
Abstract
A global forecast system model at a horizontal resolution of T1534 (\({\sim }12.5\, \hbox {km}\)) has been evaluated for the monsoon seasons of 2016 and 2017 over the Indian region. It is for the first time that such a high-resolution global model is being run operationally for monsoon weather forecast. A detailed validation of the model therefore is essential. The validation of mean monsoon rainfall for the season and individual months indicates a tendency for wet bias over the land region in all the forecast lead time. The probability distribution of forecast rainfall shows an overestimation (underestimation) of rainfall for the lighter (heavy) categories. However, the probability distribution functions of moderate rainfall categories are found to be reasonable. The model shows fidelity in capturing the extremely heavy rainfall categories with shorter lead times. The model reasonably predicts the large-scale parameters associated with the Indian summer monsoon, particularly, the vertical profile of the moisture. The diurnal rainfall variability forecasts in all lead times show certain biases over different land and oceanic regions and, particularly, over the north–west Indian region. Although the model has a reasonable fidelity in capturing the spatio-temporal variability of the monsoon rain, further development is needed to enhance the skill of forecast of a higher rain rate with a longer lead time.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In the past several decades, there has been significant improvement in the skill of weather forecasting using numerical weather prediction models. It is demonstrated globally that enhanced resolution of the general circulation models (GCM) improves the model fidelity. The increased skill in terms of better power and improved eastward propagation of the Madden–Julian oscillation (as intraseasonal variability) has been aptly shown by a non-hydrostatic icosahedral atmospheric model (Sato et al. 2005; Miura et al. 2015). Rajendran and Kitoh (2008) have shown that the seasonal mean climate simulations have improved in high-resolution models. It is also reported that community atmosphere models with higher resolution have shown improvement of simulation for the systems associated with large-scale circulation (Hack et al. 2006). Williamson et al. (1995) showed that many nonlinear driving processes of large-scale motion are represented better in high-resolution models. Also, the European Centre for Medium Range Weather Forecast (ECMWF) Integrated Forecast System (IFS) model at a 10-km resolution simulates the observed tropical cyclone frequency and intensity more reasonably than its coarser resolution versions (Manganello et al. 2012).
In the past, only a few global centres explored the GCM for operational forecasting having resolution lesser than 100 km, mainly due to the limitation of computational resources. Recently, leading global operational centres, e.g., ECMWF inducted very high-resolution GCM (with a 9-km resolution for deterministic and 16 km for ensemble prediction) for 10 days weather forecast. Many previous studies have reported the increasing tendencies of extreme events (Goswami et al. 2006; Rajeevan et al. 2008; Roxy et al. 2017 and the references therein) over the Indian region. Kim et al. (2018) highlighted the importance of the high-resolution models to capture the extreme rainfall events over the Indian region. In India, the economy is largely dependent on agriculture (Gadgil and Gadgil 2006) vis-à-vis the summer monsoon rainfall, and this as such becomes the major factor behind the need for monsoon research for improved prediction. The operational forecasting in India was based on a global forecast system (GFS) with Eulerian (EL) dynamical core model at 27 km resolution. Hence there was a need to improve the skill of weather forecast, in general, and for the extreme events, in particular, using the numerical model at higher spatial resolution.
In India, the generation of medium-range forecasts was started at National Centre for Medium Range Weather Forecast (NCMRWF) in 1994 using the T80L18 global data assimilation and forecasting system. In the course of time, assimilated volume of data and model resolution increased considerably as a result of improvements in the model, observing system and the data reception system. Major improvements in forecasting skill were observed in 2010 with the introduction of the T382L64 model configuration and further upgradation to T574L64 on comparison with previous versions of the model (Prasad et al. 2011). In the 2011 monsoon period, the T574L64 model produced 1-day gain in forecast skill compared to the T382L64 model (Prasad et al. 2014). In order to have a uniform data set (comparable skill) for a longer period that can be used for climate-related studies, a retrospective analysis is carried out with the model configuration of T574L64 from 2000 to 2011 (Prasad et al. 2017). At present, Hybrid 4D Ens-Var assimilation with the T1534L64 model resolution has been used in operational weather forecasts since 2017 April.
It is worthy to mention that from 2010 onwards, an operational seasonal forecast based on the dynamical coupled model, National Centre for Environmental Prediction (NCEP) CFSv2 (Climate Forecast System version 2 model) was used at a T382 (\({\sim }35\, \hbox {km}\)) resolution for the Indian summer monsoon (ISM) forecast (June–July–August–September) (Dandi et al. 2016). Along with the development of a dynamical seasonal forecast model, an extended range multi-model (CFS/GFS) ensemble forecast system has also been developed to issue forecast up to four pentads. The seasonal and extended range forecast system developed under ‘Monsoon Mission’ of Ministry of Earth Science, Government of India, has been found to be very effective in enhancing the skill of forecast, particularly, for the agricultural sector. Extended range forecast has also been found to be useful for providing warnings of heat wave anomalies and extreme rainfall with three pentads lead times (Borah et al. 2015; Joseph et al. 2018).

