
Abstract
Burden prediction is a vital task in the production blasting. Both the excessive and insufficient burden can significantly affect the result of blasting operation. The burden which is determined by empirical models is often inaccurate and needs to be adjusted experimentally. In this paper, an attempt was made to develop an artificial neural network (ANN) in order to predict burden in the blasting operation of the Mouteh gold mine, using considering geomechanical properties of rocks as input parameters. As such here, network inputs consist of blastability index (BI), rock quality designation (RQD), unconfined compressive strength (UCS), density, and cohesive strength. To make a database (including 95 datasets), rock samples are used from Iran’s Mouteh goldmine. Trying various types of the networks, a neural network, with architecture 5-15-10-1, was found to be optimum. Superiority of ANN over regression model is proved by calculating. To compare the performance of the ANN modeling with that of multivariable regression analysis (MVRA), mean absolute error (E a), mean relative error (E r), and determination coefficient (R 2) between predicted and real values were calculated for both the models. It was observed that the ANN prediction capability is better than that of MVRA. The absolute and relative errors for the ANN model were calculated 0.05 m and 3.85%, respectively, whereas for the regression analysis, these errors were computed 0.11 m and 5.63%, respectively. Moreover, determination coefficient of the ANN model and MVRA were determined 0.987 and 0.924, respectively. Further, a sensitivity analysis shows that while BI and RQD were recognized as the most sensitive and effective parameters, cohesive strength is considered as the least sensitive input parameters on the ANN model output effective on the proposed (burden).
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In the mining engineering, rock fragmentation should be performed with minimum cost and side effects (e.g., ground vibration, air blast, flyrock). To achieve this goal, an appropriate blast design should be applied for the blasting operation (Adhikari 1999).
Since all blast parameters including spacing, stemming, subdrilling, and delay timing are dependent on the selected burden, proper calculation and/ or prediction of the proposed burden can guarantee successfulness of the entire operation. Phenomena such as flyrock, air blast, and improper fragmentation may occur if the burden is too small, whereas high burden results in incidents like ground vibration, undesirable fragmentation, insufficient displacement, toe problem, backbreak, uneven faces, etc. In the extreme case, if burden is too high, sufficient displacement and swelling would not occur, and unfavorable phenomenon of fragment interlocking will happen (Hustrulid 1999).
To determine burden, parameters such as hole diameter, rock mass characteristics, explosive properties, required fragmentation and displacement, etc. have to be considered. In this regard, various empirical models have been developed in which just one or two of the effective parameters have been involved causing the models inefficient (Jimeno et al. 1995; Ash 1973).
To overcome shortcomings of the empirical models and to obtain more realistic and precise results, new methods such as fuzzy inference systems, artificial neural networks (ANNs), and genetic algorithm may effectively be applied (Tawadrous 2006; Monjezi et al. 2007). The ANN technique, as a branch of the “artificial intelligence”, has been developed since the 1980s. This technique is considered to be one of the most appropriate means for solving complex systems where the number of effective parameters is high (Khandelwal et al. 2004).
In the modeling process, generalization is made for the patterns presented during the training of the network. These patterns, known as data pairs, are composed of real input(s) and output(s) which have to be prepared before constructing the ANN model. In fact, prediction of output(s) for a new input(s) is possible only after presenting the prepared data to the network and completing model training. Suitability of the ANN modeling in geo-engineering applications is shown by solving linear and nonlinear multivariable problems (Sonmez et al. 2006). Monjezi and Dehghani (2008) and Monjezi et al. (2006) utilized the ANN model to improve the blasting pattern. Cai and Zhao (1997) used ANNs for analyzing the tunnel stability as well as designing the support system. Singh et al. (2001) and Khandelwal and Singh (2002) applied this approach for rock strength prediction and stability analysis of a waste dump. Maity and Saha (2004) used the ANN technique to assess damage in structures. Sonmez et al. (2006) used neural network modeling for rock modulus estimation whereas Qiang et al. (2008) used the same approach to predict size-limited structures in a coal mine. Chungsik and Kim (2007) predicted the tunneling performance using an integrated GIS and neural network. Using ANN model, Yong (2005) performed an underground blast stimulated ground vibration. More applications of this technique have been reported by other researchers (Singh et al. 2004; Maulenkamp and Grima 1999).
Artificial neural network
Artificial neural network is a simplified simulation of human brain. Likewise a brain structure, ANN contains elementary processing units (neurons) which are interconnected throughout the network by weighted vectors (Monjezi and Dehghani 2008). The neurons of the same layer are not connected to each other.
Although there exist various types of ANNs, the feed-forward back-propagation ANN is the most efficient one. Back-propagation multilayer neural networks consist of at least three layers, i.e., input, hidden, and output layers. This type of network has effectively been used in the field of rock mechanics, geosciences, mining engineering, etc. (Neaupane and Adhikari 2006; Neaupane and Achet 2004). The number of hidden layers and the number of respective neurons in each layer depend upon complexity of the problem under study. Normally, two-hidden layer networks are considered to be proper for engineering applications (Lee et al. 2003; Gomez and Kavzoglu 2005; Ermini et al. 2005; Yesilnacar and Topal 2005). With respect to number of neurons in the hidden layers, it can be said that insufficient neurons can cause “underfitting” whereas excessive selection can result in “overfitting”. In the underfitting, the required accuracy of the modeling is not achieved, whereas in the overfitting which is also called memorization, the network performance would not be reliable because instead of realizing relationship between the patterns, network just remembers the patterns (Demuth et al. 1996; Haykin 1999).
Transfer functions, known as activation functions, are used to transform the weighted sum of all input signals to a neuron and determine the neuron output intensity (Basheer and Hajmeer 2000). Nonlinear sigmoid (LOGSIG, TANSIG) and linear (POSLIN, PURELIN) functions can be used as transfer functions (Figs. 1 and 2); however, the sigmoid type is more efficient. The logarithmic sigmoid function (LOGSIG) is defined as (Demuth et al. 1996):
where e x is the weighted sum of inputs for a processing unit.

