
Abstract
Primary monitoring of 18 water quality parameters for rivers Ganga and Yamuna of Uttarakhand State was carried out to study the seasonal variation of these parameters, identify potential sources of pollution, and clustering of monitoring stations with similar characteristics. Wilcoxon signed-rank test, Paired t test and multivariate statistical techniques—principal component analysis (PCA) and cluster analysis (CA) were used to analyse the collected data. Separate analyses were conducted for summer and winter periods. The Wilcoxon signed-rank test and paired t test revealed seasonal variability in the data set with high pollution levels during summer period as compared to winter period. The CA grouped 15 monitoring stations of river Ganga and 5 monitoring stations of river Yamuna into 2 clusters of similar characteristics. The PCA resulted in the identification of four major sources of pollution for river Ganga, and three for river Yamuna. The findings of the study provide useful information in interpretation of complex datasets and for water quality assessment, identification of pollution sources/factors and understanding of temporal and spatial variations of water quality for effective river water quality management.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The surface water quality in a region is largely determined by two factors—the natural processes such as precipitation rate, soil erosion, vegetation etc. and the anthropogenic processes such as domestic and industrial effluents, agricultural runoff etc. (Singh et al. 2004). While the municipal and industrial wastewater discharge constitutes the constant polluting source, the surface runoff is affected by climatic factors. Seasonal variation in precipitation, surface runoff, groundwater flow, water interception and abstraction has a strong effect on river water quantity and quality (Zhao et al. 2011; Razmkhah et al. 2010; Kannel et al. 2008). Escalated anthropogenic activities in the basin and reduced river discharges registered during the last decades have caused multifold increase in the organic pollution load in the surface water bodies in India (Singh et al. 2004). Hence, for the long-term effective management of a river, an understanding of hydro-morphological, chemical and biological characteristic is required (Shrestha and Kazama 2007). Continuous water quality monitoring programmes are carried along different river stretches in order to study the seasonal variations in the physico-chemical and biological parameters and impact of different pollutant sources. Such programmes generate large amount of multiple parameter data distributed in space and time. Multivariate statistical techniques such as the principal component analysis (PCA) and cluster analysis (CA) are useful tools for extracting meaningful information from such large data set. These techniques have been applied successfully to analyse and interpret water quality data, study seasonal variations and identification of potential sources of river pollution (Bonansea et al. 2014; Zhao et al. 2011; Razmkhah et al. 2010; Li et al. 2009).
Uttarakhand is a newly created state in India. New infrastructure facilities are being created which include housing, roads, industries etc. The state is also in the process of preparing zoning atlas for siting industry. A study of water quality for the two major rivers that flow through the state—Ganga and Yamuna—would help in providing a database for the zoning atlas in locating appropriate sites for industries, establishments of river rehabilitation plan and designing comprehensive water quality monitoring network to assess the variations of different water quality parameters. For this purpose, primary monitoring of 18 water quality parameters at 15 monitoring stations for river Ganga and 5 monitoring stations for river Yamuna was carried in the months of January and April, representing winter and summer months, respectively. This large multiple parameter data have been analysed statistically to study the (a) seasonal variation of these parameters; (b) clustering of monitoring stations with similar characteristics; and (c) identify potential sources of pollution. Specifically, Wilcoxon signed-rank test, paired t test, PCA and CA have been used to achieve the above three objectives, respectively.
