
Abstract
Here, a comprehensive approach, based on chromatographic profiles and chemometric methods, was developed for the simultaneous qualitative and quantitative determinations of goji berry. High-performance liquid chromatography with diode-array detection (HPLC-DAD) was employed to acquire the fingerprints of 67 water extracts of goji berries of different varieties and growing years. The results indicated that the correlation coefficients among the samples of the same varieties and growing years were ˃ 0.900, although they varied from 0.726 to 0.986 among samples of different varieties and growing years. Based on these data, the chemometric analysis was applied. Further, principal component analysis (PCA), hierarchical clustering analysis (HCA), and orthogonal partial least squares discriminant analysis (OPLS-DA) were applied for the discrimination of the varieties and the growing years. Moreover, nine marker compounds were obtained as potential references for goji berries of different growing years and 10 other marker components contributed significantly to the varieties differentiation. Precisely, the goji berries of Ningqi No. 7 (N7) and Ningqi No. 9 (N9) were of higher contents than the other three varieties (Ningqi No. 1 (N1), Ningqi No. 5 (N5), and Zhongke Luchuan (ZKLC)), indicating that N7 and N9 were of higher qualities than the others. Conclusively, the chromatographic fingerprint, combined with chemometric methods, could be employed to differentiate the raw materials of different varieties and growing years. Additionally, it could be employed as a rapid and reliable tool for the quality control (QC) of goji berries.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Goji berry, Lycium barbarum L., is a solanaceous defoliated shrubbery, which is widely distributed in the arid and semiarid regions of Northwestern China. As documented in Chinese Pharmacopoeia, goji berries possess tonic actions, such as invigorating the liver and kidney, alleviating anemia and waist/knee pains, and improving vision, and have been employed as traditional Chinese medicine (TCM) for centuries (Chinese Pharmacopoeia commission 2015). There are about 80 varieties of goji berries (Wang et al. 2018). The most widely cultivated varieties, namely Ningqi No. 1 (N1), Ningqi No. 5 (N5), Ningqi No. 7 (N7), Ningqi No. 9 (N9), and Zhongke Luchuan (ZKLC), are cultivated in Ningxia, Gansu, and Qinghai. Because of its beneficial effects, goji berries account for a large market share in the functional food industry (Lu et al. 2014).
Consequently, increased attention has been paid to the quality assessment of the growing environments and chemical compositions of goji berry to guarantee the efficacy and safety in its utilization in clinical practices (Li et al. 2012; Xie et al. 2010; Zheng et al. 2010). Further, the National Medical Products Administration (NMPA) has also regulated that fingerprinting techniques, such as mass spectrometric and chromatographic fingerprints, combined with chemometric analyses, be utilized for the discrimination of botanical materials of different genotypes, plant parts, or growing environments (Hori et al. 2016; Zhao et al. 2019; Bajoub et al. 2017; Peng et al. 2017; Bertoldi et al. 2019). Based on the efficient and fast separation performance of high-performance liquid chromatography (HPLC) as well as the high sensitivity of mass spectrometry (MS), similarity analysis (SA) was performed to accurately calculate the correlation coefficients of the original data for the classification of the similarities and dissimilarities of the samples and to recognize the common peaks of the chromatographic profiles as quantitative indices (Gao et al. 2016). Principal component analysis (PCA) is an unsupervised pattern recognition technique, which is an essential tool for visualizing the similarities or dissimilarities in multivariate data (Ma et al. 2007; Kim et al. 2015). Hierarchical cluster analysis (HCA) determines the similarities between samples by measuring the distance between all the possible sample pairs in a high-dimensional space, and all the similarities between the samples were represented on two-dimensional diagrams (Lima et al. 2010). Further, the orthogonal partial least squares discriminant analysis (OPLS-DA) model can achieve accurate predictions (Bylesjö et al. 2006; Liu et al. 2018). These chemometric methods, combined with fingerprinting techniques, can afford quantitative calculation markers and enable the classification of the herb sources (Bertoldi et al. 2019; Cheng et al. 2010).
Recently, researchers have committedly applied metabolomics and chemical pattern recognition for the purpose of identification (Hori et al. 2016; Zhao et al. 2019). Lu et al. differentiated the growing environments and cultivars of goji berries, based on the differences between samples (Lu et al. 2014). However, their study was incomplete since they studied only four varieties of goji berries. Moreover, although they successfully differentiated the samples, they could not determine the best with respect to quality. Growing year is an important factor in determining the quality of goji berries, although it has not been studied. Targeted cultivation could require suitable harvest years according to the targeted active components (Jin et al. 2016). Therefore, this work, which is a vital one, is a comprehensive evaluation of the quality of goji berries, combined with those in previous reports. Rapid and effective techniques were employed to achieve the stated goal.
Here, five varieties of goji berries from six different growing years were studied, employing the developed strategy. Their chromatographic profiles were first constructed, employing HPLC. Thereafter, different chemometric methods, including SA, HCA, and PCA combined with OPLS-DA, were adopted to distinguish the samples and select their respective characteristic chemical markers. Additionally, major markers were identified by their spectral characteristics by tandem mass spectrometry (MS/MS). The varieties and growing years of goji berries with high qualities were obtained by analyzing the contents of the major markers. The identification and quality control (QC) of goji berries of different varieties and growth stages were achieved. The results of this study may be a scientific foundation for the authentication of goji berries. Simultaneously, they could avail a new approach for the study of other TCMs.
Materials and Methods
Chemicals and Materials
Acetonitrile (HPLC-grade and MS-grade) was purchased from Beijing MREDA Technology Co., Ltd. (Beijing, China). Glacial acetic acid (analytic grade) was purchased from Tianjin Damao Chemical Reagent Factory (Tianjin, China). Water (MS-grade) and glacial acetic acid (MS-grade) were obtained from Merck (Darmstadt, Germany). Fresh goji berry samples from 5 different varieties and 6 different growth stages were provided by local herbal farmers. The details of samples are shown in Table 1.
