
Abstract
Hydrological parameters are among the widely used parameters in assessing flood risk. On the other hand, anticipated flood damages, in case of flooding, are estimated with the help of expected losses in areas nearer to the watercourse. The major source of almost every-year flooding in Pakistan is the Indus River system that comprises the major rivers of Pakistan. We first use observed data to construct simulated data models based on various probability distributions namely normal, lognormal, Weibull, largest extreme value, gamma-3, and log-Pearson type-3 distributions and thereby compute probable maximum flood. Secondly, we perform log-Pearson type-3 analysis with and without historic adjustment on the observed data series of 17 years to forecast floods with return periods T of 2, 5, 10, 25, 50, 100, and 200 years. We also categorize the river structures based on the risk of flooding. Lastly, we estimate risk of flood damages in terms of expected losses based on observed data. The present study reveals that the log-Pearson type-3 distribution is relatively better for estimating probable maximum flood. We use exceedence probability to assess the risk of flooding in the various structures of the said rivers. The analysis shows that flood damages in Pakistan may be reduced by increasing the design capacity of the structures and also by giving awareness to people about the flood-generating factors.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The depleted water resources, floods, abrupt rainfall, and melting glaciers are questions of immense importance and are often attributed to changing climatic conditions. In this respect, dams, barrages, and headwork are important factors to control the flow of river waters, thereby to produce hydro power and channelize its use for the betterment of human societies. Although these are the concerns of every human society, developing countries, like Pakistan, actually face the brutality of floods because of the lack of resources and/or political disagreement in creating new control factors, such as construction of new dams or modification of existing ones.
A disaster caused by waters from heavy rains; overflow of rivers, streams, lakes, or reservoirs; or dam failures, resulting in a huge rise of water level above roads and household areas, is called flood. The consequential damages may include loss of life and public or private properties, agricultural land loss, casualties, economic or monetary loss due to the shutdown of business and industry, etc. Risk and uncertainty in water resources, rivers, dams, etc., come from the natural inconsistency of geophysical progressions and alterations in certain socioeconomic features. As a result, risk analysis is performed which consists of the measurement of the probabilities of occurrence of flood and their likely consequences (Kaczmarek 2003). The United Nations Commission for Human Settlements (UNCHS 1981) has defined the risk as it can be directly related to the perception of disaster, given that it incorporates total losses and harm which could result after a natural disaster. Risk involves estimation or assessment of a future potential condition, a function of the magnitude of a natural hazard, and the vulnerability of all exposed elements in a determined moment.
In a general setting, risk is defined as a hazard due to a chemical or physical condition which has a potential to cause damage to people, property, or environment (Crowl and Louvar 2001). Thus, it is taken to be a product of probability of occurrence of an incident and its consequent losses. When it comes to floods, we can use meteorological, hydrological parameters, Geographical Information System (GIS), socioeconomic factors, and/or a combination of the first two to account for incident likelihood (Ologunorisa and Abawua 2005). Nevertheless, flood risk is expressed in terms of damage assessment as well, but this approach should be considered as an extension within the risk analysis (Merz et al. 2010). Similarly, one useful result, particular to this study, is that of Holmes and Dinicola (2010) in which the authors say that flood risk may be assessed by means of exceedence probability.
To be specific, we use here three different methods for risk assessment: (1) through the use of hydrological parameters, viz., flood peak discharge in order to calculate probable maximum flood (PMF), (2) through log-Pearson type-3 analysis (LP3) where forecasts of the flood peak discharge are generated and exceedence probability is calculated by taking the reciprocal of the return period, and (3) through the damage assessment by means of expected losses. The use of hydrological parameters here is mainly to consider the snow-melting phenomena in the northern areas of the country which give rise to an increase in the level of water in the rivers irrespective of rainfall. Also, we attempt to give an account on those factors which governmental agencies may use to mitigate the problem of flooding.