Materials and Methods
Site Description, Data Collection and Analytical Methods
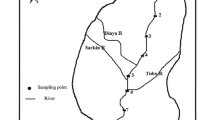
The state of Uttarakhand has diverse resources in terms of flora and fauna in the foothills of Himalayas. It lies between geo-coordinates from 30°19′48″N to 78°03′36″E. The geographical area is 53566 sq. km, out of which, about 85 % is hilly/forest/glacier area and the remaining 15 % area buzzes with commercial activities. Uttarakhand is divided into two geographical areas, namely Garhwal and Kumaon area. Garhwal area is nourished by rivers Ganga, Yamuna and Tons; while the rivers Kosi, Ramganga, Gola etc. flow through the Kumaon area. The water quality sampling was carried out for rivers Ganga and Yamuna. The sampling was done for 15 and 5 monitoring stations for river Ganga and Yamuna, respectively (Fig. 1). The Ganga originates from the western Himalayas in the state of Uttarakhand, and flows in the south-east direction through the Gangetic Plain of Northern India (about 2525 km), and finally enters the Bay of Bengal. The river Ganga actually arises due to the confluence of Bhagirathi and Alaknanda rivers at Devprayag. The Ganga receives domestic sewage and heavy effluent discharges from industries such as paper manufacturing, distillery, sugar manufacturing, electroplating and automobiles (Table 1). The river Yamuna on the other hand originates from the Yamunotri glacier at Banderpoonch peak in the Uttarkashi district of Uttarakhand. The catchment of the river extends to states of Uttarakhand, Uttar Pradesh, Himachal Pradesh, Haryana, Rajasthan, Madhya Pradesh and the entire union territory of Delhi. The river flows a stretch of 1367 km till its confluence with Ganga at Allahabad. During its course, it receives heavy discharge and pollutants from small-scale industries which include paper, sugar, spices, chemical, leather, distillery, television manufacturing, pharmaceutical and power; some waste from the pesticide industry also enters just before the confluence of river Tons with Yamuna (Table 1).

Map showing study area and sampling stations of the rivers Ganga and Yamuna
In order to assess the seasonal variation in the water quality, parameters sampling was done in January 2012 and April 2012 and sampling station network was designed in such a way so as to cover wide range of factors such as domestic wastewater drains, industrial effluent, erosion of mountains and mucks from hydroelectricity projects that influence the water quality both rivers. Samples were collected in triplicates from three points (1/4, 1/2 and 3/2) across the river width at same sites in 2000 ml polyethylene sterilized bottles (cleaned with metal free soap, washed with distilled water, soaked in 10 % nitric acid for 24 h. and finally, rinsed with ultrapure water). Water samples were stored in an insulated, ice cooled container and delivered to the laboratory on the same day. All the samples were kept at 4 °C to avoid physico-chemical changes and interference. The sampling, preservation, transportation and analysis of water samples was carried out according to the methods described in APHA-AWWA-WEF (1998). The polyethylene bottles used for storing samples were sealed with tape to make the sample free from air contact.
A total of eighteen water quality parameters were measured at different monitoring locations. The pH, turbidity, dissolved oxygen (DO), electrical conductivity (EC), total dissolved solids (TDS) and temperature (Temp.) were measured onsite by portable pH meter, turbidity meter, DO meter, conductivity meter, TDS meter and thermometer respectively; whereas the other parameters viz. total hardness (TH), 5-day biochemical oxygen demand (BOD5), total alkalinity (TA), total suspended solid (TSS), Chloride (Cl−), Sodium(Na+), Potassium(K), Phosphate (\( {\text{PO}}_{4}^{ - 3} \)), lead (Pb), Copper (Cu), Iron (Fe) and Zinc (Zn) were analysed in laboratory using standard protocol APHA-AWWA-WEF (1998). All the parameters along with the analytical methods for their measurement are summarized in Table 2.
Data Treatment and Multivariate Statistical Techniques
The raw data for all 18 water quality parameters monitored at various stations for rivers Ganga and Yamuna were subjected to statistical analysis. Exploratory data analysis was first carried out which included computation of summary statistics, assessment of strength of association between different parameters using correlation analysis. The data were further checked for normality by conducting goodness-of-fit tests; the tests revealed that most of the parameters in river Ganga do not follow the normal distribution. Thus, in order to assess seasonal variation in the water quality parameters, Wilcoxon signed-rank test (non-parametric) was carried out for river Ganga and paired t test was performed on normal distributed data of river Yamuna. The correlation analysis revealed that statistically significant association exists between the parameters, and therefore more elaborate PCA can be carried out to identify underlying interrelationship amongst the parameters. The CA was carried out for grouping similar sampling stations into common clusters. All the statistical analysis was carried out using statistical package SPSS, version 10 (SPSS 1999).