Instrumentation
An Agilent HPLC system (Agilent Technologies, America) consisting of a manual injector (G1328B), a column oven (AT-950, Automatic Science,Tianjin, China), a constant flow pump (G1312A), a photodiode array detector (G1315B) and an Agilent Chemstation software workstation, was used. UPLC−MS analysis was performed by an Agilent 1290 UPLC coupled to a quadrupole-time of flight mass spectrometry (6560 Ion Mobility-Q-TOF, Agilent Technologies, America). A KQ-250DE sonicator was used for sonication during sample extraction (Kunshan Ultrasonic Instrument Co., Ltd., China). A XQ100 grinder (Shanghai Guangsha Industry and Trade Co., Ltd., China) and a TDL-5-A centrifuge (Shanghai Anheng Scientific Instrument Factory, China) were used for processing raw samples. An DHG-9140A oven (Shanghai Jinghong Experimental Equipment Co., Ltd., China) was used to dry samples. A Sartorius BSA224S-CW analytical balance (Beijing Sartorius Instrument System Co., Ltd., China) was used to weigh the samples.
Preparation of Goji Berry Water Extracts
Goji water extracts were prepared via an ultrasonic method, as described by Liu et al. (2019). Briefly, the samples were dried, at 60 °C for 4 h, in an oven. Next, the samples were removed and placed in a desiccator to cool to room temperature (22–25 °C). Afterward, the samples were crushed with a grinder and passed through an 80-mesh sieve. A 4.0-g portion of the powder was packed in a 250-mL Erlenmeyer flask and mixed with a 12-fold volume of distilled water (w/v). The mixture was extracted with an ultrasonic instrument, at 60 °C for 30 min. After centrifuging, at 10,000 r/min for 20 min, the solutions were filtered through a 0.45-μm membrane filter for HPLC analysis.
Chromatographic Conditions
Chromatographic separation was performed at ambient temperature (22–25 °C), employing a Sepherisorb ODS C18 column. The mobile phase consisted of water, containing 0.3% glacial acetic acid (A), and acetonitrile (B) in gradient elution, starting from 95 to 75% mobile phase A in 60 min, at a flow rate of 1 mL/min. The injection volume and detection wavelength were 20 μL and 310 nm, respectively.
MS/MS spectra were utilized to identify the compounds in the real samples. Positive- and negative-ion electrospray MS/MS (ESI-MS/MS) analysis was performed, at a scanning range of m/z 100–1,700. The ion-source parameters were optimized and set as follows: ion-spray voltage, 4000 V; drying gas temperature, 350 °C; flow rate, 10 L/min; and nebulizing gas pressure, 35 psi. The sheath gas temperature was 350 °C, and the flow rate was 10 L/min. The data were acquired at a rate of 1 spectrum/s.
Method Validation
Precision
One sample extract (N1) was continuously injected (five times on a single day), according to the chromatographic conditions. The relative retention time (RRT) and relative peak area (RPA) were calculated. The precision, calculated by the marker compounds in the sample, was expressed as a relative standard deviation (RSD, %).
Stability
The sample stability was tested, employing one of the sample extracts (N1) that had been stored, at 20–25 °C, and reanalyzed after 0, 2, 4, 6, 8, and 24 h of storage. The chromatograms were detected and recorded, and RSDs of RRT and RPA were obtained, as a measure of stability.
Repeatability
The repeatability of the extraction procedure and the analysis were determined by repeating the procedure five times. The samples were injected, and the chromatograms were recorded according to the chromatographic conditions.
Data Collection and Chemometric Methods
The correlation coefficients of the entire chromatographic patterns, among all the samples, were calculated, and the simulative mean chromatogram, as well as the characteristic peaks, was generated from the computer-aided similarity-evaluation system (CASES) software, for the chromatographic fingerprint of TCM (China Committee of Pharmacopeia, 2012 version). RPA and RRT of each characteristic peak, against the internal reference peak, were calculated. Further, RPA of each characteristic peak was utilized to perform the chemometric analyses.
Chemometric analysis included the multivariate data analysis, employing unsupervised and supervised models. HCA, PCA, and OPLS-DA were employed, based on the soft independent modeling by class analogy (SIMCA) software (v. 14.1, 2015, Umetrics, Umea, Sweden; www.umetrics.com).
Firstly, HCA was employed to classify the samples, based on the similarities of their chemical properties. The samples were grouped in a high-dimensional space, thus forming a dendrogram. Subsequently, unsupervised PCA was employed to estimate the degree of clustering between several batches of the samples. PCA enabled the transformation of the original variables into new uncorrelated variables (PCs). Similarly, the reduced dimensionality of the data was obtained while simultaneously preserving the information from the original dataset (Lu et al. 2013; Hrbek et al. 2017). PCA afforded a score plot that projected the chemical differences between the chromatograms and also afforded a loading plot that correlated with the degree of variation, found in each variable (Yang et al. 2007). Additionally, OPLS-DA was subsequently applied to differentiate and obtain potential chemical marker compounds among goji berries of different varieties and growing years. The objective of OPLS-DA was to divide the systematic variation, in the X-block, into two model parts; one of which modeled the covariation between X and Y, while the other expressed the X-variation that was unrelated to Y. The parameter, Q2 > 0.5, was admitted for the good predictability of the OPLS-DA models. OPLS-DA was performed to avail a better distribution of the samples and facilitate the creation and validation of a statistical model (Triba et al. 2015; Xu et al. 2017).
