
Abstract
This paper presents a freshness classification model for determining the quality of amla (Phyllanthus emblica) using features extracted from the progressively deteriorating shapes. Estimation of the peripheral distance from the centroid is carried out to develop key features regarding the shape of the samples, followed by developing two classifier models using support vector machine (SVM) and artificial neural network (ANN) to segment the samples into Good and Deteriorated classes. The proposed algorithm is simple in analysis as it includes geometry-based computation for identifying the surface irregularities and shape changes occurring due to aging the samples. Canny edge detection model is used to obtain the peripheral edges, followed by analyzing the same using “ConvexImage.” High accuracy of classification, exceeding 90%, is achieved in most cases, using three different feature parameters so developed, either as univariate or multivariate schemes of analysis. Besides, the sample images are captured using smartphones only. Thus, high accuracy of freshness classification, along with ease of analysis and image capturing using the phone camera itself, makes the algorithm suitable for implementing in low memory devices such as smartphones, which would also make the proposed model more widely exploring.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Due to the presence of health-boosting compositional facts like phytochemicals, vitamins, minerals, organic acids, and carbohydrates, a sharp increase in fruit consumption is perceived (Hussain et al. 2018). The consumer-driven fruit market is facing a continuous increase in requirements for higher value with respect to fruit product quality. The cutting-edge researches indicate adverse health issues are related to the consumption of spoiled fruit (Adebo et al. 2021). Thus, reliable scientific methods for on-site fruit quality evaluation is a need in recent days (Przybylak et al. 2016). The conventional fruit quality evaluations are generally offline and destructive in nature. Therefore, a rapid, non-invasive, non-contact, diverse, eco-friendly, and precise system is to be developed for fruit quality assessment (Suktanarak and Teerachaichayut 2017; Caballero et al. 2017). Digital image analysis has been used to assess the quality of agricultural produce due to its proven features like non-destructive, rapid, cost-effective, and accuracy (Ma et al. 2016; Hussain et al. 2018). Though the freshness of food materials is perspective, it regulates the consumer preference most. Freshness depends on the variety of the fruit and on the experience of the evaluator (Koyama et al. 2021). Objective indices and consumer evaluation have been combined to follow the freshness concept in terms of consumer perception (Sarkar et al. 2021c; Koyama et al. 2021). Quantifiable standards like color, texture, and shape are performing as critical indicators during interpretation of sensory evaluation. On contrary, physicochemical characteristics could not reflect the perception of the consumers directly. Freshness prediction with sensory evaluation based on a traditional panel-based system is expensive, time-consuming, and skill-dependent, whereas machine learning-based techniques may have higher efficiency (Sarkar et al. 2021d). The classification is possibly similar to human sensory assessment without the intervention of a panelist once the model is built with an adequate dataset. The puffed snack (Sanahuja et al. 2018), fish (Dowlati et al. 2013; Liu et al. 2015), and olive oil (Angerosa et al. 1996) quality have already been evaluated with machine learning. Texture profile, sound-based sensors, and image processing have been considered to construct the predictive models. To evaluate the freshness of fruit, visual perception has been considered as most important (Péneau et al. 2007; Wada et al. 2007). Machine learning and digital image processing are in practice to facilitate food quality prediction. Smartphone-based digital image processing in combination with machine learning has been used in the freshness classification of squid and fish samples (Navotas et al. 2018; Hu et al. 2020).
Indian gooseberry (Phyllanthus emblica) or amla is an ethno-pharmaceutically recognized fruit from ancient times (Uddin et al. 2016). Due to the presence of the high amount of vitamin C (5–15 g/kg), emblicanin A and B, gallic acid, corilagin, quercetin, chebulagic acid, kaempferol, pedunculagin, and mucic acid, the fruit is effective in the treatment of diversified diseases, viz., cancer, neurological disorders, inflammation, indigestion, hypertension, and osteoporosis; it is a proven medicinal fruit efficacious in several infectious diseases caused by parasites and lifestyle diseases (Kapoor et al. 2020). It is a good source of dietary fiber, potassium, copper, and manganese yet low in calories, thus treated as a nutrient source for patients with diabetes, cardiovascular problems, and indigestion-related issues (Gantait et al. 2021). This seasonal fruit is available from December to March with a shelf-life of 6–9 days (Chaphalkar et al. 2017; Sarkar et al. 2021a). To get adequate nutritional features, one needs to consume fresh fruit, whereas consumption of rotten ones may initiate adverse health issues. To ascertain the freshness of the fruit changes in texture, color and shape are considered primarily (Mukherjee et al. 2021). The visual appearance followed by quality assessment is an expert-dependent attribute (Mukherjee et al. 2022).
The discontinuities within a digital image can be identified and located with the help of edge detection (Narendra and VHareesh 2011) . The discontinuity is described by an abrupt deviation in the pixel intensities to depict the object boundary in the image (Manickavasagan et al. 2014). Different edge detection techniques are there, namely, the classical, Gaussian-based, and multi-resolution methods. Edge structure, noise environment, and orientation of the edges are the variables considered for the selection of appropriate methods (Musoromy et al. 2010).