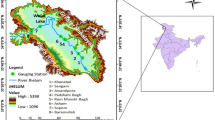
The present study focuses on forecasting the risk of flood in the Indus River system and computing an estimate of damage due to flooding. The Indus River system—having five major tributaries, Indus River,Footnote 1 Jhelum River,Footnote 2 Ravi River,Footnote 3 Chenab River,Footnote 4 and Sutlej River Footnote 5 (see Fig. 1), containing several river structures—is the main source of flooding in Pakistan. The annual rainfall of the system varies between 125 and 500 mm whereas the annual flow of its main rivers mainly depends on snow melting. Monsoon currents also affect the system severely; therefore, many a times, disastrous floods occur in one or more of the main tributaries. The system covers an area of 2,446,435.5 km2 (WCD 2000).

Location map of Indus River, Chenab River, Ravi River, Jhelum River, and Sutlej River (source: Encyclopedia Britannica, Macropedia-Arctic Biosphere, 14, pp. 229–230)
For this study, the Federal Flood Commission (FFC) of Islamabad (Pakistan) provides observed data set (1942–2008) (called D1 here) of various river structures of the said rivers. As it is discussed in the “Estimation of PMF” section, a random record of a hundred years is generated by carrying out simulation on D1. This simulated data set, D2, is used to estimate PMF in the structures corresponding to each of the following distributions: normal, lognormal, Weibull, gamma-3, largest extreme value, and LP3 (see “Estimation of PMF” section). However, in doing so, we do not remove outliers, i.e., extreme flood peaks, from our data. We generate forecasts of the magnitudes of various flood peak discharges in the river structures of the said rivers with particular return periods and exceedence probability by exploiting the LP3 analysis with and without historic record adjustment on D1 (see “Log-Pearson type-3 analysis” section). The return period T of a flood is the average time interval between two floods of same magnitude, and P = 1/T is its exceedence probability. The above-mentioned analysis is done by considering only 17 consecutive years, i.e., from 1992–2008, with T, so 2, 5, 10, 25, 50, 100, and 200 years are used. The analysis presented in “Estimation of PMF” and “Log-Pearson type-3 analysis” sections is used, firstly, to estimate the flood risk in Indus River (also see Khan and Iqbal 2009; Khan et al. 2011) and, lastly, to further the work to include the Jhelum River, the Ravi River, the Chenab River, and the Sutlej River. We also give an account to assess flood damages by calculating the individual, societal, agricultural, and structural risk measures.
Previous work
Ologunorisa and Abawua (2005) discuss some of the techniques involved in flood risk assessment by considering various case studies. The authors argue that the GIS-based analysis is more robust than meteorological, hydrological, or a mix of these two techniques. Kattlemann (1997) develops a technique of assessing floods through hydrological parameters and explains that the key parameter for such an analysis is rainfall on snow-covered catchments during warm storms. Bogdani and Selenica (1997) investigate the risk of disastrous flood in the rivers of Albania. Their study explains major aspects of flooding in rivers of Albania in which the information on disastrous floods were observed during the last 150 years. They give a concise summary of the flood region in Albania that is based on specific peak discharge which is a key parameter in their analysis.
Flood risk can also be expressed in terms of expected losses such as life loss, economic loss, and physical or property damage, etc. According to Coburn and Spence (1994), risk assessment is defined as a scientific quantification of hazard from data to understand the procedures involved. Bottelberghs (2000) states that the individual risk measure is the probability that a person always present in a disaster-prone area could have more chances to die in the case of occurrence of disaster. Jones (1992) explains the societal risk measure as the larger the population density, the greater will be the societal risk. Parker et al. (1987) proposed the expected value of economic damage to measure the economic risk. Jonkman et al. (2003) use all individual, societal, and economic risk measures to calculate the flood risk in the Netherlands. Pistrika and Tsakiris (2007) propose a three-step technique for flood risk assessment, i.e., (a) annualized hazard by computing the probability of its occurrence in the flood-prone area along with the expected damages, (b) vulnerability, i.e., flaws and the weakness of the flood-prone areas, and (c) annualized flood risk that is based on an annual basis. Smith (2004) argues that flood risk consists of the probability of occurrence of an event and the related consequences. Van Manen and Brinkhuis (2005) discuss that flood risk can also be assessed by the probability of embankment or dam failure.
