
Abstract
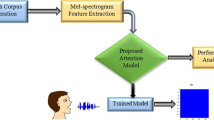
Traditional speech recognition model based on deep neural network (DNN) and hidden Markov model (HMM) is a complex and multi-module system. In other words, optimization goals may differ between modules in traditional model. Besides, additional language resources are required, such as pronunciation dictionary and language model. To eliminate the drawbacks of traditional model, we hereby propose an end-to-end speech recognition method, where connectionist temporal classification (CTC) and attention are integrated for decoding. In our model, the complex modules are replaced by a single deep network. Our model mainly consists of encoder and decoder. The encoder is constructed by bidirectional long short-term memory (BLSTM) with a triangular structure for feature extraction. The decoder based on CTC-attention decoding utilizes advanced features extracted by shared encoder for training and decoding. The experimental results on the VoxForge dataset indicate that end-to-end method is superior to basic CTC and attention-based encoder-decoder decoding, and the character error rate (CER) is reduced to 12.9% without using any language model.
Article PDF
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
References
ANUSUYA M A, KATTI S K. Speech recognition by machine: A review [J]. International Journal of Computer Science and Information Security, 2009, 6(3): 181–205.
RABINER L R. A tutorial on hidden Markov models and selected applications in speech recognition [J]. Proceedings of the IEEE, 1989, 77(2): 257–286.
HINTON G, DENG L, YU D, et al. Deep neural net-works for acoustic modeling in speech recognition: The shared views of four research groups [J]. IEEE Signal Processing Magazine, 2012, 29(6): 82–97.
GRAVES A, FERNÁNDEZ S, GOMEZ F, et al. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks [C]// 23rd International Conference on Machine Learning. Pittsburgh, Pennsylvania, USA: ACM, 2006: 369–376.
GRAVES A, JAITLY N. Towards end-to-end speech recognition with recurrent neural networks [C]// 31st International Conference on Machine Learning. Beijing, China: W&CP, 2014: 1764–1772.
BAHDANAU D, CHO K H, BENGIO Y. Neural machine translation by jointly learning to align and translate [C]// International Conference on Learning Representations. San Diego, CA, USA: Computational and Biological Learning Society, 2015: 0473.
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// 31st Conference on Neural Information Processing Systems. Long Beach, CA, USA: NIPS, 2017: 5998–6008.
MARKOVNIKOV N, KIPYATKOVA I, LYAKSO E. End-to-end speech recognition in Russian [C]// International Conference on Speech and Computer. Leizig, Germany: Springer, 2018: 377–386.
SAK H, SENIOR A, BEAUFAYS F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition [C]// 15th Annual Conference of the International Speech Communication Association. Singapore: ISCA, 2014: 1128.
HANNUN A Y, MAAS A L, JURAFSKY D, et al. First-pass large vocabulary continuous speech recognition using bi-directional recurrent DNNs [EB/OL]. (2014-08-12) [2018-11-08]. https://arxiv.org/pdf/1408.2873.pdf.
MIAO Y, GOWAYYED M, METZE F. EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding [C]// IEEE Workshop on Automatic Speech Recognition and Understanding. Scottsdale, AZ, USA: IEEE, 2015: 167–174.
MOHRI M, PEREIRA F, RILEY M. Weighted finite-state transducers in speech recognition [J]. Computer Speech & Language, 2002, 16(1): 69–88.
CHOROWSKI J K, BAHDANAU D, SERDYUK D, et al. Attention-based models for speech recognition [C]// 29th Conference on Advances in Neural Information Processing Systems. Montreal, Canada: NIPS, 2015: 577–585.
BAHDANAU D, CHOROWSKI J, SERDYUK D, et al. End-to-end attention-based large vocabulary speech recognition [C]// 41st IEEE International Conference on Acoustics, Speech and Signal Processing. Shanghai, China: IEEE, 2016: 4945–4949.
LU L, ZHANG X, CHO K, et al. A study of the recurrent nerual network encoder-decoder for large vocabulary speech recognition [C]// Proceedings of the Interspeech. Dresden, Germany: ISCA, 2015: 3249–3253.
ZEILER M D. Adadelta: An adaptive learning rate method [EB/OL]. (2012-12-22) [2018-11-08]. https://arxiv.org/pdf/1212.5701.pdf.
WATANABE S, HORI T, KARITA S, et al. ESPnet: End-to-end speech processing toolkit [C]// Proceedings of the Interspeech. Hyderabad, India: ISCA, 2018: 2207–2211.
POVEY D, GHOSHAL A, BOULIANNE G, et al. The Kaldi speech recognition toolkit [C]// IEEE Workshop on Automatic Speech Recognition and Understanding. Hawaii, USA: IEEE, 2011: 1–4.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhu, T., Cheng, C. Joint CTC-Attention End-to-End Speech Recognition with a Triangle Recurrent Neural Network Encoder. J. Shanghai Jiaotong Univ. (Sci.) 25, 70–75 (2020). https://doi.org/10.1007/s12204-019-2147-6
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12204-019-2147-6