
Abstract
Introduction
Immunotherapy is a new promising treatment for patients with advanced hepatocellular carcinoma (HCC), but is costly and potentially associated with considerable side effects. This study aimed to evaluate the role of machine learning (ML) models in predicting the 1-year cancer-related mortality in advanced HCC patients treated with immunotherapy.
Method
395 HCC patients who had received immunotherapy (including nivolumab, pembrolizumab or ipilimumab) between 2014 and 2019 in Hong Kong were included. The whole data sets were randomly divided into training (n = 316) and internal validation (n = 79) set. The data set, including 47 clinical variables, was used to construct six different ML models in predicting the risk of 1-year mortality. The performances of ML models were measured by the area under receiver operating characteristic curve (AUC) and their performances were compared with C-Reactive protein and Alpha Fetoprotein in ImmunoTherapY score (CRAFITY) and albumin–bilirubin (ALBI) score. The ML models were further validated with an external cohort between 2020 and 2021.
Results
The 1-year cancer-related mortality was 51.1%. Of the six ML models, the random forest (RF) has the highest AUC of 0.92 (95% CI 0.87–0.98), which was better than logistic regression (0.82, p = 0.01) as well as the CRAFITY (0.68, p < 0.01) and ALBI score (0.84, p = 0.04). RF had the lowest false positive (2.0%) and false negative rate (5.2%), and performed better than CRAFITY score in the external validation cohort (0.91 vs 0.66, p < 0.01). High baseline AFP, bilirubin and alkaline phosphatase were three common risk factors identified by all ML models.
Conclusion
ML models could predict 1-year cancer-related mortality in HCC patients treated with immunotherapy, which may help to select patients who would benefit from this treatment.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Hepatocellular carcinoma (HCC) accounts for more than 800,000 deaths and 20 million disability-adjusted life years globally in 2017 [1]. For advanced HCC that are not feasible for surgical resection, treatment options are limited. Although the tyrosine kinase inhibitors, such as sorafenib and regorafenib, have been shown to prolong the survival in advanced HCC patients [2], not all patients responded to these treatments. Recent advances in immunotherapy have provided new therapeutic option for patients with advanced HCC [3,4,5]. As yet, immunotherapies are expensive and are associated with considerable side effects [6], it would be highly useful if there is a clinical tool to identify patients who would most benefit from these new treatments.
Artificial intelligence and machine learning (ML) algorithm are increasingly recognized to be highly accurate in the analysis of complex clinical factors, which could help to guide clinical treatment algorithm. It has already been shown that ML models could apply in many clinical decision-making processes, such as prediction of cardiovascular risk [7], sepsis [8], papilloedema [9], cancer risk [10] and colonic lesion histology [11], etc. Recently, we have shown that the use of ML model could help to determine individual’s risk of gastric cancer development after H. pylori eradication [12]. Machine learning has also been applied in the diagnosis and prediction of prognosis of liver disease including non-alcoholic liver disease [13,14,15], viral hepatitis [16,17,18], primary sclerosing cholangitis [19, 20] as well as hepatocellular carcinoma [20, 21] with good accuracy and stability.
The current study aimed to study the role of various available ML models in the prediction of 1-year cancer-related mortality in patients with advanced HCC receiving immunotherapy with comparison to conventional logistic regression as well as two well-known scoring systems for HCC prognosis namely the C-reactive protein and Alpha Fetoprotein in ImmunoTherapY score (CRAFITY) and the albumin–bilirubin (ALBI) score. [22,23,24]
Methods
Data source
All data were retrieved from the Clinical Data Analysis and Reporting System (CDARS), which is a territory-wide electronic health care database of the Hong Kong hospital authority used for clinical research and audit. The hospital authority is wholly funded by the Hong Kong Government and is the only public healthcare provider for the local population of 7.5 million. It manages over 85% of all hospital beds and more than 7.5 million outpatient specialist consultation per year. Important clinical data including patient’s demographics, diagnosis, medication prescription and dispensing records, laboratory results and patient outcome were captured by the CDARS. These data were all anonymized in the CDARS to protect patient’s confidentially. The International Classification of Diseases, Ninth Revision (ICD-9), is used for disease coding. The CDARS database had been used in a number of population-based studies [25,26,27,28,29,30]. This study protocol was approved by the Institutional Review Board of the University of Hong Kong and the West Cluster of the Hong Kong Hospital Authority (reference no: UW 20-778). This study was reported according to transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD statement; Supplementary Table 1) as well as the MI-CLAIM criteria with the checklist of compliance provided in Supplementary Table 2.