Durotoye (2000) explains that the intense precipitation peaks throughout from December to March, the reason of oil investigation, and the human involvement with the paths of the watercourse during the extraordinary constructional works provoked floods in the Niger River. Khan and Iqbal (2009 and Khan et al. (2011) analyze the flood risk in Indus River based on hydrological parameters, and their study classifies floods based on a certain local criterion (Table 1).
Estimation of PMF
Probability distributions of continuous as well as discrete random variables are widely used in hydrological frequency analysis (Ferdows and Hossain 2005). Since floods are not regular events, therefore, the data set D2 for a hundred flood years is generated through normal, lognormal, Weibull, gamma-3, largest extreme value, and LP3 probability distributions to estimate PMF for each river structure of the said rivers (discussed in the “Introduction” section; also see Table 2). Here, the expected values of the said distributions are used to calculate PMF for the structures. The best value of PMF is selected with the help of the Anderson–Darling (AD) test. The AD test is used here to ensure how well the selected distribution fits the data; the test is performed with a significance level ℰ = 0.05.
The FFC classifies (Annual Flood Report 2006) different types of floods as low, medium, high, very high, and exceptionally very high in various river structures of Indus River, Jhelum River, Chenab River, Ravi River, and Sutlej River; see the following tables. On the basis of such classification, the level of risk is determined in each of the considered river structures (see Table 10).
Log-Pearson type-3 analysis
In data analysis, it is significant to identify outliers. In order to estimate higher and lower outlier thresholds, Flynn et al. (2006) suggest the use of Eqs. 1 and 2. If X is the ordinary logarithm of annual peak discharge, S the standard deviation of X, \( \overline X \) the mean, K n the 10 % significance level critical value for outlier test statistic for samples of size n from normal distribution, then
is the logarithmic higher outlier threshold, and
is the logarithmic lower outlier threshold.
If the data series of annual flood peak discharge possesses historic peak and high outliers, i.e., the peaks above the high outlier threshold, then there is a need to apply historic record adjustment before applying LP-3 analysis. Now, annual flood peaks below the higher outlier threshold and above the base peaks are called systematic peaks (Flynn et al. 2006) and represented by N S . At this instance, we perform historic record adjustment by computing the following estimate, W,
to mitigate the historic peaks and high outliers. Here, W is the historic weight applied to systematic peaks, N HO is the number of historic maximum peaks, N HP is the number of high outliers, and H shows the time period in years (Flynn et al. 2006). Likewise, the number of peaks above the flood base, N, is computed as,
with N BB is the number of peaks lower than the flood base. Flood peak below the lower outlier threshold may be considered a peak lower than flood base, i.e., a peak of very low magnitude or a peak of zero magnitude which is called gauge base. According to Flynn et al. (2006), the probability of a flood exceeding the flood base is
To apply historic weight W to the systematic peaks, use the following formulas of weighted mean \( \left( {\overline M } \right) \), standard deviation \( \left( {\overline S } \right) \), and skewness \( \left( {\overline G } \right) \)
where X′ and X″ are both ordinary logarithm of systematic peaks and historic maximum peaks plus high outliers, respectively. Now, we use Eqs. 1, 2, 3, 4, 5, 6, 7, and 8 to compute \( \overline X, \;S,\; G,\;{X_H},\;{X_L},\;{P_0},\; W,\;H,\;N,\;{N_S},\;{N_{\text{HP}}},\;{N_{\text{HO}}},\;{N_{\text{BB}}},\;\overline M, \;\overline S, \;\overline G \) for each river structure of the said rivers (see Table 3). The value of the probability of flood exceeding flood base (P 0) in all river structures is found to be 1. This is because no zero or low-magnitude peak (N BB = 0) is obtained during 1992 to 2008 in any one of the said river structures.
