
Abstract
Estimation of reservoir parameters (reservoir characterization) including lithology, porosity and water saturation is crucial in the oil and gas industry. These parameters can be calculated in the wells and/or laboratories but these methods are time-consuming, costly, and can cover only a small part of the reservoir. Therefore, integration of seismic and well data for reservoir characterization has received special attention in the oil and gas industry since it provides information from the entire volume of the reservoir. In this study, to establish a relationship between the seismic attributes and the petrophysical parameters of a reservoir at the location of the wells, seismic inversion was performed using model-based, linear programming sparse spike, and maximum likelihood sparse spike algorithms, and the acoustic impedance were calculated accordingly. The model-based inversion method has provided a better answer than the other two methods by providing 99% correlation between the actual and estimated acoustic impedance. Therefore, this method was used to calculate the acoustic impedance in the space between the wells. In the next step, porosity, water saturation, and lithology (quartz and dolomite volume) were estimated from different seismic attributes. In this paper, the multi-attributes regression (MAR) method and artificial neural network (ANN) were used to estimate each of the petrophysical parameters of the reservoir, and we found out that the ANN provided a more accurate estimate than the MAR method for our given dataset. The correlation between the actual and estimated values using the ANN method for porosity, water saturation, quartz volume and dolomite volume is 86, 93, 93 and 95% respectively in the training data and 75, 78, 79 and 82% in the validation data.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
One of the important goals of determining a model for petrophysical parameters (e.g., porosity, saturation, and lithology) within a reservoir is to identify production reservoir zones (Soubotcheva and Stewart 2004). These parameters can be calculated directly in the laboratory from cores or in the wells from well logs. Acquiring well log and core data are expensive processes and can calculate reservoir properties only along the well path, and at some given intervals (Das et al. 2017). Seismic reservoir characterization is the recommended technique to address these issues by including all available information (e.g., well logging, seismic, core and geological data) to produce a full mage of the subsurface reservoir (Serajamani et al. 2021). It integrates well logging data which has a good vertical resolution with seismic data with an acceptable horizontal resolution (Oldenburg et al. 1983). Therefore, a better reservoir model can be achieved even with a limited number of wells which is the scenario for the reservoirs in the pre-development phase (Brown 2001; Taner 2001). This makes seismic reservoir characterization as an optimal tool to understand reservoir properties such as thickness, net-to-gross ratio, porosity, saturation, and lithology (Chopra and Marfurt 2006).
There are many studies that used seismic reservoir characterization for reservoir property estimation. Oldenburg et al. (1983) recovered acoustic impedance from reflection seismic data to estimate petrophysical parameters. Doyen (1988) estimated reservoir porosity from seismic attributes using geostatistical algorithms. Kalkomey (1997) and Schuelke et al. (1997) estimated porosity from seismic attributes. Chen and Sideny (1997) used seismic attributes for reservoir monitoring. Hampson et al. (2001), Russell (2004) and Leite and Vidal (2011) estimated reservoir porosity from seismic attributes. The results of their studies have introduced artificial neural network (ANN) method as a fast, accurate and cost-effective tool for porosity estimation. Jalalalhosseini et al. (2014) estimated porosity by combining well and seismic data. Na’imi et al. (2014) and Viveros and Parra (2014) estimated petrophysical parameters of a reservoir from well logging and seismic data using intelligent algorithms. Zahmatkesh et al. (2017) estimated reservoir lithology and porosity using seismic data inversion. Das and Chatterjee (2016) and Gogoi and Chaterjee (2019) estimated petrophysical parameters using different seismic characterization methods. Saadu and Nwankwo (2018) determined reservoir quality using well and seismic data. Leisi and Falahat (2021) investigated and compared the conventional methods of porosity estimation using seismic data and introduced the probabilistic neural network method as a better method for porosity estimation.
In this case study, first we will compare the acoustic impedance results at well locations using three different inversion algorithms: model-based, linear programming sparse spike, and maximum likelihood sparse spike algorithm within a sandstone reservoir. Then, the efficiency of each method is examined using the correlation between the actual and estimated acoustic impedance in the wells. We will use the method with the least error as the optimal algorithm for calculating acoustic impedance in the entire reservoir. Furthermore, the acoustic impedance results (from the chosen algorithm) are converted to porosity, water saturation and the lithology using multi-attributes regression (MAR) and artificial neural network (ANN) methods. The amount of error and correlation between the actual (well logs) and estimated values in both methods are investigated and the method that has the highest correlation and the lowest error is introduced as the optimal method for converting acoustic impedance to the reservoir properties in the studied sandstone reservoir.
Geological background
Our dataset comes from one of the Persian Gulf sandstone oil reservoirs. This offshore field is in the northwest of the Persian Gulf and located inside the Dezful embayment (Fig. 1). Geologically, the studied field is an anticline with a north-south structural trend. This anticline is located in the depressed part of the folded Zagros zone and is considered a part of Abadan plain. The structure of this field is influenced by two fault systems: One from the Arabian plate with a north-south trend and the other is from the Zagros folding system with a northwest-southeast trend. In this field, the older sediments are oriented in the north northwest-south/southeast direction, but the younger formations, including Asmari and Ghar, are more oriented in the northwest-southeast direction. In this field, there are four reservoirs that produce hydrocarbons: Nahar Omar, Sarvak, Asmari and Ghar (Soleimani et al. 2013). Ghar sandstone reservoir is the focus for this study. It is mainly composed of quartz sandstones with dolomite cement along with thin layers of sandy dolomites. The Ghar formation in this field can be divided into three zones in terms of reservoir quality, and these zones are separated by shale layers (Leisi et al. 2022). In this reservoir, presence of porous sand layers has provided suitable conditions for hydrocarbon accumulation. The source and cap rock of the Ghar reservoir are the Kazdumi and the Gachsaran Formations, respectively (Fig. 2).