Results and Discussion
Validation of the Method
According to the operation methods described in the “Method Validation” section, the precision, stability, and repeatability of the method were assessed by calculating RSDs of RRT and RPA of corresponding peaks. The observed RSDs of RRT and RPA for the characteristic peaks of the repeated injections of the same sample were in the ranges of 0.15–0.71% and 0.38–2.79%, respectively, indicating that the developed analytical method was precise and accurate for the analyses of the samples. RSDs of RRT and RPA for the repeatability test were 0.04–1.53% and 0.97–4.80%, respectively. The results show that the developed method demonstrated satisfactory repeatability. Furthermore, the observed RSDs of RRT and RPA, in the sample stability test, were ˂ 1.62 and 4.50%, respectively. The results suggested that it was feasible to analyze the samples within 24 h. All the results indicated that HPLC was a valid and satisfactory method for fingerprint analyses. Moreover, the method could also be applied, for the quality evaluation of the samples.
Chromatographic Profiles and SA of Goji Berries
Chromatographic Profiles
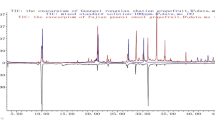
For the QC of the herbs, chromatographic profiles were effectively applied to reveal the chemical information of the botanical products and discriminate the different goji berry samples of different varieties and growing years. Here, we selected the water extraction method of goji berry to generate the chromatographic profiles. Goji berry is a TCM material. Since ancient times, the dosage forms of TCMs were generally as water decoctions without the utilization of harmful organic solvents. The study of water extraction could afford a basis for future clinical research on goji berry. Further, the purpose of this study is to establish a fast and convenient technology for the recognition of the various goji berries. Additionally, we selected water extraction, considering that a simple sample extraction method will result in the increased efficiency of the identification technology. Under optimal conditions, the HPLC profiles of the 67 batches of goji berries of different varieties and growing years in China were obtained. The chromatograms of the samples were inputted into the “Similarity Evaluation System for Chromatographic Fingerprint of TCMs” software (Chinese Pharmacopeia Commission, version 2012.130723) to generate the reference fingerprints of goji berries of different varieties and growing years. The reference fingerprints of N1 and 2 years (Y2) were employed as the reference spectra. The time window width was set to 0.3. The mean fingerprint method was employed to generate the standard chromatograms of the different varieties and growing years. It was found that a total of 33 peaks were displayed in the chromatographic profiles (Fig. 1). It could be concluded, from Fig. 1a, that the fingerprints of the different samples varied significantly. Further, the peak area of No. 24 was largest for the ZKLC sample while the other varieties possessed negligible contents of this ingredient. The peak area of No. 16 is the largest for the N7 sample while the other varieties possessed negligible contents of this ingredient. It can be concluded, from Fig. 1c, that the chromatographic profiles of the samples from different growing years were similar.

HPLC fingerprinting of samples. (a Fingerprint of different varieties; b Standard fingerprint of different varieties; c Fingerprint of different growth years; d Standard fingerprint of different growth years)
These results indicate that the different varieties of goji berries exhibited significant differences in the compositions of their ingredients. Our results verify that the genotype, geographical origin, cultivation conditions, ripeness stage, and storage time and conditions could affect the composition of the herbs. The results also agree with those of a previous report on the composition of goji berries in which the dissimilarity of goji cultivars was investigated, based on the evidence of DNA sequencing and the chemical results of PCA (Kosinska-Cagnazzo et al. 2017). In our study, the composition of the samples from different growing years was consistent because they were of the same variety. However, the relative contents of the ingredients differed slightly, as observed in the peak areas of corresponding peaks. This artificial observation was susceptible to subjective factors, hence, it was necessary to employ objective methods to analyze the obtained fingerprint data.
Additionally, the marker compounds were characterized by their precursor and product ions by MS/MS. When they were scanned in positive mode, the marker compounds produced [M + H]+, while [M − H]− were produced in the negative mode. We analyzed 11 peaks, from the fingerprint chromatograms, in the positive and negative modes. The structural information of each molecular ion, present within the compounds, was obtained by MS/MS. These characterized compounds were matched to the HPLC peaks that were detected within the samples and were numbered by elution order. We also compared RTs, the molecular weight, and the characteristic MS fragment ion data with those in published articles (Benchennouf et al. 2017; Bondia-Pons et al. 2014; Zhang et al. 2018; Zhu et al. 2017; Wang and Tang 2019). The tentative structure of the 11 peaks, in the fingerprint chromatogram, were assigned and presented in Table 2. These peaks, some of them are isomers, were identified as ferulic acid dihexose, n-hydroxyl-l-tyrosine, coumaric acid dihexose, coumaric acid hexose, coumaric acid isomer, n-acetyl-DL-tryptophan, and N,N-caffeoyl dihydrocaffeoyl spermidine dihexaose.
SA of Goji Berry
The software of “Similarity Evaluation System for Chromatographic Fingerprint of TCMs” was employed to calculate the correlation coefficient, by median date. The similarity is a measure of the distance between two samples, which exhibits their relationship: a stronger correlation is observed when the value is closer to 1 (Kim et al. 2015). Tables 3 and 5 show the similarity among the samples of the same varieties and growing years. The similarities were all ˃ 0.900, indicating that the samples exhibited similar HPLC fingerprints. Tables 4 and 6 show the similarity among the samples of different varieties and growing years. The similarities among the samples of different varieties are in the range of 0.726–0.928. There were significant differences between samples of different varieties. The correlation coefficients of the different growing years are in the range of 0.808–0.986, which indicated that the samples exhibited similar HPLC fingerprints, although there were specific differences.