Now, here, annual flood events from 1992 to 2008 are presumed to be random variables observing LP-3 probability distribution (Flynn et al. 2006). \( \overline Q \) is the flood peak discharge or the magnitude of flood peak in cubic meters per second. It follows a linear process as described here as under, subject to the condition of historic record adjustment:
where K is the frequency factor (Haan 1977). If there are no peaks above the high outlier threshold, i.e., no existence of any historic peak and high outlier (see Taunsa barrage in Table 3), then there is no need of historic record adjustment, and the flood peak discharge or the magnitude of flood peak Q in cubic meters per second as described in the Hydraulic Design Manual (2004) can simply be calculated as follows:
The Eqs. 9 and 10 are used to compute \( \overline Q \) for all river structures of the rivers (see Tables 4, 5, 6, 7, and 8) considered here by exploiting the data in Table 3.
As it is discussed earlier in the “Introduction” section that the flood risk can also be assessed in terms of exceedence probability, the risk associated with those river structures having higher exceedence probability is considered high. Nevertheless, it is important to note that exceedence probability of high floods is relatively lower than that of low floods which clearly suggests that low floods are more likely to occur after every 2 or 5 years than the high floods. Moreover, since the peak discharge is found as increasing with increasing return period, the structures should be considered more vulnerable to high floods with the passage of time.
Flood damage assessment
Floods and earthquakes are classified as natural disasters, and they often cause major damages to the social order particularly when they occur in a region of intense population with high economic activities (Kang et al. 2005). Damages can be classified into five types, viz., direct damages, indirect damages, secondary damages, uncertainty damages, and intangible damages (Kang et al. 2005). In the present study, only direct damages (damages of houses, public or private buildings, and agriculture and casualties immediately take place just after the occurrence of the disaster, as shown in Fig. 2) are considered by calculating: (a) individual risk, (b) societal risk, (c) agricultural risk, and (d) structural risk for observed damage data from 1973 to 2008. These types of risks can be calculated by using Eq. (11) as shown below:
where E(R) is the expected value of a continuous random variable R, and f(x) is the probability density function of R at x (Freunds 2004).

Percentage of losses due to floods from 1973 to 2007
For this study, loss of an individual's life, people affected, loss of agricultural lands, loss of crop areas, loss of livestock, and loss of houses damaged during floods are considered as the continuous random variables and are denoted by X, N, T, K, Q, and Y, respectively, whereas E(X), E(N), E(T), E(K), E(Q), and E(Y) are their respective expected values, and f x (x), f n (x), f T (x), f Q (x), and f Y (x) are their Weibull probability density functions.
-
(a)
Estimation of individual risk:
$$ E(X) = \int_0^{\infty } {x.{f_X}(x).dx, x > \theta, {\text{where}}\,\theta = 0} $$(12)where x is an individual dying during floods and \( {f_X}(x) = \frac{{\beta {{\left( {x - \theta } \right)}^{{\left( {\beta - 1} \right)}}}}}{{{\alpha^{\beta }}}}\left[ {{e^{{ - {{\left( {\frac{{x - \theta }}{\alpha }} \right)}^{\beta }}}}}} \right],x > \theta, \alpha > 0,\beta > 0 \), and α, β, and θ are scale, shape, and threshold parameters, respectively.