The fundamental of the SVM approach discovers the optimal separating hyperplane between classes. This may be done by observing the training cases which are present at the edge of the class descriptor. The training cases are generally known as support vectors (Bhargava and Bansal 2020). Training cases that are not included as support vectors may be discarded. This method helps to increase the efficiency of using fewer training samples as well as optimal hyperplane are also fitted. The use of small training sets leads to high classification accuracy. SVM has been used in the classification of rice and coffee bean varieties (Nga et al. 2021; Waliyansyah and Hasbullah 2021), system development for food gradation (Zhu and Spachos 2021), and carrot appearance recognition (Zhu et al. 2021).
Biological processes have been modelled reliably and efficiently with artificial neural network (ANN) for the evaluation of specific objectives (Gago et al. 2010). The arrangement and functioning of the human neural system are simulated in ANN for processing input information followed by decision-making. The non-linear and complex biological events could be modelled with ANN due to its inherent learning mechanism to establish the relationship between input and output features (Gago et al. 2010; Dutta Gupta and Pattanayak 2017).
Materials and Methods
Indian Gooseberry Sample Collection
Mature, excellent quality freshly harvested gooseberry (amla) fruits each having a weight of 15–21 g with a diameter of 2.6–3.5 cm were purchased from Agri Horticultural Society of India, Kolkata, India. Fifty samples had been segregated randomly out of a total of 383 samples. Emphasis has been given on reducing the time gap between purchases of amla and taking them to the laboratory; it must be within 15 min. Room temperature must be maintained at 25 ± 5 °C, with a relative humidity of 80 ± 5% (Mukherjee et al. 2021, 2022). They should not be exposed to direct sunlight and must be left without the addition of any preservatives so that natural decomposition can be observed.
Image Acquisition
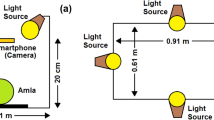
To study the decomposition rate, pictures were captured from the very first day using Redmi Note 9 Pro, with specifications 8 nm processor, 4 GB RAM, 128 GB memory, 48-megapixel camera, android system, and Samsung Isocell GM2 sensor taking view from all angles. Four LED lights were installed in the room (Eveready 20-Watt LED Batten, 20 W, 113.5 × 2.5 × 3.6 cm, luminous flux of 100 lm/W Lumen, color temperature 6000 K) to make sure there are proper lighting facilities to capture images. Fruits were placed at a distance of 20 cm from the smartphone to take images.
Evaluation of Classes of the Fruits
Sensory qualities of the fruits were judged by a group of semi-trained panel which consisted of 39 females and 30 male persons between the age group 21 and 45 years. ISO 8586–1 (1993) was followed in performing this. On the other hand, ISO 5496:2005 and ISO 10399:2004 were employed, respectively, to identify the color and to distinguish two fruits (Sarkar et al. 2021b). Whether the fruit falls under Good or Deteriorated class is determined by three specific sensory attributes, namely, shape, color, and texture.
Methodology of Analysis
Three major features of fruits and vegetables, which are analyzed mostly while assessing the quality of the samples, contain the color, texture, and shape of the fruits or vegetables. The proposed work is about analyzing there the shape of the amla samples. We have observed that the round-shaped amla fruits undergo an appreciable change in shape, especially, after major degradation in quality. The smooth surface of the samples mostly becomes uneven on degradation, thereby distorting the smooth and near circular peripheral orientation. In some of the samples, we have observed that the round shape of the sample is modified close to hexagonal shape after a few days of deterioration, and other few samples trend to degrade differently in shape. Hence, a robust algorithm is required to identify these minor changes in shape. In this work, we have used the edge analysis of the samples, followed by application of the “ConvexHull” analysis to identify the exact shape of the fruits. Finally, we have computed the peripheral distance from the centroid and tried to validate the variation in these distances among the Good and Deteriorated samples using supervised learning algorithms like support vector machine (SVM) and artificial neural network (ANN). The detailed steps of designing the algorithm are started below in sequence.
Binary Image Formation
One of the advantages of the proposed scheme is that the images need not be cropped for further analysis. Hence, the RGB images are directly converted to grayscale images in the first step of the work. We have further employed the median filtering method in order to incorporate generalization in the intensity level among the different sets of images of both Good and Deteriorated classes. Hence, we have applied median filtering over the grayscale image to obtain the median level of the images. These values are used to develop a threshold for binarizing the grayscale image itself. Hence, all the pixel intensity values belonging to higher than the threshold level are assigned as white, and values below the same are denoted as black. Thus, binary black and white images are developed from the grayscale images using the median thresholding.
Demonstration of the three different image stages of the image development, i.e., RGB image, grayscale image, and the binarized black and white image, is shown in Figs. 1 and 2. Figure 1 shows the same for a randomly chosen Good class of sample, whereas Fig. 2 displays the same for another randomly chosen sample from the Deteriorated class.

