
Abstract
Recommender systems play an important role in helping online users find relevant information by suggesting information of potential interest to them. Due to the potential value of social relations in recommender systems, social recommendation has attracted increasing attention in recent years. In this paper, we present a review of existing recommender systems and discuss some research directions. We begin by giving formal definitions of social recommendation and discuss the unique property of social recommendation and its implications compared with those of traditional recommender systems. Then, we classify existing social recommender systems into memory-based social recommender systems and model-based social recommender systems, according to the basic models adopted to build the systems, and review representative systems for each category. We also present some key findings from both positive and negative experiences in building social recommender systems, and research directions to improve social recommendation capabilities.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the development of the World Wide Web, information has increased at an unprecedented rate and the information overload problem has become increasingly severe for online users. For example, when we want to buy a computer and search “computer” in Amazon, it returns 11,100,260 products Footnote 1. Recommender systems, which attempt to tackle the information overload problem by suggesting information that is of potential interest to online users, have become important and popular (Sarwar et al. 2001; Golbeck 2006a; Massa and Avesani 2007; Koren 2009; Ma et al. 2011b). For information customers, good recommendations allow them to quickly find relevant information buried in a large amount of irrelevant information. For information providers, recommender systems not only help determine which information to offer to individual consumers, but also improve consumer loyalty because consumers tend to return to the sites that best serve their needs (Schafer et al. 2001). Such systems are widely implemented in various domains including, product recommendation on Amazon Footnote 2 and movie recommendation on Netflix Footnote 3.
Recommender systems became an independent research area in the mid-1990s (Adomavicius and Tuzhilin 2005) and have attracted much attention from multiple disciplines, such as mathematics, physics, psychology, and computer science (Ellenberg 2008). For example, the winners of the Netflix prize contest, one of the most famous competitions for recommendation, consist of psychologists, computer scientists, and physicists Footnote 4. Many techniques are used to build recommender systems, which can be generally classified into content-based methods, collaborative filtering (CF) based methods, and hybrid methods (Adomavicius and Tuzhilin 2005). Content-based methods, rooted in information retrieval (Baeza-Yates and Ribeiro-Neto 1999) and information filtering research (Belkin and Croft 1992), recommend items similar to the ones the user preferred in the past; CF-based methods predict user interests directly by uncovering complex and unexpected patterns from a user’s past behaviors and recommend items to a user from other users with similar interests and preferences in the past (Koren 2008; Su and Khoshgoftaar 2009). Hybrid methods combine content-based and CF-based methods. We will give a brief review about techniques to build recommender systems in Sect. 2.
The increasing popularity of social media greatly enriches people’s social activities with their families, friends, and colleagues, which produces rich social relations such as friendships in Facebook Footnote 5, following relations in Twitter Footnote 6 and trust relations in Epinions Footnote 7. Online social relations provide a different way for individuals to communicate digitally and allow online users to share ideas and opinions with their connected users. A user’s preference is similar to or influenced by their socially connected friends and the rationale behind the assumption can be explained by social correlation theories such as homophily (McPherson et al. 2001) and social influence (Marsden and Friedkin 1993). Homophily indicates that users with similar preferences are more likely to be connected, and social influence reveals that users who are connected are more likely to have similar preferences. Analogous to the fact that users in the physical world are likely to seek suggestions from their friends before making a purchase decision and users’ friends consistently provide good recommendations (Sinha and Swearingen 2001), social relations can be potentially exploited to improve the performance of online recommender systems (Golbeck 2006a; Ma et al. 2008, 2011b; Jamali and Ester 2009).
In this article, we present a review of existing social recommender systems and discuss some research directions that can improve the capabilities of social recommendation. The motivation of this article is multi-fold:
-
Social recommendation has been developed for several years and still there is no agreement in literature on the definition of social recommendation. These clarifications are necessary for people to gain an awareness of social recommender systems. For example, Kaifu Lee, CEO at Innovation Works, recommended a particular brand of frozen dessert maker through Chinese tweet Sina Weibo platform and a few hours later, Taobao (China’s eBay) had hundreds of sellers of the item and thousands of the machines were sold within a day. Subsequently, he wrote an article in LinkedIn entitled “The Power of Social Recommendation”, but there are many doubts about whether this kind of recommendation can be called social recommendation Footnote 8.
-
Social relations provide an independent source for recommendation; various approaches are proposed to build social recommender systems such as trust ensemble (Ma et al. 2009c), trust propagation (Jamali and Ester 2009), and social regularization (Ma et al. 2011b). A classification of existing social recommender systems can help users gain a quick understanding of many social recommender systems. A review of existing social recommender systems will let users familiarize themselves with the state-of-the-art social recommender systems.
-
On the one hand, there is recent work reporting significant recommendation performance improvement for social recommender systems (Golbeck 2006a; Ma et al. 2008, 2011b; Jamali and Ester 2009; Jiang et al. 2012). On the other hand, there are also unsuccessful attempts at applying social recommendation (Cho et al. 2011; Gao et al. 2012a; Quora 2012; IBM 2012). For example, IBM’s Black Friday report says Twitter delivered 0 % of referral traffic and Facebook sent just 0.68 % (IBM 2012). It is important to discuss key findings from both positive and negative experiences to seek a deeper understanding and further development of social recommender systems.
-
Social recommendation is still in the early stages of development, and there are many challenging issues needing further investigation. It is necessary to discuss some research directions that can improve social recommendation capabilities and make social recommendation applicable to an even broader range of applications.
Our major contributions are summarized below:
-
We give narrow and broad definitions of social recommendation to cover most existing definitions of social recommendation in the literature and discuss the unique property of social recommender systems and its implications compared with traditional recommender systems;
-
We present a classification of social recommender systems according to the basic models to build social recommender systems, and review representative systems for each category in detail;
-
We summarize key findings from some positive and negative experiences in applying social recommender systems;
-
We discuss some research directions to improve recommendation capabilities including exploiting the heterogeneity of social networks and weak dependence connections, segmenting users and items, considering the temporal information of rating and social information, understanding the role of negative relations, and integrating cross-media social networks.
The rest of this article is organized as follows. We review existing recommender systems including content-based methods, collaborative filtering based methods and hybrid methods in Sect. 2. In Sect. 3, we formally define social recommendation, discuss the unique property of social recommendation, classify and review existing social recommender systems, and discuss some key findings from both positive and negative experiences in applying social recommender systems. In Sect. 4, we discuss possible research directions for improvement of social recommendation. The article is summarized in Sect. 5.
2 Traditional recommender systems
In a typical recommender system, there is a set of users and a set of items. Let \({\mathbf{U}} = \{u_1, u_2, \ldots, u_n\}\)and \({\mathbf{V}} = \{v_1, v_2, \ldots, v_n\}\) be the sets of users and items respectively, where n is the number of users and m is the number of items. A user u i rates a subset of items with some scores. We use \(\mathbf{R} \in \mathbb{R}^{n\times m}\) to denote the rating matrix where R ij is the rating score if u i gives a rating to v j , otherwise we employ the symbol “?” to denote the unknown rating. Usually the rating matrix is very sparse, suggesting that there are lots of unknown ratings in R. For example, the density of the rating matrix in commercial recommender systems is often less than 1 % (Sarwar et al. 2001). If item v j has attributes, we use \({\mathbf{x}}_j \in {\mathbb{R}}^\ell\) to represent v j where ℓ is the number of attributes. The task of recommender systems is to predict the rating for user u i on a non-rated item v j or to recommend some items for given users, i.e., to predict missing values in R based on known ratings.
Since recommender systems first became an independent research area in the mid-1990s, there have been many recommender systems proposed, which can be generally grouped into content based, collaborative filtering (CF) based and hybrid recommender systems (Ricci et al. 2011, Jannach et al. 2010). In the following subsection, we will briefly review each category with its representative systems.
2.1 Content based recommender systems
Content based recommender systems have their roots in information retrieval (Baeza-Yates and Ribeiro-Neto 1999) and information filtering research (Belkin and Croft 1992). They recommend items similar to the ones that the user has preferred in the past. Most existing content based recommender systems focus on recommending items with textual information such as news, books and documents. The content in these systems is usually described with keywords (Balabanović and Shoham 1997; Pazzani and Billsus 1997) and the informativeness of a keyword to a document is often measured by TFIDF weight (Wu et al. 2008). TF weight of a keyword to a document denotes the frequency of the keyword in the document, while IDF weight of a keyword is defined as the inverse document frequency of the keyword.
Let x jk be the TFIDF weight of the k-th keyword in v j and the content of v j can be represented as \({\mathbf{x}_j} = \{x_{j1}, x_{j2}, \ldots, x_{jl}\}\) With these representations, content based recommender systems recommend items to a user which are similar to items the user liked in the past (Pazzani and Billsus 1997). In particular, various candidate items are compared with items previously rated by the user. A similarity measure such as a cosine similarity measure is adopted to score these candidate items. Besides the traditional heuristics based information retrieval methods, there are also content based recommender systems that use other techniques such as various classification and clustering algorithms (Pazzani and Billsus 1997; Mooney et al. 1998).
As noticed in (Balabanović and Shoham 1997; Adomavicius and Tuzhilin 2005), content based recommender systems have several limitations: (1) limited content analysis: these systems are difficult to apply to domains which have an inherent problem with automatic feature extraction such as multimedia data; (2) over-specialization: items recommended to a user are limited to those similar to items the user already rated; (3) new user problem: to let content based recommender systems understand a user’s preference, the user has to rate a sufficient number of items, hence, content based recommender systems fail to recommend items for users with few or no ratings.