Sigmoid transfer functions (Demuth et al. 1996)

Liner transfer functions (Demuth et al. 1996)
The forward and backward passes are repeated until the network error reaches to a specific threshold (Sonmez et al. 2006). Root mean square error (RMSE) can be utilized to evaluate network training process by considering differences between the model outputs and the real measured values. In this regard, training progress should be checked using data pairs which have already been considered for this purpose. As a matter of fact, increasing iterations can result in decreasing the error; however, excessive training can cause decreasing generalization capability. Therefore, the threshold error would be the minimum error obtained while testing the model with the test data pairs (Basheer and Hajmeer 2000).
Case study
The Mouteh goldmine is located some 270 km southwest of Tehran in the Isfahan province, with an elevation 2,000–2,300 m above sea level. Possible, probable, and measured reserves of the mine are 4,852,000, 2,283,000, and 1,191,800 tons, respectively. Gold average grade for the mine is 4 g/ton.
From geological point of view, the mine is situated in the acidic to relative basic Precambrian metamorphic rocks. Joints and fractures of this rock series contain metallic minerals such as pyrite and chalcopyrite. The host rock layers have mild dip toward northwest, while the gold zones have sharp dip toward northeast. Two main fractures with crossover inclination affect the Mouteh gold zone. In this mine, the ore is mainly deposited along the fractures in the highly weathered zones. A view of the Mouteh gold mine is shown in the Fig. 3.

A view of the Mouteh gold mine
Input and output parameters
In this study, to determine the relationship between burden and geomechanical properties, parameters including rock blastability index (BI), rock quality designation (RQD), unconfined compressive strength (UCS), density (D), and cohesive strength (C) have been determined and considered as input parameters for the ANN model.
To determine BI, first joint characteristics have to be recognized. In the proposed area, three joint sets with dominantly east–west dip direction were identified (Table 1). Blastability index can be calculated using Eq. 2 (ISRM International Society for Rock Mechanics 1981).
where RMD is the rock mass description, JPS is the joint plane spacing, JPO is the joint plane orientation, SGI is the specific gravity influence, and H is the rock hardness.
NX size rock samples with 54 mm diameter and 108 mm length were prepared to determine unconfined compressive strength and cohesion in the laboratory. For the ANN model construction, a database including 54 datasets was considered for training and testing the ANN model. Selecting of testing datasets was performed using sorting method to maintain generality. Testing datasets were selected at a regular interval (Table 2). Also, minimum and maximum values of the relevant parameters used in the modeling are given in Table 3.
Determination of optimum network
To reach an optimum architecture, different types of networks have to be examined. For this, root mean square error is calculated for all the models, and accordingly, the model with minimum RMSE is chosen as the optimum model. RMSE is calculated by Eq. 3. For different types of the models, RMSE was calculated (Table 4).
where A imeas, A ipred, and n are the i-th measured element, i-th predicted element, and the number of datasets, respectively (Tzamos and Sofianos 2006).
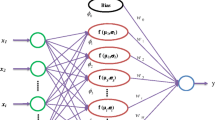
As it is seen from Table 4, the network with architecture 5-10-15-1 and LOGSIG transfer function has the minimum RMSE, hence considered to be the optimum model. Figure 4 shows a graphic presentation of the optimum network.

