
Abstract
With the tremendous growth of the internet, services provided through the internet are increasing day by day. For the adaption of web service techniques, several standards like ebXML, SOAP, WSDL, UDDI, and BPEL etc. are proposed and approved by W3C. Most of the web services are operating as a query—response model. User has to submit query according to the standard adapted, and services are supporting natural language queries nowadays. The given inputs are processed by web services server can find few similarities in sentence like nouns. The keyword for nouns is filtered accurately and saved in the list as table for each domain. Same time input query words are stored in the domain. The words stored in the domain is matched with the given input queries, later used to find the similarity between the queries In this paper, an automated technique for finding web service similarity based on query classification proposed. The proposed method adapted machine learning approach called KNN, and the data maintained in a hash indexed storage tables. As a result, the relationships between the input query and stored database have been showed in precision, recall, F1-Score and Support.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In web services discovery the major concern understands the given input user query. The queries are effectively mapped in different categories in matching engine. The domain details are stored in data engine. This provides the fast and efficient service during web search. The improvements can be seen in various applications such as travel planner, advertising, and web search. To provide the improved performance and better accuracy in searching platform the novel method of classification is introduced. The task is very challenging in widely used web search engine. The major challenge can be viewed in real time service retrieval and also handling traffic.
1.1 Web service discovery
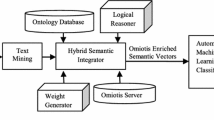
Web service can be classified based on the services they used are shown in Fig. 1. The given query is processed by web service discovery tools. The tools will read the URLs of XML file for given web services. The corresponding URL is located in web server so that it saves the related services document in local storage was proposed by (Han et al. 2015). The challenging task is processing the requested service and finding the exact result to user’s inspite of having huge web services and suppliers. The main interest of user is quality of requested service although they not need provider information.