-
(b)
Estimation of societal risk: When a particular group of people suffering from a risk in some specific hazardous location, it is defined to be a societal risk. Jonkman et al. (2003) use a simple procedure for measuring a societal risk. This is by calculating the expected value of a number of people affected during floods,
$$ E(N) = \int_0^{\infty } {x.{f_N}(x).dx, x > \theta, {\text{where}}\,\theta = 0} $$(13)where x shows casualties during floods and \( {f_N}(x) = \frac{{\beta {{\left( {x - \theta } \right)}^{{\left( {\beta - 1} \right)}}}}}{{{\alpha^{\beta }}}}\left[ {{e^{{ - {{\left( {\frac{{x - \theta }}{\alpha }} \right)}^{\beta }}}}}} \right],x > \theta, \alpha > 0,\beta > 0 \)
-
(c)
Estimation of agricultural risk: Agricultural risk can be calculated in terms of expected loss of agricultural land, expected loss of crops, and expected loss of livestock during floods.
-
1.
Expected loss of agricultural lands:
$$ E(T) = \int_0^{\infty } {x.{f_T}(x).dx, x > \theta, {\text{where}} \,\theta = 0} $$(14)where x is the loss of agricultural land during floods and \( {f_T}(x) = \frac{{\beta {{\left( {x - \theta } \right)}^{{\left( {\beta - 1} \right)}}}}}{{{\alpha^{\beta }}}}\left[ {{e^{{ - {{\left( {\frac{{x - \theta }}{\alpha }} \right)}^{\beta }}}}}} \right],x > \theta, \alpha > 0,\beta > 0 \)
-
2.
Expected loss of crops
$$ E(K) = \int_0^{\infty } {x.{f_K}(x).dx, x > \theta, {\text{where}}\, \theta > 0} $$(15)where x is the loss of crops during floods and \( {f_K}(x) = \frac{{\beta {{\left( {x - \theta } \right)}^{{\left( {\beta - 1} \right)}}}}}{{{\alpha^{\beta }}}}\left[ {{e^{{ - {{\left( {\frac{{x - \theta }}{\alpha }} \right)}^{\beta }}}}}} \right],x > \theta, \alpha > 0,\beta > 0 \)
-
3.
Expected loss of livestock:
$$ E(Q) = \int_0^{\infty } {x.{f_Q}(x).dx, x > \theta, {\text{where}}\, \theta > 0} $$(16)where x is the loss of livestock during floods and \( {f_Q}(x) = \frac{{\beta {{\left( {x - \theta } \right)}^{{\left( {\beta - 1} \right)}}}}}{{{\alpha^{\beta }}}}\left[ {{e^{{ - {{\left( {\frac{{x - \theta }}{\alpha }} \right)}^{\beta }}}}}} \right],x > \theta, \alpha > 0,\beta > 0 \)
-
1.
-
(d)
Estimation of structural risk:
$$ E(Y) = \int_0^{\infty } {x.{f_Y}(x).dx, x > \theta, {\text{where}} \,\theta = 0} $$(17)where x is the houses damaged (completely and partially) during floods and \( {f_Y}(x) = \frac{{\beta {{\left( {x - \theta } \right)}^{{\left( {\beta - 1} \right)}}}}}{{{\alpha^{\beta }}}}\left[ {{e^{{ - {{\left( {\frac{{x - \theta }}{\alpha }} \right)}^{\beta }}}}}} \right],x > \theta, \alpha > 0,\beta > 0 \)
Now, by placing the values of Weibull probability density functions in formulas 12 to 17, the mean or the expected values of the Weibull random variables X, N, T, K, Q, and Y are obtained as follows:
By using Eq. (18), we get the expected damages of floods in Pakistan shown in Table 9. The parameters α and β are obtained by applying Weibull distribution for each type of loss, i.e., life loss, people affected, land loss, crop area affected, livestock loss, and houses damaged during floods, at a significance level (ℰ) of 0.05. However, for brevity, we show (in Fig. 3) only the result obtained for the case of life loss. The p values and Anderson Darling (AD) test statistic show enough evidence for the acceptability of Weibull distribution.