The PCA is a variable reduction technique, which is used for understanding the underlying relationships between the variables. The data reduction helps in extracting information about the most meaningful parameters that describe the entire data set without loss of original information. It allows interpretation that is not revealed by simple summary statistics and reveals principal tendencies present in the data matrix. The technique involves transformations of p correlated variable into p uncorrelated orthogonal principal components (PCs), which are weighed linear combinations of the original variables. The total number of PCs extracted from PCA indicates the total number of possible sources of variation in the data set. The successive linear combinations are extracted in a manner that they are orthogonal to each other, and account for successive small amount of the total variance that has not been accounted for by its predecessors. Thus, the first PC has the highest eigen value and represents the most important source of variation in the data. The last PC accounts for the least variation in the data set. The eigenvalues of the PCs are given by the loadings, and the individual transformed observations are called scores. The projections of the original variables on the subspace of PC result in loadings; these loadings are correlation coefficients between PCs and variables. The PCs are expressed by the following Eq. (1):
where PC i is principal component i and a ji is the component loading (correlation coefficient) of the original variable x. In order to maximize the variance of loadings, different matrix rotation methods are employed. In the present study, the varimax rotation methods were used for maximizing the variance of loadings. Sharma (1996), and Johnson and Wichern (2002) provide more details on the mathematical background of PCA. The PCA has been used in water quality assessment by various researchers to identify the most important water quality parameters and their potential pollution sources at various monitoring stations (Zhao et al. 2011; Razmkhah et al. 2010; Reid and Spencer 2009; Ouyang 2005).
Cluster analysis is another data reduction method that can be used to classify the entities with similar properties, so that objects within a group are similar to each other, but different from those in other groups (Shrestha and Kazama 2007). The Euclidean distance usually gives the similarity between two samples and a distance can be represented by the difference between analytical values from the samples. In this investigation, hierarchical agglomerative CA was performed on the normalized data set by means of Ward’s method, using squared Euclidean distance as a measure of similarity (Zhao et al. 2011). The spatial variability of water quality in the whole river basin was determined by CA, using the linkage distance, D link/D max, which represents the quotient between the linkage distances for a particular case divided by the maximal linkage distance. The quotient is then multiplied by 100 as a way to standardize the linkage distance (Zhao et al. 2011; Simeonov et al. 2003; Wunderlin et al. 2001).
Result and Discussion
Seasonal Variation of Water Quality
The summary statistics in terms of mean ± standard deviation for the eighteen parameters for the summer and winter seasons is provided in Table 3. In order to assess the seasonal variability of the water quality parameters, Wilcoxon signed-rank test for paired observations was carried out for river Ganga and paired t test performed on river Yamuna. Table 3 provides the results of Wilcoxon signed-rank test and t test (Table 4).
The test shows that for river Ganga, all the water quality parameters, except BOD, pH is statistically significant (p < 0.05). All the parameters, except BOD, pH was found to be higher during summer as compared to winter period. This is an interesting observation considering that high flow rates are observed during summer period as compared to winter period due to melting of ice. Field investigations revealed that the major industries discharge untreated effluents in the river during summer period when the flow rate is high, while during winter period the industries treat their effluent and then discharge them in the river body, resulting in lower values. For Yamuna, in addition to pH, turbidity, TA, Cl−, Na, K, Pb, phosphate, BOD, Fe and Zn were also found to be statistically insignificant (p > 0.05) and all other remaining parameters were found to be statistically significant. All statistically significant parameters were found to have higher values during summer as compared to winter period. It was due to the same reason as mentioned for Ganga. No seasonal variation was observed in the statistically insignificant parameters for the two rivers.
Clustering of Similar Monitoring Stations
Cluster analysis was applied to find out the monitoring stations having similar characteristics in terms water quality parameters. The dendrogram in Figs. 2 and 3 shows grouping of all 15 monitoring stations of river Ganga and 5 monitoring stations of river Yamuna into two statistically significant clusters at (D Link/D max)_100 < 5. For the summer data, eight monitoring stations of the river Ganga (1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13 and 14) formed the first cluster; these 13 stations primarily receive raw sewage from domestic sources and sewage muck from hydro-electric projects. The stations 8 and 15, together form the second cluster. These two stations receive effluents from domestic sources as well as from automobile, electroplating and pharmaceutical industries. Similar clusters were formed for winter data.