Optimum ANN model for the burden prediction
Multivariable regression analysis
The multivariable regression analysis (MVRA) is employed to establish a mathematical formula in order to predict the dependent variables based on the known independent variables (Jennrich 1995; Eskandari et al. 2004). This method has been utilized in different mining fields (Alvarez Grima and Babuska 1999; Finol et al. 2001; Gokceoglu and Zorlu 2004; Monjezi et al. 2009, 2010). To evaluate ANN modeling, the same input parameters were considered for regression analysis (Eq. 4):
Comparison of performances
To compare performances of both the ANN and regression models, predicted burdens were compared with the actual measured burdens. For this, mean absolute error (E a) and mean relative error (E r) were calculated using Eqs. 5 and 6 (Monjezi and Dehghani 2008):
where T i , O i , and N represent measured output, predicted output, and the number of input–output data pairs, respectively.
For the ANN model, E a and E r were equal to 0.05 m and 3.85%, respectively, whereas for the statistical model, E a and E r were equal to 0.11 m and 5.63%, respectively. Figures 5 and 6 show comparison between measured and predicted burden for both the models. According to these figures, the determination coefficient (R 2) of the ANN model is better than the statistical model.

Comparison between measured and predicted burden for the ANN model

Comparison between real and predicted burden for the statistical model
Sensitivity analysis
Sensitivity analysis was carried out with the aim of determining the most effective input parameter on the output. For this, cosine amplitude method was applied (Monjezi et al. 2010; Jong and Lee 2004). In this method, all data pairs used to construct a data array X are expressed in common X-space:
Each of the elements, X i , in the data array X is a vector of lengths of m, that is:
Strengths of relations (r ij ) between output and input parameters can be calculated using Eq. 9.
Figure 7 shows the strengths of relations (r ij ) between the input parameters and burden. As it is seen, the most effective parameters on the burden are BI and RQD. Also, cohesive strength is the least effective parameter on the burden.