Patients
We identified all adult patients (aged 18 or above) with advanced HCC who had received immunotherapy between January 2014 and December 2019. HCC was identified by the ICD-9 diagnosis code of 155.0. Three immunotherapies were included in this study including nivolumab, pembrolizumab or ipilimumab. As immunotherapy has been recently approved by the Food and Drug Administration of the United States to be used in HCC only [31, 32], the use of the immunotherapy in these patients was mainly as off-label last treatment option for patients with advanced disease during the study period.
Patients were randomly divided into training set and internal validation set. There was a total of 48 clinical variables including baseline characteristics, age of receiving immunotherapy, type of immunotherapy, history of prior treatment (e.g., hepatectomy, transcatheter arterial chemoembolization, local ablative therapies including radiofrequency ablation and ethanol injection), use of tyrosine kinase inhibitors ([TKIs] sorafenib or lenvatinib), underlying liver diseases (chronic hepatitis B [HBV], chronic hepatitis C [HCV], alcoholic liver disease), comorbidities (diabetes mellitus [DM], hypertension [HT], ischemic heart disease [IHD], atrial fibrillation [AF], congestive heart failure [CHF], stroke and infection) and concomitant medication uses. Infection before or after the commencement of the first ICI was defined by ICD-9 coding including the following infectious disease codes (001–139, 320–321, 460–466, 470–478, 480–488, 540–543, 566, 567, 575.0, 576.1, 590, 595, 680–686). Laboratory parameters included alpha fetoprotein (AFP), bilirubin, alkaline phosphatase (ALP), alanine aminotransferase (ALT), aspartate aminotransferase (AST), albumin, globulin, international normalized ratio (INR), platelet count, serum creatinine, sodium (Na) and C-reactive protein (CRP). The CRP and AFP in ImmunoTherapY score (CRAFITY) and the albumin–bilirubin (ALBI) score were determined and compared with the performance of various ML models. The severity of liver disease was determined by the Child–Pugh Score (CPS).
The primary endpoint was the cancer-related mortality (with liver cancer specified as the cause of death) within 1 year after immunotherapy. Another endpoint was all-cause mortality, which was used to assess the effect of inclusion of non-cancer-related death on the outcome for the ML models.
Concurrent use of medications (including aspirin, statins, H2 receptor antagonist, proton pump inhibitors [PPIs] and antibiotics) was defined as any use within a period of 30 days before or after the commencement of the first ICI. Regarding antibiotics, it included a total of eleven classes of antibiotics, namely penicillin, cephalosporins, macrolides, carbapenems, quinolones, tetracyclines, aminoglycosides, nitroimidazoles, glycopeptides, sulpha/trimethoprim, and others (nitrofurantoin, rifampicin, and rifaximin). None of these patients received monobactams, clindamycin, linezolid, and daptomycin.
Construction of training models using different machine learning models
For all subjects in the database, case was defined as cancer-related death within 1 year. Control was defined as no cancer-related death within 1 year. A total of six common supervised type of ML algorithms including logistic regression (LR), the least absolute shrinkage and selection operator (LASSO) [33, 34], the extreme gradient boosting (XGBoost) [35], the random forest (RF) [36], stochastic gradient boosting (GBM) [37] and the sparse neural network (NN) [38] were included in the analysis. For the LR, it was characterized by applying a non-linear log transformation to the odds ratio with regression’s range bound between 0 and 1. The LASSO is a type of linear regression performed regularization, shrinkage and variable selection by penalizing for the sum of absolute values of the weight and the absolute values of weight can be reduced up to zero [33, 34]. The RF classifier consisted of a large number of uncorrelated decision tree and the prediction was the prediction of the majority. The error was minimized in RF since a large of tree can cover individual error of a particular tree [36]. The XGBoost was a type of Boosting algorithm via regularized learning objective, gradient tree boosting as well as shrinkage and column subsampling to control overfitting [35]. The GBM constructed additive regression models by sequentially fitting a simple parameterized function to current “pseudo”-residuals by least squares with each training step [37]. A sNNR was a type of neural network with minimizing the square error subject to a penalty on the L1-norm [38] (Supplementary Table 3).
The traditional logistic regression was used as the reference in this study. Missing value plot was used to visualize for any missing data, and all data were manually checked to ensure that there were no missing data in the database. Feature variables were chosen by forward and backward stepwise selection in the training set of the logistic regression. Pair-wise correlations were plotted in the correlation matrix to ensure minimal auto-correlation among the feature variables chosen. The selected variables and outcome were fit into a logistic regression model, and the regression prediction model of the 1-year cancer-related mortality was trained. The accuracy in terms of discriminating power was assessed by an independent validation set via the area under the receiver operating curve (AUC). Variable importance analysis was done using “filter” approach. A loess smoother was fit with the outcome and each variable. The R2 statistic was calculated for each model against the intercept only null model. Relative percentage of R2 statistic for each variable was returned as a relative measure of variable importance for that particular variable in a given model. Shapley value was calculated to assess the effect of individual significant feature on the machine learning model.