Weibulll probability plot of life loss in Pakistan with 95 % confidence level
Main results and conclusion
The lowest values of AD test statistic as shown in Table 2 give us two important results: (1) that we now are able to associate a level of risk with each of the considered river structures described in Table 10 and (2) that, except the Kotri and the Balloki barrage, LP3 distribution is comparatively better for estimating probable maximum flood (see the values with asterisk in Table 2). Nevertheless, in-depth analysis can be found in Khan (2011); also, similar findings are presented partly in Khan and Iqbal (2009) and Khan et al. (2011). The third main result is obtained by forecasting the floods in various river structures. We argue that low floods are more likely to occur after every 2 or 5 years than the high floods, but if a flood of very high magnitude, i.e., 100 or 200-year flood occurs in any river structure of the said rivers, the structure will get brutally damaged, and the people who are living in the nearer areas will also get severely affected. Moreover, the analysis further reveals on comparison with Table 1 that the greater the return period, the higher will be the risk of high floods. As for the other types of risk, Table 9 shows the expected damages during floods in Pakistan.
The calculations and observations in the preceding sections conclude that the river structures of the said rivers are quite risky against high floods; therefore, the structures require increasing design capacity. Not only this but for the reduction of flood risk and its losses, there is an urgent need to construct some new river structures on the said rivers with greater design capacity and/or return periods of at least 500 years so that they can deal with floods of high magnitude. The results, as computed here on the basis of available data, are also confirmed by the recent severe flooding of the year 2010 and 2011 in the same area. It is also necessary that the population living in flood-prone areas should be given education/awareness about the flood-generating factors, their likely consequences, flood hydraulics, understanding of annual flood peak inflow and outflow of river structures, precipitation, and runoff processes. This is because awareness about these factors will surely help in reducing the risk of flood damages.
Notes
The annual flow of Indus River is 205 billion m3 which is twice that of Nile River. The river has a total drainage area of about 1,165,494.6 km2, and it is 2,896.82 km long. The river contains seven river structures namely Tarbela dam, Jinnah, Chashma, Taunsa, Guddu, Kotri, and Sukkur barrage.
Jhelum River has a total length of about 774 km, and it contains three important river structures namely Mangla dam, Rasul, and Trimmu barrage.
Ravi River is often named as “The river of Lahore”; its total length is 720 km, and it also contains three significant river structures namely Shahdara, Balloki, and Sidhnai barrage.
Chenab River has a total length of about 974 km. The river comprises three main river structures, i.e., Marala, Khanki, and Qadirabad headworks.
Sutlej River, 1,450 km long, is extensively used for irrigation and contains the two most important structures, i.e., Sulemanki and Islam headworks.
References
Bogdani M, Selenica A (1997) Catastrophic floods and their risk in the rivers of Albania. In: Leavesley GH, Lins HF, Nobilis F, Parker RS, Schneider VR, Ven de Van FHM (eds) Destructive water: water caused natural disasters, their abatement and control. IAHS Publications, Wallingford, pp 83–85, no. 239
Bottelberghs PH (2000) Risk analysis and safety policy developments in the Netherlands. J Hazard Mater 71(1–3):59–84
Coburn AW and Spence RJS (1994) Vulnerability and risk assessment, Disaster Management Training Program, 2nd edn. UNDP
Crowl DA, Louvar JF (2001) Chemical process safety fundamentals with applications, 2nd edn. Pearson Education, New Jersey
Durotoye B (2000) Geo-environment constraints in the development of the Niger delta area of Nigeria. In: Oshuntokun A (ed) Environmental problems of Nigeria. Friedrich Ebert Foundation, Lagos