Categories of web services
The every web service provider has to register their service details such as descriptions and information regarding their services like details of trade, technical and services they provide for users. Classification of services was discussed by (Venkatachalam et al 2016a, b) trough Fig. 1.The services which are frequently used by users are stored in the metadata based registry. Based on this service usage in registry, the further classification can be done. After classification it is easy for web service discovery to locate the service provider for the client request. Now the provider’s web service description published and client requested service location is identified, further interface and other service mechanisms are processed. The research work of (Kumar et al. 2016) in web service discovery used algorithm for services such as KNN with Indexed storage for table gives better results.
The services provided by one electronic application to another via web is known as web services. Web Service Definition Language (WSDL), Extensible Mark-up Language (XML), Universal Description, Discovery and Integration (UDDI) open standards, Simple Object Access Protocol (SOAP) are combined together to provide one web application for the requested web service.
In the proposed model, indexed search technique is used to classify the user input queries and find the similarities between them automatically. The inspection if queries to various level is done automatically. By utilizing artificial intelligence. The trained and supervised automatic classifier is used to measure the similarities. It validate the various relevant metrics and gives result accurately.
1.2 Processing queries
The main aim of finding web service is to search the requested service approximately. There are three steps processed during the service discovery.
Step 1: advertisement of service: the provider advertises the web service in public database or repositories. When this service is searched by the client will return service description file.
Step 2: the client requested service sends to public database. Here the services are compared and matched with client requested service and service in database. The relevant service is retrieved to the user.
Step 3: most relevant from one of the retrieved service is selected to client request.
The client request is in the form of natural language. The input is processed by NLP application interface and converted to structured data. It is matched with web service annotations. The relevant matched service is retrieved to client. Finally, the two standard measures Precision and recall will calculate the accuracy of retrieved information (Batra et al. 2010).
1.3 Matching words using optimizer
Searching of service resulted in unrelavent and poor results. This is due to query words may not available in domain ontology OWLS-TC3 ( Dataset MIT Press 2009). In the proposed work this problem is handled very easily. The unidentified words synonyms are processed in domain ontology to find the relevant service. This will provide required service to client request. The query optimizer process the unmatched words, by using the wordNet closest meaning for client query is retrieved. The keyword is analysed from client query, it is matched with available web service. The closest web service is retrieved to the user. The three machine learning algorithm identified for better matching in proposed model.
The similarities of the input queries and words in repository are checked by storing in queries in database. In the proposed model, hash based indexing approach is used for data retrieval. This will provide better accuracy and efficiency. After the query is parsed, the optimizer reads the query and process to next step for estimation and planning.
This section provide performance of the proposed model using query optimization technique. It is known that in our proposed model the understanding of client request is evaluated using machine learning algorithms. The classifying queries done easily by matching the client input queries with trained queries.
2 Literature survey
The data mining algorithms are used for service discovery. There are various algorithms in data mining such as support vector machines, k nearest algorithm, centroid algorithm, K-means clustering algorithm, Decision trees algorithms, Apriori algorithms etc. The service discovered from the web services using mining algorithms obtained the pattern for wider data.
For extraction of data from html document based on the ontology concept, (Karoui et al 2006) suggested a improved approach by using the unsupervised hierarchical clustering algorithm as” Contextual Ontological Concept Extraction” (COCE) is based on k means algorithm. It is processed by a structural context. In proposed approach, in this paper used context based hierarchical algorithm which gives better results than existing COCE.
Matching services in (Platzer and Dustdar 2009) explained that using various attributes of web service for matching services are not accurate and results are unrealistic. So they proposed web 2.0 participation. The various clustering methods also expressed.
Neighborhood Counting Similarity method in (Wang and Murtagh 2016) is proposed for various kinds of numerical data in different categories and time series. The result is more better than exsisting algorithms.
The major issue in image analysis is segmenting the images. Isa et al. (2009) proposed four new algorithm for segmenting the image. The combination of FMKM algorithm and AMKM algorithm introduce proposed clustering AFMKM algorithm. The segmentation performance is excellent.
The digital images are segmented using the clustering technology. The existing algorithms used only in limited applications like medical images, microscopic images. Adaptive Fuzzy-K-means (AFKM) clustering for image segmentation was used by (Siti Noraini et al. 2010). AFKM this algorithm is used in all general images.
The different data mining algorithms are discussed in (Nayak and Devi 2011) for service discoveries. In this paper it has explain how segmentation helps in resolving problems in various service discovery. The objects are noted with similar characters in dataset. This results cluster to form groups. They used four methods for mining operations such as predictive modelling, clustering, and interface examination and deviation investigation. The advantage of this mining can be seen in delivering the service for business is done by organisation and technical values are accessed by knowledge staff for service discoveries.
The major concern in web service discovery is knowledge of users. To overcome this issue (Adala et al. 2011) implemented automatic web service discovery using semantic web services. The automatic semantic web service process NLP techniques to convert users natural language queries in to web language description. It is described in WSDL, OWL.
The database or dataset platform is used for indexing. The index method provide easy retrieval of needed data. This will increase the speed of data retrieval and its service discovery efficiency.
The semantic web services are introduced for automatic processing of web services and service discovery explained in (Aabhas et al. 2012; Isa et al. 2009). The ranking was done using semantics and its relationship. By using the semantic rankings and mining algorithm the service discovery is done. They use pattern mining algorithm which does not consider the terms. The web services context and parameters are considered as vectors for both input and output terms. The every collection of vectors compute transactions in the form of huge web services. The mining algorithm is computed in every transaction to find frequent hyper group pattern and h-confidence level.
The indexing and storage space occupied was described by (Yu and Sarwat 2016; Malar et al. 2020). The technique to reduce space was proposed as pointers i.e. tuple pointers.
The query based natural language processing and service discovery in (Venkatachalam et al 2016a, b) processed using semantic description. To overcome the disadvantage of gap between similar service descriptions, this paper proposed experiment collects input/output, description and need of services. The matching was done by using three above descriptions in web registry.
The best method for production and its planning was given in (Wenbin et al. 2017). To overcome the complexity it uses neural network and its inputs. The stability was provided using bagging algorithm. The Back Propagation Neutral network provides accuracy.
The web service discovery and its WSDL registry have no semantic relationship. To provide the relation (Venkatachalam and Karthikeyan 2018) proposed semantic web service discovery using NLP and Ontology Based Regitry.
The EEG contains unwanted noise in the signal can be removed using fuzzy logics and kernel support vector machine in paper (Yasoda et al. 2020; Venkatachalam et al. 2020). After removing the noise EEG artifacts.
3 Classifying queries using AI algorithms
The artificial intelligence provides three methods to classify the client input (queries). They are supervised learning algorithm, semi supervised learning algorithm and unsupervised learning algorithm. These algorithms are used widely to classify and group the similar queries. In this proposed section it is focused on supervised learning algorithm for automatic search queries classification.
The purpose of various machine learning algorithm is read the client input with trained effect and without program. The most effective and used algorithm is K-Nearest Neighbor (KNN) machine learning algorithm. This KNN algorithm reads the input data and cluster the terms. Clustered terms are matched with nearest data set in the data base. Based the service retrieval the machine learning algorithm are two types as follows:
-
1.
Learning (supervised and unsupervised or semi supervised learning) done by Grouping terms with label
-
2.
Similarity matching done.
Venkatachalam and Karthikeyan (2017) mentioned using KNN with fuzzy logic algorithm will give better output than above learning methods. The automatic query classification is performed. Effective feature selection is done using reduction algorithms.
Further choice can be processed by case based learning approach. In this approach important information’s are processed regularly. Such model gives regular database with test information and updates new information in the database. Clear visualization can be done so that exact matching is performed. This model is also called as memory based learning technique. The regular update is done in dataset of stored memory and matching is done in memory.
By using KNN algorithm,the classification is done as output named as label. Based the neighbors and its surrounding objects are classified. The selected objects are placed in the class with recognized attributes around the k nearest neighbors. When the object is assigned the value of k become one i.e. k = 1.
The property value in the output is used for regression process in KNN algorithm.
Example for significant of KNN is shape classification. Figure 2 shows a data set and its respective classification.
Here consider the dataset in the circle with two different shapes. Triangle is filled with pink and star is filled with blue color. The problem is green color diamond. How the classification of diamond is done.