Strengths of relation (r ij ) between the burden and input parameters
Conclusion
In this paper, superiority of the artificial neural network modeling over regression analysis in predicting burden was demonstrated. A feed-forward back-propagation neural network with architecture 5-15-10-1 and RMSE of 0.092 was found to be optimum. Performance of the ANN and regression models has been evaluated by computing mean absolute error (E a), mean relative error (E r), and determination coefficient (R 2). For the ANN model, E a, E r, and R 2 were calculated 0.05 m, 3.85%, and 0.987, respectively, whereas for the regression model, E a, E r, and R 2 were determined 0.11 m, 5.63%, and 0.924, respectively. Further, sensitivity analysis was performed to identify the most effective parameters on the burden prediction in which blastability index and rock quality designation were observed to be the most sensitive and cohesive strength to be the least sensitive parameters.
References
Adhikari GR (1999) Burden calculation for partially changed blast design conditions. Int J Rock Mech Min Sci 36:235–256
Alvarez Grima M, Babuska R (1999) Fuzzy model for the prediction of unconfined compressive strength of rock samples. Int J Rock Mech Min Sci 36:339–349
Ash RL (1973) The influence of geological discontinuities on rock blasting. Ph.D. thesis, University of Minnesota
Basheer IA, Hajmeer M (2000) Artificial neural networks: fundamentals, computing, design, and application. J Microbiol Meth 43:3–31
Cai JG, Zhao J, (1997) Use of neural networks in rock tunneling. In: Proceedings of computing methods and advances in geomechanics, IACMAG, China, pp 613–18
Chungsik Y, Kim JM (2007) Tunneling performance prediction using an integrated GIS and neural network. Comput Geotech 34:19–30
Demuth H, Beal M, Hagan M (1996) Neural network tool box 5 user’s guide. The Math Work, Natick
Ermini L, Catani F, Casagli N (2005) Artificial neural networks applied to landslide susceptibility assessment. Geomorphology 66:327–343
Eskandari H, Rezaee MR, Mohammadnia M (2004) Application of multiple regression and artificial neural network techniques to predict shear wave velocity from wireline log data for a carbonate reservoir South-West Iran. CSEG Recorder
Finol J, Guo YK, Dong Jing X (2001) A rule-based fuzzy model for the prediction of petrophysical rock parameters. J Petrol Sci Eng 29:97–113
Gokceoglu C, Zorlu K (2004) A fuzzy model to predict the uniaxial compressive strength and the modulus of elasticity of a problematic rock. Eng Appl Artif Intell 17:61–72
Gomez H, Kavzoglu T (2005) Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng Geol 78:11–27
Haykin S (1999) Neural networks, a comprehensive foundation, USA, 2nd edn. Prentice Hall, USA
Hustrulid W (1999) Blasting principles for open pit mining, vol 1. Balkema, Rotterdam
ISRM (International Society for Rock Mechanics) (1981) Suggested methods for determining hardness and abrasiveness of rocks. In: Brown ET (ed) Rock characterization, testing and monitoring—ISRM suggested methods. Pergamon, Oxford, pp 95–96
Jennrich RI (1995) An introduction to computational statistics—regression analysis. Prentice-Hall, Englewood Cliffs
Jimeno CL, Jimeno EL, Carced FJA (1995) Drilling and blasting of rocks. Balkema, Rotterdam
Jong YH, Lee CI (2004) Influence of geological conditions on the powder factor for tunnel blasting. Int J Rock Mech Min Sci 41:533–538
Khandelwal M, Singh TN (2002) Prediction of waste dump stability by an intelligent approach. In: Proceedings of the national symposium on new equipment–new technology, management and safety, ENTMS, Bhubaneshwar, pp 38–45
Khandelwal M, Roy MP, Singh PK (2004) Application of artificial neural network in mining industry. Ind Min Eng J 43:19–23
Lee S, Ryu JH, Lee MJ, Won JS (2003) Use of an artificial neural network for analysis of the susceptibility to landslides at Boun, Korea. Environ Geol 44:820–833
Maity D, Saha A (2004) Damage assessment in structure from changes in static parameters using neural networks. Sadhana 29:315–327
Maulenkamp F, Grima MA (1999) Application of neural networks for the prediction of the unconfined compressive strength (UCS) from equotip hardness. Int J Rock Mech Min Sci 36:29–39
Monjezi M, Dehghani H (2008) Evaluation of effect of blasting pattern parameters on backbreak using neural networks. Int J Rock Mech Min Sci 45:1446–1453
Monjezi M, Singh TN, Khandelwal M, Sinha S, Singh V, Hosseini I (2006) Prediction and analysis of blast parameters using artificial neural network. Noise Vib Worldw 37:8–16
Monjezi M, Dehghan H, Samimi Namin F (2007) Application of TOPSIS method in controlling fly rock in blasting operations. In: Proceedings of the 7th international science conference SGEM, Sofia, Bulgaria pp 41–9
Monjezi M, Rezaei M, Yazdian Varjani A (2009) Prediction of rock fragmentation due to blasting in Gol-E-Gohar iron mine using fuzzy logic. Int J Rock Mech Min Sci 46:1273–1280
Monjezi M, Rezaei M, Yazdian A (2010) Prediction of backbreak in open-pit blasting using fuzzy set theory. Expert Syst Appl 37:2637–2643
Neaupane KM, Achet SH (2004) Use of backpropagation neural network for landslide monitoring: a case study in the higher Himalaya. Eng Geol 74:213–236
Neaupane KM, Adhikari NR (2006) Prediction of tunneling-induced ground movement with the multi-layer perceptron. Tunn Undergr Space Technol 21:151–159
Qiang W, Siyuan Y, Jia Y (2008) The prediction of size-limited structures in a coal mine using artificial neural networks. Int J Rock Mech Min Sci 45:999–1006
Singh VK, Singh D, Singh TN (2001) Prediction of strength properties of some schistose rock. Int J Rock Mech Min Sci 38:269–284
Singh TN, Kanchan R, Saigal K, Verma AK (2004) Prediction of P-wave velocity and anisotropic properties of rock using artificial neural networks technique. J Sci Ind Res 63:32–38
Sonmez H, Gokceoglua C, Nefeslioglub HA, Kayabasic A (2006) Estimation of rock modulus: for intact rocks with an artificial neural network and for rock masses with a new empirical equation. Int J Rock Mech Min Sci 43:224–235
Tawadrous AS (2006) Evaluation of artificial neural networks as a reliable tool in blast design. In: Proceedings of the 32nd annual conference on explosives and blasting techniques. International Society of Explosives Engineers, Dallas
Tzamos S, Sofianos AI (2006) Extending the Q system’s prediction of support in tunnels employing fuzzy logic and extra parameters. Int J Rock Mech Min Sci 43:938–949
Yesilnacar E, Topal T (2005) Landslide susceptibility mapping: a comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Eng Geol 79:251–266
Yong L (2005) Underground blast induced ground shock and its modeling using artificial neural network. Comput Geotech 32:164–178
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Rezaei, M., Monjezi, M., Ghorbani Moghaddam, S. et al. Burden prediction in blasting operation using rock geomechanical properties. Arab J Geosci 5, 1031–1037 (2012). https://doi.org/10.1007/s12517-010-0269-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12517-010-0269-0