
Abstract
Background
Since 1916 there has been a recognized demand for a method of classification of orthopaedic literature inclusive enough to permit the proper collection and retrieval of all literature on the subject. Today, MEDLINE, available through the PubMed interface, has become the de facto standard for organization and retrieval of medical literature. The Medical Subject Headings (MeSH), used to provide indexing and assist in searching, are partly responsible for this standard. Understanding how MeSH is built and maintained may lead the user to a better understanding of how to use MEDLINE, and what to expect from the indexing of an article.
Questions/purposes
The purpose of this review is to provide an understanding of the organization of large quantities of indexed material, the indexing process and the considerations involved in developing an indexing vocabulary.
Where are we now?
Successful terminology development and use, a prerequisite for any sharing of information by electronic means, depends on both user (how the user is expected to use the system) and information (how the information is organized) models. MEDLINE has a simple user model and a simpler information model. The user is expected to determine what is relevant and which MeSH descriptors are appropriate.
Where do we need to go?
While MEDLINE through PubMed is a success as viewed by the number of hits, further improvements will depend on better, faster indexing with a controlled terminology. Terminology development requires careful consideration of the nature of the subject, how users employ the terminology, the overall purpose of the terminology, and the framework of the systems in which it is used.
How do we get there?
For the future, understanding terminology development might enable the user to comprehend some of the issues involved in sharing of other information by electronic means. Further improvements in the availability and accessibility of medical literature will depend on continued maintenance and development of MeSH, as well as on refinement of the indexing process.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In orthopaedics, like in other fields of medicine, the ability to communicate to one’s peers through scholarly publications is a necessity. The need to organize that literature in orthopaedics has long been recognized. In 1916, the American Orthopaedic Association recognized the need to find ways to classify orthopaedic-related articles in Index Medicus (which dates to 1879), and established a committee to do so. Later that year, the classification was published in an editorial in the American Journal of Orthopaedic Surgery (the predecessor of The Journal of Bone and Joint Surgery American) [4].
The need of such a classification is brought out by examining the methods in use by the Index Medicus and one or two journals that divide the current orthopaedic literature by subject. It will be found that it is impossible to file away the vast amount of literature that can be included in orthopaedic surgery under any such simple method as is used in the Current Literature Department of the Journal. It is evidently the custom of certain men to keep on file the important orthopaedic literature, and if this is done for any length of time, there is an absolute necessity for a comprehensive scheme that will be definite enough so that articles can be filed and found [4].
The committee tested the proposed classification over a several month period to determine whether it could indeed categorize all orthopaedic literature. They noted there might be concern that the classification was too large and not based on an anatomic or etiologic method. For example, it is difficult to classify the various papers on such subjects as back pain, because they might be classified etiologically under strain, infection, and so on. For these reasons, the rather simple and scientific method of an anatomic or etiologic basis was discarded.
The health sciences continue to become more multidisciplinary in scope and more complex. The delivery of care and the way medicine is practiced continue to evolve and change at an increasing pace. It has been said that this is the beginning stage of a new age of medicine. Recent advances in medicine, particularly in molecular and cell biology, pharmacogenetics, and developments in immunology and neurobiology have all led to approaches to preventive, diagnostic, and therapeutic strategies.
An explosion of knowledge, combined with the aging of the population, the shift from acute illness toward chronic disease, the emphasis on cost containment, the increasingly corporate nature of healthcare delivery, and the availability of information processing technology is radically changing the way that health professionals function today.
These factors will surely alter even more radically the way that health professionals of the 21st century practice. One obvious effect of the expanded knowledge base is that any single individual can master only a decreasing fraction of the total spectrum of the available information. Providing access to information resources that support rapid acquisition of knowledge is increasingly an electronic task, and organization of the material for easy retrieval is essential. The observations made and efforts begun in 1916 have even greater relevance to the case in 2009.