2.2 Collaborative filtering based recommender systems
Collaborative filtering is one of the most popular techniques to build recommender systems (Sarwar et al. 2001; Koren 2008; Su and Khoshgoftaar 2009). It can predict user interests directly by uncovering complex and unexpected patterns from a user’s past behaviors such as product ratings without any domain knowledge (Koren 2008; Su and Khoshgoftaar 2009). The underlying assumption of collaborative filtering based recommender systems is that if users have agreed with each other in the past, they are more likely to agree with each other in the future than to agree with randomly chosen users. Existing collaborative filtering methods can be categorized into memory-based methods and model-based methods (Goldberg et al. 1992; Breese et al. 1998; Su and Khoshgoftaar 2009).
2.2.1 Memory based collaborative filtering
Memory based methods use either the whole user-item matrix or a sample to generate a prediction (Su and Khoshgoftaar 2009), which can be further divided into user-oriented methods (Herlocker et al. 1999; Breese et al. 1998) and item-oriented methods (Sarwar et al. 2001; Karypis 2001). User-oriented methods predict an unknown rating from a user on an item as the weighted average of all the ratings from her similar users on the item, while item-oriented methods predict the rating from a user on an item based on the average ratings of similar items by the same user. The key problems a memory-based CF method has to solve are computing similarity and aggregating ratings. User-oriented methods and item-oriented methods can leverage similar techniques to address these two problems; thus, we use user-oriented methods as examples to illustrate representative methods for computing similarity and aggregating ratings.
Computing similarity for user-oriented methods Computing user–user similarity is a critical step for user-oriented methods. There are many techniques proposed to tackle this problem such as Pearson Correlation Coefficient (Resnick et al. 1994), Cosine similarity (Chowdhury 2010), and probability-based similarity (Karypis 2001; Deshpande and Karypis 2004), among which Pearson Correlation Coefficient and Cosine similarity are the most widely used ones.
Pearson Correlation Coefficient Each user is presented as a vector of ratings. For example, the i-th user will be denoted as R i . Pearson Correlation Coefficient measures the extent to which two variables linearly relate with each other (Resnick et al. 1994). Pearson Correlation Coefficient between u i and u j can be calculated as
where I denotes the set of items rated by both u i and u j and \({\mathbf{S}} \in {\mathbb{R}}^{n\times n}\) represents the user–user similarity matrix. \(\bar{R}_i\) denotes the average rate of u i .
-
Cosine similarity Cosine similarity computes the cosine of the angle formed by the rating vectors (Chowdhury 2010). For example, the cosine similarity between u i and u j can be calculated as,
$${\mathbf{S}}_{ij} = \frac{\sum_{k \in I} R_{ik} \cdot R_{jk} }{\sqrt{\sum_{k \in I} R_{ik}^2} \sqrt{\sum_k R_{jk}^2}},$$(2) -
Aggregating ratings for user-oriented methods After obtaining a user–user similarity matrix, user-oriented methods will predict a missing rating for a given user by aggregating the ratings of users similar to her. Various aggregating strategies have been proposed (Resnick et al. 1994; Sarwar et al. 2001; Karypis 2001) and the most widely used strategy is weighted average rating as
$$\hat{\mathbf{R}}_{ij} = \bar{\mathbf{R}}_i + \frac{\sum_{u_k \in {\mathcal{N}}_i} {\mathbf{S}}_{ik} (\mathbf{R}_{kj} - \bar{\mathbf{R}}_k )}{\sum_{u_k \in {\mathcal{N}}_i} {\mathbf{S}}_{ik}},$$(3)
where \({\mathcal{N}}_i\) is the set of users who have rated the j-th item v j .
2.2.2 Model based collaborative filtering
Model-based methods assume a model to generate the ratings and apply data mining and machine learning techniques to find patterns from training data (Yildirim and Krishnamoorthy 2008; Su and Khoshgoftaar 2009), which can be used to make predictions for unknown ratings. Compared to memory based CF, Model-based CF has a more holistic goal to uncover latent factors that explain observed ratings (Yildirim and Krishnamoorthy 2008). Well-known model-based methods include Bayesian belief net CF models (Breese et al. 1998; Miyahara and Pazzani 2000), clustering CF models (Ungar 1998; Chee et al. 2001), random walk based methods (Yildirim and Krishnamoorthy 2008; Huang et al. 2004) and factorization based CF models (Goldberg et al. 2001; Hofmann 2004; Paterek 2007; Koren 2008; Salakhutdinov and Mnih 2008). Factorization based CF methods (Koren 2008; Salakhutdinov and Mnih 2008) are very competitive if not the best and are widely adopted to build recommender systems (Chen et al. 2011).
Factorization based CF models assume that a few latent patterns influence user rating behaviors and perform a low-rank matrix factorization on the user-item rating matrix. Let \({\mathbf{u}}_i \in {\mathbb{R}}^K\) and \({\mathbf{v}}_j \in {\mathbb{R}}^K\) be the user preference vector for u i and item characteristic vector for v j respectively, where K is the number of latent factors. Factorization based collaborative filtering models solve the following problem
where \({\mathbf{U}} = [{\mathbf{U}}_1^\top, {\mathbf{U}}_2^\top, \ldots, {\mathbf{U}}_n^\top]^\top \in {\mathbb{R}}^{n\times{k}}\) and \({\mathbf{V}} = [{\mathbf{V}}_1^\top, {\mathbf{V}}_2^\top, \ldots, {\mathbf{V}}_m^\top]^\top \in {\mathbb{R}}^{m\times{K}}.\) K is the number of latent factors (patterns), which is usually determined via cross-validation. The term \(\alpha (\|{\mathbf{U}}\|_F^2 + \|{\mathbf{V}}\|_F^2)\) is introduced to avoid over-fitting, controlled by the parameter α. \({\mathbf{W}} \in {\mathbb{R}}^{n\times m}\) is a weight matrix where W ij is the weight for the rating for u i to v j . A common way to set W is W ij = 1 if R ij ≠ 0. The weight matrix W can also be used to handle the implicit feedback and encode side information such as user click behaviors (Fang and Si 2011), similarity between users and items (Pan et al. 2008; Li et al. 2010), quality of reviews (Raghavan et al. 2012) and user reputation (Tang et al. 2013c).
Collaborative filtering based recommender systems can overcome some of the shortcomings of content based recommender systems. For example, CF based systems use rating information; hence, they are domain-independent and can recommend any items. However, CF based systems have their own limitations such as the cold-start problem (new items or new users) and the data sparsity problem (Adomavicius and Tuzhilin 2005; Su and Khoshgoftaar 2009).
2.3 Hybrid recommender systems
To avoid certain limitations of content and collaborative filtering systems, hybrid approaches combine content and CF based methods. Various strategies are proposed to combine content and CF based methods, which can be roughly classified into three categories (Adomavicius and Tuzhilin 2005). We will briefly review each category with representative systems.
Combining different recommenders Under this strategy, content and CF based methods are implemented separately and then their predictions are combined to obtain the final recommendation. Various ways are proposed, such as a voting scheme (Pazzani 1999) and a linear combination of ratings (Claypool et al. 1999), to combine predictions from content and CF based methods.
Adding content based characteristics to CF models Systems with this strategy use content based profiles and uncommonly rated items to calculate user–user similarities. These systems can overcome some sparsity-related problems of CF methods and recommend items directly when item scores highly against the user’s profiles (Pazzani 1999; Good et al. 1999).
Adding CF based characteristics to content based models The most popular approach under this strategy is to use a dimensionality reduction technique on the content profile matrix. For example, in (Soboroff and Nicholas 1999) latent semantic indexing is used to create a collaborative view of a set of user profiles, which improves recommendation performance compared to pure content based approaches.
3 Social recommendation
One of the earliest social recommender systems appeared in 1997 (Kautz et al. 1997). Myriads of social media services such as Facebook and Twitter have emerged in recent years to allow people to easily communicate and express themselves conveniently. The pervasive use of social media generates social information at an unprecedented rate. For example, Facebook, the largest social networking site produces 35,000,000,000 online friendships (Guy and Carmel 2011) and the most popular user on Twitter, the largest microblogging site, has 37, 974, 138 followers Footnote 9. The rapid development of social media has greatly accelerated the development of social recommender systems (King et al. 2010; Guy and Carmel 2011). In this section, we will first give the definitions of social recommendation, discuss the opportunities for social recommendation systems compared to traditional recommender systems, classify and review existing social recommender systems, and finally summarize some key findings from positive and negative experiences in applying social recommender systems.
3.1 Definitions of social recommendation
Social recommendation has been studied since 1997 (Kautz et al. 1997) and has attracted increasing attention with the growing popularity of social media (King et al. 2010; Guy and Carmel 2011), however, it has no commonly accepted definition. In this subsection, we give narrow and broad definitions of social recommendation based on existing definitions in the literature.
A narrow definition of social recommendation is any recommendation with online social relations as an additional input, i.e., augmenting an existing recommendation engine with additional social signals. Social relations can be trust relations, friendships, memberships or following relations. A tutorial with the title “Introduction to Social Recommendation” at the 19th international world wide web conference (WWW2010) followed this narrow definition (King et al. 2010). In this definition, social recommender systems assume that users are correlated when they establish social relations (Massa 2007; Massa and Avesani 2007; Ma et al. 2008). For example, users’ preferences are likely to be similar to or influenced by their connected friends. Under this assumption, social recommendation leverages user correlations implied by social relations to improve the performance of recommendation. Representative systems under this definition include TidalTrust (Golbeck 2006b), MoleTrust (Massa and Avesani 2007; Victor et al. 2011), SoRec (Ma et al. 2009c), SocialMF (Jamali and Ester 2009), SoReg (Ma et al. 2011b) and LOCALBAL (Tang et al. 2013c).