Ten-fold cross-internal validation was used to choose the best prediction model for algorithm that required tuning (NN, RF, GBM and XGBoost). The training data were randomly divided into 10 subsets: nine were used for training the machine learning model and the remaining one was used for internal validation. This procedure was repeated 10 times with different validation subsets. The best model in each algorithm with the best parameters tuned was subsequently validated by the external validation set.
Comparison of different machine learning models and clinical score
The AUC of different models and clinical scores were compared using Delong’s test and the best cutoff point for each model was estimated by Youden’s method to calculate the sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), positive likelihood ratio (PLR) and negative likelihood ratio (NLR) for each model. Multiple comparisons were adjusted by Bonferroni correction.
Time-to-event XGBoost survival model
The training set was also input into XGBoost survival model with time-to-event analysis. The concordance index and Brier score were calculated to compare the prediction of time to event under the trained XGBoost survival model with the ground truth of the validation set.
Application of machine learning models and clinical scores to external validation cohort
To further validate the trained ML models, another external validation cohort of HCC patients who were treated with immunotherapy between January 2020 and March 2021 was retrieved from the electronic patient record (ePR) systems of the Queen Mary Hospital. The ePR system is a comprehensive patient data system used for daily clinical management of patient, which includes patient’s demographics, current and past diagnoses, admission and consultation, procedures, imaging and laboratory test results, current and past medication, smoking and drinking habit, etc.
Different ML models and clinical scores were applied to the external validation cohort and their performances were compared in terms of AUC, sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), positive likelihood ratio (PLR) and negative likelihood ratio (NLR) for each model.
All statistical analyses were performed by the R statistical software (version 3.2.3; R Foundation for Statistical Computing). The R library “caret”, “xgboost”, “gbm”, “glmnet” and “sNNR” were used for machine learning. Continuous variables were expressed as mean and SD. The Mann–Whitney U test or Wilcoxon rank-sum test was used to compare continuous variables between two groups. The chi-square test or Fisher’s exact test, where appropriate, was applied for comparing categorical variables.
Results
Patients
A total of 395 patients with advanced hepatocellular carcinoma who had received immunotherapy between January 2014 and December 2019 were included. There were 335 (84.8%) male with mean age of 60.6 years. The most common cause of HCC was related to HBV (75.6%) and the overall 1-year cancer-related mortality was 51.1%. The dataset was randomly divided into two sets with 316 patients (80%) assigned to the training set and the remaining 79 patients (20%) assigned to be the independent validation set. The characteristics of patients in the training and validation sets are summarized in Table 1.
Performance of different machine learning models
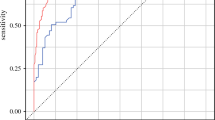
The performances of different machine learning models are summarized in Fig. 1 and Table 2. Of all the ML models, the RF had the best AUC of 0.92 (95% CI: 0.87–0.98) which was significantly higher than LR (0.82, p = 0.01). Statistical comparisons among different models are shown in Supplementary Tables 4–10.

The AUC of different machine learning models and clinical scores with the independent validation set
The Lasso, XGBoost and NN model had the highest sensitivity of 0.91. Their sensitivities were significantly higher than LR (Lasso 0.91 vs LR 0.75, p = 0.05; XGBoost 0.91 vs LR 0.75, p = 0.05; and NN 0.91 vs LR 0.75, p = 0.03; Supplementary Table 5). In contrast, the RF model had the best specificity, PPV and PLR (Supplementary Table 7 and 9). Likewise, the decision curve analysis showed the net benefits of RF, NN and GBM surpassed that of the LR throughout the threshold ranges (Supplementary Fig. 1). The concordance index was 0.81 (95% CI 0.81–0.81) with Brier score 0.21 (95% CI 0.20–0.21) for the independent validation set in the XGBoost survival model using time-to-event analysis.
Comparison of machine learning models with CRAFITY score and ALBI score
All machine learning models performed better than the CRAFITY score in terms of AUC in the validation set (Table 2). Moreover, the specificity, PPV and PLR of all machine learning models were better than the CRAFITY score (Table 2).
For the ALBI score, only RF performed significantly better than the ALBI score in terms of AUC (RF: 0.92 vs 0.84, p = 0.04). However, the XGBoost performed significantly better than ALBI in terms of sensitivity (0.91 vs 0.80, p = 0.05), NPV (0.87 vs 0.72, p = 0.05) and NLR (0.12 vs 0.28, p = 0.05), whereas GBM performed significantly better than ALBI in terms of specificity (0.86 vs 0.71, p = 0.04), PPV (0.88 vs 0.78, p = 0.04) and PLR (5.74 vs 2.72, p = 0.04).