The above results are consistent with our expected results: the similarity among the different samples was significantly different because of the multifactorial parameters. Our results also agree with those of previous ultraperformance liquid chromatography (UPLC)-MS and field ionization MS (FIMS) fingerprint reports on goji berries in which the fingerprints of goji berries of different growing environments and cultivars were significantly different (Lu et al. 2014). It is well-known that the chemical composition of the plants will accumulate and change with the growing years. A study investigated the changes in the phytochemical properties of goji berries and demonstrated that vitamin C, the total phenolic, and total anthocyanin contents varied with the harvest dates (Colak et al. 2019). This may explain why the correlation coefficients of the samples from different growing years, in this study, were different. The SA results indicate that the quality of the sample was unevenly distributed. However, SA was only employed to calculate the correlation coefficient among the samples, and it could not achieve their classification, identification, and quality evaluation. Resultantly, it was necessary to conduct the next analyses.
Multivariate Statistical Analysis
HCA
To classify the different samples, another well-known unsupervised pattern recognition method of data analysis, HCA, was performed. HCA was employed to assign a set of different goji berry samples into clusters (Gao et al. 2016). The peaks of No. 27 (Fig. 1b) and No. 25 (Fig. 1d) exhibited a stable area, good peak shape, and suitable RT. They were selected as the reference peaks, and RPAs of the other peaks were calculated. The corresponding RPA data were imported into the SIMCA 14.1 software to classify the different samples. The results of the cluster dendrograms were calculated, utilizing the hierarchical, and squared Euclidean distances (Fig. 2). Clearly, all the samples were grouped into main clusters, according to their varieties and growing year. Samples of different varieties were grouped into five clusters, including N1, N5, N7, N9, and ZKLC (Fig. 2a). Samples from different growing years were grouped into six clusters, namely Y2, Y4, Y6, Y8, Y10, and Y15 (Fig. 2b).

Dendrogram of the hierarchical clustering of samples. (a different varieties; b different growth years)
These results demonstrate that the metabolites in the samples of different varieties and growing years were substantially different. The cluster analysis revealed that the varieties and growing years exerted a certain influence on the metabolite compositions. One of the purposes of this study was to adequately classify the goji berry samples. As could be observed, the classification trend of the samples, as estimated from the dendrograms, exhibited good clustering in the same samples and substantial discrimination among different samples. Cluster analysis displayed some limitations, such as poor visualization and the inability to screen out the variables that were unrelated to the categorical variables. To further distinguish the samples, the application of other multivariate statistical analyses was necessary.
Principal Component Analysis
PCA is a partitioning process of object sets into disjoint clusters: objects in the same cluster are similar while those of different clusters differ considerably, according to their attributes (Gonzalez et al. 2017). To obtain an overview of the data structure and the distribution, similarities, and differences of the studied samples, the datasets of RPAs were subjected to PCA, employing the SIMCA 14.1 software. The peaks were investigated to determine if they could be utilized in grouping goji berries, based on the different varieties and growing years, and to determine which peaks were the most informative (if the peaks could be utilized) in distinguishing the different varieties. The first three PCs delivered the greatest eigenvalues, and thus contained the chemically relevant variance. Therefore, PC1, PC2, and PC3 were utilized for further analyses. The total variances for the first two factors are 83.15% and 86.36%, for the PCA models of the different varieties and growing years, respectively. The projection of the samples onto the first two PCs demonstrated the distribution of the samples and enabled the analysis of their discrimination (Fig. 3), where good discrimination of the samples was observed. The tested samples were grouped into five clusters, N1, N5, N7, N9, and ZKLC. Further, PCA results revealed that the N9 samples were distinctly different from others (Fig. 3a). Moreover, the samples of different growing years were clustered into six different groups, which corresponded to the different growing years of goji berry (Fig. 3b). The results show that the Y6, Y10, and Y15 samples were distinctly different from others while the variance between the Y2, Y4, and Y8 samples was relatively small.

PCA score plot of samples. (a different varieties; b different growth years)
PCA results suggested that there was a significant chemical difference between the samples, and this is consistent with the results of SA and HCA. PCA clearly separated the samples of different varieties and growing years and also distinguished the different samples adequately, thereby affording an important method for goji berry identification. Like our results, some studies have also identified the varieties and growing environments of goji berries by PCA (Lu et al. 2014; Li et al. 2017). These studies mainly identified goji berries of different origins, although the samples of different varieties and growing years were limitedly involved. The findings in our research, combined with those of previous studies, could avail a comprehensive method, for the identification and quality evaluation of goji berries of different sources.
Additionally, the loading plots, on PC2 versus PC1, are shown in Fig. 4. Each point in the plots represented a characteristic peak. The distance of each peak from the center point indicated the contribution of the variables in the sample composition: the greater the distance from the center point, the greater the contribution to the differences between the samples (Yang et al. 2007). Figure 4a shows that peaks 2, 9, 12, 13, 24, and 26 were the most important components for distinguishing the different goji berry varieties. Contrarily, peaks 26, 29, 32, and 33, mainly contributed to the distinction of goji berries of various growing years (Fig. 4b). Apart from peaks 2 and 13, the remaining chromatographic peaks were detected by MS (Table 2).

