and variance respectively.
2.2 Wigner–Ville distribution
Wigner–Ville distribution (WVD) is a simple form of the Cohen’s class of bilinear time–frequency representations with a wide use in various applications. The WVD of the signal \( x\left( t \right) \) with zero mean is defined as:
where \( x^{*} \left( t \right) \) is the complex conjugate of \( x\left( t \right) \).
In an ideal case, the WV distribution has an infinite resolution in time and frequency domains because of the absence of averaging over any finite time duration [18].
2.3 Ensemble learners
An ensemble of learners is a method for supervised classification which uses a combination of various weak learners to form a strong one. A weak learner is defined as a classifier which can label the results only a slightly better than a random guess. These weak learners are combined by different methods such as weighted sum or majority voting. The important issue in constructing an ensemble learner is the diversity among the weak learners, because combining same weak learners would give us no gain. The diversity can be achieved by different representations of the train set, called bagging (bootstrap aggregating) [19]. Bagging was introduced in 1984 by Breiman [19] and is the most common bootstrap ensemble method. In order to achieve diversity in bagging, each weak learner is trained using a random subset of the main train samples. Given the train set \( T \) for our supervised classifier, bagging generates new training sets \( T_{i} \) by sampling uniformly from \( T \). with replacement. These new bootstrap samples each are different from the original set, yet they resemble it in dtribution and variability and are used to train the weak learners. The weak learners are then combined by voting to form the classifier [20,21,22].
3 Methods
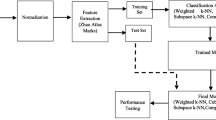
In this section, we introduce the methodology used in the paper. First, we talk about our dataset and then we follow the overall processing steps as illustrated in Fig. 1. After preprocessing, which is baseline wandering removal and beat segmentation, we extract three sets of features, RR-interval, time–frequency and higher order statistical features. These features are then fed into a classifier which is the final part of the algorithm.

Flowchart of the proposed algorithm
3.1 Dataset
We have used the MIT-BIH arrhythmia dataset [23] in our study, which includes various common and life-threatening arrhythmias. The database has 48 ECG recordings, each 30 min long, consisting two leads. For 45 recordings, the first lead is modified lead II (MLII) and for the rest it is modified lead V5. The second lead is a pericardial lead (V1 for 40 of them, V2, V4 or V5 for the others). In this paper only the first lead of the database has been used. The original labeling of the dataset has 14 classes of different rhythms listed as in Table 1. However, the Association for the Advancement of Medical Instrumentation (AAMI) [24, 25] recommends 5 more general classes of rhythms as follows. “N” beats originated from the sinus node, “S”, supraventricular ectopic beats, “V”, ventricular ectopic beats, “F”, fusion beats and “Q”, unclassified beats. This standard is adopted by many papers such as [2, 6,7,8, 11, 14,15,16, 26]. The mapping from the 14 original labels to AAMI standard labels are shown in Table 2. The heartbeat arrhythmia classification is most commonly viewed as a supervised classification problem. Thus, in random division of the train and test sets it is highly possible that the heartbeats from the same subject would appear in both sets and having correlated samples in both sets would cause overfitting and lead to promising results which are unreachable in practice. To avoid this problem a “subject-oriented” method is introduced in [2] which uses a patient-based division of the dataset, so a more realistic classifier can be trained using this scheme. The train and test sets for this method are shown respectively as DS1 and DS2 in Table 2. Using this scheme our results will be comparable with other arrhythmia classification algorithms such as [11, 14,15,16].
3.2 Data preprocessing
The MIT-BIH arrhythmia dataset is band-pass filtered at 0.1–100 Hz and then digitized at 360 samples per second [23]. We have removed the baseline wandering of these signals using two stages of median filtering as proposed by [27].
The MIT-BIH database also includes an annotation file associated with each sample. This file has the information about the type of the rhythms and the occurrence sample of the major local maxima for each individual heartbeat.