a RGB, b grayscale, and c black and white image of a random sample chosen from the Good class

a RGB, b grayscale, and c black and white image of a random sample chosen from the Deteriorated class
Obtaining the Edge From the Binary Image
We have adopted “Canny” edge detection model in the proposed work, among the several variants. It is observed that there are several brownish spots all over the amla surface besides, the directly illuminated spots of the reflected light. All of these were highlighted in the black and white images and, hence, were all detected as edges, as shown in Fig. 3a and b, respectively, to demonstrate the Good and Deteriorated samples for a random sample set.

Edge-detected image using “Canny” edge detection model of a Good class and b Deteriorated class
Canny Model
Canny (Canny 1986) introduced a very efficient edge detection algorithm by identifying the intensity discontinuities in the image. In this model, a Gaussian convolution is applied initially to the image, following a two-dimensional first-derivative operator (Hoang and Nguyen 2018). This derivative operator tries to locate the regions where there is a sharp change in intensity level between consecutive pixels, by identifying the gradient of the signal output from the derivative function. The Gaussian filter applied initially is described as
where \({G}_{\sigma }\left(m, n\right)\) is the Gaussian function, represented as
This function has a variance of \({\sigma }^{2}\), where \(\sigma\) is the standard deviation. Thus, expression (1) represents the convolution of \({G}_{\sigma }\left(m, n\right)\) with \(f\left(m, n\right)\), where m and n represent the coordinates of the image pixel location, row-wise, and column-wise and \(f\left(m, n\right)\) represents image neighborhood corresponding to pixel coordinate of \(\left(m, n\right).\) The gradient, function \(g\left(m,n\right)\), is computed using a certain gradient operator using the equation given by
where \({N}_{IC}\) represents an image neighborhood and \({g}_{m, n}\left(m,n\right)\) denotes the combined result of the estimatedgradients.This is followed by non-maximum suppression for narrowing out the edges (Canny 1986). The canny model primarily relies on two specific parameters, such as T1 and T2, which help in carrying out double thresholding analogy, where T1 is the lower threshold and T2 is the upper threshold. Hence, the edge pixels which are found higher than the upper threshold T2 are considered as strong edges, and those which are lower than the lower threshold T1 are suppressed. The edge pixels which lie in the intermediate range between T1 and T2 are also considered weak edges and primarily suppressed.
“ConvexHull” Analysis
The edges, which were detected within the main body of the samples, especially in more numbers in the Deteriorated samples, are useless for the proposed work. These edges primarily denote the illuminated spots and the brownish degradation of the fruit. In this work, we are rather concentrating more on the surface irregularities, leading to distortion in shape of the sample. Hence, these isolated edges, detected within the fruit image, need to be eliminated for finding only the peripheral edges of the samples. In this work, we have tried to explore the peripheral surface of the samples and distinguish the deterioration for judging the smoothness of the surface. The Deteriorated fruits are found to have irregular and mostly hexagonal peripheral surfaces, whereas the Good samples have smoother and circular circumference. Hence, only the peripheral surface is required to be investigated, and the internal edges need to be removed. Thus, we have use the “ConvexHull” technique for finding out the silhouette of the amla images, which would prominently identify the irregularities on the surfaces of the Deteriorated samples. The method of' “ConvexHull” is basically a matrix specifying the smallest convex polygon containing a particular region. “ConvexImage,” so developed from the “ConvexHull” analysis, is primarily a binary image (i.e., logical image) that specifies the “ConvexHull,” where all the pixels inside the hull are filled in, i.e., these are set to on.
Two different example cases of Good and Deteriorated classes are demonstrated in Figs. 4 and 5, respectively. Figures 4b and 5b show, respectively, the “ConvexHull” of the two classes. These “ConvexHull” images are further analyzed using an edge detection model to identify the peripheral edges most prominently. The final images of Figs. 4c and 5c contain only the surface edges and disregard any of the edges developed interior to the samples, as was found on direct edge analysis of the black and white images obtained as Fig. 3a and b, respectively. This clearly demonstrates the effectiveness of the “ConvexHull” model used in the present case in connection with edge analysis.

a Black and white, b “ConvexImage,” and c edge-detected binary image of the “ConvexImage” of a random sample chosen from the Good class

a Black and white, b “ConvexImage,” and c edge-detected binary image of the “ConvexImage” of a random sample chosen from the Deteriorated class
Computation of Peripheral Distance and Development of Feature Ratios
The next task is the estimation of the peripheral edges from the center of the edge-detected image. Hence, we have first computed the centroid of the image along the x and y coordinates, respectively. The edge image is basically a binary image where the black pixels are denoted by zero and the white edges are denoted by unity. Thus, we have first found out the centroid of each image and then computed the Euclidean or victor distance of each of these peripheral edge pixels (denoted by intensity level 1) from the centroid.
We have observed that the Good class of images has a smoother peripheral surface, whereas the Deteriorated samples have developed several irregularities. The most important observation that we have noticed is that many of the samples, on degradation, become close to hexagonal in shape. This is due to the reason that amla has six major axes along the surface, i.e., each major axis lies close to 60° apart. The surface straightens more in between the two major axes, and hence, the shape of some of the Deteriorated sample closes to a regular hexagon.
The method of determining these distances is shown in Fig. 6a and b, respectively, for the Good and Deteriorated samples.