PCA loading diagram of samples. (a different varieties; b different growth years)
OPLS-DA
HCA and PCA of the data revealed the clustering of the studied samples better. To clarify the discriminations among the different samples, we performed OPLS-DA. This method is employed to discriminate classes of data and to increase class separation, simplify interpretation, and identify potential biomarkers (Nikles et al. 2017). The OPLS-DA model was established with the score plot, as shown in Fig. 5. R2X, R2Y, and Q2 of the model (Fig. 5a) are 0.952, 0.986, and 0.970, respectively. Further, R2X, R2Y, and Q2 of the model (Fig. 5b) are 0.972, 0.868, and 0.805, respectively. These values indicate the stability and reliability of the OPLS-DA model (Mao et al. 2014). Figure 5 shows that most of the samples could be clearly separated into different groups, corresponding to the different varieties and growing years. Only the Y4 and Y8 samples were similar, although they could still be differentiated. Thus, OPLS-DA exhibited better performance and was more suitable than PCA and HCA, for the discrimination. Moreover, 200 random permutation tests were performed with the established OPLS-DA models to assess its validity (Zhao et al. 2019). R2 and Q2 values were higher in the original OPLS-DA models than in the permuted ones, and the regression line of the permuted Q2-points intersected the vertical axis, below zero (Fig. 6). These results demonstrate both the high goodness of fit and predictability of the established OPLS-DA model.

OPLS-DA score plot. (a different varieties; b different growth years)

Permutation test of OPLS-DA model. (a different varieties; b different growth years)
Here, the OPLS-DA model was established, and we could observe from the score plot that the samples could be clearly separated, thereby validating the results of SA, HCA, and PCA. Since OPLS-DA could screen out the data variations that were not related to the independent and categorical variables, this method demonstrated better performance and was more accurate than PCA and HCA for discrimination. Researchers, such as Jarouche, unsuccessfully employed LC-ESI-MS/MS and chemometrics to identify two varieties of goji berry. They speculated that the genes of the two varieties may be too similar and may require genetic fingerprinting and pharmacological testing for their identification (Jarouche et al. 2019). However, in our research, we successfully classified and identified goji berries of different sources, employing a particularly simple method. Unfortunately, the number of samples utilized here was relatively small because of the limitation of the sampling method. However, this challenge did not affect our conclusion. Based on the results, the sample classification was evident and could have produced the same results, even if we had increased the number of samples.
Moreover, the contribution of each major compound to the discrimination of the samples was calculated and ranked as the variable influence on projection (VIP predictive) values. A VIP predictive value indicates the importance of a variable in terms of explaining the variance in the dataset and the correlations among groups (Chen et al. 2019). The major compounds, exhibiting VIP predictive values ˃ 1.0, were selected as the marker compounds. Finally, 10 marker compounds, consisting of peaks 13, 12, 26, 9, 29, 1, 14, 6, 11, and 19, were obtained to identify the different varieties (Fig. 7a). Further, nine marker compounds, consisting of peaks 29, 32, 12, 26, 13, 9, 33, 6, and 14, were obtained to identify the different growing years (Fig. 7b). Apart from peaks 1, 6, 13, and 19, the remaining chromatographic peaks were identified by MS (Table 2). The OPLS-DA model could clearly and systematically identify five goji berry varieties and six goji berries of different growing years.

VIP predicative plot of each variable with confidence intervals for the VIP values at 95 % level. (a different varieties; b different growth years)
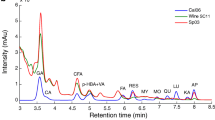
Previous pharmacological studies have revealed that goji berry from different sources exhibited different biological activities, thus creating an urgent demand for its quality evaluation (Kosinska-Cagnazzo et al. 2017; Mocan et al. 2019). To evaluate the quality of the samples, we monitored the dynamic accumulation of nine marker compounds of goji berries from different growing years. We analyzed RPAs of these compounds, as quantitative expressions. (Shi et al. 2018). Figure 8a reveals the distribution of each peak in goji berries of different growing years. Comprehensively, the content of each component exhibited a similar trend, that is, they decreased at first, and increased thereafter. The contents were significantly high in the Y2 and Y15 samples, especially in the Y15 samples. Meanwhile, the content of each component in the Y4, Y6, Y8, and Y10 samples was relatively stable. We could also conclude that the contents of peaks 33, 32, 29, and 26 were the most abundant in the samples of different growing years. These results demonstrate a large difference in the dynamic accumulations of the nine marker components. We also analyzed the 10 marker compounds in goji berries of different varieties (Fig. 8b). The contents of the 10 marker compounds were extremely high in the N7 and N9 varieties, indicating that their qualities were ˃ those of the other three varieties. Simultaneously, the N1 sample also possessed relatively high content. Therefore, we could assess the quality of goji berry through RPA of these characteristic peaks, based on fingerprint analysis.

The distribution of marker compounds. (a different growth years; b different varieties)
QC of herbal materials is rather challenging because of its chemical complexity as well as the fact that a single active substance is not responsible for the overall pharmacological potency. Previously, few researchers quantified the amounts of several or individual chemical markers, which were beneficial to the quality assessment of goji berries, but they were inadequate for discrimination (Jarouche et al. 2019; Sa et al. 2019; Jeszka-Skowron et al. 2018; Capecchi et al. 2015). HPLC fingerprint analysis, combined with pattern recognition analyses, has been demonstrated to obtain information about the overall chemical composition of the samples from different sources and to distinguish them (Bajoub et al. 2017; Bylesjö et al. 2006). Moreover, chemometric methods could also evaluate the samples comprehensively. The various results complemented and validated one another, thus ensuring the accurate classification and identification of the samples and confirming their reliability and authenticity. Chemometric methods, especially PCA and OPLS-DA, which could extract chemical information objectively, have been well-established for classification and discrimination as well as the analyses of the chemical profiles of TCMs. Accordingly, we also established a comparative method of discriminating and evaluating the quality of goji berries from five varieties and six growing years. It is, therefore, necessary to validate this method, by combining it with more comprehensive pharmacological comparisons of samples of different sources, in the future.