The studied field location in this work (Abdolahi et al. 2022)

The stratigraphy of the studied field in this paper (Abdolahi et al. 2022)
Database and methods
Our dataset includes three wells with a full suite of well logging data such as density, compressional wave velocity, porosity, water saturation, quartz volume, and dolomite volume (Fig. 3).

Log data used in this study. From left to right: velocity, density, porosity, quartz volume, dolomite volume, and saturation log
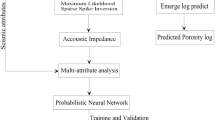
All the wells have checkshot information. The dataset also includes: a 3D post stack seismic cube, interpreted horizons, and well tops. To estimate petrophysical parameters (porosity, water saturation, quartz, and dolomite volume) of our reservoir using integration between wells and seismic data, the following steps have been taken (Fig. 4):
-
First, we corrected the time to depth relationship using checkshot data.
-
Then, a statistical method is implemented to extract the wavelet to generate synthetic seismogram (at each well) to achieve the highest cross-correlation with the seismic traces.
-
We proceed with inverting our seismic cube to the acoustic impedance cube using model based, linear programming sparse spike, and maximum likelihood sparse spike algorithm. In the model-based inversion algorithm, first, the low-frequency model must be built. This low frequency information comes from well log data to build the initial model. This initial model, furthermore, is used as the starting point for the comparison between synthetic and seismic traces. This model will be updated to achieve the best match with the seismic data. This method is sensitive to the constructed initial model and seismic wavelet. In the sparse spike inversion method, the reflection coefficients series are calculated from the seismic trace, and the goal is to fully reconstruct the frequency bandwidth. In this method, it is assumed that there is no noise in the acquisition of seismic data. Unlike the model-based method, the sparse spike method is less sensitive to the wavelet and the initial model. The sparse spike inversion method is divided into two algorithms: linear programming sparse spike and maximum likelihood sparse spike. These two algorithms are not physically different from each other and only differ from each other in terms of the number of adjustable parameters. In this inversion algorithms, first, a composite trace is extracted from seismic data near the well locations to invert for P-impedance. This inverted P-impedance at the well locations are then compared with the original impedances calculated from the well data (Serajamani et al. 2021). The inversion parameters are optimized until we achieve an acceptable match between both P-impedances, and the best algorithm is selected accordingly. In the end, the inversion parameters of the selected algorithm is extended to invert the entire 3D seismic volume into P-impedance cube (Das et al. 2017).
-
Finally, porosity, water saturation and lithology (quartz and dolomite volume) are estimated using multi- attribute regression method and artificial neural network from the P-impedance cube. Here, the optimal number of seismic attributes for estimation are determined using the cross-validation method (Russell et al. 2003). In the cross-validation method, the amount of validation error at the point where it reaches its lowest value gives the optimal number of attributes for estimating these reservoir properties. In addition to determining the optimal number of attributes, the operator length was also determined. This parameter is used to eliminate the frequency difference between well and seismic data (Russell 2004). After the optimal number of attributes and the operator length are selected, each of the petrophysical parameters of the reservoir are estimated using different seismic attributes. We used multi-attributes regression and artificial neural network to calculate these reservoir properties.