Dendrogram of cluster analysis for sampling stations according to surface water quality of Ganga

Dendrogram of cluster analysis for sampling stations according to surface water quality of Yamuna
Summer data for river Yamuna resulted in two clusters (Fig. 3). Cluster 1 comprises stations 1, 2, 3 and 5, while cluster 2 comprises station 4. Stations 1, 2, 3 and 5 receive sewage from domestic sources, whereas station 4 receives pollution load primarily from dairy waste in addition to the domestic sewage. The winter data also resulted in two clusters, with station 1, 2, 3 and 5 forming the first cluster, and station 4 forming the second cluster. These two clusters represent low and high pollution sites.
Sources Attribution of Pollution Sources
The PCA was carried out for the summer and winter data set for the two rivers (Tables 5, 6). The Kaiser’s criterion (Kaiser 1960) was followed to determine the number of PCs to be extracted. According to these criteria, the number of PCs having eigen value equal to or greater than 1 is to be accepted as the possible sources of variance in the data set. The analysed summer data for Ganga resulted in four PCs with eigenvalues greater than 1, explaining 85 % of the variance. A reasonable interpretation of the four PCs can be done using the values of the respective loadings augmented with the knowledge of major contributors of pollution at various sites. The loadings with absolute values greater than 0.5 of the maximum value are selected for the PC interpretation (Jolliffe 1986). Further, the loadings were classified as ‘strong’, ‘moderate’ and ‘weak’ corresponding to absolute loading values of > 0.75, 0.75–0.50 and 0.5–0.30, respectively (Liu et al. 2003). The first component is a measure of \( {\text{PO}}_{4}^{ - 3} \), TDS, TSS, K, Pb, Cu, Fe and Zn, parameters, which is indicative of mixed source of pollution comprising of natural and anthropogenic source (domestic sewage as well as industrial discharge) of pollution. The G8 receives large amount of debris due to continuous weathering of the mountains; the site also has a dysfunctional mega-hydroelectricity plant in river water, which continuously contributes Cu and Fe to river water due to corrosion and dismantling of machinery. Jain (2002) also reported the presence of phosphate in the same river stretch due to breakdown of the apatitic rocks. The TSS due to their composition–\( {\text{CO}}_{3}^{ - 2} \), Fe, MnO, clay and organic detritus—show positive correlation with Zn, Cu and Fe. The constituents of TSS play a significant role by providing an active surface for trace metals to be adsorbed (Boughriet et al. 1992); Zn, for instance, is positively correlated with Fe due to Zn adsorption by hydrous Fe (Adbo 2004). High erosion rate of the unstable rocks, drainage basin with a number of steep elevation and several tributaries are merging in this stretch, leading to high sediment in this belt (Das 1991). The major industries upstream of G15 site that contribute to pollution load are electroplating, pharmaceuticals and automobiles. In the correlation matrix (Table 7) also, it was found that Pb was significantly correlated with Fe, Cu and Zn. Oketola et al. (2013) also reported that Pb shared strong relationship with Cu. Temperature, DO, BOD, turbidity and TH are the main contributors of PC2, which contrast DO to other parameters and accounts for 19 % of the variance. This component points to an organic source of pollution such as agro-based industries. In correlation matrix, it was found that temperature was negatively correlated to DO. Kumari et al. (2012) reported that as temperature increases, it reduces the dissolution of ambient DO in river water. The third PC explains 17 % of variance and is a measure of turbidity, TA, TSS, EC and Cu. Turbidity, TA and TSS show very high loading factors, which is indicative of natural source of pollution—continuous erosion of soil from the river banks. Table 7 shows that TSS is significantly correlated to Na, K, EC, Pb, Cu and Fe. Temperature, pH, DO, Cl− and Na+ are the main contributors in PC4, which also contrast DO to other parameters; it may be attributed to food processing industry and slaughterhouses. PC4 explains 14 % of the total variance. In correlation matrix (Table 7), chloride was reported to be moderately correlated to Na.