Conclusions
The analytical method, developed employing HPLC fingerprint with chemometric methods, which was precise, accurate, and reliable for the quality assessment of goji berry, was successfully applied to identify goji berries of different varieties and growing years. The chemometric analysis, applied in this work, revealed that HCA and PCA could be employed to classify the samples, based on their varieties and growing years. The OPLS-DA model exhibited nearly complete goodness of fit and excellent predictive capability and could adequately discriminate goji berries of five varieties and six growing years. Moreover, nine and ten major compounds were identified as marker compounds, for the discrimination of goji berries of different growing years and varieties, respectively. Some compounds were identified or tentatively identified, based on their RTs, MS spectra, and the available literature, which further characterized chromatographic fingerprint and contributed to the quality evaluation of goji berry. The contents of the marker compounds varied among the samples. The contents were significantly high in the Y2 and Y15 samples, exhibiting a large difference in the dynamic accumulation of the nine marker components. The qualities of N7 and N9 were ˃ those of the other three varieties because of the high contents of the ten marker compounds.
Our results suggest that HPLC fingerprint, combined with chemometric analysis, was validated for potential utilization in differentiating goji berry samples of different varieties and growing years. The results of this study could be a basis for future QC studies of goji berries. Additionally, the generated data could afford valuable insights into the application of HPLC fingerprint, coupled with powerful chemometric analyses, in the QC of goji berries. These approaches will aid the prevention of possible side effects and poor quality, resulting from incorrect identifications. Furthermore, the method employed here could be applied, to achieve comprehensive QC of TCMs and other related products.
References
Bajoub A, Medina-Rodriguez S, Gomez-Romero M, Ajal E, Bagur-Gonzalez MG, Fernandez-Gutierrez A, Carrasco-Pancorbo A (2017) Assessing the varietal origin of extra-virgin olive oil using liquid chromatography fingerprints of phenolic compound, data fusion and chemometrics. Food Chem 215:245–255. https://doi.org/10.1016/j.foodchem.2016.07.140
Benchennouf A, Grigorakis S, Loupassaki S, Kokkalou E (2017) Phytochemical analysis and antioxidant activity of Lycium barbarum (Goji) cultivated in Greece. Pharm Biol 55:596–602. https://doi.org/10.1080/13880209.2016.1265987
Bertoldi D, Cossignani L, Blasi F, Perini M, Barbero A, Pianezze S, Montesano D (2019) Characterisation and geographical traceability of Italian goji berries. Food Chem 275:585–593. https://doi.org/10.1016/j.foodchem.2018.09.098
Bondia-Pons I, Savolainen O, Torronen R, Martinez JA, Poutanen K, Hanhineva K (2014) Metabolic profiling of goji berry extracts for discrimination of geographical origin by non-targeted liquid chromatography coupled to quadrupole time-of-flight mass spectrometry. Food Res Int 63:132–138. https://doi.org/10.1016/j.foodres.2014.01.067
Bylesjö M, Rantalainen M, Cloarec O, Nicholson JK, Holmes E, Trygg J (2006) OPLS discriminant analysis: combining the strengths of PLS-DA and SIMCA classification. J Chemom 20:341–351. https://doi.org/10.1002/cem.1006
Capecchi G, Goti E, Nicolai E, Bergonzi MC, Monnanni R, Bilia AR (2015) Goji Berry: Quality assessment and crop adaptation of plants cultivated in Tuscany (Italy) by combination of carotenoid and DNA analyses. Nat Prod Commun 10:1035–1036
Chen X, Wu QX, Chen ZSZ, Li TT, Zhang ZK, Gao HJ, Yun Z, Jiang YM (2019) Changes in pericarp metabolite profiling of four litchi cultivars during browning. Food Res Int 120:339–351. https://doi.org/10.1016/j.foodres.2019.02.046
ChengXM, Zhao T, Yang T, Wang CH, Bligh SWA , Wang ZT (2010) HPLC fingerprints combinedwith principal component analysis, hierarchical cluster analysis and linear discriminantanalysis for the classification and differentiation of Peganum sp. indigenous to China. Phytochem Anal 21:279–289. https://doi.org/10.1002/pca.1198
Chinese Pharmacopoeia Commission (2015) Pharmacopoeia of the People’s Republic of China: VolI. China Medical Science Press, Beijing, p 249
Colak AM, Okatan V, Polat M, Guclu SF (2019) Different harvest times affect market quality of Lycium barbarum L. berries. Turk J Agric For 43:326–333. https://doi.org/10.3906/tar-1808-17
Gao FY, Xu ZH, Wang WZ, Lu GC, Heyden YV, Zhou TT, Fan GR (2016) A comprehensive strategy using chromatographic profiles combined with chemometric methods: application to quality control of Polygonum cuspidat-um Sieb. et Zucc. J Chromatogr A 1466:67–75. https://doi.org/10.1016/j.chroma.2016.08.050
Gonzalez MD, Lanzelotti PL, Luis CM (2017) Characterization of the polyphenolic fingerprint of origanum × majoricum cambess. from argentina by high-performance liquid chromatography and multivariate analysis. Food Anal Methods 10:3275–3284. https://doi.org/10.1007/s12161-017-0894-2