The multi- attributes regression (MAR) method works like the multivariate regression method. In this method, the output parameter (target) is estimated from seismic attributes as input. In the artificial neural networks (ANN), a set of data is given to the network as input and output, and the network is trained and adjusts the input and output weights in such a way that it estimates the output if new inputs are given. Therefore, an artificial neural network consists of an arbitrary number of computational units (neuron) located in the layer(s) that connect the input to the target and specify a nonlinear relationship between them. One of the reasons for using artificial neural networks is that they have a higher ability than other methods in estimating non-linear and complex relationships between input and output parameters. Therefore, to achieve this goal, sufficient data must be available to train the network so that the network can optimally adjust the weights of the inputs. In both methods, first the relationship between each of the petrophysical parameters and seismic attributes at the wells is determined and then the distribution of each of the parameters in the space between the wells (the entire reservoir area) is calculated. In the end, we selected the best method and used it to invert the cube of P-impedance into reservoir properties.

The applied flowchart for integrating well logs and seismic data
Results and discussion
We applied the given workflow on our reservoir to calculate its petrophysical parameters including porosity, water saturation and lithology (quartz and dolomite volume). We used all three wells in our dataset to train the algorithms. Then, their results are validated by ignoring the data of one well and estimating the same properties using other wells. This procedure is repeated for all three wells. Finally, the overall correlation (between true and predicted values) is calculated. Validation of each method is done to avoid overfitting. The results are given as following:
Seismic inversion results
Seismic inversion was performed using three different algorithms: model-based, linear programming sparse spike, and maximum likelihood sparse spike algorithm. We applied these three algorithms on our dataset and the results are presented in Table 1. Note that the reported values in Table 1 represent the average error and correlation in all wells (3 wells).
According to Table 1, the model-based inversion method has provided better results than other seismic inversion methods. In Fig. 5 the correlation between the actual and estimated acoustic impedance using the model-based seismic inversion method at the location of each well is shown. Also, in Fig. 6, the correlation between synthetic and composite seismogram at the location of Well 3 is shown. The cross plot between the actual and estimated acoustic impedance using the model based seismic inversion method is shown in Fig. 7. According to Fig. 7, there is a good correlation between the actual and estimated values.

Correlation between actual and estimated acoustic impedance using the model-based inversion method at each well location

The correlation between synthetic and composite seismogram at the location of Well 3 using model-based inversion algorithm

The Cross plot between actual and estimated acoustic impedance using model-based inversion algorithm
By examining and comparing the results of each of the seismic inversion methods, we observed that the model-based inversion method provided a better answer than other methods. Because the correlation between the actual and estimated acoustic impedance in this method is higher than the other two methods and has less error. Therefore, this method has been used to calculate the acoustic impedance in the space between the wells (the entire area of the reservoir). Figure 8 shows the acoustic impedance section obtained by the model-based inversion method.