Another tutorial titled “Social Recommender Systems” at the 20th international world wide web conference (WWW2011) adopted a broad definition of social recommendation where social recommender systems are defined as any recommender systems that target social media domains (Guy and Carmel 2011). The definition covers recommender systems recommending any objects in social media domains such as items (the focus of recommender systems under the narrow definition), tags (Sigurbjörnsson and Van Zwol 2008), people (Chen et al. 2009; Agarwal and Bharadwaj 2012), and communities (Chen et al. 2009). The sources they use are not limited to online social relations but include all kinds of available social media data such as social tagging (Ma et al. 2011a), user interactions (Jiang et al. 2012) and user click behaviors (Mei et al. 2007).
With narrow and broad definitions, let us go back to examine the example of Kaifu Lee’s recommendation. Since the recommendation happens in social media domains, Kaifu Lee’s recommendation is a sort of social recommendation under the broad definition. However, the sources mentioned in this recommendation are not limited to social networks, and this recommendation does not satisfy the narrow definition.
In this article, we focus on social recommender systems under the narrow definition. The reason is two fold. First, similar techniques can be applied to implementing social recommender systems under both definitions. Second, the narrow definition is straightforward and helps readers gain a deeper understanding of state-of-the-art social recommender systems.
3.2 A unique feature of social recommendation and its implications
The increasing popularity of social media allows online users to participate in online activities which produce rich social relations. In social recommender systems, in addition to the rating information R, users can connect to each other. Let \({\bf T} \in {\mathbb{R}}^{n\times{n}}\) denote user–user social relations where T ij = 1 if u j connects to u i and zero otherwise. The availability of social relations T provides an independent source for recommendation and this unique property of social recommendation brings about new opportunities.
First, traditional recommender systems assume that users are independent and identically distributed (known as the i.i.d. assumption). However, online users are inherently connected via various types of relations such as friendships and trust relations. Figure 1 shows a simple example of connected users in social media, and Fig. 1b, c demonstrate its two data representations for traditional recommender systems and social recommender systems, respectively. In addition to the rating matrix in traditional recommender systems, users in social recommender systems are connected, providing social information. Since they are connected, users are correlated rather than independent and identically distributed. For example, (Weng et al. 2010) finds that users with following relations are more likely to share similar interests in topics than two randomly chosen users, and (Tang et al. 2013b) shows that users with trust relations are more likely to have similar preferences in item ratings. This phenomenon is observed in most online social networks and can be explained by social correlation theories such as homophily (McPherson et al. 2001) and social influence (Marsden and Friedkin 1993). Note that one user is more likely to have similar interests with her connected users than those randomly chosen users, which does not indicate that her connected users are equivalent to her most similar users w.r.t. rating information. Assume that u i connects to d users. We use C i and S i with the size d to denote sets of the connected users and the top-d similar users of u i , respectively. In Tang et al. (2013a), the authors show that the overlap between C i and S i is less than 10 %, which is consistent with the observation in Crandall et al. (2008). If we change our perspective and consider connections as similarity measurements, social information provides similarity evidence and C i is the list of the similar users w.r.t. social information (Guy et al. 2008). Then the above observation can be explained by the key finding in Guy et al. (2010)—lists of similar users obtained by different sources are found to be highly different from each other. It also suggests that an aggregation of rating and social information may be valuable. In addition to similarity evidence, social information also provides another unique evidence, i.e., familiarity evidence, which is very importance in recommendation since in the physical world, we usually ask suggestions from our friends who are familiar with our tastes (Guy et al. 2008, 2010). Both similarity and familiarity evidence from social information indicate that social networks contain complementary information to rating information and provide an independent source of information about online users. Exploiting social relations can potentially improve recommendation performance.

A simple example of connected users
Second, besides recommender systems, social recommendation involves the independent research field of social network analysis (Wasserman and Faust 1994; Scott 2011, 2012; Davis et al. 2013). Social network analysis (SNA) is the methodical analysis of social networks and has emerged as a key technique in modern sociology. It has gained a significant following in various disciplines such as communication studies, economics, geography, and computer science; consumer tools for it are now commonly available (Scott 2012). Social recommender systems can take advantage of research results from social network analysis such as social correlation theories (McPherson et al. 2001; Marsden and Friedkin 1993), status analysis (Page et al. 1999; Kleinberg 1999), community detection (Leskovec et al. 2010; Tang and Liu 2010), online trust (Massa 2007; Tang et al. 2012a) and heterogeneous networks (Sun and Han 2012) for recommendation. Research achievements from social network analysis pave ways to exploit social relations and can be applied to building social recommender systems.
3.3 Existing social recommender systems
As mentioned earlier, collaborative filtering is widely adopted to build recommender systems, and most existing social recommender systems are based on CF techniques. Therefore, our discussion in this article is focused on CF based social recommender systems. Social recommendation has two inputs, i.e., rating information and social information, as shown in Fig. 1c. Most existing social recommender systems choose CF models as their basic models to build systems and propose approaches to capture social information based on results from social network analysis. Therefore, a general CF based social recommendation framework contains two parts: (1) a basic CF model and (2) a social information model, which can be formally stated as
The basic CF model in a social recommendation CF model creates a way to classify social recommender systems. Following the classification of CF based recommender systems, we classify social recommender systems into two major categories according to their basic CF models: memory based social recommender systems and model based social recommender systems.
3.3.1 Memory based social recommender systems
Memory based social recommender systems use memory based CF models, especially user-oriented methods as their basic models. A missing rating for a given user is aggregated from the ratings of users correlated to her, denoted as N +. For a given user, traditional user-oriented methods use similar users N, while memory based social recommender systems use correlated users N + obtained from both rating information and social information. Social recommender systems in this category usually follow two steps. First, they obtain the correlated users N +(i) for a given user u i , and second is the classical last step of memory based CF methods—aggregating ratings from the correlated users obtained by the first step for missing ratings. Different social recommender systems in this category use different approaches to obtain correlated users N + in the first step; next, we will present details about some representative approaches.
Social based Weight Mean (Victor et al. 2009, 2011): For a given u i , this strategy simply considers a u i ’s directly connected users \({\mathcal{F}}(i)\) as the set of her correlated users N +(i),
TidalTrust (Golbeck 2006b) Users in this system are connected via trust relations. The authors design a metric TidalTrust to estimate trust values among users based on the following two observations: (1) shorter propagation paths produce more accurate trust estimates; (2) paths with higher trust values create better results. To estimate trust values among users, TidalTrust performs the following steps,
-
searching a shortest path from the source user to raters and setting the shortest path length as the path depth of the algorithm;
-
computing trust value from the source user to a rater at the given depth. For a pair of users u i and u k who are not directly connected, a trust value is aggregated from the trust value from u i ’s direct neighbors to u j , weighted by the direct trust values from u i to her direct neighbors as
$${\mathbf{S}}_{ij} = \frac{\sum{u_k \in {\mathcal{F}}(i)} {\mathbf{S}}_{ik} {\mathbf{S}}_{kj}}{\sum{u_k \in {{\mathcal{F}}}(i)} {\mathbf{S}}_{ik}}$$(7) -
after trust values S are calculated, N +(i) is defined as the set of users whose trust values with u i exceeds a given threshold τ,
$$N^+(i) = \{u_j | {\mathbf{S}}_{ij} \geq \tau\}$$(8)
MoleTrust (Massa and Avesani 1999, 2004, 2007): A new trust metric, MoleTrust, is proposed and consists of two major steps. First, cycles in trust networks are removed. To obtain trust values, a large number of trust propagations have to be executed. Therefore, removing trust cycles beforehand from trust networks can significantly speed up the proposed algorithm because every user only needs to be visited once to infer trust values. With this operation, the original trust network is transformed into a directed acyclic graph. Second, trust values are calculated based on the obtained directed acyclic graph by performing a simple graph random walk: first the trust of the users at 1-hop away is computed, then the trust of the users at 2-hop away, etc. After trust values are computed, MoleTrust defines users within maximum-depth and have rated the target item as correlated users N +, where maximum-depth is a predefined parameter.
Although MoleTrust has similar operations to TidalTrust, they are very different in two aspects. First, the definitions of correlated users in these two systems are different. TidalTrust adds a user u k to N +(i) only if she is on a shortest path from u i with respect to a target item, while MoleTrust considers all users who have rated the target item and that can be reached through a direct or propagated trust relation within maximum-depth as N +(i). Second, MoleTrust needs a predefined trust threshold to determine users who will be considered in the rating aggregating process, while TidalTrust determines the trust threshold automatically, which denotes the path strength (the minimum trust rating on a path).
TrustWalker (Jamali and Ester 2009): The intuition of this system is from two key observations. First, a user’s social network has little overlap with users similar to her (Crandall et al. 2008), suggesting that social information provides an independent source of information. Second, ratings from strongly trusted friends on similar items are more reliable than ratings from weakly trusted neighbors on the same target item. The first observation indicates the importance of trust-based approaches while the second observation suggests the capability of item-oriented approaches. To take advantage of both approaches, TrustWalker proposes a random walk model to combine trust based and user oriented approaches into a coherent framework. It queries a user’s direct and indirect friends’ ratings for the target item as well as similar items by performing random walk in online social networks. For example, to obtain a rating for u i to v j . Suppose that we are at a certain node u k . Then TrustWalker works as follows at each step of a random work: if u k rated v j , then it stops the random walk and returns R kj as the result of random walk; otherwise, it has two choices—(1) it also stops random walk and randomly selects one of the items v k similar to v j rated by u i and returns R ik , or (2) it continues random walk and walks to author user u k in u i ’s trust networks.
TrustWalker employs the Pearson Correlation Coefficient of ratings expressed for items to calculate item–item similarity. Since values of Pearson Correlation Coefficient are in the range of [−1, 1], only items with positive correlation with the target item are considered. The similarity between v i and v j is then computed as,
where N ij is the number of users who rated both v i and v j , and PCC(i, j) is Pearson Correlation Coefficient of v i and v j .