Hori K, Kiriyama T, Tsumura K (2016) A liquid chromatography time-of-flight mass spectrometry-based metabolomics approach for the discrimination of cocoa beans from different growing regions. Food Anal Methods 9:738–743. https://doi.org/10.1007/s12161-015-0245-0
Hrbek V, Krtkova V, Rubert J, Chmelarova H, Demnerova K, Ovesna J, Hajslova J (2017) Metabolomic strategies based on high-resolution mass spectrometry as a tool for recognition of GMO (MON 89788 variety) and non-GMO soybean: a critical assessment of two complementary methods. Food Anal Methods 10:3723–3737. https://doi.org/10.1007/s12161-017-0929-8
Jarouche M, Suresh H, Hennell J, Sullivan S, Lee S, Singh S, Power D, Xu C, Khoo C (2019) The quality assessment of commercial Lycium berries using LC-ESI-MS/MS and chemometrics. Plants-Basel 8:604. https://doi.org/10.3390/plants8120604
Jeszka-Skowron M, Oszust K, Zgola-Grzeskowiak A, Frac M (2018) Quality assessment of goji fruits, cranberries, and raisins using selected markers. Eur Food Res Technol 244:2159–2168. https://doi.org/10.1007/s00217-018-3125-1
Jin Q, Jiao CY, Sun SW, Song C, Cai YP, Lin Y, Fan HH, Zhu YF (2016) Metabolic analysis of medicinal dendrobium officinale and dendrobium huoshanense during different growth years. PLoS One 11:e0146607. https://doi.org/10.1371/journal.pone.0146607
Kim JH, Seo CS, Kim SS, Shin HK (2015) Quality assessment of Ojeok-San, a traditional herbal formula, using high-performance liquid chromatography combined with chemometric analysis. J Anal Methods Chem:607252. https://doi.org/10.1155/2015/607252
Kosinska-Cagnazzo A, Weber B, Chablais R, Vouillamoz JF, Molnar B, Crovadore J, Lefort F, Andlauer W (2017) Bioactive compound profile and antioxidant activity of fruits from six goji cultivars cultivated in Switzerland. J Berry Res 7:43–59. https://doi.org/10.3233/JBR-160144
Li XT, Li RY, Xiang HE, Zhao ZL, Liu XH (2012) Study on quality evaluation of Lycium chinense from different areas by HPLC fingerprint and cluster analysis. Mod Food. Sci Technol 28:1251–1253. https://doi.org/10.13982/j.mfst.1673-9078.2012.09.002
Li Q, Yu XZ, Xu LR, Gao JM (2017) Novel method for the producing area identification of Zhongning Goji berries by electronic nose. Food Chem 221:1113–1119. https://doi.org/10.1016/j.foodchem.2016.11.049
Lima DC, Dos Santos AMP, Araujo RGO, Scarminio IS, Bruns RE, Ferreira SLC (2010) Principal component analysis and hierarchical cluster analysis for homogeneity evaluation during the preparation of a wheat flour laboratory reference material for inorganic analysis. Microchem J 95:222–226. https://doi.org/10.1016/j.microc.2009.12.003
Liu JD, Chen N, Yang J, Yang B, Ouyang Z, Wu CX, Yuan Y, Wang WH, Chen M (2018) An integrated approach combining HPLC, GC/MS, NIRS, and chemometrics for the geographical discrimination and commercial categorization of saffron. Food Chem 253:284–292. https://doi.org/10.1016/j.foodchem.2018.01.140
Liu XX, Pei D, Liu JF, Gong Y, Wang MH, Di DL, Guo M (2019) The study of HPLC fingerprint and chemical pattern recognition of Lycii fructus. Nat Prod Res Dev 31:1675–1681. https://doi.org/10.16333/j.1001-6880.2019.10.002
Lu JW, Tan YP, Wang G (2013) Discriminative multimanifold analysis for face recognition from a single training sample per person. IEEE Trans Pattern Anal Mach Intell 35:39–51. https://doi.org/10.1109/TPAMI.2012.70
Lu WY, Jiang QQ, Shi HM, Niu YG, Gao BY, Yu LL (2014) Partial least-squares-discriminant analysis differentiating Chinese wolfberries by UPLC−MS and flow injection mass spectrometric (FIMS) fingerprints. J Agric Food Chem 62:9073–9080. https://doi.org/10.1021/jf502156n
Ma HL, Qin MJ, Qi LW, Wu G, Shu P (2007) Improved quality evaluation of Radix Salvia miltiorrhiza through simultaneous quantification of seven major active components by high performance liquid chromatography and principal component analysis. Biomed Chromatogr 21:931–939. https://doi.org/10.1002/bmc.836
Mao Q, Bai M, Xu JD, Kong M, Zhu LY, Zhu H, Wang Q, Li SL (2014) Discrimination of leaves of Panax ginseng and P. Quinquefolius by ultra high performance liquid chromatography quadrupole/time-of-flight mass spectrometry based metabolomics approach. J Pharm Biomed Anal 97:129–140. https://doi.org/10.1016/j.jpba.2014.04.032
Mocan A, Cairone F, Locatelli M, Cacciagrano F, Carradori S, Vodnar DC, Crisan G, Simonetti G, Cesa S (2019) Polyphenols from Lycium barbarum (Goji) fruit european cultivars at different maturation steps: extraction, HPLC-DAD analyses, and biological evaluation. Antioxid 8:562. https://doi.org/10.3390/antiox8110562
Nikles S, Monschein M, Zou HQ, Liu Y, He XJ, Fan DP, Lu AP, Kate Y, Giorgis I, Rudolf B (2017) Metabolic profiling of the traditional Chinese medicine formulation Yu Ping Feng San for the identification of constituents relevant for effects on expression of TNF-α, IFN-γ, IL-1β and IL-4 in U937 cells. J Pharm Biomed Anal 145:219–229. https://doi.org/10.1016/j.jpba.2017.03.049
Peng Q, Xu X, Xing WH, Hu BW, Shen C, Tian RG, Li XM, Xu QX, Chen JY, Chen FR, Zou HJ, Xie GF (2017) Ageing status characterization of Chinese spirit using scent characteristics combined with chemometric analysis. Innovative Food Sci Emerg Technol 44:212–216. https://doi.org/10.1016/j.ifset.2017.04.006