Schematic of GFS T1534 (\({\sim }12.5\, \hbox {km}\)) L64.
While the seasonal forecast is able to provide a skilful forecast of ISM over the country as a whole and the extended range forecast provides weekly anomalies over the region up to four pentads, there was an increasing demand, particularly, from the agro-met services of the India Meteorological Department to provide forecast advisories for a period of around 10 days at the sub-district level. The increasing frequency of flood due to extreme rain (Nandargi and Gaur 2015) over the major Indian cities was also a point of concern. Keeping particularly the requirement for a high-resolution forecast over the country to enhance the services and extend it to the sub-district level, a state-of-the-art very high-resolution NCEP GFS model (semi-Lagrangian (SL)) at T1534 (\({\sim }12.5\, \hbox {km}\)) has been established. In the present study, the evaluation of the high-resolution model skill over the Indian region for two monsoon seasons (2016–2017) has been carried out for the first time.
2 Model, observation and methodology
In order to fulfil the requirement for the block level forecast in India, a very high-resolution deterministic GFS with spectral resolution of T1534 (\({\sim }12.5\, \hbox {km}\)) with 64 hybrid vertical levels (top layer around 0.27 hPa) has been implemented for daily operational forecast since June 2016. The global atmospheric model in GFS is a global spectral model (GSM) version 13.0.2, adopted from NCEP (http://www.emc.ncep.noaa.gov/GFS/doc.php). The GFS model dynamical core is based on a two time-level semi-implicit SL discretisation approach (Sela 2010), while the physics is done in the linear, reduced Gaussian grid in the horizontal space. It is the first time that the SL dynamical core (previously EL) is implemented in the GFS T1534 for operational forecast over India, equivalent to other global operational centres, namely, ARPEGE (Meteo France), GEM (Environment Canada), GFS (NCEP, USA), GSM (Japan Meteorological Agency (JMA)), IFS (ECMWF), MetUM (United Kingdom Met. Office), etc. The major advantage of the SL framework over the EL approach is that it is an unconditionally stable scheme which accurately captures waves with high phase speed and sufficient accuracy. It also saves lot of computational time as compared to the EL framework due to longer time steps. A detailed description of the benefits of the SL approach is described in detail in the study by Staniforth and Côté (1991). Figure 1 and table 1 describe the schematic of GFS T1534 and the description of model physics, respectively. The initial conditions for the forecast are generated by the NCMRWF through the global data assimilation system (GDAS) cycle which has more Indian data in it. More details about the NCMRWF data assimilation system is documented by Prasad et al. (2016).

JJAS mean rainfall \((\hbox {mm day}^{-1})\) for day-1, day-3, day-5 and day-8 lead times from the GFS T1534 model forecast, compared with IMERG gridded data. Number in each panel denotes the spatial correlation coefficients between the model and observation at different lead times. The right-hand column represents model rainfall (mm day\(^{-1})\) bias at various lead times with respect to observation.

JJAS rainfall bias \((\hbox {mm day}^{-1})\) for day-1, day-3, day-5 and day-8 lead time from the GFS T1534 model forecast with respect to IMERG gridded data during June, July, August and September, respectively.

All India rainfall PDF (%, in log scale) vs. rain rate (\(\hbox {cm day}^{-1})\) categories during JJAS for different lead times derived from the GFS T1534 model forecast and compared with IMERG gridded data.

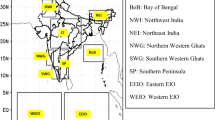
Spatial distribution of rainfall (\(\hbox {cm day}^{-1})\) for different categories during JJAS for (a) IMERG and (b–e) GFS T1534 for different lead times. (f) Rainfall PDF (%, in log scale) vs. rain rate (cm/day) categories during JJAS over CI, BOB, NWI and WG regions for different lead time derived from GFS T1534 model forecast and compared with IMERG data. The domains are chosen as in figure 11.