MeSH, the Medical Subject Headings, is a controlled vocabulary designed to be used for the indexing and cataloging of literature. Consisting of descriptors with multiple terms pointing to the descriptors as the correct terminology to use in the system, it forms the foundation by which citations can be retrieved from MEDLINE (the indexed database) through PubMed (a search engine which searches MEDLINE and other citation records). Studies within the National Library of Medicine, which spends millions every year to index the literature, have demonstrated the effect of the indexing is a demonstrable improvement in retrieval when compared to statistical methods or text word searching. Within the PubMed system is a mechanism for taking text entries and finding (mapping) the correct MeSH terms to be used within the search [4].
There are excellent resources available to teach those who wish to learn techniques of better searching and use of PubMed. There is an online tutorial available for PubMed at http://www.nlm.nih.gov/bsd/disted/pubmedtutorial/, and there are Quick Tours of a variety of topics related to PubMed at http://www.nlm.nih.gov/bsd/disted/pubmed.html#qt. The National Training Center and Clearinghouse (NTCC, http://nnlm.gov/ntcc/index.html), under NLM contract, sponsors more than 40 classroom sessions across the country each year.
The purpose of this review is to provide an understanding of the organization of large quantities of indexed material, the indexing process and the considerations of developing an indexing vocabulary. I will specifically review (1) the role of the National Library of Medicine; and (2) the lessons learned from maintaining the terminology over the years.
The Role of the National Library of Medicine
In 1957, the Board of Regents of the National Library of Medicine approved a plan for a survey of the indexing operations with the intent to incorporate a mechanized system of composition. In 1960, a new Index Medicus began publication. It was produced using the latest technology of the time.
The new Index Medicus represented a substantial advance in the production of a published index. Dr. Billings and Dr. Fletcher, his assistant, in the early days of Index Medicus and the Index-Catalogue, personally selected articles whose bibliographic information was transcribed on cards by hand. Subject headings were penciled on the cards by the editor and his assistant, then filed by hand and sent to the printers for typesetting. This manual manipulation of cards in the production of the index remained unchanged until their cessation in 1959.
In 1964, the National Library of Medicine introduced the Medical Literature Analysis and Retrieval System (MEDLARS), the first computer-based information retrieval system for accessing medical literature. Information about the articles indexed for Index Medicus, including author, title, and descriptors, was entered on 80-column punch cards. The resulting data bank was then queried to produce lists of articles on a specific subject. From across the United States, queries were sent to the National Library of Medicine. These queries on punch cards represented searches requested by physicians. Unlike a perusal of pages in a printed Index Medicus or other bibliography, this radical advance allowed the correlation of two or more topics to get a custom list of those articles that included several aspects or combinations. For example, instead of looking at many pages of entries under Bone and Bones while visually scanning for a topic expressed in the article title, using MEDLARS the physician could now make a request through his local library for a list of articles about vitamin D deficiency in adolescents and the effect on bones.
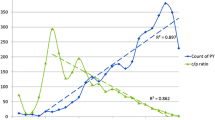
The growth of MEDLINE over this period of time has been remarkable, with an increase in citations indexed over the years (Fig. 1).

The chart shows an increase in the number of citations indexed per year by MEDLINE.
The indexing of these articles is still largely dependent on human judgment. Although there have been modernizations in the equipment used, and the software to assist the indexers, fundamentally the process remains the responsibility of a human who scans the article and assigns eight to 15 descriptors from MeSH to that article [3]. The 15 millionth citation was added to MEDLINE on February 4, 2008; PubMed reached 18 million citations in May 2008. As the complexity of medicine increased, the number of articles increased and both resulted in an accompanying growth in the vocabulary. MEDLINE is now over 16 million citations. PubMed, as most users recognize, includes citations which, because they are not indexed, are not part of MEDLINE.
This tremendous growth has led the library to continue its search for better indexing methods. The only way we will be able to keep up with the explosion of information is to improve the efficiency of the process. Over the past several years, a great deal of effort and resources have been devoted to this process [1, 2, 5, 6, 9–13].