Subgroup analyses
Subgroup analyses were performed to evaluate the performances of different ML models (Supplementary Table 11). For patients ≥ 65 years, the GBM, RF and XGBoost were significantly better than the CRAFITY score in terms of AUC. For patients < 65 years, the LG, LASSO, RF, GBM and NN were significantly better than the CRAFITY score; and LASSO and NN were significantly better than ALBI.
For patients with immunotherapy as first line, RF, GBM and NN were better than CRAFITY score, but only RF performed better than ALBI. For patients with Child’s A grading, the LASSO, XGBoost, RF, GBM and NN were better than CRAFITY score; and the XGBoost, RF and NN were better than ALBI score. For patients with viral cause of HCC, the LASSO, XGBoost, RF, GBM and NN were significantly better than CRAFITY score. For patients with cirrhosis, the RF and GBM performed better than CRAFITY score. For patient without cirrhosis, the RF, XGBoost, Lasso and GBM performed better than CRAFITY score.
Risk factors associated with 1-year cancer-related mortality by different models.
The LR model identified six factors that were associated with 1-year cancer-related mortality in HCC patients including high bilirubin, AFP, ALP and platelet level, and the presence of cirrhosis. The use of pembolizumab was found to be associated with lower mortality risk (Table 3).
Figure 2 revealed the risk factors used by different machine learning models in predicting 1-year cancer-related mortality. Baseline high AFP, bilirubin and ALP were three common risk factors identified by all ML models. Presence of infection, use of antibiotics, low albumin, high ALT, high GGT, high AST, high PT, high WBC and high platelet count were identified by five ML models (Lasso, Xgboost, RF, GBM and NN). At least three models noted the use of pembrolizumab and statin as protective factors (Fig. 2 and Supplementary Figs. 2–5). Four models identified Child’s B or C cirrhosis as risk factor. Other factors included older age, presence of cirrhosis and the history of hepatectomy.

Significant factors associated with 1-year cancer-related mortality identified by different ML models
Predictor analysis by the best machine learning model (Random Forest)
By estimation using the Stapley value for each categorical predictor used in the RF model, the adjusted relative risk for the presence of infection was 3.49 (95% CI 2.57–4.47), use of antibiotics was 2.65 (95% CI 2.41–2.91), Child’s B or C cirrhosis was 3.17 (95% CI 2.91–3.46), presence of cirrhosis was 3.85 (95% CI 3.47–4.26), prior hepatectomy was 3.88 (95% CI 3.43–4.38), use of pembrolizumab was 0.43 (95% CI 0.40–0.48), and use of statin was 0.53 (95% CI 0.46,0.60) (Supplementary Figs. 6–12).
For continuous predictors, there was positive adjusted correlation of the Stapley value for ALP, ALT, AST, GGT, PT, WBC, platelet count, AFP, bilirubin; and negative correlation for albumin and sodium level (Supplementary Figs. 13–23).
False positive and false negative rates
For the whole cohort, the LR model falsely predicted 37.7% (n = 39) of patients who would die and falsely predicted 20.3% (n = 76) to survive in 1-year. Of all models, RF had the lowest false positive rate (2.0%) and false negative rate (5.2%). All advanced ML models, except GDM, performed better than LR in terms of false positive rates (Table 4). All models were also superior to LR in terms of false negative rates.
All-cause mortality as outcome
Using the same predictors, the accuracy of all ML models was not significantly different when the outcome was changed to all-cause mortality. The AUC of LR for all-cause vs cancer-related mortality was: 0.85 (95% CI 0.76–0.94) vs 0.82 (95% CI 0.73–0.91), p = 0.65; for LASSO was 0.88 (95% CI 0.81–0.96) vs 0.87 (95% CI 0.78–0.95), p = 0.98; for XGBoost was 0.83 (95% CI 0.73–0.94) vs 0.89 (95% CI 0.81–0.97), p = 0.34; for RF was 0.90 (95% CI 0.84–0.97) vs 0.92 (95% CI 0.87–0.98), p = 0.65; for GBM was 0.87 (95% CI 0.79–0.96) vs 0.89 (95% CI 0.82–0.96), p = 0.77; for NN was 0.86 (95% CI 0.78–0.95) vs 0.89 (95% CI 0.83–0.96), p = 0.58.
Validation by the external validation cohort
A total of 43 (74.4% male, mean age 69.0 years) patients with HCC were retrieved from ePR system. The most common cause of HCC was related to HBV (76.7%). There were considerable differences in baseline characteristics between this cohort and the training set (Table 1). In particular, the overall 1-year cancer-related mortality was significantly lower in this external validation cohort than the training set (23.3% vs 51.1%, p < 0.01;). Despite the difference in baseline characteristics, both RF and LASSO still had excellent performance in terms of AUC (RF: 0.91; LASSO: 0.93) (Fig. 3), which were significantly better than CRAFITY score (0.91 vs 0.66, p < 0.01; 0.93 vs 0.66, p < 0.01) and LR (0.91 vs 0.72, p < 0.01, 0.93 vs 0.72, p < 0.01; Supplementary Table 12).