Area averaged sub-grid scale vertical turbulent flux of moisture (\(\hbox {kg m}^{-2}\, \hbox {s}^{-1})\) during JJAS of 2016–2017 over different Indian regions at different forecast lead times.
The GFS T1534 model is run daily for 10 days and the output is stored every 3 hr interval. In this paper, we have analysed both daily and diurnal runs of June–September (JJAS) for 2016 and 2017. The model is being run at the Ministry of Earth Sciences high power-computer (HPC) facility ‘Aaditya’ at the Indian Institute of Tropical Meteorology (IITM), Pune.
To validate the model forecast, the latest version (05B) of Integrated Multi-satellite Retrievals for GPM (IMERG) (Huffman et al. 2014) rainfall data at \(0.1^{\circ } \times 0.1^{\circ }\, (10\, \hbox {km})\) horizontal resolution and half-hourly temporal resolution is used in the present study during JJAS of 2016 and 2017. The utilisation of a very high-resolution rainfall data is desirable to keep all the localised features intact in the observation and model. The precipitation in IMERG is estimated from various precipitation-relevant satellite passive microwave sensors comprising the GPM constellation using the 2014 version of the Goddard Profiling Algorithm (GPROF2014). In the present study, we have used the IMERG version 05B final run data which is the latest high-quality research purpose data set, and it is available in the following webpage https://pmm.nasa.gov/data-access/downloads/gpm. More technical details about the IMERG data sets are provided in https://pmm.nasa.gov/sites/default/files/document_files/IMERG_doc_180207.pdf. For the present study, we have interpolated the IMERG rainfall data from \(0.1^{\circ } \times 0.1^{\circ }\) to \(0.125^{\circ } \times 0.125^{\circ }\) model grid point.
In addition to rainfall data, various other satellite and reanalyses-based parameters are also used to further investigate model performance. ERA interim reanalysis (Dee et al. 2011) wind and relative humidity (RH) is utilised for the validation of the corresponding model forecast for the summer monsoon of 2016 and 2017. Additionally, the OLR data from Kalpana-1 very high-resolution radiometer satellite observations (Mahakur et al. 2013) is used.
The daily rainfall time series is computed by accumulating half (3) hourly IMERG (GFS T1534) data. The model forecast data is taken from 22 May 2016 and 2017, respectively, to make JJAS (122 days) time series at various lead times for both the years. The mean JJAS rainfall is calculated based on 2-year JJAS datasets for day-1, day-3, day-5 and day-8 forecast lead times. The spatial correlation coefficient is provided in the rainfall spatial plots. To make the diurnal cycle of rainfall over different parts of India and over the oceanic region, a 3-hr time series is calculated for both the observation and model starting from 02:30 to 23:30 IST for various lead times.
3 Results and discussion
3.1 Evaluation of rainfall and dynamical parameters
The forecast rainfall with day-1, day-3, day-5 and day-8 lead for JJAS and the corresponding bias with respect to the IMERG data are shown in figure 2. While in all lead times, the model prediction shows a reasonable spatial correlation, there is a significant overestimation of rainfall over the Bay of Bengal (BoB) region and over the west coast of India. The overestimation of the model forecast with respect to the IMERG data is evident from the precipitation bias plot as well (figure 2). To understand the growth of bias, the rainfall bias with different lead times for the individual months of JJAS are plotted in figure 3. It is evident that the positive bias over the Bay region and along the west coast is present in all months and in all forecast lead time. This suggests that the model seems to have a systematic bias of overestimation over the BoB and over the west coast region. The rainfall over the land also shows an overestimation, but lesser in magnitude as compared to that over the BoB region. The spatial correlation of model forecast precipitation with that of observation remains above 0.6 until 8 days during June and July. In August, the correlation falls from 0.62 to 0.52 from day-1 to day-8 lead times, respectively. For the month of September, the model shows a correlation up to 0.6 for forecast with 8 days (figure 3) lead time. To identify the possible reason behind the model wet bias for different months and with different lead times, the rainfall probability distribution function (PDF) for all months (JJAS) from the model forecast of day-1, day-3, day-5, day-8 and the corresponding observation is shown in figure 4 (top left). The model overestimates the lighter rainfall (0.25–1.56 cm day\(^{-1})\) at all lead times, captures the moderate category of \(1.56{-}6.45\, \hbox {cm day}^{-1}\) properly in all lead times, slightly underestimates the heavy rainfall categories (\(6.45{-}11.56\, \hbox {cm day}^{-1})\) in all lead times and also the very heavy categories (\(11.56{-}20.45\, \hbox {cm day}^{-1})\) except day-8 lead during JJAS. To gain further insight, the model rainfall forecast for each month and for different lead times is analysed. In each monsoon month of JJAS, the model shows similar characteristics as seen in JJAS, of overestimating the lighter categories \((0.25{-}1.56\, \hbox {cm day}^{-1})\) and underestimating the heavy \((6.45{-}11.56\, \hbox {cm day}^{-1})\) and very heavy \((11.56{-}20.45\, \hbox {cm day}^{-1})\) categories of rainfall in all lead times of July, August and September, whereas the model overestimates the heavy and very heavy categories of June in all lead times. The model forecasts successfully capture the moderate category \((1.56{-}6.45\, \hbox {cm day}^{-1})\) rainfall in all lead times of the monsoon months. The extremely heavy category \(({\ge }20.45\, \hbox {cm day}^{-1})\) of rainfall forecasts is overestimated more in the longer lead (day-5 and day-8 forecast) in all 4 months but with reduced magnitude in August and September as compared to June and July. These results are consistent with other earlier studies, e.g., Chakraborty (2010).

Spatial distribution of zonal wind circulation bias (\(\hbox {m s}^{-1})\) in GFS T1534 with respect to ERA Interim at day-1, day-3, day-5 and day-8 lead time at 850 hPa (upper panels) and 200 hPa (lower panels).

Easterly zonal wind shear (\(\hbox {m s}^{-1})\) (U200–U850) during JJAS as obtained from the ERA Interim reanalyses and GFS T1534 at various lead times.

Latitude–pressure plot of mean regional Hadley cell circulation (vector, v-wind vs. omega \(\times 100\)) and RH (shaded in %) distribution averaged over \(65{-}95^{\circ }\hbox {E}\) during JJAS from ERA Interim (top left figure) and the GFS T1534 model forecast at different lead times, respectively.

Vertical profile of RH (shaded in %) as a function of rain rate (\(\hbox {mm day}^{-1})\) over the CI region during JJAS of 2016–2017 from observation (ERA Interim vs. IMERG, top left side) and corresponding model bias (model minus obs.) at various lead times, respectively. The rain rate at the x-axis is plotted on a log10 scale.