At the same time, as medicine and science have progressed, the number of descriptors needed to represent the topics of importance to the literature has increased remarkably. Over the past 10 years, almost 6000 new MeSH descriptors have been added, reaching a total of over 25,000 for the year 2010.
Lessons From Terminology Maintenance
In the almost 50 years since the first edition of Medical Subject Headings was published (1960), much about maintaining terminology has been learned. Experience is a great teacher. Feedback from users is paramount in determining what issues need to be addressed. These issues can be structural or about content, correcting errors, or recognizing noteworthy lasting changes in the science underlying medical practice.
Terminology is dependent in computer systems on a model of how users interact with the system and how the system is organized. Although humans in their use of language are adept at dealing with ambiguity, double meanings, ellipsis, anaphora, and the like, these abilities are highly dependent on humans’ use of contextual and nonverbal communication. Computers do not have that advantage. Computer systems depend on manipulation of (to them) meaningless symbols in a specified way. An understanding of how this is to be accomplished in a given system can be thought of as two distinguishable but not inseparable models. One is the model of users, what they are trying to do, and how they are to do it. The other is that of the information within the system. How is it organized and how will it be provided?
MeSH, as it is used in MEDLINE, has two sets of users. The first set includes the indexers and catalogers. Given their task, how can they see the appropriate descriptors in MeSH and how are they to use them? They are taught the indexing and cataloging rules and monitored to ensure these rules are followed. The rules impose certain constraints on their actions. First, they are not asked to draw any conclusions, make any diagnoses, or identify to what an article might be relevant. Second, they are to describe the article or book in terms of what it is about. An article may be about a topic, yet not relevant to a particular query. The indexing rules indexers follow rather tell them to select the highest level of specificity among the descriptors to capture what the article is discussing. Only when three or more items that are together as siblings in a hierarchical relationship (see subsequently for a discussion about hierarchies) should a more general descriptor be used. The object of any indexing help is to assist the indexers in readily finding the appropriate and related descriptors either through the use of the MeSH browser (which searches both descriptors and entry vocabulary) or through the use of the descriptors suggested by the Medical Text Indexing Process.
The second set of users of MeSH are the searchers. Most of the searchers using MeSH are unaware of the indexing rules, the arrangement of MeSH, or how to organize a Boolean search strategy. However, any changes in MeSH must take into account how a naive searcher might try to find something in PubMed and how to help them. To that end, MeSH uses an extensive entry vocabulary which, together with synonyms added from the Unified Medical Language System, form a mapping to the descriptors included in the default PubMed search of MEDLINE [7].
The information model of MEDLINE is a fairly simple one: citations should be indexed by what they are about, not what they are relevant to. The ultimate relevance for a specific need is essentially impossible to predict; thus, MEDLINE ignores that in its information model. Mention of a subject alone does not help determine what an article is about. In addition to assigning the topical descriptors in MEDLINE (i.e., what the article is about) other metadata assigned include descriptors intended to describe the publication format and, if a study, its methodology and financing.
Another lesson is that indexing requires a level of expression somewhat less specific and more general than that of a single meaning. Although today discussions of terminology are often about whether a vocabulary is “concept-based,” building an indexing system on single concepts would be inadvisable. Basing an indexing terminology on what is often thought of as a single meaning would result in a difficult situation with the literature. Articles on closely related topics would end up indexed differently with limited ability to find the articles on the related topics. An article about “smoothness” would not be obtained at the same time as an article about “roughness,” yet both concepts are talking about the same property.
Over the years MeSH and the MEDLINE indexing system have evolved and developed a set of rules and a somewhat more complicated syntax for expressing an idea. Some things, e.g., bone transplantation, can be expressed as a single descriptor. Other things, such as meniscus tear, would be expressed as a coordinated expression of the descriptor Tibial Menisci and the qualifier injury. The use of the qualifiers proved early to be necessary to avoid an excess of descriptors, with a resultant splitting apart of the literature.