The AUC of different machine learning models and clinical scores with the external validation cohort
Discussion
While immunotherapy appears to be a promising new treatment option for patients with advanced HCC, there was no reliable predictor of treatment outcome including mortality. This is the first study to evaluate the use of the latest advanced ML models which were based on baseline clinical characteristics to predict treatment outcome. We showed that the use of ML models could accurately predict the 1-year mortality of advanced HCC patient with an absolute error within 5%. In particular, both RF, GBM and NN models had high AUC in cancer-related mortality risk prediction (0.92, 0.89 and 0.89, respectively). Moreover, these advanced ML models were also significantly better than traditional LR model in terms of AUC.
Of various ML models, the RF model was found to have the best performance in the current study. Although the algorithm used by ML is usually considered to be “black box”, we performed factor analysis to gain more insights into the factors used in predicting 1-year cancer-related mortality (Fig. 2). Our analysis showed that the RF model used 18 independent variables including baseline ALP, bilirubin, AST, AFP, albumin level, GGT, ALT, sodium level, prothrombin time, white blood cell count and platelet count, Child’s score, history of hepatectomy, presence of infection, uses of antibiotics, statin and pembrolizumab to predict cancer-related mortality. By identifying these factors, it could help the investigators to understand the complex interaction between clinical variables beyond the traditional statistical methods, e.g., logistic regression model. For example, some of these advanced ML models identified use of statin and antibiotics as risk factors, which were not revealed by traditional linear models. Moreover, unlike conventional LR which usually adopt linear association, these ML models could interpret association between clinical variables that interact in a non-linear fashion.
There were three categories of factors that were associated with survival of cancer patients. First, tumor factors, such as the size and number of the tumor nodules [39], tumor involvement of nearby structures, such as vasculature or nearby organs [40, 41], expression of immune checkpoint receptors [42], and previous interventions, were known to have significant impact on the survival [43]. Interestingly, we found that prior treatment could have different impacts on different ML models. By our predictor analysis, we found that in the LASSO, XGBoost and RF models, previous hepatectomy impacted the cancer-related death in a negative way. Previous TACE would impact the cancer-related death in NN model and previous ablative therapy did significantly impact GBM model. The Stapley value of previous hepatectomy was 3.3 times higher than those who did not have prior hepatectomy in the best performance model (RF). Second, liver function tests, such as serum bilirubin, prothrombin time, albumin level, AST level, presence of ascites and hepatic encephalopathy, were demonstrated to be influencing the prognosis of HCC patients [44, 45]. Third, patient’s demographics, e.g., age and sex, and performance status such as the Eastern Cooperative Oncology Group Performance status (ECOG PS) were shown to be important prognostic factors for HCC [44, 45].
There were existing scoring systems for HCC, such as the Barcelona Clinic Liver Cancer score [46] and the Hong Kong Liver Cancer Staging score, which determine the prognosis of HCC patients and guidance of intervention of HCC patients [47, 48]. The AUC of these scoring system ranged from 0.72 to 0.78 in predicting 12-month survival [49]. However, these scoring systems require comprehensive imaging data and even histology information, and these systems are not limited to advanced HCC. Furthermore, we found that the RF model was superior to the ALBI score in the testing date set and performed better than the CRAFITY score in the external validation cohort.
There were unique advantages of the current study. Our study included a large cohort of advanced HCC patients treated with immunotherapy in Hong Kong, which could provide a novel and timely observation on the 1-year survival risk prediction of these patients. We also demonstrated the potential differences in the performance of various advanced ML models when applied to address a specific clinical condition. Moreover, our factor analysis helped to uncover the “black box” nature of these advanced ML models.
However, there are limitations of this study. First, despite being a territory-wide study, the sample size was limited as immunotherapy was still a novel treatment option for advanced HCC patients. Moreover, the best immunotherapy regime for advanced HCC patients had not been properly defined during the study period and no standardized regime was used in all patients. Despite the accuracy of ML models in the prediction of cancer-related mortality after immunotherapy, treatment decision could be influenced by many other factors including patient’s willingness to be treated, side effects of the medications and reimbursement issue. This study could only serve as a pilot study demonstrating the feasibility of using advanced ML models in guiding this decision process. Second, our cohort included mainly Chinese patients with HBV-related cancer and our results may not be applicable in other population with predominantly non-HBV-related HCC. We have, however, performed subgroup analysis, which demonstrates similar performances in patients with viral or non-viral causes of HCC (Supplementary Table 11). The trained ML models were also further tested in an external validation cohort of HCC patients with quite different baseline characteristics and even 1-year mortality, which still yield favorable results. Further, multi-country studies are needed to validate the performance of ML models for this purpose.