The results of the summer data for river Yamuna are also shown in Tables 5 and 6. The first three PCs explain 96.4 % of the variance. The PC1 is a measure of temperature, DO, pH, BOD, turbidity, TH, TA, TDS, Cl−, EC and Na+ in which, DO and BOD contrast with other parameters, it accounts for 62.3 % of the variance. In correlation matrix (Table 8), TA shows strong positive correlation with TDS, Cl, EC and Na+. The main industries contributing to the pollution load are detergent making, poultry farms and pharmaceutical industries. The second PC comprises \( {\text{PO}}_{4}^{ - 3} \), DO, turbidity, TSS, Cl−, Na+, K and TDS, with DO contrasting with other parameters. A very strong loading of \( {\text{PO}}_{4}^{ - 3} \) and K (above 0.9) is due to abundance of K naturally in that region and \( {\text{PO}}_{4}^{ - 3} \) is mainly contributed by agricultural, sewage and natural processes. This component accounts 24.3 % of the variance. It was found in the correlation matrix (Table 8) that phosphate share strong positive correlation with K, TSS, turbidity, Cl and negative correlation with DO. Temperature, pH, Pb, Cu, Fe and Zn contributes to the third PC, which accounts for 9.7 % of the variance. This can be attributed as industrial source, with effluents contributed by tube light manufacturing, electronics and fertilizer industry. Peng et al. (2010) and Odoemelam et al. (2014) reported that high pH promotes the precipitation of the heavy metals from the insoluble hydroxides, oxides and bicarbonates present in sediments, whereas increases in temperature accelerate the dissolution of bicarbonates, hydroxides in turn releasing metals from water-soluble, carbonate, and ex-changeable fraction present in the sediments (Li et al. 2013). Correlation matrix (Table 8) shows that Pb shared good positive correlation with other heavy metals (Cu, Fe and Zn) also.
The results of PCA for the winter data are also presented in Tables 5 and 6. For Ganga, the first four components account for 84.3 % of the variance. The first component is a measure of \( {\text{PO}}_{4}^{ - 3} \), TDS, TSS, EC, Na+, K, Cu, Pb, Fe and Zn pointing again to the same source of variations as one of the summer data—natural and anthropogenic source. The PC2 explains 19 % of the variance and comprises DO, TH, turbidity, TA, TSS, Fe and EC; with DO contrasting with other parameters and it was found that turbidity share significant correlation with TH, TA, TSS and EC (Table 9). The PC2 may be attributed to organic source of pollution, similar to summer data. The third PC is a measure of temperature, Cl− and Na+ contribute to 16 % of the variance. High loading of Na+ and Cl− may be attributed to food processing industry, slaughterhouses and water purification technologies. Chloride was found to be strongly correlated to Na (Table 9). The fourth PC explains 8.9 % of the variance and comprises BOD and TH again pointing to anthropogenic pollution (domestic wastewater).
The results of PCA for the Yamuna river data for the respective winter period gave three components, which accounts for 96.6 % of the total variance (Tables 5, 6). The first PC contrasts DO with other parameters—\( {\text{PO}}_{4}^{ - 3} \), turbidity, TH, TSS, TDS, Cl−, EC, K and Na+, indicating anthropogenic source from domestic sewage and effluents from industries similar to the one observed for summer data. Singh et al. (2005) reported that high TDS and TSS concentration is the indication of domestic sewage. The second PC is a measure of temperature, pH TH, TA, TDS, EC. It accounts for 26.5 % of variance. In correlation matrix (Table 10), it was found that TA was highly correlated to TDS and EC. The third PC explains 11.4 % of the variance and comprises Pb, Cu, Fe and Zn contrast to BOD as the main constituents. This is similar to the sources attributed in summer data.
Overall, the first four PCs in both summer and winter data for the river Ganga account for 86 % of the total variance. This proportion of accounted variance is substantial to provide adequate representation of data. The nature of the first two components is approximately the same. The first PC in both the datasets can be attributed to a mixed source of pollution comprising natural (weathering of rocks, soil erosion) and anthropogenic sources (domestic, agricultural runoff and industrial) of pollution. The second PC points to an organic source of pollution, such as agro-based industries. The nature of the fourth PC for the summer data is similar to the third PC of the winter data, both representing an industrial source of pollution such as food processing industry.