3.2.1 Beat segmentation
We use the annotation files as our reference in beat segmentation. The local maximums of each heartbeat (R peaks for most of cases) are extracted from the annotation files and a fixed number of samples before and after each R peak is defined for beat segmentation. While [11] uses 100 samples before R peaks and 200 samples after R peaks (total of 0.83 s), [16] selects 235 total samples (0.25 s before and 0.40 s after R peaks). Since we are using 2-dimensional time–frequency representations we choose the total amount of 256 samples (102 samples before R peaks and 153 after that) to ease the computational processes. A sample of beat segmentation is shown in Fig. 2.

Short sample from “101 m.mat” showing the beat segmentation and Pre-RR and Post-RR features
3.3 Feature extraction
In this section we introduce the features we have used in classification. Time–frequency characteristics of ECG signals along with the RR interval and statistical features are extracted for classification.
3.3.1 RR interval features
In this paper, we have used two RR-interval features as the only representatives of the time domain traits of the signal. The time distance between respective R peaks bare indispensable information about the subjects’ health and consequently the type of the rhythms. “RR variability” or “heart rate variability (HRV)” are the clinical terms used to investigate changes in the occurrence time of the R peaks which indicates the importance of these time domain features. RR based features are very popular in cardiac arrhythmia classifications and are used in various papers such as [2, 6, 8, 10,11,12, 14,15,16, 28].
Two RR based features are extracted as pre-RR and post-RR. Pre-RR is defined as the time distance between the R peak of the current heartbeat with the R peak of previous one; and the post-RR is defined as the same distance for the current and the subsequent heartbeats. Pre-RR and post-RR features are shown in Fig. 2 for a sample heartbeat.
3.4 HOS features
We have used three higher order statistical (HOS) features because they have proven to be less sensitive to the morphological changes of signal [29]. In addition, the nonlinear nature of these features can help in better highlighting the dynamic aspects of ECG signal [30]. Skewness, kurtosis and 5th order moment of each signal is extracted and put into the feature vector.
3.5 Time–frequency features
We have used Wigner–Ville distribution to get a time–frequency representation of signal and extract pseudo-energy features. Each signal is represented as a \( 256 \times 256 \) matrix after using Eq. (3) and is summed over 9 windows as shown in Fig. 3. \( W_{1} \) covers the high frequency i.e. frequencies higher than 50 Hz. \( W_{2} \) is over the beginning part of the signal before the potential PR segment; \( W_{2} \) is a window of 62 ms width over frequencies lower than 50 Hz. \( W_{3} \). and \( W_{4} \) lie on the PR segment with 160 ms width and frequencies lower than 5 Hz and mid-frequency between 5 and 50 Hz. P and T waves have most of their energies over the frequency band lower than 5 Hz and that is why we have considered two windows over this time period. \( W_{5} \) and \( W_{6} \) cover the potential occurrence time of the QRS complex with 120 ms width and with frequencies lower and higher than 20 Hz. \( W_{7} \) and \( W_{8} \) are over the QT segment with 420 ms long and frequency margin of 10 Hz. Finally, \( W_{9} \) covers the part after the potential QT segment with frequencies lower than 50 Hz. Figure 4 illustrates three samples of WVD for each class of “N”, “S” and “V” with frequencies lower than 50 Hz.

Time–frequency windowing for feature extraction

Wigner–Ville distribution for a sample first lead (lead II) of a class N, b class S and c class V
The summation over each window provides a measure of energy during that time within the specific frequency range and can be a good feature for differentiating arrhythmias. Figure 5 shows the mean energy density for all 9 windows of four main rhymes in our trainset. Although the Wigner–Ville distribution is criticized for producing cross terms, the computational advantages it offers over the other methods such as Choi-Williams distribution are critical specially in a big database as MIT-BIH.

Mean of energy density for 4 windows and three main arrhythmia classes
It should be mentioned that in order to reduce the computational costs and avoid the cross terms between positive and negative frequencies the original signals are not used in WV distribution. First the analytical signals are calculated for each heartbeat then the WVD is used. Analytical signals have the same spectrum for positive frequencies and zero spectrum for the negative frequencies can be calculated as in Eq. (4)
where \( x_{a} \left( t \right) \) is the analytical signal, \( {\mathcal{H}}\left( . \right) \) is the Hilbert transform and \( * \) is the convolution symbol.