Although the idea of not indexing items about the same topics differently has led to an emphasis on concept-based terminology, the emphasis on concepts rather than on representational integrity is misplaced. Representational integrity, our term for representing the things meaning the same in the same way terminologically, is clearly a most desirable aspect. This consistency is at the heart of an indexing system. One would not want to look for articles about bone transplantation as either a descriptor, Bone Transplants, or as Bone qualified by transplantation. One way or the other must be chosen. For a single descriptor, achieving representational integrity results from a close inspection and study of the existing descriptors, qualifiers, and the indexing rules. For a citation, complete representational integrity would imply that an article should be indexed identically by different indexers or different systems. Such a deeply and strongly defined representational integrity may be impossible to achieve.
A difficult question arises when two things are sufficiently different to need two different descriptors. Consider two concepts, DNA fingerprinting and DNA fingerprints. Would it make sense to separate the two of them in the literature or keep them together? Although the concepts are clearly distinct, their use in the literature and the inability to achieve consistent human indexing requires that the two be treated equivalently in indexing. Thus, although they retain their individual concept identity, they are linked as part of the same descriptor.
Another problem which often arises is the ambiguity of some terms. For example, to an orthopaedic surgeon “nonunion” may mean a nonunited fracture, but others may see it as reflecting the means of production, or some other meaning. Although most terms have at least some ambiguity in meaning, most computer systems have difficulty in dealing with ambiguity.
To clarify the relationships within the parts of MeSH, MeSH has evolved into a three-object model. At the lowest level is the term, at an intermediate level terms meaning the same are grouped into concepts, and at the highest level concepts closely related are organized as descriptors. Discussion of this model, and the relationships in hierarchies, are beyond the scope of this article, but recognizing the importance of these ideas to the overall development of MeSH is essential. Further information can be found in Nelson et al. [8].
An early feature of MeSH and the MEDLINE database was the decision to arrange descriptors hierarchically (Fig. 2). In multiple hierarchies, a given descriptor could be “exploded” to include all the descriptors beneath it in the hierarchy. The idea is that a search on one topic could include articles on other topics that were treed in the hierarchy below it. Today in PubMed, these “explodes” are done automatically unless the search specifically forbids it.

The orthopaedic procedure hierarchy is shown.
Organizing those descriptors hierarchically, to support “explodes,” requires some understanding of the user and the user model. Hierarchical arrangements are not always ontologic (formally represented in relationship terminology as "isa") or even meronymic (formally represented as part_of) in the relationship between the parent term and the child. Instead, what is required is the use of the practical Soergelian criterion [8]. For example, it seems intuitively obvious that a user might want articles on Accident Prevention when searching for information about Accidents. This arrangement fits the Soergelian criterion but not those of an ontologic viewpoint. Accident Prevention is not a type of Accident.
Discussion
Index Medicus was first established in 1879. Since 1916 there has been a recognized demand for a method of classification of orthopaedic literature sufficiently inclusive to permit the proper retrieval of all literature on the subject. MEDLINE has become the de facto standard for organization and retrieval of medical literature. The Medical Subject Headings (MeSH), used to provide indexing and assist in searching, are an integral part of the MEDLINE system. Users would benefit from understanding how MeSH is built and maintained and knowing what to expect from the indexing of an article. The purpose of this review was therefore to show users how large quantities of material are indexed.
While by the criteria of use, PubMed is highly successful, improvements in the NLM’s system are a major concern. Improvements in the indexing system, whether by continued and greater efforts in terminology development, or in facilitating the indexing process, are being sought on an ongoing basis. This paper has concentrated on the terminological aspects of the current system. Organizing literature, whether of orthopaedics or of any scientific endeavor, requires careful consideration of what is the intended result and a good understanding of what can be achieved.
Where do we need to go? With computer systems, the challenge becomes greater, but the resulting organization may be more functional. Any indexing process involving humans will of necessity contain certain kinds of errors, but computer system processes involve different kinds of errors. Understanding that the roles of humans and computers in the development of a database such as this can lead to a cooperative computation approach is the only way to achieve success.