Conclusion
We have demonstrated that advanced ML models, especially the RF model, were more accurate than traditional LR and conventional risk scores in predicting 1-year cancer-related mortality of advanced HCC patients using immunotherapy. The use of ML models can potentially help to select patients who would most benefit from this emerging treatment for advanced HCC.
Data availability
Supporting data for this study are available from the corresponding author and the first author upon reasonable request.
Abbreviations
- AUC:
-
Area under the receiver operator characteristics curve
- CDARS:
-
Clinical Data Analysis and Reporting System
- CI:
-
Confidence interval
- LASSO:
-
Least absolute shrinkage and selection operator
- LR:
-
Logistic regression
- ML:
-
Machine learning
- NLR:
-
Negative likelihood ratio
- NPV:
-
Negative predictive value
- PLR:
-
Positive likelihood ratio
- PPV:
-
Positive predictive value
- NN:
-
Sparse neural network
- GBM:
-
Stochastic gradient boosting
- SVM:
-
Support vector machine
- XGBoost:
-
Extreme gradient boosting
- CPS:
-
Child–Pugh score
- HCC:
-
Hepatocellular carcinoma
- MAE:
-
Mean absolute error
- ICD-9:
-
The International Classification of Diseases, Ninth Revision
- TACE:
-
Trans-arterial chemoembolization
- ICI:
-
Immune checkpoint inhibitor
- TKI:
-
Tyrosine kinase inhibitor
- HBV:
-
Chronic hepatitis B infection
- DM:
-
Diabetes mellitus
- HT:
-
Hypertension
- IHD:
-
Ischemic heart disease
- AF:
-
Atrial fibrillation
- CHF:
-
Congestive heart failure
- CRF:
-
Chronic renal failure
- PPI:
-
Proton pump inhibitors
- AFP:
-
Alpha fetoprotein
- ALP:
-
Alkaline phosphatase
- ALT:
-
Alanine aminotransferase
- AST:
-
Aspartate aminotransferase
- GGT:
-
Gamma-glutamyl transferase
- PT:
-
Prothrombin time
- INR:
-
International normalized ratio (INR)
- Na:
-
Sodium
- WBC:
-
White blood cell
References
Fitzmaurice C, Abate D, Abbasi N, et al. Global, Regional, and National Cancer Incidence, Mortality, Years of life lost, years lived with disability, and disability-adjusted life-years for 29 cancer groups, 1990 to 2017: a systematic analysis for the Global Burden of Disease Study. JAMA Oncol 2019;5(12):1749–1768
Lee MJ, Chang SW, Kim JH, et al. Real-world systemic sequential therapy with sorafenib and regorafenib for advanced hepatocellular carcinoma: a multicenter retrospective study in Korea. Invest New Drugs 2021;39(1):260–268
Sangro B, Sarobe P, Hervas-Stubbs S, Melero I. Advances in immunotherapy for hepatocellular carcinoma. Nat Rev Gastroenterol Hepatol 2021. https://doi.org/10.1038/s41575-41021-00438-41570
Xie Y, Xiang Y, Sheng J, et al. Immunotherapy for hepatocellular carcinoma: current advances and future expectations. J Immunol Res 2018;2018:1–15
Nakano S, Eso Y, Okada H, Takai A, Takahashi K, Seno H. Recent advances in immunotherapy for hepatocellular carcinoma. Cancers (Basel) 2020;12(4):1–15
Ziogas IA, Evangeliou AP, Giannis D, et al. The role of immunotherapy in hepatocellular carcinoma: a systematic review and pooled analysis of 2,402 patients. Oncologist. 2021;26(6):e1036–e1049. https://doi.org/10.1002/onco.13638
Pencina MJ, Goldstein BA, D’Agostino RB. Prediction models—development, evaluation, and clinical application. N Engl J Med 2020;382(17):1583–1586
Sendak MP, Ratliff W, Sarro D, et al. Real-world integration of a sepsis deep learning technology into routine clinical care: implementation study. JMIR Med Inf 2020;8(7): e15182
Milea D, Najjar RP, Zhubo J, et al. Artificial intelligence to detect papilledema from ocular fundus photographs. N Engl J Med 2020;382(18):1687–1695
Richter AN, Khoshgoftaar TM. A review of statistical and machine learning methods for modeling cancer risk using structured clinical data. Artif Intell Med 2018;90:1–14
Lui TKL, Wong KKY, Mak LLY, Ko MKL, Tsao SKK, Leung WK. Endoscopic prediction of deeply submucosal invasive carcinoma with use of artificial intelligence. Endosc Int Open 2019;7(4):E514–E520
Leung WK, Cheung KS, Li B, Law SYK, Lui TKL. Applications of machine learning models in the prediction of gastric cancer risk in patients after Helicobacter pylori eradication. Aliment Pharmacol Ther 2021;53(8):864–872
Vanderbeck S, Bockhorst J, Komorowski R, Kleiner DE, Gawrieh S. Automatic classification of white regions in liver biopsies by supervised machine learning. Hum Pathol 2014;45(4):785–792