(a) JJAS distribution of the diurnal phase (IST (hr)) when maximum precipitation occurs for IMERG (top left) and the GFS T1534 model forecast at different lead times, respectively. (b) Represents the distribution of diurnal absolute amplitude (\(\hbox {mm h}^{-1})\) defined as the difference between the maximum and minimum rainfall in a day from IMERG and corresponding model biases at different lead times, respectively.
The PDF does not provide the spatial distribution of the rainfall; therefore, to understand the spatial model performance for different rainfall categories, rainfall forecast along with rainfall PDF over four representative regions (central India (CI), BoB, north-west India (NWI) and the Western Ghats (WG)) are plotted in figure 5. It is evident from figure 5(b–e) that the model produces too much lighter rainfall over the BoB, CI and the NWI region and this is reflected in the PDF plots of these regions in figure 5(f) as well. In the moderate category of \(2{-}6\, \hbox {cm day}^{-1}\), the model seems to have predicted reasonably over the CI and BoB (figure 5a–f) although it underestimates over the NWI and marginally overestimates over the WG regions in all lead times. Compared to BoB and NWI, the model shows better fidelity in capturing the heavy rain (\({>}\)10 \(\hbox {cm day}^{-1})\) category over the CI and WG although with some underestimation until the day-5 lead. The spatial and PDF plots (figure 5a–f) indicate that the model has a systematic problem in capturing the BoB convection as it is significantly underestimating the heavier rainfall \(({>}\)10 \(\hbox {cm day}^{-1})\) in all lead times, and similarly over the NWI, the model predicts too many heavy events \(({>}\)10 \(\hbox {cm day}^{-1})\) which needs to be improved.
To understand the rainfall characteristics over the four major regions (shown in figure 5), namely the CI, BoB, NWI and WG, we have analysed the sub-grid scale vertical turbulent moisture flux (figure 6). It is evident that over the CI, the model predicted vertical turbulent moisture flux decreases up to around 850 hPa in all lead times while the ERA interim analyses indicate a gradual increase of moisture flux. Even between the 850 and 500 hPa level, the model predicted turbulent moisture flux is lesser than that of the results of the analyses. This as such could be one of the major issues for the model in underestimating the heavier rainfall as a weaker turbulent moisture flux would not facilitate deep convection. Over the BoB, the model predicted vertical turbulent moisture flux shows a similar distribution (unlike the lower level over the CI) as that of reanalyses, but the magnitude of moisture flux is underestimated and as such, it is evident from figure 5(f) that the model has poorly captured the heavier rain PDF over the BoB. Over the NWI region, the model shows a similar distribution (with underestimation) as that of reanalyses in the lower level (within 850 hPa) but above 800 hPa, the model overestimates the vertical turbulent moisture flux (figure 6), and this as such is manifested in the PDF \(({>}\)10 \(\hbox {cm day}^{-1})\) where the model erroneously predicts heavy events in all lead times. Over the WG, the model resembles the analysis in the lower level up to 900 hPa but beyond the 700 hPa level, the vertical turbulent moisture flux is overestimated by the model for all lead times (figure 6). Based on the analyses of the sub-grid scale vertical turbulent moisture flux, we argue that the sub-grid scale moisture transport is not properly predicted in the lower and middle troposphere which affects the convective processes that are reflected through erroneous rainfall prediction.