Computation of perpendicular peripheral distance from the centroid of the edge-detected binary image of the “ConvexImage” for a random sample chosen from the a Good class and b Deteriorated class
The edges obtained from these images are analyzed to find out the distances between the centroid and the peripheral edge points as discussed in the earlier section. These distances are the major features that are considered for subsequent analysis. It is well-known that when the samples are in good condition, the surface is smoother and the shape is closer to a circle, whereas when these deteriorate, the peripheral surface wrinkles and shrinks in many areas. Hence, the variation of the distance between the centroid and the peripheral point is more in the case of the Deteriorated samples. The same distances for the Good samples are very close to each other since the peripheral surface is much smoother and almost equally distant from the centroid. Thus, three ratios are developed using these peripheral distances as follows:
These features are analyzed further using support vector machine (SVM) model and artificial neural network (ANN) model to authenticate this difference in variation of the peripheral distances and thereby classifying models between the Good and Deteriorated classes. The whole method of image classification is described here using a sort of pseudo code, followed by describing the same using a flow diagram (Fig. 7).


Flowchart of the proposed freshness classifier
Result and Analysis
We have studied the variations of the peripheral distance from the centroid of each edge-detected image carefully. In this work, we have analyzed 170 Good samples and 170 number of the Deteriorated samples. Results show that the variation of the peripheral distances is much higher in the case of Deteriorated samples compared to the Good ones, which is in connection with the rationale so developed. These variations of a Good class of sample and a Deteriorated class of sample, picked up in random, are shown in Fig. 8.

Variations of orthogonal distance between the centroid and the peripheral edge pixels for two randomly chosen samples; one from each of the Good class (shown in blue lines) and Deteriorated class (shown in red lines)
The blue lines which are the computed peripheral distances of a Good sample are observed to lie within a range, which is much lower compared to the red lines, indicating a Deteriorated sample. In order to quantify the same, we have analyzed the three major detection parameters from these variations, given by expressions (4), (5), and (6) respectively, which are used further with the SVM and ANN classifier models. These three ratio parameters are computed for all the samples, and the variation of these three parameters is shown in Fig. 9.

Scatter diagram of the three different feature ratio points of the 170 samples belonging to the Good class (shown in green circles) and 170 samples belonging to the Deteriorated class (shown in red circles): a distribution of ratio 1, b distribution of ratio 2, and c distribution of ratio 3
It is observed from all the subfigures of Fig. 9 that there is a visible distinction between the Good and Deteriorated samples considering all three ratios. Figure 9b and c are identically close since these two ratios are depending directly on the maximum and minimum peripheral distance from the centroid. This apparent separation of the two classes using all the three features is further analyzed graphically using boxplots as shown in Fig. 10, which further emphasizes the above facts.

Boxplots showing the distribution of three different ratio feature points of the Good and Deteriorated class: a distribution of ratio 1, b distribution of ratio 2, and c distribution of ratio 3
These boxplots clearly show that the two classes with all the three feature ratios are separable with little overlap between the separating classes. The boxplots of ratio 2 and ratio 3 especially show that there are few outliers that lie within the region of the opposite classes. Hence, this qualitative separation of the feature points for all the three ratios is analyzed using SVM and ANN classifiers. We have used all the three feature ratios independently in the proposed SVM classifier, as well as taken pairs of these features and plotted them against each other. The plot of ratio 1 against ratio 2 for all the samples points, includingg the Good and Deteriorated classes, is shown in Fig. 11a, and the contour of the points is also marked with a continuous line. Apparent observation of Fig. 11a shows that there is overlap between the two classes when observed qualitatively. Hence, these features are used with the proposed SVM classifier to develop an accurate classification of the same. The SVM classification of the whole set of samples is shown in Fig. 11b which demonstrates that the two classes of samples are well separated using a single line to yield classifier accuracy exceeding 90%.

a Bivariate distribution of ratio 1 and ratio 2 values of the Good class (shown in green circles) and Deteriorated class (shown in red circles), the terminal points are contoured; b SVM classification of the same distribution of samples
Classifier Outcomes
The classifier outcomes using the two supervised learning models are shown in Tables 1 and 2.
It is observed from the table that the classifier accuracy, using both the SVM and ANN models, is very much comparable, including both the univariate and bivariate schemes. These results are further illustrated using bar diagram as shown in Fig. 12 and Fig. 13 to compare the classifier outputs from these two models, as well as compare the results from univariate and bivariate models.

A comparative analysis of (a) average, (b) maximum, and (c) minimum accuracy obtained from the SVM and ANN classifiers

A comparative analysis of the (a) standard deviation of accuracy outcomes from the mean accuracy level, and (b) range of classifier accuracy obtained from the SVM and ANN classifiers
It is further emphasized from Table 2 and from Figs. 12 and 13 that both of these models produce comparable outcomes, although SVM model possesses minor advantage over the ANN prototype in terms of marginally improved average, maximum, and the least accuracy level. This is observed from each sub-figure of Fig. 12. But, the ANN model, although is marginally behind the SVM classifier in terms of the mean classification accuracy, has one minor advantage in terms of the average deviation in accuracy outcomes from sample to sample, which is represented by the standard deviation of the results as shown in Fig. 13a. This inference is further highlighted from the range of accuracy levels from both the models, which is described in Fig. 13b. It is well observed from this sub-figure that the range of classifier accuracy levels obtained from 50 numbers of experimental observations is higher for SVM outputs in most of the cases. This further infers that the ANN classifier produces somewhat less deviation in results for consecutive experiments, although this difference is not majorly distinct.