The acoustic impedance section using the model-based inversion method
Porosity estimation results
After seismic inversion and acoustic impedance calculation, the petrophysical parameters of the reservoir were estimated from seismic attributes. The first estimated parameter in this paper is porosity. We tested multi-attributes regression (MAR) and artificial neural network (ANN) for calculating porosity. In both methods, three seismic attributes were used to estimate porosity (Table 2). These attributes have been selected using the cross-validation method, and the reason for selecting these attributes is that they have the least error and the most correlation with porosity. Table 3 shows the correlation and error of each of the used methods to estimate porosity.
According to Table 3, the ANN method has provided a better answer than the MAR method as the correlation (between actual and estimated values) of this method is higher in both training and validation data with less error. Therefore, we used ANN to convert acoustic impedance to porosity. Figures 9 and 10, and Fig. 11 display the correlation between the real and estimated porosity in the training and validation data, the comparison between real and estimated porosity logs, and a section of the estimated porosity using ANN, respectively.

Correlation between actual and estimated porosity in the training and validation data using ANN method

Comparison between the actual and estimated porosity logs using ANN method

Porosity section calculated using ANN method
Water saturation estimation results
Water saturation is the second reservoir parameter which was estimated from the acoustic impedance cube. We used MAR and ANN methods for calculating water saturation and compared their results. Here, three seismic attributes have been used in both methods to estimate water saturation (Table 4). After choosing the optimal attributes for estimation, water saturation was estimated using MAR and ANN. Table 5 shows the correlation and error (between actual and predicted values) of these two methods.
We observe that ANN method provides a more accurate estimate of water saturation compared with MAR. Figures 12 and 13, and Fig. 14 display the correlation between the real and estimated water saturation in the training and validation data, the comparison of real and estimated water saturation logs, and a section of water saturation obtained using ANN, respectively.

Correlation between the actual and estimated water saturation in training and validation data using ANN method

Comparison of the actual and estimated water saturation logs using ANN method

Water saturation section obtained using ANN method
Lithology estimation results (quartz and dolomite volume)
The last estimated reservoir parameter in this study is reservoir lithology (quartz and dolomite volume). The used methods to estimate each of the petrophysical parameters in this paper are the same, but different attributes have been used to estimate their parameters (the attributes that are most related to the target parameter). Considering that the studied reservoir is mainly composed of quartz sandstones with dolomite cement along with thin layers of sandy dolomites, therefore, in this article, the volume of quartz and dolomite has been estimated. Table 6 shows the list of selected attributes for estimating the volume of quartz and dolomite. Table 7 presents the results of each of the used methods to estimate the volume of quartz and dolomite.
We again observe that ANN has provided a more accurate estimate for both quartz and dolomite volume compared with MAR. Figures 15 and 16 display the correlation between actual and estimated values in training and validation data for quartz and dolomite volumes, respectively. Figures 17 and 18 show the comparison between actual and estimated logs for quartz and dolomite volumes, respectively. Figures 19 and 20 display the obtained section by ANN method for the volumes of quartz and dolomite, respectively.

Correlation between the actual and estimated quartz volume in training and validation data using ANN method

Correlation between the actual and estimated dolomite volume in the training and validation data using ANN method

Comparison of the actual and estimated quartz volume logs using ANN method

Comparison of the actual and estimated dolomite volume logs using ANN method

Quartz volume section obtained using ANN method

Dolomite volume section obtained using ANN method
In this study, as an effective tool for hydrocarbon field exploration and development, modelling of reservoir properties such as porosity, saturation, and lithology has been carried out to characterize their spatial distribution pattern. Our results confirm that Ghar 3 has good reservoir potential (high porosity and low water saturation) and can be considered as one of the good candidates for further field development in this area. The average maps (slice) of porosity, water saturation, and quartz and dolomite volume in the studied reservoir are shown in Figs. 21 and 22. It shows the distribution of each parameter in the reservoir.