3.3.2 Model based social recommender systems
Model-based social recommender systems choose model-based CF methods as their basic models. Matrix factorization techniques are widely used in model based CF methods. There are several nice properties of these matrix factorization techniques (Dunlavy et al. 2011; Menon and Elkan 2011): (1) many optimization methods such as gradient based methods can be applied to find a well-worked optimal solution, scaled to thousands of users with millions of trust relations; (2) matrix factorization has a nice probabilistic interpretation with Gaussian noise; (3) it is very flexible and allows us to include prior knowledge. Most existing social recommender systems in this category are based on matrix factorization (Ma et al. 2008, 2009a, 2011b; Yuan et al. 2009; Jamali and Ester 2010; Vasuki et al. 2010; Au Yeung and Iwata 2011; Yang et al. 2011; Symeonidis et al. 2011; Tang et al. 2012a, b, 2013; Noel et al. 2012; Hong et al. 2013). The common rationale behind these methods is that users’ preferences are similar to or influenced by users whom they are socially connected to. However, the low cost of social relation formation can lead to social relations with heterogeneous strengths (e.g., weak ties and strong ties mixed together) (Xiang et al. 2010). Since users with strong ties are more likely to share similar tastes than those with weak ties, treating all social relations equally is likely to lead to degradation in recommendation performance. Therefore for each social relation, these methods associate a strength, which is usually calculated by rating similarity in existing social recommender systems. For example, when we choose cosine similarity, if u i and u k are connected , S ik is calculated as the cosine similarity between the rating vectors of u i and u k , otherwise we set S ik to 0. Therefore, the strength between u i and u k S ik can be formally defined as
Unlike traditional matrix factorization based recommender systems, social recommender systems in this category can take advantage of social information, and a unified framework can be stated as,
where \(Social({\mathbf{T, S}}, \Upomega)\) is the term introduced to capture social information based on social network analysis and \(\Upomega\) is the set of parameters learned from social information. α is employed to control the contributions from social information. W controls the weights of known ratings in the learning process. According to different definitions of \(Social(\mathbf{T}, \mathbf{S}, \Upomega),\) we further divide social recommender systems in this category into three groups: co-factorization methods, ensemble methods, and regularization methods. Next, we will review some representative systems in detail for each group.
Co-factorization methods (Ma et al. 2008; Tang et al. 2013b): The underlying assumption of systems in this group is that the i-th user u i should share the same user preference vector u i in the rating space (rating information) and the social space (social information). Social recommender systems in this group perform a co-factorization in the user-item matrix and the user–user social relation matrix by sharing the same user preference latent factor. SoRec (Ma et al. 2008) and LOCABAL (Tang et al. 2013b) are two representative systems in this group.
SoRec (Ma et al. 2008): SoRec defines \(Social(\mathbf{T}, \mathbf{S}, \Upomega)\) as
where \({\mathcal{N}}_i\) is the set of users directly connected to u i and \({\mathbf{Z}} = \{{\mathbf{z}}_1,{\mathbf{z}}_2,\ldots,{\mathbf{z}}_n\} \in {\mathbb{R}}^{K\times{n}}\) is the factor-specific latent feature matrix. With this term, the user preference matrix U is learned from both rating information and social information by solving the following optimization problem:
LOCABAL (Tang et al. 2013b): LOCABAL defines \(Social(\mathbf{T}, \mathbf{S}, \Upomega)\) as
LOCABAL is different from SoRec and it is based on social correlation theories where the user preferences of two socially connected users are correlated via the correlation matrix H. In Eq. (14), for two socially connected users u i and u k , their preference vectors u i and u k are correlated through H, which is controlled by their social strength S ik where \(\mathbf{H} \in \mathbb{R}^{K \times{K}}\) is the matrix to capture the user preference correlation. A large value of S ik , i.e., u i and u k with a strong connection, indicates that their preferences u i and u k should be tightly correlated via H, while a small value of S ik indicates that u i and u k should be loosely correlated. \(Social({\mathbf{T, S}}, \Upomega)\) can be applied to both directed and undirected social networks via the correlation matrix H. For a directed social network, the learned matrix H is asymmetric, while for an undirected social network, the learned matrix H is symmetric.
With the definition of \(Social({\mathbf{T, S}}, \Upomega),\) LOCABAL solves the following optimization problem,
Note that LOCABAL and SeRoc have the same form by further factorizing z k into H u k . After obtaining factorized factors of the matrix S, we can use the factors to reconstruct S. For example, for LOCABAL, after learning U and H, we can reconstruct S as \(\hat{{\bf S}} = {\bf U}^\top {\bf H} {\bf U}.\) The reconstructed matrix \(\hat{{\bf S}}\) can be used to perform social relation prediction (Menon and Elkan 2011; Tang et al. 2013b). Therefore, one advantage of approaches in this group is that they jointly perform recommendation and social relation prediction.
Ensemble methods (Ma et al. 2009a; Tang et al. 2012a) The basic idea of ensemble methods is that users and their social networks should have similar ratings on items, and a missing rating for a given user is predicted as a linear combination of ratings from the user and her social network. We give details about two representative systems below.
STE (Ma et al. 2009a) The rating from the i-th user u i to the j-th item v j will be estimated by STE as
where \(\sum_{u_k \in \mathcal{N}_i} \mathbf{S}_{ik} \mathbf{u}_k^\top \mathbf{v}_j\) is a weighted sum of the predicted ratings for v j from u i ’s social network, and β controls the influence from social information. It is easy to verify that Eq. (16) is equivalent to the following matrix form:
STE is to minimize the following term,
where \(Social(\mathbf{T}, \mathbf{S}, \Upomega)\) is defined as,
mTrust (Tang et al. 2012a) A variant of mTrust will predict the rating from u i to v j as,
where \(\frac{\sum_{u_k \in \mathcal{N}_i} \mathbf{S}_{ik} \mathbf{R}_{kj} } {\sum_{u_k \in \mathcal{N}_i} \mathbf{S}_{ik}}\) is a weighted mean of the ratings for v j from u i ’s social network. mTrust solves the following optimization problem,
Similar to STE, we can also find a standard form of Eq. (11) from Eq. (21) for mTrust where \(Social(\mathbf{T}, \mathbf{S}, \Upomega)\) is defined as,
Note that there are two major differences between STE and mTrust. First, S ik denotes the influence from u k to u i for mTrust and will be learned from the data automatically, while S ik in STE is the predefined similarity between u i and u k . Second, STE incorporates a weighted sum of the predicted ratings from social networks, while mTrust incorporates a weighted mean of the existing ratings from social networks.
Regularization methods (Jamali and Ester 2010; Ma et al. 2011b) Regularization methods focus on a user’s preference and assume that a user’s preference should be similar to that of her social network. For a given user u i , regularization methods force her preference u i to be closer to that of users in u i ’s social network \({\mathcal{N}}_i.\) SocialMF (Jamali and Ester 2010) and Social Regularization (Ma et al. 2011b) are two representative systems in this group.
SocialMF (Jamali and Ester 2010) SocialMF forces the preference of a user to be closer to the average preference of the user’s social network and defines \(Social(\mathbf{T}, \mathbf{S}, \Upomega)\) as,
where \(\sum_{u_k \in \mathcal{N}_i} \mathbf{S}_{ik} \mathbf{u}_k\) is the weighted average preference of users in u i ’s social network \(\mathcal{N}_i\) and SocialMF requires each row of S to be normalized to 1. The authors demonstrated that SocialMF addresses the transitivity of trust in trust networks because a user’s latent feature vector is dependent on the direct neighbors’ latent feature vectors, which can propagate through the network and make a user’s latent feature vector dependent on possibly all users in the network.
With the term to capture social information, SocialMF solves the following optimization problem,
Social Regularization (Ma et al. 2011b) For a given user, users in her social network may have diverse tastes. With this intuition, social regularization proposes a pair-wise regularization as,
where the preference closeness of two connected users is controlled by their similarity based on their previous ratings. Similarity can be calculated by Pearson Correlation Coefficient or Cosine similarity of commonly rated items by two connected users. A small value of S ik indicates that the distance between latent feature vectors u i and u k should be larger, while a large value indicates that the distance between the latent feature vectors should be smaller. Eq. (25) can be rewritten into its matrix form as,
where \(\mathcal{L} = \mathbf{D} - \mathbf{S}\) is the Laplacian matrix and D is a diagonal matrix with the i-th diagonal element D(i, i) = ∑ n j=1 S (j, i).
Recommender systems with social regularization solve the following problem,
One advantage of approaches in this category is that they indirectly model the propagation of tastes in social networks, which can be used to reduce cold-start users and increase the coverage of items for recommendation.
3.4 Discussion
Social recommendation can potentially solve some challenging problems of traditional recommender systems such as the data sparsity problem and the cold-start problem, and has attracted broad attention from both academia and industry. On the one hand, social recommendation has been studied for many years in literature. Many successful systems have been proposed and recommendation performance improvement is reported. On the other hand, successful systems in industry are rare and there is a lot of work reporting unsuccessful experiences in applying social recommender systems in academia. In this subsection, we present some key findings from both positive and negative experiences in applying social recommender systems to seek deeper understanding and further development of social recommendation.
3.4.1 Positive experiences in social recommendation
In the physical world, users often seek recommendations from their friends; we have similar observations in the online worlds. For example, 66 % of people on social sites have asked friends or followers to help them make a decision and 88 % of links that 14–24 year olds clicked were sent to them by a friend and 78 % of consumers trust peer recommendations over ads and Google SERPs Footnote 10. The intuition of social recommendation makes sense and that is why people believe social recommendation can potentially improve recommendation performance. There have been many successful social recommender systems proposed in recent years in academia as reviewed in the above subsections, and we summarize some key findings from these successful experiences below.