Selected boxes over the Indian region Bay of Bengal and equatorial Indian ocean (EIO) to calculate the diurnal cycle of rainfall.
The low level (850 hPa) and upper level (200 hPa) winds are found to be reasonably predicted although there is a slight overestimation of the 850 hPa zonal wind around the equatorial Indian Ocean and of 200 hPa wind over the southern tip of the Indian land mass (figure 7). It may be worth noting that the overestimation of the zonal wind over the equatorial Indian Ocean gradually decreases and shows a negative bias by the 8-day lead time (figure 7). The zonal wind at 200 hPa shows a negative (positive) bias in all lead times to the south of the equator and over the western (eastern) equatorial Indian Ocean (figure 7). As a consequence to the better prediction of the lower-level (850 hPa) and the upper-level (200 hPa) wind fields, the easterly shear has been predicted well by the model (figure 8). However, it is also noted that there is a slight underestimation (overestimation) of wind shear around equatorial (\({\sim }10^{\circ }\hbox {N}\)) region for all lead times. For a longer lead forecast of day-8, the wind shear is found to be underestimated in the region of around \(20^{\circ }\hbox {N}\). To identify the vertical distribution of moisture and the circulation (meridional–vertical), the regional Hadley cell (average over \(65{-}95^{\circ }\hbox {E}\)) is plotted for ERA and for the model forecasts of day-1, day-3, day-5 and day-8 lead (figure 9). In all forecast lead times, the model produces a reasonably moist (RH >75%) planetary boundary layer (PBL) and the vertical extent of the moisture reaches up to 200 hPa before detraining in the upper troposphere. In the ERA interim reanalyses, \({\sim }85\%\) of RH within the PBL is seen to extend up to \(25^{\circ }\hbox {N}\), whereas the model-predicted high RH (\({\sim }85\%\)) within the PBL extends up to around \(10^{\circ }\hbox {N}\) in all lead times (figure 9). The above analysis brings out that the model forecast RH (85%) within the PBL has a lesser extent to the north of \(10^{\circ }\hbox {N}\). While the ERA reanalyses show the vertical motion between the equator and \(10^{\circ }\hbox {N}\), the model captures similar updraft only on day-1 lead and from day-3 onwards, it shows a subsidence (figure 9).
In order to gain further insight into the precipitation and moisture processes over the core CI region (\(18^{\circ }{-}27^{\circ }\hbox {N}\) and \(74^{\circ }{-}85^{\circ }\hbox {E}\)), we have analysed the vertical profile of RH as a function of the rain rate during JJAS of 2016–2017 (figure 10). This metric has been proved to be useful to look into the model moist dynamic processes (Thayer-Calder and Randall 2009; Ganai et al. 2016; Abhik et al. 2017). It is evident that for all lead times, the model is able to capture the vertical pattern of rainfall and RH pattern broadly. However, detailed analyses reveal that for all lead times, the model has systematically underestimated the lower-level moisture distribution. Lower-level moisture distribution plays an important role in triggering, sustaining and maintaining the growth of the convective system. Thus, it may be possible that the insufficient lower-level moisture in the model leads to make convection shallow which resulted in the overestimation of the lighter category of rainfall and underestimation of the heavier category rainfall.
Another important aspect of the model is the diurnal rainfall variation, namely, the diurnal phase and the diurnal absolute amplitude (figure 11a and b). The definition of the diurnal phase is that the local solar time when the maximum precipitation occurs in a day (Ganai et al. 2016). Diurnal absolute amplitude is defined as the difference between maximum rainfall and minimum rainfall in a day (Ganai et al. 2016). GFS T1534 captures the diurnal phase reasonably except over the region of NWI in all lead times. However, the model captures the diurnal phase realistically elsewhere in the country. The diurnal phase over the oceanic region, e.g., the BoB and the Arabian Sea, appears to be reasonable (figure 11a). However, the absolute amplitude of rain (figure 11b) is overestimated over the BoB, and to a lesser extent, over the Arabian Sea. The diurnal absolute amplitude appears to be reasonable over the CI region. The orographic region of WG and also over the Myanmar coast is seen to have a negative bias implying lesser absolute amplitude. To further investigate the diurnal cycle of rainfall, we have selected nine boxes over different parts of the Indian region as shown in figure 12. Figure 13 shows the diurnal cycle of rainfall over different parts of India. Over the CI region, the model captures a prominent variation but the peak rainfall is around 3 hr ahead of the observation. Over the BoB, the model shows a similar rainfall variation as that of the observation but with overestimation. The model fails to capture the rainfall variation over the NWI region, showing an early morning peak as against an afternoon peak in the observation. Over north-east India (NEI), the model diurnal variation resembles the observation but with an overestimation. The diurnal rainfall variability over the northern WGs and southern WGs are overestimated by the GFS T1534 as compared to the IMERG process. The diurnal variability over the eastern coast shows (figure 13) a distinct diurnal cycle of rainfall similar to that over the CI land mass region. Although GFS T1534 is able to capture the late afternoon peak during the rainfall, it overestimates the rainfall amount over this region and the rainfall minimum occurs ahead of the observations. Furthermore, the diurnal variation of rainfall is analysed over the western equatorial Indian Ocean (WIO) and eastern equatorial Indian Ocean (EIO), respectively. Although the EIO and WIO show weak diurnal variation, the model is able to capture the diurnal variation reasonably well over these two oceanic regions.
The above analyses bring out the fact that the model has a tendency to overestimate the rainfall over the WG, BoB and NEI but does not match in NWI. Over the CI region, the model peak rain occurs 3 hr earlier than the observation. Besides the issues with diurnal variability, the model has a tendency to predict too many lighter rainfall events over the Indian land mass and also over the BoB. These features of the model indicate the fact that the model’s cumulus and cloud parameterisation need further improvement to reduce frequent triggers of rain during the monsoon season. It may be worth mentioning that although this model is being used at 12.5 km, most of the physical parameterisation, particularly, the cloud and convective parameterisation of GFS is similar to that of the coarser resolution GFS/CFS. Such a tendency of overestimation of lighter rain in the rainfall PDF was earlier reported by Goswami et al. (2014) and Abhik et al. (2016) in analysing CFSv2T126 and CFSv2T382, respectively. Thus, while the model has good fidelity of capturing the diurnal cycle over the land and ocean and is also capable of capturing the heavier rainfall PDF, there is a need to improve the physics suitable for the higher resolution (\({\sim }12.5\, \hbox {km}\)) of the model and the subsequent modification of the convective trigger that will reduce the generation of too frequent lighter rain and may improve the model bias. Another aspect which may need improvement is the vertical resolution of the GFS T1534. The CFSv2 T126 (\({\sim }\)horizontal resolution \({\sim }110\, \hbox {km}\)), CFSv2 T382 (horizontal resolution \({\sim }38\, \hbox {km}\)), GFS T574 (horizontal resolution \({\sim }25\, \hbox {km}\)) and the current version, GFS T1534, use 64 vertical levels. While with the increase of horizontal resolution, there is a need to enhance the vertical resolution as well for resolving the vertical processes associated with the cloud and convection of the model.

Diurnal cycle of rainfall (\(\hbox {mm h}^{-1})\) as obtained from IMERG (black line) and the GFS T1534 model forecast at different lead times during JJAS of 2016–2017 over different regions shown (as boxes) in figure 12.