Sample data set for classification through machine learning algorithm
3.1 Input data classification
The similar words are more prominent in every input request queries. In the query statement the nouns are separated and considered as appropriate keyword. These keywords are stored in database table. The stored keywords are compared using in the database table and similarities are founded. Figure 2 shows the classification model.
-
1.
The similarity score for every keyword is calculated.
-
2.
The query relevance factor is identified by using pair of (cluster, query) (Fig. 3).
Fig. 3 
Overall Flows for Query Classification Model

The web services are identified based on following procedure:
-
i.
Given users request is processed in to group of similar features.
-
ii.
Similar features further processed into one stop encoding, so that text is represented as a numerical data.
-
iii.
After step two, same feature set is processed using K-Means Algorithm. The class label is generated in this step.
-
a.
KNN algorithm process the label data.
-
b.
Then it is stored in database for reference in future
-
c.
Repeat the step 1 to step 3 for input request.
-
a.
-
iv.
Encoding is done only one time for new input query. Encoded label data given processed using KNN Algorithm. Corresponding class label is matched. Finally validated by precision, recall and confusion matrix.
Both the positive and negative samples are present in training set.
A data set consists of positive and negative samples. The training phase result is labelled with class. In the testing phase similarity is calculated. The various classifications namely (True Positive, False Positive., True Negative, and False Negative) are done.
The result obtained with several feature is processed to obtain the precision and recall.
Learning algorithm using matrix It is otherwise called as error matrix. It shows the table layout which allows visualization of the performance of an algorithm. The supervised learning algorithm uses confusion matrix while unsupervised learning uses matching matrices. In the matrix, row represents the instances in a predicted class and column represents the instances in an actual class (or vice versa).
3.2 Data storage using index method
To identify the similarity between the search index is calculated using semantic approach. It extracts the nouns in the text. The retrieved data is stored in Table. The proposed work Hash based indexing provides new indexing method to store data in dataset.
For indexing (Yu and Sarwat 2016) used tuple pointers for indexing the data in table. This reduce the storage space than disk page storage method.
In the web service, the input request by the client split in to parameters and search the relevant data in the big data base. The indexing the database will reduce the retrieval time. By choosing the better indexing method will improve the performance of the system.
In our proposed work, the hash based indexing is used to store the domain attributes. Table 1 shows the attribute storage.
The indexing storage elaborated below. To elaborate more perfectly let’s take metadata attributes such as:
Row 1: R (X,Y,Z,P)–metha, 25, Monday, 5 pm.
Row 2: R(X,Y)–miral, sunday.
Row 3: R (X)–saturday.
Row 4: R (X, Y, Z)–benny, june, 56.
The algorithm procedure as follows:



4 Experiments and results
4.1 Data set augmentation
The nouns in input datas are stored in dataset as terms. That dataset is used for retrieval trough the proposed framework in the research work. Maximum the seven noun terms are clustered as a feature set. If the term not a available for certain noun then it is stored as empty value ‘N’. The proposed research uses a K-Means clustering with KNN for classification process.
In this process, 70% of data in dataset is used as a training data and remaining data is used for testing process. Totally 90 rows are query, 70 rows are training queries and 15 rows are for testing process.
The restaurant domain is chosen for query set. The precision, recall performance are calculated.
5 Methodology
The database contains query nouns which are analysed using the proposed method. To understand the query similarity (Beitzel et al. 2007) suggested AOL web services. The proposed research method applied for web search.
The different domains such as education travel and economy has different clauses of query set. OWL dataset has the domain queries considered as benchmark. The K means algorithm is used for classifying data and labelling it in whole data set. For the better knowledge, the labelling done within 4 as limit. The labelling of data done from range of 0 to 4. Nearly 90 queries are used totally. Based the seven features, the data is clustered and grouped using the noun phrase extraction process. For empty the value is assigned as empty.
For example,
< Application no, service, rooms, car, house, water, novel >
The nouns from the query is extracted and stored as seven features. Totally 90 queries are used for analysis. The One Hot Encoding method is used for labelling. Figure 4 shows the result of one stop coding.

Result of one hot encoding
Figure 4 shows the representative feature of the noun. This can be further executed using clustering algorithm.
The nouns extracted from K means algorithm is send to K means classifier (Fig. 5). The classifier labels the query set as a classification process. The class label is feed as input to KNN classifier. It works on 30% of the dataset and testing is performed. Figure 6 shows how confusion matrix presented and advantage of the proposed methodology.

Technique of query classifications

Confusion matrix
The x axis represents the predicted label and y axis represents the true label.
The observation of confusion matrix:
-
a)
There is mismatching between class 0 and class 3 in one of the instances can be noted.
-
b)
There is mismatching between class 1 and class 3 in one of the instances can be noted.
-
c)
There is mismatching between class 2 and class 3 in one of the instances can be noted.
Inference is shown mismatching between relevant to a class. Thus precision, recall, F1Score and support are further analysed.
The Fig. 7 represents the precision for the classes 0, 1, 2, 3

Precision
Hence here, the x axis refers to classes and y axis refers to precision. It is proved the efficiency of the data retrieval in the all classes. it can also see accuracy in matching.
Figure 8 represents the recall for class 0, 1, 2 and 3.

Recall
Hence here, the x axis refers to classes and y axis refers to recall. In the class 3 value is less than 1. It is seen misclassification cannot be same for all given data.
Figure 9 represents performance measures. The following observations.
-
a.
classes 0,1,2 are less than 1 in precision and f1 score.
-
b.
b. class 3 is less than 1 is noted for recall and f1 score.
-
c.
average values for above three results shows less than 1

Performance measures
This dotted lines shows working relation of the precision and recall (Fig. 10). Where,

Curve for four classes precision and recall
precision pre(= positive value to be predictive).
recall (= sensitive )for all possible values.
• x-axis denotes recall as (= tp (tp + fn)).
• y-axis denotes precision (= tp/(tp + fp))
The classes do not have exact relationship for precision and recall is:
-
a.
Class 3 of (area = 0.700)
-
b.
Class 0 of (area = 0.833)
Thus the PRC represents a chosen cut-off for all point.
The above graph shows the entire data’s features contribution process (Fig. 11).