4 Classification results
As shown in Table 3 the total number of 100,858 heartbeats from five different AAMI-recommended groups of arrhythmia are used in classification. The test and train sets are selected as in Table 2, proposed by [2]. 14 extracted features are normalized and put into the feature vector for a supervised classification. An ensemble of 100 decision trees are combined in bagging scheme to form a stable and accurate classifier. By reducing the variance, bagging avoids overfitting problems. The prior probability for each class is set to 0.2; of course, better results can be achieved by setting prior probabilities proportional to the population of each class or unbalancing the misclassification cost in favor of life threatening arrhythmias. However, we didn’t want to involve any knowledge of class populations in the classification procedures.
4.1 Performance metrics
Various approaches are adopted in literature to evaluate the classification results. In this paper, we have considered sensitivity and positive predictivity to compare the algorithm with previous studies. Sensitivity (Se) can be defined as the measure of successfully classified positive samples,
in which \( FN \) is the total number of misclassified positive samples and \( TP \) is the total number of correctly classified positive samples. Positive predictivity (Pp) measures success rate among samples classified as positive and can be defined as,
where \( FP \) is the total number of falsely classified negative samples.
4.2 Results
The results of classification are shown in Table 3 which has the total sensitivity and positive predictivity of 99.67 and 98.92%. The Table 4 illustrates the confusion matrix, the high amount of misclassified samples for class “F” is evident. However, there are only 693 misclassified beats in total which is 1.4% of the test set. Table 5 shows the overall results of our method compared with previous works. Only the results for three main classes of “N”, “S” and “V” are mentioned in papers so the \( Se \) and \( Pp \) are compared for these classes. The proposed method shows a significant improvement of classification accuracy over our previous work [16] and other papers with same database, indicating the importance of TF role in ECG analysis.
5 Conclusion
In this paper, we have proposed a new algorithm based on time–frequency representation to extract features for cardiac arrhythmia classification. Considering the normal time duration of QRS complex, PR interval and QT interval and the normal bandwidth of each P wave, T wave and QRS complex, 9 TF windows are selected. The summation over these windows along with RR-interval and HOS features are used in classification. An ensemble of decision trees is used with subject-oriented scheme. The results show extremely high accuracy in the three main classes of “N”, “S” and “V”, which contain over 99% of the database. The “F” class on the other hand has many misclassified samples as it is the case in other papers too. The TF features as a measure of energy are proven to be effective for heartbeat classification.
References
Jenkins D, Gerred S. Normal ECG. http://www.ecglibrary.com/norm.php. Accessed Febr 2015.
de Chazal P, O’Dwyer M, Reilly R. Automatic classification of heartbeats using ECG morphology and heartbeat interval features. IEEE Trans Biomed Eng. 2004;51(7):1196–206.
de Oliveira L, Andreao R, Sarcinelli-Filho M. Premature ventricular beat classification using a dynamic Bayesian network. In: Annual international conference of the IEEE engineering in medicine and biology society, EMBC, Boston, MA; 2011.
Zeng XD, Chao S, Wong F. Ensemble learning on heartbeat type classification. In: International conference on system science and engineering (ICSSE), Macao; 2011.
Cohen L. Time-frequency distributions—a review. Proc IEEE. 2002;77(7):941–81.
Ince T, Kiranyaz S, Gabbouj M. A generic and robust system for automated patient-specific classification of ECG signals. IEEE Trans Biomed Eng. 2009;56(5):1415–26.
Jiang X, Zhang L, Zhao Q, Albayrak S. ECG arrhythmias recognition system based on independent component analysis feature extraction. In: TENCON 2006 IEEE Region 10 Conference, Hong Kong; 2006.
Yang S, ShenH. Heartbeat classification using discrete wavelet transform and kernel principal component analysis. In: TENCON Spring Conference, 2013 IEEE, Sydney, NSW; 2013.