(a) Equitable threat score, (b) Peirce skill score and (c) Heidke skill score of GFS T1534 for JJAS 2016–2017 for all India land grid points.
3.2 Verification of model forecast
To further assess the performance of GFS T1534 quantitatively, skill scores are calculated. The forecast skill of GFS T1534 (JJAS of 2016–2017) is assessed based on skill scores such as equitable threat score (ETS), Peirce skill score (PSS), Heidke skill score (HSS) and so on. These scores provide information on the improvement of model forecast over some reference forecast (Wilks 2011). The dichotomous nature of precipitation allows for verification using a contingency table. The contingency table is shown in table 2. This has four components, namely, hits, ‘a’; false alarms, ‘b’; miss, ‘c’; and correct negatives ‘d’. Skill scores are based on these components.
Here we have calculated the ETS, PSS and HSS to assess the skill of GFS T1534. ETS gives an indication as to how well the forecast yes events correspond to observed yes events accounting for hits which might occur by chance. This score ranges from −1/3 to 1 with 1 being the perfect score. It is given by
where
PSS tells how well the forecast could distinguish between ‘yes’ events from ‘no’ events. It is the difference between the probability of detection and the probability of false detection. The score ranges from − 1 to 1 with 1 being the perfect score. It is given by
HSS shows the accuracy of the forecast relative to that of random chance. It ranges from − 1 to 1 with 0 showing no skill and 1 being the perfect score:
Figure 14(a–c) shows the ETS, PSS and HSS for GFS T1534 with increasing threshold and lead time, respectively. ETS attains a maximum score of 0.26 for day-1, PSS attains a maximum score of 0.43 for day-1 and HSS peaks at 0.41 for day-1. The scores decrease with increasing lead times and thresholds. Here, it is worthwhile to note that the scores do not fall to zero even for thresholds as high as 105 mm and a lead time of day-5. This indicates a reasonably good forecast skill of the model in relation to the skill seen for other models forecast over the Indian region (Taraphdar et al. 2016).
Another set of scores is shown in the performance diagram which comprises probability of detection (POD), success ratio (SR), bias score (B) and critical success index (CSI). This was devised by Roebber (2009), and the details can be found therein.
The scores are calculated based on the contingency table and expressed as
Performance diagram takes the advantage of relationships among the scores to show multiple scores at one time. Figure 15 shows the performance diagram of GFS T1534 for day-1, -3 and -5 and for thresholds of 2.5, 5, 15 and \(20\, \hbox {mm day}^{-1}\). The x- and y-axis show success ratio and probability of detection, respectively. The dashed and curved lines represent bias and critical success index, respectively. The perfect value for all these scores is 1; hence in the diagram, a good forecast will lie in the upper right corner. Here we see that the skill of the GFS T1534 forecast decreases with increasing lead times. Also for a particular lead time, the skill decreases with the increasing threshold of rainfall. The skill for lower thresholds (2.5 and 5 mm) does not vary much with the increasing lead time, indicating the ability of the model to maintain its skill for longer lead times. In the case of higher thresholds (15 and 20 mm), the skill deteriorates with increasing lead time. It is noteworthy that bias is improving with increasing lead time. Although the model shows its best skill for day-1 forecast at \(2.5\, \hbox {mm day}^{-1}\) rainfall threshold, the skill is substantial even for day-5 forecast of rainfall greater than \(20\, \hbox {mm day}^{-1}\).

Performance diagram of the GFS T1534 for JJAS 2016–2017 for all India land grid points.