Another comparison between the univariate and bivariate analysis schemes, using both the models, shows that the bivariate analysis produces marginally improved accuracy level compared to the univariate analysis-based models, as observed from the mean and maximum and minimum levels of accuracy plot of Fig. 12. This improvement of maximum accuracy attained using bivariate scheme is more predominant with the ANN model, as found from Fig. 12b. Thus, in a single note, both the proposed classifier models work almost equally efficiently in predicting the freshness class of the samples.
Analysis of the Model Performance
The model performance is evaluated considering the following:
where:
where:
\({\mathrm{P}}_{\mathrm{True}}\) = true positive,
\({\mathrm{P}}_{\mathrm{False}}\) = false positive
\({\mathrm{N}}_{\mathrm{False}}\) = false negative
\({\mathrm{N}}_{\mathrm{True}}\) = true negative
The results obtained from both the models are analyzed using the above performance parameters and also shown in Table 3.
Discussion
The proposed work is based on analyzing amla samples of different qualities for the determination of the edibility of the samples. The major highlights of the proposed work are illustrated below.
One of the major highlights of the work is that it eliminates the requirement of capturing images of amla samples following any sort of uniform protocol, such as capturing images from any particular angle or from a certain fixed distance. This is because the amla fruits are close to spherical in shape, and hence, images captured from almost any angle would mostly identify the smoothness of the shape of the Good samples and the different superficial irregularities of the Deteriorated samples. This makes the proposed algorithm more generalized in terms of image capturing, even using smartphones. This would help in wide applicability of the model and ensure robustness of the same, especially using smartphones for capturing the images.
In this work, we have used the ratio of the minimum to a maximum distance of the peripheral surface of the samples from the centroid as well as we have also analyzed the ratio of standard division to the minimum value of these peripheral distance values of any particular sample. Hence, it also eliminates the requirement of taking snapshots of the samples from any particular distance or angle. In other words, even if the sample image is small or large, the proposed method of ratio analysis would generalize these differences within appreciable limits. The above two features make the proposed algorithm more generalized as well as robust in terms of image capturing from different angles and distances. These qualities of a classifier are very much required as it is impractical for a person or the automation system which would take the sample images to follow identical protocol every time regarding the angle of the image as well as distance while capturing the images. Hence, the proposed classifier has good quality of robustness as well as practical applicability.
Apart from these features, the proposed work uses the “Canny” edge detection method which is already an established edge detection algorithm. The application of this edge detector identifies the edges in the samples which are very much essential for the work. Apart from that, we have applied the “ConvexHull” analysis on the edge-detected images to extract only the peripheral surface of the samples which are the only requirement for this proposed work. The application of this technique identifies the surface very accurately, thereby helping in accurate estimation of the distance of the surface edge points from the centroid.
The proposed work is light in computation as this incorporates only the edge detection model, followed by validation of the classified features using SVM and ANN methodologies. Hence, this low computational feature enables the proposed model to be applied even on the low memory devices, as well as enables fast computation of the results.
The classifier accuracy obtained using the two models is very high. The average accuracy of classification using the SVM and ANN models exceeds 90% for both the models, considering almost all the ratio features, either in univariate or bivariate mode. The peak accuracy exceeds 95% in both the models using some of the selected feature or feature pairs. This level of accuracy itself is very high when compared to some of the other contemporary schemes. This higher accuracy of classification combined with the robustness of the system makes the proposed algorithm very useful, especially for the detection of freshness of spherical fruit samples like that of amla.
Another very important feature of the work is that the images analyzed here are captured using smartphones only. It is also established by the work that the angles of the images as well as the distance of capturing the same does not majorly affect the classification process. Besides, the low computational burden of the method makes the algorithm suitable for application in low memory devices as well. All these features altogether make the proposed algorithm to be implemented on a very handful device like smartphones using application-based software, especially considering the fact that the images are itself captured in the same device. This would influence a wide application of the proposed classifier.
Conclusion
The proposed work is an attempt to develop an accurate freshness detection model for quality assessment of amla samples. In this work, we have analyzed the shape of the samples, which tend to deteriorate progressively with time. The peripheral surface of the samples are detected using Canny edge detection scheme, and these edges are analyzed for identifying the non-uniformity of the surface smoothness, which normally creep into the Deteriorated samples. Support vector machine (SVM) and artificial neural network (ANN) are applied further to develop two accurate classifier models, which are able to detect the Deteriorated samples with more than 95% peak accuracy level. Besides, ease of capturing the images using smartphones and without following any fixed protocol regarding the angle of capturing images, or the distance from the sample, makes the model more robust. Thus, low computational analysis, high accuracy, and increased robustness make the proposed algorithm suitable for implementation in real-time applications, especially in smartphone-based applications.