First, online users are inherently correlated (Ma et al. 2011a). They rarely make decisions independently and usually seek advice from their friends before making purchase decisions. A user’s preference is more likely to be similar to that of her social network than to those of randomly chosen users. This phenomenon is widely observed in many online social networks such as following relations in Twitter (Weng et al. 2010) and trust relations in Epinions (Tang et al. 2013b). This phenomenon can be explained by well-studied social theories such as homophily and social influence, which supports the utility of social recommendation. Furthermore, there is little overlap between a user’s social network and her similar users (Crandall et al. 2008). Connected users provide different information from similar users for recommendation, which can be exploited to improve the quality of recommendations (Jamali and Ester 2009).
Second, to create good quality recommendations, traditional recommender systems need enough historical ratings from each user. Since the rating matrix is usually very sparse due to most users rating few of the millions of items, two users don’t have enough of the number of items rated in common required by user similarity metrics to compute similarity. Therefore, the system is forced to choose neighbors in the small portion of comparable users and is probably going to miss other non-comparable but relevant users (Massa and Avesani 2007). Most of these systems are not able to generate accurate recommendations for users with few or no ratings. Social recommendation can make recommendations as long as the user is connected to a large enough component of the social network (Jamali and Ester 2010), hence social recommendation can significantly reduce cold-start users. For example, in (Massa and Avesani 2007), traditional recommender systems totally fail for new users, however, by considering ratings of trusted users, social recommendation achieves a very small error and is able to produce a recommendation for almost 17 % of the users.
Finally, on a very sparse dataset that contains a large portion of cold start users and of items rated by just one user, coverage becomes an important issue since many of the ratings become hardly predictable (Lü et al. 2012). Coverage refers to the fraction of ratings for which, after being hidden, the recommender systems are able to produce a predicted rating. By propagating trust, it is possible to reach more users; hence, to compute a predicted trust score among them and to count them as neighbors, social recommendation can improve the coverage of recommendation especially for new items. For example, in (Gao et al. 2012b), traditional recommender systems cannot be applied to new locations; however, social recommendation can achieve more than 20 % recommendation accuracy for new locations when exploiting social relations.
In summary, the key findings from successful experiences are—(1) social information contains complementary information and results from social network analysis provide the necessary technical support for social recommendation; (2) users’ opinions and tastes can be propagated via social networks, which can reduce the size of cold-start users; (3) social recommendation can significantly improve the coverage of recommendation.
3.4.2 Negative experiences in social recommendation
Due to the potential value of social information in recommender systems, social recommendation is aggressively pursued in industry. However, a recent report shows that the startup ideas of social recommendations consistently fail (Quora 2012). IBM’s Black Friday report says Twitter delivered 0 percent of referral traffic and Facebook sent just 0.68 percent (IBM 2012). Even in academia, unsuccessful attempts at social recommender systems are also reported (Leskovec et al. 2007; Cho et al. 2011; Gao et al. 2012a). In this subsection, we summarize some key points from negative experiences in applying social recommender systems.
First, the low cost of formation of connections allows one to have an inordinate number of friends in the online world. For example, a Facebook user has 130 friends on average, and an average Twitter user has 126 followers. Research by Dunbar indicates that 100–150 is the approximate natural group size in which everyone can really know each other because our minds are not designed to allow us to have more than a very limited number of people in our social world. The emotional and psychological investments that a close relationship requires are considerable, and the emotional capital we have available is limited (Dunbar 2010). Since the social network comprises of valuable friends, casual friends and event friends, users are not necessarily all that similar and social relations mixed with useful and noise connections may introduce negative information into recommender systems (Quora 2012). For example, social recommender systems simply using all available relations perform worse than traditional recommender systems (Au Yeung and Iwata 2011; Tang et al. 2012a).
Second, the available social relations are extremely sparse, and the distribution of the number of social relations follows a power-law-like distribution (Newman 2005), suggesting that a small number of users specify many social relations while a large proportion of users specify a few relations. Users with many social relations are likely to be active users (Agarwal et al. 2008) and they are likely to have many ratings, while users with fewer ratings are likely to also have fewer connections (Tang et al. 2013b). For users with enough ratings, traditional recommender systems already perform well, while for users with fewer ratings, they are likely to also have fewer social relations and social recommender systems cannot help much. For example, social recommender systems in (Leskovec et al. 2007; Cho et al. 2011; Gao et al. 2012a) gain a little or even no improvement compared to traditional recommender systems.
Finally, most existing successful social recommender systems use trust relations and recommend items to a user from her trusted users. Trust plays a central role in exchanging relationships involving unknown risk (Gefen et al. 2003), which provides information about with whom we should share information and from whom we should accept information (Golbeck 2009). The role of trust is especially critical in some online communities such as e-commerce sites and product review sites, which has been described as the “wild wild west” of the 21st century (McKnight et al. 2003). These successful social recommender systems assume that trust relations are formed when users have similar opinions to similar products. With this assumption, users are likely to seek recommendations from their trusted friends and social recommender systems are likely to be successful. However, trust is a complex concept and has different interpretations in different contexts (Dellarocas et al. 2007; Falcone and Castelfranchi 2010; Adali 2013). A user in the context of product review sites such as Epinions will trust the users if she agrees with their opinions about products, while a user in the context of P2P networks will trust others because of their reliability. Different interpretations of trust may result in different solutions for social recommendation, which suggests that more nuanced approaches are needed to exploit trust relations for recommendation. Trust relations are not necessarily equivalent to other types of social relations. For example, following a user in Twitter does not indicate one’s trust in the user. The success of exploiting trust relations for recommendation may not be applied to other relations, and different types of social relations may have very different impacts on social recommender systems (Yuan et al. 2011).
In summary, key findings from negative experiences in applying social recommender systems include—(1) social relations are too noisy and may have a negative impact on recommender systems; (2) cold-start users are likely to also have few or no social relations and it is difficult for social recommender systems to improve recommendation performance for these users; and (3) different types of social relations have different effects on social recommender systems, and successful experiences in exploiting trust relations may not be applicable to other types of relations.
3.5 Evaluation
In this subsection, we discuss the evaluation of social recommender systems, focusing on available datasets and evaluation metrics for social recommendation.
3.5.1 Datasets
There are benchmark datasets to evaluate traditional recommender systems such as Netflix data Footnote 11 and MovieLens data Footnote 12. Compared to traditional recommendation, social recommendation has recently emerged with the development of social media, and there are no agreed benchmark datasets. However, there are datasets publicly available for the purpose of research; here is a list of several representative ones.
Epinions03 Footnote 13: This dataset was collected by Paolo Massa in a 5-week crawl (November/December 2003) from the Epinions.com (Massa and Avesani 2004). In Epinions, people can write reviews for various products with ratings, and also they can add members to their trust networks or “Circle of Trust”. This dataset provides user-item rating information and user–user trust networks. Note that the trust network here is directed.
Flixster Footnote 14: This dataset was crawled from the Flixster website (Jamali and Ester 2010), which is a social networking service. In Flixster, users can rate movies and can also add some users to their friend list, establishing social networks. Flixster provides user-item rating information and user–user friendship networks. Note that social relations in Flixster are undirected.
Ciao Footnote 15: This dataset was collected by authors in (Tang et al. 2012a, b). Ciao is a product review website where users can rate and write reviews for various products, and they can also establish social relations with others. In addition to rating and social information, Ciao provides extra contextual information including temporal information about when ratings are provided, the category information of products, and information about the reviews such as the content and helpfulness votes.
Epinions11 Footnote 16: This dataset was collected during 2011 and is also from Epinions (Tang et al. 2012a, b). In addition to information in Epinion03, this dataset includes richer information for social recommendation, including temporal information for both rating and social information, categories of products, information about reviews, and distrust information, which allows advanced research about social recommendation. For example, the temporal information about when users establish trust relations can be used to study the evolution of social relations in social recommendation.
Note that some social recommendation papers use other datasets such as Epinions02 (Matthew and Pedro 2002), FilmTrust (Golbeck 2006b), and Douban (Ma et al. 2011b). We do not give details to them because these datasets are publicly unavailable or similar to datasets listed above.
3.5.2 Evaluation metrics
Although the inputs of traditional recommendation and social recommendation are different, their outputs are the same, i.e., the predicted values for unknown ratings. Therefore, metrics that evaluate traditional recommender systems can also be applied to evaluate social recommender systems.
To evaluate recommender systems, the data is usually divided into two parts—the training set \(\mathcal{K}\) (known ratings) and the testing set \(\mathcal{U}\) (unknown ratings). Recommender systems will be trained based on \(\mathcal{K},\) and the quality of recommendation will be evaluated in \(\mathcal{U}.\) Different evaluation metrics are proposed to evaluate the quality of recommendation from different perspectives, such as prediction accuracy, ranking accuracy, diversity and novelty, and coverage. Prediction accuracy and ranking accuracy are two widely adopted metrics.
Prediction Accuracy Prediction accuracy measures the closeness of predicted ratings to the true ratings. Two widely used metrics in this category are Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE).
The metric RMSE is defined as
where \(|\mathcal{U}|\) is the size of \(\mathcal{U}\) and \(\hat{ {\bf R}}_{ij}\) is the predicted rating from u i to v j .
The metric MAE is defined as
A smaller RMSE or MAE value means better performance, and due to their simplicity, RMSE and MAE are widely used in the evaluation of recommender systems. Note that previous work demonstrated that small improvement in RMSE or MAE terms can have a significant impact on the quality of the top-few recommendation (Koren 2008).
Ranking Accuracy Ranking accuracy evaluates how many recommended items are purchased by the user. Precision and recall are two popular metrics in this category. Recall captures how many of the acquired items are recommended, while precision captures how many recommended items are acquired, for example, Prec@N is used to indicate how many top-N recommended items are acquired. Long recommendation lists typically improve recall, while reducing precision. Therefore F score is a metric combining them, and it is less dependent on the length of the recommendation list.