The difference exists between the two, PC3 for summer data and PC4 for winter data. The PC3 for summer data represents a natural source of pollution—soil erosion from river banks, while PC4 for winter data is attributed due to BOD and TH. For the river Yamuna, three PCs were identified for both datasets, which explain 96 % of the total variance. The nature of the three components is about the same; PC1 representing anthropogenic source of pollution from domestic and industrial sources, PC2 representing agricultural runoff and PC3 representing industrial source. The most significant parameters for summer and winter data for the two rivers based on the PCA are presented in Table 11.
Conclusions
Uttarakhand is a newly carved out state in India. The state is in the process of preparing zoning atlas for identifying appropriate locations for industry. An essential requirement for preparing the zonal atlas is primary data of water quality along the stretches of the major rivers that flow through the state. This data once collected and analysed would help in taking informed decisions related to designing of comprehensive water quality monitoring network, identification of appropriate sites for locating industries and rehabilitation plans for the rivers. The primary data collected and subsequently analysed in the present study provide useful insights. For instance, the water quality parameters were found to be higher during summer season compared to the winter season despite of higher dilution capacity achieved due to increased flow rate resulting from ice melting; on investigation, it was found that the industries in the catchments of the two rivers discharge their untreated effluents during summer period relying on natural scavenging capacity of the rivers. This is not an approved practice. Findings of the study can help the implementing authorities to take corrective measures by forcing the polluting industries to discharge the effluents after recommended treatment, as is done during the winter period. Further, the CA findings reveal formation of two similar clusters for river Ganga and two clusters for river Yamuna. The two clusters identified for Ganga receive pollution loads from domestic and industrial sources and sewage muck from hydro-electric projects, respectively; whereas the two clusters formed for river Yamuna can be categorized as low and high pollution sites, with the former receiving major contribution from domestic sources and the latter from domestic and dairy sources, respectively. Thus, CA findings would help in grouping similar monitoring stations into clusters, which would further help in facilitating the design of optimal number of monitoring stations; this would help in reducing the number of monitoring stations and hence the cost of sampling for both the rivers. Finally, the PCA revealed underlying relationships amongst the water quality parameters and helped identifying sources of pollution. For the river Ganga, four components or sources of pollution were identified that can be attributed to mixed sources (natural and anthropogenic), organic source of pollution—agro based industries, natural source of pollution—riverbank erosion and food processing industry; for river Yamuna, three major sources of pollution were identified—anthropogenic sources of pollution from domestic and industrial sources, agricultural runoff and industrial source. Thus, the PCA helped in identifying the point and nonpoint sources of pollution for the entire stretch of rivers Ganga and Yamuna in Uttarakhand. This essentially will help in prioritizing in control measures with respect to different sources of pollution.
References
Adbo MH (2004) Distribution of some chemical elements in the recent sediments of Damietta Branch, River Nile, Egypt. Egypt Acad Soc Environ Develop (D-Environmental Studies) 5(2):125–146
APHA, AWWA, WEF (1998) Standard Methods for the Examination of Water and Wastewater, 20th edn. American Public Health Association/American Water Works Association/Water Environment Federation, Washington
Bonansea M, Ledesma C, Rodriguez C, Pinotti L (2014) Water quality assessment using multivariate statistical techniques in Río Tercero Reservoir, Argentina. Hydrol Res. doi:10.2166/nh.2014.1
Boughriet A, Ouddane B, Fischer JC, Wartel M, Leman G (1992) Variability of dissolved Mn and Zn in the Seine estuary and chemical speciation of these metals in suspended matter. Water Res 26(10):1359–1378