Ferdows M, Hossain M (2005) Flood frequency analysis at different rivers in Bangladesh: a comparison study on probability distribution functions. Thammasat Int J Sc Tech 10(3):53–62
Flynn KM, Kirby WH and Hummel PR (2006) User's manual for program PeakFQ, annual flood-frequency analysis using Bulletin 17B Guidelines: U.S. Geological Survey, Techniques and Methods
Freunds JE (2004) Mathematical statistics with application. Pearson Education, Inc., Singapore
Haan CT (1977) Statistical methods in hydrology. The Iowa University Press, Iowa
Holmes RR Jr, Dinicola K (2010) 100-year flood—it's all about chance, General Information Product 106. U.S. Geographical Survey, Washington
Texas Department of Transportation (2004) Hydraulic design manual. Texas Department of Transportation, Design Division (DES)
Jones D (1992) Nomenclature of hazard and risk assessment in the process industries. Warwickshire, UK
Jonkman SN, van Gelder PHAJM, Vrijling JK (2003) An overview of quantitative risk measures for loss of life and economic damage. J Hazard Mater Elsevier Sci B V A99:1–30
Kaczmarek Z (2003) The impact of climate variability on flood risk in poland. Risk Anal 23(3):559–566
Kang JL, Su MD, Chang LF (2005) Loss functions and framework for regional flood damage estimation in residential area. J Mar Sci Technol 13(3):193–199
Kattlemann R (1997) Flooding from rain-on snow events in the Sierra Nevada. In: Leavesley GH, Lins HF, Nobilis F, Parker RS, Schneider VR, Ven de Van FHM (eds) Destructive water: water caused natural disasters, their abatement and control. IAHS Publications, Wallingford, pp 59–95, no. 239
Khan B (2011) Flood risk assessment. M.Phil Thesis, Institute of Space and Planetary Astrophysics, University of Karachi
Khan B and Iqbal MJ (2009) Assessment of flood risk using annual peak discharges: a case study with different river structures of River Indus, in the Proceedings of the International Conference on Sustainability, Human Geography and Environmental Studies, vol. 2, pp. 136–139. Diano Marina, IMPERIA, Italy
Khan B, Iqbal MJ, Yosufzai MAK (2011) Flood risk assessment of river Indus of Pakistan. Arab J Geosci 4(1–2):115–122
Merz B, Kreibich H, Schwarze R, Thieken A (2010) Assessment of economic flood damage. Nat Hazards Earth Syst Sci 10:1697–1724
Ologunorisa TE, Abawua MJ (2005) Flood risk assessment: a review. App Sci Environ Mgt J 9(1):57–63
Parker DJ, Green CH, Thompson PM (1987) Urban flood protection benefits: a project appraisal guide. Gower Technical Press, London
Pistrika A, Tsakiris G (2007) Water resources management: new approaches and technologies. European Water Resources Association, China
Report AF (2006) Federal flood commission. Ministry of Water & Power, Islamabad
Smith K (2004) Environmental hazards: assessing risk and reducing disaster. Rutledge, London
UNCHS (1981) Settlement planning for disasters, World Meteorological Organization (1975). Drought and Agriculture, Nairobi
Van Manen SE, Brinkhuis M (2005) Quantitative flood risk assessment for polders. Reliab Eng Syst Saf 90:229–237
WCD Case study (2000) Tarbela Dam and related aspects of the Indus River Basin Pakistan, Asianics Agro-Dev, International (Pvt.) Ltd. Islamabad
Acknowledgments
We are thankful to Mr. Ahmed Kamal Pasha who works as a superintending engineer (floods) in FFC, Islamabad (Pakistan), Ministry of Water and Power, Government of Pakistan, for providing the relevant data of Annual Flood Peak Discharges. We would also like to express our sincere thanks to the Government of the Punjab, Relief and Crises Management Department, Sindh Irrigation Department, Provincial Disaster Management Authority Baluchistan, and Relief Commissioner NWFP for providing the data of flood losses for this research.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Khan, B., Iqbal, M.J. Forecasting flood risk in the Indus River system using hydrological parameters and its damage assessment. Arab J Geosci 6, 4069–4078 (2013). https://doi.org/10.1007/s12517-012-0665-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12517-012-0665-8