Another popular metric is Discount Cumulative Gain (DCG), which is defined as
where L is the ranked list of recommended items.
In this survey, we do not give a general comparison of existing social recommender systems and the reasons are three-fold. First, although some datasets are publicly available, there are still no agreed benchmark datasets for social recommendation. Second, social recommendation is a complex problem and different algorithms are designed to capture its different aspects. For example, algorithms in (Victor et al. 2009, 2011) are for controversial items, while MoleTrust is for cold-start users. Third, some algorithms may require additional sources to capture social information more effectively, for example, mTrust needs the category information of items (Tang et al. 2012a), therefore, it is difficult to seek a fair comparison for all systems. However, there are some common questions to answer when accessing a recommender system including (1) which datasets we are going to adopt; (2) which metrics we will use; (3) what kinds of items we want to recommend; and (4) which kinds of users we want to recommend to. To help readers further understand the assessment process, we summarize evaluations of representative social recommender systems w.r.t. these questions in Table 1.
4 Research directions of social recommendation
Since the performance boost varies from domain to domain, social recommendation is still in the early stages of development and an active area of exploration. In this subsection, we discuss several research directions that can potentially improve the capabilities of social recommender systems and make social recommendation applicable to an even broader range of applications.
4.1 The heterogeneity of social networks
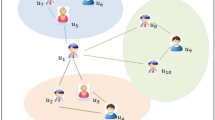
Most existing social recommender systems treat a user’s connections homogeneously. However, connections in online social networks are intrinsically heterogeneous and are a composite of various types of relations (Tang and Liu 2009; Sun and Han 2012; Tang et al. 2012a). Figure 2 illustrates an example of u 1’s social relations with {u 2, u 3, …, u 9}. The user u 1 may treat her social relations differently in different domains. For example, u 1 may seek suggestions about “Sports” from {u 2, u 3}, but ask for recommendation about “Electronics” from {u 4,u 5}. In Tang et al. (2012a), the authors found that people place trust differently to users in different domains. For example, u i might trust u j in “Sports” but not trust u j in “Electronics” at all. For different sets of items, exploiting different types of social relations can potentially benefit existing social recommender systems (Tang et al. 2012a).

An illustration of u 1’s social connections
4.2 Weak dependence connections
Most existing model-based social recommender systems solely make use of a user’s strong dependence connections, i.e., direct connections, which underestimates the diversity of users’ opinions and tastes (Quora 2012). If users in the physical world only had strong dependence connections, then life would be pretty boring since strong dependence connections indicate strong similarities. Actually, users can establish weak dependence connections with others in social networks when they are not directly connected. Weak dependency connections can provide important context information about users’ interests, and are proven to be useful in job hunting (Granovetter 1973), the diffusion of ideas (Granovetter 1983), knowledge transfer (Levin and Cross 2004) and relational learning (Tang and Liu 2009), while rarely used in recommendation.
Identifying weak dependence connections for recommendation is an interesting direction to investigate. One possible way to find weak dependence connections is to exploit users’ geo-locations. For example, (Scellato et al. 2010) notices that users geographically close are likely to share similar interests, and that users geographically close are likely to visit similar locations (Gao et al. 2012b). Another possible way is to detect groups in social networks. Connected users in online social networks form groups where there are more connections among users within groups than among those between groups (Newman 2005, Fortunato 2010). For example, in Fig. 2, {u 1, u 2, u 3, u 10, u 11, u 12} form a group while {u 1, u 3, u 5, u 13, u 14, u 15} form another group. According to social correlation theories, similar users interact at higher rates than dissimilar ones; thus, users in the same group are likely to share similar preferences, establishing weak dependency connections when they are not directly connected (Tang and Liu 2009).
4.3 User segmentation
In traditional recommender systems, for a given user, ratings of users most similar to her are aggregated to predict a missing rating. When involved in social information, besides being similar, users are socially connected. A user’s most similar users usually have little overlap with her connected users (Crandall et al. 2008). Therefore, users can be segmented into four groups as illustrated in Fig. 3—I: connected and non-similar users; II: connected and similar users; III: non-connected and similar users; and IV: non-connected and non-similar users. According to the number of attracted ratings, items can be segmented into cold-start items and normal items. Different types of users may contribute differently for different types of items. For example, connected users can improve the recommendation accuracy of cold-start locations (Gao et al. 2012b), while similar users are important to recommend normal items (Massa and Avesani 2004). Therefore, microcosmic investigations of users and items may give us a deeper understanding of the role of social networks and can potentially improve recommendation performance.

User segmentation for social recommendation, where “I”, “II”, “III” and “IV” denote connected and non-similar users, connected and similar users, non-connected and similar users, and non-connected and non-similar users respectively, while “1” and “2” denote cold-start items and normal items, respectively
4.4 Temporal information
Customer preferences for products drift over time. For example, people interested in “Electronics” at time t may shift their preferences to “Sports” at time t + 1. Temporal information is an important factor in recommender systems and there are traditional recommender systems that consider temporal information (Ding and Li 2005; Koren 2009). Temporal dynamics in data can have a more significant impact on accuracy than designing more complex learning algorithms (Koren 2009). Exploiting temporal information for recommender systems is still challenging due to the complexity of users’ temporal patterns (Koren 2009).
Social relations also change over time. For example, new social relations are added, while existing social relations become inactive or are deleted. The changes of both ratings and social relations further exacerbate the difficulty of exploiting temporal information for social recommendation. A preliminary study of the impact of the changes in both ratings and trust relations on recommender systems demonstrates that temporal information can benefit social recommendation (Tang et al. 2012b).
4.5 Negative relations
Currently most existing social recommender systems use positive relations such as friendships and trust relations. However, in social media, users also specify negative relations such as distrust and dislike. Authors in Abbassi et al. (2013) found that negative relations are even more important than positive relations, revealing the importance of negative relations for social recommendation. There are several works exploiting distrust (Ma et al. 2009; Victor et al. 2009) in social recommender systems. They treat trust and distrust separately, and simply use distrust in an opposite way to trust such as filtering distrusted users or considering distrust relations as negative weights. However, trust and distrust are shaped by different dimensions of trustworthiness, and trust affects behavior intentions differently from distrust (Cho 2006). Furthermore, distrust relations are not independent of trust relations (Victor et al. 2011). A deeper understanding of negative relations and the correlations to positive relations can help us develop efficient social recommender systems by exploiting both positive and negative social relations.
4.6 Cross media data
A user generally has multiple accounts in social media. For example, a user who has an account in Epinions might also have an account in eBay. A new user on one website might have existed on another website for a long time. For example, a user has already specified her interests in Epinions and has also written many reviews about items. When the user registers at eBay for the first time as a cold-start user, data about the user in Epinions can help eBay solve the cold-start problem and accurately recommend items to the user. Integrating networks from multiple websites can bring about a huge impact on social recommender systems and provide an efficient and effective way to solve the cold-start problem. The first difficulty of integrating data is connecting corresponding users across websites and there is recent work proposed to tackle this mapping problem (Narayanan and Shmatikov 2009; Zafarani and Liu 2009; Liu et al. 2013). The study of the mapping problem makes integration of cross-media data for social recommendation possible and brings about new opportunities for social recommender systems.
5 Conclusion
Social recommendation has attracted broad attention from both academia and industry, and many social recommender systems have been proposed in recent years. In this paper, we first give a narrow definition and a broad definition of social recommendation to cover most existing definitions of social recommendation in literature, and discuss the unique feature of social recommender systems as well as its implications. We classify current social recommender systems into memory-based social recommender systems and model-based social recommender systems according to the basic models chosen to build the systems, and then present a review of representative systems for each category. We also discuss some key findings from positive and negative experiences in applying social recommender systems. Social recommendation is still in the early stages of development and needs further improvement. Finally, we present research directions that can potentially improve performance of social recommender systems including exploiting the heterogeneity of social networks and weak dependence connections, microcosmic investigation of users and items, considering temporal information in rating and social information, understanding the role of negative relations, and integrating cross-media data.