Byra M, Styczynski G, Szmigielski C, et al. Transfer learning with deep convolutional neural network for liver steatosis assessment in ultrasound images. Int J Comput Assist Radiol Surg 2018;13(12):1895–1903
Ma H, Xu CF, Shen Z, Yu CH, Li YM. Application of machine learning techniques for clinical predictive modeling: a cross-sectional study on nonalcoholic fatty liver disease in China. Biomed Res Int 2018;2018:4304376
Konerman MA, Zhang Y, Zhu J, Higgins PD, Lok AS, Waljee AK. Improvement of predictive models of risk of disease progression in chronic hepatitis C by incorporating longitudinal data. Hepatology 2015;61(6):1832–1841
Wei R, Wang J, Wang X, et al. Clinical prediction of HBV and HCV related hepatic fibrosis using machine learning. EBioMedicine. 2018;35:124–132
Cao Y, Hu ZD, Liu XF, Deng AM, Hu CJ. An MLP classifier for prediction of HBV-induced liver cirrhosis using routinely available clinical parameters. Dis Mark 2013;35(6):653–660
Eaton JE, Vesterhus M, McCauley BM, et al. Primary sclerosing cholangitis risk estimate tool (PREsTo) predicts outcomes of the disease: a derivation and validation study using machine learning. Hepatology 2020;71(1):214–224
Andres A, Montano-Loza A, Greiner R, et al. A novel learning algorithm to predict individual survival after liver transplantation for primary sclerosing cholangitis. PLoS One 2018;13(3): e0193523
Kim JW, Ye Q, Forgues M, et al. Cancer-associated molecular signature in the tissue samples of patients with cirrhosis. Hepatology 2004;39(2):518–527
Zou H, Yang X, Li QL, Zhou QX, Xiong L, Wen Y. A comparative study of albumin-bilirubin score with child-pugh score, model for end-stage liver disease score and indocyanine green R15 in predicting posthepatectomy liver failure for hepatocellular carcinoma patients. Dig Dis 2018;36(3):236–243
Scheiner B, Pomej K, Kirstein MM, et al. Prognosis of patients with hepatocellular carcinoma treated with immunotherapy—development and validation of the CRAFITY score. J Hepatol 2022;76(2):353–363
Mao S, Yu X, Shan Y, Fan R, Wu S, Lu C. Albumin-bilirubin (ALBI) and Monocyte to lymphocyte ratio (MLR)-based nomogram model to predict tumor recurrence of AFP-negative hepatocellular carcinoma. J Hepatocell Carcinoma 2021;8:1355–1365
Chiu SS, Lau YL, Chan KH, Wong WHS, Peiris JSM. Influenza-related hospitalizations among children in Hong Kong. N Engl J Med 2002;347(26):2097–2103
Chan EW, Lau WC, Leung WK, et al. Prevention of dabigatran-related gastrointestinal bleeding with gastroprotective agents: a population-based study. Gastroenterology 2015;149(3):586–595
Cheung KS, Seto WK, Fung J, Lai CL, Yuen MF. Epidemiology and natural history of primary biliary cholangitis in the Chinese: a territory-based study in Hong Kong between 2000 and 2015. Clin Transl Gastroenterol 2017;8(8): e116
Leung WK, Wong IOL, Cheung KS, et al. Effects of Helicobacter pylori treatment on incidence of gastric cancer in older individuals. Gastroenterology 2018;155(1):67–75
Cheung KS, Chan EW, Wong AYS, Chen LJ, Wong ICK, Leung WK. Long-term proton pump inhibitors and risk of gastric cancer development after treatment for Helicobacter pylori: a population-based study. Gut 2018;67(1):28–35
Cheung KS, Chan EW, Chen L, Seto WK, Wong ICK, Leung WK. Diabetes increases risk of gastric cancer after Helicobacter pylori eradication: a territory-wide study with propensity score analysis. Diabetes Care. 2019;42(9):1769–1775
United States, Department of Health and Human Services, Food and Drug Administration. FDA grants accelerated approval to nivolumab for HCC previously treated with sorafenib. https://www.fda.gov/drugs/resources-information-approved-drugs/fda-grants-accelerated-approval-nivolumab-hcc-previously-treated-sorafenib. Accessed 6 May 2021
United States, Department of Health and Human Services, Food and Drug Administration. FDA grants accelerated approval to pembrolizumab for hepatocellular carcinoma. https://www.fda.gov/drugs/fda-grants-accelerated-approval-pembrolizumab-hepatocellular-carcinoma. Accessed 6 May 2021
Lee JH, Shi Z, Gao Z. On LASSO for Predictive Regression. arXiv Website. https://arxiv.org/abs/1810.03140.pdf. Accessed 27 July 2020.