Various data representations for whole data for features
The inference noted: class 1 does not overlap with classes 0, 2, 3.
6 Discussion
The semantic web technology is used to determine the similarities between the input queries and stored database. In the database the meaningful terms of queries as nouns and features are stored. The majority of web services act as query response model. The client gives the input in natural language as given standard and language is processed using AI tools. The input queries and terms in database find more similarities in available services. To overcome this issues the exact noun for the input query keywords are stored in the database table for every domain. When search operation is performed, similarities can be finding. In this research work, method to find similarities automatically is performed. New query classification methodology also proposed.
7 Conclusion
In this paper, new architecture is proposed for similarity matching in terms given during service request that is used during service fetching process. For analysis the few domains are taken. In this research work it has proven improvements in index based storage, similarity matching and query comparison for the few domains. For the best performance, we implemented K-Means and KNN algorithm for the quality service fetching process. The improved results was shown using precision, recall, F1score and support. This proposed new architecture works in better for service discovery. The high recall with acceptable precision was proved. The combined approach to differentiate the group of query than the individual query processing gives high recall.
Change history
12 July 2022
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s12652-022-04307-9
References
Aabhas V, Paliwal B, Vaidya J, Xiong H, Adam N (2012) Semantics-based automated service discovery. IEEE Trans Serv Comput 5(2):260–275
Adala A, Tabbane N, Tabbane S (2011) A framework for automaticweb service discovery based on semantics and NLP techniques. Adv Mult Hindawi Publ Corp 2011:1–7
Batra S, Bawa S (2010) A framework for semantic discovery of web services. In: Proceedings of the 5th international conference on ubiquitous and collaborative computing, Abertay, Dundee, pp 22–27
Dataset MIT Press (2009)1998. OWLS-TC v3.0. https://projects.semwebcentral.org/projects/owls-tc/
Han W, Zhu W, Jia Y (2015) Research and Implementation of Real-time Automatic Web Page Classification System. In: 3rd International Conference on Material, Mechanical and Manufacturing Engineering (IC3ME 2015)
Isa NAM, Salamah SA, Ngah UK (2009) Adaptive fuzzy moving K-means clustering algorithm for image segmentation. IEEE 2146 Trans Consum Electron 55(4)
Karoui L, Aufaure M-A, Bennacer N (2006) Context-based Hierarchical Clustering for the Ontology Learning”, Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence, vol (WI'06):7695–2747
Kumar VV, Satyanarayana N (2016) Self-adaptive semantic classification using domain knowledge and web usage log for web service discovery. Int J Appl Eng Res 11(6):4618–4622 (ISSN 0973–4562)
Malar ACJ, Kowsigan M, Krishnamoorthy N, Karthick S, Prabhu E, Venkatachalam K (2020) Multi constraints applied energy efficient routing technique based on ant colony optimization used for disaster resilient location detection in mobile ad-hoc network. J Ambient Intell Humaniz Comput 01767–9
Nayak G, Devi S (2011) A Survey on privacy preserving data mining: approaches and techniques. Int J Eng Sci Technol 3(3)
Platzer C, Rosenberg F, Dustdar S (2009)Web Service Clustering using multidimensional angels as proximity measures. ACM Transact Internet Technol 9
Steven MB, Eric CJ (2007) Automatic classification of web queries using very large unlabled query logs. ACM Trans Inf Syt Vol 25
Sulaiman SN, Isa NAM (2010) Adaptive fuzzy-K-means clustering algorithm for image segmentation. IEEE Trans Consum Electron 56(4)
Venkatachalam K, Karthikeyan NK (2017) Effective feature set selection and centroid classifier algorithm for web services discovery. Indones J Electr Eng Comput Sci 5
Venkatachalam K, Karthikeyan NK (2018) A framework for constraint based web service discovery with natural language user queries. J Adv Res Dyn Control Syst, Elsevier Publication 05-Special Issue, 1310–1316
Venkatachalam K, Karthikeyan NK, Kannimuthu S (2016a) Comprehensive survey on semantic web service discovery and composition. Adv Nat Appl Sci AENSI Publ 10(5):32–40
Venkatachalam K, Karthikeyan NK, Basker A (2016b) An ontology based framework for web service discovery from natural language user queries. Asian J Inf Technol 15(17):3296–3305
Venkatachalam K, Devipriya A, Maniraj J, Sivaram M, Ambikapathy AS, Amiri I (2020) A novel method of motor imagery classification using eeg signal, Artificial Intelligence in Medicine, 103
Wang H, Murtagh F (2016) A study of the neighbourhood counting similarity. IEEE Trans Knowl Data Eng 20(4)
Wu W, Peng M (2017) A data mining approach combining K-means clustering with bagging neural network for short-term wind power forecasting. IEEE Internet Things J 4(4)
Yasoda K, Ponmagal RS, Bhuvaneshwari KS, Venkatachalam K (2020) Automatic detection and classification of EEG artifacts using fuzzy kernel SVM and wavelet ICA (WICA). Soft Comput
Yu J, Sarwat M (2016) Two birds, one stone: a fast, yet lighweight, indexing scheme for modern database systems. Proc VLDB endowment 10(4):385–396
Author information
Authors and Affiliations
Corresponding author
Additional information
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s12652-022-04307-9
About this article

Cite this article
Balaji, B.S., Balakrishnan, S., Venkatachalam, K. et al. RETRACTED ARTICLE: Automated query classification based web service similarity technique using machine learning. J Ambient Intell Human Comput 12, 6169–6180 (2021). https://doi.org/10.1007/s12652-020-02186-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-020-02186-6