Notes
See Foot note 15
References
Abbassi Z, Aperjis C, Huberman BA (2013) Friends versus the crowd: tradeoffs and dynamics. HP Report
Adali S (2013) Modeling trust context in networks. Springer, Berlin
Adomavicius G, Tuzhilin A (2005) Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions. IEEE Trans Knowl Data Eng 17(6):734–749
Agarwal N, Liu H, Tang L, Yu P (2008) Identifying the influential bloggers in a community. In: Proceedings of the international conference on Web search and web data mining. ACM, New York, pp 207–218
Agarwal V, Bharadwaj K. (2012) A collaborative filtering framework for friends recommendation in social networks based on interaction intensity and adaptive user similarity. Social Network Analysis and Mining pp. 1–21
Au Yeung C, Iwata T (2011) Strength of social influence in trust networks in product review sites. In: Proceedings of the fourth ACM international conference on Web search and data mining. ACM, New York, pp 495–504
Baeza-Yates R, Ribeiro-Neto B, et al (1999) Modern information retrieval, vol 463. ACM press, New York
Balabanović M, Shoham Y (1997) Fab: content-based, collaborative recommendation. Commun ACM 40(3):66–72
Belkin N.J., Croft W.B. (1992) Information filtering and information retrieval: two sides of the same coin? Commun ACM 35(12):29–38
Breese JS, Heckerman D, Kadie C (1998) Empirical analysis of predictive algorithms for collaborative filtering. In: Proceedings of the fourteenth conference on uncertainty in artificial intelligence, pp 43–52
Chee SHS, Han J, Wang K (2001) Rectree: an efficient collaborative filtering method. In: Data warehousing and knowledge discovery. Springer, Berlin, pp 141–151
Chen WY, Chu JC, Luan J, Bai H, Wang Y, Chang EY (2009a) Collaborative filtering for orkut communities: discovery of user latent behavior. In: Proceedings of the 18th international conference on World wide web. ACM, New York, pp 681–690
Chen J, Geyer W, Dugan C, Muller M, Guy I (2009b) Make new friends, but keep the old: recommending people on social networking sites. In: Proceedings of the SIGCHI conference on human factors in computing systems. ACM, New York, pp 201–210
Chen B, Guo J, Tseng B, Yang J (2011) User reputation in a comment rating environment. In: Proceedings of the 17th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, New York, pp 159–167
Cho J (2006) The mechanism of trust and distrust formation and their relational outcomes. J Retail 82(1):25–35
Cho E, Myers SA, Leskovec J (2011) Friendship and mobility: user movement in location-based social networks. In: Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, New York, pp 1082–1090
Chowdhury G (2010) Introduction to modern information retrieval. Facet publishing, London
Claypool M, Gokhale A, Miranda T, Murnikov P, Netes D, Sartin M (1999) Combining content-based and collaborative filters in an online newspaper. In: Proceedings of ACM SIGIR workshop on recommender systems, vol 60. Citeseer, New York
Crandall D, Cosley D, Huttenlocher D, Kleinberg J, Suri S (2008) Feedback effects between similarity and social influence in online communities. In: Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, New York, pp 160–168
Davis D, Lichtenwalter R, Chawla NV (2013) Supervised methods for multi-relational link prediction. Soc Netw Anal Min, pp 1–15
Dellarocas C, Zhang XM, Awad NF (2007) Exploring the value of online product reviews in forecasting sales: the case of motion pictures. J Interact Mark 21(4):23–45
Deshpande M, Karypis G (2004) Item-based top-n recommendation algorithms. ACM Trans Inf Syst 22(1):143–177
Ding Y, Li X (2005) Time weight collaborative filtering. In: Proceedings of the 14th ACM international conference on Information and knowledge management. ACM, New York, pp 485–492
Dunbar R (2010) How many friends does one person need? Faber & Faber
Dunlavy D, Kolda T, Acar E (2011) Temporal link prediction using matrix and tensor factorizations. ACM Trans Knowl Discov Data (TKDD) 5(2):10
Ellenberg J (2008) This psychologist might outsmart the math brains competing for the netflix prize. Wired Mag, pp 114–122
Falcone R, Castelfranchi C (2010) Transitivity in trust a discussed property. Citeseer, New York
Fang Y, Si L (2011) Matrix co-factorization for recommendation with rich side information and implicit feedback. In: Proceedings of the 2nd international workshop on information heterogeneity and fusion in recommender systems. ACM, New York, pp 65–69
Fortunato S (2010) Community detection in graphs. Phys Rep 486(3):75–174
Gao H, Tang J, Liu H (2012a) Exploring social-historical ties on location-based social networks. In: Proceedings of the 6th international AAAI conference on weblogs and social media
Gao H, Tang J, Liu H (2012b) gscorr: Modeling geo-social correlations for new check-ins on location-based social networks. In: Proceedings of the 21st ACM international conference on Information and knowledge management. ACM, New York, pp 1582–1586
Gefen D, Karahanna E, Straub D (2003) Trust and tam in online shopping: an integrated model. Mis Q, pp 51–90
Golbeck J (2006a) Generating predictive movie recommendations from trust in social networks. Trust Manag, pp 93–104
Golbeck J (2006b) Generating predictive movie recommendations from trust in social networks. Springer, Berlin
Golbeck J (2009) Trust and nuanced profile similarity in online social networks. ACM Trans Web 3(4):1–33
Goldberg D, Nichols D, Oki BM, Terry D (1992) Using collaborative filtering to weave an information tapestry. Commun ACM 35(12):61–70
Goldberg K, Roeder T, Gupta D, Perkins C (2001) Eigentaste: a constant time collaborative filtering algorithm. Inf Retr 4(2):133–151
Good N, Schafer JB, Konstan JA, Borchers A, Sarwar B, Herlocker J, Riedl J (1999) Combining collaborative filtering with personal agents for better recommendations. In: Proceedings of the national conference on artificial intelligence, pp 439–446
Granovetter M (1973) The strength of weak ties. Am J Soc 78(6):1360–1380
Granovetter M (1983) The strength of weak ties: a network theory revisited. Soc Theory 1(1):201–233
Guy I, Carmel D (2011) Social recommender systems. In: Proceedings of the 20th international conference companion on World wide web. ACm, New York, pp 283–284
Guy I, Jacovi M, Shahar E, Meshulam N, Soroka V, Farrell S (2008) Harvesting with sonar: the value of aggregating social network information. In: Proceedings of the SIGCHI conference on human factors in computing systems. ACM, New York, pp 1017–1026
Guy I, Jacovi M, Perer A, Ronen I, Uziel E (2010) Same places, same things, same people?: mining user similarity on social media. In: Proceedings of the 2010 ACM conference on computer supported cooperative work. ACM, New York, pp 41–50
Herlocker J, Konstan J, Borchers A, Riedl J (1999) An algorithmic framework for performing collaborative filtering. In: Proceedings of the 22nd annual international ACM SIGIR conference on research and development in information retrieval. ACM, New York, pp 230–237
Hofmann T (2004) Latent semantic models for collaborative filtering. ACM Trans Inf Syst (TOIS) 22(1):89–115
Hong L, Doumith AS, Davison BD (2013) Co-factorization machines: modeling user interests and predicting individual decisions in twitter. In: Proceedings of the sixth ACM international conference on Web search and data mining. ACM, New York, pp 557–566
Huang Z, Zeng D, Chen H (2004) A link analysis approach to recommendation under sparse data. In: Proceedings of 2004 Americas conference on information systems
IBM (2012) Ibm’s black friday report says twitter delivered 0 percent of referral traffic and facebook sent just 0.68 percent. In: https://strme.wordpress.com/2012/11/27/ibms-black-friday-report-says-twitter-delivered-0-percent-of-referral-traffic-and-facebook-sent-just-0-68-percent/
Jamali M, Ester M (2009) Trustwalker: a random walk model for combining trust-based and item-based recommendation. In: Proceedings of the 15th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, New York, pp 397–406
Jamali M, Ester M (2010) A matrix factorization technique with trust propagation for recommendation in social networks. In: Proceedings of the fourth ACM conference on recommender systems. ACM, New York, pp 135–142
Jannach D, Zanker M, Felfernig A, Friedrich G (2010) Recommender systems: an introduction. Cambridge University Press, Cambridge
Jiang M, Cui P, Liu R, Yang Q, Wang F, Zhu W, Yang S.(2012) Social contextual recommendation. In: Proceedings of the 22th ACM international conference on Information and knowledge management. ACM, New York
Karypis G (2001) Evaluation of item-based top-n recommendation algorithms. In: Proceedings of the tenth international conference on Information and knowledge management. ACM, New York, pp 247–254
Kautz H, Selman B, Shah M (1997) Referral web: combining social networks and collaborative filtering. Commun ACM 40(3):63–65
King I, Lyu MR, Ma H (2010) Introduction to social recommendation. In: Proceedings of the 19th international conference on World wide web. ACM, New York, pp 1355–1356
Kleinberg J (1999) Authoritative sources in a hyperlinked environment. J ACM 46(5):604–632
Koren Y (2008) Factorization meets the neighborhood: a multifaceted collaborative filtering model. In: Proceeding of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, New York, pp 426–434
Koren Y (2009) Collaborative filtering with temporal dynamics. In: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, New York, pp 447–456
Leskovec J, Adamic LA, Huberman BA (2007) The dynamics of viral marketing. ACM Trans Web 1(1):5
Leskovec J, Huttenlocher D, Kleinberg J (2010) Predicting positive and negative links in online social networks. In: Proceedings of the 19th international conference on world wide web
Levin DZ, Cross R (2004) The strength of weak ties you can trust: the mediating role of trust in effective knowledge transfer. Manag Sci 50(11):1477–1490
Li Y, Hu J, Zhai C, Chen Y (2010) Improving one-class collaborative filtering by incorporating rich user information. In: Proceedings of the 19th ACM international conference on Information and knowledge management. ACM, New York, pp 959–968
Liu J, Zhang F, Song X, Song YI, Lin CY, Hon HW (2013) What’s in a name?: an unsupervised approach to link users across communities. In: Proceedings of the sixth ACM international conference on Web search and data mining. ACM, New York, pp 495–504
Lü L, Medo M, Yeung CH, Zhang YC, Zhang ZK, Zhou T (2012) Recommender systems. Phys Rep
Ma H, Yang H, Lyu M, King I (2008) Sorec: social recommendation using probabilistic matrix factorization. In: Proceeding of the 17th ACM conference on Information and knowledge management. ACM, New York, pp 931–940