Another of the highly important issues dealing with any large database indexed with a controlled vocabulary is what to do when the controlled vocabulary changes. This issue cannot be ignored or glossed over. Many otherwise promising efforts have failed because they did not take this issue into account. In MEDLINE, with over 16 million indexed citations, it would be difficult, if not impossible, to reindex all of them manually. There must be a way to accommodate changes in the vocabulary as time and science march on. Ideas and categories become obsolete and new ones arise. The update model for MeSH in MEDLINE includes both automatically changing the descriptors listed on a given citation according to changes in the database, but also, when appropriate, using a combination of descriptor and free-text searching to identify where a certain group of citations needs an additional descriptor. A full description of the process, together with xml files containing the actual changes made for each year, are made available on the MeSH home pages.
How do we get there? For the future, understanding terminology development might enable the user to comprehend some of the issues involved in sharing of other information by electronic means. Further improvements in the availability of medical literature will depend on continued maintenance and development of MeSH, as well as on refinement of the indexing process. As indexing systems change and evolve, it appears likely that the application of controlled terminology will continue to be a necessary part of that indexing. An information model and a user model which guide the development of the indexing process and the terminology development are essential.
References
Aronson AR, Bodenreider O, Chang HF, Humphrey SM, Mork JG, Nelson SJ, Rindflesch TC, Wilbur WJ. The NLM Indexing Initiative. Proc AMIA Symp. 2000:17–21.
Aronson AR, Mork JG, Gay CW, Humphrey SM, Rogers WJ. The NLM Indexing Initiative’s Medical Text Indexer. Stud Health Technol Inform. 2004;107(Pt 1):268–72.
Barnett O. Assisting health professions education through information technology. Past, Present, and Future of Biomedical Information. Bethesda, MD: National Library of Medicine; 1987. NIH Publication No 88-2911, pp 88–103.
Classification of orthopedic literature. Am J Orthop Surg. 1916;14:613–617.
Gay CW, Kayaalp M, Aronson AR. Semi-automatic indexing of full text biomedical articles. AMIA Annu Symp Proc. 2005:271–275.
Kim W, Wilbur WJ. A strategy for assigning new concepts in the MEDLINE database. AMIA Annu Symp Proc. 2005:395–399.
Knecht LS, Nelson SJ. Mapping in PubMed. J Med Libr Assoc. 2002;90:475.
Nelson SJ, Johnston D, Humphreys BL. Relationships in Medical Subject Headings. In: Bean CA, Green R, eds. Relationships in the Organization of Knowledge. New York, NY: Kluwer Academic Publishers; 2001:171–184.
Névéol A, Shooshan SE, Claveau V. Automatic inference of indexing rules for MEDLINE. BMC Bioinformatics. 2008;9 (Suppl 11):S11.
Névéol A, Shooshan SE, Humphrey SM, Mork JG, Aronson AR. A recent advance in the automatic indexing of the biomedical literature. J Biomed Inform. 2009;42:814–823.
Névéol A, Shooshan SE, Humphrey SM, Rindflesh TC, Aronson AR. Multiple approaches to fine-grained indexing of the biomedical literature. Pac Symp Biocomput. 2007:292–303.
Névéol A, Shooshan SE, Mork JG, Aronson AR. Fine-grained indexing of the biomedical literature: MeSH subheading attachment for a MEDLINE indexing tool. AMIA Annu Symp Proc. 2007:553–557.
Névéol A, Zeng K, Bodenreider O. Besides precision & recall: exploring alternative approaches to evaluating an automatic indexing tool for MEDLINE. AMIA Annu Symp Proc. 2006:589–593.
Author information
Authors and Affiliations
Corresponding author
Additional information
Each author certifies that he or she has no commercial associations (eg, consultancies, stock ownership, equity interest, patent/licensing arrangements, etc) that might pose a conflict of interest in connection with the submitted article.
About this article
Cite this article
Nelson, S.J., Schulman, JL. Orthopaedic Literature and MeSH. Clin Orthop Relat Res 468, 2621–2626 (2010). https://doi.org/10.1007/s11999-010-1387-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11999-010-1387-4