Kelvin PM. Machine Learning: A Probabilistic Perspective. Cambridge: MIT Press; 2012
Chen T, Guestrin C. XGBoost: a scalable tree boosting system. arXiv Website. https://arxiv.org/pdf/1603.02754.pdf. Accessed 24 Mar 2019.
Schonlau M, Zou RY. The random forest algorithm for statistical learning. Stata J 2020;20(1):3–29
Friedman JH. Stochastic gradient boosting. Comput Stat Data Anal 2002;38:367–378
Suraj S, Akshayvarun S, Venkatesh B. Training Sparse Neural Networks. arXiv Website. https://arxiv.org/abs/1611.06694.pdf. Accessed 27 July 2020.
Bruix J, Llovet JM. Prognostic prediction and treatment strategy in hepatocellular carcinoma. Hepatology 2002;35(3):519–524
Ikai I, Yamamoto Y, Yamamoto N, et al. Results of hepatic resection for hepatocellular carcinoma invading major portal and/or hepatic veins. Surg Oncol Clin N Am 2003;12(1):65–75 (ix)
Pawlik TM, Poon RT, Abdalla EK, et al. Hepatectomy for hepatocellular carcinoma with major portal or hepatic vein invasion: results of a multicenter study. Surgery 2005;137(4):403–410
Chang H, Jung W, Kim A, et al. Expression and prognostic significance of programmed death protein 1 and programmed death ligand-1, and cytotoxic T lymphocyte-associated molecule-4 in hepatocellular carcinoma. APMIS 2017;125(8):690–698
Li J, Huang L, Liu C, et al. Risk factors and clinical outcomes of extrahepatic recurrence in patients with post-hepatectomy recurrent hepatocellular carcinoma. ANZ J Surg. 2021;91(6):1174–1179. https://doi.org/10.1111/ans.16737
Chen KL, Gao J. Factors influencing the short-term and long-term survival of hepatocellular carcinoma patients with portal vein tumor thrombosis who underwent chemoembolization. World J Gastroenterol 2021;27(13):1330–1340
Xiong D, Zhang K, Xu M. Prognostic factors of nivolumab in advanced hepatocellular carcinoma: a systematic review and meta-analysis. Panminerva Med. 2021. https://doi.org/10.23736/S0031-0808.21.04282-8
Llovet JM, Bru C, Bruix J. Prognosis of hepatocellular carcinoma: the BCLC staging classification. Semin Liver Dis 1999;19(3):329–338
Yau T, Tang VY, Yao TJ, Fan ST, Lo CM, Poon RT. Development of Hong Kong Liver Cancer staging system with treatment stratification for patients with hepatocellular carcinoma. Gastroenterology 2014;146(7):1691–1700
Forner A, Reig ME, de Lope CR, Bruix J. Current strategy for staging and treatment: the BCLC update and future prospects. Semin Liver Dis 2010;30(1):61–74
Heinrich S, Sprinzl M, Schmidtmann I, et al. Validation of prognostic accuracy of MESH, HKLC, and BCLC classifications in a large German cohort of hepatocellular carcinoma patients. United European Gastroenterol J. 2020;8(4):444–452
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
WKL was involved in the study design and conception; interpretation of the data; drafting of manuscript and study supervision. KSC were involved in the data acquisition and critical review of the manuscript. TKLT was involved in the study design, conception, data analysis and drafting of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Human and animal research
This article does not contain any studies with animals performed by any of the authors.
Consent to participate
This study was approved by the ethics committees of our hospital and fully complied with the Declaration of Helsinki and the Guideline for Good Clinical Practice.
Consent for publication
Informed consent for publication was obtained from all author.
Plant reproducibility
This article does not contain any information regarding this issue.
Clinical trials registration
This article does not have clinical trial registration.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Lui, T.K.L., Cheung, K.S. & Leung, W.K. Machine learning models in the prediction of 1-year mortality in patients with advanced hepatocellular cancer on immunotherapy: a proof-of-concept study. Hepatol Int 16, 879–891 (2022). https://doi.org/10.1007/s12072-022-10370-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12072-022-10370-3