Availability of Data and Material
All the data used in the manuscript are available in the tables and figures.
Code Availability
Not applicable.
References
Adebo OA, Molelekoa T, Makhuvele R et al (2021) A review on novel non-thermal food processing techniques for mycotoxin reduction. Int J Food Sci Technol 56:13–27. https://doi.org/10.1111/ijfs.14734
Angerosa F, Di GL, Vito R, Cumitini S (1996) Sensory evaluation of virgin olive oils by artificial neural network processing of dynamic head-space gas chromatographic data. J Sci Food Agric 72:323–328. https://doi.org/10.1002/(SICI)1097-0010(199611)72:3%3c323::AID-JSFA662%3e3.0.CO;2-A
Asif MJ, Shahbaz T, Rizvi STH, Iqbal S (2018) Rice grain identification and quality analysis using image processing based on principal component analysis. In: 2018 International Symposium on Recent Advances in Electrical Engineering (RAEE). pp 1–6. https://doi.org/10.1109/RAEE.2018.8706891
Bhargava A, Bansal A (2020) Automatic detection and grading of multiple fruits by machine learning. Food Anal Methods 13:751–761. https://doi.org/10.1007/s12161-019-01690-6
Burkapalli VCPC, Patil (2020) Food image segmentation using edge adaptive based deep-CNNs. Int J Intell Unmanned Syst 8:243–252. https://doi.org/10.1108/IJIUS-09-2019-0053
Caballero D, Pérez-Palacios T, Caro A et al (2017) Prediction of pork quality parameters by applying fractals and data mining on MRI. Food Res Int 99:739–747. https://doi.org/10.1016/j.foodres.2017.06.048
Canny J (1986) A computational approach to edge detection. IEEE Trans Pattern Anal Mach Intell PAMI-8:679–698. https://doi.org/10.1109/TPAMI.1986.4767851
Chaphalkar R, Apte KG, Talekar Y et al (2017) Antioxidants of Phyllanthus emblica L bark extract provide hepatoprotection against ethanol-induced hepatic damage: a comparison with silymarin. Oxid Med Cell Longev 2017:3876040. https://doi.org/10.1155/2017/3876040
Dang H, Song J, Guo Q (2010) A fruit size detecting and grading system based on image processing. In: 2010 Second International Conference on Intelligent Human-Machine Systems and Cybernetics. pp 83–86. https://doi.org/10.1109/IHMSC.2010.120
Dowlati M, Mohtasebi SS, Omid M et al (2013) Freshness assessment of gilthead sea bream (Sparus aurata) by machine vision based on gill and eye color changes. J Food Eng 119:277–287. https://doi.org/10.1016/j.jfoodeng.2013.05.023
Dutta Gupta S, Pattanayak AK (2017) Intelligent image analysis (IIA) using artificial neural network (ANN) for non-invasive estimation of chlorophyll content in micropropagated plants of potato. Vitr Cell Dev Biol - Plant 53:520–526. https://doi.org/10.1007/s11627-017-9825-6
Gago J, Landín M, Gallego P (2010) Strengths of artificial neural networks in modeling complex plant processes. Plant Signal Behav 5:743–745. https://doi.org/10.4161/psb.5.6.11702
Gaikwad B, Manza R (2012) Use of edge detection operators for agriculture video scene feature extraction from mango fruits. Adv Comput Res 4:50–53
Gantait S, Mahanta M, Bera S, Verma SK (2021) Advances in biotechnology of Emblica officinalis Gaertn. syn. Phyllanthus emblica L a nutraceuticals-rich fruit tree with multifaceted ethnomedicinal uses. 3 Biotech 11:62. https://doi.org/10.1007/s13205-020-02615-5
Hetal NP, Jain R, Joshi M (2011) Fruit detection using improved multiple features based algorithm. Int J Comput Appl 13:1–5
Hoang N-D, Nguyen Q-L (2018) Metaheuristic optimized edge detection for recognition of concrete wall cracks: a comparative study on the performances of Roberts, Prewitt, Canny, and Sobel algorithms. Adv Civ Eng 2018:7163580. https://doi.org/10.1155/2018/7163580
Hu J, Zhou C, Zhao D et al (2020) A rapid, low-cost deep learning system to classify squid species and evaluate freshness based on digital images. Fish Res 221:105376. https://doi.org/10.1016/j.fishres.2019.105376
Hussain A, Pu H, Sun D-W (2018) Innovative nondestructive imaging techniques for ripening and maturity of fruits – a review of recent applications. Trends Food Sci Technol 72:144–152. https://doi.org/10.1016/j.tifs.2017.12.010
Hussain Hassan NM, Nashat AA (2019) New effective techniques for automatic detection and classification of external olive fruits defects based on image processing techniques. Multidimens Syst Signal Process 30:571–589. https://doi.org/10.1007/s11045-018-0573-5