Das TM (1991) Some aspects of the biogeography of the Ganga. In: Krishna Murti CR, Bilgrami KS, Das TM, Mathur RP (eds) The Ganga a scientific study. The Ganga Project Directorate, New Delhi, pp 187–193
Jain CK (2002) A hydro-chemical study of a mountainous watershed: the Ganga, India. Water Res 36:1262–1274
Johnson RA, Wichern DA (2002) Applied multivariate statistical analysis. Pearson Education Inc., Upper Saddle River
Jolliffe IT (1986) Principal component analysis. Springer, University of Geneva, New York
Kaiser HF (1960) The application of electronic computers to factor analysis. Educ Psychol Meas 20:141–151
Kannel PR, Leea S, Leeb YS (2008) Assessment of spatial–temporal patterns of surface and ground water qualities and factors influencing management strategy of groundwater system in an urban river corridor of Nepal. J Environ Manag 86:595–604
Kumari M, Tripathi S, Pathak V, Tripathi BD (2012) Chemometric characterization of river water quality. Environ Monit Assess 185:3081–3092. doi:10.1007/s10661-012-2774-y
Li Y, Xu L, Li S (2009) Water quality analysis of the Songhua River basin using multivariate techniques. J Water Resour Prot 2:110–121
Li H, Shi A, Li M, Zhang X (2013) Effect of pH, temperature, dissolved oxygen, and flow rate of overlying water on heavy metals release from storm sewer sediments. J Chem. doi:10.1155/2013/434012
Liu CW, Lin KH, Kuo YM (2003) Application of factor analysis in the assessment of groundwater quality in a Blackfoot disease area in Taiwan. Sci Total Environ 313(1–3):77–89
Odoemelam SA, Okorie DO, Oko IO (2014) Physicochemical parameters and heavy metal content of water, fish and sediments from cross river at afikpo north local Government area of Ebonyi state, Nigeria. J Chem 3(1):1–11
Oketola A, Adekolurejo SM, Osibanjo O (2013) Water quality assessment of River Ogun using multivariate statistical techniques. J Environ Protect 4(5):466–479. doi:10.4236/jep.2013.45055
Ouyang Y (2005) Evaluation of river water quality monitoring stations by principal component analysis. Water Res 39:2621–2635
Peng J, Chen S, Dong P (2010) Temporal variation of sediment load in the Yellow River basin, China, and its impacts on the lower reaches and the river delta. Catena 83(2–3):135–147
Razmkhah H, Abrishamchi A, Torkian A (2010) Evaluation of spatial and temporal variation in water quality by pattern recognition techniques: a case study on Jajrood River (Tehran, Iran). J Environ Manag 91:852–860
Reid MK, Spencer KL (2009) Use of principal components analysis (PCA) on estuarine sediment datasets: the effect of data pre-treatment. Environ Pollut 157:2275–2281
Sharma S (1996) Applied multivariate techniques. John Wiley & Sons Inc, Hoboken
Shrestha S, Kazama F (2007) Assessment of surface water quality using multivariate statistical techniques: a case study of the Fuji river basin, Japan. Environ Model Softw 22(4):464–475
Simeonov V, Stratis JA, Samara C, Zachariadis G, Voutsa D, Anthemidis A (2003) Assessment of the surface water quality in Northern Greece. Water Res 37(17):4119–4124
Singh KP, Malik A, Mohan D, Sinha S (2004) Multivariate statistical techniques for the evaluation of spatial and temporal variations in water quality of Gomti River (India): a case study. Water Res 38:3980–3992
Singh KP, Malik A, Sinha S (2005) Water quality assessment and apportionment of pollution sources of Gomti River (India) using multivariate statistical techniques: a case study. Anal Chim Acta 538:355–374
SPSS-10 (1999) Statistical package for the social sciences. Spss Inc, Chicago
Wunderlin DA, Diaz MP, Ame MV, Pesce SF, Hued AC, Bistoni MA (2001) Pattern recognition techniques for the evaluation of spatial and temporal variations in water quality. A case study: Suquia river basin (Cordoba, Argentina). Water Res 35(12):2881–2894
Zhao J, Fu G, Lei K, Li Y (2011) Multivariate analysis of surface water quality in the three Gorges area of China and implications for water management. J Environ Sci 23(9):1460–1471
Acknowledgments
The authors gratefully acknowledge the cooperation of Mr. Neeraj Sharma for editorial assistance. The editors and anonymous referees are gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sharma, M., Kansal, A., Jain, S. et al. Application of Multivariate Statistical Techniques in Determining the Spatial Temporal Water Quality Variation of Ganga and Yamuna Rivers Present in Uttarakhand State, India. Water Qual Expo Health 7, 567–581 (2015). https://doi.org/10.1007/s12403-015-0173-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12403-015-0173-7