Sa RR, Caldas JD, Santana DD, Lopes MV, Dos Santos WNL, Korn MGA, Santos AD (2019) Multielementar/centesimal composition and determination of bioactive phenolics in dried fruits and capsules containing Goji berries (Lycium barbarum L.). Food Chem 273:15–23. https://doi.org/10.1016/j.foodchem.2018.05.124
Shi CJ, Liu XM, Cheng ZQ, Wang SS, Yuan QH, Liu L, Song Y (2018) Comparation of chemical composition of Cyathula offinalis between different growth years by HPLC characteristic fingerprint combined with chemometrics. Chin Tradit Herbal Drugs 49:5404–5409. https://doi.org/10.7501/j.issn.0253-2670.2018.22.027
Triba MN, Le ML, Amathieu R, Goossens C, Bouchemal N, Nahon P, Rutledge DN, Savarin P (2015) PLS/OPLS models in metabolomics: the impact of permutation of dataset rows on the K-fold cross-validation quality parameters. Mol BioSyst 11:13–19. https://doi.org/10.1039/c4mb00414k
Wang Q, Tang HR (2019) Composition differences of polyphenolic compounds in fruits of Lycium ruthenicum Murr. and Lycium barbarum L. J Shanghai Jiaotong Univ (Med Sci) 39:39–46. https://doi.org/10.3969/j.issn.1674-8115.2019.01.008
Wang HQ, Li JN, Tao WW, Zhang X, Gao XJ, Yong JJ, Zhao JJ, Zhang LM, Li YZ, Duan JA (2018) Lycium ruthenicum studies: molecular biology, phytochemistry and pharmacology. Food Chem 240:759–766. https://doi.org/10.1016/j.foodchem.2017.08.026
Xie Z, Liu W, Huang H, Slavin M, Zhao Y, Whent M, Blackford J, Lutterodt H, Zhou H, Chen P, Wang TTY, Wang S, Yu L (2010) Chemical composition of five commercial Gynostemma pentaphyllum samples and their radical scavenging, antiproliferative, and anti-inflammatory properties. J Agric Food Chem 58:11243–11249. https://doi.org/10.1021/jf1026372
Xu SZ, Yang GJ, Feng F (2017) Investigation of distinction chemical markers for Rhubarb authentication based on high-performance liquid chromatography-time-of-flight mass spectrometry and multivariate statistical analysis. Food Anal Methods 10:3934–3946. https://doi.org/10.1007/s12161-017-0952-9
Yang J, Chen LH, Zhang Q, Lai MX, Wang Q (2007) Quality assessment of Cortex cinnamomi by HPLC chemical fingerprint, principle component analysis and cluster analysis. J Sep Sci 30:1276–1283. https://doi.org/10.1002/jssc.200600389
Zhang G, Chen SS, Zhou W, Meng J, Deng K, Zhou HN, Hu N, Suo YR (2018) Rapid qualitative and quantitative analyses of eighteen phenolic compounds from Lycium ruthenicum Murray by Uplc-Q-Orbitrap MS and their antioxidant activity. Food Chem 269:150–156. https://doi.org/10.1016/j.foodchem.2018.06.132
Zhao Y, Zhao YY, Du Y, Kang JS (2019) Characterization and classification of three common Bambusoideae species in Korea by an HPLC-based analytical platform coupled with multivariate statistical analysis. Ind Crop Prod 130:389–397. https://doi.org/10.1016/j.indcrop.2018.12.096
Zheng G, Zheng Z, Xu X, Hu Z (2010) Variation in fruit sugar composition of Lycium barbarum L. and Lycium chinense Mill. of different regions and varieties. Biochem Syst Ecol 38:275–284. https://doi.org/10.1016/j.bse.2010.01.008
Zhu PF, Dai Z, Wang B, Wei X, Yu HF, Yan ZR, Zhao XD, Liu YP, Luo XD (2017) The anticancer activities phenolic amides from the stem of Lycium barbarum. Nat Prod Bioprospect 7:421–431. https://doi.org/10.1007/s13659-017-0134-x
Acknowledgments
Authors gratefully acknowledge the financial support by the National Science and Technology Major Project (grant number 2018ZX09711001-001-002), the Key Research and Development Program of Gansu Province (grant number 18YF1FA126), the Key Research and Development Program of Ningxia Hui Autonomous Region (grant number 2019BEF02006) and the Major International S&T Cooperation Project from Ministry of Science and Technology of the People’s Republic of China (grant number 2016YFE0129000).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Conceptualization: Duolong Di, Jianteng Wei, and Mei Guo; Material preparation, data collection and analysis: Xuxia Liu, Han Wang, Kaixue Zhang, Jianfei Liu, Maohe Wang, Yuan Gong; Writing original draft preparation: Xuxia Liu; Writing review and editing: Han Wang; Funding acquisition: Duolong Di, Xinyi Huang, and Zhigang Yang; All authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Conflict of Interest
Xuxia Liu declares that she has no conflict of interest. Han Wang declares that she has no conflict of interest. Xinyi Huang declares that he has no conflict of interest. Zhigang Yang declares that he has no conflict of interest. Kaixue Zhang declares that she has no conflict of interest. Jianfei Liu declares that he has no conflict of interest. Maohe Wang declares that he has no conflict of interest. Yuan Gong declares that she have no conflict of interest. Jianteng Wei declares that he has no conflict of interest. Duolong Di declares that he has no conflict of interest. Mei Guo declares that she has no conflict of interest.
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed Consent
Not applicable.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Liu, X., Wang, H., Huang, X. et al. Quality Assessment and Classification of Goji Berry by an HPLC-based Analytical Platform Coupled with Multivariate Statistical Analysis. Food Anal. Methods 13, 2222–2237 (2020). https://doi.org/10.1007/s12161-020-01827-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12161-020-01827-y