Hussein WB, Moaty AA, Hussein MA, Becker T (2011) A novel edge detection method with application to the fat content prediction in marbled meat. Pattern Recognit 44:2959–2970. https://doi.org/10.1016/j.patcog.2011.04.028
Kapoor MP, Suzuki K, Derek T et al (2020) Clinical evaluation of Emblica officinalis Gatertn (Amla) in healthy human subjects: health benefits and safety results from a randomized, double-blind, crossover placebo-controlled study. Contemp Clin Trials Commun 17:100499. https://doi.org/10.1016/j.conctc.2019.100499
Koyama K, Tanaka M, Cho B-H et al (2021) Predicting sensory evaluation of spinach freshness using machine learning model and digital images. PLoS One 16:e0248769
Limsiroratana S, Ikeda Y (2005) Detection of fruits in natural background (part 2). J Japanese Soc Agric Mach 67:54–60. https://doi.org/10.11357/jsam1937.67.5_54
Liu X, Jiang Y, Shen S et al (2015) Comparison of Arrhenius model and artificial neuronal network for the quality prediction of rainbow trout (Oncorhynchus mykiss) fillets during storage at different temperatures. LWT - Food Sci Technol 60:142–147. https://doi.org/10.1016/j.lwt.2014.09.030
Ma J, Sun D-W, Qu J-H et al (2016) Applications of computer vision for assessing quality of agri-food products: a review of recent research advances. Crit Rev Food Sci Nutr 56:113–127. https://doi.org/10.1080/10408398.2013.873885
Mahale B, Korde S (2014) Rice quality analysis using image processing techniques. In: International Conference for Convergence for Technology-2014. pp 1–5. https://doi.org/10.1109/I2CT.2014.7092300
Manickavasagan A, Al-Shekaili HN, Thomas G et al (2014) Edge detection features to evaluate hardness of dates using monochrome images. Food Bioprocess Technol 7:2251–2258. https://doi.org/10.1007/s11947-013-1219-0
Mendoza F, Aguilera JM (2004) Application of image analysis for classification of ripening bananas. J Food Sci 69:E471–E477. https://doi.org/10.1111/j.1365-2621.2004.tb09932.x
Mendoza F, Dejmek P, Aguilera JM (2007) Colour and image texture analysis in classification of commercial potato chips. Food Res Int 40:1146–1154. https://doi.org/10.1016/j.foodres.2007.06.014
Mukherjee A, Chatterjee K, Sarkar T (2022) Entropy-aided assessment of amla (Emblica officinalis) quality using principal component analysis Biointerface. Res Appl Chem 12:2162–2170. https://doi.org/10.33263/BRIAC122.21622170
Mukherjee A, Sarkar T, Chatterjee K (2021) Freshness assessment of Indian gooseberry (Phyllanthus emblica) using probabilistic neural network. J Biosyst Eng. https://doi.org/10.1007/s42853-021-00116-8
Musoromy Z, Ramalingam S, Bekooy N (2010) Edge detection comparison for license plate detection. In: 2010 11th International Conference on Control Automation Robotics & Vision. pp 1133–1138. https://doi.org/10.1109/ICARCV.2010.5707935
Mustafa NBA, Fuad NA, Ahmed SK, et al (2008) Image processing of an agriculture produce: determination of size and ripeness of a banana. In: 2008 International Symposium on Information Technology. pp 1–7. https://doi.org/10.1109/ITSIM.2008.4631636
Narendra V, VHareesh K. (2011) Study and comparison of various image edge detection techniques used in quality inspection and evaluation of agricultural and food products by computer vision. Int J Agric Biol Eng 4:83–90
Navotas IC, Santos CN V, Balderrama EJM, et al (2018) Fish identification and freshness classification through image processing using artificial neural network. J Eng Appl 13(18):4912–4922.
Nga TTK, Pham TV, Tam DM et al (2021) Combining binary particle swarm optimization with support vector machine for enhancing rice varieties classification accuracy. IEEE Access 9:66062–66078. https://doi.org/10.1109/ACCESS.2021.3076130
Pedreschi F, León J, Mery D, Moyano P (2006) Development of a computer vision system to measure the color of potato chips. Food Res Int 39:1092–1098. https://doi.org/10.1016/j.foodres.2006.03.009
Péneau S, Brockhoff PB, Escher F, Nuessli J (2007) A comprehensive approach to evaluate the freshness of strawberries and carrots. Postharvest Biol Technol 45:20–29. https://doi.org/10.1016/j.postharvbio.2007.02.001
Pratibha N, Hemlata M, Krunali M (2017) Analysis and identification of rice granules using image processing and neural network. Int J Electron Commun 10:25–33.