The average map (slice) of: (A) porosity, and (B) water saturation in the studied reservoir

The average map (slice) of: (A) Quartz volume, and (B) Dolomite volume in the studied reservoir
Conclusion
In this paper, petrophysical parameters of a sandstone reservoir (porosity, water saturation, quartz volume and dolomite volume) were estimated from seismic attributes using multi-attributes regression and artificial neural network. To achieve this goal, in the first step, seismic inversion was performed using model-based, linear programming sparse spike, and maximum likelihood sparse spike algorithm to calculate the acoustic impedances. Then, the optimal inversion algorithm was chosen using the correlation and error between the real and estimated acoustic impedance at the well locations. We observed that the model-based inversion algorithm (99% correlation and 13% error) provides better results in our studied reservoir compared with the other two methods. Then, porosity, water saturation, quartz volume and dolomite volume are estimated from different seismic attributes including the inverted P-impedance cube. For this purpose, the multi-attributes regression method and artificial neural network were used. We observed that the artificial neural network method provided more accurate estimation compared with the multi-attributes regression method. The correlation between the actual and estimated values in the ANN method for porosity, water saturation, quartz volume and dolomite volume are 86, 93, 93 and 95%, respectively in the training data and are 75, 78, 79 and 82% in the validation data. In addition to correlation, the error of the ANN is lower than the MAR method. The reason that the ANN has provided a better answer than the MAR method is linked to the fact that neural networks have a high ability to estimate nonlinear and complex relationships between the input and the target parameters. We found out that the model-based inversion algorithm combined with the artificial neural network method is an optimal workflow to estimate petrophysical properties in reservoirs with similar geology to our dataset. Our results also show that the studied reservoir is mainly composed of quartz and dolomite and in the porous zones, the volume of quartz become more than the dolomite and hydrocarbon presence increases.
Data availability
If you need the used data in this article or the methods of use, contact Ahsan Leisi, who is the responsible author for this article.
References
Abdolahi A, Chehrazi A, Kadkhodaie A, Amir Abbas Babasafari (2022) Seismic inversion as a reliable technique to anticipating of porosity and facies delineation, a case study on Asmari formation in Hendijan field, southwest part of Iran. J Petroleum Explor Prod Technol 12:3091–3104. https://doi.org/10.1007/s13202-022-01497-y
Brown AR (2001) Understanding seismic attributes. Geophysics 66(1):47–48
Chen Q, Sideny S (1997) Seismic attribute technology for reservoir forecasting and monitoring. The Leading Edge
Chopra S, Marfurt K (2006) Seismic attributes- A promising aid for geologic prediction. CSEG Recorder 31(5):110–120
Das B, Chatterjee R (2016) Porosity mapping from inversion of post-stack seismic data. Georesursy 18(4):306–313. https://doi.org/10.18599/grs.18.4.8
Das B, Chaterjee R, Singha Dk, Kumar R (2017) Post-stack seismic inversion and attribute analysis in shallow offshore of Krishna-Godavari basin, India. J Geol Soc India 90(1):32–40
Doyen PM (1988) Porosity from seismic data: a geostatistical approach. Geophusics 53(10)
Gogoi T, Chaterjee R (2019) Estimation of petrophysical parameters using seismic inversion and neural network modeling in Upper Assam basin, India. Geosci Front 10:1113–1124. https://doi.org/10.1016/j.gsf.2018.07.002
Hampson DP, Schuelke JS, Quirein JA (2001) Use of multiattribute transforms to predict log properties from seismic data. Geophysics 66(1):220–236
Jalalalhosseini SM, Ali H, Mostafazadeh M (2014) Predicting porosity by using seismic multi-attributes and well data and combining these available data by geostatistical methods in a South Iranian oil field. Petroleum Sci Tech 32(1):29?37. https://doi.org/10.1080/10916466.2011.584102