Thomas M, Das MKAS. Automatic ECG arrhythmia classification using dual tree complex wavelet based features. Int J Electron Commun (AEÜ). 2015;69(4):715–21.
Osowski S, Hoai LT, Markiewicz T. Support vector machine-based expert system for reliable heartbeat recognition. IEEE Trans Biomed Eng. 2004;51(4):582–9.
Ye C, Kumar B, Coimbra M. Heartbeat classification using morphological and dynamic features of ECG signals. IEEE Trans Biomed Eng. 2012;59(10):2930–41.
Lagerholm M, Peterson C, Braccini G, Edenbrandt L. Clustering ECG complexes using Hermite functions and self-organizing maps. IEEE Trans Biomed Eng. 2002;47(7):838–48.
Jiang W, Kong S. Block-based neural networks for personalized ECG signal classification. IEEE Trans Neural Netw. 2007;18(6):1750–61.
Llamedo M, Martinez J. Heartbeat classification using feature selection driven by database generalization criteria. IEEE Trans Biomed Eng. 2011;58(3):616–25.
de Lannoy G, Francois D, Delbeke J, Verleysen M. Weighted conditional random fields for supervised interpatient heartbeat classification. IEEE Trans Biomed Eng. 2012;59(1):241–7.
Ghorbani Afkhami R, Azarnia G, Tinati MA. Cardiac arrhythmia classification using statistical and mixture modeling features of ECG signals. Pattern Recognit Lett. 2016;70:45–51.
Ghorbani Afkhami R, Tinati MA. ECG based detection of left ventricular hypertrophy using higher order statistics. In: 23rd Iranian Conference on Electrical Engineering (ICEE), Tehran; 2015.
Pachori RB, Nishad A. Cross-terms reduction in the Wigner–Ville distribution using tunable-Q wavelet transform. Sig Process. 2016;120:288–304.
Breiman L, Friedman J, Stone CJ, Olshen R. Classification and regression trees. London: Chapman and Hall; 1984.
Zaunseder S, Huhle R, Malberg H. CinC challenge—assessing the usability of ECG by ensemble decision trees. In: Computing in cardiology, Hangzhou; 2011.
Maimon O, Rokach L. Data mining and knowledge discovery handbook. Berlin: Springer; 2010.
Opitz D, Maclin R. Popular ensemble methods: an empirical study. J Artif Intell Res. 1999;11:169–98.
Mark R, Moody G. MIT-BIH database and software catalog. http://ecg.mit.edu/dbinfo.html (1997). Accessed Feb 2015.
“Recommended practice for testing and reporting performance results of ventricular arrhythmia detection algorithms,” Association for the Advancement of Medical Instrumentation, 1987.
“Testing and reporting performance results of cardiac rhythm and ST segment measurement algorithms,” Association for the Advancement of Medical Instrumentation, 1998.
Rodriguez J, Goñi A, Illarramendi A. Real-time classification of ECGs on a PDA. IEEE Trans Inf Technol Biomed. 2005;9(1):23–34.
Awodeyi A, Alty S, Ghavami M. Median filter approach for removal of baseline wander in photoplethysmography signals. In: European Modelling Symposium (EMS), Manchester; 2013.
Prasad G, Sahambi J. Classification of ECG arrhythmias using multi-resolution analysis and neural networks. In: Conference on Convergent Technologies for the Asia-Pacific Region, TENCON, vol. 1, p. 227–231, 2003.
Martis R, Acharya R, Ray A. Application of higher order cumulants to ECG signals for the cardiac health diagnosis. In: International Conference of the IEEE EMBS, Boston; 2011.
Ebrahimzadeh A, Khazaee A. Higher order statistics for automated classification of ECG beats. In: International conference on electrical and control engineering (ICECE), Yichang; 2011.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sultan Qurraie, S., Ghorbani Afkhami, R. ECG arrhythmia classification using time frequency distribution techniques. Biomed. Eng. Lett. 7, 325–332 (2017). https://doi.org/10.1007/s13534-017-0043-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13534-017-0043-2