Priyadumkol J, Kittichaikarn C, Thainimit S (2017) Crack detection on unwashed eggs using image processing. J Food Eng 209:76–82. https://doi.org/10.1016/j.jfoodeng.2017.04.015
Przybylak A, Boniecki P, Koszela K et al (2016) Estimation of intramuscular level of marbling among Whiteheaded Mutton Sheep lambs. J Food Eng 168:199–204. https://doi.org/10.1016/j.jfoodeng.2015.07.035
Rabby MKM, Chowdhury B, Kim JH (2018) A modified canny edge detection algorithm for fruit detection & classification. In: 2018 10th International Conference on Electrical and Computer Engineering (ICECE). pp 237–240. https://doi.org/10.1109/ICECE.2018.8636811
Sanahuja S, Fédou M, Briesen H (2018) Classification of puffed snacks freshness based on crispiness-related mechanical and acoustical properties J. Food Eng 226:53–64. https://doi.org/10.1016/j.jfoodeng.2017.12.013
Sarkar T, Mukherjee A, Chatterjee K (2021a) Supervised learning aided multiple feature analysis for freshness class detection of Indian gooseberry (Phyllanthus emblica). J Inst Eng Ser A. https://doi.org/10.1007/s40030-021-00585-2
Sarkar T, Saha S, Saluddin M, Chakraborty R (2021b) Drying kinetics, Fourier-transform infrared spectroscopy analysis and sensory evaluation of sun, hot-air, microwave and freeze dried mango leather. J Microbiol Biotechnol Food Sci 10:1–7
Sarkar T, Salauddin M, Pati S, et al (2021c) The fuzzy cognitive map–based shelf-life modelling for food storage. Food Anal Methods. https://doi.org/10.1007/s12161-021-02147-5
Satone M, Diwakar S, Joshi V (2017) Automatic bruise detection in fruits using thermal images. Int J Adv Res Comput Sci Soft Eng 7:727–732. http://doi.org/10.23956/ijarcsse/SV7I5/0116
Siswantoro J, Prabuwono AS, Abdullah A, Idrus B (2015) Automatic image segmentation using sobel operator and k-means clustering: a case study in volume measurement system for food products. In: 2015 International Conference on Science in Information Technology (ICSITech). pp 13–18. https://doi.org/10.1109/ICSITech.2015.7407769
Suktanarak S, Teerachaichayut S (2017) Non-destructive quality assessment of hens’ eggs using hyperspectral images. J Food Eng 215:97–103. https://doi.org/10.1016/j.jfoodeng.2017.07.008
Thendral R, Suhasini A, Senthil N (2014) A comparative analysis of edge and color based segmentation for orange fruit recognition. In: 2014 International Conference on Communication and Signal Processing. pp 463–466. https://doi.org/10.1109/ICCSP.2014.6949884
Uddin MS, Al MA, Hossain MS et al (2016) Exploring the effect of Phyllanthus emblica L. on cognitive performance, brain antioxidant markers and acetylcholinesterase activity in rats: promising natural gift for the mitigation of Alzheimer’s disease. Ann Neurosci 23:218–229. https://doi.org/10.1159/000449482
Wada Y, Tsuzuki D, Kobayashi N et al (2007) Visual illusion in mass estimation of cut food. Appetite 49:183–190. https://doi.org/10.1016/j.appet.2007.01.009
Waliyansyah RR, Hasbullah UHA (2021) Comparison of tree method, support vector machine, naïve Bayes, and logistic regression on coffee bean image. Emit Int J Eng Technol 9:126–136. https://doi.org/10.24003/emitter.v9i1.536
Zhu L, Spachos P (2021) Support vector machine and YOLO for a mobile food grading system. Internet of Things 13:100359. https://doi.org/10.1016/j.iot.2021.100359
Zhu H, Yang L, Fei J et al (2021) Recognition of carrot appearance quality based on deep feature and support vector machine. Comput Electron Agric 186:106185. https://doi.org/10.1016/j.compag.2021.106185
Sarkar T, Mukherjee A, Chatterjee K, Shariati, MA et al (2021d) Comparative Analysis of Statistical and Supervised Learning Models for Freshness Assessment of Oyster Mushrooms. Food Anal Methods https://doi.org/10.1007/s12161-021-02161-7
Acknowledgements
We acknowledge the authority, staff, and students of Malda polytechnic, Malda, to being with us throughout the study.
Funding
Thanks to GAIN (Axencia Galega de Innovación) for supporting this review (grant number IN607A2019/01).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Ethics Approval
Not applicable.
Consent to Participate
All authors have given their full consent to participate.
Consent for Publication
All authors have given their full consent for publication.
Conflict of Interest
Tanmay Sarkar declares that he has no conflict of interest. Alok Mukherjee declares that he has no conflict of interest. Kingshuk Chatterjee declares that he has no conflict of interest. Vladimir Ermolaev declares that he has no conflict of interest. Dmitry Piotrovsky declares that he has no conflict of interest. Kristina Vlasova declares that she has no conflict of interest. Mohammad Ali Shariati declares that he has no conflict of interest. Paulo E. S. Munekata declares that he has no conflict of interest. Jose M. Lorenzo declares that he has no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Tanmay Sarkar and Alok Mukherjee contributed equally
Rights and permissions
About this article

Cite this article
Sarkar, T., Mukherjee, A., Chatterjee, K. et al. Edge Detection Aided Geometrical Shape Analysis of Indian Gooseberry (Phyllanthus emblica) for Freshness Classification. Food Anal. Methods 15, 1490–1507 (2022). https://doi.org/10.1007/s12161-021-02206-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12161-021-02206-x