Kalkomey CT (1997) Potential risks when using seismic attributes as predictors of reservoir properties. The Leading Edge
Leisi A, Falahat R (2021) Investigation of some porosity estimation methods using Seismic Data in one of the South Iranian Oil Fields. Petroleum Res 31(119):22–25. https://doi.org/10.22078/pr.2021.4438.3007
Leisi A, Kheirollahi H, Shadmanaman N (2022) Investigation and comparison of conventional methods for estimating shear wave velocity from well logging data in one of the sandstone reservoirs in southern Iran. Iran Gournal Geophys. https://doi.org/10.30499/IJG.2022.320098.1385
Leite EP, Vidal AC (2011) 3D porosity prediction from seismic inversion and neural networks Emilson. Comput Geosci J 37:1174–1180. https://doi.org/10.1016/j.cageo.2010.08.001
Na’imi S, Shadizadeh S, Riahi MA, Mirzakhanian M (2014) Estimation of reservoir porosity and water saturation based on seismic attributes using support vector regression approach. J Appl Geophys 107:93–101. https://doi.org/10.1016/j.jappgeo.2014.05.011
Oldenburg DW, Scheuer ST, Levy S (1983) Recovery of the acoustic impedance from reflection seismograms. Geophysics 48(10):1318–1337
Russell B (2004) The application of multivariate statistics and neural networks to the prediction of reservoir parameters using seismic attributes. Ph.D. Dissertation. University of Calgary, Alberta
Russell B, Hampson D, Lines L (2003) Application of the radial basis function neural network to the prediction of log properties from seismic attributes. ASEG Ext Abstracts. https://doi.org/10.1071/ASEG2003ab151
Saadu YK, Nwankwo CN (2018) Petrophysical evaluation and volumetric estimation within Central swamp depobelt, Niger Delta, using 3-D seismic and well logs. Egyptian J Petroleum 27:531–539. https://doi.org/10.1016/j.ejpe.2017.08.004
Schuelke JS (1997) Reservoir architecture and porosity distribution, Pegasus Field, West Texas -- an integrated sequence stratigraphic–seismic attribute study using neural networks. INT 5.2
Serajamani M, Nikrouz R, Kadkhodaie A (2021) Estimation of Acoustic Impedance of the tight Sandstones using seismic inversion methods: a Case Study from Whicher-Range Gas Field in the Perth Basin, Australia. Petroleum Res 30(115):17–19. https://doi.org/10.22078/pr.2020.4018.2829
Soleimani B, Bahadori A, Meng F (2013) Microbiostratigraphy, microfacies and sequence stratigraphy of upper cretaceous and paleogene sediments, Hendijan oilfield, Northwest of Persian Gulf, Iran. Nat Sci 5(11):1165–1176
Soubotchev N, Stewart RR (2004) Predicting porosity logs from seismic attributes using geostatistics. CREWES Research Report 16
Taner TM (2001) Seismic attributes. CSEG Recorder 26(7):49–56
Viveros U, Parra JO (2014) Artificial neural networks applied to estimate permeability, porosity and intrinsic attenuation using seismic attributes and well-log data. J Appl Geophys 107:45–54. https://doi.org/10.1016/j.jappgeo.2014.05.010
Zahmatkesh I, Kadkhodaie A, Soleimani B, Golalzadeh A, Azarpour M (2017) Estimating vsand and reservoir property from seismic attributes and acoustic impedance inversion: a case study from the Mansuri oilfield, SW Iran. J Petrol Sci Eng. https://doi.org/10.1016/j.petrol.2017.11.060
Funding
No funding was obtained for this study.
Signed by all authors as follows:
Ahsan Leisi.
Mohammad Reza Saberi.
Author information
Authors and Affiliations
Contributions
Both authors have played a significant role in preparing the article. Ahsan Leisi has done modeling and simulation, and Mohammad Reza Saberi has interpreted the results.
Corresponding author
Ethics declarations
Competing interests
This research was carried out according to the agreement of the authors and did not have any financial support or financial competition.
Additional information
Communicated by H. Babaie
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Leisi, A., Saberi, M.R. Petrophysical parameters estimation of a reservoir using integration of wells and seismic data: a sandstone case study. Earth Sci Inform 16, 637–652 (2023). https://doi.org/10.1007/s12145-022-00902-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-022-00902-8