RMSE of (a) U component of wind at 850 hPa (solid) and at 200 hPa (dashed) and (b) V component of wind at 850 hPa (solid) and at 200 hPa (dashed) for JJAS 2016–2017 for the domain \(10^{\circ }\hbox {S}\)–\(40^{\circ }\hbox {N}\) and \(50^{\circ }\)–\(120^{\circ }\hbox {E}\).
Furthermore, to analyse the skill of the model in the prediction of winds, verification of the wind forecast is carried out in terms of root mean square error (RMSE). RMSE is calculated for u (figure 16a) and v (figure 16b) components of wind at 850 and 200 hPa for the ISM domain (\(10^{\circ }\hbox {S}{-}40^{\circ }\hbox {N}\) and \(50{-}120^{\circ }\hbox {E}\)). The RMSE gives the average magnitude of the forecast error. For both components of winds, there is a gradual increase in RMSE with lead time. RMSE is less for the v component compared to u at 850 and 200 hPa. A point to note is that the error for u and v at 850 hPa is considerably less than that at 200 hPa. Even at day-5, RMSE does not go beyond \(3\, \hbox {m s}^{-1}\) for 850 hPa level and it lies below \(6\, \hbox {m s}^{-1}\) for 200 hPa level which indicates good skill of the model in predicting winds.
4 Conclusions
The deterministic forecast from the high-resolution GFS T1534 (12.5 km) model has been evaluated for two monsoon seasons, e.g., 2016 and 2017. The model being initialised with the GDAS assimilation at NCMRWF is run every day for the next 10 days forecast at IITM. The evaluation of the high-resolution model forecast reveals that the model broadly is able to capture the heavy rainfall PDFs, although it has a systematic error of producing more than the observed lighter categories of rain rates. The tendency of overestimating lighter rain rates is evident in the spatial plots and for all the lead times of the forecast. A critical evaluation of the moisture distribution reveals that the model is able to capture the vertical structure associated with the regional Hadley cell reasonably although the low level moisture (RH >85%) maxima extends only up to around \(10^{\circ }\hbox {N}\) as against the ERA interim reanalyses where the maximum moisture within the boundary layer extends up to \(20^{\circ }\hbox {N}\). The model shows good fidelity in forecasting the diurnal phase over the country except over the NWI region. The diurnal cycle over the CI region needs further improvement in terms of time of peak rain. The diurnal rainfall over the WG, BoB, east coast and the north-eastern region needs to be further improved to reduce the overestimation.
The model shows reasonable skill for various rainfall categories although the skill reduces with the lead time. While the model shows fidelity in capturing the lower (850 hPa) and upper (200 hPa) level wind and moisture distribution, there is a need to enhance the skill for higher categories of rain rates with longer lead. Further model development initiatives are being undertaken in improving the model performance with reduced forecast error with longer lead time.
References
Abhik S, Krishna R P M, Mahakur M, Ganai M, Mukhopadhyay P and Dudhia J 2017 Revised cloud processes to improve the mean and intraseasonal variability of Indian summer monsoon in climate forecast system: Part 1; J. Adv. Model. Earth Syst. 9(2) 1002–1029.
Abhik S, Mukhopadhyay P, Krishna R P M, Salunke K D, Dhakate A R and Rao S A 2016 Diagnosis of boreal summer intraseasonal oscillation in high resolution NCEP climate forecast system; Clim. Dyn. 46(9–10) 3287–3303.
Borah N, Sahai A K, Abhilash S, Chattopadhyay R, Joseph S, Sharmila S and Kumar A 2015 An assessment of real-time extended range forecast of 2013 Indian summer monsoon; Int. J. Climatol. 35 2860–2876.
Chakraborty A 2010 The skill of ECMWF medium range forecasts during the year of tropical convection 2008; Mon. Weather Rev. 138 3787–3805.
Dandi A R, Sabeerali C T, Chattopadhyay R, Rao D N, George G, Dhakate A, Salunke K, Srivastava A and Rao A S 2016 Indian summer monsoon rainfall simulation and prediction skill in the CFSv2 coupled model: Impact of atmospheric horizontal resolution; J. Geophys. Res. Atmos. 121(5) 2205–2221.
Dee D P, Uppala S M, Simmons A J, Berrisford P, Poli P, Kobayashi S, Andrae U, Balmaseda M A, Balsamo G, Bauer P, Bechtold P, Beljaars A C M, van de Berg L, Bidlot J, Bormann N, Delsol C, Dragani R, Fuentes M, Geer A J, Haimberger L, Healy S B, Hersbach H, Hólm E V, Isaksen L, Kållberg P, Köhler M, Matricardi M, McNally A P, Monge-Sanz B M, Morcrette J-J, Park B-K, Peubey C, de Rosnay P, Tavolato C, Thépaut J-N and Vitart F 2011 The ERA-interim reanalysis: Configuration and performance of the data assimilation system; Quart. J. Roy. Meteorol. Soc. 137 553–597, https://doi.org/10.1002/qj.828.
Finley J P 1884 Tornado predictions; Am. Meteorol. J. 1 85–88.
Gadgil S and Gadgil S 2006 The Indian monsoon, GDP and agriculture; Econ. Polit. Wkly 41 4887–4895.
Ganai M, Krishna R P M, Mukhopadhyay P and Mahakur M 2016 The impact of revised simplified Arakawa–Schubert scheme on the simulation of mean and diurnal variability associated with active and break phases of Indian summer monsoon using CFSv2; J. Geophys. Res. Atmos. 121(16) 9301–9323.
Goswami B N, Venugopal V, Sengupta D, Madhusoodanan M S and Xavier P K 2006 Increasing trend of extreme rain events over India in a warming environment; Science 314(5804) 1442–1445.