Ma H, King I, Lyu MR (2009a) Learning to recommend with social trust ensemble. In: Proceedings of the 32nd international ACM SIGIR conference on research and development in information retrieval. ACM, New York, pp 203–210
Ma H, Lyu MR, King I (2009b) Learning to recommend with trust and distrust relationships. In: Proceedings of the third ACM conference on recommender systems. ACM, New York, pp 189–196
Ma N, Lim E, Nguyen V, Sun A, Liu H (2009c) Trust relationship prediction using online product review data. In: Proceeding of the 1st ACM international workshop on complex networks meet information and knowledge management. ACM, New York, pp 47–54
Ma H, Zhou TC, Lyu MR, King I (2011a) Improving recommender systems by incorporating social contextual information. ACM Trans Inf Syst 29(2):9
Ma H, Zhou D, Liu C, Lyu M, King I (2011b) Recommender systems with social regularization. In: Proceedings of the fourth ACM international conference on Web search and data mining. ACM, New York, pp 287–296
Marsden P, Friedkin N (1993) Network studies of social influence. Soc Methods Res 22(1):127–151
Massa P (2007) A survey of trust use and modeling in real online systems. Trust E Serv Technol Prac Chall
Massa P, Avesani P (2004) Trust-aware collaborative filtering for recommender systems. In: On the move to meaningful internet systems 2004: CoopIS, DOA, and ODBASE. Springer, Berlin, pp 492–508
Massa P, Avesani P (2005) Controversial users demand local trust metrics: an experimental study on epinions. com community. In: Proceedings of the national conference on artificial intelligence, vol 20. p. 121. Menlo Park, CA; Cambridge, MA; London; ; MIT Press; 1999
Massa P, Avesani P (2007) Trust-aware recommender systems. In: Proceedings of the 2007 ACM conference on recommender systems. ACM, New York, pp 17–24
Matthew R, Pedro D (2002) Mining knowledge-sharing sites for viral marketing. In: Proceedings of the eighth ACM SIGKDD international conference on knowledge discovery and data mining
McKnight D, Choudhury V, Kacmar C (2003) Developing and validating trust measures for e-commerce: an integrative typology. Inf Syst Res 13(3):334–359
McPherson M, Smith-Lovin L, Cook J (2001) Birds of a feather: homophily in social networks. Annu Rev Soc, pp 415–444
Mei T, Yang B, Hua XS, Yang L, Yang SQ, Li S (2007) Videoreach: an online video recommendation system. In: Proceedings of the 30th annual international ACM SIGIR conference on research and development in information retrieval. ACM, New York, pp 767–768
Menon A, Elkan C (2011) Link prediction via matrix factorization. Mach Learn Knowl Discov Databases, pp 437–452
Miyahara K, Pazzani MJ (2000) Collaborative filtering with the simple bayesian classifier. In: PRICAI 2000 topics in artificial intelligence. Springer, Berlin, pp 679–689
Mooney RJ, Bennett PN, Roy L (1998) Book recommending using text categorization with extracted information. In: Proc. Recommender Systems Papers from 1998 Workshop, Technical Report WS-98-08
Narayanan A, Shmatikov V (2009) De-anonymizing social networks. In: 2009 30th IEEE symposium on security and privacy. IEEE, New york, pp 173–187
Newman ME (2005) Power laws, pareto distributions and Zipf’s law. Contemp Phys 46(5):323–351
Noel J, Sanner S, Tran KN, Christen P, Xie L, Bonilla EV, Abbasnejad E, Della Penna N (2012) New objective functions for social collaborative filtering. In: Proceedings of the 21st international conference on World Wide Web. ACM, New York, pp 859–868
Page L, Brin S, Motwani R, Winograd T (1999) The pagerank citation ranking: bringing order to the web. Stanford InfoLab
Pan R, Zhou Y, Cao B, Liu NN, Lukose R, Scholz M, Yang Q (2008) One-class collaborative filtering. In: Eighth IEEE international conference on data mining. IEEE, New York, pp 502–511
Paterek A. (2007) Improving regularized singular value decomposition for collaborative filtering. In: Proceedings of KDD cup and workshop, vol 2007, pp 5–8
Pazzani MJ (1999) A framework for collaborative, content-based and demographic filtering. Artif Intell Rev 13(5–6):393–408
Pazzani M., Billsus D. (1997) Learning and revising user profiles: the identification of interesting web sites. Mach Learn 27(3):313–331
Quora (2012) Why does the startup idea of social recommendations consistently fail? In: http://www.quora.com/Why-does-the-startup-idea-of-social-recommendations-consistently-fail
Raghavan S, Gunasekar S, Ghosh J (2012) Review quality aware collaborative filtering. In: Proceedings of the sixth ACM conference on recommender systems. ACM, New York, pp 123–130
Resnick P, Iacovou N, Suchak M, Bergstrom P, Riedl J (1994) Grouplens: an open architecture for collaborative filtering of netnews. In: Proceedings of the 1994 ACM conference on Computer supported cooperative work. ACM, New York, pp 175–186
Ricci F, Rokach L, Shapira B (2011) Introduction to recommender systems handbook. In: Recommender systems handbook, pp 1–35
Salakhutdinov R, Mnih A (2008) Probabilistic matrix factorization. Adv Neural Inf Process Syst 20:1257–1264
Sarwar B, Karypis G, Konstan J, Riedl J (2001) Item-based collaborative filtering recommendation algorithms. In: Proceedings of the 10th international conference on World Wide Web. ACM, New York, pp 285–295
Scellato S, Mascolo C, Musolesi M, Latora V (2010) Distance matters: geo-social metrics for online social networks. In: Proceedings of WOSN 10
Schafer JB, Konstan JA, Riedl J (2001) E-commerce recommendation applications. Data Min Knowl Discov 5(1):115–153
Scott J (2011) Social network analysis: developments, advances, and prospects. Soc Netw Anal Min 1(1):21–26
Scott J (2012) Social network analysis. SAGE Publications Limited, London
Sigurbjörnsson B, Van Zwol R (2008) Flickr tag recommendation based on collective knowledge. In: Proceedings of the 17th international conference on world wide web. ACM, New York, pp 327–336
Sinha R, Swearingen K (2001) Comparing recommendations made by online systems and friends. In: Proceedings of the Delos-NSF workshop on personalization and recommender systems in digital libraries, vol. 106. Dublin, Ireland
Soboroff I, Nicholas C (1999) Combining content and collaboration in text filtering. In: Proceedings of international joint conference on artificial intelligence workshop: machine learning for information filtering
Su X, Khoshgoftaar T (2009) A survey of collaborative filtering techniques. Adv Artif Intell 2009:4
Sun Y., Han J. (2012) Mining heterogeneous information networks: principles and methodologies. Synth Lect Data Min Knowl Discov 3(2):1–159
Symeonidis P, Tiakas E, Manolopoulos Y (2011) Product recommendation and rating prediction based on multi-modal social networks. In: Proceedings of the fifth ACM conference on recommender systems. ACM, New York, pp 61–68
Tang L, Liu H (2009) Relational learning via latent social dimensions. In: Proceedings of the 15th ACM SIGKDD international conference on knowledge discovery and data mining, pp 817–826
Tang L, Liu H (2010) Community detection and mining in social media. Synth Lect Data Min Knowl Discov 2(1):1–137
Tang J, Gao H, Liu H (2012a) mTrust: Discerning multi-faceted trust in a connected world. In: Proceedings of the fifth ACM international conference on web search and data mining. ACM, New York, pp 93–102
Tang J, Gao H, Liu H, Das Sarma A (2012b) eTrust: Understanding trust evolution in an online world. In: Proceedings of the 18th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, New York, pp 253–261
Tang J, Gao H, Hu X, Liu H (2013a) Context-aware review helpfulness rating prediction. In: RecSys
Tang J, Gao H, Hu X, Liu H (2013b) Exploiting homophily effect for trust prediction. In: Proceedings of the sixth ACM international conference on Web search and data mining. ACM, New York, pp 53–62
Tang J, Hu X, Gao H, Liu H (2013c) Exploiting local and global social context for recommendation. In: IJCAI
Ungar LH, Foster DP (1998) .: Clustering methods for collaborative filtering. In: AAAI workshop on recommendation systems, vol 1
Vasuki V, Natarajan N, Lu Z, Dhillon IS (2010) Affiliation recommendation using auxiliary networks. In: Proceedings of the fourth ACM conference on recommender systems. ACM, New York, pp 103–110
Victor P, Cornelis C, De Cock M, Teredesai AM (2009) A comparative analysis of trust-enhanced recommenders for controversial items. In: Proceedings of the international AAI conference on weblogs and social media, pp 342–345
Victor P, De Cock M, Cornelis C (2011) Trust and recommendations. In: Recommender systems handbook. Springer, Berlin, pp 645–675
Wasserman S, Faust K (1994) Social network analysis: methods and applications, vol 8. Cambridge University Press, Cambridge
Weng J, Lim E, Jiang J, He Q (2010) Twitterrank: finding topic-sensitive influential twitterers. In: Proceedings of the third ACM international conference on web search and data mining. ACM, New York, pp 261–270
Wu HC, Luk RWP, Wong KF, Kwok KL (2008) Interpreting tf-idf term weights as making relevance decisions. ACM Trans Inf Syst (TOIS) 26(3):13
Xiang R, Neville J, Rogati M (2010) Modeling relationship strength in online social networks. In: Proceedings of the 19th international conference on World wide web
Yang SH, Long B, Smola A, Sadagopan N, Zheng Z, Zha H (2011) Like like alike: joint friendship and interest propagation in social networks. In: Proceedings of the 20th international conference on World wide web. ACM, New York, pp 537–546
Yildirim H., Krishnamoorthy M.S. (2008) A random walk method for alleviating the sparsity problem in collaborative filtering. In: Proceedings of the 2008 ACM conference on recommender systems. ACM, New York, pp 131–138
Yuan Q, Zhao S, Chen L, Liu Y, Ding S, Zhang X, Zheng W (2009) Augmenting collaborative recommender by fusing explicit social relationships. In: Workshop on recommender systems and the social web, Recsys 2009
Yuan Q, Chen L, Zhao S (2011) Factorization vs. regularization: fusing heterogeneous social relationships in top-n recommendation. In: Proceedings of the fifth ACM conference on recommender systems. ACM, New York, pp 245–252
Zafarani R, Liu H (2009) Connecting corresponding identities across communities. In: Proceedings of the 3rd international conference on weblogs and social media (ICWSM09)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Tang, J., Hu, X. & Liu, H. Social recommendation: a review. Soc. Netw. Anal. Min. 3, 1113–1133 (2013). https://doi.org/10.1007/s13278-013-0141-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13278-013-0141-9