Goswami B B, Deshpande M, Mukhopadhyay P, Saha S K, Rao S A, Murtugudde R and Goswami B N 2014 Simulation of monsoon intraseasonal variability in NCEP CFSv2 and its role on systematic bias; Clim. Dyn. 43 2725–2745, https://doi.org/10.1007/s00382-014-2089-5.
Hack J J, Caron J M, Danabasoglu G, Oleson K W, Bitz C and Truesdale J 2006 CCSM–CAM3 climate simulation sensitivity to changes in horizontal resolution; J. Clim. 19 2267–2289.
Huffman G, Bolvin D, Braithwaite D, Hsu K, Joyce R and Xie P 2014 Integrated multi-satellite retrievals for GPM (IMERG), version 4.4; NASA’s Precipitation Processing Center. Accessed 31 March 2015, https://arthurhou.pps.eosdis.nasa.gov/gpmdata/.
Joseph S, Mandal R, Sahai A K, Phani R, Dey A and Chattopadhyay R 2018 Diagnostics and real-time extended range prediction of heat waves over India; IITM Research Report (ISSN 0252-1075), ESSO/ IITM/SERP/ SR/03(2018)/192.
Kim I W, Oh J, Woo S and Kripalani R H 2018 Evaluation of precipitation extremes over the Asian domain: Observation and modelling studies; Clim. Dyn. https://doi.org/10.1007/s00382-018-4193-4.
Mahakur M, Prabhu A, Sharma A K, Rao V R, Senroy S, Singh R and Goswami B N 2013 High-resolution outgoing longwave radiation dataset from Kalpana-1 satellite during 2004–2012; Curr. Sci. 105 1124–1133.
Manganello J V, Hodge K I and Kinter J L et al. 2012 Tropical cyclone climatology in a 10-km global atmospheric GCM: Toward weather-resolving climate modeling; J. Clim. 25 3867–3893.
Miura H, Suematsu T and Nasuno T 2015 An ensemble hindcast of the Madden–Julian oscillation during the CINDY2011/DYNAMO field campaign and influence of seasonal variation of sea surface temperature; J. Meteorol. Soc. Jpn. 93A 115–137.
Nandargi S S and Gaur A 2015 Extreme rainfall events over the Uttarakhand State (1901–2013); Int. J. Sci. Res. 4(4) 700–703.
Prasad V S, Mohandas S, Das Gupta M, Rajagopal E N and Datta S K 2011 Implementation of upgraded global forecasting systems (T382L64 and T574L64) at NCMRWF; NCMRWF Technical Report No. NCMR/TR/5/2011 May 2011, 72p, http://www.ncmrwf.gov.in/ncmrwf/gfs.report.final.pdf.
Prasad V S, Mohandas S, Dutta S K, Das Gupta M, Iyengar G R, Rajagopal E N and Basu S 2014 Improvements in medium range weather forecasting system of India; J. Earth Syst. Sci. 123(2) 247–258.
Prasad V S, Johny C J and Sodhi J S 2016 Impact of 3D Var GSI-ENKF hybrid data assimilation system; J. Earth Syst. Sci. 125(8) 1509–1521.
Prasad V S, Johny C J, Mali P, Singh S K and Rajagopal E N 2017 Retrospective analysis of NGFS for the years 2000–2011; Curr. Sci. 112(2) 370–377.
Rajeevan M, Bhate J and Jaswal A K 2008 Analysis of variability and trends of extreme rainfall events over India using 104 years of gridded daily rainfall data; Geophys. Res. Lett. 35(18).
Rajendran K and Kitoh A 2008 Indian summer monsoon in future climate projection by a super high-resolution global model; Curr. Sci. 95(11) 1560–1569.
Roebber P J 2009 Visualizing multiple measures of forecast quality; Wea. Forecasting 24(2) 601–608.
Roxy M K, Ghosh S, Pathak A, Athulya R, Mujumdar M, Murtugudde R, Terray P and Rajeevan M 2017 A threefold rise in widespread extreme rain events over central India; Nat. Commun. 8(1) 708.
Sato M, Tomita H, Miura H, Iga S and Nasuno T 2005 Development of a global cloud resolving model – a multi-scale structure of tropical convections; J. Earth Simul. 3 11–19.
Sela J 2010 The derivation of sigma pressure hybrid coordinate semi-Lagrangian model equations for the GFS; NCEP Office Note 462, 31p.
Staniforth A and Côté J 1991 Semi-Lagrangian integration schemes for atmospheric models – A review; Mon. Weather Rev. 119 2206–2223.
Taraphdar S, Mukhopadhyay P, Leung L R and Landu K 2016 Prediction skill of tropical synoptic scale transients from ECMWF and NCEP ensemble prediction systems; Math. Clim. Weather Forecast. 2 26–42, https://doi.org/10.1515/mcwf-2016-0002.
Thayer-Calder K and Randall D A 2009 The role of convective moistening in the Madden–Julian oscillation; J. Atmos. Sci. 66(11) 3297–3312.
Wilks D S 2011 Statistical methods in atmospheric sciences; 3rd edn, International Geophysics Series, No. 100, Academic Press, USA, 669p.
Williamson D L, Kiehl J T and Hack J J 1995 Climate sensitivity of the NCAR community climate model (CCM2) to horizontal resolution; Clim. Dyn. 11 377–397.
Acknowledgements
IITM is an autonomous research institution, fully supported by the Ministry of Earth Sciences (MoES), Govt. of India, New Delhi. The authors are grateful for the comments from the anonymous reviewers and the editor which contributed to the improvement and the clarity of the paper. The GFS model is run on the ‘Aaditya’ MoES high power computing system located at IITM, Pune. The authors thank IMD for TRMM and the Rain gauge merged daily rainfall data. RPMK gratefully acknowledges Dr S Moorthi, National Center for Environmental Prediction, USA for the help in understanding the semi-Lagrangian framework. The authors from IITM, Pune are grateful to the director, IITM for the encouragement and the support.
Author information
Authors and Affiliations
Corresponding author
Additional information
Corresponding Editor: A K Sahai
Rights and permissions
About this article

Cite this article
Mukhopadhyay, P., Prasad, V.S., Krishna, R.P.M. et al. Performance of a very high-resolution global forecast system model (GFS T1534) at 12.5 km over the Indian region during the 2016–2017 monsoon seasons. J Earth Syst Sci 128, 155 (2019). https://doi.org/10.1007/s12040-019-1186-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12040-019-1186-6